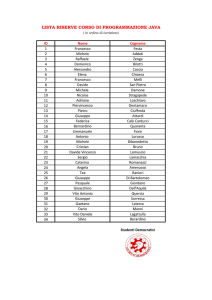
Metriche e Strumenti
di Valutazione delle Prestazioni
nel Calcolo Parallelo
(cenni)
Speedup
Definizione 1 (Speedup Ideale)
Rapporto tra il tempo di esecuzione del migliore algoritmo sequenziale T*
ed il tempo di esecuzione del corrispondente algoritmo parallelo ottenuto
utilizzando p processori:
*
*
p
p
Definizione 2 (Speedup Algoritmico)
S =
T
T
Tipico andamento dello
speedup
Speedup
Rapporto tra il tempo di esecuzione dell’algoritmo su di un unico
processore (T 1) ed il tempo di esecuzione dello stesso su p processori (T p)
Michele Colajanni – Efficienza delle Applicazioni Parallele
Numero processori
2/22
1
Efficienza
Misura del grado di inutilizzo dell’elaboratore parallelo
Ep =
Sp
p
Per definizione, 0 <= Ep <= 1
efficienza
Buona misura per la presentazione di più risultati in quanto, rispetto
allo speedup (espresso in funzione di p), “normalizza” i tempi di
esecuzione
1
Dati
3/22
Michele Colajanni – Efficienza delle Applicazioni Parallele
Legge di Amdhal (1967)
Si assuma che in un determinato problema possa essere distinto in due
parti: una inerentemente sequenziale (sia f la percentuale di tale sezione
sul calcolo complessivo) ed una completamente parallelizzabile:
Tempo di esecuzione:
N
1− f
Tp = ( f +
)T1
p
Allora lo speedup è limitato da:
S
p
≤
f
1
1− f
f +
p
per p → ∞
S p → 1/ f
Conseguenza
Una piccola frazione di operazioni sequenziali può limitare fortemente
lo speedup ottenibile da un computer parallelo
Esempio
Se f=0.1 à Sp
10, indipendentemente da quanti processori si hanno
Michele Colajanni – Efficienza delle Applicazioni Parallele
4/22
2
Legge di Barsis-Gustafson
Motivazioni
Diversi studi sperimentali condotti presso il Sandia National Laboratory hanno
dimostrato che per molti problemi era possibile ottenere speedup quasi lineari (circa
1000 con 1024 processori)
Ciò ha condotto ad una rivisitazione della legge di Amdhal:
Il difetto della legge di Amdhal è quello di considerare f e p scorrelati,
cioè dipendenti dalle proprietà statiche dell’algoritmo senza tener conto
della dimensione dello spazio computazionale
Scalando la dimensione del problema con il numero di processori usati,
si ha invece che:
• T 1 non è più indipendente dal numero di processi utilizzati
• T p risulta indipendente dal numero di processori
Ribaltamento del paradigma di Amdhal:
Amdhal: quanto sarà Tp dato T1
Barsis: quanto sarà T1 dato Tp
Michele Colajanni – Efficienza delle Applicazioni Parallele
5/22
Legge di Barsis-Gustafson (cont.)
Esecuzione parallela = Ts + Tw
s
w
s
pw
Esecuzione sequenziale = Ts + p Tw
Sia s la frazione di tempo che una macchina parallela spenderebbe nella
parte seriale del programma e w la frazione che la stessa macchina
parallela spenderebbe nelle parti parallelizzabili del programma medesimo.
S p (scalato) =
Ts + pTw
Ts
Tw
=
+
+p
= s + pw
Ts + Tw Ts + Tw
Ts + Tw
Normalizzando anche in questo caso , cioè supponendo w+s=1, si ha:
= s + p (1 - s) = s + p – ps = p + ( 1 – p ) s
Michele Colajanni – Efficienza delle Applicazioni Parallele
6/22
3
E’ possibile avere speedup superlineare (?)
• Confronto “ disonesto”
(es.: Algoritmo sequenziale non buono)
• Caratteristiche HARDWARE
(Soprattutto dovuto a gerarchie di memoria: cache/disco)
• Anomalie ALGORITMICHE
(es.: algoritmi di ricerca)
T1=11 (tempo sequenziale con tradizionale
Soluzione
algoritmo di ricerca)
T2=4 (tempo parallelo con 2 processori)
Speedup = 11/4 = 2.75!!
