ATLAS: il calcolo
Alessandro De Salvo
25-5-2015
A. De Salvo – 25 maggio 2015
ATLAS: Utilizzo risorse Tier 1 in Italia
3.5 PB
70e3
NTUP
Expired
AOD
HITS
May 2014
May 2015
May 2014
May 2015
WCT
INFN T1
Job Efficiency
WCT
T1
Frascati
Napoli
Milano
INFN T1
(8.05%)
Roma
2
ATLAS: Utilizzo risorse Tier 2 in Italia
80e3
Napoli
4 siti T2 (D/S)
Frascati
Milano
Napoli
Roma 1
Roma
Frascati
May 2014
Milano
May 2015
4.5 PB
Frascati
Napoli
NTUP
Job Efficiency
Milano
AOD
Expired
Roma
May 2014
May 2015
3
ATLAS: Utilizzo risorse Tier 2 in Italia [2]
Frascati
05/2014
Milano
05/2015
05/2014
Napoli
05/2014
05/2015
Roma
05/2015
05/2014
05/2015
Plot di accounting (Faust): la linea verde è il pledge per sito
Buone performance dei siti
Qualche problema a livello ATLAS centrale per riempire i siti fino ad aprile 2015
Multicore job correttamente accountati solo da gennaio 2015 (problema nei sensori di APEL)
4
Network
DDM Ingoing
DDM Outgoing
5
FRASCATI
MILANO
NAPOLI
ROMA
Traffico di Rete
Availability / Reliability 2011-2015
Valori medi 2011/2015
Frascati
Milano
rel
ava
rel
ava
97%
94%
91%
89%
Napoli
Availability =
time_site_is_available/total_time
Reliability =
time_site_is_available/
(total_time-time_site_is_sched_down)
6
Roma
rel
ava
rel
ava
96%
95%
97%
96%
Novità 2014/2015 nei siti
Tutti i siti T1 e T2
Tutti i siti sono abilitati per il processing multicore
Buona parte della produzione è ormai multicore, l’analisi ancora no
Gestione dinamica abilitata per ora solo al CNAF (ma seguiranno MI e RM)
Situazione nell’ultimo anno
Tutti i siti molto stabili e con ottime reliability/availability
Problema ad un rack a Roma (2 ventole su 3 rotte) che ha portato ad una
riduzione di potenza temporanea della CPU, pur non impattando da un punto
di vista ATLAS
Migrazione ad APEL senza grossi problemi, pur avendo dovuto adattare le
procedure alle situazioni dei singoli siti
Milano: Condor
RM e NA: multi-sito con singolo publisher
“Prove di matrimonio” tra ATLAS e CMS a RM
Testata con successo una configurazione comune di WN
A breve verranno create le code di overflow, una per ogni esperimento, che permetteranno
un overlap incrementale, ove sia possibile
7
Partecipazione italiana alle attività di ATLAS
ATLAS Italia partecipa alle attività di ADC in diversi aspetti
Database (Coordinamento, Frontier, Conditions)
Installazione del software (CVMFS e distribuzione)
Monitoring
Network infrastructure (LHCONE)
Storage
VO management
Altre attività (PRIN)
Federazioni di xrootd e HTTPD
DPM
Cloud Computing
Hadoop (EventIndex)
Network Infrastructure (LHCONE)
Proof on Demand
La partecipazione alle rimanenti attività è largamente limitata dalla
disponibilità di persone
Attività sulle GPU, inserite in un FIRB
Interesse della comunità per GPU e multiprocessing/ottimizzazione del codice, ma
NON c’è manpower
8
Risorse Attività ATLAS 2016
Lo Scrutiny Group ha approvato ad aprile 2015 le seguenti risorse per ATLAS
9
Risorse Disponibili 2015 - CPU
CPU disponibili fine 2015
CPU
Frascati
Milano
Napoli
Roma
Totale
HS06
16672
20890
29363
20032
86957
To be
pledge
d
10718
10924
14790
10924
47356
Pledge
46800
Le CPU totali a disposizione dei Tier2 comprendono anche risorse non pledged:
•le CPU obsolete (fino al 2015 e già rifinanziate) ancora in produzione ma in corso di spegnimento
•CPU per uso locale (cluster proof) o in griglia ma dedicate principalmente alle attività italiane (Tier3) finanziate
con fondi vari
– Proof on Demand, share per analisi e simulazione MC per il ruolo atlas/it
•CPU non a completa disposizione dei siti
– (es. scope + Recas a NA, ex SuperB, Belle2, a LNF)
Nel conto delle CPU pledged NON sono comprese le CPU gara dei rimpiazzi 2015, tranne che per Frascati,
