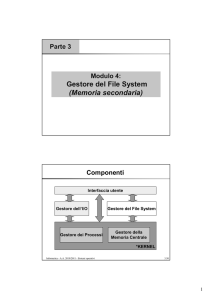
Il gestore della memoria
La memoria è una risorsa importante e va gestita con attenzione. Sebbene la maggior parte dei personal computer dei
nostri giorni abbia una quantità di memoria dieci volte superiore a quella dell'IBM 7094 (il calcolatore più grande del
mondo nei primi anni 60), i programmi stanno crescendo in dimensione alla stessa velocità con cui crescono le
memorie. parafrasando la legge di Parkinson, possiamo dire che "I programmi si espandono fino a riempire la memoria
disponibile". In questo capitolo studieremo come i sistemi operativi gestiscono la loro memoria.
La parte di sistema operativo che si occupa della gestione della memoria si chiama gestore della memoria. Il suo
compito è quello di tener conto delle parti di memoria usate e di quelle non utilizzate, di allocare memoria ai processi
quando ne abbiano bisogno e di deallocarla quando hanno finito e infine di gestire gli scambi fra memoria principale e
disco, quando la memoria principale non è abbastanza grande per contenere tutti i processi.
Monoprogrammazione senza swapping o paginazione
I sistemi di gestione della memoria possono essere divisi in due classi: quelli che spostano i processi avanti e indietro
dai dischi alla memoria durante l'esecuzione (sistemi con swapping o paginazione) e quelli che non lo fanno.
Il più semplice schema di gestione della memoria è quello in cui c'è un solo processo in memoria in ogni istante e
questo processo può usare tutta la memoria. L'utente occupa l'intera memoria con un programma prelevato dal disco o
dal nastro e prende il controllo dell'intera macchina. Sebbene questo approccio fosse comune fino al 1960 attualmente
non viene più usato, nemmeno sui più economici personal computer, per lo più perché implica che ogni processo deve
contenere al suo interno un gestore di dispositivo per ognuno dei dispositivi usati.
La tecnica che viene usata di solito sui microcalcolatori più semplici è la seguente: La memoria viene divisa fra il
sistema operativo ed un singolo processo utente. Il sistema operativo può stare nella parte bassa della memoria RAM
oppure può trovarsi in ROM nella memoria alta, oppure i gestori dei dispositivi possono risiedere in ROM nella
memoria alta e il sistema operativo in RAM nella memoria bassa, questo ultimo modello usato dal PC-IBM, con i
gestori dei dispositivi allocati in ROM. Il programma che si trova nella ROM viene chiamato BIOS
Quando il sistema viene organizzato in questo modo, un solo processo può essere in esecuzione ad un generico istante.
L'utente batte un comando dal terminale ed il sistema operativo carica il programma richiesto dal disco in memoria e lo
esegue. Quando il processo termina, il sistema operativo scrive un carattere di prompt sul terminale ed attende un
comando dal terminale per caricare un nuovo processo, sovrapponendolo al primo
.
Multiprogrammazione e uso della memoria
Sebbene la monoprogrammazione venga in qualche caso usata per i piccoli calcolatori, sui calcolatori più grandi viene
usata raramente. Ciò perchè i grandi calcolatori offrono spesso servizi interattivi a diversi utenti contemporaneamente,
il che richiede la capacità di avere contemporaneamente più di un processo in memoria, in modo da ottenere delle
prestazioni ragionevoli. Caricare un processo, farlo girare per 100 millisecondi e poi spendere qualche altro centinaio di
millisecondi per scaricarlo sul disco risulta inefficiente, ma se il quanto venisse posto a molto di più dei 100
millisecondi, il tempo di risposta risulterebbe alto.
Un' altra ragione a favore della multiprogrammazione di un calcolatore è che molti processi passano una frazione
significativa del loro tempo aspettando che vengano completate operazioni di ingresso/uscita sul disco. Una situazione
comune vede un processo leggere blocchi di dati da un file su disco all'interno di un ciclo e ;poi eseguire un qualche
calcolo sui contenuti dei blocchi letti. Se impiega 40 millisecondi per leggere un blocco e 10 miJ1isecondi per eseguire i
calcoli, con la monoprogrammazione la CPU sarebbe inattiva in attesa del disco per 1'80% del tempo.
Multiprogrammazione con partizione fissa
Quando si ha più di un processo come si deve organizzare la memoria? Il modo più semplice è quello di dividere la
memoria in n partizioni, magari diverse. Questa suddivisione può essere fatta manualmente dagli operatori, per
esempio, quando il sistema viene avviato; quando arriva un lavoro, può essere messo nella coda d'ingresso della
partizione più piccola che lo possa contenere. Dal momento che le partizioni sono fisse, in questo schema, tutto lo
spazio di una partizione non usato dal lavoro va sprecato.
