UNIVERSITA’ DEGLI STUDI DI ROMA
TOR VERGATA
Facoltà di Ingegneria
Tesi di laurea:
Progetto e realizzazione di un sistema di
gestione di risorse multimediali basato sullo
standard MPEG-7
Relatore
Correlatori
Prof. Mario SALERNO
Ing. Giovanni COSTANTINI
Ing. Francesco ROMANO
Candidato
Nicola LA VERGHETTA
Sessione Estiva
Anno accademico 2002/2003
Indice
INDICE
Indice .................................................................................................................... 1
Indice delle figure ................................................................................................ 6
Premessa............................................................................................................. 10
Capitolo 1 .......................................................................................................... 14
Contesto generale....................................................................................................................14
1.1
Internet, un grande contenitore di risorse .................................................................14
1.1.1
Scenario ............................................................................................................14
1.1.2
Bisogni e prospettive: lo standard MPEG-7 .....................................................16
Capitolo 2 .......................................................................................................... 18
Le Teche RAI ed il progetto “Internet TV” .........................................................................18
2.1
Cos’è un archivio? ....................................................................................................18
2.1.1
L’archivio multimediale ...................................................................................19
2.1.2
L’archivio digitale ............................................................................................19
2.2
Alcuni tra i maggiori archivi multimediali mondiali................................................20
2.2.1
2.3
Gli archivi multimediali radiotelevisivi............................................................21
Le Teche RAI ...........................................................................................................23
2.3.1
Obiettivi e utenti ...............................................................................................23
2.3.2
Il patrimonio delle Teche di RAI......................................................................23
2.3.3
La gestione delle Teche RAI: il catalogo multimediale e Octopus ..................26
2.3.4
Nuove possibilità di utilizzo per gli utenti........................................................27
2.4
Il progetto “Internet TV” ..........................................................................................28
2.5
L’idea del “News Archive System”..........................................................................30
1
Indice
Capitolo 3 .......................................................................................................... 32
Le tecnologie di sviluppo........................................................................................................32
3.1
XML (eXtensible Markup Language) ......................................................................32
3.1.1
Le caratteristiche di XML.................................................................................34
3.1.2
Come usare XML .............................................................................................36
3.2
Le tecnologie e gli standard per XML......................................................................37
3.2.1
Gli XML Schema e la validazione dei documenti XML..................................38
3.2.2
XSLT: una tecnologia per la stilabilità delle risorse XML ..............................40
3.2.3
Il retriving dei dati in XML: XPath ..................................................................42
3.3
Le tecnologie Java-based..........................................................................................43
3.3.1
Java e XML ......................................................................................................45
3.3.2
Le Java Servlet .................................................................................................46
3.3.3
Le JavaServer Pages (JSP) ...............................................................................49
3.3.4
I JavaBeans.......................................................................................................51
Capitolo 4 .......................................................................................................... 53
Il database di News Archive System .....................................................................................53
4.1
I legami tra XML ed i database ................................................................................53
4.2
La scelta del tipo di database....................................................................................54
4.2.1
4.3
La differenza tra dati e documenti....................................................................55
I database XML nativi ..............................................................................................57
4.3.1
Vantaggi dell’uso di database XML nativi.......................................................58
4.3.2
Caratteristiche dei database XML nativi ..........................................................60
4.4
Apache Xindice ........................................................................................................61
4.4.1
Le caratteristiche di Xindice.............................................................................61
4.4.2
L’architettura di Xindice ..................................................................................63
4.4.3
Un esempio concreto di utilizzo .......................................................................63
Capitolo 5 .......................................................................................................... 67
MPEG-7: Multimedia Content Description Interface ........................................................67
5.1
Overview ..................................................................................................................67
5.2
Introduzione a MPEG-7 ...........................................................................................67
5.2.1
Obiettivi dello standard ....................................................................................67
2
Indice
5.2.2
MPEG-7 nella realtà dei metadati multimediali ...............................................68
5.2.3
Potenza e significato di uno standard ..............................................................69
5.3
Gli elementi dello standard MPEG-7 .......................................................................70
5.3.1
I Descriptor ......................................................................................................71
5.3.2
I Description Scheme .......................................................................................71
5.3.3
Il Description Definition Language..................................................................72
5.4
MPEG-7 Multimedia Description Scheme...............................................................73
5.4.1
Overview ..........................................................................................................73
5.4.2
L’elemento radice Mpeg7 ed i relativi tipi di livello superiore........................74
5.4.3
Content Description: segmentazione del contenuto multimediale ...................79
Capitolo 6 .......................................................................................................... 81
Analisi dei requisiti.................................................................................................................81
6.1
Gli Use case diagram................................................................................................81
6.1.1
Gli attori del sistema.........................................................................................81
6.1.2
Gli amministratori di News Archive System...................................................82
6.1.3
Gli utenti di News Archive System .................................................................83
6.2
I sequence diagram di sistema ..................................................................................84
6.2.1
Database Manager - Create...............................................................................84
6.2.2
Database Manager - Read & Delete .................................................................84
6.2.3
Database Manager - Update .............................................................................85
6.2.4
News Archive Administrator - Create ..............................................................86
6.2.5
News Archive Administrator - Read & Delete.................................................86
6.2.6
News Archive Administrator - Create MPEG-7...............................................87
6.2.7
User - Query .....................................................................................................87
Capitolo 7 .......................................................................................................... 89
Progetto dell’applicazione......................................................................................................89
7.1
Il design pattern Model-View-Controller dell’architettura ......................................89
7.1.1
Un esempio di applicazione del paradigma MVC............................................89
7.1.2
Applicazione dell'MVC alle Web Application J2EE .......................................91
7.1.3
L’architettura di News Archive System ..........................................................92
7.2
Il modello dei dati: un XML Schema conforme a MPEG-7.....................................93
3
Indice
7.2.1
Le specifiche per i dati ....................................................................................93
7.2.2
Definizione dello schema per l’applicazione...................................................94
7.2.3
L’elemento DescriptionMetadata ....................................................................95
7.2.4
L’elemento MediaLocator: localizzazione temporale e fisica della risorsa .....96
7.2.5
L’elemento StructuralUnit: il ruolo del segmento Audio-Video.....................97
7.2.6
L’elemento CreationInformation: creazione e classificazione ........................98
7.2.7
L’elemento UsageInformation: uso del contenuto audiovisivo.....................102
7.2.8
L’elemento MediaTime .................................................................................104
7.2.9
L’elemento MediaSourceDecomposition : descrizione fisica del contenuto 107
7.2.10
L’elemento TemporalDecomposition : descrizione delle singole sequenze ..110
7.3
Progettazione di un sito Internet per News Archive System..................................112
7.3.1
Modello concettuale del sito e progetto della navigazione.............................112
7.3.2
Supporto per gli utenti e versione in lingua inglese .......................................113
Capitolo 8 ........................................................................................................ 114
Implementazione...................................................................................................................114
8.1
Implementazione delle funzionalità per lo User.....................................................116
8.1.1
Ricerca di telegiornali.....................................................................................116
8.1.2
Ricerca per servizi ..........................................................................................119
8.2
Implementazione delle funzionalità per gli amministratori....................................121
8.2.1
Creare collezioni.............................................................................................123
8.2.2
Visualizzare documenti ..................................................................................124
8.2.3
Cancellare elementi ........................................................................................124
8.2.4
Inserire documenti ..........................................................................................129
8.2.5
Aggiornare i documenti ..................................................................................129
8.2.6
Creare un documento MPEG-7 per la descrizione dei telegiornali RAI .......133
Capitolo 9 ........................................................................................................ 136
Uso dell’applicazione............................................................................................................136
9.1
Un breve tour guidato .............................................................................................136
9.1.1
News Archive Administrator: creazione di un documento MPEG-7 .............136
9.1.2
Database Manager: un’operazione di Xupdate...............................................139
9.1.3
User: esecuzione di una query ........................................................................141
4
Indice
9.2
Test di usabilità.......................................................................................................144
9.2.1
Definizione di usabilità...................................................................................144
9.2.2
I princìpi di usabilità.......................................................................................145
9.2.3
Considerazioni di usabilità sul News Archive System...................................146
Capitolo 10 ...................................................................................................... 150
Risultati ottenuti e sviluppi futuri.......................................................................................150
Bibliografia....................................................................................................... 152
Appendici ......................................................................................................... 155
App.A Ambiente di sviluppo e informazioni sul codice prodotto .....................................155
App.B Il consorzio Elis e i Vivai d’Impresa ......................................................................156
App.C Lo schema dei dati..................................................................................................157
App.D Un documento MPEG-7 di descrizione di un telegiornale.....................................164
App.E I metadati ................................................................................................................172
App.F Unified Modeling Language...................................................................................174
Ringraziamenti ................................................................................................ 177
5
Indice delle figure
INDICE DELLE FIGURE
Fig. 1-1 Uso della banda...........................................................................................................15
Fig. 2-1 I maggiori archivi radiotelevisivi europei...................................................................22
Fig. 2-2 Alcuni archivi radiotelevisivi mondiali ......................................................................22
Fig. 2-3 Consistenza patrimonio televisivo RAI ......................................................................24
Fig. 2-4 Patrimonio area radiofonica nazionale .......................................................................24
Fig. 2-5 Patrimonio di biblio-mediateca RAI...........................................................................24
Fig. 2-6 Il sistema Teche RAI ..................................................................................................27
Fig. 3-1 Gerarchia dei linguaggi XML.....................................................................................33
Fig. 3-2 catalog.xml - un documento XML..............................................................................34
Fig. 3-3 catalog.dtd - una DTD per catalog.xml.......................................................................34
Fig. 3-4 Le maggiori tecnologie e standard XML ....................................................................37
Fig. 3-5 catalog.xsd - un XML Schema per catalog.xml..........................................................39
Fig. 3-6 Riferimento all’ XML Schema in catalog.xml ...........................................................39
Fig. 3-7 Il processo XSLT ........................................................................................................40
Fig. 3-8 catalog.xsl – un foglio di stile XSL per catalog.xml ..................................................41
Fig. 3-9 Riferimento all’XSL appropriato in catalog.xml .......................................................41
Fig. 3-10 Pagina HTML ottenuta dalla trasformazione XSLT di catalog.xml.........................41
Fig. 3-11 Il processo di trasformazione XSLT attraverso i Formattino Object........................42
Fig. 3-12 Risultato di un’esecuzione di un’espressione XPath complessa...............................43
Fig. 3-13 Architettura di un’applicazione Java ........................................................................45
Fig. 3-14 Architetture Web dinamiche servlet-JSP-based........................................................46
Fig. 3-15 Una servlet di esempio..............................................................................................48
Fig. 3-16 Application e WebServer..........................................................................................50
Fig. 3-17 Separazione dei ruoli.................................................................................................51
Fig. 4-1 I principali database XML nativi ................................................................................58
Fig. 4-2 Un esempio concreto di utilizzo dell’API XML:DB ..................................................65
Fig. 5-1 L’obiettivo dello standard MPEG-7 ...........................................................................70
6
Indice delle figure
Fig. 5-2 Livelli di descrizione offerti dall’MDS ......................................................................74
Fig. 5-3 Organizzazione dell’elemento radice Mpeg7 e dei tipi di livello superiore ...............75
Fig. 5-4 La semantica dell’elemento radice Mpeg-7................................................................76
Fig. 5-5 Strumenti di descrizione per il Content Management e il Content Description .........77
Fig. 5-6 Gerarchia dei top level type di Content Descriprion e Description Metadata ............78
Fig. 5-7 Visione generale degli strumenti per la decomposizione dei segmenti ......................80
Fig. 6-1 Gli attori del sistema ...................................................................................................82
Fig. 6-2 Le funzionalità degli attori DM e NAA......................................................................83
Fig. 6-3 Le funzionalità dell’attore User ..................................................................................83
Fig. 6-4 Diagramma di sequenza di sistema DM - Create........................................................84
Fig. 6-5 Diagramma di sequenza di sistema DM - Delete & Read ..........................................85
Fig. 6-6 Diagramma di sequenza di sistema DM - Update ......................................................85
Fig. 6-7 Diagramma di sequenza di sistema NAA - Create .....................................................86
Fig. 6-8 Diagramma di sequenza di sistema NAA - Delete & Read ........................................86
Fig. 6-9 Diagramma di sequenza di sistema NAA - Create MPEG-7......................................87
Fig. 6-10 Diagramma di sequenza di sistema USER - Query ..................................................87
Fig. 7-1 Un errore progettuale ..................................................................................................89
Fig. 7-2 MVC ...........................................................................................................................90
Fig. 7-3 MVC nelle applicazioni Web .....................................................................................91
Fig. 7-4 Architettura di News Archive System ........................................................................92
Fig. 7-5 Struttura dei dati per la descrizione dei telegiornali RAI ...........................................94
Fig. 7-6 L’elemento DescriptionMetadata................................................................................95
Fig. 7-7 Semantica dei descrittori di DescriptionMetadata DS utilizzati .................................95
Fig. 7-8 Struttura gerarchica del DescriptionMetadataType ....................................................96
Fig. 7-9 L’elemento MediaLocator ..........................................................................................96
Fig. 7-10 Struttura gerarchica di MediaLocatorType...............................................................97
Fig. 7-11 L'elemento StructuralUnit.........................................................................................98
Fig. 7-12 L’elemento CreationInformation ..............................................................................99
Fig. 7-13 Struttura gerarchica di CreationType........................................................................99
Fig. 7-14 Semantica di CreationInformationType..................................................................100
Fig. 7-15 Semantica di CreationType.....................................................................................100
Fig. 7-16 Semantica di CreatorType.......................................................................................101
Fig. 7-17 Semantica di CreationCoordinatesType .................................................................101
7
Indice delle figure
Fig. 7-18 Struttura gerarchica di ClassificationType .............................................................102
Fig. 7-19 Semantica di ClassificationType.............................................................................102
Fig. 7-20 L’elemento UsageInformation ................................................................................103
Fig. 7-21 Struttura gerarchica di UsageInformationType ......................................................103
Fig. 7-22 L’elemento MediaTime ..........................................................................................104
Fig. 7-23 Semantica di MediaTimeType................................................................................105
Fig. 7-24 Diagramma del MediaTimeType............................................................................105
Fig. 7-25 L’elemento MediaSourceDecomposition ...............................................................107
Fig. 7-26 Struttura gerarchica di MediaInformationType ......................................................108
Fig. 7-27 Semantica di MediaFormatType.............................................................................109
Fig. 7-28 L’elemento TemporalDecomposition .....................................................................110
Fig. 7-29 Struttura gerarchica di TemporalDecompositionType............................................111
Fig. 7-30 Il modello concettuale del sito ................................................................................112
Fig. 7-31 Gli strumenti di navigazione...................................................................................112
Fig. 8-1 Convenzioni stilistiche..............................................................................................114
Fig. 8-2 Mappa dei Class Diagram UML ...............................................................................115
Fig. 8-3 Il class diagram Start.................................................................................................115
Fig. 8-4 Il class diagram User.................................................................................................116
Fig. 8-5 Il class diagram News Search ...................................................................................117
Fig. 8-6 Il diagramma di sequenza “reale” per una ricerca su telegiornali ............................118
Fig. 8-7 Il class diagram per il Real server.............................................................................120
Fig. 8-8 Il class diagram Report Search .................................................................................121
Fig. 8-9 Il class diagram Administrator Login .......................................................................121
Fig. 8-10 Funzionalità del Database Manager........................................................................122
Fig. 8-11 Funzionalità del News Archive Administrator .......................................................123
Fig. 8-12 Il class diagram Create Collection ..........................................................................124
Fig. 8-13 Il class diagram View Document............................................................................126
Fig. 8-14 Il class diagram Delete Items..................................................................................127
Fig. 8-15 Il class diagram Insert Document ...........................................................................128
Fig. 8-16 Operazioni di update implementate ........................................................................130
Fig. 8-17 Il class diagram Update...........................................................................................131
Fig. 8-18 Il diagramma di sequenza “reale” per un’operazione di update .............................132
Fig. 8-19 Il class diagram CreateMpeg7Doc..........................................................................134
8
Indice delle figure
Fig. 8-20 Il diagramma di sequenza “reale” per la creazione di un documento MPEG-7 .....135
Fig. 9-1 Scelta del tipo di amministratore di sistema .............................................................137
Fig. 9-2 News Archive Administrator homepage...................................................................137
Fig. 9-3 La form per la creazione di un documento MPEG-7................................................138
Fig. 9-4 Inserimento di un AudioVisualSegment...................................................................138
Fig. 9-5 Database Manager homepage ...................................................................................139
Fig. 9-6 Scelta dell’operazione di XUpdate ...........................................................................140
Fig. 9-7 La form per le operazioni di XUpdate ......................................................................140
Fig. 9-8 Homepage dell’utente ...............................................................................................141
Fig. 9-9 La form di News Search ...........................................................................................142
Fig. 9-10 Risultato di una query sui telegiornale....................................................................142
Fig. 9-11 News Media Profile ................................................................................................143
Fig. 9-12 Pagina di visualizzazione dei servizi di un telegiornale .........................................144
L’ XML Schema dei dati conforme a MPEG-7 .....................................................................163
Una descrizione MPEG-7 di un telegiornale..........................................................................171
9
Premessa
PREMESSA
Sebbene Internet sia ancora uno strumento utilizzato da una minoranza della popolazione
mondiale ed in particolare europea ed italiana, è fuori dubbio che nel futuro diverrà uno e,
probabilmente l’unico, “contenitore” di risorse, collegamenti e servizi. Ci aspetta un domani
nel quale, ancora più d’oggi, saranno disponibili on-line, a pagamento o free, molti aspetti
della nostra quotidianità; già oggi, Internet permette di fare acquisti di ogni genere, prenotare
voli, treni, viaggi, trascorrere il proprio tempo libero ascoltando musica o guardano film, ma
anche lavorare, ricercare, osservare, discutare, incontrarsi.
Se al’inizio erano prevalentemente le comunità scientifiche di tutto il mondo ad essere i
registi e gli attori di Internet, oggi siamo tutti coinvolti in questa rivoluzione. Con estrema
semplicità è possibile aver accesso allo “spazio Web” per pubblicare qualsiasi tipo di
informazione e contenuto sotto forma di una varietà sempre crescente di entità multimediali.
La maggior parte dei siti attuali è corredata di immagini, suoni, video e non è remota la
possibilità di poter “eternare” anche altre sensazioni che riguardano l’olfatto od il gusto.
In un contesto, dove chiunque diventa un potenziale “produttore e consumatore” di
Internet, è facile immaginare come la semplicità di ricerca e la disponibilità reale delle risorse,
sia il necessario valore aggiunto che esse dovranno possedere se non si vuole che Internet
“esploda” e muoia per le stesse ragioni che l’hanno reso un così grande “agglomerato di
conoscenza”.
L’equazione valore delle risorse = facilità di reperimento, rappresenta la colonna portante
di questo lavoro di tesi.
La RAI (l’ente pubblico per la tele-radio diffusione in Italia) possiede uno dei più grandi
patrimoni del mondo in termini di risore audiovisuali, che narrano la nostra storia e
raffigurano la nostra società da oltre mezzo secolo. Attualmente questo materiale è
conservato, sotto forma di un’incredibile varietà di formati e media differenti, nella diverse
cineteche RAI sparse sul territorio nazionale. E’ facile comprendere come tale ricchezza abbia
10
Premessa
bisogno di quel valore aggiunto di cui si è parlato, per raggiungere quel grado di maturità che
oggi viene richiesto a qualsiasi risorsa multimediale che si affaccia sull’universo di Internet.
Sono queste le ragioni che hanno spinto la RAI a trovare l’appoggio del consorzio ELIS (si
veda appendice B) per sperimentare nuove vie che conducano alla valorizzazione delle
proprie risorse mediatiche.
Il progetto, denominato “Internet TV”, è partito alla fine del 2000 e questo lavoro di tesi è
la conclusione della terza fase.
Le richieste di RAI di un sistema flessibile ma standard per la descrizione delle proprie
risorse multimediali, hanno portato, nella prima fase, alla ricerca ed allo studio delle nuove
tecnologie disponibili nell’ambito della descrizione e presentazione di risorse (XML, XSL…)
e alla scelta di adottare il nuovissimo standard MPEG-7 per la descrizione di contenuti
multimediali audiovisivi.
La seconda fase ha risposto all’esigenza di un sistema prototipale che mettesse in luce la
effettiva potenza dello standard MPEG-7 nell’ambito della descrizione di segmenti
audiovisivi. Ciò ha condotto alla realizzazione di un sistema di archiviazione e ricerca dei
telegiornali RAI, MPEG-7-based, sulla piattaforma di un database XML nativo commerciale
(Tamino di Software AG) adatta a mantenere i requisiti di interoperabilità richiesti.
Questa terza fase nasce con l’obiettivo di recuperare gran parte del lavoro svolto finora, al
fine di effettuare il porting del sistema di archiviazione MPEG-7-based, verso architetture che
si fondano completamente su tecnologie open source.
Dopo una fase preliminare di studio delle tecologie usate nella precedente realizzazione, e
di ricerca di nuovi strumenti necessari al raggiungimento dell’obiettivo, si sono prese le
opportune decisioni riguardo il linguaggio di programmazione (naturalmente Java, data la
natura Web-oriented dall’applicazione), i paradigmi progettuali ed il tipo e la versione di
database da utilizzare.
L’architettura Model-View-Controller e il pattern J2EE (Java2EnterpriseEdition) Data
Access Object per la definizione di un persistance layer hanno consentito la realizzazione di
un progetto modulare, riusabile e scalabile.
Il database Xindice di Apache è la naturale risposta open source al database commerciale
Tamino. Tra tutti i datatbase XML nativi open source la scelta è caduta su quello dell’Apache
Gruop non solo perché è sembrato essere il più affidabile e “vivo” per quanto riguarda il
11
Premessa
continuo sviluppo e aggiornamento, ma anche per il consolidato successo di numerose
applicazioni sviluppate da Apache. Inoltre si è deciso di ribadire la scelta di un database XML
nativo, piuttosto che relazionale, vista la necessità di memorizzare documenti in formato
MPEG-7 e quindi XML.
Definiti gli strumenti e le tecnologie di sviluppo, si è passati all’implementazione vera e
propria del sistema, poi denominato “News Archive System”. Si tratta di una serie di interfacce
Web-based, per il completo controllo del database sia a livello di amministratore di sistema
(operazioni di content management), sia a livello di utente del sistema (operazioni di ricerca e
“uso” delle risorse). Il primo problema affrontato è stato quello di realizzare un’interfaccia
general purpose per Xindice, ovvero uno strumento che permette l’accesso a tutte le
funzionalità del database - navigazione, creazione, modifica, visualizzazione e cancellazione
delle risorse - svincolato dalla particolare applicazione. Quindi, si è passati allo sviluppo di
una serie di interfacce, specifiche per l’applicazione, mirate alla ricerca di telegiornali e di
servizi all’interno dei telegiornali stessi, con la possibilità sia di visualizzare il contenuto
multimediale, sia di avere descrizioni approfondite sul media in esame. Infine, è stata
implementata un’interfaccia per il cosiddetto News Archive Administrator, ovvero un
amministratore pensato in modo specifico per in News Archive System in grado, tra l’altro, di
creare documenti MPEG-7 in modo semiautomatico, mediante la compilazione di apposite
form.
Il
prototipo
di
News
Archive
System
è
disponibile
all’URL:
http://62.110.204.10:8080/RAI_project/index.html.
I capitoli che seguono, ripercorrono la linea di progetto adottata. Ad un breve sguardo sul
contesto di lavoro (Cap. 1), seguirà una panoramica sugli archivi, in generale, e sulle Teche
RAI in particolare (Cap. 2). Verranno quindi proposte, ad un opportuno livello di
approfondimento, le tecnologie impiegate per lo sviluppo dell’applicazione (Cap. 3) e
verranno date alcune motivazioni sulla scelta del database (Cap. 4). Seguirà una panoramica
dello standard MPEG-7 (Cap. 5) per arrivare alle descrizione vera a propria dell’applicazione,
attraverso l’illustrazione delle specifiche di sistema, il progetto dall’applicazione e la sua
implementazione (Cap. 6-7-8). Per finire verrà descritto un breve tour guidato ed il test di
usabilità di News Archive System (Cap. 9) seguiti da alcune considarezioni riguardo i sui
possibili sviluppi futuri (Cap. 10).
In appendice, oltre ad essere riportato lo schema dei dati ed un documento MPEG-7 di
esempio, vengono fornite informazioni sul codice prodotto e sull’ambiente di sviluppo, sul
12
Premessa
centro ELIS - e sui valori umani e professionali che ne sono alla base - sui metadati e sul
linguaggio UML.
13
Capitolo 1 - Contesto generale
CAPITOLO 1
Contesto generale
1.1
Internet, un grande contenitore di risorse
1.1.1 Scenario
Internet non è solo un’entità che eroga servizi, ma soprattutto un’inesauribile fonte di
informazioni di ogni genere messe in rete perché possano essere condivise. Una specie di
archivio senza un centro e una periferia nel quale è possibile reperire risorse spesso
liberamente accessibili. Un’importante caratteristica della rete è la capacità che essa ha di
supportare file di tipo multimediale: non solo testi, dunque, ma anche immagini, audio, video
e, in un futuro non troppo lontano, anche odori, sensazioni tattili e gustative. Ognuna di
queste risorse può essere considerata come un documento multimediale nella sua accezione
più generale.
La fisionomia di Internet è quella di un perfetto archivio, in grado di immagazzinare un
numero infinito di documenti multimediali senza limiti di spazio, e di renderli accessibili a
privati o ad istituzioni, gratuitamente o a pagamento. Si tratta, insomma, di un mezzo in grado
di “eternare” testimonianze, documenti originali, rappresentazioni, che abbiano carattere
storico o interesse culturale.
Con l’avvento di apparecchiature elettroniche dalla potenza fino a pochi anni fa
inimmaginabile, e soprattutto con la crescita esponenziale di Internet e delle reti di computer
in generale, la diffusione di documenti multimediali si è espansa a vista d’occhio. Questo è
dovuto al fatto che produrre contenuto multimediale oggi è decisamente più semplice che in
passato. Con l’uso di telecamere digitali, dei personal computer e della Rete stessa, ad
esempio, ogni individuo nel mondo è potenzialmente un “produttore di contenuti” che
possono essere facilmente pubblicati e distribuiti. Le stesse tecnologie rendono disponibile
14
Capitolo 1 - Contesto generale
on-line questi contenuti, che sarebbero rimasti, solo qualche anno fa, inaccessibili. La naturale
conseguenza di tutto ciò è che oggi qualunque tipo di informazione è corredata, come
minimo, da immagini di vario tipo (fotografie, disegni, grafici), se non da contenuti di più alta
complessità come suoni (ad esempio musica o “parlato”), filmati ed una combinazione di essi
in diversi scenari.
Inoltre è sempre più vasto il campo di sistemi elettronici che utilizzano tali risorse in modo
automatico, non solo per il loro scambio ma anche per operazioni decisamente più complesse
come ad esempio l'indicizzazione ed il filtraggio.
Oggi non è azzardato affermare che il valore delle informazioni spesso, se non sempre,
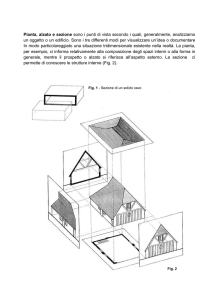
dipende dalla facilità del loro reperimento, accesso e gestione. La fig. 1-1 mostra com’è
cambiamo il “consumo” di banda degli utenti di Internet dal 1996 ad oggi; è chiaro che i
contenuti multimediali hanno già assunto un’importanza pari, o addirittura superiore, ad i
tradizionali contenuti testuali.
Fig. 1-1 Uso della banda
In tale contesto assume un’importanza fondamentale la dimensione di tali dati, specie
quando occorre memorizzarli e/o trasmetterli. Ciò rende per nulla semplice una gestione
efficiente delle risorse, sia in ambito locale (quando si ha la possibilità di usare grandi
dispositivi di storage) che in ambito “distribuito”, quando si aggiunge un ulteriore
inconveniente dovuto alla larghezza di banda dei canali di comunicazione, tipicamente
sempre troppo limitata rispetto alle reali esigenze di trasmissione.
La gestione dei contenuti multimediali diventa ancor più problematica se è finalizzata
all’accesso e quindi alla ricerca; ogni utente, anche il meno esperto, già si accorge della
difficoltà, per esempio, di reperire immagini su Web in modo efficiente.
15
Capitolo 1 - Contesto generale
Gli attuali motori di ricerca, infatti, basano la loro esplorazione esclusivamente sulla parte
testuale di un documento, tralasciando ogni contenuto multimediale presente, se non per il
titolo del file che contiene tale informazione. Inoltre, i motori di ricerca si affidano ad
operatori umani per descrivere il contenuto multimediale, mediante parole chiave e
annotazioni. Per due ragioni un tale fatto non è più accettabile: non solo si tratta di un
processo assai costoso e il costo aumenta continuamente all’aumentare dei contenuti; ma,
soprattutto, queste descrizioni sono soggettive e il loro uso è spesso limitato al dominio
dell’applicazione per la quale esse sono state create.
I fatti dimostrano che le ricerche-utente sono basate sul contenuto e sulla sua semantica più
che sulla risorsa stessa. L'utente dei motori di ricerca tradizionali trova quindi difficoltà nello
"adattarsi" al sistema e nel dover traslare le sue richieste (di alto livello) in un set di feature
comprensibili dal motore (e quindi di basso livello).
Viene a mancare, in ultima analisi, quello che si chiama il quality access to content (ossia
la qualità dell'accesso ai contenuti) che, per essere realizzato, implica soluzioni innovative
nell'identificazione dei contenuti e tecniche accurate e “personalizzate” di filtraggio, ricerca,
reperimento e gestione.
1.1.2 Bisogni e prospettive: lo standard MPEG-7
Nello scenario delineato, appare dunque necessario descrivere, indicizzare e annotare, in
maniera automatica e oggettiva, informazioni multimediali, e specialmente dati audiovisuali,
per sostituire o integrare descrizioni manuali e text-based. Tali feature automaticamente
estratte, oltre al vantaggio di essere automaticamente generate, e quindi oggettive,
garantiscono l’indipendenza dal dominio dell’applicazione e la possibilità di essere “native” al
contenuto multimediale stesso. Nell’ambito delle risorse multimediali audiovisive, descrizioni
native potrebbero essere date per descrivere feature come il colore, la forma, la texture
(nell’ambito di immagini) o timbro e melodia (nell’ambito di suoni) permettendo agli utenti di
fare ricerche comparando descrizioni. Ci sono tuttavia, feature esprimibili solo mediante
testo, come ad esempio, l’autore o il titolo di un libro.
Il gruppo di esperti MPEG (“Moving Pictures Expert Group”), afferente all’ISO
(International Standards Organization), ha finora focalizzato la propria attenzione verso
standard di compressione di dati di tipo multimediale, portando con successo all’affermazione
16
Capitolo 1 - Contesto generale
degli standard MPEG-1, MPEG-2 e MPEG-4. Attualmente, MPEG ha spostato le proprie
ricerche verso nuovi orizzonti, riguardanti non più la compressione bensì la descrizione dei
contenuti multimediali, oggi presenti in ogni ambito della comunicazione. Il risultato è il
nuovissimo standard MPEG-7 (la cui definizione formale è Multimedia Content Description
Interface). Il progetto MPEG-7 ha l’obiettivo di specificare uno standard per descrivere i più
disparati tipi di contenuto multimediale: se i suoi predecessori nella famiglia MPEG, ovvero
l’MPEG-1, MPEG-2 e MPEG-4, rappresentano il contenuto stesso ovvero la risorsa
multimediale (“i bit”), l’MPEG-7 rappresenta informazione sul contenuto multimediale (“i bit
sui bit”). Mentre i primi, riproducono il contenuto, l’ultimo lo descrive.
Anche senza MPEG-7, ci sono molti modi per descrivere contenuti multimediali in vari
sistemi di gestione di risorse digitali. Tuttavia, questi sistemi non permettono una ricerca su
archivi differenti e non facilitano lo scambio dei contenuti tra database diversi che usano
differenti sistemi di descrizione. Creare uno standard significa aumentare l’interoperabilità tra
i diversi sistemi e, quindi, dar vita ad un ambiente in cui strumenti di fornitori differenti
possono lavorare assieme creando un’infrastruttura per la gestione trasparente dei contenuti.
I punti di forza dello standard MPEG-7 sono, appunto, l’aumento di interoperabilità e la
prospettiva di offrire prodotti a costi più bassi attraverso la creazione di un mercato
considerevole con nuovi servizi standard-based e un crescente numero di utenti. Lo standard
stimolerà sia i fornitori di contenuti che gli utenti e semplificherà l’intero processo di
identificazione dei contenuti. Affinché le soluzioni proprietarie non prevalgano, ostacolando
in tal modo l’interoperabilità, lo standard dovrà rivelarsi semplice e “robusto”. La sfida di
MPEG-7 è stata quella di confrontare i bisogni con le tecnologie disponibili, o, in altre parole,
di riconciliare ciò che è possibile con ciò che è utile.
Nel prossimo capitolo, verranno affrontate queste stesse problematiche proiettate nella
sfera degli archivi digitali, concentrando in particolare l’attenzione sulle Teche RAI, una
struttura creata ad hoc per gestire i processi di conservazione, catalogazione e digitalizzazione
sia degli archivi che dei programmi quotidianamente prodotti della RAI.
17
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
CAPITOLO 2
Le Teche RAI ed il progetto “Internet TV”
In questo capitolo, si discuteranno gli aspetti fondamentali riguardanti gli archivi
audiovisivi digitali, con un breve sguardo ai maggiori archivi multimediali al mondo e verrà
descritta la realtà del grande archivio multimediale radiotelevisivo italiano, le Teche RAI. In
questo contesto, si illustrerà il progetto “Internet TV” fino ad arrivare alle motivazioni che
hanno spinto a definirne questa terza fase.
2.1
Cos’è un archivio?
Ognuno di noi è potenzialmente il produttore di un archivio, perchè ognuno di noi è
portatore di memoria. Fino ad oggi, nella cultura occidentale, il supporto principale della
memoria è stato il documento cartaceo, che ha costituito una specie di estensione fisica delle
possibilità di "stoccaggio" della memoria individuale e collettiva.
Questo è ciò che ci hanno consegnato i nostri padri, insieme ai monumenti, alle opere
d'arte, agli oggetti materiali che ancora ci circondano. Questo è ciò che ancora oggi noi
produciamo e consegnamo al futuro.
