Natura struttura e funzione del materiale genetico
La struttura del materiale genetico
-fine anni ’40: i cromosomi veicolano i geni
- anni ’50 à vari esperimenti provano che il DNA è la molecola-deposito
informazione genetica (i biologi Alfred Hershey e Martha Chase dimostrarono che alcuni
virus sono in grado di riprogrammare le cellule ospiti per produrre nuovi virus, iniettando il
proprio DNA dentro le cellule)
-1953: Watson e Crick à modello DNA a doppia elica, coerente con funzione di deposito
informazione
Testa
Coda
Fibre della coda
DNA
Due tipi di acidi nucleici
•DNA : deposito informazioni
•RNA: a) espressione informazione (es. sintesi proteica)
b) alcuni virus: deposito inform. genetica
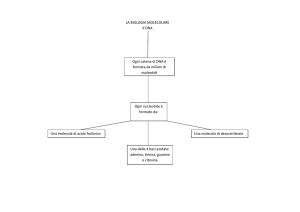
DNA e RNA sono polimeri di nucleotidi
•Il DNA è un acido nucleico costituito da lunghe catene di nucleotidi.
Scheletro zucchero-fosfato
A
C
Gruppo fosfato
Base azotata
Zucchero
Nucleotide
del DNA
A
C
Gruppo
fosfato
O
H3C
T
T
Base azotata
(A, G, C, o T)
O
O
P O
HC
O
T
T
N
H C
CH
H
Zucchero
(deossiribosio)
Nucleotide del DNA
Polinucleotide
del DNA
H
Timina (T)
O
CH
G
C
CH2 H C N C O
O–
G
C
•Il DNA ha 4 tipi di basi azotate:
adenina (A), timina (T), citosina (C) e guanina (G)
H
O
H3C
H
C
C
H
H
N
C
N
C
H
O
C
C
N
C
N
H
Timina (T)
C
Citosina (C)
Pirimidine
N
N
H
H
H
H
O
C
N
C
C
N
C
N
H
O
N
N
C
H
C
N
H
H
C
C
C
N
N
C
H
Adenina (A)
Guanina (G)
Purine
H
N
H
H
•Anche l’RNA è un acido nucleico ma è composto da uno zucchero
leggermente differente (il ribosio) e una base azotata chiamata uracile (U) al
posto della timina.
Base azotata
(A, G, C, o U)
O
Gruppo
fosfato
H
O
O
P
O
H
CH2
C
N
C
H
Ossigeno
C
C
N
O
Uracile (U)
O–
O
C H
H C
H C
C H
O
OH
Zucchero
(ribosio)
Legenda
Idrogeno
Carbonio
Azoto
Fosforo
Il DNA ha la forma di un’elica a doppio filamento
•Nel 1953 James Watson e Francis Crick determinarono la struttura
tridimensionale del DNA, basandosi anche sul lavoro di Rosalind Franklin.
struttura del DNA: 2 filamenti di
polinucleotidi attorcigliati l’uno
sull’altro in una doppia elica.
come una scala di corda dotata di
rigidi pioli.
Torsione
– I legami idrogeno tra le basi tengono uniti i 2 filamenti.
