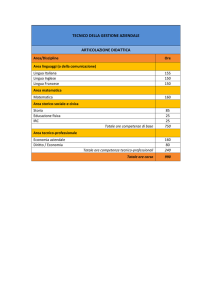
RISPOSTE LINGUAGGI E TRADUTTORI
1)TEOREMA DI RICE:
Se F⊆FC e SF={ x : fx∈F } SF è ricorsivo ⇔ F=∅( S=∅) oppure F=FC (S=N)
DIM.
La dimostrazione è per assurdo e quindi si suppone che SF è ricorsivo con 0⊂F⊂ FC cioè F≠∅ e
F≠FC
Se quindi enumero tutte le macchine di Touring Mi posso trovare:
♦ Il primo indice i ∈ SF tale che fi∈F (1)
♦ Il primo indice j ∉ SF tale che fj ∉F (2)
Considerando la funzione caratteristica di SF ho che:
1K f x ∈ F
C SF ( x) =
0 L f x ∉ F
E questa per ipotesi di ricorsività è calcolabile, allora è calcolabile anche il complementare (N - SF )
con funzione caratteristica:
i K f x ∉ F
C S F ( x) =
jL fx ∈ F
(3)
Ora per il teorema del punto fisso (Kleene)
∃ x ∈ S F : f x = f C sF ( x )
Dove il punto fisso può assumere il valore di i o j. Ora notiamo l’assurdo infatti:
♦ se C S F (x ) = i allora per la (3)
per Kleene e dalla (1)
f x ∉ F e ciò è in contraddizione con la scelta di i infatti
f x = f C sF ( x ) = f i
♦ se C S F (x ) = j allora per la (3)
f x ∈ F e ciò è in contraddizione con la scelta di j come
in precedenza.
La tesi è valida c.v.d..
In poche parole:
Se prendo tutte le macchine di Turing che corrispondono ad una funzione tale insieme non è
generabile.
Inoltre non possiamo neanche decidere in maniera automatica, presa una data MT se essa possa o
meno calcolare la funzione.
Non è quindi possibile stabilire per mezzo di un algoritmo se un dato algoritmo sia in grado di
risolvere un problema, ne se due programmi siano equivalenti (ossia calcolino la stessa funzione).
(3) ESPRESSIONI REGOLARI
Le espressioni regolari sono un formalismo in grado di descrivere i linguaggi regolari ovvero
generati da grammatiche regolari.Un grammatica è di tipo 3 o regolare se: π⊆Vn × Vn (Σ∪{ε})in
tal caso si parla di ricorsione sinistra oppure se π⊆Vn × (Σ∪{ε})Vn in tal caso si parla di ricorsione
destra. Informalmente le espressioni regolari sono delle stringhe del tipo: a*cb*(dc*/eb*)f.
Espressioni regolari e grammatiche regolari hanno lo stesso potere espressivo infatti esiste un
algoritmo che mi permette di passare dalle une alle altre.Le espressioni regolari operano su di un
alfabeto Σ di simboli terminali e contengono operatori.
Sia Σ un alfabeto di almeno due simboli, allora possiamo definire formalmente ( in maniera
ricorsiva) il linguaggio delle espressioni regolari la cui sintassi risulta:
♦
♦
♦
♦
♦
∀ a ∈ Σ, a è una espressione regolare (a∈ ERΣ)
∀ e ∈ ERΣ , (e)+ & (e)* ∈ ERΣ
∀ e , f ∈ERΣ , (e ⋅ f ) & (e / f) ∈ ERΣ
ε ∈ ERΣ
nessun’altra stringa appartiene a ERΣ .
Il linguaggio delle espressioni regolari ha una sintassi ed una semantica che associa ad ogni
espressione regolare un insieme di simboli. A questo punto bisogna definire la funzione semantica
S:
♦ ∀ a ∈ Σ, S(a)={a}
♦ ∀ e ∈ ERΣ , S(e)+ = {Sn(e)} ∪{ ε } & S(e)* = {Sn(e)}
♦ ∀ e , f ∈ERΣ , S(e ⋅ f )=S(e) ⋅ S(f) & S(e / f)=S(e) / S(f)
♦ S{ε} = ε
Le espressioni regolari vengono riconosciute da automi a stati finiti(ASF) . Per costruire l’automa è
necessario costruire sotto-automi relativi alle varie sotto- espressioni regolari della espressione
totale e poi fondere il tutto in un automa finale. Per l’espressione regolare a*cb*(dc*/eb*)f l’automa
è il seguente:
(4) CALCOLO PROPOSIZIONALE
Il calcolo proposizionale è una teoria formale CP={S,F,A,R} così definita:
Simboli (S) :
♦ connettivi logici ¬, ∨ , ∧ , ≡ , ⊃
♦ le parentesi “(“ e “)”
♦ un insieme numerabile di simboli proposizionali (asserzioni o variabili)
Formule ben formate (F) . E’ un sottoinsieme delle espressioni; è l’insieme delle espressioni
sintatticamente corrette :
♦ Tutti i simboli proposizionali sono fbf
♦ Se V e W sono fbf allora lo sono (¬V),V∨ W,V∧W, V≡W,V⊃W
Assiomi Logici (A) . E’è un sottoinsieme di Fsi tratta di formule che come vedremo sono sempre
vere):
♦ A1. A ⊃ (B ⊃ A)
♦ A2. (A⊃ (B ⊃ C)) ⊃ ((A ⊃ B) ⊃ (A ⊃ C))
♦ A3. (¬B ⊃¬A) ⊃ ((¬B ⊃ A) ⊃ B)
Regola di inferenza (R) .E’ un insieme finito di relazioni del tipo (condizioni / conclusioni). Le
regole di inferenze sono quelle regole che a partire da formule vere mi portano in nuove formule
vere. L’unica regola di inferenza nel calcolo proposizionale è il MODUS PONENS :
A,A⊃B
B
Cioè se A è VERA e A ⊃ B è VERA allora anche B è VERA.
Lo scopo del calcolo proposizionale il calcolo del valore di verità di una asserzione logica (che in
generale è una formula ben formata) ovvero, data una certa formula sintatticamente corretta
vogliamo andare a vedere se essa è vera o meno.
Con il calcolo proposizionale si possono esprimere delle asserzioni elementari che possono essere
vere o false e, con l’aiuto dei connettivi logici è possibile formulare delle asserzioni più complesse.
Il calcolo proposizionale è una teoria formale Corretta (o fondata) e Completa:
Corretta stà ad indicare che tutto ciò che si riesce a dimostrare è vero ovvero che tutti i teoremi del
calcolo proposizionale sono tautologie (A |- B implica B|=A ovvero se B è derivabile da A allora B
implica logicamente A)
Completa stà ad indicare che tutto ciò che è vero all’interno della teoria si può dimostrare ovvero
che tutte le tautologie del calcolo proposizionali sono teoremi. (A|=B implica A|-B ovvero se B
implica logicamente A allora B è derivabile da A)
(5) LA MACCHINA DI TOURING
Prima di definire la Macchina di Touring conviene fare delle precisazioni in modo da arrivare per
gradi ad una sua corretta definizione. Consideriamo come punto di partenza l’insieme delle funzioni
calcolabili ovvero quelle funzioni per le quali esiste un esecutore replicabile in grado di calcolarle.
Tale esecutore deve essere semplice e deve essere tale che tutte le macchine calcolatrici siano
riconducibili ad esso. La macchina che prendiamo in considerazione è la Macchina di Touring cioè
un automa con testina di scrittura/lettura su nastro bidirezionale "potenzialmente" illimitato. Ad
ogni istante la macchina si trova in uno stato appartenente ad un insieme finito e legge un carattere
sul nastro. La funzione di transizione in modo deterministico, fa scrivere un carattere, fa spostare la
testina in una direzione o nell'altra, fa cambiare lo stato.
Le macchine di Turing:
• forniscono una definizione formale del concetto di algoritmo
• consentono il riconoscimento, almeno"parziale", di tutti i linguaggi di tipo 0
• sono in grado di simulare ogni linguaggio di programmazione ed ogni altro modello di
calcolo ("tesi di Church-Turing").