Così nascono gli archivi, depositi documentari caratterizzati dal fatto che ogni documento
è intimamente legato all'altro da una rete di relazioni. Comprendere il linguaggio con cui il
documento si esprime e le relazioni che lo legano agli altri è ciò che ci consente di
comprendere l'archivio nel suo insieme e quindi anche di trovarvi ciò che cerchiamo.
18
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
2.1.1 L’archivio multimediale
Un archivio multimediale è una collezione di risorse su media differenti, ovvero una
raccolta di contenuti conservati su diversi tipi di supporto. In un archivio multimediale
possono trovarsi assime documenti cartacei, pellicole, stampe fotografiche ma anche suoni,
voce, musica e video registrati su supporti che vanno dai dischi in vinile, ad ogni genere di
nastro magnetico, fino ai modermi sistemi digitali quali CD-ROM, DVD-ROM, e Hard-Disk.
Se nel passato la raccolta, la conservazione e la ricerca di tali risorse era difficile, costosa e
poco efficiente, oggi, con l’esplosione della produzione di contenuti audio-visuali e con
l’avvento di Internet, è quasi impossibile immaginare un sistema di archiviazione
“tradizionale”.
2.1.2 L’archivio digitale
Un archivio digitale è un sistema di gestione di risorse digitali (Digital Asset Management
System) il cui compito è quello di gestire dati in formato digitale come testo, immagini, file
audio e video, in modo che questi possano essere riusabili. Un tale sistema mira a
massimizzare il valore delle risorse, permettendone un agevole salvataggio e recupero ed
accrescendone, di conseguenza, l’utilizzo e la protezione. Una risorsa digitale è,
sostanzialmente, un file contrassegnato da informazioni descrittive (i metadati, si veda
l’appendice E). Questo file può contenere sia dati non strutturati - come ad esempio
un’immagine, un clip audio o video - sia dati strutturati - come ad esempio un documento ma ciò che è importante capire è che a nulla servono questi dati, se non sono accompagnati da
altri dati, i metadati appunto, che ne rendono possibile il recupero ed il riutilizzo.
Alcuni esempi di risorse digitali potrebbero essere pubblicazioni, dati scientifici, archivi di
immagini, siti Web, corsi di educazione a distanza (E-learning), filmati e fin anche i database
stessi.
I punti di seguito elencati fornisco una visione generale e riassuntiva di quelli che sono gli
obiettivi della gestione di risorse digitali. Un archivio digitale dovrebbe garantire:
•
il controllo della proprietà (rights management) e della sicurezza;
•
l'autenticità dei documenti;
19
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
•
la riusabilità sia per utilizzo a breve che a lungo termine;
•
una gestione efficace delle risorse per massimizzare efficienza, produttività e
profitto;
•
l’integrità dei dati (requisito essenziale per il salvataggio e la trasmissione);
•
la permanenza dei dati (archiving);
•
una facile ricerca e aggiornamento dei contenuti (querying e updating).
Sulla base di queste considerazioni, il progettista di un sistema di gestione di risorse
digitali, si troverà a dover fronteggiare una serie di scelte progettuali che riguardano
essenzialmente:
•
la scelta e le limitazioni dell’hardware;
•
la gestione della persistenza delle risorse nel data repository;
•
il controllo e la sicurezza delle risorse digitali;
•
la gestione dei diritti;
•
la creazione del contenuto;
•
l’interoperabilità tra librerie digitali.
2.2 Alcuni tra i maggiori archivi multimediali mondiali
Il più alto esempio di archivio multimediale è sicuramente, anche per il valore etico
dell’iniziativa, il VHF, cioè Survivors of the Shoah Virtual History Fondation, nato nel 1994
per iniziativa del regista Steven Spielberg che, dopo aver girato il film “Schindler’s List”, ha
provato l’esigenza di approfondire lo studio della tragedia dell’Olocausto. L’iniziativa si è
proposta di riprendere e preservare le testimonianze degli scampati ai campi di
concentramento. Al momento, l’archivio raccoglie oltre 50.000 testimonianze di persone
provenienti da 57 paesi, in 32 lingue. L’accesso all’incredibile messe di informazioni,
preziosissime da un punto di vista storico e didattico, è possibile solo in parte, ma è allo
studio la creazione di un accesso diretto via Internet anche per i privati.
Il Multimedia Archive di AccuNet AP comprende il materiale raccolto dalla Associated
Press, una mole imponente di fotografie, testi, audio e grafica, divisa in tre grandi database:
20
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
uno dedicato interamente al nord America, uno all’Europa e all’Asia, e uno “internazionale”
riservato al resto del mondo. Sono disponibili circa 800.000 articoli aggiornati, 500.000
audioclip dagli anni ’20 fino a 48 ore fa, e in più illustrazioni, grafici e mappe. L’accesso è
possibile tramite abbonamento.
Per quanto riguarda l’Italia, da segnalare l’ottimo Archivio Storico dell’Istituto Luce, un
organismo nato nel periodo fascista e autore dei famosi “cinegiornali” che anticipavano
l’odierna comunicazione televisiva di tipo informativo. L’Istituto attualmente si occupa di
promozione e distribuzione cinematografica. Sono infatti i cinegiornali, oltre i documentari e i
repertori, le tre categorie nelle quali è possibile la ricerca. Il periodo coperto va dall’epoca dei
Lumière fino ai giorni nostri. Il materiale, solo recentemente informatizzato, comprende 3.500
ore di filmati e oltre 1.000.000 di negativi, preziose testimonianze nel campo della storia,
dello spettacolo e del costume.
2.2.1 Gli archivi multimediali radiotelevisivi
Gli archivi multimediali radiotelevisivi sono, in genere, di proprietà dei maggiori enti
radiotelevisivi mondiali che registrano, catalogano e conservano gran parte della produzione
audiovisiva giornaliera. Solo di recente questi archivi stanno diventando digitali; gran parte
delle risorse è ancora sui tradizionali supporti magnetici. Le fig. 2-1 e 2-2 riassumono il
panorama internazionale riguardo gli archivi radiotelevisivi.
Archivi
BBC (UK)
RAI (ITA)
INA, Istituto
Nazionale
dell’Audiovisivo
(FR)
Risorse
Audio
Risorse Video
750.000
1.500.000 (film
registrazioni
e videocassette)
radio
500.000 ore *
400.000 ore *
500.000 ore di
programmi
600.000 ore di
televisivi e di
programmi
attualità
radio
cinematografica
1.500.000 ore
Sveriges TV
di film stranieri
(SE)
e a maggioranza
non di propria
21
Risorse
Fotografiche
3.000.000 di
fotografie
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
produzione
NAA (NL)
470.000 ore
RTVE (ES)
400.000 ore
SWR (DE)
110.000 ore
HRT (HR)
136.000 ore
YLE (FIN)
140.000 ore
* fine restauro
Fig. 2-1 I maggiori archivi radiotelevisivi europei
Archivi
Risorse Video
ABC News (NY – USA)
1.800.000 titoli
TV Globo (BR)
390.000 ore
National Archive of Canada
150.000 ore
Fig. 2-2 Alcuni archivi radiotelevisivi mondiali
Questi dati sono stati resi noti durante la conferenza della Federazione internazionale degli
archivi televisivi (FIAT), che si è svolta a Firenze dal 26 settembre al 1 ottobre '98.
Un dato interessante discusso durante la conferenza riguarda il tipo di utenti che
consultano gli archivi multimediali; in ordine decrescente, essi appartengono alle seguenti
categorie: giornalisti, programmisti, registi, docenti e studenti universitari, biblioteche, centri
di ricerca, ricercatori individuali, mediateche regionali e privati.
Non è un caso che i giornalisti siano i primi “consumatori” di contenuti multimediali.
Nell’ambito dei progetti internazionali volti alla realizzazione di sistemi di archiviazione e
gestione di metadati multimediali, orientati alla ricerca di informazioni giornalistiche, va
menzionato quello della Vanderbilt University. Si tratta del Television News Archive, ovvero
della più grande collezione al mondo di news televisive. Sono stati classificati oltre 30.000
telegiornali della sera delle maggiori emittenti televisive americane (ABC, CBS, NBC dal
1968 fino ai giorni nostri e CNN) e più di 9.000 ore di servizi speciali. Il materiale presente
nell’archivio può essere identificato attraverso il TV-NewsSearch Database e ne può essere
richiesta una copia per scopi di ricerca o studio.
22
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
2.3
Le Teche RAI
Un esempio di archivio multimediale digitale è proprio quello che si sta costruendo per i
programmi della televisione e della radio pubbliche in Italia, attraverso la realizzazione delle
Teche RAI, un sistema di library digitale basato su un catalogo multimediale creato per gestire
i processi di conservazione, catalogazione e digitalizzazione sia degli archivi “storici”
(ricordiamo che la RAI ha mezzo secolo di storia, con un patrimonio di risorse radiofoniche e
televisive di dimensioni notevoli) che dei programmi quotidianamente prodotti.
La RAI sta compiendo enormi sforzi in questa direzione, per aumentare il valore delle sue
immense risorse, rendendole più fruibili; dal 1997 è, infatti, iniziata una ristrutturazione
completa dei suoi archivi: nonostante il 70% della produzione televisiva RAI fosse
conservato, il problema principale era costituito dalla necessità di documentare tale materiale.
Al termine del lavoro di recupero degli archivi storici della televisione e della radio, le Teche
RAI conterranno circa 500.000 ore di video e 400.000 ore di audio.
2.3.1 Obiettivi e utenti
Si possono individuare due principali obiettivi delle Teche RAI.
•
Le Teche, un immenso archivio di informazioni fruibili per programmisti, autori,
giornalisti, rivoluzionano il modo di accesso alle risorse degli archivi RAI e
diminuiscono drasticamente i tempi di ottenimento delle risorse, ovunque siano
dislocate.
•
Le Teche sono fonti di contenuti non solo per utenti interni all’azienda ma anche
per utenti esterni: l'archivio oggi alimenta in maniera cospicua canali tematici
satellitari (RAI Educational e RAI Sport).
2.3.2 Il patrimonio delle Teche di RAI
La RAI ha un immenso patrimonio di risorse riassunto dalle fig. 2-3, 2-4 e 2-5 (i dati sono
del 2000).
23
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
Consistenza Patrimonio Televisivo
Trasmesso
storico
Trasmesso
quotidiano
TECA centrale – CSS1
(1954/1997)
368.000 ore
TECA nazionale sport (C/O
CPTV MI 1954/1997)
137.000 ore
Programmi, televisione e
sport dal 1998
oltre 52.000 ore
TECHE di sede regionale
oltre 97.000 ore
TG nazionali
15.000 ore
TG regionali
40.000 ore
Grezzo girato
Fig. 2-3 Consistenza patrimonio televisivo RAI
Patrimonio Area Radiofonica Nazionale
Esecuzioni musicali
30.000 ore
Giornale radio
60.000 ore
Programmi
200.000 ore
Dischi d’acquisto
900.000 brani
Copioni
50.000 documenti
Spartiti, partiture, parti
d’orchestra e libretti
120.000 documenti
Archivio
nastri
ARCHIVI
CARTACEI
Fig. 2-4 Patrimonio area radiofonica nazionale
Patrimonio di Biblio-Mediateca RAI
Altri materiali
Fototeca nazionale
Libri
60.000 unità
Riviste
500 raccolte
Giornali quotidiani
50 reccolte
Prodotti editoriali su CDROM
Oltre 150
Archivio RAI
300.000 foto
Archivio ex-radiocorriere
900.000 foto
Fig. 2-5 Patrimonio di biblio-mediateca RAI
Le risorse possono essere logicamente divise in risorse “storiche” e risorse “attuali”.
Risorse storiche
Le risorse storiche sono costituite da tutto il patrimonio radiotelevisivo e fotografico della
RAI fino al 1997. Tali risorse sono distribuite nel territorio nazionale nelle cosiddette Teche
24
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
Centrali, la più grande delle quali è la Teca Master di Roma, e sono formate in gran parte da
materiale in formato cartaceo e da cassette video analogiche. Tutto questo materiale soffre,
quindi, del deterioramento del tempo e necessita dell’intervento umano per le operazioni di
ricerca. Un giornalista, ad esempio, che voglia un estratto di un giornale radio del 1973, deve
recarsi presso una Teca centrale, fare una richiesta scritta all’addetto, il quale o lo cercherà
manualmente oppure affiderà il compito a delle gru robotizzate che individueranno il
contenitore della risorsa richiesta. Ogni teca ha un suo archivio (talvolta anche parziale) in
formato digitale e, tuttavia, ogni teca ha il suo “standard” di descrizione dei dati: si
comprende da tutto ciò come la grande quantità delle risorse è sfruttata con poco rendimento,
essendo poco agevole lo scambio di informazioni tra le teche e i tempi di “attesa” piuttosto
lunghi (può passare anche una settimana dalla richiesta all’ottenimento della risorsa).
Risorse attuali
Le risorse attuali sono costituite da tutta la programmazione trasmessa quotidianamente
delle tre emittenti RAI in formato digitale. Tale materiale è archiviato nella cosiddetta Teca
Fast, la videoteca digitale di RAI, inizialmente progettata per contenere materiale
digitalizzato a media qualità, poi elevata al rango di unica teca digitale per l’accesso “veloce”
a risorse di archivio di elevata qualità. Questa comprende un’architettura di codifica
automatica del materiale televisivo trasmesso in diretta dai tre canali nazionali di RAI, con
una connessione ai “banchi di messa in onda” e al riferimento temporale dell’Istituto Galileo
Ferraris, che, insieme, consentono di riconoscere automaticamente l’inizio di ogni programma
trasmesso (escludendo le pubblicità) e codificare esattamente l’orario di trasmissione.
La Teca Fast ha l'obiettivo di fornire materiale con una qualità utilizzabile per le hard
news, per le produzioni tematiche e ad uso broadband, con funzioni anche di disaster
recovery, di premontaggio, e obiettivi di evoluzione verso il montaggio virtuale dalla stessa
consolle del ricercatore o montatore.
Con i servizi implementati nell’architettura dell’archivio Teca Fast, l’utente connesso al
sistema può visionare o riversare le sequenze audiovisive, con comandi tipici di un
videoregistratore, con le tipiche funzionalità di visualizzazione del time code sincrono con il
filmato, oltre alla visualizzazione delle sequenze video a schermo pieno, con audio di qualità
elevata.
25
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
Un database relazionale SQL puro si interfaccia con il sistema di acquisizione e codifica
della Teca Fast e contiene informazioni sui contenuti della Teca Fast stessa e sullo stato delle
attività (una specie di memoria temporanea del sistema). Il database viene interrogato tramite
un’interfaccia grafica via Web browser. Per effettuare richieste dei contenuti audiovisivi
archiviati, il client deve inviare al DBMS (DataBase Management System) solamente poche
informazioni riguardanti la data di trasmissione sulla rete, l’identificatore della rete di
emittenza, l’orario di inizio trasmissione della sequenza di interesse (un istante qualsiasi della
giornata di trasmissione, con la precisione del secondo) e l’orario di fine della sequenza da
estrarre. Sono queste le informazioni che vanno fornite all’atto della richiesta di materiale sia
di Teca Fast che delle Teche Centrali.
Da questa breve carrellata sulle risorse della RAI, si comprende come il suo intero
patrimonio sia eterogeneo, sia per la differenza dei supporti di archiviazione sia per la non
uniformità delle descrizioni sia, infine, per le diverse modalità di accesso alle risorse.
2.3.3 La gestione delle Teche RAI: il catalogo multimediale e Octopus
Oltre ad una serie di iniziative di recupero dei materiali di archivio, come il riversamento
su supporti video digitali delle vecchie cassette deteriorate, le Teche RAI perseguono
l’obiettivo del completamento di un Catalogo Multimediale. Si tratta di uno strumento per gli
utenti interni (produttori, registi, giornalisti ed, in generale, per tutti coloro che operano nel
settore della produzione) che dovrebbe colmare, almeno in parte, il problema dell’eterogeneità
delle Teche Centrali e Teca Fast e ridurre in maniera significativa i tempi di accesso alle
Teche Centrali, al fine di ottenere la risorsa richiesta in un tempo decisamente minore rispetto
alla procedura tradizionale.
Il Catalogo Multimediale è un sistema che offre funzionalità di ricerca sul palinsesto
televisivo RAI, riportando documentazione testuale e anteprime di immagini, audio e video
estratti in bassa qualità dai materiali televisivi stessi, e si interfaccia opportunamente ad un
sistema informatico che è in grado di effettuare richieste di materiali filmati di archivio, alle
diverse sedi connesse alla rete aziendale. Si tratta di un sistema accessibile on-line, con un
comune browser, dall’interno della rete intranet RAI, per fini produttivi e solo in piccola parte
i suoi contenuti sono resi accessibili al pubblico esterno, attraverso il sito Internet delle Teche.
26
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
Come accennato in precedenza, ogni archivio delle Teche RAI presenta un sistema
informativo interno per la gestione delle risorse e spesso si tratta di sistemi diversi che
adottano modelli di descrizione dei materiali differenti. Con il Catalogo Multimediale e il
sistema Octopus, un motore di ricerca di tutte le risorse RAI che consente anche di delineare e
salvare profili utente, è possibile effettuare ricerche dalla intranet RAI sui contenuti catalogati
dai diversi archivi nazionali.
I contenuti del Catalogo Multimediale e le risorse delle Teche (Fast e Centrali) devono
essere mantenuti “allineati” in modo che l’utente, dopo avere consultato il catalogo ed
individuato i segmenti dei programmi di interesse, possa inviare i codici di identificazione
relativi alla teca appropriata (“ordini di lavoro”) e ricevere una copia del materiale scelto
eliminando completamente la necessità di visionare i materiali.
La figura sottostante riassume tutte le risorse delle Teche RAI:
Fig. 2-6 Il sistema Teche RAI
2.3.4 Nuove possibilità di utilizzo per gli utenti
Si può facilmente intuire ora come le innovazioni dell’archivio si ripercuotano
direttamente sulla produzione, il confezionamento ed il montaggio dei programmi. La regia
può, ad esempio, connettersi in rete informatica direttamente con l'archivio digitale Teca Fast
di RAI e richiedere le risorse, intese come sequenze video, necessarie alla produzione; in
alterntiva con una connessione al Catalogo Multimediale di Teche RAI è possibile attingere a
27
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
documenti testuali, foto digitalizzate, programmi radio e sequenze video codificate in MPEG4. I giornalisti e gli operatori possono visionare i video digitalizzati e archiviati nel database
centrale, che è direttamente interrogabile e accessibile attraverso le postazioni delle redazioni
connesse alla intranet aziendale, e cercare negli archivi tutti i video per i quali sono
disponibili delle descrizioni o una qualche catalogazione, utilizzando un normale Web
browser. Una volta individuati e raccolti i video i giornalisti potranno richiedere una copia
degli originali (per materiali su supporto audiovisivo tradizionale, tipicamente archiviati in
una delle Teche Centrali) o editarli e trasmetterli ad alta qualità televisiva attraverso i video
server disponibili (per materiali presenti nella teca digitale, la Teca Fast stessa).
2.4
Il progetto “Internet TV”
Dai paragrafi precedenti, si evince che, seppur i problemi di interoperabilità e
standardizzazione che affliggono le Teche RAI sono stati affrontati mediante la creazione del
Catalogo Multimediale, questa risulta essere solo una soluzione “tampone” al problema.
Infatti la mancanza di uno standard di descrizione delle risorse ha tre effetti negativi:
•
isola il sistema Teche RAI da altri sistemi esterni;
•
preclude la diffusione delle risorse per grandi numeri di utenti, ad esempio
attraverso un sito Web pubblico;
•
non favorisce i possibili futuri aggiornamenti delle strutture (sia a livello fisico che
logico: una riorganizzazione dei server, ad esempio, comporterebbe una completa
reimplementazione di Octopus).
In questo contesto si colloca il progetto Internet TV nell’ambito dei Vivai d’Impresa presso
il Centro ELIS (si veda l’appendice B). Questo progetto non vuole essere una soluzione
definitiva ai “mali” delle Teche, ma si propone di indicare delle linee guida per poterli
risolvere e degli esempi di soluzioni.
Le basi del progetto “Internet TV” si possono sinteticamente riassumere in quattro punti:
1) interoperabilità con i sistemi preesistenti (requisito necessario se si pensa
all’eterogeneità dell’intero patrimonio RAI);
28
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
2) accesso attraverso interfacce Web (come avviene nella intranet di RAI, non
precludendo possibili distribuzioni per utenti “comuni” su Internet, free o a
pagamento);
3) definizione di un modello dei dati standard per la gestione dei metadati e la ricerca
dei contenuti;
4) collegamento alla risorsa fisica (video streaming su richiesta).
Questo lavoro di tesi costituisce la terza fase di questo progetto che è cominciato alla fine
del 2000.
Il progetto Internet TV fase 1 si è occupato essenzialmente di studiare la struttura delle
Teche, con particolare attenzione a Teca Fast, e di acquisire competenze su MPEG-7, una
delle tecnologie XML-based emergenti nell’ambito della standardizzazione dei contenuti, e
sulle infrastrutture Web, quali ad esempio DBMS nativo XML, motivandone la scelta rispetto
a sistemi tradizionali (DBMS relazionali o a oggetti).
Lo scopo del progetto Internet TV fase 2 è stato la realizzazione di un sistema informativo
(denominato “TV News Archive”) per la gestione di metadati audiovisivi, basato sulle
tecnologie più innovative che si stanno imponendo in questo settore, e finalizzato alla
diffusione di risorse audiovisive in rete geografica.
Così come si può interrogare la Teca Fast specificando pochi parametri (vedi sopra), allo
stesso modo si può interrogare TV News Archive, fornendo la stessa quadrupletta di dati. Le
risorse televisive, su cui utilizzare l'applicazione, sono stati i telegiornali trasmessi dalle tre
reti nazionali, suddivisi in base alle notizie di ciascun servizio. L’interoperabilità con altri
sistemi è stata garantita utilizzando il database XML nativo Tamino, di Software AG, per lo
storage dei contenuti: esso, infatti, implementa funzionalità di accesso e scambio dati con tutti
i principali DBMS, oltre ad avere un DBMS SQL interno.
Le interfacce per l’interrogazione del DBMS, con funzionalità di ricerca avanzate, sono
state create utilizzando funzioni JavaScript ed oggetti ActiveX, svincolando l’utente finale da
conoscenze sullo standard MPEG-7 o sulle tecnologie sottostanti.
29
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
2.5
L’idea del “News Archive System”
News Archive System (http://62.110.204.10:8080/RAI_project/index.html) è il prodotto
della terza fase del progetto “Internet TV”.
Prendendo spunto dai risultati ottenuti nelle precedenti fasi e d’accordo con i responsabili
del progetto, sono stati individuate le seguenti priorità:
1. Studio dei progetti precedenti e definizione dei nuovi obiettivi:
-
porting del prototipo realizzato nella fase 2 verso tecnologie completamente open
source e server-side: architetture Web J2EE (Java 2 Enterprise Edition) e database
XML nativo Apache Xindice;
-
potenziamento delle funzionalità del precedente progetto, con priorità per
l’update dei documenti on-line senza la necessità di dover estrarre il documento dal
database, modificarlo e reinserirlo;
-
completa fruibilità del contenuto tramite definizione di un’architettura che possa,
in futuro, rendere disponibile i contenuti su qualsiasi piattaforma (sia essa un pc
collegato a Internet o un telefono di terza generazione UMTS piuttosto che un
palmare);
-
portabilità dell’applicazione e possibilità di riutilizzo in ambiti diversi da quello
dei telegiornali;
2. Studio delle tecnologie e degli strumenti da utilizzare: XML, lo standard MPEG-7 e
XML-Schema, Apache Xindice, JSP-Servlet-JavaBeans, XSL;
3. Scelte e paradigmi progettuali: l’architettura MVC, il pattern Data Access Object per
la
definizione
di
un
persistance
layer, definizione
dell’architettura
logica
dell’applicazione (divisione tra parte utente, parte “amministratore limitata” e parte
“amministratore completa”), utilizzo di UML (si veda l’appendice F) per la
progettazione e descrizione delle classi da implementare;
4. Implementazione: partendo da un’interfaccia Web-based e general-purpose per
Xindice (essenzialmente la parte amministratore completa), verrà poi realizzata la parte
utente (specifica dell’applicazione) e, infine, la parte amministratore limitata (specifica
dell’applicazione);
30
Capitolo 2 - Le Teche RAI ed il progetto “Internet TV”
5. Definizione dell’interfaccia grafica: scelta di un tema comune per il sito chiaro,
efficace e poco pesante;
6. Valutazione di usabilità del sito, in base ai parametri riguardanti:
-
la chiarezza dell’interfaccia utente del sito;
-
la semplicità dell’interfaccia utente;
-
il livello di standardizzazione dell’interfaccia utente del sito;
-
l’efficacia della veste grafica;
-
la presenza di barre di navigazione;
-
la presenza ed evidenza nella home page di strumenti di ausilio alla navigazione
(indici e mappe);
-
la disponibilità di documentazione di aiuto;
-
le funzioni di diagnosi e risoluzione degli errori;
-
la presenza di versioni del sito in altre lingue.
Questi “passi progettuali” rappresentano la base per gli argomenti trattati nei prossimi
capitoli.
31
Capitolo 3 - Le tecnologie di sviluppo
CAPITOLO 3
Le tecnologie di sviluppo
3.1
XML (eXtensible Markup Language)
XML è un formato di testo semplice e altamente flessibile derivato dall’SGML (Standard
Generalized Markup Language - ISO 8879:1986), lo standard internazionale per creare
documenti intercambiabili e strutturati. Con SGML si può assemblare un documento da fonti
diverse (come ad esempio file di word processor, risultati di query su database, grafici,
videoclip e altri frammenti SGML), definire la struttura del documento mediante una speciale
grammatica chiamata Document Type Definition (DTD), aggiungere elementi di marcatura
per mostrare le unità strutturali di un documento e validare i documenti secondo la DTD
definita.
SGML è molto potente (si pensi che è stato utilizzato per descrivere documenti tra i più
disparati quali antichi manoscritti irlandesi, cartelle cliniche di pazienti o spartiti musicali) ma
troppo pesante per lavorare in ambiente Web: da ciò è nata l’esigenza di costruirne una
versione light che ne mantenesse le funzionalità rimuovendo le caratteristiche inutili. Così è
nato XML.
Come SGML, XML in realtà non è un linguaggio, bensì un metalinguaggio utilizzato per
costruire altri linguaggi. XML è, infatti, usato per creare documenti strutturati e
autodescriventi che siano conformi ad un insieme di regole definite per ogni specifico
linguaggio. XML fornisce la base ad un’ampia varietà di linguaggi industry e disciplinespecific. Esempi ne sono Mathematical Markup Language (MathML), Electronic Business
XML (ebXML), Voice Markup Language (VXML) e anche il linguaggio generato dallo
standard MPEG-7.
32
Capitolo 3 - Le tecnologie di sviluppo
Fig. 3-1 Gerarchia dei linguaggi XML
Originariamente, XML fu ideato per affrontare le sfide della pubblicaziona elettronica su
larga scala e attualmente sta giocando un ruolo sempre più importante nello scambio di
un’ampia varietà di dati sul Web e non solo.
Dall’analisi dell’acronimo, è possibile definire XML in una maniera meno “storica” e più
applicativa. XML è un linguaggio testuale di marcatura (Markup Language) esattamente
come lo è HTML, il quale, anzi, può essere visto come un esempio di una particolare
applicazione SGML o XML stessa. Così come in HTML, i dati si identificano usando dei tag
(i marcatori, appunto, da cui il nome Markup Language) ma, diversamente da HTML, i tag
XML identificano i dati piuttosto che specificare come mostrarli.
Mentre un tag di HTML ci dice qualcosa del tipo “fammi vedere questo dato in grassetto”
(<b>…</b>), un tag XML si comporta come il nome di un campo o di una variabile in un
programma ovvero mette un’etichetta e identifica un dato (<message>…</message>). Poiché
identificare un dato da il senso di cosa significhi il dato stesso (come interpretarlo, cosa farci),
XML è spesso descritto come un meccanismo per specificare la semantica dei dati.
XML è anche eXtensible, differenziandosi anche in questo caso da HTML: con XML,
infatti, si possono scrivere tag “personalizzati” proprio come si può scegliere in un
programma il nome di una variabile, mentre HTML permette solo l’uso di tag definiti nelle
specifiche. La fig. 3-2 mostra un esempio di catalogo di CD in formato XML.
33
Capitolo 3 - Le tecnologie di sviluppo
<?xml version="1.0" encoding="UTF-8"?>
<catalog>
<cd>
<title>The best of U2</title>
<artist>U2</artist>
<price>10.95</price>
</cd>
<cd>
<title>Hail to the thief</title>
<artist>Radiohead</artist>
<price>9.95</price>
</cd>
</catalog>
Fig. 3-2 catalog.xml - un documento XML
Un altro elemento dell’estensibilità di XML è la possibilità di creare un file, chiamato
schema, per descrivere la struttura di un tipo particolare di documento XML. Per esempio, si
può scrivere uno schema per catalog.xml che specifichi quali tag possono essere usati e
dove possono occorrere. Qualsiasi documento XML che rispetti i vincoli stabiliti in uno
schema è detto essere conforme allo schema. Per la descrizione degli schemi, XML eredita da
SGML la grammatica DTD:
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT
<!ELEMENT
<!ELEMENT
<!ELEMENT
<!ELEMENT
catalog (cd+)>
cd (title, artist, price)>
title (#PCDATA)>
artist (#PCDATA)>
price (#PCDATA)>
Fig. 3-3 catalog.dtd - una DTD per catalog.xml
Tuttavia, esistono altri linguaggi di descrizione di schemi più potenti e più flessibili di
DTD come ad esempio XML Schema, su cui si basa MPEG-7 e di cui si parlerà ampiamente
in seguito.
3.1.1 Le caratteristiche di XML
L’importanza ed il consenso di XML sono sempre più in aumento. Le ragioni sono,
ovviamente, molteplici ed in questo paragrafo si cercherà di illustrarne le più significative.
Caratteristica fondamentale è la portabilità di XML. E’ lo schema a dare innanzitutto
portabilità ai dati. Se ad una applicazione viene dato in input sia catalog.xml che il file
catalog.dtd, questa può processare il documento conformemente alle regole specificate
34
Capitolo 3 - Le tecnologie di sviluppo
dalla DTD. Per esempio, data la DTD catalog.dtd, un parser verrà a conoscenza della
struttura e del tipo di contenuto per ogni documento XML basato su quella DTD. Se il parser
è un parser di convalida, potrà decidere se il documento è valido o meno. Inoltre sia i
documenti che gli schemi XML sono scritti in formato testuale e sono quindi leggibili e
“parseable” sia da umani che da software di text-editing. La portabilità è ulteriormente
accentuata dal fatto che un documento XML non include istruzioni di formattazione e quindi
lo stesso dato può essere pubblicato su differenti media.
Sebbene XML permetta la portabilità dei documenti, le parti che interagiscono devono
“mettersi d’accordo” su certe condizioni: per esempio, oltre a convenire di usare XML per
comunicare, due o più applicazioni devono accordarsi sull’insieme di elementi che useranno e
sul loro significato, definendo, eventualmente anche uno “spazio dei nomi” (namespaces) per
evitare collisioni e per rendere univoco e universale il significato dei costrutti del documento.
Come accennato, i file XML sono file di testo e non in formato binario, per questo possono
essere facilmente editati e “debuggati”. XML fornisce la scalabilità necessaria sia per
l’impiego in piccoli file di configurazione che in grandi repository di dati di una azienda.
XML permette l’identificazione dei dati e non la loro presentazione. Si pensi, ad esempio
ad un programma di gestione delle email; poiché differenti parti di informazione vengono
identificate mediante i tag, l’applicazione di lettura potrà estrarre il solo testo della email, un
programma di ricerca potrà cercare messaggi inviati a particolari destinatari ed una rubrica
elettronica potrà rintracciare l’informazione riguardante un indirizzo dal resto del messaggio
in modo semplice e naturale. In sostanza, poiché vengono identificate parti differenti di
informazione, possono essere usate in modi diversi da applicazioni distinte.
Un’altra caratteristica fondamentale è la stilabilità. In applicazioni che necessitano di
presentare i dati, un foglio di stile standard XSL - di cui si parlerà più avanti - permette di
scegliere il modo in cui farlo. XML è completamente style-free; si può quindi usare un foglio
di stile completamente diverso per produrre output in postscript, TEX, PDF o addirittura in un
formato che non si è ancora inventato.
I documenti XML possono essere riusati “inline”, ovvero possono essere composti da
entità separate. Si può fare lo stesso con HTML ma solo linkando documenti. A differenza di
HTML, le entità XML possono essere incluse “in line” in un documento. Questo permette di
modularizzare i documenti senza far ricorso a link. Nonostante ciò anche in XML possono
35
Capitolo 3 - Le tecnologie di sviluppo
essere definiti link così come in HTML, ma con funzionalità aggiuntive (link bidirezionali e
multiple-target).
Un documento XML deve essere ben formato, ovvero ogni tag deve averne uno di chiusura
e tutti i tag devono essere completamente annidati; ciò lo rende non solo altamente strutturato,
ma soprattutto facilmente processabile. A questo si aggiunge anche la presenza di una
struttura gerarchica che non solo ne velocizza la procedura d’accesso (è come consultare un
indice dei contenuti perché si può andare direttamente alla parte di interesse) ma ne aumenta
anche il grado di riorganizzabilità essendo ogni pezzo ben delimitato.
3.1.2 Come usare XML
Con XML è possibile descrivere e strutturare i dati per un programma che li processa.
Uno scenario tipico di questo uso sono le applicazioni client/server, che usano XML per
descrivere i dati che si scambiano. Più in generale, si può dire che XML è potenzialmente la
risposta al problema dello scambio dei dati in tutti i tipi di transazione, purchè le parti si
accordino sullo stesso significato semantico di tutti i marcatori: quindi degli standard comuni
sono necessari e molti sforzi si stanno compiendo in questa direzione (MPEG-7 è solo un
esempio). Nel frattempo sono molto importanti i meccanismi che permettono delle
“traduzioni” dei tag XML.
In XML è possibile generare automaticamente grandi parti di codice che non variano, per
poi focalizzare l’attenzione sulla programmazione che è specifica dell’applicazione. Questa
procedura è nota come binding e resa possibile dalla DTD o dall’XML Schema che
definiscono una struttura dati XML. Inoltre, salvare un componente o una classe da
riutilizzare in XML, ovvero in un formato di testo anziché in binario, permette di fare
modifiche in maniera molto semplice “search and replace”, favorendo il trasferimento di
oggetti tra applicazioni scritte in linguaggi differenti.
