
Capitolo 5
Le infrastrutture HardWare
Il processore
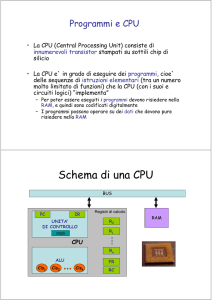
CPU – Central Processing Unit
Unità Centrale di Elaborazione
Organizzazione tipica di un
calcolatore “bus oriented”
CPU
Dispositivi di I/O
Unità di
controllo
Unità
aritmetico
logica (ALU)
Terminale
Stampante
Registri
CPU
Memoria
centrale
Unità
disco
Bus
L’ “esecutore”
¾
Un calcolatore basato sull’architettura di Von Neumann esegue un
programma sulla base dei seguenti principi:
• dati e istruzioni sono memorizzati in una memoria unica che permette sia la
scrittura che la lettura;
• i contenuti della memoria sono indirizzati in base alla loro posizione,
indipendentemente dal tipo di dato o istruzione contenuto;
• le istruzioni vengono eseguite in modo sequenziale.
¾
Il linguaggio per cui la CPU si comporta da esecutore è detto linguaggio
macchina (ogni CPU ha il suo). Le istruzioni scritte in linguaggio
macchina sono piuttosto rudimentali:
• il concetto di tipo di dato è quasi assente,
• il numero di operandi è limitato (in genere non più di due),
• il numero di operazioni previste è ridotto.
Struttura istruzione
codice operativo
dest
src1
src2
Linguaggio assemblatore
add
R01
R02
R03
Linguaggio macchina
000000 00000 100000 00001 00010 00011
Ciclo Fetch–Decode–Execute
Fetch
Decode
Execute
Le parti di una CPU
¾
Data path (o percorso dei dati)
• è la parte che si occupa dell’effettiva elaborazione dei dati;
• comprende dispositivi diversi
• una o più unità aritmetico-logiche, dette ALU (Arithmetic Logic Unit);
• alcune unità di memorizzazione temporanea, i registri, memoria ad alta velocità usata per
risultati temporanei e informazioni di controllo (il valore massimo memorizzabile in un registro è
determinato dalle dimensioni del registro).
¾
Unità di controllo
• coordina le operazioni di tutto il processore (anche quelle del data path!);
• regola il flusso dei dati e indica quali registri debbano essere collegati agli ingressi e
all’uscita dell’ALU;
• invia all’ALU il codice dell’operazione da eseguire;
• riceve indicazioni sull’esito dell’operazione appena eseguita dall’ALU e gestisce
opportunamente queste informazioni;
• comprende alcuni registri di uso specifico
•
•
•
•
Program Counter (PC) – qual è l’istruzione successiva;
Instruction Register (IR) – istruzione in corso d’esecuzione;
Program Status Word (PSW) – registra informazioni sulle operazioni aritmetico logiche della ALU
…
Data Path
Registri
R00 R01 R02 R03
X
X
+
Y
Y
… … … …
Registri
ingresso ALU
X
Y
add
esito
Registro
uscita ALU
A
L
U
X
+
Y
PSW
Bus indirizzi
Data path
Unità di
controllo
Bus dati
CPU
Bus controllo
Unità di controllo
IR
PC
Memoria
CPU
¾
In grado di eseguire solo istruzioni
codificate in linguaggio macchina
¾
Ciclo Fetch – Decode - Execute
1. Prendi l’istruzione corrente dalla memoria (quella individuata dal
contenuto del PC) e mettila nell’IR (Instruction Register),
contemporaneamente incrementa il Program Counter (PC) in modo che
contenga l’indirizzo dell’istruzione successiva (fetch)
2. Determina il tipo di istruzione da eseguire (decode)
3. Se l’istruzione usa dei dati presenti in memoria, determinane la
posizione;
4. Carica la parola, se necessario, in un registro della CPU;
5. Esegui l’istruzione (execute)
6. Torna al punto 1 e inizia a eseguire l’istruzione successiva.
Tipologie di istruzioni
¾
Architettura di riferimento: load/store
• le operazioni aritmetico-logiche possono essere eseguite solo su dati che siano
già stati caricati nei registri;
• le operazioni di caricamento dei dati dalla memoria nei registri (load) e di
archiviazione dei risultati dai registri nella memoria (store) debbono essere
previste esplicitamente.
