
LINGUAGGI PER LA MODELLAZIONE DEI DATI AZIENDALI
Carlo Batini, Daniele Tatti
1.
Introduzione alla fase di analisi dati e funzioni
Nel ciclo di vita di un sistema informativo, la fase di analisi ha lo scopo di descrivere in
maniera formale ed esente da ambiguità (per quanto possibile) le specifiche del sistema,
intendendo per specifiche del sistema l’insieme dei servizi che gli utenti del sistema
informativo richiedono ad esso.
Esempio
Gli utenti di un sistema informativo che fornisca servizi di posta elettronica richiedono
di poter spedire messaggi a qualunque destinazione, specificando l’indirizzo finale in
modo semplice e simbolico, avendo la possibilità di allegare file con diverso formato,
potendo ottenere una ricevuta di ritorno, avendo la sicurezza che il messaggio non è letto
se non dal ricevente, ecc.
Esempio
Gli utenti di un sistema di prenotazione analisi cliniche hanno l’esigenza di disporre di
una prenotazione nel più breve tempo possibile, eventualmente con servizio presso
l’abitazione, su un insieme di analisi che può richiedere diverse tipologie di prelievi, con
diverse modalità di tariffazione a seconda del tipo di assistenza di cui dispongono, ecc.
L'analisi coinvolge usualmente tre diverse caratteristiche del sistema informativo,
riguardanti rispettivamente i dati oggetto del sistema, le funzioni che devono esse svolte
dal sistema, usualmente mediante elaborazioni di varia natura, le risorse tecnologiche
utilizzate per realizzare tali funzioni.
Più precisamente:
• i dati riguardano tutte le tipologie di informazioni codificate e strutturate utilizzate
dalle funzioni di elaborazione e memorizzate temporaneamente o permanentemente
nel sistema informativo. Nel sistema di posta elettronica di cui all’esempio 1
tipologie significative di dati riguardano gli indirizzi degli utenti, i siti ove sono
allocate le caselle degli utenti, diverse caratteristiche degli utenti, quali l’istituzione
cui appartengono, il client associato all’utente, il profilo, le modalità di accounting,
ecc.
• le funzioni riguardano tutte le tipologie di elaborazioni, interrogazioni, acquisizioni,
stampe o archiviazioni, trasferimenti di informazioni disponibili nel sistema per gli
1
•
utenti. Nel sistema di posta elettronica le tipologie di funzioni riguardano la
composizione, l’invio, la lettura e la stampa di un messaggio, la selezione,
l’inserimento, l’apertura e il salvataggio di un allegato, la consultazione e la
gestione di una rubrica di indirizzi di posta, e così via;
le risorse tecnologiche sono i sistemi di elaborazione, memo rizzazione,
trasmissione, di ingresso uscita, che devono essere acquisiti installati e gestiti per
rendere il sistema funzionante. Nel sistema di posta elettronica. Le risorse sono i
client associati agli utenti, i server (es. il domain name server, le reti locali, i
collegamenti con reti geografiche, ecc.
In genere, la fase di analisi viene associata alle prime due tipologie di risorse, ma
abbiamo citato anche le risorse tecnologiche per completezza, essendo un qualunque
sistema informativo associabile alle tre risorse costituite dai dati, dalle funzioni, e dalle
tecnologie informatiche.
Dati e funzioni devono essere specificati in questa fase del ciclo di vita, perché senza una
qualche forma di specifica non è possibile procedere alle fasi successive. Possiamo dire
che l’oggetto fondamentale della attività di analisi è proprio quello di fornire una
specifica dei dati e delle funzioni, a partire da una descrizione usualmente informale
delle esigenze degli utenti, descrizione che chiameremo requisiti degli utenti. I requisiti
degli utenti sono usualmente espressi come esito di interviste, e sono quasi sempre
espressi in linguaggio naturale orale o scritto. Anche la specifica dati funzioni può
essere fornita in linguaggio naturale scritto, ovvero a voce, ovvero può semplicemente,
per piccoli sistemi, essere definita "nella testa" del singolo analista. Questi modi di
descrivere la specifica sono da evitare perché non sarà più possibile (o sarà molto
complicato e fonte di contenziosi) successivamente verificare in fase di test o collaudo in
che misura il sistema operante rispetta le specifiche iniziali.
Specificare in modo non ambiguo dati e funzioni costituenti un sistema informativo può
farsi:
• con un prototipo, cioè con un sistema funzionante, realizzato con ridotto numero di
risorse ed in tempi brevi, che in genere non rispetta i livelli di qualità legati alla
efficienza e alla robustezza, e che invece "in piccolo" realizza tutte le funzionalità
del sistema, su tutte le tipologie dei dati.
• con un modello formale di specifica, cioè mediante la loro descrizione in termini di
un insieme di strutture di rappresentazione dei dati e delle funzioni, strutture di
rappresentazione usualmente descritte in un linguaggio dotato di una sintassi e
semantica formale, che nel loro insieme sono chiamate modello. Le descrizioni
formali dei dati e delle funzioni nel modello scelto sono chiamate schema dei dati e
schema delle funzioni. Uno schema dei e uno schema delle funzioni sono perciò
una descrizione formale dei dati e delle funzioni di interesse in un particolare
sistema informativo, definite a partire dai requisiti degli utenti.
Quando le specifiche sono descritte per mezzo di un modello formale, la scelta del
modello è importante anche per scegliere le modalità o fasi con cui condurre la analisi.
2
In particolare, è possibile scegliere un unico modello per descrivere dati e funzioni, cioè
un modello che abbia al suo interno strutture di rappresentazione che permettano di
descrivere sia le proprietà statiche (ciò che abbiamo chiamato i dati) delle risorse
informative gestite dal sistema informativo, sia le loro proprietà dinamiche o
comportamentali (le funzioni), ovvero due modelli distinti, uno per i dati e uno per le
funzioni. A seconda della scelta, sarà diverso il percorso o metodo con cui condurre la
analisi, e il suo prodotto finale.
Per quanto riguarda il prodotto finale della analisi, nel caso di due modelli diversi per i
dati e per le funzioni, si arriverà a produrre due schemi distinti, quelli che abbiamo
appunto chiamato schema dei dati e schema delle funzioni. Nel caso di un unico
modello, si produrrà evidentemente uno schema complessivo.
Per quanto riguarda il metodo, in entrambi i casi sarà necessario che le specifiche dei
dati e delle funzioni rispettino una imp ortante proprietà chiamata completezza delle
specifiche. Le specifiche sono dette complete quando ogni requisito sui dati descritto
nelle specifiche dati ha corrispondentemente rappresentati nelle specifiche funzioni tutti i
requisiti funzionali ad esso logicamente correlati, e viceversa. In altro parole, non può
accadere che vi sia una funzione per la quale non sono rappresentati i dati da essa
utilizzati, e viceversa. Per arrivare a produrre specifiche dati e funzioni complete sarà
necessario seguire opportune strategie, nei due contesti che abbiamo delineato. Ad
esempio nel caso si utilizzino due modelli si potrà seguire la strategia evidenziata in
figura 1.
Requisiti
PRIMO
SCHEMA DATI
SECONDO
PRIMO
SCHEMA DATI
SCHEMA FUNZIONI
TERZO
SECONDO
SCHEMA FUNZIONI
SCHEMA DATI
SCHEMA DATI
SCHEMA FUNZIONI
FINALE
FINALE
Figura 1 - Strategia per l’analisi dati funzioni nel caso di utilizzo di due modelli distinti
3
2.
L’analisi dei dati
In questo contributo presenteremo un modello per la descrizione di sistemi informativi
nella fase di analisi dei dati. Prima di parlare del modello, e del suo utilizzo,
introdurremo alcun i concetti preliminari utili nel contesto dei sistemi informativi, quali
archivio e base di dati.
2.1.
Archivi e basi di dati
La parola archivio è utilizzata in informatica ad indicare un insieme di dati aventi tutti la
stessa struttura, chiamati spesso record, ognuno strutturato a sua volta in un insieme di
campi elementari caratterizzati da un particolare valore. Ad esempio in un archivio
anagrafico i record sono gli insiemi di dati relativi alle singole persone, i campi sono il
nome, il cognome, il luogo e data di nascita, l’indirizzo, il CAP e il luogo di residenza. I
valori che possono essere assunti dai campi appartengono a domini, quali gli interi, le
stringhe di caratteri, i booleani.
Le informazioni rappresentate in un archivio possono essere organizzate in molti modi:
ad esempio, ordinandole per cognome, ovvero per data di nascita. Si suole perciò
distinguere negli archivi un aspetto che chiameremo concettuale, che descrive la natura
delle informazioni rappresentate, ed un aspetto fisico, che descrive le modalità di
rappresentazione. Secondo un' altra coordinata, possiamo distinguere in un archivio un
aspetto intensionale, che riguarda il significato delle informazioni rappresentate
nell’archivio, indipendentemente dal loro valore (ad es. l’archivio PERSONE, l’archivio
FORNITORI, il campo DATA-DI-NASCITA, il campo COGNOME), ed un aspetto
estensionale, costituito dai valori rappresentati ('PAOLO’, 'ROMA, '7 giugno 1949',
'00134'). La parte intensionale non cambia nel tempo, mentre la parte estensionale è
soggetta a continui aggiornamenti, aggiunte, cancellazioni di informazioni.
Esempio
Nella nostra vita quotidiana accade spesso che le informazioni da noi gestite siano
frammentate in diversi 'contenitori': agende, bollette, calendari, fogli sparsi. Ed è proprio
tale frammentazione che pone talvolta vari problemi nella gestione delle informazioni.
Se ad esempio teniamo due agende, una a casa e una al posto di lavoro, la variazione di
un numero di telefono ci obbligherà a due diversi aggiornamenti.
Un analogo problema è sorto per le Amministrazioni statali, le imprese manifatturiere e
produttrici di servizi, gli enti di credito, che hanno progressivamente utilizzato i sistemi
informatici per automatizzare archivi di varia natura, iniziando dai dati operativi (ad
esempio, i dati necessari alla produzione di un certificato richiesto da un cittadino in una
anagrafe comunale) fino agli archivi utilizzati per esigenze di previsione e
pianificazione (ad esempio, i dati sulle nascite e sulle morti in un dato intervallo di anni,
necessari per prevedere lo sviluppo edilizio e le esigenze di istruzione).
