 - Servizio di Hosting di Roma Tre")
LABORATORIO DI METOLOGIE E TECNOLOGIE GENETICHE
PCR (Polymerase chain reaction)
La PCR è un metodo di biologia molecolare, utile per amplificare (i.e. creare copie
multiple di) DNA, inventato da Kary Mullis alla fine degli anni ’80.
Lo scopo della PCR è di produrre un enorme numero di copie di una sequenza di
DNA, sia essa un gene o parte di questo.
Nella pratica corrente i principali componenti della PCR sono:
DNA stampo, che contiene il frammento da amplificare;
Due primers (Forward e Reverse), che determinano l’inizio e la fine della
regione da amplificare;
DNA Polimerasi, che copia la regione da amplificare (si usano le DNA
polimerasi di batteri termofili, che sono stabili ad elevate temperature; es. Taq
Polimerasi);
Nucleotidi, per la sintesi di nuovo DNA;
Buffer, che fornisce l’ambiente chimico ideale per la DNA Polimerasi.
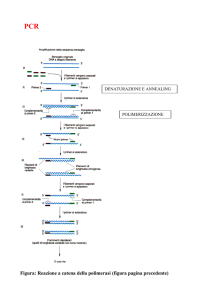
Il processo della PCR consta di tre steps principali che vengono ripetuti dalle 30 alle
40 volte, attraverso l’utilizzo di un termociclatore.
1). Denaturazione a 94oC (Melting):
Durante la denaturazione, i due filamenti di DNA si separano e tutte le reazioni
enzimatiche si arrestano (es. l’estensione del filamento del ciclo precedente);
2). Annealing a 50 – 60 oC:
La temperatura di questo stadio dipende dai primers usati.
Durante l’annealing vengono utilizzati due primers (Forward e Reverse), che si
legano ai loro siti specifici. Si formano e si rompono continuamente i legami
ionici tra i filamenti dei primers ed i singoli filamenti di DNA che funzionano
da templato (filamento stampo). I primers che si appaiano esattamente con il
filamento stampo formano i legami più stabili ed, in questo piccolo tratto di
doppia elica, si lega la polimerasi, che così inizia a copiare il filamento stampo;
3). Estensione a 70 – 75 oC (Elongation):
La temperatura di elongation dipende dalla DNA Polimerasi.
Durante l’estensione, la Polimerasi estende i primers aggiungendo le basi
(complementari al templato) all’estremità 3’. Il risultato sono 2 copie di DNA a
doppio filamento.
1
Figura 1: Le tre fasi della PCR.
Poichè entrambi i filamenti sono copiati durante la PCR, si ha un aumento
esponenziale del numero di copie della sequenza di DNA.
X=X0(2N) N= NUMERO DI CICLI
Con 100 molecole di DNA come stampo, dopo 30 cicli, la PCR produrrà
PIU’ DI 100 MILIONI DI COPIE.
2
Figura 2: Amplificazione esponenziale durante la PCR.
Caratteristiche della PCR
•
Si possono utilizzare piccole quantità di DNA(ng);
•
La qualità del DNA può anche non essere buona;
•
Alta riproducibilità, specificità e sensibilità;
•
Applicazioni cliniche e nella ricerca;
•
Molto rapida e poco costosa;
•
Puo’ essere usata solo se si conosce la sequenza del DNA.
A cosa serve la PCR?
La PCR può essere utilizzata in un’ampia varietà di analisi tra cui:
Genetic fingerprinting (usata in medicina legale);
Test di paternità;
Studi di evoluzione e filogenesi;
Identificazione di malattie ereditarie;
Identificazione di malattie virali;
Clonaggio di un gene;
Analisi di DNA antico;
Genotipizzazione di specifiche mutazioni e polimorfismi.
3
POLIMORFISMI
I polimorfismi sono variazioni di sequenza nelle regioni codificanti e non (es.:
sostituzioni nucleotidiche, delezioni/inserzioni, duplicazioni/delezioni geniche). Per
definizione un polimorfismo è una variante allelica, che si verifica nella popolazione
con una frequenza di almeno l’1%. Es.: I gruppi sanguigni umani ABO.
Il polimorfismo si differenzia da una mutazione spontanea, che si verifica, invece,
con una frequenza < 1%.