– Ogni base è appaiata con una specifica base complementare:
A con T, (2 legami idrogeno)
G con C (3 legami idrogeno)
G
C
T
A
A
Coppie di basi
appaiate
C
T
C
G
C
G
A
T
O
OH
P
–O
O
H2C
O
O
O
P
–O
O
H2C
–O
T
OH
A
T
O
A
O
P
O
H2C
O
C
–O
A
T
A
O
P
O
H2C
O
T
A
A
O
CH2
O O–
O P
O
O
CH2
O
O–
P
O
O
O
CH2
O
O–
P
HO O
T
OH
G
CH2
O O–
P
O
O
G
O
A
O
C
G
O
G
T
Legame idrogeno
C
T
Modello a nastro
Struttura chimica
Modello computerizzato
Modello molecolare coerente con funzione di deposito informazione
genetica
L’informazione genetica è rappresentata dalla sequenza di
basi che è tradotta in sequenza di amminoacidi nelle
proteine (codice genetico)
La complementarità specifica tra le basi è alla base dei
processi di:
•trasmissione (DUPLICAZIONE),
•trasferimento (TRASCRIZIONE-TRADUZIONE)
•ed evoluzione (RICOMBINAZIONE) dell’informazione
genetica
Organizzazione dei genomi
GENE: segmento di DNA contenente una specifica informazione
sottoforma di sequenza nucleotidica (es informazione per la
sintesi di polipeptide)
Genoma: insieme di geni
Procarioti: genoma costituito da una sola molecola di DNA ds
circolare
Eucarioti: genoma formato da numerose molecole di DNA ds
lineari (cromosomi)
Dimensione dei genomi
•Grande variabilità
•Dimensione non sempre corrisponde alla complessità della specie
Virus- decine di migliaia di basi
Batteri-milioni di basi
Mammiferi-miliardi di basi
Piante-centinaia di miliardi di basi
numero di interazioni geniche
à Complessità
Nelle cellule il DNA non puo’ essere contenuto in forma estesa!
à Strategie di compattamento mediante associazione con proteine e superavvolgimenti
Nei batteri il DNA circolare presente nel
nucleoide è superavvolto e ripiegato in
anse trattenute da segmenti di RNA e
proteine
Negli eucarioti il DNA si avvolge attorno ad ottameri di proteine istoniche
(molto basiche) per dare i nucleosomi
La cromatina eucariotica è una struttura complessa formata
da DNA e proteine (istoniche e non)
Si forma una “struttura a collana di perle” che si impacchetta
ulteriormente ripiegandosi in un solenoide
Doppia elica di DNA
(2 nm di diametro)
Istoni
Linker
TEM
«Perle di una
collana»
Nucleosoma
(10 nm di diametro)
TEM
Fibra elicoidale compatta Superavvolgimento
(30 nm di diametro)
(300 nm di diametro)
Cromosoma in metafase
700
nm
Flusso dell’informazione genetica
DNAàDNA
DNAàRNAàPROTEINE
Replicazione del DNA
dipende dall’accoppiamento specifico tra le basi azotate
• i 2 filamenti del DNA di partenza si separano (l’elica si srotola).
• ogni filamento funziona da stampo per formare un filamento
complementare.
• gli enzimi DNA-polimerasi legano tra loro i nucleotidi per formare un
nuovo filamento.
G C
A
A
T
A
C
G
C
G
C
G
A
T
A
T
A
Molecola originaria
del DNA.
T
T
G
C
A
C
A
T
A
T
A
T
G
C
G
C
G
C
G
C
G
C
T
A
T
A
T
T
A
A
Entrambi i filamenti originari
si comportano da stampo.
T
A
A
T
A
A
G
T
T
C
G
T
G
G
G
T
G
T
A
C
T
C
C
C
A
C
A
C
A
G
A
Due nuove molecole
di DNA identiche.
T
T
C
G
G
C
C
C
G
A
A
T
G
T
T
A
T
A
T
A
La duplicazione inizia presso specifici punti di origine della duplicazione sulla
doppia elica àbolle di replicazione.
Punto di origine
della duplicazione
Filamento originario
Filamento di nuova sintesi
Bolla di duplicazione
Due molecole figlie di DNA
Replicazione
prima di mitosi e meiosi à Stessa informazione genetica per tutte cellule e trasmissione a
discendenza
– La cellula sintetizza un filamento nuovo in maniera continua (direzione
5’à3’) usando l’enzima DNA-polimerasi.
– L’altro filamento è sintetizzato in brevi segmenti consecutivi (sintesi
discontinua) uniti poi dall’enzima DNA-ligasi.