Gli usi reali di XML sono continuamente in espansione: per esempio, aziende partner
usano XML per scambiarsi dati tra di loro in maniere nuove e più semplici. Le informazioni
connesse all’e-business come i listini dei prezzi, gli inventari ed i cataloghi e le transazioni
sono rappresentate in XML e trasferite via Internet utilizzando gli standard ed i protocolli
comuni. Ci sono anche degli usi specialistici ed in via di sviluppo di XML, quali il Java
Speech Markup Language (JSML, che definisce un formato di testo standard di marcatura per
36
Capitolo 3 - Le tecnologie di sviluppo
i sintetizzatori vocali) ed il Synchronized Multimedia Integration Language (SMIL, che
consente una semplice authoring di presentazioni interattive audiovisuali consentendo
l'integrazione nei siti Web, di filmati, suoni e testo).
Poiché XML è uno standard industriale, può essere utilizzato nei sistemi senza
preoccuparsi della dipendenza dal produttore. In tale contesto XML si pone come
un’alternativa all’interazione dei sistemi permettendo, invece, un’integrazione a livello dei
dati che rende assai meno forte la relazione tra la propria applicazione e i sistemi e, di
conseguenza, migliore la flessibilità complessiva dell’architettura.
Oltre ai suoi usi come traduttore e scambiatore di dati tra sistemi, XML può essere anche
utilizzato come formato di salvataggio dati nativo in tutte quelle situazioni in cui occorre
gestire repository di documenti e dati che posseggono una struttura gerarchica.
3.2
Le tecnologie e gli standard per XML
Fig. 3-4 Le maggiori tecnologie e standard XML
Ci sono numerosi standard e tecnologie che derivano dall’XML, molti dei quali sono in
continuo sviluppo, il cui intento comune è di rendere XML più standardizzato e più flessibile:
l’adozione di molte è cruciale per il successo di XML e dei suoi standard correlati. Questa
sezione ha la pretesa non di descriverle tutte ma di porre l’attenzione su quelle tecnologie che
sono state usate nel News Archive System.
37
Capitolo 3 - Le tecnologie di sviluppo
3.2.1 Gli XML Schema e la validazione dei documenti XML
Le specifiche che assicurano la validità di documenti XML sono la DTD (definita già nella
specifica XML) e numerose proposte di schemi standard che usano la sintassi XML per
descrivere i criteri di validazione (esempi ne sono XML Schema, Relax-NG del consorzio
OASIS, SOX, Schematron).
DTD - Document Type Definition
Se è vero che la DTD è definita direttamente nella specifica di XML, d’altra parte possono
esistere documenti XML senza DTD. Una DTD specifica i tipi di tag ammissibili in un
documento XML e la loro struttura permettendo, quindi, la validazione di una classe di
documenti XML.
Una DTD può validare la struttura di documenti XML relativamente semplici, ma è
difficile da usare per definire la struttura di documenti di crescente complessità. Ciò è una
conseguenza del fatto che una DTD:
-
non è un file XML ben formato e quindi non può essere “parsed” da un parser XML e
ha bisogno di specifici strumenti per essere creata;
-
ha un supporto limitato per definire i tipi di dato;
-
ha limitate capacità di modellazione non supportando, ad esempio, il riuso di strutture
già definite;
-
non può validare il contenuto di un elemento, ad esempio, assicurando che il testo
racchiuso dentro i tag <date>... </date> sia una data valida.
XML Schema
Date le limitazione della Document Type Definition, il World Wide Web Consortium
(W3C) ha deciso di realizzare un meccanismo di schematizzazione più potente ed efficiente:
XML Schema.
Una XML Schema Definition (XSD) è una definizione di una grammatica XML-based per
documenti XML ed è essa stessa un file XML. Utilizzando XSD, sia i vincoli sui dati che le
relazioni tra le strutture e i namespace degli elementi possono essere specificati in maniera più
38
Capitolo 3 - Le tecnologie di sviluppo
completa che mediante DTD. XML Schema consente una definizione molto precisa sia dei
tipi di dato semplici che complessi e permette ai tipi di ereditare proprietà da altri tipi.
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<xs:element name="artist">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="Radiohead"/>
<xs:enumeration value="U2"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
<xs:element name="catalog">
<xs:complexType>
<xs:sequence>
<xs:element ref="cd" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="cd">
<xs:complexType>
<xs:sequence>
<xs:element ref="title"/>
<xs:element ref="artist"/>
<xs:element ref="price"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="price">
<xs:simpleType>
<xs:restriction base="xs:decimal">
<xs:enumeration value="10.95"/>
<xs:enumeration value="9.95"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
<xs:element name="title" type="xs:string"/>
</xs:schema>
Fig. 3-5 catalog.xsd - un XML Schema per catalog.xml
<catalog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="C:\catalog.xsd">
Fig. 3-6 Riferimento all’ XML Schema in catalog.xml
Tuttavia, XML Schema è molto complesso e necessità si una notevole fase di studio prima
di poter essere utilizzato per creare schemi validi. La fig. 3-5 mostra l’XML Schema relativo
al documento preso in esame nel paragrafo 3.1; il notevole aumento di lunghezza del file XSD
rispetto a quello DTD è già un segnale della maggiore complessità.
39
Capitolo 3 - Le tecnologie di sviluppo
3.2.2 XSLT: una tecnologia per la stilabilità delle risorse XML
Un vantaggio chiave di XML rispetto agli altri formati di dati è la possibilita, fornita da
alcune tecnologie e standard, di convertire un insieme di dati XML dalla originaria forma
testuale in altre forme. Proprio di questo aspetto si occupa l’eXtensible Stylesheet Language
for Transformations (XSLT). XSLT fornisce un ambiente di lavoro per la trasformazione dei
documenti XML.
Un foglio di stile XSL è un insieme di istruzioni di trasformazione per convertire una
(classe di) source XML in un documento obiettivo (target) di output.
Fig. 3-7 Il processo XSLT
Per eseguire una trasformazione XSLT occorre un processore XSLT. Il motore XSLT open
source più popolare è Xalan dell’Apache Software Foundation. Esso è particolarmente adatto
per traduzioni in un singolo passo ed è un trasformatore interprete (a differenza, ad esempio di
XSLTC, che è un compilatore ed è più adatto per trasformazioni che verranno usate più
volte). Un processore XSLT trasforma la struttura ad albero di un documento XML sorgente
attraverso l’associazione di alcuni pattern all’interno del documento sorgente, mediante dei
template nel foglio di stile XSL che si intende applicare. Ad esempio, si può trasformare
catalog.xml in HTML, al fine di pubblicare le informazioni in esso contenute, creando un
foglio di stile XSL che “immerga” i dati recuperati dal file XML nel codice HTML. La figura
seguente mostra il foglio di stile XSL per catalog.xml.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
40
version="1.0"
Capitolo 3 - Le tecnologie di sviluppo
<xsl:template match="/">
<html>
<head><title>My Catalog</title></head>
<body>
<h1>Products In My Music Shop</h1>
<table border="1" cellspacing="2" bgcolor="#e6e6e6">
<tr>
<td><b>Title</b></td>
<td><b>Artist</b></td>
<td><b>Price</b></td>
</tr>
<xsl:for-each select="//cd" >
<tr>
<td><xsl:value-of select="./title" /></td>
<td><xsl:value-of select="./artist" /> </td>
<td><xsl:value-of select="./price" /> Euros </td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Fig. 3-8 catalog.xsl – un foglio di stile XSL per catalog.xml
<?xml-stylesheet type="text/xsl" href="C:\catalog.xsl"?>
Fig. 3-9 Riferimento all’XSL appropriato in catalog.xml
La fig. 3-10 mostra il risultato ottenuto applicando il foglio di stile catalog.xsl al
documento catalog.xml .
Fig. 3-10 Pagina HTML ottenuta dalla trasformazione XSLT di catalog.xml
41
Capitolo 3 - Le tecnologie di sviluppo
Le capacità di XSLT non sono tuttavia limitate a trasformazioni da testo puro ad HTML
ma anche verso altri formati quali PDF, PostScript, CD-ROM e dispositivi quali video
monitor, terminali WAP e UMTS e qualsiasi altro tipo di interfaccia multimediale. Per tale
ragione, la versione raccomandata di XSL 1.0 specifica anche un set di oggetti di
formattazione (XSL Formatting Objects).
Come mostrato in fig. 3-11 i Formatting Object sono istruzioni che definiscono il layout e
la presentazione delle informazioni e sono molto utili per i mezzi di stampa e per il lavoro di
design e rappresentano una forma intermedia tra i documenti XML sorgenti indipendenti dal
mezzo e ed il formato od il dispositivo di output scelto.
Fig. 3-11 Il processo di trasformazione XSLT attraverso i Formattino Object
3.2.3 Il retriving dei dati in XML: XPath
Salvare e recuperare i dati in formato XML è l’argomento di molto lavoro in corso
riguardante XML. Il bisogno di tecnologie per il salvataggio e il recupero si è risolto nella
creazione di un gran numero di specifiche assai correlate tra loro. Una tra queste è XPath
(XSL Path Language).
XPath è un linguaggio per indirizzare strutture XML ed è utilizzato da altri standard XML,
tra i quali XSLT, XPointer e XQuery. XPath modella un documento XML come un albero di
nodi con le opportune relazioni di parentela; tali nodi sono di tipi differenti: nodo radice,
elemento, nodo testuale, attributo, commento, namespace e istruzione di processing. XPath
definisce una sintassi per creare espressioni, che sono composte da una serie di location step
separati da una slash (/) che individuano un insieme di nodi in un documento XML. Ad
esempio, una slash (/) è una semplice espressione XPath. Come si può vedere
catalog.xsl
in
quest’espressione rappresenta il nodo radice di un documento XML. Le
espressioni XPath possono rappresentare, oltre a un insieme di nodi, un valore booleano, un
numero o una stringa e possono partire dall’elemento radice o essere relative ad una posizione
42
Capitolo 3 - Le tecnologie di sviluppo
specifica in un documento. Per il nostro catalogo di cd, il seguente XPath rappresenta tutti i
nodi cd nel catalogo:
// cd
XPath ha, inoltre, un insieme predefinito di funzioni che permette di sviluppare espressioni
molto complesse:
/cd[title ='The best Of U2' and contains(artist, "2")]
essa seleziona tutti gli elementi cd che contengono un elemento title il cui contenuto sia
“The best Of U2” e che contengono un elemento artist il cui valore contiene “2”; in
questo caso quest’espressione indirizza il seguente elemento di catalog.xml
<cd>
<title>The best of U2</title>
<artist>U2</artist>
<price>10.95</price>
</cd>
Fig. 3-12 Risultato di un’esecuzione di un’espressione XPath complessa
XPath è uno degli strumenti più ampiamente usato in News Archive System specie, com’è
ovvio, nelle operazioni di query.
3.3
Le tecnologie Java-based
Java fu concepito da James Gosling, Patrick Naughton, Chris Warth, Ed Frank e Mike
Sheridan presso Sun Microsystems, nel 1991. Furono necessari 18 mesi per sviluppare la
prima versione funzionante. All’inizio, questo linguaggio venne battezzato Oak, ma nel 1995
il nome venne modificato in Java. Fatto piuttosto sorprendente, la spinta originale non
provenne da Internet. Infatti, la motivazione principale era la necessità di un linguaggio
indipendente dalla piattaforma che potesse essere utilizzato per creare software da incorporare
in vari dispositivi di elettronica di consumo, come i forni a microonde e i telecomandi.
Il problema del C e del C++ (e della maggior parte degli altri linguaggi) è che sono
concepiti per essere compilati per una destinazione specifica. Sebbene sia possibile compilare
un programma C++ per qualsiasi tipo di CPU, per riuscirci è necessario un intero compilatore
C++ mirato per quella specifica CPU. Ma i compilatori sono costosi e la loro creazione
richiede molto tempo. Era necessaria una soluzione più semplice e più vantaggiosa dal punto
di vista economico.
43
Capitolo 3 - Le tecnologie di sviluppo
Gosling & Co. incominciarono a lavorare su un linguaggio portabile e sicuro, indipendente
dalla piattaforma, che potesse essere utilizzato per produrre un codice che girasse su una vasta
gamma di CPU sotto diversi ambienti. Alla fine questo sforzo condusse alla creazione di Java.
La chiave che consente a Java di risolvere sia i problemi di sicurezza, sia quelli di
portabilità è il fatto che l’output di un compilatore Java non è un codice eseguibile. Si tratta,
invece, di un bytecode, un insieme altamente ottimizzato di istruzioni concepite per essere
eseguite da una macchina virtuale emulata dal sistema runtime di Java (la Java Virtual
Machine): la JVM traduce le istruzioni dei codici binari indipendenti dalla piattaforma
generati dal compilatore Java, in istruzioni eseguibili dalla macchina locale. In altre parole, il
sistema runtime è un interprete del bytecode.
Dato che i programmi Java vengono interpretati piuttosto che compilati, come avviene per
esempio per programmi C++ compilati su un codice eseguibile, è molto più semplice eseguirli
in una vasta gamma di ambienti.
Il fatto che Java venga interpretato contribuisce anche a renderlo sicuro. Dato che
l’esecuzione di ogni programma Java avviene sotto il controllo del sistema runtime, questo
può contenere il programma e impedire che generi effetti indesiderati all’esterno del sistema.
La natura di linguaggio a oggetti di Java consente di sviluppare applicazioni utilizzando
oggetti concettuali piuttosto che procedure e funzioni. La sintassi object oriented di Java
supporta la creazione di oggetti concettuali, il che consente al programmatore di scrivere
codice stabile e riutilizzabile (“write once, run everywhere”), utilizzando il paradigma object
oriented secondo il quale appunto il programma è scomposto in concetti piuttosto che
funzioni o procedure.
La sua stretta parentela con il linguaggio C a livello sintattico fa sì che un programmatore
che abbia già fatto esperienza con linguaggi come C, C++, Perl sia facilitato
nell’apprendimento di Java.
Il bytecode di Java è prodotto dal compilatore e ha bisogno di uno strato di software, la
Java Virtual Machine, per essere eseguito. La JVM è un programma scritto mediante un
qualunque linguaggio di programmazione dipendente dalla piattaforma, e traduce le istruzioni
Java, nella forma di bytecode, in istruzioni native del processore locale.
Non essendo il bytecode legato ad una particolare architettura hardware, questo fa sì che
per trasferire un’applicazione Java da una piattaforma ad un’altra è necessario solamente che
44
Capitolo 3 - Le tecnologie di sviluppo
la nuova piattaforma sia dotata di un’apposita JVM. In presenza di un interprete,
un’applicazione Java potrà essere eseguita su qualunque piattaforma senza necessità di essere
ricompilata.
Fig. 3-13 Architettura di un’applicazione Java
Un ultimo aspetto interessante della tecnologia Java è quello legato agli sviluppi che la
tecnologia sta avendo. Negli ultimi anni molti produttori di hardware anno iniziato a rilasciare
processori in grado di eseguire direttamente il bytecode di Java a livello di istruzioni
macchina senza l’uso di una virtual machine.
3.3.1 Java e XML
XML rende i dati portabili e la piattaforma Java rende portabile il codice. E' difficile
immaginare due tecnologie più complementari: Java permette di scrivere programmi portabili
praticamente su ogni tipo di architettura, XML permette di fare la stessa cosa con i dati,
offrendo un metodo semplice e indipendente dalla piattaforma di rappresentare i contenuti. Lo
sviluppo e la diffusione di questi due strumenti apre la strada a nuovi scenari nel mondo dei
servizi Internet sia per quanto riguarda le applicazioni relative allo scambio di dati in rete, sia
per quanto riguarda le applicazioni più propriamente Web (presentazione dei contenuti e
management di siti).
La comunità Java sta attivamente partecipando e implementando le specifiche di molte
delle tecnologie discusse nel paragrafo 3.2. In più, Java è spesso il primo linguaggio di
45
Capitolo 3 - Le tecnologie di sviluppo
programmazione a implementare tali tecnologie emergenti. Ciò è dovuto alla natura
complementare del codice Java e dei dati XML, entrambi indipendenti dalla piattaforma.
Numerosi gruppi hanno implementato funzionalità XML in Java (meglio note come API,
Application Program Interface) in modi e tempi differenti, e tale fatto ha portato alla
proliferazione di API sovrapposte o incompatibili. Per risolvere tale questione e rendere lo
sviluppo di applicazioni XML in Java più semplice, la Sun Microsystems sta coordinando lo
sviluppo delle API Java per XML attraverso il Java Community Process (JCP). Sotto tale
processo, la comunità di sviluppatori Java sta standardizzando e semplificando le numerose
API Java per XML.
Le Java API for XML (JAX) sono attualmente una famiglia di specifihe di API correlate tra
loro tra le quali JAXP, Java API for XML Parsing and Processing, è la collezione si strumenti
software Java per XML utilizzata nel News Archive System.
3.3.2 Le Java Servlet
Esistono diverse tecnologie per sviluppare applicazioni Web e per la creazione di contenuti
dinamici, che vanno dalla convenzionale CGI (Common Gateway Interface) a soluzioni
proprietarie come ISAPI di Microsoft e NSAPI di Netscape, alla tecnologia Active Server
Pages (ASP) di Microsoft, fino alle tecnologie Java Servlet e Java Server Pages (JSP)
proposte da Sun Microsystems.
Fig. 3-14 Architetture Web dinamiche servlet-JSP-based
Le Java Servlet sono semplici programmi Java, indipendenti dalla piattaforma, che girano
in un Web Server, svolgendo il ruolo di middle-layer tra una richiesta proveniente da un Web
46
Capitolo 3 - Le tecnologie di sviluppo
browser, o un altro client HTTP, e i database o applicazioni sul server HTTP. Il Web Server
di fatto mette a disposizione delle servlet un container (o servlet engine), un’estensione del
Web server, che si occuperà sia della gestione del loro ciclo di vita e dell’ambiente all’interno
del quale le servlet girano, sia dei servizi di sicurezza. Le servlet interagiscono con i client
attraverso un paradigma request/response implementato dal servlet container, che è quindi
responsabile del passaggio dei dati dal client verso le servlet e, viceversa, del ritorno al client
dei dati prodotti dall’esecuzione delle servlet.
In estrema sintesi, il compito di una servlet è quello di:
•
leggere i dati inviati dagli utenti: tali dati sono usualmente immessi in una form
HTML, ma possono provenire direttamente dal Web browser, da altri client HTTP
o da un applet Java;
•
cercare altre informazioni che possono essere racchiuse nella richiesta HTTP: ad
esempio alcuni dettagli sulle capacità del browser, eventuali cookies, l’host name
del client e così via;
•
generare il risultato: tale processo può richiedere lo scambio di informazioni con
un database, l’invocazione di un’applicazione correlata o la diretta elaborazione
della risposta;
•
formattare il risultato all’interno di un documento: nella maggior parte dei casi,
questo implica l’“immersione” delle informazioni all’interno di una pagina HTML;
•
impostare i parametri di risposta HTTP appropriati: ciò vuol dire specificare al
Web browser che tipo di documento verrà restituito (HTML, ad esempio), settare i
cookies e i parametri di caching e altri compiti simili;
•
inviare il nuovo documento al client: questo può essere restituito in formato di testo
(HTML), formato binario (un’immagine GIF, ad esempio) o anche in un formato
compresso (gzip). Molte richieste dei client possono essere soddisfatte restituendo
documenti precostruiti, e tali richieste potrebbero essere soddisfatte dai server
senza invocare servlet. In molti casi, tuttavia, un risultato statico non è sufficiente e
si deve generare dinamicamente una pagina a seconda della richiesta. Sono
numeroso le circostanze per le quali una pagina Web deve essere costruita “al
volo”, come ad esempio quando:
47
Capitolo 3 - Le tecnologie di sviluppo
-
la pagina Web è basata sui dati che il client ha inviato. Un esempio ne
sono le pagine restituite dai motori di ricerca e le pagine di conferma di un
ordine di un negozio on-line, entrambi specifiche di una particolare richiesta
di un cliente;
-
la pagina Web è costruita su dati che cambiano frequentemente. Un
esempio ne sono le previsioni del tempo, o le novità principali di un
giornale on-line;
-
la pagina Web usa informazioni di database aziendali o di altre risorse
server-side. Un esempio potrebbe essere un sito di e-commerce che usa una
servlet per costruire una pagina Web, nella quale viene presentata una lista
dei prodotti disponibili.
La fig. 5-2 raffigura una banale servlet in cui vengono sottolineati, in grassetto, i suoi
compiti specifici.
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
public class MyServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse
response)
throws IOException, ServletException
{
response.setContentType(“text/html”);
PrintWriter out = response.getWriter();
// Cercare altre informazioni nella richiesta HTTP: la sessione
corrente
HttpSession session = request.getSession(true);
// Lettura dei dati inviati dall’utente
String customerName = (String) session.getAttribute(“name”);
String productName = (String) request.getParameter(“product”);
// Elaborazione, formattazione e restituzione del risultato al client
out.println(“<html>”);
out.println(“<body>”);
out.println(“<head>”);
out.println(“<title>Servlet Example</title>”);
out.println(“</head>”);
out.println(“<body>”);
out.println(“ You are “ + customerName);
out.println(“ You have selected this product : “ + productName);
out.println(“</body>”);
out.println(“</html>”);
}}
Fig. 3-15 Una servlet di esempio
48
Capitolo 3 - Le tecnologie di sviluppo
In linea di principio, l’uso delle servlet non è ristretto al Web o agli Application Server che
gestiscono richieste HTTP, ma esse possono anche essere utilizzate anche da altri tipi di
server: ad esempio all’interno di server FTP o di posta per estendere le loro funzionalità.
Inoltre, le servlet permettono la distribuzione di contenuti dinamici in un modo portabile ed
indipendente dalla piattaforma e dal Web server. Un’applicazione browser-based che chiama
servlet non ha bisogno di supportare Java dato che l’output di una servlet può essere HTML o
XML o qualsiasi altro tipo di contenuto e non avrà nulla a che fare con Java. In passato una
grossa limitazione alla diffusione delle servlet era data dal fatto che l’unico Web server in
grado di eseguirli era Java Web Server. In seguito sono stati sviluppati diversi servlet engine
che hanno la possibilità di collegarsi ai Web server più comuni rendendoli compatibili con le
servlet.
3.3.3 Le JavaServer Pages (JSP)
JSP è la tecnologia, basata sul linguaggio di programmazione Java, per la realizzazione di
applicazioni Web in grado di gestire contenuti dinamici in modo semplice, ma con grande
potenza e flessibilità. L’idea che sta alla base di questa tecnologia è quella di combinare il
tradizionale linguaggio HTML (che si occupa di presentare i dati) con un linguaggio di
programmazione (per accedere ai dati) interpretato da un engine, che è costituito, nel caso
della tecnologia JSP, dal Web Server o dall’Application Server.
La caratteristica che differenzia sostanzialmente le pagine Web statiche (scritte in HTML)
da quelle dinamiche, come le JavaServer Pages, consiste nel fatto che le prime sono
semplicemente servite dal Web Server, mentre le seconde sono prima elaborate da un engine
che interpreta il codice e lo esegue (essenzialmente il container “traduce” la JSP in una
servlet). Quindi JSP è una tecnologia lato server in senso stretto, che non coinvolge il client,
che è costituito dal solo browser.
Per eseguire una JavaServer Page è richiesta la presenza di un Web Server in grado di
supportare tale tecnologia; in alternativa, si può ricorrere al meccanismo dell’Application
Server, che permette di estendere le funzionalità del Web Server: quando un client richiede
una risorsa non gestibile direttamente dal server (ad esempio una pagina JSP), attraverso
chiamate di sistema tale richiesta viene passata all’Application Server (vedi fig. 3-16). Questo
meccanismo è adottato sempre più diffusamente, dato che non obbliga a cambiare il software
49
Capitolo 3 - Le tecnologie di sviluppo
dal lato server, ma permette di agire su un livello che sta sopra il Web Server, consentendo in
tal modo una maggiore flessibilità e modularità.
Fig. 3-16 Application e WebServer
Sia servlet sia pagine JSP descrivono come processare una richiesta (da un client HTTP)
per creare una risposta. Tuttavia, mentre le servlet sono espresse in Java, le pagine JSP sono
documenti testuali che includono una combinazione di HTML, tag JSP e codice Java.
Sebbene entrambe possano essere usate per risolvere gli stessi problemi, ciascuna è destinata
a compiere compiti specifici.
La tecnologia Servlet è stata sviluppata come meccanismo per accettare richieste da
browser, reperire dati da database o altre fonti nel back-end, realizzare la logica applicativa
sui dati (specialmente nei casi in cui la servlet accede direttamente al database), e formattare
tali dati per la presentazione nel browser (di solito in HTML). Una servlet usa istruzioni di
print per inviare codice HTML al browser. Incorporare HTML in istruzioni print causa due
problemi. Primo, i Web designer non possono prevedere il look di una pagina HTML fino
all’esecuzione. Secondo, quando i dati od il loro formato di visualizzazione cambiano,
localizzare le sessioni appropriate di codice nel servlet è molto difficile. In aggiunta, quando
la logica di presentazione ed il contenuto sono mischiati, i cambiamenti nel contenuto
richiedono che la servlet sia ricompilato e ricaricata sul Web server.
Le pagine JSP possono accedere ai dati, anche senza utilizzare codice Java, attraverso un
meccanismo per specificare un mapping da un componente JavaBeans (di cui parleremo a
breve) al formato di presentazione HTML (o XML). In tal modo, si riduce la conoscenza
richiesta dal Web designer di Java e si realizza ancor meglio la separazione della
presentazione dei dati dal loro contenuto. Dato che le pagine JSP sono text-based, un Web
designer può usare strumenti di sviluppo grafici per creare e visualizzare il loro contenuto.
50
Capitolo 3 - Le tecnologie di sviluppo
Come le servlet, la tecnologia JSP è un modo efficiente di fornire contenuti dinamici in
maniera portabile e platform o application-independent.
Fig. 3-17 Separazione dei ruoli
In estrema sintesi si può dire che JSP fornisce un modo facile per sviluppare contenuti
dinamici servlet-based, con il vantaggio aggiuntivo di separare il contenuto dalla
presentazione, permettendo la suddivisione dei ruoli per specifiche competenze. I vantaggi di
questo disaccoppiamento si ripercuotono anche sulla modalità di sviluppo e sulla
manutenzione dell’applicazione, permettendo a team di lavoro differenti di lavorare in
maniera indipendente ma parallela.
3.3.4 I JavaBeans
Le pagine JSP sono estensioni delle servlet Java e di conseguenza consentono di ottenere
tutti i risultati di questi ultimi. Come accennato, lo svantaggio delle servlet è rappresentato
dalla difficoltà di manutenzione del codice HTML delle applicazioni eccessivamente
complesse (e quindi con una gran mole di codice). Anche per quanto riguarda JSP, includere
troppo codice all’interno di una pagina, comporta una ridotta leggibilità dello stesso ed una
non netta separazione fra la parte di presentazione dei contenuti e la parte di creazione degli
stessi.
51
Capitolo 3 - Le tecnologie di sviluppo
La soluzione a questi problemi è rappresentata dai JavaBeans (o bean), componenti
software contenenti una classe Java, che possono venire inclusi in una pagina JSP,
permettendo quindi un ottimo incapsulamento del codice, peraltro riutilizzabile. La sezione di
codice puro, sostituito da richiami ai metodi delle classi incluse, sarà pressoché invisibile al
Web designer. Utilizzando i bean si riesce a rimuovere gran parte del codice da una pagina
JSP. Il risultato è una pagina più semplice sia da leggere che da mantenere. La tecnologia
JavaBeans è quindi preziosa per costruire componenti portabili e riusabili che possono essere
usati con la tecnologia JSP. Un JavaBeans è un componente software riutilizzabile (classe
Java) che può essere manipolato visualmente in un tool di sviluppo software. Il suo modello è
molto semplice, ma potente e le sue parti fondamentali sono:
•
metodi, ossia funzioni che permettono di accedere alle istanze del bean per ottenere
e/o manipolare informazioni;
•
proprietà di lettura e/o scrittura che rappresentano gli attributi dell'oggetto;
•
eventi che un bean può segnalare o ricevere dal mondo esterno (ad esempio il click
su un bottone).
52
Capitolo 4 - Il database di News Archive System
CAPITOLO 4
Il database di News Archive System
4.1
I legami tra XML ed i database
Una delle prime questioni sollevate in merito ad XML ed ai database riguarda, in sostanza,
una domanda che gli esperti si sono posti sul fatto che i documenti XML siano essi stessi un
database. Un documento XML è un database solo nel senso più “stretto” del termine, ovvero
esso è una collezione di dati e questo non lo rende differente da ogni altro file. Tuttavia, può
essere considerato come un “formato di database”, ed in tal senso, XML ha alcuni vantaggi.
Per esempio è autodescrittivo (la marcatura descrive la struttura e i nomi dei tipi dei dati,
sebbene non la semantica), è portabile (utilizza la codifica Unicode), è può descrivere i dati in
strutture ad albero o a grafo. Tuttavia ha anche degli svantaggi: ad esempio, è ridondante e
l’accesso ai dati è lento per la necessità di parsing.
Una domanda più utile da porsi è se XML, e le tecnologie ad esso correlate, costituiscono
un database nel senso “lasco” del termine, ovvero un DataBase Management System
(DBMS). XML, da un lato, fornisce molte delle funzionalità che si possono trovare in un
DBMS: la possibilità di salvataggio e memorizzazione dei dati (documenti XML), di
definizione di schemi (DTD, XML schema), di utilizzo di linguaggi di query (XQuery,
XPath, XQL, XML-QL, QUILT) e così via. D’altro canto, un file XML è carente in altre
funzionalità che invece sono presenti nei database reali: storage efficiente, indicizzazione,
sicurezza, integrità dei dati e delle transazioni, accesso multiutente, trigger, query attraverso
documenti multipli.
Così, mentre può essere possibile usare un documento XML come database in ambienti
con un piccolo quantitativo di dati, pochi utenti e modesti requisiti di performance, questo può
risultare catastrofico in molti ambienti di produzione che hanno molti utenti, precisi requisiti
di integrità dei dati e il bisogno di prestazioni elevate.
53
Capitolo 4 - Il database di News Archive System
Un buon esempio del tipo di database per il quale un documento XML è adatto sono i file
di configurazione di un’applicazione. E’ molto più facile definire un piccolo linguaggio XML
e scrivere un’applicazione per interpretare tale linguaggio, che scrivere un parser per file
delimitati, ad esempio, da virgole. Inoltre, XML consente di avere entry annidate, cosa molto
difficile da ottenere con file delimitati da virgole.
Esempi di insiemi di dati più sofisticati, per i quali un documento XML potrebbe essere
adatto come database, sono liste di contatti personali (nomi, numeri telefonici, indirizzi), la
lista dei siti preferiti del browser o le descrizioni di file MP3. Tuttavia, dato il basso costo e la
facilità di utilizzo di database come dBASE e Access, sono poco motivabili le ragioni che
giustificherebbero l’uso di un documento XML come database. L’unico vero vantaggio di
XML è la portabilità dei dati, anche se questo non è un vantaggio reale, data l’ampia
disponibilità di tool atti a convertire i dati prelevati da un comune database relazionale in
documenti XML (DBMS XML-enabled).
4.2
La scelta del tipo di database
A seconda che si abbiano dati da pubblicare o si voglia un repository per memorizzare le
pagine di un sito o si debba realizzare un’applicazione di e-commerce in cui XML è usato
come formato di trasporto e scambio di dati, la struttura dell’architettura e la scelta del tipo di
database sarà diversa.
Ad esempio, si supponga di avere un’applicazione di e-commerce che usi XML come
mezzo di trasporto dei dati. Tali dati hanno una struttura molto regolare (clienti, ordini e
fornitori, ad esempio) e sono usati anche da applicazioni non XML. In tal caso, l’utilizzo di un
database relazionale e un modulo che operi il mapping tra XML e il database è sicuramente
una scelta appropriata.
Si supponga, invece, di avere un sito Web costruito su documenti che rappresentano, ad
esempio, dei telegiornali con informazioni anche sul loro contenuto semantico, proprio come
accade nel News Archive System. In questo caso, non si vuole solo gestire il sito, ma anche
fornire un modo agli utenti di ricercare i contenuti. Questi documenti, non hanno una struttura
lineare, ma gerarchica, ed è fondamentale conservarne la struttura. In questo contesto può
risultare più adatto l’utilizzo di un database XML e, quindi, di un content management system
(un’applicazione dedicata a gestire documenti, costruita sopra un database XML nativo).
54
Capitolo 4 - Il database di News Archive System
. Tale scelta consente di mantenere la struttura fisica del documento, di supportare le
transazioni a livello di documento e eseguire query in un linguaggio di query XML.
4.2.1 La differenza tra dati e documenti
Uno dei fattori principali nella scelta di un database riguarda l’uso che si intende farne in
merito alle entità da memorizzare: dati o documenti. Le scelte saranno diverse a seconda che
XML sia usato solo come mezzo di trasporto per i dati tra il database e un’applicazione
(anche non XML), oppure venga adoperato in modo “integrale”. E’ fondamentale, quindi,
comprendere la differenza che c’è tra i documenti orientati ai dati (data-centric) e quelli
orientati ai documenti (document-centric).
I documenti data-centric
Si tratta, come detto, di documenti che usano XML come mezzo di trasporto per i dati.
Sono progettati per essere consumati da elaboratori piuttosto che da umani e il fatto che sia
usato XML è spesso superfluo. Questo implica che ci siano per l’applicazione, o per il
database, momenti in cui non è importante che i dati siano memorizzati in documenti XML.
Esempi di documenti data-centric sono gli ordini di vendita di un negozio, le tabelle dei voli
in un aeroporto o l’inventario delle provviste di un supermercato.
I documenti data-centric sono caratterizzati da una struttura piuttosto regolare, una
granularità dei dati piuttosto fine (il che significa che la più piccola unità di dati significativa è
a livello di elementi testuali o di attributi) e da elementi con contenuto raramente misto.
L’ordine con cui i figli di un elemento occorrono è generalmente poco significativo, eccetto
nella validazione del documento.
I documenti con numerose parti testuali sono, in genere, data-centric. Ad esempio, si
consideri una pagina di Amazon.com che mostri informazioni riguardo ad un libro. Sebbene il
contenuto delle pagine sia più che altro testuale, la struttura di tale testo è altamente regolare,
molto di essa è comune a tutte le pagine che descrivono libri, e ogni pezzo di testo specifico
della pagina è limitato in grandezza. Così la pagina potrebbe esser costruita da un semplice
documento XML data-centric, che contenga informazioni su un libro singolo e che sia
recuperato da un database, e da un foglio di stile XSL che aggiunga le informazioni che sono
55
Capitolo 4 - Il database di News Archive System
comuni a tutte le pagine che descrivono libri. In generale, ogni sito Web che costruisce
dinamicamente HTML mediante riempimento di template con i dati di un database può, con
molta probabilità, venir sostituito da una serie di documenti XML data-centric e da uno o più
fogli di stile XSL.
