BASI DI DATI 2
Sommario
Sommario ............................................................................................................................................. 1
Lezione 1 .............................................................................................................................................. 3
Dipendenze Funzionali ................................................................................................................ 3
Forme Normali ................................................................................................................................. 3
Lezione 2 .............................................................................................................................................. 5
Algoritmo per la copertura minimale ............................................................................................... 5
Dipendenze multivalore (MVD) ...................................................................................................... 6
Decomposizione LJ in relazioni 4NF............................................................................................... 6
Lezione 3 .............................................................................................................................................. 7
Il Sistema Informativo ..................................................................................................................... 7
Il ciclo di vita ................................................................................................................................... 7
Fasi del Macro Ciclo di vita ............................................................................................................. 7
Fasi del Micro Ciclo di vita.............................................................................................................. 7
Il processo di progettazione di un database ..................................................................................... 8
La progettazione fisica nei database relazionali .............................................................................. 9
Denormalizzare uno schema .......................................................................................................... 10
Lezione 4 ............................................................................................................................................ 11
Memorizzazione di record ed organizzazione dei file ................................................................... 11
Tecnologia RAID ........................................................................................................................... 12
Lezione 5 ............................................................................................................................................ 13
Indici .............................................................................................................................................. 13
Alberi di ricerca ............................................................................................................................. 15
Definizione formale B-Tree ........................................................................................................... 15
I B+-Tree......................................................................................................................................... 16
Lezione 6 ............................................................................................................................................ 18
Gestione delle transazioni .............................................................................................................. 18
Algoritmo per la serializzabilità ................................................................................................. 21
Lezione 7 ............................................................................................................................................ 22
Tecniche per il controllo della concorrenza ............................................................................... 22
Tecniche di Locking ................................................................................................................... 22
Regole per lock shared/esclusivi ................................................................................................ 24
Il protocollo Two-Phase Locking ............................................................................................... 24
Lezione 8 ............................................................................................................................................ 26
Tecniche di Recovery ................................................................................................................. 26
Protocollo WAL (Write-Ahead Logging) ................................................................................... 27
Tecniche di recovery basate su aggiornamento differito ............................................................ 27
1
BASI DI DATI 2
Recovery con deferred update in ambiente multiutente............................................................. 27
Tecniche di Recovery basate su Immediate Update ................................................................... 28
Backup-Restore del DB ............................................................................................................. 28
Lezione 9 ............................................................................................................................................ 29
Concetti sui database Object-Oriented ....................................................................................... 29
Gli Oggetti.................................................................................................................................. 29
Incapsulamento di Operazioni, Metodi e Persistenza ................................................................ 30
Gerarchie ed Ereditarietà nei DBMS O-O ................................................................................. 31
Oggetti Complessi ...................................................................................................................... 31
Lezione 10 .......................................................................................................................................... 32
Standard, linguaggi e progettazione di database ad oggetti ....................................................... 32
L’Object Definition Language ................................................................................................... 33
L’Object Query Language .......................................................................................................... 33
Progettazione concettuale di database ad oggetti ....................................................................... 35
Lezione 11 – Basi di Dati Distribuite ed Architetture Client-Server ................................................. 36
La tecnologia per i DDB ............................................................................................................ 36
Tipi di architetture multiprocessore ........................................................................................... 36
Architettura di un DDB .............................................................................................................. 36
Tipi di trasparenza ...................................................................................................................... 36
Funzionalità addizionali caratteristiche dei DDBMS ................................................................ 37
Frammentazione dei Dati ........................................................................................................... 38
Replicazione ed Allocazione di dati ........................................................................................... 39
Esempi di frammentazione, allocazione e replicazione ............................................................. 40
Esempio: Conti correnti bancari ........................................................................................................ 42
Livelli di trasparenza .................................................................................................................. 43
Efficienza ................................................................................................................................... 43
Tipi di DDB................................................................................................................................ 43
Sistemi per la gestione dei DB Federati ..................................................................................... 44
Architettura Client-Server .......................................................................................................... 45
Lezione 12 – XML e basi di dati in Internet ...................................................................................... 47
Approcci alla memorizzazione di documenti XML....................................................................... 48
XPath.............................................................................................................................................. 49
XQuery ........................................................................................................................................... 50
Esempi ............................................................................................................................................ 50
2
BASI DI DATI 2
Lezione 1
Nella progettazione della base di dati bisogna utilizzare una semantica chiara, ovvero l'utente deve
capire, in modo facile, il contenuto degli attributi in modo da rendere facili e veloci le query.
Esistono delle misure informali di qualità per disegni di schemi di relazioni:
semantica degli attributi;
riduzioni dei valori ridondanti dalle tuple;
riduzione dei valori null delle tuple;
non consentire tuple spurie.
La riduzione dei valori ridondanti consente di risparmiare memoria. Inoltre si devono evitare
Update Anomalies che si dividono in:
Insertion Anomalies: inserimento di una nuova tupla che contiene valori nulli che non
possono essere inseriti in questo modo (es. se un dipartimento ha un manager non posso
inserire un dipartimento senza avere il manager).
Deletion Anomalies: la cancellazione di tuple potrebbe portare ad una grande
inconsistenza, ad esempio se ho una tabella impiegato con un attributo dipartimento e non
ho una tabella solo per dipartimento, cancellando l'ultimo impiegato di quel dipartimento
eliminerei l'esistenza di quest’ultimo dall'intero DB.
Modification Anomalies: se cambio il valore di un attributo da una tupla devo aggiornare
tutte le altre che hanno quel valore, altrimenti l’attributo diventa inconsistente.
Un altro aspetto da considerare è l'eliminazione dei valori null dalle tuple. Si possono creare delle
nuove relazioni per eliminare gli attributi che causano la presenza di valori null. Avere molti valori
null è uno spreco di spazio ed inoltre può dare problemi nel fare il join.
Bisogna considerare anche le tuple spurie che possono generarsi nel fare un join, ad esempio una
cattiva scelta di chiavi primarie ed esterne potrebbe portare ad un join completamente sbagliato
che genera tuple che non rispecchiano la realtà. Se consideriamo una tabella impiegato con
l'attributo progetto e una tabella dove si considera il progetto (in generale) con tutte le ore di
lavoro che ha richiesto, se eseguiamo un join attribuiamo tutte quelle ore ad ogni impiegato.
Dipendenze Funzionali
Le dipendenze funzionali (FD) rappresentano un vincolo tra due insiemi di attributi del database,
sono denotate da X → Y (Y è funzionalmente dipendente da X).
La cosa importante è che per vedere le inferenze di X, si effettua la chiusura denotata da X +, ovvero
si vede a partire da X tutti gli attributi che si possono raggiungere.
La notazione F ‡ X → Y denota che la FD X → Y è inferita da F.
Le regole principali sono:
(IR 1) Reflexive Se 𝑋 ⊇ 𝑌allora X → Y
(IR 2) Augumentation X → Y ‡ XZ → YZ
(IR 3) Transitive ,X → Y , Y → Z- ‡ X → Z
Inoltre:
(IR 4) Decomposition o Projective ,X → YZ- ‡ X → Z
(IR 5) Union ,X → Y , X → Z- ‡ X → YZ
(IR 6) Pseudotransitive , X → Y , WY → Z- ‡ WX → Z
È stato provato che le prime tre regole sono regole di inferenze corrette e complete (Armstrong).
Forme Normali
Le forme normali forniscono un ambito formale per analizzare schemi di relazione basato su chiavi
3
BASI DI DATI 2
e dipendenze degli attributi. Gli schemi devono superare il test altrimenti la relazione che viola il
test deve essere decomposta in tante relazioni tali che singolarmente superino il test.
(1NF) Non consente attributi multivalore o composti. La soluzione è quella di rimuovere gli
attributi della relazione annidata, crearne una nuova e propagare la chiave primaria in essa.
(2NF) Non consente dipendenze parziali dalla chiave primaria (ovvero se la chiave primaria non è
composta da un solo attributo non possono esserci attributi che dipendono da una parte della
chiave, ma devono dipendere da tutta la chiave). Se uno schema di relazione non è in 2NF può
essere ulteriormente normalizzato in un certo numero di relazioni in 2NF, in cui gli attributi non
primi sono associati solo con la parte di chiave primaria da cui sono funzionalmente dipendenti
pienamente.
(3NF) Non ammette dipendenze transitive ovvero tutti gli attributi dell'entità devono dipendere
solo dalla chiave primaria e non da attributi che sono dipendenti dalla chiave primaria. Inoltre la
relazione deve essere 2NF.
Uno schema R è nella forma di Boyce Codd se ogni qualvolta vale in R una dipendenza funzionale X
→ A, allora X è una superchiave di R.
4
BASI DI DATI 2
Lezione 2
La progettazione di un DB relazionale può avvenire in modo Top-Down (si parte dall'ER e si effettua
la normalizzazione) oppure Bottom-Up (si considera lo schema del DB solo in termini di
dipendenze funzionali e poi si effettua la normalizzazione).
Nell'applicare la normalizzazione bisogna conservare gli attributi (basta controllare se gli attributi
di ogni entità sono presenti nel nuovo schema) e le dipendenze (bisogna “navigare” nel nuovo
schema e per ogni relazione dobbiamo vedere se la parte destra della dipendenza è raggiungibile
partendo da quella sinistra, percorrendo cammini dettati da una dipendenza).
Algoritmo per la copertura minimale
Una copertura minimale di un insieme E di dipendenze funzionali è un insieme minimale F di
dipendenze che è equivalente a E. Si parte dall'insieme di tutte le dipendenze funzionali possibili,
poi si procede ad eliminare le entità che non comportano modifiche delle dipendenze funzionali.
Algoritmo di sintesi relazionale
Decomposizione dependency-preserving in schemi di relazione 3NF:
1. trovare una copertura minimale G di F;
2. per ogni parte sinistra X di una dipendenza funzionale che appare in G, creare uno schema
di relazione {X U A1 U A2… U Am- in D dove X → A1, X → A2, … ,X → Am sono le sole
dipendenze in G aventi X come parte sinistra.
3. mettere in uno schema di relazione singolo tutti gli attributi rimanenti, per garantire la
proprietà di attribute-preservation.
Algoritmo Lossless Join
Questo algoritmo consente di verificare se lo schema rispetta la proprietà di join non additivo,
ovvero se si possono effettuare join tra le tabelle che consentono di ricavare tutte le informazioni
memorizzate nel database. Una decomposizione con lossless join garantisce che non vengano
generate tuple spurie applicando una operazione di natural join alle relazioni nella
decomposizione. La teoria delle decomposizioni lossless join si basa sull'assunzione che nessun
valore null è ammesso per gli attributi di join.
Si parte mettendo sulle righe le relazioni del nuovo schema e sulle colonne gli attributi e tutte le
righe bij dove l'indice i indica la riga e j la colonna. Poi per ogni relazione si mette a j in
corrispondenza degli attributi presenti nella relazione (sia parte destra che sinistra).
Poi si procede iterativamente fino a quando o non si ha una riga con tutte a oppure non avvengono
modifiche nel modo seguente: le dipendenze vengono valutate a coppia, per ogni 2 dipendenze
che hanno la parte sinistra in comune (ovvero hanno aj nella tabella) si aggiornano le tabelle della
parte sinistra copiando il valore aj dall'altra relazione.
Se alla fine si ha una riga con tutti valori aj allora si rispetta il lossless join altrimenti no.
5
BASI DI DATI 2
Dipendenze multivalore (MVD)
Sono conseguenza della 1NF che non consente ad un attributo di assumere un insieme di valori. In
presenza di due o più attributi indipendenti multivalued nello stesso schema, siamo costretti a
ripetere ogni valore di un attributo con un valore dell'altro.
Uno schema R è in 4NF se, per ogni dipendenza mulivalore non-trival (non banale) X ->> Y in F+, X è
superchiave per R.
Relazioni contenenti MVD non-trivial tendono ad essere relazioni “tutta chiave”, nel senso che la
chiave è formata da tutti gli attributi.
ENAME ↠ PNAME è una MVD banale
Esempio:
ENAME ↠ PNAME, ENAME ↠ DNAME
ma ENAME non è una superchiave.
EMP non è in 4NF.
Si scompone in:
Decomposizione LJ in relazioni 4NF
Decomposizione di un schema in relazioni 4NF con la proprietà LJ:
porre D = {R};
finché esiste uno schema di relazione Q in D che non è in 4NF {
scegliere uno schema di relazione Q in D che non è in 4NF;
trovare una MVD non banale X -» Y in Q che viola 4NF;
rimpiazzare Q in D con due schemi (Q – Y) e (X U Y);
}
6
BASI DI DATI 2
Lezione 3
Il Sistema Informativo
Il sistema informativo è composto da:
Dati
DBMS
Hardware
Media di memorizzazione
Applicativi che interagiscono con i dati
Personale che gestisce o usa il sistema
Gli applicativi che gestiscono l'aggiornamento dei dati
I programmatori che sviluppano gli applicativi
Il ciclo di vita
Il ciclo di vita di un sistema informativo (risorsa per la raccolta, gestione, uso e disseminazione) è
detto macro ciclo di vita. Il ciclo di vita di un sistema di base di dati è detto micro ciclo di vita.
Fasi del Macro Ciclo di vita
1. Analisi di fattibilità: si analizzano le aree di applicazione, si effettuano gli studi dei
costi/benefici e si determina la complessità del sistema.
2. Raccolta ed analisi dei requisiti: consiste nella raccolta dei requisiti e definizione delle
funzionalità del sistema.
3. Progettazione: si divide in progettazione del database e progettazione degli applicativi.
4. Implementazione: si implementa il Sistema Informativo, si carica il database e si
implementano e testano le transazioni.
5. Validazione e Testing: si verifica che il sistema soddisfi i requisiti e le performance richieste.
6. Rilascio e manutenzione: questa fase può essere preceduta da una di addestramento del
personale. Se emergono nuove funzionalità da implementare si devono ripetere tutti i passi
precedenti.
Fasi del Micro Ciclo di vita
1. Definizione del Sistema: si definisce l'ambito del sistema, i suoi utenti e le funzionalità. Si
identificano le interfacce per gli utenti, i vincoli sui tempi di risposta ed i requisiti hardware.
2. Progettazione della Base di Dati: si realizza la progettazione logica e fisica per il DBMS
scelto.
3. Implementazione della base di dati: si creano i file del database vuoti e si implementa
dell'eventuale software applicativo di supporto.
4. Caricamento/Conversione dei dati: si popola il database, o si utilizzano file esistenti o si
crea da capo.
5. Conversione delle applicazioni: si convertono le vecchie applicazioni software al nuovo
sistema.
6. Test e Validazione: si testa il nuovo sistema.
7. Operation: il sistema di base di dati con le applicazioni diventa operativo. All'inizio si
preferisce associare l'utilizzo del nuovo sistema in concomitanza con il vecchio.
8. Controllo e Manutenzione: il sistema è in continuo monitoraggio.
7
BASI DI DATI 2
Il processo di progettazione di un database
Gli scopi della fase di progettazione sono:
1. soddisfare i requisiti sui dati che interessano gli utenti e a cui accedono le applicazioni;
2. fornire una strutturazione delle informazioni naturale e facile da comprendere;
3. soddisfare i requisiti di elaborazione e di prestazioni (tempo di risposta, spazio di
memorizzazione).
È difficile raggiungere tutti gli scopi perché alcuni sono in contrasto tra loro.
La progettazione di un database è composta da:
1. Raccolta ed analisi dei requisiti:
Identificare le aree di applicazione, gli utenti che useranno il DB.