POLIMORFISMO
MUTAZIONE
PREVALENZA
alta (>1%)
bassa (<1%)
RISCHIO INDIVIDUALE
basso
alto
RISCHIO ATTRIBUIBILE
ALLA POPOLAZIONE
apprezzabile
basso
STUDI APPROPRIATI
studi di coorte
studi di controllo
famiglie
A che serve lo studio dei polimorfismi?
Le analisi dei polimorfismi sono usate:
Nella tipizzazione dei tessuti (es.: per la donazione di organi);
In studi di popolazione (es.: studio del grado di diversità genetica in una
popolazione);
Per l’identificazione di malattie genetiche.
Come nascono i polimorfismi?
Per mutazione.
Che cosa mantengono i polimorfismi nella popolazione?
Molti sono i fattori che mantengono un polimorfismo nella popolazione, tra cui:
Effetto del fondatore;
Deriva genica;
Polimorfismo bilanciato.
4
Negli ultimi anni è stato dimostrato che più di 1/3 dei loci eucariotici sono
rappresentati da varianti alleliche e che un locus è tanto più polimorfico, quanto più i
suoi alleli sono equifrequenti.
Le varianti alleliche possono o meno causare alterazioni funzionali della proteina e
nel fenotipo, a seconda che siano presenti nelle regioni codificanti o non codificanti.
Se un polimorfismo è in una sequenza codificante di un gene, in un esone, si può
verificare una sostituzione aminoacidica, determinando cambiamenti nella proteina
risultante. Un polimorfismo in un promotore può alterare i livelli di trascrizione. Un
polimorfismo caratterizzato dalla delezione dell’intero gene, come per l’allele nullo
GSTM1, elimina l’attività funzionale dell’enzima.
Si possono, inoltre, verificare sostituzioni aminoacidiche, originantesi dalla
sostituzione di un singolo nucleotide. Gli alleli la cui sequenza rivela solo un singolo
nucleotide cambiato sono chiamati polimorfismi a singolo nucleotide o SNPs (Single
Nucleotide Polymorphisms). In questo caso l’effetto della sostituzione dipende dalle
caratteristiche chimiche dell’amminoacido sostituito. Cambiamenti nella funzione
della proteina possono avere effetti profondi sul fenotipo, che possono essere
osservati sotto particolari condizioni, come l’esposizione a sostanze chimiche o
stress. Molto spesso questi cambiamenti possono creare, o eliminare, siti per gli
enzimi di restrizione che tagliano il DNA. La digestione con l’enzima può così
produrre frammenti di DNA di diversa lunghezza, identificabili con l’elettroforesi.
L’RFLP-PCR (Restriction Fragments Length Polymorphism) è un metodo indiretto
di indagine utile per l’individuazione degli SNPs.
Dove può essere posizionato un SNP?
In regioni non codificanti (questi polimorfismi non sono identificabili dal
prodotto proteico);
In regioni codificanti (in questi polimorfismi la struttura proteica può essere
alterata).
Il genoma umano contiene approssimativamente 1 milione di SNPs dei quali 500000
in zone non codificanti e 200000 in zone codificanti, dove si hanno sostituzioni
amminoacidiche. Il numero di SNPs per gene varia da 0 a 9.
La diversa risposta individuale alle condizioni ambientali dipende dalla presenza
delle variazioni di sequenza all’interno di geni critici. Questi polimorfismi genetici
possono influenzare i livelli di espressione, la struttura, o l’attività catalitica degli
enzimi del metabolismo e della riparazione del DNA, influenzando la suscettibilità
individuale. Alcuni esempi includono: 1). la relazione tra enzimi che attivano o
detossificano (glutatione S-transferasi) i potenziali carcinogeni, 2). La suscettibilità,
degli individui con polimorfismi nel gene XRCC1, a vari tipi di danni genotossici.
Ci sono una dozzina di geni che modulano la risposta alle esposizioni ambientali.
L’analisi dei polimorfismi in questi geni può essere utile per capire la distribuzione
del rischio all’esposizione nelle popolazioni umane e, possibilmente, predire i rischi
individuali dovuti all’esposizione.
5
Enzimi detossificanti (del metabolismo):
Glutatione S-transferasi.
Le glutatione S-transferasi (GSTs) sono una famiglia di enzimi conosciuti per il loro
importante ruolo nella detossificazioni di molti cancerogeni trovati nelle sigarette. Le
GSTs sono proteine dimeriche, che catalizzano le reazioni tra il glutatione ed i loro
substrati, come i radicali aromatici eterociclici e gli epossidi. La coniugazione facilita
l’escrezione consentendo, dunque, la detossificazione.