I documenti document-centric
Si tratta, solitamente, di documenti destinati ad essere “consumati” da umani. Esempi
possono essere libri, email e manuali di applicazioni. Sono caratterizzati da una struttura
piuttosto irregolare, da una granularità grossa dei dati (l’unità di dati indipendente più piccola
può essere a livello di un elemento con contenuto misto o l’intero documento stesso) e da
molto contenuto misto. L’ordine con cui i figli di un elemento compaiono è quasi sempre
significativo.
In pratica, la distinzione tra documenti data-centric e document-centric non sempre è
chiara. Ad esempio, un documento come una fattura, di sua natura data-centric, potrebbe
contenere dati a grana grossa e poco strutturati, come una descrizione; analogamente, un
manuale utente di un’applicazione, di sua natura document-centric, potrebbe contenere dati
(spesso, anzi metadati) a grana fine come il nome dell’autore e la data di pubblicazione.
Malgrado questo, caratterizzare i propri documenti come data-centric o document-centric è
di estrema importanza per decidere che tipo di database usare. Come regola generale, i dati
andrebbero memorizzati in un database tradizionale (XML-enabled), in strutture tabellari,
mentre i documenti andrebbero memorizzati in un database XML nativo (ovvero realizzato
essenzialmente per salvare documenti XML) o in un content management system.
Tali regole non sono assolute. I dati, specialmente quelli semi-strutturati, possono essere
salvati in database XML nativi e i documenti possono essere salvati in database tradizionali
quando sono richieste poche caratteristiche specifiche di XML. Inoltre, i confini tra database
tradizionali e XML nativi non sono più ben definiti, dal momento che, ad esempio, i database
relazionali forniscono funzionalità XML aggiuntive e i database XML nativi supportano il
salvataggio di frammenti di un documento in database esterni (di solito relazionali).
56
Capitolo 4 - Il database di News Archive System
4.3
I database XML nativi
Il termine “database XML nativo” è stato utilizzato nella campagna pubblicitaria di
Tamino, il database XML nativo della Software AG e, per il successo di tale campagna, il
termine è diventato di uso comune tra le compagnie che sviluppano prodotti simili. Tuttavia,
essendo un termine di marketing, non ha mai avuto una definizione tecnica formale.
I membri della mailing list di XML:DB, un’organizzazione punto di riferimento
nell’universo dei database XML, hanno coniato questa difinizione:
“un database XML nativo:
•
definisce un modello logico per un documento XML (non per i dati contenuti nel
documento stesso) e memorizza e recupera dati seguendo tale modello;
•
ha come unità logica fondamentale di memorizzazione un documento XML, proprio
come una riga di una tabella lo è per un database relazionale;
•
non deve avere nessun particolare modello di memorizzazione fisico. Ad esempio,
può essere costruito su un database relazionale, object-oriented o a struttura
gerarchica oppure usare un formato proprietario di memorizzazione come file
indicizzati o compressi.
I database XML nativi sono pensati principalmente per il salvataggio di documenti XML.
Come gli altri database, supportano caratteristiche quali transazioni, sicurezza, accesso
multiutente, API di accesso e linguaggi di query. La differenza sta nel fatto che il loro
modello interno è basato su XML e non su un modello relazionale, come, ad esempio, accade
per i database tradizionali.
La fig. 4-1 mostra una rassegna dei principali database XML nativi attualmente in
circolazione.
Prodotto
Sviluppatore
Licenza
4Suite,
4Suite Server
FourThought
Open
Source
Birdstep RDM
XML
Birdstep
Commercial
Centor
Interaction
Server
DBDOM
Centor Software
Commercial
Corp.
K. Ari Krupnikov
57
Open
Source
Capitolo 4 - Il database di News Archive System
dbXML
dbXML Group
Commercial
eXist
Wolfgang Meier
Open
Source
eXtensible
Information
Server (XIS)
eXcelon Corp.
Commercial
GoXML DB
XML Global
Commercial
Infonyte DB
Infonyte
Commercial
Lore
Stanford
University
Research
Lucid XML
Data
Manager
Ludic'i.t.
Commercial
MindSuite
XDB
Wired Minds
Commercial
Neocore XML
Management
System
NeoCore
Commercial
ozone
ozone-db.org
Open
Source
Sekaiju /
Yggdrasill
Media Fusion
Commercial
SQL/XMLIMDB
QuiLogic
Commercial
Tamino
Software AG
Commercial
Virtuoso
OpenLink
Software
Commercial
XDBM
Matthew Parry,
Paul Sokolovsky
Open
Source
X-Hive/DB
X-Hive
Corporation
Commercial
Xindice
Apache
Software
Foundation
Open
Source
Fig. 4-1 I principali database XML nativi
4.3.1 Vantaggi dell’uso di database XML nativi
Ci sono numerose situazioni e ragioni per utilizzare un database XML nativo.
I database XML nativi sono chiaramente molto utili per salvare documenti documentcentric. Questo è dovuto al fatto che i database XML supportano, a differenza dei database
XML-enabled, caratteristiche come la rilevanza dell’ordine dei documenti ed alcune speciali
funzioni per il loro processamento. La maggior parte di tali database restituiscono i dati come
XML: se da un lato ciò può essere un vantaggio, dall’altro può rivelarsi un problema. Sono
58
Capitolo 4 - Il database di News Archive System
pochi, infatti, i database XML nativi che supportano il binding degli elementi o degli attributi
con le variabili di applicazione. Se l’applicazione necessita di avere i dati in un altro formato,
come spesso accade, occorne fare il parsing dell’XML restituito prima di poter usare i dati.
I database XML nativi sono utili anche per salvare documenti il cui “formato naturale” sia
XML, indipendentemente dal contenuto di tali documenti. Ad esempio, si supponga di
mandare messaggi tramite documenti XML in un sistema di e-commerce. Sebbene tali
documenti siano probabilmente data-centric, il loro formato naturale è XML. Quindi, quando
sono salvati in una coda di messaggi, ha molto più senso usare una coda di messaggi basata su
un database XML nativo, piuttosto che su un database non XML. Questo discorso vale anche
per i dati semi-strutturati, ovvero che hanno una struttura regolare, ma così variabile che il
mapping dei dati in un database relazionale, comporterebbe un numero cospicuo di colonne
con valori nulli o un numero cospicuo di tabelle. La mancanza di una configurazione
prestabilita è un vantaggio in applicazioni come motori di ricerca Web, in cui nessuna DTD o
insiemi di DTD possono essere applicati a tutti i documenti in questione. La memorizzazione
di documenti che non hanno DTD, pur essendo ben formati, è un’operazione molto complessa
per un database non XML. Infatti, un database XML nativo può accettare, salvare ed
elaborare ogni tipo di documento XML senza una “configurazione” prestabilita. Trasferire i
dati di un documento XML verso un database relazionale richiede, come cosa primaria, di
creare un mapping e uno schema di database.
I database XML nativi supportano i linguaggi di query XML, consentendo di soddisfare
anche richieste come: “Dammi tutti i documenti nei quali il terzo paragrafo dall’inizio
contiene una parola in grassetto”, query che sono piuttosto difficili da esprimere in un
linguaggio come SQL.
Un altro fattore importante a favore dei database XML nativi è la velocità di retrieval dei
dati. A seconda del tipo di memorizzazione fisica dei dati, il database XML nativo, potrebbe
essere capace di recuperare i dati più velocemente di un database relazionale. La ragione di
ciò risiede nel fatto che alcune strategie di memorizzazione, usate dai database XML nativi,
salvano fisicamente insieme interi documenti o usano puntatori fisici (piuttosto che logici) tra
le parti del documento. Questo permette il retrieving dei documenti senza join (associazioni) o
con join fisici, entrambi più veloci dei join logici eseguiti dai database relazionali. L’ovvio
inconveniente in questo caso è che l’incremento di prestazioni si verifica solo quando si
recuperano i dati nell’ordine con cui sono memorizzati su disco. Se si vuole avere una vista
59
Capitolo 4 - Il database di News Archive System
differente del documento le performance saranno probabilmente peggiori che in un database
relazionale. Così, si memorizzano dati in un database XML nativo per ragioni di performance
solo quando un solo tipo di vista dei dati predomina nell’applicazione.
4.3.2 Caratteristiche dei database XML nativi
In un database XML nativo, i dati sono organizzati in collezioni, ovvero con una struttura
logica simile a quella di un file system, tramite una struttura gerarchica con collezioni,
sottocollezioni e documenti. Ad esempio, si pensi alla memorizzazione dei manuali di tutti i
prodotti di una compagnia in un database XML nativo. In tale scenario, si vorrà definire una
gerarchia di collezioni: si avrà una collezione per ogni tipo di prodotto e, all’interno di questa
collezione, delle collezioni per tutti i capitoli in ogni manuale.
Quasi tutti i database XML nativi supportano uno o più linguaggi di query. I più popolari
tra questi sono XPath (con estensioni per query su documenti multipli) e XQL, sebbene siano
supportati anche numerosi linguaggi di query proprietari. Un linguaggio di query che
probabilmente verrà supportato da molti database XML in futuro è XQuery del W3C.
Sono disponibili una gran varietà di strategie per l’update dei documenti, dal semplice
rimpiazzamento o cancellazione dei documenti esistenti, fino a linguaggi che specificano
come modificare frammenti di un documento. Come regola generale, ogni prodotto che può
modificare frammenti di un documento ha il suo proprio linguaggio, sebbene molti prodotti
supportino il linguaggio XUpdate dell’iniziativa XML:DB.
Naturalmente quasi tutti i database XML offrono il supporto per le transazioni, il locking e
la concorrenza. Tuttavia, il locking delle risorse, ovvero la disponibilità di una risorsa
garantita ad un solo utente per volta, è spesso a livello di interi documenti, piuttosto che a
livello di frammenti di documento e, di conseguenza, la gestione delle concorrenze può
risultare piuttosto inefficiente quando si sceglie come “documento” un’entità troppo grande, o
troppo piccola. Ad esempio, se una guida utente è stata partizionata in singoli capitoli, ognuno
dei quali è un documento, allora si verificheranno problemi di concorrenza, non appena due
applicazioni vogliono scrivere lo stesso capitolo nello stesso istante, ma se questo è valutato
come un evento poco probabile nell’applicazione, questa struttura può essere accettabile.
Viceversa, se tutti i dati dei clienti di una grande azienda sono salvati su un singolo
60
Capitolo 4 - Il database di News Archive System
documento, il locking a livello di documento può risultare disastroso. Tuttavia, nel futuro,
quasi tutti database XML offriranno la possibilità di effettuare locking a livello di frammento;
Per accedere alle funzionalità di quasi tutti i database XML nativi, vengono specificate
delle Application Programming Interfaces (API). Di solito, le API hanno la forma di
un’interfaccia, con metodi che si connettono al database, eseguono query e ne manipolano i
risultati. Se le query restituiscono documenti (o frammenti di documenti) multipli, è possibile
scandirli tramite un apposito iteratore. Sebbene la maggior parte dei database XML nativi
offrono API proprietarie, l’XML:DB ha sviluppato delle API, indipendenti dal produttore che
sono state implementate da molti database, anche non XML nativi.
4.4
Apache Xindice
Apache Xindice (si pronuncia proprio come in italiano!) è un database XML nativo, basato
su un modello semistrutturato, scritto interamente in Java nell’ambito di un progetto
denominato dbXML Core.
Xindice usa XPath come linguaggio di query e il già citato XML:DB XUpdate come
linguaggio di update, fornendo un’implementazione delle API XML:DB per Java. E’ anche
possibile accedere a Xindice con altri linguaggi di programmazione mediante l’uso di plugin
XML-RPC. La versione ufficiale di Xindice attualmente è la 1.0 (anche se la 1.1 è disponibile
da tempo su CVS (Concurrent Version System), ma manca di gran parte della
documentazione) e supporta la memorizzazione di documenti ben formati. Questo può
rappresentare un vantaggio enorme in termini di flessibilità in quanto Xindice non pone
vincoli sullo schema da utilizzare per la validazione, ma richiede l’implementazione di un
modulo di validazione e ciò significa anche rinunciare alla possibilità di definire tipi di dati (il
supporto per XML Schema sarà presto fornito). Tuttavia, il progetto Xindice è più che mai
vivo e in continuo sviluppo.
4.4.1 Le caratteristiche di Xindice
In Xindice, tutti i documenti sono organizzati in una gerarchia di collezioni; una
collezione può contenere sottocollezioni figlie, documenti XML e XMLObjects (verranno
definiti più avanti), ad eccezione di quella principale - denominata /db ovvero il database -
61
Capitolo 4 - Il database di News Archive System
che può contenere solo sottocollezioni. Tale struttura è pressoché uguale a quella di un file
system. Ad esempio, la seguenti espressioni:
/db/my-collection/my-child-collection
/db/my-collection/my-document
myhost.domain.com:4080/db/my-collection/my-child-collection/my-document
indicano rispettivamente una collezione, un documento e un documento in una connesione
remota, tutti indirizzabili attraverso un path; i documenti, possono essere interrogati
singolarmente o a livello della (sotto)collezione cui appartengono. Inoltre, si possono creare
collezioni che contengono documenti dello stesso tipo oppure raggruppare tutti insieme i
documenti nel database in un’unica collezione.
Per interrogare le collezioni di documenti si usa XPath (nessun database XML nativo, ad
oggi, implementa XQuery, ma è già pronta la working draft per XPath 2.0), seguendo le
specifiche del W3C. Questo permette un meccanismo ragionevolmente flessibile per
interrogare i documenti, permettendo la loro “navigazione” e il restringimento dell’albero dei
risultati restituito. Migliori performance delle query su grandi quantità di documenti si
possono ottenere defininendo indici sia su elementi che su valori. Questo può far diminuire di
qualche ordine di grandezza il tempo di risposta alla query.
Quando si salva un file XML sul database, si vuole la possibilità di apportare future
modifiche al documento, senza doverlo estrarre dal database. L’mplementazione XML:DB di
XUpdate è il meccanismo da usare per fare degli update server-side dei dati. Esso è un
linguaggio XML-based per specificare le modifiche da effettuare in un documento e consente
a tali modifiche di esser applicate ad un’intera collezione come ad un singolo documento.
Xindice fornisce ai programmatori Java un’implementazione dell’API XML:DB, con il
proposito di dare portabilità alle applicazioni su database, ed anche un Command Line
Management Tools che ne è una versione eseguibile da riga di comando.
Infine gli XML Objects sono delle estensioni per il server che ne accrescono le potenzialità
(in pratica, delle classi Java di help). Nella versione 1.1 di Xindice sono stati eliminati e nel
News Archive System non verranno utilizzati.
62
Capitolo 4 - Il database di News Archive System
4.4.2 L’architettura di Xindice
Xindice è stato costruito in una maniera altamente modulare ed è quindi possibile
aggiungere o rimuovere componenti, che lo rendono adattabile a qualsisi ambiente ed in
qualsiasi applicazione. Essendo Xindice un database XML interamente scritto in Java, deve
essere ospitato da una Java Virtual Machine (JVM) che ha il compito, tra gli altri, di
memorizzare alcuni dati, riguardanti, ad esempio, la gerarchia delle collezioni e lo stato della
connessione del client, in oggetti Java. Inoltre è necessario l’accesso ai file che contengono i
dati XML su disco ed ai metadati correlati. I file sono memorizzati in una gerarchia di
directory chiamata database root.
Xindice può essere eseguito da una JVM in due modi diversi, a seconda di come i client
intendono usare Xindice.
In embedded mode, un’applicazione Java imposterà un’istanza di Xindice nella sua JVM e
soltanto questa applicazione può accedere e manipolare i dati in Xindice. I client che usano
l’API XML:DB, useranno il cosiddetto embedded driver per accedere all’istanza di Xindice
che gira all’interno della stessa JVM in qualità di application host.
In server mode, Xindice gira come un’applicazione J2EE standard in qualche Web
application container, come Apache Tomcat. In questa modalità d’uso, la JVM che ospita
Xindice, è proprio la JVM che fa girare il Web application container. I client si connettono a
Xindice da differenti JVM, probabilmente locate su macchine fisicamente differenti, usando
XML-RPC, uno standard Remote Procedure Call progettato per lavorare su architettura
HTTP.
I dati contenuti nei documenti XML di una collezione sono memorizzati in un singolo file
che ha estensione .tbl che è locato nella directory database root. Una classe speciale Java,
chiamata filer, si preoccupa di leggere e scrivere i dati XML in tale file.
4.4.3 Un esempio concreto di utilizzo
Si vuole illustrare un esempio di utilizzo, preso dal codice sorgente di News Archive
System, che verrà utilizzato per mettere in luce le caratteristiche fondamentali della
programmazione
mediante
l’API
XML:DB
63
per
Xindice.
Si
tratta
della
classe
Capitolo 4 - Il database di News Archive System
XindiceDeleteHandler.java, una servlet che si occupa di cancellare i documenti e le
collezioni selezionate da un utente nell’interfaccia Web di Xindice che è stata realizzata.
import
import
import
import
javax.servlet.*;
javax.servlet.http.*;
java.util.*;
java.io.*;
// xindice libraries importing
import org.xmldb.api.base.*;
import org.xmldb.api.modules.*;
import org.xmldb.api.*;
import org.apache.xindice.client.xmldb.DatabaseImpl;
// For the Xindice specific CollectionManager service
import org.apache.xindice.client.xmldb.services.*;
import org.apache.xindice.xml.dom.*;
public class XindiceDeleteHandler extends HttpServlet {
public void doPost(
HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
response.setContentType("text/html");
PrintWriter out
= response.getWriter();
HttpSession session = request.getSession(true);
String from = (String) session.getAttribute("from");
String url ="";
String msg ="";
// Bean retrieval
AdminBean formHandler =
(AdminBean) session.getAttribute("FormHandler");
//********Xindice Routines***************************
org.xmldb.api.base.Collection col = null;
try {
String
driver =
"org.apache.xindice.client.xmldb.DatabaseImpl";
Class
c
= Class.forName(driver);
Database database = (Database) c.newInstance();
DatabaseManager.registerDatabase(database);
col = DatabaseManager.getCollection(
"xmldb:xindice://" +
formHandler.getCurrentCollection());
// deleting all the checked collections
ArrayList collectionArray =
formHandler.getCollectionArray();
CollectionManager service =
(CollectionManager)
col.getService("CollectionManager",
"1.0");
int l = 0;
64
Capitolo 4 - Il database di News Archive System
for(int i = 0; i < collectionArray.size(); i++) {
service.removeCollection((String)
collectionArray.get(i));
l = i + 1;
}
if(from.equals("dbmanager"))
msg = l + " Collections deleted \\n";
// deleting all the checked documents
ArrayList documentArray = formHandler.getDocumentArray();
int
m
= 0;
for(int i = 0; i < documentArray.size(); i++) {
Resource document =
col.getResource((String) documentArray.get(i));
col.removeResource(document);
m = i + 1;
}
msg = msg + m + " Documents deleted ";
formHandler.setMessage(msg);
col.close();
} catch(Exception e) {
formHandler.setMessage("Exception occured " +
e.getMessage());
}
session.setAttribute("FormHandler", formHandler);
if(from.equals("dbmanager"))
url = "/currentcollectionview.jsp?idcoll="
+ formHandler.getCurrentCollection();
else
url = "/newsarchiveview.jsp?idcoll=/db/News";
RequestDispatcher dispatcher =
getServletContext().getRequestDispatcher(url);
dispatcher.forward(request, response);
}
}
Fig. 4-2 Un esempio concreto di utilizzo dell’API XML:DB
Il programma importa alcuni package XML:DB, relativi alle classi base richieste dall’API:
import org.xmldb.api.base.*;
import org.xmldb.api.modules.*;
import org.apache.xindice.xml.dom.*;.
org.xmldb.api.base.* è il modulo base dell’API ed è richiesto per tutte le applicazioni
che usano XML:DB API.. Prima di poter utilizzare l’API occorre creare e registrare il driver
del database che vogliamo usare. In questo caso, poiché si sta utilizzando Xindice, verrà usato
come driver org.apache.xindice.client.xmldb.DatabaseImpl.
String driver = "org.apache.xindice.client.xmldb.DatabaseImpl";
65
Capitolo 4 - Il database di News Archive System
Class c = Class.forName(driver);
Database database = (Database) c.newInstance();
DatabaseManager.registerDatabase(database);
Ora che il database è registrato è possibile recuperare la collezione con la quale si intende
lavorare.
col = DatabaseManager.getCollection(
"xmldb:xindice://" + formHandler.getCurrentCollection());
Nell’API XML:DB le collezioni sono ottenute chiamando il metodo getCollection che
gestisce un URI che specifica la collezione che si desidera. Il formato di questo URI varierà a
seconda dell’implementazione del database in uso ma comincia sempre con la stringa xmldb:
seguita dal nome dello specifico database, in questo caso xindice:. Il resto dell’URI è un
path usato per rintracciare la collezione di lavoro.
Ora bisogna stabilire un riferimento tra il servizio CollectionManager e la collezione
stessa in modo da ottenere servizi per estendere le funzionalità dell’API XML:DB e
consentire la definizione di funzionalità opzionali.
CollectionManager service =
(CollectionManager) col.getService("CollectionManager",
"1.0");
for(int i = 0; i < collectionArray.size(); i++) {
service.removeCollection((String) collectionArray.get(i));
l = i + 1;}
Per ottenere un servizio, bisogna conoscerne il nome, la versione ed il tipo di interfaccia
qualora sia necessario il casting dei risultati, ovvero la trasformazione tra due diversi formati
di rappresentazione dei dati.
Le risorse sono un concetto importante all’interno dell’API XML:DB. Dato che si può
avere accesso ai file XML attraverso le API e poiché un database XML può potenzialmente
immaginazzinare più tipi di dati, le risorse forniscono una metodo astratto di accesso ai dati
nel database. L’implementazione di Xindice supporta solo XMLResource ma altri produttori
supportano anche altri tipi di risorse.
L’istruzione col.close(); chiude la connessione al database e rilascia tutte le risorse
allocate.
66
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
CAPITOLO 5
MPEG-7: Multimedia Content Description Interface
5.1
Overview
Fondato nel 1988, il Moving Picture Experts Group (MPEG) ha sviluppato gli standard di
compressione audio-video che hanno cambiato il modo di produrre contenuti audio-visuali di
numerose industrie, rendendo possibile la loro diffusione attraverso ogni tipo di canale di
distribuzione e quindi il loro utilizzo da parte di un gran numero di dispositivi.
Già dal Novembre 1993 l’MPEG cominciò ad indagare circa la necessità di sviluppare uno
standard che permettesse agli utenti di identificare il contenuto della programmazione
televisiva trasmessa da “500 canali” (lo slogan di quegli anni che è l’effetto della
digitalizzazione della televisione sul business della Community Antenna Television, CATV).
Questa fu l’idea iniziale, ma il progetto MPEG-7 partì ufficialmente solo nel 1997.
MPEG-7 è destinato a ricoprire un ruolo chiave nell’imminente evoluzione della
multimedialità. Se da un lato MPEG-1, MPEG-2 ed MPEG-4 hanno fornito gli strumenti
attraverso i quali l’attuale abbondanza di risorse audiovisive si è resa disponibile, dall’altro
MPEG-7 fornirà la strada per navigare attraverso questa abbondanza di contenuti.
5.2
Introduzione a MPEG-7
5.2.1 Obiettivi dello standard
Lo standard MPEG-7 si propone di definire una serie di strumenti e standard per la
descrizione di contenuti, in particolare di tipo multimediale, e quindi audio-visuali, a
prescindere dal formato della risorsa stessa. Tale standard deve essere quanto più possibile
flessibile e povero di vincoli, pur mantenendo l’obiettivo fondamentale dell’interoperabilità.
67
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
MPEG-7 non tratta i dati in senso stretto, ma i dati riguardanti i dati (“bits about the bits”),
ormai noti come metadati.
MPEG-7 fornisce gli strumenti per operare indifferentemente in ambiente real-time o non
real-time. La prima modalità è resa possibile dal BiM (Binary format for MPEG-7) che
garantisce una rappresentazione di descrizioni MPEG-7 compatta ed adatta ad essere inserita
in uno streaming audio-video (i metadati “viaggiano” assieme ai dati). Nella modalità non
real-time, utilizzata in questo progetto, i documenti MPEG-7, testuali, sono esterni alla risorsa
multimediale che viene descritta e possono tranquillamente essere dislocati altrove, in un altro
computer o addirittura in un’altra rete.
Tale standard è stato pensato per essere utilizzato non solo in modalità automatica da
opportuni dispositivi elettronici, ma anche da utenti per una gestione manuale di quelle che
possono essere le risorse di cui si vogliono creare matadati. Infatti, anche se l’obiettivo
dell’MPEG-7 è la descrizione di contenuti multimediali, anche altri tipi di risorse, ad esempio
testuali, possono essere considerate come contenuti di tipo informativo e quindi descritte
mediante le tecniche definite dallo standard.
Fine ultimo dell’MPEG-7 è quindi, in uno scenario futuro che vedrà sempre più presente il
Web nella vita di tutti i giorni, far si che il Web sia “esplorabile” per quanto riguarda i
contenuti multimediali, così come oggi lo è per documenti di tipo testuale.
5.2.2 MPEG-7 nella realtà dei metadati multimediali
Attualmente sono già in uso meccanismi di descrizione di contenuti multimediali, i più
importanti tra i quali sono:
• SMPTE Metadata Dictionary;
• Dublin Core;
• EBU P/Meta;
• TV Anytime;
Naturalmente si tratta di soluzione proprietarie, e quindi eterogenee, che non garantiscono
la compatibilità. MPEG-7 si pone l’obiettivo di mantenere la compatibilità con le soluzioni
68
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
già esistenti, in modo da rendere meno traumatica la migrazione verso uno standard candidato
a divenire unico in tale ambito.
Nel confronto con le soluzioni già disponili od emergenti per la descrizione di risorse
multimediali, MPEG-7 può essere caratterizzato da:
•
la sua genericità, legata alla sua capacità di descrivere contenuti, in modo
consistente, provenienti da molteplici domini applicativi;
•
l’integrazione di descrittori di alto e basso livello all’interno di una singola
architettura, che permette di combinare la potenza di entrambi i tipi di descrittori;
•
l’estensibilità, fornita dal DDL (Description Definition Lenguage, di cui si parlerà
in seguito), che permette all’utente di aumentare le capacità di MPEG-7 in accordo
con le proprie necessità, e allo standard di evolvere integrando nuovi tool di
descrizione.
5.2.3
Potenza e significato di uno standard
Come detto in precedenza uno dei punti fermi degli standard MPEG è l’interoperabilità.
Ciò vuol dire che si deve solamente specificare il minimo necessario e non più di questo.
Nell’MPEG-7 questo si traduce nella sola standardizzazione del formato - sintassi e sematica
- e nella sua decodifica. Elementi che sono esplicitamente non specificati sono le tecniche per
l’estrazione e la codifica, e la fase di “consumo”, ovvero di uso della descrizione. Sebbene
dei buoni tool di estrazione e codifica saranno essenziali per il successo di applicazioni
MPEG-7, così come la stima del movimento od il controllo del flusso lo sono per applicazioni
MPEG-1 e MPEG-2, e la video segmentazione per alcune applicazioni MPEG-4, la loro
standardizzazione non è necessaria per l’interoperabilità; le specifiche dei tool di analisi dei
contenuti - in modo automatico o semiautomatico - sono fuori dal campo di azione dello
standard, come pure i software ed i dispositivi che useranno le descrizioni prodotte.
Considerando un generico processo di “generazione" ed "utilizzo” di una descrizione di un
documento (vedi fig. 5-1) si nota come la sola area operativa dello standard sia la specifica
della Description e non i processi che la utilizzano, che invece, secondo il gruppo MPEG,
dovranno essere ambito di future ricerche e competizioni fra aziende diverse, in modo da
ottenere i risultati migliori.
69
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
Description
generation
Description
consumption
Description
Re search and
future competition
Scop e of MPEG-7
Fig. 5-1 L’obiettivo dello standard MPEG-7
MPEG-7, diventato standard nel 2001 (ISO/IEC 15938), permette essenzialmente di creare
e rendere possibile l’utilizzo di descrizioni, attraverso una serie di descrittori e schemi di
descrizione
standardizzati
definiti
mediante
un
opportuno
linguaggio
anch’esso
standardizzato.
5.3
Gli elementi dello standard MPEG-7
Lo standard fornisce tre importanti tipi di elementi che dettano le regole per la costruzione
di documenti MPEG-7: Descriptor (D), Description Scheme (DS) e un Description Definition
Language (DDL). I Descriptor MPEG-7 sono progettati per descrivere singole caratteristiche
di un contenuto multimediale, mentre i Description Scheme permettono di realizzare
descrizioni complesse integrando assieme Descriptor e Description Scheme diversi. L’MPEG7 Description Definition Language fornisce un linguaggio per definire nuovi Descriptor e
nuovi Description Scheme, e permette anche l’estensione e la modifica dei Descriptor e
Description Scheme già esistenti nello standard.
Sebbene gli elementi sopra citati rappresentino il cuore dello standard, questo viene
usualmente suddiviso nelle seguenti parti:
1. MPEG-7 Systems - strumenti di supporto;
2. MPEG-7 Description Definition Language - linguaggio che permette la creazione di
nuovi D e DS;
3. MPEG-7 Audio - i D e i DS associati esclusivamente a descrizioni di tipo Audio;
4. MPEG-7 Visual - i D e i DS associati esclusivamente a descrizioni di tipo Video;
5. MPEG-7 Multimedia Description Schemes (MDS) i D e i DS associati a descrizioni e
“features” generiche, applicabili ad ogni informazione multimediale;
70
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
6. MPEG-7 Reference Software - implementazione software delle parti più rilevanti dello
standard;
7. MPEG-7 Conformance - linee guida e procedure per testare la conformità allo
standard delle varie implementazioni.
Nei paragrafi successivi verranno illustrati in maniera più approfondita i soli concetti di D
e DS, un breve sguardo al DDL per poi passare all’MDS.
5.3.1
I Descriptor
I Descriptor MPEG-7 sono stati progettati per descrivere sia caratteristiche audio-visuali di
basso livello - il colore, la texture, il movimento, la potenza sonora, e così via - sia di alto
livello - un contenuto semantico, un evento o un concetto astratto - sia informazioni di altro
tipo circa l’immagazzinamento dei media o i processi di gestione delle risorse. Naturalmente
molte di queste caratteristiche potranno essere estratte in modo automatico, soprattutto quelle
di basso livello, ma molte avranno bisogno di un operatore umano, soprattutto per quanto
riguarda i contenuti semantici che sono descrizioni ad alto livello per eccellenza.
5.3.2 I Description Scheme
I Description Scheme MPEG-7, come già accennato, aumentano le funzionalità dei
descrittori MPEG-7, combinando singoli D e DS, in particolare stabilendo una relazione tra i
D e i DS di cui è costituito. I Description Scheme possono riguardare il dominio audio e video
in maniera specifica o una descrizione multimediale generica. Tipicamente, infatti, un DS
generico corrisponde a metadati immutabili che riguardano la creazione, la produzione, l’uso
e la manutenzione di un contenuto multimediale. I Description Scheme multimediali (MDS)
si riferiscono a tutti i tipi di media contenenti audio, video o dati testuali, mentre i Descriptor
specifici di un dominio, come quelli per il colore, la texture, la melodia e così via, fanno
riferimento soprattutto al dominio audio o video. Così come per i D, anche per i DS alcuni
possono essere automaticamente generati ed altri richiedono l’intervento umano.
71
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
5.3.3 Il Description Definition Language
L’MPEG-7 DDL costituisce il fondamento dell’intero standard. Si tratta di un linguaggio
per definire la struttura ed il contenuto di documenti MPEG-7. Il DDL non è un linguaggio di
modellazione, ma uno schema language per rappresentare il risultato della modellazione di
dati audio-visuali, attraverso una serie di vincoli sintattico - strutturali e di costanti alle quali i
D e i DS MPEG-7 devono essere conformi.
Si tratta, in sostanza, di una estensione del linguaggio XML Schema. Se il proposito di un
XML Schema è quello di definire una classe di documenti XML, il proposito di un MPEG-7
Schema è quello di definire una classe di documenti MPEG-7.
Le istanze MPEG-7 sono documenti XML, conformi a un particolare schema MPEG-7 espresso in DDL - che descrivono contenuto multimediale.
Con l’MPEG-7 DDL è possibile esprimere non solo una struttura, ma anche la gerarchia e
la relazione spazio - temporale e concettuale tra gli elementi di un DS e tra i DS stessi. Inoltre
è indipendente dalla piattaforma utilizzata, ed è perfettamente comprensibile sia da una
macchina che dall’uomo.
In generale un documento XML deve sottostare (nella sua struttura) ai vincoli descritti
nello schema cui fa riferimento, come tipi degli elementi contenuti, attributi e loro valori,
cardinalità, e così via. Il linguaggio DDL può quindi essere scisso in tre componenti
normativi:
•
XML Schema Structural Component;
•
XML Schema datatype Component;
•
MPEG-7 extensions to XML Schema.
In accordo con le specifiche dell’XML Schema, la sezione XML Schema Structural
Component è la prima delle due previste dallo standard, e definisce la descrizione della
struttura che dovranno avere i documenti creati a partire dallo schema.
La sezione XML Schema datatype Component è la seconda parte delle due previste dallo
standard, e definisce:
•
un set di tipi primitivi “built-in” (“nativi” dello standard) come xsd:string,
xsd:Integer;
72
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
•
un
set
di
tipi
derivati
“built-in”
(“nativi”
dello
standard)
come
xsd:positiveInteger, derivato da xsd:Integer;
•
meccanismi mediante i quali gli utenti possono definire i loro tipi derivati.
Al fine di descrivere nella loro totalità e completezza dati di tipo multimediale, lo standard
definisce delle necessarie estensioni all'XML Schema (MPEG-7 extensions to XML Schema),
quali:
•
tipi di dato come vettori e matrici, sia a dimensione fissa che variabile;
•
tipi di dato primitivi “built-in” (come “basicTimePoint” e “basicDuration”), al
fine di descrivere vincoli di tipo temporale.
A causa di ciò, in alcune applicazioni, non è possibile utilizzare un parser XML Schema,
poiché le estensioni non potrebbero essere riconosciute; risulta quindi necessaria, in quei casi,
l’implementazione di “Parser DDL” ad-hoc.