¾
Un processore in architettura load/store dovrà quindi essere in grado di
eseguire le seguenti categorie di istruzioni:
• Istruzioni aritmetico-logiche (Elaborazione dati)
• Somma, Sottrazione, Divisione, …
• And, Or, Xor, …
• Maggiore, Minore, Uguale, Minore o uguale, …
• Controllo del flusso delle istruzioni
• Sequenza
• Salto condizionato o non condizionato (per realizzare selezioni e cicli)
• Trasferimento di informazione
• Trasferimento dati e istruzioni tra CPU e memoria
• Trasferimento dati e istruzioni tra CPU e dispositivi di ingresso/uscita (attraverso le
relative interfacce)
Esempi di istruzioni
Istruzione
Significato
Categoria
R01,R02,R03
R01 ← R02 + R03
aritmetico-logica
addi R01,R02,421
R01 ← R02 + 421
aritmetico-logica
lw
R01,R02,421
R01 ← M[R02 + 421]
trasferimento
sw
R01,R02,421
M[R02 + 421] ← R01
trasferimento
beq
R01,R02,–421 se (R01 == R02) vai a PC–421
j
84210
add
vai a 84210
salto (condizionato)
salto (non condizionato)
Istruzioni aritmetico-logiche
¾
Un’istruzione aritmetico-logica, ad esempio
add RZ,RX,RY, viene eseguita in quattro passi:
1. l’istruzione viene prelevata dalla memoria e scritta nell’IR mentre il
PC viene incrementato (si tratta della fase di fetch già descritta in
precedenza);
2. viene letto il contenuto dei due registri RX e RY (in pratica l’unità
di controllo attiva i collegamenti tra i registri RX e RY, individuati dal
contenuto dell’IR, e i registri di ingresso all’ALU e provvede a
effettuare il trasferimento dei dati);
3. la ALU opera sui dati letti dal banco dei registri, eseguendo
l’operazione indicata dal codice compreso nell’istruzione (l’unità di
controllo attiva il collegamento di un pezzo dell’IR con l’ingresso di
controllo dell’ALU);
4. il risultato calcolato dall’ALU viene scritto nel registro RZ (anche il
registro destinazione viene individuato a partire dal contenuto
dell’IR).
Istruzioni di trasferimento
¾
Un’istruzione di trasferimento, ad esempio
lw RY,RX,base, viene eseguita in cinque passi:
1. l’istruzione viene prelevata dalla memoria e scritta
nell’IR mentre il PC viene incrementato;
2. viene letto il contenuto del registro RX;
RX
3. la ALU opera sui dati letti dal banco dei registri e sulla
base scritta nell’IR;
4. il risultato calcolato dall’ALU viene utilizzato come
indirizzo per la memoria dati;
5. il dato proveniente dalla memoria viene scritto nel
registro RY.
RY
Istruzioni di controllo
¾
Un’istruzione di trasferimento, ad esempio
beq RX,RY,salto, viene eseguita in quattro
passi:
1. l’istruzione viene prelevata dalla memoria e scritta
nell’IR mentre il PC viene incrementato;
2. viene letto il contenuto dei due registri RX e RY;
RY
3. la ALU opera sui dati letti dal banco dei registri,
eseguendo l’operazione indicata dal codice compreso
nell’istruzione (nel caso dell’esempio si tratta di una
sottrazione, per verificare poi se il risultato è uguale o
diverso da zero); contemporaneamente il contenuto del
PC viene sommato al valore del salto per calcolare
l’eventuale destinazione del salto;
4. l’esito dell’operazione viene utilizzato per decidere quale
valore debba essere memorizzato nel PC.