Molecola di DNA-polimerasi
5¢
3¢
DNA originario
3¢
5¢
Filamento sintetizzato
senza interruzioni
3¢
5¢
5¢
3¢
DNA-ligasi
Direzione complessiva della duplicazione
Filamento sintetizzato
in segmenti consecutivi
Flusso dell’informazione genetica
Il flusso dell’informazione genetica: DNAà RNAà proteine
• Genotipo= informazione genetica contenuta nel DNA (sequenza
nucleotidica di DNA)
• Fenotipo= insieme di tratti specifici di un’organismo (risultato di
proteine)
• Il gene è una sequenza di DNA contenente l’istruzione per la
produzione di un polipeptide (fornisce cioè le istruzioni per la
sintesi proteica).
•anni ’40: esperimenti di Beadle & Tatum
Si determina la relazione tra geni ed enzimi grazie a ricerche su alcuni ceppi
della muffa del pane definiti «mutanti nutrizionali».
ALTERAZIONE DNA àDIFETTO PROTEINA àDIFETTO DI CRESCITA
•Un gene à un enzima
•Un geneà un polipeptide
L’istruzione contenuta nel gene è prima trasferita dal DNA a una molecola
di RNA (trascrizione) e poi dall’RNA a una proteina (traduzione).
DNA
Trascrizione
NUCLEO
RNA
Traduzione
CITOPLASMA
Proteina
Il linguaggio chimico del DNA (e dell’RNA) si
basa su sequenza di nucleotidià gene= seq
specifica e definita di nucleotidi
Il linguaggio delle proteine si basa su seq. di
amminoacidi
Molecola di DNA
Gene 1
Gene 2
•Trascrizione: DNAàRNA: stesso linguaggio
•Traduzione: RNAàpolipeptide: dal
linguaggio degli acidi nucleici a quello dei
polipeptidi
Gene 3
Filamento di DNA
A A
A C C G G C A A
A A
Trascrizione
RNA
Traduzione
U U U G G C C G U U U U
Codone
Polipeptide
Amminoacido
Il codice genetico
Il flusso d’informazione si basa su un codice a triplette di basi: CODONI
le istruzioni che specificano la sequenza di amminoacidi di un polipeptide
sono scritte nel DNA come codoni
Seconda base azotata
C
A
Il codice genetico è
universale!
Quasi tutti gli organismi (dai
batteri alle piante agli animali)
condividono lo stesso codice
genetico.
Prima base azotata
U
UUU
UUC
Phe UCU
UCC
UUA
UCA
Leu
Ser
UAU
UAC
G
Tyr UGU
UGC
Cys U
C
UAA Stop
UGA Stop
A
UUG
UCG
UAG Stop
UGG Trp
G
CUU
C CUC
CUA
CUG
CCU
CCC
CAU
CAC
CGU
CGC
U
AUU
A AUC
AUA
Leu
Ile
Met o
AUG inizio
G
GUU
GUC
GUA
GUG
Val
Pro
His
Arg
C
CCA
CCG
CAA
CAG
CGA
Gln CGG
ACU
ACC
AAU
AAC
Asn AGU
AGC
Ser
AAA
AAG
Lys AGA
AGG
Arg A
G
GAU
GAC
Asp GGU
GGC
ACA
ACC
GCU
GCC
GCA
GCG
Thr
Ala
GAA
GAG
Glu GGA
GGG
A
G
U
C
U
Gly C
A
G
Terza base azotata
U
Caratteristiche del codice genetico
Basato su triplette di basi
Non sovrapposto
Continuo senza virgole
Degenerato: con più codoni codificanti per lo stesso aa, ma
non ambiguo in q. ad ogni codone corrisponde un solo
Il codice genetico mette in relazione una seq nucleotidica con seq
amminoacidica
Questo codice molecolare consente di decifrare l’informazione genetica del
DNA
Filamento da trascrivere
T
A
C
T
T
C
A
A
A
A
T
C
A
T
G
A
A
G
T
T
T
T
A
G
U
A
G
DNA
Trascrizione
A
U
G
A
A
G
U
U
U
mRNA
Codone
di inizio
Codone
di arresto
Traduzione
Polipeptide
Met
Lys
Phe
La trascrizione:
trasferimento dell’informazione genetica dal DNA all’RNA
•Avviene nel nucleo degli eucarioti
•Un’elica di DNA funziona come stampo
•Stesse regole appaiamento
•RNA polimerasi
Nucleotidi dell’RNA
RNA-polimerasi
T C C A
A
T
T
A
A U C C A
T A G G T
Direzione
della trascrizione
RNA appena sintetizzato
Filamento
stampo di DNA
Fasi di trascrizione di un gene:
1.