Piu formalmente è detta macchina di Turing un automa <Σ, Q, q0∈Q , QF∈Q ,δ> dove
δ : (Q-QF)×Σ→Q×Σ×{SIN,DES,FERMO} dotato di un nastro semiinfinito
La funzione di transizione δ di una macchina di Turing è una funzione che quando siamo in uno
stato (per semplificazione a meno di quelli finali), essa cambia stato, e sul nastro riscrive e si sposta.
E’ detta configurazione di una macchina di Turing l’insieme dello stato attuale e dello stato del
nastro con la posizione attuale: <q , α.aβ> ⇒ <q’ , α’.bβ’>
Si noti che la computazione è una computazione fatta di simboli: f : Σ*→Σ* in generale. Una
particolare computazione è f : Σ*→{0,1}. Si noti che quest’ultima computazione altro non è che il
riconoscimento di un linguaggio. In questo caso dunque, computare significa riconoscere linguaggi.
Abbiamo detto che una MT è in grado di riconoscere linguaggi; in particolare una MT può essere
accettante o decidente. Da questo punto di vista si possono dare due definizioni:
•
un linguaggio si dice ACCETTATO da un MT se
1. ∀ x ∈ L, la MT raggiunge lo stato finale.
2. ∀ x ∉ L, la MT non si ferma.
•
un linguaggio si dice RICONOSCIUTO da un MT se
1. ∀ x ∈ L, la MT raggiunge lo stato finale di accettazione.
2. ∀ x ∉ L, la MT raggiunge lo stato finale di rifiuto.
Esistono linguaggi accettati e non decidibili: sono linguaggi semidecidibili ovvero linguaggi per i
quali se la stringa appartiene riusciamo a decidere, se non appartiene la macchina potrebbe andare
in loop e non terminare. Il problema è che il programma non può decidere su se stesso quando và in
loop in quanto è un problema osservatore-osservato. La macchina di Turing è un ottimo
riconoscitore di linguaggi: è possibile dimostrare che tutti i linguaggi definiti da una grammatica
sono accettabili da una macchina di Turing, ovvero che tutti e soli i linguaggi definiti da una
grammatica sono semidecidibili.
Le MT possono essere enumerate ossia è possibile stabilire una bisezione(corrispondenza 1 ad 1 tra
dominio e condominio):
K : N → {MTΣ }
con MTΣ le macchine di Touring che hanno come insieme dei simboli ∑ .
Se h è la cardinalità di ∑ e q è la cardinalità di Q, si possono avere (1+3 ⋅q ⋅ h)q⋅h macchine di
Touring che possono essere ordinate seguendo un criterio sistematico, ad esempio un ordine
lessicografico.
(6) LA MACCHINA DI TOURING UNIVERSALE
E' possibile descrivere una macchina di Turing con una stringa di caratteri e fornire tale descrizione
come input ad un'altra macchina di Turing.
Quello che vogliamo ora vedere è come la macchina di Turing può calcolare se stessa. Esistono
ovvero delle macchine di Turing universali ?
Una macchina di Turing universale è una macchina di Turing MU che sviluppi la seguente
funzione:
MTU(y⋅x) = My(x) ∀ My∈MT
dove y è un numero intero che rappresenta la macchina di Turing e x è un input.
Le macchine universali esistono, basterà dimostrare l’esistenza di una singola macchina di Turing
per dimostrare che inoltre ne esistono infinite.
Immaginiamo per comodità che la macchina M sia una macchina a singolo nastro e che la macchina
universale MTU sia una macchina più nastri.
Avendo l’input y e x separati con un separatore #, la prima fase (banale) e di creare (in base alla
Godellizzazione) su un nastro una rappresentazione in quintuple della macchina
M <qi,αi,qf, αf ,mov> .
Su un altro nastro copieremo invece x .
Un nastro ci servirà per segnalare lo stato corrente .
Quello che farà la macchina universale a questo punto è di inizializzare la prima cella del nastro
“stato corrente” al simbolo q0 (di default) e leggere il carattere corrente nel nastro dove c’è x,
dopodiché cercare sul nastro che contiene il codice della macchina la quintupla che inizi con il
simbolo di stato corrente e il simbolo di x corrente e fare le azioni indicate dai 3 simboli successivi,
fino a che non si arriva a dei simboli finali (evidenziati con un qualche formalismo) che danno la
terminazione
.
La macchina non fa che eseguire una per una le trasformazioni richieste dalle quintuple della
macchina M contenute sul nastro che contiene la rappresentazione.
Al termine cancella dal nastro la descrizione della macchina da calcolare.
Si noti che l’esistenza di macchine di Turing universali ha diverse conseguenze.
In primo luogo è la possibilità di impiegare le MT per la simulazioni di calcolatori di tipo general
purpose.
La forza e la debolezza allo stesso tempo della macchina di Turing universale è che essa calcola un
numero e a sua volta è essa stessa un numero.
Di fatto le MTU simulano una macchina RAM in quanto la descrizione o meglio la codifica di
My(x) corrisponde al programma di calcolo che viene fornito in ingresso assieme all’input.
Per ogni probleme la MTU dà la risposta che darebbe una MT elementare specifica per il problema
in esame: quindi una MT può calcolare se stessa.
(7) GERARCHIE DI LINGUAGGI
Considerando come formalismo per definire i linguaggi le grammatiche, è possibile classificare
queste ultime e quindi ottenere una classificazione dei linguaggi da esse generati.
Le grammatiche vengono suddivise generalmente in quattro categorie:
♦ Tipo 3 o regolari se: π⊆Vn × Vn (Σ∪{ε})in tal caso si parla di ricorsione sinistra oppure
se π⊆Vn × (Σ∪{ε})Vn in tal caso si parla di ricorsione destra. Si hanno regole del tipo:
regolari destre : X → uY , X → u con X,Y ∈VN, u ∈∑*
regolari sinistre : X → Yu , X → u con X,Y ∈VN, u ∈∑*
♦ Tipo 2 o non contestuali : sono grammatiche G=<Σ,VN,S∈VN,Π> dove
Π=VN×V* ovvero grammatiche in cui nella parte sinistra delle regole di
produzione ci sia uno e un solo simbolo ed esso sia non terminale.Si hanno
regole del tipo: X → x con X ∈VN , x ∈V+
♦ Tipo 1 o contestuali : sono grammatiche G=<Σ,VN,S∈VN,Π> dove Π=Q×Z
dove Q=V*⋅VN⋅V* e Z∈V+ e tale che |Q|≤|Z| ovvero delle grammatiche in
cui nella parte sinistra delle regole di produzione ci sia almeno un simbolo
non terminale e tale che la cardinalità di stringa dell’elemento a sinistra sia
minore o uguale di quella a destra.In pratica le regole possono assumere due
forme:
1. Q → Z
con
|Q|≤|Z|
2. uXv → uxv
con
u,v ∈ V* , X ∈VN , x ∈V+
Ovvero la sostituzione di X con x avviene solo se x appare nel contesto tra u e v.
♦ Tipo 0 o a struttura di frase : la parte sx delle regole deve contenere almeno un simbolo
non terminale.
Si hanno regole della forma : X → w con x=aXb , (a,b) ∈ V* , X ∈VN, w ∈V*
Le relazioni che intercorrono tra le varie grammatiche sono riassunte nel seguente schema che ci
permette di capire inoltre che tipi di linguaggi vengono generati dai vari tipi di grammatiche:
Per def. è detto linguaggio L un certo sottoinsieme del linguaggio universale ovvero L⊆Σ*. Il
problema dell’appartenenza è così esplicabile:
Sia un certo linguaggio L formato da un certo alfabeto Σ,,L⊆Σ* e sia una certa stringa σ∈Σ*, σ∈L
?
