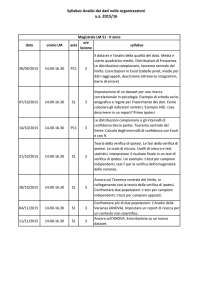
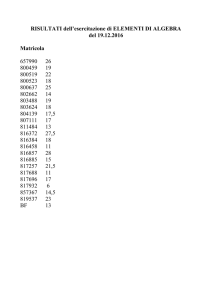
Algoritmi Avanzati
A.A. 2016–2017, primo semestre
Traccia delle lezioni
Mauro Brunato
Versione 2016-12-22
Caveat lector
Lo scopo principale di questi appunti è quello di ricostruire quanto detto a lezione. Queste note non
sono complete, e la loro lettura non permette, da sola, di superare l’esame. Le fonti utili a ricostruire
un discorso coerente e completo sono riportate alla pagina web del corso, dov’è disponibile anche la
versione più recente di queste note:
http://disi.unitn.it/~brunato/AA/
Alcune fonti per approfondimenti sono indicate nelle note a pie’ di pagina di questo documento.
Si suggerisce di confrontare la data riportata sul sito web con quella che appare nel frontespizio per
verificare la presenza di aggiornamenti.
Changelog
2016-12-22
• Link a codice risolutivo dell’esercizio 9
2016-12-21
• Bugfix
• Soluzioni agli esercizi
2016-12-19
• Cenni di apprendimento non supervisionato
• Decima esercitazione
• Esercizi
2016-12-11
• Algoritmo greedy per la selezione delle feature
• Nona esercitazione
2016-12-06
• Selezione delle feature
• Completamento dell’ottava esercitazione
2016-11-19
• Accenno alle reti neurali
• Alberi di decisione
• Settima esercitazione
• Ottava esercitazione
2016-10-26
• Funzione di decisione a soglia per modello logit
• Settima esercitazione
2016-10-24
• Quarto esercizio
2016-10-23
• Regressione logistica, discesa lungo il gradiente
• Quinta esercitazione
• Sesta esercitazione
• terzo esercizio
i
2016-10-11
• leave-one-out, K-fold cross validation
• regressione lineare e polinomiale
• Quarta esercitazione
• Secondo esercizio
2016-10-02
• Completata l’introduzione
• Criteri di valutazione dei modelli
• Primo esercizio
• Seconda e terza esercitazione
2016-09-19
Versione iniziale:
• Introduzione
• Prima esercitazione
ii
Indice
I
Appunti di teoria
1
1 Introduzione alla Data Science
1.1 La Data Science . . . . . . . . . . . . . . . . . .
1.2 Modelli di dati . . . . . . . . . . . . . . . . . . .
1.3 Formalizzazione del problema dell’apprendimento
1.3.1 L’addestramento e il modello . . . . . . .
1.4 Algoritmi di machine learning: alcuni esempi . .
1.4.1 K-Nearest-Neighbors (KNN) . . . . . . .
1.4.2 Regressione polinomiale . . . . . . . . . .
. . . . . . .
. . . . . . .
automatico
. . . . . . .
. . . . . . .
. . . . . . .
. . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2
2
3
3
4
4
4
5
2 Valutare la bontà di un modello
2.1 Criteri di valutazione . . . . . . . . . . . . . .
2.1.1 Valutare un modello di regressione . .
2.1.2 Valutare un modello di classificazione
2.2 Training e validazione . . . . . . . . . . . . .
2.2.1 Una soluzione estrema: leave-one-out .
2.2.2 K-fold cross-validation . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
6
6
6
6
8
9
9
3 Alcune tecniche di machine learning
3.1 K-nearest-neighbors . . . . . . . . . . . . . . . . . . . . . . . . . .
3.1.1 Input categorici . . . . . . . . . . . . . . . . . . . . . . . . .
3.1.2 Problemi di regressione . . . . . . . . . . . . . . . . . . . .
3.2 Regressione lineare: il metodo dei minimi quadrati . . . . . . . . .
3.2.1 Generalizzazione per funzioni non lineari . . . . . . . . . . .
3.2.2 Problemi di classificazione . . . . . . . . . . . . . . . . . . .
3.3 Regressione logistica . . . . . . . . . . . . . . . . . . . . . . . . . .
3.3.1 Stima dei coefficienti del modello . . . . . . . . . . . . . . .
3.3.2 Utilizzo del modello . . . . . . . . . . . . . . . . . . . . . .
3.4 Alberi di decisione . . . . . . . . . . . . . . . . . . . . . . . . . . .
3.4.1 Addestramento di un albero di ricerca . . . . . . . . . . . .
3.4.2 Passo induttivo: riduzione dell’imprevedibilità . . . . . . .
3.4.3 Partizione ricorsiva del dataset e condizione di terminazione
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
10
10
10
10
11
12
13
14
14
15
15
16
17
18
4 Selezione delle feature
4.1 Dati continui: il coefficiente di correlazione . . . . . . . . . . . . . . .
4.2 Variabili categoriche: l’informazione mutua . . . . . . . . . . . . . . .
4.2.1 Stima dell’informazione mutua in presenza di variabili continue
4.2.2 Qualche tranello . . . . . . . . . . . . . . . . . . . . . . . . . .
4.3 Un algoritmo greedy per la selezione delle feature . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
19
19
20
21
21
22
iii
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
5 Cenni di apprendimento non supervisionato
5.1 Distanze e somiglianze . . . . . . . . . . . . .
5.1.1 Dati non numerici . . . . . . . . . . .
5.2 Clustering agglomerativo gerarchico . . . . .
5.2.1 Distanze fra insiemi . . . . . . . . . .
5.2.2 L’algoritmo . . . . . . . . . . . . . . .
5.2.3 Similitudini e distanze . . . . . . . . .
II
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Esercitazioni di laboratorio
23
23
24
24
24
25
26
27
1 Lettura dei dati e semplici statistiche
1.1 Scopo dell’esercitazione . . . . . . . .
1.2 Alcune operazioni di base . . . . . . .
1.2.1 Lettura dei dati . . . . . . . . .
1.2.2 Selezione di colonne . . . . . .
1.2.3 Valori distinti . . . . . . . . . .
1.2.4 Condizioni e sottotabelle . . . .
1.2.5 Selezioni multiple . . . . . . . .
1.3 Script . . . . . . . . . . . . . . . . . .
1.4 Conclusioni . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
28
28
28
28
29
29
29
30
31
31
2 Algoritmo KNN e determinazione dei parametri
2.1 Scopo dell’esercitazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.2 Script . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
2.3 Osservazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
32
32
32
32
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3 I rischi di un modello troppo
3.1 Scopo dell’esercitazione . .
3.2 Script . . . . . . . . . . . .
3.3 Osservazioni . . . . . . . . .
raffinato
34
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
4 K-fold cross-validation
4.1 Scopo . . . . . . . .
4.2 Prima parte . . . . .
4.2.1 Script . . . .
4.2.2 Risultati . . .
4.3 Seconda parte . . . .
4.3.1 Script . . . .
4.3.2 Risultati . . .
4.4 Discussione . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
36
36
36
36
36
37
37
37
37
5 Regressione lineare ai minimi quadrati
5.1 Scopo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.2 Procedimento . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
5.3 Script . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
38
38
38
38
6 Regressione logistica
6.1 Scopo . . . . . . . .
6.2 Procedimento . . . .
6.2.1 Discesa lungo
6.3 Script . . . . . . . .
6.4 Discussione . . . . .
40
40
40
40
41
41
.
.
.
.
.
.
.
.
.
.
il
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . . .
. . . . . .
gradiente
. . . . . .
. . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
iv
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
7 Curve di prestazione
7.1 Scopo . . . . . . .
7.2 Procedimento . . .
7.3 Script . . . . . . .
7.4 Discussione . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
43
43
43
43
44
8 Alberi di decisione e random forest
8.1 Scopo . . . . . . . . . . . . . . . . . . . . . . . .
8.2 Prima parte: implementazione . . . . . . . . . .
8.2.1 Codice . . . . . . . . . . . . . . . . . . . .
8.2.2 Risultati . . . . . . . . . . . . . . . . . . .
8.3 Seconda parte: utilizzo di una libreria esterna . .
8.3.1 Codice . . . . . . . . . . . . . . . . . . . .
8.3.2 Risultati . . . . . . . . . . . . . . . . . . .
8.4 Terza parte: utilizzo di un dataset più complesso
8.4.1 Codice . . . . . . . . . . . . . . . . . . . .
8.4.2 Risultati . . . . . . . . . . . . . . . . . . .
8.4.3 Albero di decisione . . . . . . . . . . . . .
8.4.4 Random forest . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
47
47
47
47
47
47
48
48
48
48
48
48
50
9 Selezione delle feature
9.1 Scopo . . . . . . . .
9.2 Metodo . . . . . . .
9.3 Codice . . . . . . . .
9.4 Risultati . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
51
51
51
51
51
10 Clustering
10.1 Scopo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
10.2 Il codice . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
10.3 Risultati . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
54
54
54
54
III
58
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Domande ed esercizi
A Domande teoriche e spunti di riflessione
A.1 Introduzione alla Data Science . . . . .
A.1.1 Prerequisiti e modello di dati . .
A.1.2 Formalizzazione . . . . . . . . . .
A.2 Metodologia . . . . . . . . . . . . . . . .
A.3 Algoritmi di machine learning . . . . . .
A.3.1 Modelli lineari, minimi quadrati
A.3.2 Modello logit . . . . . . . . . . .
A.3.3 Alberi di decisione . . . . . . . .
A.4 Selezione delle feature . . . . . . . . . .
A.4.1 Clustering . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
B Esercizi
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
59
59
59
59
59
60
60
60
60
60
60
61
v
Parte I
Appunti di teoria
1
Capitolo 1
Introduzione alla Data Science
1.1
La Data Science
Immagazzinare dati è fin troppo facile, e visti i costi ormai irrisori lo fanno tutti. Il problema è farne
uso: i dati grezzi non sono immediatamente comprensibili, bisogna estrarre informazioni (fruibili da
persone o da algoritmi) a fini migliorativi.
Questo è lo scopo della Data Science1 ; con sfumature diverse, si parla anche di “Business analytics”,
“Business Intelligence”. Anche le discipline della Statistica e della Ricerca Operativa occupano lo stesso
ambito, ma i loro nomi sono spesso associati a tecniche classiche e non sempre la loro definizione include
il machine learning, che costituisce invece il nucleo del nostro corso.
In Figura 1.1 troviamo alcune “parole chiave” che definiscono le varie discipline e operazioni che
portano dalla raccolta dati iniziale al risultato finale.
Il modus operandi più consueto consiste nell’utilizzare i dati per creare un modello (statistico,
matematico, informatico) degli stessi da utilizzare poi per acquisire conoscenza sul sistema in esame,
prendere decisioni, modificare processi, eccetera. Spesso, il risultato finale di tale processo sono nuovi
dati che possono essere utilizzati per affinare il modello, e cosı̀ via. Vedremo vari esempi nel resto del
corso, che si concentrerà principalmente sulla fase dell’analisi dei dati e del machine learning.
1 https://en.wikipedia.org/wiki/Data_science.
Analisi
descrittiva
Analisi
predittiva
Analisi
prescrittiva
Modelli
Azioni
Grafici
Dati
Descrizioni
statistiche
Ottimizzazione
Ricerca operativa
Decision making
Machine learning
Inferenza statistica
Figura 1.1: Alcune parole chiave
2
Risultati
Monitoraggio
1.2
Modelli di dati
Le collezioni di dati oggetto di analisi possono essere di tre tipi diversi2 :
• Dati strutturati : già in forma tabulare o relazionale.
Pronti per essere consumati da un programma di analisi.
Esempi: database, file di testo in formato csv (Comma-separated values). . .
• Dati semistrutturati : fatti per essere umanamente leggibili, ma le cui informazioni sono sempre
reperibili nelle stesse posizioni, o in corrispondenza di determinati marcatori.
È necessaria una fase di parsing del documento per individuare le posizioni in cui i dati sono
registrati (ad esempio l’estrazione dell’albero DOM per un file XML o HTML).
Esempi: pagine web generate dinamicamente a partire da dati strutturati, documenti creati a
partire da modelli, fogli excel ben progettati, file XML e JSON. . .
• Dati non strutturati : realizzati senza criteri di struttura, ma solamente per essere umanamente
leggibili.
Per estrarre dati consumabili sono spesso necessarie euristiche NLP (Natural Language Processing).
Esempi: pagine web scritte a mano, documenti a formato libero. . .
1.3
Formalizzazione del problema dell’apprendimento automatico
Nella prima parte del corso ci occuperemo dell’apprendimento supervisionato (supervised learning), in
cui si chiede al sistema di prevedere un esito sulla base di alcuni dati in ingresso. Ad esempio:
• date alcune misure fisiche, determinare la specie di un organismo vivente;
• date alcune informazioni su un conto bancario, determinare se un cliente sarà disposto ad
accettare un certo investimento.
Assumeremo sempre che le informazioni in ingresso siano esprimibili come una tupla numerica (vettori
in Rn ), e che l’informazione da prevedere sia invece scalare (un singolo valore).
Formalmente, possiamo descrivere il problema come segue: abbiamo un dataset costituito da m
“campioni”:
D = {(xi , yi ) : i = 1 . . . , m}.
• le grandezze xi sono gli “ingressi” del nostro algoritmo, solitamente rappresentati da tuple numeriche. Rappresentano le variabili indipendenti del sistema, quelle che possiamo misurare (o
impostare) direttamente. Ad esempio delle dimensioni fisiche, informazioni di censo. . .
• le yi sono le “uscite”, ovvero i valori che desideriamo imparare a predire sulla base delle xi appena
citate. Possono essere numeriche (ad esempio, una probabilità, un’età) oppure categoriche (la
varietà di un fiore, una risposta sı̀/no).
Sulla base degli esempi forniti in D, il sistema deve fornire una mappa
f : Rn
→ C
x
7→ y
che fornisca una stima (previsione, predizione) del valore di uscita y sulla base del vettore in ingresso
x.
L’insieme Rn , che rappresenta lo spazio in cui si trovano i dati di ingresso, è anche detto “spazio
delle feature”, dove per “feature” si intende ciascuna delle n dimensioni che lo compongono.
L’insieme di appartenenza dell’uscita y (indicato con C qui sopra) può essere:
2 Vedere
https://en.wikipedia.org/wiki/Data_model se si desidera approfondire.
3
• variabile con continuità in un intervallo dei reali; in tal caso si parla di un problema di regressione
(in inglese “regression” o, più comunemente, “fit”);
• un insieme finito di valori, numerici o alfanumerici, detti classi o categorie; si parla in tal caso
di un problema di classificazione.
1.3.1
L’addestramento e il modello
La funzione f , detta anche “modello”, deve quindi rappresentare per quanto possibile una dipendenza
funzionale dei valori y1 , . . . , ym dai corrispondenti vettori di feature x1 , . . . , xm ; per essere utile, questa
dipendenza deve poter essere generalizzata, ovvero applicabile anche a nuove istanze x ∈ Rn non
presenti fra gli m campioni del dataset D.
Non è detto che tale dipendenza funzionale sia sempre molto precisa. Ci si potrebbe aspettare
che il modello, ad esempio, fornisca sempre la risposta corretta per i campioni del dataset (cioè che
f (xi ) = yi per ogni i = 1, . . . , m). Questo non è sempre possibile, né desiderabile, per varie ragioni:
• non sempre il vettore delle feature x è perfettamente rappresentativo del campione; potrebbero essere state tralasciate alcune feature importanti, quindi il sistema potrebbe essere incerto
nell’attribuzione di un valore y;
• spesso i dati sono “rumorosi” (errori di misura o, peggio, di trascrizione), quindi alcuni esempi
del dataset D potrebbero essere imprecisi o errati;
• vedremo che un sistema che “impara a memoria” le risposte da dare sui campioni di D non sarà
sempre in grado di fornire risposte adeguate su un nuovo esempio; si pensi a uno studente che,
invece di imparare i principi generali della materia, si limiti a studiare a memoria lo svolgimento
degli esercizi.
1.4
Algoritmi di machine learning: alcuni esempi
Ecco due esempi di algoritmi di machine learning, che verranno utilizzati nelle prime esercitazioni di
laboratorio:
1.4.1
K-Nearest-Neighbors (KNN)
Supponiamo di avere un problema di classificazione (yi da un insieme finito). Se abbiamo un dataset
D = {(xi , yi )} di esempi e ci viene fornito un nuovo elemento x per il quale prevedere il valore di y,
possiamo decidere che la classe dell’elemento incognito sia uguale alla classe dell’elemento più simile
che troviamo in D:
• cerchiamo l’elemento del dataset (xi , yi ) ∈ D in cui xi è più simile al nuovo x;
• assumiamo che la classe dell’elemento incognito sia uguale alla classe di quest’elemento: y = yi .
Il motivo è che la classe non è distribuita casualmente fra gli elementi (il che renderebbe completamente
inutile qualunque tentativo di prevederla), ma che elementi simili in x siano simili anche in y. In altre
parole, assumiamo una certa “continuità” nella mappa x 7→ y.
