POLITECNICO DI TORINO
III Facoltà di Ingegneria dell’Informazione
Corso di Laurea Magistrale in Ingegneria Informatica
Tesina di Intelligenza Artificiale
Clustering su dati climatici usando Kohonen
map
Professore:
prof. Elio Piccolo
Studente:
Pietro Martorana
A.A. 2014/2015
Introduzione
Nella breve trattazione che segue si descriveranno le scelte architetturali e
metodologiche adottate al fine di implementare un sistema software di clustering di
dati meteo relativi al Nord America considerando gli anni 2011, 2012, 2013 e 2014
singolarmente e complessivamente.
In particolare, per poter clusterizzare i dati meteorologici nei singoli anni e nel
complessivo dei 4 anni considerati, si useranno le mappe di Kohonen e si
considereranno 5 fattori principali: temperatura massima giornaliera media per ogni
mese, temperatura minima giornaliera media per ogni mese, totale delle
precipitazioni per ogni mese, totale neve caduta per ogni mese, velocità del vento
giornaliera media per ogni mese.
I dati sono stati prelevati dal servizio ftp del sito www.ncdc.noaa.gov.
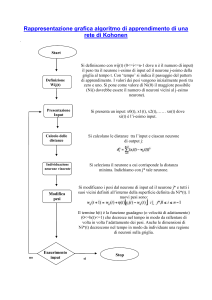
Il Clusterizzatore e le mappe di Khonen
Un sistema di clusterizzazione ha solitamente il compito di fornire all’utente finale
una “suddivisione” del mondo reale in classi aventi caratteristiche omogenee.
L’obiettivo della clusterizzazione è di creare un modello che sia in grado, dato un
pattern di input, di assegnare tale pattern ad un cluster specifico.
In particolare usando le mappe di Khonen per fare clusterizzazione (o mapping),
quello che si avrà saranno una matrice di neuroni di output (N = numero di neuroni
di output), ed un certo numero M di neuroni di input totalmente connessi agli
output tramite la matrice di pesi “W”.
La caratteristica principale delle mappe di Khonen è l’autoapprendimento, ciò
implica che usando dei pattern di input di addestramento (che possono essere gli
stessi che successivamente si useranno per il mapping), le mappe di Khonen
aggiornano la matrice dei pesi autonomamente.
Una volta conclusa la fase di autoapprendimento basterà prendere i pattern da
clusterizzare, immetterli in input ed osservare quale neurone di output è più
“vicino” al pattern di input.
Le formule usate tipicamente sono:
Fase di addestramento
o Calcolo della distanza dei nodi di input dai nodi output con la distanza
2
euclidea classica 𝑑𝑗 = 𝑀−1
𝑖=0 (𝑥𝑖 𝑡 − 𝑤𝑖𝑗 (𝑡))
o Aggiornamento dei pesi tramite una formula ripetuta un certo numero
di volte considerando il nodo j* con la minore distanza
𝑤𝑖𝑗 𝑡 + 1 = 𝑤𝑖𝑗 𝑡 + 𝛼 𝑡 ∗ 𝜑(𝐷𝐼𝑆 𝑗, 𝑗 ∗ ) ∗ (𝑥𝑖 (𝑡) − 𝑤𝑖𝑗 (𝑡)))
Fase di mapping
o Calcolo della distanza dei nodi di input dai nodi di output e scelgo di
mappare il mio input con il neurone di output che presenta la minore
distanza, usando la distanza Euclidea
2
𝑑𝑗 = 𝑀−1
𝑖=0 (𝑥𝑖 𝑡 − 𝑤𝑖𝑗 (𝑡))
In questo caso ho deciso di adottare le due formule sopracitate, in cui:
𝛼 𝑡 = 𝐴𝑚𝑎𝑥 ∗ (
𝜑 𝐷𝐼𝑆 𝑗, 𝑗 ∗
𝐴𝑚𝑖𝑛
𝐴𝑚𝑥
𝑡
)𝑇𝑚𝑎𝑥
= (1 −
𝑑2
𝑟2
)
𝑑 = 𝐷𝐼𝑆(𝑗, 𝑗 ∗ )
𝑟 𝑡 = 𝑅𝑚𝑎𝑥 ∗ (
𝑅𝑚𝑖𝑛
𝑅𝑚𝑎𝑥
𝑅𝑚𝑖𝑛 = 1 e 𝑅𝑚𝑎𝑥 =
𝑡
)𝑇𝑚𝑎𝑥
2
𝑁
2
𝐴𝑚𝑖𝑛 = 0.1 e 𝐴𝑚𝑎𝑥 = 1
𝑁 = 16
𝑇𝑚𝑎𝑥 = 3
𝑀 = 60
Per la selezione del vicinato, cioè gli output j da considerare per calcolare
l’aggiornamento dei pesi, ho deciso di controllare la 𝜑 𝐷𝐼𝑆 𝑗, 𝑗 ∗ , se è < di zero
allora sono andato fuori range massimo e quindi non aggiorno i pesi.
Tmax settata a 3 significa che faccio tre iterazioni per ogni pattern di input durante
l’aggiornamento dei pesi.