Analizzare la documentazione esistente.
Esaminare il contesto operativo e l'utilizzo pianificato delle informazioni, inclusa
l'analisi delle transazioni e la specifica dei dati di input e output delle transazioni.
Intervistare gli utenti finali per determinare le priorità di importanza.
Design dello schema concettuale, che si divide in due attività:
i. (Progettazione dello schema concettuale) Lo scopo dello schema concettuale
è fornire una comprensione completa della struttura, semantica, relazioni e
vincoli del database. È una descrizione stabile del contenuto. Un data model
di alto livello deve godere di tali proprietà:
o Espressività: deve permettere una facile distinzione tra tipi di dati,
relazioni e vincoli.
o Semplicità e comprensibilità: il modello deve essere semplice per
facilitare la comprensione.
o Minimalità: dovrebbe aver pochi concetti di base.
o Rappresentazione
diagrammatica:
dovrebbe
avere
una
rappresentazione diagrammatica per rappresentare schemi
concettuali di facile comprensione.
o Formalità: Il modello deve fornire dei formalismi per specificare in
modo non ambiguo i dati.
Per progettare uno schema concettuale è necessario individuare le seguenti
componenti di base: entità, relazioni, attributi, vincoli di cardinalità, chiavi,
gerarchie di specializzazione/generalizzazione, entità deboli.
Esistono differenti strategie per creare uno schema concettuale, partendo
dai requisiti:
o top-down;
o bottom-up;
8
BASI DI DATI 2
2.
3.
4.
5.
o inside-out: specializzazione del bottom-up in cui l'attenzione è
focalizzata su un nucleo centrale di operazioni e la modellazione si
allarga verso l'esterno;
o mixed: si possono usare più metodi.
Bisogna evitare i conflitti che possono incorrere in una progettazione, quali:
o conflitti di nome: sinonimi e omonimi;
o conflitti di tipo: esempio un attributo in uno schema e un tipo di
entità in un altro;
o conflitti di dominio: esempio conflitti di unità di misura;
o conflitti tra vincoli: due schemi possono imporre vincoli differenti.
ii. (Progettazione di transazioni e applicazioni) Si esaminano le applicazioni del
database per produrre specifiche di alto livello. Lo scopo di questa attività è
di progettare le transazioni o applicazioni del database in modo
indipendente dal DBMS. Una tecnica usata per specificare le transazioni
prevede l'identificazione di: input, output e comportamento funzionale. È
possibile raggruppare le transazioni in tre categorie:
o transazioni di retriva;
o transazioni di update;
o transazioni miste.
Scelta del DBMS, influenzata da tre fattori:
tecnici;
economici;
aziendali.
Mapping del data model (design logico), la creazione di schemi concettuali ed esterni nel
datamodel specifico del DBMS selezionato avviene in due passi:
traduzione da E/R a relazionale;
mapping del passo precedente per lo specifico DBMS.
Progettazione dello schema fisico, considerando:
Tempo di risposta;
Utilizzazione di spazio;
Throughput delle transazioni
Implementazione e tuning(monitoraggio) del database system.
Le sei fasi non sono eseguite in sequenza: spesso modifiche ad un livello devono essere propagate
a quello superiore, creando dei cicli di feedback.
La progettazione fisica nei database relazionali
Nella progettazione fisica le performance delle query migliorano in presenza di indici o schemi
hash, le operazioni di inserimento, modifica e cancellazione sono rallentate.
Le decisioni sull'indicizzazione ricadono in una delle 5 categorie:
1. Quando indicizzare un attributo: un attributo deve essere indicizzato se è chiave o se è
utilizzato in condizione di select o di join da una query.
9
BASI DI DATI 2
2. Quale attributo indicizzare: un indice può essere definito su uno o più attributi. In caso di
più attributi coinvolti da una query è necessario definire un indice multi attributo
3. Quando creare un indice clustered: al più un indice per tabella può essere primario o
clustering. Le query su range di valori si avvantaggiano di tali indici, mentre quelle che
restituiscono dati non si avvantaggiano.
4. Quando utilizzare indici hash invece di indici ad albero: i DB in genere usano i B+-Tree,
utilizzabili sia con condizioni di uguaglianza sia con query su range di valori. Gli indici hash,
invece, funzionano solo con condizioni di uguaglianza.
5. Quando utilizzare hashing dinamico: con file di dimensioni molto variabili è consigliabile
utilizzare tecniche di hashing dinamico.
Denormalizzare uno schema
Lo scopo della normalizzazione è di separare attributi in relazione logica, per minimizzare la
ridondanza ed evitare le anomalie di aggiornamento. Tali concetti a volte possono essere sacrificati
per ottenere delle performance migliori su alcuni tipi di query che occorrono frequentemente.
Questo processo è detto denormalizzazione. Il progettista aggiunge degli attributi ad uno schema
per rispondere a delle query o a dei report per ridurre gli accessi a disco, evitando operazioni di
join.
10
BASI DI DATI 2
Lezione 4
Memorizzazione di record ed organizzazione dei file
I database sono salvati in file memorizzati tipicamente su dischi magnetici. Ci sono due tipi di
memorie:
● Memoria Primaria composta dalle memorie che sono accessibili direttamente dalla CPU:
○ Prime in assoluto le memorie cache che operano in tempi confrontabili con quelli della
CPU (Static RAM).
○ Memoria DRAM (dynamic ram): memoria centrale che memorizza i programmi e i dati,
ha il vantaggio di essere economica ma di contro è volatile.
● Memoria Secondaria composta dai dischi magnetici, dischi ottici e nastri; sono più lente e
più economiche di quelle primarie. Sono dette memorie di massa e non sono volatili.
Vengono utilizzate anche per copie di backup.
Si stanno facendo sempre più interessanti le memorie Flash, con prestazioni che si avvicinano alla
DRAM ma con il vantaggio di non essere volatili.
Risulta così evidente che i database, avendo una grande mole di dati da immagazzinare e
manipolare, ricorrono a memorie secondarie. I dati sono organizzati come file di record e possono
essere:
● File heap (File non ordinato);
● File sequenziale (ordinato su un campo);
● File hash (funzione hash applicata ad un campo particolare)
● Btree (strutture ad albero)
I dischi magnetici possono essere dischi fissi di diversi GB oppure rimovibili da qualche GB e si
basano entrambi sugli stessi concetti e tecnologie.
Le informazioni su un disco sono organizzate in tracce che a loro volta sono divise in settori o
blocchi di dimensioni che variano da 512 bytes a 16 Kb, questa suddivisione viene fatta dal sistema
operativo durante la formattazione del disco. La lettura e scrittura avviene da parte della testina,
grazie alla rotazione del disco. Per ottimizzare le prestazioni si trasferiscono più blocchi consecutivi
sulla stessa traccia o cilindro. Il principale collo di bottiglia nel database system è costituito dalla
localizzazione dei file su disco. I dati solitamente sono memorizzati sotto forma di record. Ognuno
di essi è una collezione di dati o item ed ogni record ha una collezione di campi. Un file è una
sequenza di record che possono avere o la stessa dimensione o dimensioni variabili. Si può anche
spezzare un record su più blocchi o anche un blocco può avere più record. L'allocazione di blocchi
può essere contigua (lettura veloce ma difficile l'inserimento) o linked (facile l'espansione ma
latenza nella lettura). Un file header contiene informazioni sugli indirizzi su disco dei blocchi o
informazioni sui formati dei campi, che sono utili ai programmi. La ricerca semplicemente inizia e
va avanti blocco per blocco finché non viene individuato il dato.
Le operazioni che possono essere effettuate sui file sono o di retrieval (recupero informazioni) che
non cambiano i dati o di update (inserimento, cancellazione e modifica) che modificano i dati.
Gli heap file sono i file più semplici da organizzare, in quanto memorizzano in base a come
ricevono i dati, però la ricerca è molto costosa (è lineare alla grandezza del file). Per la
cancellazione o si lascia un buco oppure si usa un flag e i dati non vengono cancellati
effettivamente. In entrambi i casi c'è bisogno di una riorganizzazione periodica.
I file sequenziali vengono ordinati in base ad un campo che può essere quello chiave. Il vantaggio è
nella ricerca per il campo ordinato, mentre per una ricerca su un campo diverso non porta nessun
vantaggio. Di contro però l'inserimento richiede lo spostamento dei dati inseriti precedentemente
così come la cancellazione richiede uno shift dei dati che succedono quello cancellato. La modifica
dipende da come viene fatta la ricerca (se sul valore ordinato o meno) e da quale campo si
11
BASI DI DATI 2
modifica (se si modifica un campo non ordinato non comporta nessuna modifica).
L'Hashing consente l'accesso molto veloce e può essere utilizzato per organizzare i record in un file
(hashing interno) o per organizzare i file sul disco (hashing esterno). Il problema è la collisione, che
può essere risolta:
scegliendo una buona funzione hash, cercando di distribuire i record in maniera uniforme
nell'address space, minimizzando il numero di collisioni;
con Open Addressing a partire dalla posizione occupata si controllano gli slot successivi e si
occupa il primo libero;
con il Chaining dove in caso di collisione si va ad inserire il dato in una posizione di
overflow;
utilizzando il Multiple Hashing dove viene applicata una nuova funzione hash se la prima da
luogo ad una collisione e se anche questa dà una collisione si procede con l'open
addressing.
Di norma si consiglia di avere il DB occupato per lo 0.7-0.9 per avere una buona riuscita
dell'hashing. Con l'hashing esterno la collisione è meno sentita in quanto diversi record possono
essere assegnati allo stesso bucket (singolo blocco del disco o cluster di blocchi). Al riempimento di
un cluster si utilizza anche qui un indice di overflow. L'hashing esterno velocizza l'accesso se la
ricerca viene fatta sul campo dove viene applicata la funzione di hash altrimenti è una ricerca
costosa (lineare). La cancellazione può avvenire rimuovendo il record dal bucket, ma se esso ha
una lista di overflow si sposta nel bucket uno dei record della lista. L'hashing statico può essere
fastidioso in quanto si potrebbe avere o troppo spazio inutilizzato o molte collisioni e per questo si
ricorre all'hashing dinamico col quale si aumenta o diminuisce spazio per un bucket in base alle
cancellazioni o inserimenti. I vantaggi di questa tecnica sono:
le performance non degradano mai;
i bucket sono allocati dinamicamente a seconda della necessità;
riorganizzare il file significa spezzare un bucket e distribuire il suo contenuto in due;
mentre gli svantaggi consistono nella necessità di effettuare due accessi per reperire un record
(uno per la directory e uno per il bucket).
Tecnologia RAID
Utilizzando un RAID di dischi si migliora l'affidabilità per un numero pari alla sua grandezza. L'idea
alla base è quella di vedere tanti piccoli dischi come un grosso disco ad alte prestazioni. Il concetto
principale è la suddivisione dei dati, un file viene suddiviso su più dischi che possono accedere in
parallelo offrendo migliori prestazioni. Introduce ridondanza. Si utilizza il mirroring, ovvero i dati
vengono letti da una sola copia e nel momento in cui questa fallisce si ricorre all'altra. Lo striping
(frammentazione del dato su più dischi) può avvenire a più livelli di granularità: a livello di bit (si
suddivide un byte in modo da scrivere il bit j sul j-mo disco) oppure a livello di blocchi (si scrive
ogni blocco del file su un disco diverso). Lo striping però abbassa l'affidabilità e quindi si deve
ricorrere al mirroring e a codici a correzione di errori.
Il RAID ha diverse implementazioni, identificate con 7 livelli dallo 0 al 6:
RAID 0: Nessuna ridondanza di dati
RAID 1: Dischi Mirrored
RAID 2: Ridondanza con correzione di errore, usando codici Hamming
RAID 3: Singolo disco di parità
RAID 4: Suddivisione a livello di blocco e disco di parità
RAID 5: Blocchi e informazioni di parità suddivise su più dischi
RAID 6: Utilizza i codici Reed-Soloman per la ridondanza, per gestire il failure
contemporaneo di due dischi con soli due dischi in più.
12
BASI DI DATI 2
Lezione 5
Indici
Gli indici sono strutture aggiuntive di accesso al file, usate per velocizzare il reperimento delle
informazioni, concettualmente è simile all'indice del libro. Permettono di accelerare notevolmente
le operazioni di ricerca e sono basati su un singolo file ordinato oppure su strutture dati ad albero
(B+-tree). I valori nell'indice sono ordinati così da consentire l'esecuzione di una ricerca binaria. La
ricerca è più efficiente poiché il file indice è più piccolo del file di dati.
Esistono più tipi di indici:
indice primario: specificato su un campo chiave di ordinamento;
indice clustering: specificato su un campo non chiave di ordinamento;
indice secondario: specificato su un campo non di ordinamento;
Un indice può essere denso se contiene un'entry per ogni possibile valore del campo chiave
oppure sparso se contiene un numero di entry minore a quelle possibili. L'inserimento e la
cancellazione presentano difficoltà come per i file ordinati. Ci sono vari tipi di indici:
Indici a livello singolo: si definisce l'indice su un solo campo, chiamato indexing field. Un
indice memorizza il valore del campo index e una lista di puntatori a tutti i blocks del disco
che contengono record con quel valore di campo. I valori nell'indice sono ordinati, così
consentono una ricerca binaria che è più efficiente.
Indice Primario: specificato su un campo chiave di ordinamento di un file ordinato di
record. Ogni record è composto da due campi, il primo contiene la chiave primaria, il
secondo contiene il puntatore al blocco del disco che contiene il record. Il numero di entry
è pari al numero di blocchi del file. Gli indici primari sono indici sparsi. La ricerca è
efficiente, per inserire bisogna spostare record per fare spazio e cambiare alcune entry nel
file indice (è possibile utilizzare un file di overflow non ordinato oppure l'utilizzo di una lista
di puntatori di record di overflow per ciascun blocco), mentre per la cancellazione si usano i
marcatori di cancellazione.
Indice Clustering: file ordinato su un campo non chiave detto campo di clustering. L'indice
di clustering è un file ordinato con due campi: il primo contiene un valore del campo
clustering, il secondo un puntatore al primo blocco del file che contiene un record con tale
valore del campo clustering. È un indice sparso in quanto c'è una voce per ogni valore
distinto. L'inserimento e la cancellazione portano delle difficoltà perché i file sono ordinati
fisicamente, per migliorare questo aspetto a volte si preferisce assegnare un intero blocco
per ogni valore cluster.
13
BASI DI DATI 2
Indice Secondario: specificato su un campo non di ordinamento di un file di record. È
possibile avere più indici associati allo stesso file: in questo modo si velocizzano ricerche
effettuate su campi non ordinati. È composto da 2 campi:
o primo campo di (indicizzazione) che è dello stesso tipo di un campo non ordering;
o secondo campo puntatore a un blocco del disco o a un record.
Esistono due tipi di indici secondari a seconda di com'è il primo campo:
1. se è chiave contiene un valore distinto per ogni record di dati, risulta essere denso
in quanto c'è un’entrata per ogni record;
2. se non è chiave, più record possono avere lo stesso valore e può essere
implementato in vari modi:
a. una entry per ogni record, indice denso;
b. con un record di lunghezza variabile per ogni entry;
c. le entry sono a taglia fissa ed il puntatore non punta più un blocco, ma punta
ad un insieme di puntatori i quali ognuno di essi punta al disco, e se i
puntatori sono in eccesso si crea una lista a puntatori di blocchi.
L'inserimento è immediato mentre il retrival richiede un accesso in più al blocco.
Indici Multilivello: l'idea è di ridurre la dimensione dell'indice per velocizzare la ricerca binaria.