5.4
MPEG-7 Multimedia Description Scheme
5.4.1 Overview
Il Multimedia Description Scheme (MDS) Group è un gruppo di lavoro di MPEG,
formatosi stabilmente nel Luglio 1999, per sviluppare la quinta parte dello standard MPEG-7,
ovvero quella riguardante la definizione di Description Scheme orientati alla descrizione di
contenuti multimediali. Gli MDS sono, quindi, strutture di metadati usate per descrivere ed
annotare dati di tipo audio-visuale.
Gli MDS sono divisi in categorie che riguardano descrizioni video, audio ma anche
generiche. Infatti, sebbene gli MDS contengano Descriptor e Description Scheme MPEG-7,
possono anche essere aggiunte delle estensioni (ovvero D e DS) che permettano di adattarsi
allo specifico dominio di un’applicazione.
I Multimedia Description Scheme forniscono, quindi, una strada per descrivere, in XML,
importanti concetti che riguardano un contenuto multimediale allo scopo di renderne più
facile la ricerca, l’indicizzazione ed il filtraggio. I Description Scheme di cui è costituito sono
stati progettati per descrivere sia gli aspetti generali del content management, sia le
caratteristiche specifiche del contenuto multimediale (content description). Alcuni DS
73
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
possono essere utilizzati per specificare metadati “immutabili” come quelli che riguardano la
creazione, la produzione, l’uso e l’amministrazione di dati multimediali (per esempio il titoli o
l’autore di un programma televisivo). Altri DS permettono la descrizione diretta del contenuto
ad un diverso numero di livelli (struttura del segnale, caratteristiche, modello e semantica).
Fig. 5-2 Livelli di descrizione offerti dall’MDS
Altri DS ancora sono stati progettati per garantire una navigazione ed un accesso efficiente
ai dati multimediali stessi.
Per generare uno schema per l’organizzazione di metadati multimediali, non è sufficiente
definire D e DS specializzati, ma occorrono anche una serie di strumenti che abbiano la
funzione di collante tra i D e i DS stessi. Gli Schema Tool sono la risposta dell’MDS Gruop a
tale necessità.
Gli Schema Tool specificano l’organizzazione del tipo di gerarchia dei Descriptor e dei
Descriptor Scheme sia a livello di radice che di livello superiore (Top Level Type: i descrittori
che servono a generare elementi figli - Top Level Element - di elementi genitori).
In pratica vengono definite le regole di costruzione degli schemi di metadati multimediali
delineando il modo di congiungere i vari D e DS radice, con lo specifico tipo di livello
superiore, per formare delle descrizioni complete di diversi tipi di contenuto multimediale,
come ad esempio immagini, video, audio, miscellanea multimediale, collezioni, e così via.
Il concetto chiave degli Schema Tool riguarda, quindi, la correlazione che viene ad
istaurarsi tra descrittori “genitori” e “figli”, ovvero tra elementi radice ed i tipi di livello
superiore.
5.4.2 L’elemento radice Mpeg7 ed i relativi tipi di livello superiore
L’elemento radice Mpeg7 è l’elemento principale che racchiude l’intera descrizione; in tal
senso serve da “intestazione” ad una descrizione MPEG-7 e specifica, quindi, un modello
valido per la descrizione.
74
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
Fig. 5-3 Organizzazione dell’elemento radice Mpeg7 e dei tipi di livello superiore
Ogni entità nella fig. 5-3 corrisponde a Descriptor e Description Scheme o unione di essi. I
cammini tra i box indicano le relazioni ed i valori tra parentesi graffe indicano gli estremi
massimi e minimi della molteplicità della relazione.
I due tipi di descrizioni di schema validi sono: la descrizione completa di documenti
(complete), oppure quelle ottenute tramite istanze che portano informazioni parziali o
aggiuntive, come nel caso delle unità di descrizione (Description Unit), ovvero un insieme di
strumenti di descrizione costruito per una particolare applicazione.
Come si può notare dalla fig. 5-3, l’elemento radice Mpeg7 ammette diversi tipi di livello
superiore adatti ad alcuni compiti di descrizione specifici riassunti nella tabella seguente.
Nome
Mpeg7
DescriptionMetadata
DescriptionUnit
ContentDescription
Definizione
E’ l’elemento radice di una descrizione.
Descrive i metadati stessi, ovvero
fornisce
informazioni
riguardo,
ad
esempio, la data di creazione del
documento MPEG-7, il personale addetto
alla creazione o l’ente per cui la
descrizione è stata creata (opzionale).
Descrive una istanza di uno
strumenti MPEG-7 (opzionale).
degli
Descrive dati multimediali o astrazioni di
contenuto multimediale.
ContentDescription corrisponde al tipo di
base astratto di differenti modelli per la
descrizione dei diversi tipi e astrazioni di
contenuto multimediale (opzionale).
75
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
ContentManagement
Descrive
la
gestione
dei
dati
multimediali.
ContentManagement
corrisponde al tipo astratto di base dei
differenti modelli per la descrizione della
gestione di contenuto multimediale
(opzionale).
Fig. 5-4 La semantica dell’elemento radice Mpeg-7
Quando si tenta di creare uno schema di descrizione MPEG-7, occorre scegliere quale
strada percorrere, ovvero quali tra gli strumenti di descrizione a disposizione utilizzare per
ottenere descrizioni utili alla particolare applicazione che si vuol realizzare. E’ possibile
usare, come si è visto, Description Unit personalizzate, ma il più delle volte, se possibile,
conviene utilizzare i D e i DS raccolti nei tipi di livello superiore Content Description o
Content Management a seconda del fine per il quale le descrizioni dovranno essere create.
Nella tabella seguente vengono mostrate le cinque classi di strumenti di descrizione in cui
possono essere suddivisi gli MDS per il Content Management ed il Content Description; ogni
classe è corredata di una breve descrizione generica dei D e DS in essa contenuti.
Categoria
MDS
Content
Management
Insieme di
strumenti di
descrizione
Funzionalità
Media
Descrizione del supporto di
memorizzazione: il formato di
memorizzazione, la codifica del
contenuto
multimediale,
l’identificazione del supporto.
Creation &
Production
Metadati che descrivono la
creazione e produzione del
contenuto:
tipiche
caratteristiche sono il titolo, il
creatore, la classificazione, lo
scopo della creazione, e via
dicendo. Questa informazione è
in
gran
parte
generata
dall’autore dal momento che
non è possibile estrarla dal
contenuto.
Usage
Metadati relativi all’uso del
contenuto:
caratteristiche
tipiche sono i proprietari dei
diritti, i diritti di accesso,
pubblicazione, e le informazioni
finanziarie. Tale informazione
sarà probabilmente soggetta a
variazioni nel ciclo di vita del
contenuto multimediale.
76
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
Structural
Aspect
Descrizione
del
contenuto
multimediale dal punto di vista
della
sua
struttura:
la
descrizione è strutturata intorno
ai segmenti che rappresentano i
componenti
fisici
spaziali,
temporali o spazio-temporali del
contenuto multimediale. Ogni
segmento può essere descritto
da caratteristiche basate sui
segnali (signal based: come
colore, texture, forma, moto, e
caratteristiche audio) e alcune
elementari
informazioni
semantiche.
Semantic
Aspect
Descrizione
del
contenuto
multimediale dal punto di vista
della sua semantica e delle
nozioni concettuali. Questo si
basa sui concetti di oggetti,
eventi, concetti astratti e loro
relazioni.
Content
Description
Fig. 5-5 Strumenti di descrizione per il Content Management e il Content Description
Questi cinque insiemi di strumenti di descrizione sono stati presentati come entità distinte;
in realtà ognuno di questi è correlato con gli altri e può essere parzialmente incluso in ogni
altro.
Sebbene nello svilluppo dell’applicazione News Archive System siano stati utilizzati i soli
D e DS che riguardano il Content Description, data l’importanza cruciale dell’argomento, si
ritiene utile dare una breve descrizione degli strumenti di descrizione sia di Content
Description che di Content Management.
Partendo dal tipo astratto BasicDescription si può descrivere la seguente gerarchia:
•
BasicDescription (astratto): fornisce la specifica di una base astratta per i tipi di
livello superiore ContentDescription e ContentManagement;
o ContentDescription (astratto): fornisce la specifica di una base astratta per
i tipi di livello superiore ContentEntity e ContentAbstraction per la
descrizione di contenuto multimediale;
ContentEntity: fornisce un modello di contenitore per descrivere
diversi tipi di entità di contenuto multimediale come immagini,
video, audio, collezioni, e via dicendo;
ContentAbstraction (astratta): fornisce la specifica di una base
astratta per vari tipi di livello superiore per la descrizione di
77
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
contenuti
multimediali
ModelDescription,
(questi
tipi
sono
SummaryDescription,
WorldDescription,
ViewDescription,
VariationDescription);
o ContentManagement (astratto): fornisce la specifica di una base astratta
per i tipi di livello superiore seguenti per la descrizione delle operazioni di
gestione dei contenuti multimediali;
UserDescription: fornisce un modello di contenitore per la
descrizione di un utente in un sistema multimediale;
CreationDescription: fornisce un modello di contenitore per la
descrizione del processo di creazione del contenuto multimediale;
UsageDescription: fornisce un modello di contenitore per la
descrizione dei modi d’uso di un contenuto multimediale;
ClassificationDescription: fornisce un modello di contenitore per la
descrizione di uno schema di classificazione relativo al contenuto
multimediale.
I tipi di livello superiore sono organizzati secondo la gerarchia mostrata nella figura seguente.
B asic
D escription
(abstract)
C ontent
D escription
(abstract)
C ontent
E ntity
C ontent
M anagem ent
(abstract)
C ontent
A bstraction
(abstract)
- U serD escriptio n
- C reatio nD escriptio n
- U-sageD escrip tion
- C lassification D escrip tion
Audio -V isu al
- W orldD escription
- Im age
- M o delD escription
- V ideo
- S um m aryD escriptio n
- V iew D escription
- Au dio
- Au dioV isu al
- M ixedC o nten t
- C onten tC ollectio n
- V ariatio nD escriptio n
Fig. 5-6 Gerarchia dei top level type di Content Descriprion e Description Metadata
Per la natura dell’applicazione News Archive System, orientata alla ricerca di segmenti
audio-visuali, si ritiene, a questo punto, interessante approfondire quali D e DS l’MDS Group
ha progettato riguardo il tema della “segmentazione” semantica di contenuti multimediali.
78
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
5.4.3 Content Description: segmentazione del contenuto multimediale
In effetti, nello sviluppo di uno schema di metadati per il News Archive System, l'elemento
principale, presente nella parte di Content Description, è il Segment Description Scheme che
riguarda la descrizione degli aspetti fisici e logici del contenuto audio-visuale. I Segment DS
possono essere usati per formare strutture ad albero dei segmenti.
Un segmento rappresenta una sezione di un istanza di contenuto audiovisivo. Il Segment
DS è definito come una classe astratta (nel senso della programmazione ad oggetti) e possiede
tutta una serie di sotto-classi per la descrizione specifica di ogni tipo di segmentazione.
Ogni segmento può essere descritto, inoltre, da informazioni sulla sua creazione (Creation
Information), sull'uso (Usage Information), sul media (Media Information) e da annotazioni
testuali (Textual Annotation), ed può essere decomposto in sotto-segmenti attraverso Segment
Decomposition DS.
Il Segment DS è ricorsivo e può essere suddiviso in sotto-segmenti e questi possono
formare una gerarchia (struttura ad albero). La struttura ad albero dei segmenti che ne risulta
viene utilizzata per definire il media sorgente e la struttura temporale e/o spaziale del
contenuto audio-visivo.
Per esempio un programma video può essere segmentato temporalmente in vari livelli di
scene, shot, e micro-segmenti; una tavola dei contenuti può essere generata basandosi su
questa struttura e strategie simili possono essere usate per i segmenti spaziali e spaziotemporali.
Un segmento può, inoltre, essere suddiviso in vari media sorgenti come per esempio
diverse tracce audio o vari punti di vista da diverse inquadrature. La suddivisione gerarchica è
utile per delineare efficienti strategie di ricerca (ricerche globali o ricerche locali) e permette
inoltre alla descrizione di essere scalabile: un segmento può essere descritto dal suo diretto set
di D e DS ma può anche essere descritto dall'unione dei D e dei DS relativi ai suoi sottoelementi. Da notare è che un segmento può essere suddiviso in diversi sotto-segmenti di
diverso tipo, per esempio un segmento video può essere decomposto in regioni in movimento
che possono essere a loro volta decomposte in regioni statiche.
La figura in basso mostra, in modo sintetico, l'organizzazione degli strumenti per la
descrizione delle decomposizioni strutturali dei segmenti.
79
Capitolo 5 - MPEG-7: Multimedia Content Description Interface
Segment
Decomposition DS
(abstract)
SpatialSegment
Decomposition DS
(abstract)
StillRegionSpatialDecomposition DS
StillRegion3DSpatialDecomposition DS
VideoSegmentSpatialDecomposition DS
MovingRegionSpatialDecomposition DS
AudioVisualSegmentSpatialDecomposition DS
TemporalSegment
Decomposition DS
(abstract)
VideoSegmentTemporalDecomposition DS
MovingRegionTemporalDecomposition DS
InkSegmentTemporalDecomposition DS
AudioSegmentTemporalDecomposition DS
AudioVisualSegmentTemporalDecomposition DS
AudioVisualRegionTemporalDecomposition DS
AnalyticEditedVideoSegmentTemporalDecomposition DS
MediaSource
SegmentDecomposition DS
(abstract)
SpatioTemporal
SegmentDecomposition
DS (abstract)
VideoSegmentMediaSourceDecomposition DS
MovingRegionMediaSourceDecomposition DS
InkSegmentMediaSourceDecomposition DS
AudioSegmentMediaSourceDecomposition DS
AudioVisualSegmentMediaSourceDecomposition DS
MultimediaSegmentMediaSourceDecomposition DS
VideoSegmentSpatioTemporalDecomposition DS
MovingRegionSpatioTemporalDecomposition DS
AudioVisualSegmentSpatioTemporalDecomposition DS
AudioVisualRegionSpatioTemporalDecomposition DS
AnalyticEditedVideoSegmentSpatioTemporalDecomposition DS
Fig. 5-7 Visione generale degli strumenti per la decomposizione dei segmenti
Il SegmentDecomposition DS è un tipo astratto che descrive una decomposizione
gerarchica
di
un
segmento.
Lo
SpatialSegmentDecomposition
DS,
il
TemporalSegmentDecomposition DS, lo SpatioTemporalSegmentDecomposition DS ed il
MediaSourceSegment-Decomposition DS sono Segment Decomposition specializzati e sono
definiti come tipi astratti che descrivono decomposizioni spaziali, temporali, spazio-temporali
e di media sorgente rispettivamente.
Il News Archive System è basato, fondamentalmente, sulla suddivisione temporale dei
servizi dei telegiornali delle tre reti RAI; è chiaro, quindi, che tra tutti i
SegmentDecomposition DS sarà largamente impiegato solo TemporalSegmentDecomposition
DS ed, in particolare, l’AudioVisualSegmentTemporalDecomposition DS (vedi par. 7.2.10).
80
Capitolo 6 - Analisi dei requisiti
CAPITOLO 6
Analisi dei requisiti
Come visto nel paragrafo 2.5, il progetto News Archive System si è prefisso alcuni
obiettivi iniziali che hanno ispirato il processo di sviluppo dell’applicazione. In questo
capitolo, si descriveranno i requisiti dell’applicazione e si studierà come essa dovrà
funzionare dal punto di vista dell’utente, in termini di funzionalità offerte. Verranno utilizzati
gli strumenti messi a disposizione da UML (Unified Modeling Language, si veda l’appendice
F), lo standard industriale per specificare, visualizzare, costruire e documentare la produzione
di software, quali gli use case diagram ed i sequance diagram di sistema. Infine, sulla base
delle funzionalità descritte, verrà presentato un modello concettuale del sito.
6.1
Gli Use case diagram
6.1.1 Gli attori del sistema
Il seguente use case diagram descrive gli utenti, o attori, del sistema che possono essere
suddivisi in due grandi categorie: user e administrator. Tuttavia, per mantenere l’applicazione
il più possibile portabile e per ridurre la complessità d’uso e la possibilità di errori, si è
pensato di differenziare gli amministratori in due tipologie. Il sistema deve, quindi, servire tre
tipi di utenti:
•
il Database Manager (DM): colui che può sfruttare tutte le funzionalità offerte dal
database, sia in termini di risorse che di strumenti e ha il completo controllo delle
operazioni CRUD (Create Read Update Delete) anche in remoto;
81
Capitolo 6 - Analisi dei requisiti
•
il News Archive Administrator (NAA): l’amministratore specializzato per il
particolare tipo di applicazione, ovvero colui che ha una vista semplificata del
database dei telegiornali avendo a disposizione operazioni CRUD “dedicate”;
•
l’User: l’utente del database. Nel particolare contesto dell’applicazione, è colui che
ha necessità di accedere e ricercare le risorse multimediali a partire da criteri di
ricerca più o meno sofisticati. Tipici user sono giornalisti, produttori, registi o
documentatori. Si noti, che a differenza dei primi due attori, un user non deve
autenticarsi.
Fig. 6-1 Gli attori del sistema
6.1.2
Gli amministratori di News Archive System
Lo use case diagram di fig. 6-2 descrive più in dettaglio lo use case Content Management
di fig. 6-1, ovvero illustra le funzionalità specifiche degli amministratori. Il News Archive
Administrator non ha la possibilità di aggiornare i documenti, sfruttando un sottoinsieme delle
funzionalità del Database Manager (ad esempio, il DM può creare collezioni in ogni parte del
database, mentre il NAA, proprio per le specifiche della particolare applicazione, può creare
solo documenti all’interno della collezione “News” - per maggiori dettagli si veda avanti).
82
Capitolo 6 - Analisi dei requisiti
Fig. 6-2 Le funzionalità degli attori DM e NAA
6.1.3
Gli utenti di News Archive System
Il seguente use case diagram descrive le azioni che possono essere eseguite dall’attore User
che sono, essenzialmente, due tipi di ricerca: quella per telegiornali e quella per servizi.
Fig. 6-3 Le funzionalità dell’attore User
Dalle specifiche, si vuole che le ricerche prevedano vari parametri, alcuni comuni tra
ricerca di telegiornali e servizi (intervallo di data, fascia oraria, emittente) e altri propri della
83
Capitolo 6 - Analisi dei requisiti
ricerca per telegiornale (regista, conduttore, direttore di produzione e direttore di fotografia) e
per servizio (giornalista, parole chiave per rintracciare il servizio e genere del servizio).
Inoltre, può essere di interesse per un utente vedere un rapporto tecnico-informativo di un
dato telegiornale.
6.2
I sequence diagram di sistema
I diagrammi di sequenza di sistema forniscono una specifica concettuale più dettagliata
degli use case sopra descritti.
6.2.1 Database Manager - Create
Il diagramma di fig. 6-2 descrive l’operazione di creazione di documenti o collezioni da
parte del Database Manager; logicamente quest’operazione è del tutto simile a quella di
navigazione di un file system e di creazione di un file o di una directory.
Fig. 6-4 Diagramma di sequenza di sistema DM - Create
6.2.2 Database Manager - Read & Delete
Il diagramma di fig. 6-5 descrive le operazioni di cancellazione di documenti o collezioni
e di vista dei documenti da parte del Database Manager; logicamente queste operazioni sono
del tutto simili a quella di navigazione di un file system e di cancellazione di un file o di una
directory oppure di apertura di un file.
84
Capitolo 6 - Analisi dei requisiti
Fig. 6-5 Diagramma di sequenza di sistema DM - Delete & Read
6.2.3 Database Manager - Update
Il diagramma di fig. 6-6 descrive le operazioni di update di uno o più documenti da parte
del Database Manager; si noti la possibilità di scegliere il tipo di update e di validare il nuovo
documento ottenuto.
Fig. 6-6 Diagramma di sequenza di sistema DM - Update
85
Capitolo 6 - Analisi dei requisiti
6.2.4 News Archive Administrator - Create
Il diagramma di fig. 6-7 descrive l’operazione di creazione di documenti da parte del News
Archive Administrator; si noti che, a differenza del DM, il NAA non fa il browsing del
database, in quanto i telegiornali sono contenuti tutti dentro la collezione “News”.
Fig. 6-7 Diagramma di sequenza di sistema NAA - Create
6.2.5 News Archive Administrator - Read & Delete
Il diagramma di fig. 6-8 descrive le operazioni di cancellazione di documenti e di vista dei
documenti da parte del News Archive Administrator.
Fig. 6-8 Diagramma di sequenza di sistema NAA - Delete & Read
86
Capitolo 6 - Analisi dei requisiti
6.2.6 News Archive Administrator - Create MPEG-7
Il diagramma di fig. 6-9 descrive l’operazione di creazione di un documento MPEG-7 da
parte del News Archive Administrator; questa operazione è specializzata per l’applicazione
che si deve realizzare.
Fig. 6-9 Diagramma di sequenza di sistema NAA - Create MPEG-7
6.2.7 User - Query
Fig. 6-10 Diagramma di sequenza di sistema USER - Query
87
Capitolo 6 - Analisi dei requisiti
Il diagramma di fig. 6-10 descrive l’operazione di ricerca di una risorsa (telegiornali o
servizi) da parte dell’User; questa operazione è specializzata per News Archive System:
88
Capitolo 7 - Progetto dell’applicazione
CAPITOLO 7
Progetto dell’applicazione
In questo capitolo, si parlerà delle scelte progettuali effettuate a livello di architettura, del
modello dei dati utilizzato e si accennerà agli aspetti salienti della fase di progettazione vera e
propria del sito che ospita l’applicazione News Archive System.
7.1
Il design pattern Model-View-Controller dell’architettura
L’architettura Model-View-Controller (MVC) è stata presa come riferimento per la
progettazione di News Archive System. Si descriveranno, con un esempio, le idee base di tale
architettura, come sia possibile applicare il paradigma MVC alle applicazioni Web e, infine, si
descriverà l’architettura “reale” di News Archive System.
7.1.1 Un esempio di applicazione del paradigma MVC
Si immagini di avere la necessità di scambiare un messaggio fra due classi, cioè una classe
deve invocare il metodo di un'altra per prenderle un valore e registrarlo al suo interno. Il
problema può essere risolto scrivendo le seguenti classi Model e View.
Fig. 7-1 Un errore progettuale
89
Capitolo 7 - Progetto dell’applicazione
Tutto questo risolve il problema ma è sbagliato "formalmente" per i seguenti motivi:
l’obiettivo della programmazione ad oggetti è quello di progettare classi che possano vivere
autonomamente in un qualsiasi altro contesto, e che possano essere riutilizzabili. In questo
caso, invece, per adoperare la classe View in un altro progetto, occorrerebbe “portarsi dietro”
anche la classe Model, oppure modificare la classe View; questo non è accettabile ed è in
contrasto con la filosofia della programmazione ad oggetti.
Il sistema potrebbe essere riprogettato aggiungendo anche una nuova classe Controller.
Fig. 7-2 MVC
In questa situazione il problema viene ugualmente risolto, con tre classi, di cui due
indipendenti, invece che due classi dipendenti; secondo la filosofia ad oggetti, questo è un
progetto “migliore”. Fra le tre, è la classe Controller a dipendere dall’applicazione e quindi
sicuramente non la potrà essere utilizzata in un altro progetto. I Controller sono le classi più
importanti nella progettazione, sono quelle che hanno la logica applicativa per risolvere le
problematiche specifiche delle applicazioni e utilizzano, nel modo più opportuno ai loro
scopi, le classi Model e View.
In definitiva, il Controller dice al Model come gestire i dati e dice alla View come
rappresentarli, passando i dati dal Model alla View.
90
Capitolo 7 - Progetto dell’applicazione
7.1.2 Applicazione dell'MVC alle Web Application J2EE
In una Web Application J2EE, il paradigma MVC si applica secondo il seguente schema di
fig. 7-3.
Ovviamente ci sono piccole differenze, ma queste sono dovute al tipo di architettura, anche
se l'idea di fondo è la stessa. La servlet solitamente prende i dati inviati dal browser, istanzia
un JavaBean e ne setta le proprietà di classe con i valori presi; quindi richiama i metodi del
JavaBean, che è in grado di ottenere ed elaborare i dati. Successivamente la servlet fa un
forward della request ad una JSP che, presi i dati di interesse dal JavaBean, li formatterà
secondo il layout prestabilito e li rappresenterà sul video.
Fig. 7-3 MVC nelle applicazioni Web
Una tale architettura rende possibile la divisione della logica applicativa dalla sua
rappresentazione, così da minimizzare il grado di accoppiamento tra gli oggetti. In pratica,
essa permette di slegare chi fa HTML da chi produce codice Java, in modo che tutti possano
lavorare contemporaneamente. I programmatori non si devono più preoccupare di scrivere
servlet con centinaia di righe HTML, e chi fa HTML non si deve preoccupare di conoscere
Java (ovviamente all'inizio si devono prendere delle convenzioni, fissate dall'analista).
Se in produzione ci dicono di dover cambiare la pagina HTML in ingresso o dei risultati,
magari per aggiungere un banner o delle promozioni, basta modificare o l'HTML o la JSP con
un comune editor. Alla successiva chiamata di quella funzione, la JSP viene ricompilata in
automatico e l'utente vedrà la nuova versione, con il vantaggio che non è stato necessario nè
fermare il servizio nè toccare il codice della business logic.
91
Capitolo 7 - Progetto dell’applicazione
7.1.3 L’architettura di News Archive System
La necessità di effettuare un porting del sistema precedente (Internet TV fase 2) verso
architetture open-source svincolandosi, quindi, da un database commerciale come Tamino, ha
portato a “scommettere” su un progetto nuovo e più che mai vivo come Xindice, il database
XML nativo di Apache, di cui si è già discusso.
La necessità di costruire un’applicazione modulare, riusabile e scalabile ha giustificato la
scelta di utilizzare un’architettura J2EE semplificata (Tomcat ha il ruolo di Servlet Engine e
di Application Server) basata su MVC, implementando, in più, un persistance layer tramite il
pattern J2EE Data Access Object (DAO).
Fig. 7-4 Architettura di News Archive System
Il DAO può essere inteso come uno “strato software” che fa sì che l’interazione con il
database sia delegata e ristretta solo a poche classi - che nello specifico sono quelle che
iniziano con il prefisso Xindice - così che un eventuale cambio di database comporta la sola
riprogrammazione di queste classi. Si noti che, rispetto alla tipica implementazione del MVC,
in questo caso, i JavaBean sono destinati solo a ruolo di contenitori dei dati scambiati tra
utenti e database, e non interagiscono con il database.
Si è scelta una architettura J2EE semplificata perché i bisogni dell’applicazione non sono
di fascia alta: non bisogna, ad esempio, gestire la concorrenza (gli accessi sono tutti read-only
ed esiste un solo amministratore che “scrive”), né implementare la sicurezza, cose che, però
sono il naturale sviluppo di questa applicazione e che, con il lavoro fatto in questa fase,
possono essere molto agevolate, in termini di riutilizzo di codice e di struttutura applicativa.
Essendo la riusabilità la principale linea guida, è sembrato giusto “ripartire” da alcuni
spunti della precedente fase (visualizzazione dei dati mediante XSL, adozione di un database
XML nativo) per poi adattarli e trasformarli alle nuove esigenza.
92
Capitolo 7 - Progetto dell’applicazione
E’ sembrato pertinente continuare ad utilizzare un database XML nativo, non solo perché
uno degli obiettivi principali era il porting di Tamino in un database XML open source, ma
anche perché lo standard MPEG-7, utilizzato per la descrizione dei telegiornali, è orientato ai
documenti e quindi, avendo a che fare con dati esclusivamente sotto forma di file XML, non
sono necessari mapping verso altre strutture dati.
7.2
Il modello dei dati: un XML Schema conforme a MPEG-7
Dopo che nel capitolo 6 si è parlato delle specifiche dell’applicazione, in relazione alle
funzionalità da offrire agli utenti del sistema, qui si descriveranno le specifiche sui dati. Sulla
base delle argomentazioni affrontate nel capitolo 5 è stato costruito uno schema per i dati,
riprendendo lo schema definito nella seconda parte di progetto (ripulendolo di alcune
ridondanze), secondo le esigenze riscontrate nell’ambiente applicativo della Teca Fast Rai. In
questo paragrafo, si descriverà tale schema, in relazione anche agli MDS dell’MPEG-7
utilizzati, di cui verrà data una spiegazione semantica.
7.2.1
Le specifiche per i dati
I dati (in questo caso si può parlare, in realtà, di documenti) di cui si vuole tenere traccia
sono i telegiornali che rappresentano l’entità minima di memorizzazione; nel database si avrà
un file per ogni telegiornale nella collezione News. La considerazione logica basilare è che
ogni telegiornale è costituito da più servizi.
Un documento contiene i metadati riguardanti le informazioni di creazione del documento
stesso (autore, data di creazione) e la descrizione del contenuto. Il telegiornale (e quindi il suo
contenuto) è visto sotto il punto di vista di risorsa multimediale (piuttosto che, ad esempio, di
come un utente lo acceda o lo “usi”) e in quanto tale, sono d’interesse informazioni come:
•
la data di messa in onda, la durata del telegiornale, la collocazione fisica della
risorsa;
•
il conduttore, l’emittente, il regista, il direttore di produzione e della fotografia;
•
le coordinate di creazione (luogo e data di registrazione del telegiornale);
93
Capitolo 7 - Progetto dell’applicazione
•
la classificazione della risorsa e il target di pubblico (un telegiornale può essere
classificato come “magazine” e consigliabile ad un pubblico di età maggiore ai
dieci anni);
•
informazioni sui diritti della risorsa;
•
informazioni relative alla decomposizione della sorgente della risorsa (formato,
bitrate, framerate).
L’importante distinzione logica tra telegiornale e servizi fa sì che sia d’interesse
memorizzare le seguenti informazioni relative ai servizi:
•
il giornalista autore del servizio, il genere del servizio e una sua descrizione
semantica;
•
la durata e la sua collocazione temporale all’interno del telegiornale
corrispondente.
7.2.2
Definizione dello schema per l’applicazione
In base alle specifiche, sono stati individuati nello standard MPEG-7, dei D e DS per
descrivere i dati di interesse. Nel far questo, si è utilizzato come linea guida anche lo schema
definito nella fase 2 del progetto, normalizzandolo e riorganizzandolo.
La figura di seguito mostra la struttura dell‘XML Schema, conforme a MPEG-7, relativo
alla reltà d’interesse.
Fig. 7-5 Struttura dei dati per la descrizione dei telegiornali RAI
Facendo riferimento all’introduzione fatta sui tipi di dato, i Descriptor e i Description
Schema base impiegati da MPEG-7 MDS, si vogliono ora illustrare i singoli strumenti di
descrizione implementati nella costruzione della struttura dati del documento.
94
Capitolo 7 - Progetto dell’applicazione
7.2.3
L’elemento DescriptionMetadata
Partendo dall’elemento radice analizziamo tutta la struttura e il tipo di informazioni che
sono state inserite. Il primo elemento, di livello superiore, è DescriptionMetadata.
Fig. 7-6 L’elemento DescriptionMetadata
L’elemento DescriptionMetadata fa riferimento al DescriptionMetadata DS dello standard
MPEG-7 per descrivere le informazioni riguardanti la descrizione stessa (metadati sui
metadati).
Il DescriptionMetadata DS riporta informazioni riguardanti l’identificazione della
descrizione (privata o pubblica), la creazione della descrizione, e i diritti associati alla
descrizione stessa (che diventa un contenuto di valore).
Nel caso di News Archive System si è utilizzato un sottoinsieme dei descrittori messi a
disposizione da Description Metadata DS, la cui semantica è raffigurata nella fig. 7-7.
DescriptionMetadataType
Descrive i metadati riguardo i metadati stessi
Nome
Descrizione
Comment
Descrive i commenti riguardo alla
descrizione a cui viene allegato tale
DS, utilizzando una annotazione di
tipo testuale.
Creator
Descrive un autore della descrizione
cui viene allegato questo DS.
Questo può essere una persona,
un’organizzazione,
o
un’applicazione
software
che
genera
automaticamente
i
metadati. Diversi creatori sono
consentiti se i metadati sono stati
creati
come
risultato
della
cooperazione di diversi soggetti.
CreationTime
Descrive
l’istante
in
cui
la
descrizione cui tale DS è allegato è
stata creata.
Fig. 7-7 Semantica dei descrittori di DescriptionMetadata DS utilizzati
95
Capitolo 7 - Progetto dell’applicazione
In particolare, si è scelto un DescritionMetadata DS che possiede i tre descrittori Top
Level: Comment DS, Creator DS e CreationTime D. Il Comment DS permette l’inserimento
di elementi FreeTextAnnotation, ovvero testo liberamente scelto dal creatore del documento
MPEG-7. Il Creator DS, attraverso gli elementi Role e Agent, permette di identificare i
creatori stessi ed il CreationTime D indica la data di creazione del documento.
Fig. 7-8 Struttura gerarchica del DescriptionMetadataType
7.2.4 L’elemento MediaLocator: localizzazione temporale e fisica della risorsa
Si passa quindi a descrivere il contenuto multimediale stesso, attraverso una serie di
descrittori tutti derivanti dall’AudioVisual DS, che a sua volta è un Top Level Type di
MultimediaContent DS e, in ultima analisi, di ContentDescription DS.
Fig. 7-9 L’elemento MediaLocator
MediaLocator DS è il primo di questi descrittori ed è inserito per contenere le informazioni
sulla localizzazione temporale o fisica della risorsa multimediale, sia essa interna o esterna
alla descrizione.
96
Capitolo 7 - Progetto dell’applicazione
Tipiche informazioni possono essere la data e l’ora di trasmissione sulla rete nazionale
pubblica (come in questo caso), ma anche dati utili al collegamento fisico del contenuto
multimediale, come l’indirizzo del server dove risiede la risorsa fisica, come si vedrà in
seguito, quando si analizzerà la struttura logica (divisione in sequenze).
Non va dimenticato che le informazioni di inizio trasmissione (data e ora) e sulla locazione
fisica della sequenza, sono fondamentali per l’individuazione della risorsa, attraverso gli
attuali sistemi di richiesta audiovisivi all’interno degli archivi RAI.
In particolare, per specifica di progetto dettata dai responsabili dell’archivio digitale Teca
Fast, le due informazioni temporali di time code di inizio e data di trasmissione sono
necessarie per poter effettuare una richiesta del programma individuato, attraverso una
connessione intranet al sistema Teca Fast (assieme all’altra informazione fondamentale
dell’identificatore del canale televisivo sul quale è stato trasmesso il programma).
