ATLAS: il calcolo
Alessandro De Salvo
5-9-2013
A. De Salvo – 5 settembre 2013
ATLAS: Utilizzo risorse Tier 2 in Italia
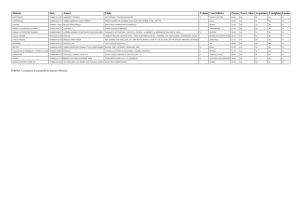
Site reliability/availability
Valori medi 2011/2013
Pledge
2013
Pledge
2012
Frascati
Milano
rel
ava
rel
ava
97%
90%
89%
90%
Napoli
4 siti T2
Frascati
Milano
Napoli
Roma 1
Roma
rel
ava
rel
ava
94%
95%
97%
97%
Sistema di replica dinamico
dei dati PD2P, basato sulla
popolarità del dati, già dal
2010. Ottimizzazione dell’uso
del disco dei Tier2
permettendo la copia di dati
interessanti.
Il calcolo è un investimento importante ma
con le performance ottenute, ai massimi
livelli internazionali, è di fondamentale
importanza per il raggiungimento dei
risultati di fisica in tempi rapidi
2
Review dei Tier2
La giunta ha richiesto una review dei Tier2 italiani
Il 3 settembre è stata inviata la richiesta di redigere un
documento di max 10 pagine per ogni sito, da completare entro il
15 novembre 2013
Storia
dei Tier2 e particolarità dei centri
Infrastrutture, funzionamento e performance
Sostenibilità per il 2015 e oltre
Risorse umane
Possibili criticità dei centri
Termine della review: febbraio 2014
3
Utilizzo delle risorse per il 2013-2015
2013
2014
Possibile riprocessamento dei dati e MC 2010-2012 per studi
ulteriori
Produzione di ulteriore nuovo MC per l’analisi
Attività molto intensa di analisi utente e di gruppo
Produzione di sample più grandi di MC per il run ad alta energia
Reprocessing completo finale dei dati e MC del 2010-2012,
utilizzando l’evoluzione del modello dei dati preparato per la presa
dati del 2015
Attività di preparazione del Run 2 (full dress reharsal)
2015
Processamento e riprocessamento dei nuovi dati ad alta energia
Produzione associata di MC per I nuovi dati
Incremento di attività utente e di gruppo
4
Preparazione al run del 2015
ATLAS ha piani ambiziosi per
l’upgrade delle attività di
Software e Computing
Software: ricostruzione, simulazione,
analisi
Ottimizzazione delle performance degli
algoritmi, utilizzando in modo più adeguato
le CPU moderne
Riduzione dell’utilizzo di memoria
Parallelismo a livello di evento e di
algoritmo
Riduzione della dimensione degli eventi
Computing distribuito
Nuovo sistema di Data Management (Rucio)
Upgrade del Production System
(PanDA + JEDI + DEfT)
File based data management, subscriptions
and rules, ..