Per questo motivo si creano vari livelli di indici. Al primo livello vi è un file indice ordinato con
un valore distinto per ogni entry. Al secondo livello vi è un indice primario sul primo livello e
utilizza le block anchors. Si possono aumentare i livelli, ma conviene solo se il livello
precedente occupa più di un blocco sul disco
14
BASI DI DATI 2
Alberi di ricerca
Un albero di ricerca è una struttura dati ad albero, utilizzato per recuperare un record dato il valore
di uno dei suoi campi. Un albero può essere memorizzato su disco assegnando ogni nodo ad un
blocco su disco. Il problema fondamentale è che l'inserimento o la cancellazione di record non
garantiscono il bilanciamento dell'albero. Gli alberi di ricerca vengono utilizzati per recuperare un
record memorizzato in un file su disco. I valori nell'albero sono i valori di un campo del record,
detto campo di ricerca. Ad ogni valore nell'albero è associato un puntatore o al record nel file dati
con tale valore o al disk block contenente il record.
I B-Tree ed i B+-Tree sono alberi di ricerca bilanciati, progettati per ottimizzare operazioni su dischi
magnetici o su altri tipi di memoria. Assicurano che l'albero sia sempre bilanciato e che lo spreco di
spazio nei nodi sia limitato.
Definizione formale B-Tree
Dato un B-Tree di ordine p:
1. Ogni nodo interno ha la forma <P1, <K1, Pr1>, P2, <K2, Pr2>, ..., Pq-i, <Kq-1, Prq-1>, Pq> con q ≤ p
a. Ogni Pi è un puntatore ad un albero (un altro nodo nel B-Tree).
b. Ogni Pri è un data pointer (puntatore al record con valore Ki del campo chiave di
ricerca).
2. All'interno di ogni nodo deve valere che K1 < K2 <... < Kq-1
3. Per ogni valore X del campo chiave di ricerca nel sottoalbero puntato da Pi vale:
a. Ki-1 < X < Ki
(per 1 < i < q),
b. X < Ki
(per i = 1),
c. Ki-1 < X
(per i = q)
4. Ogni nodo ha al più p puntatori ad albero.
5. Ogni nodo, tranne la radice ed i nodi foglia, ha almeno (p/2) (parte intera superiore)
puntatori ad albero. Il nodo radice ne ha almeno 2, a meno che non sia l’unico nodo
nell'albero.
6. Un nodo con q (q ≤ p) puntatori ad albero ha q-1 valori del campo chiave di ricerca (e quindi
q-1 data pointer).
15
BASI DI DATI 2
7. Tutti i nodi foglia sono allo stesso livello. I nodi foglia hanno la stessa struttura dei nodi
interni, tranne per i puntatori ad albero, che sono nulli.
Per quanto riguarda la costruzione inizialmente l'albero ha solo il nodo radice. Nell'inserire una
nuova entry il nodo viene scisso in due nodi a livello 1 e nella radice resta il valore mediano,
mentre gli altri valori vengono distribuiti equamente tra i due nuovi nodi. Se un nodo non è radice
e nell'inserimento esso è pieno, quel nodo viene scisso in due nodi allo stesso livello e l'entrate
mediana è spostata al nodo padre insieme ai due puntatori dei nodi della scissione. Se anche il
nodo padre è pieno anche a lui si applica questo procedimento, se si trovano sempre nodi pieni si
sale fino alla radice fino a trovarsi al primo caso. Se la cancellazione fa si che un nodo risulti pieno
per meno della metà esso è combinato con i suoi vicini, ciò può propagarsi fino alla radice,
riducendo il numero di livelli dell'albero.
I B+-Tree
Una differenza sostanziale tra i B-Tree ed i B+-Tree è che in quest'ultimi i puntatori ai dati sono
memorizzati sono nelle foglie. Se la ricerca viene fatta sul campo su cui viene fatto l'ordinamento,
si avrà direttamente il puntatore al dato, altrimenti si avrà il puntatore ad un blocco che contiene
puntatori ai record del file creando così un altro livello di indirezione.
I nodi foglia sono collegati da puntatori così da fornire un accesso ordinato ai record sul campo
chiave. I nodi interni corrispondono agli altri livelli di un indice multi-livello.
Struttura dei nodi interni di un B+-Tree di ordine p
1. Ogni nodo interno ha Ia forma <P1, K1, P2, K2,..., Pq-1, Kq-1, Pq>, con q ≤ p
a. Ogni Pi è un puntatore ad albero.
2. In ogni nodo interno si ha K1 < K2 <... < Kq-1
3. Per ogni valore X del campo di ricerca nel sottoalbero puntato da P i vale che:
a. Ki-1 < X ≤ Ki
(per 1< i <q),
b. X ≤ Ki
(per i = 1),
c. Ki-1 < X
(per i = q).
4. Ogni nodo interno ha al più p puntatori ad albero.
5. Ogni nodo interno, tranne la radice, ha almeno (p/2) (parte intera superiore) puntatori ad
albero. Il nodo radice ne ha almeno 2 se è un nodo interno.
6. Un nodo interno con q puntatori, q ≤ p, ha q-1 valori del campo di ricerca.
Struttura dei nodi foglia di un B+-Tree di ordine p
1. Ogni nodo foglia ha la forma < <K1, Pr1>, <K2, Pr2>, …, <Kq-1, Prq-1>, Pnext>, con q ≤ p:
a. Ogni Pri è un data pointer.
16
BASI DI DATI 2
b. Pnext è un puntatore al prossimo nodo foglia del B+-Tree.
2. In ogni nodo foglia si ha K1 < K2 <... <Kq-1, con q ≤ p.
3. Ogni Pri è un data pointer, che referenzia:
a. Il record con valore Ki nel campo di ricerca oppure
b. il blocco del file contenente tale record, oppure
c. un blocco di puntatori a record che referenziano i record con valore del campo di
ricerca Ki, se il campo di ricerca è non chiave.
4. Ogni nodo foglia ha almeno p/2 (parte intera superiore) valori.
5. Tutti i nodi foglia sono allo stesso livello.
Con i B+-Tree partendo dalla foglia più a sinistra si può effettuare una vista di tutta la lista
seguendo il puntatore next. Se il campo di ricerca non è chiave, è necessario un ulteriore livello di
indirezione, simile a quello della struttura ad indice secondario con campo non chiave. Un nodo
interno di B+-Tree contiene più entrate di un nodo interno di B-Tree, poiché nel B+-Tree tali nodi
hanno solo valori di ricerca e puntatori ad albero. L'inserimento in un B+-Tree:
all'inizio la radice è l'unico elemento ed è quindi anche una foglia;
quando viene generato un overflow (ovvero in quel nodo non si può aggiungere una entry,
essendo pieno), le due entry più piccole vengono lasciate nella foglia che ha generato
overflow, le restanti vengono inserite in un nuovo nodo foglia, il valore mediano viene
replicato nel padre e nel padre viene creato un puntatore al nuovo nodo. Se anche nel
padre avviene un overflow, si procede come nelle foglie.
Per la cancellazione si procede eliminando la entry dalla foglia. Se essa ricorre in un nodo interno
viene rimossa e sostituita dal valore immediatamente alla sua sinistra. La cancellazione può
causare l'underflow (si riduce il numero di entrate in una foglia per meno del minimo consentito)
ed in questo caso si deve effettuare la fusione con un fratello (si tenta prima il sinistro, se non è
possibile con il destro, altrimenti si fondono tre nodi in due) e ridistribuire le entrate. La
cancellazione si può propagare fino ad arrivare alla radice.
17
BASI DI DATI 2
Lezione 6
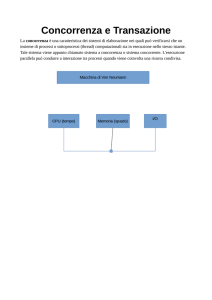
Gestione delle transazioni
La transazione fornisce un meccanismo per descrivere le unità logiche di elaborazione delle basi di
dati. È possibile classificare i database system in base al numero di utenti che possono utilizzare il
sistema in modo concorrente. Un DBMS è single user se al più un utente per volta può usare il
sistema, invece è multi-user se più utenti possono usare il sistema concorrentemente. Più utenti
possono accedere al database simultaneamente grazie al concetto di multiprogrammazione che
consente ad un computer di elaborare più programmi o transazioni simultaneamente. Sui sistemi
monoprocessore, l'esecuzione concorrente dei programmi è quindi intervallata mentre su sistemi
multiprocessore, invece, l'esecuzione dei programmi avviene realmente in parallelo.
Informalmente una transazione è un insieme di operazioni che accedono al DB, viste logicamente
come un'interruzione singola ed indivisibile. Le possibili operazioni di accesso al DB che una
transazione può effettuare sono:
Read_item(x): si trova l'indirizzo del blocco che contiene x, si copia il blocco in ram e poi
copiato nella variabile del programma;
Write_item(x): si trova l'indirizzo del blocco che contiene x, si copia il valore di x in un buffer
in ram e successivamente si aggiorna il blocco identificato.
Transazioni inviate da più utenti, che possono accedere e aggiornare gli elementi del DB, sono
eseguite concorrentemente. Se l'esecuzione concorrente non è controllata, si possono avere
problemi di database inconsistente.
I problemi che possono verificarsi con le transazioni sono:
aggiornamento perso: Supponiamo che T1 e T2 siano avviate insieme e che le loro
operazioni siano interleaved dal sistema operativo. Il valore finale di X potrebbe essere
scorretto se T2 legge il valore di X prima che T1 lo salvi: l’aggiornamento di T1 è quindi
perso.
aggiornamento temporaneo: Una transazione aggiorna un elemento ma poi fallisce per
qualche motivo. L’elemento aggiornato è però letto da un’altra transazione prima che esso
sia riportato al suo valore originario.
totalizzazione scorretta: Se una transazione sta calcolando una funzione di aggregazione su
un certo insieme di record, mentre altre transazioni stanno aggiornando alcuni di tali
record, la funzione può calcolare alcuni valori prima dell'aggiornamento ed altri dopo.
letture non ripetibili: Avviene se una transazione T1 legge due volte lo stesso item, ma tra
le due letture una transazione T2 ne ha modificato il valore. Esempio: durante una
prenotazione di posti aerei, un cliente chiede informazioni su più voli. Quando il cliente
decide, la transazione deve rileggere il numero di posti disponibili sul volo scelto per
completare la prenotazione, ma potrebbe non trovare più la stessa disponibilità.
Quando viene inoltrata una transazione, il sistema deve far sì che:
tutte le operazioni siano completate con successo ed il loro effetto sia registrato
permanentemente nel DB, oppure
la transazione annullata non abbia effetti né sul DB né su qualunque altra transazione.
Le failure vengono in genere suddivise in fallimenti di transazione, di sistema e di media.
Possibili ragioni di una failure:
1. Un crash di sistema durante l'esecuzione della transazione.
2. Errore di transazione o di sistema. Esempi: overflow, divisione per zero, valori errati di
parametri, …
3. Errori locali o condizione eccezionali rilevati dalla transazione. Esempio: i dati per la
transazione possono non essere trovati o essere non validi, tipo un ABORT programmato a
18
BASI DI DATI 2
fronte di richiesta di un prelievo da un fondo scoperto.
4. Controllo della concorrenza. Il metodo di controllo della concorrenza può decidere di
abortire la transazione perché viola la serializzabilità o perché varie transazioni sono in
deadlock.
5. Fallimento di disco. Alcuni blocchi di disco possono perdere i dati per un malfunzionamento
in lettura o scrittura, o a causa di un crash della testina del disco.
6. Problemi fisici e catastrofi. Esempi: fuoco, sabotaggio, furto, caduta di tensione, errato
montaggio di nastro da parte dell’operatore, …
Una transazione è un’unità atomica di lavoro che o è completata nella sua interezza o è
integralmente annullata. Per motivi di recovery, il sistema deve tenere traccia dell’inizio e della fine
o dell’abort di ogni transazione. Il manager di recovery tiene quindi traccia delle seguenti
operazioni:
BEGIN_TRANSACTION: marca l’inizio dell’esecuzione della transazione.
READ o WRITE: specifica operazioni di lettura o scrittura sul DB, eseguite come parte di una
transazione.
END_TRANSACTION: specifica che le operazioni di READ e WRITE sono finite e marca il
limite di fine di esecuzione della transazione.
COMMIT_TRANSACTION: segnala la fine con successo della transazione, in modo che
qualsiasi cambiamento può essere reso permanente, senza possibilità di annullarlo.
ROLL-BACK (o ABORT): segnala che la transazione è terminata senza successo e tutti i
cambiamenti o effetti nel DB devono essere annullati.
Operazioni addizionali:
UNDO: simile al roll-back, eccetto che si applica ad un’operazione singola piuttosto che a
una intera transazione.
REDO: specifica che certe operazioni devono essere ripetute.
Per effettuare il recovery di transazioni abortite, il sistema mantiene un log (o journal) per tenere
traccia delle operazioni che modificano il database. l log è strutturato come una lista di record. In
ogni record è memorizzato un ID univoco della transazione T, generato in automatico dal sistema.
Tipi di entry possibili nel log:
[start_transaction, T] la transazione T ha iniziato la sua esecuzione.
*write_item, T, X, old_value, new_value+ la transazione T ha cambiato il valore dell’item X
da old_value a new_value.
*read_item, T, X+ La transazione T ha letto l’item X.
[commit, T] La transazione T è terminata con successo e le modifiche possono essere
memorizzate in modo permanente.
[abort, T]La transazione T è fallita.
Il file di log deve essere tenuto su disco. Di fronte ad una failure, solo le entry su disco vengono
usate nel processo di recovery. Poiché un blocco viene tenuto in memoria finché non è pieno,
prima che una transazione raggiunga il punto di commit, ogni parte del log in memoria deve essere
scritta (scrittura forzata o force writing).
Le transazioni dovrebbero possedere alcune proprietà (dette ACID properties, dalle loro iniziali):
1. Atomicità: una transazione è un’unità atomica di elaborazione da eseguire o
completamente o per niente (responsabilità del recovery subsystem).
2. Consistency preserving: una transazione deve far passare il database da uno stato
consistente ad un altro (responsabilità dei programmatori).
3. Isolation: Una transazione non deve rendere visibili i suoi aggiornamenti ad altre
transazioni finché non è committed (responsabilità del sistema per il controllo della
concorrenza)
4. Durability: Se una transazione cambia il database e il cambiamento è committed, queste
19
BASI DI DATI 2
modifiche non devono essere perse a causa di fallimenti successivi (responsabilità del
sistema di gestione dell'affidabilità).
Informalmente, uno schedule è l'ordine in cui sono eseguite le operazioni di più transazioni
processate in modo interleaved. Formalmente, uno schedule (o storia) S di n transazioni T 1, T2, …,
Tn è un ordinamento delle operazioni delle transazioni, soggetto al vincolo che per ogni
transazione Ti che partecipa in S, le operazioni in Ti, in S devono apparire nello stesso ordine di
apparizione in Ti.
Due operazioni in uno schedule sono in conflitto se:
appartengono a differenti transazioni,
accedono allo stesso elemento X,
almeno una delle due operazioni è una write_item(X).
Uno schedule S di n transazioni T1, T2, …, Tn è uno schedule completo se valgono le seguenti
condizioni:
1. Le operazioni in S sono esattamente quelle in T1, T2, …, Tn, incluso un’operazione di commit
o di abort come ultima operazione di ogni transazione in S.
2. Per ogni coppia di operazioni dalla stessa transazione Ti, il loro ordine di occorrenza in S è lo
stesso che in Ti.
