04/10/05
GENETICA MOLECOLARE
CELLULA EUCARIOTICA
Ogni cellula ha una forma e una funzione diversa. All’interno della cellula c’è il nucleo, che
contiene il Genoma, ovvero l’insieme delle informazioni scritte (DNA) che è ciò che è presente nei
cromosomi.
CELLULA PROCARIOTICA
Le cellule procariotiche non hanno il nucleo e il DNA è libero nella cellula. Sono avvolti da una
parete cellulare e da una membrana cellulare.
BATTERIOFAGI
Non sono in grado di vivere da soli. Devono infettare una cellula batterica per poter svolgere le
proprie funzioni. Sono costituiti da un capside che contiene il DNA o l’acido nucleico di cui sono
dotati. Questo è connesso ad uno stelo proteico, che serve per contattare la parete batterica e, con
degli enzimi, degrada la parete causando l’infezione. L’acido nucleico dirige la sintesi di nuovi fagi
che poi usciranno dalla cellula e si propagheranno all’esterno infettando altre cellule.
COSTITUENTI CELLULARI
Zuccheri = Polisaccaridi
Acidi Grassi = Membrane, Lipidi, Grassi
Amminoacidi = Proteine
Nucleotidi = Acidi nucleici
Il corpo umano è costituito dal 70% di acqua e dal 30% da composti chimici: Proteine, RNA,
Piccole molecole o ioni, Polisaccaridi e DNA.
PROTEINE
Capire la struttura di una proteina è importante per conoscere la sua funzione.
Con la svolta della ricerca, si è riusciti a sequenziare l’intero genoma umano e, perciò, si è potuto
capire come conoscere la sequenza degli amminoacidi nella proteina. In ogni proteina sono
riconosciuti dei domini funzionali, come quello chinasico = fosforila dei substrati, perchè la
sequenza di amminoacidi glielo permette. Molti domini servono per riconoscere determinate
proteine.
Tutte le proteine hanno una vita media che dipende dalla loro stabilità:
- Esse fanno vivere la cellula
- Svolgono funzione ormonale
- svolgono funzione strutturale
- sono anche enzimi: catalizzatori biologici che permettono reazioni, rendendole più veloci.
1
DNA
Il DNA fu scoperto da
Nel 1953 Watson e Crick scoprono la struttura del DNA, con l’aiuto di Chargaff, che valutò
numericamente le quantità di basi azotate all’interno dello stesso.
Il DNA è costituito da due lunghe catene polinucleotidiche formanti un’elica destrorsa. I nucleotidi
sono composti da uno zucchero (Deossiribosio) al quale è attaccato un gruppo fosfato e una base
azotata tra quattro possibili: Adenina, Citosina, Guanina e Timina. I nucleotidi sono tenuti assieme
tramite gli zuccheri e i fosfati. In più, i due filamenti, per permettere i legami a idrogeno tra le basi
(A e T – G e C), devono essere posti antiparallelamente tra loro.
Basandosi su una foto a raggi X, Watson e Crick notarono delle precise distanze che poi si scoprì
essere importanti. Tra due nucleotidi adiacenti c’è una distanza di 0,34 nm. Il passo è di 34 nm
ovvero di dieci nucleotidi.
11/10/05
Il DNA deve essere capace di replicarsi, di controllare l’espressione dei tratti genici (proteine,
enzimi) e, di mutare in maniera stabile
MUTAZIONE
Cambiamento di carattere nucleotidico del DNA che viene poi trasmesso alla progenie. Ha effetti
negativi, ma anche positivi, poichè senza di essa non ci sarebbe stata l’evoluzione. Ha modificato le
funzioni delle cellule adattandole all’ambiente.
2
ESPERIMENTO DI GRIFFITH
Griffith prese due colonie di batteri, una R avirulenta con strutture rugose, e una S virulenta con
strutture liscie.
Iniettando il ceppo S in un topo, questo moriva. Iniettando quello R, continuava a vivere.
Iniettando il ceppo S scaldato, in modo da uccidere i batteri, il topo viveva. Denaturandolo aveva
perciò perso la caratteristica di essere virulento.
Mettendo assieme il ceppo R con quello S scaldato, il topo moriva. Nei batteri di tipo S esiste una
caratteristica che dà la virulenza e, interagendo con i batteri R era in grado di mantenerla,
modificandoli.
ESPERIMENTO DI AVERY
Mettendo il ceppo R con le proteine del ceppo R e, separatamente il ceppo R con del DNA del
ceppo S, si è visto che in un caso, il topo viveva, e nell’altro moriva. questo significava che nel
DNA del ceppo S era presente l’informazione che dava la virulenza e che era in grado di
trasformare i batteri R in S. Nonostante ciò, c’era ancora molto scetticismo.
La svolta avvenne con l’uso di batteriofagi.
ESPERIMENTO DI HERSHEY E CHASE
Hershey e Chase svolgevano studi su un fago, ovvero un virus in grado di infettare i batteri; in
particolare il fago di loro interesse era noto come "T2". Questo virus è in grado di attaccare E. coli
(un batterio utilizzato spesso come modello in questo genere di studi).
All'epoca era noto che T2 era formato esclusivamente da DNA protetto da un involucro proteico.