Ovvero in termini più informali, il problema dell’appartenenza è quella di stabilire se, data una
certa stringa essa appartiene o meno al linguaggio. Questo problema ci permette di dividere i
linguaggi in classi: in particolare un linguaggio descrivibile può essere decidibile o non decidibile
a seconda che noi possiamo risolvere o meno il problema dell’appartenenza.
L’insieme dei linguaggi generati da grammatiche sono semidecidibili e tutti i linguaggi
semidecidibili sono descrivibili da grammatiche, ovvero: LG=LSEMIDEC
Il fatto che tutti i linguaggi generati da grammatiche sono semidecidibili è diretto in quanto la
grammatica stessa fornisce un algoritmo semidecidibile di ricerca.
Per l’altra uguaglianza, ci limitiamo a dire che tutti i linguaggi semidecidibili sono tali in
riferimento ad un modello di Touring (che per l’assunto di Church è la macchina “più potente”
(!!!) ).
A questo punto si può dimostrare che il modello di Touring è equivalente al modello di calcolo
delle grammatiche. All’interno dei linguaggi semidecidibili, esiste una classe di linguaggi
decidibili e sapendo questo è diretto riuscire a scrivere un algoritmo deterministico che riconosca o
meno tutte le stringhe di questi linguaggi in un tempo finito.in generale L è in decidibile se il
problema dell’appartenenza non è risolto in tempo finito.
Possiamo dunque sintetizzare nel seguente schema i linguaggi:
(8) QUANTO COSTA IL PARSING LL(1)
Consideriamo come input la dimensione delle regole grammaticali ||Π||. Indichiamo con m il
numero delle regole. Per il calcolo dei FIRST ad ogni passata, aggiungiamo almeno un elemento
ad un simbolo non terminale quindi l’algoritmo è :
O(|Vn| x |Σ| x ||Π||) ovvero O(||Π||3)
Stessa cosa vale per i FOLLOWS. Rispetto al calcolo di FIRST e FOLLOWS la costruzione della
tabella di parsing è trascurabile.
(9) QUANDO UN LINGUAGGIO E’ NP-COMPLETO? UN ESEMPIO?
Partiamo con il dare una definizione della classe NP. Per dare una definizione formale di tale classe
di problemi, abbiamo bisogno di introdurre il concetto di Macchina di Turing non deterministica.
Le Macchine di Turing non deterministiche sono defnite in modo analogo a quelle deterministiche,
con la di_erenza che viene omessa la richiesta che per ogni stato qi e per ogni simbolo a vi sia al più
una istruzione che inizia con qia.
Ne segue che in una computazione eseguita tramite una Macchina di Turing non deterministica
l'operatore puo trovarsi in una certa fase della computazione con la macchina nello stato qi e con il
cursore posizionato sul simbolo a, in presenza di più di una istruzione che inizia con qia.
Siamo pronti a definire la classe NP dei problemi decidibili in tempo polinomiale non detrministico.
Sia ∑ un alfabeto finito, e sia S ⊆ ∑ *. Diciamo che S è in NP se esistono una Macchina
di Turing non deterministica M ed un polinomio P(x) tali che per ogni σ ∈ A:
♦ Se σ ∈ S, almeno uno dei rami di computazione di M su input σ termina in al
massimo P(|σ|) passi in uno stato di accettazione.
♦ Se σ ∉ S, nessun ramo di computazione di M su input σ termina entro P(|σ |) passi in
uno stato di accettazione.
Poichè le Macchine di Turing deterministiche sono un caso particolare delle Macchine di Turing
non deterministiche, dalla definizione segue subito che un problema in P è anche in NP. Il problema
di decidere se valga o meno l'implicazione inversa costituisce uno dei più importanti problemi
aperti dell'informatica teorica. Ecco ora la definizione a partire da altre due definizioni
fondamentali:
♦ Siano ∑1 , ∑2 alfabeti finiti, e sia S ⊆∑1* , e T⊆∑2*. Diciamo che T è P-riducibile a S
se esiste una funzione computabile in tempo polinomiale h tale che per ogni σ∈∑2* sia
σ ∈ T sse h(σ)∈ S.
♦ Un insieme S ⊆∑1*si dice NP-hard se per ogni T∈ NP, T è P-riducibile a S.
Def: S si dice NP-completo se S è in NP e se è NP-hard.
Dalla definizione segue subito che se un insieme NP-completo S è in P, allora P = NP.
Infatti, la funzione caratterisitca CS di S è computabile in tempo polinomiale.
Dato allora un insieme X∈NP esiste una funzione h computabile in tempo polinomiale tale che
per ogni σ sia σ ∈X sse h(σ)∈S.
La funzione caratteristica di X è allora CX(σ) = CS(h(σ)), che essendo composizione di due
funzioni computabili in tempo polinomiale, risulta essa stessa computabile in tempo polinomiale.
Quindi X è in P.
Viceversa, è evidente che se P = NP, allora ogni problema NP-completo è in P.
Per quanto riguarda l’esempio :
Teorema Di Cook: il problema di SAT è NP-completo.( Il calcolo preposizionale è NP-completo)
IL problema SAT è così definito: dato un insieme di variabili logiche booleane, avendo una
congiunzione di clausole c1∧…∧cm : ci è un disgiunzione di variabili o della loro negazione
c1∧…∧cm è soddisfaibile?
SAT ∈NP è banale in quanto possiamo creare non deterministicamente un’assegnamento di
variabili ad hoc.
Stiamo cercando di dimostrare che ∀ L’∈NP, L’<ptime L (il simbolo <ptime significa “è riducibile in
tempo polinomiale). Si dimostra prendendo qualsiasi linguaggio L’ in NP,
poiché se L’ è in NP, esiste una macchina di Turing non deterministica M’ che riconosce L’ in un
tempo f(n) polinomiale. Quello che cerchiamo di fare è di rappresentare con la logica una macchina
di Turing, andiamo dunque a individuare in ogni tempo possibile e in ogni stato possibile una
variabile logica associata così:
Qit i=1,..,q t=1,..,f(n)
Le limitazioni quì sono che per ogni t, deve esistere uno e un solo Qit=1. Questo è così definibile:
∀t, Qit=1 ⇒Qjt=0 ∀j≠i
∀t, ∃i : Qt,i =1
Questo è facilmente scrivibile sotto forma di clausole. Similmente faremo per lo stato della testina,
inoltre avremo variabili a tre indici per lo stato del nastro. Infine avremo delle condizioni sulle
configurazioni iniziali, sugli stati accettanti e sulla funzione di transizione della macchina di Turing.
Così facendo abbiamo realizzato un algoritmo polinomiale (infatti esso viene fuori dal prodotto dei
passi di computazione (che sono supposti polinomiali) degli stati dell’automa e della lunghezza
dell’input) che porta qualsiasi linguaggio L∈NP in termini di un problema SAT.
Per quanto riguarda l’esempio: Problema del kernel
Sia un grafo orientato G=<N,A>, sia un sottoinsieme di N, K⊆N, allora K è un kernel se:
1. ∀ i,j ∈K, (i,j)∉A
2. ∀ i ∈N-K, ∃ j∈K : (j,i) ∈A
Questo problema è composto di N scelte non deterministiche e di una verifica deterministica
quadrata. Quindi questo problema è NP. Per dimostrare la NP completezza ci basterà ridurre tutto in
tempo polinomiale a SAT in modo tale che SAT è soddisfacibile in P time ⇔ il prob. Del Kernel è
risolvibile in P time. L’idea è quella di associare ad ogni nodo una variabile logica.
Inserisco poi degli archi doppi da A1 a ¬A1 e così via per tutte le variabili logiche. Infine creo m
nodi in self loop c1,..,cm e associo un arco per ogni variabile logica dalla variabile logica che
compare in ci a ci.
Si pu vedere che trovare un Kernel per questo grafo corrisponde a trovare un assegnamento di
variabili
(11) PROBLEMI Log-space CON RELATIVO ESEMPIO {anche (26)}
Innanzitutto introduciamo il LogSPACE LS = {L / L è riconosciuto da una MT deterministica con
spazio logaritmico.Questa è una classe interessante, poiché è interna a P infatti:
DSPACE(f(n)) ⊆ DTIME(ef(n))
Un esempio di problema logSpace è : dato un albero e due nodi, stabilire se X è antenato di Y.
