Appunti di Statistica Descrittiva∗
30 dicembre 2009
1
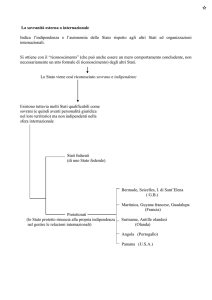
La tabella a doppia entrata
Per studiare dei fenomeni con 2 caratteristiche statistiche si utilizza l’espediente della tabella a doppia entrata. Per
esempio si vuole studiare se le persone con una certa età prediligono se andare al mare o in montagna. Se X è
l’età e Y il luogo di villeggiatura, la tabella a doppia entrata è un modo per descrivere la frequenza del numero di
persone che, nel campione considerato, preferiscono andare in montagna o al mare a partità di età. Generalmente
la tabella a doppia entrata date le caratteristiche statistiche X e Y e le modalità x1 , . . . , xh e y1 , . . . , yk si presenta
in questa maniera:
X/Y
y1
y2
···
yj
···
yk
ni·
x1
n11
n12
···
n1j
···
n1k
n1·
x2
..
.
n21
..
.
n22
..
.
···
n2j
..
.
···
n2k
..
.
n2·
..
.
xi
..
.
ni1
..
.
ni2
..
.
···
nij
..
.
···
nik
..
.
ni·
..
.
xh
nh1
nh2
···
nhj
···
nhk
nh·
n·j
n·1
n·2
···
n·j
···
n·k
n
dove nij viene chiamata genericamente la frequenza congiunta, ovvero la frequenza dell’evento che contemporaneamente possiede l’attributo della modalità xi e l’attributo della modalità yj , mentre ni· e n·j sono le frequenze
marginali rispettivamente di X e di Y . La tabella delle frequenze assolute ha queste proprietà:
ni· =
k
X
nij
j=1
n·j =
h
X
nij
i=1
∗ Questa dispensa è frutto della mente malata di Federico Carlini. Quindi, se trovaste errori, mandate una mail a questo losco
individuo a [email protected], così potrò sistemare il tutto. Vi ringrazio per la collaborazione!
1
n=
h X
k
X
k
X
nij =
i=1 j=1
n·j =
j=1
h
X
ni·
i=1
La tabella con le frequenze relative invece si ottiene sostituendo le frequenze assolute nij con le frequenze relative
fij calcolate in questa maniera:
fij =
nij
n
e avremo anzichè le marginali assolute n·i o nj· , le marginali relative f·i o fj· ,
fi· =
h
X
fij
i=1
f·j =
k
X
fij
j=1
e si può dimostrare che:
h X
k
X
fij =
i=1 j=1
k
X
fi· =
j=1
h
X
f·j = 1
i=1
Proviamo a vedere questi concetti in un esempio numerico. Si considerino tutti gli studenti del dipartimento di
Economia che in estate sono andati al mare o in montagna. Chiamiamo X la caratteristica che distingue il luogo di
villeggiatura (ovvero montagna/mare) e chiamiamo Y la caratteristica che distingue le classi di età (vale la regola
che coloro che vanno in montagna non possono andare al mare). Proviamo ora a scrivere la tabella a doppia entrata
con le frequenze assolute:
X/Y
19 a 21
21 a 23
23 a 25
ni·
montagna
40
30
50
40 + 30 + 50 = 120
mare
100
150
80
100 + 150 + 80 = 330
n·j
40 + 100 =140
30 + 150 = 180
50 + 80 = 130
140 + 180 + 130
=
450
120 + 330
=
450
Se dovessimo riscrivere la tabella con le frequenze relative, si trova che
X/Y
19 a 21
21 a 23
23 a 25
fi·
montagna
40/450 = 0, 089
30/450 = 0.067
50/450 = 0.111
0.267
mare
100/450 = 0.222
150/450 = 0.333
80/450 = 0.178
0.733
f·j
0.311
0.4
0.289
1
E si può notare come tutte le proprietà descritte precedentemente siano vere.
2
1.1
La distribuzione marginale
La distribuzione marginale vorrebbe riassumere nient’altro che la distribuzione di X e la distribuzione di Y , senza
che si osservino i legami tra le due varabili (per essere veri statistici si direbbere unconditionally o non condizionatamente). Quindi se dovessimo rappresentare la marginale assoluta di Y date le modalità y1 , . . . , yk , e la marginale
relativa di X date le modalità x1 , . . . , xh , esse si possono rappresentare tramite tabelle come:
Y
nij
X
fij
y1
n·1
x1
f1·
y2
..
