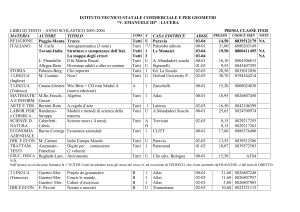
ATLAS
Attività di Computing
@7 TeV
Gianpaolo Carlino
INFN Napoli
Parma, 22 Settembre 2010
• Attività di computing
• Gli sviluppi del CM
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
1
LHC data taking @ 7 TeV
Al 30 Agosto si sono raccolti ~ 3.5 pb-1
Luminosita’ di picco = 1.03x1031 cm-2 s-1
(27 Agosto)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
2
2010 LHC – Data taking
Logical Data: dataset registrati
Physical Data: comprende tutte
le repliche distribuite in GRID
Event size
Tot. Volume
Logic. data
Phys. data
4.6 PB
14 PB
RAW
1.6 MB
2.0 PB
ESD
1.0 MB
1.9 PB
6.9 PB
AOD
0.1 MB
110 TB
2.0 PB
330 TB
4.1 PB
dESD
RAW Event Size
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
3
2010 LHC – Data Distribution
Trasferimenti: Tier-0 Tier-1 Tier-2
• Throughput medio di progetto: ~2 GB/sec (commissioning fino a 3 GB/s)
• Raggiunti picchi ~10 GB/sec nella campagna di reprocessing
• Efficienza di trasferimento: 100%
MB/s
per day
6 GB/s
Data and MC
reprocessing
Start of
7 TeV
data-taking
Start of
1011 p/bunch
operation
~2 GB/s
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
4
2010 LHC – Data Distribution in IT
MB/s
per day
Throughput totale in IT
200
MB/s
aprile
maggio
giugno
luglio
o AOD = 100%
o RAW = custodial + backup share (5% + 5%)
o ESD = 5% + 5% fino a luglio, poi 30% al CNAF
per favorire l’analisi degli utenti
o dESD = 100% ai Tier2 fino a luglio
o ESD e dESD ai Tier2 con sottomissione
dinamica da agosto
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
5
Attività in ATLAS
Produzione
Simulazione, Ricostruzione, Reprocessing
Numero medio di job
con Panda
Sep 2009 – Sep 2010
Uso significativo della Grid
per l’analisi.
Uso “reale” molto superiore
degli stress test effettuati
durante il commissioning
Analisi
Ganga, Pathena
7TeV data
Distributed Analysis Highlights
:
Data are distributed to 70+ sites
100 users per day accessing data
April-Sep:
~ 22 M successful analysis jobs.
> 150 billion events analysed
Parma, 22 Settembre 2010
UAT09
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
6
Uso risorse in Italia
VO ATLAS only
Uso delle CPU nella
Grid per “Country”
nei Tier1 e Tier2
(EGEE portal)
Numero totale di successful job
(Analisi + Produzione):
Aprile – Settembre 2010
(ATLAS dashboard)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
7
Uso risorse al CNAF
Uso delle CPU nella
Grid nei Tier1 per
tutte le VO LHC
(EGEE portal)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
8
Uso risorse al CNAF
Monitor CNAF
Reprocessing
CPU 2010-I
No Production
Inizio Analisi
CPU 2010-II
Risorse ATLAS al CNAF:
Disponibili (03/10 – 09/10): 8700 HS06
Pledge 2010 (09/10) : 16000 HS06
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
9
Uso risorse nei Tier2
Uso delle CPU nella Grid per i Tier2 Italiani per tutte le VO LHC: Gennaio – Luglio 2010
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
10
Analisi Distribuita
User Analysis Successful Job - PanDA Backend
CA, 3%
US, 36%
CERN, 6%
DE, 15%
ES, 4%
FR, 15%
UK, 6%
NL, 6%
TW, 2%
1.
2.
3.
4.
ND, 4%
IT, 3%
Perché la percentuale dell’ Italia è cosi bassa?