I due scienziati prepararono in parallelo due colture di E. coli:
Nel terreno di coltura della prima introdussero fosforo marcato radioattivamente (l'isotopo
32
P).
Nel terreno di coltura della seconda introdussero zolfo marcato radioattivamente (l'isotopo
35
S).
3
I batteri delle due colture metabolizzarono da una parte il fosforo marcato e dall'altra lo zolfo
marcato introducendo questi atomi radioattivi nelle biomolecole presenti all'interno delle cellule. In
particolare:
Il fosforo marcato si troverà in gran parte nei nucleotidi e di conseguenza anche negli acidi
nucleici; non sarà presente invece in quantità significative nelle proteine.
Lo zolfo marcato si troverà nelle proteine (in particolare nell'amminoacido cisteina) e non si
troverà nei nucleotidi.
A questo punto i ricercatori infettarono parallelamente le due colture batteriche con il fago T2.
Questo virus utilizza l'apparato biosintetico delle cellule di E. coli per replicare il proprio DNA e
per sintetizzare le proteine del rivestimento.
Dal momento che i nucleotidi e gli amminoacidi utilizzati nella sintesi del DNA e delle proteine
virali sono quelli presenti all'interno della cellula infettata, ne risulta che i fagi sviluppati
dall'infezione nel prima coltura avranno un DNA marcato radioattivamente, mentre quelli sviluppati
dall'infezione della seconda coltura avranno il rivestimento proteico esterno marcato
radioattivamente.
Hershey e Chase separarono i fagi neoformati (quelli marcati) dai due terreni di coltura e,
separatamente, li utilizzarono per infettare altre due colture di E. coli, in questo caso cresciute su
terreni "standard" privi di isotopi radioattivi.
Nel caso in cui i fagi infettanti avessero il DNA marcato, in seguito all'infezione gran parte
della radioattività veniva misurata all'interno delle cellula batteriche colpite (e nel DNA di
una parte dei nuovi fagi sviluppatisi in seguito a questa infezione).
Nel caso in cui i fagi infettanti avessero il rivestimento proteico marcato la radioattività
veniva misurata solamente all'esterno delle cellule batteriche colpite (e non era presente sul
rivestimento proteico dei nuovi fagi sviluppatisi in seguito a questa infezione).
Il processo utilizzato per determinare se la radioattività provenisse dall'interno o dall'esterno delle
cellule fu il seguente: dopo un certo tempo dall'inizio dell'infezione, il terreno di coltura veniva
posto in un omogenizzatore. La conseguente agitazione provocava il distacco del rivestimento
proteico dei virus dalla membrana cellulare (in questo caso si parla di "ombre fagiche" poiché
questi rivestimenti proteici non contengono il DNA che è già stato iniettato nella cellula). Il tutto
veniva poi centrifugato: la parte cellulare (contenente eventualmente il DNA marcato) rimaneva sul
fondo della provetta, mentre i rivestimenti proteici distaccati dalle membrane cellulari rimanevano
in sospensione. A seconda di dove si misurava la maggiore radioattività era possibile dedurre se la
molecola marcata si trovasse o meno all'interno della cellula.
4
Il DNA codifica l’informazione tramite l’ordine, o sequenza dei nucleotidi in ciascun filamento.
Ciascuna base può essere considerata come una lettera di un alfabeto a quattro lettere in cui sono
scritti i messaggi biologici nella struttura chimica del DNA
Quasi tutto il DNA di una cellula eucariotica è contenuto nel nucleo. L’involucro nucleare permette
alle proteine che agiscono sul DNA di concentrarsi dove sono necessarie nella cellula.
La funzione del DNA è quella di portare i geni. I genomi degli eucarioti sono divisi in cromosomi e,
il genoma umano è lungo circa 1 m. Ogni molecola di DNA è un cromosoma, a cui si associano a
proteine che ripiegano e compattano la struttura. Con l’eccezione delle cellule germinali, ogni
cellula contiene due copie di ciascun cromosoma. Uno del padre e uno della madre. L’insieme dei
46 cromosomi umani è detto cariotipo.
GLI ISTONI
Le proteine che si legano al DNA per formare i cromosomi, sono divisi in Istoni e le proteine non
istoniche. Il complesso di entrambe le classi di proteine con il DNA è detto cromatina.
Normalmente il DNA è molto poco condensato. Si addensa nelle fasi di mitosi e meiosi.
Gli istoni sono responsabili del primo livello di base dell’organizzazione dei cromosomi, i
nucleosomi.
Ogni nucleosoma è composto da otto proteine istoniche (due molecole di H2A, H2B, H3 e H4) e
del DNA a doppio filamento lungo 146 nucleotidi che si avvolge attorno al nucleo ottamerico di
istoni. Questa struttura a perline è possibile poichè gli istoni sono proteine molto basiche che sono
quindi in grado di legarsi al DNA. Inoltre, sono le proteine eucariotiche più conservate e, perciò è
certo che svolgano la stessa funzione in tutti gli esseri viventi. Ciascuna particella centrale del
nucleosoma è separata dalla successiva da una regione di DNA linker che può variare in lunghezza.