La tecnologia disponibile ha incoraggiato inizialmente una automazione che possiamo
definire "a pelle di leopardo": ogni volta che nasceva una nuova esigenza, veniva
realizzata una nuova applicazione (un insieme di programmi), e creati uno o più archivi
4
utilizzati dalla applicazione. In questo modo (vedi un esempio in figura 2: il simbolo di
cilindro è tradizionalmente utilizzato per rappresentare archivi) accade che le stesse
informazioni possano essere rappresentate in diversi archivi, dando luogo a ridondanza
di rappresentazione, rischi di incoerenze nelle diverse rappresentazioni della stessa
informazione, e scarsa trasparenza da parte di un utente nella possibilità di utilizzare
informazione prodotta da altri, essendo tale informazione sotto il diretto controllo del
settore organizzativo che la ha originata.
Matricola
Cognome
UFFICIO GESTIONE
Nome
DEL PERSONALE
Titolo studio
Livello
Stato civile
Valutazioni
Ufficio
UFFICIO
Cognome
Nome
Matricola
Livello
Mansione
ORGANIZZAZIONE
Livello
Matricola
Cognome
Nome
Assegni
Premio
Mese
Ore
UFFICIO
AMMINISTRAZIONE
DEL PERSONALE
Figura 2 - Struttura di un insieme di archivi tradizionali
Le basi di dati nascono proprio per dare una risposta a questi problemi. Una base di dati
(vedi anche figura 3) può essere definita come un insieme di archivi in cui ogni
informazione di interesse viene rappresentata una sola volta, e acceduta da un insieme di
applicazioni secondo criteri di riservatezza che sono stabiliti in modo centralizzato. La
base di dati è dunque anzitutto un concetto organizzativo, prima ancora che tecnologico:
integrare le informazioni aziendali in un unico contenitore logico significa aumentare la
possibilità di circolazione delle informazioni e quindi integrare maggiormente la stessa
organizzazione. Peraltro, è possibile fare questo in modo efficace solo disponendo di
opportuni sistemi software di gestione, detti sistemi di gestione di basi di dati, o DBMS,
Data Base Management System, sviluppati negli anni '70 ed '80, e ormai diventati di
uso comune. Un sistema di gestione di basi di dati permette ai vari utenti di utilizzare in
modo coordinato i dati memorizzati, per mezzo di linguaggi di manipolazione ed
interrogazione efficienti e facili da utilizzare.
5
APPLICAZIONE 1
APPLICAZIONE 1
APPLICAZIONE 1
Figura 3 - Struttura di una base di dati
Anche in una base di dati, come in un insieme di archivi tradizionali, possiamo
distinguere un aspetto intensionale, detto anche schema logico (o schema) della base di
dati, ed un aspetto estensionale, costituito dai dati memorizzati. I sistemi software di
gestione di basi di dati utilizzano per descrivere lo schema logico un insieme di modelli
chiamati usualmente modelli logici: i più utilizzati sono stati nel passato il modello
gerarchico, il modello reticolare e oggi il modello relazionale. In figura 4 riportiamo
una stessa realtà di interesse rappresentata per mezzo dei modelli gerarchico e
relazionale; la realtà che vogliamo rappresentare è quella delle librerie, che vendono
libri, scritti da vari autori. I due modelli descrivono tale realtà nel seguente modo:
1. nel modello gerarchico si distinguono due tipi di strutture di rappresentazione, i
record e i legami logici tra record. I record hanno il significato già introdotto
all’inizio del capitolo, sono cioè insiemi di campi; i legami logici descrivono le
corrispondenze definite tra record. Nel nostro esempio, si hanno tre record,
LIBRERIA, LIBRO, AUTORE, e due legami, uno tra LIBRERIA e LIBRO, che
descrive per ogni libreria, i libri venduti, e l’altro tra LIBRO e AUTORE, che
descrive per ogni libro, i suoi autori.
2. nel modello relazionale le informazioni di interesse sono raggruppate in relazioni,
rappresentate in modo naturale da tabelle. Ogni relazione (LIBRERIA, LIBRO,
ecc.) è costituita da un insieme di attributi, che costituiscono i dati elementari
rappresentabili (nel caso di LIBRERIA, PARTITA-IVA, NOME, INDIRIZZO). Le
relazioni sono utilizzate uniformemente nel modello per rappresentare entrambe le
strutture del modello gerarchico, i record e i legami logici. Ad esempio il record
LIBRERIA del modello gerarchico è rappresentato con una relazione LIBRERIA
nel modello relazionale (e gli attributi corris pondono esattamente ai campi), e
l’insieme tra i record LIBRERIA e LIBRO è rappresentato con una seconda
relazione DISPONIBILITÀ, in cui, come si vede, la corrispondenza tra ogni libreria
6
ed i libri che presso di essa sono disponibili è rappresentata riportando nella
relazione l’attributo NOME-LIBRERIA (che corrisponde a NOME nella relazione
LIBRERIA) e l’attributo CODICE-LIBRO (che corrisponde a CODICE-L nella
relazione LIBRO).
LIBRERIA
LIBRERIA
PARTITA-IVA
NOME
INDIRIZZO
INDIRIZZO
PARTITA-IVA
NOME
CODICE-L
EDITORE PAGINE
CITTA'
CITTA'
LIBRO
TITOLO
LIBRO
CODICE-L
TITOLO
NUMERO
EDITORE
COPIE
AUTORE
CODICE
NOME
COGNOME
NAZIONALITA'
SESSO
PAGINE
DISPONIBILITA'
NOMELIBRERIA
CODICE
LIBRO
NUMERO
COPIE
AUTORE
CODICE-A
NOME
COGNOME
DATA
NASCITA
SESSO
SCRITTO
TITOLO
COGNOME
MODELLO RELAZIONALE
MODELLO GERARCHICO
Figura 4 - Librerie e libri descritti nei modelli gerarchico e relazionale
2.2. I modelli concettuali e le astrazioni
In fase di analisi, per rappresentare le specifiche, si preferisce non utilizzare i modelli
logici, in quanto troppo vicini al modo in cui i dati sono rappresentati nel sistema
informatico, ed in particolare nel sistema di gestione della base di dati. Le specifiche
vengono piuttosto descritte per mezzo di un modello ancora astratto, formale,
indipendente dal modello scelto per la realizzazione tecnologica, producendo in questo
modo uno schema concettuale dei dati; nella fase di progettazione, lo schema
concettuale viene tradotto in termini dello schema logico, rappresentazione dei dati
espressa nel modello logico.
In questa sezione esamineremo il meccanismo fondamentale di rappresentazione dei
modelli concettuali, le astrazioni; nella prossima sezione esamineremo un particolare
modello concettuale, il modello Entità Relazione.
I modelli concettuali non sono rivolti tanto a descrivere la realizzazione informatica,
quanto piuttosto la realtà di interesse; sono, per cosi' dire, modelli rivolti verso la realtà,
più che verso il sistema di gestione di basi di dati. Per essere in grado di rappresentare
classi di dati in modo semplice, comprensibile, indipendente dalla tecnologia
informatica, un modello concettuale deve essere in grado di descrivere astrazioni.
Intendiamo per astrazione un procedimento mentale che permette di evidenziare alcune
proprietà, ritenute significative, degli oggetti osservati, escludendone altre giudicate
non rilevanti. Ogni processo di astrazione è applicato ad un insieme di oggetti ed il suo
risultato è la definizione di un nuovo oggetto, che, come spesso si dice, si trova ad un
livello di astrazione superiore rispetto agli altri.
7
Come esempio di astrazione (vedi Figura 5.a) consideriamo il processo mediante il
quale a partire dalle singole persone e considerando le proprietà che le accomunano, si
giunge al concetto di persona, cioè alla definizione di una classe, che rappresenta un
insieme di oggetti (le singole persone). Il precedente tipo di astrazione, presente in tutti i
modelli concettuali, è chiamato astrazione di classificazione. Altre due astrazioni
usualmente considerate sono:
•
la aggregazione, mediante la quale si può giungere alla definizione di una classe
come astrazione di un insieme di parti componenti o proprietà. Ad esempio,
definite le classi NOME, COGNOME, ETÀ, SESSO, STIPENDIO, una loro
astrazione di aggregazione è la classe PERSONA (vedi Figura 5.b).
•
la generalizzazione, mediante la quale si può giungere alla definizione di una
classe come unione di un insieme di classi, ognuna delle quali è contenuta della
classe data. Cosi', ad esempio, definite le classi UOMO e DONNA, possiamo
definire come loro generalizzazione la classe PERSONA (vedi Figura 5.c).
Corrispondentemente, possiamo definire i procedimenti inversi alle precedenti
astrazioni, che permettono di raffinare concetti in termini di concetti più elementari. Ad
esempio, tra essi, possiamo definire la specializzazione come il procedimento che
permette di definire oggetti a partire da classi.
PERSONA
PERSONA
PERSONA
Classificazione
Aggregazione
NOME COGNOMEETA' SESSO
Astrazione di classificazione
(a)
Astrazione di aggregazione
Generalizzazione
UOMO
DONNA
Astrazione di generalizzazione
b)
(c)
Figura 5 - Le astrazioni utilizzate nei modelli concettuali
Come si vede, si può arrivare ad uno stesso concetto (quello di PERSONA), per mezzo
di tre procedimenti di astrazione diversi, ognuno dei quali, cioè, utilizza una diversa
astrazione. Si può anche osservare che ognuna delle tre astrazioni coglie un aspetto della
realtà che non può essere rappresentato per mezzo delle altre due.
2.3. Il modello Entità Relazione
In questa sezione descriviamo un particolare modello concettuale, che adotta in certa
misura le astrazioni descritte nella sezione precedente. Una caratteristica interessante del
modello è la adozione per i concetti di una rappresentazione grafica, che riportiamo in
Figura 6.