Lo svantaggio dell' organizzare i lavori in ingresso in code separate diventa evidente nel caso in cui la coda per una
partizione grande sia vuota ma quella per una partizione piccola sia piena. Un'organizzazione alternativa è quella di
mantenere una singola coda. Ogni qualvolta una partizione diventa libera, il lavoro più vicino alla testa della coda che
può entrare nella partizione vi viene caricato ed è quindi mandato in esecuzione. Dal momento che non è desiderabile
sprecare una partizione molto grande per far girare un lavoro piccolo, un' altra strategia è quella di cercare nell'intera
coda in ingresso ogni volta che si libera una partizione e scegliere il lavoro più grande che può entrarci. Da notare che
quest'ultimo algoritmo discrimina negativamente i lavori piccoli, considerandoli immeritevoli di un'intera partizione,
mentre di solito è preferibile dare ai lavori più piccoli (che si ipotizzano interattivi) il servizio migliore, non quello
peggiore.
Una via d'uscita è di avere sempre a disposizione una partizione piccola. Questa partizione permetterà ai lavori piccoli
1
di girare senza dover allocare per loro una partizione grande.
Un altro approccio prevede una regola che dice che un lavoro che può andare in esecuzione non venga lasciato da parte
per più di k volte. Ogni volta che viene lasciato da parte, prende un punto. Quando è arrivato a k punti, non può più
venir lasciato da parte .
Swapping
Con i sistemi batch organizzare la memoria in partizioni fisse è facile ed efficiente. Fino a quando si possono tenere in
memoria abbastanza lavori per tenere sempre occupata la CPU, non c'è ragione di andare a cercare qualcosa di più
complicato. Con il timesharing (condivisione di tempo) la situazione è diversa: ci sono normalmente tanti utenti che la
memoria non è sufficiente a contenere tutti i loro processi e diventa così necessario tenere i processi in eccesso sul
disco. Per far girare questi processi, essi devono naturalmente essere prima caricati in memoria; spostare i processi dalla
memoria al disco e viceversa viene detto swapping (scambio) e rappresenta l'argomento delle prossime sezioni.
Multiprogrammazione con partizioni variabili
In linea di principio, un sistema di swapping può essere basato su partizioni fisse; ogni qualvolta un processo si blocca,
esso può essere spostato sul disco e nella partizione si può caricare dal disco un altro processo. In pratica, le partizioni
fisse non sono una buona soluzione quando la memoria è scarsa dal momento che se ne spreca troppa per via dei
programmi che sono più piccoli delle loro partizioni. Si può allora usare un altro algoritmo per la gestione della
memoria; esso è noto con il nome di partizioni variabili.
Quando si usano le partizioni variabili, il numero e la dimensione dei processi in memoria variano dinamicamente
durante la giornata; Facciamo un esempio: Inizialmente il solo processo A risiede in memoria, poi vengono creati o
caricati dal disco i processi B e C. il processo A termina oppure viene scaricato sul disco, poi arriva D e B viene
scaricato; infine, arriva il processo E.
La differenza principale fra le partizioni fisse e le partizioni variabili è che il numero, la dimensione e la posizione delle
partizioni variano dinamicamente, con l'arrivo e la partenza dei processi, e non sono fisse. La flessibilità data dal non
essere legati ad un numero di partizioni che possono essere troppo grandi o troppo piccole migliora l'utilizzazione della
memoria ma complica anche l'allocazione ed il rilascio della memoria, così come il tener traccia dell' allocazione.
E possibile combinare tutti i buchi in un unico, grande buco, spostando tutti i processi il più indietro possibile: questa
tecnica è nota con il nome di compattazione della memoria e normalmente non viene eseguita, dal momento che
richiede un sacco di tempo di CPU.
Una cosa su cui vale la pena di riflettere è quanta memoria deve essere allocata quando si crea un processo o lo si
carica in memoria. Se i processi vengono creati con una dimensione fissa, che non cambia mai, allora l'allocazione è
semplice: si alloca esattamente la quantità di memoria necessaria, nè più nè meno.
Se i segmenti dati dei processi possono crescere, allora si possono avere dei problemi quando un processo tenta di
crescere. Se vicino al processo si trova un buco, esso può essere allocato al processo ed il processo vi può crescere.
D'altra parte se il processo è adiacente ad un altro processo, il processo in crescita deve essere spostato in un buco di
memoria abbastanza grande per contenerlo, oppure occorre scaricare umo o più processi per poter creare un buco
abbastanza grande per contenerlo. Se un processo può crescere mentre è in memoria e l'area di swap (scambio) sul
disco è piena, il processo deve attendere oppure deve essere ucciso.
Se ci si aspetta che la maggior parte dei processi crescano durante l'esecuzione, allora probabilmente è una buona idea
allocare una piccola quantità di memoria extra quando un processo viene caricato dal disco o spostato in memoria, per
ridurre l' overhead dovuto allo scaricamento o allo spostamento quando un processo non entra più nella memoria che
gli è stata allocata. Ad ogni buon conto, quando un processo viene scaricato sul disco, va scaricata solo la memoria che
viene effettivamente utilizzata; salvare anche la memoria extra allocata al processo è uno spreco.