Un ulteriore compattamento dei nucleosomi, porta ad altre strutture, dove si ha il coinvolgimento
dell’istone H1, più grande degli altri, che si lega a ogni nucleosoma modificando il percorso del
5
DNA che esce dal nucleosoma. Si pensa che il compattamento avvenga anche grazie alle code degli
otto istoni che collegano i nucleosomi vicini.
Le proteine non istoniche invece sono proteine che si associano al DNA in particolari momenti con
valore funzionale.
12/10/05
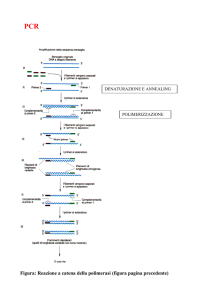
REPLICAZIONE DEL DNA
La replicazione del DNA non è un evento continuo per gli eucarioti. Il ciclo cellulare dice quali
sono le tappe che una cellula compie per poter replicarsi. Nella maggior parte delle cellule ciò
avviene soltanto in una fase specifica del ciclo cellulare, chiamata fase di sintesi del DNA o fase S.
L’uso del DNA come stampo è il processo in cui la sequenza nucleotidica di un filamento di DNA
viene copiata mediante appaiamento complementare delle basi, in una sequenza complementare di
DNA. Questo processo comporta il riconoscimento di ciascun nucleotide nel filamento stampo di
DNA da parte di un nucleotide libero e richiede che i due filamenti siano separati.
Il primo enzima che polimerizza nucleotidi è la DNA Polimerasi.
Ciascun filamento del DNA vecchio serve da stampo per un nuovo filamento. La doppia elica sarà
quindi costituita da un filamento vecchio e uno nuovo e la replicazione è semiconservativa.
6
DNA POLIMERASI
La DNA Polimerasi catalizza l’aggiunta sequenziale di un deossiribonucleotide all’estremità 3’ di
una catena polinucleotidica accoppiata a un filamento stampo.
Favorisce il legame fosfodiestere tra due nucleotidi adiacenti e non devono insorgere errori
(mutazioni). Per formare il legame covalente ha bisogni di energia e per questo si serve di
deossisubstrati: dCTP, dGTP, dTTP, dATP. Inoltre non è in grado di fare legami tra i
deossiribonucleotidi, se non copiando da un filamento in modo complementare. Non è lei che inizia
la sintesi, ma copia, allungando, solo filamenti di DNA esistenti. La DNA polimerasi svolge attività
polimerasica, ovvero la sintesi del Dna, e l’attività nucleasica, ovvero l’eliminazione dei nucleotidi.
Nei mammiferi esistono 5 DNA Polimerasi: α, β, γ (nei mitocondri), δ e ε.
FORCELLA DI REPLICAZIONE
La zona in cui avviene la replicazione del DNA è la forcella di replicazione. A causa
dell’andamento antiparallelo dei due filamenti nella doppia elica, la replicazione avverrebbe in
senso 5’-3’ su un filamento e 3’-5’ sull’altro e con due polimerasi diverse. Una polimerasi che
lavora in direzione 3’-5’ non esiste. Studi sulla replicazione hanno portato alla scoperta che su un
filamento, esistono dei pezzi di DNA lunghi 1000-2000 nucleotidi, noti come frammenti di
Oakazaki, polimerizzati in 5’-3’, su un filamento.
Per questo la forcella di replicazione è asimmetrica. Il filamento sintetizzato in modo continuo è
chiamato filamento guida, quello sintetizzato in modo discontinuo è chiamato filamento ritardato.
7
CORREZIONE DEL FILAMENTO
La prima correzione è eseguita dalla DNA Polimerasi e avviene appena prima dell’aggiunta di un
nuovo nucleotide. Il nucleotide corretto ha una maggiore affinità per la polimerasi in movimento del
nucleotide non corretto, poichè soltanto quello corretto può appaiarsi correttamente con lo stampo.
Un nucleotide non corretto ha una maggior possibilità di dissociarsi durante il passaggio di un
nucleotide corretto. Ciò permette alla polimerasi di controllare l’esatta geometria di appaiamento
delle basi. Questa correzione è detta attività esonucleasica. Le polimerasi trattano un filamento male
appaiato in un sito catalitico a parte, tagliando qualsiasi residuo non appaiato in direzione 3’-5’.
DNA PRIMASI E RNA PRIMER
Per un filamento guida è necessario un primer speciale all’inizio della replicazione. Sulla forcella la
DNA polimerasi ha sempre a disposizione un’estremità della catena alla quale aggiungere
nucleotidi. Sul filamento ritardato, ogni volta che la DNA Polimerasi completa un frammento deve
sintetizzare un frammento completamente nuovo in un sito più a valle. é richiesto un filamento
primer (RNA primer) sintetizzato dalla DNA Primasi. Gli RNA primer sono sintetizzati ad
intervalli di 200 nucleotidi sul filamento ritardato. Ogni primer è lungo 10 nucleotidi. Ogni primer è
eliminato da uno speciale enzima di riparazione che riconosce il filamento di RNA in un elica di
DNA e lo elimina, e la DNA ligasi unisce i frammenti di Oakazaki.
Perchè la sintesi di DNA proceda, la doppia elica di DNA deve essere aperta davanti alla forcella di
replicazione in modo che ci sia la possibilità di unire nuovi deossiribonucleotidi. Ciò viene svolto
dalla DNA elicasi che si intercala nel DNA e, tramite l’idrolisi di ATP, si muove lungo esso,
aprendo l’elica.