8
STRUTTURA DI CLASSIFICAZIONE
ENTITA'
SIMBOLO
nome
RELAZIONE
nome
ATTRIBUTO
nome
SEMPLICE
ATTRIBUTO
nome
AGGREGATO
nome
nome
SOTTOINSIEME
GENERALIZZAZIONE
Figura 6 - Rappresentazione grafica dei concetti nel modello Entità Relazione
Nel modello sono definiti cinque tipi di strutture di rappresentazione: entità, relazioni,
attributi, sottoinsiemi, generalizzazioni. Sono anche definibili alcuni vincoli di integrità,
che rappresentano proprietà esprimibili sui concetti presenti nello schema. Nel seguito
esamineremo un particolare tipo di vincolo di integrità, le cardinalità.
Entità
Le entità corrispondono a classi di oggetti del mondo reale (oggetti che chiameremo in
seguito istanze della entità) che hanno proprietà omogenee ai fini della applicazione. Tra
queste le proprietà elementari (cioè non strutturabili in proprietà più atomiche) sono
dette attributi semplici. A un attributo semplice è associato un insieme di valori, detto
anche dominio, che rappresentano l’insieme dei valori elementari che l’attributo può
assumere. Cosi', ad esempio, PERSONA è una entità tipica di uno schema anagrafico, e
NOME, COGNOME, ETÀ, SESSO, sono proprietà elementari che noi siamo interessati
9
a descrivere di ogni persona, e quindi sono nel modello attributi della entità PERSONA;
la entità può quindi vedersi come astrazione di classificazione delle singole persone e
come astrazione di aggregazione delle quattro proprietà NOME, COGNOME, ETÀ,
SESSO. Accanto agli attributi semplici è comodo poter definire attributi composti, che
costituiscono aggregazioni di attributi. Ad esempio DATA può vedersi come attributo
composto dagli attributi GIORNO, MESE, ANNO.
Relazioni
Le relazioni corrispondono a classi di fatti del mondo reale che sono significativi ai fini
della applicazione; tali fatti mettono in relazione istanze di due o più entità. Ad esempio,
in un censimento della popolazione possiamo essere interessati ad esprimere la relazione
tra le persone e le città in cui sono nati, e chiamare tale relazione È-NATO; tale
relazione può vedersi come astrazione di aggregazione applicata alle due entità
PERSONA e CITTÀ. Accanto ad essa, possiamo essere interessati ad altre relazioni
definite sulle stesse entità: ad esempio la relazione tra la persona e il luogo di residenza
(relazione RISIEDE), la relazione tra persona e luoghi in cui ha avuto residenza (HARISIEDUTO). Mostriamo lo schema costituito dalle tre relazioni e le due entità in
Figura 3.9.
Ancora riguardo alle relazioni, è bene osservare che accanto a relazioni definite tra due
entità, come tutte le precedenti, ci possono essere relazioni definite su più di due entità.
Un esempio è la relazione FORNITA, tra le entità FORNITORE, PARTE,
PRODOTTO. Una parte può essere fornita da diversi fornitori, e per diversi prodotti. Se
vogliamo cogliere la situazione più generale possibile, dobbiamo rappresentare questo
tipo di fatti per mezzo di terne di informazioni (un fornitore, una parte, un prodotto), e
dunque, nello schema, per mezzo di una relazione tra tre entità. In questo caso, la
relazione ha un attributo, che rappresenta la generica QUANTITÀ che un fornitore
fornisce per una certa parte e per un certo prodotto.
Esempio
Mostriamo alcuni esempi di schemi concettuali. Lo schema di Figura 7 rappresenta la
realtà informativa di un campionato di calcio.
10
PARTITA
GIRONE
GIORNATA
NUMERO
GIORNO
DATA
MESE
ANNO
TRA
GIOCA_IN_CASA
NOME
CITTA'
SQUADRA
ALLENATORE
GIOCA
IN
NOME
COGNOME
RUOLO
GIOCATORE
DATA
NASCITA
GIORNO
MESE
ANNO
Fig. 3.10: Schema concettuale di un campionato di calcio
Figura 7 - Lo schema concettuale di un campionato di calcio
Nello schema compaiono:
1. La entità SQUADRA rappresenta l’insieme delle squadre che partecipano al
campionato. Delle squadre vogliamo conoscere il NOME (ad esempio Juventus,
Roma, Milan), la CITTÀ (nei tre casi precedenti Torino, Roma, Milano), ed il
COGNOME dell’allenatore.
2. La entità GIOCATORE rappresenta i giocatori che giocano nelle squadre (in tutte le
squadre). Per ogni giocatore vogliamo ricordare il NOME, il COGNOME, la
DATA-DI-NASCITA (attributo composto dagli attributi GIORNO, MESE, ANNO)
ed il RUOLO che ricopre nella squadra. Riguardo al RUOLO, facciamo per il
momento la ipotesi che ogni giocatore abbia un unico ruolo, sempre fisso nel
tempo. Facciamo anche la ipotesi che anche l’insieme dei ruoli sia fisso nel tempo
11
3.
(ad es. Portiere, Terzino sinistro, Ala destra, ecc.), ed in tutte le squadre si adottino
gli stessi ruoli.
La entità PARTITA rappresenta l’insieme delle partite svolte nel campionato (ad
esempio ROMA - MILAN della seconda giornata del girone di ritorno, JUVENTUS
- VERONA della settima giornata del girone di andata, ecc.). Di ogni partita si
vuole ricordare il GIRONE e la GIORNATA in cui si è svolta, la DATA (anche in
questo caso distinta in GIORNO, MESE ed ANNO), ed il NUMERO della partita
nell’ambito della giornata (ad esempio prima partita, seconda partita, ecc.).
Accanto alle precedenti entità sono definite nello schema le seguenti relazioni:
1. GIOCA-IN tra le entità GIOCATORE e SQUADRA, che rappresenta per ogni
giocatore la squadra in cui gioca, ovvero, simmetricamente, per ogni squadra
l’insieme dei giocatori che giocano nella squadra.
2. TRA, definita tra le due entità SQUADRA e PARTITA, che rappresenta per ogni
partita le squadre coinvolte (ad es. nella partita ROMA - MILAN sono coinvolte le
squadre ROMA e MILAN). La relazione TRA ha un attributo, chiamato GIOCAIN-CASA, che per ognuna delle due squadre coinvolte nella partita dice se la
squadra gioca o meno in casa. Il dominio di questo attributo è formato dai due
valori [SI, NO]. È importante convincersi che l’attributo GIOCA-IN-CASA è una
proprietà della relazione TRA, e non della entità PARTITA o della entità
SQUADRA. Infatti per assegnargli un valore noi dobbiamo conoscere la partita e la
squadra cui si riferisce: è perciò una proprietà della relazione tra le due entità.
Generalizzazioni
Le Generalizzazioni mettono in relazione un insieme di entità (dette nel seguito entità
figlie) con una nuova entità (detta entità padre) che di esse è astrazione appunto di
generalizzazione. Possiamo ad esempio affermare che PERSONA è generalizzazione di
UOMO e DONNA, ovvero che LUOGO è generalizzazione di COMUNE e STATO
ESTERO. Nelle generalizzazioni potranno essere definiti attributi e relazioni che sono
significativi solo per una delle entità figlie. È questo il caso dello schema di Figura 8 in
cui l’attributo SITUAZIONE-MILITARE (che rappresenta lo stato della persona dal
punto di vista del servizio militare: esente, arruolato, ecc.) ha senso solo per gli uomini.
PERSONA
DONNA
UOMO
SITUAZIONE MILITARE
Figura 8 - Un esempio di generalizzazione
12
Una fondamentale proprietà delle generalizzazioni è la seguente: in una astrazione di
generalizzazione, ogni proprietà della entità padre è anche proprietà delle entità figlie.
Per proprietà intendiamo gli attributi, le relazioni e le generalizzazioni cui partecipa la
entità. Così se ETÀ è attributo di PERSONA e PERSONA è generalizzazione di UOMO
e DONNA, ETÀ è chiaramente attributo anche di tali due nuove entità.
Si noti che una entità può essere l’entità padre di più generalizzazioni: ad esempio, in
una applicazione scolastica, la entità PERSONA può essere da una parte
generalizzazione nelle entità PROFESSORE e STUDENTE, e dall’altra nelle entità
UOMO e DONNA.
Sottoinsiemi
Un sottoinsieme è un caso particolare di generalizzazione, quella che sussiste tra l’entità
padre e una sola entità figlia. Ad esempio la entità ATTACCANTE è sottoinsieme di
GIOCATORE nello schema del campionato, perché ogni giocatore attaccante è anche
un giocatore, ma esistono giocatori che non sono attaccanti (per fortuna!). Anche per i
sottoinsieme è definita la proprietà in precedenza definita per le generalizzazioni. Ad
esempio tutti gli attributi e le relazioni associati a GIOCATORE nello schema di Figura
3.10 vanno automaticamente associati anche alla entità ATTACCANTE.
Esempio
Considerare lo schema Entità Relazione di Figura 9.
NATA
NOME
RISIEDE
PERSONA
COGNOME
NOME
CITTA'
PROVINCIA
REGIONE
ETA'
NATO
UOMO
ETA'
DONNA
ALTEZZA
ETA'
FA
SERVIZIO
MILITARE
LAVORATRICE
Figura 9 - Schema concettuale dell'esempio
13
Lo schema rappresenta varie proprietà di uomini e donne rilevanti, ad esempio,
nell’analisi di un sistema anagrafico. Ipotizziamo che l’interesse degli utenti di tale
sistema sia legato agli effetti del servizio di leva obbligatorio sulla capacità delle
famiglie di produrre reddito. Vorremmo rappresentare quindi le persone, le città in cui
vivono, la loro relazione con il servizio militare ecc. Attraverso astrazioni di
classificazione vengono perciò definite alcune entità principali (PERSONA, CITTÀ),
mentre operazioni di generalizzazione producono le altre entità (UOMO, DONNA,
MILITARE, LAVORATRICE).