Vi sono diverse tecniche con cui un S.O. può tener conto dell’uso della memoria.
La memoria virtuale
Spesso ci si trova nella condizione che un programma sono troppo grandi per essere caricati in memoria. Di fronte a
questo problema si sono travate soluzioni tra cui quella nota con il nome di memoria virtuale. L'idea di base che sta
dietro alla memoria virtuale è che la dimensione combinata di programma, dati e stack può eccedere la dimensione della
memoria fisica per essi disponibile. Il sistema operativo mantiene in memoria le parti che sono in uso in un certo
momento, mentre le altri parti vengono mantenute sul disco. Per esempio, un programma da 1M può girare in una
macchina da 256K scegliendo in maniera accurata quali 256K mantenere in memoria ad ogni istante, con pezzi di
programma che vengono caricati e scaricati fra disco e memoria secondo le necessità.
2
La memoria virtuale può anche funzionare con sistemi multiprogrammati. Per esempio, otto programmi da 1M possono
essere allocati ciascuno in una partizione da 256K di una memoria da 2M, con ciascun programma che si comporta
come se avesse a disposizione una macchina privata con 256K di memoria. Di fatto, memoria virtuale e
multiprogrammazione stanno molto bene insieme; mentre un programma aspetta che una sua porzione venga caricata in
memoria, è di fatto in attesa di un'operazione di ingresso/uscita e non può girare, così la CPU può essere assegnata ad
un altro processo.
La paginazione
La maggior parte dei sistemi con memoria virtuale usa la tecnica, della paginazione. Su un qualunque calcolatore, esiste
un insieme di indirizzi di memoria che possono essere prodotti dai programmi. Quando un programma usa un'istruzione
tipo
MOVE REG,1000
esso sposta il contenuto della memoria all'indirizzo 1000 dentro a REG (o viceversa, a seconda della macchina). Gli
indirizzi possono essere generati usando l'indicizzazione, i registri base, i registri segmento ed altri metodi.
Questi indirizzi generati dal programma vengono detti indirizzi virtuali e formano lo spazio di indirizzamento virtuale.
Sui calcolatori privi di memoria virtuale, l'indirizzo virtuale viene direttamente spedito sul bus della memoria e causa la
lettura o la scrittura della cella di memoria fisica che ha quello stesso indirizzo. Quando si usa la memoria virtuale, gli
indirizzi virtuali non finiscono direttamente sul bus della memoria. Invece, vanno a finire ad una unità della gestione
della memoria che trasforma gli indirizzi virtuali sugli indirizzi della memoria fisica.
Lo spazio di indirizzamento virtuale viene diviso in unità chiamate pagine: le corrispondenti unità nella memoria fisica
vengono dette pagine fisiche (page frame). Le pagine e le pagine fisiche hanno sempre la stessa dimensione;
In teoria, la traduzione degli indirizzi virtuali in indirizzi fisici funziona così: L'indirizzo virtuale viene diviso in un
numero di pagina virtuale (i bit di ordine superiore) e in un offset (i bit di ordine inferiore); il numero di pagina virtuale
viene usato come indice della tabella delle pagine per trovare l'elemento relativo a quella pagina virtuale. Dall'
elemento relativo alla pagina virtuale, viene derivato il numero di pagina fisica (se esiste); questo viene attaccato alla
parte alta dell' offset, rimpiazzando il numero di pagina virtuale, per formare un indirizzo fisico che può essere spedito
alla memoria.
Lo scopo della tabella delle pagine è quello di mappare pagine virtuali in pagine fisiche.
Da un punto di vista matematico, la tabella delle pagine è una funzione, con il numero di pagina virtuale come
argomento e il numero di pagina fisica come risultato. Usando il risultato di questa funzione, il campo che denota la
pagina virtuale in un indirizzo virtuale può essere sostituito dal numero della pagina fisica, in modo da formare un
indirizzo di memoria fisica.
Vi sono diversi algoritmi di sostituzione delle pagine in memoria tra cui “quella non usata di recente”,”first in,first out”
“della seconda opportunità”,”dell’orologio”,”usata meno di recente”.
La segmentazione
La memoria virtuale descritta fino ad ora è uni-dimensionale dal momento che gli indirizzi virtuali vanno dall' indirizzo
O ad un indirizzo massimo, un indirizzo dopo l'altro; per molti problemi, può essere molto meglio avere uno o più spazi
di indirizzamento separati piuttosto che averne uno solo. Per esempio, un compilatore ha tante tabelle che vengono
costruite man mano che procede la compilazione, fra le quali troviamo solitamente:
1. il testo sorgente, che viene salvato per la stampa dei listati (nei sistemi batch);
2. la tabella dei simboli, contenente i nomi e gli attributi delle variabili;
3. la tabella che contiene tutti le costanti usate, intere e in virgola mobile;
4. l'albero di derivazione, contenente l'analisi sintattica del programma;
5. lo stack, usato per le chiamate di procedura del compilatore.