3. Per ogni coppia di operazioni in conflitto, una deve occorrere prima dell’altra nello
schedule.
Uno schedule completo non contiene transazioni attive, perché sono tutte committed o aborted.
Dato uno schedule S, si definisce proiezione committed C(S), uno schedule che contiene solo le
operazioni in S che appartengono a transazioni committed. Vorremmo garantire che per una
transazione committed non è mai necessario il roll-back. Uno schedule con tale proprietà è detto
recoverable.
Negli schedule recoverable nessuna transazione commited ha necessità di roll-back. Si possono
però avere roll-back in cascata se una transazione non committed legge un dato scritto da una
transazione fallita. Uno schedule è detto capace di evitare il roll-back in cascata, se ogni
transazione nello schedule legge elementi scritti solo da transazioni committed.
Uno schedule è detto stretto se le transazioni non possono né leggere né scrivere un elemento X
finché l’ultima transazione che ha scritto X non è completata (con commit o abort). Schedule stretti
semplificano il processo di recovery poiché occorre solo ripristinare la before image (old_value) di
un dato X.
Oltre a caratterizzare gli schedule in base alla possibilità di recovery, vorremmo classificarli anche
in base al loro comportamento in ambiente concorrente. Uno schedule è seriale se per ogni
transazione T nello schedule, tutte le operazioni di T sono eseguite senza interleaving. Altrimenti è
non seriale. Gli schedule seriali limitano la concorrenza o le operazioni di interleaving:
Se una transazione aspetta una operazione di I/O, non si può allocare la CPU ad un’altra
transazione.
Se una transazione T dura a lungo, le altre transazioni devono aspettare che finisca.
20
BASI DI DATI 2
Gli schedule seriali, in pratica, sono inaccettabili. Gli schedule non seriali possono dare i problemi
dell’aggiornamento perso, dell’aggiornamento temporaneo, della somma scorretta, etc. Uno
schedule S di n transazioni è serializzabile se è “equivalente” a qualche schedule seriale delle
stesse n transazioni. Dati n schedules, abbiamo n! possibili seriali. Due schedule sono detti result
equivalent se producono lo stesso stato finale del DB. Questa non è una definizione accettabile in
quanto la produzione dello stesso stato può essere accidentale. Una definizione più appropriata è
quella di conflict equivalent: due schedule sono conflict equivalent se l’ordine di ogni coppia di
operazioni in conflitto è lo stesso in entrambi gli schedule. Uno schedule è conflict serializzable se
è conflict equivalent a qualche schedule seriale S’.
Algoritmo per la serializzabilità
L’algoritmo cerca solo le operazioni di read_item e write_item, per costruire un grafo di precedenza
(o grafo di serializzazione). Un grafo di precedenza è un grafo diretto G=(N, E), con un insieme di
nodi N={T1, T2, …, Tn} ed un insieme di archi diretti E={e1, e2, …, em}.
Ogni arco è della forma (Tj → Tk), con 1 ≤ j, k ≤ n, ed è creato se un operazione in Tj appare nello
schedule prima di qualche operazione in conflitto in Tk.
Se non ci sono cicli nel grafo di precedenza relativo ad uno schedule S possiamo creare uno
schedule seriale equivalente S’ ordinando le transazioni che partecipano allo schedule come segue:
se esiste un arco fra Ti e Tj, Ti deve apparire prima di Tj nello schedule seriale equivalente.
Il concetto di transazione in SQL è simile a quanto visto finora: una transazione è una singola unità
logica di lavoro con la proprietà dell’atomicità. Di default, in SQL ogni singola istruzione è una
transazione. Ogni transazione in SQL ha tre caratteristiche, specificate per mezzo dell’istruzione
SET TRANSACTION che inizia una transazione:
1. Modalità di accesso: specifica se l’accesso ai dati è in sola lettura o in lettura/scrittura.
2. Dimensione dell’Area Diagnostica: specifica lo spazio da usare per informazioni all’utente
sull’esecuzione delle transazioni.
3. Isolation Level: specifica la politica di gestione delle transazioni concorrenti.
È molto importante utilizzare due commit (uno prima e uno dopo). SET TRANSACTION deve essere
la prima istruzione SQL di una transazione.
1. Il COMMIT appena prima assicura che ciò sia vero.
2. Il COMMIT alla fine rilascia le risorse possedute dalla transazione.
La modalità di accesso può essere specificata come READ ONLY o READ WRITE (default).
La modalità READ WRITE permette l’esecuzione di comandi di aggiornamento, inserimento,
cancellazione e creazione.
La modalità READ ONLY serve unicamente per il recupero di dati.
Alcune transazioni effettuano istruzioni di SELECT su diverse tabelle e dovranno vedere dati
coerenti, dati che si riferiscono allo stesso istante di tempo. SET TRANSACTION READ ONLY
specifica questo meccanismo più protetto di gestione dei dati.
Nessun comando può modificare i dati di un’area su cui vengono effettuate operazioni di SELECT
attraverso questo tipo di transazioni. L’opzione dimensione dell’area di diagnosi DIAGNOSTIC SIZE
n specifica un valore intero n, che indica il numero di condizioni che possono essere mantenute
contemporaneamente nell’area di diagnosi.
Oltre alle già viste violazioni di “letture sporche” e “letture non ripetibili”, usando SQL può sorgere
il problema delle “letture fantasma”. Per esempio, supponiamo che una transazione T1 legga una
serie di righe basate su una condizione di WHERE. Se una transazione T2 aggiunge dei valori che
soddisfano la condizione di WHERE, una riesecuzione di T1 vedrà delle righe nuove (fantasma), non
presenti in precedenza. In caso di errore in una qualsiasi istruzione SQL, l’intera transazione viene
annullata (rollback).
21
BASI DI DATI 2
Lezione 7
Tecniche per il controllo della concorrenza
L’esecuzione di transazioni concorrenti senza alcun controllo può comportare svariati problemi al
database. È necessario evitare che interferiscano fra di loro e garantire l’isolamento. Si usano delle
tecniche di gestione delle transazioni, per garantire che il database sia sempre in uno stato
consistente. Ci sono essenzialmente 2 tecniche che permettono ciò:
Tecniche di locking: i data item sono bloccati per prevenire che transazioni multiple
accedano allo stesso item concorrentemente;
Timestamp: un timestamp è un identificatore unico per ogni transazione generato dal
sistema. Un protocollo può usare l’ordinamento dei timestamp per assicurare la
serializzabilità.
Tecniche di Locking
Un lock è una variabile associata ad un data item nel DB, e descrive lo stato di quell’elemento
rispetto alle possibili operazioni applicabili ad esso. I lock sono quindi un mezzo per sincronizzare
l’accesso da parte di transazioni concorrenti agli elementi del DB. Diversi tipi di lock possono essere
usati per il controllo della concorrenza. In particolare, esamineremo i lock binari che possono
assumere due valori (o stati):
Locked (o valore 1)
Unlocked (o valore 0)
A ciascun elemento X del DB viene associato un distinto lock: Se Lock(X)=1, le operazioni del DB
non possono accedere all’elemento X. Se Lock(X)=0, si può accedere all’elemento X quando
richiesto.
I lock binari sono più semplici ma molto restrittivi, non sono molto usati nella pratica. I lock
shared/esclusivi, molto usati nei DBMS commerciali, forniscono maggiori capacità di controllo e
concorrenza. Le operazioni di lock_item e unlock_item devono essere implementate come unità
indivisibili (sezioni critiche), nel senso che non è consentito alcun interleaving dall’avvio fino o al
termine dell’operazione di lock/unlock o all’inserimento della transazione in una coda di attesa.
Lock_Item (X):
B: if Lock(X) = 0 then Lock(X) = 1;
else begin
wait (until Lock(X)=0 e il lock manager seleziona la transazione);
goto B;
end
Unlock_Item (X):
Lock(X) = 0;
if qualche transazione è in attesa
then sveglia una delle transazioni in attesa;
Per implementare un lock binario è necessaria solo una variabile binaria LOCK associata ad ogni
data item X del database. Ogni lock può essere visto come un record con tre campi: <nome data
item, LOCK, transazione> con associata una coda delle transazioni che stanno provando ad
accedere all’elemento.
Usando uno schema di lock binario, ogni transazione deve obbedire alle seguenti regole:
1. Una transazione T deve impartire l’operazione di Lock_Item(X) prima di eseguire una
Read_Item(X) o Write_Item(X).
22
BASI DI DATI 2
2. Una transazione T deve impartire l’operazione di Unlock_Item(X) dopo aver completato
tutte le operazioni di Read_Item(X) e Write_Item(X).
3. Una transazione T non impartirà un Lock_Item(X) se già vale il lock sull’elemento X.
4. Una transazione T non impartirà un Unlock_Item(X) a meno che non valga già un lock
sull’elemento X.
Al più una transazione può mantenere il lock su un elemento X; vale a dire che due transazioni non
possono accedere allo stesso elemento concorrentemente. Se una transazione deve scrivere un
data item X deve avere un accesso esclusivo su X. Per questo motivo si utilizza un multiple mode
lock, cioè un lock che può avere più stati.
Le operazioni di lock diventano tre e devono essere considerate indivisibili:
1. Read_Lock(X):
B: if LOCK(X) = “unlocked”
then begin
LOCK(X) = “read_locked”;
numero_di_read (X) = 1;
end; else
if LOCK(X) = “read_locked”
then numero_di_read (X) = numero_di_read (X) + 1;
else begin
wait (until LOCK(X) = “unlocked” and il gestore di lock sceglie la transazione);
goto B;
end
2. Write_Lock(X):
B: if LOCK(X) = “unlocked”
then LOCK(X) = “write_locked”;
else begin
wait (until LOCK(X) = “unlocked” e il gestore di lock sceglie la transazione);
goto B;
end;
3. Unlock(X):
if LOCK(X) = “write_locked”
then begin
LOCK(X) = “unlocked”;
sveglia una delle transazioni in attesa se ne esistono;
end;
else if LOCK(X) = “read_locked”
then begin
numero_di_read (X) = numero_di_read (X) – 1;
if numero_di_read (X) =0
then begin
LOCK(X) = “unlocked”;
sveglia una delle transazioni in attesa se ne esistono;
end
end;
Un lock ha tre possibili stati:
1. Read_Locked (share locked)
23
BASI DI DATI 2
2. Write_Locked (exclusive locked)
3. Unlocked
Regole per lock shared/esclusivi
Usando uno schema di shared/exclusive, ogni transazione deve obbedire alle seguenti regole:
1. Una transazione T deve impartire l’operazione di Read_Lock(X) o Write_Lock(X) prima di
eseguire una Read_Item(x).
2. Una transazione T deve impartire l’operazione di Write_Lock(X) prima di eseguire una
Write_Item(X).
3. Una transazione T deve impartire l’operazione di Unlock(X) dopo aver completato tutte le
operazioni di Read_Item(x) o Write_Item(X).
4. Una transazione T non impartirà un Read_Lock(X) se già vale il lock in lettura o scrittura
sull’elemento X.
5. Una transazione T non impartirà un Write_Lock(X) se già vale il lock in lettura o scrittura
sull’elemento X.
6. Una transazione T non impartirà un Unlock(X) a meno che non valga già un lock
sull’elemento X.
Per permettere le conversioni di lock, è necessario che sia mantenuto un identificatore della
transazione nella struttura del record per ciascun lock. Occorre un protocollo (cioè una serie di
regole) per stabilire il posizionamento delle operazioni di lock/unlock in ogni transazione.
Il protocollo Two-Phase Locking
Una transazione T segue il protocollo Two-Phase Locking (2PL) se tutte le operazioni locking
(Read_Lock, Write_Lock) precedono la prima operazione di Unlock nella transazione.
Una transazione del genere può essere divisa in due fasi:
expanding phase: possono essere acquisiti nuovi lock su elementi ma nessuno può esserne
rilasciato.
shrinking phase: i lock esistenti possono essere rilasciati ma non possono essere acquisiti
nuovi lock.
Se la conversione di lock è permessa, l’upgrading deve essere fatta durante la fase di espansione ed
il downgrading durante la contrazione. È dimostrabile che se ogni transazione in uno schedule
segue il protocollo 2PL, allora lo schedule è serializzabile. 2PL può però limitare la concorrenza in
uno schedule: la garanzia della serializzabilità viene pagata al costo di non consentire alcune
situazioni di concorrenza possibili, poiché alcuni elementi possono essere bloccati più del
necessario, finché la transazione necessita di effettuare letture e scritture.
Il protocollo 2PL appena visto è detto 2PL di base. Una variazione del 2PL è nota come 2PL
conservativo (o statico): richiede che una transazione, prima di iniziare, blocchi tutti gli elementi a
cui accede, pre-dichiarando i propri read_set e write_set: insieme di dataset letti/scritti. Se
qualche data item dei due insiemi non può essere bloccato, la transazione resta in attesa finché
tutti gli elementi necessari non divengono disponibili.
La variazione più diffusa del protocollo 2PL è il 2PL stretto, che garantisce schedule stretti, in cui le
transazioni non possono né scrivere né leggere un elemento X finché l’ultima transazione che ha
scritto X non termina (con commit o abort). Nel 2PL stretto, quindi, una transazione non rilascia
nessun lock esclusivo finché non termina.
In molti casi il sottosistema per il controllo della concorrenza genera automaticamente le richieste
di lock. Il protocollo di lock a due fasi garantisce la serializzabilità, ma non consente tutti i possibili
schedule serializzabili. Causa deadlock (quando due (o più) transazioni aspettano qualche item
bloccato da altre transazioni T’ in un insieme) e starvation (una transazione è nello stato di
starvation se non può procedere per un tempo indefinito mentre altre transazioni nel sistema
24
BASI DI DATI 2
continuano normalmente).
La dimensione di un data item è detta granularità del data item. La granularità può essere:
Fine: riferita a data item di piccole dimensioni. (es. campo di un record)
Grossa: riferita a data item di dimensioni maggiori. (es: file, database)
La granularità influenza le prestazioni nel controllo della concorrenza e del recovery. Maggiore è il
livello di granularità, minore è la concorrenza permessa. Un'altra forma di granularità è quella
multipla: un lock può essere chiesto su item a qualsiasi livello di granularità.
25
BASI DI DATI 2
Lezione 8
Tecniche di Recovery
Se viene sottomessa una transazione T:
tutte le operazioni di T sono completate ed il loro effetto è registrato permanentemente nel
DB,
T non ha nessun effetto né sul DB né su altre transazioni (failure). Il sistema non può
permettere che alcune operazioni di T siano portate a termine ed altre no.
Effettuare un recovery (o recupero) da una transizione fallita significa ripristinare il database al più
recente stato consistente appena prima del failure. Il sistema deve tener traccia dei cambiamenti
causati dall’esecuzione di transazioni. Tali informazioni sono memorizzate nel system log. Strategie
di recovery tipiche:
Se il danno è notevole, a causa di un failure catastrofico (es. crash di un disco), si ripristina
una precedente copia di back-up.
Se, a seguito di un failure non catastrofico, il database è solo in uno stato inconsistente, si
effettua l’undo delle operazioni che hanno causato l’inconsistenza. Eventualmente si
effettua il redo di alcune operazioni. Non è necessario effettuare il restore del database,
poiché basta la consultazione del system log.
Concettualmente possiamo distinguere due tecniche principali per il recovery da failure non
catastrofici:
Tecniche ad aggiornamento differito (algoritmo NO-UNDO/REDO): con questa tecnica, i
dati non sono fisicamente aggiornati fino all’esecuzione della commit di una transazione.