New TRF, log file merging, …
Merging at T2s, dynamic job
definition based on scouts, …
Procedure operative e workflow
Ottimizzazione delle analisi
di gruppo e utenti finali
5
Cambi nel workflow di analisi
Il formato AOD sembra non essere l’ “Analysis Object Data” per la maggior parte delle analisi
La produzione dei formati di dati di gruppo (D3PD/NTUP) è effettuata centralmente
La situazione corrente rallenta l’analisi, crea problemi nella Grid, riempiendo I dischi, e non scala al
2015 con il Run 2
E’ necessario cambiare il modello di analisi e il suo workflow per aumentare il thoughput
Aggiornamento del workflow
Aggiornamento del formato degli AOD per farlo diventare direttamente leggibile da ROOT
Introduzione di un reprocessing AOD2AOD per ottimizzare l’utilizzo delle risorse
Introduzione di un “Derivation framework” per la produzione di formati di gruppo specifici, tramite
skimming/slimming/thinning degli AOD secondo un modello a treno, rimpiazzando il modello
corrente per la produzione di DPD
Introduzione di un common analysis framework, che metta a disposizione dei tool di analisi più
semplici e una integrazione migliore con la Grid
6
Nuovi protocolli di accesso ai dati
Sperimentazione dei nuovi protocolli di accesso
xrootd e HTTP supportano lo streaming su WAN
Sperimentazione dei protocolli di accesso remoti e comparazione con i protocolli di
storage nativi a disposizione
I protocolli verranno adottati sulla base delle performance, dell’affidabilità
e della semplificazione che manifesteranno
Valutazione successiva di un modello per la rottura del modello di località
dei dati per i job
Migrazione finale all’infrastruttura di Storage Federato
Impatto sull’infrastruttura (storage e network)
Attualmente basato su sulla tecnologia xrootd (FAX)
L’utilizzo dello storage federato comporterà un cambio di paradigma,
sia a livello centrale che a livello utente
Possibilità di accesso diretto ai file anche su siti che non hanno un file system Posix
(es. GPFS al CNAF, …), quindi ad esempio tutti I siti DPM (LNF, NA, RM, …)
Utilizzo più massiccio della rete
Maggiore affidabilità di analisi e ottimizzazione dello spazio disco
7
Uso di risorse opportunistiche
Cloud commerciali a basso costo o gratuite
Utilizzo di VM allocate staticamente in una cloud è stato ampiamente
dimostrato in produzione (includendo anche la farm HLT)
ATLAS si concentrerà ad ottimizzare la gestione dinamica delle risorse di
calcolo attraverso delle interfacce di provisioning di VM
(ad esempio OpenStack)
Si lavorerà sull’ottimizzazione del workflow per l’utilizzo di risorse
opportunistiche
Il piano consiste nell’integrare la AutoPilot Factory 2 con OpenStack/EC2
Il nuovo “event server”, ossia il dispatcher di eventi per la parallelizzazione dei task,
sarà molto utile in questo ambito
Possibilità di utilizzo di risorse di tipo HPC, ma alcuni problemi
Whole-node scheduling
Assenza di disco nei nodi
Nessuna connessione outbound
8
Partecipazione italiana alle attività di ATLAS
ATLAS Italia partecipa alle attività di computing di ATLAS in diverse aree di lavoro
Cloud support [all]
Database [D. Barberis]
Installazione del software (CVMFS e distribuzione) [A. De Salvo]
Monitoring [S. Tupputi]
Network infrastructure (LHCONE) [E. Capone, A. De Salvo]
Scrutiny Group [G. Carlino]
Storage [A. De Salvo, A. Doria, E. Vilucchi]
Cloud Computing
Hadoop (EventIndex)
Network Infrastructure (LHCONE)
Proof on Demand
La partecipazione alle rimanenti attività è largamente limitata dalla disponibilità di persone