2.
3.
Inizio
Allungamento
terminazione
Il tipo di RNA che codifica per sequenze di amminoacidi è detto RNA messaggero
(mRNA).
La polimerasi avanzando sul
DNA inserisce nucleotidi
complementari allo stampo
(DNA ss) sulla catena nascente
di RNA (direzione 5’à3’)
La doppia elica DNA si riforma
a valle della RNA polimerasi
(regione ibrida RNA-DNA
limitata a pochi nucleotidi)
L’RNA resta associato
all’enzima durante tutta la
trascrizione
L’RNA eucariotico viene modificato prima di lasciare il nucleoà
processamento dell’mRNA
Esone Introne Esone
Introne
Esone
DNA
Trascrizione
Aggiunta del cappuccio e della coda
Cappuccio
CAP e TAIL: alle estremità
dei segmenti sono aggiunti
un cappuccio e una coda.
SPLICING
Le regioni di geni non
codificanti, introni, vengono
rimosse.
Gli esoni (regioni codificanti)
si saldano per produrre una
singola molecola codificante
di mRNA.
RNA
trascritto
con cappuccio e coda
Gli introni
vengono rimossi
Coda
Gli esoni si legano tra loro
mRNA
Sequenza codificante Nucleo
Citoplasma
La traduzione:
trasferimento dell’informazione genetica dall’RNA alle proteine
– Il messaggio sull’mRNA è tradotto in sequenza amminoacidica
– avviene nel citoplasma sui ribosomi (gli organuli che coordinano le
operazioni necessarie per passare dalle sequenze nucleotidiche
alle catene polipeptidiche).
– Richiede tRNA, rRNA, mRNA ed energia
I ribosomi e i tRNA interagiscono con l’mRNA per
tradurlo in polipeptide
L’ RNA transfer (tRNA) è un “interprete molecolare”: permette la
traduzione del messaggio genetico dell’mRNA nel messaggio proteico.
Sito d’attacco dell’aminoacido
Legame idrogeno
Il tRNA ha un’ansa, con una speciale tripletta di
basi chiamata anticodone (complementare a un
particolare codone dell’mRNA).
Ad una estremità c’è invece il sito di attacco di
uno specifico amminoacido
Catena polinucleotidica di RNA
Sito d’attacco
dell’amminoacido
Anticodone
Anticodone
L’enzima aa-tRNA sintetatsi “carica” l’aa sul suo
tRNA corrispondente
•Le cellule contengono almeno 20 ≠ Aa-tRNAsintetasi (una per aa)
•Quando per un determinato Aa esistono più tRNA,
la stessa Aa-tRNA- sintetasi li riconosce tutti
•Le Aa-tRNA-sintetasi riconoscono i nucleotidi
localizzati in almeno 2 ≠ regioni della molecola di
tRNA
Molecole
di tRNA
RIBOSOMI
Polipeptide
in via di formazione
Subunità
grande
mRNA
Subunità piccola
Il ribosoma è un organello costituito da 2
subunità, ciascuna formata da proteine e da
RNA ribosomiale (rRNA).
