STATISTICA DESCRITTIVA
Appunti ad uso degli studenti
a cura di Giorgio Garau
Gennaio 2004
1 I metodi quantitativi
1.1 Introduzione . . . . . . . . . . . . . . . . . .
1.2 Le fonti statistiche . . . . . . . . . . . . . .
1.2.1 I sistemi informativi statistici . . . .
1.3 Concetti di base . . . . . . . . . . . . . . . .
1.4 Le rappresentazioni grafiche . . . . . . . . .
1.4.1 Tabelle e grafici per dati quantitativi
1.4.2 Tabelle e grafici per dati qualitativi .
1.5 Densità di frequenza e funzione di
ripartizione . . . . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . . . . . . 34
2 I rapporti statistici
3 Gli indici di posizione
3.1 Introduzione . . . . . . . . . . . . . .
3.2 Media . . . . . . . . . . . . . . . . .
3.2.1 Alcune proprietà della media .
3.3 Altri indici di posizione: Moda e
Mediana . . . . . . . . . . . . . . . .
3
3
7
13
18
21
22
31
41
45
. . . . . . . . . . . . . . 45
. . . . . . . . . . . . . . 45
. . . . . . . . . . . . . . 51
. . . . . . . . . . . . . . 54
4 Misure di variabilità
4.1 Indici di dispersione . . . . . . . . . . . . . . . . . . . . . . . .
4.2 Indici di concentrazione . . . . . . . . . . . . . . . . . . . . . .
4.2.1 Rappresentazione grafica: Lorenz (1904) e Gini (1914)
4.3 Asimmetria e Curtosi . . . . . . . . . . . . . . . . . . . . . . .
63
63
71
71
83
5 I fenomeni bivariati
89
5.1 La correlazione . . . . . . . . . . . . . . . . . . . . . . . . . . 94
5.2 La regressione . . . . . . . . . . . . . . . . . . . . . . . . . . . 97
A Soluzione esercizi
111
A.1 I metodi quantitativi . . . . . . . . . . . . . . . . . . . . . . . 111
A.2 I fenomeni bivariati . . . . . . . . . . . . . . . . . . . . . . . . 117
1
2
I metodi quantitativi
1.1
Introduzione
There are three kind of lies: lies, damned lies and Statistics
Mark Twain
A cosa serve la statistica
La statistica serve ad organizzare i dati e l’informazione numerica, per descrivere ed avere intuizioni su come vanno le cose, sulle tendenze, sui rapporti
tra i fenomeni. Vediamo alcuni esempi.
1. consideriamo una serie storica dei quotidiani venduti o del numero di conflitti nel mondo. La Statistica consente di studiare le serie, cioè di scomporre
le diverse componenti, mettendo in evidenza trend, ecc.
2. consideriamo alcuni indicatori di fenomeni sociali come la soglia della
povertà, l’ampiezza delle famiglie o il rapporto tra SAU e superficie comunale. Ognuno di essi consente di studiare un fenomeno più o meno complesso.
3. ipotizziamo di fare un sondaggio tra gli studenti (caratteristiche socio economiche) e spiegare il senso della scelta casuale delle unità e cosa succede se
la scelta delle stesse non avviene in modo casuale. La Statistica ci dice come
costruire dei piani di campionamento, come concepire dei questionari e come
fare delle stime. E ci aiuta ad interpretare gli errori e a studiarli.
Vediamo di seguito i diversi punti del programma in relazione alle funzioni del metodo statistico e allo scopo del corso: fornire allo studente alcuni
strumenti quantitativi per poter interpretare la realtà.
1.
2.
3.
4.
5.
I metodi quantitativi
L’analisi esplorativa dei dati
L’analisi bivariata
Probabilità e variabili casuali
L’inferenza statistica
I metodi quantitativi
Iniziamo, soffermandoci su alcuni punti. Nelle scienze sociali la statistica ha
il ruolo di quantificare sotto tre aspetti:
Dal punto di vista descrittivo è chiaro che la traduzione in numeri ha
una sua validità legata alla funzione di sintesi (pensate alla estrema sintesi
di informazioni contenute in un indicatore come il PIL pro capite, indicatore
del tenore di vita di un paese.
Per quanto riguarda l’osservazione, la raccolta di informazione, è chiaro
che l’obiettività del dato può essere raggiunta solo attraverso l’adozione di
convenzioni. Inoltre la confrontabilità di informazioni raccolte in posti diversi
non può che basarsi su una definizione quantitativa dei fenomeni (Esempio:
confronto della comodità dei trasporti urbani in due città, si può calcolare sia
il numero di corse all’ora, sia la spesa (una quota costante e una proporzionale
alla distanza: K + L etc.) per km di linea).
Infine nel trattamento dell’informazione è chiara la necessità di
QUANTIFICARE e di tradurre in quantificabile ogni informazione.
Come possono essere ottenute queste informazioni quantitative?
Nelle SCIENZE ESATTE la raccolta dati si fa con esperienze ripetute, reiterazione di un dato fenomeno in un ambiente costituito. Un altro modo di
raccogliere dati può essere quello tipico in medicina e biologia che utilizza
GRUPPI DI CONTROLLO per verificare se un trattamento è efficace oppure
no.
Nelle SCIENZE SOCIALI talvolta si usa il 2◦ modo, ad esempio introducendo delle norme (limitazione di velocità, lancio di prodotti nuovi) in
città-campione prima di estenderle a tutto il territorio nazionale. In generale
è però estremamente difficile controllare i fattori esterni al nostro esperimento
per cui, spesso, la sola possibilità di raccogliere delle informazioni è legata
all’OSSERVAZIONE delle UNITA’ STATISTICHE.
Alcune cattive interpretazioni della statistica
Si fa di seguito riferimento ad uno studio sulla discriminazione sessuale nei
criteri di ammissione ai corsi post-laurea di una università italiana. L’analisi
dei risultati totali ci dice che:
8.442 uomini presentano domanda ed il 44% viene accettato
4.321 donne presentano domanda ed il 35% viene accettato
4
I metodi quantitativi
Assumendo che gli uomini e le donne che hanno fatto domanda siano ugualmente preparati, sembra essere una forte prova empirica del fatto che gli
uomini e le donne ricevono un diverso trattamento all’atto dell’ammissione:
l’Università sembra avere una preferenza per gli uomini.
“Apparentemente sembrerebbe che ci sia una discriminazione sessuale ma
vediamo di porci alcune domande”
Corsi
Uomini
post
Numero
%
laurea di domande di ammessi
A
825
62
B
560
63
C
325
37
D
417
33
E
191
28
F
373
6
Donne
Numero
%
di domande di ammessi
108
82
25
68
593
34
375
35
393
24
341
7
Consideriamo ora il problema più in dettaglio e confrontiamo i tassi di ammissione nei diversi Corsi post-laurea (prendiamo solo i primi 6 Corsi, ai
quali si riferiscono oltre un terzo delle domande di ammissione e il cui comportamento può essere considerato come quello tipico di tutta l’Università);
5
I metodi quantitativi
scopriremo che tali tassi si equivalgono, anzi nel corso A sembra vi sia una
discriminazione nei confronti degli uomini.
Tuttavia, quando si considerano tutti i 6 corsi risulta un tasso di ammissione del 44% per gli uomini e del 30% per le donne, una differenza di ben
14 punti percentuali. Ciò sembra paradossale, ma c’è una spiegazione:
è più facile entrare nei primi 2 Corsi (A e B), e più della metà degli
uomini vi ha fatto domanda.
è più difficile entrare negli altri quattro Corsi e più del 90% delle donne
vi ha fatto domanda.
Insomma le donne scelgono studi più difficili. Nel risultato finale vi è l’influenza della scelta dei corsi che si confonde con l’effetto relativo al sesso. In
conclusione si palesa una discriminazione sottile e che consiste nel mantenere
basso il tasso di ammissione nelle materie scelte “naturalmente” dalle donne.
Andiamo un po’ oltre e vediamo come la statistica ci consente di sintetizzare i 12 tassi di ammissione. Utilizzeremo il concetto di media che vedremo
più avanti ma potete ora intuire a che cosa serve.
Numero totale di domande
Corsi Numero totale
di domande
A
933
B
585
C
918
D
792
E
584
F
714
4526
La media ponderata del tasso di ammissione, calcolata usando come pesi il
numero totale (maschi e femmine) di domande presso ciascun Corso, per gli
uomini è:
62 · 933 + 63 · 585 + 37 · 918 + 33 · 792 + 28 · 584 + 6 · 714
= 39%
4526
Mentre per le donne . . .
82 · 933 + 68 · 585 + 34 · 918 + 35 · 792 + 24 · 584 + 7 · 714
= 43%
4526
SORPRESA: C’è discriminazione nei confronti degli uomini.
6
I metodi quantitativi
1.2
Le fonti statistiche
Come si possono raccogliere le INFORMAZIONI?
• Per rilevazione esaustiva di tutte le unità statistiche che compongono
la popolazione (CENSIMENTI);
• Per rilevazione CAMPIONARIA: SONDAGGI.
Vediamo un esempio di questi due tipi di rilevazione che ci aiuteranno anche
ad entrare “dolcemente” nel mondo dei dati utilizzando qualche “chiave di
lettura” che li renderà meno antipatici.
I CENSIMENTI sono una fotografia della Nazione, eseguiti ogni 10 anni, che
forniscono indicazioni dettagliate sulla struttura demografica del paese, consentendo di esaminare le seguenti caratteristiche qualitative e quantitative:
• anagrafica: età, sesso, stato civile, cittadinanza, luogo di nascita, residenza.
• condizione della popolazione: attiva e non attiva.
• professione: qualifica tecnologica dell’attività individuale determinata
dal genere di lavoro.
• posizione nella professione (dipendente o indipendente, dirigente o quadro
oppure operaio . . . )
• ramo di attività economica.
7
I metodi quantitativi
alcune osservazioni:
1. le percentuali sono più utili per effettuare confronti nel tempo e nello
spazio;
2. sempre a fini di confronto vi è la necessità di definire univocamente i
fenomeni oggetto di studio, ad esempio, la popolazione attiva, è costituita dalle persone con età maggiore ai 14 anni che risultano:
• occupate: cioè hanno un’occupazione in proprio o alle dipendenze
oppure collaborano senza un regolare rapporto di lavoro con un
familiare che svolga un’attività in proprio.
• disoccupate: sono alla ricerca di occupazione (che hanno perduto
precedentemente). Possono anche essere persone in cerca di prima
8
I metodi quantitativi
occupazione o che hanno cessato un’attività in proprio per cercare
un’occupazione dipendente.
3. la composizione del tasso medio (o generico) di attività permette di
osservare le differenze territoriali:
• nel confronto Nord-Sud il tasso di attività dipende da:
(a) struttura della popolazione, cioè composizione per età infatti
al Sud vi sono più giovani
(b) tasso di partecipazione, infatti al Sud vi sono più donne che
cercano lavoro.
• La differenza tra tasso di attività e occupati fornisce la disoccupazione palese, diversa tra Nord e Sud:
Nord: 0.429-0.393 = 0.036
Sud:
0.356-0.264 = 0.092
4. l’analisi di tali rapporti a un livello territoriale più disaggregato avrebbe
sicuramente fornito differenze più accentuate e quindi si può osservare
che:
L’AGGREGAZIONE SMUSSA LE DIFFERENZE
Prima di passare alle indagini campionarie facciamo un’altra osservazione.
L’ISTAT fornisce, nell’occasione della Relazione Generale sulla Situazione
Economica del Paese, delle statistiche ufficiali. Nel 1981, anno di censimento,
vi fu tra le 2 fonti una differenza di 1.444.000 nel numero di occupati (in meno
nel Censimento rispetto alla Relazione). Ciò si può spiegare con la paura dei
risvolti fiscali del Censimento che determinò una modifica in peggio dello
status del lavoro al momento della compilazione. Intanto, nei Censimenti la
correttezza della rilevazione è affidata alla responsabilità del capo-famiglia.
Le indagini campionarie consentono di ottenere risultati simili ai Censimenti con un notevole risparmio di forze e di soldi. Intanto sono svolte da
intervistatori specializzati e ciò riduce il rischio appena descritto. Consideriamo, per effettuare dei confronti con il Censimento, l’Indagine sulle forze di
lavoro che l’ISTAT svolge in via ufficiale dal 1958, con cadenza trimestrale,
al fine di seguire da vicino gli effetti del divenire economico-sociale su occupazione, disoccupazione e atteggiamento della popolazione nei confronti del
mercato del lavoro.
I risultati coincidono con quelli dei Censimenti anche se la terminologia
è talvolta differente. Si indica ad esempio, con forze di lavoro, nelle indagini
9
I metodi quantitativi
campionarie, ciò che si indica con popolazione attiva nelle rilevazione censuarie.
Se si trasformano i dati in valori percentuali si vede la differenza tra dati
censuari e campionari:
% disoccupati
Censimento Indicatori campionari Differenza
Centro - Nord 1480/36504=0.0405
1036/36308=0.0285
0.012
Sud 1846/20053=0.0921
877/19983=0.0439
0.0482
Sulla misura della popolazione (non essendoci timori di risvolti fiscali) gli
scarti sono invece veramente minimi:
Centro N ord : 36504/36308 = 1.0054
Sud : 20053/19983 = 1.0035
Entrambi gli scarti sono inferiori all’1% . . .
SORPRESA: il sud fa’ meglio !
10
I metodi quantitativi
Gli archivi integrati
Vediamo ora un altro modo per costruire dei dati interessanti per lo statistico
che studia i fenomeni economico-sociali. Con l’integrazione di archivi, una
pratica che sta prendendo piede in questi ultimi anni, accettata a livello
ufficiale ISTAT e non, si hanno i seguenti vantaggi:
- costi limitati
- tempestività senza rinunciare al dettaglio
- qualità delle informazioni raccolte
Facciamo un semplice esempio per chiarire di che cosa si tratta. Supponiamo
di avere 2 archivi, costruiti per fini amministrativi. Come si possono utilizzare al meglio le informazioni contenute all’interno di questi 2 archivi?
L’integrazione consiste nell’insieme di procedure che ci permettono di ottenere l’Archivio Integrato a partire da due archivi originari. Vi sono tuttavia alcuni punti da individuare: la necessità di normalizzare gli archivi;
la ricerca di una chiave per abbinare (linkage) le unità contenute nei due
archivi; la definizione di una probabilità di abbinamento per i legami non
certi (o probabilistici), infine, l’attribuzione dei caratteri più probabili alle
unità dell’Archivio Integrato.
UTILITA’: Un archivio per l’analisi socio-economica di fenomeni del tipo:
- mortalità d’impresa;
- indagini sulla produttività;
- altri tipi di indagine.
Vediamo di commentare lo schema seguente.
11
I metodi quantitativi
Oggi, comunque, si raccolgono i dati ed è opportuno che questi siano considerati come facenti parte di un sistema informativo.
12
I metodi quantitativi
1.2.1
I sistemi informativi statistici
Come abbiamo visto uno degli obiettivi della Statistica è la raccolta delle informazioni. Dobbiamo chiederci a questo punto che cos’è una informazione
e che cosa rappresenta l’informazione per la Statistica. Possiamo rispondere
che è la sua materia prima, il pane quotidiano, l’ingrediente primario. Allora
che differenza c’è fra dati ed informazioni? Facciamo un esempio: 19.224.000
è semplicemente un numero, non ci da’ alcun apporto informativo, perché può
rappresentare il numero di lampadine prodotte in un anno da una fabbrica,
il reddito medio di una categoria di persone in un certo anno, la popolazione
occupata, residente in Italia nel 1981. L’informazione rappresenta un incremento di conoscenza, rispetto al dato/numero puro che, calato in un certo
contesto come ad esempio quello della popolazione attiva e occupata in Italia,
assume un particolare significato ai fini dll’analisi statistica. Esiste infatti un
sottile legame tra dati ed informazioni ed è per questo motivo che è necessario
capire come rendere i dati informativi.
In letteratura il Sistema Informativo Statistico (SIS) è un metodo conoscitivo capace di ridurre l’incertezza della realtà e di raccogliere, archiviare,
trasformare e diffondere l’informazione statistica.
A cosa serve il SIS? Vediamo un esempio applicato alle strategie di politiche del lavoro. In questo caso il SIS rende efficiente l’uso dell’informazione
su tre livelli distinti. In primo luogo permette di avere una visione completa e coerente di tutte le politiche, nel senso che evidenzia le interazioni
fra i diversi provvedimenti. E’ importante capire se un provvedimento legislativo è influenzato da un altro o se agisce indisturbato. Questo sarà infatti determinante nella misurazione dell’effetto di quella politica. In secondo
luogo il SIS permette di rilevare un inefficiente uso delle risorse a disposizione
qualora si verifichi una compresenza di misure riferite agli stessi destinatari.
Potrebbe esserci una sovrapposizione delle opportunità di finanziamento che
provocherebbe cosı̀ uno scoraggiamento da parte delle imprese a presentare
domanda perché già in graduatoria nell’assegnazione di altri finanziamenti.
Il risultato sarebbe uno spreco di risorse finanziarie da parte, nel nostro caso,
dell’Assessorato del Lavoro. In terzo luogo il sistema informativo statistico
mette in relazione in maniera corretta politiche e risultati riuscendo a misurare gli effetti di ogni singolo provvedimento. Il grande vantaggio del SIS è
quello di eliminare le ridondanze del sistema trovando le giuste relazioni fra
gli attori.
