70
A
3000
.
Capitolo Terzo
p.
A
2500
B
1500
C
1000
D
S.
2000
B
C
D
500 1000 1500 2000 2500 3000 3500
br
A
i
500
(b)
(a)
li
Fig. 1 - Ortogramma a colonne (a) e ortogramma a nastri (b)
4. MISURE DI ASSOCIAZIONE E DI COGRADUAZIONE
C
op
yr
ig
ht
©
Es
se
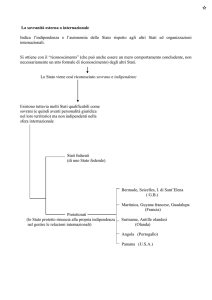
Per misurare la forza o intensità della relazione tra due variabili la statistica ha approntato delle misure; a tal proposito si distingue:
— se le variabili sono nominali, si parla di misure di associazione;
— se le variabili sono ordinali, si parla di misure di cograduazione.
La distinzione non è tassativa in quanto le misure di associazione possono essere applicate anche alle variabili ordinali.
Per misurare la forza di tale relazione andiamo ad analizzare il concetto
di indipendenza in statistica.
È noto dalla matematica che una variabile Y si dice indipendente da una
variabile X se la prima rimane costante al variare dei valori assunti dalla
seconda. In caso contrario si dice che Y è funzione di X.
Per analizzare l’indipendenza tra variabili ci serviremo di un esempio,
basta solo premettere che gli indici statistici in grado di evidenziare l’indipendenza di una variabile da un’altra sono basati sulle frequenze osservate
e attese o teoriche, ed esprimono la forza della relazione tra le stesse. Essi
assumono valori tanto più piccoli quanto più esiste indipendenza tra i caratteri investigati.
71
A
.
Analisi bivariata
p.
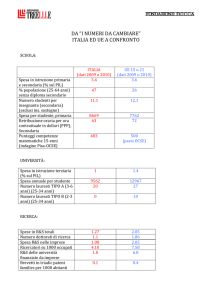
Sia data la seguente tabella a doppia entrata:
Tabella delle frequenze osservate
Totale
Y2
Y3
2
5
15
X2
4
14
10
X3
7
6
12
Totale
13
25
37
22
28
25
75
Tabella 2
li
br
Y1
X1
S.
Variabile Y
i
Variabile X
Es
se
Nella tabella, nella cella all’incrocio della modalità Y1 di Y e della modalità X1 di X è riportato il valore numerico 2; lo stesso sta a indicare che 2
sono le unità che presentano simultaneamente la modalità Y1 di Y e la modalità X1 di X. Il valore numerico 2 è una frequenza osservata fo effettivamente. Andiamo a calcolare la corrispondente frequenza attesa fe sotto l’ipotesi
di indipendenza tra variabili.
Essa si ottiene dalla seguente proporzione:
fe : 13 = 22 : 75
C
op
yr
ig
ht
©
dove:
— 13 è una frequenza marginale e sta a indicare il numero di unità che
presentano la modalità Y1 di Y a prescindere da X;
— 22 è una frequenza marginale e sta a indicare il numero di unità che
presentano la modalità X1 di X a prescindere da Y;
— 75 è il totale generale e indica il numero totale di unità statistiche.
Pertanto, il valore della frequenza attesa è:
fe =
13 ⋅ 22
= 3, 813
75
72
A
.
Capitolo Terzo
p.
In maniera analoga sono calcolate le restanti frequenze attese riportate
nella tabella seguente:
Variabile X
S.
Tabella delle frequenze teoriche
Variabile Y
Totale
Y1
Y2
Y3
X1
3,813
7,333
10,853
X2
4,853
9,333
13,813
X3
4,333
8,333
12,333
25
Totale
13
25
37
75
28
Tabella 3
li
br
i
22
L’indice chi-quadrato, o χ , elaborato da Karl Pearson (1857-1936),
costituisce un criterio di valutazione della differenza esistente tra frequenze
teoriche e frequenze osservate; la sua espressione analitica è la seguente:
se
2
∑
(f
Es
χ2 =
o
− fe )
2
fe
Con riferimento alla distribuzione riportata nella tabella, esso assume valore:
( 2 − 3, 813) + (5 − 7, 333)
2
χ2 =
(6 − 8,3333) + (12 − 12, 333)
2
2
2
©
= 9, 029
3, 813
7, 333
8, 333
12, 333
Le applicazioni dell’indice in statistica sono molteplici. È un indice assoluto, ammette valore minimo 0 se esiste indipendenza tra le variabili, ma
non ammette valore massimo in senso matematico, ovvero ammette il massimo relativo che dipende dalla numerosità dei casi. È proprio questo un
limite all’applicabilità dell’indice nel confronto tra distribuzioni diverse,
per ovviare ad un simile inconveniente si ricorre ad indici che costituiscono
delle trasformazioni dell’indice di Pearson.