8
Le proteine che legano il DNA a singolo filamento (SSB) si legano cooperativamente ai filamenti di
DNA senza coprire le basi, aiutando l’elicasi a stabilizzare la conformazione svolta a singolo
filamento e impendendo che il filamento formi eliche a forcina.
PINZA PROTEICA
La tendenza a dissociarsi rapidamente da una molecola di DNA permette a una DNA polimerasi che
ha appena finito di sintetizzare un frammento di essere riciclata, per poter iniziare la sintesi del
frammento successivo. La DNA polimerasi viene lasciata attaccata al DNA tramite una pinza
proteica e viene solo liberata quando la polimerasi incontra la doppia elica.
La pinza ha la forma di un grosso anello intorno all’elica di DNA. Un lato dell’anello si lega alla
parte posteriore della DNA polimerasi e l’intero anello scorre lungo il DNA mentre la DNA
polimerasi si muove.
Il suo assemblaggio richiede idrolisi di ATP da parte del caricatore della pinza. Sul filamento
ritardato, ogni volta che la polimerasi incontra l’estremità 5’ del frammento precendente, viene
rilasciata, e la polimerasi si associa ad un’altra pinza.
9
SCHEMA RIASSUNTIVO DELLA REPLICAZIONE DEL DNA
17/10/05
BOLLA DI REPLICAZIONE
Le posizioni in cui l’elica di DNA viene aperta per la prima volta sono le origini di replicazione.
Nelle loro vicinanze si forma una bolla di replicazione, dove si legano le proteine iniziatrici. Le
origini di replicazione studiate nei batteri hanno dimostrato di avere zone contenenti Adenina e
Timina, più facili da staccare perchè ci sono meno legami a idrogeno.
Per il DNA eucariotico è necessaria almeno una replicazione per ogni cromosoma. Esistono perciò
delle forcelle di replicazione per ogni cromosoma (10000-20000 origini di replicazione per ogni
cromosoma).
10
DNA TOPOISOMERASI
Oltre alle DNA polimerasi ci sono le Topoisomerasi. Esse legano il DNA è svolgono gli
aggrovigliamenti del DNA. Può essere vista come una nucleasi reversibile che si attacca all’ossatura
di fosfato di DNA, rompendo un legame fosfodiestere in un filamento.
La Topoisomerasi I produce una rottura su un singolo filamento, permettendo alle due sezioni
dell’elica di ruotare attorno al legame fosfodiestere.
11
La Topoisomerasi II forma un legame covalente con entrambi i filamenti. Questa è attivata da siti
su cromosomi quando le due doppie eliche si incrociano:
1- Rompe reversibilmente la doppia elica per creare un passaggio di DNA
2- Fa passare la seconda doppia elica vicina attraverso la rottura
3- Risalda la rottura e si dissocia dal DNA.
TELOMERASI
Poichè le DNA polimerasi polimerizzano DNA solo nella direzione 5’-3’, la sintesi del filamento
ritardato a livello di una forcella deve avvenire discontinuamente, tramite un meccanismo di
cucitura all’indietro che produce brevi filamenti di DNA. Quando la forcella raggiunge l’estremità
di un cromosoma lineare, non c’è posto per produrre l’RNA primer necessario per iniziare l’ultimo
frammento di Oakazaki sulla punta della molecola. Gli eucarioti hanno sequenze nucleotidiche
speciali alle estremità dei loro cromosomi, che sono incorporate in telomeri e attraggono un enzima
chiamato telomerasi. Le sequenze di DNA telomerico sono molte ripetizioni in tandem di una breve
sequenza GGGTTA e si estende per 10000 nucleotidi. La telomerasi sintetizza una nuova copia
della ripetizione, usando uno stampo di RNA che è componente dello stesso enzima, mentre la
DNA polimerasi sintetizza il filamento complementare.
Il meccanismo descritto assicura che l’estremità 3’ del DNA sia più lunga della 5’ con la quale è
appaiata, lasciando un’estremità sporgente, che forma un’ansa all’indietro, per infilare il suo
terminale nel doppio DNA della sequenza telomerica ripetuta. Questa assicura la protezione dagli
enzimi di degradazione
RIPARAZIONE DEL DNA
Insieme di meccanismi che permettono alle cellule di mantenere il DNA nella sua corretta struttura.
Intervengono degli enzimi di riparazione. Solo 1 su 10000 nucleotidi può essere sbagliato e la
frequenza di mutazione è molto rara: 1 su 109 nucleotidi.