Da questo primo frammento di schema possiamo poi passare a considerare le proprietà
fondamentali delle entità fin qui trovate, ricordando che le entità sono null’altro che
aggregazioni di attributi (definizione intensionale di entità). Del numero potenzialmente
illimitato di attributi, è facile identificare quelli più immediatamente rilevanti per il
nostro universo del discorso: il nome ed il cognome (elementi di identificazione
personale), l’età e l’altezza (legati all’idoneità al servizio di leva), la provincia e la
regione di residenza (vincoli alla destinazione finale del militare di leva).
Si può notare che accanto all’entità CITTÀ non sono state introdotte anche le entità
PROVINCIA e REGIONE, malgrado i citati vincoli sulle destinazioni dei militari di
leva facciano riferimento ala regione di residenza. Nel caso di classi di oggetti la cui
estensione è delimitata, magari in seguito a norme o a standard di qualsiasi natura, come
è il caso della CITTÀ o della REGIONE, vale una evidente regola di economia che
suggerisce di elevare al rango di entità soltanto una, normalmente la più numerosa, e
rappresentare le altre come attributi della prima. Al termine di questo passo, gli attributi
sono sparsi nello schema senza un particolare ordine.
Passando alle relazioni, si può notare che i concetti anagrafici di luogo di residenza e di
luogo di nascita sono stati rappresentati non tramite nuove entità (ad esempio
CITTÀ_DI_RESIDENZA) ma come relazioni tra entità esistenti (PERSONA e CITTÀ):
appare chiaramente che la relazione è il costrutto che permette di introdurre nuove classi
“mettendo a fattore” quelle già definite.
Detto questo, si lascia al lettore la scelta di procedere con i seguenti passi.
1. Ristrutturare lo schema tenendo conto della proprietà fondamentale delle
generalizzazioni descritta in precedenza.
2. Lo schema rappresenta solo le lavoratrici donne; modificare lo schema
rappresentando ora tutti i lavoratori, uomini e donne.
3. Tra le proprietà delle città, l’attributo regione può essere visto anche come un
attributo del concetto PROVINCIA. Ristrutturare lo schema in tal senso.
Cardinalità
Le cardinalità sono proprietà di relazioni; la cardinalità minima di una entità definita in
una relazione è il minimo numero di volte che ogni occorrenza della entità può essere
coinvolta in una occorrenza della relazione. Il valore 0 significa che può esistere una
occorrenza di entità non coinvolta in alcuna occorrenza di relazione. Il valore 1 (n)
significa che non può esistere occorrenza senza essere coinvolta in 1 (n) relazioni.
Analoga definizione vale per la cardinalità massima. Le cardinalità minime e massime n
ed m di una entità in una relazione sono indicate con il simbolo (n,m) accanto alla entità.
Ad esempio, nella relazione TRA dello schema di Figura 3.11, le cardinalità sono:
14
1. (2,2) per la entità PARTITA (una partita si svolge esattamente tra due squadre).
2. (1,1) per la entità SQUADRA (una squadra è coinvolta esattamente una volta in una
partita).
Nella relazione GIOCA-IN le cardinalità sono:
1. (11, n) per la entità SQUADRA (una squadra deve avere come minimo 11 giocatori,
ma in generale ne ha molti di più).
2. (1,1) per la entità GIOCATORE (un giocatore, in un campionato, gioca esattamente
in una squadra).
3.
La progettazione di schemi concettuali: un esempio
Vogliamo in questa sezione approfondire alcuni problemi connessi con le attività legate
all’utilizzo di schemi, descritte nella precedente sezione. Ci riferiamo in particolare alle
attività di progettazione.
Nel corso del progetto di uno schema noi siamo interessati a produrre schemi che siano
la fedele e completa descrizione dei requisiti, ed allo stesso tempo siano chiari e facili da
comprendere. Riguardo alla facilità di comprensione, occorre notare che nel modello
Entità Relazione le stesse informazioni possono essere rappresentate in generale in molti
modi possibili. Consideriamo ad esempio gli schemi di Figura 10.
PERSONA
NOME
COGNOME
ETA'
SESSO
NOME
COGNOME
ETA'
CITTA' NASCITA
PROVINCIANASCITA
PERSONA
NATO
DONNA
UOMO
NOME
CITTA'
SITUAZIONE MILITARE
Primo schema
Secondo schema
Figura 10 - Due schemi concettuali che rappresentano gli stessi requisiti
I due schemi rappresentano le stesse informazioni, alcune volte allo stesso modo, altre
volte con strutture diverse. Infatti, ad esempio:
1. la città in cui è nata una persona è rappresentata nel primo schema per il tramite di
una relazione associata a PERSONA, nel secondo semplicemente mediante un
attributo.
15
2.
gli uomini sono rappresentate nel primo schema come le persone di sesso maschile,
nel secondo mediante la entità UOMO.
I due schema hanno lo stesso contenuto informativo (rappresentano cioè lo stesso
insieme di requisiti), ed ognuno enfatizza determinati aspetti mettendone, per cosi' dire,
altri in secondo piano.
Passando ora più specificatamente al progetto di uno schema, vogliamo ora mostrare e
discutere a titolo di esempio alcune strategie con cui possiamo procedere nel corso del
progetto. Le più importanti strategie sono le seguenti:
1. La strategia top-down produce lo schema finale attraverso una serie di raffinamenti
successivi (vedi Figura 11a), partendo da uno schema iniziale con pochi concetti
molto astratti, e raffinando via via lo schema con trasformazioni che aumentano
progressivamente il grado di dettaglio nella rappresentazione della realtà di
interesse. Mostriamo in Figura 3.15 alcuni esempi di trasformazioni elementari (o
primitive, nel seguito) tipiche della strategia top-down. Come si vede, ogni
primitiva raffina un concetto elementare (una entità o relazione) in una struttura più
complessa.
2. La strategia bottom-up (Figura 11b) procede rappresentando ogni aspetto
elementare della realtà di interesse per mezzo di un semplice schema concettuale,
procedendo poi a fondere questi schemi fin quando non si ottiene lo schema finale.
RAFFINAMENTI
La strategia top-down
La strategia bottom-up
a)
(b)
Figura 11 - Le strategie top-down e bottom -up
Esempio
Mostriamo un esempio di applicazione delle due metodologie progettando lo schema
concettuale di una applicazione anagrafica, in cui si vuole rappresentare dati relativi ad
16
un insieme di persone. Partiamo dalle seguenti specifiche. Vogliamo rappresentare un
insieme di dati relativi ad una applicazione anagrafica. In particolare i dati riguardano:
1. Le persone, di cui si vuole rappresentare il nome, il cognome, il sesso, e l’età.
2. I posti dove le persone vivono e dove sono nati. I posti possono essere di due tipi:
comuni, o stati esteri. Nel caso siano comuni, si vuole ricordare la provincia e
regione in cui è situato il comune. Nel caso di stati esteri, si vuole rappresentare la
popolazione.
3. Per le persone occupate si vuole ricordare il posto dove lavorano; per le persone non
occupate si vuole ricordare se abbiamo o meno lavorato nel passato.
DATI
SULLE PERSONE
DATI
ANAGRAFICI
DATI
SUI LUOGHI
Figura 12 - La trasformazione top-down primitiva
Possiamo inizialmente rappresentare l'applicazione per mezzo di una unica entità (vedi
Figura 12), che racchiude l’intero significato dello schema, chiamata DATI
ANAGRAFICI. Possiamo poi raffinare questa entità per mezzo di una trasformazione
che individua all’interno della applicazione due gruppi di dati, DATI-SULLEPERSONE e DATI-SUI-LUOGHI, in relazione tra di loro. Se ora consideriamo i
concetti dello schema possiamo osservare quanto segue:
1. La entità DATI-SULLE-PERSONE può essere raffinata in tre entità distinte,
PERSONA, OCCUPATO e NON-OCCUPATO, tra cui è definita una gerarchia di
generalizzazione.
2. La entità DATI-SUI-LUOGHI può esser raffinata, con un ragionamento simile, in
una gerarchia di generalizzazione formata da LUOGO, STATO-ESTERO e DATISUI-COMUNI. Quest' ultimo nome è meno preciso dei precedenti perchè al
contrario degli stati esteri, vogliamo rappresentare vari tipi di proprietà dei comuni:
comune è perciò ancora un concetto provvisorio, che va ulteriormente raffinato.
3. La relazione RIFERITO-A è troppo generica; la possiamo raffinare in tre relazioni
distinte, NATO, VIVE e LAVORA. Le prime due sono riferite alla entità
PERSONA, la terza alla entità OCCUPATO.
Le trasformazioni applicate sono mostrate in Figura 13a. Come risultato di queste
trasformazioni otteniamo lo schema di Figura 13b.
17
PERSONA
DATI
SULLE
PERSONE
Trasformazione primitiva
sulle persone
NON
OCCUPATO
OCCUPATO
LUOGO
Trasformazione primitiva
sui luoghi
DATI SUI
LUOGHI
STATO
ESTERO
Trasformazione primitiva
sulle relazioni
RIFERITO
A
DATI SUI
COMUNI
VIVE
NATO
LAVORA
(a) Un insieme di trasformazioni top-down
LAVORA
NATO
PERSONA
PERSONA
LUOGO
VIVE
OCCUPATO
STATO
ESTERO
NON
OCCUPATO
DATI SUI
COMUNI
(b) Lo schema dopo la applicazione delle trasformaziomi
Figura 13 - Un insieme di trasformazioni top-down ed il corrispondente schema prodotto
Lo schema di Figura 13 non descrive ancora tutto il contenuto informativo delle
specifiche. In particolare:
1.
2.
3.
Non abbiamo ancora descritto gli attributi di PERSONA.
Per quanto riguarda i comuni, noi vogliamo rappresentare sia la provincia che la
regione. Possiamo rappresentare queste informazioni espandendo la entità DATISUI-COMUNI in due entità COMUNE e PROVINCIA, associando alle due entità
gli attributi NOME-COMUNE, NOME-PROVINCIA e REGIONE.
Infine, dovremo aggiungere gli attributi alla entità NON- OCCUPATO.
Aggiungendo ora allo schema finale tali concetti e le cardinalità, otteniamo lo schema di
Figura 14.