L’indice normalizzato di Cramer si ottiene dalla radice quadrata seguente:
op
yr
ig
ht
+ ... +
V=
χ2
N ( k − 1)
C
dove k è uguale al minore tra il numero r di righe e numero c di colonne
nella tabella.
73
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
L’indice varia tra 0 (indipendenza) e 1 (dipendenza massima).
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
○
p.
Quali sono i valori minimo e massimo dell’indice?
○
A
○
.
Analisi bivariata
○
○
○
○
○
○
S.
Con riferimento alla distribuzione in tabella, l’indice assume valore:
9, 029
= 0, 245
75 ( 3 − 1)
V=
br
i
Il valore trovato indica una prossimità all’indipendenza tra le variabili.
se
li
4.1 Associazione tra variabili dicotomiche
Quanto esposto finora si riferiva al caso in cui i dati sperimentali fossero
classificati secondo due criteri, rispettivamente, con r e c livelli. Nelle situazioni pratiche, nella ricerca sociale, si ha a che fare con dati classificati
secondo due livelli, ossia con variabili dicotomiche.
In questo caso i dati sono rappresentati mediante tabelle doppie del tipo:
Y
Es
X
1
2
a
2
c
Totale
a+c
b
a+b
d
c+d
b+d
N=a+b+c+d
©
1
ht
Tabella 4
ig
2
In questo caso, l’espressione del χ è la seguente:
χ2 =
N ( ad − bc )
2
( a + b ) (c + d ) ( a + c ) ( b + d )
C
op
yr
L’indice di Cramer sarà:
V=
Totale
χ2
=
N
ad − bc
( a + b ) (c + d ) ( a + c ) ( b + d )
74
A
.
Capitolo Terzo
p.
ESEMPIO
Laureati
Non laureati
Occupati
30
6
Non occupati
17
12
Totale
47
18
S.
Volendo valutare la relazione tra possesso di un diploma di laurea e occupazione,
nella tabella seguente sono riportati i dati relativi a 65 individui, raggruppati in base
al possesso o meno del diploma di laurea e allo stato occupazionale.
Totale
36
br
i
29
65
Tabella 5
li
Calcoliamo l’indice di Cramer per misurare l’associazione tra diploma di laurea e
occupazione.
se
2
Il valore del χ è:
65 ⋅ ( 30 ⋅ 12 − 6 ⋅ 17 )
2
(30 + 6) (17 + 12) (30 + 17) (6 + 12)
per cui l’indice di Cramer è:
= 4, 899
Es
χ2 =
©
V =
4, 899
= 0, 275
65
C
op
yr
ig
ht
4.2 Misure di cograduazione
Si è già detto che, se entrambe le variabili sono ordinali, esistono altre
misure atte a valutare la forza della relazione tra le stesse: le misure di cograduazione.
Esse sono basate sui valori assunti dalle variabili X e Y su tutte le possibili coppie di casi. In particolare, una coppia di casi si dice concordante se
su un caso i valori delle variabili X e Y sono entrambi maggiori (o minori)
dei valori di entrambe sull’altro caso. Analogamente, una coppia si dice
discordante se una variabile assume, rispetto a un caso, un valore minore
mentre l’altra variabile assume un valore minore rispetto ai valori assunti
sull’altro caso.
75
A
.
Analisi bivariata
p.