Il Mapping dei dati climatici
Per poter fare il mapping dei dati climatici, ho preso in considerazione tutte le
stazioni meteorologiche relative ai 4 anni (cioè se ne è stata aggiunta qualcuna solo
nel 2014 l’ho aggiunta pure) che mi permettevano di avere i dati per tutti i mesi
dell’anno che stavo considerando, così da ottenere un vettore di dati da 12*5 = 60
elementi per ogni stazioni per ogni anno (5 = numero di dati climatici considerati per
ogni mese tra quelli forniti).
Tali dati sono stati salvati su un file in cui in ogni riga abbiamo: il numero della
stazione considerata, l’anno e i 60 valori dei dati considerati.
Tali vettori li ho usati per l’addestramento, cioè ognuno di essi è stato considerato
una sola volta ed iterato 3 volte sulla formula di aggiornamento dei pesi.
Una volta ottenuti i pesi, salvati su un file (16 righe in quanto ho 16 neuroni di
output) l’addestramento è concluso, perciò si può passare alla fase di mapping.
In questa seconda fase i passi sono i seguenti:
Per ogni pattern di input si calcola la distanza da ogni pattern di output
Si considera il pattern di output con la minore distanza e si salva nel DB il
numero della stazione, l’anno considerato, il neurone “migliore” e la distanza
relativa
Avendo questi dati, quando devo visualizzare il mapping per i singoli anni, posso
andare a prelevare i dati relativi ad una stazione direttamente dalla corrispondenza
stazione-anno, invece per considerare il mapping per tutti gli anni ho effettuato un
ragionamento sulla soluzione migliore che è il seguente:
Se nei vari anni una stazione è stata mappata un numero maggiore di volte su
un neurone rispetto ad altri, considera quello per il mapping
Se non esiste questo neurone principale, considero quello con distanza
minore (se sono presenti due neuroni 2 volte ciascuno, per esempio,
considero la somma delle distanze e mappo la stazione con il neurone avente
la somma minore)
Nel caso di dati assenti, rappresentati con le lettere “M” e “T” nei vettori di dati
forniti dal servizio ftp web sopracitato, non ho calcolato la distanza, cioè ho
considerato che fosse irrilevante ai fini della classificazione.
Nel calcolo delle distanze, e quindi dei pesi, ho adottato una normalizzazione delle
varie grandezze al valore massimo corrispondente con il dato climatico considerato,
cioè, per esempio, la temperatura massima tra tutte le temperature è 85.9, quindi
ogni dato prelevato, lo consideravo così: 𝑇 =
𝑇𝑟𝑖𝑙𝑒𝑣𝑎𝑡𝑎
85.9
.
Scelte architetturali
Per l’implementazione del sistema software per implementare questo mapping, ho
utilizzato i seguenti componenti:
Google Maps Api, utili per mostrare con cerchietti colorati (con colore relativo
al neurone di output assegnato alla stazione corrispondente) i vari mapping
MySql DB, utile per salvare i dati relativi al mapping.
nel caso di specie ho adottato tre tabelle:
o Stations in cui ho salvato il numero della stazione meteorologica e le
relative coordinate geografiche
o Neu_color in cui ho salvato il numero del neurone e il colore
associatogli
o Clusters in cui ho salvato il numero della stazione, l’anno, il neurone
mappato per quell’anno e la relativa distanza
Php e javascript come linguaggi per poter interagire tramite web con il DB e
con le Api di Google Maps
Interfaccia Utente
La schermata iniziale si presenta nel modo seguente:
“All years data” è in grassetto in quanto è ciò che viene mostrato all’apertura della
pagina iniziale, cioè il mapping relativo a tutti e 4 gli anni considerati. Per agevolare
la comprensione dei colori e quindi dei cluster, ho apposto una legenda da poter
aprire in caso di necessità (cliccare su “Open Legend”):
Cliccando su “Data 2011”, “Data 2012”, “Data 2013” o “Data 2014” spunterà il
mapping dell’anno scelto, e la scritta sarà in grassetto come nell’esempio riportato
nella figura successiva:
Conclusioni
Osservando le mappe nei vari anni o nel complessivo dei 4 anni, si nota come è
presente una suddivisione tra varie zone climatiche con qualche piccolo dato
rumoroso (qualche colore presente nelle zone dell’Alaska presente anche nella parte
centrale degli USA e non solo all’estremo Nord) o qualche eccezione dovuta magari
a stazioni sulle montagne o microclimi relativi.
Si nota infatti che:
Nella zona calda, nel Sud, è presente una preponderanza di nero, viola e blu
Nella zona temperata, quella Centrale, sono presenti maggiormente i colori
giallo e verde acceso
Nella zona più fredda, nel Nord, sono presenti rosso, arancione e marrone
principalmente
Nella zona dell’Alaska sono preseti principalmente, nella zona Sud, quella più
“calda”, rosso, arancione e marrone come al Nord degli USA, e nelle zone più
al nord varie tonalità di verde (tranne acceso), grigio e “panna”.