Per ovviare a possibili errori nel dataset e per “ammorbidire” i risultati nelle sone di confine fra una
classe e l’altra, possiamo prendere più di un elemento “simile” a x e scegliere la classe più rappresentata
al loro interno3 :
• sia N = {i1 , . . . , iK } l’insieme degli indici dei K elementi del dataset più simili a x;
• scegliere per y la classe che appare più spesso nella sequenza yi1 , . . . , yiK .
3 https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
4
La “somiglianza” di un elemento del dataset xi con l’elemento incognito x può essere determinata in
base alla loro distanza euclidea:
d(xi , x) = kxi − xk2 .
Ovviamente, due elementi sono tanto più simili quanto la loro distanza è piccola. Si veda un esempio
di implementazione in Python nella seconda esercitazione di laboratorio (capitolo 2).
1.4.2
Regressione polinomiale
Un problema di regressione (y variabile con continuità in un intervallo reale), richiede di cercare la
funzione y = f (x) che, calcolata sulle x del dataset, approssima al meglio le y corrispondenti: f (xi )
approssima al meglio yi per ogni i = 1, . . . , m.
Una ricerca fra “tutte le funzioni” non è ben definita, né auspicabile. Un approccio classico consiste
nel limitarsi a cercare f fra i polinomi di grado non superiore a un valore prefissato. Sul significato di
“approssimare al meglio”, rimandiamo al prossimo capitolo; la tecnica di regressione sarà discussa alla
sezione3.2.
5
Capitolo 2
Valutare la bontà di un modello
In questo capitolo raccoglieremo varie osservazioni su come valutare se un modello, determinato sulla
base di un insieme di esempi, è utile allo scopo di effettuare previsioni su dati nuovi oppure no.
Assumiamo, per ora, che il dataset complessivo D sia stato ripartito in due sottoinsiemi:
• un sottoinsieme T , detto di addestramento (training), utilizzato per costruire il modello;
• un sottoinsieme V , detto di validazione, usato per valutare se il modello è adeguato.
I due sottoinsiemi costituiscono una partizione di D (la loro unione è D e la loro intersezione è nulla).
Per valutare la bontà di un algoritmo, utilizzeremo i dati contenuti in D per costruire il modello f .
Valuteremo poi il modello f sui dati di V . Si osservi che i dati di V non sono utilizzati nella definizione
del modello, ma sono “tenuti da parte” per valutarlo.
2.1
2.1.1
Criteri di valutazione
Valutare un modello di regressione
Supponiamo che la variabile dipendente y sia un valore reale che varia con continuità in un intervallo.
Dato il modello f , costruito in base agli esempi contenuti in T , e un esempio di validazione (x, y) ∈ V ,
l’errore che il modello commette su questo campione può essere definito come la differenza fra il valore
previsto f (x) e il valore effettivo y:
= f (x) − y.
L’errore quadratico medio (root mean square error, RMSE) è calcolato su tutti i campioni dell’insieme
di validazione:
v
u
2
u 1 X
RMSE = t
f (x) − y .
|V |
(x,y)∈V
Trattandosi di un errore, il modello è tanto migliore quanto questo valore è piccolo. Si veda ad esempio
la terza esercitazione di laboratorio (capitolo 3).
2.1.2
Valutare un modello di classificazione
Nel caso della classificazione, l’errore commesso su un singolo esempio di validazione non varia con
continuità, ma è binario (o c’è, o non c’è).
Accuratezza
Una prima valutazione possibile è il conteggio del numero di errori commessi dal modello (rapportato
alla sua numerosità). Si tratta del cosiddetto “tasso di errore” (error ratio):
1 X
χ6= (f (x), y),
Tasso d’errore =
|V |
(x,y)∈V
6
dove χ6= (·, ·) è la funzione caratteristica della disuguaglianza:
(
1 se y1 6= y2
χ6= (y1 , y2 ) =
0 altrimenti.
La misura complementare al tasso di errore è detta accuratezza (accuracy) e conta il numero di
previsioni corrette, sempre rapportato al numero totale di esempi in V :
Accuratezza =
1
|V |
X
χ= (f (x), y) = 1 − Tasso d’errore.
(x,y)∈V
Matrice di confusione
Non sempre gli errori hanno la stessa importanza. Si pensi al problema di classificare i funghi tra
“velenosi” e “mangerecci”. Un errore in un senso comporta lo spreco di un fungo; un errore nell’altro
senso comporta una possibile intossicazione. Un modello con un’accuratezza del 99% può essere ottimo,
ma quell’1% di errore può avere conseguenze molto diverse.
Immaginiamo che il modello debba prevedere la velenosità di un fungo. Alla domanda “questo
fungo è velenoso?”, il sistema può dare una risposta positiva o negativa. La risposta fornita può
essere corretta oppure no. Possiamo dunque distribuire le previsioni del nostro modello nella seguente
“matrice (o tabella) di confusione”1 :
Risposta
corretta
Sı̀
No
Previsione
Sı̀
No
TP FN
FP TN
Le quattro caselle della tabella contano il numero di previsioni positive corrette (veri positivi, true
positives, TP), risposte positive errate (falsi positivi, false positives, FP), risposte negative errate (falsi
negativi, false negatives, FN) e risposte negative corrette (veri negativi, true negatives, TN).
Si noti che, nella nomenclatura, i termini “positivo” e “negativo” si riferiscono alla previsione
fornita dal modello, mentre i termini “vero” e “falso” fanno riferimento alla correttezza di queste
risposte rispetto alle risposte esatte contenute in V , note al sistema di valutazione, ma non al modello.
Si tratta di contatori, e
TP + FP + TN + FN = |V |.
La matrice di confusione contiene tutte le informazioni necessarie a ricavare numerose stime di
bontà di un classificatore. Ad esempio, l’accuratezza sopra definita può essere definita come
Accuratezza =
TP + TN
.
TP + TN + FP + FN
Sensibilità
Possiamo ottenere anche misure più “specializzate”; ad esempio, nel caso del modello per la classificazione dei funghi vogliamo essere sicuri che il sistema non fornisca falsi negativi (che non risponda
di “no” in presenza di un fungo velenoso), cioè che colga tutti gli esempi positivi. In questo caso ci
interessa un modello con la sensibilità (sensitivity) il più elevata possibile:
Sensibilità =
TP
.
TP + FN
Questa misura trascura completamente i funghi “negativi” (mangerecci) e si limita a contare quante
volte, fra i funghi “positivi” (velenosi) il modello ha fornito la risposta corretta. Altrimenti detto,
questa misura considera solo la prima riga della tabella di confusione.
1 https://en.wikipedia.org/wiki/Confusion_matrix
7
Si osservi che è facile realizzare un modello con sensibilità massima: è sufficiente che risponda “Sı̀”
a ogni istanza che gli viene presentata. È facile, insomma, realizzare un sistema che elimina tutti i
funghi velenosi: basta buttarli via tutti. Le istanze positive saranno tutte individuate, e la sensibilità
sarà del 100%. La sensibilità, quindi, è una misura poco utile in sé, e va sempre associata a qualche
altra misura nella valutazione della bontà del modello.
In alcuni contesti, la sensibilità è detta “Recall”, in quanto misura della capacità del modello di
“richiamare” tutti i casi positivi.
Precisione
Un’altra misura, utile in altre situazioni (ad esempio nella valutazione dei risultati forniti da un motore
di ricerca), è la precisione (precision):
Precisione =
TP
.
TP + FP
Questa misura conta quante volte le risposte positive del modello sono corrette.
Anche in questo caso è possibile realizzare un sistema con precisione massima: basta che il modello
risponda “Sı̀” soltanto nei casi in cui è assolutamente certo della risposta (ad esempio, quando vede
un’Amanita Muscaria rossa a pallini bianchi), rispondendo sempre “No” in caso di incertezza. Tutte
le sue risposte positive saranno corrette (con alta probabilità) e la precisione sarà pari al 100%.
Misure combinate
Per poter tenere conto sia della precisione che della sensibilità di un modello in un’unica misura, si
utilizza la F1 -score, calcolata come media armonica delle due:
F1 -score =
2 · Sensibilità · Precisione
1
.
=
1
1
Sensibilità + Precisione
+
Sensibilità Precisione
2
La F1 -score è un caso particolare (con pesi unitari) della Fβ -score, in cui β 2 è il peso della sensibilità.
Un’altra misura frequentemente utilizzata è il coefficiente di correlazione di Matthews (Matthews
correlation coefficient, MCC):
TP · TN − FP · FN
MCC = p
(TP + FP)(TP + FN)(TN + FP)(TN + FN)
A differenza delle altre misure, il MCC varia in [−1, 1].
Classificazione a più di due classi
La definizione di matrice di confusione può facilmente essere generalizzata a più di due classi, con una
riga e una colonna per ogni valore di classe; la tabella ha una casella per ogni combinazione di valore
predetto e valore reale; la diagonale contiene le previsioni corrette.
Solitamente, si considera a turno ogni classe come “positiva” e tutte le altre negative, ottenendo
quindi una diversa matrice di confusione binaria, con relative misure di precisione e sensibilità per ogni
classe.
2.2
Training e validazione
La definizione degli insiemi di training e di validazione non è semplice. Si vorrebbe che l’insieme di
training sia il più vasto possibile, in modo da ottenere un modello attendibile, ma è necessario che
l’insieme di validazione non sia troppo piccolo, altrimenti le misure risentono di una varianza eccessiva.
Esistono varie tecniche di suddivisione del dataset, dette di cross-validation 2 .
2 https://en.wikipedia.org/wiki/Cross-validation_(statistics)
8
2.2.1
Una soluzione estrema: leave-one-out
Invece di utilizzare una singola partizione come training set, ripetiamo l’addestramento m volte, ogni
volta tenendo da parte un diverso campione da usare coome validazione. Stimiamo l’RMSE su tutte
le previsioni effettuate dai diversi modelli.
• Per i = 1, . . . , m
– Sia Ti ← D \ {(xi , yi )} (tutto il dataset tranne l’i-esima riga è usato come training);
– Addestra il modello fi usando Ti ;
– Prevedi il valore “tenuto da parte”: ỹi = fi (xi ).
pP
(ỹi − yi )2 /m.
• Calcola il RMSE come
Vantaggi: ogni addestramento utilizza quasi l’intero dataset, quindi è rappresentativo di tutti i
dati raccolti; la validazione copre l’intero dataset, quindi è una stima molto robusta dell’errore che
ci si può aspettare su nuovi dati. Svantaggi: richiede l’addestramento di m modelli diversi, con m
potenzialmente molto elevato.
2.2.2
K-fold cross-validation
Si ripartisce il dataset in K insiemi di uguale numerosità (±1), detti fold, D = F1 ∪ · · · ∪ FK .
• Per i = 1, . . . , K
– Sia Ti ← D \ Fi (tutti i fold tranne l’i-esimo sono usati come training);
– Addestra il modello fi usando Ti ;
– Prevedi i valori “tenuti da parte”: ỹ = fi (x), x ∈ Fi (usando dunque Fi come insieme di
validazione).
pP
(ỹi − yi )2 /m (errori di predizione su tutti i fold).
• Calcola il RMSE come
Si tratta di un metodo statisticamente robusto e molto utilizzato. Valori comuni per il parametro
K sono K = 5 e K = 10. La metodologia leave-one-out è un caso estremo di K-fold cross-validation
con K = m.
Stratificazione
Se il problema è di classificazione e una delle classi è molto meno frequente delle altre, può accadere
che la “concentrazione” della classe meno numerosa vari molto da un fold all’altro, comportando stime
dell’errore molto rumorose. Lo stesso effetto si può avere anche con classi bilanciate, ma dataset piccoli.
In questi casi è opportuno che la procedura di suddivisione del dataset nei diversi fold mantenga
costanti i rapporti di numerosità delle varie classi, ad esempio operando la suddivisione separatamente
per ciascuna classe. Si parla in questo caso di suddivisione stratificata 3 .
3 https://en.wikipedia.org/wiki/Stratified_sampling,
9
parte introduttiva
Capitolo 3
Alcune tecniche di machine learning
3.1
K-nearest-neighbors
Abbiamo già visto questo algoritmo alla Sezione 1.4.1. In questa sezione descriveremo alcuni “trucchi”
per applicare l’algoritmo a problemi con caratterisctiche diverse.
3.1.1
Input categorici
Finora abbiamo sempre assunto che il vettore delle feature (ingresso) sia sempre composto di quantità
reali: x ∈ Rn . Può accadere però che alcune osservazioni non riguardino grandezze continue, ma
qualità discrete e non ordinate (colore, sesso, specie).
L’algoritmo KNN si basa però sul calcolo di una distanza in uno spazio Rn , quindi è necessario
convertire le grandezze categoriche in una o più grandezze reali. Il metodo più intuitivo consiste nel
sostituire a ogni colonna categorica del dataset tante colonne reali quanti sono i valori che la categoria
può assumere, e utilizzare una rappresentazione unaria per decidere i valori delle colonne sostitutive.
Ad esempio, supponiamo che il seguente dataset descriva dei fiori, con le seguenti osservazioni: lunghezza del petalo (continua), colore (classi “rosso”, “giallo” o “azzurro”), altezza (continua), presenza
di spine (“sı̀”, “no”). Ecco come un dataset può essere trasformato in questo caso:
1 2.1 rosso
5.0 no
2.1 1 0 0 5.0 0
3.2 0 0 1 5.4 0
2 3.2 azzurro 5.4 no
2.6 1 0 0 7.2 1
3 2.6 rosso
7.2 sı̀
⇒
X=
1.9 0 1 0 4.4 0
4 1.9 giallo
4.4 no
3.0 0 0 1 5.6 1
5 3.0 azzurro 5.6 sı̀
2.5 0 1 0 6.0 0
6 2.5 giallo
6.0 no
La colonna del colore è stata spezzata in tre colonne numeriche; la prima codifica il valore “rosso” (vale
1 se l’attributo categorico è “rosso”, 0 altrimenti), e cosı̀ via. Come eccezione, se l’attributo è binario
può essere trasformato in una sola colonna numerica, nella quale 0 e 1 codificano i due possibili valori
categorici.
3.1.2
Problemi di regressione
L’algoritmo di classificazione KNN decide il valore dell’output in base alla classe più rappresentata fra
i primi K vicini. Se l’output è continuo, la decisione a maggioranza non ha più senso (i valori possono
essere tutti diversi); in tal caso si può assumere come valore dell’output la media delle y, modificando
in tal senso l’algoritmo:
• sia N = {i1 , . . . , iK } l’insieme degli indici dei K elementi del dataset più simili a x;
• scegliere per y la media dei valori di output yi1 , . . . , yiK .
10
In altri termini, se N = {i1 , . . . , iK } sono gli indici dei K primi vicini del campione x, la classe del
campione può essere prevista come
1 X
ỹ =
yi ,
K
i∈N
oppure pesando la media con pesi che decrescono al crescere della distanza fra gli elementi del dataset
e il campione incognito:
X
yi
kx − xi k + i∈N
ỹ = X
1
i∈N
kx − xi k + dove un piccolo valore è sommato ai denominatori per evitare divisioni per zero.
3.2
Regressione lineare: il metodo dei minimi quadrati
Supponiamo di avere un dataset D = {(xi , yi )|i = 1, . . . , m}, con xi , yi ∈ R (scalari). Il modello più
semplice che possiamo voler studiare è quello lineare:
y ∼ βx,
dove β è un coefficiente da determinare e la relazione “ ∼ ” indica che la relazione è approssimata.
Se fissiamo il valore del coefficiente β, allora l’errore che il nostro modello commette rispetto ai
valori noti è
v
m
uX
u
u
(βxi − yi )2
t
i=1
.
RMSE =
m
Per trovare il valore di β che minimizza l’RMSE, dunque, ci basta derivare quest’ultimo rispetto a β
(tralasciando la radice, che è monotona) e uguagliare la derivata a zero:
m
d X
(βxi − yi )2 = 0;
dβ i=1
2
m
X
xi (βxi − yi ) = 0;
i=1
β
m
X
x2i −
i=1
m
X
m
X
β=
xi yi = 0;
i=1
xi yi
i=1
m
X
.
(3.1)
x2i
i=1
L’estensione a un problema con più feature in input è la seguente. Dobbiamo trovare un vettore
di coefficienti β = (β1 , . . . , βn ) ∈ Rn , dove n è il numero di feature. Dato un vettore x di input, la
previsione di uscita è ỹ = x · β. Stanti i campioni del dataset, l’errore quadratico medio è dunque
v
2
u
v
uX
m
n
m
uX
X
u
u
2
u
xij βj − yi
u
(xi · β − yi )
u
t
t
i=1
j=1
i=1
RMSE =
=
.
m
m
11
Questa volta abbiamo una funzione in più variabili, troviamo il minimo annullando tutte le derivate
parziali rispetto alle βk :
2
m
n
∂ X X
xij βj − yi = 0
∂βk i=1 j=1
∀k = 1, . . . , n;
2
m
n
X
∂ X
xij βj − yi = 0;
∂βk j=1
i=1
m
X
i=1
m
X
2
n
X
xij βj − yi xik = 0;
j=1
xTki (X · β − y)i = 0
∀k = 1, . . . , n.
i=1
In forma matriciale, le equazioni per k = 1, . . . , n assumono la seguente forma:
X T (Xβ − y) = 0,
X T Xβ = X T y,
β = (X T X)−1 X T y.