L’elemento AudioVisual consente di istanziare un elemento figlio proprio di tipo
MediaLocator, che risulta, quindi, molto utile per l’identificazione, ad un livello gerarchico
sufficientemente elevato, di queste informazioni fondamentali.
In News Archive System, essendo la risorsa esterna alla descrizione, si utilizza il
descrittore MediaUri D per la localizzazione fisica, mentre per la localizzazione temporale,
vengono utilizzate un punto temporale e una durata attraverso il descrittore MediaTime DS
che verrà illustrato più avanti.
Fig. 7-10 Struttura gerarchica di MediaLocatorType
7.2.5
L’elemento StructuralUnit: il ruolo del segmento Audio-Video
StructuralUnit DS descrive il ruolo del segmento nella struttura dell'intero contenuto
multimediale a cui appartiene. Le unità strutturali del contenuto multimediale dipendono dalla
97
Capitolo 7 - Progetto dell’applicazione
classificazione del contenuto multimediale. Per esempio, la notizia, il sommario o il rapporto,
possono essere le unità strutturali in un programma di notizie; la storia, la scena e la sequenza
potrebbero essere le unità strutturali in un movie.
Fig. 7-11 L'elemento StructuralUnit
I possibili valori per un’unità strutturale possono essere:
•
“logical” : quando si riferisce all’intera struttura logica;
•
“physical” : quando si riferisce al file fisico;
•
“description” : quando si riferisce alla descrizione vera e propria della risorsa
audiovisiva creata con un MPEG-7 editor;
•
“structure” : quando si riferisce alla descrizione della struttura logica in cui è stata
divisa le risorsa audiovisiva.
StructuralUnit DS viene utilizzato molte volte all’interno dello schema definito, ma in questa
posizione ha valore “logical”, stando a significare che il telegiornale è l’unità logica
fondamentale.
7.2.6
L’elemento CreationInformation: creazione e classificazione
I metadati riguardanti la creazione (ad esempio regia, conduttore, titolo) e la classificazione
(ad
esempio
format,
genere)
del
telegiornale,
sono
contenuti
nell’elemento
CreationInformation della struttura dati progettata. Tali informazioni sono suddivise in due
sottoblocchi separati, inglobate negli elementi Creation e Classification.
98
Capitolo 7 - Progetto dell’applicazione
Gli strumenti di descrizione necessari alla descrizione dei metadati possono essere generati
da operatori umani o estratti da altri database riguardanti il processo di generazione e
produzione del contenuto multimediale.
Fig. 7-12 L’elemento CreationInformation
In generale, il CreationInformation DS di MPEG-7 contiene:
•
Informazioni riguardanti il processo di creazione che non possono essere
“percepite” nel materiale audiovisivo o multimediale (ad esempio l’autore di una
sceneggiatura, il regista di un film o il target di utenza) e informazioni sul processo
di creazione che, invece, possono essere “percepite” nel contenuto multimediale
(ad esempio gli attori nel video, i musicisti in un concerto);
•
Le informazioni di classificazione (ad esempio l’audience, il genere, la fascia di età
consigliata).
La figura seguente rappresenta i descrittori, derivanti da CreationInformation DS, che sono
stati utilizzati nella definizione dello schema per News Archive System.
Fig. 7-13 Struttura gerarchica di CreationType
99
Capitolo 7 - Progetto dell’applicazione
CreationInformationType
Descrive le caratteristiche legate alla creazione del contenuto
multimediale
Nome
Definizione
Creation
Descrive da chi, quando, dove il
contenuto multimediale è stato
creato.
Classification
Descrive la classificazione orientata
all’utente e al servizio del contenuto
multimediale.
Fig. 7-14 Semantica di CreationInformationType
Andiamo ad analizzare in dettaglio la semantica riguardo gli elementi Creation, prima, e
Classification, poi.
Creation Descritpion Scheme
Nella fig. 7-15, sono raffigurate le descrizioni semantiche riguardanti l’elemento Creation e
i descrittori di livello superiore utilizzati nella definizione dello schema.
In News Archive System, il regista, il direttore di produzione e della fotografia e il
conduttore stesso sono considerati “creatori” del contenuto multimediale, ognuno con un
differente ruolo. Questa situazione è modellata utilizzando il descrittore Creator DS, la cui
semantica è illustrata in fig. 7-16.
CreationType
Descrive la creazione del contenuto, incluse location, date, azioni,
materiali, personale dello staff (tecnico e artistico) e organizzazioni
coinvolte
Nome
Definizione
Title
Descrive un titolo testuale del contenuto
multimediale. Sono consentiti diversi
titoli. Questi possono corrispondere a
differenti tipi (indicati dall’attributo tipo)
o a differenti linguaggi.
Creator
Descrive un creatore del contenuto
multimediale. Esso consente di descrivere
persone, organizzazioni, gruppi, etc.
coinvolti nella creazione assieme col ruolo
ricoperto.
CreationCoordinates
Descrive il posto e la data di creazione
del contenuto multimediale.
Fig. 7-15 Semantica di CreationType
100
Capitolo 7 - Progetto dell’applicazione
CreatorType
Descrive il creatore del contenuto multimediale o della descrizione.
Il creatore può essere una persona (o più), o un gruppo (o più
gruppi), o una o piu’ organizzazioni coinvolte nel processo di
creazione
Nome
Definizione
Role
Descrive il ruolo giocato dal creatore nel processo
di creazione. Un esempio di schema di
classificazione
per
questo
elemento
è
MPEG7RoleCS.
Agent
Descrive l’agente (persona, organizzazione
gruppo) coinvolto nella creazione.
o
Fig. 7-16 Semantica di CreatorType
Inoltre, sono necessarie informazioni riguardo il luogo e la data esatta di creazione della
risorsa multimediale. A questo scopo è stato inserito il descrittore CreationCoordinates DS di
cui si fornisce la seguente descrizione semantica.
CreationCoordinatesType
Descrive il luogo e la date di creazione della risorsa multimediale
Nome
Definizione
CreationLocation
Descrive il luogo di creazione,
ovvero la locazione geografica della
sede, il tipo di struttura (ad
esempio uno studio di produzione
piuttosto che un teatro) ed il nome
del complesso edilizio (ad esempio
Saxa Rubra, cinema “Corso”, e via
dicendo).
CreationDate
Descrive la data di creazione
secondo il descrittore TimePoint D.
Fig. 7-17 Semantica di CreationCoordinatesType
Classification Description Scheme
L’elemento Classification fa riferimento allo schema di descrizione di MPEG-7
Classification DS.
101
Capitolo 7 - Progetto dell’applicazione
Fig. 7-18 Struttura gerarchica di ClassificationType
Questo descrive le informazioni di classificazione del contenuto multimediale. Le
descrizioni risultanti facilitano la ricerca e filtraggio di contenuti multimediali, basandosi sulle
preferenze dell’utente (come ad esempio lingua, stile, genere) e le classificazioni orientate al
servizio (come ad esempio scopo, fasce d’età, segmentazione del mercato, recensione da parte
dei media). La fig. 7-19 ne illustra la semantica.
ClassificationType
Descrive la classificazione del contenuto multimediale
Nome
Definizione
Form
Descrive
il
tipo
di
produzione
del
documento, come ad esempio, film,
telegiornale (news), programma, magazine,
documentario.
Genre
Descrive di cosa si occupa il contenuto
multimediale (classificazione piu’ ampia)
come ad esempio sport, politica, economia.
Target
Descrive
il
target
del
contenuto
multimediale in termini di classificazione di
mercato, età e nazionalità.
Fig. 7-19 Semantica di ClassificationType
7.2.7
L’elemento UsageInformation: uso del contenuto audiovisivo
L’elemento UsageInformation fa riferimento alla parte di descrizione che specifica le
informazioni riguardo l’uso del contenuto multimediale.
Nella figura seguente è possibile vedere la collocazione gerarchica di tale elemento nella
struttura dello schema.
102
Capitolo 7 - Progetto dell’applicazione
Fig. 7-20 L’elemento UsageInformation
Con UsageInformation DS si possono implementare descrittori sia per poter ottenere
informazioni sui diritti, sia per descrivere i costi e i ricavi generati dal contenuto
multimediale, sia per descrivere i dettagli riguardanti la disponibilità del contenuto
multimediale per l’uso; inoltre è possibile descrivere i dettagli concernenti l’uso del contenuto
multimediale. In News Archive System, viene utilizzato per descrivere le informazioni sui
proprietari e sui diritti delle risorse:
Fig. 7-21 Struttura gerarchica di UsageInformationType
Il descrittore Rights DS descrive le connessioni coi proprietari dei diritti d’autore del
contenuto multimediale (IPR, Intellectual Property Rights) e i diritti di accesso (Access
Rights).
La proprietà dei diritti è dinamica e, in quanto tale, può passare da un proprietario ad un
altro. Per esempio, i diritti per una produzione televisiva (o parte di essa) sono spesso
licenziati e assegnati. Per consentire ai sistemi informatici di rilevare la situazione attuale dei
diritti, Rights DS trasporta un identificatore che può essere interpretato attraverso un’apposita
agenzia.
Per gli scopi della gestione dei diritti, (peraltro oggetto di un successivo lavoro di sviluppo
da parte dei committenti di questa sperimentazione) tali agenzie e sistemi devono
103
Capitolo 7 - Progetto dell’applicazione
progressivamente essere in grado di abilitare i proprietari di diritti d’autore a dichiarare
l’identità del proprietario attuale dei diritti stessi.
In questa fase si intende la proprietà dei diritti come un’entità trattata staticamente,
prevedendo, inizialmente, che tali informazioni vengano inserite all’atto della creazione della
descrizione del contenuto audio-visivo di un programma. Si prevede in successive revisioni di
approfondire questa tematica di grande interesse per i proprietari di diritti, sui contenuti di
grandi dimensioni, come la RAI.
7.2.8
L’elemento MediaTime
In MediaTime DS, vengono racchiuse informazioni temporali per la corretta descrizione
del telegiornale.
Fig. 7-22 L’elemento MediaTime
Le informazioni di inizio e durata della sequenza sono fondamentali per l’individuazione
della risorsa attraverso il motore di ricerca implementato nel corso di questo progetto.
In particolare, per specifica di progetto, le due informazioni temporali sono necessarie per
poter visualizzare un determinato sevizio del telegiornale individuato attraverso una
connessione remota al Server di streaming.
Vale la pena descrivere in modo generale il descrittore MediaTime DS, poiché il suo uso è
diffuso in tutto lo schema: esso specifica una nozione del tempo che è codificato con il media
descritto. Per l’individuazione degli intervalli di tempo, MediaTime DS è composto di due
elementi: il tempo di inizio e la durata. Se deve essere specificato un solo riferimento
temporale, la durata può essere omessa.
104
Capitolo 7 - Progetto dell’applicazione
MediaTimeType
Uno schema di descrizione per la specifica di un riferimento
temporale del media o di un intervallo temporale del media, che
utilizza I descrittori seguenti per specificare il tempo
Nome
Definizione
MediaTimePoint
Un
elemento
che
specifica
un
riferimento temporale del media
utilizzando la data Gregoriana e il
tempo giornaliero.
MediaRelTimePoint
Un
elemento
che
specifica
un
riferimento temporale del media
utilizzando un numero di giorni e l’ora
giornaliera.
MediaDuration
Un elemento che specifica la durata di
un periodo di tempo del media
fornendo i giorni e l’orario (opzionale).
MediaIncrDuration
Un elemento che specifica la durata di
un periodo di tempo del media
contando le unità temporali.
Fig. 7-23 Semantica di MediaTimeType
MediaTime DS utilizza due diverse modalità per descrivere un riferimento temporale o un
periodo:
•
Utilizzando il formato Gregoriano di data e orario (MediaTimePoint D,
MediaRelTimePoint D, MediaDuration D).
•
Contando
le
unità
temporali
specificate
attraverso
degli
attributi
(MediaIncrDuration D). Nel caso di segmenti video, queste unità temporali
possono corrispondere al frame rate.
Un diagramma della struttura del MediaTime DS implementato, viene riportato nella
seguente figura:
Fig. 7-24 Diagramma del MediaTimeType
105
Capitolo 7 - Progetto dell’applicazione
Sebbene in questa parte dello schema si utilizzino solo i descrittori MediaRelTimePoint D
e MediaIncrDuration D, si vuol dare una descrizione generale degli strumenti di MediaTime
DS.
Il MediaTimePoint D specifica un istante di inizio, secondo l’orario Gregoriano. Il formato
si basa sulla norma ISO 8601.
Il MediaTimePoint D specifica un riferimento temporale del media utilizzando la data e
l’orario Gregoriano senza specificare il TZD, Time Zone Difference (a questo proposito si
rimanda alla definizione del tipo di dato TimePoint nel listato completo di MDS Schema
MPEG-7 documento FCD N3966).
Il formato del valore del descrittore MediaTimePoint D è: YYYY-MM-DDThh:mm:ss:nnn
FNNN.
I simboli utilizzati per le cifre dei corrispondenti elementi di data e tempo sono i seguenti:
•
Y: Year, Anno che può essere un numero variabile di cifre, (la data può anche
essere omessa);
•
M: Month, Mese;
•
D: Day, Giorno;
•
h: hour, ora;
•
m: minute, minuto;
•
s: second, secondo;
•
n: numero di frazioni, nnn può essere un numero arbitrario di cifre tra 0 e NNN-1
(NNN e con esso nnn possono avere un numero di cifre arbitrario);
•
N: numero di frazioni di un secondo che vengono tenute in conto da nnn. NNN può
avere un numero arbitrario di cifre non limitato a tre.
Vengono utilizzati anche dei delimitatori per la specifica dell’orario (T) e il numero delle
frazioni di secondo (F).
Parallelamente alla specifica della data Gregoriana, per consentire una precisione maggiore
del secondo, è disponibile la specifica del time code di orario con il conteggio del numero
(nnn) delle frazioni di secondo (FNNN). Se viene utilizzato il conteggio delle frazioni, il
numero di frazioni che costituiscono un singolo secondo (FNNN) deve essere specificato
106
Capitolo 7 - Progetto dell’applicazione
insieme al numero di conteggio delle frazioni (nnn). Attraverso FNNN si definisce intervallo
di valori del numero conteggiato di frazioni di secondo (nnn). Quindi l’intervallo di valori di
‘nnn’ è limitato tra 0 e FNNN-1.
Il MediaRelTimePoint D, così come il MediaDuration D, utilizza un diverso formato per
l’espressione di istanti temporali “relativi”, il primo, e durate, il secondo. Non c’è quindi il
riferimento ad una data, come nel calendario Gregoriano, ma solo espressioni di tempo e
relative frazioni. Il formato del frammento di dato di interesse è il seguente:
hhHmmMssSnnNNNF con un significato dei simboli del tutto equivalente a quanto sopra
esposto, e con i caratteri in grassetto obbligatori.
Il MediaIncrDuration D, infine, viene utilizzato in modo specifico sia per definire la durata
dell'intero video sia per le singole sequenze. Il suo valore è espresso in frame. Per poter
ottenere un formato di tempo compatibile con i parametri utilizzati da Real Server è
necessario convertire il valore espresso dall’elemento MediaIncrDuration. Il formato fa
riferimento ad un sottoinsieme della norma ISO 8601 (per ridurre i problemi di conversione).
Le frazioni di secondo sono specificate in accordo con quanto dichiarato nell’attributo
timeUnit dell’elemento MediaIncrDuration, ed in modo consistente con tutti gli altri
riferimenti temporali nel documento.
7.2.9
L’elemento MediaSourceDecomposition : descrizione fisica del
contenuto
Le informazioni fisiche del file come dimensioni, formato e una serie di parametri sulla
codifica
del
contenuto
video,
vengono
descritte
mediante
MediaSourceDecomposition.
Fig. 7-25 L’elemento MediaSourceDecomposition
107
l’elemento
Capitolo 7 - Progetto dell’applicazione
Il contenuto della descrizione MPEG-7, infatti, può essere disponibile in diverse modalità,
formati, schemi di codifica, e di esso possono essere disponibili diverse istanze. Per esempio
un evento sportivo può essere registrato in due diverse modalità, audio e audio-video. Ognuna
di queste due modalità può essere codificata con diversi algoritmi di codifica. Questo
comporta la creazione di diversi profili del media. Inoltre possono essere rese disponibili
diverse istanze o copie di uno stesso contenuto multimediale per una data codifica.
Per descrivere tali informazioni si utilizza l’elemento MediaInformation, che viene
instanziato dopo MediaSourceDecomposition, che identifica e descrive le informazioni
specifiche del supporto e del formato del contenuto multimediale.
Fig. 7-26 Struttura gerarchica di MediaInformationType
Il MediaInformation DS può essere composto da uno o più MediaProfile DS.
Il MediaProfile DS descrive un profilo del contenuto multimediale oggetto della
descrizione. Il concetto di profilo fa riferimento alle diverse variazioni che possono essere
prodotte da un supporto originale, a seconda dei valori scelti di volta in volta per la codifica, il
formato di memorizzazione, e via dicendo. Il profilo corrispondente al documento
multimediale originale, o ad una sua copia master, viene considerato come il profilo master o
“master media profile”. Per ogni profilo possono esserci una o più istanze del profilo master.
In News Archive System, MediaProfile DS instanzia un descrittore MediaFormat DS.
Il MediaFormat DS (il tipo che definisce l’omonimo elemento MediaFormat istanziato
nello schema) fornisce informazioni relative al formato del file e ai parametri di codifica del
MediaProfile.
Importante è analizzarne la semantica, ricca di elementi che descrivono il formato
dell’istanza di contenuto multimediale:
108
Capitolo 7 - Progetto dell’applicazione
MediaFormatType
Descrive il formato e i parametri di codifica del MediaProfile
Nome
Definizione
Content
Identifica il media presente nel
contenuto multimediale.
Medium
Descrive
il
supporto
di
memorizzazione fisica sul quale il
Mediaprofile è memorizzato.
Descrive il
MediaProfile.
FileFormat
formato
file
del
FileSize
Indica la dimensione in bytes del
file in cui il MediaProfile è
memorizzato.
System
Descrive il formato del profilo del
media a livello broadcast, un
esempio di valore è il sistema
televisivo “PAL”.
BitRate
Indica il bit rate nominale in bit/s
del Media Profile.
VisualCoding
Descrive
la
codifica
della
componente
visiva
del
MediaProfile.
Se una entità di contenuto è
audiovisiva,
VisualCoding
e
AudioCoding
sono
entrambe
utilizzati.
VisualCoding
Format
Descrive il formato di codifica
della
componente
video
del
MediaProfile. Come sopra, se una
entità di contenuto multimediale è
audiovisiva,
VisualCoding
e
AudioCoding
sono
entrambe
utilizzati.
aspectRatio
Descrive l’aspect ratio (fattore di
forma)
dei
pixel
(larghezza/altezza).
Frame
Descrive il frame dell’immagine e
i frame video.
height
Indica l’altezza delle immagini e
dei frames in pixel.
Width
Indica la larghezza delle immagini
e dei frames in pixel. Il quoziente
di larghezza e altezza è il fattore
di forma del campionamento, che
è come il fattore di forma
dell’immagine ottica se il pixel è
quadrato.
Rate
Indica il frame rate in Hz.
Fig. 7-27 Semantica di MediaFormatType
109
Capitolo 7 - Progetto dell’applicazione
7.2.10 L’elemento TemporalDecomposition : descrizione delle singole sequenze
Analizziamo adesso in dettaglio come è possibile descrivere le singole sequenze video una
volta che queste sono state individuate. E’ fondamentale riuscire ad avere una struttura
flessibile e semplice, così da permettere query il più possibile precise. Nel caso di News
Archive System, le sequenze individuano il singolo servizio giornalistico. La possibilità di
ricercare e visualizzare singole sequenze video, rende questa applicazione, come da specifiche
RAI, utilizzabile come prototipo di riferimento.
La struttura logica del video viene dinamicamente mappata nel documento MPEG-7 e i
riferimenti temporali di inizio e durata della sequenza vengono inseriti nel documento MPEG7.
Fig. 7-28 L’elemento TemporalDecomposition
TemporalDecomposition DS è lo schema di descrizione che identifica come si intende
dividere la risorsa audiovisiva. In questo caso l’attributo “criteria” ha come valore “structure”
in quanto identifica la struttura logica. Seguono anche gli attributi “overlap” e “gap” il cui
valore per entrambi è “true”, ciò significa che non vi è né sovrapposizione tra le sequenze, né
presenza di spazi vuoti tra le sequenze.
Sono
instanziati,
dopo
AudioVisualSegment quante
L’AudioVisualSegment
l’elemento
TemporalDecomposition,
tanti
elementi
sono le sequenze video che sono state individuate.
DS,
che
deriva
direttamente
dall’AudioVisualSegmentTemporalDecompostion DS di cui si è accennato nel paragrafo
5.4.3, è utile per la conservazione di informazioni sulle singole sequenze ed utilizza gran parte
degli strumenti Top Level già illustrati nei precendenti paragrafi.
110
Capitolo 7 - Progetto dell’applicazione
Fig. 7-29 Struttura gerarchica di TemporalDecompositionType
Analizziamo in dettaglio i singoli elementi che descrivono il servizio giornalistico.
1. MediaLocator DS: contiene informazioni sulla localizzazione della risorsa fisica.
Si inserisce il collegamento al video e al frame chiave. In questa parte della
descrizione verranno usati solo gli elementi Image e MediaUri.
2. StructuralUnit DS: descrive il ruolo del segmento nella struttura del documento,
in questo caso si attribuisce il valore “description” in quanto il segmento AV si
riferisce proprio alla descrizione.
3. CreationInformation DS: contiene informazioni sulla creazione (nome giornalista
ed emittente) e sulla classificazione (genere del servizio).
4. TextAnnotation DS: Contiene una descrizione semantica del singolo servizio.
5. MediaTime DS: Descrive l’intervallo temporale in cui si trova il singolo servizio.
L'inizio (rispetto all'intero telegiornale) e la durata del servizio giornalistico
potrebbero venire inserite automaticamente da un tool di acquisizione e
generazione di descrizioni MPEG-7.
Questi parametri vengono successivamente passati al server di streaming per poter
visualizzare la singola sequenza (servizio giornalistico) descritta. In questo caso sono stati
utilizzati i solo descrittori MediaRelTimePoint D e MediaIncrDuration D.
111
Capitolo 7 - Progetto dell’applicazione
7.3
Progettazione di un sito Internet per News Archive System
7.3.1 Modello concettuale del sito e progetto della navigazione
Fig. 7-30 Il modello concettuale del sito
Questo lavoro di tesi è costituito anche dal sito dell’applicazione News Archive System
(http://62.110.204.10:8080/RAI_project/index.html). La fig. 7-30 descrive il modello
concettuale del sito, pensato in base alle funzionalità da offrire, descritte nel precedente
capitolo. Si può notare come la struttura organizzativa sia gerarchica fino ai primi 2 livelli
(corrispondenti all’identificazione degli attori) e poi più strutturata (a Entità-Relazioni) nei
due livelli successivi.
La seguente figura descrive invece la progettazione degli strumenti di navigazione nel sito.
Seppure il sito non sia vasto, per agevolare ogni utente, è stata creata una piccola barra di
navigazione per raggiungere le pagine di interesse.
Fig. 7-31 Gli strumenti di navigazione
112
Capitolo 7 - Progetto dell’applicazione
Per un amministratore dovrà essere sempre possibile raggiungere la sua pagina iniziale (in
sostanza, fare il logout) e la pagina di informazioni, mentre per un utente deve essere sempre
possibile ritornare alla homepage del sito e della parte utente e consultare la pagina di
informazioni.
7.3.2 Supporto per gli utenti e versione in lingua inglese
In questa fase, è stato utile pensare alla possibilità di fornire una piccola guida che
aiutasse l’utente nelle operazioni e alla possibilità di fornire l’intero sito anche in lingua
inglese. La decisione presa è un compromesso che consite nell’aver implementato una guida
in lingua italiana che supporti l’utente, che sia di facile comprensione e agevoli l’utilizzo del
sito, mantenendo il sito in lingua inglese. Inoltre, sia la pagina iniziale che quella di
informazioni sono presenti sia in lingua italiana che inglese. Questa soluzione “ibrida” è
sembrata la più efficace perché può raccogliere un bacino di utenza molto più vasto (gli utenti
italiani sono supportati dalla guida, quelli “english-speaker” dal contenuto del sito) e perché si
può semplicemente specializzare la guida per una determinata lingua.
113
Capitolo 8 - Implementazione
CAPITOLO 8
Implementazione
In questo capitolo si descriverà l’implementazione dell’applicazione News Archive
System, facendo uso di class diagram UML, in particolare degli stereotipi per descrivere le
applicazioni Web e di sequence diagram di sistema “reali”, nei casi più significativi e più
complessi.
Le convenzioni stilistiche adottate sono raffigurate nella figura seguente, tenendosi il più
possibile vicini agli standard. Le pagine server side sono state divise in Model (tipicamente
JavaBean e le classi del persistance layer), View (quasi sempre JSP), Controller (servlet),
Helper class (classi ausiliarie, che svolgono funzionalità accessorie) e package (ad esempio, il
modulo di validazione). Si è adottato un riferimento (nella figura, la scritta in blu) per i
collegamenti tra class diagram diversi.
Fig. 8-1 Convenzioni stilistiche
La figura seguente rappresenta la mappa di tutti i class diagram utilizzati per descrivere e
documentare l’applicazione e costituisce una guida per orientarsi in tutto il capitolo.
114
Capitolo 8 - Implementazione
Fig. 8-2 Mappa dei Class Diagram UML
Fig. 8-3 Il class diagram Start
La fig. 8-3 raffigura il class diagram Start: index.html rappresenta l’homepage del sito ed
è, come detto, disponibile anche in lingua inglese come la pagina per le informazioni sugli
115
Capitolo 8 - Implementazione
sviluppatori. I link a homepage.jsp (la home page dell’attore user) e a login.jsp (la homepage
dell’attore administrator) implementano la separazione logica dei ruoli di user e administrator.
8.1
Implementazione delle funzionalità per lo User
La fig. 8-4 raffigura il class diagram User e implementa le due possibili funzionalità
richieste per lo user, ovvero una ricerca per telegiornali e una ricerca per servizi.
Fig. 8-4 Il class diagram User
8.1.1 Ricerca di telegiornali
Le due figure seguenti descrivono la funzione di ricerca di telegiornali da parte dell’user.
La fig. 8-5 è il class diagram News Search e illustra come venga implementato l’MVC in
questo caso; le servlet NewsFormProcess.java e NewsQuery.java svolgono il ruolo di
Controller, il JavaBean NewsBean e il modulo XindiceXpathHandler.java si occupano
rispettivamente di “fotografare” alcuni dati del database e dell’interazione vera e propria con
Xindice (Model), mentre le pagine JSP e la servlet MyTransformer.java si occupano della
presentazione dei dati (View).
Si è deciso di dettagliare più a fondo tale funzionalità fornendo anche il diagramma di
sequenza “reale” (fig. 8-6). Qui si può chiaramente osservare il flusso delle operazioni: la
servlet NewsFormProcess.java setta i dati immessi dall’utente mediante la form_newssearch
nel bean NewsBean.java e gestisce gli errori di input del client, invocando le sue funzioni di
116
Capitolo 8 - Implementazione
validazione per controllare che i dati inseriti dall’utente siano validi (ad esempio, in una
ricerca per fascia oraria, il campo “since” deve essere minore o uguale del campo “to”).
Fig. 8-5 Il class diagram News Search
117
Capitolo 8 - Implementazione
In caso di errore nella validazione, la servlet setta nel bean un attributo “message” e
passerà il controllo alla newssearch.jsp che costruirà la pagina per il client, mostrando una
finestra di avviso dell’errore avvenuto. In caso di input corretto il controllo passa alla servlet.
Fig. 8-6 Il diagramma di sequenza “reale” per una ricerca su telegiornali
118
Capitolo 8 - Implementazione
NewsQuery.java si occupa di costruire la stringa XPath per interrogare Xindice, prendendo
i valori degli attributi dal bean. Il modulo XindiceXpathHandler.java esegue l’interazione con
il database e restituisce i risultati alla servlet NewsQuery.java che passa il controllo alla
servlet MyTransformer.java che si occupa di presentare i dati al client, mediante una
trasformazione con un foglio di stile XSL. A questo punto, l’utente ha la visualizzazione dei
telegiornali che soddisfano i criteri da lui immessi.
L’utente può, ora, voler visualizzare la risorsa (vedi il class diagram Real Server della fig.
8-7) oppure vedere tutti i servizi di quel telegiornale o richiedere un profilo tecnico dettagliato
sul telegiornale. Quest’ultima richiesta è processata dalla servlet ViewMediaProfile.java (il
nome è improprio, perché gestisce entrambi i casi) che interagisce con il database tramite il
modulo XindiceXpathHandler.java e affida sempre a MyTransformer.java il compito di
visualizzare la risposta alla query.
8.1.2 Ricerca per servizi
La ricerca per servizi è architetturalmente identica a quella per telegiornali; si noti qui il
riutilizzo di classi come MyTransformer.java per la processazione dell’XSL e di
XindiceXPathHandler.java per l’interazione con il database (fig. 8-8). Una volta ottenuti i
risultati, anche in questo caso, l’utente ha la possibilità di vedere il singolo servizio oppure il
telegiornale di cui fa parte connettendosi al Real Server, mediante una richiesta rstp, azione
descritta dal riferimento al class diagram Real Server (fig. 8-7).
119
Capitolo 8 - Implementazione
Fig. 8-7 Il class diagram per il Real server
120
Capitolo 8 - Implementazione
Fig. 8-8 Il class diagram Report Search
8.2
Implementazione delle funzionalità per gli amministratori
Una differenza sostanziale tra un user e un administrator è che quest’ultimo deve effettuare
un login per poter accedere alle funzionalità di amministratore, siano esse complete (DM) che
specifiche dell’applicazione (NAA). Inoltre è richiesto che chiunque digiti un indirizzo
corrispondente ad una pagina riservata non abbia accesso a tale risorsa.
Entrambi queste problematiche sono state affrontate ad un livello basic, con l’intenzione
più che altro di incoraggiare lo sviluppo di tali funzionalità in futuro. Infatti, la password
(“ziopino”) di login è unica e “cablata” nel codice, e per la protezione delle pagine JSP
riservate agli amministratori è stato utilizzato un JavaBean di sessione (LoginBean.java).
Fig. 8-9 Il class diagram Administrator Login
Osservando la fig. 8-9, nella LoginFormProcess.java viene settato un attributo nel bean se
la password inserita dall’utente è corretta; tale bean viene usato poi da tutte le pagine JSP
121
Capitolo 8 - Implementazione
degli amministratori per controllare “se si è passati per la pagina di login”, ovvero si hanno i
privilegi di amministratore (NAA o DM). In caso di login effettuato, il controllo passa ad
adminchoice.jsp, la homepage degli amministratori. In caso di password invalida, il controllo
viene rimandato a login.jsp, avendo settato nel bean il messaggio di errore da far stampare in
risposta al client. Da adminchoice.jsp si può scegliere il tipo di amministratore: nel caso si
voglia essere Database Manager si segue il link per currentcollectionview.jsp, mentre nel caso
si voglia essere News Archive Administrator, si segue il link per newsarchiveview.jsp.
Le seguenti figure descrivono tutte le possibili funzionalità di un Database Manager e di un
News Archive Administrator e indicano i riferimenti agli appropriati class diagram che le
descrivono in dettaglio. Si noti come tre delle quattro funzionalità del NAA, vengono
implementate allo stesso modo delle analoghe del DM, magari limitandole parzialmente (nel
NAA si può solo cancellare e inserire documenti all’interno della collezione News, ad
esempio)
Fig. 8-10 Funzionalità del Database Manager
122
Capitolo 8 - Implementazione
Fig. 8-11 Funzionalità del News Archive Administrator
8.2.1 Creare collezioni
La fig. 8-12 descrive l’operazione del Database Manager di creazione di una collezione in
un dato punto del database.
123
Capitolo 8 - Implementazione
Fig. 8-12 Il class diagram Create Collection
currentcollectionview.jsp crea una pagina client e il client sceglie di eseguire l’operazione
seguendo il link a option.jsp la quale costruisce la relativa form in cui si deve inserire il nome
della
collezione.
Successivamente,
la
form
viene
processata
dalla
servlet
CreateFormProcess.java che setta, al solito, il nome della collezione in un attributo del bean,
valida l’input e delega la servlet XindiceInsertCollectionHandler.java di interagire con il
database ed eseguire l’operazione.
8.2.2 Visualizzare documenti
La fig. 8-13 descrive l’operazione, effettuabile sia dal Database Manager che dal News
Archive Administrator, di visualizzazione di un documento XML presente nel database. Una
precisazione da fare è che, quando un’operazione è effettuabile da entrambi i tipi di
amministratore (ed è quindi implementata con le stesse classi), la cosa che differisce sempre è
la vista del database che essi hanno: nel caso di DM, l’utente ha una vista del database
completa tramite la pagina costruita da currentcollectionview.jsp, mentre nel caso di NAA, la
pagina viene costruita da newsarchiveview.jsp e si ha una vista parziale costituita solo dalla
collezione News del database in cui vengono memorizzati i telegiornali. Nei diagrammi UML
per operazioni comuni, c’è sempre currentcollectionview.jsp, che quindi va letta come
newsarchiveview.jsp, per l’operazione relativa al NAA.
Come si vede dalla figura, l’interazione con il database è affidata ad una classe dedicata
XindiceView.java. Essa non è una servlet ma i suoi servizi vengono richiesti da xmlview.jsp
per visualizzare semplicemente il documento XML selezionato. XindiceView.java è una
classe ausiliaria molto utile perché disaccoppia la vista dal modello anche quando si naviga
semplicemente tra le collezioni del database; infatti, essa è utilizzata sempre da
currentcollectionview.jsp (newsarchiveview.jsp) per visualizzare il contenuto di una
sottocollezione (collezione News).
8.2.3 Cancellare elementi
La fig. 8-14 descrive l’operazione, effettuabile sia dal Database Manager che dal News
Archive Administrator, di cancellazione di elementi in una collezione. Tuttavia, il NAA può
124
Capitolo 8 - Implementazione
solo cancellare documenti all’interno della collezione News mentre il DM può cancellare
collezioni e documenti e anche tutte e due contemporaneamente. L’architettura MVC è
rispettata anche in questo caso con la servlet XindiceDeleteHandler.java che si occupa
dell’interazione con il database.
