:")
l
Hidden Markov Models (HMM):
l Catene
l Goal:
18
di Markov
effettua una sequenza di decisioni
l Processi
che si realizzano nel tempo, gli stati al tempo t sono
influenzati dallo stato al tempo t-1
l Applicazioni:
speech recognition, gesture recognition, parts of
speech tagging and DNA sequencing,
l Qualsiasi
processo temporale senza memoria
ωT = {ω(1), ω(2), ω(3), …, ω(T)} sequenza di stati
Possiamo avere ω6 = {ω1, ω4, ω2, ω2, ω1, ω4}
l Il
sistema può rivisitare uno stato in passi differenti e non è
necessario che tutti gli stati vengano visitati
10
19
l
First-order Markov models
l Le
realizzazioni delle sequenze sono descritte da probabilità
di transizione
P(ωj(t + 1) | ωi (t)) = aij
10
20
10
21
θ = (aij, ωT)
P(ωT | θ) = a14 . a42 . a22 . a21 . a14 . P(ω(1) =
ωi)
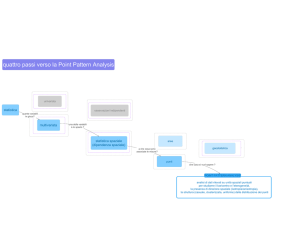
Esempio: speech recognition
“produzione del parlato”
Produzione della parola: “pattern” rappresentata da
fonemi
/p/ /a/ /tt/ /er/ /n/ // ( // = silent state - terminale)
Transizioni da /p/ ad /a/, da /a/ a /tt/, da /tt/ a /er/,
da /er/ a /n/ e da /n/ ad uno stato silente
10
• Hidden Markov Model (HMM)
• Interazione degli stati visibili con quelli hidden
∑bjk= 1 ∀ j dove bjk=P(Vk(t) | ωj(t)).
• 3 problemi sono associati a questo modello
• Il problema della valutazione
• Il problema della decodifica
• Il problema del learning
Pattern Classification, Chapter 3 (Part 3)
Pattern Classification, Chapter 3 (Part 3)
• Il Problema della valutazione
Rappresenta la probabilità che il modello produca una
sequenza VT di stati visibili. Dato da:
rmax
P ( V T ) = ∑ P ( V T | ω rT )P (ω rT )
r =1
dove ciascun r indicizza una particolare sequenza
ω rT = {ω ( 1 ),ω ( 2 ),...,ω ( T )} di T stati hidden.
(1)
t =T
P ( V T | ω rT ) = ∏ P ( v ( t ) | ω ( t ))
t =1
(2)
T
r
t =T
P( ω ) = ∏ P ( ω ( t ) | ω ( t − 1 ))
t =1
Pattern Classification, Chapter 3 (Part 3)
Usando le equazioni (1) e (2), possiamo scrivere:
T
rma x T
P(V ) = ∑∏ P(v(t ) | ω (t )) P(ω (t ) | ω (t − 1)
r =1 t =1
Interpretazione: La probabilità di osservare una particolare sequenza
di T stati visibili VT è uguale alla somma delle probabilità condizionate
sulle rmax possibili sequenze di stati hidden in cui il sistema ha
compiuto una particolare transizione, moltiplicato per la probabilità
che esso ha emesso il simbolo visibile nella nostra sequenza target
Esempio: Sia ω1, ω2, ω3 stati hidden; v1, v2, v3 stati visibili
e V3 = {v1, v2, v3} la sequenza di stati visibili
P({v1, v2, v3}) = P(ω1).P(v1 | ω1).P(ω2 | ω1).P(v2 | ω2).P(ω3 | ω2).P(v3 | ω3)
+…+ (possibili termini nella somma = tutte le possibili (33= 27)
combinazioni!)
Pattern Classification, Chapter 3 (Part 3)
v1
v2
v3
First possibility:
ω1
(t = 1)
Second Possibility:
ω2
(t = 2)
v1
ω2
(t = 1)
ω3
(t = 3)
v2
v3
ω3
(t = 2)
ω1
(t = 3)
P({v1, v2, v3}) = +…+P(ω2).P(v1 | ω2).P(ω3 | ω2).P(v2 | ω3).P(ω1 | ω3).P(v3 | ω1)
+ …+
Pertanto:
3
P({v1 , v2 , v3}) =
P(v(t ) | ω (t )).P(ω (t ) | ω (t − 1))
∏
possibile sequenza
∑
di stati hidden
t =1
Pattern Classification, Chapter 3 (Part 3)
rma x T
P(V T ) = ∑∏ P(v(t ) | ω (t )) P(ω (t ) | ω (t − 1)
r =1 t =1
Calcolo della P(VT) molto complessa. La possiamo calcolare
ricorsivamente introducendo:
αi(t) probabilità che HMM è nello stato ωi al tempo t avendo generato
i primi t elementi di VT
Pattern Classification, Chapter 3 (Part 3)
c
α 2 (3) = b2 k ∑ α i (2)ai 2
i =1
Pattern Classification, Chapter 3 (Part 3)
Qual’è la probabilità di
Generare
Supponiamo si parte da ω1(0)
Pattern Classification, Chapter 3 (Part 3)
Pattern Classification, Chapter 3 (Part 3)
Se indichiamo con θ=(aij,bjk) il nostro modello di HMM, possiamo usare
Bayes per calcolare la probabilità del modello noto la sequenza
osservata:
T
P
(
V
| θ) P(θ)
P(θ | V T ) =
P(V T )
Nei problemi di Pattern recognition avremo un HMM per ogni classe
E classificare una sequenza di test in base al modello HMM che ha
fornito la massima probabilità
P(VT|θ) lo fornisce l’algoritmo forward
P(θ) probabilità a priori fornito da una sorgente esterna, per esempio, nel
riconoscimento vocale può essere un modello di linguaggio (contesto
semantico/parola precedente)
Pattern Classification, Chapter 3 (Part 3)
• Il problema della decodifica (sequenza di stati
ottimale)
Data una sequenza di stati visibili VT, il problema della
decodifica è quello di trovare la sequenza più probabile di
stati hidden.