Le CPU sono sature e le risorse 2010 saranno in attività solo a dicembre
in Italia c’è ancora un utilizzo significativo del WMS (non presente in queste percentuali)
usiamo il Tier1 per l’analisi solo da agosto (solo UK non usa il Tier1)
al momento il formato più popolare è l’ESD, più completo e adatto per lo studio delle performance
•
gli utenti italiani mandano i loro job nelle altre cloud dove sono i dati
•
il disco si riempie di dati inutili
Era necessario modificare il modello di Analisi
e di replica dei dati. Da agosto nuovo modello
in fase di test in 3 clouds tra cui l’ Italia
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
11
Analisi Distribuita
Job di Analisi con Panda in Italia
• non viene riportato l’uso del
WMS comunque significativo in
Italia
• nei Tier2 ~50% delle risorse per
l’analisi (evidente dall’accounting
di giugno in assenza di
produzione)
Esempio di job running su un Tier2
nell’ultimo mese
codice colori:
• Produzione
• Analisi WMS
• Analisi Panda
• Analisi Panda ruolo italiano
(gli italiani vengono mappati sia su panda che su
panda/it)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
12
IL CM – analisi critica e sviluppi
5 mesi di presa dati. Sufficiente esperienza per una valutazione critica del CM
• La griglia sembra funzionare
• scala oltre i livelli testati nelle varie fasi di commissioning
• gli utenti stanno familiarizzando con i tool di analisi e gestione dei dati,
selezionando quelli migliori (panda vs. WMS), sono mediamente soddisfatti
anche se ovviamente vorrebbero efficienza 101% e risorse infinite
• Critiche negli anni al nostro CM
• richiesta eccessiva di spazio disco
• proliferazione del formato dei dati
• eccesso di repliche dei dati
• Superamento dei punti deboli
• accounting dell’accesso ai dati: determinazione della loro popolarità
• cancellazione automatica dei dati meno popolari
• replica dinamica ai Tier2 solo dei dati utilizzati dagli utenti
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
13
Accounting dell’accesso ai dati
•
•
•
•
Alla base del sistema di cancellazione delle repliche
Fornisce una statistica dei formati più utilizzati (popolari) per l’analisi
Fornisce una statistica dell’uso dei siti
Fornisce una statistica dei tool di analisi più usati
ESD formato decisamente più popolare
• necessario per molti tipi di analisi di performance
e detector
• in alcuni casi è un approccio “conservativo” degli
utenti che, in dubbio, preferiscono utilizzare formati
più completi
• non può scalare con la luminosità e il numero di
utenti
Gruppi di Fisica e Performance
• Migliorare il contenuto dei formati di dati skimmati
Computing
• Cancellare i dati non (più) utilizzati (data deletion system)
• Diminuire il numero di repliche di dati trasferendo solo i dati richiesti dagli utenti (sistema
di repliche dinamico)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
14
Data deletion
• ~ 30% dei siti è overfull, con ridotto spazio disco a disposizione
• I dataset meno popolari possono essere cancellati dopo essere stati replicati nei siti
• bisogna assicurare la custodialità prevista dal Computing Model
• permette di replicare sempre tutti i dati nuovi per l’analisi senza penalizzare le cloud più piccole
• risparmio significativo di spazio disco
ATLAS usa un sistema automatico di cancellazione basato sulla classificazione dei dataset e la misura
del numero di accessi
• custodial data: cancellabili solo se obsoleti (RAW, ESD o AOD prodotti nella cloud)
• primary data: cancellabili solo se diventano secondary (dati previsti dal CM)
• secondary data: solo questi possono essere cancellati se non popolari in base alla loro anzianità
Cancellazione dei dati secondari meno
popolari quando lo spazio disco occupato
supera una soglia di sicurezza
Permette una continua rotazione dei dati
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
15
Evoluzione del Computing Model
Perché replicare i dati se poi vengono cancellati?
• Attualmente si replicano milioni di file (spesso molto piccoli)
• replica in tutti i siti (70+) e solo in 30-40 vengono acceduti
• stesso numero di repliche per ogni physics stream anche se il pattern d’accesso è
diverso
• cancellazione dei dati meno popolari e sottoscrizione a mano di quelli più popolari
Non esiste un metodo più intelligente?
• ATLAS sta studiando l’evoluzione del Computing Model verso un modello meno rigido
che ottimizzi le risorse disponibili: riduzione del disco necessario e utilizzo di tutte le
CPU idle
• il paradigma è invariato: i job vanno dove sono i dati ma, sfruttando l’efficienza del
sistema di data management e le performance della rete, la replica dei dati è
triggerata dai job stessi
• Panda Dynamic Data Placement Model (PD2PM)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
16
CM gerarchico originale (data push)
Tier-0
Tier-1
Tier-2
Tier-1
Tier-2
Tier-2
Tier-1
………
Tier-2
Modello usato attualmente da ATLAS
Funziona. Ma non ottimizza le risorse e non sfrutta
appieno la rete oggi disponibile
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
………
Tier-1
Nel modello MONARC
(anni '90) ogni sito era
connesso ad un solo sito
del livello superiore e i
dati venivano distribuiti
gerarchicamente
17
CM gerarchico originale (data push)
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
18
CM dinamico (data pull)
Tier-0
Tier-1
Tier-2
Tier-1
Tier-2
Tier-2
Tier-1
………
Tier-2
Modello in test attualmente nelle cloud US, UK e IT.