Durante il commit, gli aggiornamenti sono salvati persistentemente prima nel log e poi nel
database. Se la transazione fallisce, non è necessario l’undo; può però essere necessario il
redo di alcune operazioni.
Tecniche ad aggiornamento immediato (algoritmo UNDO/REDO): Il database può essere
aggiornato fisicamente prima che la transazione effettui il commit. Le modifiche sono
registrate prima nel log (con un force-writing) e poi sul DB, permettendo comunque il
recovery. Se una transazione fallisce dopo aver effettuato dei cambiamenti, ma prima del
commit, l’effetto delle sue operazioni nel DB deve essere annullato: occorre effettuare il
rollback della transazione (UNDO).
Per migliorare l’efficienza degli accessi a disco, i blocchi del disco contenenti i dati manipolati
spesso dal DBMS, sono conservati (cached) in un buffer della memoria centrale: i dati sono quindi
aggiornati in memoria, prima di essere riscritti su disco. Sebbene la gestione del caching sia un
compito del sistema operativo, spesso è il DBMS ad occuparsene esplicitamente, a causa dello
stretto accoppiamento con le tecniche di recovery. Quando il DBMS richiede l’accesso ad un data
item, se ne controlla la presenza in cache:
1. Se già è presente, il DBMS ne ottiene l’accesso.
2. Se non è presente:
a. Deve essere individuato il blocco su disco contenente l’item.
b. Il blocco deve essere copiato nella cache.
c. Se la cache è piena, sono necessarie strategie tipiche dei sistemi operativi per il
rimpiazzamento delle pagine (LRU, FIFO, ecc …).
Ad ogni blocco nella cache si può associare un dirty bit, per evidenziare se qualche elemento del
buffer è stato modificato o meno. Al caricamento di un blocco in un buffer, il suo dirty bit è posto a
0. In seguito ad una modifica del contenuto del buffer, il suo dirty bit è posto a 1. Un buffer deve
essere salvato su disco solo se il suo dirty bit vale 1. Esistono due strategie principali per lo
svuotamento di buffer modificati:
26
BASI DI DATI 2
In place updating: Il buffer è riscritto nella stessa posizione originaria sul disco. Si mantiene
in cache una singola copia di ogni blocco del disco. È necessario usare un log per il recovery.
Shadowing: Un buffer può essere riscritto in una locazione differente, permettendo la
presenza su disco di più versioni di un data item: Sia il vecchio valore (BFIM), sia quello
aggiornato (AFIM) di un data item possono essere presenti sul disco contemporaneamente.
Il log contiene due tipi di informazioni: quelle per l’UNDO e quelle per il REDO. Un’entry del log di
tipo UNDO include il vecchio valore (BFIM) dell’item salvato (necessario per effettuare un UNDO).
Un’entry del log di tipo REDO include il nuovo valore (AFIM) dell’item salvato (necessario per
effettuare un REDO). le entry appropriate devono essere salvate nel log su disco prima di applicare
i cambiamenti del database.
Protocollo WAL (Write-Ahead Logging)
L’AFIM non può sovrascrivere la BFIM di un elemento sul disco finché non sono stati memorizzati i
record di log di tipo UNDO della transazione. L’operazione commit non può essere completata
finché non sono scritti su disco tutti i record di log di tipo UNDO e di tipo REDO. Nel Log vengono
utilizzate particolari entry, dette checkpoint; tutte le transazioni che hanno effettuato la commit
prima del checkpoint non richiedono operazioni di REDO in caso di crash, poiché le loro modifiche
sono già state rese permanenti. Per creare un checkpoint si effettuano le seguenti operazioni:
1. Sospendere temporaneamente l’esecuzione di tutte le transazioni.
2. Scrivere su disco il contenuto di tutti i buffer modificati (scrittura forzata).
3. Scrivere una entry di checkpoint nel log.
4. Riprendere l’esecuzione delle transazioni sospese.
Se una transazione fallisce per una qualsiasi ragione, può essere necessario effettuarne il rollback.
Il rollback di una transazione T richiede il rollback di tutte le transazioni che hanno letto il valore di
qualche dato scritto da T, e così via (rollback in cascata).
Tecniche di recovery basate su aggiornamento differito
Sappiamo che con questa tecnica i dati non sono aggiornati fisicamente fino all’esecuzione della
commit di una transazione. Un protocollo di deferred update:
Una transazione non può cambiare il database finché non raggiunge il punto di commit.
Una transazione non raggiunge il punto di commit finché tutte le sue operazioni di
aggiornamento non sono registrate nel log e il log è scritto su disco.
L’algoritmo è NO-UNDO / REDO: non è mai necessario l’Undo. Il Redo è richiesto solo se il crash si
ha dopo il commit, ma prima dell’aggiornamento del DB. Nel Recovery con Deferred Update
in ambiente monoutente, l’algoritmo di recovery è abbastanza semplice: l’algoritmo RDU-S
(Recovery usando la Deferred Update in ambiente Single-user) chiama una procedura REDO per
rieseguire delle operazioni di Write-Item. La procedura RDU-S mantiene due liste di transazioni:
transazioni committed a partire dall’ultimo checkpoint; transazioni attive (contiene al più una
transazione, perché il sistema è single-user).
Algoritmo RDU-S:
Applicare l’operazione REDO a tutte le operazioni write_item delle transazioni committed nel log,
nell’ordine in cui sono scritte nel log. Rilanciare le transazioni attive.
REDO (WRITE-OP):
Per effettuare il Redo dell’operazione WRITE-OP esaminare la sua entry nel log [write_item, T, X,
new-value] e porre il valore dell’elemento X a new-value (l’AFIM).
Recovery con deferred update in ambiente multiutente
In ambienti multiutente, i processi di recovery e di controllo della concorrenza sono interrelati:
27
BASI DI DATI 2
maggiore è il grado concorrenza, più tempo viene impiegato per effettuare il recovery.
Algoritmo RDU-M:
Usa due liste di transazioni:
1. Transazioni committed T a partire dall’ultimo checkpoint.
2. Transazioni attive T’.
Algoritmo:
Fare il REDO di tutte le operazioni di Write delle transazioni committed nel log, nell’ordine
in cui sono state scritte nel log.
Le transazioni attive e non ancora committed devono essere rilanciate.
Tecniche di Recovery basate su Immediate Update
Quando una transazione effettua un comando di aggiornamento: L’operazione viene registrata nel
Log (write-ahead logging protocol) e applicata nel DB (necessità di roll-back). I tipi di
aggiornamenti immediati si dividono in 2 categorie:
1. Se tutti gli aggiornamenti di una transazione sono riportati nel DB prima del commit, non è
mai richiesto il REDO (algoritmo di recovery di tipo UNDO/NO-REDO).
2. Se la transazione raggiunge il commit prima che tutti gli aggiornamenti siano riportati nel
DB può essere necessario il REDO (algoritmo di recovery di tipo UNDO/REDO) .
Nel caso in cui si utilizzano sistemi multidatabase, il meccanismo di recovery è a due livelli: Local
recovery manager e Global recovery manager (coordinatore). Tutti i database coinvolti dalla
transazione segnalano al coordinatore di aver completato la loro parte. Il coordinatore manda ad
ogni partecipante il messaggio “prepare for commit”. Ogni partecipante forza su disco tutte le
informazioni per il recovery locale e risponde “OK” al coordinatore. Se per qualche ragione non
può fare il commit risponde “not OK”. Se il coordinatore riceve “OK” da tutti i partecipanti: manda
un comando di commit ai DB coinvolti. Ogni partecipante segnala il [commit] nel Log, ove
necessario, ed aggiorna il DB. Se qualche partecipante ha fornito un “not OK”: la transazione
fallisce. Il coordinatore invia un messaggio UNDO ai partecipanti.
Backup-Restore del DB
La principale tecnica è quella del back-up di database. Periodicamente il DB e il log sono ricopiati
su un device di memoria economico. In caso di failure catastrofico, tutto il DB viene ricaricato su
dischi e seguendo il log gli effetti delle transazioni committed vengono ripristinati. Per non perdere
tutte le transazioni effettuate dall’ultimo back-up, i file di log sono ricopiati molto frequentemente.
È possibile fare ciò grazie alle ridotte dimensioni di tali file rispetto alla taglia dell’intero database.
28
BASI DI DATI 2
Lezione 9
Concetti sui database Object-Oriented
Il primo linguaggio di programmazione object-oriented (O-O) è SIMULA (fine anni ’60).
SIMULA definisce:
Il concetto di classe, che raggruppa la struttura di dati interna di un oggetto in una dichiarazione di classe.
Un tipo di dato astratto, che nasconde la struttura interna e specifica tutte le possibili
operazioni esterne, portando al concetto di incapsulamento.
Il linguaggio O-O puro più diffuso al momento è JAVA.
Gli Oggetti
Un oggetto tipicamente ha due componenti:
Uno stato (o valore).
Un comportamento (o operazioni).
Un oggetto è simile ad una variabile, ma con due differenze:
Può rappresentare una struttura dati complessa.
Può avere una serie di operazioni specifiche, definite dal programmatore.
In un linguaggio di programmazione O-O, gli oggetti esistono solo durante l’esecuzione del
programma (sono detti transienti). Un database ad oggetti può estendere l’esistenza di un oggetto
memorizzandolo su una memoria secondaria:
Gli oggetti sono quindi persistenti, esistendo anche dopo la terminazione del programma
che li ha definiti.
Gli oggetti persistenti possono essere condivisi da più programmi.
Un obiettivo dei database O-O è di mantenere una corrispondenza diretta tra gli oggetti del mondo
reale e del database, in modo che gli oggetti non perdano la loro integrità ed identità. A tal fine,
essi forniscono per ciascun oggetto un identificatore univoco di oggetto, detto OID, generato dal
sistema (può essere visto come equivalente al concetto di chiave primaria nei database relazionali).
Alcuni DBMS O-O, utilizzano come OID l’indirizzo in memoria dell’oggetto (ciò può creare problemi
in caso di riorganizzazione della memoria). Più correttamente, altri sistemi utilizzano un intero
lungo, che, grazie ad una funzione hash, viene mappato sull’indirizzo di memoria dell’oggetto.
Una caratteristica dei database O-O è che gli oggetti possono essere caratterizzati da una struttura
complessa arbitraria. La struttura interna di un oggetto comprende la specifica di:
Variabili di istanza (mantengono i valori che definiscono lo stato interno dell’oggetto. Sono
simili al concetto di attributo, ma sono incapsulate nell’oggetto e non sono
necessariamente visibili all’esterno. Possono essere di un tipo di dato arbitrario).
Operazioni: Per incoraggiare l’incapsulamento, molti sistemi O-O prevedono la definizione
delle operazioni applicabili a un oggetto. In tal caso un’operazione è definita in due parti: la
signature (o interfaccia), che specifica il nome dell’operazione e gli argomenti; il metodo (o
corpo), contenente l’implementazione dell’operazione.
Affinché un sistema possa definirsi object-oriented, deve supportare due caratteristiche fondamentali:
Una gerarchia di classi (o ereditarietà): consente la specifica di nuovi tipi o classi ereditando
la struttura e le operazioni di tipi o classi già definite. In questo modo si facilita lo sviluppo
incrementale dei tipi ed il riuso del codice.
Il polimorfismo degli operatori: un nome di operazione può riferire a varie implementazioni
distinte, in base al tipo di oggetti cui è applicato. Esempio: l’operatore “+” è polimorfo,
29
BASI DI DATI 2
poiché può essere applicato ad operandi di tipi diversi: se gli operandi sono interi, viene
invocata l’addizione su interi. Se gli operandi sono reali, viene invocata l’addizione su reali.
Nei primi DBMS O-O si riteneva che le relazioni non dovessero essere esplicitamente
rappresentate, ma piuttosto descritte da appropriati metodi che localizzano gli oggetti relati.
Questo approccio si è rilevato sbagliato quando applicato a database complessi con relazioni
multiple, poiché non si ha la visibilità delle relazioni.
Alcuni modelli O-O richiedono che qualsiasi cosa sia rappresentata come oggetto, sia esso un valore semplice o un oggetto complesso.
Lo stato di un oggetto complesso può essere costruito da altri oggetti (o valori) mediante un costruttore di tipo. Formalmente un oggetto è una tripla (i, c, v), dove:
i è l’OID,
c è un costruttore di tipo,
v è il valore (o stato): Il valore di un oggetto v è interpretato sulla base del valore di c nella
tripla (i, c, v).
Costruttori di base: atom, set, tuple, list, bag (è identico ad un set, ma non è necessario che tutti gli
oggetti siano distinti) ed array.
Set, list, array e bag sono detti collection types (o bulk types), per distinguerli dai tipi di base.
Usando i grafi, è possibile definire oggetti uguali ed identici:
Due oggetti hanno valori identici se i grafi sono identici, inclusi gli OID, ad ogni livello.
Due oggetti hanno valori uguali se la struttura del grafo è la stessa, ma ai nodi interni
possono corrispondere diversi OID
I costruttori di tipo sono utilizzati per definire le strutture dati in uno schema di database O-O.
Gli attributi che riferiscono ad altri oggetti sono referenze. Si rappresentano così relazioni tra tipi di
oggetti.
Incapsulamento di Operazioni, Metodi e Persistenza
I concetti di information hiding e di incapsulamento possono essere applicati agli oggetti dei
database. La struttura interna dell’oggetto è nascosta, e l’oggetto è accessibile solo attraverso un
certo numero di operazioni predefinite. Gli utenti esterni dell’oggetto devono solo conoscere
l’interfaccia dell’oggetto, che definisce nomi e argomenti di ciascuna operazione.
L’implementazione è nascosta all’utente esterno. Un metodo è invocato mediante l’invio
all’oggetto di un messaggio di eseguire il corrispondente metodo.
La richiesta di un completo incapsulamento è troppo stringente per applicazioni di database. Un
modo di allentarla è di dividere la struttura di un oggetto in:
attributi visibili, accessibili in lettura a operatori esterni o al query language ad alto livello,
attributi nascosti, completamente incapsulati accessibili solo attraverso operazioni
predefinite.
Una classe è una definizione di un tipo di oggetto, insieme con le operazioni per quel tipo.
Operazioni tipiche:
Costruttore di oggetto
Modificatori di oggetto
Recupero di informazioni relative all’oggetto
Non tutti gli oggetti sono permanenti nel database:
Gli oggetti transienti esistono durante l’esecuzione del programma e scompaiono con la
terminazione del programma.
Gli oggetti persistenti, memorizzati nel database, sopravvivono all’esecuzione del
programma.
Meccanismi di persistenza:
30
BASI DI DATI 2
Assegnazione di un nome usato per ritrovare l’oggetto (naming). Con il meccanismo di
naming si intende l’assegnamento di un nome univoco e persistente ad un oggetto,
attraverso cui questo può essere referenziato da altri programmi.
Rendere l’oggetto raggiungibile da altri oggetti persistenti (reachability). Il meccanismo di
reachability funziona rendendo degli oggetti raggiungibili da oggetti persistenti. Un oggetto
B è detto raggiungibile da un oggetto A se una sequenza di referenze nel grafo dell’oggetto
porta da B ad A.
Usiamo un oggetto di nome N, il cui valore è una lista o un insieme di oggetti di una classe
C. Gli oggetti di C sono resi persistenti aggiungendoli alla lista o insieme, e rendendoli
quindi accessibili da N. Si dice che N definisce una collezione persistente di oggetti di classe
C.