.
n·2
..
.
x2
..
.
f2·
..
.
yk−1
n·(k−1)
xh−1
f(h−1)·
yk
n·k
xh
fh·
n
1
Oppure si può ricorrere a quest’altra notazione:
nY = (n·1 , n·2 , . . . , n·k )
fX = (f1· , f2· , . . . , fk· )
Quindi, per essere più intuitivi, se volessimo calcolare la distribuzioni marginale di Y dobbiamo “fregarcene” di
quello che succede alla caratteristica X. Inoltre è bene ricordarsi che dalle distribuzioni congiunte si possono
ottenere le distribuzioni marginali univocamente, ma non è possibile il viceversa. Nell’esempio precedente avremo
che la distribuzione marginale assoluta di Y e la distribuzione marginale relativa di X sono:
Y
nij
19 a 21
140
21 a 23
180
23 a 25
70
fij
montagna
0.267
mare
0.733
1
450
1.2
X
La distribuzione condizionata
La distribuzione condizionata è un altro concetto importante e più sofisticato della marginale, in cui cerchiamo
di capire le distribuzioni di una caratteristica (ad esempio la Y ) rispetto ad una modalità dell’altra caratteristica
(ad esempio xi ). La distribuzione condizionata viene descritta dalle tabelle seguenti, la prima per la distribuzione
assoluta, mentre la seconda per la distribuzione relativa.
3
Y |xi
n
Y |xi
f
y1 |xi
ni1
y1 |xi
ni1 /ni· = fi1 /fi·
y2 |xi
..
.
ni2
..
.
y2 |xi
..
.
ni2 /ni· = fi2 /fi·
..
.
yk−1 |xi
ni(k−1)
yk−1 |xi
ni(k−1) /ni· = fi(k−1) /fi·
yk |xi
nik
yk |xi
nik /ni· = fik /fi·
ni·
1
Ogni distribuzione relativa, come al solito, ha la caratteristica che le frequenze relative sommano ad 1. Ma intuitivamente cosa significa calcolare la distribuzione condizionale? In prima analisi significa vedere qual è la distribuzione
delle frequenze di una caratteristica statistica (in questo caso la Y ) rispetto ad una sola modalità della caratteristica
statistica X. In generale, per ogni xi 6= xj , si avranno le distribuzioni condizionate Y |xi e Y |xj diverse. Ovviamente
nulla ci vieta di trovare le condizionali X|yj ,che avranno anch’esse certe caratteristiche distributive. Per ultimo si
ricordi che con qualche condizione sulle distribuzioni condizionate ed alcune condizioni sulle distribuzioni marginali
si possono trovare le congiunte.
Se vogliamo calcolare le distribuzioni condizionate assoluta di Y |x2 e la distribuzione condizionata relativa di X|y1
nell’esempio numerico otteniamo
Y |x2
n
y1 |x2
100
y2 |x2
150
y3 |x2
80
X|y1
f
x1 |y1
40/140 = 0.286
x2 |y2
100/140 = 0.714
1
330
2
Indipendenza stocastica
Si dice che i 2 fenomeni X ed Y sono detti stocasticamente indipendenti se:
1. Le distribuzioni condizionali relative di Y |xi sono uguali per ogni i = 1, . . . , h
2. Le distribuzioni condizionali relative di X|yj sono uguali per ogni j = 1, . . . , k
3. Le distribuzioni condizionali relative di Y |xi sono uguali alla distribuzione marginale relativa di Y
4. Le distribuzioni condizionali relative di X|yj sono uguali alle distribuzioni marginali relativa di X
Per capire meglio cosa sia l’indipendenza stocastica facciamo un esempio numerico. Abbiamo una tabella a doppia
entrata così fatta:
X/Y
2
3
5
ni·
1
5
10
20
35
2
10
20
40
70
n·j
15
30
60
105
4