PC
Unità funzionali richieste
dai diversi tipi di istruzioni
Tipo di istruzione
Aritmetico-logico
Unità funzionali utilizzate
Memoria Banco
Banco
ALU
(istruzioni) registri
registri
Trasferimento
Memoria Banco
Memoria Banco
ALU
(dati) registri
(registri ← memoria) (istruzioni) registri
Trasferimento
Memoria Banco
Memoria
ALU
(dati)
(registri → memoria) (istruzioni) registri
Salto
(condizionato)
Salto
(non condizionato)
Memoria Banco
ALU
(istruzioni) registri
Memoria
(istruzioni)
Durata indicativa di ogni categoria di
istruzione (tempi in ns).
Tipo di istruzione
Memoria Lettura ALU Memoria Scrittura
istruzioni registro
dati
registro Totale
(MI)
(LR) (AL)
(MD)
(SR)
Aritmetico-logico
10
5
10
–
5
30
Trasferimento
(registri ← memoria)
10
5
10
10
5
40
Trasferimento
(registri → memoria)
10
5
10
10
–
35
Salto
(condizionato)
10
5
10
–
–
25
Salto
(non condizionato)
10
–
–
–
–
10
Un esempio
Esecuzione di una successione di quattro istruzioni per il
caricamento di due dati dalla memoria nei registri R01 e R02,
la loro somma e la registrazione in memoria del risultato.
lw R01,R11,421
lw R02,R11,842
MI LR AL
40 ns
add R03,R01,R02
Tempo
MD SR
MI LR AL
MD SR
40 ns
MI LR AL SR
35 ns
MI LR AL
sw R03,R11,421
145 ns
Ordine di esecuzione
delle istruzioni
30 ns
MD
Architettura di una CPU
¾
Obiettivo: definire l’architettura complessiva di un
processore
¾
Metodo: partiamo dai componenti che servono per
completare l’esecuzione delle diverse fasi di ciascuna
istruzione
¾
Ipotesi semplificativa: assumiamo di avere a disposizione
due memorie distinte, una per le istruzioni e una per i dati
Fetch
¾
Fase di fetch
• prelievo istruzione
corrente (da PC)
• caricamento nell’IR
• incremento PC
¾
Elementi necessari
• i due registri (PC e IR)
• memoria per le istruzioni
• sommatore (per
incrementare il PC senza
l’intervento dell’ALU)
+1
PC
Indirizzo
lettura
Istruzione
Memoria
Istruzioni
IR
Istruzioni Aritmetico-Logiche
¾
Sequenza
1. Lettura di due registri (a meno che
uno dei due operandi non sia diretto)
2. Esecuzione di un’operazione che
coinvolge l’ALU
3. Scrittura del risultato in un registro.
¾
WR
Elementi necessari
• Registri
• ogni lettura richiede un ingresso (il
numero del registro) e un’uscita (il
valore letto),
• una scrittura richiede due ingressi (il
numero del registro e il valore da
scriverci)
• servono quindi quattro ingressi (due
per la lettura di due registri sorgenti e
due per la scrittura) e due uscite (per
le due letture).
• ALU
• Unità di controllo
• indica all’ALU quale operazione
eseguire;
• indica ai registri quando
leggere/scrivere i dati;
• Attiva le opportune linee di
collegamento.