VO management [A. De Salvo]
Altre attività (PRIN)
Federazioni di xrootd e HTTPD
DPM
Attività sulle GPU, inserite in un FIRB
Interesse della comunità per GPU e multiprocessing/ottimizzazione del codice, ma NON c’è
manpower
2 FTE al CERN, pagati dall’INFN in-kind e riconosciuti come M&O-A
9
Responsabilità italiane nel calcolo di ATLAS
ATLAS database
Dario Barberis [coord]
https://twiki.cern.ch/twiki/bin/viewauth/AtlasComputing/AtlasDistributedComputing
Coordinamento calcolo ATLAS IT
Alessandro De Salvo [coord]
https://web2.infn.it/atlas/index.php/organigramma
https://twiki.cern.ch/twiki/bin/viewauth/AtlasComputing/InternationalComputingBoard
Grid software release / CVMFS
Alessandro De Salvo [coord]
https://twiki.cern.ch/twiki/bin/viewauth/AtlasComputing/AtlasDistributedComputing
SAM monitoring
Salvatore Tupputi [deputy coord]
https://twiki.cern.ch/twiki/bin/viewauth/AtlasComputing/AtlasDistributedComputing
Scrutiny Group
Gianpaolo Carlino
https://twiki.cern.ch/twiki/bin/viewauth/AtlasComputing/InternationalComputingBoard
VO management
Alessandro De Salvo [coord]
https://twiki.cern.ch/twiki/bin/viewauth/AtlasComputing/AtlasDistributedComputing
10
Risorse Disponibili 2013 - CPU
CPU disponibili 2013 “pledged”
CPU
Frascati
Milano
Napoli
Roma
Totale
HP06
5633
10159
10798
9850
36440
To be
pledged
34200
Le CPU totali a disposizione dei Tier2 comprendono anche risorse che non pledged:
•CPU per uso locale (cluster proof) o in griglia ma dedicate principalmente alle attività italiane (Tier3) finanziate
con fondi vari
– Proof on Demand, share per analisi e simulazione MC per il ruolo atlas/it
•le CPU obsolete (fino al 2013 e già rifinanziate) ancora in produzione ma in corso di spegnimento
•CPU non a completa disposizione dei siti
– (es. scope a NA, SuperB a LNF)
Queste CPU concorrono alla definizione della linea blu dell’accounting che in alcuni casi è significativamente
maggiore della linea rossa
Nel conto delle CPU pledged sono comprese le CPU gara CNAF 2013 ancora da installare
11
Risorse Disponibili 2013 – Disco
Storage disponibile 2013 “pledged”
Disco
Frascati
Milano
Napoli
Roma
Totale
Totale
disponibile
546
1133
1180
1058
3917
to be
pledged
3517
Lo storage totale disponibile nei Tier2 comprende anche l’area locale in cui sono
conservati i dati di tutti gli utenti italiani (LOCALGROUP), non solo gli utenti locali
•La dimensione di queste aree è di circa 100 TB per Tier2
•In gran parte già occupata, gli utenti dovranno cancellare i dati vecchi non più
necessari per fare spazio ai dati del 2013
•l’utilizzo di queste aree è irrinunciabile per cui il loro volume va sottratto allo storage da
dichiarare pledged
12
Risorse obsolete
2014/2015
ATLAS: Risorse Obsolete nel 2014/2015
•
•
•
CPU 2014 CPU 2015
(HS06)
(HS06)
Disco 2014
(TBn)
Disco 2015
(TBn)
Frascati
1187
2304
0
120
Milano
4979
3735
192
176
Napoli
5312
3415
184
180
Roma
4707
3072
92
180
Tot
16185
12526
468
656
Le CPU obsolete sono le macchine con più di 3 anni di vita
Lo storage obsoleto comprende le SAN con più di 5 anni di vita
La sostituzione del materiale obsoleto, specie per i dischi, è fondamentale per il buon
funzionamento dei centri e quindi dell’intero sistema di computing italiano di ATLAS
13
Risorse Attività ATLAS 2014
Lo Scrutiny Group ha approvato ad aprile 2013 le seguenti risorse per ATLAS
14
Richiesta Risorse 2014 - I
Le risorse necessarie per il 2014 sono determinate dalla volontà di conservare il