ancora da espletare
10
Risorse Disponibili 2015 – Disco
Storage disponibile fine 2015
Disco
Frascati
Milano
Napoli
Roma
Totale
Totale
disponibile
868
1242
1546
1238
4894
to be
pledged
688
Pledge
3712
1062
1366
1058
4174
Lo storage totale disponibile nei Tier2 comprende anche l’area locale in cui sono
conservati i dati di tutti gli utenti italiani (LOCALGROUP), non solo gli utenti locali
•La dimensione di queste aree è di circa 180 TB per Tier2
•In gran parte già occupata, gli utenti dovranno cancellare i dati vecchi non più
necessari per fare spazio ai dati del 2015
•l’utilizzo di queste aree è irrinunciabile per cui il loro volume va sottratto allo storage da
dichiarare pledged
11
Risorse obsolete 2016
Risorse Obsolete nel 2016
CPU (HS06)
Disco (TBn)
Frascati
3048
120
Milano
3048
405
Napoli
2088
204
Roma
3048
444
Tot
11232
1173
•
Le CPU obsolete sono le macchine comprate nel 2012 e installate fine 2012 inizi 2013 (non sono comprese
le macchine installate successivamente). Le CPU hanno garanzia triennale, tranne quelle acquistate a
partire dal 2014
•
Lo storage obsoleto comprende le SAN comprate nel 2010 e installate >= giugno 2011. Garanzia
quinquennale
•
La sostituzione del materiale obsoleto, specie per i dischi, è fondamentale per il buon funzionamento dei
centri e quindi dell’intero sistema di computing italiano di ATLAS
12
Richiesta Risorse 2016 - I
Le risorse necessarie per il 2016 sono determinate dalla volontà di conservare il ruolo significativo
nel computing di ATLAS acquisito negli ultimi anni conservando gli share di risorse pledged per le
attività centrali:
• Tier1: 9%
• Tier2: 9% CPU e 7% Disco
e di garantire la competitività agli utenti italiani mediante l’uso di risorse dedicate nei Tier2 e Tier3
CPU T1
(kHS06)
Disco T1
(PB)
Tape T1
(PB)
CPU T2
(kHS06)
Disco T2
(PB)
13
ATLAS
Share
IT
ATLAS IT
2016
ATLAS IT
disponibile
Totale
2016
520
9%
46.8
40.5*
6.3
47
9%
4.23
3.33*
0.9
116
9%
10.5
5.9*
4.6
566
9%
50.9
47.4
3.5
72
7%
5.04
4.17
0.9
* Pledge 2015
Richiesta Risorse 2016 - II
Totale
Le risorse per le attività italiane sono già disponibili e non inclusi
nel disponibile “pledged” 2016 e non sono necessarie ulteriori
richieste
New 2016
Obs 2016
Richieste 2016
K€
CPU T2 (kHS06)
3.5
11.2
14.7
176.4
Disco T2 (TB)
870
1173
2043
449.5
Totale
625.9
Prezzi stimati:
•CPU = 12 k€/kHS
•Disco = 220 k€/PB
14
Richiesta Risorse 2016 - III
Overhead per rete e server aggiuntivi
Algoritmo Bozzi (cfr. presentazione CSN1 Bari Settembre 2011):
•Rete: 6% (cpu) + 5% (disco) = 33.2 k€
•Server: 7% (cpu + disco) = 43.9 k€
A cosa servono:
•Rete: switch di rack
•Server: servizi di grid
A cosa corrispondo questi finanziamenti:
•Rete: 1÷2 switch con modulo 10 Gbps
• Per collegare le nuove risorse e/o sostituire i primi switch ormai fuori
manutenzione
•Server: 1÷3 server per sezione
15
Richiesta Risorse 2016 – Riepilogo (A)
Richieste totali e per sito: totale delle richieste
CPU
Pledged
2015
[kHS06]
Disco
Pledged
2015
[TBn]
CPU
Obs
2016
[kHS06]
Disco
Obs
2016
[TBn]
CPU
New
2016
[kHS06]
Disco
New
2016
[TBn]
CPU Tot
2016
[kHS06]
Disco Tot
2016
[TBn]
OH
Rete
[K€]
OH
Server
[K€]
Tot
[K€]
Frascati
10.7
688
3.05
120
1.17
493
4.22
613
9.8
13
208.5
Milano
10.9
1062
3.05
405
1.17
208
4.22
613
9.8
13
208.5
Napoli
14.8
1366
2.09
204
0
0
2.09
204
3.7
4.8
78.5
Roma
10.9
1058
3.05
444
1.17
169
4.22
613
9.8
13
208.5
Tot
47.3
4174
11.24
1173
3.50
870
14.75
2043
33.1
43.8
704.0
Prezzi stimati:
•CPU = 12 k€/kHS
•Disco = 220 k€/PB
16
Richiesta Risorse 2016 – Riepilogo (B)
Richieste totali e per sito: risorse strettamente necessarie
Tagli possibili, in ordine di rilevanza:
1. Riduzione dell’overhead fino al 50%
2. Rimpiazzo delle solo CPU obsolete già nel 2015