Reazioni
di fase I
Reazioni
di fase II
O
OSSIDAZIONI
(es. CYP1A1,CYP2E1)
CONIUGAZIONI
(es. GST, NAT2)
OH
ELIMINAZIONE
O
ADDOTTO AL DNA
Figura 3: Detossificazione dei composti potenzialmente cancerogeni, da parte degli enzimi
GSTs.
Oltre al loro ruolo nella fase II della detossificazione, i GSTs modulano l’induzione
di altri enzimi e proteine importanti per le funzioni cellulari, come la riparazione del
DNA. Questa classe di enzimi è importante per mantenere l’integrità genomica e,
come risultato, può svolgere un ruolo importante nella suscettibilità al cancro.
Gli enzimi GTSs sono codificati da cinque distinti loci, noti come: alpha (A), mu
(M), pi (P), theta (T) e zeta (Z). Due loci, in particolar modo, GSTM1 e GSTT1,
svolgono un ruolo di rilevanza nella suscettibilità al cancro testa-collo.
6
GSTM1
• Il gene GSTM1 si trova sul cromosoma 1 in posizione p13.3;
•
Individui con delezioni omozigoti del locus GSTM1 non hanno un’attività
•
enzimatica funzionale;
Sono stati identificati tre alleli al locus GSTM1:
Un allele nullo (delezione completa);
Due alleli (GSTM1a e GSTM1b) che differiscono per una sostituzione C → G
in posizione 534. Questa sostituzione porta ad una sostituzione amminoacidica
Lys → Asn in posizione 172.
Il metabolismo dei cancerogeni coinvolge una serie di steps di attivazione, che
produce intermedi reattivi e steps di detossificazione, che produce composti
idrosolubili e, quindi, eliminabili. L’attivazione può comportare la formazione di
composti che si legano al DNA, formando prodotti noti come “addotti”. L’accumulo
di addotti a livello di loci critici, come oncogeni e geni oncosoppressori, può portare
a mutazioni somatiche e ad alterazioni del ciclo cellulare.
Individui che non sono capaci di produrre l’enzima GSTM1 accumulano
potenzialmente più addotti al DNA.
Le nostre conoscenze su come le variazioni genetiche influenzano gli enzimi del
metabolismo hanno fornito nuove spiegazioni su come i carcinogeni riescono a
danneggiare il DNA. Numerosi studi hanno dimostrato che i polimorfismi del
metabolismo sono importanti determinanti del rischio di cancro a livello della
popolazione.
La formazione di addotti al DNA si verifica costantemente, nonostante i meccanismi
di detossificazione. I mammiferi hanno un complesso sistema di riparazione del
DNA, che corregge gli addotti al DNA, le basi danneggiate o altre lesioni prima che
eventi di replicazione stabilizzino questi cambiamenti permanentemente.
L’interazione di tutti questi fattori protettivi determina il grado con cui questi danni
sono convertiti in mutazioni e, quindi, in malattie.
7
Figura 4: Interazione tra i vari fattori protettivi.
Recentemente sono stati compiuti molti sforzi per caratterizzare le variazioni nei geni
della riparazione.
Riparazione del DNA:
Se i sistemi di riparazione del DNA correggono il danno al DNA, endogeno o indotto
da cancerogeni, le conseguenze dei genotipi metabolici “ad alto rischio” possono
essere meno significative. Gli enzimi della riparazione mantengono l’integrità del
codice genetico minimizzando gli errori di replicazione (causati da DNA templato
riarrangiato o danneggiato) e rimuovendo i segmenti di DNA danneggiato.
La fedeltà dei meccanismi di riparazione può essere influenzata da polimorfismi che
alterano l’attività enzimatica. E’ noto che individui che mancano di alcuni elementi
della riparazione del DNA hanno una maggiore predisposizione allo sviluppo di
tumori e che cambiamenti nell’attività di riparazione del DNA può influenzare la
sensibilità di un tumore al trattamento con alcuni agenti anti-tumorali.