Il DNA subisce cambiamenti importanti in seguito a fluttuazioni termiche, per esempio 5000 basi
puriniche (A eG) vengono perse ogni giorno perchè vanno incontro a depurinazione spontanea, cioè
i legami N-glicosilici si idrolizzano. 100 basi di C e U vanno invece incontro a deamminazione
spontanea. Le radiazioni ultraviolette del sole possono produrre un legame covalente fra due
pirimidine adiacenti nel DNA a formare, per esempio, dimeri di timina. Se questi cambiamenti non
12
venissero corretti, ci sarebbe la delezione di una o più basi, o una loro sostituzione. Le lesioni a cui
può andare incontro il DNA sono:
- Delezione della base
- Alterazione della base = quando c’è una base scorretta
- Inserzione di un nucleotide
- Legami fra pirimidine
- Tagli ai singoli o doppi legami
- Deamminazioni = i gruppi amminici vengono sostituiti o rimossi
- Metilazioni = aggiunta di gruppi metilici
- Depurinazioni = dovuta a temperature elevate
Esistono vie multiple per la riparazione del DNA, che usano enzimi diversi che agiscono su tipi
diversi di lesioni
ESCISSIONE DELLE BASI
Le DNA glicosilasi scorrono lungo il DNA e possono riconoscere un tipo specifico di basi alterate e
catalizzarne la rimozione idrolitica.
L’AP endonucleasi riconosce lo zucchero privo della base creato e taglia l’ossatura fosfodiestere e
la DNA elicasi e polimerasi ripristinano la giusta sequenza.
13
ESCISSIONE DEI NUCLEOTIDI
Può riparare il danno causato da qualsiasi grosso cambiamento nella struttura della doppia elica del
DNA. Un complesso multienzimatico scansiona il DNA cercando una distorsione della doppia
elica. L’ossatura fosfodiestere del filamento anormale viene tagliata su entrambi i lati della
distorsione e un oligonucleotide viene eliminato da una DNA elicasi. La grossa interruzione viene
poi riparata dalla DNA polimerasi e dalla DNA ligasi .
18/10/05
STRUTTURA E SEQUENZIAMENTO DEL DNA
Il genoma è l’insieme delle informazioni genetiche contenute nel DNA. Solo il 2-5% del DNA è
costituito da geni (esoni) che codificano le proteine. Ci sono poi altre sequenze ripetute o uniche
che non hanno nessuna informazione genetica.
Il gene è l’unità fondamentale che si occupa di portare le informazioni per formare la proteine o tipi
di RNA.
Il gene contiene una sequenza regolatrice, indispensabile per il corretto funzionamento del gene,
responsabile dell’espressione di un gene al livello e al momento appropriato e nel tipi appropriato di
cellula. Questa può trovarsi davanti o dietro o in mezzo al gene. Ci sono poi zone di DNA non
codificante che interrompono i tratti di DNA codificante (esoni) e sono gli introni.
14
GENOMA UMANO 3000 Mb
1- Geni e sequenze associate 900 Mb
- Non codificante 810 Mb
- Introni
- Regioni di controllo
- Pseudogeni
- Codificante (esoni) 90 Mb
2- DNA extragenico 2100 Mb
- DNA unico e a basso numero di copie 1680 Mb
- DNA ripetitivo 420 Mb
- In tandem
- Microsatelliti
- Minisatelliti
- Satelliti
- Disperso
- SINE
- LINE
- Retroposomi
Pseudogeni: Sono sequenze che assomigliano a dei geni, ma che non hanno valore genico. Sono
originati spesso dalla duplicazione genica. Sono importanti per l’evoluzione genica. Sono i più
bersagliati dalle mutazioni e non danno alcun effetto e, più vengono mutati, più la loro identità si
allontana a quella dei geni.
Il DNA ripetitivo è costituito da sequenze che danno una certa plasticità al genoma stesso. Le
sequenze ripetute disperse si distinguono solo dalla sequenza nucleotidica:
- Satelliti: nel DNA centromerico. (da 5 a 200 nucleotidi)
- Minisatelliti: (DNA telomerico,) fino a 5 nucleotidi
- Microsatelliti: Fino a 4 nucleotidi.
Famiglia di geni = Insieme di geni duplicati che codificano proteine con sequenze amminoacidiche
simili ma non uguali.
DUPLICAZIONE GENICA E RICOMBINAZIONE GENICA
L’organizzazione del genoma eucariotico in esoni e introni, rende molto più semplice l’evoluzione
di nuove proteine, in seguito a ricombinazione genica. La complessità delle specie non dipende dal
numero di geni ma da come sono controllati.
RNA
Il DNA nei genomi non dirige la sintesi di proteine da solo, ma usa invece RNA come molecola
intermedia. Quando la cellula ha bisogno di una particolare proteina, la sequenza nucleotidica
codificante quella proteina viene prima copiata in RNA (Trascrizione) e successivamente l’RNA
viene usato come stampo per la sintesi delle proteine (Traduzione).
Il primo passaggio della lettura di una parte necessaria delle istruzioni genetiche di una cellula, è
quello di copiare una porzione particolare della sequenza del suo DNA – un gene – in una sequenza
di RNA.
L’RNA è simile al DNA, a parte l’avere un ribosio al posto del deossiribosio e un Uracile al posto
della Timina.
La sintesi avviene sempre nella direzione 5’-3’.
15
Si hanno tre tipi di RNA:
1- mRNA: comprende le informazioni per specificare le proteine. Trasporta le informazioni
genetiche copiate dal DNA ( sono instabili e durano pochi secondi nei procarioti e qualche ora negli
eucarioti, poichè non ha molte strutture secondarie che lo preservano dalla distruzione).
2- rRNA: Si unisce ad una serie di proteine per formare i ribosomi.