Ognuna delle prime quattro tabelle cresce man mano che la compilazione va avanti; L'ultima cresce e diminuisce in
maniera non prevedibile durante il processo di compilazione. In una memoria uni-dimensionale, queste cinque tabelle
dovrebbero essere allocate in porzioni contigue di memoria.
Consideriamo cosa accade se un programma ha un numero eccezionalmente alto di variabili: la porzione di memoria
allocata per la tabella dei simboli potrebbe riempirsi, ma ci potrebbe essere ancora molto spazio libero nelle altre
tabelle. Naturalmente, il compilatore potrebbe inviare un messaggio che dica che la compilazione non può continuare
per via delle troppe variabili, ma così facendo non si fa una bella figura se nelle altre tabelle esiste spazio inutilizzato.
Una soluzione semplice ed estremamente generale è quella di dotare la macchina di molti spazi di indirizzamento
completamente indipendenti, chiamati segmenti. Ciascun segmento consiste di una sequenza lineare di indirizzi, da O
ad un qualche massimo; la lunghezza di ciascun segmento può andare da O al massimo stabilito. Segmenti diversi
possono avere lunghezze diverse e di solito così accade; in più le lunghezze dei segmenti possono cambiare durante
3
l'esecuzione. La lunghezza del segmento dello stack può essere allungata quando vi si carica qualcosa e accorciata
quando si vi preleva qualcos' altro.
Dal momento che ciascun segmento costituisce uno spazio di indirizzamento separato, Sègmenti diversi possono
crescere e contrarsi in maniera indipendente senza influenze reciproche. Se uno stack che sta in un certo segmento ha
necessità di crescere, può farlo dal momento che non c'è nient' altro, in quello spazio di indirizzamento, sul quale può
andare a sbattere. Naturalmente, un segmento si può riempire, ma normalmente i segmenti sono molto grandi e così
questo evento è piuttosto raro. Per specificare un indirizzo in questa memoria bi-dimensionale il programma deve
fornire un indirizzo formato da due parti: un numero di segmento ed un indirizzo all'interno del segmento.
Se i segmenti sono molto grandi può risultare poco conveniente caricarli in memoria nella loro interezza: per questo si è
pensato ad una soluzione alternativa che alcuni S.O. hanno adottato. Si effettua una paginazione dei segmenti. Pertanto
si ha una gestione della memoria di segmentazione con paginazione.
Il file system
Tutte le applicazioni su calcolatore hanno bisogno di memorizzare e rintracciare informazioni. Durante l'esecuzione, un
processo può memorizzare una quantità limitata di informazioni nello spazio degli indirizzi ad esso concesso e ad ogni
modo, la capacità di memoria è limitata alla dimensione dello spazio degli indirizzi virtuali. Per alcune applicazioni
questo spazio riservato è adeguato, ma per altre, come prenotazioni aeree, applicazioni bancarie o applicazioni contabili
di grandi compagnie, è spesso troppo limitato.
Un secondo problema nel mantenere le informazioni all'interno dello spazio degli indirizzi di un processo è che
l'informazione viene perduta quando un processo termina. Per molte applicazioni (ad esempio, per le basi di dati)
l'informazione deve essere conservata per settimane, mesi o a volte per sempre, per cui è inaccettabile che essa possa
essere dispersa quando il processo termina. Inoltre l'informazione non deve essere perduta quando si ha un guasto
meccanico del computer e si interrompono i processi in corso in quell'istante.
Un terzo problema consiste nel fatto che frequentemente è necessario per più processi accedere contemporaneamente ad
una parte delle informazioni. Se abbiamo un elenco telefonico in linea memorizzato nello spazio degli indirizzi di un
solo processo, solo quel processo può accedervi, e così solo un numero di telefono può essere cercato in quel momento;
il modo per risolvere questo problema consiste nel rendere l'informazione stessa indipendente da qualsiasi processo.
Abbiamo così individuato tre requisiti essenziali per la memorizzazione duratura dell'informazione:
deve essere possibile memorizzare una grossa quantità di informazioni;
l'informazione deve essere conservata anche dopo la terminazione del processo che la usa;
più processi devono avere la possibilità di accedere all' informazione in modo concorrente.
La soluzione di tutti questi problemi consiste nel registrare l'informazione su dischi e in altri supporti esterni in unità
dette file. Se necessario, i processi possono leggere e scrivere nuovi file. L'informazione memorizzata nei file deve
essere permanente, non deve essere influenzata dalla creazione e dalla terminazione del processo; un file potrà essere
distrutto solo quando il suo proprietario lo cancella esplicitamente.