(3.2)
Notare che se n = 1 la formula appena ricavata si riduce alla (3.1).
Visto che la formula (3.2) fornisce il vettore di coefficienti βk che minimizza la somma dei quadrati
degli scarti sul dataset, si parla di regressione ai minimi quadrati 1 (least-squares regression).
3.2.1
Generalizzazione per funzioni non lineari
La regressione ai minimi quadrati si può utilizzare per trovare i coefficianti di qualunque combinazione
lineare di funzioni. Nel caso generale, possiamo cercare i coefficienti di un modello esprimibile nella
seguente forma:
y ∼ β1 φ1 (x) + β2 φ2 (x) + · · · + βp φp (x),
(3.3)
dove φ1 (·), . . . , φp (·) sono p “funzioni di base” (sul vettore di feature x) che vogliamo combinare
linearmente.
Per fare questo, dalla matrice X del dataset originario otteniamo la matrice trasformata Z, con m
righe e p colonne, la cui i-esima riga contiene i valori delle p funzioni di base calcolati sulla riga xi del
dataset originario:
z i = φ1 (xi ), . . . , φp (xi )
o, in forma matriciale,
φ1 (x1 )
φ1 (x2 )
Z= .
..
φ2 (x1 )
φ2 (x2 )
..
.
···
···
..
.
φ1 (xm ) φ2 (xm ) · · ·
φp (x1 )
φp (x2 )
..
.
φp (xm )
In questo modo, il modello (3.3) può essere riscritto come
y ∼ β1 z1 + β2 z2 + · · · + βp zp
e il vettore β può essere calcolato applicando la formula (3.2) alla matrice Z:
β = (Z T Z)−1 Z T y.
1 https://en.wikipedia.org/wiki/Linear_regression.
12
Caso particolare: regressione affine
Ad esempio, supponiamo di voler calcolare i coefficienti β0 e β1 del seguente modello, con x e y scalari:
y ∼ β0 + β1 x,
dove abbiamo introdotto un termine costante, trasformando la dipendenza da lineare ad affine. Possiamo riscrivere il modello come
y ∼ β0 φ0 (x) + β1 φ1 (x),
dove φ0 (x) = 1 (funzione costante), mentre φ1 (x) = x (identità). Possiamo dunque applicare l’equazione dei minimi quadrati alla matrice Z con due colonne, la prima delle quali contiene la costante 1,
mentre la seconda contiene i valori originari di x:
1 x1
1 x2
Z = .
.. .
..
.
1 xm
Regressione polinomiale
Più in generale, consideriamo di voler determinare i coefficienti del seguente modello polinomiale (con
x scalare) di grado d:
d
X
y ∼ β0 + β1 x + β2 x 2 + · · · + β d x d =
βd x d ;
i=0
in questo caso, le funzioni di base saranno le potenze di x:
φi (x) = xi ,
i = 0, . . . , d.
La matrice Z è la seguente:
3.2.2
1
1
Z = .
..
x1
x2
..
.
x21
x22
..
.
...
...
..
.
1
xm
x2m
...
xd1
xd2
.. .
.
(3.4)
xdm
Problemi di classificazione
È possibile utilizzare la regressione polinomiale per problemi di classificazione. L’adattamento è abbastanza semplice se la categoria in uscita ha due valori. In tal caso, si possono associare due valori reali
(ad esempio, ±1) alle due classi e trattare ciò che risulta come problema di regressione. Ad esempio,
se la categoria in output può assumere i valori “verde” e “rosso”:
1 rosso
+1
+1
2 rosso
−1
3 verde
4 rosso
⇒
y=
+1
5 verde
−1
+1
6 rosso
7 verde
−1
Determinato il modello y ∼ f (x), il suo risultato su un input x non sarà necessariamente in ±1, ma
una semplice regola di decisione ci permetterà di stabilire il valore della classe:
(
rosso se f (x) ≥ 0
ỹ =
verde altrimenti.
13
1.0
0.8
σ(t)
0.6
0.4
0.2
0.0
10
5
0
t
5
10
Figura 3.1: La funzione sigmoide
3.3
Regressione logistica
Introduciamo la funzione sigmoide:
σ(t) =
1
.
1 + e−t
(3.5)
Come si può vedere dal suo grafico in Fig. 3.1, la funzione assume valori in (0, 1); alcune proprietà
utili:
lim σ(t) = 0;
lim σ(t) = 1;
σ(t) = 1 − σ(−t);
σ 0 (t) = σ(t) 1 − σ(t) .
t→−∞
t→+∞
Dato che la funzione restringe la variabilità del proprio argomento all’intervallo aperto (0, 1), può
essere utilizzata per modellare un problema di classificazione a due classi. In particolare, se assegniamo
i valori 0 e 1 alle due classi, possiamo utilizzare un modello lineare, filtrandone il risultato attraverso
una sigmoide:
y ∼ σ (β · x) .
Il modello è detto regressione logistica, o logit 2 . Dato che il risultato può variare con continuità fra 0
e 1, il modello può esprimere una probabilità.
3.3.1
Stima dei coefficienti del modello
Proviamo a stimare il vettore dei coefficienti β che minimizza gli scarti al quadrato3 . Sia
ỹi = σ(β · xi ),
dove xi è il vettore di feature dell’i-esimo campione. Allora vogliamo trovare il vettore β che minimizza
le somme degli scarti:
m
X
f (β) =
(ỹi − yi )2 .
i=1
Come nel caso della regressione lineare, possiamo trovare le derivate parziali rispetto ai coefficienti:
m
X
∂
(β) = 2
(ỹi − yi )ỹi (1 − ỹi )xik
∂βk
i=1
∀k = 1, . . . , n.
2 https://en.wikipedia.org/wiki/Logistic_regression
3 Trattandosi di una stima di probabilità, il modo corretto sarebbe una stima di massima verosimiglianza (maximum
likelihood), ma non introdurremo qui il concetto.
14
L’azzeramento di tutte queste equazioni non lineari in β non porta a un sistema di equazioni
risolvibili analiticamente. Per minimizzare la RMSE, dunque, utilizziamo il metodo della discesa lungo
il gradiente (gradient descent)4 . Ricordiamo che il gradiente di una funzione scalare in n variabili
β1 , . . . , βn è il vettore delle derivate parziali rispetto agli argomenti:
∂f ∂f
∂f
∇f =
,
,...,
.
∂β1 ∂β2
∂βn
Il gradiente di f rappresenta la direzione di massima crescita della funzione. Per minimizzare la
funzione, dunque, applichiamo il seguente metodo:
• Inizializza β con valori casuali.
• Ripeti:
– Calcola ∇f (β);
– Sposta β di un piccolo passo in direzione opposta al gradiente:
β ← β + η∇f (β).
Il parametro η, detto learning rate, serve a evitare di spostare troppo rapidamente β: l’approssimazione
che lega il gradiente alla direzione di discesa vale solo localmente, e salti troppo ampi possono causare
peggioramenti. Versioni più sofisticate dell’algoritmo di base prevedono che η possa variare in base
ai risultati ottenuti, oppure che diminuisca col tempo. Il numero di iterazioni del metodo può essere
impostato a priori; in alternativa, una condizione di terminazione potrebbe essere il raggiungimento
di un livello di errore prefissato, o la mancanza di miglioramenti significativi da un certo numero di
iterazioni.
3.3.2
Utilizzo del modello
Previsioni di classi
Il modello logistico può essere usato per restituire una probabilità. Nel caso considerato, ỹ stima la
probabilità Pr(y = 1). Se vogliamo invece che il modello restituisca un valore di classe (0 oppure 1),
dobbiamo fissare un valore di soglia θ ∈ [0, 1] ed applicare una funzione di decisione. Dato il vettore
di features x e il corrispondente valore ottenuto dal modello logit ỹ = σ(x · β), la previsione sarà data
dalla funzione a soglia:
(
0 se σ(x · β) < θ
Previsioneθ (x) =
(3.6)
1 altrimenti.
L’esercitazione 7 è dedicata allo studio delle prestazioni del modello logit al variare del parametro θ.
Reti neurali
Un singolo regressore (lineare o logistico) può essere visto come un modello estremamente semplificato
di neurone, con gli ingressi in luogo dei dendriti, l’uscita come assone e i coefficienti β in luogo della
funzione di attivazione della sinapsi (βi < 0 se la sinapsi inibisce, βi > 0 se eccita). La combinazione di
più regressori, che in questo contesto sono detti “percettroni”5 , costituisce una rete neurale artificiale 6 .
3.4
Alberi di decisione
Un albero di decisione è un albero, tipicamente binario, nel quale ogni nodo interno rappresenta una
possibile domanda a risposta binaria, mentre le foglie rappresentano delle decisioni. Nel contesto del
4 https://en.wikipedia.org/wiki/Gradient_descent
5 https://en.wikipedia.org/wiki/Perceptron
6 https://en.wikipedia.org/wiki/Artificial_neural_network
15
machine learning, un albero rappresenta una mappa y ∼ f (x): a partire dalla radice, ciascun nodo
interno è una domanda relativa al vettore di feature x (tipicamente nella forma “xj ≤ θ?”) e ogni
foglia rappresenta una stima ỹ del valore di y (o una distribuzione di probabilità sui suoi possibili
valori).
3.4.1
Addestramento di un albero di ricerca
Nel seguito, consideriamo la variabile casuale Y da cui sono estratti i valori di uscita del dataset D.
Alcune osservazioni di base sulla “prevedibilità” di Y sono le seguenti:
• se Y ha un solo valore, ovvero se ha più valori, ma uno solo di essi ha probabilità pari a 1, allora
la variabile è prevedibilesenza bisogno di ulteriori informazioni;
• più in generale, se un valore è molto più probabile degli altri (sole, pioggia o neve nel mezzo
dl Sahara oggi?), allora è possibile “azzardare” una previsione anche in assenza di informazioni
aggiuntive (le feature x);
• più Y è vicina all’uniformità (tutti i suoi valori sono equiprobabili), più difficile è azzardare una
previsione.
Prima misura di imprevedibilità: l’entropia di Shannon
Supponiamo che Y abbia ` valori diversi, di probabilità p1 , . . . , p` ; Alice osserva una sequenza di
eventi estratti da Y e vuole comunicare questa sequenza a Bob. Quanti bit deve usare, come minimo?
Consideriamo alcuni casi semplici.
• Se p1 = 1 e p2 = · · · = p` = 0, allora non c’è bisogno di inviare informazioni: Bob sa già che ogni
evento risulterà nell’unico valore certo.
• Se ` è una potenza di 2 (` = 2r ) e p1 = · · · = p` = 1` , allora il meglio che Alice possa fare è
codificare ogni valore di Y con una diversa combinazione di r bit.
• Supponiamo che ` = 4 e che Y abbia la seguente disribuzione:
p1 =
1
,
2
p2 =
1
,
4
p3 = p4 =
1
.
8
Allora è possibile adottare una codifica, detta di Huffman7 , in cui la lunghezza del codice dipende
dalla probabilità del valore:
1 7→ 1,
2 7→ 10,
3 7→ 110,
4 7→ 111.
Questa codifica permette di ridurre il numero atteso di bit da spedire al seguente valore:
1 bit se Y = 1
2 bit se Y = 2
3 bit se Y = 3
3 bit se Y = 4
z}|{
1
·1
2
z}|{
1
·2
4
z}|{
1
·3
8
z}|{
1
·3
8
+
+
+
=
7
= 1.75,
4
il che costituisce un miglioramento rispetto all’uso della codifica uniforme a 2 bit.
Il numero atteso di bit da trasmettere rappresenta una misura dell’uniformità della variabile casuale.
Si noti che, in tutti i casi elencati sopra, il numero di bit da trasmettere per comunicare l’esito i della
variabile casuale è pari a
1
= − log2 pi .
(3.7)
b(i) = log2
pi
7 https://en.wikipedia.org/wiki/Huffman_coding
16
Un risultato fondamentale della Teoria dell’Informazione di Shannon è precisamente che l’equazione (3.7) è vera in generale. Quindi, il numero atteso di bit necessari a trasmettere un evento estratto
dalla variabile casuale Y è
`
X
H(Y ) = −
pi log2 pi .
(3.8)
i=1
La grandezza H(Y ) è detta entropia di Shannon 8 della variabile casuale Y . Se la distribuzione di
probabilità di Y è concentrata in un singolo valore di probabilità 1, allora H(Y ) = 0. Invece, l’entropia
è massima quando Y è uniforme, e vale H(Y ) = log2 `.
Seconda misura di imprevedibilità: l’impurità di Gini
Supponiamo che Alice osservi un evento i estratto da Y . Bob cerca di indovinare i generando un valore
casuale ı̃ con la stessa distribuzione di probabilità, a lui nota. Qual è la probabilità che Bob sbagli?
• Se Y ha un solo valore di probabilità 1, allora Bob indovina di certo.
• Più in generale, se Y ha un valore molto più probabile degli altri, è poco probabile che Bob
sbagli.
• Intuitivamente, la probabilità di errore è massima quando la distribuzione di Y è uniforme.
Se Alice osserva il valore i Bob genererà il valore corretto con probabilità pi , quindi sbaglierà con
probabilità 1 − pi . La probabilità di errore complessiva, mediata su tutti i possibili esiti, è
GI(Y ) =
`
X
pi (1 − pi ) = 1 −
i=1
`
X
p2i .
(3.9)
i=1
La grandezza GI(Y ) è detta impurità di Gini 9 della variabile casuale Y . Se la distribuzione di probabilità di Y è concentrata in un singolo valore di probabilità 1, allora GI(Y ) = 0. Invece, l’impurità di
Gini è massima quando Y è uniforme, e vale GI(Y ) = 1 − 1` , valore che tende asintoticamente a 1 al
crescere del dominio di Y .
3.4.2
Passo induttivo: riduzione dell’imprevedibilità
A partire da un dataset D, la cui variabile di output è modellata dalla variabile casuale Y , vogliamo
spezzarlo in due parti, sulla base di un criterio della forma xj < θ. Chiamiamo la partizione risultante
(Dxj <θ , Dxj ≥θ ). Ciascuno dei due sottoinsiemi del dataset induce una diversa variabile casuale di
output, Y |xj < θ e Y |xj ≥ θ. La partizione dipende dunque da due parametri, j e θ. Vogliamo che
l’impurità delle due variabili casuali indotte sia minima, in particolare che lo sia l’impurità “attesa”,
basata sulla numerosità dei due sottoinsiemi. Se utilizziamo l’entropia come misura di impurità, allora
vogliamo trovare j e θ che minimizzano il seguente valore atteso:
Ej,θ (H) =
|Dxj <θ |
|Dxj ≥θ |
H(Y |xj < θ) +
H(Y |xj ≥ θ).
|D|
|D|
(3.10)
Il criterio di minimizzazione dell’entropia attesa è detto “Information Gain Criterion”. Tecnicamente,
l’information gain è la diminuzione dell’entropia passando dal dataset intero ai due sotto-dataset:
IGj,θ (Y ) = H(Y ) − Ej,θ (H).
(3.11)
È chiaro che minimizzare l’entropia attesa (3.10) equivale a massimizzare il guadagno informativo (3.11).
8 https://en.wikipedia.org/wiki/Entropy_(information_theory) — si noti che la lettera H è in realtà una Eta
maiuscola.
9 https://en.wikipedia.org/wiki/Decision_tree_learning#Gini_impurity, da non confondere con il coefficiente di
Gini usato in econometria.
17
Allo stesso modo, possiamo utilizzare l’impurità di Gini GI come criterio da minimizzare.
In questo modo, l’informazione “xj < θ” permette di fare riferimento a uno di due sotto-dataset
nei quali l’incertezza sul valore di Y è ridotta.
Come abbiamo visto dalle formule (3.8) e (3.9), la stima dell’entropia e dell’impurità di Gini
richiederebbero la conoscenza delle distribuzioni di probabilità delle variabili casuali, che noi possiamo
stimare sulla base delle frequenze dei valori assunti.
3.4.3
Partizione ricorsiva del dataset e condizione di terminazione
Per ottenere un albero, detto “albero di decisione” (decision tree)10 , possiamo applicare ripetutamente
il passo induttivo a ciascun sotto-dataset, riducendo di volta in volta l’impurità. La procedura termina
“naturalmente” quando il sotto-dataset associato a un nodo contiene un solo elemento: a questo punto
la variabile casuale associata all’output ha un solo valore quindi è necessariamente pura.
Per limitare la profondità dell’albero risultante, è possibile introdurre ulteriori criteri di terminazione per il passo induttivo:
• quando la profondità dell’albero raggiunge un limite massimo;
• quando l’impurità di un nodo è inferiore a una soglia predefinita;
• quando il numero di elementi nel sotto-dataset associato a un nodo è inferiore a un minimo
predefinito.
Riassumendo, l’algoritmo per costruire un albero di decisione è il seguente:
1. Se il dataset D soddisfa un criterio di terminazione, non fare nulla. Altrimenti:
(a) per ogni combinazione j, θ:
i. Calcola i due sotto-dataset Dxj <θ e Dxj ≥θ ;
ii. Calcola l’impurità attesa usando (3.10) o una sua variante;
iii. Se l’impurità è la minore trovata finora, ricorda i valori ottimali j ∗ ← j, θ∗ ← θ.