3- tRNA: Molecola principale che serve per decifrare le informazioni del mRNA; inoltre serve oer
far avvenire la sintesi delle proteine.
Gli enzimi che eseguono la trascrizione sono le RNA polimerasi.
Catalizza la formazione di legami fosfodiestere che uniscono nucleotidi per formare una catena
lineare. L’RNA polimerasi si muove un passo alla volta lungo il DNA, svolgendo l’elica davanti al
suo sito attivo per esporre una regione di filamento stampo per l’accoppiamento complementare. I
substrati sono nucleotidi trifosfato (ATP, CTP, GTP e TTP). Il rilascio quasi immediato del RNA
dal DNA durante la sintesi significa che molte copie di RNA possono essere prodotte da un singolo
gene.
TRASCRIZIONE NEI PROCARIOTI
Per trascrivere correttamente un gene, l’RNA polimerasi deve riconoscere dove iniziare questo
processo. Nei batteri, un fattore sigma si lega al promotore, sequenza speciale di nucleotidi che
indica il punto di partenza per la trascrizione, del DNA e attiva la RNA polimerasi, che inizia a
trascrivere il DNA in mRNA.
Per terminare la sintesi, si deve avere invece un terminatore, con basi di A e T, che ripiegano
l’RNA a forcina, che forza l’apertura della RNA polimerasi.
16
TRASCRIZIONE NEGLI EUCARIOTI
Nell’uomo esistono tre tipi di RNA polimerasi.
RNA polimerasi I = trascrive i geni per gli rRNA
RNA polimerasi II = trascrive tutti gli mRNA e alcuni dei piccoli RNA nucleari che partecipano
allo splicing del mRNA.
RNA polimerasi III = trascrive gli rRNA 55 e diversi RNA relativamente corti e stabili.
Le RNA polimerasi eucariotiche richiedono dei fattori generali di trascrizione, che devono
assemblarsi al promotore con la polimerasi prima dell’inizio della trascrizione.
Per l’uomo, il promotore, è costituito da una sequenza consenso di A e T, chiamata TATA Box ed è
a 25 nucleotidi dall’inizio della trascrizione. Quando la RNA polimerasi deve riconoscere la TATA
box, vede l’associazione dei fattori di trascrizione e si chiude sul DNA:
1- TFIID si lega alla TATA box, tramite la subunità TBP (TATA binding protein) del DNA a
doppia elica.
2- Successivamente di attaccano TFIIA e TFIIB, poi TFIIE e RFIIH, formando il complesso di
inizio della trascrizione, insieme alla RNA polimerasi.
3- TFIIH fosforila la coda CTD (C Terminal Domain) della RNA polimerasi. I fattori di
trascrizione si staccano e la trascrizione ha inizio.
17
MATURAZIONE DEL RNA CON I PROCESSING
La trascrizione è solo il primo passaggio di una serie di reazioni che comprende la modificazione
covalente di entrambe le estremità dell’RNA e la rimozione delle sequenze introniche, tramite
splicing.
Le modificazioni alle estremità sono il capping al 5’ e la poliadenilazione al 3’
Inoltre negli eucarioti, la traduzione non è associata alla trascrizione, e viene svolta all’esterno del
nucleo.
Quando si è parlato della CTD, essa ha una serie di fattori che permettono ai processing (capping,
poliadenilazione) di avvenire.
18
CAPPUCCIO AL 5’
Non appena la polimerasi ha prodotto circa 25 nucleotidi, l’estremità 5’ è modifciata per l’aggiunta
di un cappuccio costituito da un nucleotide guanidilico modificato:
- fosfatasi = rimuove il fosfato dall’estremità 5’ dell’RNA.
- guanil trasferasi = aggiunge un GMP in legame inverso (5’ a 5’ invece di 5’ a 3’)
- metil trasferasi = aggiunge un metile alla guanosina.
Il cappuccio riconosce le posizioni 5’ e protegge il trascritto primario dalla degradazione enzimatica
svolta dalle nucleasi.
CODA AL 3’
Mediante la poliadenilpolimerasi (poli-A polimerasi o PAP), si ha un’aggiunta di molte adenine
all’estremità terminale dell’RNA immaturo.
La coda serve ad:
- Identificare la vecchiaia dell’RNA, poichè mano a mano che il tempo passa, le nucleasi tendono a
- degradare la molecola togliendo le adenine. Gli mRNA più vecchi avranno quindi meno adenine
rispetto ai nuovi.
- Aiuta l’esportazione del mRNA dal nucleo al citosol
- Stabilizza l’mRNA
- Ruolo di sintesi proteica
19
Due proteine note come CstF ( Cutting stimolation factor F) e CPSF (Cutting of Poliadenylation
specificity Factor) viaggiano con la coda dell’RNA polimerasi e sono traferite alla sequenza di
modificazione dell’estremità 3’. Una volta che si solo legate all’RNA, si inseriscono altri fattori, e
infine la poli-A polimerasi che aggiunge uno alla volta circa 200 nucleotidi A all’estremità 3’. La
poli-A polimerasi non richiede uno stampo e quindi la coda non è codificata direttamente nel
genoma. Alla coda si attaccano le proteine che legano poli-A e determinano la lunghezza finale
della coda. Queste rimangono attaccate alla coda mentre il mRNa attraversa il nucleo.