8
La riparazione del DNA può verificarsi secondo molteplici pathways, che dipendono
dal tipo di danno:
Base excision repair (BER) coinvolge più di 25 geni deputati alla riparazione
delle basi danneggiate, dei siti abasici ed altri danni causati per lo più
dall’azione di radicali liberi;
Mismatch repair comprende almeno sei geni che correggono i nucletidi mal
appaiati che risultano durante la replicazione del DNA;
Nucleotide excision repair (NER) comprende più di 35 geni coinvolti nella
rimozione del danno indotto da raggi UV (dimeri di pirimidine) e addotti al
DNA prodotti dall’esposizione a sostanze chimiche;
Two double-strand-break, non homologous end joining and homologous
recombination repair (HRR) contano più di 20 geni coinvolti nella riparazione
di rotture dell’elica del DNA prodotte dall’esposizione alle radiazioni o dovute
alla riparazione incompleta da parte di altri pathway.
Polimorfismi nei geni della riparazione possono alterare la funzione della proteina
corrispondente e la capacità individuale di riparare il DNA danneggiato.
Recentemente è stata dimostrata una correlazione tra i polimorfismi associati al gene
XRCC1 e l’insorgenza del cancro.
XRCC1 (X-Ray Repair Cross Complementig 1)
Il gene XRCC1 si trova sul cromosoma 19 in posizione q13.2;
E’ composto da 17 esoni;
La proteina codificata è lunga 677 aa.;
La proteina ha domini di legame con la Polimerase-ß, DNA ligasi III and Poly
(ADP-ribose) polimerasi (PARP) ed è coinvolta nel pathway di riparazione
BER.
9
Figura 5: Pathway BER e ruolo di XRCC1.
10
Figura 6: Il gene XRCC1.
Polimorfismi in XRCC1
Codone 194 – Esone 6, Base 26304 C → T; Arg → Trp
Frequenza allelica= 0,15
Codone 206 – Esone 9, Base 26651 A → G; Pro → Pro
Frequenza allelica= 0,30
Codone 399 – Esone 10, Base 28152 G → A; Arg → Gln
Frequenza allelica= 0,25.
Studi di associazione riguardanti il polimorfismo 399 del gene XRCC1
La variante allelica al codone 399 è stata associata ad un aumento di addotti al DNA
indotti da aflatossine.
E’ stata evidenziata un’associazione positiva tra la variante allelica al codone 399 e la
presenza di addotti al DNA, in cellule mononucleate presenti nel sangue, ed con
un’aumentata frequenza di scambi tra cromatidi fratelli (SCE) in linfociti di individui
fumatori.
Esiste un’associazione positiva tra la presenza del polimorfismo nel codone 399 e
l’insorgenza del cancro testa-collo, cancro polmonare, cancro allo stomaco e cancro
alla mammella.
Esiste invece un’associazione inversa tra lo stesso polimorfismo e l’insorgenza del
cancro alla vescica e del cancro della pelle (del tipo non-melanoma).
11
XRCC3 (X-Ray Repair Cross Complementig 3)
Il gene XRCC1 si trova sul cromosoma 14 in posizione q32.3;
E’ composto da 10 esoni;
La proteina codificata è lunga 347 aa.;
Proteina facente parte della famiglia di RAD51, la quale facilita, per l’appunto,
l’assemblaggio del filamento nucleoproteico di RAD51 lungo il filamento crossricombinante. Interviene nella riparazione delle rotture a doppio filamento, in
particolare nell’ Homologous Recombination Repair.
Figura 7: Pathway HRR e ruolo di XRCC3.
Polimorfismi in XRCC3
IVS 5-14, Base 17893 A → G; Modifica della giunzione Introne-Esone
Frequenza allelica= 0,30
Codone 241 – Esone 7, Base 18067 C → T; Thr → Met
Frequenza allelica= 0,25.
12
Studi di associazione riguardanti il polimorfismo 399 del gene XRCC1
La variante allelica al codone 241 è stata associata ad un aumento di addotti al DNA
in leucociti circolanti di persone sane e ad un aumento di aberrazioni cromosomiche.
E’ stata evidenziata un’associazione positiva tra la variante allelica al codone 241 e
l’insorgenza di tumore alla pelle di tipo melanoma, cancro alla vescica e di tumore
alla prostata. Di contro non sono state trovate relazioni tra questo polimorfismo e
l’aumentata probabilità di manifestare il tumore ai polmoni, allo stomaco, alla pelle
ed alla vescica.
SCOPO DELL’ESERCITAZIONE
Determinazione dei polimorfismi dei geni XRCC1 e XRCC3, mediante PCR.