Cerchiamo di capire come opera il SIS. E’ in primo luogo un sistema informativo, cioè analizza la realtà oggetto di studio, per esempio il mercato
del lavoro in Sardegna, ed evidenzia i soggetti, che d’ora in poi chiameremo
attori, le loro caratteristiche e i processi che li legano. Il SIS ha il pre13
I metodi quantitativi
gio, quindi, in primo luogo di mettere in connessione tutte le informazioni
disponibili che si riferiscono ad una stessa realtà informativa ed in secondo
luogo di trattare in maniera integrata i dati raccolti.
Come si fa a concepire un SIS, qual’è il punto di partenza? Il primo passo
è quello di definire i requisiti, cioè le informazioni necessarie per descrivere in
modo corretto ed esaustivo la realtà di interesse per il sistema informativo.
Riferendoci al mercato del lavoro tale tappa coincide con l’individuazione
di tutte le strutture che contribuiscono a dare vita al mercato del lavoro,
quindi gli agenti istituzionali, come gli Assessorati, le Province ed i Comuni,
i soggetti privati, cioè le imprese.
Il passo successivo è quello della definizione dei suoi confini interni ed
esterni. Fondamentalmente per fare questo bisogna capire chi è il committente e chi sono gli utenti ultimi del SIS, cioè chi usufruirà del prodotto finito.
I bisogni dell’utenza sono infatti l’input, i dati in ingresso che devono essere
filtrati dal sistema informativo statistico per renderli informazioni utili per
capire la struttura della realtà.
Il terzo passo consiste in una esplorazione delle fonti che hanno dato origine al fenomeno studiato. Sempre in riferimento al mercato del lavoro è in
questa fase che viene intrapresa l’analisi della normativa (compresa quella che
definisce il ruolo degli attori istituzionali). Queste prime tre tappe permettono di elaborare un modello concettuale che strutturi la realtà individuando
gli attori e le loro caratteristiche. Tuttavia lo sforzo che viene richiesto in
questa fase è quello di cogliere anche le relazioni che legano gli attori fra
di loro. L’obiettivo è infatti quello di riuscire a cogliere e rappresentare in
modo semplice ed efficace gli aspetti della realtà interessanti ai fini dell’analisi
statistica.
La modellazione concettuale è l’anello di congiunzione fra analisi della
realtà e progettazione logica e fisica del SIS. Essa coinvolge quindi da un lato
gli esperti di dominio, cioè gli interlocutori esperti della realtà d’interesse, gli
statistici, che si occuperanno dell’aspetto più tecnico di analisi e di misura
delle relazioni e gli informatici che cureranno, invece, la realizzazione fisica
del database o del portale.
14
I metodi quantitativi
Schema SIS
La fase successiva è quella della modellazione logica, cioè della traduzione
formale del modello concettuale. A questo livello si tiene conto del sistema
di gestione (Data Base Management System DBMS) adottato per la realizzazione informatica. Il modello più frequentemente utilizzato è quello del
database relazionale che permette di legare singole tabelle (contenenti attori
e loro caratteristiche) definendo delle relazioni. Consideriamo uno dei DB relazionali di frequente uso come ACCESS, il quale attraverso il sistema delle
query (operazione di interrogazione guidata) consente di mettere in relazione
informazioni residenti in tabelle diverse. La fase di modellazione logica ha
l’obiettivo di consentire una maggiore fruibilità del prodotto finito, cioè del
data base.
L’ultima fase prevede la modellazione fisica del modello logico. Questo
significa che lo schema logico deve essere convertito in schema fisico tenendo
presente le particolari caratteristiche hardware e software del sistema informatico che si intende utilizzare. A questo livello si distingue, ad esempio,
l’impostazione client-server nella quale il client può solo ricevere informazioni
da quella peer-to-peer nella quale entrambi gli utenti possono scambiarsi le
informazioni.
15
I metodi quantitativi
L’obiettivo della progettazione fisica è l’efficienza della realizzazione fisica
del sistema informatico. Le diverse fasi possono essere riassunte con lo schema
seguente:
Schema progettazione SIS
La fase che maggiormente coinvolge lo statistico, ovviamente è quella che
riguarda il modello concettuale. Vediamo ora come è possibile modellare
un SIS di un provvedimento molto importante, cioè quello che riguarda le
Iniziative locali per lo sviluppo e l’occupazione 1
1
16
Si tratta dell’art. 19 L.R. 37/98
I metodi quantitativi
Analizziamo solamente una parte del SIS dell’art. 19 e vediamo come viene
strutturato:
SIS art.19
I rettangoli rappresentano gli attori, mentre le linee rappresentano le relazioni
fra attori. Dalla lettura dell’articolo di legge possiamo individuare soggetti e
verbi che in un ottica SIS diventano attori e relazioni. L’esercizio è quello di
capire che tipo di relazione intercorre fra i singoli soggetti, cioè una relazione
uno a molti o uno a uno. L’esperto di dominio aiuta lo statistico in questa
fase. Ci si chiede se un Comune può partecipare ai diversi strumenti della
Programmazione integrata, legame uno a molti, ma è anche vero che ad uno
stesso strumento di Programmazione integrata possono accedere più Comuni,
quindi la relazione è di tipo molti a molti.
Studiamo invece la relazione che coinvolge le attività produttive che valorizzano le risorse locali; questo è un chiaro esempio di legame uno a molti,
infatti una stessa unità produttiva può valorizzare più risorse locali, ma non è
vera la relazione inversa, cioè che le risorse locali valorizzano tutte le attività
produttive.
Se analizziamo, ad esempio, la relazione riferita alle attività produttive
che generano posti di lavoro possiamo capire come intervenga il ruolo dello
statistico nella misurazione dei posti creati. Attraverso una valutazione
d’impatto possiamo capire se i posti di lavoro creati sono da attribuire
17
I metodi quantitativi
all’intervento dell’art.19 o se si sarebbero creati indipendentemente dal provvedimento normativo. Il vantaggio di aver costruito un SIS sull’art. 19 è proprio
quello di riuscire ad attribuire ad ogni politica il suo effetto.
1.3
Concetti di base
La statistica descrittiva si può definire come un complesso di metodi che
comprendono la raccolta, la presentazione e la caratterizzazione di un
insieme di dati con lo scopo di descriverne le varie caratteristiche in
maniera appropriata.
La statistica inferenziale può essere definita come il complesso dei metodi
che consentono di stimare una caratteristica di una popolazione, oppure
di prendere una decisione che concerne l’intera popolazione, sulla base
dei soli risultati campionari.
Per chiarire meglio le definizioni, si rendono necessarie alcune ulteriori definizioni.
Una popolazione (o universo) è l’insieme di elementi o delle “cose” che si
prendono in considerazione.
Un campione è la porzione della popolazione che si seleziona per l’analisi.
Un parametro è una misura di sintesi che descrive una caratteristica dell’intera popolazione.
Una statistica è una misura di sintesi che si calcola per descrivere una
caratteristica soltanto sulla base di un campione della popolazione.
Individuo o unità statistica: è l’unità di base della rilevazione.
Carattere, ciascun tipo di informazione. Esempio: gli studenti che seguono
un corso di statistica compongono la popolazione, mentre i caratteri sono il
sesso, l’età, la data di nascita, ecc.
Supponete che il preside della vostra facoltà voglia condurre un sondaggio per
conoscere le impressioni degli studenti sulla qualità della vita universitaria.
La popolazione, o universo, in questo caso si compone di tutti gli studenti
attualmente iscritti, mentre il campione consiste dei soli studenti selezionati
per partecipare al sondaggio. Lo scopo del sondaggio è descrivere alcune
18
I metodi quantitativi
caratteristiche dell’intera popolazione (i parametri). Questo viene fatto utilizzando le statistiche che si ottengono sulla base del campione di studenti
per stimare le caratteristiche di interesse nella popolazione. Pertanto, uno
degli aspetti principali della statistica inferenziale consiste nell’utilizzo delle
statistiche campionarie per trarre delle conclusioni circa i parametri della
popolazione.
L’utilità di ricorrere ai metodi della statistica inferenziale deriva dalle
opportunità del campionamento. Quando una popolazione è molto ampia,
ottenere informazioni dall’intera popolazione diventa troppo costoso e complicato, e in certi casi può rivelarsi materialmente impossibile. Le valutazioni
sulle caratteristiche della popolazione si devono dunque basare sulle informazioni contenute in un campione estratto dalla popolazione. La teoria
della probabilità è l’anello di congiunzione, perché consente di determinare
la probabilità che i risultati provenienti dal campione riflettano i risultati
ottenibili dall’intera popolazione.
Tipi di dati
Gli statistici analizzano una varietà di fenomeni o caratteristiche. Tali fenomeni o caratteristiche si chiamano variabili.
Una variabile è una caratteristica che cambia da persona a persona. In
un’indagine, gli intervistatori sottopongono a ogni soggetto una batteria
di domande come: quanti anni ha? Quanti componenti ha il suo nucleo
familiare? Qual’è il reddito totale della sua famiglia? E’ sposato? Ha
un’occupazione? Le variabili corrispondenti a tali domande saranno rispettivamente: età, numero di componenti della famiglia, reddito familiare, stato
coniugale e stato occupazionale. Ad alcune domande si risponde con un numero (es.: età, numero di componenti della famiglia, reddito familiare), ad
altre con una parola o una frase (es.: single, sposato, vedovo, occupato, disoccupato, non appartenente alla forza lavoro). Le variabili possono essere
quindi qualitative o quantitative.
Le variabili qualitative danno luogo a risposte qualitative, non numeriche,
come si o no, maschio o femmina, cattolico, protestante o islamico. Un
esempio è dato dalla risposta alla domanda: “Possedete attualmente
titoli di stato?”, infatti si può rispondere solo si o no.
Le variabili quantitative danno luogo a risposte quantitative, ossia all’indicazione di grandezze numeriche, come l’altezza in centimetri in risposta
alla domanda “Quanto siete alti?” oppure: “A quante riviste siete abbonati?”. Ci sono due tipi di variabili quantitative:
19
Esercizi
I metodi quantitativi
variabili discrete producono risposte numeriche che derivano da un
processo di conteggio. Es.:“Il numero di riviste a cui si è abbonati”
perché la risposta è un numero intero.
variabili continue generano risposte che derivano da un processo di
misurazione. Es.: la vostra altezza, perché la risposta può assumere un qualunque valore nel continuo, a seconda della precisione dello strumento di misurazione.
Esercizi
1. Per ognuna delle seguenti variabili, dite se sono qualitative o quantitative. Se la variabile è quantitativa dite se il fenomeno di interesse è discreto
o continuo.
(a)
(b)
(c)
(d)
(e)
(f)
Numero di telefoni per famiglia
Tipo di telefono usato a casa
Numero di telefonate interurbane
fatte al mese
Durata (in minuti) dell’interurbana
più lunga fatta ogni mese
Colore del telefono usato
principalmente
Costo mensile (in euro) delle
telefonate interurbane fatte
(g)
(h)
(i)
(l)
(m)
Possesso di un telefono cellulare
Numero di telefonate locali fatte
ogni mese
Durata (in minuti) della telefonata
locale più lunga fatta ogni mese
Esistenza di una linea telefonica
collegata a un modem
Esistenza di una linea telefonica
collegata a un fax
2. Supponete che le seguenti informazioni siano ottenute da studenti intervistati all’uscita della libreria dell’università nel corso della prima settimana
di lezione. Indicate quali sono le variabili qualitative.
(a)
(b)
(c)
(d)
(e)
Ammontare speso per libri
Numero di libri di testo acquistati
Tempo dedicato agli acquisti
Corso di laurea seguito
Sesso
(f)
(g)
(h)
(i)
Possesso di un personal computer
Possesso di un videoregistratore
Numero di corsi seguiti nel semestre
attuale
Mezzo di pagamento
3. Classificate ognuna delle seguenti variabili come qualitative o quantitative
e, in quest’ultimo caso, come discrete o continue.
(a)
(b)
20
occupazione
altezza
(c)
(d)
regione di residenza
numero di automobili possedute
I metodi quantitativi
1.4
Le rappresentazioni grafiche
Le rappresentazioni grafiche illustrano mediante figure, linee, simboli, gli aspetti più notevoli di un fenomeno reale. Esse consentono una visualizzazione
immediata della struttura e dell’andamento del fenomeno e il confronto tra
più distribuzioni, mettendo in evidenza valori anomali.
Prima di passare alle rappresentazioni grafiche occorre definire cosa siano
le Distribuzioni di frequenza per caratteri qualitativi e quantitativi discreti.
Un primo livello di sintesi consiste nell’associare a ciascuna categoria, o
modalità, il numero di volte in cui questa compare nei dati; questo numero
viene detto frequenza assoluta o numerosità; l’insieme delle modalità e delle
loro frequenze definisce la distribuzione di frequenza. Date N categorie e
indicati con k ≤ N i valori diversi fra loro presenti in esse, la distribuzione
di frequenza è la seguente:
Modalità Frequenze
x1
n1
x2
n2
...
...
xk
nk
P
n1 indica la frequenza assoluta o numerosità di x1 ;
ni = N dove N è il
numero delle unità classificate. Si definisce quindi frequenza relativa della
modalità x1 il rapporto tra la frequenza assoluta ni ed il numero complessivo
delle osservazioni effettuate N .
fi =
ni
N
Dove:
k
X
i=1
fi =
k
X
ni
i=1
k
1 X
1
=
ni = N = 1
N
N i=1
N
L’insieme delle modalità e delle frequenze relative viene detto distribuzione
di frequenza. Le distribuzioni di frequenza possono essere facilmente rappresentate attraverso dei grafici. La rappresentazione utilizzata differisce a
seconda della tipologia di dati esaminati.
21
I metodi quantitativi
1.4.1
Tabelle e grafici per dati quantitativi
Il diagramma gambo-foglia
L’utilità del diagramma gambo-foglia consiste nella sua grande immediatezza
visiva, che ci consente di individuare facilmente intorno a quali valori si concentrano le osservazioni. Il diagramma gambo-foglia si costruisce dividendo
ciascuna osservazione nella sua parte principale (il “gambo” dell’albero) e in
quella secondaria (le “foglie” dell’albero). Si analizzino i dati seguenti:
33 31 39 31 42 42 33 31 37 33 47 34 36 33 34 41 38 31 39 43 51 29 32 35 35
Il fatto che 34 appaia una volta e 42 due volte non mi informa correttamente
sulla ripartizione per classi d’età. Sulla scelta delle classi vediamo ora 2
proprietà dei dati quantitativi che permetteranno una presentazione dei dati
più ricca:
1. le modalità sono ordinabili
2. la distanza tra due modalità ha un significato e quindi le basi dei rettangoli sono confrontabili.
La prima proprietà permette di riordinare i dati e di rappresentarli con un
diagramma gambo-foglia (stem and leaf) dove il gambo è la prima cifra e le
foglie le altre cifre.
25-29
30-34
35-39
40-44
45-49
50-55
2 9
3− 1 1 1 1 2 3 3 3 3 4 4
3+ 5 5 6 7 8 9 9
4− 1 2 2 3 4
4+ 7
5 1
In questa rappresentazione si possono osservare le seguenti caratteristiche:
• campo di variazione: 29-51
• concentrazione dei valori: (30-39)
• assenza di buchi
• distribuzione asimmetrica
22
I metodi quantitativi
In tal modo si può rappresentare la distribuzione dei dati secondo il carattere
considerato. L’ordinabilità consente inoltre di cumulare le frequenze. Rovesciando lo stem and leaf si ottiene un diagramma a barre.
Esempio
La tabella seguente riporta la distribuzione delle altezze (comprese tra 165 e
180 cm) di 191 tra gli operai di una fabbrica:
Per rappresentare la distribuzione attraverso un grafico a gambo e foglia, si
costruisce una tabella a due colonne. Nella prima colonna, per ogni altezza
rappresentata dalle tre cifre dei centimetri, si riportano le cifre corrispondenti
alle centinaia e alle decine, mentre nella seconda colonna le relative unità,
queste ultime sono indicate tante volte quanti sono gli operai con l’altezza
indicata.
Gambo
16
16
16
16
16
17
17
17
17
17
17
17
17
17
17
18
Foglia
5555
6666
7777
8888
9999
0000
1111
2222
3333
4444
5555
6666
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
7
8
9
0
1
2
3
4
5
6
8
9
0
1
2
3
4
8
9
0
1
2
3
4
8
9
0
1
2
3
4
8
0
1
2
3
4
0
1
2
3
4
0
1
2
3
4
1
2222
33333333333333
44
666
8888888888
999999999999
0000000000000000000
Diagramma a barre
Vediamo un altro esempio. Costruiamo il diagramma a barre relativo alla
distribuzione delle famiglie per numero di componenti.
23
I metodi quantitativi
xi
1
2
3
4
5
≥6
ni
50
80
200
220
100
150
Istogramma
All’aumentare del numero di osservazioni l’ordinamento e il diagramma gambofoglia diventano inadeguati a rappresentare il fenomeno e diventa necessario
sintetizzare ulteriormente i valori, al fine di presentare, analizzare e interpretare correttamente i risultati.
I dati vengono opportunamente divisi in classi o categorie e poi riportati
in forma tabellare, ottenendo una distribuzione di frequenze assolute delle
osservazioni.