Dato reg. src2
Num. reg. src2
IR
Num. reg. src1
Dato reg. src1
Banco registri
Num. reg. dest
Dato da scrivere
OP
ALU
esito
Trasferimento dati da memoria (load)
¾
Sequenza
• legge un registro perché contiene
parte dell’indirizzo
• usa l’ALU per calcolare l’indirizzo
effettivo della cella di memoria
cui si vuole accedere
• manda il risultato alla memoria
dati
• legge dalla memoria dati il valore
da scrivere nei registri
¾
Elementi
• Registri
• lettura per calcolare l’indirizzo
• scrittura per salvare il dato
trasferito
• ALU
• calcola l’indirizzo effettivo
• Memoria dati
• Unità di controllo
WR
Dato reg. src2
Num. reg. src2
IR
OP
esito
WR
RD
ALU
Indirizzo per lettura
Num. reg. src1
Dato reg. src1
Banco registri
Dato letto
Memoria dati
Num. reg. dest
Indirizzo per scrittura
Dato da scrivere
Dato da scrivere
Trasferimento dati a memoria (store)
¾
Sequenza
• legge due registri (uno contiene
parte dell’indirizzo l’altro il dato
da scrivere in memoria)
• usa l’ALU per calcolare l’indirizzo
effettivo della cella di memoria
cui si vuole accedere
• manda il risultato alla memoria
dati insieme al dato da scrivere
¾
Elementi
• Registri
• lettura per calcolare l’indirizzo
• lettura del dato da trasferire
• ALU
• calcola l’indirizzo effettivo
• Memoria dati
• Unità di controllo
WR
OP
Dato reg. src2
Num. reg. src2
IR
Num. reg. src1
Dato reg. src1
Banco registri
esito
WR
RD
Indirizzo per lettura
ALU
Dato letto
Memoria dati
Num. reg. dest
Indirizzo per scrittura
Dato da scrivere
Dato da scrivere
Combinazione di load e store
WR
Dato reg. src2
Num. reg. src2
IR
Num. reg. src1
Dato reg. src1
Banco registri
OP
ALU
esito
WR
RD
Indirizzo per lettura
Dato letto
Memoria dati
Num. reg. dest
Indirizzo per scrittura
Dato da scrivere
Dato da scrivere
¾
Salti condizionati
Salti
• calcolo dell’indirizzo di
destinazione del salto
• valutazione della condizione (per
capire se saltare o no)
¾
Salti non condizionati
• sostituire una parte del PC con
alcuni dei bit contenuti nell’IR
¾
Σ
Elementi necessari
• Sommatore aggiuntivo
• Registri solo in lettura (il risultato
non deve essere salvato ma solo
esaminato per valutare l’esito
dell’operazione)
• ALU
• Unità di controllo
¾
PC+1
Elementi necessari
• … nulla in più …
Destinazione
del salto
WR
Dato reg. src2
Num. reg. src2
IR
Num. reg. src1
Dato reg. src1
Banco registri
Num. reg. dest
Dato da scrivere
OP
ALU
esito
Combinazione di tutti gli elementi
PC+1
Σ
WR
+1
PC
Destinazione
del salto
Indirizzo
lettura
Dato reg. src2
Num. reg. src2
Istruzione
Memoria
Istruzioni
IR
Num. reg. src1
Dato reg. src1
Banco registri
Cerchio: multiplexer
OP
ALU
esito
WR
RD
Indirizzo per lettura
Dato letto
Memoria dati
Num. reg. dest
Indirizzo per scrittura
Dato da scrivere
Dato da scrivere
Questa unità di calcolo può eseguire tutte le
operazioni elementari in un unico ciclo di clock
NOTA:il clock è un segnale periodico che sincronizza il funzionamento
dei dispositivi elettronici digitali.
Incrementare le prestazioni
con il parallelismo
Migliorare le prestazioni di una CPU
¾
La frequenza di clock
• influenza direttamente il tempo di ciclo del data path e
quindi le prestazioni di un calcolatore;
• è limitata dalla tecnologia disponibile.
¾
Il parallelismo permette di migliorare le prestazioni
senza modificare la frequenza di clock. Esistono
due forme di parallelismo:
• parallelismo a livello delle istruzioni
(architetture pipeline o architetture superscalari);
• parallelismo a livello di processori
(Array computer, multiprocessori o multicomputer).
Architettura pipeline
¾
Organizzazione della CPU come una “catena di
montaggio”
• la CPU viene suddivisa in “stadi”, ognuno dedicato
all’esecuzione di un compito specifico;
• l’esecuzione di un’istruzione richiede il passaggio
attraverso (tutti o quasi tutti) gli stadi della pipeline;
• in un determinato istante, ogni stadio esegue la parte di
sua competenza di una istruzione;
• in un determinato istante, esistono diverse istruzioni
contemporaneamente in esecuzione, una per ogni stadio.
Esempio di pipeline
/1
Pipeline in cinque stadi:
S1 [MI] lettura istruzioni dalla memoria, caricamento IR e
incremento PC;
S2 [LR] lettura dai registri degli operandi richiesti;
S3 [AL] esecuzione delle operazioni aritmetico-logiche
necessarie;
S4 [MD] accesso alla memoria dati (per lettura/load o
scrittura/store);
S5 [SR] scrittura nei registri dei risultati.