I file sono gestiti dal sistema operativo; nella progettazione di un sistema operativo. principali argomenti trattati sono la
struttura, il nome, l'accesso, l'uso e la protezione dei file stessi. Quella parte del sistema operativo che si occupa
complessivamente dei file è chiamata. file system.
Dal punto di vista degli utenti, l'aspetto più importante di un file system è come si presenta ad essi, cioè cosa costituisce
un file, come sono protetti, nominati, quali operazioni sono permesse sui file e così via. Alcuni particolari, quali l'uso di
liste collegate (linked list) e mappe di bit (bit map) per tenere traccia della memoria libera e il numero dei settori che
fanno parte di un blocco logico, sono meno interessanti sebbene molto importanti per la progettazione del file system.
I file
I file sono un meccanismo di astrazione. Essi offrono un modo di memorizzare l'informazione su disco e di ritrovarla in
un secondo momento in modo che l'utente non debba essere coinvolto da come e da dove le informazioni sono
memorizzate e da come funzionano realmente i dischi.
Probabilmente la caratteristica più importante di ogni meccanismo di astrazione è il modo in cui gli oggetti gestiti sono
denominati, per cui si inizierà ad esaminare il file system dal problema della denominazione dei file. Quando un
processo crea un file esso dà un nome al file; quando il processo termina, il file continua a esistere e altri processi
possono utilizzare le sue informazioni usandone il nome.
Le regole precise per denominare i file qualche volta variano da sistema a sistema, ad ogni modo tutti i sistemi
operativi permettono l'uso di stringhe lunghe da uno a otto lettere come nomi legittimi dei file; pertanto Andrea, Bruce
e Cathy sono nomi possibili di file. Spesso sono anche permessi e ritenuti validi numeri e caratteri speciali: pertanto
anche i nomi 2, urgente! e Fig.2-14 spesso sono ammessi.
4
Alcuni file system distinguono tra lettere maiuscole e minuscole, altri no . UNIX appartiene alla prima categoria; MSDOS appartiene alla seconda categoria.
Molti sistemi operativi dividono la denominazione del file in due parti, con la seconda parte separata da un punto, come
in prog.c. La parte che segue il punto si chiama estensione del file (file extension) e di solito indica qualche
informazione relativa al file. In MS-DOS, per esempio, i nomi dei file sono composti da 1 a 8 caratteri, più una
estensione opzionale da 1 a 3 caratteri. In UNIX, la dimensione dell'estensione, se presente, è lasciata all'utente e un file
può avere due o più estensioni, come inprog.c.z dove.z è usata di solito per indicare che il file (prog.c) è stato
compresso usando l'algoritmo di compressione di Ziv-Lempel.
In alcuni casi l'estensione del file è solo una convenzione e non è fatta valere in nessun modo. Un file denominato
file.text è probabilmente un qualche tipo di file text, ma questo nome serve da promemoria all'utente più che per
trasmettere qualche informazione specifica al computer. D'altra parte un compilatore C può pretendere che i file da
compilare abbiano estensione .c e in caso contrario rifiutarsi di effettuare la compilazione.
Convenzioni di questo tipo sono utili specialmente quando lo stesso programma può manipolare diversi tipi di file
differenti. Il compilatore C, per esempio, può ricevere in ingresso una lista di file da compilare e collegare insieme, di
cui alcuni sono file C e altri sono file in linguaggio assembler. A questo punto l'estensione diventa essenziale per far
sapere al compilatore che tipo di file sta trattando.
Struttura dei file
I file possono essere strutturati in molti modi. Tre possibilità comunemente usate
1. Il file è una sequenza non strutturata di byte; in effetti al sistema operativo non interessa sapere cosa contiene il file
e tutto ciò che vede sono byte. Un qualsiasi significato deve essere attribuito a livello di programma utente.
Entrambi i sistemi operativi UNIX e MS-DOS utilizzano questo tipo di approccio. Poiché il sistema operativo tratta
i file come se non fossero nient'altro che una sequenza di byte, si ottiene la massima flessibilità da parte sua. I
programmi utente possono inserire nei file qualsiasi cosa e dar loro un nome secondo quanto ritengono opportuno.
Il sistema operativo non fornisce alcun aiuto ma non interferisce nemmeno; per gli utenti che vogliono fare
qualcosa di inusuale ciò può essere molto importante.
2. Il file è una sequenza di record a lunghezza fissa, ognuno con una sua struttura interna. L'idea fondamentale di un
file come sequenza di record rispecchia l'idea che l'operazione di lettura restituisce un record e che le operazioni di
scrittura riscrivono o aggiungono un record. Negli anni passati, quando erano utilizzate schede di carta a 80
colonne, molti sistemi operativi basavano il loro file system su file composti da record di 80 caratteri, a immagine
delle schede. Questi sistemi trattavano anche file composti da record di 132 caratteri, che erano usati per una riga di
stampa (che a quel tempo aveva 132 colonne). I programmi leggevano l'input su blocchi di 80 caratteri e lo
scrivevano su blocchi di 132 caratteri, sebbene naturalmente gli ultimi 52 avrebbero potuto essere spazi. Con
l'avvento dei terminali CRT, che hanno linee a lunghezza variabile, l'idea di un file come sequenza di record a
lunghezza fissa sta perdendo popolarità
3. Il file è formato da un albero di record, non tutti necessariamente della stessa lunghezza, ognuno contenente un
campo chiave (key field) in una posizione ben definita nel record. L'albero è ordinato rispetto al campo chiave,
permettendo una ricerca veloce per una chiave determinata. In questo caso l'operazione di base non è accedere al
"successivo" record, sebbene ciò sia anche possibile, bensì accedere al record individuato da una chiave specifica.