Innanzitutto si osservi come le righe (e le colonne) siano proporzionali l’una con l’altra (ovvero ogni riga (colonna)
è combinazione lineare delle altre righe (colonne)). Ora proviamo a calcolare le distribuzioni delle frequenze relative
condizionate e otteniamo che:
5 10 20
10 20 40
fY |x1 =
, ,
fY |x2 =
, ,
35 35 35
70 70 70
fX|y1 =
5 10
,
15 15
fX|y2 =
10 20
,
30 30
fX|y3 =
20 40
,
60 60
Ora calcoliamo le distribuzioni delle frequenze relative marginali per ottenere che:
fY =
15 30 60
,
,
105 105 105
fX =
35 70
,
105 105
A questo punto si nota facendo i calcoli che fY |x1 = fY |x2 = fY e che fX|y1 = fX|y2 = fX|y3 = fX e questa è la
proprietà per la quale si definisce l’indipendenza stocastica. Quindi:
Definizione 1: Parliamo di indipendenza stocastica tra X ed Y se e solo se le distribuzioni condizionate relative
ad una variabile (Y e X) sono uguali alle distribuzioni delle frequenze marginali relative della stessa variabile, cioè
in una tabella a doppia entrata in generale vale che:
fY |x1 = fY |x2 = . . . = fY |xh = fY
fX|y1 = fX|y2 = . . . = fX|yk = fX
2.1
Frequenze teoriche
Ora proviamo a calcolare le frequenze teoriche dell’esercizio del paragrafo precedente, definite come:
n̂ij =
ni· · n·j
n
con n, ovvero il numero totale di osservazioni.
Se si provano a calcolare quindi le frequenze teoriche nell’esercizio del paragrafo precedente si ottiene che:
n̂ij
2
3
5
n̂i·
1
5
10
20
35
2
10
20
40
70
n̂·j
15
30
60
105
e si nota come esse siano identiche a quelle di partenza. Pertanto un’altra condizione che può essere utile per parlare
di indipendenza stocastica è la seguente.
5
Definizione 1(bis): Parliamo di indipendenza stocastica tra Y ed X se e solo se le frequenze teoriche sono uguali
alle frequenze osservate, ovvero
nij = n̂ij
che implica, tramite la definizione 1, che:
nij
n·j
=
= Kj
ni·
n
∀i = 1, . . . h
ni·
nij
=
= Hi
n·j
n
∀j = 1, . . . k
con Hi e Kj fissati.
2.2
Indici di connessione: χ2 di Pearson
Prima di definire questo indice bisogna parlare della tabella delle contingenze, dove ogni elemento della stessa è
definito come
cij = (nij − n̂ij )
Questa matrice ha le seguenti proprietà:
h
X
cij = 0
i=1
k
X
cij = 0
j=1
h X
k
X
cij = 0
i=1 j=1
L’indice di Pearson assoluto è un indice che serve a quantificare la dipendenza funzionale tra due variabili X ed Y .
Esso viene definito in questo modo:
χ2 =
h X
k
2
X
(cij )
i=1 j=1
n̂ij
=
k
h X
2
X
(nij − n̂ij )
n̂ij
i=1 j=1
Intuitivamente esso mi dice quanto dista, pesando opportunamente coi diversi valori delle frequenze teoriche, la
frequenza osservata da quella teorica. Tale indice se è pari a χ2 = 0 allora vi è indipendenza stocastica mentre se
tale indice è pari a χ2 = n · min{(h − 1), (k − 1)} allora vi è massima dipendenza funzionale tra i fenomeni X ed Y .
A questo punto si preferisce avere un indice standard che permette comparazioni tra diverse tabelle, e si costruisce
il χ2N normalizzato come
χ2N =
χ2
n · min{(h − 1), (k − 1)}
che ha la caratteristica per cui
0 ≤ χ2N ≤ 1
6
dove per 0 si intende che vi sia indipendenza stocastica mentre per 1 si intende che esista massima dipendenza.