La distribuzione delle frequenze si può allora riportare in una tabella in
cui i dati sono organizzati in opportune classi o categorie.
Nella costruzione della tabella una particolare attenzione merita la scelta
del numero di classi e dell’ampiezza di ciascuna di esse nonché la definizione
dei confini tra una classe e l’altra.
La distribuzione delle frequenze relative si ottiene rapportando le frequenze assolute della distribuzione delle frequenze al numero delle osservazioni. La distribuzione delle percentuali si ottiene poi moltiplicando per
100 ciascuna frequenza relativa. Si lavora con le frequenze relative o percentuali quando si devono fare dei confronti tra più insiemi di dati, ciascuno
con un numero differente di osservazioni.
24
I metodi quantitativi
Un altro metodo utile di presentazione dei dati, in grado di facilitare
l’analisi e l’interpretazione dei fenomeni, consiste nella tabella della distribuzione cumulativa. Questa distribuzione si può ottenere sia a partire dalle
frequenze assolute, sia da quelle relative o percentuali.
L’Istogramma è una rappresentazione grafica di caratteri quantitativi
continui con modalità raggruppate in classi. Esso è costituito da una serie
di rettangoli contigui che si sviluppano su un’asse orizzontale e che hanno la
base coincidente con l’ampiezza delle classi in cui si suddividono le modalità
del carattere. L’altezza è uguale o proporzionale alle frequenze (assolute o
relative) delle unità statistiche di ciascuna classe, l’area è sempre uguale alle
frequenze di classe. Anche quando l’altezza è uguale alla frequenza di classe,
per assicurare l’uguaglianza tra area e frequenza, si assume come unità di
misura delle basi l’ampiezza di classe.
Negli istogrammi con classi di modalità di uguale ampiezza i rettangoli
hanno base uguale all’ampiezza di classe e altezza uguale o proporzionale alla
frequenza di classe. La figura seguente riporta l’istogramma della popolazione
degli utenti del sistema formativo (dal nido all’Università) per classi di età
in una regione italiana.
Negli istogrammi con classi di modalità di diversa ampiezza i rettangoli hanno
base uguale all’ampiezza di classe e altezza uguale alla densità di frequenza,
data dal rapporto tra frequenza e ampiezza di classe; l’area rappresenta
la frequenza di ogni classe.
25
I metodi quantitativi
Esempio
Costruire l’istogramma relativo alla distribuzione delle aziende per classi
d’investimento (in migliaia di euro), di seguito riportata:
Classi
Numero
di investimento di aziende
[30, 50)
24
[50, 100)
38
[100, 200)
26
[200, 300)
32
[300, 500]
40
Totale
160
Per costruire un istogramma per la rappresentazione di una variabile statistica divisa in classi, è necessario, in primo luogo, calcolare l’ampiezza delle
classi, ottenuta come differenza tra il confine superiore e quello inferiore
della classe. Quindi, bisogna calcolare la densità di frequenza di ciascuna
classe, ottenuta come rapporto tra la frequenza e l’ampiezza della classe corrispondente. Vanno poi riportate, in un sistema di assi cartesiani ortogonali,
sull’asse delle ascisse le modalità relative a ciascuna classe e sull’asse delle ordinate le densità di frequenza corrispondenti. Infine, vanno costruiti per ogni
classe i rettangoli aventi come base l’ampiezza della classe e come altezza la
densità.
Classi
Numero
di investimento di aziende
[30, 50)
24
[50, 100)
38
[100, 200)
26
[200, 300)
32
[300, 500]
40
Totale
160
26
Ampiezza
Densità
delle classi di frequenza
20
1.20
50
0.76
100
0.26
100
0.32
200
0.20
-
Esercizi
I metodi quantitativi
Esercizi
1. Costruite il diagramma gambo-foglia per i seguenti dati di un campione
di 7 risultati ottenuti dagli studenti nell’esame di statistica (voto max 100):
80 54 69 98 53 74 93
2. Sono di seguito rappresentati i book value (valore delle attività contabili
dell’azienda diviso per il numero di azioni in circolazione) di 50 azioni scambiate sulla borsa di New York:
7
8
10
10
7
9 8 6 12 6 9 15 9 16
5 14 8 7 6 10 8 11 4
6 16 5 10 12 7 10 15 7
8 8 10 18 8 10 11 7 10
8 15 23 13 9 8 9 9 13
a. Ordinate le osservazioni
b. Costruite il diagramma gambo-foglia
c. Sulla base delle informazioni ottenute ai punti a. e b. potete affermare
la prevalenza nel campione di azioni con book value modesti oppure di
azioni con book value elevati?
27
Esercizi
I metodi quantitativi
d. Ritenete più facile imbattersi in un’azione con un book value inferiore
a 10 dollari oppure in una con book value superiore a 20?
3. Costruite l’istogramma relativo alla seguente distribuzione per classi di
età.
xi
0-5
5-8
8-10
10-20
20-50
ni
fi
ai di
Fi
hi
10
10/75 5
2
0.13 0.026
10
0.13
3 3.3 0.26 0.043
5
0.067 2 2.5 0.327 0.033
20
0.267 10 2
0.6 0.026
30
0.39 30 1
1
0.013
n=75
1
4. Nella figura che segue consideriamo un istogramma della pressione sanguinea, in percentuali per millimetro, di un campione di donne, osservate
nell’ambito di un’inchiesta.
28
Esercizi
I metodi quantitativi
Siete in grado di rispondere alle seguenti domande? (Costruite la tabella
delle frequenze)
a. Percentuale di donne la cui pressione è > 130 mm è più vicina a 25, 50
o 75%?
b. Quale dei due intervalli corrisponde all’effettivo maggiore (quindi con
densità maggiore), 112-113 o 137-138?
c. Qual è la percentuale di donne che hanno una pressione compresa tra
120 e 135 mm?
d. A quale delle due classi corrisponde l’effettivo maggiore (con densità
maggiore)? (125-130 / 140-150)
5. L’istogramma seguente rappresenta i salari mensili dei lavoratori parttime. Nessuno guadagna più di 1.000 $ al mese e il rettangolo corrispondente
alla classe 200-500 è stato omesso. Quanto deve essere alto?
29
Esercizi
I metodi quantitativi
6. Considerate il seguente istogramma:
Tra le aree disegnate valgono le relazioni:
B = 1.7 × A
C = 1.5 × B
D = 0.8 × B
Calcolate:
a. le frequenze associate ad ogni classe
b. la densità di frequenza
c. la percentuale di persone che hanno un’età superiore a 18 anni
30
I metodi quantitativi
1.4.2
Tabelle e grafici per dati qualitativi
Diagramma a canne d’organo
Il diagramma a canne d’organo, è una delle possibili rappresentazioni grafiche
dei caratteri qualitativi. Ciascuna barra del diagramma rappresenta una
modalità della variabile, e la lunghezza della barra è proporzionale alla frequenza o alla percentuale di osservazioni caratterizzate dalla modalità considerata. La rappresentazione dei valori attraverso il diagramma a barre
consente di confrontare direttamente le percentuali o le frequenze che corrispondono a ciascuna modalità. I dati possono essere visualizzati ma poiché
sono qualitativi non ordinabili, l’ordine nel grafico è arbitrario quindi non è
importante ai fini dell’analisi.
Consideriamo i seguenti dati, che sono il risultato di una elezione alla
quale si presentarono 5 candidati. A, B, B, E, A, D, D, E, A, E, E, C.
i
xi
ni
fi : ni /n
1
A
3
3/12=0.25
2
B
2
2/12 =0.17
3
C
1
0.08
4
D
2
0.17
5
E
4
0.33
n = 12
1
le frequenze assolute (ni ) ci permettono di individuare la modalità più
frequente;
le frequenze relative (fi ) ci consentono di effettuare dei confronti.
31
I metodi quantitativi
Diagramma a torta
Un altro strumento grafico ampiamente utilizzato per rappresentare dati
qualitativi da una tabella di sintesi è il diagramma a torta. Si ottiene dividendo l’angolo di 360◦ in fette la cui dimensione è proporzionale alla percentuale di osservazioni che cadono in ciascuna categoria. Il diagramma a
torta è il più visivo e maggiormente utilizzato quando si confrontano, ad
esempio, i risultati delle elezioni in due anni diversi. Nel caso di caratteri
quantitativi l’analisi delle frequenze e della loro rappresentazione grafica necessita di un’operazione: il raggruppamento in classi. Esso riveste una certa
arbitrarietà che si rivela, però, utile quando si presentano casi poco frequenti.
32
Esercizi
I metodi quantitativi
Esercizi
1. La distribuzione dei residenti di un piccolo comune per titolo di studio è
la seguente:
titolo di studio residenti
analfabeti
alfabeti
elementare
media inf.
media sup.
laurea
1
10
50
220
125
16
Si chiede di:
a. definire il carattere, le unità statistiche,la popolazione;
b. calcolare le frequenze relative (fi ) e percentuali (100fi );
c. calcolare le frequenze cumulate (Ni );
d. calcolare le frequenze retrocumulate (Ri );
2. I tipi di trasporto preferiti dagli ospiti presenti in un villaggio turistico
sono i seguenti:
tipo
ospiti
auto
nave
camper
treno
aereo
altro
25
12
23
12
55
2
Si chiede di:
a. definire il carattere, le unità statistiche,la popolazione;
b. calcolare le frequenze relative (fi ) e percentuali (100fi );
c. calcolare le frequenze cumulate (Ni );
d. calcolare le frequenze retrocumulate (Ri );
33
I metodi quantitativi
1.5
Densità di frequenza e funzione di
ripartizione
Riprendiamo nell’ordine alcuni concetti utilizzati nella costruzione e nell’analisi dell’istogramma; tali concetti sono alla base dello studio delle distribuzioni
di cui l’istogramma costituisce la rappresentazione grafica nel caso di fenomeni reali, cioè osservati.
- frequenza relativa, ni / n
- densità di frequenza, di =
- frequenza cumulata,
j
X
ni
ai
fi
i=1
Per avere un’idea dell’andamento della frequenza cumulata si usa la funzione
di ripartizione, cosı̀ definita:
0 per x < x1
Fi per xi < x < xi+1
F (x) =
1 per x ≥ xk
Funzione di ripartizione delle famiglie secondo il numero di componenti in
Puglia (linea continua) e in Umbria (linea tratteggiata)
34
I metodi quantitativi
Vediamo come la rappresentazione grafica di più funzioni di ripartizione permette di individuare alcune caratteristiche delle distribuzioni. Si può notare
che:
- entrambe le curve sono crescenti
- entrambe le curve variano tra 0 e 1 e presentano dei salti in corrispondenza di diverse modalità (la funzione è costante per intervalli)
- le curve crescono più rapidamente nel tratto iniziale e medio in cui si
addensa la maggior parte delle frequenze
- la funzione di ripartizione dell’Umbria non scende mai al di sotto di
quella della Puglia. Significa che, in termini relativi, le frequenze associate alle modalità più basse sono maggiori in Umbria e quindi la
dimensione delle famiglie è sistematicamente minore in Umbria.
Perugia
classi
ni
Fi
0-10 67.126 0.116
10-20 79.549 0.254
20-30 76.689 0.384
30-40 75.968 0.515
40-50 78.412 0.650
50-60 83.735 0.794
60-75 87.727 0.945
75-100 31.782
1
Napoli
ni
552.471
598.262
461.233
383.322
323.248
296.876
265.173
81.997
Fi
0.186
0.388
0.544
0.673
0.783
0.883
0.971
1
35
I metodi quantitativi
Il grafico nella figura precedente rappresenta una distribuzione in classi ed
il valore della funzione di ripartizione è noto solo in corrispondenza degli
estremi delle classi; se si fa l’ipotesi di distribuzione uniforme all’interno
delle classi, la funzione diviene una spezzata e all’interno della classe si ha
un’interpolazione lineare. Alcune osservazioni:
• a parità di ascisse la curva per Napoli è sempre più elevata: indica cioè
che la popolazione è sistematicamente più giovane;
• l’inclinazione di entrambe le curve si attenua come ci si avvicina alle
età avanzate (i.e. nelle ultime classi si hanno meno effettivi).
Esercizio:
La funzione di ripartizione è definita in R , devo cioè calcolare F (x) per
x ∈ (−∞, +∞); l’espressione analitica della funzione di ripartizione è:
0 per x < 18
3/12
per 18 ≤ x < 19
8/12 per 19 ≤ x < 20
F (x) =
10/12
per 20 ≤ x < 21
11/12 per 21 ≤ x < 22
1 per x ≥ 22
Il grafico è:
36
I metodi quantitativi
Come si può ottenere il numero di studenti di età superiore a 21 anni? E’
sufficiente procedere cosı̀:
Il numero di studenti di età inferiore a 21 anni = 1 - 10/12 = 2/12
Prima di iniziare l’esercizio seguente è necessaria una precisazione; se la variabile è continua si hanno 2 possibilità:
• conosciamo il valore di Fi nei punti estremi delle classi;
– supponiamo di avere una ripartizione uniforme delle fi all’interno
della classe
– interpoliamo tra Fi e Fi−1 utilizzando la densità di frequenza
• conosciamo il valore di fi e quindi di Fi in ogni punto dell’intervallo.
Utilizziamo i dati della seguente tabella (tempi di percorrenza casa-università)
e calcoliamo la densità (che nel caso di una variabile continua corrisponde
all’altezza dell’istogramma o comunque della curva).
tempo freq. relative
(yi , yi+1 )
fi
(0,10]
1/12
(10,20]
3/12
(20,40]
6/12
(40,60]
2/12
densità
Fi
di
0.0083 1/12
0.025
4/12
0.025 10/12
0.0083
1
Possiamo ora rappresentare la funzione di ripartizione.
37
I metodi quantitativi
Relazione tra funzione di ripartizione (F(x)) e funzione di densità
(f(x))
d F (x)
dx
La funzione di densità si può ottenere derivando la funzione di ripartizione.
La derivata prima di una funzione, F 0 (x) ci informa sull’andamento della
funzione e cioè:
f (x) =
F 0 (x) > 0 ⇔ CRESCE
F 0 (x) < 0 ⇔ DECRESCE
38
I metodi quantitativi
Vediamo alcuni esempi.
Funzione lineare: y = a + bx
y0 = b
Funzione quadratica: y = a + bx2
y 0 = 2bx2−1 = 2bx
39
I metodi quantitativi
Funzione costante: y = a
y0 = 0
La derivata seconda ci informa invece su come la funzione cresce (o decresce),
cioè sulla concavità della stessa:
F 0 > 0 ⇒ F cresce
F 00 < 0 ⇒ F cresce, ma sempre meno
E’ chiaro che per avere F 00 devo avere almeno una funzione di secondo grado,
infatti nel caso di funzione lineare (o di primo grado) la derivata seconda
sarà pari a zero.
y = a + bx
40
y0 = b
y 00 = 0
I rapporti statistici
I rapporti statistici sono rapporti fra due grandezze legate da una relazione
logica, di cui almeno una di natura statistica. Essi vengono prevalentemente
calcolati per eliminare l’influenza di circostanze che, altrimenti, non renderebbero confrontabili i dati.
Esempio si voglia confrontare, per un dato anno e con riferimento ad un
dato Paese, il numero di figli in due gruppi famigliari caratterizzati da diversa
età media dei genitori. Si abbiano le seguenti informazioni:
Età media
Numero Numero
genitori
famiglie
di figli
26-35
3499
4102
46-55
4013
5966
Non è corretto confrontare il numero di figli dei due gruppi famigliari e concludere che i genitori nella classe d’età 46-55 hanno più figli, perché è diverso
il numero di famiglie. Per eliminare l’influenza della diversa numerosità dei
due gruppi si possono calcolare due rapporti dividendo il numero di figli per
il numero di famiglie. Si tratta di rapporti statistici perché sia il numeratore
che il denominatore sono dati statistici. Si otterrà quindi:
R1 =
4102
= 1, 172
3499
R2 =
5966
= 1, 487
4013
Quale informazione forniscono i due rapporti?
R1 indica il numero medio di figli delle famiglie con genitori “giovani”.
R2 indica il numero medio di figli delle famiglie con genitori “adulti”.
Il confronto fra i due valori R1 e R2 consente di concludere che i genitori
“adulti” hanno un maggior numero di figli dei genitori “giovani”. Il significato del rapporto è immediato: esso indica quanta parte del numeratore
I rapporti statistici
spetta idealmente ad una unità del denominatore.
I rapporti statistici più utilizzati nelle applicazioni sono:
- I rapporti indici (o numeri indici)
- I rapporti di composizione (o di parte al tutto)
- I rapporti di coesistenza
- I rapporti di densità
- I rapporti di derivazione
- I rapporti di durata
- I rapporti di ripetizione
Vediamone alcuni:
I numeri indice
Nel settore dell’analisi economica assume particolare importanza lo studio
delle variazioni dei principali aggregati (reddito, prezzi, quantità, etc.) nella
loro dinamica temporale e/o spaziale. A volte è ancora più importante
confrontare le reciproche variazioni, i livelli di interdipendenza fra tassi di
crescita, etc. Scopo principale dei numeri indici è quello di misurare le variazioni di aggregati economici in situazioni diverse, secondo un criterio standard
che agevoli i confronti spaziali e/o temporali. Sia pt il prezzo rilevato per un
certo bene al tempo t = 0, 1, . . . , n (settimane, mesi, anni, etc.). Dati due
prezzi ps e pt rilevati in due tempi s, t, si definisce numero indice dei prezzi
al tempo s rispetto al tempo t la quantità:
ps
· 100
t Is =
pt
Tale valore sarà maggiore di 100 se ps > pt e l’eccedenza a 100 misurerà
l’incremento percentuale dei prezzi nel periodo da t a s. Al contrario nel
caso in cui t Is < 100.