Stadio 1
Stadio 2
Stadio 3
Stadio 4
Stadio 5
Memoria
Istruzioni
(MI)
Lettura
Registri
(LR)
ALU
Memoria
Dati
(MD)
Scrittura
Registri
(SR)
10 ns
5 ns
(AL)
10 ns
10 ns
5 ns
Con e senza pipeline
¾
Esempio a ds:
• Senza pipeline
T = 145
• Con pipeline
T = 80
• Rapporto
145/80 = 1.81
¾
Per esempio con
1000 istruzioni
• Senza pipeline
T ≥ 30ms
• Con pipeline
T = 10ms+40ns
• Rapporto
30/10.00004 =
2.99998
MI LR AL
lw R01,R11,421
Tempo
MD SR
40 ns
lw R02,R11,842
MI LR AL
MD SR
40 ns
add R03,R01,R02
MI LR AL SR
145 ns
Ordine di esecuzione
delle istruzioni
lw R02,R11,842
add R03,R01,R02
35 ns
MI LR AL
sw R03,R11,421
lw R01,R11,421
30 ns
MI
10 ns
LR
MI
10 ns
sw R03,R11,421
AL
LR
MI
10 ns
MD
AL
LR
MD SR
AL
MI
LR
80 ns
Ordine di esecuzione
delle istruzioni
Tempo
SR
SR
AL
MD
MD
Prestazioni di una pipeline
¾
Il tempo di esecuzione (latenza) della singola
istruzione non diminuisce, anzi aumenta
• il tempo di attraversamento (latenza) della pipeline
corrisponde al numero degli stadi (N) moltiplicato per il
tempo di ciclo (T);
• il tempo di ciclo è limitato dallo stadio più lento!
¾
Aumenta il numero di istruzioni completate
nell’unità di tempo (throughput)
• si completa un’istruzione a ogni ciclo di clock;
• l’incremento di throughput è quasi proporzionale al
numero degli stadi!
Esecuzione in pipeline
Stadi
Stadio 5
(SR)
Stadio 4
(MD)
Stadio 3
(AL)
Stadio 2
(LR)
Stadio 1
(MI)
Istruzione 1
Istruzione 2
10 ns
Istruzione 3
20 ns
Istruzione 4
30 ns
Istruzione 5
40 ns
Istruzione 6
50 ns
60 ns
Tempo
Esecuzione in pipeline
Stadi
Stadio 5
(SR)
Istruzione 1
Istruzione 2
Istruzione 1
Istruzione 2
Istruzione 3
Istruzione 1
Istruzione 2
Istruzione 3
Istruzione 4
Istruzione 1
Istruzione 2
Istruzione 3
Istruzione 4
Istruzione 5
Istruzione 2
Istruzione 3
Istruzione 4
Istruzione 5
Istruzione 6
Stadio 4
(MD)
Stadio 3
(AL)
Stadio 2
(LR)
Stadio 1
(MI)
Istruzione 1
10 ns
20 ns
30 ns
40 ns
50 ns
60 ns
Tempo
Esempio di pipeline
S1
S2
S3
S4
/2
S5
tempo
t1 Istr.
Istr. 11
t2 Istr.
Istr. 22 Istr.
Istr. 11
t3 Istr.
Istr. 33 Istr.
Istr. 22 Istr.
Istr. 11
t4 Istr.
Istr. 44 Istr.
Istr. 33 Istr.
Istr. 22 Istr.
Istr. 11
t5 Istr.
Istr. 55 Istr.
Istr. 44 Istr.
Istr. 33 Istr.
Istr. 22 Istr.
Istr. 11
t6 Istr.
Istr. 66 Istr.
Istr. 55 Istr.
Istr. 44 Istr.
Istr. 33 Istr.