Esso inoltre ha la caratteristica di essere simmetrico ovvero:
χ2N (Y |X) = χ2N (X|Y )
(Bonus question : provare a ragionare perchè χ2 è simmetrico)
2.3
Indice χ2 e indipendenza stocastica
Per capire come sono correlati l’indice χ2 e l’indipendenza stocastica, calcoliamo prima nell’esempio la tabella delle
contingenze e otteniamo:
cij
2
3
5
ci·
1
0
0
0
0
2
0
0
0
0
c·j
0
0
0
0
Dato che l’indice χ2 è definito come:
2
χ =
h X
k
X
(cij )2
i=1 j=1
n̂ij
allora si nota come nel nostro esempio, dacchè la matrice dei cij è coperta di zeri, χ2 = 0. Quindi si può interpretare
questo fatto, secondo la seguente definizione:
Definizione 1(ter): Si dice che X ed Y siano indipendenti stocasticamente se e solo se la tabella delle contingenze
è coperta da zeri il che implica, per la definizione stessa di χ2 , che l’indice stesso sia pari a
χ2 = 0
3
Regressione in media
Per andare ad analizzare se esiste una dipendenza tra i dati e descrivere quale sia l’andamento al variare di Y ad
X utilizziamo modelli teorici del tipo
y ∗ = g(x)
che approssimino al meglio le diverse osservazioni (xi , yi ). Il modello sicuramente non rappresenterà la realtà (le
frequenze osservate) , quindi esso avrà un termine di errore che lo definiamo come la differenza tra valore osservato
y e il valore teorico del modello y ∗ ovvero
ei = yi − yi∗ = yi − g(xi ) ∀i
Questo errore di misura bisognerà minimizzarlo per ottenere la migliore interpolante tra modello teorico e dati
osservati, minimizzando una funzione L(y − y ∗ ). Come funzione, in particolare, si prende la media quadratica e
quindi il problema diventa
min M (e) = min M [(y − g(x))2 ]
7
ovvero si cerca di minimizzare la “distanza” quadratica (sempre positiva) tra i dati osservati e il modello condizionato
sulle x. Prima di partire a descrivere il modello definiamo gli ingredienti che si utilizzano per calcolare questa
funzione.
3.1
Media marginale
La media marginale è relativa sia ad X sia ad Y e vengono definite come:
M (X) = µX =
h
X
xi ni· /n =
i=1
M (Y ) = µY =
k
X
xi fi·
i=1
yj n·j /n =
j=1
3.2
h
X
k
X
yj f·j
j=1
Varianza marginale
La varianza marginale anch’essa e relativa sia ad X sia ad Y ed essendo il momento centrale secondo vengono
definite come:
Var(X) =
2
σX
h
h
X
X
2
=
(xi − µX ) ni· /n =
(xi − µX )2 fi·
Var(Y ) = σY2 =
3.3
i=1
i=1
k
X
k
X
(yj − µY )2 f·j
j=1
j=1
(yj − µY )2 n·j /n =
Medie condizionate
Le medie condizionate sono le medie delle distribuzioni Y |xi o X|yj e vengono definite come
M (Y |xi ) = µY (xi ) =
k
X
yj nij /ni·
j=1
M (X|yj ) = µX (yj ) =
h
X
xi nij /n·j
i=1
3.4
Varianze condizionate
Le varianze condizionate sono le varianze delle distribuzioni Y |xi o X|yj e vengono definite come:
Var(Y |xi ) = σY2 (xi ) =
k
X
(yj − µY )2 nij /ni·
j=1
2
Var(X|yj ) = σX
(yj ) =
h
X
(xi − µX )2 nij /n·j
i=1
8
3.5
La scomposizione della varianza
Esiste un teorema che recita così: la varianza totale di una certa variabile aleatoria si può suddividere in 2 addendi:
la varianza residua e la varianza spiegata. Ovvero:
σY2 = σ̄Y2 + σY2∗
in cui
σ̄Y2 = Var(µY (X)) =
h
X
(µY (xi ) − µY )2 fi·
i=1
è la varianza delle medie condizionate (o varianza spiegata o betweeness), mentre
σY2∗ =
h
X
Var(Y |xi ) =
i=1
h X
k
X
(yj − µY (xi ))2 fij
i=1 j=1
è la media delle varianze condizionate (o varianza residua o within).
La dimostrazione sta nel fatto di aggiungere e togliere dalla varianza totale la media condizionale delle xi e poi
svolgendo i calcoli si scopre che il doppio prodotto è nullo!