20
SPLICING
I geni eucariotici sono spezzati in piccoli pezzi di sequenze codificanti (sequenze espresse o esoni)
intervallati da sequenze intercalate o introni; così la porzione codificante di un gene eucariotico è
spesso soltanto una piccola frazione della lunghezza del gene.
Sia gli introni che gli esoni sono trascritti in RNA. Le sequenze introniche sono rimosse dall’RNA
appena sintetizzato dal processo di splicing dell’RNA.
Ciascun evento di splicing rimuove un introne, procedendo attraverso due reazioni sequenziali di
trasferimento di fosfato, note come transesterificazioni; queste uniscono due esoni rimuovendo un
introne come cappio.
Per tagliare le sequenze introniche, si sono sequenziati gli introni, soprattutto nelle zone di unione
tra esoni ed introni e si è visto che al 5’ degli introni (nel sito DONATORE) tutti cominciano con
una seguenza GU e nel sito ACCETTORE (3’) gli introni finiscono con una sequenza AG.
Negli introni piccoli o grandi, tutto quello che era più importante sono quelle sequenze di inizio e di
fine e inoltre era importante una sequenza a circa 30 nucleotidi dal sito accettore chiamata sequenza
BRENCH POINT A (solo l’adenina è ambigua nel brench point) e intorno vi sono dei nucleotidi
con varia ambiguità.
Mutando le sequenze GU e AG (iniziale e finale) si vedeva che lo splicing non avveniva e quindi
erano fondamentali.
21
LO SPLICEOSOMA
Lo splicing dell’RNA è eseguito in gran parte da molecole di RNA e non da proteine. Le molecole
di RNA riconoscono i confini introne-esone e partecipano alla chimica dello splicing. Queste
molecole di RNA sono relativamente brevi e nella forma principale di splicing dei pre-mRNA ne
sono coinvolte 5 (U1, U2, U4, U5 e U6). Questi, noti come snRNA (small nuclear RNA) sono
associati a sette subunità proteiche per formare snRNP (small nuclear ribonucleic protein). Queste
snRNP formano il nucleo dello spliceosoma, che esegue lo splicing.
Lo spliceosoma riconosce i segnali di splicing su una molecola di pre-mRNA, avvicina le due
estremità dell’introne e fornisce l’attività enzimatica per i due passaggi di reazione. Il sito del punto
di ramificazione viene prima riconosciuto dalla BBP (proteina che lega il punto di ramificazione).
22
L’snRNP U2 sposta BBP e U2AF e forma coppie di basi consenso del sito del punto di
ramificazione e l’snRNP U1 forma coppie di basi con la giunzione di splicing 5’. La tripla snRNP
U4-U6-U5 entra nello spliceosoma. U4 eU6 sono tenuti assieme da interazioni di coppie di basi e
l’snRNP U5 è associata più debolmente. U4 e U6 successivamente si dividono e permettono a U6 di
spostare U1 alla giunzione di splicing 5’. Successivamente si crea un sito attivo e posizionano le
porzioni appropriate dell’RNA substrato per far avvenire la reazione di splicing.
DAL mRNA ALLE PROTEINE
La conversione dell’informazione da RNA in proteine rappresenta una traduzione dell’informazione
in un altro linguaggio che usa simboli completamente diversi. Inoltre, poichè ci sono solo quattro
nucleotidi diversi nel mRNA e venti tipi diversi di amminoacidi, questa traduzione non può essere
spiegata da una corrispondenza diretta uno a uno fra un nucleotide e un amminoacido. La sequenza
nucleotidica di un gene, per mezzo del mRNA, è tradotta nella sequenza degli amminoacidi di una
proteina seguendo regole che sono note come codice genetico.
CODICE GENETICO
Il codice genetico venne decifrato da Niremberg e Matthaei 10 anni dopo Watson e Crick. Sono
partiti da una sintesi di mRNAconosciuti (formati da nucleotidi che contenevano solo Uracile, in
vitro). Fecero la sintesi proteica e analizzarono il peptide ottenuto e videro che era un
polifenilanalina. Successivamente presero un mRNa formato da due nucleotidi contenenti Citosina e
Adenina, intervallati tra loro. Il peptide ottenuto risultò essere un polistindin-Treonina. Le sequenze
allora dovevano per forza essere lette a triplette, poichè se fossero state lette a coppie, sarebbe
risultata una poliistidina.
Il codice genetico è degenerato perchè più triplette codificano uno stesso amminoacido. Ci sono 61
codon che codificano i 20 amminoacidi e 3 codon di stop. (UAA, UAG, UGA). Ciò mette al riparo
dall’effetto causato dalle mutazioni puntiformi in uno o più nucleotidi. Se non fosse degenerato ci
sarebbero 20 codon consenso e 44 codon nonsenso. L’inizio di ogni traduzione avviene con la
sequenza AUG, che codifica la metionina.
Inoltre, il codice genetico è universale. Per dimostrarlo si prese un mRNA procariotico e lo si mise
in vitro, nell’apparato di sintesi di un eucariote e questo ha sintetizzato le informazioni ivi
contenute.