In un modello di DB tipico (ER, modello relazionale, etc.) si assume che tutti gli oggetti siano persistenti. In un approccio O-O:
Una dichiarazione di classe di XXX specifica solo il tipo e le operazioni per una classe di
oggetti.
L’utente deve separatamente definire un oggetto persistente di tipo set (XXX) o list (XXX),
avente come valore una collezione di referenze a tutti gli oggetti persistenti XXX.
Gerarchie ed Ereditarietà nei DBMS O-O
Nelle applicazioni di DB esistono numerosi oggetti dello stesso tipo. Ogni DBMS deve offrire la
possibilità di classificare gli oggetti in funzione del loro tipo.
Un tipo viene definito assegnandogli un nome e definendo un certo numero di attributi e operazioni. TYPE_NAME: function, function, … , function
Esempio: PERSON: Name, Address, Birthdate, Age, SSN dove Name, Address, Birthdate e SSN sono
implementati come attributi memorizzati; Age è implementato come metodo per il calcolo dell’età,
in base al valore della data di nascita ed alla data corrente.
Un sottotipo è utile per creare un nuovo tipo simile ma non identico a un tipo predefinito. Un sottotipo eredita tutte le funzioni del tipo predefinito, che viene detto supertipo.
Quando un oggetto viene creato, tipicamente può appartenere ad uno o più dei tipi dichiarati.
Alcuni sistemi O-O prevedono una superclasse di sistema predefinita (detta ROOT o OBJECT), da cui
derivano tutti gli oggetti successivamente definiti. La classificazione procede specializzando oggetti
nelle classi addizionali, creando una gerarchia di classe per il sistema.
Oggetti Complessi
Uno dei principali motivi che ha portato allo sviluppo di DBMS O-O è la necessità di rappresentare
oggetti complessi. Gli oggetti complessi si dividono in:
Strutturati. Negli oggetti complessi strutturati, la struttura è definita dalla ripetuta
applicazione dei costruttori di tipo dell’OODBMS.
Non Strutturati. Permettono di gestire tipi di dati multimediali: Immagini bit-map, Stringhe
di testo lunghe (documenti), Video. Poiché i dati sono “non strutturati”, il DBMS non ne
conosce la struttura, quindi solo l’applicazione che li utilizza può interpretarne il significato.
31
BASI DI DATI 2
Lezione 10
Standard, linguaggi e progettazione di database ad oggetti
Definire uno standard per un particolare tipo di database system è importante, poiché offre tre
vantaggi:
Portabilità: È la capacità di eseguire un’applicazione su sistemi differenti con modifiche
minime.
Interoperabilità: È la capacità di un’applicazione di accedere a più sistemi distinti.
Confrontabilità di prodotti commerciali: è la capacità di confrontare prodotti commerciali
determinando quali parti dello standard sono supportate da ogni prodotto.
Un consorzio di produttori di DBMS O-O, chiamato ODMG (Object Database Management Group)
ha proposto uno standard, detto ODMG 1.0 poi rivisto nell’ODMG 2.0.
Lo standard è composto da quattro parti:
Il modello ad oggetti.
Il linguaggio di definizione degli oggetti (ODL).
Il linguaggio di interrogazione degli oggetti (OQL).
I binding con i linguaggi di programmazione: ne sono stati definiti con Java, C++ e
SMALLTALK
L’Object Model di ODMG è il paradigma su cui sono basati i linguaggi di definizione (ODL) ed interrogazione (OQL).
Oggetti e letterali sono i costrutti di base del modello ad oggetti. Entrambi possono avere delle
strutture complesse. Un oggetto ha sia un identificatore che uno stato (valore corrente). Un
letterale ha solo un valore. Lo stato di un oggetto può cambiare nel tempo. Un letterale è
sostanzialmente un valore costante.
Un oggetto è descritto da quattro caratteristiche:
Identificatore: Ogni oggetto deve avere un identificatore, univoco in tutto il sistema.
Nome: Opzionalmente, un oggetto può avere un nome (ed essere usato come entry point:
ritrovando tali oggetti attraverso il nome unico, si possono reperire altri oggetti ad essi
collegati).
LifeTime: Specifica se l’oggetto è persistente o transiente.
Struttura: Specifica se l’oggetto è atomico o è una collezione.
Nel modello ad oggetti, un letterale è un valore senza OID con una struttura semplice o complessa.
Sono ammessi tre tipi di letterali:
Atomici: Sono i tipi di dati di base, quali Char, Long, Boolean, ecc.
Strutturati: Sono delle strutture complesse, predefinite (es. Date, Time, Intervalecc.) o
definite dall’utente.
Collezioni: Sono una collezione (senza ID) di oggetti o di valori. Possono essere Set, Bag, List
ed Array.
Un’interfaccia è una definizione di metodi astratti cioè senza implementazione.
Una classe è una specifica di metodi e stati, istanziabile in quanto è possibile creare istanze di
oggetti corrispondenti alla definizione della classe. Esistono due tipi di ereditarietà:
Ereditarietà di Interfaccia, specificata col simbolo “:” il supertipo deve essere un’interfaccia
ed il sottotipo una classe o un’interfaccia.
Ereditarietà di classe, specificata con la keyword extends; è utilizzata esclusivamente tra
classi.
Non è permessa ereditarietà di classe multipla mentre è permessa ereditarietà di interfaccia multipla.
32
BASI DI DATI 2
Le collezioni nel modello ad oggetti sono SET<T>, BAG<T>, LIST<T> e ARRAY<T>, dove T è il tipo di
oggetti o valori della collezione. Un altro tipo di collezione è DICTIONARY<K,V>: è un insieme di
associazioni <k,v>, dove k è una chiave (un valore unico di ricerca) associata al valore v. Può essere
usato per creare un indice su una collezione di valori.
Dato un oggetto collection O, sono disponibili le seguenti operazioni predefinite (dot notation):
O.cardinality()
O.is_empty()
O.insert_element(e)
O.remove_element(e)
O.contains_element(e)
(arrow notation):
O->copy()
O->same_as(e)
Gli attributi che hanno una struttura complessa sono definiti attraverso struct. Nel modello ad
oggetti, qualsiasi oggetto definito dall’utente non di tipo collection, è di tipo atomico. Gli oggetti
atomici sono specificati per mezzo della keyword class.
Un attributo è una proprietà che descrive qualche aspetto dell’oggetto. Una relazione è una
proprietà che specifica i legami tra due oggetti del DB. Ogni tipo oggetto può avere un insieme di
signature di operazioni. I nomi delle operazioni devono essere univoci all’interno di una classe.
Nel modello ad oggetti di ODMG 2.0 è possibile definire un extent che si comporta come un
oggetto set, contenente tutti gli oggetti persistenti di una determinata classe.
Se due classi A e B hanno extents all_A e all_B, e la classe B è sottotipo di A, allora la collezione di
oggetti in all_B deve essere un sottoinsieme di quelli di all_A. Questo vincolo è fatto valere dal
database system.
Una classe con un extent può avere una o più chiavi. Una chiave è composta da una o più
proprietà (attributi o relazioni), con valori univoci per ogni oggetto nell’extent.
Un factory object è un oggetto usato per creare altri oggetti, attraverso le operazioni che mette a
disposizione. L’interfaccia ObjectFactory ha una singola operazione, la new(), che restituisce un
nuovo oggetto con un OID.
Poiché un ODBMS può creare più DB, il modello ad oggetti di ODMG mette a disposizione gli oggetti Database e DatabaseFactory.
L’Object Definition Language
L’ODL è progettato per supportare i costrutti semantici del modello ad oggetti di ODMG 2.0. È
usato principalmente per definire classi ed interfacce ed è indipendente dal linguaggio di
programmazione utilizzato.
L’Object Query Language
L’Object Query Language è il linguaggio di interrogazione proposto dal modello ad oggetti di
33
BASI DI DATI 2
ODMG. Poiché l’OQL è progettato per interagire fortemente con linguaggi di programmazione quali
C++, SMALLTALK e Java, una query in OQL restituisce oggetti che possono essere facilmente tradotti nei tipi di tali linguaggi.
Il costrutto di base di OQL per l’interrogazione dati è, come in SQL, Select…From…Where
Per ogni query è richiesto un entry point. Questo può essere qualunque oggetto persistente con un
nome. In presenza di collezioni, si definisce una variabile iteratore che spazia su ogni oggetto della
collezione. La query, in genere, seleziona degli oggetti dalla collezione, in base alla clausola where.
Il risultato di una query è:
Un Bag, per gli statement select… from
Un Set, per gli statement select distinct… from
Determinato un entry point, si può usare il concetto di espressione di percorso per specificare un
percorso fino agli attributi ed agli oggetti relati. Un’espressione di percorso parte da un oggetto
persistente con nome (o un iteratore), ed è seguito da zero o più nomi di attributi/relazioni,
usando la notazione punto. Esempio (Q2): csdepartment.chair.rank;
Una query OQL può restituire una struttura complessa, specificata nella query utilizzando la keyword struct. Esempio:
select struct(
name:struct(last_name:s.name.lname, first_name:s.name.fname),
degrees:(
select struct(deg:d.degree,yr: d.year, college: d.college)
from d in s.degrees
from s in csdepartment.chair.advises;
Il risultato della query è una collezione di struct. La specifica di viste in OQL usa il concetto di query
con nome (namedquery). Si utilizza la keyword define per specificare un identificatore della query,
che deve essere un nome univoco in tutto il DB. Una vista può anche avere una serie di argomenti.
Esempio:
define has_minors(deptname) as select s from s in students where s.minors_in.dname = deptname.
Sappiamo che una query OQL restituisce una collezione di oggetti (bag, set o list): se la collezione
contiene un solo oggetto, può essere utile ottenere direttamente il riferimento a tale oggetto, piuttosto che alla collezione. Ciò può essere effettuato per mezzo dell’operatore element:
Element (select d from d in departments where d.dname=”Computer Science”);
Dovendo quasi sempre gestire collezioni di oggetti, OQL mette a disposizione una serie di operazioni da applicare a tali strutture. Tra queste operazioni troviamo:
Operatori di aggregazione(min, max, count, sum e avg).
Quantificatori(esistenziali ed universali).
Operatori di appartenenza.
Le espressioni di appartenenza e quantificazione restituiscono un booleano. Sia v una variabile,
cuna collezione, b un’espressione booleana ed e un elemento di c:
(e in c) è vera se e appartiene alla collezione c.
(for all v in c:b) è vera se tutti gli elementi in c soddisfano b.
(exists v in c:b) è vera se esiste almeno un elemento in c che soddisfa b.
Collezioni rappresentate da liste ed array hanno operazioni addizionali, quali:
1. Il recupero dell’i-esimo, del primo o dell’ultimo elemento.
2. Estrazione di una sottocollezione.
3. Concatenazione di liste.
first( select struct (faculty:f.name.lname,salary:f.salary)from f in faculty order by f.salary desc);
34
BASI DI DATI 2
La clausola groupby di OQL, sebbene simile a quella di SQL, fornisce riferimenti espliciti alla
collezione di oggetti in ogni gruppo o partizione.
Progettazione concettuale di database ad oggetti
Una delle principali differenze di progettazione tra database ad oggetti e database relazionali è nella gestione delle relazioni: nei DB O-O le relazioni sono gestite con proprietà di relazione o attributi
riferimento che includono gli OID degli oggetti relati (problemi con le relazioni n:m). È possibile
mappare in schemi O-O degli schemi EER non contenenti né categorie né relazioni con grado maggiore di 2 (il grado indica il numero di entità che fanno parte della relazione).
La procedura è composta da sette passi:
1. Passo 1: creare una classe ODL per ogni tipo entità o sottoclasse EER.
Il tipo della classe ODL dovrebbe includere tutti gli attributi della classe EER usando
un costruttore di tupla al top level del tipo.
Gli attributi multivalued sono dichiarati usando costruttori di set, bag o liste.
Attributi composti sono mappati in un costruttore di tupla(struct).
Dichiarare un extentper ogni classe, specificandone la chiave.
2. Passo 2: aggiungere proprietà di relazione o attributi di referenza per ogni relazione binaria
nelle classi ODL che partecipano alla relazione.
Gli attributi possono essere creati in una sola o in entrambe le direzioni.
Gli attributi sono single-valuedper relazioni binarie nella direzione 1:1e N:1. Sono
collezioni per relazioni 1:N o M:N.
Se esistono attributi di relazioni, un costruttore tupla può essere usato per creare
una struttura della forma <referenza, attributi di relazione>.
3. Passo 3: includere metodi appropriati per ogni classe. Questi non sono disponibili dallo
schema EER e devono essere aggiunti al progetto riferendosi ai requisiti originari.
Il metodo costruttore dovrebbe includere il codice di verifica dei vincoli che devono
valere alla creazione un nuovo oggetto.
Un metodo distruttore dovrebbe verificare ogni vincolo che può essere violato
durante la cancellazione di un oggetto.
Altri metodi dovrebbero includere i controlli per ogni ulteriore vincolo rilevante.
4. Passo 4: una classe ODL che corrisponde a una sottoclasse nello schema EER eredita il tipo
e i metodi della sua superclasse nello schema ODL.
I suoi attributi specifici e i riferimenti sono specificati come visto nei passi 1 e 2.
5. Passo 5: i tipi di entità deboli possono essere mappati come i tipi di entità regolari.
Alternativamente, i tipi deboli che non partecipano in alcuna relazione eccetto che
quella identificante, possono essere mappati come se fossero attributi composti
multivalued del tipo entità possessore, usando il costruttore set<struct<…>> o
list<struct<…>>
6. Passo 6: le categorie (o tipi unione) creano dei problemi nel mapping in ODL.
Si può definire una classe che rappresenti la categoria, ed una relazione 1:1 tra la
categoria ed ogni sua superclasse.
Un’alternativa è utilizzare il tipo unione, se è disponibile.
7. Passo 7: relazioni n-arie (n>2) possono essere mappate in un tipo oggetto separato con
referenze appropriate a ciascuna classe partecipante.
Queste referenze sono basate su un mapping di una relazione 1:N da ciascun tipo di
entità partecipante alla relazione n-aria.
Le relazioni M:N possono anch’esse usare questa opzione, se richiesto.
35
BASI DI DATI 2
Lezione 11 – Basi di Dati Distribuite ed Architetture Client-Server
La tecnologia per i DDB
La tecnologia per i DDB è il risultato dell’unione di due tecnologie:
La tecnologia delle basi di dati.
La tecnologia delle reti e della comunicazione che ha avuto un’evoluzione enorme (tel. Cellulari, Internet, …).
Utilizzare un DDB consente alle organizzazioni di: effettuare un processo di decentralizzazione che
viene raggiunta a livello di sistema e di integrare le informazioni a livello logico.
Un database distribuito è un singolo database logico che è sparso fisicamente attraverso
computer in località differenti e connessi attraverso una rete di comunicazione dati.
Un sistema per la gestione di basi di dati distribuite (DDBMS) è un sistema software che gestisce
un database distribuito rendendo la distribuzione trasparente all’utente.
La rete deve consentire agli utenti di condividere i dati: un utente della località A deve essere in
grado di accedere (ed eventualmente aggiornare) i dati della località B.
Tipi di architetture multiprocessore
Architettura a memoria condivisa: diversi processori condividono sia la memoria primaria, sia la
secondaria.
Architettura a disco condiviso: i processori condividono la memoria secondaria, ma ognuno possiede la propria memoria primaria.
Usando queste architetture i processori possono comunicare senza utilizzare la rete (meno
overhead). I DBMS che si basano su queste architetture si chiamano ParallelDBMS.