18
LAVORA
(1,1)
(1,n)
COGNOME
NOME
(1,n)
NOME
SESSO
ETA'
PERSONA
LUOGO
NATO
(1,1)
(1,1)
(1,n)
VIVE
OCCUPATO
NON
OCCUPATO
STATO
ESTERO
COMUNE
HA LAVORATO?
POPOLAZIONE
(1,1)
IN
(1,n)
NOME
REGIONE
PROVINCIA
Figura 14 - Lo schema finale
Applicando la strategia bottom-up, possiamo procedere secondo il seguente ordine:
1. le proprietà elementari, cioè gli attributi;
2. un primo insieme di aggregazioni, rappresentate dalle entità;
3. le generalizzazioni ed i sottoinsiemi definiti tra entità;
4. un secondo insieme di aggregazioni rappresentate dalle relazioni.
Seguendo questo procedimento c'è in genere necessità di ristrutturare di volta in volta lo
schema, poiché una visione unitaria della proprietà dello schema si può avere solo
quando i diversi concetti siano stati rappresentati; ad esempio (vedi figura 15), è
possibile che siano stati individuate le due entità UOMO e DONNA, e ad entrambe
siano state associati gli stessi attributi. Dopo aver individuato la entità PERSONA,
generalizzazione di entrambe, è necessario ristrutturare lo schema assegnando gli
attributi alla nuova entità.
NOME
COGNOME
PERSONA
SESSO
ETA'
NON
OCCUPATO
HA LAVORATO?
OCCUPATO
Figura 15 - Ristrutturazione degli attributi
19
Riassumendo i vantaggi e gli svantaggi delle due strategie, possiamo affermare che la
strategia top-down, disciplinando le modalità di raffinamento dello schema, produce
sempre schemi che rappresentano l’intera applicazione in modo integrato e strutturato,
senza richiedere la necessità di modifiche o aggiornamenti su parti dello schema; allo
stesso tempo, è talvolta difficile da applicare in maniera rigorosa, proprio per questa sua
caratteristica di richiedere sempre una visione complessiva della realtà di interesse. Il
metodo bottom-up è in un certo senso nella situazione opposta: apparentemente è facile
da applicare, ma può dar luogo a sorprese.
4.
Possibili ulteriori utilizzi degli schemi dei dati nei sistemi informativi
In questo capitolo abbiamo visto l’attività di produzione di uno schema dei dati come
strettamente legata alla attività di analisi. In effetti gli schemi dei dati possono essere
prodotti e utilizzati anche in diversi altri contesti. Essi sono:
• la individuazione del contenuto informativo comune a due o più basi di dati;
• la individuazione delle ridondanze e delle incoerenze tra più basi di dati;
• la produzione dello schema dati della organizzazione;
• l’integrazione di due o più schemi dati.
Per ciascuno di essi vediamo il significato, l’utilità nel ciclo di vita dei sistemi
informativi come possa essere svolta la attività, e qualche esempio di utilizzo.
4.1. Individuazione del contenuto informativo comune a due o più basi di dati
Abbiamo detto che le basi di dati del sistema informativo di una grande organizzazione
sono sempre sviluppate nel tempo in maniera disorganica. Per esempio la sola Pubblica
Amministrazione centrale italiana gestisce circa 600 basi di dati di dimensione maggiore
di un gigabyte, sviluppate negli ultimi 30 anni. Può essere utile per molte ragioni
comprendere quale sia il contenuto informativo comune a due o più basi di dati, ed in
particolare:
• per capire se sia opportuno unificare o fondere le due basi di dati, allo scopo di
aumentare il numero di interrogazioni o elaborazioni che possono essere effettuate
sull’insieme delle due basi di dati, e semplificarne la gestione e l’aggiornamento.
• per capire, anche mantenendo distinte le due basi di dati, quali interrogazioni o
elaborazioni ulteriori potrebbero essere fatte collegando le due basi di dati in un
sistema distribuito.
• Per capire quali ulteriori informazioni dovrebbero essere descritte in una o in
entrambe le basi di dati per accrescere il contenuto informativo complessivo delle
basi di dati.
Per individuare le eventuali ridondanze, intendendo per ridondanza la presenza delle
stesse tipologie di informazioni nelle diverse basi di dati. In un sistema distribuito, la
presenza di ridondanze è una scelta che va fatta con molta cura, perché ogni ridondanza
obbliga a gestire gli aggiornamenti delle diverse copie della stessa informazione
attraverso elaborazioni che possono essere anche molto complesse, quanto più
l’informazione è duplicata nel sistema. Avendo a disposizione gli schemi concettuali di
20
partenza, il contenuto informativo comune può essere individuato analizzando le entità e
le relazioni dei due schemi e selezionando le entità e relazioni con gli stessi nomi, e
quelle che pur non avendo gli stessi nomi risultato corrispondere allo stesso concetto del
mondo reale (sinonimi).
4.2.
Individuazione delle incoerenze tra più basi di dati
In questo caso vogliamo comprendere quanto le scelte progettuali effettuate in termini di
informazioni rappresentate negli schemi abbiamo portato ad introdurre scelte concettuali
diverse nella rappresentazione della stessa tipologie di informazione. Per esempio, in
una base dati anagrafica è possibile modellare l’indirizzo di residenza con diverse
modalità concettuali:
a. con un unico attributo INDIRIZZO, rappresentato con una stringa di caratteri di
lunghezza fissata (esempio, 50 caratteri alfabetici)
b. con quattro
attributi VIA, NUMERO
CIVICO, CODICE AVVIAMENTO
POSTALE, CITTÀ, rappresentati rispettivamente con una stringa di caratteri, un
numero, un numero, una stringa di caratteri.
c. Con opportune varianti delle scelte precedenti.
Spesso nel passato, al fine di ottimizzare lo spazio occupato in memoria, sono state
effettuate scelte di tipo a, che portano ad una riduzione del numero degli attributi. Ma
anche in questo caso, se ci si trovava a realizzare diverse basi di dati in cui compariva lo
stesso attributo Indirizzo, potevano essere scelte per le stringhe di caratteri diverse
lunghezze. Nella Pubblica amministrazione centrale esistono decine di basi di dati in
cui è rappresentato un attributo indirizzo: le basi di dati fiscali, quelle catastali, quelle
previdenziali, e cosi via.
Una diversa rappresentazione delle stesse informazioni in basi di dati diverse porta a
diversi effetti indesiderati: prima di tutto non è più possibile, o, meglio, diventa molto
più difficile, collegare le basi di dati per il tramite della informazione rappresentata in
modo incoerente, perché essa può assumere valori diversi. In secondo luogo, diventa
molto oneroso l’aggiornamento delle diverse copie. In terzo luogo diventa onerosa
qualunque progetto di integrazione delle basi di dati, perché è necessario ricostruire la
versione corretta della informazione.
4.3.
Integrazione di due o più schemi dati
Avere a disposizione gli schemi concettuali delle basi di dati diventa importante anche in
qualunque attività di integrazione delle stesse.(vedi figura 16).
21
DBMS
Utenti
Utenti
DBMS
Utenti
DBMS
Utenti
(b) Unica base dati centralizzata
(a) Basi di dati separate
DBMS
Utenti
Utenti
DBMS
Utenti
DBMS
Utenti
Utenti
(c) Base dati distribuita
DBMS
DBMS
(f) Uso di traduttori
Utenti
DBMS
DBMS
(e) Base dati federata
adaccoppiamento debole
(c) Base dati federata ad
accoppiamento forte
Utenti
DBMS
Utenti
DBMS
DBMS
Utenti
DBMS
Utenti
Utenti
Utenti
(g) Base di dati con estrazione di dati
(h)Data warehouse
Figura 16 - Forme di integrazione tra basi di dati
La forma più stretta di integrazione tra basi di dati si ottiene mediante la integrazione
delle diverse basi di dati in una unica base dati (figura 16.b), cioè il ritorno alla
precedente situazione di totale centralizzazione. In questo caso, avere a disposizione gli
schemi concettuali delle basi di dati da integrare permette di arrivare ad una integrazione
di natura semantica tra le diverse basi di dati, che tiene cioè conto del significato delle
informazioni presenti, e facilita perciò la comprensione tra gli utenti e la correttezza
delle elaborazioni. Per fare un esempio, se nelle attuali basi di dati compaiono due
archivi in uno dei quali sono riportati in distinte tabelle i fatturati di un insieme di
aziende nei dodici distinti mesi dell’anno, espressi in migliaia di lire e nell’altro tale
insieme di informazioni è rappresentato in una unica tabella, espressi in milioni, nella
base dati integrata tali differenze di rappresentazione vengono rimosse, dando luogo ad
una unica omogenea rappresentazione. Questa forma di integrazione è in realtà molto
difficile da attuare, per la grande rapidità con cui dati e basi di dati evolvono nelle
organizzazioni, e spesso inopportuna o non realizzabile, per la autonomia che utenti e
gruppi di utenti intendono mantenere sulle basi di dati da essi create e aggiornate.
Una variante della precedente scelta è quella delle basi di dati distribuite, in cui la base
dati è ancora gestita da un unico DBMS, ma può essere frammentata in tante basi di dati
locali. Ciò in genere migliora l’efficienza per accessi locali, ma rende più complessi
problemi di aggiornamento su diverse basi di dati. In questa soluzione, usualmente, lo
22
schema concettuale dell’insieme delle basi di dati è l’elemento di partenza per compiere
le scelte razionali sulle modalità di distribuzione.
Tutte le soluzioni successivamente esposte indeboliscono progressivamente il tipo di
integrazione tra le diverse basi di dati. In una base dati federata ad accoppiamento forte
le diverse basi di dati vengono gestite autonomamente da diversi DBMS, ma esiste un
nuovo componente software che ha la possibilità di accedere omogeneamente alle
diverse basi di dati, coordinandone le operazioni. In questo caso lo schema concettuale è
indispensabile per permettere a tale componente software di comprendere dove siano
allocate nella federazione le diverse tipologie di informazione, e in quale formato
concettuale e logico. In una base di dati federata ad accoppiamento debole, rispetto alla
precedente, il nuovo componente garantisce soltanto una visione virtuale integrata, ma
non ha potere di intervento gestionale sui sistemi che rimangono fortemente autonomi.