Primo Step:
Purificazione di DNA da sangue intero;
Quantificazione del DNA e sua diluizione;
Secondo step:
Preparazione dei campioni;
Reazione della PCR;
Check del prodotto di PCR (per verificare l’assenza di contaminazioni);
Terzo step:
Determinazione del genotipo:
a). Digestione enzimatica (per XRCC1/XRCC3);
b). Corsa elettroforetica;
c). Lettura delle bande ottenute.
13
Primo step
Purificazione di DNA da sangue intero
1) Lisi dei campioni di sangue:
Mettere in una eppendorf da 1,5 ml 200 μl di
sangue (a temperatura ambiente) ed aggiungere
25 μl di proteinasi K.
Aggiungere 200 μl di buffer B3 ai campioni e
vortexare vigorosamente (10-20S).
Incubare i campioni a 70oC per 10-15 min.
2). Regolare le condizioni di legame del DNA:
Aggiungere 210 μl di etanolo (96-100%) ad
ogni campione e vortexare ancora.
3). Legare il DNA:
Caricare ogni campione in una colonnina NucleoSpin
Blood posizionata dentro una eppendorf da
1,5ml. Centrifugare 1 min. a 11,000x g.
14
4). Lavare la membrana:
Primo lavaggio
Mettere la colonnina NucleospinBlood in una nuova
eppendorf da 1,5 ml ed aggiungere 500 μl di buffer
BW. Centrifugare 1 min. a 11,000 x g.
Secondo lavaggio
Mettere la colonnina NucleospinBlood in una nuova eppendorf
da 1,5 ml ed aggiungere 600 μl di buffer B5. Centrifugare 1
min. a 11,000x g.
5). Eluizione del DNA:
Mettere la colonnina NucleospinBlood in una nuova
eppendorf da 1,5 ml ed aggiungere 100 μl di buffer BE,
precedentemente riscaldato a 70oC. Incubare a
temperatura ambiente per 1 min. Centrifugare 1 min. a
11,000 x g.
15
Quantificazione del DNA purificato
Preparare 1 eppendorf da 0,5 ml per ogni campione. Aggiungere in ogni
eppendorf 390 μl di H2O distillata e 10 μl di campione.
Lettura allo spettrofotometro:
Prima lettura: bianco.
Mettere nella cuvetta al quarzo 400 μl di H2O distillata ed iniziare la
lettura.
Letture successive. Campioni
Caricare i campioni nella cuvetta al quarzo e procedere con la lettura.
Lo spettrofotometro indicherà tre valori:
A260: Assorbanza del DNA
A280: Assorbanza delle proteine
A260 / A280 = Purezza del DNA (deve essere tra 1,7 e 1,8).
N.B.: se la lettura è negativa, non c’è nulla.
Calcolo della concentrazione del DNA:
A260 x Fattore di diluizione x 40
Con:
Fattore di diluizione → 40
40 → Valore dell’assorbanza pari a 1 quando la concentrazione del DNA è
pari a 40 μg/ml.
Esempio:
A260 = 0,055
La concentrazione è pari a 110 μg/ml.
La concentrazione finale del DNA deve essere di 10 ng/ μl, quindi:
16
110/10 = 10 ca.
Il campione di DNA va diluito 10 volte in H2O distillata per ottenere una
concentrazione finale di 10 ng/μl.
Secondo step
XRCC1 ex10/XRCC3 ex7
Preparazione dei campioni
SCOPO: I polimorfismi che verrnno studiati sono delle sostituzioni aminoacidiche
Arg → Gln (codone 399) e Thr → Met (codone 241), localizzate, rispettivamente,
all’interno dell’esone 10 del gene XRCC1 e dell’esone 7 del gene XRCC3. Tali
polimorfismi sono dovuti: per XRCC1 ad una sostituzione G → A (nucleotide
28152), in grado di eliminare un sito di restrizione specifico per l’enzima HpaII/Msp
I, presente, invece, nell’allele wild-type; per XRCC3 ad una sostituzione C → T
(nucleotide 18067), in grado di creare un sito di restrizione specifico per l’enzima
NiaIII/Hsp92II . Dopo aver amplificato, tramite una PCR multipla (in cui vengono
amplificate due frammenti genici diversi in due serie di campioni), un segmento di
circa 200 bp per tutti e due i geni, la determinazione del genotipo verrà effettuata
mediante digestione enzimatica.
Campioni utilizzati:
Totale campioni da utilizzare per ogni polimorfismo: 6 campioni genotipizzati.
Per ogni serie di campioni sarà presente un controllo negativo per valutare la
presenza o meno di contaminazione.