Infatti per rappresentare z (padre) userò uno spazio logaritmico. Questa classe è facile per la sua
immediatezza. Una estensione di questa classe è NL che è l’insieme dei linguaggi tale che ∃ una
macchina di Turing non deterministica che usa uno spazio logaritmico. Abbiamo quindi la nozione
di NL-completo:
♦ L è NLcompleto se:
1) L ∈ NL
2) ∀L’∈ NL, L’<logspce L
(RELAZIONE DI APPARTENENZA O MEMBERSHIP)
( COMPLETEZZA O HARDNESS)
Un esempio di problema NL completo è se dati due nodi x y in un grafo generale , se esiste un
cammino da x a y.
In termini insiemistica è possibile osservare il seguente schema che chiarisce le idee:
Si hanno rispetto a queste classi due problemi aperti e cioè:
♦ L = NL ?
♦ P = NL ?
(13) TEOREMA DI COOK (VEDI (9))
(14) COMPLESSITA’ DEL FATTORIALE
Il calcolo del fattoriale può essere effettuato utilizzando due algoritmi:
Algoritmo iterativo:
FACT1(n) :
k := 1;
if n > 0 then
for i := 1 to n do k := k∗i;
FACT1 :=k.
Algoritmo ricorsivo:
FACT2(n) :
if n = 0 then FACT2 := 1
else FACT2 := FACT2(n -1) * n
Da un punto di vista statico l'algoritmo ricorsivo è leggermente più vantaggioso di quello iterativo
essendo il corpo dell'algoritmo più corto e semplice;
Da un punto di vista dinamico entrambi gli algoritmi eseguono n operazioni di moltiplicazione, se n
è l'intero in input;
Tuttavia, sebbene secondo le precedenti osservazioni potremmo concludere che i due algoritmi
abbiano le stesse caratteristiche di effcienza, analizzando le esigenze di memoria si arriva ad una
diversa conclusione:
♦ entrambi richiedono una memoria di dimensione pari a log2n! per contenere la
rappresentazione binaria del risultato;
♦ FACT1 usa solo 2 variabili i e k di dimensione rispettivamente log2n e log2n! ;
♦ FACT2 richiede una memoria maggiore:
n
∑ log
j =1
2
j! quindi è meno efficiente di FACT1.
Con un modello a costi uniformi quindi considerando che tutte le operazioni hanno costo unitario
si ottiene che per FACT la complessità risulta:
Θ(n)
Con un modello a costi log. tenendo conto che ogni informazione (nel caso del fattoriale “n”) è
rappresentata da una sequenza di bit si ottiene che la complessità risulta:
O(n2 log(n))
(15) LINEAR INPUT nota anche come RISOLUZIONE SLD.
Il Principio di Risoluzione è un sistema di deduzione per la logica a clausole che utilizza una sol a
regola di inferenza (detta appunto risoluzione ) e che non presenta assiomi logici. E’ un sistema
formale applicabile alle teorie del primo ordine in forma di clausole ed è molto più efficiente del
metodo assiomatico deduttivo.
In poche parole serve come prova della dimostrazione di teoremi.
Nell’ambito della programmazione logica visto che il PdR non è adottabile in quanto molto oneroso
dal punto di vista computazionale, considerando che un ProLog [è un insieme di clausole definite (
Clausole che contengono uno e un solo atomo negativo)] che sono gli assiomi della teoria e su cui
si possono fare delle interrogazioni ( determinare se una formula è un teorema della teoria)) è un
insieme di clausole di Horn, si può adottare una strategia di risoluzione mutata e detta Linear Input
( risoluzione SLD).
La linear input è ancora più veloce della risoluzione lineare, però è non completa per le clausole
generali ma solo per il sottoinsieme delle clausole di Horn. Essa parte da una clausola parent, essa
ad ogni passo sfrutta solo le clausole della teoria e l’ultima clausola creata in quel momento.
Così facendo evitiamo di dover tenere traccia di tutti i risolventi calcolati ma teniamo traccia solo
dell’ultimo.
Come funziona?
Sia un programma logico P ed una clausola goal G0 (una clausola che contiene solo atomi negativi
e dove ciascun atomo negativo è chiamato sottogoal) , la risoluzione SLD cerca di derivare la
contraddizione logica da P∪{G0}.
Al generico passo i, dalla clausola goal Gi e dalla clausola Ci del programma P si cerca di derivare il
novo risolvente Gi+1, la risoluzione SLD in particolare seleziona un atomo Am dal goal Gi e lo
unifica con la testa della clausola Ci attraverso la sostituzione unificatrice più generale θi.
Il nuovo risolvente Gi+1 si ottiene sostituendo l’atomo selezionato con il corpo della clausola Ci
applicando l’mgu θi.
Ovvero:
Gi : ←A1,…,Ak
Ci : A←B1,…,Br
E si ha che:
[Am]θi = [A]θi
allora la risoluzione SLD deriva:
Gi+1 : : ←A1,…A m-1 , B1,…,Br,1 , Am+1..,Ak
La risoluzione SLD è corretta cioè ogni risposta calcolata per P∪{G0} è una risposta corretta per
P∪{G0} e completa ovvero, se σ è una risposta corretta per P∪{G0} allora esiste una risposta
calcolata per P∪{G0} ed una sostituzione λ tale che σ = λθ.
Vogliamo vedere quali siano i possibili non determinismi di questa regola. Nel caso SLD abbiamo
due in determinismi:
♦ La prima riguarda il come scegliere l’atomo del goal. Questa scelta è detta regola di
calcolo. La regola più usata è la Left Most. Avendo una regola di calcolo R la
derivazione SLD di P∪{G0} via R è una derivazione SLD di P∪{G0} nella quale si usa
la funzione R per determinare l’atomo selezionato a ogni passo di risoluzione.
♦ La seconda riguarda il fatto che possono esistere più teste di clausole unificabili con
l’atomo selezionato. In generale che possono quindi esistere più soluzioni alternative per
uno stesso goal. Notiamo che la realizzazone effettiva di un dimostratore basato su
risoluzione SLD richiede la definizione non solo di una regola di calcolo ma anche di
una strategia di ricerca che stabilisce come esplorare l’albero SLD alla ricerca dei rami
di successo. Gli alberi SLD sono una forma grafica utile per rappresentare graficamente
la risoluzione SLD: dati un programma logico P, una clausola goal G0, ed una regola di
calcolo R, un albero SLD P∪{G0} via R è definito come segue: ogni nodo dell’albero è
un goal, la radice dell’albero è il goal G0, il nodo vuoto non ha figli dato il nodo
←A1,..,Am-1,Am,Am+1,…,Ak se Am è l’atomo selezionato dalla regola di calcolo allora
questo nodo ha un figlio per ciascuna clausola del tipo C:A←B1,..,Bn tale che A e Am
sono unificabili.Ciascun nodo figlio è etichettato con la clausola goal
←[A1,..,Am-1, B1,..,Bn,Am+1,…,Ak] θ ed il ramo del nodo padre al figlio con la mgu θ e la
clausola C ( ogni ramo corrisponde ad una possibile derivazione SLD .
Tipicamente abbiamo due strategie:
la Depth First e la
Breadth First.
1.Depth First. Si Parte dal nodo radice e si visitano sempre per primi i nodi a maggiore
profondità mentre seleziona arbitrariamente i nodi di uguale profondità. Quando non si è
raggiunto uno stato finale e non esistono altri nodi lungo il cammino che si stà
considerando (oppure se vogliamo generare tutte le soluzioni), dobbiamo innescare un
meccanismo di backtraking
2.Breadth First. consiste nel visitare l’albero a livelli, ovvero a ventaglio.Così facendo
si genera tutto l’albero fino a che su uno dei livelli non si trova un nodo finale.