125
Capitolo 8 - Implementazione
Fig. 8-13 Il class diagram View Document
126
Capitolo 8 - Implementazione
Fig. 8-14 Il class diagram Delete Items
127
Capitolo 8 - Implementazione
Fig. 8-15 Il class diagram Insert Document
128
Capitolo 8 - Implementazione
8.2.4 Inserire documenti
La figura precedente descrive l’operazione di inserimento di un documento XML nel
database sia per il News Archive System che per il Database Manager. Questa operazione è
possibile anche da remoto, a differenza del precedente progetto. Si presti attenzione alla
servlet UploadFormProcess.java che riceve la richiesta di una pagina client in cui si è
selezionato un file dall’hard disk e che utilizza la classe ausiliaria UploadFile.java per
effettuare il trasferimento del file nella directory /XmlDocsRepository dell’applicazione.
Successivamente,
si
inserirà
il
documento
nel
database
mediante
la
servlet
XindiceInsertDocumentHandler.java.
Questa parte potrà essere riprogrammata in futuro in maniera più efficiente senza la
necessità di dover prima memorizzare il file sul server per poi inserirlo nel database.
8.2.5 Aggiornare i documenti
Le figure nelle prossime pagine (figg. 8-17 e 9-18) descrivono l’operazione di update di
uno o più documenti on-line, sfruttando il linguaggio XUpdate, supportato da Xindice. Questa
è una delle principali funzionalità aggiuntive implementate in News Archive System.
L’update è tra le operazioni che coinvolgono più classi nell’applicazione intera e, data la sua
importanza, si è deciso di descrivere l’operazione di “inserimento di un elemento in una data
posizione” mediante una sequence diagram di sistema reale.
Si noti nel class diagram l’UpdateBean.java, il bean utilizzato per i valori immessi
dall’utente che servono per costruire la stringa di XUpdate e che possono variare a seconda
delle operazioni richieste. Si è deciso di implementare le operazioni di update riassunte nella
figura sottostante:
Operazione
Parametri richiesti
Creazione di un nodo figlio
Inserimento di un elemento
prima o dopo di uno dato
Inserimento di un attributo
129
•
Espressione XPath
•
Nome del tag
•
Espressione XPath
•
Nome del tag
•
Contenuto dell’elemento
•
Espressione XPath
Capitolo 8 - Implementazione
Inserimento di un elemento o
attributo in una data posizione
•
Nome dell’attributo
•
Valoredell’attributo
•
Espressione XPath
•
Nome del tag
•
Contenuto dell’elemento o
attributo
Aggiornamento del contenuto di
un elemento o attributo
•
Posizione desiderata
•
Espressione XPath
•
Contenuto dell’elemento o
attributo
Rinominazione di un elemento o
•
Espressione XPath
attributo
•
Nuovo nome
•
Espressione XPath
Cancellazione di un elemento o
attributo
Validazione contro l’XML
Schema
Fig. 8-16 Operazioni di update implementate
Si noti nel class diagram di fig. 8-17 la servlet XindiceXUpdateHandler.java che si occupa
dell’interazione con il database per eseguire l’operazione di XUpdate.
La fig. 8-18 illustra un sequence diagram si sistema “reale”: l’utente, spuntando gli
elementi, (è possibile fare XUpdate anche per più di un documento) richiede che questi siano
aggiornati; la servlet FormProcess.java elabora la richiesta, validando l’input e settando in un
attributo del bean AdminBean.java i nomi dei documenti da aggiornare. Successivamente, il
controllo passa alla xmlUpdate.jsp che si occupa di visualizzare lo schema (nel caso di più
documenti selezionati) o il singolo documento, affiancato da una barra degli strumenti con
tutte le possibili opzioni dell’XUpdate; scegliendone una, Update.jsp costruirà una pagina
client contenente la form di inserimento dei valori per eseguire l’XUpdate. Una volta inviati
tali dati, la servlet XupdateFormProcess.java, li processerà, li setterà nel bean e poi li
validerà, avvisando, come di consueto, l’utente in caso di input scorretto o incompleto. In
caso positivo, il bean costruirà la stringa di XUpdate che verrà passata al modulo
XindiceXUpdateHandler.java, che eseguirà l’aggiornamento e validerà anche i file aggiornati
contro lo schema XML. Il risultato del processo di validazione non influirà sulla procedura di
aggiornamento, rendendo quindi possibile ottenere documenti XML ben formati ma non
validi secondo lo schema definito. Tutte queste informazioni verranno visualizzate al client e
130
Capitolo 8 - Implementazione
nel caso in cui i documenti non siano validi, verranno restituiti dei suggerimenti dei tag da
utilizzare.
Fig. 8-17 Il class diagram Update
131
Capitolo 8 - Implementazione
Fig. 8-18 Il diagramma di sequenza “reale” per un’operazione di update
132
Capitolo 8 - Implementazione
8.2.6 Creare un documento MPEG-7 per la descrizione dei telegiornali RAI
Una funzionalità specialistica del News Archive Administrator, come già accennato, è
quella di avere la possibilità di creare documenti che descrivano i telegiornali secondo lo
schema definito, svincolando completamente così l’utente NAA dalla conoscenza della
tecnologia XML, degli schemi e, in definitiva, da MPEG-7 stesso. In questo modo, si fornisce
una funzionalità che riduce drasticamente la possibilità di errori e il tempo necessario a creare
la descrizione di un telegiornale. L’Mpeg7Bean.java è il bean utilizzato per conservare alcuni
dei parametri immessi dall’utente, in particolare quelli che occorrerà riutilizzare in seguito. La
logica è quella di “appendere” un servizio dopo l’altro (un Audio Visual Segment, secondo la
nomenclatura di MPEG-7): la servlet che processa la form di immissione ai dati è
CreationDocumentFormProcess.java che setta i dati nel bean e inserisce il documento
mediante la già citata XindiceInsertDocumentHandler.java memorizzando prima il nuovo file
su disco e poi inserendolo nel database. Si noti in fig. 8-19 che successivamente si possono
appendere ulteriori AudioVisualSegment, inserendo altri dati in una form, processata dalla
servlet appendAudioVisualSegment.jsp. La fig. 8-20 mostra, invece, il sequence diagram di
sistema “reale” di questa operazione che dovrebbe risultare, a questo punto, facilmente
interpretabile.
133
Capitolo 8 - Implementazione
Fig. 8-19 Il class diagram CreateMpeg7Doc
134
Capitolo 8 - Implementazione
Fig. 8-20 Il diagramma di sequenza “reale” per la creazione di un documento MPEG-7
135
Capitolo 9 - Uso dell’applicazione
CAPITOLO 9
Uso dell’applicazione
9.1
Un breve tour guidato
In questo capitolo, si vuole illustrare brevemente il funzionamento “reale” del News
Archive System, attraverso una sorta di tour guidato che illustri le sue principali funzionalità.
In particolare, si procederà con la creazione di un documento standard MPEG-7 da parte del
News Archive Administrator, verrà effettuato un XUpdate da parte del Database Manager e,
per finire, un User eseguirà una query al database finalizzata alla visualizzazione della risorsa
cercata.
9.1.1 News Archive Administrator: creazione di un documento MPEG-7
Come già spiegato nei precedenti capitoli, esistono due tipi di amministratori di sistema
che hanno accesso ad operazioni CRUD più o meno avanzate. Entrambi però hanno l’obbligo
di effettuare un login e, quindi, di scegliere il tipo di categoria a cui appartengono (News
Archive Administrator o Database Manager).
136
Capitolo 9 - Uso dell’applicazione
Fig. 9-1 Scelta del tipo di amministratore di sistema
Una volta autenticato, il News Archive Administrator accede alla collezione News del
database, ovvero l’unica alla quale gli è permesso l’accesso, e può scegliere di effettuare
l’operazione desiderata. Supponiamo decida di creare un documento MPEG-7; sarà
sufficiente cliccare sul pulsante Create Document nella barra degli strumenti a destra.
Fig. 9-2 News Archive Administrator homepage
A questo punto occorrerà riempire un’apposita form, e automaticamente il sistema
provvederà a creare un documento MPEG-7 valido e ben formato, per poi inserirlo nel
database.
137
Capitolo 9 - Uso dell’applicazione
Fig. 9-3 La form per la creazione di un documento MPEG-7
L’amministratore può quindi decidere di terminare la procedura di creazione o di
“appendere” altre descrizioni di segmenti audio-video. Nella maggior parte dei casi sarà
necessario aggiungere tanti AudioVisualSegment, quanti sono i segmenti audio-video del
telegiornale che si sta descrivendo, compilando, iterativamente, le seguente form.
Fig. 9-4 Inserimento di un AudioVisualSegment
Ogni AudioVisualSegment inserito corrisponde ad una operazione di update; ciò vuol dire
che le singole descrizioni dei servizi saranno disponibili alle ricerche dell’utente al momento
stesso della loro creazione, senza dover attendere che la descrizione dell’intero telegiornale
138
Capitolo 9 - Uso dell’applicazione
sia completata. Poiché la creazione manuale di un documento MPEG-7 richiede un tempo
considerevole, è facile intuire l’importanza di questa caratteristica del sistema.
9.1.2 Database Manager: un’operazione di Xupdate
Le operazioni di login e scelta di categoria sono del tutto analoghe a quelle evidenziate nel
paragrafo precedente. Il Database Manager avrà accesso, però, a diverse funzionalità CRUD e
quindi ad una homepage amministratore differente.
Fig. 9-5 Database Manager homepage
L’amministratore può navigare, senza limitazioni, l’intero albero del database, non ha a
disposizione le form per la creazione di documenti MPEG-7, ma può eseguire qualsiasi
operazione di update sui documenti. Si supponga di voler eseguire proprio una operazione di
update. L’amministratore seleziona i documenti che desidera modificare e sceglie Update
checked items nella barra degli strumenti a destra.
Se si è scelto più di un documento, viene mostrato lo schema a cui questi si riferiscono,
assieme alle operazione di XUpdate disponibili; in caso contrario viene mostrato il documento
stesso.
139
Capitolo 9 - Uso dell’applicazione
Fig. 9-6 Scelta dell’operazione di XUpdate
E’ da notare che resta sempre aperta la possibilità di passare dalla visualizzazione dello
schema a quella del documento, e viceversa, attraverso i due pulsanti posti in basso a destra
nella barra degli strumenti.
Dopo aver analizzato il documento, o lo schema, si sceglie l’operazione e si clicca sul link
opportuno. Non rimane che riempire la form che viene mostrata e attendere il risultato della
procedura di update.
Fig. 9-7 La form per le operazioni di XUpdate
140
Capitolo 9 - Uso dell’applicazione
Se non si sono commessi errori, il sistema darà un avviso del successo dell’operazione e
mostrerà uno dei documenti aggiornati. Va ricordato che le operazioni di Xupdate sono più
“forti” dello schema, nel senso che vengono eseguite nonostante dovessero rendere non più
validi i documenti. L’amministratore potrà accorgersi di ciò tramite la procedura di
validazione, che viene automaticamente invocata dopo un’operazione di XUdpate; quindi,
nonostante un messaggio di “documento non valido”, questo sarà stato ugualmente
modificato.
9.1.3 User: esecuzione di una query
L’utente non ha bisogno di effettuare il login e può subito scegliere tra due alternative di
ricerca: quella indirizzata agli interi telegiornali (News Search) o quella specializzata per i
singoli servizi dei telegiornali (Report Search).
Fig. 9-8 Homepage dell’utente
Si supponga di voler effettuare una News Search. Il sistema mostrerà una form che l’utente
compilerà, secondo criteri di ricerca più o meno avanzati, in base alle proprie esigenze. La
guida nella barra degli strumenti, potrà fornirgli utili indicazioni in tal senso. Per esempio:
“tutti i telegiornali di RAI UNO tra il 2001 e 2003 nella fascia oraria tra le 20 e le 21”.
141
Capitolo 9 - Uso dell’applicazione
Fig. 9-9 La form di News Search
Il motore di query cercherà, nella collezione News del database, tutti i documenti che
soddisfano i criteri specificati nella form e produrrà la seguente pagina dei risultati.
Fig. 9-10 Risultato di una query sui telegiornale
Dalla fig. 9-10 è possibile notare che:
•
Ogni telegiornale trovato viene visualizzato su di una sola riga;
142
Capitolo 9 - Uso dell’applicazione
•
Vengono visualizzate solo le informazioni più importanti per ogni telegiornale (il
canale televisivo, la data e l’ora di messa in onda, il conduttore, il regista e la
durata);
•
Viene mostrato il keyframe ed il link al Real Server che permette la visione
dell’intero telegiornale;
•
Per ogni telegiornale sono disponibili due operazioni: View Media Profile e All
Reports.
View Media Profile consente l’accesso ad informazioni complete e dettagliate sul
telegiornale sia tecniche (per esempio bit rate, formato di codifica, dimensione delle
immagini) sia di altro tipo (per esempio il direttore di fotografia piuttosto che quello di
produzione od il regista).
Fig. 9-11 News Media Profile
All Reports, invece, permette di visualizzare informazioni riguardo tutti i servizi di cui è
composto un telegiornale. La struttura di una pagina di visualizzazione dei servizi è del tutto
analoga a quelli dei telegiornali.
Sono presenti, inoltre, informazioni circa il genere di servizio ed una cosiddetta
FreeTextAnnotation, ovvero una breve descrizione semantica del servizio stesso. Questa volta
non solo viene data la possibilità di visionare l’interno telegiornale, ma anche un singolo
servizio, attraverso il link posto in alto a sinistra sul keyframe; cliccando verrà
143
Capitolo 9 - Uso dell’applicazione
automaticamente avviata l’applicazione Real Player che, aperto il collegamento con il Real
Server, comincerà la riproduzione del filmato (vedi fig. 9-12).
Fig. 9-12 Pagina di visualizzazione dei servizi di un telegiornale
9.2 Test di usabilità
9.2.1 Definizione di usabilità
Le definizioni di usabilità che sono state proposte sono varie e alcune molto suggestive. Si
riportano qui le tre, che hanno orientato, in linea di principio, il piccolo test di usabilità
eseguito su News Archive System.
Lo standard ISO/IEC 9126 “Information technology - Software product evaluation Quality characteristics and guidelines for their use” definisce l'usabilità come “la capacità del
software di essere compreso, appreso, usato e gradito dall’utente quando usato in determinate
condizioni”.
Lo standard ISO 9241-11 “Ergonomic requirements for office work with visual display
terminals - Guidance on usabilità”, invece, definisce l'usabilità come “il grado in cui un
prodotto può essere usato da specifici utenti per raggiungere specifici obiettivi con efficacia,
efficienza e soddisfazione in uno specifico contesto d'uso”.
144
Capitolo 9 - Uso dell’applicazione
Jakob Nielsen, il “guru” dell'usabilità del Web, definisce l'usabilità come la misura della
qualità dell'esperienza dell'utente in interazione con qualcosa, sia esso un sito Web o un
applicazione software tradizionale o qualsiasi altro strumento con il quale l'utente può
operare. Secondo Nielsen, un prodotto è usabile quando è facile da apprendere, consente una
efficienza di utilizzo, è facile da ricordare, permette pochi errori di interazione e di bassa
gravità ed è piacevole da usare.
In sintesi, quindi, per essere usabile, un prodotto deve:
•
essere adeguato ai bisogni e alle aspettative degli specifici utenti finali che lo usano
in determinate condizioni;
•
risultare facile da capire, da imparare, da usare, ed essere gradevole;
•
consentire di eseguire le specifiche attività lavorative in modo corretto, veloce e
con soddisfazione.
9.2.2 I princìpi di usabilità
Fondati sul modo di ragionare e operare delle persone quando interagiscono con un
prodotto software, i princìpi di usabilità rappresentano un riferimento importante di cui tenere
assolutamente conto sia in fase di progettazione che in fase di valutazione dell'usabilità
(Jakob Nielsen ha basato sui cosiddetti “princìpi euristici”, un metodo di valutazione noto,
appunto, come valutazione euristica).
I princìpi riportati in queste pagine possono essere considerati una sintesi di quanto si può
rintracciare in letteratura su questo argomento:
•
realizzare un dialogo semplice e naturale;
•
semplificare la struttura dei compiti;
•
agevolare il riconoscimento piuttosto che il ricordo;
•
fornire feedback in modo da rendere visibile lo stato del sistema;
•
prevenire gli errori di interazione e facilitarne il recupero;
•
essere consistenti;
•
parlare il linguaggio dell'utente;
145
Capitolo 9 - Uso dell’applicazione
•
fornire help e manuali.
9.2.3 Considerazioni di usabilità sul News Archive System
Si effettueranno ora delle considerazioni di usabilità sul News Archive System, in base ai
princìpi appena enunciati.
“Realizzare un dialogo semplice e naturale”
La progettazione di un dialogo semplice e naturale è agevolata principalmente da
considerazioni sul modo di lavorare dell'utente e da una opportuna scelta di soluzioni di
interfaccia.
Per far ciò si è cercato di tener conto del modo di operare dell’utente e di organizzazione i
contenuti e la struttura del sistema definendo, ad esempio, l'ordine dei menu, l’ordine di
presentazione delle finestre o delle pagine, l’organizzazione dei contenuti e degli oggetti
all’interno delle finestre o delle pagine.
Fornire un buon modello concettuale del sistema e renderne evidente l'organizzazione, la
logica d'interazione, e così via, vuol dire far si che l'utente possa prevedere gli effetti delle
proprie azioni. Inoltre si evita di presentare informazioni superflue o che si usano raramente:
le informazioni irrilevanti possono entrare in “competizione” con quelle fondamentali e
togliere a queste ultime la necessaria visibilità.
“Semplificare la struttura dei compiti”
I compiti o le attività che l'utente deve svolgere, in interazione con il sistema, devono avere
una struttura semplice. Il News Archive System è progettato per ridurre al minimo la necessità
di elaborazione delle informazioni da parte dell'uomo dovuta all'utilizzo dello strumento
informatico. Ad esempio viene offerta la possibilità di creare documenti MPEG-7 validi e ben
formati in modalità del tutto automatica per il News Archive Administrator, così come un
utente può effettuare una ricerca con l’ausilio di una guida on line e di menù a tendina che
minimizzano gli errori.
146
Capitolo 9 - Uso dell’applicazione
“Agevolare il riconoscimento piuttosto che il ricordo”
Osservando l'interfaccia, l'utente deve poter capire cosa deve fare, come può farlo e, una
volta eseguita un’azione, deve poter capire cosa è successo e quali sono stati i risultati.
Dal momento che è più facile riconoscere e ricordare una cosa vedendola direttamente,
piuttosto che recuperare l’informazione dalla memoria, il modo più semplice per agevolare
l'utente è quello di rendergli visibili le cose sull'interfaccia, ovvero fornirgli dei sussidi esterni
che gli agevolano il ricordo.
Di qui lo sviluppo di una barra degli strumenti per l’amministratore, ovvero la sezione
destra di ogni pagina in cui si raccolgono gli strumenti disponibili in base al contesto
operativo. Ciò evita che l’utente debba imparare a memoria certi comandi o informazioni.
Inoltre l’adozione di finestre di pop-up per informare sul successo di un operazione, su
eventuali errori o semplicemente per la richiesta di conferme, aiuta l’utente a capire se
l'azione richiesta è stata eseguita dal sistema.
Tutte le pagine sono state dotate di un titolo significativo che illustri adeguatamente il tipo
di informazione visualizzata o le azioni da svolgere e sono volutamente strutturate in modo
simile, in modo da non costringere l’utente a continue osservazioni dell’intera finestra o
pagina per ritrovare determinati oggetti o gruppi di informazioni.
“Fornire feedback in modo da rendere visibile lo stato del sistema”
Il feedback rappresenta l'informazione di ritorno in risposta all'azione che l'utente ha
eseguito sulla interfaccia e ha lo scopo di rendere visibile all’utente lo stato corrente del
sistema, in modo da evitare errori, incomprensioni e blocchi durante l'interazione.
Anche il tempo di downloading va inteso come feedback del sistema. Nelle applicazioni di
retriving, come quella in questione, è molto importante tenere in considerazione questo
aspetto soprattutto per ciò che riguarda la visualizzazione dei risultati della ricerca. In effetti il
News Archive System presenta tutti i risultati trovati in un'unica pagina Web. Un possibile
sviluppo futuro potrebbe essere quello di dotare il sistema di un meccanismo di ordinamento e
segmentazione dei risultati al fine di rendere più “leggero” il download delle pagine.
147
Capitolo 9 - Uso dell’applicazione
“Prevenire gli errori di interazione e facilitarne il recupero”
Commettere errori nell’interazione con un prodotto è naturale. Anzi, qualsiasi errore che
possa teoricamente essere commesso, prima o poi accadrà!
Ogni azione dell'utente va concepita come un tentativo verso una giusta direzione. L'errore
non è altro che una azione specificata in modo incompleto o inesatto. Ci sono alcuni tipi di
errori che sono difficilmente eliminabili, come le sviste; altri tipi di errore, invece, si possono
prevenire con una buona progettazione dell’interfaccia: sono gli errori commessi a seguito di
una applicazione sbagliata di regole di interazione o per la mancanza di sufficienti e adeguate
informazioni e conoscenze.
Tutte le form compilate dagli utenti del News Archive System limitano al massimo la
probabilità di errore, ad esempio pre-compilando alcuni campi o usando menu a tendina, e
soprattutto prevedono una procedura di validazione da parte del sistema. Inoltre le form mal
compilate non andranno perse, ma saranno riproposte all’utente qualora ne fosse verificata la
scorrettezza; ciò vuol dire evitare che l’utente debba compilarla di nuovo da capo.
Inoltre sono sempre disponibili opzioni di navigazione, così come funzioni che permettono
di uscire dal programma o di ritornare alla homepage. In tal modo, si evita che un utente
venga lasciato “in un vicolo cieco” e che commetta forzatamente un errore per uscirne.
“Essere consistenti”
La consistenza si riferisce al fatto che la sintassi (per esempio linguaggio, campi di input,
colori) e la semantica (comportamenti associati agli oggetti) del dialogo devono essere
uniformi e coerenti all’interno di tutto il prodotto software.
La consistenza permette all'utente di trasferire agevolmente la conoscenza da una
applicazione all'altra, aumenta la predicibilità delle azioni e dei comportamenti del sistema e
ne favorisce l'apprendibilità. Il News Archivi System usa sempre gli stessi font, lo stesso stile
dei link ed in definitiva lo stesso template per le varie pagine.
Ma è necessaria anche una consistenza degli effetti: gli stessi oggetti devono avere lo
stesso comportamento e produrre gli stessi effetti in situazioni equivalenti. E’ il caso delle due
interfacce del Database Manager e del News Archive Administrator o del News Search e del
148
Capitolo 9 - Uso dell’applicazione
Report Search. In entrambi i casi si è cercato di uniformare i termini usati per definire
operazioni analoghe.
“Parlare il linguaggio dell'utente”
Il linguaggio utilizzato a livello di interfaccia deve essere semplice e familiare per l’utente
e rispecchiare i concetti e la terminologia a lui noti.
E’ stato volutamente evitato un linguaggio tecnico e orientato al sistema che utenti non
esperti di informatica possono non comprendere mentre, dove possibile, si è preferito
utilizzare icone standard (documenti, directory, parent collection).
Anche per quanto concerne la lingua si è cercato un “giusto mezzo” tra solo italiano e solo
inglese. La homepage è stata, quindi, redatta in entrambe le lingue, mentre le altre pagine, pur
essendo in inglese, presentano una guida in italiano. Ciò permetterà ad utenti stranieri di
navigare con estrema facilità e ad utenti italiani di “imparare a navigare” in modo altrettanto
semplice.
“Fornire help e manuali”
L'argomento della documentazione (help in linea o manuali utente) è piuttosto controverso
per diversi motivi:
•
un buon prodotto, teoricamente, non dovrebbe richiedere la consultazione della
documentazione;
•
la documentazione viene spesso usata per compensare eventuali problemi di
usabilità del prodotto;
•
nella maggior parte dei casi, gli utenti ignorano questi strumenti di supporto.
Per queste ragioni si è scelto di realizzare un cosiddetto “help in linea” che si pone come
compromesso tra una guida esaustiva ed il lasciare l’utente a se stesso. In tal modo l’utente ha
sempre a disposizione informazioni essenziali che, unite con l’intuitività dell’interfaccia, gli
permetteranno di usare sempre il News Archive System in modo veloce ed efficiente.
149
Capitolo 10 - Risultati ottenuti e sviluppi futuri
CAPITOLO 10
Risultati ottenuti e sviluppi futuri
Gli obiettivi inizialmente prefissati mi hanno fatto confrontare con un problema “reale”, in
cui oltre allo studio di numerose tecnologie connesse alla realizzazione dell’applicazione, è
stato necessario trovare un accordo con le piattaforme esistenti, analizzando a fondo ciò che
era stato fatto e perchè.
La fase di studio iniziale è stata fondamentale per comprendere le necessità del contesto e
l’importanza di un processo di standardizzazione nelle risorse multimediali.
La fase implemetativa è stata lunga è difficoltosa, ma in ciò sono stati di grande aiuto i
principali forum e mailing list di comunità di sviluppatori correlate.
Alla fine, il porting del precedente progetto verso architetture completamente open-source
e server-side è stato un obiettivo pienamente raggiunto e anzi si sono migliorate e aggiunte
alcune funzionalità, la più importante delle quali è sicuramente la possibilità di eseguire un
update on-line di documenti XML ed in particolare MPEG-7.
Il News Archive System si rivela estremamente facile da usare, rendendo la sua
complessità intrinseca ed i dettagli implementativi completamente trasparenti agli utenti, e
ponendo la massima cura nella gestione degli errori, in modo da non lasciare mai l’utente
“abbandonato al suo destino”.
Lo sforzo prodotto per garantire la riusabilità dei componenti e del codice nelle fasi di
progettazione e implementazione è stato fortemente premiato e anzi costituisce la prima linea
di sviluppo possibile per questo lavoro: riutilizzare codice e componenti in una struttura che
permetta l’implementazione di funzionalità aggiuntive quali la gestione della concorrenza, la
sicurezza e le transazioni. In questo modo, si renderebbe l’applicazione meno prototipale e più
connessa ad un reale utilizzo.
150
Capitolo 10 - Risultati ottenuti e sviluppi futuri
In quest’ottica un’altra linea di sviluppo è tracciabile: nel caso di molti utenti avrebbe
senso fornire l’applicazione di un modulo di Digital Rights Management (DRM) ovvero
gestire i diritti e i privilegi di una risorsa, ad esempio limitarne l’uso o renderla a pagamento.
Tutto questo potrebbe essere facilmente descritto nei documenti grazie ai descrittori messi a
disposizione dallo standard MPEG-7.
La flessibilità e la modularità dell’intero sistema lo rende “rivendibile” anche in altri
ambiti di gestione di risorse digitali diverse da quelle multimediali, in cui i dati sono
document-centric ed in cui la struttura della base di dati sia fortemente variabile nel tempo.
Tra gli obiettivi raggiunti, infine, vi è sicuramente l’aver dato qualità ai dati rendendoli
fruibili; mediante future implementazioni di semplici moduli dedicati sarà possibile
pubblicare le informazioni custodite in News Archive System su qualsiasi tipo di media palmari, telefonia di terza generazione, WAP, CD-ROM, carta stampata, televisione digitale,
e persino dispositivi non ancora inventati - con il minimo sforzo progettuale e con il minimo
impatto sul sistema.
.
151
Bibliografia
BIBLIOGRAFIA
•
Contenuti editoriali di Interfree, “Archivi multimediali: il futuro della memoria”,
http://contenuti.interfree.it/128/IDNotizia3600.htm.
•
Il sito internet delle Teche RAI, http://www.teche.rai.it/.
•
R. David Vernon, Oya Y. Rieger, “Digital Asset Management: An Introduction to Key
Issues”, 2002, http://www.cit.cornell.edu/oit/Arch-Init/DigAssetMgmt.pdf.
•
La FAQ su SGML, http://lamp.infosys.deakin.edu.au/sgml/sgmlfaq.txt.
•
B. McLaughlin, Java & XML, 2nd Edition, O’Reilly, 2001.
•
K.A. Gabrick, D.B. Weiss, J2EE and XML Development, Manning, 2002.
•
Java Web Services Tutorial v.1.1,
http://java.sun.com/webservices/docs/1.1/tutorial/doc/index.html, capp. 2 – 8.
•
XML, http://www.w3.org/XML/.
•
XML:DB, http://www.xmldb.org/.
•
XML Schema, http://www.w3.org/XML/Schema.
•
Le API XML:DB, http://www.xmldb.org/xapi/index.html.
•
Xerces, http://xml.apache.org/xerces2-j/index.html.
•
XSL, http://www.w3.org/Style/XSL/.
•
Xalan, http://xml.apache.org/xalan-j/index.html.
•
XPath, http://www.w3.org/TR/xpath.
•
XUpdate, http://www.xmldb.org/xupdate/.
•
Xindice, http://xml.apache.org/.
•
F. Marini, J2EE: il libro, http://www.javaportal.it/j2eelibro.htm.
152
Bibliografia
•
F. Rombaldoni, “La piattaforma J2EE”, 2001,
http://www-db.deis.unibo.it/courses/SI2/Relazioni/J2EE.pdf.
•
Java Community Process, http://www.jcp.org/en/home/index.
•
G. Raffa, “MPEG-7: "MultiMedia Content Description Interface"”, 2001,
http://digilander.libero.it/beppewww/mpeg/index.htm.
•
B.S. Manjunath, P. Salembier, T. Sikora, Introduction to MPEG-7 Multimedia
Content Description Interface, John Wiley & Sons Ltd., 2002.
•
L. Saladini, “Analisi e progettazione object oriented: UML e il processo di sviluppo
iterativo Interface”, in: Sistemi informativi Volume 2 – Modelli e Progettazione,
FrancoAngeli, cap.2.
•
P. Atzeni, “Progettazione e sviluppo di siti e applicazioni web”, in: Sistemi informativi
Volume 2 – Modelli e Progettazione, FrancoAngeli, cap.3.
•
Il pattern MVC, http://java.sun.com/blueprints/patterns/MVC.html.
•
Il pattern J2EE DAO,
http://java.sun.com/blueprints/corej2eepatterns/Patterns/DataAccessObject.html.
•
R. Bourret, “XML and Databases”, 2003,
http://www.rpbourret.com/xml/XMLAndDatabases.htm.
•
P. Merialdo, Materiale Didattico di Basi di Dati, 2002,
http://merialdo.dia.uniroma3.it/didattica/index0102.html#sistemiDistribuiti.
•
P. Atzeni, Dispense di Basi di Dati, 2002,
http://www.dia.uniroma3.it/~atzeni/Corsi/ProgrammaPage/SD.html.
•
L. Cabibbo, “Oggetti e persistenza”, 2003,
http://cabibbo.dia.uniroma3.it/sisel/persistenza2003.pdf.
•
B. Eckel, Thinking in Java, 2nd edition, Revision 12, 2000.
•
M. Hall, Core Servlets and JavaServer Pages, Sun Microsystems Press/Prentice Hall,
2001, http://pdf.coreservlets.com/Core-Servlets-and-JSP.pdf.
153
Bibliografia
•
M.S. Dougherty, “Are XML Databases Necessary?”, 2003,
http://www.db2mag.com/db_area/archives/2003/q1/webdev.shtml.
•
C. Stortone, Userware: progettare per l’utente,
http://web.tiscali.it/no-redirect-tiscali/userware/index.html.
•
Jakob Nielsen’s website, http://www.useit.com/.
•
UML, http://www.uml.org/.
154
Appendici
APPENDICI
App.A
Ambiente di sviluppo e informazioni sul codice prodotto
Configurazione di sistema
•
Sistema operativo: Microsoft
Windows
2000
Professional
version
5.0.2195 Service Pack 3 Build 2195
•
Produttore del sistema: Hewlett-Packard, Model HP Vectra
•
Processore: x86 Family 6 Model 8 Stepping 6 Genuine Intel 800 Mhz
•
Memoria fisica totale: 522.736 KB
Strumenti utilizzati
•
Compilatore Java: sun microsystems jdk 1.3.1_07
•
Servlet engine e Web server: Apache jakarta-tomcat 4.1.18
•
Database XML nativo: Apache xindice 1.0
•
Server di streaming audio-video: Helix Universal Server 9.0
Software ausiliari
•
XML, XSD e XSL editor: Altova XMLSpy 4.3
•
Per i diagrammi UML: Enterprise Architect 3.51
•
HTML e JSP editor: Macromedia Dreamweaver MX 6.0
•
Java code editor: Helios Software TextPad 4.5.0
Informazioni sul codice
•
Pagine dinamiche JSP (13): adminchoice.jsp,
appendAudioVisualSegment.jsp, createTgMpeg7Doc.jsp,
currentcollectionview.jsp, homepage.jsp, login.jsp,
155
Appendici
newsarchiveview.jsp, newssearch.jsp, option.jsp, reportsearch.jsp,
Update.jsp, xmlUpdate.jsp, xmlview.jsp
•
Pagine statiche HTML (4): index.html, indexE.html, WhoWeAre.html,
WhoWeAreE.html
•
Codice Java (28 file):
o Java Bean (6): AdmninBean.java, LoginBean.java, Mpeg7Bean.java,
NewsBean.java, ReportBean.java, UpdateBean.java
o Java Servlet (17): AppendAVSFormProcess.java,
CreateCollectionFormProcess.java,
CreationDocumentFormProcess.java, FormProcess.java,
LoginFormProcess.java, MyTransformer.java,
NewsFormProcess.java, NewsQuery.java, ReportFormProcess.java,
ReportQuery.java, UpdateAppendAVS.java,
UploadFormProcess.java, ViewMediaProfile.java,
XindiceDeleteHandler.java,
XindiceInsertCollectionHandler.java,
XindiceInsertDocumentHandler.java, XupdateFormProcess.java
o Java Helper Class (5): UploadFile.java, XindiceView.java,
XindiceXpathHandler.java, XindiceXUpdateHandler.java,
XmlValidate.java
•
Fogli di stile XSL (3): newsMediaProfile.xsl, NewsView.xsl,
ReportView.xsl
•
News Archive System XML-MPEG-7 Schema (1): Schema.xsd
•
File di configurazione del sistema (1): NewsArchiveConfig.txt
•
Righe totali di codice: circa 10.000
App.B
Il consorzio Elis e i Vivai d’Impresa
Il Centro ELIS fu eretto nel 1965 con i donativi offerti dai cattolici di tutto il mondo in
omaggio al papa Pio XII. Da allora l’ELIS opera come struttura di solidarietà in Italia e in
altri Paesi in tutti i continenti realizzando attività e iniziative educative allo scopo di prevenire
il disagio umano e sociale, trasmettendo professionalità, comunicando uno stile di vita e una
cultura del lavoro.