Esempio
Ad esempio se il prezzo del petto di pollo dal 1997 al 1998 è aumentato da
13.500 a 14.000, allora si ha:
1997 I1998
42
=
14.000
· 100 = 103.7
13.500
I rapporti statistici
cioè vi è stato un aumento del 3.7%.
Al contrario se il prezzo del latte fresco, dal 1997 al 1998 è sceso da 2.050 a
1.950 lire al litro, allora si ha:
1.950
· 100 = 95.1
1997 I1998 =
2.050
cioè vi è stata una diminuzione del 4.9%
Notiamo che gli indici sono positivi, anche nell’ipotesi di diminuzione dei
prezzi, ed inoltre danno luogo a numeri puri, cioè non dipendono dall’unità
di misura del fenomeno.
Rapporti di durata
Alcuni fenomeni collettivi sono soggetti a rinnovamento periodico a causa di
immissioni e di uscite di unità che avvengono dal loro interno.
ESEMPI: depositi bancari, merce di un magazzino, abitanti di un paese.
Per tali fenomeni è interessante conoscere la durata media di permanenza
nel collettivo degli elementi omogenei elementari che concorrono nel tempo
a costituire il fenomeno collettivo.
Se ammettiamo che in un intervallo di tempo sia costante la consistenza
del fenomeno e sia pure costante la parte del fenomeno che periodicamente
è soggetta a rinnovarsi, il rapporto fra tali quantità si chiama rapporto di
durata ed esprime la durata media di permanenza nel collettivo delle unità
elementari che costituiscono il suo rinnovamento periodico.
Se indichiamo con:
C0 : consistenza del fenomeno al principio del periodo
C1 : consistenza del fenomeno alla fine del periodo
E : quantità in ingresso all’inizio del periodo
U : quantità in uscita alla fine del periodo
allora, considerate le due quantità:
C0 + C1
= consistenza media
2
Il rapporto di durata è dato da:
D=
C0 +C1
2
E+U
2
E+U
=
2
=
flusso medio
C0 + C1
E+U
43
I rapporti statistici
Il reciproco del rapporto di durata si chiama rapporto di ripetizione.
Esempio
In un magazzino in data 01.01.1990 sono presenti merci per un valore di 450
milioni di lire; alla data del 31.12.1990 le merci presenti hanno un valore di
550 milioni di lire. Nell’anno considerato sono entrate merci per un valore
di 600 milioni e ne sono uscite per un valore di 550 milioni. La permanenza
media di una lira investita nelle merci del magazzino risulta:
D=
450 + 550
= 0.8696 anni cioè 317 giorni.
600 + 550
I rapporti di composizione
Sono chiamati anche rapporti di parte al tutto. Si ottengono rapportando
una intensità (o una frequenza) parziale all’intensità (o frequenza) totale. Il
risultato in genere viene moltiplicato per 100 ottenendo i rapporti percentuali.
In una distribuzione di frequenze consentono di confrontare l’incidenza
(il contributo) di ciascuna modalità alla numerosità totale. Essi quindi non
sono altro che le frequenze relative.
In una distribuzione di quantità consentono di valutare il contributo alla
quantità totale di una categoria, di una classe, ecc.
Esempio
Consumi di energia elettrica per categoria di utilizzatori (milioni di kwh).
Italia 1980.
Categorie di utilizzatori
Agricoltura
Industria
Trasporti e telecomunicazioni
Commercio, servizi e pubblica
amministrazione
Illuminazione pubblica
Usi domestici
Totale
Consumi (milioni kwh) Consumi %
2.594
1.59
100.007
61.11
5.937
3.63
14.450
8.83
2.548
38.109
163.645
1.56
23.28
100.00
I rapporti di composizione permettono, in quanto numeri puri, di fare confronti temporali o confronti spaziali.
44
Gli indici di posizione
3.1
Introduzione
La rappresentazione dei dati, sebbene sia una componente essenziale della
statistica descrittiva, non è di per sé esaustiva. Quando si considerano dati
quantitativi, non è sufficiente presentare adeguatamente i dati e trarre indicazioni su questi a partire dall’osservazione di tali rappresentazioni. Una
buona analisi dei dati richiede anche che le caratteristiche principali delle
osservazioni siano sintetizzate con opportune misure e che tali misure siano
adeguatamente analizzate e interpretate.
Molte sono le misure che rappresentano le caratteristiche di posizione, di
variabilità e di forma e che quindi possono essere utilizzate in ogni analisi o
interpretazione per riassumere le caratteristiche principali di un insieme di
dati.
Gli indici di posizione, o medie, sintetizzano la posizione di una distribuzione di frequenza mediante un valore reale rappresentativo della globalità
del fenomeno e tale da riassumere gli aspetti ritenuti più importanti. Di
seguito si esaminano le misure di posizione: media, mediana e moda.
3.2
Media
DEFINIZIONE: Si dice che M è la media di n dati x1 , . . . , xn assume lo
stesso valore quando al posto di x1 , . . . , xn si pone M . Ossia, la media è
quella quantità che, sostituita a ciascuna modalità del carattere, lascia inalterata una proprietà. Quindi i dati, a seconda del tipo di media che si vuol
calcolare, saranno legati da una relazione del tipo f (x1 , . . . , xn ).
Nella Media Aritmetica la relazione è la somma
x1 + x2 + . . . + xn = M
+ . . . + M}
| + M {z
n V OLT E
Gli indici di posizione
n
X
xi = n · M
i=1
P
xi
n
Se alcune modalità si ripetono più frequentemente di altre si usa la Media
Aritmetica ponderata
M=
P
M=
xi · ni X
=
xi · fi
n
Esempio
Calcolare il peso medio di questi quattro sacchi: 10, 12, 20, 26 (misure in
Kg). Il peso è infatti un carattere additivo (sommabile)
10 + 12 + 20 + 26
68
=
= 17 Kg
4
4
Esempio
xi
1
4
6
7
ni
15
25
32
8
80
P
M=
x1 ≤ M ≤ xn
fi
15/80
25/80
32/80
8/80
1
xi · ni
363
=
= 4.5375 Media ponderata
n
80
1+4+6+7
18
=
= 4.5 Media semplice
4
4
In questo caso il risultato non è molto diverso, ma se dovessi cambiare i pesi,
come nell’esempio successivo, allora i valori sarebbero molto diversi:
M=
xi
1
4
6
7
46
ni
32
25
15
8
80
M=
278
= 3.475
80
Gli indici di posizione
Oltre alla media aritmetica è possibile definirne anche delle altre che di volta
in volta lasciano inalterata una proprietà diversa:
La Media Geometrica è utile soprattutto quando si voglia calcolare la media di processi di tipo moltiplicativo (inflazione, remunerazione del capitale,
crescita di popolazioni) su vari periodi di tempo.
Nella Media Geometrica la relazione è il prodotto
x1 · x2 · . . . · xn = M
· . . . · M} = M n
| · M {z
n V OLT E
v
u n
uY
√
n
Mediag = n x1 · . . . · xn = t
xi
i=1
Mediag ponderata =
p
n
xn1 1 · . . . · xnnn
Se si usano le frequenze relative la Mg ponderata diventa:
q
n
Y
1
f1
fn
Mediag ponderata = x1 · . . . · xn =
xfi i
i=1
Esempio
Calcolare il tasso medio di variazione dei prezzi del pane dal 1980 al 1985.
81
80
= 1.065 ;
82
81
= 1.098 ;
83
82
= 1.052 ;
84
83
= 1.110 ;
85
84
= 1.015
Verifichiamo se le grandezze sono moltiplicative:
V81
V80
· VV82
·
81
indice.
V83
V82
dopo aver semplificato si ottiene
V8 3
V8 0
che è ancora un numero
Questa proprietà dei numeri indice si chiama TRANSITIVITA’.
47
Gli indici di posizione
Mg =
√
5
1.065 · 1.098 · . . . · 1.015 =
√
5
1.38598 = 1.06746 → 6.746%
La Media Armonica si usa, ad esempio, quando si voglia calcolare la velocità media in un tragitto, conoscendo le velocità medie tenute sui vari
intervalli spaziali che costituiscono il tragitto.
Nella Media Armonica la proprietà che rimane inalterata consiste nella
somma dei reciproci. Questo tipo di media si utilizza quando, ad esempio, le grandezze sono inversamente proporzionali:
1
1
1
1
+ ... +
=
+ ... +
x1
xn
M
M
X 1
1
n
=n·
=
xi
M
M
n
Ma = P 1
xi
n
Mediaa ponderata = P ni
xi
Esempio
Consideriamo un paniere di n beni con rispettivi n prezzi. Supponendo di
spendere sempre S indipendentemente dalle quantità acquistate, e cioè:
p1 =
S1
q1
p2 =
S2
q2
...
pn =
il prezzo medio sarà cosı̀ calcolato:
Spesa tot.
ST OT
n·S
=
=P
Quantità acq.
QT OT
qi
Se si considera che:
X
48
qi =
S
S
+ ... +
p1
pn
Sn
qn
ponendo S1 = S2 = . . . = Sn = S
Gli indici di posizione
Si ottiene:
n·S
n
PS =P1
pi
che è la media armonica dei prezzi.
pi
In questo primo caso pi e qi sono inversamente proporzionali. Supponiamo
ora che S sia direttamente proporzionale alla quantità acquistata e cioè si
spende: S1 per acquistare una quantità q del bene 1 S2 per acquistare una
quantità q del bene 2 . . . Sn per acquistare una quantità q del bene n.
Il prezzo medio sarà sempre cosı̀ calcolato:
P
P
ST OT
Si
Si
p1 · q + . . . + pn · q
Prezzo medio =
=
=
=
QT OT
q + ... + q
n·q
n·q
poiché q non cambia si può mettere in evidenza
P
P
q · pi
pi
=
p̄ =
n·q
n
media aritmetica dei prezzi
Consideriamo infine le Medie Potenziate:
Si definisce media potenziata di ordine r di una variabile quantitativa X
l’espressione:
(
1
r
Mr = {M (X r )} =
n
1X r
x
n i=1 i
) r1
Ponendo nell’equazione precedente
r = 1
r = 2
r = -1
r → 0
Si ottengono rispettivamente:
la media aritmetica,
49
Gli indici di posizione
la media quadratica,
la media armonica,
la media geometrica se limr→0 Mr = Mg .
Vediamo la media quadratica:
x21
+ ... +
x2n
2
2
= M + ... + M = n · M
2
x2i
= M2
n
P
rP
Mq =
2
x2i
n
Se invece si considera la somma dei cubi:
x31
+ ... +
x3n
3
3
= M + ... + M = n · M
3
x3i
= M3
n
P
rP
Mc =
3
x3i
n
La media potenziata di ordine k sarà:
rP
Mk =
k
xki
n
Riassumendo, M , la media di n dati x1 , . . . , xn è quel valore che sostituito
ai singoli x1 , . . . , xn lascia inalterata una proprietà.
SOMMA → Media aritmetica
PRODOTTO → Media geometrica
SOMMA DEI RECIPROCI → Media armonica
SOMMA DEI QUADRATI → Media quadratica
SOMMA DEI CUBI → Media cubica
50
Gli indici di posizione
Esempio
A partire dai dati che seguono si calcolino i diversi tipi di medie.
xi
3
5
9
12
15
ni
fi
x2i
xni i
1 0.0833 9
3
3
0.25
25
125
4
0.33
81 6561
2 0.166 144 144
2 0.166 225 Q
225
n
12
1
i=1
M=
X xi · ni
Mg =
n
108
=9
12
p
n
xn1 1 · . . . · xnnn =
n
M a = P ni =
xi
rP
Mq =
=
ni /xi
x2i · ni
xi · ni
0.333
9
3
0.6
75
15
0.444
324
36
0.166
288
24
0.133
450
P
P
P 30
= 1.676
= 1146
= 108
√
12
3 · 125 · . . . · 225 =
√
12
79716 · 106 = 8.09957
12
= 7.1599
1.676
x2i · ni
=
n
r
1146 √
= 95.5 = 9.77241
12
Tutte le medie sono comprese tra 3 e 15 (valore più piccolo e valore più
grande delle modalità).
3.2.1
Alcune proprietà della media
La media è un OPERATORE LINEARE:
omogeneità, M (k · x) = k · M (x)
additività, M (x + y) = M (x) + M (y)
51
Gli indici di posizione
Dimostrazione:
P
M (k · x) =
k · xi
=k·
n
P
xi
= k · M (x)
n
P
P
P
xi
yi
(xi + yi )
=
+
= M (x) + M (y)
M (x + y) =
n
n
n
Media di una TRASFORMAZIONE LINEARE
Sia y = a + b · x una trasformazione lineare. La media di y sarà quindi:
M (y) = a + b · M (x)
Dimostrazione:
dati i valori x1 , . . . , xn allora yi assumerà i seguenti valori:
y1 = a + bx1 , . . . , yn = a + bxn
Sommando membro a membro:
y1 + . . . + yn = (a + bx1 ) + . . . + (a + bxn )
X
yi = |a + .{z
. . + a} +b
n volte
X
xi
e dividendo per n si ottiene:
yi
a
= n · + b · M (x) ⇐⇒ M (y) = a + b · M (x)
n
n
52
Esercizi
Gli indici di posizione
Esercizi
1. E’ dato un insieme di 10 valori. Ogni valore può essere 1, 2, 3. Quale
dovrebbe essere questo insieme affinché la media valga 1? E affinché valga
3? La media potrebbe valere 4?
2. Quale di questi due insiemi di valori ha la media maggiore? Oppure hanno
la stessa media? Cercate di rispondere senza effettuare calcoli.
a) 10, 7, 8, 3, 5, 9.
b) 10, 7, 8, 3, 5, 9, 11.
3. 10 persone in una stanza hanno un’altezza media pari a 168 cm. Un’undicesima persona, alta 195 entra nella stanza. Trovate la media delle 11 persone.
4. Ventuno persone in una stanza hanno un’altezza media pari a 168 cm.
Una ventiduesima persona entra nella stanza. Quanto dovrebbe essere alta
questa persona affinché l’altezza media salga di 2 cm?
53
Gli indici di posizione
3.3
Altri indici di posizione: Moda e
Mediana
Il valore modale o moda, è il più semplice valore di posizione ed è calcolabile
per qualunque tipologia di dati considerati.
Per caratteri qualitativi o quantitativi discreti la moda è la modalità a cui
è associata la massima frequenza. Se le modalità a cui è associata la massima
frequenza sono due o più di due, si parlerà di distribuzioni bimodali, trimodali
ecc.
Nel caso di variabili continue si lavora con dati riclassificati; se le classi
hanno la stessa ampiezza, si individua la classe modale in corrispondenza
della massima frequenza (fi ); se le classi hanno ampiezze diverse si assume
come classe modale quella a cui compete la massima densità di frequenza (di
oppure fi /ai ).
Esempio
Nella seguente distribuzione sono indicati gli appartamenti di un condominio
(ni ) ed il numero di stanze (xi ).
xi
1
2
3
4
5
6
7
8
tot
ni
11
49
81
86
38
14
4
3
286
fi
0.038 0.171 0.283 0.301 0.133 0.049 0.014 0.010
1
Considerato che la frequenza massima (86) corrisponde alla modalità 4, si
avrà che la moda (M o) = 4.
La media invece si può calcolare come somma delle frequenze relative (fi ):
M = 0.038 + 0.343 + 0.850 + 1.203 + 0.664 + 0.294 + 0.098 + 0.084 = 3.573
54
Gli indici di posizione
In una sequenza di dati ordinati dal più piccolo al più grande la mediana
o valore mediano, Me, occupa la posizione intermedia. La mediana è quel
valore che bipartisce in parti uguali la totalità delle frequenze; è il valore di
xi a cui corrisponde sulla cumulata delle frequenze il valore 0.5.
Utilizzando dati discreti:
se il numero di osservazioni (n) è dispari: il termine mediano (o centrale)
è quello che corrisponde all’osservazione di rango (o posizione)(n + 1)/2;
se il numero di osservazioni (n) è pari: sia n = 2h, allora la mediana è,
per convenzione, uguale alla media aritmetica dei due termini in posizione
centrale:
h=
n
2
h+1=
n
2
+ 1 quindi M e =
xh +xh+1
2
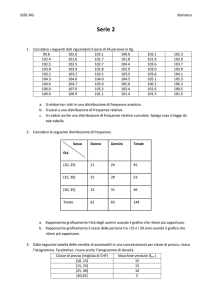
Utilizzando dati continui raggruppati in classi, si individua innanzitutto la
classe mediana, cioè quella nella quale si arriva al 50% delle frequenze; si
opera quindi per interpolazione all’interno della classe mediana, sotto l’ipotesi
che al suo interno le frequenze siano ripartite in maniera uniforme. Consideriamo la seguente distribuzione per classi di età:
xi
[0-5)
[5-8)
[8-10)
[10-20)
[20-50)
n i c i ai
di
fi
Fi
10 2.5 5 0.133 2 0.133
10 6.5 3 0.133 3.3 0.266
5
9
2 0.067 2.5 0.333
20 15 10 0.267 2 0.600
30 35 30 0.400 1
1
La media (x̄)1 per dati raggruppati in classi si calcola sostituendo alle xi il
valore centrale della classe, ci :
x̄ :
X
ci · fi
x̄ = (2.5 · 10 + 6.5 · 10 + 9 · 5 + 15 · 20 + 35 · 30)/75 =
= 25 + 65 + 455 + 300 + 1050 = 1485/75 = 19.8
M o = [5 − 8) corrisponde alla classe con densità di frequenza maggiore
M e = 75/2 = 37.5 quindi la classe mediana è: [10 − 20)
1
si indica con x̄ il valore medio di dati campionari.