3. Riduzione dello spazio locale dei siti (-120 TBn)
Massimo risparmio, ma in condizioni molto complicate per i siti: 173 kEUR
CPU
Pledged
2015
[kHS06]
Disco
Pledged
2015
[TBn]
CPU
Obs
2016
[kHS06]
Disco
Obs
2016
[TBn]
CPU
New
2016
[kHS06]
Disco
New
2016
[TBn]
CPU Tot
2016
[kHS06]
Disco Tot
2016
[TBn]
OH
Rete
[K€]
OH
Server
[K€]
Tot
[K€]
Frascati
10.7
718
0.96
120
1.17
453
2.13
573
3.9
5.3
161.0
Milano
10.9
1092
0.96
405
1.17
168
2.13
573
3.9
5.3
161.0
Napoli
14.8
1396
0
204
0
0
0
204
1.1
1.5
48.0
Roma
10.9
1088
0.96
444
1.17
129
2.13
573
3.9
5.3
161.0
Tot
47.3
4294
2.88
1173
3.50
750
6.39
2043
12.8
17.4
531.0
Prezzi stimati:
•CPU = 12 k€/kHS
•Disco = 220 k€/PB
17
Conclusioni
Il Computing di ATLAS ha dimostrato di essere robusto ed
affidabile per il processamento dei dati, sia MC che analisi finale
Computing Model di ATLAS è stato quasi completamente
ridisegnato, sia a livello del codice di ricostruzione/analisi sia dei
servizi infrastrutturali, incrementandone l’efficienza
I siti italiani sono stati sempre attivi ed efficienti
Le richieste totali del 2016 sono ~700 kEUR, con possibilità di
scendere fino a ~530 kEUR considerando solo le risorse
strettamente necessarie
Si sta indagando anche la possibilità di estendere di 1 o 2 anni il
periodo di manutenzione dello storage in dismissione nel 2016
18
Backup slides
19
Nuovo Computing Model di ATLAS nel Run2
Nuovo sistema di computing
Rucio (Data Management)
Prodsys-2 (Workload Management)
FAX ed Event Service per ottimizzare
l’utilizzo delle risorse
Ottimizzazione della Produzione ed Analisi
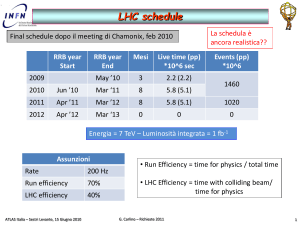
Run-1: 75% / 25% (slots occupancy ~ cputime usage)
Run-2: 90% / 10% (stima grossolana)
La maggior parte dell’analisi (Derivation) sarà spostata sulla (group)
production
L’analisi rimanente sarà più veloce e I/O intensive
Riduzione del merging e produzione di file più grandi
Code dinamiche in Panda, basate sui requirement dei job
Direct I/O (xrootd e WebDAV/HTTPS)
20
Lifetime dei dati
Modello di lifetime dei dati
Ogni dataset avrà un lifetime settato in fase di creazione
La lifetime può essere infinita (ad esempio per i dati RAW) e può essere estesa, ad
esempio se il dataset è stato utilizzato di recente oppure se esiste una eccezione
conosciuta
Ogni dataset avrà una retention policy, ad esempio i RAW saranno memorizzati in doppia
copia su tape e gli AOD almeno una copia su tape
Durante la loro lifetime I dataset verranno contrassegnati come dati primari, e quindi non
cancellabili
I dataset con lifetime spirata verranno contrassegnati come secondari e potranno
scomparire in ogni momento dai dischi e dai tape, ad eccezione dei Group disk e
LocalGroup disks
Utilizzo maggiore del tape, ma non dal punto di vista degli utenti finali, tranne casi
particolari
21
Novità del Computing di ATLAS nel Run2
Utilizzo più efficiente delle risorse
Maggiore flessibilità nel Computing Model
(Clouds/Tiers)
Eliminazione dei ruoli stretti T1/T2/T3
Global Panda queue
Global Storage Pool (STABLE, UNSTABLE, VOLATILE)
Diminuzione delle risorse utilizzate (multicore)
Ottimizzazione del workflow delle analisi
(Derivation Framework/Analysis Model)
La maggior parte delle analisi:
Processeranno una grande mole di dati
Utilizzeranno meno tempo di CPU
Un singolo job di analisi sui dataset derivati può utilizzare
fino a 40MB/s (vs. 4 MB/s nel Run-1 con gli AOD)
Utilizzo di risorse opportunistiche
Grid, Cloud, HPC, Volunteer Computing
22
S. Campana – ATLAS Jamboree – Dec 2014
Risorse opportunistiche: HPC
23
S. Campana – ATLAS Jamboree – Dec 2014
Risorse opportunistiche: Cloud
24
Risorse opportunistiche: Volunteer Computing
Panda Server
BOINC PQ
ARC
Control
Tower
•
•
Boinc-based