(16) TESI DI CHURCH
Tutti i formalismi noti per modellare i dispositivi di calcolo discreti hanno, al più, il medesimo
potere computazionale delle MT. Una profonda analisi delle capacità delle MT e della
computazione meccanica in generale, ha condotto Alonso Church a formulare la sua tesi.
TESI DI CHURCH: PRIMA PARTE
♦ Non esiste alcun formalismo, per modellare una determinata computazione algoritmica,
che sia più potente delle MT e dei formalismi ad essa equivalenti.
La tesi di Church è intrinsecamente non dimostrabile, poiché è basata sulla nozione intuitiva di
calcolo algoritmico: essa è sostenuta dall'esperienza (dal 1936 ad oggi non è stato individuato
nessun formalismo più potente delle MT) e dall'evidenza intuitiva.
TESI DI CHURCH: SECONDA PARTE
♦ Ogni algoritmo può essere codicato in termini di una MT (o di un formalismo
equivalente)
Se si riesce a descrivere un algoritmo per risolvere un problema in modo preciso, seppur informale,
allora si è in grado anche di progettare una MT che risolve lo stesso problema, indipendentemente
dalla lunghezza e tediosità di un simile procedimento.
I termini “algoritmico",”meccanico", “effettivo" e “computabile" sono sinonimi.L'insieme delle
funzioni T-calcolabili coincide con l'insieme delle funzioni calcolabili. Per dimostrare che una
funzione f è calcolabile non è necessario esibire una MT che calcoli f; è sufficiente, per la tesi di
Church, fornire una procedura effettiva scritta in pseudo-codice o in un linguaggio di
programmazione.
In poche parole ∀f calcolabile da una macchina di computazione ∃ M∈Macchine di Turing che
calcola f.
(17) DEFINIZIONE DI PROBLEMI SEMIDECIDIBILI E INDECIDIBILI
anche(32)
Innanzitutto bisogna definire cosa intendiamo per problema. Un calcolo matematico; una decisione
di un’assemblea di condominio…..! Nell’ambito informatico e più in particolare nell’ambito del
corso è stata focalizzata l’attenzione su una classe particolare di problemi : i Problemi di Decisione.
+
Un problema di decisione è tale se è rappresentato da una funzione : f : Σ → {0,1}
Un problema di decisione P è equivalente al Linguaggio:
P ≡ L = {σ / σ è una risposta vera della funzione associata a P}
E’ possibile vedere intuitivamente come molti problemi si possono opportunamente descrivere
come riconoscimento di linguaggi, come traduzione da un linguaggio ad un altro o come calcolo di
una determinata funzione ed è possibile fare vedere come ogni problema matematicamente
formalizzato sia descrivibile in uno di questi modi, alla sola condizione che il dominio del problema
sia un insieme numerabile. Se così è infatti i suoi elementi si possono porre in corrispondenza
biettiva con elementi di N o di Σ*.Per arrivare ad una definizione piuttosto chiara di
(problemi)linguaggi semidecidibili e in decidibili , conviene fare riferimento al problema della
appartenenza di una stringa ad un linguaggio. Il problema dell’appartenenza è così esplicabile:
sia un certo linguaggio L formato da un certo alfabeto Σ, L⊆Σ* e sia una certa stringa σ∈Σ*, σ∈L ?
Ovvero in termini più informali, il problema dell’appartenenza è quella di stabilire se, data una certa
stringa essa appartiene o meno al linguaggio. Questo problema ci permette di dividere i linguaggi
in classi: in particolare un linguaggio descrivibile può essere decidibile o indecidibile a seconda che
noi possiamo risolvere o meno il problema dell’appartenenza( considerando insiemi di funzioni la
differenza deriva dal teorema di RICE). Invece si dice che un linguaggio è semidecidibile se è
possibile verificare l’appartenenza(x∈L?) in un tempo finito mentre non esistono garanzie per la
non appartenenza(x∉L?) che potrebbe anche richiedere tempi infiniti. Ma come li risolvo i problemi
ed in particolare con che macchine? Uso la MT perché per la tesi di Church nessun algoritmo,
indipendentemente dallo strumento utilizzato per implementarlo, può risolvere problemi che non
siano risolvibili dalla MT: la MT è il calcolatore più potente che abbiamo e che potremo mai
avere!Allora è ben posta la domanda: “Quali sono i problemi risolvibili algoritmicamente o
automaticamente che dir si voglia?”: Gli stessi risolvibili dalla semplicissima MT!Se ora considero:
♦ Problema =calcolo di una funzione f: N→N
♦ fy =funzione calcolata dalla y-esima MT
NB: fy(x) =indefinito se My non si ferma quando riceve in ingresso x.
Aggiungiamo la convenzione fy(x) = indefinito se e solo se My non si ferma quando riceve in
ingresso x: basta far sì che una qualsiasi MT se si fermasse in uno stato che non porta alla
definizione di un valore significativo fy(x) si porti in un nuovo stato che la fa procedere all’infinito,
ad esempio spostando la testina sempre a destra, senza più fermarsi (e` solo una comodità).Vediamo
ora un esempio di problema indecidibile:
Il problema della terminazione del calcolo.
Come posso risolverlo? Ad esempio:
♦ Costruisco un programma
♦ Fornisco dei dati in ingresso
♦ So che in generale il programma potrebbe non terminare l’esecuzione (in gergo: “andare
in loop”)
♦ Posso determinare se questo fatto si verificherà?
In termini assolutamente equivalenti di MT:
♦ Data la funzione g(y,x) =1 se fy(x) ≠indefinito, g(y,x) = 0 se fy(x) = indefinito. Esiste una
MT che calcola g?
Risposta: NO! Ecco perché il compilatore (un programma) non può segnalarci nella sua diagnostica
che il programma che abbiamo scritto andrà in loop con certi dati (mentre può segnalarci se
abbiamo dimenticato un end).
Stabilire se un’espressione aritmetica è ben parentetizzata è un problema risolvibile (decidibile).
Stabilire se un dato programma con un dato in ingresso andrà in loop è un problema irrisolvibile
(indecidibile)algoritmicamente (sono “molte”(anche in termini qualitativi) le cose che il calcolatore
non sa fare).
Dimostrazione:
Ipotesi assurda: g è computabile.Allora anche
h(x) =1 se g(x,x) = 0 (fx(x) =indefinito), indefinito altrimenti (fx(x) ≠indefinito) e` computabile.
(NB: ci siamo posti sulla diagonale y=x e abbiamo scambiato il si col no,poi abbiamo fatto sì che il
no diventasse una non terminazione (sempre fattibile). Se h è computabile h = fx0 per qualche x0.
Domanda h(x0) =1 o h(x0) = indefinito?
Supponiamo h(x0) =fx0(x0) =1
Ciò significa g(x0,x0) =0 ovvero fx0(x0) = indefinito:Contraddizione!
Allora supponiamo il contrario: h(x0) =fx0(x0) = indefinito
Ciò significa g(x0,x0) =1ovvero fx0(x0) ≠indefinito:Contraddizione!
In ambo i casi c’è contraddizione e quindi la tesi è valida!Questo teorema ci dice che non esiste una
MT che dica se un’altra MT termina. In generale il problema della irresolubilità algoritmica dei
problemi può presentarsi quando devo prendere in considerazione infiniti casi( generalizzazione).
Inoltre si capisce bene che le MT definiscono solo funzioni parziali e nel precedente teorema g era
non computabile solo perché totale. Per una singola istanza un problema è sempre computabile
anche se non è detto che lo si sa risolvere.
(18) LINGUAGGIO UNIVERSALE
Il linguaggio universale ∑* di alfabeto ∑ è l’insieme infinito di tutte le stringhe di tale alfabeto
compresa la stringa vuota:
Σ * = U Σ i = Σ + ∪ Σ 0 = Σ + ∪ {ε }
i ≥0
∑* è quindi la chiusura del linguaggio associato a ∑ .
Ogni linguaggio formale è dunque un sottoinsieme del linguaggio universale di uguale alfabeto.