55
Gli indici di posizione
Interpolazione all’interno della classe mediana
Per le variabili continue, il raggruppamento in classi delle modalità consente
di determinare solo la classe mediana nella quale ricade l’unità statistica che
bipartisce la distribuzione ordinata delle modalità. Un singolo indice sintetico
può essere ottenuto approssimando la funzione di ripartizione attorno alla
mediana.
Il modo più semplice è quello di ipotizzare un’approssimazione lineare che
conduce alla determinazione della mediana mediante la formula:
M e − xM e−1
0.5 − FM e−1
=
xM e − xM e−1
FM e − FM e−1
56
Gli indici di posizione
M e − xM e−1 =
0.5 − FM e−1
(xM e − xM e−1 )
FM e − FM e−1
M e = xM e−1 +
0.5 − FM e−1
(xM e − xM e−1 )
FM e − FM e−1
Utilizzando questa regola calcoliamo la Me dell’esercizio precedente.
M e = 10 +
0.17
0.5 − 0.33
(20 − 10) = 10 +
· 10 = 10 + 6.29 = 16.29
0.6 − 0.33
0.27
Quale indicatore utilizzare per sintetizzare un insieme di numeri?
MEDIA O MEDIANA?
1
2
M=
3
4
Me =
5
1
2
M=
3
4
Me =
50
-100
2
M=
3
4
5
Me =
In alcune situazioni è consigliato l’uso della mediana. In particolare quando
fanno parte della nostra distribuzione dei dati “strani” o meglio
ABERRANTI che possono riflettere:
errori di misura
comportamenti anomali
57
Gli indici di posizione
Posizione di Moda, Media e Mediana nelle distribuzioni unimodali
Un altro indice di posizione che considera però solo i valori estremi presi
dalla variabile è il Midrange, che è dato dalla media tra la più piccola e la
più grande delle osservazioni di un insieme di dati. Si calcola sommando il
valore più piccolo e quello più grande e dividendo per due:
Midrange =
Xpiu0
piccola
+ Xpiu0
2
grande
I quartili sono le misure di posizione non centrale più ampiamente usate.
Vengono impiegati in particolar modo quando si sintetizzano o si descrivono
le caratteristiche di ampi insiemi di dati quantitativi. Mentre la mediana è
un valore che divide a metà la serie ordinata delle osservazioni, i quartili sono
misure descrittive che dividono i dati ordinati in quattro parti. Altri quantili
usati di frequenza sono i decili, che dividono i dati ordinati in dieci parti, e i
percentili, che dividono i dati ordinati in cento parti.
Il primo quartile, Q1 è il valore tale che il 25% delle osservazioni è più
piccolo di Q1 e il 75% è più grande di Q1 .
Q1 = osservazioni di posto
58
(n + 1)
nella serie ordinata
4
Gli indici di posizione
Il terzo quartile, Q3 è il valore tale che il 75% delle osservazioni è più
piccolo di Q3 e il 25% delle osservazioni è più grande di Q3 .
Q3 = osservazioni di posto
3(n + 1)
nella serie ordinata
4
La Media interquartile è una misura di sintesi che viene utilizzata per evitare
i problemi che possono sorgere in presenza di valori estremi. La media interquartile data dalla media tra il primo e il terzo quartile dell’insieme dei
dati.
Media interquartile =
Q1 + Q3
2
Un modo efficace di rappresentare una distribuzione attraverso solo alcuni
dei suoi valori è il boxplot o diagramma riassuntivo a 5 valori. Vediamo come
si costruisce:
1. Si calcolano i valori Q0 (= xmin ), Q1 , Q2 (= M e), Q3 , Q4 (= xmax );
2. Si disegna una scatola di estremi Q1 − Q3 , tagliata sulla mediana;
3. Si calcolano i valori: a = Q1 − 1.5(Q3 − Q1 ) e b = Q3 + 1.5(Q3 − Q1 )
4. Si calcolano i valori: α = minimo dei valori maggiore di a; β = massimo
dei valori minori di b
59
Gli indici di posizione
5. Si disegnano i baffi sui valori α e β
6. I valori oltre a e b sono disegnati con dei puntini.
Esempio
Peso delle femmine
49 50 50 51 51 52 52 52 53 53 53 53 55 55 55 55 56 56 57 58 58 60 60 60 62
63 63 64 65 65 67 69 69 70 70 78 82
60
Q0 =
49 ∆Q =
11
Q1 =
53
a=
35.75
Q2 = Me = 57
α=
49
Q3 =
64
b=
81.75
Q4 =
82
β=
78
Gli indici di posizione
Peso dei maschi
53 56 60 60 64 65 67 68 68 69 69 70 72 72 72 74 75 75 75 75 78 78 78 78 79
80 93 84 88 88 88 92 96 98
Q0 =
53 ∆Q =
12
Q1 =
68
a=
50
Q2 = Me = 75
α=
53
Q3 =
80
b=
98
Q4 =
98
β=
98
61
Gli indici di posizione
62
Misure di variabilità
4.1
Indici di dispersione
Una caratteristica importante di un insieme di dati è la variabilità. La variabilità è la quantità di dispersione presente nei dati. Due insiemi di dati possono differire sia nella posizione che nella variabilità; oppure, come mostrato
in figura, possono essere caratterizzati dalla stessa variabilità, ma da diversa
misura di posizione;
o ancora, come mostra questa figura, possono essere dotati della stessa misura
di posizione, ma differire notevolmente in termini di variabilità.
Misure di variabilità
Date le seguenti distribuzioni di voti {1, . . . , 6 }
A
xi
1
2
3
4
5
6
fi
1/40
3/40
16/40
16/40
3/40
1/40
1
B
xi
1
2
3
4
5
6
fi
4/40
8/40
8/40
8/40
8/40
4/40
1
Le due distribuzioni possono essere confrontate:
secondo la media: A) M =3.5 ; B) M =3.5
secondo la variabilità del carattere intorno alla media.
Il grafico permette di intuire che la distribuzione B è più dispersa.
Come misurare la variabilità?
Prenderemo in considerazione cinque misure di variabilità: il range, il range
interquartile, la varianza, lo scarto quadratico medio e il coefficiente di variazione.
Range o campo di variazione
Il range è la differenza tra l’osservazione più grande e quella più piccola in un
insieme di dati. E’ importante sottolineare che il range deve assumere sempre
valori maggiori di zero. Quindi dobbiamo considerare il valore assoluto:
64
Misure di variabilità
Range = |Xmin − Xmax |
Il range interquartile è la differenza tra il terzo e il primo quartile in un
insieme di dati:
Range interquartile = |Q3 − Q1 |
Varianza e scarto quadratico medio
Sebbene il range sia una misura della dispersione totale e il range interquartile una misura della dispersione centrale, nessuna di queste due misure di
variabilità tiene conto di come le osservazioni si distribuiscano o si concentrino intorno a una misura di tendenza centrale, come ad esempio la media.
Consideriamo perciò due misure della variabilità, la varianza (σ 2 ) e lo scarto
quadratico medio ( σ, radice quadrata della varianza), che sintetizzano la
dispersione dei valori osservati attorno alla loro media.
n
1X
(xi − M )2
σ =
n i=1
2
2
σ =
Pn
(xi − M )2 ni
i=1P
n
i=1 ni
(La seconda formula si usa quando alcuni scarti si ripetono più frequentemente di altri).
Una difficoltà nella interpretazione della varianza deriva dal fatto che essa è
espressa nell’unità di misura del fenomeno elevato al quadrato. Per questo
motivo si usa lo scarto quadratico medio (o deviazione standard) è cosı̀
definito:
v
u n
u1 X
σ=t
(xi − M )2
n i=1
Esempio
Utilizzando le precedenti distribuzioni A) e B) calcoliamo la varianza e lo
scarto quadratico medio:
65
Misure di variabilità
A
xi
1
2
3
4
5
6
fi
0.025
0.075
0.4
0.4
0.075
0.025
1
(xi − M )2
6.25
2.25
0.25
0.25
2.25
6.25
2
σA)
= 0.8502
2
σB)
= 2.25
(xi − M )2 · fi
0.1563
0.1688
0.1
0.1
0.1688
0.1563
0.8502
B
xi
1
2
3
4
5
6
fi
0.1
0.2
0.2
0.2
0.2
0.1
1
(xi − M )2
6.25
2.25
0.25
0.25
2.25
6.25
(xi − M )2 · fi
0.625
0.45
0.05
0.05
0.45
0.625
2.25
σA) = 0.9221
σB) = 1.5
Si può confermare l’intuizione grafica: nella classe B) i voti sono maggiormente dispersi intorno alla media.
Coefficiente di variazione
La varianza e lo scarto quadratico medio sono indici assoluti per cui è opportuno introdurre indici relativi o normalizzati. Un indice relativo molto
usato, purché la media sia maggiore di zero (M > 0), è il rapporto tra lo
scarto quadratico medio σ e la media aritmetica M . Si tratta del coefficiente
di variazione CV :
q P
v
n
u n 1
2
(x
−
M
)
u 1 X xi − M 2
i=1 i
σ
n
t
=
=
CV =
M
M
n i=1
M
L’ultima espressione mostra che il coefficiente di variazione può anche essere interpretato come la radice quadrata della media quadratica degli scarti
−M )
xi
= (M
) − 1.
relativi rispetto alla media aritmetica, cioè delle quantità: (XiM
Scostamento semplice medio dalla media e dalla mediana
Talvolta
viene anche proposto lo scostamento semplice medio: S(M ) =
Pn
1
i=1 (xi − M ); questa non è però una buona misura perché la somma
n
degli scarti positivi annulla quella degli scarti negativi dando sempre luogo
ad una media nulla1 . Questo inconveniente può essere evitato ignorando tutti
i segni negativi e facendo la media dei valori assoluti degli scarti:
n
1X
S(M ) =
|xi − M |
n i=1
1
66
S(M ) =
1
n
P
(xi − M ) =
1
n(
P
xi −
P
M) =
1
n
P
xi − n1 (nM ) = M − M = 0
Misure di variabilità
P
|xi − M | =
6 0 ma non permette
di mettere in evidenza gli scarti maggiori,
P
perciò si usa il quadrato, (xi − M )2 6= 0 e si accentuano gli scarti maggiori.
La somma dei quadrati degli scarti è minima quando gli scarti sono calcolati
da M .
Dimostrazione:
Sia A 6= M
X
(xi − M )2 ≤
ma
X
X
(xi − A)2 =
(xi − A)2
X
[(xi − M ) + (M − A)]2
il secondo membro della precedente equazione è uguale a:
X
(xi − M )2 +
X
X
(M − A)2 + 2 · (M − A) ·
(xi − M )
|
{z
}
{z
}
|
>0
=0
|
{z
}
=0
quindi
X
(xi − A)2 =
X
(xi − M )2 + |{z}
...
>0
Come varia
P
(xi − A)2 in funzione di A?
• innanzitutto per valori equidistanti da M ,
P
(xi − A)2 è uguale.
• siccome il valore che si aggiunge è elevato al quadrato la funzione avrà
un andamento esponenziale.
esempio: xi = {2, 3, 7, 12}; M =
24
4
X
(xi − 6)2 = 62
X
(xi − 5)2 =
X
xi − 7)2 = 66
X
(xi − 4)2 =
X
(xi − 8)2 = 78
=6
67
Misure di variabilità
In conclusione la somma degli scarti al quadrato è un minimo quando gli
scarti sono misurati rispetto alla media e cresce esponenzialmente come
l’indicatore medio di riferimento cambia.
Si può anche calcolare lo scostamento semplice medio dalla mediana (sempre
in valore assoluto):
n
1X
S(M e) =
|xi − M e|
n i=1
che è il minimo fra tutti i possibili scarti assoluti.
Verifica
xi
4
8
10
14
20
ni
5
8
2
4
1
20
Ni
5
13
15
19
20
P
M=
68
|xi − M e|
4
0
2
6
12
xi
4
8
10
14
20
xi · ni
180
=
=9
n
20
P
S(M ) =
xi · ni
20
64
20
56
20
180
|xi − M | · ni
= 3.33
n
|xi − M e|ni
20
0
4
24
12
60
Me =
|xi − M |
5
1
1
5
11
|xi − M |ni
25
8
2
20
11
66
10◦ + 11◦
=8
2
P
S(M e) =
|xi − M e| · ni
=3
n
Misure di variabilità
S(M e) < S(M )
Per confrontare la variabilità di due distribuzioni aventi un’unità di misura
diversa oltreché per costruire degli indicatori relativi (vedi coefficienti di variazione) si divide l’indice di variabilità per il corrispondente indicatore di
tendenza centrale:
S(M )
=
M
P
S(M e)
=
Me
|xi − M |/n
P
xi /n
P
|xi − M e|/n
Me
Le proprietà della varianza
1) σ 2 = M(x2 ) − [M(x)]2 la varianza è pari alla media aritmetica dei
quadrati meno il quadrato della media aritmetica.
Dimostrazione:
P
P 2
(xi − M )2
[xi − (2 · xi · M ) + M 2 ]
2
=
=
σ =
n
n
P 2
P
P 2
xi − 2 · M · xi + n · M 2
xi − 2 · M · n · M + n · M 2
=
=
=
n
n
P 2
P 2
P 2
xi − 2 · n · M 2 + n · M 2
xi − n · M 2
xi
=
=
=
− M2 =
n
n
n
= M (x2 ) − [M (x)]2
2) σ 2 (k) = 0
3) σ 2 (k · x) = k2 · σ 2 (x)
Dimostrazione:
σ 2 (k · x) = M · [k · x − M (k · x)]2 = M · [k · x − k · M (x)]2 =
= k 2 · M · [x − M (x)]2 = k 2 · σ 2 (x)
69
Misure di variabilità
4) σ 2 · (k + x) = σ 2 (x)
σ 2 · (k + x) = M · [k + x − M (k + x)]2 = M · [k + x − k − M (x)]2 =
M · [x − M (x)]2 = σ 2 (x)
5) sia y = a + bx
σ 2 (y) = σ 2 (a + bx) = σ 2 (a) +b2 · σ 2 (x) = b2 · σ 2 (x)
| {z }
=0
6) sia z = x + y
σ 2 (z) = σ 2 (x) + σ 2 (y) + 2σxy
Se x e y sono incorrelate, allora σ 2 (z) = σ 2 (x) + σ 2 (y)
Le differenze medie
Le differenze medie sono indici di mutua variabilità che esaminano le differenze tra le modalità prese a due a due e ne operano una sintesi tramite
una opportuna media. La differenza semplice media è un indice assoluto di
mutua variabilità ottenuto operando i confronti tra le n modalità prese a
due a due, non considerando i confronti tra ciascuna modalità e se stessa
(n(n − 1) confronti in tutto) e facendo la media aritmetica delle differenze.
Pn Pn
∆=
i=1
|xi − xj |
n(n − 1)
j=1
La differenza semplice media con ripetizione è un indice assoluto di mutua
variabilità ottenuto operando i confronti tra le n modalità a due a due, considerando anche i confronti tra ciascuna modalità e se stessa (n2 confronti in
tutto) e facendo la media aritmetica delle differenze.
Pn Pn
∆R =
70
i=1
j=1
n2
|xi − xj |
Misure di variabilità
4.2
Indici di concentrazione
La concentrazione è una misura della mutua variabilità, cioè della variabilità
tra ogni possibile modalità di una variabile e tutte le altre. Prima di definire
le situazioni limite di concentrazione è necessario sottolineare a quali variabili
(e fenomeni) si può applicare un’analisi di concentrazione.
Una variabile quantitativa si dice trasferibile se può passare (materialmente
o idealmente) da un possessore ad un altro. Esempi di variabili trasferibili
sono il reddito e la popolazione.
P
Indichiamo con T = ni=1 yi il totale posseduto da n unità statistiche. La
concentrazione studia il modo in cui l’ammontare totale T si distribuisce fra
le n classi. E’ utile considerare due situazioni estreme:
concentrazione minima (ovvero equidistribuzione): le n unità statistiche possiedono uguale quantità della variabile
Pn
yi
T
yi = = i=1 = ȳ
n
n
concentrazione massima: una unità possiede il totale e le altre n − 1
possiedono un ammontare nullo della variabile
yn = T
yi = 0 (i = 1, . . . , n − 1).
Il reddito di un paese è tanto più concentrato quanto più il reddito complessivo è posseduto da una frazione modesta delle unità statistiche, ovvero
quanto più poveri vi sono in quel paese. La concentrazione cresce con il
crescere della frazione di unità statistiche che possiede il carattere in misura
inferiore alla media ovvero con il diminuire delle unità statistiche che possiedono il carattere in misura superiore alla media; cioè quando da una situazione di maggiore equidistribuzione si passa ad una situazione in cui un
piccolo numero di unità statistiche possiede una parte rilevante del totale.