Questo tipo di file chiaramente è molto differente dai flussi di byte non strutturati usati in UNI X e in MS- DOS ed
è usato largamente sui grossi mainframe usati per l'elaborazione dati commerciale.
Tipi di file
Diversi sistemi operativi trattano molti tipi di file. UNIX e MS-DOS, per esempio hanno file regolari, directory, file di
caratteri speciali e file di blocchi speciali. I file regolari sono quelli che contengono l'informazione dell'utente. Le
directory sono file di sistema che conservano la struttura del file system e le analizzeremo più avanti. I file speciali a
caratteri riguardano l'input/output e sono usati per modellare unità seriali come terminali, stampanti e reti. I file
speciali a blocchi sono usati per modellare i dischi. In questo capitolo ci occuperemo principalmente dei file regolari.
Generalmente i file regolari sono sia file di tipo ASCII che file di tipo binario. I file di tipo ASCII sono formati da linee
di tipo testo. In qualche sistema ogni linea termina con un carattere di invio.
Il grosso vantaggio dei file di tipo ASCII è che essi possono essere visualizzati e stampati così come sono e possono
essere editati con un qualsiasi programma text editor.
Inoltre, se un gran numero di programmi usa file di tipo ASCII per l'input e l'output, è facile collegare l'output di un
programma all'input di un altro, come nelle pipeline della shell. (L'interconnessione tra processi non è per niente facile,
ma se si usa una convenzione standard, come quella ASCII, allora tutto diventa più semplice).
Altri file sono i file di tipo binario: stamparli sulla stampante produce un listato incomprensibile pieno di ciò che
apparentemente sembra informazione casuale. Di solito questi file hanno una loro struttura interna. Esempio di file
binario è un archivio.
5
Accesso ai file
I primi sistemi operativi offrivano solo un tipo di accesso ai file: l'accesso sequenziale.
In questi sistemi un processo poteva leggere tutti i byte o i record di un file in ordine, partendo dall'inizio, ma non era
possibile saltarne qualcuno o leggerli fuori dall'ordine. I file sequenziali possono essere riavvolti, comunque, cosicché
possono essere letti tanto spesso quanto necessita; sono convenienti quando l'unità di memoria è il nastro magnetico,
piunosto che il disco.
Quando si cominciò a usare i dischi per memorizzare i file diventò possibile leggere i byte o i record di un file in modo
non ordinato, o accedere ai record attraverso la chia\"e piuttosto che attraverso la loro posizione. I file i cui byte o
record possono essere letti in qualunque ordine sono detti file ad accesso casuale.
I file ad accesso casuale sono indispensabili per molte applicazioni, ad esempio i sistemi di basi di dati. Se un cliente di
una linee aerea chiama e vuole prenotare un posto su un volo particolare, il programma di prenotazioni deve essere in
grado di accedere al record di quel determinato volo senza dover prima leggere i record di migliaia di altri voli.
Per specificare da dove partire con la lettura si usano due metodi. Nel primo, ogni operazione di lettura dà la posizione
nel file da cui partire con la lettura. Nel secondo, una speciale operazione, SEEK, dà la possibilità di selezionare la
posizione corrente. Dopo aver fatto ciò, il file può essere letto sequenzialmente dalla nuova posizione corrente.
In qualche sistema operativo dei mainframe più vecchi, i file sono classificati ad accesso sequenziale o casuale al
momento della loro creazione e ciò permette al sistema operativo di utilizzare tecniche di memorizzazione differenti per
le due classi. I sistemi operativi moderni non fanno questa distinzione, tutti i file da loro trattati sono automaticamente
ad accesso casuale.
Attributi dei file
Ogni file ha un nome e i suoi dati; inoltre tutti i sistemi operativi associano un'altra informazione a ogni file, per
esempio, la data e l'ora del momento della creazione e la sua dimensione. Queste parti extra sono chiamate attributi del
file. La lista degli attributi varia considerevolmente da sistema a sistema.
Tra gli attributi troviamo :
I flag sono bit o campi corti che controllano o abilitano qualche proprietà specifica; i file nascosti, per esempio, non
compaiono nella lista di tutti i file. Il flag di archiviazione è un bit che mantiene traccia del fatto che il file è stato
salvato: il programma di ripristino lo azzera, il sistema operativo lo mette a l ogni volta che un file è modificato e in
questo modo il programma di ripristino può comunicare quali file hanno bisogno di essere salvati. Il flag temporaneo
permette che un file sia marcato per la cancellazione automatica quando termina il processo che lo aveva creato.