Istr. 22
Esecuzione in pipeline
Stadi
Stadio 5
(SR)
Istr. N–4
Istr. N–3
Istr. N–2
Istr. N–1
Istr. N
Istr. N+1
Stadio 4
(MD)
Istr. N–3
Istr. N–2
Istr. N–1
Istr. N
Istr. N+1
Istr. N+2
Stadio 3
(AL)
Istr. N–2
Istr. N–1
Istr. N
Istr. N+1
Istr. N+2
Istr. N+3
Stadio 2
(LR)
Istr. N–1
Istr. N
Istr. N+1
Istr. N+2
Istr. N+3
Istr. N+4
Stadio 1
(MI)
Istr. N
Istr. N+1
Istr. N+2
Istr. N+3
Istr. N+4
Istr. N+5
t1
t2
t3
t4
t5
t6
Tempo
In ogni istante (e.g. t3) ci sono 5 istruzioni in esecuzione
Esecuzione in pipeline
S1
S2
S3
S4
S5
ii
ii -- 11
ii -- 22
ii -- 33
ii -- 44
ti+1 ii +
+ 11
ii
ii -- 11
ii -- 22
ii -- 33
ti+2 ii +
+ 22
ii +
+ 11
ii
ii -- 11
ii -- 22
ti+3 ii +
+ 33
ii +
+ 22
ii +
+ 11
ii
ii -- 11
ti+4 ii +
+ 44
ii +
+ 33
ii +
+ 22
ii +
+ 11
ii
ti
All’istante ti+2 ci sono 5 istruzioni in esecuzione
Esecuzione in pipeline
Stadi
Stadio 5
(SR)
Istr. N–4
Istr. N–3
Istr. N–2
Istr. N–1
Istr. N
Istr. N+1
Stadio 4
(MD)
Istr. N–3
Istr. N–2
Istr. N–1
Istr. N
Istr. N+1
Istr. N+2
Stadio 3
(AL)
Istr. N–2
Istr. N–1
Istr. N
Istr. N+1
Istr. N+2
Istr. N+3
Stadio 2
(LR)
Istr. N–1
Istr. N
Istr. N+1
Istr. N+2
Istr. N+3
Istr. N+4
Stadio 1
(MI)
Istr. N
Istr. N+1
Istr. N+2
Istr. N+3
Istr. N+4
Istr. N+5
t1
t2
t3
t4
t5
t6
Tempo
Ogni stadio (e.g. AL) esegue la parte di sua competenza
di istruzioni successive l’una all’altra.
Esecuzione in pipeline
S1
S2
S3
S4
S5
ii
ii -- 11
ii -- 22
ii -- 33
ii -- 44
ti+1 ii +
+ 11
ii
ii -- 11
ii -- 22
ii -- 33
ti+2 ii +
+ 22
ii +
+ 11
ii
ii -- 11
ii -- 22
ti+3 ii +
+ 33
ii +
+ 22
ii +
+ 11
ii
ii -- 11
ti+4 ii +
+ 44
ii +
+ 33
ii +
+ 22
ii +
+ 11
ii
ti
Lo stadio S3 esegue la parte di sua competenza
di istruzioni successive l’una all’altra.
Caratteristiche delle CPU
¾I
microprocessori sono identificati dalla casa
costruttrice (per PC Intel, AMD o Motorola)
tramite sigle. La sigla è associata a
caratteristiche interne del processore quali la
frequenza di clock e il parallelismo di
elaborazione (ossia il numero di bit che
possono essere elaborati simulataneamente).
¾ Processore a 16 bit ha registri interni che
contengono i dati di 16 bis e spesso anche la
dimensione del bus dei dati coincide. Siamo
ormai a 64 bit.
Evoluzione architetture
¾
Vista la disponibilità di un maggior numero di transistor si
inseriscono più pipeline nella stessa CPU
• aumenta il parallelismo perché è possibile eseguire
contemporaneamente diversi flussi di istruzioni;
istruzioni
• è necessario garantire che non ci siano conflitti tra le istruzioni che
vengono eseguite insieme; di solito il controllo è affidato al
compilatore.
Stadio 1
Memoria
Istruzioni
(MI)
Stadio 2
Stadio 3
Stadio 4
Stadio 5
Lettura
Registri
(LR)
ALU
Memoria
Dati
(MD)
Scrittura
Registri
(SR)
Memoria
Dati
(MD)
Scrittura
Registri
(SR)
Lettura
Registri
(LR)
(AL)
ALU
(AL)
Architetture superscalari
In alternativa si possono
replicare le unità funzionali
• rappresentano lo stadio più
lento della pipeline (in genere
richiedono diversi cicli di clock);
• è più semplice evitare i conflitti
tra le diverse istruzioni.
