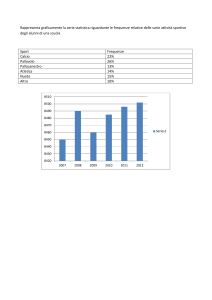
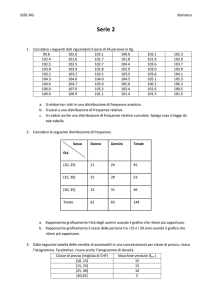
UNIVERSITA’ DEGLI STUDI DI PERUGIA
Dipartimento di Chimica, Biologia e Biotecnologie
Via Elce di Sotto, 06123 –Perugia
Corso di Laurea di Scienze biomolecolari e ambientali
Laurea magistrale
Corso di ANALISI DEI SISTEMI ECOLOGICI
Sito del corso: www.dcbb.unipg.it/cdlscienzebiomol
Alessandro Ludovisi
Sito docente: www.dcbb.unipg.it/alessandro.ludovisi
Tel. 075 585 5712
e-mail address: [email protected]
METODI STATISTICI
1
DISTRIBUZIONI E TEST ASSOCIATI
• DISTRIBUZIONE c2 (CHI-QUADRO)
• DISTRIBUZIONE t DI STUDENT
• DISTRIBUZIONE DI POISSON
LA DISTRIBUZIONE c2 (CHI-QUADRO)
La distribuzione chi-quadro è la distribuzione di probabilità di una variabile aleatoria definita come:
k
c ( k ) xi 2 x12 x2 2 ...xk 2
2
i 1
dove x1,…, xk sono variabili aleatorie indipendenti con distribuzione normale standard N(0,1). k è quindi il
numero dei termini della sommatoria, detto anche gradi di libertà.
Per il teorema del limite centrale, la distribuzione c2(k) converge ad una distribuzione normale per k che tende
a infinito. Più precisamente, se c2(k) segue la distribuzione c2, allora la distribuzione di c 2 ( k ) k
tende ad una distribuzione normale standard N(0,1)
2k
k=1
Probabilità
k=2
k=3
k=4
k=5
k=6
k=7
Nelle applicazioni pratiche (test chi-quadro), la
variabile aleatoria su cui si effettua il test è lo
scarto tra valori osservati e attesi (come
frazione rispetto al valore atteso), che è attesa
distriburisi secondo c2 , ammesso che si
comporti appunto come aleatoria.
Si testa infatti che lo scarto sia il semplice frutto
di variazioni casuali
IL TEST c2 (CHI-QUADRO)
La variabile test chi-quadro si ottiene sommando, per ogni evento Ei il quadrato degli scarti tra le
frequenze teoriche e quelle osservate pesato sulle frequenze teoriche:
k
c 2( k )
i 1
oi ei 2
ei
Evento
E1
E2
...
Ek
Frequenze osservate
o1
o2
...
ok
Frequenze attese
e1
e2
...
ek
N.B.: le frequenze sono sempre frequenze assolute. Frequenze percentuali o relative vanno sempre ritrasformate
in frequenze assolute moltiplicandole per il numero di osservazioni, perché il test è sensibile alla dimensione del
campione.
Se c² (k)= 0, le frequenze osservate coincidono esattamente con quelle teoriche. Se invece c²(k) > 0,
esse differiscono. Più grande è il valore di c²(k) , più grande è la discrepanza tra le frequenze osservate e
quelle teoriche.
Il test del chi-quadro serve a saggiare l'ipotesi che la discrepanza tra frequenze attese e frequenze
osservate sia dovuta:
Ipotesi H0: al caso (campione limitato, imprecisione, errore distribuito, ecc.);
Ipotesi H1: al fatto che il campione provenga da una popolazione diversa da quella da cui deriva la frequenza
attesa.
IL TEST c2 (CHI-QUADRO)
La significatività della discrepanza tra frequenze osservate e attese, ovvero la certezza con la quale si può
rigettare l’ipotesi Ho, si può valutare dalla tavola di distribuzione teorica del chi-quadro, che è funzione dei gradi
di libertà (g.d.l.) legati al campione:
g.d.l. = (n. di righe-1) x (n. di colonne -1)
IL TEST c2 (CHI-QUADRO)
Supponiamo che in un campione si osservi che determinati eventi E1, E2, …, Ek si realizzino con frequenze
o1, o2, …, ok dette frequenze osservate. Supponiamo d’altra parte che vi siano motivi per attendersi una
distribuzione di frequenze e1, e2, …, ek dette frequenze teoriche o attese:
Evento
E1
E2
...