Durante la traduzione il ribosoma
coordina l’interazione tra tRNA e mRNA
Sito di legame per l’mRNA
Subunità
grande
Successivo
amminoacido
da
aggiungere al
polipeptide
Polipeptide
in via di
formazione
tRNA
mRNA
Subunità
piccola
Codoni
Le subunità ribosomali si pre-assemblano nella regione granulare del
nucleolo
Le subunità escono dal nucleo si associano solo durante sintesi proteica
Inizio del messaggio genetico
Fasi della traduzione
mRNA con inizio e
fine messaggio
Fine
TRADUZIONE
1) inizio:
associazione tra mRNA, 1° aa (tRNA) e le 2 subunità ribosomiali
Met
Met
Subunità
ribosomiale
più grande
tRNA di partenza
Sito P
UA C
A U G
Codone
d’inizio
mRNA
Sito A
U A C
A U G
Subunità ribosomiale
più piccola
2) Allungamento
Amminoacido
Polipeptide
Completata la fase d’inizio, al
primo amminoacido se ne
aggiungono altri, uno alla volta
Il processo di allungamento Movimento
dell’mRNA
prevede tre tappe:
•riconoscimento del codone;
•formazione del legame
peptidico;
•Traslocazione
3) Terminazione
L’allungamento continua
fino a quando un codone di
STOP (UAA, UAG, UGA)
giunge nel sito A del
ribosoma, terminando la
traduzione.
Sito P
mRNA
Sito A
Codoni
1
1
Anticodone
Riconoscimento del codone
Codone
di arresto
2
2 Formazione
del legame peptidico
Nuovo
legame peptidico
Traslocazione
3 3 Traslocazione
Il passaggio di informazioni genetiche nella cellula segue la direzione
DNA®RNA®proteina
percorso in diverse tappe
1
2
3
4
5
Elementi fondamentali di un gene:
•promotore e regioni regolative,
•tratto codificante,
•terminatore di trascrizione
Negli eucarioti il tratto codificante è “interrotto” da introni!!
The sequence of a prokaryotic
protein-coding gene is colinear
with the translated mRNA; that is,
the transcript of the gene is the
molecule that is translated into the
polypeptide.
The sequence of a eukaryotic proteincoding gene is typically not colinear
with the translated mRNA; that is, the
transcript of the gene is a molecule
that must be processed to remove
extra sequences (introns) before it is
translated into the polypeptide.
Negli eucarioti trascrizione e traduzione avvengono in luoghi e momenti
diversi (nucleo e citoplasma)
Nei procarioti trascrizione e traduzione avvengono in contemporanea e
nello stesso luogo!
MUTAZIONI
La sequenza dei codoni nel DNA «scrive lettera per lettera» la struttura
primaria di un polipeptide
àLe mutazioni possono cambiare il significato dei geni
– mutazione = qualsiasi variazione nella sequenza nucleotidica del
DNA rispetto alla sua conformazione originale.
– Le mutazioni sono causate da errori nella duplicazione del DNA,
da ricombinazione e/o da agenti mutageni.
.
– Possono interessare regioni estese o singoli nucleotidi
Alterazioni/riarrangiamenti cromosomici possono provocare
patologie congenite e/o tumori
• Delezioni, duplicazioni, inversioni:
Delezione
Duplicazione
Cromosomi
omologhi
Inversione
Traslocazioni:
Traslocazione
Cromosomi
non omologhi
Cromosoma 9
Cromosoma 22
Traslocazione
«Cromosoma Philadelphia»
Gene cancerogeno attivato
Alterazioni di singoli o pochi nucleotidi
La mutazione di un singolo nucleotide è la base molecolare
dell’anemia falciforme
DNA di emoglobina normale
C
T
DNA di emoglobina mutante
T
mRNA
C
A T
mRNA
G
A
A
Emoglobina normale
Glu
G U
A
Emoglobina dell’anemia falciforme
Val
Le mutazioni puntiformi possono consistere in:
• sostituzione di una base (missense, nonsense)
• inserzione o delezione di nucleotidi (scivolamento fase di lettura).