L⊆∑*
Si possono definire delle operazioni sui sottoinsiemi del linguaggio universale.Dati due linguaggi
Lx e Ly si definiscono:
♦ Il linguaggio unione Lz = Lx ∪ Ly = {z | z ∈ Lx oppure z ∈ Ly }
♦ Il linguaggio intersezione Lz = Lx ∩ Ly = {z | z ∈ Lx e z ∈ Ly }
♦ Il linguaggio differenza Lz = Lx -Ly = {z | z ∈ Lx e z ∉ Ly }
Sui linguaggi valgono le relazioni di uguaglianza (=), disuguaglianza ( ≠), inclusione (⊆),
inclusionestretta (⊂), sottoinsieme (⊆ ) e sottoinsieme stretto ( ⊂ ) con il significato usuale delle
teoria degli insiemi. La concatenazione di due linguaggi Lx e Ly è il linguaggio che contiene tutte le
stringhe che si possono ottenere dallaconcatenazione di una qualsiasi stringa di Lx con una qualsiasi
stringa di Ly : LxLy ={xy | x ∈ Lx e y ∈ Ly }; Lε = εL = L; LΦ = ΦL= Φ. Φ è il linguaggio vuoto.
(19) PROBLEMA DI POSY
(20) QUANDO UN LINGUAGGIO è P-COMPLETO + (9)
Definiamo la classe P dei linguaggi decidibili in tempo polinomiale come segue:
P = {L = L(M) / M è un algoritmo con TimeM(n)∈ O(nc) per qualche intero positivo c.
Un linguaggio (problema decisionale) L è detto trattabile (risolvibile praticamente) se L∈P. Un
linguaggio (problema decisionale) L è detto intrattabile se L∉P. La classe P, dei problemi
decisionali decidibili in tempo polinomiale viene fatta coincidere, in base alla definizione
precedente, con la classe dei problemi risolvibili praticamente. La validità di tale corrispondenza è
avallata dai seguenti fatti:
La definizione della classe P è robusta nel senso che P è invariante in tutti i modelli computazionali.
La classe P rimane la stessa indipendentemente dal fatto che essa sia definita in termini di Macchine
di Turing tempo-polinomiali, in termini di programmi tempo-polinomiali scritti in un qualsiasi
linguaggio di programmazione o in termini di algoritmi tempo-polinomiali derivanti da qualsiasi
ragionevole formalizzazione della nozione di computazione (il termine tempo-polinomiale
rappresenta un modo sintetico per dire a complessità polinomiale rispetto alla risorsa tempo).Ciò è
conseguenza di un risultato fondamentale della teoria della complessità che dice che tutti i modelli
computazionali (formalizzazioni della nozione intuitiva di algoritmo) realistici, sono
polinomialmente equivalenti. Il fatto che due modelli computazionali siano polinomialmente
equivalenti vuol dire che, se c'è un algoritmo tempo-polinomiale per un problema algoritmico U in
un formalismo, allora c'è un algoritmo tempo-polinomiale per U nell'altro formalismo e viceversa.
La MT, la RAM e tutti i linguaggi di programmazionesono modelli computazionali
polinomialmente equivalenti. Pertanto, se è possibile scrivere un algoritmo tempo-polinomiale per
U in C++ allora esiste un algoritmo tempo-polinomiale per U in ogni ragionevole formalismo
computazionale. D'altro canto, se si dimostra che non esiste una MT tempo-polinomiale che decide
un linguaggio L, allora si può essere sicuri che non esiste un programma tempo-polinomiale che
decide L.
L è P completo se:
1) L ∈ P
2) ∀L’∈P, L’<logspce L
Un problema P completo è per esempio la versione decisionale della programmazione lineare
oppure il problema della raggiungibilità in un ipergrafo (un grafo con sincronizzazione (un
workflow).
(21) SE X’ E’ UN INSIEME RICORS. ENUM., Può NON ESSERE RICORSIVO?
Partiamo dal definire il significato di R.E e R. Abbiamo già visto come la nozione di computazione
può essere vista attraverso diverse formalizzazioni. Vogliamo ora soffermarci sul problema della
decidibilità di un insieme. Intuitivamente esso consiste nella risoluzione del problema
dell’appartenenza di un elemento ad un insieme dato. Ci preoccuperemo in particolare dei
sottoinsiemi di N che verranno indicati dalla lettera S.
E’ detta funzione caratteristica di un insieme la funzione definita:
∀x∈N, cs=1 se x∈S, 0 altrimenti.
Sulla scorta di questa definizione andiamo inolte a definire che:
♦ S ⊆ N è ricorsivo (decidibile)solo se la funzione caratteristica ad esso associato è
calcolabile.
Esempio
S={x | (X)≠⊥ } non è ricorsivo
S’={x | (X)=⊥} non è ricorsivo
S={x | x è pari} è ricorsivo
♦ S⊆N è ricorsivo ⇒ Š=N-S è ricorsivo
Infati basterà scrivere che:
CŠ(x)= 1 se Cs(x)=0, 0 altrimenti
Oltre a questa definizione, andiamo a definire una classe di insiemi ancora più interessante:
♦ S⊆N è ricorsivamente enumerabile (semidecidibile)se:
1) S=N o S=0
2) ∃t totale e computabile tale che S=cod(t)
Quello che stiamo dicendo è che associamo ad una funzione t un elemento dell’insieme:
t(0)→y0 t(1)→y1 ...
Non è escluso che esistano dei doppioni. Quindi se voglio sapere se un certo elemento appartiene ad
S devo scandire fino a che non trovo quel numero. Si noti che dunque sulla non esistenza non
possiamo dire nulla.
♦ Se S è ricorsivo ⇒S è ricorsivamente numerabile
Dobbiamo trovare t: l’insieme è non vuoto (altrimenti la dimostrazione è banale).
Ci basterà definire infatti la seguente funzione:
cs∈FTC(ovvero poiché è ricorsivo, cs è una funzione totale e computabile)
∃z∈ S
t(x) = x se cs(X)=1, z altrimenti
S coincide banalmente con il condominio di t.
A questo punto sulla scorta di tali definizioni e considerando il seguente teorema è possibile fare
l’esempio:
♦ Sia S⊆N tale che ∀x∈S, fx è totale e computabile e ∀f∈FTC,∃x∈S, fx=f allora S non è
ricorsivamente enumerabile
Vediamo quindi che se voglio avere tutte e sole le funzioni totali e computabili non posso. Infatti
questo enunciato complica l’obiettivo di avere formalismi che comprendono tutte e sole le funzioni
computabili totali, poiché un formalismo che consentisse una enumerazioni di tali funzioni
andrebbe contro tale teorema.Pertanto visto che le funzioni non totali( parziali in generale) sono
scomode, potrei cercare di farle diventare totali ma nel farlo potrei perdere la calcolabilità.
Non esiste una funzione totale e computabile che sia un’estensione della funzione computabile ma
non totale g(x) ={se fx(x) ≠⊥ allora fx(x) +1, altrimenti ⊥}.
S è RE ⇔
♦ S= Dh, con h computabile e parziale: S={x | h(x) ≠⊥
♦ S=Ig, con g computabile e parziale: S={x | x = g(y) , y∈N}
Si, esistono insiemi semidecidibili che non sono decidibili. Consideriamo il seguente insieme:
K={x | fx(x) ≠⊥}
♦ K è semidecidibile perché K=Dh con h(x) =fx(x).
♦ Ma cK(x) (= 1 se fx(x) ≠⊥, 0 altrimenti) non è computabile ⇒ K non è decidibile
Allora gli insiemi RE (i linguaggi riconosciuti dalle MT) non sono chiusi rispetto al complemento.
Graficamente:
(22) DIMOSTRARE CHE UN INSIEME RIC. E’ CORIC. ENUMERABILE E RIC.
ENUMERABILE
S ⊆ N è ricorsivo solo se la funzione caratteristica ad esso associato è calcolabile
S⊆N è ricorsivamente enumerabile se:
1) S=N o S=0
2) ∃t totale e computabile tale che S=cod(t)
Se S è ricorsivo ⇒S è ricorsivamente enumerabile
Dobbiamo trovare t: l’insieme è non vuoto (altrimenti la dimostrazione è banale).