Max Speedup (lineare) = 2
Spazio di ricerca
Assegnato al
Processore 1
Spazio di ricerca
Assegnato al
Processore 2
Michele Colajanni – Efficienza delle Applicazioni Parallele
7/22
Analisi delle prestazioni (Modelli analitici)
• Modelli deterministici
• Modelli stocastici
• Modelli a reti di code con Fork-Join
• Task Graph
• Markoviani
Michele Colajanni – Efficienza delle Applicazioni Parallele
8/22
4
Esempio Modelli Deterministici
(Tempo di esecuzione)
Vi sono tre indici temporali che caratterizzano l’esecuzione di un
programma parallelo:
• Tempo di comunicazione
Tcomm
• Tempo di calcolo
Top
• Tempo totale di esecuzione su p processori
COMMUNICATION PENALTY
In molti algoritmi e sistemi paralleli il tempo speso per le
COMUNICAZIONI è una considerevole frazione del tempo totale
necessario a risolvere un problema.
Tale penalizzazione, detta Communication Penalty, può essere espressa
dal rapporto tra il tempo di esecuzione su p processori inclusivo delle
comunicazioni ed il tempo al netto delle comunicazioni, ossia:
CP =
Michele Colajanni – Efficienza delle Applicazioni Parallele
Tex ( p )
Top ( p )
9/22
Cause di inefficienza delle
Applicazioni parallele
(e possibili rimedi)
5
Processo implementativo di un programma SPMD
Programma
Sequenziale
Decomposizione del
Dominio dei Dati
1
2
(Schema di
memorizzazione)
Primitive di
Comunicazione
Programma parallelo
(versione 1)
Strategia
di tuning
Programma parallelo
(versione 2)
Michele Colajanni – Efficienza delle Applicazioni Parallele
11/22
Parametri che Influenzano le Prestazioni
• Bilanciamento del Carico
• Rapporto Comunicazioni/Computazioni
• Colli di Bottiglia
(sequenzializzazioni, sincronizazioni)
• “Tuning” dei Programmi
Michele Colajanni – Efficienza delle Applicazioni Parallele
12/22
6
Programmare i multicomputers
•
Le macchine MIMD a memoria distribuita (muticomputers) raggiungono
buone prestazioni (speedup) soltanto se sono programmate in maniera
opportuna.
•
Sono molto più difficili da programmare rispetto alle SIMD o alle MIMD a
memoria condivisa.
•
In particolare, esiste una granularità ottima dei processi (dati) per ciascun
tipo di problema che deve essere risolto su di un particolare mulicomputer.
•
Nel caso in cui l’insieme di processi abbia una granularità maggiore o minore
di quella ottima, in generale lo speedup non sarà né lineare né
proporzionale al numero di processi presenti.
Michele Colajanni – Efficienza delle Applicazioni Parallele
13/22
Bilanciamento del Carico
Obiettivo: Assegnare a tutti i processori un analogo WORKLOAD
===> Livelli di utilizzazione “simili” significano prestazioni più elevate
POSSIBILI TECNICHE DI MIGLIORAMENTO
• Diminuire la granularità
• Ridistribuzione dinamica di strutture dati o di task
• Ridistribuzione di strutture dati statiche
• Aumentare il livello di multiprogrammazione (per ciascun nodo)
Michele Colajanni – Efficienza delle Applicazioni Parallele
14/22
7
Bilanciamento Dinamico (a Posteriori) dei
Processi
Ottenuto mediante MIGRAZIONE DEI PROCESSI (o STRUTTURE DATI).
Vi sono tre metodi per controllare e gestire l’operazione (centralizzata) della
migrazione:
• Iniziativa del Destinatario
I processori con piccolo workload richiedono più processi
(Adatto nel caso di sistemi molto carichi)
• Iniziativa del Mittente
I processori con eccessivo workload richiedono di poter cedere alcuni
processi ad altri processori
(Adatto nel caso di sistemi poco carichi)
• Metodo Ibrido
Si passa dal primo al secondo metodo a seconda del livello di carico
del sistema.
Michele Colajanni – Efficienza delle Applicazioni Parallele
15/22
Pro e Contro del Bilanciamento Dinamico
+ Si ottiene, tipicamente, un utilizzo maggiore dei processori
± Bisogna evitare la cosiddetta “migrazione circolare”, utilizzando algoritmi
opportuni e valori soglia
- Vi sono elevati costi aggiuntivi sia nel determinare il workload dei
processori che il workload totale
- L’operazione di migrazione di un processo è costosa e dovrebbe essere
effettuata solo per i processi con lunghi tempi di esecuzione
(informazione che spesso non è possibile determinare a priori)
- In genere, tutti i metodi di bilanciamento dinamico intervengono troppo
tardi (quando le prestazioni del sistema sono già degradate). Il
bilanciamento “forward-looking” è possibile solo conoscendo i tempi
di run dei singoli processi.
- Nei sistemi eccessivamente carichi, tutti i metodi di bilanciamento
dinamico non hanno “punti di riferimento”. Per di più, i costi
introdotti dalla gestione del bilanciamento tendono a far peggiorare
ulteriormente le prestazioni del sistema.