ALU 1
execute
ALU 2
LOAD
STORE
S1
S2
S3
fetch
decode
lettura
operandi
FP 1
FP 2
S5
write back
Multiprocessori
¾
Diverse CPU condividono una memoria comune:
• le CPU debbono coordinarsi per accedere alla memoria;
• esistono diversi schemi di collegamento tra CPU e
memoria, quello più semplice prevede che ci sia un bus
condiviso;
• se i processori sono veloci il bus diventa un collo di bottiglia;
• esistono soluzioni che permettono di migliorarne le prestazioni, ma
si adattano a sistemi con un numero limitato di CPU (<20).
¾
La memoria condivisa rende più semplice il
modello di programmazione:
• si deve parallelizzare l’algoritmo, ma si può trascurare la
“parallelizzazione” dei dati.
CPU
CPU
CPU
CPU
mem
bus condiviso
Multicalcolatori
¾
Sistemi composti da tanti calcolatori collegati fra loro
• ogni calcolatore è dotato di una memoria privata e non c’è memoria
in comune;
• comunicazione tra CPU basata su scambio di messaggi.
¾
Non è efficiente collegare ogni calcolatore a tutti gli altri,
quindi vengono usate topologie particolari:
• griglie a 2/3 dimensioni, alberi e anelli;
• i messaggi, per andare da fonte a destinazione, spesso devono passare
da uno o più calcolatori intermedi o switch.
• Tempi di trasferimento dei messaggi dell’ordine di alcuni
microsecondi sono comunque facilmente ottenibili.
¾
Sono stati costruiti multicalcolatori con ~10.000 CPU.
Struttura di un multicomputer
mem
mem
mem
mem
CPU
CPU
CPU
CPU
bus condiviso
Evoluzione delle CPU Intel
Frequenza Dim. registri Numero di
(MHz)
bus dati
transistor
CPU
Anno
8086
1978
4.77 — 12
8/16
29 000
80286
1982
8 — 16
16/16
134 000
80386
1986
16 — 33
32/32
275 000
80486
1989
33 — 50
32/32
1 200 000
Pentium
1993
60 — 200
32/64
3 100 000
Pentium II
1997
233 — 400
32/64
7 500 000
Pentium III
1999
450 — 1133
32/64
24 000 000
(Willamette)
2000
1300 — 2000
32/64
42 000 000
(Northwood)
2002
2000 — 3400
32/64
55 000 000
(Prescott)
2004
2800 — 3800
32/64
125 000 000
Pentium 4
Legge di Moore
Osservazione fatta da Gordon Moore nel 1965:
il numero dei transistor per cm2
raddoppia ogni X mesi
In origine X era 12. Correzioni successive hanno
portato a fissare X=18. Questo vuol dire che c’è un
incremento di circa il 60% all’anno.
# Transistor [CPU Intel]
100 000 000
10 000 000
1 000 000
100 000
1989
1991
1993
1995
1997
1999
Legge di Moore e progresso
¾
¾
¾
¾
¾
Il progresso della tecnologia provoca un aumento
del numero di transistor per cm2 e quindi per chip.
Un maggior numero di transistor per chip permette
di produrre prodotti migliori (sia in termini di
prestazioni che di funzionalità) a prezzi ridotti.
I prezzi bassi stimolano la nascita di nuove
applicazioni (e.g. non si fanno video game per
computer da milioni di $).
Nuove applicazioni aprono nuovi mercati e fanno
nascere nuove aziende.
L’esistenza di tante aziende fa crescere la
competitività che, a sua volta, stimola il progresso
della tecnologia e lo sviluppo di nuove tecnologie.







![Fortran 90[/95] Info Linguaggi di programmazione Linguaggi](http://s1.studylibit.com/store/data/001621488_1-ab5fae7ea7fb4306336d0fc0fbeee8b0-300x300.png)