Dimostrazione: Partiamo dalla varianza totale per capire poi quali sono le componenti:
k
X
(yj − µY )2 f·j =
(yj − µY (xi ) + µY (xi ) − µY )2 f·j =
j=1
j=1
=
k
X
k
X
(yj − µY (xi ))2 f·j +
j=1
j=1
{z
|
k
k
X
X
(µY (xi ) − µY )2 f·j + 2
(yj − µY (xi ))(µY (xi ) − µY )f·j
I
}
|
j=1
{z
II
}
|
{z
III
}
Primo addendo:
I)
k
X
(yj − µY (xi ))2 f·j =
j=1
k
X
(yj − µY (xi ))2
j=1
h
X
fij =
i=1
h X
k
X
(yj − µY (xi ))2 fij = σY2∗
i=1 j=1
Secondo addendo:
h
h X
k
k
X
X
X
(µY (xi ) − µY )2 fi· = σ̄Y2
(µY (xi ) − µY )2 fij =
II) (µY (xi ) − µY )2 f·j =
j=1
i=1 j=1
i=1
Terzo addendo:
III) Si può dimostrare che è pari a 0, moltiplicando e dividendo per fi· , e utilizzando le proprietà della media.
3.6
L’indice di adattamento
Esso viene indicato con ηY2 ed esso indica la percentuale di variabilità spiegata dal modello delle medie condizionali.
Esso è pari a
ηY2 =
σ 2∗
σ̄Y2
= 1 − Y2
2
σY
σY
ed è normalizzato nel senso che vale
0 ≤ ηY2 ≤ 1
9
in cui se l’indice è pari a 0 indica indipendenza in MEDIA e mentre se l’indice è pari 1 vi è dipendenza FUNZIONALE.
La differenza tra indipendenza stocastica e in media è la seguente:
1. Indipendenza stocastica : esiste se vi è uguaglianza di frequenza relativa delle variabili condizionate (quindi
conserva proprietà simmetriche)
2. Indipendenza in media : esiste se vi è uguaglianza tra le medie delle variabili condizionate Y |X o X|Y (quindi
non è simmetrica)
Inoltre vale che:
Indipendenza stocastica ⇒ Indipendenza in media
ma NON è VERO il viceversa!!!!!
Quindi, in generale vale che
2
ηX
6= ηY2
tranne se vi sia:
1. indipendenza stocastica
2. perfetta dipendenza funzionale biunivoca
3. uguaglianza tra la distribuzione delle medie condizionate di Y |X, la distribuzione delle medie condizionate di
2
e σY2 .
X|Y e uguaglianza tra le varianze marginali σX
4
Indipendenza in media
Ora proviamo a ragionare su un’altro concetto che è quello relativo alll’indipendenza in media. Partiamo da una
tabella a doppia entrata per capire tramite un esempio:
X/Y
5
10
20
ni·
1
0
3
2
5
3
2
0
3
5
n·j
2
3
5
10
Si può dimostrare che in questa tabella non vi sia indipendenza stocastica (dimostrarlo!)
Ora calcoliamo, anzichè le distribuzioni, le medie condizionate rispetto alla Y e poi rispetto alla X e otteniamo :
µY (x1 ) = 10 ·
µX (y1 ) = 3 ·
2
2
3
5
+ 20 ·
=3
2
5
= 14
µY (x2 ) = 5 ·
µX (y2 ) = 1 ·
3
3
=1
2
5
+ 20 ·
3
5
= 14
µX (y3 ) = 1 ·
2
5
+3·
3
5
=
11
5
Ora calcoliamo le medie marginali rispetto alla Y e poi rispetto alla X:
µY = 5 ·
2
3
5
+ 10 ·
+ 20 ·
= 14
10
10
10
10
µX = 1 ·
5
5
+3·
=2
10
10
Da qui si può notare come per la variabile Y si trovi che µY (x1 ) = µY (x2 ) = µY mentre per la variabile X abbiamo
che le medie sono tutte diverse. Infatti µX (y1 ) 6= µX (y2 ) 6= µX (y3 ) 6= µX . Ora definiamo che cosa intendiamo per
indipendenza in media:
Definizione 2:
Si dice che la variabile Y (X) ha indipendenza in media se sono tutte uguali le medie condizionali di Y (X) e tutte
queste sono pari alla media marginale di Y (X). Quindi deve valere in generale che:
µY (x1 ) = µY (x2 ) = . . . = µY (xh ) = µY
per l’indipendenza in media della Y oppure
µX (y1 ) = µX (y2 ) = . . . = µX (yk ) = µX
per l’indipendenza in media della X.