(b) Associa i parametri migliori (j ∗ , θ∗ ) alla radice e genera due figli, sinistro e destro, associati
rispettivamente a Dxj∗ <θ∗ e Dxj∗ ≥θ∗ .
(c) Applica ricorsivamente la procedura ai figli sinistro e destro.
In presenza di un vettore di feature x = (x1 , . . . , xn ), la procedura per “decidere” il corrispondente
valore di y è la seguente:
1. Se il nodo corrente è una foglia, allora:
• y è la classe prevalente nel sotto-dataset associato a quel nodo.
2. Altrimenti:
• Se xj < θ, ripeti la procedura sul sottoalbero di sinistra;
• Altrimenti scendi a destra.
Si rinvia all’esercitazione 8 per l’implementazione “ingenua” di un algoritmo di creazione ed utilizzo
di un albero di decisione, e per l’uso di una libreria e la rappresentazione grafica dell’albero.
10 https://en.wikipedia.org/wiki/Decision_tree_learning
18
Capitolo 4
Selezione delle feature
Spesso, l’insieme delle feature presentate da un dataset è sovrabbondante: molte feature possono
essere irrilevanti per la predizione dell’output, altre possono essere inutilmente ripetitive. La necessità
di trattare un numero eccessivo di feature comporta un certo numero di problemi:
• i tempi di apprendimento (ovvero di costruzione del modello) si allungano;
• il rischio di overfit è maggiore, in quanto il modello ha più informazioni sulle quali “specializzarsi”;
• più dati possono comportare più rumore, quindi predizioni meno precise.
È dunque importante saper riconoscere a priori quali feature sono più importanti per saper prevedere
l’output.
Gli strumenti matematici per quantificare tale importanza sono molte. Vediamo due esempi, a
seconda del tipo di feature e di output che stiamo considerando. Nel seguito considereremo due
colonne del dataset, di cui una tipicamente sarà l’output, e le chiameremo X e Y . Con lo stesso nome
ci riferiremo sia alle colonne della tabella (quindi alle osservazioni), sia alle variabili casuali sottostanti,
una relazione tra le quali intendiamo stimare.
4.1
Dati continui: il coefficiente di correlazione
Se X e Y sono continue, la covarianza può essere stimata come
m
σX,Y ∼
1 X
(xi − x̄)(yi − ȳ),
m i=1
(4.1)
dove x̄ e ȳ sono i valori medi delle osservazioni di X e Y rispettivamente. La covarianza tende ad
essere positiva quando gli scarti delle xi e delle yi rispetto alla media tendono ad avere segno concorde,
negativa se tendono ad essere discordi. Cattura quindi possibili dipendenze lineari (affini) fra X e Y .
La covarianza però dipende molto dalla magnitudine di X e Y , e quindi le covarianze fra variabili
diverse non sono sempre confrontabili.
Per migliorare la confrontabilità, possiamo normalizzare la covarianza (4.1) rispetto alla variabilità
delle due variabili casuali, misurata in base allo scarto quadratico medio, ottenendo il coefficiente di
correlazione di Pearson1 :
σX,Y
.
(4.2)
ρX,Y =
σX σY
Il coefficiente varia tra −1 e 1. I valori estremi significano che i punti (xi , yi ) sono perfettamente
allineati. Un valore pari a 0 non significa che non vi siano dipendenze, ma solo che queste non sono
lineari. La Figura 4.1 mostra alcuni esempi.
1 https://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient
19
1
0.8
0.4
1
1
1
0
0
0
0
0
-0.4
-0.8
-1
-1
-1
-1
0
0
0
Figura 4.1: Esempi di indici di correlazione calcolati per insiemi di punti con diverse dispersioni,
pendenze, relazioni. Si osservi come le relazioni non lineari nella terza riga non siano assolutamente
rilevate (immagine presa da Wikipedia, stesso articolo).
4.2
Variabili categoriche: l’informazione mutua
Abbiamo già visto il concetto di entropia H(Y ) di una variabile casuale Y . Data una seconda variabile
casuale X, l’entropia condizionata H(Y |X) risponde alla domanda “Quanti bit servono mediamente
per comunicare l’esito di Y se si è già a conoscenza dell’esito di X?” Ovviamente, se X e Y non sono
del tutto indipendenti, allora l’osservazione di X conterrà qualche informazione sull’esito di Y , quindi
in generale
H(Y |X) ≤ H(Y ),
con l’uguaglianza verificata quando X e Y sono indipendenti.
Il calcolo dell’entropia condizionata è una generalizzazione di (3.10) al caso in cui X può avere più
di due casi distinti. L’entropia condizionata è il valore atteso dell’entropia di Y al variare di X fra i
usoi possibili valori:
X
H(Y |X) =
Pr(X = x)H(Y |X = x).
(4.3)
x∈X
Infine, l’informazione mutua I(X; Y ) di X e Y è la diminuzione dell’entropia di Y data dalla
conoscenza di X:
I(X; Y ) = H(Y ) − H(Y |X).
(4.4)
È possibile verificare che si tratta di una grandezza simmetrica in X e Y , ed è possibile calcolarla con
la seguente formula:
XX
p(x, y)
I(X; Y ) =
p(x, y) log2
,
(4.5)
p(x)p(y)
x∈X y∈Y
dove x e y variano rispettivamente nel dominio delle variabili casuali X e Y , p(x, y) = Pr(X = x ∧ Y =
y) è la probabilità congiunta, mentre p(x) e p(y) sono le probabilità marginali.
Per definizione, l’informazione mutua varia fra 0 e l’entropia di Y 2 . Alcuni casi particolari:
• I(X; Y ) = 0 significa che H(Y ) = H(Y |X), ossia che la conoscenza della sola X è ininfluente
sulla determinazione di Y ;
2 In realtà, dato che I(X; Y ) = I(Y ; X), il massimo valore che l’informazione mutua può assumere è il minimo fra
H(Y ) e H(X).
20
• I(X; Y ) = H(Y ) significa che H(Y |X) = 0, quindi l’osservazione di X determina esattamente il
valore di Y , e non c’è bisogno di bit aggiuntivi per comunicarne il valore.
In generale, più alto è il valore di I(X; Y ) più possiamo concludere che la conoscenza di X è importante
per determinare il valore di Y .
4.2.1
Stima dell’informazione mutua in presenza di variabili continue
Possiamo trasformare una variabile X continua in un’equivalente variabile categorica X 0 a ` classi
impostando un numero finito ` − 1 di soglie θ1 < θ2 < · · · < θ`−1 , e trasformando un valore continuo
x ∈ X in un valore discreto x0 ∈ {1, . . . , `} nel seguente modo:
1
2
.
0
x = ..
`−1
`
se x < θ1
se θ1 ≤ x < θ2
(4.6)
se θ`−2 ≤ x < θ`−1
se x ≥ θ`−1 .
Questo procedimento si chiama discretizzazione o quantizzazione. Nel caso in cui ` = 2 (quindi con
una soglia) si parla anche di binarizzazione. La determinazione del numero di soglie e dei loro valori
può avvenire in diversi modi:
• impostazione a priori: ad esempio, spesso nei questionari la trasformazione dell’età avviene per
fasce predeterminate (minore di 18, da 19 a 25, ecc.);
• suddivisione dell’intervallo di variabilità in parti uguali: si prende l’intervallo [min X, max X] e
lo si suddivide in ` parti uguali:
θi = min X + i ·
max X − min X
.
`
(4.7)
• Suddivisione per quantili: si individuano le soglie in modo che le ` classi siano ugualmente
rappresentate; ad esempio, se ` = 2 si sceglierà la mediana di X; se ` = 4 si utilizzeranno il 25◦ ,
il 50◦ e il 75◦ percentile.
La suddivisione in parti uguali dell’intervallo di variabilità, per quanto semplice da realizzare, può essere
pericolosa nel caso di distribuzioni molto asimmetriche o concentrate: si pensi al caso in cui una delle
x sia molto più grande delle altre: quasi tutta la distribuzione potrebbe cadere nel primo intervallo. La
determinazione dei quantili è invece più onerosa (richiede un ordinamento), ma estremamente robusta
rispetto allo stesso problema.
4.2.2
Qualche tranello
Non sempre l’uso dell’informazione mutua tra singole feature e l’output è sufficiente a identificare le
feature più importanti. Consideriamo il seguente esempio (tavola di verità dell’OR esclusivo):
X1
0
0
1
1
X2
0
1
0
1
Y
0
1
1
0
Osserviamo che Y è uniformemente distribuita fra i due valori, quindi la sua entropia, in bit, è H(Y ) =
1. Anche le distribuzioni parziali di Y per X1 = 0 e per X1 = 1 sono uniformi. Segue che H(Y |X1 ) = 1,
quindi l’informazione mutua fra Y e X1 è nulla: I(X1 ; Y ) = 0. Per simmetria, lo stesso risultato vale per
X2 . Il risultato ci dice che la conoscenza della sola X1 , o della sola X2 , non fornisce alcuna informazione
21
sul valore di Y . Nonostante ciò, l’informazione combinata di X1 e X2 determina perfettamente Y ;
quindi, non sempre ha senso escludere le feature che, in isolamento, sembrano poco correlate con
l’output.
Per contro, supponiamo che la seguente tabella serva a determinare se un esemplare di una data
specie ittica possa essere venduto o no, in base alla lunghezza:
Lunghezza
(centimetri)
6,42
3,21
4,94
..
.
Lunghezza
(pollici)
2,53
1,26
1,94
..
.
2,23
0,88
Vendibile
(sı̀/no)
sı̀
no
sı̀
..
.
no
Se un’analisi dell’informazione mutua identifica una forte dipendenza dell’output “vendibile” dalle due
colonne “lunghezza”, ha senso utilizzarle entrambe? Molto probabilmente no: una volta nota una delle
due colonne “lunghezza”, l’altra non apporta nessuna informazione aggiuntiva, e probabilmente andrà
scartata.
4.3
Un algoritmo greedy per la selezione delle feature
Il seguente algoritmo mantiene un insieme di feature selezionate, inizialmente vuoto. Ad ogni iterazione,
valuta l’informazione mutua fra la tupla composta da tutte le feature selezionate fino a quel momento
più una feature candidata Xj e l’uscita Y .
1. selected ← {};
2. available ← {features del dataset};
3. Ripetere finché |selected| < numero desiderato di feature:
(a) j ∗ ← argmax I(Xselected , Xj ; Y );
j∈available
(b) Aggiungere j ∗ a selected;
(c) Levare j ∗ da available.
L’algoritmo è utilizzato nell’esercitazione 9: si rinvia al codice dell’esercitazione per chiarimenti.
22
Capitolo 5
Cenni di apprendimento non
supervisionato
Il contesto analizzato finora prevede la descrizione delle osservazioni tramite un vettore di feature, la
definizione di un “output” (numerico o categorico) e si richiede al sistema di generare un “modello”
(funzione) che mappi ogni vettore di feature su un valore di output, minimizzando l’errore atteso su
esempi nuovi.
In alcuni casi l’output non è disponibile; si pensi al dataset iris senza la colonna che determina
la varietà del fiore. Un task potrebbe essere proprio quello di identificare, pur non conoscendo a priori
la classificazione, gruppi di fiori simili, stabilendo quindi dei raggruppamenti senza conoscerli a priori.
Questo è l’ambito del clustering 1 , o apprendimento non supervisionato (unsupervised learning).
In questo genere di problemi, abbiamo a disposizione:
• una lista di oggetti
• un vettore di feature per ciascun oggetto, oppure una matrice che assegna a ciascuna coppia di
oggetti una distanza o una somiglianza.
Sulla base di queste sole informazioni, si richiede di formulare una partizione degli oggetti in gruppi
onogenei, detti cluster.
5.1
Distanze e somiglianze
Se le feature sono numeriche, xi ∈ Rn , allora possiamo calcolare la distanza euclidea fra due oggetti
xi e xj :
v
u n
uX
dist(xi , xj ) = kxi − xj k2 = t (xik − xjk )2 ;
(5.1)
k=1
allo stesso modo, possiamo definire distanze basate su altre norme (in particolare la norma 1 e la norma
infinito).
In altri contesti è vantaggioso definire una misura di somiglianza o similarità fra oggetti. In tal
caso, è possibile utilizzare la cosiddetta cosine similarity 2 come il prodotto scalare dei due vettori
normalizzato rispetto alle loro lunghezze:
sim(xi , xj ) =
xi · xj
;
kxi kkxj k
la cosine similarity è pari al coseno dell’angolo compreso fra i due vettori.
Alcune proprietà:
1 Vedere
https://en.wikipedia.org/wiki/Cluster_analysis, parte introduttiva
2 https://en.wikipedia.org/wiki/Cosine_similarity
23
(5.2)
• la distanza, per definizione, è piccola per oggetti vicini (quindi simili), grande per oggetti lontani
fra loro (quindi dissimili);
• al contrario, una misura di somiglianza è grande per oggetti simili (vicini) e piccola per oggetti
diversi (quindi lontani);
• la cosine similarity varia da −1 (per oggetti rappresentati da vettori con verso opposto) a 1 (per
vettori allineati e concordi).
5.1.1
Dati non numerici
Se vogliamo calcolare distanze o similarità fra oggetti non rappresentati da vettori numerici, abbiamo
varie scelte, ad esempio convertendo ciascuna feature non numerica in un corrispondente insieme di
feature numeriche utilizzando la rappresentazione unaria già vista in 3.1.1.
Documenti testuali
Un documento di testo può essere rappresentato da un lungo vettore di feature in cui ogni feature
indica il numero di apparizioni un dato termine all’interno del testo.
In alternativa, un documento di testo può essere visto come un insieme di parole. In tal caso, per
misurare la somiglianza di due documenti si può utilizzare il cosiddetto coefficiente di Jaccard 3 . Dati
due insiemi A e B, il loro coefficiente di Jaccard è dato dal numero di elementi in comune, normalizzato
rispetto al numero di elementi dei due insiemi:
J(A, B) =
5.2
|A ∩ B|
.
|A ∪ B|
(5.3)
Clustering agglomerativo gerarchico
Supponiamo di avere un insieme di m oggetti, numerati da 1 a m, e di conoscere una matrice di
distanze mutue D = (dij ), con i, j = 1, . . . , m. La matrice D è ovviamente simmetrica e contiene zeri
sulla diagonale (ogni oggetto ha distanza 0 da sé stesso).
L’idea dell’algoritmo di clustering agglomerativo gerarchico4 è quella di partire da tutti gli elementi
separati, considerando ciascun elemento come un cluster a sé stante, e iterativamente unire insieme i
due cluster più vicini, fino a ridurre l’insieme a un unico cluster.
5.2.1
Distanze fra insiemi
Possiamo estendere la nozione di distanza fra elementi a distanza fra insiemi in vari modi. Tale
estensione è detta linkage 5 , e le varianti più comuni sono:
• Single linkage — la distanza fra due insiemi A e B è la minima distanza fra elementi nei due
insiemi:
dist(A, B) = min dij .
(5.4)
i∈A
j∈B
Questa definizione corrisponde all’idea intuitiva di distanza come la “minima strada” necessaria
per spostarsi fra due insiemi.
• Complete linkage — la distanza fra due insiemi A e B è la massima distanza fra elementi nei due
insiemi:
dist(A, B) = max dij .
(5.5)
i∈A
j∈B
Questa definizione corrisponde all’idea di distanza come “caso peggiore” per spostarsi fra due
insiemi.
3 https://en.wikipedia.org/wiki/Jaccard_index
4 https://en.wikipedia.org/wiki/Hierarchical_clustering
5 https://en.wikipedia.org/wiki/Hierarchical_clustering#Linkage_criteria
24
(1)
(2)
6
6
3
3
5
5
1
1
2
4
2
1
2
3
4
5
4
6
(3)
1
2
3
4
5
6
1
2
3
4
5
6
1
2
3
4
5
6
(4)
6
6
3
3
5
5
1
1
2
4
2
1
2
3
4
5
4
6
(5)
(6)
6
6
3
3
5
5
1
1
2
4
2
1
2
3
4
5
4
6
Figura 5.1: I passi del clustering agglomerativo gerarchico per un insieme di cinque punti nel piano.
• Average linkage — la distanza fra due insiemi A e B è la distanza media fra gli elementi nei due
insiemi:
1 X
dist(A, B) =
dij .
(5.6)
|A||B| i∈A
j∈B
Questa definizione corrisponde al “caso medio”.
Si osservi che tutte queste definizioni si riducono alla distanza già definita nella matrice nel caso in cui
A e B siano composti da un solo elemento.
5.2.2
L’algoritmo
1. C ← {1, 2, . . . , m}
2. Finché |C| > 1:
(a) Trova i due elementi c1 , c2 ∈ C per i quali dist(c1 , c2 ) è minima;
(b) Registra i due elementi c1 , c2 e la loro distanza dist(c1 , c2 );
(c) Leva i due elementi c1 e c2 da C, sostituendoli con la loro unione c1 ∪ c2 .
La registrazione delle operazioni eseguite permette di ricostruire una struttura gerarchica detta
dendrogramma. Vediamo un semplice esempio di clustering agglomerativo in Fig. 5.1, con a fianco il
dendrogramma risultante.