La lunghezza del record, la posizione della chiave e i campi di lunghezza della chiave sono presenti solo nei file i cui
record possono essere ritrovati usando una chiave: essi forniscono l'informazione necessaria per trovare le chiavi.
Le varie indicazioni di orario mantengono una traccia del momento in cui il file è stato creato, più recentemente visitato
e modificato. Tutto ciò è utile per vari scopi; per esempio un file sorgente che è stato modificato dopo la creazione del
file oggetto corrispondente dovrà essere ricompilato. Questi campi forniscono le informazioni necessarie.
La dimensione corrente indica la grandezza del file in quel momento. I sistemi operativi di qualche mainframe
richiedono che la dimensione massima sia specificata quando si crea il file, per permettere al sistema operativo di
riservare una quantità massima di memoria; i sistemi di mini e personal computer riescono a gestire i file senza queste
informazioni.
Operazioni sui file
I file servono a memorizzare informazioni e a permettere che esse siano rintracciate in un secondo momento. Segue una
discussione delle chiamate di sistema più usate relative ai file.
l. CREATE. Il file è creato senza dati. Lo scopo di questa chiamata è informare che il file sta per essere creato e
selezionare alcuni attributi.
2. DELETE. Quando il file è in disuso da lungo tempo, deve essere cancellato per liberare spazio su disco: per questo
scopo c' è sempre una chiamata di sistema. Inoltre qualche sistema operativo cancella automaticamente ogni file non
usato per n giorni.
3. OPEN. Prima di usare un file, un processo lo deve aprire; lo scopo della chiamata OPEN è permettere al sistema
operativo di andare a prendere gli attributi e l'elenco degli indirizzi del disco nella memoria principale per un accesso
veloce alle chiamate seguenti.
4. CLOSE. Quando sono terminati tutti gli accessi, gli attributi e gli indirizzi del disco non sono ulteriormente necessari,
così il file potrà essere chiuso per liberare spazio nella tabella interna; molti sistemi favoriscono ciò imponendo un
numero massimo di file aperti sui processi.
5. READ. I dati sono letti dal file. Di solito i byte provengono dalla posizione corrente; il chiamante deve specificare la
quantità di dati di cui ha bisogno e fornire anche un buffer per contenerli.
6
6. WRITE. I dati vengono scritti nel file, di nuovo, normalmente alla posizione corrente. Se la posizione corrente
corrisponde alla fine del file, si incrementa la sua dimensione; se la posizione corrente è nel mezzo del file, i dati
esistenti vengono coperti dai nuovi e persi definitivamente.
7. APPEND. Questa chiamata è una forma restrittiva di WRITE. Essa può solo aggiungere dati alla fine del file. I
sistemi che forniscono un insieme minimo di chiamate di sistema generalmente non hanno 1'APPEND, ma molti
sistemi forniscono molte maniere alternative di fare la stessa cosa, e qualche volta hanno l'APPEND.
8. SEEK. Per i file ad accesso casuale è necessario specificare un metodo per dire dove prendere i dati. Un approccio
comune è una chiamata di sistema, SEEK, che riposiziona il puntatore alla posizione corrente in un posto specifico del
file; completata questa chiamata, i dati si possono leggere o scrivere in quella posizione.
9. RENAME. Spesso succede che un utente ha bisogno di cambiare il nome di un file esistente: questa chiamata di
sistema lo rende possibile. Questa chiamata di sistema non sempre è strettamente necessaria, perché il file può sempre
essere copiato in un nuovo file è quindi il vecchio file può essere cancellato. Di solito ciò è sufficiente.
LE DIRECTORY
Per tener traccia dei file, il file system normalmente fornisce le directory che, in molti sistemi, sono a loro volta dei
file. In questo paragrafo parleremo delle directory, della loro organizzazione, delle loro proprietà e delle operazioni che
si possono effettuare su di esse.
Tipicamente una directory contiene un certo numero di elementi, uno per file. Solitamente si presentano due situazioni:
nella prima ogni elemento contiene il nome del file, i suoi attributi e gli indirizzi del disco dove sono memorizzati i dati.
Un' altra possibilità è che un elemento di directory contiene il nome del file e un puntatore a un' altra struttura dati in
cui si trovano gli attributi e gli indirizzi del disco. Queste due tecniche sono usate comunemente.
Quando si apre un file, il sistema operativo esamina la sua directory finché trova il nome del file da aprire, quindi ricava
gli attributi e gli indirizzi del disco.
Il numero di directory varia da sistema a sistema.
Il progetto più semplice per il sistema è utilizzare una singola directory che contiene tutti i file di tutti gli utenti, ma di
solito si utilizza una gerarchia generale (ad esempio un albero di directory). ogni utente può avere tante directory quante
sono necessarie e così i file possono essere raggruppati in modo naturale.