Le tecnologie a gateway (traduttori o filtri tecnologici) permettono di tradurre richieste
formulate in un linguaggio per un DBMS A in termini di richieste per il linguaggio
adottato dal DBMS B. Hanno il vantaggio che non richiedono nessuno o limitato
sviluppo di software aggiuntivo, ma richiedono componenti ad hoc per ogni singola
relazione tra sistemi distinti, e fanno perdere la trasparenza resa possibile dalle soluzioni
precedenti.
Il meccanismo più debole di integrazione tra basi di dati è quello della estrazione e
trasferimento di dati, con aggiornamento periodico della base dati locale a partire dalla
base dati remota.
In tutte le precedenti forme di integrazione, questa viene instaurata operando sulle basi di
esistenti con nuovi componenti architetturali. Nei data warehouse (magazzini o depositi
di dati) viene creata (periodicamente) una nuova base dati, che nasce dalla integrazione
stretta delle basi di dati esistenti, e tale nuova base dati viene resa accessibile con potenti
linguaggi per l’analisi e la estrazione di informazioni rilevanti a fini decisionali. La
produzione dello schema concettuale integrato delle basi di dati è il passo preliminare
fondamentale a tutte le attività di produzione del data warehouse.
4.4. Produzione dello schema dati della organizzazione
Nella vita di una organizzazione, esistono momenti, ad esempio nella fase di
pianificazione dei sistemi informativi, in cui si ha necessità di acquisire una visione
integrata e di alto livello, indipendente ciò dalle tecnologie utilizzate e dalle scelte
contingenti effettuate, dello stato del sistema informativo della organizzazione. Si pensi
ad una Pubblica Amministrazione nella quale sia in corso un processo di
riorganizzazione delle competenze, modifica delle strutture organizzative con fusione di
alcune, introduzione di strutture di coordinamento, accorpamento delle stesse funzioni
in una unica struttura, ecc.
In tali situazioni, può essere molto utile costruire lo schema concettuale di alto livello
delle informazioni trattate nella organizzazione, chiamato talvolta “Enterprise schema”
23
o Schema di organizzazione. Naturalmente tale schema può essere prodotto a diversi
livelli di dettaglio, e quindi, nella sua versione più estesa può contenere centinaia di
entità e relazioni differenti. È ragionevole arrivare alla definizione di uno Schema di
organizzazione in cui il numero di entità e relazioni sia contenuto nell’ordine delle
decine, non superando mai le 40-50, che possono considerarsi una soglia al di sopra
della quale diventa molto complesso e costoso produrre lo schema. Le entità e relazioni
che compariranno nello Schema di organizzazione saranno di conseguenza macroentità
e macrorelazioni, cioè entità e relazioni che nascono dalla aggregazione di informazioni
elementari utilizzate nella organizzazione.
Come conseguenza del procedimento di costruzione accennato, lo Schema di
organizzazione contiene le tipologie di informazioni più importanti trattate nella
organizzazione. Collegando in una matrice tali tipologie di informazione, ma soprattutto
le entità, con i processi che creano, aggiornano e utilizzano le informazione (vedi figura
17) si ha una visione sintetica ma efficace dei flussi informativi tra processi, che
permette di individuare le entità aggiornate da più processi, ovvero i gruppi di processi
ed entità caratterizzati da alta coesione interna, chiamati in alcune metodologie Aree di
business. Una simile matrice può essere prodotta collegando le Unità Organizzative e le
Entità.
P rocessi/ Entità
Entità1
Processo1
Processo2
Processo3
Processo4
Processo5
Crea
Entità2
Entità3
Usa
Usa
Usa
Crea
Entità4
Entità5
Entità6
Crea
Usa
Aggiorna
Crea
Usa
Usa
Entità7
Usa
Crea
Crea
Crea
Usa
Figura 17 - Matrice Processi/Entità
Esempio
Negli anni 1993–1995 l’AIPA ha condotto una rilevazione dello stato dei sistemi
informativi della Pubblica Amministrazione centrale che ha portato a costruire circa 260
schemi concettuali delle principali basi di dati, con circa 4200 entità e relazioni
rappresentate. Tali schemi sono stati successivamente raggruppati secondo criteri di
omogeneità di materia in 31 diverse aree (vedi figura 17): protocollo, organi collegiali,
fisco, dogane, ecc., producendo per ciascuna area uno schema concettuale. Tale schema
concettuale è il risultato della integrazione di tutti gli schemi di partenza che
appartengono alla stessa area, e di una successiva attività di selezione delle macroentità
principali dello schema integrato. La scelta delle aree è stata effettuata secondo criteri di
similitudine degli schemi, e come conseguenza la numerosità degli schemi che sono
ricaduti in ciascuna area (riportata in figura insieme al numero delle entità) è molto
disomogenea.
A questo punto i 31 schemi concettuali di area sono stati ulteriormente integrati in 19
schemi di materia, ove le materie sono state scelte sulla base di classificazioni esistenti
24
nella Pubblica Amministrazione: risorse di supporto, risorse finanziarie, giustizia,
sicurezza, ecc. Per ciascuna materia, è stato costruito uno schema concettuale secondo i
due procedimenti di integrazione e scelta delle macroentità principali. Tale
procedimento è stato utilizzato per costruire gli ulteriori schemi integrati corrispondenti
ai servizi sociali ed economici, ai servizi generali, i servizi diretti, raggruppati
successivamente in un unico schema dei servizi, che insieme allo schema delle risorse è
stato infine integrato in quello che possiamo definire lo Schema di organizzazione della
Pubblica Amministrazione, rappresentato a tre diversi livelli di aggregazione.
SCHEMA INTEGRATO DELLE BASI DI DATI DELLA PA DI 1° LIVELLO
SCHEMA INTEGRATO DELLE BASI DI DATI DELLA PA DI 2° LIVELLO
SCHEMA INTEGRATO DELLE BASI DI DATI DELLA PA DI 3° LIVELLO
RISORSE
SERVIZI
SERVIZI SOCIALI ED ECONOMICI
SERVIZI DIRETTI
SERVIZI SOCIALI
TRASPORTI
10/178
AZIENDE AGRICOLE
AZIENDE INDUSTRALI
9/112
LAVORO
TRASPORTI
LAVORO PRODUZIONE COMUNICAZIONI
9/118
AMBIENTE
BENI CULTURALI
ISTRUZIONE
CULTURA
10/100
8/213
3/134
ASSISTENZA
5/56
SERVIZIO SANITARIO
6/155
CRIMINALITA'
SICUREZZA INTERNA
6/130
10/76
ATTIVITA' GIURIDICA
EDILIZIA
GIUSTIZIA SICUREZZA SANITA' ISTRUZIONE
AMBIENTE
6/76
RELAZIONI ITALIANE ALL' ESTERO
RELAZIONI ESTERE IN ITALIA
4/36
DIFESA
6/53
CATASTO
CERTIFICAZIONI
PREVIDENZA
9/118
3/66
4/121
RAPPRESENTANZE
3/75
ENTI TERRITORIALI
SERVIZI
ASSICURAZIO- AFFARI
STATISTICA
SOCIALI E CERTIFICAZIONE
NE SOCIALE ESTERI
TERRITORIALI
6/95
DIPENDENTI
FORMAZIONE
BENI IMMOBILI
RISORSE
UMANE
37/336
STRUMENTI
AUTOMEZZI
3/59
2/89
2/65
TRASFERIMENTO FONDI
A ENTI LOCALI PER ENTI PUIBBLICI
3/30
6/69 FISCO
8/293
RISORSE
STRUMENTALI E
IMMOBILIARI
RISORSE
FINANZIARIE
3/182
DOGANE
CAPITOLI DI SPESA
PROTOCOLLO
2/12
2/93
ORGANI COLLEGIALI
RISORSE DI
SUPPORTO
SERVIZI ECONOMICI
3/53
SERVIZI GENERALI
Figura 18 - Le attività per la produzione degli schemi concettuali della Pubblica Amministrazione
Riportiamo in figura lo schema più astratto, in cui comp aiono le entità:
• Soggetto, cui corrispondono i soggetti fisici e giuridici che chiedono servizi alla
Pubblica amministrazione.
• Bene, che corrisponde all’insieme dei Beni mobili e Immobili su cui la Pubblica
Amministrazione ha responsabilità ed eroga servizi.
• Documento, che corrisponde all’insieme dei documenti che la Pubblica
Amministrazione utilizza e produce nei processi amministrativi.
• Riferimento Territoriale, costituito dall’insieme di tutte le modalità
amministrative e geografiche con cui è possibile descrivere il territorio (es, comune,
provincia, particella catastale, ecc.).
• Unità Organizzativa, che descrive tutte le suddivisioni organizzative in cui si
articola la Pubblica Amministrazione centrale (ministeri, direzioni generali,
divisioni, uffici, unità periferiche).
25
Unità
organizzativa
Bene
Soggetto
Documento
Riferimento
territoriale
Figura 19 - Lo schema concettuale delle macroentità principali della Pubblica Amministrazione
Rappresentiamo infine in figura 20 una descrizione grafica di matrice Unità
Organizzative/Entità, in cui per le entità Organizzative sono rappresentate le Pubbliche
amministrazioni Centrali (descritte da acronomi, es. MF è il Ministero delle Finanze) e le
entità sono la macroentità Persona Fisica e tutte quelle per cui Persona fisica è negli
schemi una Generalizzazione: si vede ad esempio come moltissime siano le
amministrazioni che hanno competenza amministrativa sui lavoratori. La figura è un
possibile punto di partenza per procedere ad una razionalizzazione nella gestione delle
informazioni sulle persone fisiche che porti alla individuazione di una o un numero
limitato di amministrazioni con responsabilità di aggiornamento sulle singole sottoentità
e alla creazione di una rete di accesso per tutte le amministrazioni che abbiano rilevante
esigenze di utilizzo.