Gene normale
mRNA
Proteina
A U G A A G U U U G G C G C A
Met
Lys
Phe
Gly
Ala
Sostituzione di una base azotata
A U G A A G U U U A G C G C A
Met
Lys
Delezione di una base azotata
Phe
Ser
Ala
U Mancante
A U G A A G U U G G C G C A U
Met
Lys
Leu
Ala
His
Mutazioni sul DNA: la cellula possiede sistemi di riparazione per limitare danni
e allo stesso tempo garantire una certa variabilità genetica
I sistemi di riparazione si basano su vari enzimi: endonucleasi (che tagliano il
DNA alterato) e DNA polimerasi (che risintetizzano tratto corretto) e ligasi.
•Le mutazioni su cellule germinali
saranno trasmesse a progenie
•Quelle su cellule somatiche
possono dare neoplasie e/o
invecchiamento cellulare
I virus
I virus possono essere considerati come insiemi di geni
impacchettati da proteine.
Non sono veri esseri viventi in quanto riescono a riprodursi solo
infettando cellule viventi, utilizzandone strutture ed energia.
I virus infettano vari tipi di organismi “ospite”:
•Virus che infettano batteri à BATTERIOFAGI o FAGI
•Virus che infettano cellule vegetali o animali
Testa
Coda
FAGI
DNA
Fibre della coda
un fago può avere due tipi di cicli riproduttivi
Il fago si attacca alla cellula
• In un fago esistono due tipi di cicli
riproduttivi:
1
1
DNA del fago
La cellula si
rompe liberando
i fagi
Cromosoma batterico
Il fago inietta DNA
7
2
Numerose
divisioni cellulari
4
Ciclo litico
Si assemblano i fagi
Ciclo lisogeno
Il DNA fagico
assume un aspetto circolare
3
5
OPPURE
Vengono sintetizzati
nuovo DNA fagico e nuove proteine
Il batterio lisogeno si riproduce
normalmente, duplicando il profago
a ogni divisione cellulare
Profago
6
Il DNA fagico si inserisce
nel cromosoma batterico per ricombinazione
Molti virus sono causa di malattie in piante ed animali
(raffreddore, influenza, varicella, AIDS, epatite, poliomielite,…)
Molti, come il virus dell’influenza o del mosaico del tabacco, hanno
come materiale genetico RNA, invece di DNA.
Involucro esterno
RNA
Rivestimento proteico
Proteine RNA
Estroflessione glicoproteica
Ciclo riproduttivo di virus animale ad RNA dotato di rivestimento
membranoso
VIRUS
Glicoproteina
Rivestimento proteico
RNA virale
(genoma)
Involucro esterno
Ingresso
Membrana plasmatica 1
della cellula ospite
•L’RNA virale funziona come stampo
per la sintesi sia di proteine virali sia
di nuove copie di genoma
•usano parte della membrana della
cellula ospite come rivestimento;
•possono rimanere latenti per lunghi
periodi (herpesvirus)
Viral RNA
(genome)
4
mRNA
2
Eliminazione
del rivestimento
3
Sintesi di RNA
Sintesi di
proteine
Nuove
proteine virali
5 Sintesi di RNA
Filamento
stampo
Nuovo genoma
virale
6 Assemblaggio
Uscita
Uscita
7
Il virus HIV, responsabile dell’AIDS, assembla il DNA utilizzando l’RNA
come stampo à è un retrovirus.
Involucro esterno
Glicoproteina
Rivestimento proteico
RNA
(due filamenti
identici)
Trascrittasi inversa
l’HIV (human immunodeficiency virus) usa il proprio RNA come stampo per
produrre DNA (enzima trascrittasi inversa o retrotrascrittasi) da inserire nel
DNA cromosomico dell’ospite.
HIV attacca globuli bianchi essenziali per il sistema immunitario




![mutazioni genetiche [al DNA] effetti evolutivi [fetali] effetti tardivi](http://s1.studylibit.com/store/data/004205334_1-d8ada56ee9f5184276979f04a9a248a9-300x300.png)