Tra queste misure riteniamo degna di attenzione, il gamma (γ ) di Go-
γ =
S.
odman e Kruskal (1954), che è una misura simmetrica della differenza tra
numero di coppie concordanti (C) e numero di coppie discordanti (D) e la
cui espressione analitica è la seguente:
C−D
C+D
li
br
i
Gamma assume:
— valore minimo – 1 nel caso di perfetta relazione negativa;
— valore massimo + 1 nel caso di perfetta relazione positiva.
Esso assume valore 0 se non esiste relazione.
se
5. RAPPORTI DI PROBABILITÀ E ODDS RATIO
ig
ht
©
Es
Si è visto ampiamente che una proporzione (o frequenza relativa) è
data dal rapporto tra una data frequenza e il numero totale dei casi; a questo
punto introduciamo un rapporto tra frequenze, il rapporto di probabilità
(odds), indicato con la lettera greca omega ω , esso si istituisce tra la frequenza di una data categoria e la frequenza di una categoria alternativa per
una variabile dicotomica, oppure tra la probabilità che un’unità della popolazione appartenga a una data categoria e la probabilità che non appartenga
alla stessa.
Un esempio può essere il seguente: se una distribuzione di frequenza è
fondata su una variabile Diploma di laurea si può stabilire un rapporto tra
laureati e non laureati.
In simboli si ha:
Rapporto di probabilità ( odds ) = ω =
pi
f1
=
f2 1 − pi
C
op
yr
dove:
— f1 è la frequenza di una data categoria;
— f2 è la frequenza della categoria alternativa;
— pi è la probabilità della i – esima unità di appartenere a una data categoria;
— 1 – pi è la probabilità della i-esima unità di non appartenere a quella
categoria.
76
A
.
Capitolo Terzo
se
li
br
i
S.
p.
Mentre le probabilità variano tra 0 e 1, gli odds assumono valore minimo 0 ma non ammettono valore massimo.
Un rapporto di probabilità assume valore 1 se la probabilità che un evento si verifichi è pari alla probabilità che non si verifichi. Inoltre, assume:
— valori inferiori a 1 se la probabilità che si verifichi un evento è inferiore
alla probabilità che non si verifichi;
— valori superiori a 1 se la probabilità che si verifichi un evento è superiore
alla probabilità che non si verifichi.
È particolarmente usato in medicina nello studio casi/controlli.
Il rapporto di probabilità può essere riferito anche a due variabili ed è
una misura dell’associazione tra le stesse.
Con riferimento alla tabella 5 istituiamo i rapporti di probabilità condizionati (o odds condizionati):
ω1 =
Es
Laureati:
Non laureati:
ω2 =
a 30
=
= 1, 765
c 17
b 6
=
= 0, 5
d 12
©
Mentre, le corrispondenti probabilità condizionate (percentuali di riga
e di colonna) sono:
ht
Laureati:
a
30
=
= 0, 638
a + c 47
p2 =
6
b
=
= 0, 333
b + d 18
ig
Non laureati:
p1 =
op
yr
Il rapporto tra gli odds condizionati si chiama odds ratio e può essere
tradotto in italiano come rapporto di associazione; è pari a:
Rapporto di associazione ( odds ratio ) =
=
ω 1 a c ad 30 ⋅ 12
= 3, 529
=
=
=
ω 2 b d bc 6 ⋅ 17
C
Il suo significato è il seguente: posto pari a 1 il rapporto occupati/disoccupati tra coloro che posseggono un diploma di laurea, esso assume valore
77
A
.
Analisi bivariata
S.
p.
3,529 tra coloro che non posseggono il diploma di laurea. È più del triplo il
rapporto occupati/disoccupati dei possessori di diploma di laurea rispetto a
quelli che non ne sono in possesso.
Il rapporto di associazione può assumere valore minimo pari a 0 e valore
massimo pari a +∞. Se assume valore 1 si verifica indipendenza tra le variabili.
i
Glossario
C
op
yr
ig
ht
©
Es
se
li
br
Correlazione: grado di dipendenza lineare tra due variabili X e Y, per cui al variare di X
varia anche Y e viceversa. La forza di tale legame si misura con il coefficiente di correlazione lineare. Si parla di correlazione multipla quando si vuole indicare la dipendenza di una
variabile da più altre; di correlazione parziale per indicare la dipendenza di una variabile
da un’altra al netto delle eventuali relazioni lineari esistenti tra le rimanenti.