156
Appendici
"Vivai d'Impresa" è un’iniziativa del centro ELIS stesso, finanziata dalle maggiori aziende
nell’ambito ICT (Telecom Italia; Siemens; EDS, RAI, WIND, ESA, HP,…), per realizzare un
Master per laureati e laureandi in cerca di una tesi di Laurea su progetti avanzati in contesti
aziendali di telecomunicazioni e produzione multimediale. Il Master è, inoltre, orientato alla
creazione d'impresa, facilitata dall'inserimento nell'incubatore ELIS.
Sul modello delle società di consulenza, i vivaisti, dopo un colloquio di orientamento,
vengono assegnati ai progetti commissionati dalle aziende promotrici sotto la supervisione di
un senior manager che ha anche il compito di seguirne l'apprendimento e effettuare, al
termine del progetto, la valutazione e certificazione delle effettive competenze maturate.
Storicamente il progetto Vivai d’Impresa, nato nel Settembre 2000, ha avuto come
obiettivo principale quello di creare un ambiente innovativo ed efficace capace di offrire, oltre
ad un programma di formazione (ad esempio, tutti i partecipanti seguono alcuni corsi della
CISCO ACADEMY), anche tutti gli strumenti necessari per maturare competenze nell’area
ICT, cercando di favorire la nascita di nuove iniziative imprenditoriali nell’ambito della net
economy.
App.C
Lo schema dei dati
<?xml version="1.0" encoding="UTF-8"?>
<!--W3C Schema generated by XML Spy v4.3 U (http://www.xmlspy.com)-->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified">
<xs:element name="AdministrativeUnit" type="xs:string"/>
<xs:complexType name="AgeType">
<xs:attribute name="min" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AgentType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AudioVisualType">
<xs:sequence>
<xs:element name="MediaLocator" type="MediaLocatorType"/>
<xs:element name="StructuralUnit" type="StructuralUnitType"/>
<xs:element name="CreationInformation"
type="CreationInformationType"/>
<xs:element name="UsageInformation"
type="UsageInformationType"/>
<xs:element name="MediaTime" type="MediaTimeType"/>
<xs:element name="MediaSourceDecomposition"
157
Appendici
type="MediaSourceDecompositionType"/>
<xs:element name="TemporalDecomposition"
type="TemporalDecompositionType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="AudioVisualSegmentType">
<xs:sequence>
<xs:element name="MediaInformation"
type="MediaInformationType" minOccurs="0"/>
<xs:element name="MediaLocator" type="MediaLocatorType"
minOccurs="0"/>
<xs:element name="StructuralUnit" type="StructuralUnitType"
minOccurs="0"/>
<xs:element name="CreationInformation"
type="CreationInformationType" minOccurs="0"/>
<xs:element name="TextAnnotation" type="TextAnnotationType"
minOccurs="0"/>
<xs:element name="MediaTime" type="MediaTimeType"
minOccurs="0"/>
</xs:sequence>
<xs:attribute name="id" type="xs:string"/>
</xs:complexType>
<xs:element name="BitRate" type="xs:int"/>
<xs:complexType name="ClassificationType">
<xs:sequence>
<xs:element name="Form" type="FormType" minOccurs="0"/>
<xs:element name="Genre" type="GenreType"/>
<xs:element name="Target" type="TargetType" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="CommentType">
<xs:sequence>
<xs:element ref="FreeTextAnnotation"/>
</xs:sequence>
</xs:complexType>
<xs:element name="Content" type="xs:string"/>
<xs:complexType name="ContentDescriptionType">
<xs:sequence>
<xs:element name="MultimediaContent"
type="MultimediaContentType"/>
</xs:sequence>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
<xs:element name="Country" type="xs:string"/>
<xs:complexType name="CreationType">
<xs:sequence>
<xs:element ref="Title"/>
<xs:element name="Creator" type="CreatorType"
maxOccurs="unbounded"/>
<xs:element name="CreationCoordinates"
type="CreationCoordinatesType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="CreationCoordinatesType">
<xs:sequence>
<xs:element name="CreationLocation"
type="CreationLocationType" minOccurs="0"/>
<xs:element name="CreationDate" type="CreationDateType"/>
</xs:sequence>
158
Appendici
</xs:complexType>
<xs:complexType name="CreationDateType">
<xs:sequence>
<xs:element ref="TimePoint"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="CreationInformationType">
<xs:sequence>
<xs:element name="Creation" type="CreationType"/>
<xs:element name="Classification" type="ClassificationType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="CreationLocationType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
<xs:element name="Role" type="RoleType"/>
<xs:element ref="Country"/>
<xs:element ref="AdministrativeUnit"/>
</xs:sequence>
</xs:complexType>
<xs:element name="CreationTime" type="xs:string"/>
<xs:complexType name="CreatorType">
<xs:sequence>
<xs:element name="Role" type="RoleType"/>
<xs:element name="Agent" type="AgentType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="DescriptionMetadataType">
<xs:sequence>
<xs:element name="Comment" type="CommentType"/>
<xs:element name="Creator" type="CreatorType"/>
<xs:element ref="CreationTime"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="FileFormatType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string" use="required"/>
</xs:complexType>
<xs:element name="FileSize" type="xs:int"/>
<xs:complexType name="FormType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string" use="required"/>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="FormatType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="FrameType">
<xs:attribute name="aspectRatio" type="xs:decimal"
use="required"/>
<xs:attribute name="height" type="xs:short" use="required"/>
<xs:attribute name="rate" type="xs:byte" use="required"/>
159
Appendici
<xs:attribute name="width" type="xs:short" use="required"/>
</xs:complexType>
<xs:element name="FreeTextAnnotation" type="xs:string"/>
<xs:complexType name="GenreType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string" use="required"/>
</xs:complexType>
<xs:element name="GivenName" type="xs:string"/>
<xs:complexType name="IDNameType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="IDOrganizationType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
</xs:complexType>
<xs:element name="Image" type="xs:anyURI"/>
<xs:element name="MediaDuration" type="xs:string"/>
<xs:complexType name="MediaFormatType">
<xs:sequence>
<xs:element ref="Content"/>
<xs:element name="Medium" type="MediumType"/>
<xs:element name="FileFormat" type="FileFormatType"/>
<xs:element ref="FileSize"/>
<xs:element name="System" type="SystemType"/>
<xs:element ref="BitRate"/>
<xs:element name="VisualCoding" type="VisualCodingType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="MediaIncrDurationType">
<xs:simpleContent>
<xs:extension base="MediaIncrDurationSimpleType">
<xs:attribute name="timeUnit" type="xs:string"
use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:simpleType name="MediaIncrDurationSimpleType">
<xs:restriction base="xs:int"/>
</xs:simpleType>
<xs:complexType name="MediaInformationType">
<xs:sequence>
<xs:element name="MediaProfile" type="MediaProfileType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="MediaLocatorType">
<xs:sequence>
<xs:element name="MediaTime" type="MediaTimeType"
minOccurs="0"/>
<xs:element ref="Image" minOccurs="0"/>
<xs:element ref="MediaUri" minOccurs="0"/>
</xs:sequence>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MediaProfileType">
160
Appendici
<xs:sequence>
<xs:element name="MediaFormat" type="MediaFormatType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="MediaRelTimePointType">
<xs:simpleContent>
<xs:extension base="MediaRelTimePointSimpleType">
<xs:attribute name="timeBase" type="xs:string"
use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:simpleType name="MediaRelTimePointSimpleType">
<xs:restriction base="xs:string"/>
</xs:simpleType>
<xs:complexType name="MediaSourceDecompositionType">
<xs:sequence>
<xs:element name="AudioVisualSegment"
type="AudioVisualSegmentType"/>
</xs:sequence>
<xs:attribute name="criteria" type="xs:string" use="required"/>
<xs:attribute name="gap" type="xs:boolean" use="required"/>
<xs:attribute name="overlap" type="xs:boolean" use="required"/>
</xs:complexType>
<xs:complexType name="MediaTimeType">
<xs:sequence>
<xs:element ref="MediaTimePoint" minOccurs="0"/>
<xs:element ref="MediaDuration" minOccurs="0"/>
<xs:element name="MediaRelTimePoint"
type="MediaRelTimePointType" minOccurs="0"/>
<xs:element name="MediaIncrDuration"
type="MediaIncrDurationType" minOccurs="0"/>
</xs:sequence>
</xs:complexType>
<xs:element name="MediaTimePoint" type="xs:string"/>
<xs:element name="MediaUri" type="xs:anyURI"/>
<xs:complexType name="MediumType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string" use="required"/>
</xs:complexType>
<xs:element name="Mpeg7">
<xs:complexType>
<xs:sequence>
<xs:element name="DescriptionMetadata"
type="DescriptionMetadataType"/>
<xs:element name="ContentDescription"
type="ContentDescriptionType"/>
</xs:sequence>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
<xs:complexType name="MultimediaContentType">
<xs:sequence>
<xs:element name="AudioVisual" type="AudioVisualType"/>
</xs:sequence>
<xs:attribute name="type" type="xs:string" use="required"/>
</xs:complexType>
161
Appendici
<xs:complexType name="NameType" mixed="true">
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element ref="GivenName"/>
</xs:choice>
<xs:attribute name="lang" type="xs:string"/>
<xs:attribute name="type" type="xs:string"/>
</xs:complexType>
<xs:complexType name="RightsType">
<xs:sequence>
<xs:element name="RightsId" type="RightsIdType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RightsIdType">
<xs:sequence>
<xs:element name="IDOrganization" type="IDOrganizationType"/>
<xs:element name="IDName" type="IDNameType"/>
<xs:element ref="UniqueID"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RoleType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string"/>
<xs:attribute name="type" type="xs:string"/>
</xs:complexType>
<xs:complexType name="StructuralUnitType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" use="required">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN"/>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="SystemType">
<xs:sequence>
<xs:element name="Name" type="NameType"/>
</xs:sequence>
<xs:attribute name="href" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="TargetType">
<xs:sequence>
<xs:element name="Age" type="AgeType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="TemporalDecompositionType">
<xs:sequence>
<xs:element name="AudioVisualSegment"
type="AudioVisualSegmentType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="criteria" type="xs:string" use="required"/>
<xs:attribute name="gap" type="xs:boolean" use="required"/>
<xs:attribute name="overlap" type="xs:boolean" use="required"/>
</xs:complexType>
<xs:complexType name="TextAnnotationType">
<xs:sequence>
<xs:element ref="FreeTextAnnotation"/>
162
Appendici
</xs:sequence>
</xs:complexType>
<xs:element name="TimePoint" type="xs:string"/>
<xs:element name="Title" type="xs:string"/>
<xs:element name="UniqueID" type="xs:string"/>
<xs:complexType name="UsageInformationType">
<xs:sequence>
<xs:element name="Rights" type="RightsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="VisualCodingType">
<xs:sequence>
<xs:element name="Format" type="FormatType"/>
<xs:element name="Frame" type="FrameType"/>
</xs:sequence>
</xs:complexType>
</xs:schema>
L’ XML Schema dei dati conforme a MPEG-7
163
Appendici
App.D
Un documento MPEG-7 di descrizione di un telegiornale
<?xml version="1.0"?>
<Mpeg7 type="complete" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="C:\Documents and
Settings\Administrator\Desktop\Prova.xsd">
<DescriptionMetadata>
<Comment>
<FreeTextAnnotation>Descrizione delle informazioni descrittive del
contenuto audiovisivo di un telegiornale della RAI</FreeTextAnnotation>
</Comment>
<Creator>
<Role href="CreatorCS">
<Name>Students</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Nicola La Verghetta e Federico Tonioni</GivenName>
</Name>
</Agent>
</Creator>
<CreationTime>2003-03-13T21:05:00:000:00</CreationTime>
</DescriptionMetadata>
<ContentDescription type="ContentEntityType">
<MultimediaContent type="AudioVisualType">
<AudioVisual>
<MediaLocator type="TemporalSegmentLocatorType">
<MediaTime>
<MediaTimePoint>2003-03-11T20:30:00:000:00</MediaTimePoint>
<MediaDuration>P0DT0H27M45S14N30F</MediaDuration>
</MediaTime>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:1">
<Name lang="en">logical</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>TG2</Title>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Speaker</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Antonio Romita</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS">
<Name>Regia</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Teresa Pelliccia</GivenName>
</Name>
</Agent>
</Creator>
164
Appendici
<Creator>
<Role href="CreatorCS">
<Name>Direttore di produzione</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Ettore Mondini</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS">
<Name>Direttore fotografia</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Carlo Petroni</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationLocation>
<Name type="TextualType">Roma, Lazio</Name>
<Role>
<Name>Studi di produzione</Name>
</Role>
<Country>it</Country>
<AdministrativeUnit>Studi Rai Saxa Rubra3</AdministrativeUnit>
</CreationLocation>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
</Creation>
<Classification>
<Form href="urn:mpeg:TVAnytime_v0.1FormatCS:1.3"
type="GenreType">
<Name>Magazine</Name>
</Form>
<Genre href="GenreCS">
<Name>Cultura , Attualita&apos;</Name>
</Genre>
<Target>
<Age min="&gt;10"/>
</Target>
</Classification>
</CreationInformation>
<UsageInformation>
<Rights>
<RightsId>
<IDOrganization>
<Name>Rai Produzione Radio Televisiva</Name>
</IDOrganization>
<IDName>
<Name>Rai TV Rights</Name>
</IDName>
<UniqueID>RAICANALE2-TV001-ITALY-3758696</UniqueID>
</RightsId>
</Rights>
</UsageInformation>
<MediaTime>
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H0M0S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">49964</MediaIncrDuration>
</MediaTime>
<MediaSourceDecomposition criteria="description" gap="true"
165
Appendici
overlap="true">
<AudioVisualSegment id="description-8">
<MediaInformation>
<MediaProfile>
<MediaFormat>
<Content>audiovisual</Content>
<Medium href="urn:mpeg:MPEG7MediumCS:2.1.1">
<Name lang="en">HardDisk </Name>
</Medium>
<FileFormat href="urn:mpeg:MPEG7FileFormatCS:3">
<Name lang="en">real</Name>
</FileFormat>
<FileSize>31831183</FileSize>
<System href="urn:mpeg:MPEG7SystemCS:1">
<Name lang="en">PAL</Name>
</System>
<BitRate>150000</BitRate>
<VisualCoding>
<Format href="urn:mpeg:MPEG7VisualCodingFormatCS:2">
<Name lang="en">realvideo</Name>
</Format>
<Frame aspectRatio="1.33333333333333" height="132"
rate="30" width="176"/>
</VisualCoding>
</MediaFormat>
</MediaProfile>
</MediaInformation>
</AudioVisualSegment>
</MediaSourceDecomposition>
<TemporalDecomposition criteria="structure" gap="true" overlap="true">
<AudioVisualSegment id="structure-24">
<MediaLocator type="TemporalSegmentLocatorType">
<Image>http://62.110.204.10:8080/RAI_project/tecaprova/Frame/11-0303Sera/tg2intro.jpg</Image>
<MediaUri>rtsp://62.110.204.10:554/News/11-0303Sera/tg2.rm</MediaUri>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:4">
<Name lang="en">structure</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>Servizio1:Introduzione</Title>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Giornalista</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Antonio Romita</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
166
Appendici
</Creation>
<Classification>
<Genre href="GenreCS">
<Name>Attualita&apos; - Guerra</Name>
</Genre>
</Classification>
</CreationInformation>
<TextAnnotation>
<FreeTextAnnotation/>
</TextAnnotation>
<MediaTime>
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H1M1S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">480</MediaIncrDuration>
</MediaTime>
</AudioVisualSegment>
<AudioVisualSegment id="structure-26">
<MediaLocator type="TemporalSegmentLocatorType">
<Image>http://62.110.204.10:8080/RAI_project/tecaprova/Frame/11-0303Sera/tg2serv1.jpg</Image>
<MediaUri>rtsp://62.110.204.10:554/News/11-0303Sera/tg2.rm</MediaUri>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:4">
<Name lang="en">structure</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>Servizio 1</Title>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Giornalista</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Carlo Maria Rosario</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
</Creation>
<Classification>
<Genre href="GenreCS">
<Name>Attualita&apos; - Guerra</Name>
</Genre>
</Classification>
</CreationInformation>
<TextAnnotation>
<FreeTextAnnotation>Bagdad: per sopravvivivere si diventa
cercatori d&apos;oro</FreeTextAnnotation>
</TextAnnotation>
<MediaTime>
167
Appendici
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H1M17S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">3450</MediaIncrDuration>
</MediaTime>
</AudioVisualSegment>
<AudioVisualSegment id="structure-30">
<MediaLocator type="TemporalSegmentLocatorType">
<Image>http://62.110.204.10:8080/RAI_project/tecaprova/Frame/11-0303Sera/tg2intro.jpg</Image>
<MediaUri>rtsp://62.110.204.10:554/News/11-0303Sera/tg2.rm</MediaUri>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:4">
<Name lang="en">structure</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>Servizio 2:Introduzione</Title>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Giornalista</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Antonio Romita</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
</Creation>
<Classification>
<Genre href="GenreCS">
<Name>Politica Estera - Guerra</Name>
</Genre>
</Classification>
</CreationInformation>
<TextAnnotation>
<FreeTextAnnotation/>
</TextAnnotation>
<MediaTime>
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H3M25S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">390</MediaIncrDuration>
</MediaTime>
</AudioVisualSegment>
<AudioVisualSegment id="structure-32">
<MediaLocator type="TemporalSegmentLocatorType">
<Image>http://62.110.204.10:8080/RAI_project/tecaprova/Frame/11-0303Sera/tg2serv2.jpg</Image>
168
Appendici
<MediaUri>rtsp://62.110.204.10:554/News/11-0303Sera/tg2.rm</MediaUri>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:4">
<Name lang="en">structure</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>Servizio 2</Title>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Giornalista</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Dario Laruffa</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
</Creation>
<Classification>
<Genre href="GenreCS">
<Name>Politica Estera - Guerra</Name>
</Genre>
</Classification>
</CreationInformation>
<TextAnnotation>
<FreeTextAnnotation>New York: Slitta al consiglio di sicurezza
dell&apos;ONU il voto sulla nuova risoluzione che prevede un ultimatum di pochi
giorni a Saddam Hussein</FreeTextAnnotation>
</TextAnnotation>
<MediaTime>
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H3M38S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">2280</MediaIncrDuration>
</MediaTime>
</AudioVisualSegment>
<AudioVisualSegment id="structure-28">
<MediaLocator type="TemporalSegmentLocatorType">
<Image>http://62.110.204.10:8080/RAI_project/tecaprova/Frame/11-0303Sera/tg2serv2bis.jpg</Image>
<MediaUri>rtsp://62.110.204.10:554/News/11-0303Sera/tg2.rm</MediaUri>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:4">
<Name lang="en">structure</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>Servizio 2 bis</Title>
<Creator>
169
Appendici
<Role href="CreatorCS" type="GenreType">
<Name>Giornalista</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Antonio Caprarica</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
</Creation>
<Classification>
<Genre href="GenreCS">
<Name>Politica Estera - Guerra</Name>
</Genre>
</Classification>
</CreationInformation>
<TextAnnotation>
<FreeTextAnnotation>Londra: Per evitare una rottura
all&apos;ONU proposta una dilazione dell&apos;ultimatum a Saddam, ma Bush potrebbe
non aspettare</FreeTextAnnotation>
</TextAnnotation>
<MediaTime>
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H4M54S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">2100</MediaIncrDuration>
</MediaTime>
</AudioVisualSegment>
<AudioVisualSegment id="structure-34">
<MediaLocator type="TemporalSegmentLocatorType">
<Image>http://62.110.204.10:8080/RAI_project/tecaprova/Frame/11-0303Sera/tg2intro.jpg</Image>
<MediaUri>rtsp://62.110.204.10:554/News/11-0303Sera/tg2.rm</MediaUri>
</MediaLocator>
<StructuralUnit href="SegmentTypeCS:4">
<Name lang="en">structure</Name>
</StructuralUnit>
<CreationInformation>
<Creation>
<Title>Servizio 3:Introduzione</Title>
<Creator>
<Role href="CreatorCS" type="GenreType">
<Name>Giornalista</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>Antonio Romita</GivenName>
</Name>
</Agent>
</Creator>
<Creator>
170
Appendici
<Role href="CreatorCS" type="GenreType">
<Name>Emittente</Name>
</Role>
<Agent type="PersonType">
<Name>
<GivenName>RAI_DUE</GivenName>
</Name>
</Agent>
</Creator>
<CreationCoordinates>
<CreationDate>
<TimePoint>2003-03-11T20:30:00:000:00</TimePoint>
</CreationDate>
</CreationCoordinates>
</Creation>
<Classification>
<Genre href="GenreCS">
<Name>Politica Estera - Guerra</Name>
</Genre>
</Classification>
</CreationInformation>
<TextAnnotation>
<FreeTextAnnotation/>
</TextAnnotation>
<MediaTime>
<MediaRelTimePoint
timeBase="/Mpeg7/ContentDescription/MultimediaContent[1]/AudioVisual[1]/MediaTime">
P0DT0H6M33S0N30F</MediaRelTimePoint>
<MediaIncrDuration
timeUnit="P0DT0H0M0S1N30F">390</MediaIncrDuration>
</MediaTime>
</AudioVisualSegment>
</TemporalDecomposition>
</AudioVisual>
</MultimediaContent>
</ContentDescription>
</Mpeg7>
Una descrizione MPEG-7 di un telegiornale
171
Appendici
App.E
I metadati
Metadato, letteralmente “dati rigurdardanti dati”, è un termine che si incontra sempre più
spesso e che viene inteso in modi differenti dalle diverse comunità di professionisti che
progettano, creano, descrivono e usano informazioni riguardo sistemi e risorse. Dal momento
che queste comunità - ed anche le tecnologie di archiviazione, informazione e comunicazione
- stanno sempre più venendo a contatto fra loro, è necessario comprendere il ruolo critico che
i diversi tipi di metadati possono giocare nello sviluppo di sistemi informativi efficienti,
interoperabili e scalabili.
Fino alla metà degli anni ’90, “metadato” era un termine prevalentemente usato dalle
comunità scientifiche impegnate nel gestire e nel garantire l’interoperabilità di dati
geospaziali, oppure da quelle impegnate nella gestione dei dati e nella progettazione e
manutenzione di sistemi in generale. Per queste comunità, il metadato poteva essere visto sia
come una raccolta di standard industriali e disciplinari sia come una sorta di documentazione
addizionale, interna ed esterna; nella pratica era considerato come ogni altro dato necessario
all’identificazione, la rappresentazione, l’interoperabilità, la gestione tecnica, le performance
e l’uso di dati che contenessero le informazioni di un sistema.
Probabilmente il modo migliore per comprendere il significato del termine metadato è
quello di interpretare il metadato come “la somma totale di ciò che uno può dire circa un
qualsiasi oggetto che possa produrre informazione (information object) e ad ogni livello di
aggregazione”. In questo contesto, un information object è qualsiasi cosa che possa essere
individuata e manipolata da un uomo e da un sistema come entità discreta. L’oggetto può
essere composto da una singola parte, o può essere una aggregazione di più parti. In generale
tutti gli information object, nonostante la forma fisica od intellettuale che essi prendano,
possiedono tre caratteristiche - contenuto, contesto e struttura - ognuna delle quali può essere
pensata come un metadato.
•
Il contenuto riguarda ciò che l’oggetto contiene o di cui parla, ed è intrinseco ad un
information object
•
Il contesto indica gli aspetti circa il chi, cosa, perchè, dove e come un oggetto sia
stato creato ed è estrinseco all’information object stesso
•
La struttura si riferisce ad un set formale di associazioni all’interno o tra singoli
information object e può essere sia intrinseca che estrinseca.
172
Appendici
I professionisti dell’informazione e della conservazione del patrimonio culturale, come
segretari di musei, bibliotecari e personale addetto all’archiviazione in genere, stanno sempre
più utilizzando il termine metadato riferendosi a quelle informazioni, di notevole valore
aggiunto, che essi creano per ordinare, descrivere e, per altri aspetti, accrescere la possibilità
stessa di accesso agli information object.
Lo sviluppo di librerie di metadati sta permettendo un accesso intellettuale e fisico ai
contenuti sempre più veloce ed efficiente. Le librerie di metadati includono indici, riassunti, e
registri di cataloghi creati secondo le regole classiche della catalogazione e secondo nuovi
standard per la definizione della struttura e della forma del contenuto come ad esempio
MARC (MAchine-Readable Cataloging format), oppure secondo soluzione proprietarie come
LCSH (Library of Congress Subject Headings) e AAT (Art & Architecture Thesaurus).
Probabilmente non è mai stata posta sufficiente enfasi sulla struttura delle informazioni
nello sviluppo dei metadati da parte di queste comunità. Tuttavia, la struttura è sempre stata
importante nell’organizzazione e nella rappresentazione delle informazioni, ancor prima della
loro computazione. Il ruolo della struttura sta diventando sempre più importante con lo
sviluppo di capacità di processamento sempre più potenti e sofisticate. Le comunità
dell’informazione sono sempre più consapevoli che più gli information object sono strutturati,
più questa struttura può essere utilizzata per la ricerca, la manipolazione e la correlazione con
altri information object. Realizzare, documentare e far rispettare questa struttura richiede,
tuttavia, specifici tipi di metadati.
In breve, in un ambiente dove un utente può avere un accesso potenzialmente illimitato
agli information object (come accade sul Web), i metatadi devono:
•
certificare l’autenticità ed il grado di integrità del contenuto;
•
determinare e documentare il contesto del contenuto;
•
identificare ed utilizzare la relazione strutturale che esiste tra e dentro gli
information object;
•
fornire una sfera di “punti di accesso” intellettuali per un sempre crescente e
diverso universo di utenti;
Sebbene l’argomento metadati meriterebbe una più attenta ed approfondita analisi, si
possono riassumere alcuni concetti fondamentali con le seguenti affermazioni.
173
Appendici
1. I metadati non devono essere per forza digitali. Sebbene la sede naturale di
un metadato possa sembrare essere un sistema di informazione digitale, ciò
non toglie che dalla notte dei tempi metadati siano stati creati nelle forme e
coi i mezzi più diversi.
2. I metadati riguardano molto più che la semplice descrizione di un oggetto.
Un metadato può riguardare anche il contesto, la gestione, il processamento,
la conservazione e l’uso delle risorse descritte.
3. I metadati possono provenire da una gran varietà di sorgenti. Essi possono
essere creati dell’uomo, o automaticamente da un computer, o ancora
desunti da una relazione con un’altra risorse, come un hyperlink.
4. I metadati continuano ad aumentare durante la vita di un information
object. Il metadato viene creato e modificato in vari momenti della vita di
una risorsa.
I metadati di un information object posso essere al tempo stesso dati di un altro
information object.
App.F
Unified Modeling Language
La prima draft pubblica di UML venne introdotta nell’Ottobre 1995, ma solo nel 1997 la
Versione 1.0 venne presentata all’OMG (Object Management Group).
UML è un linguaggio di progettazione e, come tale, è solo parte di un metodo di sviluppo
del Software più generale. In sostanza un metodo è formato, anche, dalle direttive che
indicano al progettista cosa fare, quando farlo, dove e perchè.
UML è costituito da una sintassi, una semantica e da un paradigma. In tale contesto, la
sintassi è costituita sia dall’insieme delle parole della lingua utilizzata (i simboli dei
diagrammi) e sia dalle regole che specificano come organizzare frasi corrette (come
combinare i simboli, quali e come possono essere associati).
La semantica si occupa del significato delle parole (simboli), sia considerate singolarmente e sia nel contesto nel quale vengono utilizzate (significato dei simboli in un
particolare diagramma).
174
Appendici
Infine, un particolare paradigma potrebbe contenere le direttive atte a conferire al proprio
stile di scrittura maggiore chiarezza ed eleganza (come realizzare modelli chiari, leggibili,
eleganti).
In genere, UML permette di rappresentare, per mezzo di un formalismo rigoroso, le proprie
idee, le decisioni prese, le soluzione adottate nello sviluppo del software. Il grande vantaggio
è che, poiché UML è uno standard internazionale, non legato alle singole imprese, facilita la
divulgazione delle informazioni permettendo ad un qualsiasi sviluppatore di comprendere
ogni dettaglio del progetto, con il solo studio del modello.
L’UML è costituito da:
•
Viste: mostrano i differenti aspetti di un sistema attraverso la realizzazione di un
certo numero di diagrammi. Si tratta di astrazioni, ognuna delle quali analizza il
sistema da modellare con un’ottica diversa (funzionale, non funzionale,
organizzativa). La somma di tali viste fornisce il quadro d’insieme.
•
Diagrammi: permettono di esprimere le viste logiche per mezzo di grafici, l’UML
ne prevede ben nove tipi differenti, ognuno dei quali è, tipicamente, destinato ad
essere utilizzato per una particolare vista.
•
Elementi del modello: sono i concetti che permettono di realizzare i vari
diagrammi; indicano gli attori, le classi, i package, gli oggetti.
Soffermiamoci sul concetto di Vista e vediamo quali View sono previste:
•
Use case view: serve per analizzare i requisiti utente, ossia, cosa il sistema dovrà
fare. A questo livello di analisi, bisogna studiare il sistema considerandolo come
una scatola nera e concentrarsi sul cosa fare astraendosi il più possibile dal come.
•
Design view (detta anche logical view): descrive come le funzioni debbano essere
realizzate, analizzando il sistema dall’interno. In questa vista si trova sia la struttura
statica del sistema (diagramma delle classi e diagramma degli oggetti), sia la
collaborazione dinamica dovuta alle interazioni tra gli oggetti.
•
Implementation view (detta anche component view): è la descrizione di come il
codice viene aggregato in moduli (package) e le relative interdipendenze.
•
Process view (detta anche concurrency view): consiste nell’individuare i processi
ed i processori. Ciò al fine di dar luogo ad un utilizzo efficiente delle risorse, di
175
Appendici
poter stabilire l’esecuzione parallela di determinati oggetti, di gestire correttamente
eventuali eventi asincroni.
•
Deployment view: mostra l’architettura fisica del sistema e l’ubicazione delle
componenti software nella struttura stessa.
176
Ringraziamenti
RINGRAZIAMENTI
La pagina dei ringraziamenti di una tesi è una piccola nicchia dove il candidato esprime i
suoi sentimenti (ebbene anche i candidati hanno un cuore!), è libero dagli schemi o dalla
tradizione letteraria, non guarda “gli altri come hanno fatto”, si tranquillizza e ringrazia.
Per mio conto, vorrei ringraziare in primis i miei genitori Lucia ed Elio, anzi Mamma e
Papà, senza l’appoggio dei quali ora non potrei scrivere queste righe; grazie per avermi saputo
ascoltare, grazie per essermi stati vicino nei momenti di difficoltà, grazie. Grazie al mio
fratellino (/one) Marco ovvero Baggio ovvero “Mithicoh!”.
Un sincero grazie va al Prof. Mario Salerno e all’Ing. Giovanni Costantini, che hanno
creduto in me e nel mio progetto e mi hanno dato il giusto sostegno ed i giusti consigli per
arrivare fin qui durante questi mesi di lavoro.
Grazie all’ELIS, che mi ha dato l’opportunità di vivere un’esperienza resa ancor più
interessante e stimolante dal mio tutor, Ing. Francesco Romano. Grazie a tutti i vivaisti, ed in
particolare a Federico (sei davvero il migliore di tutti e ricordati che… “te meno!!!”),
Antonello, Roberto, Paolo, Francesco, Francesco, Stefano e Manuel (il “finto” boss), con i
quali ho condiviso le mie esperienze, i miei sogni e i miei progetti, e soprattutto sette mesi
strabilianti.
Un grazie ad i miei “compagni d’università”. Paolo, per la sua sincerità e lealtà (senza il
tuo aiuto non sarei qui…), Valerio (all’esame di “progetto di filtri integrati” meritavi la lode!),
Alexandro che ho avuto la sfortuna di conoscere da poco, Gianfranco (senza di te starei
ancora a trafficare con le cartacce burocratiche) e Pietro che mi ha sempre spinto ad andare
avanti perché “è meglio pensare alla salute…” (ma dove lo trovo uno come te per gli esami di
geometria e analisi?).
Un grazie di cuore ai miei “coinquilini”. Grazie Danielino, sei stato per me un esempio,
una guida e soprattutto un caro amico che spero di non perdere mai. Grazie Carletto (meno
male che eri sveglio tu la notte a spiegarmi gli o piccoli e o grandi…). Grazie anche a Flavia,
177
Ringraziamenti
Claudia (la “mia psicologa”…), Loris, Gianfranco (…ti devo dire che il tuo masterizzatore si
è rotto…) e Arianna.
E come non ringraziare i vecchi e cari amici del liceo? Anche se siete stati lontani dai miei
occhi per sei anni, non lo siete stati dal mio cuore. Grazie a Luigi (Giggiottolo), occorrerebbe
un capitolo a parte per raccontare tutte le nostre “storie”. Grazie a Francesca, la mia
cerimoniera, la mia amica sincera, la mia cantante… è bello sapere che ci sei sempre quando
ho bisogno di te. Grazie ad Alessia, che sto ancora aspettando mi venga a trovare. Un grazie
anche a Francesca, Cristina, Marco, Marilena, Luana, Catherine, Giuliano, Luca, Antonello,
Flavio, Andrea, Romano.
Grazie a tutti gli amici di queste estati spensierate. Nicola, Luca, Vincenzo, Vincenzo,
Grabriele, Alessandro, Rinaldo, Anna, Roberto, Sonia, Michele, Annamaria, Pamela, Marco,
Stefania.
Grazie alla mia amica Sara, la mia ballerina, che sa ascoltare, sa consigliare… vorrei avere
la stessa forza che hai tu nell’affrontare le cose della vita.
Un grazie particolare alle mie nonne, Antonietta e Nicoletta, che si son sempre preoccupate
che io mangiassi a sufficienza (l’ho fatto, nonne… e si vede!), ai miei zii ed ai miei cugini
tutti.
Un ringraziamento sincero alla signora Mariuccia, al signor Stefano a e Massimo, siete
stati una seconda famiglia per me, mi avete sempre fatto sentire come uno di casa, grazie.
Un grazie a tutti coloro che per necessità o virtù non sono riuscito a rigraziare in queste
poche righe.
Infine, ma certamente non per ordine di importanza, un ringraziamento tutto speciale e con
tutto il cuore a Serena ♥. Questi anni con te sono stati i più belli della mia vita, nonostante le
P
P
difficoltà, lo studio e le inevitabili incomprensioni; grazie per aver aspettato quando c’era da
aspettare, grazie per aver capito quando c’era da capire, grazie per essermi stata vicina
sempre. Spero tu abbia sempre un posto speciale accanto a me.
178