Si rinvia all’esercitazione 10 per un esempio su un insieme di dati più complesso.
25
5.2.3
Similitudini e distanze
Cosı̀ come presentato, l’algoritmo si basa sulla ricerca sistematica dei cluster di distanza minima. Nel
caso in cui abbiamo a disposizione una matrice di similitudini, invece delle distanze, possiamo operare
in due modi:
• Trasformare le similitudini in distanze utilizzando una funzione decrescente. Ad esempio, la
cosine similarity e il coefficiente di Jaccard possono essere entrambi trasformati in distanze
sottraendoli da 1.
• Oppure, possiamo riformulare l’algoritmo e le funzioni di linkage invertendo sistematicamente
tutti i minimi e i massimi. Negli esercizi seguiamo questo secondo approccio.
26
Parte II
Esercitazioni di laboratorio
27
Esercitazione 1
Lettura dei dati e semplici
statistiche
Per le esercitazioni utilizzeremo il linguaggio Python nella sua versione 21 . La maggior parte di quanto
riportato sarà compatibile con la versione 3.
1.1
Scopo dell’esercitazione
È dato un file in formato CSV, berkeley.csv2 , contenente dati nella forma seguente:
Department,Sex,Status
Dept. F,Male,Denied
Dept. C,Female,Denied
Dept. C,Male,Denied
Dept. F,Male,Denied
Dept. E,Female,Denied
...
Dept. B,Male,Admitted
Dept. D,Female,Admitted
Dept. C,Female,Denied
Dept. F,Female,Denied
Il file contiene una lista di record di domande di ammissione alle scuole di dottorato di diversi
dipartimenti. Per ogni domanda sono registrati il dipartimento, il sesso del richiedente e l’esito.
Vogliamo verificare il tasso di ammissione complessivo e quello diviso per sesso, affinando poi
l’analisi sui singoli dipartimenti.
1.2
1.2.1
Alcune operazioni di base
Lettura dei dati
Per leggere il file in una struttura dati utilizzeermo il modulo pandas di Python. Avviamo l’interprete
con il comando python2:
Python 2.7.12 (default, Jul 1 2016, 15:12:24)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> data = pd.read csv(’berkeley.csv’)
1 https://docs.python.org/2/
2 http://disi.unitn.it/
~brunato/berkeley.csv
28
>>> data
Department
Sex
0
Dept. F
Male
1
Dept. C Female
2
Dept. C
Male
3
Dept. F
Male
...
4483
Dept. D Female
4484
Dept. C Female
4485
Dept. F Female
[4486 rows x 3 columns]
Status
Denied
Denied
Denied
Denied
Admitted
Denied
Denied
La “lunghezza” della tabella ci dà il numero di righe:
>>> len(data)
4486
1.2.2
Selezione di colonne
Per selezionare una colonna è sufficiente usarne il nome come indice della tabella:
>>> data[’Department’]
0
Dept. F
1
Dept. C
2
Dept. C
...
4483
Dept. D
4484
Dept. C
4485
Dept. F
Name: Department, dtype: object
Se il nome della colonna è un identificatore valido, come nel nostro caso, lo si può usare direttamente come selettore, semplificando la sintassi. Il seguente comando ottiene lo stesso risultato:
>>> data.Department
1.2.3
Valori distinti
Se vogliamo la lista di valori unici e diversi contenuti nella colonna department, dobbiamo soltanto
trasformarla in un insieme (che non ammette molteplicità e ripetizioni):
>>> set(data.Department)
set([’Dept. F’, ’Dept. D’, ’Dept. E’, ’Dept. B’, ’Dept. C’, ’Dept. A’])
Ovviamente, un insieme non ha ordine. Se vogliamo una lista più ordinata, la otteniamo con la funzione sorted():
>>> sorted(set(data.Department))
[’Dept. A’, ’Dept. B’, ’Dept. C’, ’Dept. D’, ’Dept. E’, ’Dept. F’]
1.2.4
Condizioni e sottotabelle
Se vogliamo identificare le righe della tabella che rispettano una certa condizione, possiamo applicare
i consueti operatori di confronto a un’intera colonna, ottenendo una serie di valori booleani:
>>> data.Status == ’Admitted’
0
False
1
False
2
False
3
False
29
...
4483
True
4484
False
4485
False
Name: Status, dtype: bool
Se vogliamo contare il numero di True in questa serie dobbiamo semplicemente sommarla, l’interprete
opera automaticamente un cast verso i valori interi, interpretando True come 1 e False come 0:
>>> (data.Status == ’Admitted’).sum()
1715
Per calcolare il tasso di ammissione dobbiamo dividere il numero di ammessi, calcolato sopra, per
il numero totale di domande:
>>> (data.Status == ’Admitted’).sum() / float(len(data))
0.38230049041462327
Possiamo usare la stessa serie booleana per selezionare una sottotabella. Ad esempio, la seguente
è la tabella con i richiedenti di sesso femminile:
>>> data[data.Sex==’Female’]
Department
Sex
Status
1
Dept. C Female
Denied
4
Dept. E Female
Denied
5
Dept. E Female
Denied
7
Dept. F Female Admitted
...
4483
Dept. D Female Admitted
4484
Dept. C Female
Denied
4485
Dept. F Female
Denied
[1835 rows x 3 columns]
1.2.5
Selezioni multiple
Possiamo combinare le selezioni con gli operatori logici “&” e “|”:
>>> (data.Department == ’Dept. E’) & (data.Sex == ’Male’)
0
False
1
False
2
False
3
False
4
False
...
4483
False
4484
False
4485
False
dtype: bool
Notare l’uso delle parentesi per correggere le priorità degli operatori (altrimenti “&” prevarrebbe su
“==”). Il conteggio avviene come al solito:
>>> ((data.Department == ’Dept. E’) & (data.Sex == ’Male’)).sum()
191
Lo stesso risultato si può ottenere passando per una tabella intermedia, selezionando prima le righe
del dipartimento e poi contando solo per sesso:
>>> data d = data[data.Department == ’Dept. E’]
>>> (data d.Sex == ’Male’).sum()
191
30
1.3
Script
Lo script completo e commentato è disponibile sulla pagina web del corso3 , il risultato dell’esecuzione
è il seguente:
Overall admission rate: 0.382300490415
Admission rates by sex:
Female 0.303542234332
Male 0.436816295737
Admission rates by department and sex:
Dept. A
Female 0.824074074074
Male 0.620606060606
Dept. B
Female 0.68
Male 0.601923076923
Dept. C
Female 0.340640809444
Male 0.369230769231
Dept. D
Female 0.349333333333
Male 0.330935251799
Dept. E
Female 0.239185750636
Male 0.277486910995
Dept. F
Female 0.0703812316716
Male 0.058981233244
1.4
Conclusioni
Si noti il seguente fatto apparentemente contraddittorio4 , da discutere a lezione: il tasso di ammissione
diviso per sesso sembra indicare una forte discriminazione a favore dei maschi (ammessi per più del 43%,
contro il 30% delle femmine); se però andiamo a cercare i dipartimenti colpevoli di tale discriminazione,
scopriamo che la maggior parte è equa, se non a favore delle femmine, e che quei due dipartimenti in
cui l’ammissione è sbilanciata verso i maschi lo sono comunque per percentuali molto piccole (3%–4%).
3 http://disi.unitn.it/
4 Si
~brunato/berkeley_stats.py
tratta di un esempio del Paradosso di Simpson: https://en.wikipedia.org/wiki/Simpson%27s_paradox.
31
Esercitazione 2
Algoritmo KNN e determinazione
dei parametri
2.1
Scopo dell’esercitazione
• Implementare l’algoritmo KNN1 ;
• leggere il file iris.data;
• per ogni valore del parametro K da 1 a 20:
– per 30 iterazioni di test:
∗ separare il dataset in un insieme di training e uno di validazione;
∗ contare il numero di errori di classificazione commessi sull’insieme di validazione;
– calcolare il numero medio di errori sulle 30 prove:
• rappresentare in un grafico il numero medio di errori al variare di K.
2.2
Script
Disponibile alla pagina web del corso2 . I risultati, variabili fra un’esecuzione e l’altra, sono visibili in
Fig. 2.1.
2.3
Osservazioni
Cosı̀ com’è implementato, l’algoritmo è estremamente inefficiente: ordiniamo tutte le distanze invece
di tenere in memoria solo le prime K con una lista di priorità, scorriamo ogni volta l’elenco completo
dei punti, stiamo usando un linguaggio interpretato.
A parte questo, la dimensione del dataset (150 elementi) è troppo piccola per avere risultati attendibili con soli 30 test. Possiamo comunque vedere un andamento inizialmente discendente, con un
minimo non molto preciso intorno a K = 10, e molto rumore. Parte del corso sarà dedicata al problema
di trovare stime adeguate e meno rumorose.
1 http://archive.ics.uci.edu/ml/datasets/Iris
2 http://disi.unitn.it/
~brunato/knn.py
32
Numero medio di errori su 30 test
3.5
3.0
2.5
2.0
0
5
10
Valore del parametro K
15
Figura 2.1: Errore medio al variare del parametro K
33
20
Esercitazione 3
I rischi di un modello troppo
raffinato
3.1
Scopo dell’esercitazione
• Generare un semplice dataset “rumoroso” in cui y h auna semplice dipendenza lineare da x
(scalare anch’esso);
• applicare la regressione polinomiale, di grado crescente, ai dati;
• verificare, su grafico, che i polinomi trovati dalla regressione collimano con sempre maggior
precisione coi dati, ma hanno un comportamento sempre più erratico al di fuori di questi;
• verificare in modo più preciso il fenomeno utilizzando un secondo insieme di validazione.
3.2
Script
Lo script che genera il grafico dei polinomi di regressione, dal grado 0 al grado 9, per 10 punti di test,
è disponibile alla pagina web del corso1 .
Lo script genera 10 punti della forma (xi , yi ) con xi ∈ [0, 1] uniforme e yi = 1 + 2x + , con
∼ N (µ = 0, σ = 0.05) piccolo errore normalmente distribuito.
I risultati sono visibili in Fig. 3.1: i polinomi passano attraverso i punti (crocette) con sempre
maggior precisione al crescere del grado, ma hanno comportamenti sempre più erratici.
Il secondo script2 genera anche un insieme di validazione e confronta l’RMSE che i polinomi ottengono sull’insieme di training con quello ottenuto sull’insieme di validazione, con il risultato visibile in
Tabella 3.1.
3.3
Osservazioni
Un polinomio di grado maggiore è in grado di approssimare sempre meglio un insieme prefissato di
punti; in particolare, se abbiamo m punti, un polinomio di grado m − 1 è in grado di interpolarli con
precisione assoluta (salvo errori numerici).
Se il grado è elevato, però, il polinomio si specializza sul dataset, imparando anche gli errori.
Quando lo stesso polinomio viene usato su dati nuovi, il suo valore predittivo è pressoché nullo.
Quando si utilizzano tecniche di machine learning, è sempre importante trovare il giusto compromesso: vogliamo un sistema abbastanza sofisticato da effettuare previsioni utili su dati nuovi (in grado
cioè di generalizzare), ma non cosı̀ sofisticato da apprendere anche il rumore casuale di cui tutti i dati
inevitabilmente soffrono.
1 http://disi.unitn.it/
2 http://disi.unitn.it/
~brunato/polyfit.py
~brunato/polyfit_validation.py
34
3.0
Coordinata y
2.5
2.0
1.5
1.0
0.0
Dataset
0
1
2
3
4
5
6
7
8
9
0.2
0.4
0.6
Coordinata x
0.8
1.0
Figura 3.1: Andamento dei polinomi di regressione al crescere del grado.
Tabella 3.1: Andamento del RMSE sull’insieme di training (usato per calcolare i polinomi) e
sull’insieme di validazione (tenuto da parte a scopo di verifica.
Grado RMSE training RMSE validazione
0
0.414
0.559
1
0.042
0.036
2
0.037
0.037
3
0.031
0.086
4
0.031
0.125
0.017
0.778
5
6
0.017
0.284
7
0.009
26.56
8
0.009
28.42
9
≈0
1312
35
Esercitazione 4
K-fold cross-validation
4.1
Scopo
• Generalizzare il metodo KNN a input categorici e a problemi di regressione
• Applicare la K-fold cross validation a un modello
In questa esercitazione utilizziamo il dataset abalone 1 , contenente misure di esemplari di molluschi
a conchiglia. Una delle feature è categorica a tre valori: M (maschio adulto), F (femmina adulta), I
(infante); le altre sono reali. La variabile dipendente, da prevedere, è l’età del mollusco, espressa in
temrini del numero di anelli di accrescimento presenti sulla conchiglia. Si tratta dunque di un problema
di regressione.
4.2
Prima parte
Dobbiamo adottare alcuni accorgimenti per trasformare le variabili in ingresso in variabili continue, e
convertire la funzione KNN in modo che fornisca un output continuo.
4.2.1
Script
La colonna categorica del dataset, la prima, è convertita in tre colonne numeriche, una per ogni possibile
valore, utilizzate in rappresentazione unaria (0 in tutte le colonne tranne quella corrispondente al valore
categorico, che viene posta a 1).
In seguito, modifichiamo la precedente implementazione dell’algoritmo KNN per fornire un output
numerico anziché categorico, restituendo la media dei valori y dei K primi vicini, invece della classe di
maggioranza.
Lo script è disponibile alla pagina web del corso2 .
4.2.2
Risultati
Sperimentiamo il risultato con una semplice partizione del dataset originario (75% per il training,
25% per la validazione) e calcoliamo gli errori sull’insieme di validazione (stampiamo l’indice, il valore
corretto, il valore predetto e la differenza):
0 8.0 12.5 -4.5
1 9.0 10.5 -1.5
2 6.0 7.4 -1.4
...
1041 7.0 8.5 -1.5
1 http://archive.ics.uci.edu/ml/datasets/Abalone
2 http://disi.unitn.it/
~brunato/AA/abalone.py
36
1042 11.0 11.4 -0.4
1043 8.0 8.3 -0.3
2.26451469854
L’ultima riga riporta l’RMSE di validazione.
4.3
Seconda parte
La nostra implementazione dell’algoritmo KNN è lenta, dunque nella seconda parte utilizziamo il
regressore KNN fornito dalla libreria Scikit-learn 3 .
Utilizziamo due funzionalità di sklearn:
• la classe sklearn.neighbors.KNeighborsRegressor, che implementa un regressore basato sui
K primi vicini;
• la classe sklearn.cross validation.KFold, che implementa la K-fold cross-validation.
4.3.1
Script
Il codice dello script si trova alla pagina web del corso4 .
Per implementare la K-fold cross-validation, creiamo l’oggetto
kf = KFold(n_samples,n_folds=5)
Quest’oggetto può essere utilizzato come iteratore in un ciclo for e fornisce ad ogni iterazione una
coppia di liste di indici, da utilizzare rispettivamente come indici dell’insieme di training e dell’insieme
di validazione:
for idx_tr,idx_val in kf:
X_tr = X[idx_tr]
X_val = X[idx_val]
Y_tr = Y[idx_tr]
Y_val = Y[idx_val]
...
Per applicare l’algoritmo KNN alla regressione, creiamo un oggetto di tipo KNeighborsRegressor,
passando il numero di vicini come parametro:
neigh = KNeighborsRegressor(n_neighbors=K)
In seguito, “addestriamo” l’oggetto tramite il metodo fit passando l’array X e Y di training:
neigh.fit(X_tr, Y_tr)
Invochiamo infine il metodo di predizione:
Y_pred = neigh.predict(X_val)
4.3.2
Risultati
L’algoritmo KNN offerto dalla libreria è molto più veloce di quello “fatto in casa”, e permette di eseguire
il maggior numero di addestramenti richiesto dalla K-fold cross validation. Lo script restituisce l’RMSE
finale:
2.28901206875
4.4
Discussione
Si suggerisce di sperimentare con diversi valori del parametro di vicinato.
3 http://scikit-learn.org/
4 http://disi.unitn.it/
~brunato/AA/abalone_kfold.py
37
Esercitazione 5
Regressione lineare ai minimi
quadrati
5.1
Scopo
Prendendo spunto dall’Esercitazione 3, realizzare una funzione per la regressione lineare; estendere la
funzione alla regressione polinomiale attraverso la matrice di Vandermonde.
5.2
Procedimento
Realizziamo un dataset in cui la variabile indipendente x, scalare, è uniformemente distribuita in [0,1];
calcoliamo la variabile dipendente come
y ∼ 2x + N (0, 0.05).
Le istanze xi e yi sono raccolte rispettivamente in una matrice a una colonna e m righe, X, e un
vettore colonna di m elementi y. Possiamo dunque realizzare la funzione che calcola la pseudo-inversa
di Moore-Penrose della matrice X e la applica al vettore y.
Possiamo poi applicare la stessa funzione alla matrice (3.4), ottenendo i coefficienti per la regressione
polinoniale del grado desiderato.