I path Dame
Quando il file system è organizzato come un albero di directory, è necessario un qualche modo per specificare i nomi
dei file. Comunemente vengono usati due metodi differenti. Nel primo metodo ad ogni nome è dato un path name
assoluto (nome assoluto di cammino) che consiste nel cammino dalla directory radice al file. I path name assoluti
partono sempre dalla directory radice,a differenza dei path name relativi essi partono dalla directory di lavoro e
ripercorrono l’albero da essa alla radice fino a giungere al nodo dove posizionato il file da cercare.
Operazioni sulle directory
Le chiamate di sistema per la gestione delle directory cambiano maggiormente da sistema a sistema rispetto a quelle
relative ai file. Ciononostante, per dare un'idea di quali sono e di come funzionano, si darà un esempio (preso da
UNIX).
CREA TE. Crea una directory vuota, con l'eccezione di dot e dot dot che sono inseriti automaticamente dal sistema (o,
in pochi casi, dal programma mkdir).
DELETE. Cancella una directory. Solo una directory vuota può essere cancellata; una directory che contiene solo dot e
dot dot è considerata vuota, perché questi elementi normalmente non possono essere cancellati.
OPENDIR. Le directory si possono leggere; per esempio, per elencare tutti i file di una directory, un programma apre
la directory per leggere i nomi di tutti i file che essa contiene. Prima che una directory possa essere letta, essa deve
essere aperta.
CLOSEDIR. Quando una directory è stata letta, dovrebbe essere chiusa per liberare lo spazio della tabella interna.
READDIR. Questa chiamata restituisce il prossimo elemento in una directory aperta. In passato era possibile leggere
directory usando la chiamata di sistema READ, ma tale approccio ha lo svantaggio di forzare il programmatore a
conoscere e a occuparsi della struttura interna delle directory. Al contrario, READDIR restituisce sempre un elemento
in un formato standard, indipendentemente dalle possibili strutture di directory usate.
RENAME. Sotto molti aspetti le directory sono come i file e si possono ride nominare nello stesso modo dei file.
LINK. Il collegamento è una tecnica che permette a un file di essere presente in più di una directory. Questa chiamata
di sistema specifica un file esistente e un path name e crea un link (collegamento) dal file esistente al nome specificato
dal path. In questo modo lo stesso file può essere presente in più directory.
UNLINK. Un elemento di directory è rimosso. Se il file che è stato sganciato è presente solo in una directory (il caso
7
normale), esso è rimosso dal file system. Se è presente in più directory, viene rimosso solo il path name specificato, gli
altri restano. In UNIX, la chiamata di sistema per cancellare i file (discussa precedentemente) è infatti UNLINK.
La lista appena citata contiene le chiamate più importanti ma ve ne sono altre.
Implementazione dei file system
Ora è giunto il momento di passare dal punto di vista dell'utente del file system al punto di vista di chi lo realizza (l'
implementato re). Gli utenti si preoccupano di come i file sono chiamati, quali operazioni sono permesse su di essi,
come si visita l'albero di directory e altri aspetti dell'interfaccia. Gli implementatori sono interessati al modo in cui i
file e le directory sono memorizzate, alla gestione dello spazio su disco e al modo in cui far funzionare ogni cosa in
modo efficiente e affidabile. Nei paragrafi seguente si esamineranno questi argomenti per studiarne gli aspetti
importanti e il modo in cui sono trattati.
Implementazione dei file
Il fattore chiave nell'implementazione della memorizzazione dei file è tener traccia di quali blocchi del disco associare
a ciascun file. Si usano vari metodi in sistemi differenti; in questo paragrafo se ne esamineranno alcuni.
Allocazione contigua
Lo schema di allocazione più semplice è quello di memorizzare ogni file come un blocco contiguo di dati sul disco.
Questo schema ha due vantaggi significativi. Primo, è semplice da implementare perché per tener traccia di dove sono i
blocchi di un file ci si limita alla memorizzazione di un numero, cioè l'indirizzo su disco del primo blocco; secondo, è
molto efficace perché l’intero file si può leggere dal disco con una sola operazione, ma ha lo svantaggio della
frammentazione del disco e non sempre si conosce la dimensione del file e quindi la dimensione dello spazio libero di
disco necessario a contenerlo
Allocazione a lista concatenata
Con questo metodo il file viene memorizzato in blocchi non contigui. La prima parola di ogni blocco contiene
l’informazione sul blocco successivo.
Allocazione a lista concatenata
In questo metodo le parole puntatori ai blocchi sono contenute in una tabella che deve essere sempre mantenuta in
memoria.
Gli i-mode
In questo metodo per tener tracci dei blocchi di un file si associa ad ogni file una piccola tabella che elenca gli attributi
e gli indirizzi del disco dei blocchi del file.
8