Il problema può essere espresso matematicamente come:
trovare la “migliore” sequenza di stati (hidden states)
ωˆ (1),ωˆ (2),..., ωˆ (T ) tale che :
ωˆ (1),ωˆ (2),..., ωˆ (T ) = arg max P[ω (1),ω (2),..., ω (T ), v(1), v(2),..., V (T ) | λ ]
ω (1),ω ( 2 ),...,ω (T )
Si noti che la somma è sparita, poiché vogliamo trovare
Solo l’unico caso migliore!
Pattern Classification, Chapter 3 (Part 3)
dove:
λ = [π,A,B]
π = P(ω(1) = ω) (probabilità dello stato iniziale)
A = aij = P(ω(t+1) = j | ω(t) = i)
B = bjk = P(v(t) = k | ω(t) = j)
Nell’esempio precedente, questo calcolo corrisponde alla
selezione del miglior path tra:
{ω1(t = 1),ω2(t = 2),ω3(t = 3)}, {ω2(t = 1),ω3(t = 2),ω1(t = 3)}
{ω3(t = 1),ω1(t = 2),ω2(t = 3)}, {ω3(t = 1),ω2(t = 2),ω1(t = 3)}
{ω2(t = 1),ω1(t = 2),ω3(t = 3)}
Pattern Classification, Chapter 3 (Part 3)
HMM Decoding
1
2
3
4
5
Inizializza Path←{}, t←0
for t←t+1
j←j+1
for j←j+1
6
7
until j=c
c
α j (t ) ← b jk v(t )∑i =1α i (t − 1)aij
j ʹ′ ← argmax α j (t )
j
8
9
10
11
Append ω ʹ′j a Path
until t=T
return Path
end
Pattern Classification, Chapter 3 (Part 3)
Pattern Classification, Chapter 3 (Part 3)
La transizione da ω3 a ω2 non è permessa
Pattern Classification, Chapter 3 (Part 3)
• Il problema dell’apprendimento/learning (Stima
dei parametri)
Consiste nel determinare un metodo per modificare i
parametri del modello λ = [π,A,B] in modo da soddisfare
un criterio di ottimizzazione. Abbiamo bisogno di cercare
il modello migliore
λˆ = [ πˆ , Â , B̂ ]
Tale da massimizzare la probabilità della sequenza di
osservazione :
Max P ( V T | λ )
λ
Usiamo una procedura iterativa come Baum-Welch o
basata sul Gradiente per trovare l’ottimalità locale
Pattern Classification, Chapter 3 (Part 3)
Introduciamo una nuova variabile:
γij(t) – probabilità di transizione tra ωi(t-1) e ωj(t) dato
che il modello λ ha generato VT con qualunque path
γ ij (t ) =
α i (t − 1)aijb jk β j (t )
P(V T | θ)
Numero atteso di transizioni tra ωi(t-1) e ωj(t) è
Mentre il numero atteso totale da ωi è
T
∑∑ γ
t =1
ik
T
∑γ
ij
(t )
t =1
(t )
k
Pattern Classification, Chapter 3 (Part 3)
Pertanto la stima di aij e bjk sono definite da:
T
aˆij =
∑γ
ij
(t )
t =1
T
∑∑ γ
t =1
ik
(t )
k
T
bˆ jk =
(t )
∑ ∑γ
jl
∑∑ γ
(t )
t =1
v ( t ) = vk
T
t =1
l
jl
l
Pattern Classification, Chapter 3 (Part 3)
Si parte da delle stime approssimate o arbitrarie di aij e bjk e si
raffinano con l’algoritmo Baum-Welch forward-backword
finché converge:
T
(1)
∑γ
aˆij =
ij
t =1
T
ik
(t )
∑ ∑γ
jl
(t )
∑∑ γ
(t )
∑∑ γ
t =1
(2)
1
2
bˆ jk =
(t )
k
T
t =1
v ( t ) = vk
T
t =1
l
jl
l
Pattern Classification, Chapter 3 (Part 3)
:")