5.3
Script
Il codice dello script si trova alla pagina web del corso1 . Il risultato dell’esecuzione è la stampa dei
coefficienti usati nella generazione dei dati e dei corrispondenti coefficienti ricavati dalla regressione:
[-0.34838007
[-0.34661484
0.77965468
0.7875078
0.50341544
0.48750263
0.52526419]
0.53331808]
A seconda dei valori impostati, del numero di punti e del grado del polinomio, la corrispondenza può
essere più o meno precisa. In Fig. reffig:lsq vediamo l’andamento della nuvola di punti generata dal
programma e il corrispondente polinomio di regressione.
1 http://disi.unitn.it/
~brunato/AA/lsq.py
38
2.0
1.5
1.0
0.5
0.0
0.5
0.0
0.2
0.4
0.6
0.8
Figura 5.1: Il polinomio di regressione (terzo grado).
39
1.0
Esercitazione 6
Regressione logistica
6.1
Scopo
Dato un dataset di classificazione, con due classi rappresentate dai valori 0 e 1, calcolare un modello
logistico.
6.2
Procedimento
Utilizziamo il dataset Blood Transfusion Service Center 1 , che riporta alcuni parametri relativi ai donatori di sangue (mesi dall’ultima donazione, mesi dalla prima donazione, numero di donazioni, quantità
di sangue donato) e vi associa una variabile binaria che dice se il donatore si è presentato a donare
nuovamente.
Normalizzazione
Osserviamo che le diverse colonne di ingresso hanno diversi ordini di grandezza: alcune hanno valori
nel campo delle unità, altre nelle migliaia. Per evitare problemi di instabilità numerica, dobbiamo
normalizzare le colonne del dataset in modo che i valori abbiamo lo stesso intervallo di variabilità,
[0, 1]. Data la colonna j = 1, . . . , n, siano
mj =
min xij ;
Mj = max xij .
i=1,...,m
i=1,...,m
La normalizzazione della matrice avviane dunque con la seguente mappa affine:
xij 7→
xij − mj
.
Mj − m j
Un’avvertenza: se il dataset è suddiviso fra training e validation set, bisogna assicurarsi che i minimi
mj e i massimi Mj siano calcolati soltanto sulle righe del training set. Infatti, i valori del validation
set non devono influire in alcun modo nel training. Gli stessi minimi e massimi andranno poi utilizzati
anche nella normalizzazione dei valori di validazione, che potrebbero quindi uscire dall’intervallo [0, 1].
6.2.1
Discesa lungo il gradiente
Come abbiamo visto, non è possibile trovare i valori ottimali dei coefficienti in forma chiusa. Utilizziamo
dunque il metodo della discesa lungo il gradiente. Impostiamo un valore della learning rate η = 0.01.
Ad ogni passo, valutiamo sia l’RMSE sul training set, sia quello sul validation set. Ovviamente, il
gradiente va valutato solamente sul training set.
1 https://archive.ics.uci.edu/ml/datasets/Blood+Transfusion+Service+Center
40
6.3
Script
Il codice dello script si trova alla pagina web del corso2 . Il programma genera un grafico dell’andamento
dell’RMSE di training e di validazione al crescere del numero di iterazioni, come in Fig. 6.1.
6.4
Discussione
La curva di training è (ovviamente) sempre in discesa. Quella di validazione è solitamente più alta (la
discesa tiene conto solo dell’insieme di training), e raggiunge un punto di minimo per poi (tipicamente)
risalire, come si vede in Fig. 6.1.
2 http://disi.unitn.it/
~brunato/AA/logit.py
41
0.54
Training
Validazione
0.52
0.50
RMSE
0.48
0.46
0.44
0.42
0.40
0.38
0
200
400
600
Iterazione
Figura 6.1: Discesa lungo il gradiente.
42
800
1000
Esercitazione 7
Curve di prestazione
7.1
Scopo
Dato un problema di classificazione a due classi, il modello logit produce un output continuo in (0, 1).
Resta il problema di determinare un opportuno valore di soglia θ ∈ [0, 1] da applicare alla funzione di
decisione (3.6).
7.2
Procedimento
Lo script creato per l’esercitazione 6 determina, alla fine del processo iterativo di discesa lungo il
gradiente, i valori ottimali dei coefficienti (pesi) β = (β1 , . . . , βn ).
Sulla base di questi, e degli esempi di validazione xval
i , possiamo determinare i corrispondenti valori
del modello ỹival = σ(β · xval
i ). A seconda della soglia θ ∈ [0, 1], ciascun valore sarà poi interpretato
come appartenente alla classe positiva (1) o negativa (0) sulla base della funzione (3.6).
In particolare, al variare di θ varierà la matrice di confusione, e quindi le misure di prestazione ad
essa collegate: precisione, sensibilità, score F1 .
7.3
Script
Il codice dello script si trova alla pagina web del corso1 . Una volta determinati i pesi β e i valori del
modello logit per gli esempi di validazione, ripetiamo un ciclo al variare di θ ∈ [0, 1] a intervalli di 10−2 .
A ciascuna iterazione, calcoliamo la matrice di confusione e le misure ad essa collegate, raccogliendole
in alcune liste per poi rappresentarle in alcuni grafici.
In particolare, siamo interessati ai seguenti grafici:
• Sensibilità contro precisione — sappiamo che la sensibilità e la precisione sono obiettivi spesso
contrastanti, quindi una curva che riporta la relazione fra le due ci permette di individuare il
valore di θ corrispondente a un compromesso fra le due.
• Score F1 contro θ — un’altra possibilità è quella di individuare il valore di θ che massimizza
(a meno di rumore sperimentale) lo score F1 , che normalmente costituisce un buon compromesso
fra le due misure parziali sopra citate.
• Curva ROC — consideriamo i casi estremi: per θ = 0, classifichiamo tutti gli esempi come
positivi. Questo significa che la nostra sensibilità vale 1, però vale 1 anche la “False Positive
Rate”, definita come
FP
.
FPR =
FP + TN
1 http://disi.unitn.it/
~brunato/AA/tradeoff.py
43
1.0
0.9
Precision
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.0
0.2
0.4
0.6
Sensitivity
0.8
1.0
Figura 7.1: Precisione contro sensibilità.
Quando invece θ = 1, noi rigettiamo come negativi tutti gli esempi. Quindi la sensibilità crolla
a zero, come pure la FPR appena definita.
Il grafico che rappresenta la sensibilità (che in questo contesto è detta “True Positive Rate”)
contro la FPR si chiama curva ROC (“Receiver Operating Characteristic”, perché era utilizzata
per analizzare segnali radar)2 ed è molto utile per valutare la prestazione di un classificatore
binario. In generale, più l’area sottesa dalla curva è alta, più il classificatore funziona bene per
molti valori di θ.
7.4
Discussione
Lo script fornisce risultati simili a quelli rappresentati nelle Figure 7.1–7.3. Si osservi come, al di là
del rumore statistico causato dalla bassa numerosità del dataset, la precisione e la sensibilità siamo
effettivamente obiettivi in contrasto (anche se localmente il grafico di Fig. 7.1 può essere crescente).
Dalla Fig. 7.2 vediamo che lo score F1 raggiunge un massimo per qualche valore intermedio di θ
per il quale si raggiunge un compromesso paritario fra precisione e sensibilità.
Infine, la curva ROC di Fig. 7.3, la cui area sottesa è decisamente minore del massimo ottenibile (l’intero rettangolo 1×1), dimostra che il classificatore è intrinsecamente poco affidabile, indipendentemente
dal valore di soglia scelto.
2 https://en.wikipedia.org/wiki/Receiver_operating_characteristic
44
0.6
0.5
F1 score
0.4
0.3
0.2
0.1
0.0
0.0
0.2
0.4
θ
0.6
0.8
Figura 7.2: Andamento dell’F1 -score al crescere della soglia θ.
45
1.0
1.0
True Positive Rate
0.8
0.6
0.4
0.2
0.0
0.0
0.2
0.4
0.6
False Positive Rate
Figura 7.3: Curva ROC.
46
0.8
1.0
Esercitazione 8
Alberi di decisione e random forest
8.1
Scopo
Dato un dataset di classificazione con feature continue, ci proponiamo di:
1. implementare in Python un albero di decisione addestrato sulla base del dataset;
2. utilizzare una libreria nella quale l’algoritmo è già implementato ed esplorarne qualche funzionalità.
8.2
Prima parte: implementazione
Utilizziamo Pandas per leggere il dataset; per prima cosa scriviamo una funzione per stimare l’entropia
di una distribuzione sulla base di un vettore di sue manifestazioni, da applicare all’output del dataset.
Per i nostri scopi, un albero sarà rappresentato da una quadrupla:
A = (|∗ , θ∗ , A§|∗ <θ∗ , A§|∗ ≥θ ),
dove A§|∗ <θ∗ e A§|∗ ≥θ∗ sono rispettivamente i sottoalberi sinistro e destro; una foglia sarà invece
rappresentata da un singolo valore di uscita, ỹ, da utilizzare come predizione.
8.2.1
Codice
Il codice è disponibile in http://disi.unitn.it/~brunato/AA/tree.py. La costruzione e la navigazione dell’albero sono ricorsive; la costruzione si basa su una funzione ausiliaria che, sulla base di un
dataset, determina la suddivisione migliore dal punto di vista del guadagno informativo.
8.2.2
Risultati
L’albero, addestrato sulla base dell’intero dataset, è riportato in figura 8.1. Le stringhe sono i nodi
foglia; ogni nodo interno è una 4-tupla.
Si noti come la procedura di costruzione abbia subito identificato, a livello della radice, una
prima condizione (x2 < 3) che permette immediatamente di identificare tutti i campioni di varietà
iris setosa. Il sottoalbero di destra è poi dedicato a distinguere le due rimanenti varietà, più difficili
da distinguere fra loro.
8.3
Seconda parte: utilizzo di una libreria esterna
In questo caso utilizziamo la libreria scikit-learn per addestrare un albero sullo stesso dataset.
47
(2, 3.0,
’Iris-setosa’,
(3, 1.8,
(2,
5.0,
(3, 1.7, ’Iris-versicolor’, ’Iris-virginica’),
(3, 1.6,
’Iris-virginica’,
(0, 7.2, ’Iris-versicolor’, ’Iris-virginica’))),
(2, 4.9,
(0, 6.0, ’Iris-versicolor’, ’Iris-virginica’),
’Iris-virginica’)))
Figura 8.1:
Rappresentazione dell’albero di decisione sul dataset iris,
dell’information gain
8.3.1
massimizzazione
Codice
Il codice, molto semplice, consiste nella lettura del dataset e nella costruzione e addestramento dell’oggetto della libreria. È disponibile in http://disi.unitn.it/~brunato/AA/sktree-iris.py.
La rappresentazione dell’albero viene salvata nel file iris.dot, dal quale si può generare un
documento PDF tramite il comando
dot -Tpdf iris.dot -o iris.pdf
8.3.2
Risultati
La libreria scikit-learn consente di generare una rappresentazione grafica dell’albero di decisione
attraverso il formato .dot della libreria graphviz. L’esito è visibile in Figura 8.2.
L’albero conferma la suddivisione già trovata con il nostro codice: la condizione x2 ≤ 2.45 individua
una foglia pura, mentre il sottoalbero di destra va ulteriormente suddiviso. Si noti come l’impurità di
Gini decresca al crescere delle suddivisioni.
8.4
Terza parte: utilizzo di un dataset più complesso
Lavoriamo poi sul dataset adult.data. Si tratta di un dataset misto, con alcune colonne numeriche
ed altre di tipo categorico.
8.4.1
Codice
Il codice commentato si trova in http://disi.unitn.it/~brunato/AA/sktree-adult.py. Dopo
la lettura dei dati, è necessario convertire ciascuna delle colonne categoriche in colonne numeriche
utilizzando la consueta rappresentazione unaria (descritta in 3.1.1 e già utilizzata nell’esercitazione 4).
Una volta fatto questo, possiamo addestrare un albero di decisione o una random forest e verificarne
il risultato.
8.4.2
Risultati
8.4.3
Albero di decisione
Il primo test riguarda l’addestramento e la visualizzazione di un albero di decisione. Dato il grande
numero di campioni e di colonne, l’albero di default, senza limiti in profondità o in purezza, risulta molto
grande. Una volta limitato a tre livelli, otteniamo l’albero rappresentato in Fig. 8.3. Per chiarezza,
abbiamo operato una sostituzione lessicale delle stringhe nella forma X[n] con i corrispondenti nomi
di colonna.
48
X[2] <= 2.45
gini = 0.6667
samples = 150
value = [50, 50, 50]
False
True
gini = 0.0
samples = 50
value = [50, 0, 0]
X[3] <= 1.65
gini = 0.0408
samples = 48
value = [0, 47, 1]
gini = 0.0
samples = 47
value = [0, 47, 0]
gini = 0.0
samples = 1
value = [0, 0, 1]
X[3] <= 1.75
gini = 0.5
samples = 100
value = [0, 50, 50]
X[2] <= 4.95
gini = 0.168
samples = 54
value = [0, 49, 5]
X[2] <= 4.85
gini = 0.0425
samples = 46
value = [0, 1, 45]
X[3] <= 1.55
gini = 0.4444
samples = 6
value = [0, 2, 4]
X[1] <= 3.1
gini = 0.4444
samples = 3
value = [0, 1, 2]
gini = 0.0
samples = 43
value = [0, 0, 43]
gini = 0.0
samples = 2
value = [0, 0, 2]
gini = 0.0
samples = 1
value = [0, 1, 0]
X[0] <= 6.95
gini = 0.4444
samples = 3
value = [0, 2, 1]
gini = 0.0
samples = 3
value = [0, 0, 3]
gini = 0.0
samples = 2
value = [0, 2, 0]
gini = 0.0
samples = 1
value = [0, 0, 1]
Figura 8.2: Albero di decisione generato da scikit-learn sul dataset iris con i parametri di default
(impurità di Gini, nessuna terminazione).
marital-status=Married-civ-spouse <= 0.5
gini = 0.3656
samples = 32561
value = [24720, 7841]
True
capital-gain <= 7073.5
gini = 0.1221
samples = 17585
value = [16436, 1149]
education-num <= 12.5
gini = 0.4943
samples = 14976
value = [8284, 6692]
age <= 20.5
gini = 0.0682
samples = 311
value = [11, 300]
capital-gain <= 5095.5
gini = 0.4429
samples = 10507
value = [7029, 3478]
education-num <= 12.5
gini = 0.0935
samples = 17274
value = [16425, 849]
gini = 0.0481
samples = 13864
value = [13522, 342]
gini = 0.2531
samples = 3410
value = [2903, 507]
False
gini = 0.0
samples = 4
value = [4, 0]
gini = 0.0446
samples = 307
value = [7, 300]
gini = 0.4174
samples = 9979
value = [7018, 2961]
gini = 0.0408
samples = 528
value = [11, 517]
capital-gain <= 5095.5
gini = 0.4039
samples = 4469
value = [1255, 3214]
gini = 0.4426
samples = 3788
value = [1252, 2536]
gini = 0.0088
samples = 681
value = [3, 678]
Figura 8.3: Albero di decisione generato da scikit-learn sul dataset adult con impurità di Gini e
profondità massima pari a 3.
49
In seguito, operiamo una suddivisione del dataset in training e validazione; una volta addestrato
l’albero completo, la validazione fornisce la seguente matrice di confusione (valori veri in riga, positivi
in seconda riga/colonna):
[[5359 731]
[ 799 1252]]
Se impostiamo un livello massimo nell’albero di decisione (ad esempio max depth=10 nel costruttore),
otteniamo la seguente matrice:
[[5847 243]
[ 980 1071]]
La capacità di discriminare i casi negativi (altrimenti detta “specificità”) è aumentata, a spese della
capacità di discriminare quelli positivi (“sensibilità”). Anche la precisione è aumentata. Un numero più
basso di livelli rende il sistema più “prudente”: in presenza di un numero di negativi molto maggiore dei
positivi, tende ad assumere, conservativamente, la negatività di molti più casi. Possiamo aggiungere
class weight=’balanced’ per dare un “peso” maggiore ai casi positivi nel calcolo della purezza dei
nodi:
[[4796 1294]
[ 313 1738]]
Abbiamo portato la sensibilità alle stelle, sacrificando però la capacità del sistema di discriminare i
casi negativi. . .
8.4.4
Random forest
Una random forest si ottiene addestrando molti alberi “deboli” (poco profondi e senza spaziare su
tutte le feature a ogni nodo), ottenendo un gruppo di “predittori deboli” che viene fatto decidere a
maggioranza.
Con i parametri di default, il costruttore sklearn.ensemble.RandomForestClassifier genera
una foresta di 10 alberi di decisione “completi” (senza restrizioni), ottenendo la seguente matrice di
confusione:
[[5650 440]
[ 890 1161]]
Vediamo cosa accade se apportiamo le seguenti modifiche:
• riduciamo artificialmente la profondità massima degli alberi a 5: max depth=5,
• imponiano l’analisi di un numero massimo di due feature alla creazione di ogni nodo: max features=2,
• utilizziamo 100 alberi: n predictors=100.
La matrice diviene:
[[6090
[2051
0]
0]]
Che cos’è successo?
50
Esercitazione 9
Selezione delle feature
9.1
Scopo
Stimando l’informazione mutua fra feature in ingresso e la classe in uscita, individuiamo in maniera
greedy un sottoinsieme di feature molto informative nei riguardi dell’output.