17
Preparare la miscela di reazione (Master Mix) per ogni gene in una eppendorf da
0,5/1,5 ml, secondo il seguente protocollo:
PCR CALCULATION SHEET
Esercitazione
XRCC1 ex10-XRCC3 ex7
Components
Date: 07/12/2005
Name or
brand
Other component DMSO
dH2O
dw
10x buffer
MgCl2
dNTP
Primer 1
Primer 2
Glycerol
DNA Polymerase Taq
Stock solution
1
1
10
50
1,25
20
20
1
5
X
X
X
mM
mM
µM
µM
X
U/µl
Added
Final concentration
amount in µl in PCR
0,0
102,0
14,8
5,9
13,1
2,2
2,2
0,0
0,7
Desired MasterMix volume ->
141,0
To be used in PCR ->
133,0
0,0
1,0
7,0
20,0
DNA Polymerase added in Hot Start (µl/sample)
Sample volume (µl)
Number of samples
Total volume of PCR reaction
Add MasterMix
Total volume ->
0,00
0,69
1,00
2,00
0,11
0,30
0,30
0,00
0,03
X
X
X
mM
mM
µM
µM
X
U/µl
1:10 or 1:5 dilution !!
Calculation OK
19,0
140
Allestire una microprovetta da 0,2 ml (strip) per ogni campione. Aggiungere in ogni
strip 1 μl di DNA diluito (10 ng/μl) e 19 μl di Master Mix, per un volume totale di
reazione di 20 μl. Nel controllo negativo non va aggiunto DNA, ma solo 20 μl di
Master Mix.
N.B.: Durante la preparazione della Master Mix tutti i suoi componenti vanno tenuti
in ghiaccio.
La Taq polimerasi va aggiunta all’ultimo poco prima della reazione di PCR per
impedire amplificazioni aspecifiche.
Inoltre la Taq (HOTSTART Taq) che andremo ad utilizzare possiede una
carattersistica che cerca di limitare le amplificazioni aspecifiche che possono
avvenire a temperatura ambiente. Infatti possiede un ligando nel sito attivo che viene
rimosso soltanto dopo uno step iniziale a 95°C per 5 minuti.
18
Reazione della Multiplex PCR
Condizioni della PCR per XRCC1 399:
94oC 30 sec. - Denaturazione
61oC 30 sec. – Annealing
72 oC 30 sec - Estensione
35 cicli
72 oC 5 min.
4oC for ever.
Condizioni della PCR per XRCC3 241:
94oC 30 sec. - Denaturazione
60oC 30 sec. – Annealing
72 oC 30 sec - Estensione
35 cicli
72 oC 5 min.
4 oC for ever.
Condizioni per la PCR multipla:
E’ possibile effettuare una PCR multipla poichè le T di annealing sono molto simili.
In questo caso verrà utilizzata la T di annealimg per XRCC1 (61°C).
95°C 5 min – Attivazione della HOTSTART Taq
94oC 30 sec. - Denaturazione
35 cicli
61oC 30 sec. – Annealing
o
72 C 30 sec - Estensione
72 oC 5 min.
4 oC for ever.
Check del prodotto di PCR
Prima che il prodotto di PCR venga utilizzato, è necessario verificare che :
•
Il prodotto si sia formato;
•
Il prodotto sia della dimensione corretta;
•
Non ci sia stata contaminazione (in questo caso è presente una banda anche nel
controllo negativo)
Preparazione del gel di agarosio
Si utilizza un buffer (TBE) 10X, che va quindi diluito 10 volte.
Gel al 2%:
19
2g di agarosio in 100 ml di buffer 1:10 (diluito, cioè, con H2O distillata).
Far sciogliere alla T = 100o C.
Caricare il gel nell’apposita celletta.
Far solidificare il gel (occorrono 30 min.)
Corsa elettroforetica
Mettere su carta parafilm 1μl di colorante (loading dye) ed aggiungere 5 μl di
campione, mettere i campioni colorati nei relativi pozzetti.
Lasciare lo spazio per il controllo negativo e per il marker (DNA Ladder 50pb);
vanno aggiunti 0,5 – 0,7 μl di marker.
Valori per l’elettroforesi:
300 mA;
100 V;
1:20 h (80 min.);
4 W.
Dopo l’elettroforesi, prendere il panetto di gel e lasciarlo immerso per 30 min. in
BrEt (1 goccia di BrEt diluito 1:10, in un contenitore di H2O), al buio, a +4oC.