4.2.1
Rappresentazione grafica: Lorenz (1904) e Gini
(1914)
Si consideri una distribuzione unitaria i cui termini sono non negativi e disposti in ordine crescente:
0 ≤ a1 ≤ a2 ≤ . . . ≤ ai ≤ . . . ≤ an
71
Misure di variabilità
Consideriamo le prime unità (i), che saranno le più povere e confrontiamo
ciò che esse possiedono con ciò che ad esse spetterebbe in una situazione di
equidistribuzione, in cui ai = µ (ogni unità possiede esattamente il valore
medio). Definiamo2 :
Ai = a1 + . . . + ai e A∗i = µ + . . . + µ = iµ
Se dividiamo per l’ammontare complessivo del carattere, An
An = a1 + . . . + ai + . . . + an = nµ = A∗n
si ottiene:
Qi =
A∗
iµ
i
Ai
Pi = i =
=
An
An
nµ
n
numero delle unità
unità totali
Qi = % del carattere posseduto dalle prime i unità
Pi =
Vale la relazione:
Ai
i
|{z}
≤
media sino ad i
An
n
|{z}
media generale
Che può essere cosı̀ trasformata:
i Ai
An i
≤
An i
n An
Ai
An
≤
i
n
Qi
≤ Pi
Qi è tanto più vicino a Pi quanto più siamo prossimi alla situazione di equidistribuzione. Consideriamo nel seguente esercizio la concentrazione della popolazione tra le 5 province del Lazio (1990):
i
ai
Ai
Rieti
1 146 146
Viterbo 2 278 424
Latina
3 471 895
Frosinone 4 483 1378
Roma
5 3778 5156
2
Pi
0.2
0.4
0.6
0.8
1
Qi
0.028
0.082
0.174
0.267
1
In generale si indica con un asterisco (*) una situazione ipotetica, virtuale di riferimento. In questo caso A∗i rappresenta ciò che spetterebbe alle prime i unità in situazione
di equidistribuzione
72
Misure di variabilità
Si riportano in un grafico i valori di Pi e Qi ottenendo la spezzata di Lorenz.
Vediamo di seguito come si legge il grafico:
- Sulla bisettrice si trovano i punti tali che pi = qi .
- L’area tra la bisettrice e la spezzata di Lorenz è la curva di concentrazione.
- Interpretazione dell’area: più è grande, maggiore è la concentrazione.
- Esempio: nelle 3 province più piccole risiede il 17.4% contro il 60%
(equidistribuzione).
Consideriamo ora il caso in cui il carattere (trasferibile) sia ripartito in classi:
è cioè noto l’ammontare Xi del carattere posseduto congiuntamente dalle ni
unità che appartengono alla classe i.
73
Misure di variabilità
Fatturato
(milioni euro)
0–1
1–5
5–10
10–25
≥ 25
ni
Xi
Ni
PN (i) AN (i)
QN (i)
144
457
171
112
27
87
1168
1200
1757
1278
144
601
772
884
911
0.158
0.660
0.847
0.970
1
0.0158
0.2286
0.4472
0.7672
1
87
1255
2455
4212
5490
Le aziende della prima classe (cioè il 15.8% delle aziende totali) contribuiscono solo al 1.58% del fatturato totale.
E’ necessario sottolineare che negli esempi abbiamo considerato 2 fenomeni
diversi a cui corrispondono 2 diverse curve di concentrazione tra di loro non
confrontabili.
Nei due esempi ci si è limitati a considerazioni grafiche che in alcuni casi permettono comunque di osservare la dinamica dei fenomeni di concentrazione.
E’ tuttavia opportuno affiancare al grafico una misura della concentrazione
e nel nostro caso pare naturale una misura dell’area compresa tra la retta di
equidistribuzione e la spezzata di Lorenz. Come si procede?
Nel caso di distribuzioni unitarie l’area può essere scomposta nella somma
di n trapezi; in particolare l’i − esimo trapezio ha basi pari a Pi−1 − Qi−1 e
Pi − Qi e altezza costante pari a n1
74
Misure di variabilità
1 1
Area Si : ((Pi − Qi ) + (Pi−1 − Qi−1 )) ·
·
|
{z
} |{z}
n 2
somma delle 2 basi
altezza
Ricorda: Area del trapezio = ((BM A + BM I ) × h)/2
La somma delle aree di questi n trapezi può cosı̀ scriversi:
n
X
n
n−1
X
1 1
1 X
[(Pi − Qi ) + (Pi−1 − Qi−1 )] · =
[ (Pi − Qi ) +
(Pi − Qi )] =
n 2
2n i=1
i=1
i=0
75
Misure di variabilità
se si considera che (Pn − Qn ) = 0 . . . e anche (P0 − Q0 )
n−1
n−1
n−1
X
1 X
1X
=
[ (Pi − Qi ) +
(Pi − Qi )] =
(Pi − Qi )
2n i=1
n i=1
i=1
Se dividiamo S per il valore massimo che può prendere l’area di concentrazione si ottiene un indice che varia tra 0 e 1. Qual’è questo valore massimo? Corrisponde alla metà dell’area del quadrato di lato unitario, cioè
1/2.
n−1
2X
Quindi g =
(Pi − Qi )
n i=1
. . . ma siccome tale area non è proprio uguale a 1/2, divideremo per n-1:
n−1
g=
2 X
(Pi − Qi )
n − 1 i=1
Riprendiamo ora il primo esercizio, quello sulla concentrazione della popolazione, e otteniamo:
2
g = [(0.2 − 0.028) + 0.318 + 0.426 + 0.533] = 0.7245
4
Questo valore indica un grado di concentrazione molto elevato, pari al 72%
della concentrazione massima.
Nel caso di distribuzioni in classi si avrà invece un’area, scomposta in un
numero di trapezi uguale al numero delle classi considerate. L’altezza non
sarà più costante ma sarà uguale a PN (i) − PN (i−1) = fi
|
{z
}
vedi graf ico
S sarà quindi uguale a:
k
1X
S=
[(PN (i) − QN (i) ) + (PN (i−1) − QN (i−1) )]fi
2 i=1
Anche in questo caso il valore di massima concentrazione può essere approssimato ad 1/2 per cui si può calcolare un rapporto di concentrazione: R = 2S.
Riprendiamo i dati del secondo esempio:
76
Misure di variabilità
fi
PN (i) − QN (i)
0.158
0.1422
0.502
0.4314
0.188
0.4008
0.123
0.2028
0.029
0
PN (i−1) − QN (i−1)
0
0.1422
0.4314
0.4008
0.2028
(B1 + B2 ) · fi
0.02247
0.28795
0.15645
0.07424
0.00588
0.54799 ↔ R
In questo secondo caso la concentrazione è pari al 55% della concentrazione
massima.
Esercizio
Analizzare in quale settore (A o B) vi è maggiore concentrazione degli addetti
fra le imprese.
settore A
n.addetti n.imprese
3
5
5
5
10
4
12
5
20
1
20
settore B
n.addetti n.imprese
2
5
3
5
10
4
12
5
35
1
20
Si legge cosı̀: nel settore A 5 imprese su 20 hanno 3 addetti; altre 5 ne hanno
5 e cosı̀ via.
Calcolate il numero medio di addetti e la varianza.
Indichiamo con:
X = addetti del settore A
Y = addetti del settore B
77
Misure di variabilità
Xi
3
5
10
12
20
M (X) =
Yi
2
3
10
12
35
ni
5
5
4
5
1
20
ni
5
5
4
5
1
20
3 × 5 + 5 × 5 + . . . + 20 × 1
160
=
=8
20
20
P
X 2 ·fi
z }|i {
V (X) = M (X 2 ) −(M (X))2 =
32 · 5 + 52 · 5 + 102 · 4 + 122 · 5 + 202 · 1
=
− 82 = 20.5
20
M (Y ) =
10 + 15 + 40 + 60 + 35
=8
20
V (Y ) = M (Y 2 ) − (M (Y ))2 =
4 × 5 + 9 × 5 + ...
− 64 = 125.5 − 64 = 56.5
20
Le medie sono uguali ma la variabilità è maggiore nel settore B.
Ciò è dovuto alla presenza di una impresa con ben 35 addetti. Possiamo
quindi supporre che nel settore B ci sarà maggiore concentrazione!?!
Riportiamo i dati necessari alla costruzione della curva di concentrazione:
fi
0.25
0.25
0.20
0.25
0.05
78
A
Fi (Pi )
Qi
0.25
15/160
0.50
40/160
0.70
80/160
0.95 140/160
1
1
fi
0.25
0.25
0.20
0.25
0.05
B
Fi (Pi )
Qi
0.25
10/160
0.50
25/160
0.70
65/160
0.95 125/160
1
1
Misure di variabilità
Effettivamente nel settore B vi è maggiore concentrazione (l’area di concentrazione è più grande) e in questo caso per confrontare i 2 settori è sufficiente
costruire il grafico, non è cioè necessario calcolare R. Consideriamo ora un
3◦ settore le cui imprese hanno le seguenti dimensioni (per numero di addetti):
settore C
n.addetti n.imprese
2
5
5
5
8
4
10
5
43
1
20
La concentrazione degli addetti è maggiore nel settore B o nel settore C?
Chiamiamo Z il numero di addetti in C e scriviamo:
79
Misure di variabilità
Zi n i
2 5
5 5
8 4
10 5
43 1
Fi (Pi )
Qi
0.25
10/160
0.50
35/160
0.70
67/160
0.95 117/160
1
1
M (Z) = (10 + 25 + 32 + 50 + 43)/20 = 8
V (Z) = (20 + 125 + 256 + 500 + 1919)/20 − 64 = 141 − 64 = 77
In effetti si ha una maggiore variabilità in C piuttosto che in B, ma per
quanto riguarda la concentrazione è necessario costruire la curva:
In questo caso le due curve si intersecano, quindi il grafico non basta più,
bisogna calcolare un indice di concentrazione:
B:
80
fi
PN (i) − QN (i)
0.25 0.25-0.0625
0.25 0.50-0.15625
0.20 0.70-0.40625
0.25 0.95-0.78125
0.05
0
PN (i−1) − QN (i−1)
0
0.1875
0.34375
0.29735
0.16875
Π
0.046
0.132
0.116
0.115
0.008
R = 0.457
Misure di variabilità
C:
fi
PN (i) − QN (i)
0.25 0.25-0.0625
0.25 0.50-0.2187
0.20 0.70-0.4187
0.25 0.95-0.7312
0.05
0
PN (i−1) − QN (i−1)
0
0.1875
0.2813
0.2813
0.2188
Π
0.046
0.117
0.112
0.125
0.01
R = 0.401
In effetti, anche se di poco, nel settore B si osserva una maggior concentrazione che nel settore C.
Le aziende di un settore sono classificate per classi di fatturato e forma
giuridica:
y SPA
x
1-5
0
3
5-10
10-30 25
30-50 12
40
SNC
SAS
altre
122
87
1
0
210
15
45
10
0
70
23
35
14
8
80
160
170
50
20
400
Confrontiamo la concentrazione del fatturato nelle SPA e nelle SNC. Attenzione, conosciamo il numero di aziende che appartiene ad ogni classe di
fatturato ma non il loro fatturato che può essere stimato, come?
Ricordatevi dell’ipotesi che usualmente si fa quando si calcola la media per
dati raggruppati in classi. Si ipotizza che vi sia una distribuzione uniforme
con densità uguale in tutto l’intervallo e si prende come rappresentativo della
classe il punto centrale della stessa. Con tali ipotesi si ottiene:
81
82
PN i
0
0.075
0.7
1
xi
0
22.5
500
480
PN i−1 − QN i−1
0
0.229
0.014
0
Ni
0
3
28
40
SNC
fi
ni
Ni
PN i
xi
AN i
QN i PN i − QN i
1-5 0.581 122 122 0.581 366
366
0.352
0.229
5-10 0.414 87 209 0.995 652.5 1018.5 0.981
0.014
10-30 0.005 1 210
1
20
1038.5
1
0
30-50
0
0 210
1
0
1038.5
1
0
ni
0
3
25
12
PN i−1 − QN i−1
0
0
0.053
0.179
fi
1-5
0
5-10 0.075
10-30 0.625
30-50 0.3
SPA
AN i
QN i PN i − QN i
0
0
0
22.5 0.022
0.053
522.5 0.521
0.179
1002.5
1
0
(B + b) · h
0.1328
0.1009
0
0
R = 0.2337
(B + b) · h
0
0.0039
0.1449
0.0537
R = 0.2025
Misure di variabilità
Misure di variabilità
4.3
Asimmetria e Curtosi
Per un insieme comprendente un numero n di dati (xi ), è possibile esprimere
lo scostamento della distribuzione dei dati, rispetto alla distribuzione gaussiana teorica, ricorrendo al coefficiente di asimmetria g1 e al coefficiente di
curtosi g2 :
asimmetria negativa (g1 < 0) cioè coda destra della distribuzione eccessivamente lunga;
asimmetria positiva (g1 > 0) cioè coda sinistra della distribuzione eccessivamente lunga;
platicurtosi (g2 < 0) cioè distribuzione eccessivamente appiattita, con code
troppo corte;
leptocurtosi (g2 > 0) cioè distribuzione eccessivamente alta, con code troppo lunghe;
normocurtosi (g2 = 0) cioè “piatta” come una normale.
Gli indici di forma si calcolano basandosi sul metodo dei “momenti attorno
alla media”. In statistica i “momenti” sono dei parametri che caratterizzano
la distribuzione. Utilizziamo ora i primi quattro momenti attorno alla media:
- momento di ordine primo (m1 ): è dato dalla sommatoria degli scarti
dalla media elevati per 1 ed il risultato è diviso per n (la numerosità
campionaria).
P
(xi − x̄)1
m1 =
=0
n
Il momento di ordine primo (m1 ) vale sempre zero, abbiamo già visto
come la sommatoria degli scarti della media da come risultato zero.
- momento di ordine secondo (m2 ): è uguale alla “varianza non corretta”;
si ottiene dalla sommatoria degli scarti dalla media elevati per 2 ed il
risultato è diviso per n (la numerosità del campione).
P
(xi − x̄)2
m2 =
n
- momento di ordine terzo (m3 ): è dato dalla sommatoria degli scarti
dalla media elevati per 3 ed il risultato è diviso per n, la numerosità
del campione. In una curva simmetrica m3 = 0, mentre in una curva
83
Misure di variabilità
asimmetrica m3 può assumere un segno positivo o negativo. Se m3 è
positivo (+m3 ) indica che la sommatoria degli scarti positivi è maggiore
della sommatoria degli scarti negativi: questo indica una asimmetria
sinistra con la coda più lunga che cade a destra. Se m3 è negativo (−m3 )
indica che la sommatoria degli scarti negativi è superiore a quella degli
scarti positivi: questo indica una asimmetria destra con la coda più
lunga che cade a sinistra.
P
(xi − x̄)3
m3 =
n
- momento di ordine quarto (m4 ): è dato dalla sommatoria degli scarti
dalla media elevati per 4 ed il risultato è diviso per n (la numerosità
del campione). E’ il parametro attraverso il quale analizziamo le caratteristiche della curtosi.
P
(xi − x̄)4
m4 =
n
Conoscendo il momento di ordine secondo (m2 ), il momento di ordine terzo
(m3 ) e il momento di ordine quarto (m4 ) intorno alla media, è possibile
calcolare i valori del coefficiente di asimmetria e del coefficiente di curtosi:
m3
coefficiente di asimmetria: g1 =
√
m2 · m2
coefficiente di curtosi: g2 =
m4
−3
(m2 )2
L’errore standard (s1 ) del coefficiente di asimmetria e l’errore standard (s2 )
del coefficiente di curtosi sono calcolate rispettivamente come:
r
r
6
24
;
s2 =
s1 =
n
n
Il coefficiente di asimmetria, se positivo, indica una coda sinistra eccessivamente lunga, se negativo indica una coda destra eccessivamente lunga. Per
valutarne la significatività si impiega il rapporto fra il coefficiente di asimmetria ed il suo errore standard: se è maggiore di 2 l’asimmetria va considerata
come significativa.
Il coefficiente di curtosi, se positivo, indica una distribuzione eccessivamente alta, con code troppo lunghe, se negativo indica una distribuzione
eccessivamente appiattita, con code troppo corte. Per valutarne la significatività si impiega il rapporto fra il coefficiente di curtosi ed il suo errore
standard: se è maggiore di 2 la curtosi va considerata come significativa.
84
Misure di variabilità
Vediamo qualche esempio grafico
Se la coda più lunga è a sinistra della media, cioè esistono molti valori con
forti scarti negativi e pochi valori con deboli scarti positivi, si parla di asimmetria negativa e si vuole che il valore dell’indice di asimmetria assuma segno
negativo.
Nel caso opposto (molti valori con forti scarti positivi, pochi con deboli scarti
negativi), si parla di asimmetria positiva e si vuole che il valore dell’indice di
asimmetria assuma segno positivo.
Quando invece gli scarti negativi sono bilanciati da quelli positivi avremo
una distribuzione simmetrica che avrà un indice di asimmetria uguale a 0.