Utilizziamo il dataset adult già usato nell’esercitazione precedente.
9.2
Metodo
Sappiamo stimare l’informazione mutua solamente fra variabili discrete. Discretizziamo dunque le
variabili continue in quartili, come descritto alla Sez. 4.2.1 di pag. 21.
Manteniamo l’insieme degli indici delle k colonne già selezionate all’iterazione k {Xi1 , . . . , Xik }
(inizialmente vuoto). Ad ogni iterazione, individuiamo una colonna j, non ancora selezionata, tale che
l’informazione mutua
I(Xi1 , . . . , Xik , Xj ; Y )
(9.1)
risulti massima. In altri termini, cerchiamo, fra le colonne non ancora selezionate, quella colonna Xj
che, congiuntamente a quelle già selezionate, contribuisce massimamente alla determinazione di Y .
9.3
Codice
Il codice è disponibile in http://disi.unitn.it/~brunato/AA/mi.py. Per il calcolo dell’informazione
mutua utilizziamo la formula (4.5); per stimare (9.1) consideriamo la k + 1-pla (Xi1 , . . . , Xik , Xj ) come
un’unica variabile casuale discreta il cui valore è la concatenazione dei valori di tutte le variabili (vedere
la funzione merge columns() del codice).
9.4
Risultati
La prima iterazione formisce il seguente risultato:
Iteration 0
[(’relationship’, 0.16536575798521508),
(’marital-status’, 0.1565278651256618),
(’education’, 0.093590841088614582),
(’occupation’, 0.092922483954970755),
(’age’, 0.080607613133633849),
(’education-num’, 0.077274997172956897),
(’capital-gain’, 0.042939513129562637),
(’hours-per-week’, 0.041216330448880553),
51
0.40
0.35
workclass
relationship
age
capital-gain
sex
hours-per-week
race
native-country
education-num
capital-loss
education
fnlwgt
marital-status
occupation
I(Xi1 , , Xik , Xj ; Y)
0.30
0.25
0.20
0.15
0.10
0.05
0.00
0.0
0.5
1.0
1.5
2.0
2.5
Iteration k
3.0
3.5
4.0
Figura 9.1: Informazione mutua cumulata ad ogni iterazione. Ogni volta, la colonna più alta viene
selezionata e non appare in seguito.
(’sex’, 0.037171387438321261),
(’workclass’, 0.021571590198122704),
(’capital-loss’, 0.011884529057259303),
(’native-country’, 0.0086953420208611774),
(’race’, 0.0083779463285105233),
(’fnlwgt’, 0.00060960004423052654)]
La prima feature selezionata è dunque relationship, che possiede un’informazione mutua rispetto
all’output di 0.165. Per quanto si possa essere tentati di selezonare anche marital-status, il dubbio
è che le due colonne contengano informazioni ridondanti. Infatti, alla seconda iterazione (una volta estratta relationship), le stime dell’informazione mutua di ciascuna colonna congiunta a quella
selezionata sono le seguenti:
Iteration 1
[(’education’, 0.24745627624114344),
(’occupation’, 0.23827766535189779),
(’education-num’, 0.23390744104625438),
(’capital-gain’, 0.19758534201729014),
(’age’, 0.18949495795875018),
(’hours-per-week’, 0.18762482215223128),
(’workclass’, 0.17984315514610913),
(’native-country’, 0.17676059525947257),
(’capital-loss’, 0.17308456098647693),
(’marital-status’, 0.16996079463723257),
(’race’, 0.16886491977436294),
(’sex’, 0.16864758949346831),
(’fnlwgt’, 0.16639405991224215)]
si noti come l’informazione mutua fornita da marital-status una volta selezionato relationship
non è molto maggiore dell’informazione offerta dalla sola relationship. Invece, education offre un
contributo molto maggiore.
52
0.18
workclass
relationship
age
capital-gain
sex
hours-per-week
race
native-country
education-num
capital-loss
education
fnlwgt
marital-status
occupation
∆I = I(Xi1 , , Xik , Xj ; Y) − I(Xi1 , , Xik ; Y)
0.16
0.14
0.12
0.10
0.08
0.06
0.04
0.02
0.00
0.0
0.5
1.0
1.5
2.0
2.5
Iteration k
3.0
3.5
4.0
Figura 9.2: Informazione mutua: contributo di ogni colonna rispetto a quelle già selezionate.
L’andamento dell’informazione mutua è rappresentato in Fig. 9.11 . Ad ogni iterazione è rappresentata l’informazione mutua cumulativa delle colonne selezionate alle iterazioni precedenti e quella
corrente. Si noti che, una volta selezionata la prima feature all’iterazione 0, la seconda feature diventa
inutile perché non aggiunge informazione.
Un quadro più chiaro è raffigurato in Fig. 9.2. Ad ogni iterazione è mostrata l’informazione contribuita da ciascuna colonna non ancora selezionata rispetto all’insieme di colonne già selezionate. Si
nota come, una volta selezionata la colonna relationship all’iterazione 0, il contributo informativo
di marital-status crolla quasi a zero.
1 È
disponibile lo script http://disi.unitn.it/~brunato/AA/plot.py per tracciare i plot.
53
Esercitazione 10
Clustering
10.1
Scopo
In quest’esercitazione lavoreremo sul dataset iris, ma trascureremo l’informazione di categoria (l’ultima colonna, contenente la varietà del fiore) e rimescoleremo le righe per eliminare qualunque informazione esplicita sulla classificazione dei fiori, mantenendo solamente le misure dei petali e dei
sepali.
Utilizzeremo una procedura di clustering gerarchico per valutare se le sole informazioni di misura
permettono di ricostruire le tre classi in cui il dataset era originariamente organizzato.
10.2
Il codice
Il codice è disponibile in http://disi.unitn.it/~brunato/AA/clustering.py.
Leggiamo il file iris.data e rimescoliamone le righe. Normalizziamo le colonne dividendo ciascuna
di esse per il suo massimo (in questo caso il valore 0 è significativo, quindi lo teniamo invariato).
In seguito, calcoliamo la matrice delle distanze mutue. Passiamo tale matrice a una procedura di
clustering gerarchico. Il pacchetto che useremo si chiama scipy.cluster.hierarchy, e permette di
effettuare il clustering gerarchico sulla base di vari criteri di collegamento. L’operazione di clustering
restituisce una lista delle operazioni di aggregazione operate in successione, e il pacchetto offre una
funzione che permette di tracciare un dendrogramma.
Infine, utilizziamo l’ordine di rappresentazione delle foglie nel dendrogramma per riordinare i dati
(che avevamo inizialmente permutato) in modo da visualizzare un eventuale ordine “scoperto” dalla
procedura di clustering.
10.3
Risultati
Una volta calcolata la matrice delle distanze, possiamo rappresentarla graficamente tramite una “mappa di calore” (heatmap), ovvero una matrice di pixel il cui colore codifica (in una scala che va tipicamente dal blu al rosso) i valori contenuti in una matrice numerica. Nel nostro caso, la matrice delle
distanze è rappresentata in Fig. 10.1. Si noti come, al di là dell’ovvia simmetria, le distanze risultino
casualmente distribuite.
Nonostante la casualità dell’ordine e il fatto di aver trascurato le informazioni di classe, la procedura
di clustering produce un dendrogramma che evidenzia chiaramente la presenza di tre cluster distinti,
di cui uno particolarmente diverso dagli altri due. In particolare, la struttura in tre gruppi è evidente
quando si utilizza il criterio di collegamento completo (parte destra di Fig. 10.2), mentre il collegamento
singolo tende a produrre un albero troppo sbilanciato.
La rappresentazione del dendrogramma, oltre ad essere utile a verificare la struttura dei cluster
a colpo d’occhio, permette anche di riordinare gli elementi in modo da tenere vicino elementi simili.
Infatti, il dendrogramma è tracciato in modo che i suoi rami non si accavallino, e l’ordine delle foglie
54
0.20
0.15
Distance
0
20
40
0.00
Element ID
1000
26
82
107
18
89
105
46
35
80
27
737
113
113
102
122
84
124
48
128
140
63
149
81
91
115
8
117
130
66
15
64
120
60
108
19
112
50
133
47
23
41
139
51
37
88
127
74
90
144
125
32
103
1261
77
129
119
141
147
85
145
96
42
136
59
123
70
10
25
135
28
142
75
93
49
99
36
79
20
16
101
137
104
134
132
69
44
106
38
30
132
5
57
17
21
14
131
4
52
31
45
58
94
98
78
97
109
9
111
71
148
34
121
6
95
65
33
55
12
83
40
53
39
54
92
24
143
61
110
116
138
56
62
29
86
114
87
67
72
68
118
22
43
76
146
102
1000
26
82
130
107
18
89
105
66
122
51
139
84
124
108
63
91
81
149
488
117
15
115
64
120
128
140
23
41
19
60
112
37
50
133
47
88
127
113
27
73
35
80
463
1147
52
119
45
34
98
31
39
141
74
126
771
129
96
42
136
147
85
145
99
49
90
28
17
21
131
14
30
132
38
106
144
137
5
57
13
104
134
20
16
101
125
32
103
36
792
69
70
59
123
10
25
135
142
44
75
93
22
956
121
97
109
78
71
148
9
111
68
118
65
33
55
12
83
40
53
61
110
116
138
43
76
146
86
29
56
62
114
87
67
72
58
94
143
24
54
92
Distance
0
20
40
60
80
100
120
140
60
80
0.35
0.25
55
100
0.10
0.4
0.05
0.2
120
140
Figura 10.1: Matrice delle distanze fra gli elementi di iris.data, righe rimescolate casualmente,
colonne normalizzate con massimo a 1.
0.30
1.2
1.0
0.8
0.6
0.0
Element ID
Figura 10.2: Dendrogrammi generati dalla procedura di clustering gerarchico con single linkage
(sinistra) e complete linkage (destra).
0
20
40
60
80
100
120
140
0
20
40
60
80
100
120
140
Figura 10.3: La matrice delle distanze di Fig. 10.1, con le righe e le colonne permutate nell’ordine delle
foglie del dendrogramma di Fig. 10.2 (destra).
56
tiene vicini elementi che si trovano in cluster più compatti. Riordiniamo dunque la matrice delle distanze di Fig. 10.1 utilizzando l’ordine delle foglie del dendrogramma con complete linkage di Fig. 10.2;
la matrice permutata (sia nell’ordine delle righe che delle colonne, ovviamente) mostra chiaramente
una struttura a blocchi con tre gruppi di ugual dimensione sulla diagonale (Fig. 10.3).
Possiamo concludere che, nonostante tutte le informazioni di classificazione presenti nel file siano state eliminate (rimescolamento) o trascurate (ultima colonna), la procedura di clustering ha
chiaramente “riscoperto” l’esistenza di tre gruppi distinti ed equinumerosi all’interno del dataset.
57
Parte III
Domande ed esercizi
58
Appendice A
Domande teoriche e spunti di
riflessione
Questo capitolo raccoglie alcune domande di autovalutazione per verificare autonomamente la comprensione degli argomenti del corso.
A.1
A.1.1
Introduzione alla Data Science
Prerequisiti e modello di dati
• Il confine fra dati strutturati e semi-strutturati è molto sfumato; quali potrebbero essere dei casi
limite, di attribuzione incerta?
• So descrivere il formato CSV? E XML?
• So interrogare un database relazionale?
• So calcolare la media e la varianza di una serie di dati numerici?
A.1.2
Formalizzazione
• Qual è la distinzione fra un problema di classificazione e uno di predizione?
• Perché in generale dobbiamo assumere che le x siano un vettore, mentre non si perde in generalità
se si considerano solo y scalari?
• Perché non si punta sempre a un modello in grado di riprodurre perfettamente gli output
dell’insieme di training?
• Perché abbiamo usato KNN come esempio per problemi di classificazione e non di regressione?
Perché, viceversa, non abbiamo usato la regressione polinomiale per un problema di classificazione?
A.2
Metodologia
• Perché è importante che i sottoinsiemi di addestramento T e di validazione V costituiscano una
partizione del dataset D?
• So motivare i termini “Sensibilità” e “Precisione”?
• Perché la K-fold cross validation è cosı̀ utilizzata?
• Quali accorgimenti sono importanti per una buona cross-validation, soprattutto in condizioni
estreme?
59
A.3
A.3.1
Algoritmi di machine learning
Modelli lineari, minimi quadrati
• Ho dimestichezza con la notazione vettoriale e matriciale?
• Riesco a riprodurre i passaggi matematici della soluzione del problema ai minimi quadrati nel
caso scalare?
• E nel caso multidimensionale?
• Perché le φi (·) si chiamano “funzioni di base”?
A.3.2
Modello logit
• So dimostrare le proprietà della funzione sigmoide?
• Come mai non si può ricavare il valore ottimale dei coefficienti lineari in forma algebrica, ma
bisogna usare un metodo iterativo?
• Qual è il ruolo del coefficiente η nella discesa lungo il gradiente?
• Che cosa ottengo nei casi estremi della funzione di decisione (3.6), quando cioè imposto θ = 0
oppure θ = 1?
A.3.3
Alberi di decisione
• Perché l’entropia e l’impurità di Gini sono buoni indicatori della “purezza” dell’output di un
dataset?
• Perché un albero rappresenta una struttura comoda per prendere delle decisioni?
• Perché l’impurità di Gini della radice dell’albero in Fig. 8.2 vale proprio
destro vale 12 ?
A.4
2
3?
E perché nel figlio
Selezione delle feature
• Perché il riquadro centrale in figura 4.1 a pag. 20 non riporta nessun valore? Non dovrebbe essere
0?
• Il coefficiente di correlazione è sempre nullo in caso di dipendenza non lineare?
• La “mutual information” definita in (4.4) sulla base dell’“entropia condizionale” (4.3) è sospettosamente simile all’“information gain” (3.11) definito sulla base dell’“entropia attesa” (3.10).
Sono la stessa cosa?
A.4.1
Clustering
• In che caso (similitudine o distanza) devo minimizzare, e in che caso devo massimizzare?
• Che cos’è il linkage criterion?
• So leggere un dendrogramma?
60
Appendice B
Esercizi
Esercizio 1
Un modello di previsione è addestrato a valutare la presenza di una specifica patologia in un paziente
sulla base di alcune feature.
Il modello viene valutato su una popolazione di pazienti per i quali l’effettiva presenza della patologia
è stata controllata da un medico, ottenendo i seguenti responsi:
Paziente
Patologia
Previsione
1
Sı̀
Sı̀
2
No
No
3
No
Sı̀
4
Sı̀
Sı̀
5
Sı̀
Sı̀
6
No
No
7
No
No
8
Sı̀
No
9
No
No
10
Sı̀
Sı̀
Paziente
Patologia
Previsione
11
No
Sı̀
12
No
No
13
No
No
14
Sı̀
No
15
Sı̀
Sı̀
16
No
No
17
Sı̀
Sı̀
18
No
No
19
No
Sı̀
20
Sı̀
Sı̀
La riga “Patologia” riporta il responso del medico, da considerarsi sempre corretto; la riga “Previsione”
riporta la valutazione del modello.
1.1) Calcolare la matrice di confusione dell’esperimento.
1.2) Calcolare le varie misure considerate: accuratezza, sensibilità, precisione, F1 -score del modello.
Soluzione 1
1.1) Contiamo quante volte compare ciascuna delle quattro combinazioni “Sı̀/Sı̀” (TP), “Sı̀/No” (FN),
“No/Sı̀” (FP), “No/No” (TN):
Patologia
Sı̀
No
Previsione
Sı̀
No
7
2
3
8
1.2)
Accuratezza =
Precisione =
7+8
3
= = 0, 75;
20
4
Sensibilità =
7
7
=
= 0, 7;
7+3
10
F1 -score =
7
7
= ≈ 0, 78;
7+2
9
2·
7
9
7
9
+
7
10
7
10
·
=
14
≈ 0, 74.
19
Possiamo osservare che in un sistema diagnostico medico i falsi negativi sono particolarmente gravi.
Infatti, mentre una diagnosi falsamente positiva è solitamente corretta da esami ulteriori, una diagnosi
negativa rischia di non avere seguito e di lasciar progredire la patologia. È dunque necessario prestare
particolare attenzione alla casella FN = 2.
61
Esercizio 2
È dato il seguente dataset (m = 4 campioni, x e y scalari):
x
6
9
5
12
1
2
3
4
y
2
5
3
6
Determinare il coefficiente β del modello lineare
y ∼ βx
che minimizza l’errore quadratico medio rispetto ai dati forniti.
Soluzione 2
Vogliamo determinare il valore di β che minimizza la seguente somma di scarti al quadrato:
f (β) = (6β − 2)2 + (9β − 5)2 + (5β − 3)2 + (12β − 6)2 .
Deriviamo f rispetto a β ed eguagliamo a zero:
d
f (β) = 2 · 6 · (6β − 2) + 2 · 9 · (9β − 5) + 2 · 5 · (5β − 3) + 2 · 12 · (12β − 6) = 0.
dβ
Semplificando i fattori pari a 2 in tutti i termini:
36β − 12 + 81β − 45 + 25β − 15 + 144β − 72 = 286β − 144 = 0,
infine
144
72
=
≈ 0, 503.