47 MF, MT
40
MI, MS
38
39
48
37
36
165
35
82
89
Contribuente
ufficio iva
153
163
MI, MT, MD
assistito
162
utente anagrafe
tributaria
appartenente
catasto
tossicodipendente
520
161
contribuente
di guerra
601
studente
straniero
Segretario
comunale
politica
81
disoccupato
MI
lavoro
candidato
653
giustizia
Alla ricerca di
nuova occupazione
160
74
92
190
101
2
88
54
171
autonomo
654
104
4
105
lavoratore
segnalato
affari esteri
straniero
italiano
80
Tossicodipendente
segnalato
detenuto
dipendente
66
in attesa di giudizio
Richiedente
cittadinanza
663
53
71
603
MAE, MF, 7
19
11
108
12 MGG, MI,
10
120
651
21
MIBCA, MLP,
9
2 0 MT,
65 MLPS,
2 4 25
97 109
68MTN,5MCE,
93
96
1
501
131
MD, MURST
45
172 137
64
656
173
55
86
136
516 515
531
506
111
602 170
507
87
16
scuola
pensioni
Persona fisica
52
600
borsista
142
vita
sociale
fisco
Salute ed
assistenza
pensionato
Alla ricerca di
prima occupazione
6
MAE, MURST,
MPI
con handicap
invalidità civile
164
casalinga
volontario
Ricorrente per
invalidità civile
91
MGG, MI,
MIBCA ,
180 650 MT, MTN
526
110
174
59
98
Richiedente
visto
condannato
99
residente
all’estero
72
63
18
27
MAE, MGG,
MI
90
5
132
73
MAE, MI,
MLPS
Figura 20 - Entità che ricadono nella tipologia delle persone fisiche e amministrazioni interessate alla loro
creazione, aggiornamento e utilizzo nei processi amministrativi su cui hanno competenza
26
5.
Uno studio di caso
In questa sezione verrà discusso un caso di analisi e modellazione dei dati ispirato alla
gestione del personale della pubblica amministrazione. Come vedremo, questo tema
presenta allo stesso tempo degli aspetti familiari ed intuitivi insieme ad aspetti di una
certa complessità e problematicità.
5.1.
Introduzione
L’ambito informativo di cui ci vogliamo occupare è stato oggetto di innumerevoli
analisi in conseguenza della sua evidente centralità sociale e politica. Le recenti norme
sul pubblico impiego, ad esempio la legge 421/1992 e il decreto legislativo 29/1993,
hanno affrontato finalità di razionalizzazione della gestione e di contenimento della
spesa che non possono evidentemente prescindere dalla disponibilità di migliori
strumenti informatici e quindi di un’analisi approfondita della realtà. A questo fine la
Presidenza del Consiglio dei Ministri ha dato impulso a diverse attività realizzative e di
studio, e l’Autorità per l’Informatica nella Pubblica Amministrazione ha curato tra
l’altro una rilevazione delle funzioni di amministrazione del personale e uno studio
delle basi di dati del personale nella pubblica amministrazione.
Alcuni dati possono fare intuire le dimensioni di questo ambito di analisi. Come è noto,
della gestione del trattamento economico del personale pubblico è investito
istituzionalmente il Ministero del Tesoro, e precisamente la Ragioneria Generale dello
Stato per quanto riguarda circa 60.000 dipendenti degli uffici centrali e la Direzione
Generale dei Servizi Periferici per circa 1.300.000 dipendenti degli uffici periferici.
Anche le singole amministrazioni però gestiscono talvolta parte delle stesse
informazioni, e in ogni caso devono gestire molte altre informazioni non di competenza
del Ministero del Tesoro. Nel complesso sono utilizzate a questi fini non meno di 37
basi di dati che presentano un’enorme varietà di copertura dei dati e delle funzioni
effettivamente presenti rispetto a quelle desiderabili.
Le origini di questa situazione sono facilmente riconducibili alla naturale autonomia
delle singole amministrazioni, alla loro diversa consistenza in termini di personale, e
alla lunga storia dei sistemi per la gestione del personale, storicamente tra i primi ad
essere stati automatizzati e poi informatizzati.
Per dare un’idea della complessità funzionale insita nella gestione del personale della
pubblica amministrazione, si può notare che la rilevazione appena citata ha identificato,
limitatamente al comparto dei ministeri, ben 150 funzioni elementari, suddivise in tre
livelli di aggregazione, che possono essere visti come una sorta di modello funzionale di
riferimento. Al livello più alto sono state distinte otto macrofunzioni:
1. gestione delle presenze ed assenze
2. acquisizione del personale e cessazione del rapporto di lavoro
3. sviluppi professionali e modificazione del rapporto
4. trattamento economico di servizio
5. trattamento di previdenza e di quiescenza; infermità e causa di servizio
6. contenzioso e disciplina
27
7.
8.
formazione del personale
funzioni accessorie
Ciascuna delle 150 funzioni elementari identificate al livello di maggiore dettaglio,
invece, deve la propria esistenza ad una lista di disposizioni normative che ne regola lo
svolgimento. Per fare solo alcuni esempi, sono considerate funzioni elementari la
gestione
• del trattamento economico di missione (regolato dalla legge 836/1973),
• dei ricorsi amministrativi straordinari presso il Presidente della Repubblica (quattro
riferimenti normativi a partire dal regio decreto 1054/1924),
• della liquidazione dell’indennità di rischio per centralinisti non vedenti (legge
113/1985),
• delle assenze per incarichi di direzione presso aziende sanitarie locali (decreto
legislativo 502/1992).
Quando i requisiti di un sistema sono il risultato di una stratificazione durata molti
decenni, come in questo caso, non può stupire che anche gli archivi, da quelli cartacei
alle basi di dati, soffrano di disorganicità. Lo studio sulle basi di dati del personale ha
evidenziato infatti come alcune amministrazioni, soprattutto nel passato, abbiano gestito
fino a dieci basi di dati diverse al proprio personale, spesso dedicando una specifica base
di dati alla gestione di un aspetto minore, ad esempio le donazioni volontarie di sangue
dei dipendenti.
5.2. Raccolta dei requisiti
Soprattutto in un ambito così complesso, l’analisi dei dati non può partire che da una
descrizione testuale delle attività e delle funzioni di gestione del personale, che potrà
presentare inizialmente carattere di incompletezza e di incoerenza. Come si è visto, parte
integrante dei requisiti è l’intero corpo normativo che regola il settore del pubblico
impiego, e che comprende molte decine di testi di interpretazione talvolta non
immediata. Per il nostro scopo, ci limiteremo qui a considerare i requisiti fondamentali,
già anticipati in precedenza.
Un sistema informativo del personale della pubblica amministrazione deve gestire tutte
gli aspetti riassunti dalle macrofunzioni elencate precedentemente e che risultano dalle
norme vigenti (leggi, regolamenti, contratti collettivi eccetera).
Questa formulazione dei requisiti ha una prima conseguenza niente affatto banale: il
sistema informativo del personale della pubblica amministrazione è regolato da requisiti
normativi in parte comuni a tutte le amministrazioni, e quindi la sua realizzazione
attuale, come insieme debolmente coordinato di sistemi informativi eterogenei, è da
riguardarsi come accidentale. Alcune delle funzioni del sistema del personale,
solitamente indicate come funzioni “di governo” e che comprendono ad esempio la
pianificazione delle assunzioni o l’elaborazione del conto annuale, oppure la definizione
di indirizzi strategici nella formazione del personale, indicano chiaramente la natura
“unitaria” di tale sistema informativo, pur nel rispetto dei confini di responsabilità di
28
ciascuna amministrazione. Si tratta quindi di un buon esempio di sviluppo “a pelle di
leopardo” di un sistema informativo.
Ricordando quanto detto nella sezione 3 sulla progettazione dei dati, possiamo ora
applicare i due procedimenti top-down e bottom-up e sottoporre a verifiche di coerenza e
di completezza gli schemi di dati via via disegnati. Nel nostro caso, in considerazione del
materiale a nostra disposizione rappresentato dagli studi specifici condotti
sull’argomento, faremo un esempio di applicazione del procedimento top-down.
L’obiettivo finale sarà un modello dei dati “unitario” che possa rappresentare i dati
relativi a tutte le funzioni identificate dallo studio citato, e rispetto al quale sia anche
possibile valutare il grado di copertura e di integrazione dei sistemi del personale di
ciascuna amministrazione. Accenneremo anche al procedimento bottom-up che ha
condotto allo schema unitario del personale. Analogamente, facendo riferimento alla
sezione 4, esamineremo ulteriori usi degli schemi di dati nei sistemi informativi.
5.3.
Modellazione dei dati e raffinamento di schemi
Partiamo da un primo schema il cui scopo è delimitare in modo chiaro l’ambito
informativo. Lo schema contiene un solo oggetto, l’entità “lavoratore dipendente
pubblico”.
Lavoratore dipendente
pubblico
Figura 21 - Entità iniziale
Per definire meglio questa entità da un punto di vista intensionale è possibile ora
aggiungere i primi attributi. Notare che a questo stadio tutti i dati rilevanti devono
necessariamente comparire come attributi dell’unica entità, e ciò può rendere illeggibile
lo schema. È quindi conveniente procedere gradualmente prima al raffinamento del
modello e poi all’arricchimento delle entità con i rispettivi attributi. Gli attributi
identificati fin qui sono quelli indispensabili all’identificazione del lavoratore.
cognome
nome
data di nascita
sesso
Lavoratore dipendente
pubblico
Figura 22 - Attributi iniziali dell'entità
29
matricola
codice fiscale
stipendio
ufficio
Passiamo a considerare alcune naturali generalizzazioni. Accade il più delle volte che
l’entità che rappresenta l’ambito informativo di un sistema si trovi al centro di una
catena di generalizzazioni che introduce nel modello nuove entità. Per fare un esempio,
dal momento che evidentemente anche un dipendente di una azienda privata può
concorrere a posti nella pubblica amministrazione, un’amministrazione che bandisce
concorsi pubblici può essere tenuta a gestire dati relativi a qualifica ed anzianità di
dipendenti privati. È opportuno quindi introdurre un’entità “lavoratore”, i cui attributi
rappresenteranno dati su lavoratori generici, mantenendo gli attributi specifici
dell’ambito di interesse nella entità “lavoratore dipendente pubblico”.
cognome
Lavoratore
nome
data di nascita
codice fiscale
sesso
matricola
stipendio
ufficio
Lavoratore dipendente
pubblico
Dipendente di uffici centrali
Candidato
Aspirante ad impiego
pubblico
Dipendente di uffici periferici
Figura 23 - Gerarchia sull'entità LAVORATORE
Tra l’altro, l’introduzione di una “superentità” e la conseguente ridistribuzione degli
attributi contribuisce ad una maggiore chiarezza dello schema di dati.