85
Misure di variabilità
Vediamo un esempio di curtosi negativa (platicurtica)
ed ora un esempio di curtosi positiva (leptocurtica)
. . . ancora un altro esempio
86
Misure di variabilità
87
Misure di variabilità
Utilizzando i dati della tabella precedente calcoliamo gli indici di asimmetria
e di curtosi e valutiamo la loro significatività. Innanzitutto calcoliamo x̄ che
è uguale a 53.6. Calcoliamo quindi i vari momenti. Il momento di ordine
secondo:
P
(xi − x̄)2
57840.32
m2 =
=
= 1156.806
n
50
Il momento di ordine terzo:
P
4148723.482
(xi − x̄)3
=
= 82974.47
m3 =
n
50
Possiamo ora calcolare il coefficiente di asimmetria g1 :
m3
82974.47
√
=
= 2.109
√
m2 · m2
1156.806 · 1156.806
Il coefficiente di asimmetria è positivo quindi la distribuzione mostra una
asimmetria positiva. Per valutarne la significatività dobbiamo però calcolare il rapporto con la sua deviazione standard. La deviazione standard del
coefficiente di asimmetria si calcola con la seguente formula:
r
r
6
6
s1 =
=
= 0.346
n
50
g1
2.109
il rapporto
=
= 6.09 > 2
s1
0.346
Calcoliamo adesso il momento di ordine quarto:
P
(xi − x̄)4
586095182.1
m4 =
=
= 11721903.64
n
50
Possiamo ora calcolare il coefficiente di curtosi:
m4
11721903.64
−3=
− 3 = 5.759
g2 =
2
(m2 )
(1156.806)2
Il coefficiente di curtosi è positivo quindi la distribuzione mostra un andamento leptocurtico. Però per valutarne la significatività dobbiamo calcolare
il rapporto con la sua deviazione standard. La deviazione standard del coefficiente di curtosi si calcola con la seguente formula:
r
r
24
24
s2 =
=
= 0.693
n
50
da cui si ottiene il rapporto:
g2
5.759
=
= 8.313 > 2
s2
0.693
88
I fenomeni bivariati
Iniziamo lo studio dei fenomeni bivariati cioè di quei fenomeni che possono
essere caratterizzati studiando congiuntamente due variabili (X,Y). Vediamo
innanzitutto a cosa corrisponde graficamente:
Nel grafico ogni individuo è rappresentato da un punto avente due coordinate.
I fenomeni bivariati
In questo grafico, invece, si rappresenta nella terza dimensione l’intensità o
frequenza associata ad ogni punto (che in questo caso ha due coordinate).
Andiamo con ordine, innanzitutto si rilevano, per ogni unità statistica, 2
caratteri e poi si ordinano i dati in tabelle a doppia entrata:
x1
..
.
y1
n11
..
.
...
...
yi
n1i
...
...
yq
n1q
xi
..
.
ni1
..
.
...
nii
...
niq
xp
np1
...
npi
...
npq
di dimensioni p × q, dove nij ∈ N rappresentano le frequenze congiunte
assolute e vale:
XX
i
j
nij =
XX
j
nij = N
i
Le modalità dei caratteri xi , yi possono essere di tipo qualitativo o quantitativo; se X e Y sono entrambe quantitative si parla di tabella di correlazione,
altrimenti si parla di tabella di contingenza.
Procediamo con un esempio. Consideriamo le 2 distribuzioni doppie, riferite
a 2 collettività:
collettività (a)
X
Y
2
1
2
1
2
1
4
2
4
2
4
2
4
2
6
3
6
3
6
3
collettività (b)
X
Y
2
1
2
1
2
2
4
1
4
2
4
2
4
3
6
2
6
3
6
3
Le modalità possono essere tabulate in tabelle a doppia entrata:
90
I fenomeni bivariati
(b)
(a)
y 1
x
2
4
6
2 3
y 1
x
2
4
6
3 0 0 3
0 4 0 4
0 0 3 3
3 4 3 10
2
1
0
3
2 3
1
2
1
4
0 3
1 4
2 3
3 10
Come si possono evidenziare le frequenze congiunte?
Sui margini ritroviamo le distribuzioni di frequenza dei 2 caratteri X,Y e
possiamo cosı̀ calcolarci alcune statistiche descrittive ormai note:
x¯a = (2 · 3 + 4 · 4 + 6 · 3)/10 = 4
x¯b = (2 · 3 + 4 · 4 + 6 · 3)/10 = 4
y¯a = (1 · 3 + 2 · 4 + 3 · 3)/10 = 2
y¯b = (1 · 3 + 2 · 4 + 3 · 3)/10 = 2
184
σx2a
z
}|
{
(4
·
3
+
16
·
4
+
36
·
3)
= M (x2a ) − (M (xa ))2 =
− 16 = 2.4
10
σx2b = M (x2b ) − (M (xb ))2 = 2.4
σxa = 1.549 = σxb
46
σy2a
z
}|
{
= M (ya2 ) − (M (ya ))2 = (1 · 3 + 4 · 4 + 9 · 3) /10 − 4 = 0.6
σy2b = 0.6
σya = σyb = 0.775
Vediamo di rappresentare graficamente i 2 casi indicando con cerchi di diametro maggiore i punti cui corrispondono frequenze maggiori:
91
I fenomeni bivariati
Dal disegno si vede che in (a) la connessione tra i 2 caratteri è maggiore che
in (b), ma come si può misurare la connessione?
Analizziamo la variabilità congiunta di X e Y; innanzitutto spostiamo l’origine
degli assi nel punto (x̄, ȳ) di modo che nel nuovo sistema le coordinate dei
punti saranno xi − x̄, yi − ȳ e vediamo 3 casi limite:
P
Consideriamo la somma dei prodotti i (xi − x̄)(yi − ȳ); nel caso (1) questa
somma sarà > 0 perché i punti sono tutti in I dove moltiplico scarti entrambi
positivi o in IV dove moltiplico scarti entrambi negativi; nel caso (2) tale
somma sarà invece < 0 perche’ sia in II che in III moltiplico scarti positivi
con scarti negativi . . . e nel caso (3) tale somma avrà un valore prossimo a 0.
Ma, come si può confrontare tale valore nei 2 casi seguenti (4) e (5)?
92
I fenomeni bivariati
. . . bisogna semplicemente dividere il tutto per la numerosità rispettiva, si
ottiene allora, la covarianza:
cov(x, y) = σxy
P
(xi − x̄)(yi − ȳ)
=
N
oppure utilizzando le frequenze congiunte di una tabella a doppia entrata:
P P
cov(x, y) =
i
j (xi
− x̄)(yj − ȳ)nij
N
La covarianza non è altro che una media dei prodotti degli scarti di x e y
dalle rispettive medie, calcoliamola:
−2
−1
2
1
z }| { z }| {
z }| { z }| {
(a) : (2 − 4) (1 − 2) ·3+(4−4)(2−2)·4+(6 − 4) (3 − 2) ·3 = (6+0+6)/10 = 1.2
−2
−1
0
0
0
z }| { z }| {
z }| {
z }| {
z }| {
(b) : (2 − 4) (1 − 2) ·2+(2−4) (2 − 2) ·2+(4 − 4)(1−2)·1+(4 − 4)(2−2)·2+. . . +
2
1
z }| { z }| {
(6 − 4)(2 − 2) · 1 + (6 − 4) (3 − 2) ·2 = (4 + 4)10 = 0.8
In questo caso, 2 collettività di dimensioni uguali, la covarianza permette
di misurare la connessione dei 2 caratteri e come avevamo “intuito”, nella
collettività (a) tale connessione è maggiore che in (b). Se le modalità hanno
invece dimensioni diverse, allora la covarianza è una misura inefficiente.
93
I fenomeni bivariati
5.1
La correlazione
L’idea è di “standardizzare” le covarianze per avere una misura della connessione che non dipenda dalle dimensioni di X e Y (vedi coefficiente di
variazione) e ciò può essere ottenuto calcolando il coefficiente di correlazione
lineare (di Bravais - Pearson):
P
(xi − x̄)(yi − ȳ)
ryx = i
Nσ x σ y
oppure, considerando la tabella e doppia entrata:
P P
i
j (xi − x̄)(yj − ȳ)fij
P P
ryx =
σx σy i j fij
Calcoliamo il coefficiente nei due casi:
(a) :
1.2
'1
1.549 × 0.775
(b) :
0.8
' 0.667
1.549 × 0.775
In pratica mentre cov(x, y) ∈ (−∞, +∞), rxy ∈ [−1, 1]; chiaramente però se
cov(x, y) = 0 allora rxy = 0 e in questo caso si dice che non vi è correlazione
lineare tra X e Y.
In sintesi:
per r = 1 si ha il massimo di correlazione diretta
per r = -1 si ha il massimo di correlazione inversa
per r = 0 non si ha correlazione
La correlazione si dice diretta se ai valori crescenti di una variabile corrispondono valori pure crescenti dell’altra variabile, ad esempio reddito e consumi,
altezza e peso. La correlazione si dice inversa se ai valori crescenti di una
variabile corrispondono valori decrescenti dell’altra variabile, ad esempio altitudine e pressione atmosferica.
Ritorniamo ora alle tabelle a doppia entrata e consideriamo le medie condizionate, cioè:
M (x/y = 1) = ?
94
→ estraiamo la colonna corrispondente a y=1
I fenomeni bivariati
(a):
x
2
4
6
fi
3
0
0
M (x/y = 1) = (6 + 0 + 0)/3 = 2
(b):
x
2
4
6
fi
2
1
0
M (x/y = 1) = (4 + 4 + 0)/3 = 8/3 ' 3
in effetti se vi è connessione tra le 2 variabili la media condizionata (con la
condizione) sarà diversa dalla media non condizionata, nel caso in cui invece
tali medie coincidano; questo significa che l’imposizione di una condizione
sul calcolo della media non modifica il risultato del calcolo e si potrà quindi
concludere circa l’indipendenza delle 2 variabili.
Presentiamo ora una maniera statistica per decidere sulla dipendenza o
indipendenza di 2 caratteri, non necessariamente quantitativi. Consideriamo
ad esempio la collettività in (b) rappresentata nella tabella a doppia entrata
(pag. 88); si tratta di una tabella di frequenze osservate. Posso ora immaginare di costruire una tabella di frequenze teoriche, che corrisponderebbe al
caso in cui vi sia perfetta indipendenza dei 2 caratteri e poi, per finire posso
costruirmi una misura della ”distanza” tra queste 2 tabelle per verificare se
tale distanza sia frutto del caso o sia sistematica; in questo secondo caso
rivelerebbe un legame tra i 2 caratteri.
Andiamo in ordine. Per costruire la tavola teorica si utilizza la condizione di
fattorizzazione:
fij = fi · fj ∀i, j
che mi dice che le frequenze congiunte possono essere ottenute come prodotto
delle frequenze marginali.
N.B. Quando vedremo le principali regole del calcolo delle probabilità,
sentirete parlare di indipendenza stocastica o di regola del prodotto. In
questo caso se 2 eventi sono indipendenti la probabilità che si verifichino entrambi è data dal prodotto delle probabilità associate ai singoli eventi.
Esempio: (dal Cicchitelli/Perrone)
Si consideri la seguente distribuzione secondo il sesso e l’atteggiamento nei
confronti del fumo dedotta da un indagine effettuata su 191 soggetti.
95
I fenomeni bivariati
Atteggiamento
Sesso Favorevoli Contrari Indifferenti
M
9
55
19
83
F
10
71
27
108
19
126
46
191
Costruiamo innanzitutto la tabella delle frequenze teoriche:
Sesso
Favorevoli
Contrari
M
(19 · 83)/191 = 8.26
54.75
F
10.74
71.25
19
126
Indifferenti
19.99
83
26.01
108
46
191
Distanza tra le 2 tabelle; in generale la misura della distanza è un numero
reale (∈ R) che riassume la vicinanza o similarità di due punti. Nel nostro
caso per misurare la distanza tra due tabelle cioè tra i diversi elementi di 2
tabelle, si utilizza la distanza del χ2 cosı̀ definita:
X X (nij − n̄ij )2
χ =
n̄ij
i
j
2
dove n̄ij sono le frequenze teoriche. Il χ2 è allora uguale a:
(9 − 8.26)2 (55 − 54.75)2 (19 − 19.99)2 (10 − 10.74)2
+
+
+
+
8.26
54.75
19.99
10.74
+
(71 − 71.25)2 (27 − 26.01)2
+
= 0.21
71.25
26.01
Se dividiamo questo valore per 191 (totale delle frequenze) si ottiene l’indice
del χ2 , che risulta essere pari a 0.0011. Questo valore indica una connessione
molto debole, praticamente inesistente, tra i due caratteri.
96
I fenomeni bivariati
5.2
La regressione
Regredire significa “variare in conseguenza di”; la regressione di y rispetto
ad x significa studiare la relazione y = f (x). Si studia la regressione lineare
semplice, cioè il modello di regressione rappresentato dalla forma:
y = a + bx
dove a è l’intercetta e b è il coefficiente angolare della retta y. Il modello è
ciò che permette di spiegare la realtà, cioè i dati che si osservano ma è chiaro
quindi che a meno di casi molto fortunati si avrà:
y = a + bx + e
dove e rappresenta l’errore. Questo termine, come vedremo in seguito, sintetizza errori sulla forma funzionale scelta e sulle variabili esplicative considerate. Questo significa che i punti non giaciono esattamente sulla retta,
o in altri termini, che il modello spiega la y a meno di un errore la cui entità determinerà poi la affidabilità dello stesso. Vediamo di esemplificare
graficamente
In a) è rappresentato il caso più frequente in cui i punti (di coordinate x e
y) si disperdono nello spazio assumendo una forma di nuvola. In b) invece
è rappresentato il caso molto fortunato in cui i punti si allineano lungo una
retta.
Più generalmente, nel caso della regressione multipla si ha:
y=
f (x , . . . , xn ) ← numero di regressori o variabili indipendenti
|{z} 1
qualsiasi
97
I fenomeni bivariati
Ritorniamo al caso della regressione lineare semplice e puntualizziamo: come
la nuvola di punti può essere approssimata da una retta o in altri termini
come si può far passare una retta in una nuvola di punti e come la stessa può
migliorare la capacità di rappresentarli tutti?
Di seguito sono rappresentate due rette diverse che passano attraverso una
stessa nuvola di punti
L’esempio grafico sottolinea che se non si utilizza un criterio, risulta impossibile scegliere tra le due rette. Come primo criterio consideriamo la minimizzazione della distanza tra i punti osservati e i punti sulla retta o punti
stimati.
X
X
i) M in
(yi − ŷi ) = M in
ui (residui)
In questo caso il criterio adottato ci farebbe scegliere b) (perché la somma
degli errori positivi compensa quella degli errori negativi). Scegliamo allora
un altro criterio:
X
ii) M in
|yi − ŷi |
i
98
I fenomeni bivariati
In tal caso b) sarebbe preferito (la somma vale 3 che è minore di 4) anche se
è evidente che è preferibile a) perché la retta passa in mezzo alla nuvola di
punti. Consideriamo ora il criterio dei minimi quadrati ordinari (M.Q.O.).
M in
X
(yi − ŷi )2 = M in
X
(yi − a − bxi )2 = M in S
si calcolano le derivate rispetto ad a e b e si eguagliano a zero.
X
∂
S = −2
(yi − a − bxi ) = 0
∂a
X
∂
S = −2
[xi (yi − a − bxi )] = 0
∂b
La soluzione di questo sistema (due equazioni e due incognite) permette di
ottenere i seguenti valori di a e b:
P
(xi − x̄)(yi − ȳ)
σx,y
P
b=
⇔ 2
2
(xi − x̄)
σx
a = ȳ − bx̄.
Interpretazione dei coefficienti.
a è l’intercetta della retta, è quel valore di y quando x = 0, su di essa si
scarica gran parte della nostra ignoranza (sulla forma funzionale cosı̀
come sui regressori).
b è il coefficiente di regressione che ci informa su come varia y al variare
di x.
99
I fenomeni bivariati
Esempio
Per interpretare i coefficienti vediamo un esercizio sulla relazione tra prezzo
del pane (xi ) e il prezzo della pasta (yi ). I dati si riferiscono a 20 regioni
d’Italia; i valori medi e i parametri della retta sono:
x̄ = 582;
ȳ = 619;
b = 0.1252;
a = ȳ − bx̄ = 619 − 0.1252(582) = 546.13
⇒ ŷ = 546.13 + 0.1252 · x
e cioè il prezzo della pasta è “composto” di una parte costante (' 546.16
lire) e una parte che dipende (' 13%) dal prezzo del pane.
Vediamo di seguito alcuni casi particolari:
1. In presenza di “outliers” (dati aberranti), bisogna fare molta attenzione
all’uso della retta in termini previsivi. La soluzione consiste in:
a) Eliminazione del dato
b) Tecniche di regressione robusta, basata sul concetto di mediana piuttosto che su quello di media.
100
I fenomeni bivariati
2. Pericolo di estrapolazione (quando supponiamo che il modello sia lineare
anche se in effetti non lo è):
a)
b)
In questo caso si parla di regressione degenerata; il punto a destra attira la
retta ma potrebbe anche rappresentare un errore di misura.