Da questa definizione si puo’ capire che l’indipendenza in media non è simmetrica, infatti si parla di indipendenza
in media per la Y (o per la X).
4.1
La scomposizione della varianza
La varianza della variabile Y si può scomporre in 2 componenti, cioè:
σY2 = σ̄Y2 + σY2∗
dove σ̄Y2 è la varianza spiegata, ovvero la varianza delle medie condizionate, mentre σY2∗ è la varianza residua, ovvero
la media delle varianze condizionate.
Ora soffermiamoci sulla varianza residua, e proviamo a calcolarla. Per calcolarla ci servono innanzitutto le varianze
condizionate di Y e otteniamo
σY2 (x1 ) = M (Y 2 |x1 ) − µ2Y (x1 ) = 102 ·
σY2 (x2 ) = M (Y 2 |x2 ) − µ2Y (x2 ) = 52 ·
2
5
3
5
+ 202 ·
+ 202 ·
3
5
2
5
− 142 = 24
− 142 = 54
E ne calcoliamo la media ovvero
σY2∗ = M (σY2 (xi ) = 24 ·
5
5
+ 54 ·
= 39
10
10
Poi calcoliamo la varianza di Y come
σY2 = M (Y 2 ) − µ2Y = 52 ·
2
3
5
+ 102 ·
+ 202 ·
− 142 = 39
10
10
10
Si noti come in questo caso abbiamo che M (σY2 (xi )) = σY2 . Questa è la seconda caratteristica che ci permette di
dire che Y ha indipendenza in media. Si può dimostrare che in questo esempio che la variabile X ha la proprietà
2∗
2
che σX
< σX
. Quindi una seconda definizione di indipendenza in media sarà:
11
Definizione 2(bis): Si dice che la caratteristica Y ha indipendenza in media se e solo se
σY2∗ = σY2
4.2
Indice di adattamento
L’indice di adattamento per la Y (analogamente viene definito per la X cambiando i pedici) viene definito in questo
modo:
ηY2 =
σ̄Y2
σY2∗
=
1
−
σY2
σY2
Dalla definizione 2(bis) abbiamo che se σY2∗ = σY2 allora vale che
quindi:
ηY2 = 1 −
σY2∗
= 1 se vi è indipendenza in media per la Y ,
σY2
σY2∗
=1−1=0
σY2
Perciò si può scrivere che in generale vale che:
Definizione 2(ter): Si dice che la caratteristica Y ha indipendenza in media se e solo se
ηY2 = 0
5
Relazione tra indipendenza stocastica e indipendenza in media
Esiste una relazione tra indipendenza stocastica e indipendenza in media.
Teorema 3: L’indipendenza stocastica implica l’indipendenza in media, ma non il viceversa.
Questo lo si può dimostrare nel primo esercizio, come? Ad esempio dimostrando che esiste indipendenza in media per
l’esercizio del paragrafo 1! Invece si può dimostrare facilmente che nell’esercizio del paragrafo 2, esiste indipendenza
in media per la Y , ma non è vero che vi è indipendenza stocastica.
Il teorema 3 può essere riscritto anche attraverso gli indici χ2 e ηY2 cioè
Teorema 3(bis): Per l’indipendenza stocastica e l’indipendenza in media valgono le seguenti relazioni:
2
χ2 = 0 ⇒ ηY2 = 0 e ηX
= 0 contemporaneamente
mentre
2
ηY2 = 0 oppure ηX
= 0 ; χ2 = 0
6
La regressione lineare
Osserviamo le variabili (xi , yi ) per i = 1, . . . , n ponendo il caso che la frequenza delle osservazioni sia pari ad 1
(questo per farci sveltire i calcoli). Il modello di regressione lineare parte con l’idea che ciò che possa descrivere
meglio la dipendenza funzionale dei due fenomeni sia una retta. Quindi ora costruiamo il modello
ŷi = a + bxi
12
che descrive la media condizionale di Y |X. Come in tutti i modelli, la media condizionale, espressa dalla retta, ha
un errore che, se yi sono i valori osservati, viene espresso da
ei = yi − ŷi = yi − a − bxi
che viene chiamato residuo. Per stimare poi i parametri del modello si procede come nella regressione in media
ovvero si minimizza la media quadratica dei residui, ovvero
min e2 = min(y − a − bx)2
e
a,b
e sta a significare che si risolve il problema di massimizzazione.