Successivamente prelevare il panetto ed immergerlo in H2O per 15 min., per
eliminare l’eccesso di colorante, al buio, a +4oC.
Verificare alla lampada UV la presenza di DNA.
Lettura delle bande
Analizzare le bande ottenute con l’amplificazione. La dimensione delle bande viene
calcolata rispetto alle bande del marker (ogni banda ha una dimensione di 50 bp).
Dall’analisi delle bande bisogna ottenere:
- una sola banda da 213 bp per XRCC1;
- una sola banda da 215 bp per XRCC3;
- Controllo negativo → nessuna banda (se compare una banda si è avuta una
contaminazione con DNA che è stato amplificato).
20
Terzo Step
Determinazione del genotipo
Digestione enzimatica tramite l’enzima HpaII/MspI per XRCC1 e
NiaIII/Hsp92II per XRCC3:
Aggiungere ad ogni campione 0,5 μl dell’ enzima di restrizione corrispondente ed
incubare a 37oC overnight (o per 4 ore).
L’identificazione del genotipo dei campioni esaminati verrà effettuata in base alla
presenza di due frammenti di restrizione:
XRCC1 ex 10 (l’enzima taglia il sito wt):
wt Æ2 bande a 161bp e 52bp
het Æ 3 bande a 213bp, 161bp e 52bp
homo Æ1 banda a 213bp
XRCC3 ex 7 (l’enzima taglia il sito polimorfico):
wt Æ1 banda a 215bp
het Æ3 bande a 215bp, 105bp e 110bp
homo Æ2 bande a 105bp e 110bp
Esempio di foto di gel:
XRCC1(Arg399Gln)
213bp
161bp
52bp
hom het wt hom het het
wt hom wt
M50
XRCC3(Thr241Met)
215bp
110bp
105bp
wt
hom
wt
hom het
wt
M50
Legenda: wtÆomozigote selvatico; hetÆeterozigote; homoÆomozigote mutante;
NegÆcontrollo negativo.
21
Corsa elettroforetica
Successivamente alla digestione enzimatica, i campioni vanno sottoposti ad
elettroforesi, in un gel di poliacrilamide; questo passaggio consente la separazione
delle bande (qualora il segmento di DNA da studiare sia stato digerito) e, quindi,
permette di identificare la presenza del polimorfismo.
Gel di poliacrilamide
Volume totale : 10 ml.
Gel al 10% in TBE.
5,5 ml H2O distillata;
3,5 ml acrilammide (30% ca.);
1 ml buffer (TBE o TAE);
100 μl APS (10%) – (Ammonium Persulfate, si prepara una soluzione di 0,1 g di
APS in 1 ml di H2O distillata);
7,5 μl TEMED.
L’APS ed il TEMED vanno aggiunti per ultimi, perché determinano la
polimerizzazione del gel.
Far polimerizzare il gel (40 min. ca.).
Elettroforesi
Mettere su carta parafilm 1μl di colorante (loading dye) ed aggiungere 5 μl di
campione, mettere i campioni colorati nei relativi pozzetti.
Lasciare lo spazio per il marker (DNA Ladder 50pb); vanno aggiunti 0,5 – 0,7 μl di
marker. Se è stato fatto il check, non è necessario aggiungere il controllo negativo nei
pozzetti.
Valori per l’elettroforesi:
400 mA;
200 V;
00:20 h (20 min.);
17 W.
Dopo l’elettroforesi, prendere il gel e lasciarlo immerso per 15 min. in BrEt (1 goccia
di BrEt diluito 1:10, in un contenitore di H2O), al buio, a +4oC.
Successivamente prelevare il gel ed immergerlo in H2O il tempo necessario per
l’analisi alla lampada UV.
Verificare alla lampada UV la presenza di DNA digerito.
Lettura delle bande ottenute
Fotografare il gel con la Polaroid ed analizzare le bande ottenute
22
I componenti della miscela di reazione
¾ Magnesio
La concentrazione del Magnesio è un fattore cruciale, che influenza la performance della Taq
DNA Polimerasi. I componenti della reazione, incluso il DNA templato, gli agenti alchilanti
presenti nei campioni (EDTA o citrato), dNTPs e le proteine, influenzano la quantità di
Magnesio libero. E’ importante, dunque, che nella preparazione della miscela di reazione
non ci siano elevate concentrazioni di agenti alchilanti, come EDTA, o di gruppi ionici
negativi, come i fosfati. I dNTPs rappresentano la maggiore parte dei gruppi fosfato nella
reazione, quindi una qualsiasi variazione della loro concentrazione influenza la
concentrazione del Magnesio disponibile. In assenza di un’adeguata quantità di Magnesio
disponibile, la Taq DNA Polimerasi non è attiva. Inoltre, un eccesso di Magnesio disponibile
riduce la “fedeltà” dell’enzima e può aumentare il livello di amplificazioni aspecifiche.