Architettura Shared Nothing: ogni processore possiede la sua memoria primaria e secondaria e
comunicano attraverso la rete:
Non esiste memoria comune.
I nodi sono simmetrici ed omogenei.
Architettura di un DDB
Un database distribuito è caratterizzato dall’eterogeneità dell’hardware e dei sistemi operativi di
ogni nodo.
Un database distribuito richiede DDBMS multipli, funzionanti ognuno su di un sito remoto.
Gli ambienti di database distribuiti si differenziano in base a:
Il grado di cooperazione dei DDBMS.
La presenza di un sito master che coordina le richieste che coinvolgono dati memorizzati in
siti multipli.
Tipi di trasparenza
La Gestione dei dati distribuiti implica diversi livelli di trasparenza: sono nascosti i dettagli riguardo
l’ubicazione di ogni file entro il sistema.
Trasparenza di distribuzione o di rete: Libertà dell’utente dai dettagli della rete.
o Trasparenza di locazione: un comando utilizzato è indipendente dalla località
dei dati e dalla località di emissione del comando.
o Trasparenza di naming: la specifica di un nome di un oggetto implica che una
volta che un nome è stato fornito, gli oggetti possono essere referenziati usando
quel nome, senza dover fornire dettagli addizionali.
36
BASI DI DATI 2
o Trasparenza di replicazione:
Copie dei dati possono essere mantenute in siti multipli per una migliore
disponibilità, prestazioni ed affidabilità.
L’utente non percepisce l’esistenza delle copie.
o Trasparenza di frammentazione: Sono possibili due tipi di frammentazione:
La frammentazione orizzontale che distribuisce una relazione attraverso
insiemi di tuple.
La frammentazione verticale che distribuisce una relazione in sottorelazioni formate da un sottoinsieme delle colonne della relazione originale.
Una query globale dell’utente deve essere trasformata in una serie di frammenti di
query.
La trasparenza di frammentazione consente all’utente di non percepire l’esistenza di
frammenti.
I Vantaggi dei DDB sono:
Affidabilità: la probabilità che il sistema sia funzionante ad un certo istante.
Disponibilità: la probabilità che il sistema è continuamente disponibile durante un intervallo di tempo.
Quando un sito fallisce, gli altri possono continuare ad operare.
Solo i dati del sito fallito sono inaccessibili.
La replicazione dei dati aumenta ancora di più l’affidabilità e la disponibilità.
In un sistema distribuito è più facile espandere il sistema in termini di aggiungere nuovi dati, accrescere il numero di siti, o aggiungere nuovi processori.
La localizzazione dei dati: i dati sono mantenuti nei siti più vicini a dove sono più utilizzati.
Ciò comporta una riduzione di accesso a reti geografiche.
Ogni sito ha un database di taglia più piccola e le query e le transazioni sono processate più
rapidamente.
Le transazioni su ogni sito sono in numero minore rispetto ad un database centralizzato.
Funzionalità addizionali caratteristiche dei DDBMS
Rispetto ai tradizionali DBMS, i DDBMS devono fornire le seguenti funzionalità:
Mantenere traccia dei dati, della loro distribuzione, frammentazione e replicazione nel catalogo.
Processare query distribuite: l’abilità di accedere a siti remoti e trasmettere query e dati tra
i vari siti attraverso la rete di comunicazione.
Gestire le transazioni distribuite, query e transazioni devono accedere ai dati da più di un
sito mantenendo l’integrità del DB.
Gestire la replicazione dei dati: decidere quando replicare un dato e mantenere la consistenza fra le copie.
Gestire il recovery di un DDB: fallimento di uno dei siti e dei link di comunicazione.
Sicurezza, le transazioni distribuite devono essere gestite garantendo la sicurezza dei dati e
l’accesso degli utenti.
Gestire il catalogo distribuito, il catalogo deve contenere i dati dell’intero DB ed essere globale.
Deve essere deciso come e dove distribuire il catalogo.
A livello hardware, si devono considerare le seguenti differenze rispetto ai DBMS:
Esistono diversi computer, detti siti o nodi.
I siti devono essere connessi attraverso una rete di comunicazione per trasmettere dati e
comandi fra i siti.
37
BASI DI DATI 2
I siti possono essere connessi attraverso una rete locale e/o distribuiti geograficamente e connessi
ad una rete geografica.
Il design dei DDB prevede l’applicazione di tecniche relative a:
Frammentazione dei dati.
Replicazione dei dati.
Allocazione dei frammenti.
Frammentazione dei Dati
Deve essere deciso quale sito deve memorizzare quale porzione del DB. Assumiamo che non ci sia
replicazione dei dati. Una relazione può:
Essere memorizzata per intero in un sito.
Essere divisa in unità più piccole distribuite.
Un frammento orizzontale di una relazione è un sottoinsieme delle tuple della relazione.
Le tuple vengono assegnate ad un determinato frammento orizzontale in base al valore di uno o
più attributi. La segmentazione orizzontale divide una relazione raggruppando righe per creare sottoinsiemi di tuple, ciascuno con un significato logico.
La segmentazione orizzontale derivata applica la partizione di una relazione primaria anche a relazioni secondarie, collegate alla prima con una chiave esterna.
La segmentazione verticale divide una relazione “verticalmente” per colonne. Un frammento verticale di una relazione mantiene solo determinati attributi di una relazione.
Es:
EMPLOYEE può essere
suddiviso in due frammenti:
uno contenente le informazioni personali (NAME, BDATE, ADDRESS e SEX).
L’altro contenente SSN, SALARY, SUPERSSN, DNO.
La frammentazione dell’esempio precedente non consente di ricostruire la tupla EMPLOYEE
originale: non ci sono attributi in comune fra i due frammenti. Soluzione: aggiungere SSN agli
attributi personali. È necessario includere la chiave primaria o una chiave candidata in ogni
frammento verticale.
Ogni frammento orizzontale su di una relazione R può essere specificato attraverso un’operazione
.
Un frammento orizzontale tale che le condizioni C1, … , Cn includono tutte le tuple della relazione
è detto frammentazione orizzontale completa. In molti casi i frammenti sono disgiunti: Nessuna
tupla in R soddisfa Ci AND CJ per i ≠j.
Un frammento verticale può essere specificato da una operazione dell’algebra relazionale
.
Un insieme di frammenti verticali la cui lista di proiezioni L1, … , Ln include tutti gli attributi di R e
condivide solo la chiave primaria è detta frammentazione verticale completa.
Per quel che riguarda la frammentazione verticale completa: Devono essere soddisfatte le seguenti
condizioni:
38
BASI DI DATI 2
Per ricostruire la relazione R dai frammenti verticali è necessario fare l’OUTER join dei frammenti.
È possibile combinare la frammentazione orizzontale e verticale (generando una frammentazione
mista).
Uno schema di frammentazione di un DB è la definizione di un insieme di frammenti che include
tutte le tuple e gli attributi del DB e consente la ricostruzione dell’intero DB applicando una sequenza di operazioni di OUTER JOIN e UNION.
Lo schema di allocazione descrive l’allocazione dei frammenti ai siti del DB.Associa ad ogni
frammento il sito in cui deve essere memorizzato. Un frammento memorizzato su più di un sito si
dice replicato.
Replicazione ed Allocazione di dati
La replicazione consente di migliorare la disponibilità dei dati. Modalità di replicazione:
Replicare l’intero DB in ogni sito, migliora la prestazione per le query, overhead eccessivo
per l’aggiornamento dei dati, controllo della concorrenza e recovery complessi.
Nessuna replicazione, frammenti disgiunti (eccetto per la chiave).
Replicazione parziale, soluzioni intermedia: alcuni frammenti possono essere replicati ed
altri no.
Lo schema di replicazione è una descrizione della replicazione dei frammenti. Ogni segmento deve
essere assegnato ad un sito del DB (Questo processo si chiama allocazione dei dati).
La scelta dei siti e del grado di replicazione dipende da:
Prestazioni.
Obiettivi di disponibilità del sistema.
Tipo e frequenza delle transazioni sottomesse ad ogni sito.
I Criteri per distribuire i dati: trovare una soluzione ottima alla soluzione dei dati è un problema difficile:
Se è richiesta un’alta disponibilità e le transazioni possono essere sottomesse ad ogni sito e
molte transazioni sono solo di retrieval, si può adottare una soluzione di replicazione totale.
Se alcune transazioni che accedono a porzioni del DB sono sottomesse solo da particolari
siti, su quei siti possono essere allocati i frammenti corrispondenti.
Se sono richiesti molti aggiornamenti è conveniente ridurre la replicazione dei dati.
39
BASI DI DATI 2
Esempi di frammentazione, allocazione e replicazione
Supponiamo che un’organizzazione abbia tre siti, uno per ogni dipartimento. I siti 2 e 3 sono
relativi ai dipartimenti 4 e 5, rispettivamente. Da ognuno di questi siti si accede di frequente ai dati
associati agli impiegati e ai progetti dei dipartimenti corrispondenti. Assumiamo che i siti 2 e 3
accedano soprattutto alle informazioni NAME, SSN, SALARY, SUPERSSN di EMPLOYEE.
Il sito 1 è usato dagli amministratori per accedere ai dati dell’intera compagnia regolarmente.
L’intero DB può essere memorizzato al sito1.
I frammenti dei siti 2 e 3 sono determinati frammentando orizzontalmente DEPARTMENT in base
alla chiave DNUMBER. Applichiamo la frammentazione derivata alle relazioni EMPLOYEE, PROJECT
e DEPT_LOCATION basate sulla chiave esterna che referenzia il dipartimento.
Frammentiamo verticalmente la relazione EMPLOYEE per includere solo gli attributi {NAME, SSN,
SUPERSSN, DNO}.
Problemi con la relazione WORKS_ON (M:N): WORKS_ON(ESSN, PNO, Hours) non ha per attributo
il numero di dipartimento. Ogni tupla collega un impiegato ed un progetto.
Possiamo frammentarla in base:
Al dipartimento per cui l’impiegato lavora.
Al dipartimento che controlla il progetto.
Scegliamo la seconda ipotesi.
Dati al sito2
Dati al sito 3
Relazione WORKS_ON
40
BASI DI DATI 2
a) Frammenti di WORKS_ON per gli impiegati che lavorano nel dipartimento 5:
b) Frammenti di WORKS_ON per gli impiegati che lavorano nel dipartimento 4:
c) Frammenti di WORKS_ON per gli impiegati che lavorano nel dipartimento 1:
Allocazione dei segmenti
L’unione dei frammenti G1, G2, G3, G4 e G7 sono allocati nel sito 2.
L’unione dei frammenti G4, G5, G6, G2 e G8 sono allocati nel sito 3.
I frammenti G2 e G4 sono replicati in entrambi i siti.
Questa strategia di allocazione permette di eseguire il JOIN tra i frammenti locali EMPLOYEE o
PROJECT dei siti 2 e 3 e il frammento locale WORKS_ON completamente in locale.
Esempio: per il sito 2, l’unione dei frammenti G1, G4 e G7 restituisce tutte le tuple di
WORKS_ON relativi ai progetti controllati dal dipartimento 5.
Per il sito 3 vale lo stesso per i segmenti G2, G5 e G8.
41
BASI DI DATI 2
Esempio: Conti correnti bancari
CONTO-CORRENTE (NUM-CC,NOME,FILIALE,SALDO)
TRANSAZIONE (NUM-CC,DATA,PROGR, AMMONTARE, CAUSALE)
Frammentazione orizzontale principale
Es:
CONTO1 =
Filiale=1CONTO-CORRENTE
CONTO2 =
Filiale=2CONTO-CORRENTE
CONTO3 =
Filiale=3CONTO-CORRENTE
Frammentazione orizzontale derivata
Es:
TRANS1 =TRANSAZIONE
TRANS2 =TRANSAZIONE
TRANS3 =TRANSAZIONE
CONTO1
CONTO2
CONTO3
Allocazione dei frammenti
Rete:
3 siti periferici
1 sito centrale
Allocazione:
locale
centrale
42
BASI DI DATI 2
Livelli di trasparenza
Modalità per esprimere interrogazioni offerte dai DBMS commerciali (LIVELLI):
FRAMMENTAZIONE: il programmatore non si deve preoccupare se o no il DB è distribuito
o frammentato.
ALLOCAZIONE: il programmatore dovrebbe conoscere la struttura dei frammenti, ma non
deve indicare la loro allocazione.
LINGUAGGIO: il programmatore deve indicare nella query sia la struttura dei frammenti
che la loro allocazione.
Efficienza
Ottimizzazione delle query. Modalità di esecuzione:
seriale
parallela
Esecuzione seriale
Esecuzione parallela
Transazioni distribuite
BEGIN TRANSACTION UPDATE CONTO1@1 SET SALDO = SALDO + 500.000 WHERE NUM-CLI=45;
UPDATE CONTO2@2 SET SALDO = SALDO -500.000 WHERE NUM-CLI=35; COMMIT-WORK
END TRANSACTION
Tipi di DDB
Si differenziano per diversi fattori:
Grado di omogeneità del software dei DDBMS
o DDB omogenei: tutti i server e tutti gli utenti usano lo stesso software.
o DDB eterogenei, altrimenti.
Grado di autonomia locale:
o Se il sito locale non può funzionare come un DBMS stand-alone non ha nessuna
autonomia locale, all’utente il sistema “appare” come un DBMS centralizzato.
o Se le transazioni locali possono accedervi, ha qualche grado di autonomia locale.
Sistemi di Database federati: ogni server è un DBMS centralizzato e autonomo con:
o I suoi propri utenti locali.
o Transazioni locali.
o DBA.
o E, quindi, un alto grado di autonomia locale.
È presente una vista globale o schema della federazione di database.
Un sistema multidatabase (DB federati) non ha uno schema globale e interattivamente ne viene
43
BASI DI DATI 2
costruito uno in base alle necessità dell’applicazione.
In un FDB eterogeneo, i DB coinvolti possono essere relazionali, reticolari, gerarchici, …
È necessario introdurre dei traduttori di query.
Sistemi per la gestione dei DB Federati
Tipi differenti di eterogeneità:
Differenze nei modelli di dati.
Differenze nei vincoli:
le modalità per la specifica dei vincoli varia da sistema a sistema.
Differenze nei linguaggi di query:
anche con lo stesso modello di dati i linguaggi e le loro versioni possono variare.
Eterogeneità semantica:
Differenze di significato, interpretazione, uso degli stessi dati o di dati correlati.
Costituisce la principale difficoltà nella progettazione degli schemi globali di basi di dati
eterogenee.
Lo schema a cinque livelli
1. Lo schema per un gruppo di utenti o un’applicazione
2. Schema globale risultante dall’integrazione di più schemi
3. Sottoinsieme dello schema componente
4. Modello dati comune
5. Schema concettuale
I DB distribuiti incontrano un numero di controlli di concorrenza e problemi di recovery che non
sono presenti nei DB centralizzati.
Alcuni sono elencati di seguito:
Trattamento di copie multiple di dati: il controllo della consistenza deve mantenere una
consistenza globale. Allo stesso modo il meccanismo di recovery deve recuperare tutte le
copie e conservare la consistenza dopo il recovery.
Fallimenti di singoli siti: la disponibilità del DB non deve essere influenzata dai guasti di uno
o due siti e lo schema di recovery li deve recuperare prima che siano resi disponibili.
Guasto dei collegamenti di comunicazione: Tale guasto può portare ad una partizione della
rete che può influenzare la disponibilità del DB anche se tutti i siti sono in esecuzione.
Commit distribuito: una transazione può essere frammentata ed essere eseguita su un
numero di siti. Questo richiede un approccio basato sul commit a due fasi per il commit
della transazione.