6.1
La covarianza
Ci serve ancora un ingrediente per capire come si stimino i parametri, ovvero il concetto di covarianza che, in questo
caso con frequenza pari ad 1, lo si può scrivere come
Cov(X, Y ) =
n X
n
X
[(xi − µX )(yi − µY )]
n
i=1 j=1
P
=
i
xi yi
− µX µY
n
mentre se le frequenze non fossero pari ad 1 si avrà
Cov(X, Y ) =
h X
k
h X
k
X
X
[(xi − µX )(yi − µY )] · fij =
xi yi fij − µX µY
i=1 j=1
i=1 j=1
e ricordiamo anche che
Var(X ± Y ) = Var(X) + Var(Y ) ± 2Cov(X, Y )
Si può dimostrare infatti, grazie a questa condizione (facendo prima il modulo e poi la radice quadrata di tutto)
che:
|Cov(X, Y )| ≤ σX σY
6.2
La correlazione lineare
E’ un indice che serve ad identificare qual’è la correlazione lineare tra due variabili X ed Y , cercandola di
normalizzare. Essa viene espressa con
ρ=
Cov(X, Y )
σX σY
ed ha la proprietà di essere compresa nell’intervallo
−1 ≤ ρ ≤ 1
ed essa assume valore pari a 0 se vi è incorrelazione, pari ad 1 se la correlazione è perfettamente lineare e diretta
(il coefficiente angolare della retta è positivo) ed è pari a -1 se la correlazione è perfettamente lineare ma inversa (il
coefficiente angolare della retta è negativo).
13
6.3
Stima dei parametri
Per stimare i parametri bisogna minimizzare lo squarto quadratico medio, ovvero
min e2 = min(yi − a − bxi )2 = min f (xi )
e
a,b
a,b
si ottiene che le condizioni di minimizzazione, per una singola osservazione saranno date da
∂f
= −2(yi − a − bxi ) = 0
∂a
∂f
= −2(yi − a − bxi )xi = 0
∂b
da cui sommando i termini si ottiene che
Pn y − Pn a − Pn bx = 0
i
i=1
i=1
i=1 i
P
P
P
n
n
n
2
i=1 xi yi −
i=1 axi −
i=1 bxi = 0
che mi danno le soluzioni
b̂ =
Cov(X, Y )
2
σX
â = M (Y ) − b̂M (X) = µY − b̂µX
È bene ricordarsi che X può essere qualsiasi funzione degli x quindi se dovessimo studiare per esempio la retta di
regressione1
y = a + b log x
basta sostituire ad x la trasformazione logaritmica log x e si completano così i calcoli.
6.4
L’indice ρ2
Questo è un indice di bontà di adattamento della regressione lineare ovvero quanto il mio modello (la retta)
descrive bene il comportamento dei dati. Quindi diciamo che si può vedere come un indice ηY2 particolare, ovvero
l’interpolante qua è per forza di cose lineare. Anche in questo caso, prima di parlare dell’indice ρ2 dobbiamo parlare
di varianza totale, varianza residua e varianza totale. Esse seguono, tramite un teorema, questa relazione:
2
σY2 = σSP
+ σY2 R
dove la prima è la varianza totale la seconda è la varianza spiegata e la terza è la varianza totale. Ne segue qui che
l’indice di bontà di adattamento lineare è descritto da
ρ2 =
2
σSP
σY2 R
=
1
−
σY2
σY2
1 Una particolare trasformazione è ey = abx che può diventare attraverso una trasformazione logaritmica una regressione lineare del
tipo y = log a + (log b)x e chiamando α = log a e β = log b si ottiene
y = α + βx
14
e vale che
0 ≤ ρ2 ≤ 1
a stare a dire che se ρ2 = 0 allora vi è incorrelazione tra i dati mentre se ρ2 = 1 la dipendenza lineare è massima
(ovvero che i dati osservati stanno effettivamente su una retta).
7
Per ricapitolare...
Si NOTI bene:
1. L’indice η 2 si riferisce a qualsiasi funzione di regressione (ciò implica che può anche non essere una retta...)
2. L’indice ρ2 si riferisce solo ad una retta di regressione!!!
15