101
I fenomeni bivariati
Concludiamo ora sulla valutazione dei risultati e un primo aspetto importante
è quello legato a R2 , coefficiente di determinazione, che fornisce una misura
della qualità dell’aggiustamento della retta sui dati. In riferimento al grafico
si può considerare la yi come somma delle due componenti ŷi e ui :
yi = ŷi + ui
oppure
yi − ŷi = ui
yi = valore effettivo; ŷi = valore teorico; ui = errore.
Tutto ciò è vero anche per dati centrati (rispetto al valore medio):
yi = y − ȳ (vedi operazioni di standardizzazione)
se eleviamo al quadrato e sommiamo, si ottiene:
102
X
yi2 =
X
X
ŷi ui =
(ŷi2 + 2ŷi ui + u2i ), consideriamo
X
ŷi (yi − ŷi ) =
X
ŷi yi −
X
ŷi2
X
ŷi ui
I fenomeni bivariati
ma se i dati sono centrati si ha ŷi = bxi (si dimostra graficamente)
per cui
X
ŷi yi = b
X
xi yi e
X
ŷi ui = b
X
x i y i − b2
ŷi2 = b2
X
x2i
si ha
X
X
x2i ma
X
xi yi = b
X
x2i
P
xi yi
perché b = P 2
xi
perciò
X
ŷi ui = b · b
X
x2i − b2
X
x2i = 0
e infine si può scrivere:
X
yi2 =
X
ŷi2 +
X
u2i ;
divido per N
103
I fenomeni bivariati
P 2 P 2
ŷi
ui
yi2
=
+
N
N
N
P
↓
P
(yi − ȳ)2
N
varianza y
=
varianza di y +
spiegata dalla
retta di
regressione
varianza
dei
residui
σy2 = σŷ2 + σu2 divido per σy2
1=
σŷ2 σu2
+
σy2 σy2
↓
(% di varianza spiegata dal modello)
σŷ2
σu2
=
1
−
= R2 coefficiente di determinazione
σy2
σy2
↓
(% varianza residua)
0 ≤ R2 ≤ 1
R2 è uguale ad 1 se il secondo termine (varianza residua) è uguale a 0. In tal
caso il modello spiega tutto.
R2 è uguale a 0 se il secondo termine è uguale ad 1 e ciò significa (σu2 = σy2 )
che la varianza residua è uguale alla varianza totale.
Un altro aspetto della regressione che ci aiuta a valutare la bontà dei risultati
è l’analisi dei residui, ui , che ci permette di individuare dei comportamenti
tipici degli errori e quindi di rimettere in discussione le ipotesi sul loro comportamento. Si suppone infatti che E(u2i ) = σu2 , ∀i, che la varianza dei residui
sia costante e indipendente da xi , che non vi sia cioè relazione tra il valore
che prende la variabile esplicativa e l’ampiezza dell’errore. Se invece vi è tale
104
I fenomeni bivariati
relazione si parla di eteroschedasticità e il grafico dei residui si presenta
cosı̀:
Un caso tipo di eteroschedasticità si ha quando si stimano i consumi delle
famiglie
Ci = a + bRi + ui
↑
bilanci delle f amiglie
perché effettivamente la dispersione delle spese aumenta all’aumentare del
reddito. Se supponiamo che tale aumento sia proporzionale alla varianza:
E(u2i /Ri ) = Ri2 σ 2 ,
∀i
si può ritrovare l’omoschedasticità dividendo per Ri e cioè stimando:
Ci
a
ui
=
+b+
Ri
Ri
Ri
|{z}
vi
e si avrebbe E(vi ) = E
E(u2i ) =
1
E(u2i )
Ri2
=
1
Ri2
ui
Ri
=
1
E(ui )
Ri
· Ri2 · σ 2 = σ 2 ,
=0
∀i
Diversamente dall’analisi della correlazione, in cui si considera solo la forza
del legame tra le variabili, nell’analisi di regressione è importante il senso
(verso) della causalità che fa si che una volta scelta la variabile indipendente, uguale a x per convenzione, e la variabile dipendente, uguale a y per
convenzione, la retta da stimare sia:
y = a + bx
105
I fenomeni bivariati
In altri termini mentre posso sempre scrivere:
x = a1 + b 1 y
è un po più difficile pensare di invertire il senso di una relazione funzionale,
in economia come in ogni altro campo.
C = f (y) e non y = f (C)
con C = consumo e y = reddito.
Esempio
xi
1
2
3
4
yi
2.5
4.5
6.5
8.5
Disegniamo i punti su un piano cartesiano:
Calcoliamo x̄ e ȳ:
x = 2.5;
106
y = 5.5
I fenomeni bivariati
poi calcoliamo a, b e ŷ
xi
yi
xi − x̄
(xi − x̄)2
yi − ȳ
(yi − ȳ)2
(xi − x̄)(yi − ȳ)
ŷi
ui
1
2.5
-1.5
2.25
-3
9
4.5
2.5
0
2
4.5
-0.5
0.25
-1
1
0.5
4.5
0
3
6.5
0.5
0.25
1
1
0.5
6.5
0
4
8.5
1.5
2.25
P
=5
3
9
4.5
P
= 10
8.5
0
P
= 20
P
(xi − x̄)(yi − ȳ)
10
P
b=
)=
=2
a = ȳ − bx̄ = 5.5 − 2 · 2.5 = 0.5
2
(xi − x̄
5
P
(yi − ŷi )2
2
ui = yi − ŷi
σu =
=0
ŷ = 0.5 + 2 · x
N
R2 = 1 −
σu2
0
=
1
−
= 1 il modello spiega perfettamente tutto
σy2
5
Proviamo adesso ad aggiungere un punto per vedere cosa succede:
107
I fenomeni bivariati
xi
yi
xi − x̄
(xi − x̄)2
yi − ȳ
(yi − ȳ)2
(xi − x̄)(yi − ȳ)
ŷi
(y − ŷ)2
1
2.5
-1.7
2.89
-2.9
8.41
4.93
2.59
0.01
2
4.5
-0.7
0.49
-0.9
0.81
0.63
4.24
0.07
3
6.5
0.3
0.09
1.1
1.21
0.33
5.90
0.36
3.5
5
0.8
0.64
-0.4
0.16
-0.32
6.72
2.97
4
8.5
1.3
1.69
P
= 5.8
3.1
9.61
4.03
P
= 9.6
7.55
0.90
x̄ = 2.7;
ȳ = 5.4;
σy2
P
= 20.2
P
(y − ȳ)2
=
= 4.04
5
9.6
= 1.66;
a = 0.93;
5.8
σ2
R2 = 1 − u2 = 0.79
ŷ = 0.93 + 1.66 · x
σy
b=
108
4.31
P
(x − x̄)2
=
= 1.16
5
P
(y − ŷ)2
2
σu =
= 0.86
5
σx2
Esercizi
I fenomeni bivariati
Esercizio 1.
Su un campione di individui maschi (della stessa età) partecipanti ad un
corso di cultura fisica, si sono rilevate le seguenti variabili:
Y = tempo impiegato per correre un percorso di 2.400 metri (in minuti)
X = peso corporeo (in Kg)
individui
A
B
C
D
E
F
G
Y
12.37
8.85
13.08
14.03
10.05
12.12
10.54
X
81.47
68.84
83.32
87.66
71.45
79.15
73.32
a) Si determini la retta di regressione lineare tra i due fenomeni avente
significato logico e se ne illustri la validità;
b) Si commenti il tempo di percorrenza teorico per un individuo di 0 kg
109
Esercizi
110
I fenomeni bivariati
Soluzione esercizi
Soluzione esercizi
A.1
I metodi quantitativi
Tipi di dati
Esercizio 1
(a)
(b)
(c)
(d)
(e)
(f)
quantitativa
qualitativa
quantitativa
quantitativa
qualitativa
quantitativa
discreta
discreta
continua
(g)
(h)
(i)
(l)
(m)
qualitativa
quantitativa discreta
quantitativa continua
qualitativa
qualitativa
continua
Tabelle e grafici per dati quantitativi
Esercizio 1
5
6
7
8
9
34
9
4
0
38
n=7
Esercizio 2
a. Ordinamento
4 5 5
8 8 8
10 10 10
15 16 16
6 6 6 6 7 7
8 8 8 8 9 9
10 10 10 11 11 12
18 23
7 7 7 7 8 8
9 9 9 9 10 10
12 13 13 14 15 15
Soluzione esercizi
b. Diagramma gambo-foglia dei book value:
0 4556666777777888888888999999
1 000000001122334555668
2 3
c. Sono più frequenti i valori meno elevati, infatti l’intera distribuzione si
concentra sotto i 10 dollari. Più della metà delle azioni del campione ha un
book value inferiore ai 10 dollari.
d. E’ molto più facile trovare un’azione con un book value inferiore a 10
dollari, piuttosto che superiore a 20. Infatti 28 delle 50 azioni del campione
hanno un book value inferiore a 10,mentre una sola azione ha un valore superiore a 20 dollari.
Esercizio 3
Esercizio 4
In questo esercizio si dispone della rappresentazione grafica ma per rispondere
alle domande bisogna ricostruire la tabella delle frequenze.
112
Soluzione esercizi
xi
hi = fi /ai
90-100
1%
100-110
1.5%
110-115
3%
115-120
4%
120-125
2%
125-130
1.5%
130-140
1%
140-150
0.75%
150-160
0.5%
ai fi = hi · ai
10
10%
10
15%
5
15%
5
20%
5
10%
5
7.5%
10
10%
10
7.5%
10
5%
P
fi = Fi
10
25
40
60
70
77.5
87.5
95
100
Ecco le risposte:
1. 100%-77.5%=22.5%
Tale percentuale è quindi più vicina a 25%.
2. 112-113 poiché tale intervallo appartiene a un rettangolo caratterizzato
da una maggior densità di frequenza:
110-115=3% ; 130-140=1%
3. 120-135 : 120-125=10% +
125-130=7.5% +
1/2(130 − 140) = 5% data l’ipotesi di uguale ripartizione
Totale: 22.5%
4. 125-130 ⇒ 7.5%
140-150 ⇒ 7.5 %
Nei due casi trattati l’effettivo è uguale.
Esercizio 5
0-1 =
1-2 =
5-10 =
10%
20%
5% × 5
= 25%
La somma dei rettangoli disegnati vale il 55%, quindi rimane il 45%.
⇒
45%
3
|{z}
ampiezza della base
= 15%
Soluzione esercizi
Esercizio 6
a.
A+B+C+D = A+1.7A+[1.5(1.7A)]+[0.8(1.7A)] = A+1.7A+2.55A+1.36A = 6.61A
A=
100
6.61
= 15.13
b.
xi
5-10
15-20
20-22
22-30
fi
0.1513
0.3858
0.2058
0.2572
di
0.1513/5 = 0.030
0.3858/5 = 0.077
0.2058/2 = 0.103
0.2572/8 = 0.032
c.
3
× 0.3858 = 0.2315;
5
0.1513 + 0.2315 = 0.3828;
1 − 0.3828 = 0.6172
la percentuale di persone che hanno più di 18 anni è 61.72%.
114
Soluzione esercizi
Tabelle e grafici per dati qualitativi
Esercizio 1
a. Il carattere X = titolo di studio è di tipo qualitativo rettilineo; la popolazione di riferimento è formata da tutti i residenti nel comune; l’unità statistica è rappresentata dal singolo residente.
b. L’ampiezza di classe si ottiene dalla differenza tra il limite superiore ed il
limite inferiore delle classi; le frequenze specifiche (o ridotte) sono date dal
rapporto tra frequenza assoluta e ampiezza di classe. Le frequenze relative si
ottengono rapportando ciascuna frequenza assoluta al totale delle frequenze;
il totale delle frequenze relative è pari a uno. Le frequenze percentuali si
ottengono moltiplicando per 100 ciascuna frequenza relativa; il totale delle
frequenze percentuali è pari a 100.
c. Le frequenze cumulate si ottengono sommando successivamente dall’alto
verso il basso le frequenze di classe.
d. Le frequenze retrocumulate si ottengono sommando successivamente dal
basso verso l’alto le frequenze di classe.
xi
analfabeti
alfabeti
elementare
media inf.
media sup.
laurea
ni
Ni R i
fi
100fi
1
1 422 0.002 0.2
10 11 421 0.024 2.4
50 61 411 0.119 11.9
220 281 361 0.521 52.1
125 406 141 0.296 29.6
16 422 16 0.038 3.8
Soluzione esercizi
Esercizio 2
a. Il carattere X = tipo di trasporto è di tipo qualitativo sconnesso; la
popolazione di riferimento è formata da tutti gli ospiti del villaggio; l’unità
statistica è rappresentata dal singolo ospite.
b. Le frequenze relative si ottengono rapportando ciascuna frequenza assoluta al totale delle frequenze; il totale delle frequenze relative è pari a uno. Le
frequenze percentuali si ottengono moltiplicando per 100 ciascuna frequenza
relativa; il totale delle frequenze percentuali è pari a 100.
c. Le frequenze cumulate si ottengono sommando successivamente dall’alto
verso il basso le frequenze di classe.
d. Le frequenze retrocumulate si ottengono sommando successivamente dal
basso verso l’alto le frequenze di classe.
xi
auto
nave
camper
treno
aereo
altro
116
ni
Ni R i
fi
100fi
25 25 129 0.194 19.4
12 37 104 0.093 9.3
23 60 92 0.178 17.8
12 72 69 0.093 9.3
55 127 57 0.426 4.26
2 129 2 0.016 1.6
129
1
100
Soluzione esercizi
A.2
I fenomeni bivariati
La regressione
Esercizio 1.
a) Nel caso in esame, appare del tutto naturale considerare il peso corporeo
(X) come variabile esplicativa ed il tempo impiegato per correre il percorso
(Y) come variabile dipendente. Si considera quindi la retta di regressione:
ŷi = a + bxi
i = 1, 2, . . . , 7
che esprime il tempo impiegato come funzione (lineare) del peso dell’individuo. Per stimare i parametri, occorre calcolare:
x̄ = 77.887
yi
12.37
8.85
13.08
14.03
10.05
12.12
10.54
σx2 =
xi
81.47
68.84
83.32
87.66
71.45
79.15
73.32
x − x̄
3.583
-9.047
5.433
9.773
-6.437
1.263
-4.567
(x − x̄)2
12.48
81.85
29.57
95.51
41.44
1.59
20.86
283.60
ȳ = 11.577
y − ȳ
0.793
-2.727
1.503
2.453
-1.527
0.543
-1.037
(y − ȳ)2
0.629
7.437
2.259
6.017
2.332
0.295
1.076
20.044
√
(x − x̄)2
= 40.51; σx = 40.51 = 6.365
7
σxy
2.84
24.67
8.16
23.97
9.83
0.69
4.74
74.90
ŷ
12.52
9.19
13.01
14.16
9.88
11.91
10.37
(y − ŷ)2
0.024
0.114
0.005
0.016
0.030
0.044
0.029
0.261
Soluzione esercizi
(x − x̄)(y − ȳ)
= 10.7004
7
Di conseguenza si ottiene:
σxy =
b=
10.7004
= 0.2641
40.51
a = 11.577 − 0.2641 · 77.887 = −8.994
La retta di regressione adattata con il metodo dei minimi quadrati risulta
quindi:
ŷi = −8.994 + 0.2641xi
i = 1, 2, . . . , 7
Il coefficiente di regressione segnala che, all’aumentare di un kg del peso
corporeo, si osserva in media un incremento nel tempo di percorrenza pari a
circa 0.26 minuti (cioè circa 16 secondi).
L’intercetta corrisponderebbe invece al tempo di percorrenza stimato per
un individuo di peso nullo. Ovviamente,nel presente contesto, tale valore non
presenta alcun significato interpretativo, in quanto non è possibile ipotizzare
che un soggetto abbia peso pari a zero.
Per valutare la bontà della regressione occorre dapprima calcolare lo
scostamento quadratico medio della variabile dipendente, che risulta:
r
(y − ȳ)2
σy =
= 1.692
7
Si ricava quindi:
R2 = 1 −
σu2
= 0.987
σy2
Lo stesso risultato si può ottenere anche cosı̀:
rxy =
σxy
= 0.9935;
σx · σy
R2 = (0.9935)2 = 0.987
L’adattamento della retta di regressione ai dati risulta quasi perfetto: la relazione con il peso corporeo spiega infatti il 98.7% della varianza dei tempi
di percorrenza.
b) Fissando il valore y = 60, si ottiene:
ŷ(60) = −8.994 + 0.2641 · 60 = 6.852
Il valore stimato del tempo di percorrenza per un individuo di 60 kg risulta
quindi pari a 6.852 minuti (cioè a 6 minuti e 51 secondi circa). Si osservi
118
Soluzione esercizi
tuttavia che, pur essendo il coefficiente di determinazione molto prossimo a
1, si tratta di una proiezione di limitata attendibilità, in quanto il valore
x = 60 risulta esterno al campo di osservazione dei valori rilevati. Infatti,
il modello adattato può ritenersi appropriato solo per rappresentare i tempi
di percorrenza degli individui (iscritti al corso di cultura fisica) con peso
corporeo compreso tra 68.84 e 87.66 kg.
Soluzione esercizi
120
Bibliografia
Wonnacott T.H., Wonnacott R.J. (1995) Introduzione alla statistica, Franco
Angeli Milano.
Freedman D., Pisani R., Purves R. (1998) Statistica, Mc Graw - Hill, Milano.
Piccolo D., Vitale C., (1984) Metodi statistici per l’analisi economica, Il
Mulino, Bologna.