23
tRNA
La traduzione di mRNA in proteine dipende da molecole adattatrici che possono riconoscere e
legare sia il codone che l’amminoacido in un altro sito. Questi adattatori sono piccoli RNA chiamati
transfer-RNA (tRNA).
La forma finale è quella di un trifoglio che subisce ripiegamenti sino a diventare una L. Ad un
estremità c’è l’anticodone, che si associa per complementarietà al mRNA e, dall’altra, al 3’ della
molecola, l’amminoacido corrispondente alla sequenza dell’anticodone. Esistono perciò tRNA per
ogni amminoacidi.
LEGAME TRA L’AMMINOACIDO E IL tRNA
Il riconoscimento e l’attacco dell’amminoacido corretto dipendono dall’amminoaciltRNA sintetasi,
che accoppia covalentemente ciascun amminoacido al proprio tRNA. Mediante idrolisi di ATP
l’amminoacido viene prima adenilato, dopodichè si lega al tRNA e rilascia una molecola di AMP.
24
RIBOSOMI
La sintesi proteica viene eseguita sul ribosoma, una complessa macchina catalitica composta da più
di 50 proteine diverse, le proteine ribosomali, e da RNA ribosomali (rRNA). I ribosomi sono
costituiti da due subunità, una maggiore e una minore che si adattano assieme al mRNA. La
subunità minore fornisce una struttura sulla quale i tRNA possono essere adattati accuratamente ai
codoni del mRNA, mentre la subunità maggiore catalizza la formazione dei legami peptidici che
uniscono insieme gli amminoacidi in una catena polipeptidica.
I ribosomi procarioti sono formati da rRNA e proteine; il ribosoma si chiama 70S (S sta per
coefficiente di sedimentazione) che si divide in due subunità:
- 50S formato da rRNA 23S e 5S più 34 proteine
- 30S formato da un unico rRNA 16S che è compensato da 21 proteine.
I ribosomi eucarioti si chiamano 80S ed è diviso in due subunità:
- 60S dove coesistono 3 rRNA da 5,8S, 28S e 5S più 49 proteine
- 40 S formato da una molecola di rRNA 18S e 33 proteine.
Quando non svolgono la sintesi proteica, le subunità dei ribosomi sono dissociate e libere nel
citoplasma.
Un ribosoma contiene quattro siti di legame per molecole di RNA: uno è per il mRNA e tre (sito A,
sito P e sito E) sono per il tRNA. Una molecola è tenuta con forza nei siti A e P soltanto se
l’anticodone forma coppie di basi con un codone complementare.
I ribosomi, quando si attaccano al mRNA lasciano uno spazio iniziale (start) e uno finale,
terminando prima dell’estremità (stop). Tali regioni sono chiamate regioni non tradotte (UTR) una
al 3’ e una al 5’, con differenti lunghezze.
- nei procarioti vi è una sequenza chiamata Shine-Dalgarno, che è la sequenza segnale di 67
nucleotidi ricchi di G e A, e, si è visto che in quel punto si attacca il ribosoma per iniziare la
traduzione.
- negli eucarioti è sufficiente il cappuccio del mRNA per far iniziare la sintesi proteica, a cui si
associano anche i fattori di inizio eucariotici, eIF4E che si lega al cappuccio e eIF4G.
25
1- La sintesi inizia, comunemente, con il codone AUG che
traduce la Metionina. Esso viene caricato sul ribosoma,
assieme agli eIF. Solo il tRNA iniziatore è capace di legarsi
alla subunità minore senza che il ribosoma sia completo. Un
tRNA che porta l’amminoacido successivo alla catena si lega
al sito A, formando coppie di basi con il codone del mRNA,
mentre nel sito P c’è il tRNA precedente con la catena
polipeptidica.
2- L’estremità carbossilica della catena polipeptidica viene
rilasciata dal tRNA al sito P, rompendo il legame tra tRNA e
amminoacido, e si unisce al gruppo amminico libero
dell’amminoacido legato al tRNA sul sito A. Questa reazione
è catalizzata dalla peptidil transferasi, contenuta nella major
subunit.
3- Cambiamenti conformazionali spostano l’mRNA di tre
nucleotidi attraverso il ribosoma, per far arrivare un nuovo
amminoaciltRNA. Il tRNA senza l’amminoacido, spostatosi
sul sito E, si stacca dal risobosoma.
26
La sintesi ha termine quando sul ribosoma è presente uno dei
tre codoni di stop, o quando fattori di terminazione
promuovono l’idrolisi del peptidil-tRNA. I codoni di stop,
nonsono riconosciuti da un tRNA e non specificano un
amminoacido, ma segnalano invece al ribosoma di fermare la
traduzione. Fattori di rilascio si attaccano al ribosoma conun
codone di stop sul sito A. Questo legame forza la peptidil
transferasi del ribosoma a catalizzare l’aggiunta di una
molecola d’acqua invece di un amminoacido al peptidiltRNA.
Questa reazione libera l’estremità carbossilica del peptide e lo
separa dal tRNA.
27
CONTROLLO DELL’ESPRESSIONE DEI GENI
28





![mutazioni genetiche [al DNA] effetti evolutivi [fetali] effetti tardivi](http://s1.studylibit.com/store/data/004205334_1-d8ada56ee9f5184276979f04a9a248a9-300x300.png)