16/22
Michele Colajanni – Efficienza delle Applicazioni Parallele
8
Bottleneck di Sequenzializzazione
Obiettivo: Evitare che tutti i processi si mettano in attesa di un singolo processore.
===>Ogni sequenzializzazione forzata del codice influenza in modo considerevole le prestazioni.
Bottleneck del
processore
Bottleneck
del codice
Es., Fattorizzazione LU (decomposizione per colunne)
POSSIBILE TECNICHE DI MIGLIORAMENTO
• Modificare o migliorare l’algoritmo in modo da sovrapporre il codice sequenziale
con altre computazioni
• Distribuire i workload di processori sovraccarichi (bottleneck) tra più processori
17/22
Michele Colajanni – Efficienza delle Applicazioni Parallele
Bottleneck di Sincronizzazione
Obiettivo: Limitare i punti in cui tutti i processori debbano sincronizzarsi.
===> L’ultimo processo ad arrivare al punto di sincronizzazione determina
il tempo di esecuzione globale.
LU factorization (no send-ahead)
POSSIBILI TECNICHE DI MIGLIORAMENTO
• Inviare i valori necessari alle computazioni di altri processori
non appena sono disponibili (send-ahead)
• Modificare o riorganizzare l’algoritmo in modo da eliminare i
punti di sincronizzazione dove non strettamente necessari
Michele Colajanni – Efficienza delle Applicazioni Parallele
18/22
9
Rapporto Comunicazioni/Computazioni
Obiettivo: Minimizzare il rapporto tempo di comunicazione tempo di computazioni
di un programma.
===> Rapporti COMUNICAZIONI/COMPUTAZIONI più bassi implicano prestazioni
più elevate
POSSIBILI TECNICHE DI MIGLIORAMENTO
• Aumentare la granularità
• Ristrutturare il programma in modo da avere meno messaggi, ciascuno
di dimensione maggiore
• Ristrutturare le comunicazioni in modo da combinare messaggi “logicamente multipli”
in messaggi singoli
Michele Colajanni – Efficienza delle Applicazioni Parallele
19/22
“Tuning” dei Programmi
(Ambito: Data Parallelism con Allocazione Statica)
OBIETTIVO 1: MIGLIORARE IL BILANCIAMENTO DEL CARICO
Esempio (Fattorizzazione LU)
• Passare da una decomposizione geometrica ad una decomposizione
ciclica del dominio dei dati
Michele Colajanni – Efficienza delle Applicazioni Parallele
20/22
10
“Tuning” dei Programmi
(Ambito: Data Parallelism con allocazione statica)
OBIETTIVO2: ELIMINARE LE SINCRONIZZAZIONI NON NECESSARIE
Esempio (Fattorizzazione LU)
(1) Algortimo naive (decomposizione per righe)
for k=1 to n-1 do
if (k in mynode)
then broadcast(ak*)
else receive(ak*)
for all (i>k in mynode) do
lik=aik/akk
for j=k+1 to n do
aij=aij-likakj
(2) Algoritmo 1-send-ahead (decomposizione per righe)
if (1 in mynode) then broadcast(ai*)
for k=1 to n-1 do
if not(k in mynode) then receive(ak*)
for all (i>k in mynode) do
lik=aik/akk
for j=k+1 to n do
{aij=aij-likakj
if ((i=k+1) ∧ (i≠n)) then broadcast(ai*) }
Michele Colajanni – Efficienza delle Applicazioni Parallele
21/22
“Tuning” dei Programmi
(Ambito: Data Parallelism con Allocazione Dinamica)
Sebbene lo schema manager-worker migliori considerevolmente il Bilanciamento del Carico,
è possibile effettuare ulteriori miglioramenti agendo sulla granularità dei compiti e
dell’allocazione dei processi.
Esempio (N Regine)
• Determina il numero migliore (del punto di vista del bilanciamento) per ciò che
concerne i sottoproblemi da creare
[Numero di sottoproblemi e numero di messaggi sono inversamente proporzionali]
---> si tende a migliorare il bilanciamento del carico e il rapporto comunic./comput.
• Invia due sottoproblemi per ciascuna comunicazione Manager-Worker
[In tal modo si consente al Worker di sovrapporre una computazione per ogni
richiesta pendente al Manager]
---> si riduce il bottleneck di sequenzializzazione e si migliora il rapporto
comunicazione/computazione
• Se il manager risulta essere poco “carico”, sfrutta il multitasking: aggiungi un
processo Worker anche sul processore che esegue il processo Manager
• Se il Manager risulta essere troppo “carico”, suddividi il lavoro del Manager tra più
processori
Michele Colajanni – Efficienza delle Applicazioni Parallele
22/22
11