Ek
Frequenze osservate
o1
o2
...
ok
Frequenze attese
e1
e2
...
ek
Le frequenze attese possono essere stabilite:
• a priori, ovvero costruendo una distribuzione rispetto alla quale si vuole
valutare l’aderenza del campione
• in base alla conoscenza della popolazione statistica o del fenomeno in
esame
TEST CHI-QUADRO DELLA BONTA’ DELL’ADATTAMENTO (o CHI-QUADRO di
PEARSON)
• costruendo una distribuzione attesa cumulata in base alle frequenze
osservate su n campioni
TEST CHI-QUADRO PER CAMPIONI INDIPENDENTI
IL TEST c2 (CHI-QUADRO) - BONTÀ DI ADATTAMENTO (O CHI-QUADRO DI PEARSON)
Le frequenze attese sono stimate in base alla legge nota o ipotizzata, ripartendo il numero totale di osservazioni
nelle k categorie
Categoria
1
2
…
k
Frequenze
osservate
f1
f2
…
fk
ftot
Frequenze
attese
= p1·ftot
= p2·ftot
…
= pk·ftot
ftot
NB: Il test si considera
affidabile se tutte le
frequenze attese
raggiungano un valore
minimo (a seconda
delle esigenze), in
genere almeno pari a
5.
Probabilità
teorica
p1
p2
…
pk
1
Lanci di moneta
Categoria (esito del lancio)
Osservato Atteso
TESTA
CROCE
Gradi di libertà
Chi quadro - livello di confidenza per Ho
Chi quadro - probabilità sinistra
Chi quadro - probabilità destra
pi
(%) (%) Chi-quadro valori
20
22.5
0.5 44.4 50.0
0.28
25
45
22.5
45
0.5 55.6 50.0
1 100 100
0.28
0.56
1
0.4561
0.5439
0.4561
1.0000
IL TEST c2 (CHI-QUADRO) - BONTÀ DI ADATTAMENTO (O CHI-QUADRO DI PEARSON)
Le frequenze attese sono stimate in base alla legge nota o ipotizzata, ripartendo il numero totale di osservazioni
nelle k categorie
Lanci di dado
Categoria (esito del lancio)
1
2
3
4
5
6
Gradi di libertà
Chi quadro - livello di confidenza per Ho
Chi quadro - probabilità sinistra
Chi quadro - probabilità destra
Osservato Atteso
28
35
35
35
42
35
35
35
28
35
42
35
210
210
5
0.347105
0.6529
0.3471
pi
0.17
0.17
0.17
0.17
0.17
0.17
1
(%)
13.3
16.7
20.0
16.7
13.3
20.0
100
(%) Chi-quadro valori
16.7
1.40
16.7
0.00
16.7
1.40
16.7
0.00
16.7
1.40
16.7
1.40
100
5.60
IL TEST c2 (CHI-QUADRO) - TEST PER CAMPIONI INDIPENDENTI
Il test verifica l'ipotesi nulla che due campioni derivino dalla stessa popolazione (di cui non è richiesto conoscere
la distribuzione). Le frequenze attese sono stimate in base alla distribuzione cumulata dei campioni esaminati
TABELLA DI CONTINGENZA
Categoria F. Osservate F. Osservate
campione 1 campione 2
1
f1
f’1
2
f2
f’2
…
…
…
k
fk
f’k
ftot
f’tot
F. Cumulate
(marginali)
F1 = f1 + f’1
F2 = f2 + f’2
…
Fk = fk + f’k
F = ftot + f’tot
F. Attese
F. Attese
campione 1 campione 2
= F1/F ·ftot
= F1/F ·f’tot
= F2/F ·ftot
= F2/F ·f’tot
…
…
= F2/F ·ftot
= F2/F ·f’tot
ftot
F’tot
In pratica, si assume che se i due campioni provengono dalla stessa popolazione, la loro distribuzione
deve essere statisticamente uguale a quella cumulata, a parità di dimensione del campione (ftot).
Di fatto, il rapporto tra i marginali (F1) e il totale degli eventi (F) rappresenta uno stimatore delle
probabilità per le varie categorie
NB: Il test si considera affidabile se tutte le frequenze attese raggiungano un valore minimo (a seconda delle
esigenze), in genere almeno pari a 5.