• La distribuzione dei dati ai Tier1 non cambia
• I Tier2 sono delle cache utilizzando il sistema di
data deletion basato sulla popolarità dei dati
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
………
Tier-1
Nel modello Grid dinamico
(anni 2010) i dati sono in
parte distribuiti e in
parte richiesti dal livello
superiore.
In prospettiva ogni sito è
connesso a tutti i siti del
livello superiore.
19
Panda Dynamic Data Placement Model
Modello di distribuzione dei dati basato sull’idea di considerare gli storage dei Tier2 come cache
Oggi i job vanno verso i dati pre-placed
nuovo modello più reattivo, PD2PM:
• nessun dato (o solo alcuni formati) pre-placed nei Tier2, stop alla replica automatica
• immutata la distribuzione dei dati nei Tier1
• Panda esegue la replica dei dati verso i Tier2 quando c’è un job al Tier1 che li richiede
• i successivi job girano al Tier2 dove è stata eseguita e completata la replica
• clean up dei Tier2 quando lo storage è pieno basato sul sistema di popolarità
il modello, nella sua fase finale, funzionerà collegando i Tier2 con i Tier1 di ogni cloud
• anche solo l’applicazione all’interno della singola cloud permette comunque di ottimizzare
l’uso dello storage e delle CPU
Questo modello è in fase di test in 3 cloud (US, FR e IT), bisogna valutare attentamente le
performance prima di renderlo operativo e basare su di esso il nuovo CM
• test iniziale in USA che si avviava verso una catastrofe ultravioletta del disco dei Tier2
• l’Italia ha iniziato il test a fine luglio appena è stata installata al CNAF la prima parte del
disco 2010 ed è stata abilitata l’analisi utente
• aumentato lo share di ESD (formato più popolare d’analisi) al Tier1 al 30%
• interrotto il pre-placement automatico di ESD e dESD ai Tier2
promettente, ma richiede ancora molto studio, soprattutto per la nostra tipologia di Tier2
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
20
Panda Dynamic Data Placement Model
Il plateau non è ancora
visibile a causa della
piccola dimensione della
cache
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
21
I Tier3
Modello ATLAS per i Tier3
• ATLAS ha sviluppato un modello di Tier3 definendo le funzionalità e i tool specifici
• Analisi interattiva (Root, Proof) e sviluppo di codice
• Storage locale (ntuple)
• Molti siti già attivi in tutto il mondo e soprattutto in America, molto importanti per
l’attività locale
• Tipologia Tier3:
• sito pienamente “grigliato”
• Tier3 @Tier2 (tipologia più diffusa in ATLAS)
• piccola farm locale non “grigliata” per l’interattivo
• in Italia
• task force in alcuni proto-Tier3 (Genova, Roma3, Trieste/Udine) che ha portato
avanti lo sviluppo del modello in base alle tipologie dei nostri centri
• utilizzo delle farm già esistenti nelle sezioni (p.es. farm INFN-GRID)
• la sperimentazione continua coinvolgendo sempre più strettamente gli utenti
per arrivare ad un modello finale
• sarebbe molto utile un riconoscimento dell’importanza di questi siti
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
22
Conclusioni
• Le attività di computing nei 5 mesi di dati a 7 TeV hanno dimostrato che la griglia
funziona e dal primo momento i dati sono stati analizzati con le tecniche dell’analisi
distribuita
• Il Computing Model è sottoposto ad una analisi critica individuandone gli aspetti da
migliorare. Alcune modifiche sostanziali già attuate.
• Tutti i siti italiani, Tier1 e Tier2, garantiscono un livello di affidabilità più che
sufficiente e un efficiente utilizzo delle risorse
• Le risorse richieste nel 2011 garantiranno alla cloud italiana di confermare e
aumentare la propria competitività
Parma, 22 Settembre 2010
G. Carlino – ATLAS, Attività di Computing @ 7 TeV
23