Ci basterà definire infatti la seguente funzione:
cs∈FTC(ovvero poiché è ricorsivo, cs è una funzione totale e computabile)
∃z∈S ,t(x) = x se cs(X)=1, z altrimenti
S coincide banalmente con il condominio di t.
Un insieme è coricorsivamente enumerabile se il suo complemento e ricorsivamente enumerabile.
TEO: S è ricorsivo ⇔ è ricorsivamente enumerabile e coricorsivamente enumerabile
dim.
⇒.
S è ricorsivo ⇒ S è ricorsivamente enumerabile
S è ricorsivo ⇒ Š=N-S è ricorsivo ⇒ Š è ricorsivamente enumerabile ⇒ S è coricorsivamente
enumerabile
⇐.
S è ricorsivamente e coricorsivamente enumerabile allora ∃ 2 funzioni computabili tali che:
∃ t : s = cod(t)
∃ t’ :s’ = cod(t’)
cg(x)= 1 se x ∈ cod(t), 0 se x ∈ cod(t’).
Cioè la funzione caratteristica è calcolabile ⇒ ricorsivo.
(23) MODELLO DI PROGRAMMAZIONE LOGICA anche (30)
Partiamo dalla nozione di Interpretazione che nella logica proposizionale ci serve per sapere se la
rappresentazione che abbiamo dato per mezzo degli enunciati è vera o falsa.
Una interpretazione I è una funzione che definisce un insieme non vuoto D ed assegna:
♦ a ciascun simbolo di costante in C una costante in D
♦ a ciascun simbolo di funzione n-ario in F una funzione f:D→Dn
♦ a ciascun simbolo di predicato in P una relazione in Dn (ovvero un prodotto cartesiano
che restituisce vero o falso).
Si consideri C={“0”}, F={“s”} con s funzione unaria e P={“p”} come predicato binario.
Interpretiamo in 3 diverxsi modi:
I1:D=N, “0” è il numero naturale 0, s è il successore di un numero, p la relazione binaria ≤.
I2:D=Z-N∪{0},“0” è il numero naturale 0, s è il predecessore di un numero,p la relazione binaria ≤ .
I3: D=Z-N∪{0}, “0” è il numero naturale 0, s rappresenta il predecessore di un numero, p la
relazione binaria ≤ .
Interpretato cosa sono questi simboli, posso scrivere ora una espressione e capire se nel dominio di
interpretazione la relazione è vera o falsa. Data una interpretazione andiamo a ricercare quali sono i
significati delle formule.
Per quanto riguarda le formule ground, una formula atomica ground ha valore vero sotto una
interpretazione se il corrispondente predicato è soddisfatto.
La verità di una formula composta ground si ottiene da quelle delle sue componenti utilizzando le
tavole di verità.
Una formula del tipo ∃XF è vera in una interpretazione I se esiste almeno un elemento d del
dominio tale che la formula ottenuta sostituendo d ad X è vera in I
Una formula ∀XF, è vera se per ogni elemento del dominio D, la formula F è vera in I .
Una interpretazione I è detta modello per una formula ben formata chiusa F se F è vera in I.
Una fbf è soddisfacibile se e solo per essa esiste almeno un modello cioè SSE esiste almeno una
interpretazione in cui essa è vera.
Una fbf F è logicamente valida se e solo se tutte le interpretazioni sono un modello per F cioè SSE
ha valore vero per tutte le possibili interpretazioni.
Un insieme S di formule chiuse si dice soddisfacibile se e solo se esiste almeno una interpretazione
in cui tutte le formule sono vere. Tale interpretazione è detta modello per S.
Un insieme S di formule chiuse si dice insoddisfacibile se non esiste un modello per S cioè SSE no
esiste nessuna interpretazione che soddisfi tutte le formule.
Ad esempio:
♦ F = {∃X, p(X,s(0))} è vera in I1 ⇒ I1 è un modello per F.
♦ S = {∀Xp(X,X),p(s(0),0)⊃p(0,s(0))} I1 e I3 sono modelli.
♦
Se consideriamo una Teoria come per esempio il Calcolo dei predicati del primo ordine, un modello
non è altro che una interpretazione I che soddisfa tutti gli assiomi logici e propri della teoria stessa.
Se la teoria ha almeno 1 modello allora risulta soddisfacibile.
(24) RIDUZIONE DEL PROBLEMA SAT.
Un problema A si riduce polinomialmente a un problema B se, data un'istanza a di A, è possibile
costruire in tempo polinomiale un'istanza b del problema B tale che a è affermativa se e solo se b è
affermativa.La notazione A <P B indica che A si riduce a B (in genere sottointenderemo
polinomialmente). Si noti che se A <P B, risolvendo effcientemente B siamo in grado di risolvere
efficientemente anche A. Quindi, possiamo dire che se A <P B , il problema B è almeno tanto
difficile quanto lo è A.
Osserviamo che se A A <P B →B e B ∈ P allora A ∈ P o, equivalentemente, se A <P B e
A ∈NP / P allora B∈NP / P. Un'altra osservazione di rilievo è che la riduzione polinomiale
è chiaramente una relazione transitiva ossia A <P B e B <P C implicano A <P C.
Diremo che due problemi di decisione A e B sono polinomialmente equivalenti (A e B
sono di “pari diffcoltà") se A <P B e B<P A.
Diamo una descrizione più dettagliata della “operazione" di riduzione polinomiale.
Una riduzione (o trasformazione) polinomiale da un linguaggio L1 su un alfabeto A1* ad un
linguaggio L2 su un alfabeto A2* è una funzione che soddisfa le seguenti condizioni:
♦ esiste una MT deterministica che calcola f in tempo polinomiale.
♦ ∀ x ∈ A1* x∈ L1 se e solo se f(x) ∈ L2.
Consideriamo un importante problema classico della programmazione logica. Com'è noto, una
qualunque espressione logica può essere posta in forma normale congiuntiva. Se chiamiamo
letterale una variabile booleana o una variabile booleana negata, possiamo esprimere una formula in
FNC come un insieme di clausole C1,C2, …. ,Cm ognuna delle quali è una disgiunzione di letterali.
Un insieme di valori delle variabili booleane prende il nome di assegnamento di verità.SAT è
NP-completo. Dobbiamo ora mostrare che, dato un arbitrario problema A ∈ NP, questo si riduce a
SAT. Consideriamo un’istanza w di A e sia p il polinomio che limita il tempo di calcolo del
verificatore M che riconosce A. È possibile costruire una formula proposizionale di dimensione
polinomiale in |w| che dice che M, partendo dallo stato iniziale con w sul nastro di input e una certa
stringa sul nastro dei certificati, dopo p(|w|) passi si trova nello stato accettante (le variabili di tale
formula codificano, per ogni istante di tempo, una configurazione di M e la stringa sul nastro dei
certificati; si noti che possiamo assumere che un nastro non contenga mai più di p(|w|) simboli
diversi da _). Una tale formula è soddisfacibile sse w ∈A, e quindi A <P SAT.
ESEMPIO: k-INDIPENDENTE (stabilire se un grafo ha un insieme indipendente con almeno k
vertici). Data una formula F in forma normale congiunta formata da k clausole sulle variabili
proposizionali x1,...,xm (il lettore dovrebbe immaginare una possibile codifica in 2* per tale clausola
,e notare che la lunghezza di tale codifica è una limitazione superiore sia per k che per m),
costruiamo un grafo G nel seguente modo: per ogni clausola di C composta da L letterali
aggiungiamo L vertici, ciascuno etichettato dal corrispondente letterale, uniti in un cricca. Infine,
rendiamo adiacenti (cioè poniamo un lato tra) due vertici sse sono etichettati da letterali opposti.