Riprendiamo ora il procedimento top-down e aggiungiamo nuovi oggetti attorno
all’entità di base. Per il momento è possibile lasciare le relazioni senza un nome, in
quanto i nomi attribuiti sarebbero ancora generici ed arbitrari.
30
Concorso
Situazione amministrativa
cognome
Ufficio
nome
data di nascita
sesso
Lavoratore dipendente
pubblico
Situazione familiare
matricola
codice
fiscale
Provvedimenti
Competenze e ritenute
Figura 24 - Risultato dell'aggiunta di oggetti attorno all'entità iniziale
Per quanto riguarda le entità, alcuni degli attributi (“ufficio”, “stipendio”) vengono a
chiarirsi come attributi complessi, o meglio come nuove entità e nuove relazioni
collegate all’entità iniziale. Ad esempio, raffinando ulteriormente la relazione “ufficio”“lavoratore dipendente pubblico” racchiusa nel rettangolo tratteggiato si ottiene lo
schema seguente.
31
cognome
nome
data di nascita
sesso
Lavoratore dipendente
pubblico
matricola
codice
fiscale
Comune
Ufficio
Ente o amministrazione
Ministero
Ente locale
Ufficio pagatore
Ufficio gestore del personale
Organismo scolastico
Richiesta di trasferimento
Sede di lavoro
Sede estera
Figura 25 - Raffinamento di una relazione
Si può sottolineare che l’introduzione di generalizzazioni nello schema non è
evidentemente il risultato di un esercizio astratto o arbitrario ma riflette piuttosto
l’accrescimento della conoscenza conseguente al processo di analisi. Ad esempio,
l’entità “ufficio” appare ora come vertice di una generalizzazione che permette di
distinguere tra “ufficio pagatore”, “ufficio gestore” e “sede di lavoro”. Questa
generalizzazione discende da una distinzione probabilmente familiare al lettore, ma
soprattutto riflette differenze a livello di dati: tra gli attributi dell’entità “sede di lavoro”
possiamo facilmente ipotizzare il numero degli addetti che vi lavorano, dato scarsamente
pertinente per l’entità “uffico pagatore” di cui potranno forse interessare gli estremi
bancari.
Per fare un esempio un po’ meno intuitivo, la generalizzazione con vertice l’entità “ente
o amministrazione” rispecchia alcune specificità che sconsigliano un trattamento
informatico omogeneo dei trasferimenti del personale del Ministero della Pubblica
Istruzione rispetto a quello degli altri ministeri e degli enti locali. Analoga
considerazione si può fare per la gestione dei trasferimenti da o verso sedi di lavoro
situate all’estero.
Applichiamo ora il procedimento di raffinamento all’entità “competenza o ritenuta”,
racchiusa in un rettangolo tratteggiato nella figura 24. L’articolazione della
generalizzazione rappresentata nella figura è la più complessa tra quelle contenute nello
schema dei dati unitario.
32
Competenza o ritenuta
Rivalutazione monetaria
interessi legali
Detrazione di imposta
Arretrato
Stipendio base
Ritenuta extraerariale
Competenza fissa
Indennità integrativa speciale
Indennità aggiunta di famiglia
Riduzione di stipendio per
scioperi o ritardi
Retribuzione individuale di
anzianità
Assegno ad personam
Altra competenza accessoria
Altra competenza o ritenuta
Straordinario
Competenza accessoria
Tredicesima
Indennità di incentivazione e
produttività
Assegno codificato
Indennità di amministrazione
Indennità di funzione
Incentivo alla produttività
Indennità per progetto
finalizzato
Indennità budget di struttura
Figura 26 - Raffinamento di un’entità
Continuando ad applicare il procedimento top-down potemmo ottenere l’intero schema
di dati integrato contenuto nello studio dell’AIPA. Lo studio stesso è invece un
importante applicazione del procedimento bottom-up che, partendo da 37 basi di dati e
dai relativi schemi concettuali per un totale di 526 tra entità e relazioni, ha permesso di
ottenere uno schema integrato contenente solo 140 oggetti (96 entità e 44 relazioni).
5.4. Schemi di dati e contenuto informativo: indici di copertura
Nella sezione 4. sono stati discussi gli utilizzi degli schemi di dati diversi dalla
modellazione a scopo progettuale. Questi usi sono essenzialmente legate ad una
maggiore conoscenza della realtà informativa di uno o più sistemi informatici. In
particolare, come abbiamo appena visto, lo studio dei sistemi informativi del personale
delle pubbliche amministrazioni può essere condotto per tutti e quattro gli scopi elencati
nella sezione 4.
La disponibilità di uno schema integrato o di uno schema dati dell’organizzazione, sia
pure limitato ad un ambito specifico come quello del personale, rende possibile misurare
33
la completezza e, indirettamente, la coerenza del contenuto informativo delle basi di dati
all’interno di una organizzazione complessa.
Si possono introdurre due misure del grado di frammentazione informativa delle basi di
dati, utilizzate nella rilevazione più volte citata. La prima misura il contenuto
intensionale, cioè la “complessità” della base di dati, attraverso il numero di oggetti
informatici. La seconda misura il contenuto estensionale, cioè le “dimensioni” della base
di dati, attraverso il numero di occorrenze associate a ciascuna entità o relazione. La
complessità delle basi di dati del personale rilevate varia da 3 oggetti (in pratica due
entità e una relazione) a 68, mentre le dimensioni variano grosso modo tra il migliaio di
occorrenze di diverse basi di dati minori presso molte amministrazioni e i dieci milioni
di occorrenze di una grande base di dati del Ministero del Tesoro. Questi dati sono
riassunti nella seguente tabella.
minimo
3
~103
comp lessità (n° oggetti)
dimensioni (n° occorrenze)
massimo
68
~107
Figura 27 - Complessità e dimensioni delle basi di dati del personale
È possibile anche definire una semplice misura del grado di copertura delle basi di dati
del personale, ottenuta dividendo il numero di oggetti rappresentati in una base di dati
con il numero complessivo degli oggetti contenuti in uno schema integrato di
riferimento. Ricordiamo che per oggetto intendiamo un’entità o una relazione.
Nello schema finale dello studio di caso (figura 28), che contiene 43 oggetti, sono stati
evidenziati i 6 oggetti presenti in uno schema dei dati di una ipotetica amministrazione.
L’indice di copertura, calcolato su questo schema parziale, è pari al 14%. In realtà, lo
studio AIPA contiene degli indici di copertura calcolati sull’intero schema dei dati
unitario, che contiene 140 oggetti. Ciò ha permesso di classificare le basi di dati del
personale esistenti presso le amministrazioni in base al loro grado di copertura, compresi
tra l’11% e il 64%.
34
cognome
nome
data di
sesso
matricol
codice
fiscale
Lavoratore dipendente
pubblico
Comune
Richiesta di trasferimento
Ufficio
Ente o amministrazione
Ministero
Ufficio pagatore
Ente locale
Ufficio gestore del
personale
Sede di lavoro
Organismo scolastico
Sede estera
Competenza o ritenuta
Rivalutazione monetaria
interessi legali
Detrazione di imposta
Arretrato
Stipendio base
Ritenuta extraerariale
Competenza fissa
Indennità integrativa
speciale
Altra competenza accessoria
Indennità aggiunta di
famiglia
Riduzione di stipendio per
scioperi o ritardi
Retribuzione individuale di
anzianità
Assegno ad personam
Altra competenza o ritenuta
Straordinario
Competenza accessoria
Tredicesima
Indennità di incentivazione
e produttività
Indennità di
amministrazione
Incentivo alla produttività
Figura 28 - Schema finale dello studio di caso
35
Assegno codificato
Indennità di funzione
Indennità per progetto
finalizzato
Indennità budget di struttura
6.
Riferimenti
A. ALBANO, R. ORSINI - Basi di dati - Boringhieri Editore, Torino, 1986.
P. ATZENI, C. BATINI, V. DE ANTONELLIS - La teoria relazionale dei dati Boringhieri Editore, Torino, 1986.
C. BATINI, S. CERI , S.B.NAVATHE – Conceptual Database Design: An Entity
Relationship Approach - Benjamin & Cummings, 1991.
C. BATINI, G. DE PETRA, M. LENZERINI, G. SANTUCCI - La progettazione
concettuale dei dati - F. Angeli Editore, Milano, 1986.
C. BATINI, M. LENZERINI - Basi di dati, in G. CIOFFI, V. FALZONE (a cura di)
Manuale di Informatica - Calderini Editore, Bologna, seconda edizione, 1988.
C. BATINI, G. LONGOBARDI, M. MAGGI - Le basi di dati del personale nella
pubblica amministrazione: analisi del livello di integrazione e copertura - AIPA.
R. EL MASRI, S. NAVATHE - Foundamentals of Database Systems - Benjamin and
Cummings, 1989.
P. NAGGAR, M. MELLONE - Progetto SIUP - Rilevazione sulle funzioni di
amministrazione del personale - AIPA, 1998.
J. ULLMAN - Principles of Database and Knowledge base Systems - Computer Science
Press, Seconda Edizione, 1988.
36


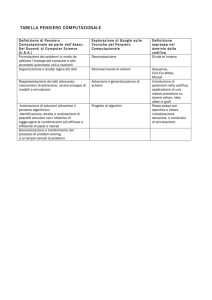
![[inserire TITOLO] - Economia@UniGe](http://s1.studylibit.com/store/data/006909177_1-1c8fc1a590f60bf6abd54c974a058545-300x300.png)