Low priority jobs with high CPU-I/O ratio
•
Grid Catalogs
and Storage
•
Need virtualisation for ATLAS sw environment
•
•
•
Volunteer PC
CERNVM image and CVMFS
No grid credentials or access on volunteer hosts
•
ARC CE
Non-urgent Monte Carlo simulation
ARC middleware for data staging
The resources should look like a regular
Panda queue
•
ARC Control Tower
Boinc Client
Boinc server
(vLHC@Home)
Shared Directory
DB on
demand
VM
Volunteers growth
•
Currently >10000 volunteers
300 new volunteers/week
Continuous 2000-3000 running jobs
• almost 300k completed jobs
• 500k CPU hours
• 14M events
• 50% CPU efficiency
D. Cameron – Pre-GDB on Volunteer Computing – Nov
2014
ATLAS @ HOME
CERN
25
Storage Federation
Goal reached ! >96% data covered
We deployed a Federate Storage Infrastructure (*): all data accessible from any location
Analysis (and production) will be able to access remote (offsite) files
Jobs can run at sites w/o data but with free CPUs. We call this “overflow”.
S. Campana – ATLAS Jamboree – Dec 2014
26
Nuovi tipi di Reprocessing nel Run2
Derivation Framework
AODtoAOD Reprocessing
Risolve problemi che necessitano solo di input di AOD
Intrinsecamente correlato con il Derivation Framework
RAWtoAOD - Fast Reprocessing
Modello in super-streaming, con scopo finale la produzione per
(gruppi di) analisi
Potenzialmente può risolvere problemi nell’input di AOD
Esegue operazioni intensive di CPU su eventi selezionati
I lumi-block completi appaiono solo dopo il passaggio del
Derivation Framework
Riprocessamento veloce dove vengono aggionate solo le
Condition Data
RAWtoAOD - Full Reprocessing
Riprocessamento veloce dove vengono applicate le nuove
calibrazioni e viene aggiornato il software
27
Derivation Framework
S. Campana – ATLAS Jamboree – Dec 2014
28
Analysis Model per il Run2
•
Common analysis data format: xAOD
• replacement of AOD & group
ntuple of any kind
• Readable both by Athena & ROOT
•
Data reduction framework
• Athena to produce group derived
data sample (DxAOD)
• Centrally via Prodsys
• Based on train model
• one input, N outputs
• from PB to TB
S. Campana – ATLAS Jamboree – Dec 2014
29
Event facilities
Event Service
Event level processing,
implementato a livello di ProdSys
(e pilot)
L’event service verrà inzialmente
utilizzato su risorse tradizionali
(grid/cloud) e successivamente
anche su HPC e oltre
Inizialmente sarà usato per la
simulazione, per poi essere
ampliato a tutto il resto,
fino all’utilizzo di un Event Streaming Service
Integrazione con G4Hive e Multi-Threading
Event Index
Semplificazione del TagDB di ATLAS,
trasformandolo in un indice
degli eventi (EventIndex),
con puntatori allo storage che contiene
gli eventi in vari formati (da RAW a NTUP)
Basato su Hadoop
Imminente sostituzione del TagDB
con l’EventIndex
30
Performance del software
Ricostruzione
Raggiunto il fattore 3 di miglioramento
rispetto al Run-1, previsto dal
nuovo Computing Model!
Dimensione degli AOD
Raggiunta la dimensione prevista
dal Computing Model
31
Infrastruttura italiana
• ATLAS in Italia continuerà ad usare per il Run2 il Tier1 e i Tier2
allo stesso modo del Run1
• Tier1 + 4 Tier2 (Tier2 di tipo ‘S’ – Stable) con risorse sempre più
equalizzate
• Interfaccia primaria di tipo Grid
• Full mesh con accesso ai dati locali e tramite Federazioni di Storage
• Cambiamenti in fase di studio o di sviluppo
• Interfacce di tipo Cloud
• Prototipo di Tier-2 distribuito
•
•
•
•
Progetto PRIN LHC-StoA, tra NA e RM
Possibile estensione a più siti T2
Attualmente il target è quello della condivisione di servizi in HA multiregione, ma può
anche essere esteso
Attività promettente, limitata solo dall’esigua quantità di manpower che può essere
dedicato a tale scopo