286
143
Osserviamo infatti che i valori di y sono sempre vicini alla metà di x, quindi è prevedibile un valore di
β vicino a 1/2.
β=
62
Esercizio 3
Nello stesso contesto dell’esercizio 1, supponiamo che il modello di previsione sia sostituito da un
modello logistico che restituisce la probabilità che la patologia sia positiva:
i
yi
ỹi
1
Sı̀
.7
2
No
.4
3
No
.6
4
Sı̀
.8
5
Sı̀
.7
6
No
.1
7
No
.4
8
Sı̀
.6
9
No
.5
10
Sı̀
.8
i
yi
ỹi
11
No
.7
12
No
.2
13
No
.4
14
Sı̀
.4
15
Sı̀
.6
16
No
.3
17
Sı̀
.5
18
No
.6
19
No
.6
20
Sı̀
.7
Per rispondere “Sı̀” oppure “No”, il sistema si basa su un valore di soglia θ preimpostato. La previsione
sarà:
(
Sı̀ se ỹi ≥ θ
Previsionei =
No altrimenti.
3.1) Supponiamo che il sistema decida di efettuare una previsione positiva se il risultato del modello
logistico è maggiore o uguale a θ = 0.5. Ricavare la corrispondente matrice di confusione e i principali
criteri di valutazione delle prestazioni: accuratezza, precisione, sensibilità, F1 -score.
3.2) Valutare gli stessi criteri per una probabilità di soglia pari a 0.7. Trattandosi di una decisione su
una patologia, è meglio utilizzare un valore di θ grande o piccolo?
Soluzione 3
3.1) Con la soglia pari a θ = 0, 5, la tabella delle previsioni diventa:
i
yi
ỹi
1
Sı̀
Sı̀
2
No
No
3
No
Sı̀
4
Sı̀
Sı̀
5
Sı̀
Sı̀
6
No
No
7
No
No
8
Sı̀
Sı̀
9
No
Sı̀
10
Sı̀
Sı̀
i
yi
ỹi
11
No
Sı̀
12
No
No
13
No
No
14
Sı̀
No
15
Sı̀
Sı̀
16
No
No
17
Sı̀
Sı̀
18
No
Sı̀
19
No
Sı̀
20
Sı̀
Sı̀
Contiamo quante volte compare ciascuna delle quattro combinazioni “Sı̀/Sı̀” (TP), “Sı̀/No” (FN),
“No/Sı̀” (FP), “No/No” (TN):
Patologia
Accuratezza =
Precisione =
Sı̀
No
8+6
7
=
= 0, 7;
20
10
Previsione
Sı̀
No
8
1
5
6
Sensibilità =
8
8
=
≈ 0, 62;
8+5
13
F1 -score =
8
8
= ≈ 0, 89;
8+1
9
2·
8
9
8
9
+
8
13
8
13
·
=
16
≈ 0, 73.
22
3.2) Con la soglia pari a θ = 0, 7, la tabella delle previsioni diventa:
i
yi
ỹi
1
Sı̀
Sı̀
2
No
No
3
No
No
4
Sı̀
Sı̀
5
Sı̀
Sı̀
6
No
No
7
No
No
8
Sı̀
No
9
No
No
10
Sı̀
Sı̀
i
yi
ỹi
11
No
Sı̀
12
No
No
13
No
No
14
Sı̀
No
15
Sı̀
No
16
No
No
17
Sı̀
No
18
No
No
19
No
No
20
Sı̀
Sı̀
63
La matrice di confuzione ora sarà
Patologia
Accuratezza =
Precisione =
Sı̀
No
5 + 10
3
= = 0, 75;
20
4
5
5
= ≈ 0, 83;
5+1
6
Previsione
Sı̀
No
5
4
1
10
Sensibilità =
F1 -score =
5
5
= ≈ 0, 56;
5+4
9
2·
5
9
5
9
+
5
6
5
6
·
=
2
≈ 0, 67.
3
Come osservato in precedenza, in un sistema diagnostico medico è meglio privilegiare la sensibilità,
quindi abbassare la soglia. In questo caso si può osservare che non tutti i criteri sono concordi.
64
Esercizio 4
È dato il seguente dataset, con 15 campioni, una feature in ingresso, e una classe a due valori in uscita.
i
1
2
3
4
5
xi
4.0
2.8
6.1
9.2
4.5
yi
Sı̀
No
Sı̀
No
Sı̀
i
6
7
8
9
10
xi
7.3
1.2
0.7
5.5
6.0
yi
Sı̀
No
No
Sı̀
No
i
11
12
13
14
15
xi
3.2
8.4
0.2
6.8
4.3
yi
No
No
No
Sı̀
Sı̀
4.1) Valutare la prestazione dell’algoritmo K-nearest-neighbors con K = 1 e K = 3, utilizzando una
3-fold cross validation in cui i tre fold sono gli elementi di indici 1–5, 6–10 e 11–15. Utilizzare gli indici
di accuratezza, precisione, sensibilità e l’F1 -score.
4.2) Quale scelta si rivela essere la migliore per il parametro K? Lo è in maniera univoca, oppure
dipende dal parametro considerato?
65
Esercizio 5
Utilizzando lo stesso dataset dell’Esercizio 4, un decision tree deve discriminare in base alla colonna x
utilizzando il criterio di impurità di Gini.
Dovendo scegliere fra le due soglie θ = 3.5 e θ = 7, quale risulterà migliore?
Soluzione 5
Iniziamo con θ = 3.5. Stimando le probabilità con le frequenze otteniamo:
Pr(Y = No|X ≥ 3.5) = 1;
Pr(Y = Sı̀|X < 3.5) = 0;
Pr(Y = Sı̀|X < 3.5) =
7
;
10
Pr(Y = No|X ≥ 3.5) =
(B.1)
3
.
10
Il caso X < 3.5 è puro (ci sono solo “No”), quindi
GI(Y |X < 3.5) = 0.
Calcoliamo l’impurità di Gini del caso X ≥ 3.5:
GI(Y |X ≥ 3.5)
=
=
1 − Pr(Y = Sı̀|X ≥ 3.5)2 + Pr(Y = No|X ≥ 3.5)2
9
21
49
+
=
.
1−
100 100
50
La media pesata sulla base della probabilità dei due casi, che fornisce l’impurità attesa, è dunque:
GI(Y |X)
=
=
GI(Y |X < 3.5) Pr(X < 3.5) + GI(Y |X ≥ 3.5) Pr(x ≥ 3.5)
5
21 10
7
0 +
=
.
15 50 15
25
Per θ = 7, un analogo conteggio delle righe e degli output fornisce:
Pr(Y = Sı̀|X < 7) = Pr(Y = No|X ≥ 7) =
1
Pr(Y = Sı̀|X < 7) = ;
3
1
;
2
(B.2)
2
Pr(Y = No|X ≥ 7) = .
3
Osserviamo come entrambe le distribuzioni siano molto più uniformi di prima, il che ci fa pensare che
θ = 7 non sia una buona scelta. Infatti, l’impurità di Gini per il caso X < 7 è la più elevata possibile
per una variabile a due valori:
GI(Y |X < 7) = 1 − Pr(Y = Sı̀|X < 7)2 + Pr(Y = No|X < 7)2
1 1
1
= 1−
+
= ,
4 4
2
L’impurità del caso X ≥ 7 è invece:
GI(Y |X ≥ 7)
=
=
1 − Pr(Y
1
1−
+
9
= Sı̀|X ≥ 7)2 + Pr(Y = No|X ≥ 7)2
4
4
= .
9
9
L’impurità attesa, calcolata anche in questo caso come media pesata delle due impurità, risulta essere:
GI(Y |X)
= GI(Y |X < 7) Pr(X < 7) + GI(Y |X ≥ 7) Pr(x ≥ 7)
1 12 4 3
22
=
+
=
,
2 15 9 15
45
un valore decisamente più elevato rispetto alla prima soglia.
La soglia θ = 3.5 è dunque migliore perché porta a un’impurità attesa più bassa.
66
Esercizio 6
È dato il seguente dataset di 8 elementi con due feature categoriche e output categorico:
x1
x2
y
Verde
Sı̀
+
Rosso
No
+
Rosso
Sı̀
+
Verde
Sı̀
-
Rosso
No
+
Verde
No
-
Rosso
Sı̀
-
Verde
No
-
6.1) Quale domanda apparirà al livello più alto (radice) di un albero di decisione, e perché?
6.2) Qual è l’impurità di Gini dell’output del dataset completo, e quale l’impurità media dei due nodi
figli?
Soluzione 6
6.1) Osserviamo che nel dataset complessivo le due classi di output sono equiprobabili: ci troviamo
dunque nel caso peggiore sia dal punto di vista dell’entropia, sia in base all’impurità di Gini:
Pr(Y = +) = Pr(Y = −) =
1
.
2
Se discriminiamo i dati sulla base della prima colonna, la distribuzione delle Y cambia:
Pr(Y = +|X1 = Verde) =
1
;
4
Pr(Y = −|X1 = Verde) =
3
Pr(Y = +|X1 = Rosso) = ;
4
3
;
4
(B.3)
1
Pr(Y = −|X1 = Rosso) = .
4
Ne segue che la prima colonna contiene informazione utile a determinare l’output. Discriminando in
base alla seconda colonna, invece, le distribuzioni dell’output nei due sottocasi restano uniformi:
Pr(Y = +|X2 = Sı̀) = Pr(Y = −|X2 = Sı̀) = Pr(Y = +|X2 = No) = Pr(Y = −|X2 = No) =
1
.
2
Il contenuto informativo è nullo, quindi la radice conterrà la domanda “X1 è Verde?” (o Rosso).
6.2) Date le distribuzioni trovate in (B.3), possiamo calcolare l’impurità di Gini dei due figli:
GI(Y |X1 = Verde) = 1 − Pr(Y = +|X1 = Verde)2 + Pr(Y = −|X1 = Verde)2
9
3
1
= 1−
+
= ;
16 16
8
67
Esercizio 7
È dato un insieme di cinque elementi con le seguenti distanze mutue:
A
B
C
D
B
6
C
1
7
D
5
2
6
E
3
4
3
5
7.1) Eseguire la procedura di clustering agglomerativo gerarchico con single-linkage criterion.
7.2) Ripetere la procedura con il complete linkage criterion.
Soluzione 7
7.1) I due elementi più vicini sono A e C, con distanza 1. Uniamoli in un singolo cluster e riscriviamo
la tabella tenendo conto del single linkage (distanza minima):
B
6
A,C
B
D
D
5
2
E
3
4
5
A questo punto selezioniamo B e D, ottenendo:
B,D
5
A,C
B,D
E
3
4
Ora uniamo E ad A,C:
A,C,E
B,D
4
Infine uniamo insieme i due cluster rimanenti. Il dendrogramma risultante è
A
C
E
0
Distanza
1
2
3
4
7.2) La soluzione con il complete linkage è molto simile.
68
B
D
Esercizio 8
Considerare l’insieme M di cinque strumenti musicali:
M = {Violino, Corno francese, Sassofono, Fagotto, Ottavino}.
La seguente tabella descrive l’intervallo di frequenze suonabili da ciascuno strumento:
Strumento
Violino
Corno francese
Sassofono
Fagotto
Ottavino
Tono più basso (Hz)
100
80
230
60
600
Tono più alto (Hz)
2600
1300
1400
660
4200
La similarità sim(a, b) tra due strumenti è data dall’ampiezza dell’intervallo comune ai due strumenti.
Ad esempio, il violino e il fagotto si sovrappongono fra 100Hz e 660Hz, quindi la loro similarità è
sim(Violino, Fagotto) = 660 − 100 = 560.
8.1) Applicare una procedura di clustering agglomerativo gerarchico all’insieme M. Si utilizzi il
complete linkage criterion, considerando che stiamo lavorando con similitudini e non distanze:
sim(A, B) = min sim(a, b).
a∈A
b∈B
Tracciare il corrispondente dendrogramma.
8.2) Ripetere l’operazione utilizzando il single linkage criterion e tracciare il corrispondente
dendrogramma.
Soluzione 8
La tabella delle distanze, realizzata considerando per ogni coppia di strumenti l’ampiezza dell’intesezione fra gli intervalli delle frequenze, è la seguente:
V
C
S
F
C
1200
S
1170
1070
F
560
580
430
O
2000
700
800
60
8.1) I due strumenti più simili sono il violino (V) e l’ottavino (O), dunque li raccogliamo in un cluster
{V, O} e calcoliamo le similarità di quest’ultimo con gli altri strumenti utilizzando il complete linkage
criterion (minima similarità) richiesto in questo punto:
{V, O}
C
S
C
700
S
800
1070
F
60
580
430
La massima similarità nella tabella è fra gli elementi C ed S, che raccogliamo nel cluster {C, S}.
Calcoliamo le nuove distanze:
{V, O}
{C, S}
{C, S}
700
F
60
430
A questo punto, uniremo i due cluster {V, O} e {C, S}:
{V, O, C, S}
69
F
60
Quindi uniamo gli ultimi due cluster. Risulta il seguente dendrogramma:
V
O
C
S
F
2000
Similarità
2000
1000
1070
700
0
60
8.2) Come prima, alla prima iterazione i due strumenti più simili sono il violino (V) e l’ottavino
(O), dunque li raccogliamo in un cluster {V, O} e calcoliamo le similarità di quest’ultimo con gli altri
strumenti, utilizzando però il single linkage criterion (massima similarità) richiesto in questo punto:
{V, O}
C
S
C
1200
S
1170
1070
F
660
580
430
La massima similarità nella tabella è fra il cluster {V, O} e l’elemento C; formiamo dunque il cluster
{V, O, C}. Calcoliamo le nuove distanze:
{V, O, C}
S
S
1170
F
580
430
A questo punto, uniremo il cluster {V, O, C} e l’elemento S:
{V, O, C, S}
F
580
Quindi uniamo gli ultimi due cluster. Risulta il seguente dendrogramma:
V
O
C
2000
Similarità
2000
1200
1000
1170
580
0
70
S
F
Esercizio 9
La seguente tabella mostra due collezioni di papiri dell’antico Egitto (ogni riga è un diverso documento).
#
H# $
La collezione di Alice
Papiro 1.
Papiro 2.
La collezione di Bob
Papiro 1.
"$H
$"
Papiro 3.
Papiro 4.
H$"
Papiro 2.
Papiro 3.
Papiro 4.
$
H "#
9.1) Dato che ogni glifo rappresenta una parola, calcolare i coefficienti di Jaccard fra i quattro
documenti della collezione di Alice. Ripetere il calcolo per i quattro documenti nella collezione di
Bob.
9.2) Un esperto sostiene che i papiri della collezione di Bob riguardano due argomenti distinti, mentre
la collezione di Alice è più uniforme.
Anche se probabilmente non conoscete l’antico egizio, applicate una procedura di clustering agglomerativo per sostenere questa tesi. Utilizzare le somiglianze fra documenti calcolate al punto 9.1 e il
single linkage criterion (massima similarità).
Soluzione 9
È possibile verificare la soluzione con il codice disponibile al link
http://disi.unitn.it/~brunato/AA/alicebob.py
Per comodità, riscriviamo i documenti in possesso di Alice e Bob come insiemi, sostituendo ai geroglifici
delle lettere latine:
a1 = {A, B, C, D};
a2 = {E, C, B, F};
a3 = {G, F, E, B};
a4 = {B, H, F, G};
b1 = {A, B, H, D};
b2 = {A, E, F, G};
b3 = {H, B, D, F};
b4 = {E, A, G, C}.
Ricordiamo che il coefficiente di Jaccard di due insiemi è dato dalla misura della loro intersezione divisa
per la misura dell’unione. Ad esempio:
r0 (a1 , a2 ) =
|a1 ∩ a2 |
|{B, C}|
1
=
= .
|a1 ∪ a2 |
|{A, B, C, D, E, F}|
3
La tabella completa della collezione di Alice risulta:
a1
a2
a3
a2
1/3
a3
1/7
3/5
a4
1/7
1/3
3/5
Fra le due similitudini massime (3/5) scegliamo quella fra a2 e a3 e li uniamo in un cluster. La tabella
delle distanze, tenuto conto del single linkage, diventa
a1
{a2 , a3 }
{a2 , a3 }
1/3
a4
1/7
3/5
L’elemento a4 viene dunque aggregato al cluster {a2 , a3 } e le similarità diventano:
71
{a2 , a3 , a4 }
a1
1/7
Per la collezione di Bob, la tabella delle similitudini è la seguente:
b1
b2
b3
b2
1/7
b3
3/5
1/7
b4
1/7
3/5
0
b2
1/7
b4
1/7
3/5
Al primo passo scegliamo di unire b1 e b3 :
{b1 , b3 }
b2
Segue l’unione di b2 e b4 :
{b2 , b4 }
1/7
{b1 , b3 }
Ecco i due dendrogrammi a confronto:
Alice
a2
a3
a4
Bob
a1
a2
a3
a4
a1
1
Similarità (Jaccard)
Similarità (Jaccard)
1
3/5
3/5
1/7
1/7
0
0
Dalle figure si nota come la collezione di Bob sia maggiormente bilanciata su due argomenti distinti, a
differenza di quella di Alice in cui tre papiri risultano simili.
72