¾ Buffer
Il buffer standard per la PCR contiene 50 mM KCl, 10 mM Tris-Cl (PH 8.3 a temperatura
ambiente). Quando incubato a 72oC, il PH della reazione diminuisce più di un’unità,
producendo un buffer il cui PH è approssimativamente 7.2.
¾ Primers
Gli oligonucleotidi usati per i primers devono avere una lunghezza di almeno 16 nucleotidi
e, preferibilmente, di 20-24 nucleotidi. Questi oligonucletidi sono troppo corti per formare
ibridi stabili alle temperature usate per la polimerizzazione (72 oC). La Taq Polimerasi inizia
a lavorare non appena i primers si sono legati al loro templato alle basse temperature (50-60
oC). I prodotti così estesi sono abbastanza lunghi da rimanere legati al templato, non appena
la temperatura è rapidamente aumentata a 72 oC.
I primers devono contenere il 40-60% di G+C e va fatta molta attenzione nella scelta della
sequenza, perchè con un’ elevata quantità di G+C è possibile la formazione di strutture
secondarie interne. Le estremità 3’ dei primers non devono essere complementari, per
impedire la produzione di dimeri tra i primer durante la reazione di PCR.
Idealmente entrambi i primers si “annilano” alla stessa temperatura. La temperatura di
annealing dipende dal primer con la temperatura più bassa (melting temperature – Tm).
Generalmente gli oligonucletodi sono usati ad una concentrazione di 1 μM. Questa
concentrazione è sufficiente per almeno 30 cicli di amplificazione. La presenza di
concentrazioni più elevate di oligonucleotidi può causare “priming” a siti ectopici, con
conseguente amplificazione di sequenze indesiderate. Al contrario, la PCR è estremamente
inefficiente quando la concentrazione dei primers è limitata.
¾ Deossiribonucleotidi trifosfati (dNTPs)
I dNTPs sono usati a concentrazioni saturanti.
I
¾ Taq DNA Polimerasi
Possono essere utilizzate due forme di Taq DNA Polimerasi: l’enzima purificato dal
microorganismo Thermus acquaticus ed una forma geneticamente ingegnerizzata dell’enzima
sintetizzato in E.coli. Entrambe le forme di polimerasi hanno un’attività esonucleasica 5’ →
3’, ma mancano dell’attività 3’ → 5’. Le proprietà delle due polimerasi sono sostanzialmente
equivalenti. L’aggiunta di un eccesso di enzima può portare ad amplificazioni di sequenze
non bersaglio.
¾ Sequenza target
Un’amplificazione corretta della regione d’interesse dipende dalla quantità e dalla qualità
del DNA templato. I reagenti comunemente utilizzati per purificare gli acidi nucleici (sali,
guanidina, proteasi, solventi organici e SDS) sono dei potenti inibitori delle DNA
polimerasi. La precipitazione con etanolo dei campioni di acici nucleici elimina la maggior
parte degli agenti inibitori.
La quantità di templato richiesta per un’amplificazione corretta dipende dalla complessità
del campione di DNA.
¾ Effetti indesiderati durante la reazione a catena
Spesso si possono verificare reazioni a catena indesiderate, che iniziano a temperatura
ambiente, una volta che tutti i componenti della reazione sono stati aggiunti. Queste
reazioni non volute, includono amplificazioni aspecifiche e formazioni di dimeri tra
primers.
II
 - Servizio di Hosting di Roma Tre")
![mutazioni genetiche [al DNA] effetti evolutivi [fetali] effetti tardivi](http://s1.studylibit.com/store/data/004205334_1-d8ada56ee9f5184276979f04a9a248a9-300x300.png)
![(Microsoft PowerPoint - PCR.ppt [modalit\340 compatibilit\340])](http://s1.studylibit.com/store/data/001402582_1-53c8daabdc15032b8943ee23f0a14a13-300x300.png)