IL TEST c2 (CHI-QUADRO) - TEST PER CAMPIONI INDIPENDENTI
Conteggi fitoplancton
Valori osservati
Categorie (specie)
Ankistrodesmus falcatus
Chlamidomonas sp
Cocconeis placentula
Cryptomonas erosa
Lingbja limnetica
Peridinium sp
Rhodomonas minuta
Scenedesmus biyuga
Tetraedron minimum
Gradi di libertà
Chi quadro - livello di confidenza per Ho
Staz.1A
Staz.1B
Staz.1C
13
58
27
24
11
26
52
14
24
2
50
3
6
2
8
55
22
4
7
80
7
13
0
7
99
13
7
22
130
10
19
2
15
154
35
11
13.8
81.3
6.3
11.9
1.3
9.4
96.3
21.9
6.9
8.4
49.6
3.8
7.3
0.8
5.7
58.8
13.4
4.2
12.9
76.1
5.9
11.1
1.2
8.8
90.2
20.5
6.4
249
152
233
398
249
152
233
16
0.00000
Conteggi fitoplancton
Categorie (specie)
Ankistrodesmus falcatus
Chlamidomonas sp
Cocconeis placentula
Cryptomonas erosa
Lingbja limnetica
Peridinium sp
Rhodomonas minuta
Scenedesmus biyuga
Tetraedron minimum
Gradi di libertà
Chi quadro - livello di confidenza per Ho
Valori attesi
Totali
marginali
Valori osservati
Totali
Staz.1B Staz.1C marginal
2
7
9
50
80
130
3
7
10
6
13
19
2
0
2
8
7
15
55
99
154
22
13
35
4
7
11
152
233
385
8
0.05383
Valori osservati
Staz.1B Staz.1C
3.6
5.4
51.3
78.7
3.9
6.1
7.5
11.5
0.8
1.2
5.9
9.1
60.8
93.2
13.8
21.2
4.3
6.7
152
233
Staz.1A
Staz.1B
Staz.1C
IL TEST c2 IN PAST
> PAST
N.B.: I DATI DEVONO ESSERE ORGANIZZATI IN TABELLE
DI CONTINGENZA
Pubblicò la sua distribuzione William Sealy Gosset
sotto lo pseudonimo "Student" (Mr Student)
La distribuzione di Student governa variabili aleatorie campionarie, ovvero perché la fabbrica di birra 1876-1937
Guinness presso la quale era
variabili per le quali i parametri di popolazione (media, varianza, etc.) non impiegato vietava ai propri
dipendenti di pubblicare
siano noti, ma stimati in base ad un campione (cioè quasi sempre!!)
articoli affinché questi non
divulgassero segreti di
Si può dimostrare che, data una popolazione normalmente
produzione.
LA DISTRIBUZIONE t DI STUDENT
distribuita con media μ e deviazione standard σ, le medie
campionarie ( X i ) sono anch'esse normalmente distribuite
con media μ e deviazione standard pari alla deviazione
standard della popolazione divisa per la radice del numero di
elementi del campione σ/√n (che corrisponde all’errore
standard
La distribuzione di Student governa la distribuzione delle
medie campionarie standardizzate:
tn
X
s/ n
in cui s è la deviazione standard campionaria e s/√n
l’errore standard campionario
La distribuzione di Student tende ad una distribuzione normale al crescere di n
LA DISTRIBUZIONE t DI STUDENT
La distribuzione di Student è utilizzata per verificare:
- se una media campionaria si discosta significativamente dalla media di un a popolazione (ove nota)
- se una media campionaria si discosta significativamente da un valore di riferimento (X R)
In questi casi è sufficiente calcolare t, come:
t n 1
X
s/ n
t n 1
X XR
s/ n
e confrontarlo con i valori tabulati per dati gradi di libertà
(=n -1) e livello di confidenza ()
- se una singola osservazione X appartiene ad una data
popolazione campionaria di media ( X ) e numerosità n
In questi casi è sufficiente calcolare t, come:
t n 1
X X
s n n1
e confrontarlo con i valori tabulati per dati gradi di libertà
(=n -1) e livello di confidenza ()
LA DISTRIBUZIONE t DI STUDENT
La distribuzione di Student è anche usata per verificare:
- se due campioni appaiati (dipendenti) appartengono alla stessa popolazione. In questo caso il test si focalizza
sulle differenze (di) tra le n coppie di osservazione testate
t n 1
d d
sd / n
dove d è la media delle differenze tra singole osservazioni
appaiate, d è la differenza media attesa (=0 usualmente)
e sd è la deviazione standard campionaria delle differenze.