Notiamo ora che l’esistenza in G di un insieme indipendente I con k o più vertici corrisponde a un
assegnamento che rende F vera. Infatti, dato che i vertici corrispondenti a una clausola formano una
cricca, non possiamo scegliere più di un vertice per clausola; dobbiamo quindi prendere esattamente
un vertice per clausola. Inoltre, dato che vertici corrispondenti a letterali opposti sono adiacenti,
possiamo costruire un assegnamento che renda veri tutti i letterali che etichettano vertici in I .
D’altra parte, un assegnamento che rende F vera deve rendere vero almeno un letterale per clausola.
Se quindi prendiamo per ogni clausola uno dei vertici etichettati da letterali veri, otteniamo un
insieme indipendente di cardinalità k.
ESEMPIO: k-CRICCA è NP-completo. basta notare che un insieme indipendente di un grafo è una
cricca del grafo complemento, cioè il grafo che ha gli stessi vertici, ma adiacenza invertita
(due vertici sono cioè adiacenti nel complemento sse non sono adiacenti nel grafo di partenza), e
quindi k-INDIP.<P k-CRICCA.
(25) PROBLEMA DEL KERNEL
Dato un grafo orientato G=( N,A), K⊆N è un Kernel se:
• ∀ i,j ∈ K, (i,j) ∉ A
• ∀ i ∈ N-K, ∃ j ∈ K : (j,i) ∈ A
Il problema del Kernel è NP-completo!
Dim.
K∈NP è vero perché K è un certificato succinto( K è composto da n scelte no deterministiche e di
una verifica deterministica quadrata. Per dimostrare che il problema del kernel è un problema Npdifficile devo ora dimostrare che SAT <P P(kernel).
Bisogna costruire un algoritmo polinomiale che data una formula SAT restituisce un grafo che gode
della seguente proprietà:
IL GRAFO POSSIEDE ALMENO UN KERNEL SSE LA FORMULA è SODDISFACIBILE.
Il grafo viene costruito con l’idea di associare ad ogni nodo una variabile:
1. ∀ variabile Ai (i=1…..n) si introducono i nodi Ai e ¬Ai e due archi (Ai , ¬Ai ) e (¬Ai , Ai )
2. ∀ clausola cj (j=1……m) si introduce il nodo cj e l’arco (cj ,cj ).
3. ∀ clausola cj=B1 ∨ B2∨ . . . ∨ BKj (j=1....n) dove Bp è una variabile , si introducono Kj archi
(B1 Cj) , (B2 Cj). . . (BKj Cj)
Quindi trovare un kernel per tale grafo significa trovare un assegnamento di variabili che verifichi
una formula SAT ⇒ Kernel∈NP perché SAT <P P(kernel).
(26) COS’E’ NL? VEDI(11)
(27) L’NP-completezza è INDIPENDENTE DAL MODELLO DI CALCOLO?
(28) TEOREMA DI KLEENE
Sia t una qualunque funzione totale e computabile. Allora è sempre possibile trovare un intero p tale
che fp = ft(p)
DIM
Sia u un intero (cioè un qualsiasi indice di MT).
Partendo da u costruiamo una MT di indice g(u) che implementi il seguente algoritmo applicato ad
un valore x dato:
♦ si calcoli z = fu(u)
♦ se la computazione di fu(u) termina, si calcoli fz(x)
Poichè la procedura precedente è effettiva, esiste, per la tesi di Church, una MT in grado di
implementarla; perciò g(u) è una funzione totale (esiste una MT opportuna per ogni u,
anche nel caso in cui fu(u) non è definita) e calcolabile (si può costruire effettivamente).
Riassumendo:
♦ fg(u)(x) = ff(u)(x) se fu(u) è definita
♦ indefinita se fu(u) non è definita
Si noti che g(u) è totale, mentre fg(u) non lo è necessariamente.
Ora, sia t una qualsiasi funzione calcolabile e totale. Allora la funzione t°g ottenuta per
composizione è anch'essa totale e calcolabile. Sia allora v un indice di MT che calcola t°g e si
ponga u = v nella costruzione precedente. Si noti che fv(v) = t°g(v) è definita essendo t°g totale.
Perciò abbiamo:
fg(v) = ffv(v) = ft°g(v) e quindi p = g(v) è un punto fisso di t.
(31) DIFFERENZA TRA MODELLO IN GENERALE E MODELLO DI
HERBRANDT
(29) IN UN PROGRAMMA LOGICO CON NEGAZIONE ESISTE UN
MODELLO MINIMO?AL Più MINIMALE
Abbiamo visto che un linguaggio di programmazione è caratterizzato da 3 componenti
fondamentali:
♦ SINTASSI : si occupa della paret formale del linguaggio astraendo il suosignificato.
♦ SEMANTICA : assegna un significato alle frasi del linguaggio.
♦ APPLICABILITA’ : si occupa degli aspetti pratici del linguaggio dalla sua analisi al
suo utilizzo effettivo.
Esistono differenti modi per definire la semantica di un linguaggio di programmazione. Unao di
questi modi è la semantica a modelli.
La semantica a modelli permette di determinare il significato di un programma utilizzando il
concetto di Modello e Conseguenza logica.
Una interpretazione I è detta modello per una formula ben formata chiusa (che non contiene
variabili libere) F se F è vera in I.
Nell’ambito della semantica a modelli dato un insieme di FBF P è definito Universo di Herbrandt di
P l’insieme di tutti i termini “ground” che possono essere costruiti a partire dai simboli di costante e
di funzione che compaiono in P.
Formalmente H(P)={x / x costante∈P come termine}
Una Base di Herbrandt di un insieme di FBF P è l’insieme di tutte le formule atomiche “ground”
che si possono costruire utilizzando i simboli di predicato che compaiono in P aventi come
argomenti gli elementi dell’universo.(B(P).
A questo punto è possibile definire il Modello di Herbrandt M(P):
♦ Dato un insieme di FBF P , un Modello di Herbrandt per P è un’interpretazione di
Herbrandt che è un modello per P.
Per un programma logico P l’intersezione di tutti i modelli di Herbrandt è ancora un modello detto
Modello minimo di Herbrandt MP.
Una Interpretazione di Herbrandt, dato un insieme di FBF P, è una funzione I tale che:
♦ Il dominio è H(P).
♦ Ciascun simbolo di costante è associato a se stesso.
♦ Se f è un simbolo di funzione n-aria in P, la funzione di interpretazione F : H(P)n→H(P)
mappa la sequenza di termini “ground” (t1,...,tn)∈H(P) nel termine f(t1,...,tn) ∈H(P).
♦ Se p è un simbolo di predicato n-ario in P, I associa un sottoinsieme di simboli di
predicato n-ario in B(P), {p(t1,...,tn)}
Un modello è minimale se non esiste un sottoinsieme del modello che sia anch’esso un modello.
Quando c’e la negazione in un programma logico non esiste un modello minimo unico ma più
modelli minimali.
Per i programmi logici con negazione esiste una classe di programmi per cui esiste un unico
modello minimale; questi programmi si dicono STRATIFICATI ed il modello è detto modello
STRATIFICATO.
Un programma logico è Stratificato quando non c’è ricorsione attraverso negazione:
♦ Se esiste un simbolo di predicato s che è definito ricorsivamente questo non è negato.
Per ogni programma è possibile costruire il grafo di dipendenza G=(N,A) dove:
♦ N={simboli di predicato}
♦ A={(s1,s2)e} archi etichettati con etichetta e.
Un PL è stratificato se non esistono cicli con archi etichettati con negazione nel grafo.
Esempio:
P:
collega(a,b)←
collega(c,b)←
collega(X,Z)← collega(X,Y) , collega(Y,Z)
collega(X,Y)← collega(Y,X)
H(P)={a,b,c}
B(P)={ collega(a,a) collega(a,b) collega(a,c) collega(b,a) collega(b,b) collega(b,c) collega(c,a)
collega(c,b) collega(c,c)}
M(P)=B(P)
MP=M(P)= B(P)
(2) ASSIOMI DI ARMSTRONG
(10) CRICCA MAX COME ESEMPIO DI NP-COMPLETO
(12) ESEMPIO DI ALG. CON COMPLEX PSEUDO POLINOMIALE