Deadlock distribuito: poiché le transazioni sono processate su siti multipli, due o più siti
possono essere coinvolti in un deadlock. Di conseguenza devono essere considerate le
tecniche per il trattamento dei deadlock.
Controllo della concorrenza distribuito basato su una copia designata dei dati: si designa
una particolare copia di ogni dato (copia designata). Tutte le richieste di lock ed unlock
vengono inviate solo al sito che la contiene.
Tecnica del sito primario: un singolo sito è designato come sito primario il quale fa da
coordinatore per la gestione delle transazioni.
Tecnica del sito primario
Gestione delle transazioni: il controllo della concorrenza ed il commit sono gestiti da questo sito.
La tecnica del lock a due fasi è usata per bloccare e rilasciare i data item. Se tutte le transazioni in
tutti i siti seguono la politica delle due fasi allora viene garantita la serializzabilità.
Vantaggi: i data item sono bloccati (locked) solamente in un sito ma possono essere usati da qualsiasi altro sito.
44
BASI DI DATI 2
Svantaggi: tutta la gestione delle transazioni passa per il sito primario che potrebbe essere sovraccaricato. Nel caso in cui il sito primario fallisce, l’intero sistema è inaccessibile.
Per assistere il recovery un sito di backup viene designato come copia di backup dei sito primario.
Nel caso di fallimento del sito primario, il sito di backup funziona da sito principale.
Tecnica della copia primaria
In questo approccio, invece di un sito, una partizione dei data item è designata come copia primaria. Per bloccare un data item soltanto sulla copia primaria di quel data item viene eseguito illock.
Vantaggi: le copie primarie sono distribuite su vari siti, e un singolo sito non viene sovraccaricato
da un numero elevato di richieste di lock ed unlock.
Svantaggi: l’identificazione della copia primaria è complesso. Una directory distribuita deve essere
gestita possibilmente in tutti i siti.
Recovery dal fallimento di un coordinatore
In entrambi gli approcci un sito coordinatore o un sito copia possono essere indisponibili. Questo
richiede la selezione di un nuovo coordinatore.
Approccio del sito primario senza sito di backup: Abortire e far ripartire tutte le transazioni attive
in tutti i siti. Si elegge un nuovo coordinatore che inizia il processing delle transazioni.
Sito primario con copia di backup: Sospende tutte le transazioni attive, designa il sito di backup
come sito primario ed identifica un nuovo sito di backup. Il nuovo sito primario riceve il compito di
gestire tutte le transazioni per riprendere il processo.
Il sito primario e quello di backup falliscono: Si usa un processo di elezione per selezionare un
nuovo sito coordinatore.
Controllo della concorrenza basata sul voting
Non esiste la copia primaria del coordinatore.Spedire una richiesta di lock ai siti che hanno i data
item.Se la maggioranza dei siti concedono il lock allora la transazione richiedente ottiene il data
item. Le informazioni di lock (concesse o negate) sono spedite a tutti questi siti.Per evitare un
tempo di attesa inaccettabile, viene definito un periodo di time-out. Se la transazione richiedente
non riceve alcuna informazione di voto allora la transazione viene abortita.
Architettura Client-Server
Discutiamo l’architettura Client-Server in generale e poi l’applichiamo ai DBMS. In un ambiente
con un grande numero di PC, stampanti, etc. Si definiscono dei server specializzati con funzionalità
specifiche.
Le risorse fornite da server specializzati possono essere messe a disposizione di diversi client.
Una macchina client fornisce all’utente l’appropriata interfaccia per utilizzare questi server impiegando la potenza di calcolo locale per eseguire applicazioni locali.
Differenti approcci sono stati proposti su come suddividere le funzionalità tra client e server.
Una possibilità è di includere le funzionalità in un DBMS centralizzato a livello server.
Un SQL server è fornito al client (ogni client):
Formula la query.
Fornisce l’interfaccia utente.
Fornisce funzioni di interfaccia dei linguaggi di programmazione.
SQL è uno standard: I server SQL di diversi produttori possono accettare query SQL.
I client possono collegarsi al dizionario dei dati che include la distribuzione dei dati fra i vari server
SQL.
Nel momento in cui si elabora una query:
1. Il client parsa una query e la decompone in un certo numero di query ai siti indipendenti.
2. Ogni server processa la query locale e manda il risultato al sito client.
3. Il client combina il risultato delle sotto query per produrre il risultato della query
sottomessa in origine.
45
BASI DI DATI 2
In questo approccio, il server SQL è detto anche transaction server o back-end machine. Il client è
detto application processor o front-end machine.
In un tipico DDBMS, si è soliti dividere i moduli software su tre livelli:
1. Software server, responsabile per la gestione dei dati locali di un sito.
2. Software client, gestisce l’interfaccia utente, accede al catalogo del DB e processa tutte le
richieste che richiedono l’accesso a più di un sito.
3. Software di comunicazione, fornisce le primitive di comunicazione che sono usate dal
client per trasmettere comandi e dati tra i vari siti.
46
BASI DI DATI 2
Lezione 12 – XML e basi di dati in Internet
Nonostante l’HTML (HyperText Markup Language) è ampiamente usato per la formattazione e la
strutturazione dei documenti Web. XML invece di limitarsi a specificare solamente il modo in cui le
pagine Web sono formattate per la visualizzazione sullo schermo, può essere usato per fornire
informazioni riguardanti la struttura ed il significato dei dati in essi contenuti.
Le informazioni memorizzate nei DB sono conosciute come dati strutturati perché sono
rappresentate in un formato rigido. In alcune applicazioni i dati sono raccolto con modalità ad-hoc
prima ancora di sapere come dovranno essere memorizzati e gestiti. Questi tipi di dati sono
conosciuti come dati semi strutturati. Una terza categoria è conosciuta come dati non strutturati.
Sono caratterizzati da una presenza molto limitata di informazioni relative ai tipi di dati.
Le etichette (o tag) sugli archi orientati rappresentano i nomi dello schema. I nodi interni rappresentano gli oggetti individuali o gli attributi composti. I nodi foglia rappresentano i valori effettivi
degli attributi di tipo semplice (atomico).
HTML utilizza un numero elevato di tag predefiniti che specificano dei comandi per la formattazione dei documenti Web.
Due concetti fondamentali vengono usati per costruire un documento XML:
elementi ed attributi. In XML gli attributi forniscono informazioni aggiuntive per descrivere
gli elementi rispetto l’HTML.
Vi sono ulteriori concetti come: entità, gli identificatori, e i riferimenti.
Come per l’HTML, gli elementi sono identificati dai loro tag di inizio e tag di fine. Nella rappresentazione ad albero:
i nodi interni rappresentano gli elementi complessi,
i nodi foglia rappresentano gli elementi semplici.
Per questo motivo il modello XML è chiamato modello ad albero o modello gerarchico.
I documenti XML possono essere classificati in tre tipi principali:
1. Documenti XML incentrati sui dati:
a. Questi documenti possiedono molti dati di dimensioni ridotte che seguono una
struttura specifica e possono provenire da un DB strutturato.
2. Documenti XML incentrati sul documento:
a. Questi sono documenti con grandi quantità di testo (libri ed articoli).
3. Documenti XML ibridi:
a. Questi documenti possono possedere parti contenenti dati strutturati e altri
costituiti principalmente da testo o da dati non strutturati.
Un Documento XML ben formato (Well-Formed) è sintatticamente corretto. Il DOM (Document
Object Model): Permette ai programmi manipolare la rappresentazione ad albero risultante
dall’elaborazione di un documento XML ben formato. Un criterio più rigido per un documento XML
è la validità. In questo caso il documento deve essere well-formed, e in più i nomi degli elementi
usati nelle coppie di tag di inizio e di fine devono seguire la struttura specificata in un file DTD o
XSD.
Senza DTD :
<?XML version="1.0" standalone=“yes”?>
<NEWSPAPER>.. </NEWSPAPER>
DTD esterno:
<?XML version="1.0" standalone=“no”?>
<!DOCTYPE NEWSPAPER SYSTEM “newspaper.dtd”>
<NEWSPAPER>.. </NEWSPAPER>
47
BASI DI DATI 2
DTD interno:
<?XML version="1.0" standalone="no"?>
<!DOCTYPE NEWSPAPER [
<!ELEMENT NEWSPAPER(…)> ...
Un * che segue il nome dell’elemento significa che l’elemento può essere ripetuto zero o più
volte nel documento. Un + che segue il nome dell’elemento significa che l‟elemento può essere ripetuto una o più volte nel documento. Un ? che segue il nome dell‟elemento significa che
l‟elemento può essere ripetuto zero o una volta. Un elemento presente senza nessuno dei tre
simboli precedenti deve comparire esattamente una volta all‟interno del documento.
Tipi di attributi
CDATA: dati di tipo carattere
(val1 | val2 | val3): un valore della lista
ID: identificatore
IDREF, IDREFS: valore di un attributo di tipo ID nel documento (o insieme di valori)
ENTITY, ENTITIES: nome (nomi) di entità
NMTOKEN, NMTOKENS: caso ristretto di CDATA (una sola parola o insieme di parole)
#REQUIRED: il valore deve essere specificato; #IMPLIED: il valore può mancare; #FIXED “valore”:
se presente deve coincidere con “valore”.
I tipi di dati inclusi nel DTD non sono molto generali. Le DTD hanno una loro sintassi e richiedono
processori particolari. Sarebbe un vantaggio specificare gli schemi dei documenti XML utilizzando
le regole sintattiche di XML.
XML Schema Scopo: Definire gli elementi e la composizione di un documento XML in modo più
preciso del DTD. Un XML Schema definisce regole riguardanti:
– Elementi
– Attributi
– Gerarchia degli elementi
– Sequenza di elementi figli
– Cardinalità di elementi figli
– Tipi di dati per elementi e attributi
– Valori di default per elementi e attributi
Gli XSD sono: Estendibili (ammettono tipi riusabili definiti dall‟utente). In formato XML. Più ricchi e
completi dei DTD. Capaci di supportare tipi di dati diversi da PCDATA. Capaci di gestire namespace
multipli.
Esistono quattro tipi di elementi complessi:
– Vuoti (empty)
– Contenenti solo altri elementi.
– Contenenti solo testo.
– Contenenti testo e/o altri elementi.
Gli elementi xsd:annotation e xsd:documentation sono utilizzati per fornire commenti ed altre descrizioni nel documento XML.
Approcci alla memorizzazione di documenti XML
1. Utilizzo di un DBMS per la memorizzazione dei documenti in formato testuale: possiamo
usare un DBMS relazionale o ad oggetti per memorizzare l’intero documento XML come
campi di testo.
48
BASI DI DATI 2
2. Utilizzo di un DBMS per la memorizzazione dei documenti come dati: questo approccio può
funzionare per la memorizzazione di un collezione di documenti conformi a uno specifico
XML DTD o XML schema. Poiché tutti i documenti hanno la stessa struttura, è possibile
progettare un DB relazionale (o a oggetti) per memorizzare gli elementi di livello foglia
all‟interno dei documenti XML.
3. Progettazione di un sistema specializzato per la memorizzazione di dati XML nativi: Si
potrebbe progettare ed implementare un nuovo tipo di sistema di DB basato sul modello
gerarchico (ad albero).
4. Creazione o pubblicazione do documenti XML personalizza a partire da DB relazionali
preesistenti: Siccome ci sono enormi quantità di dati già memorizzate in DB relazionali,
alcune parti potrebbero necessitare di essere formattate come documenti per lo scambio o
la visualizzazione sul Web.
La maggior parte dei documenti estratti da un DB utilizza solamente un sottoinsieme di attributi, di
tipi entità e relazioni.
È possibile avere un sottoinsieme più complesso con uno o più cicli indicanti relazioni multiple tra
le entità. In questi casi decidere il modo in cui creare le gerarchie del documento risulta più difficile.
Una maniera per eliminare i cicli è quella di replicare I tipi entità coinvolti nei cicli.
Tra le varie proposte avanzate come linguaggi di interrogazione XML sono emersi due standard:
1. XPath che fornisce dei costruttori di linguaggio per la specifica di path expression volti ad
identificare determinati nodi (elementi) che corrispondono a particolari pattern contenuti
nel documento XML.
2. XQuery è un linguaggio di interrogazione più generale che utilizza le espressioni XPath ma
che possiede costrutti aggiuntivi.
XPath
Una espressione XPath ritorna una collezione di nodi (elementi) che soddisfa determinati pattern
in essa specificati. I nomi nella espressione XPath sono i nomi dei nodi contenuti nel nell’albero del
documento XML, che possono essere i nomi di tag (elementi) o nomi di attributi, possibilmente
con l’aggiunta di condizioni di qualifica volte a limitare ulteriormente i nodi che soddisfano i
pattern. Nella specifica di un path sono utilizzati due separatori:
lo slash (/) singolo ed il doppio slash (//):
– Lo slash singolo prima di un tag specifica che quel tag deve essere un figlio diretto del tag
precedente (padre),
– mentre il doppio slash indica che il tag può essere un discendente di qualunque livello.
Una espressione XPath è una stringa contenente nomi di elementi e operatori di navigazione e selezione:
. Nodo corrente
.. Nodo padre del nodo corrente
/ nodo radice, o figlio del nodo corrente
49
BASI DI DATI 2
// discendente del nodo corrente
@ attributo del nodo corrente
qualsiasi nodo
[p] predicato (se l’espressione p, valutata, ha valore booleano)
[n] posizione (se l’espressione n, valutata, ha valore numerico)
Una path expression può iniziare con doc(posizione_documento). Restituisce l’elemento radice del
documento specificato e tuttoil suo contenuto: doc(“libri.xml”).
XQuery
XQuery usa le espressioni XPath ma ha ulteriori costrutti. Si basa su XPath per identificare framenti
XML: È basato sulla elaborazione di sequenze di nodi. Una interrogazione XQuery è un’espressione
complessa che consente di estrarre parti di un documento e costruire un altro documento. XQuery
permette di specificare di interrogazioni più generali su uno o più documenti XML. La forma tipica
di una interrogazione XQuery è conosciuta come espressione FLWR, FLWR indica le quattro
principali clausole di XQuery ed hanno il seguente formato:
FOR < itera i valori delle variabili su sequenze di nodi >:
o La clausola for valuta la path expression, che restituisce una sequenza di elementi,
LET < variabili legate a collezioni di nodi >
o La valutazione di una clausola let assegna alla variabile un singolo valore: l‟intera
sequenza dei nodi che soddisfano l’espressione.
WHERE < esprime condizioni di qualificazione sui legami >
o La clausola WHERE esprime una condizione: solamente le tuple che soddisfano tale
condizione vengono utilizzate per invocare la clausola RETURN.
RETURN < specificazione del risultato dell’interrogazione >
o Genera l’output di un’espressione FLWR che può essere:Un nodo, Un “foresta”
ordinata di nodi, Un valore testuale (PCDATA).
Esempi
1. Questa interrogazione ritrova il nome ed il cognome degli impiegati che guadagnano più di
70000. La variabile $x è legata ad ogni elemento employeeName figlio degli elementi
employee per cui il valore di employeeSalary è maggiore di 70000.
2. Questa è un modo alternativo di ritrovare gli stessi elementi della query (1).
3. Questa query illustra un operazione di join può essere eseguita in presenza di più di una
variabile. La variabile $x è legata a ogni elemento projectWorker figlio del progetto numero
5, mentre la variabile $y è legata ad ogni elemento employee. La condizione di join
confronta i valori ssn al fine di recuperare i nomi degli impiegati.
50