- se due campioni non appaiati (indipendenti), anche di numerosità
diversa (nA e nB), appartengono alla stessa popolazione:
t n A n B 2
X A XB
sp
1
nA
n1B
Dove X A , X B sono le medie campionarie di due campioni A e B
e sp è la deviazione campionaria calcolata accorpando le
osservazioni dei due campioni.
Si assumono media e varianza comune (ipotesi nulla).
CAMPIONI APPAIATI E NON APPAIATI
Caratteristica distintiva di 2 campioni dipendenti o appaiati è poter
accoppiare ogni osservazione di un campione con una e una sola
osservazione dell'altro campione. Di conseguenza, i due gruppi hanno
necessariamente lo stesso numero di dati.
Si possono configurare tre tipi di appaiamento:
1- dati auto-appaiati: confronto tra osservazioni fatte sui medesimi
elementi, ma in momenti o condizioni diverse (e.g. una variabile
ambientale osservata su ambienti diversi in due campionamenti)
2 - dati naturalmente appaiati, confronto tra osservazioni fatte su
elementi omogenei a coppie, in condizioni diverse (e.g. una variabile
misurata su soggetti di età diversa sottoposti a trattamenti diversi,
eventualmente non reversibili)
3 - dati artificialmente appaiati: confronto tra osservazioni fatte su
elementi assunti omogenei a coppie in condizioni diverse
(e.g. una variabile ambientale osservata su coppie di ambienti simili,
per le quali uno dei due campioni funge da controllo e l’altro è
sottoposto ad impatti o trattamenti.
Campioni indipendenti sono da
considerare osservazioni fatte su
elementi omogenei e non, con
numerosità anche diverse e
distribuzioni eventualmente diverse
(da verificare tramite il test)
LA DISTRIBUZIONE t DI STUDENT
La distribuzione di Student è anche usata per verificare:
- se un coefficiente di correlazione si discosta significativamente dal valore nullo (assenza di correlazione)
In questo caso, l’errore standard di r è dato da
1 r 2
er
n 2
t n 2
r ( 0 )
er
Il numero di gradi di libertà in questo caso è n-2.
Per questo test, sono disponibili tabelle in cui sono tabulati
direttamente i valori di correlazione
STAT 1
LA DISTRIBUZIONE t DI STUDENT
La distribuzione di Student è anche usata per verificare se i coefficienti di regressione lineare si discostano
significativamente da valori attesi.
Per il coefficiente angolare b, l’errore standard è dato da:
eb
s e2
2
X i X
t n 2
b b
eb
i ,n
dove se è la deviazione standard dell’errore associato alla
regressione, e b il valore atteso di b, che assume valore nullo
o valore arbitrario da testare.
Per l’intercetta della retta a, l’errore standard è dato da:
2
1
X
e a s e2
n X i X
i ,n
2
t n 2
a
ea
dove è il valore atteso di a, che assume valore nullo
o valore arbitrario da testare
TEST t DI STUDENT IN PAST
> PAST
N.B.: I DATI DEVONO
ESSERE ORGANIZZATI IN
MODO CHE I CAMPIONI SIANO
INCOLONNATI
LA DISTRIBUZIONE DI POISSON
E' un modello probabilistico discreto adoperato per rappresentare la distribuzione dei
conteggi di eventi indipendenti che si realizzano in sequenza (temporale o spaziale).
Rappresentando dei conteggi, una variabile poissoniana è una variabile casuale
discreta ( Xi ) che può assumere qualsiasi valore intero non-negativo.
La distribuzione di Poisson può essere ottenuta come limite delle distribuzioni
binomiali per n∞ e pi0 ed è perciò anche nota come legge di probabilità degli
eventi rari.
Siméon-Denis Poisson
(1781-1840)
Secondo la Poisson, la probabilità associata a ciascun valore di conteggio Xi è data da:
X i
p X i
e
Xi !
dove Xi è il conteggio i-esimo ( 0, 1, 2, 3, etc.) e è la media attesa per la distribuzione degli Xi , che
può evidentemente assumere valori non interi.
Come si vede, la distribuzione dipende da un singolo parametro (), il quale peraltro si dimostra
essere pari alla varianza attesa per la distribuzione degli Xi
2
LA DISTRIBUZIONE DI POISSON
Per molto elevati (>1000) una
variabile aleatoria con distribuzione
Poisson viene solitamente approssimata
con la distribuzione normale.
Per 10< <1000 sono invece
necessarie delle correzioni di continuità,
legate ai diversi domini delle due
distribuzioni (una discreta, una continua).
La radice quadrata di una variabile
aleatoria con distribuzione di Poisson è
approssimata da una distribuzione
normale meglio di quanto lo sia la
variabile stessa.
La distribuzione di Poisson trova la sua applicazione più ampia per bassi valori di <50, ove la
statistica gaussiana è inapplicabile. I paramentri di distribuzione poissoniani (media e varianza)
campionari, rappresentano stimatori non distorti dei valori attesi, anche per bassi valori di conteggio.
Inoltre, l’attesa coincidenza dei valori di media e varianza è particolarmente utile per valutare
statisticamente la modalità di distribuzione spaziale di una popolazione
LA DISTRIBUZIONE DI POISSON
Il comportamento (e la ratio)della distribuzione Poisson si può evidenziare tramite applicazione a casi
concreti di conteggio entro un’area suddivisa in settori reticolati
3
4
2
0
2
2
2
1
2
media
varianza
1 campione
campionario
Poisson
2.00
1.25
La distribuzione campionaria dell’esempio (nel grafico
le frequenze osservate per ogni valore di conteggio 0,
1, 2, 3, 4 sono divise per 9), mostra andamento
compatibile con l’atteso Poisson, ma piuttosto diverso,
così come media e varianza campionaria sono tra loro
dissimili.
Una corrispondenza migliore si ottiene se si mediano i
risultati di 100 campioni generati casualmente e aventi
media 2. La varianza si approssima a 2.
100 campioni
campionario
Poisson
INDICI DI FORMA DI UNA DISTRIBUZIONE –SIMMETRIA E CURTOSI
Si tratta di indici che forniscono una mera descrizione della distribuzione dei dati
La SIMMETRIA indica la corrispondenza dei valori di frequenza a una data distanza da un valore centrale assunto
dalla variabile (tipicamente la mediana, per massima generalità).
Asimmetria a destra
Asimmetria a sinistra
Valutare la simmetria tramite la visualizzazione dei dati può essere critico, sia per l’eventuale ridotta dimensione
del campione, sia per la scelta arbitraria delle classi di frequenza. Il grado di asimmetria può essere misurato
tramite vari indici, che sono nulli per distribuzione simmetrica, positivi per asimmetria a sinistra e negativi per
asimmetria a destra:
skewness di Pearson;
N.B.: La perfetta
coincidenza moda,
g1 o G1 di Fisher;
median e media è
b1 di Pearson.
Per l’indice G1 di Fisher si assume che |G1|<0.5 si ha simmetria, 0.5<|G1|<1
si ha moderata asimmetria e |G1|>1 si ha forte asimmetria
condizione necessaria,
ma non sufficiente per la
simmetria
INDICI DI FORMA DI UNA DISTRIBUZIONE –SIMMETRIA E CURTOSI
Quando si descrive la forma delle curve unimodali simmetriche, con il termine CURTOSI (dal greco kurtos, che
significa curvo o convesso) si intende il grado di appiattimento, rispetto alla curva normale o gaussiana, che è
detta mesocurtica
Leptocurtica
o ipernormale
Platicurtica
o iponormale
Il grado di curtosi può essere misurato tramite vari indici che, essendo il risultato di un confronto, sono rapporti,
e quindi misure adimensionali:
- g2 o G2 di Fisher;
b2 di Pearson
Gli indici assumono valore nullo, se la distribuzione è normale o mesocurtica, positivo, se la distribuzione è
leptocurtica o ipernormale e negativo, se la distribuzione è platicurtica o iponormale.
NORMAL PROBABILITY PLOT
L’aderenza di una distribuzione rispetto alla normale
può essere anche visualizzata attraverso i «normal
probability plots», che riportano i quantili attesi per i
valori osservati lungo una retta, a confronto con i
quantili osservati
L’aderenza può essere quantificata tramite correlazione.
Fornisce indicazioni analoghe a quelle dell’istogramma
con normale sovrapposta, ma maggiore dettaglio, perché
ogni singolo punto è riportato (evidenzia gli outliers)
Quantili osservati
— Quantili attesi