ruolo significativo nel computing di ATLAS acquisito negli ultimi anni
conservando gli share di risorse pledged per le attività centrali:
• Tier1: 10%
• Tier2: 9% CPU e 7% Disco
e di garantire la competitività agli utenti italiani mediante l’uso di risorse
dedicate nei Tier2 e Tier3
CPU T1
(kHS06)
Disco T1
(PB)
CPU T2
(kHS06)
Disco T2
(PB)
ATLAS
Share
IT
ATLAS IT
2014
ATLAS IT
disponibile
Attività
2014
355
10%
35.5
31.9*
3.6
33
10%
3.3
3.3*
0
390
9%
35.1
34.2
0.9
49
7%
3.5
3.5
0
* Pledge 2013
15
Richiesta Risorse 2014 - II
+ Recas
- Napoli
Totale
Le risorse per le attività italiane sono già disponibili e non inclusi
nel disponibile “pledged” 2013 e non sono necessarie ulteriori
richieste
Attività
2013
Attività
Italiane
Obs
Richieste
2014
K€
CPU T2
(kHS06)
0
0
16.2
0.9
205.2
Disco T2
(TB)
0
0
468
0
163.8
Attività
2013
Attività
Italiane
Obs
Richieste
2014
K€
CPU T2
(kHS06)
0
0
10.9
0
130.8
Disco T2
(TB)
0
0
284
0
99.4
Prezzi stimati:
•CPU = 12 k€/kHS
•Disco = 350 k€/PB
Richieste
effettive
16
Richiesta Risorse 2014 - III
Overhead per rete e server aggiuntivi
Algoritmo Bozzi (cfr. presentazione CSN1 Bari Settembre 2011):
•Rete: 6% (cpu) + 5% (disco) = 12.8 k€
•Server: 7% (cpu + disco) = 16.1 k€
A cosa servono:
•Rete: switch di rack
•Server: servizi di grid
A cosa corrispondo questi finanziamenti:
•Rete: 4.3 k€ per Tier2, uno switch (escluso NA)
•Per collegare le nuove risorse e/o sostituire i primi switch ormai fuori manutenzione
•Server: 5.4 k€ per Tier2, un server per sezione (escluso NA)
17
Richieste Totali 2014
Risorse T2
Le richieste di Napoli, come d’accordo con i referee, vengono inserite solo per
tracciare le risorse, ma verranno azzerate in quanto saranno fornite da Recas
18
Conclusioni
Il Computing di ATLAS ha dimostrato di essere robusto ed affidabile per il
processamento dei dati, sia MC che analisi finale, tuttavia sono stai
individuati dei punti dove è necessario migliorare
Durante il LS1 il Computing Model di ATLAS subirà un sostanziale
cambiamento, apportando modifiche sia al codice di ricostruzione/analisi sia
ai servizi infrastrutturali
L’Italia contribuisce in modo sostanziale alle attività centrali di calcolo e
tramite i centri nazionali (T1 e T2)
Le richieste sono diminuite in conseguenza delle nuove risorse provenienti
dal progetto RECAS nelle sedi di BA, NA, CS e CT
E’comunque fondamentale fornire supporto ai Tier2 esistenti per quel che
riguarda le dismissioni
I Tier2 italiani verranno sottoposti a review, il cui termine è previsto per
febbraio 2014
19
Backup slides
20
Risorse obsolete 2014
Risorse Obsolete nel 2014
CPU (HS06)
Disco (TBn)
Frascati
1187
0
Milano
4979
192
Napoli
5312
184
Roma
4707
92
Tot
16185
468
Tot – NA
10873
284
•
Le CPU obsolete sono le macchine comprate nel 2010 e installate fine 2010 inizi 2011 (non sono comprese le macchine
installate successivamente). Le CPU hanno garanzia triennale
•
Lo storage obsoleto comprende le SAN comprate nel 2008 e installate giugno 2009. Garanzia quinquennale
•
Le dismissioni di Napoli sono finanziate da RECAS
•
La sostituzione del materiale obsoleto, secie per i dischi, è fondamentale per il buon funzionamento dei centri e quindi
dell’intero sistema di computing italiano di ATLAS
21
Utilizzo risorse in Italia: Federazione T2
Pledge
2013
Pledge
2012
22
Utilizzo del disco nei Tier 2 ATLAS Italia
3000
Terabytes
2500
2000
NTUP
1500
Il sistema di replica
dinamico dei dati
PD2P, basato sulla
popolarità del dati, già
dal 2010 ha ottimizzato
l’uso del disco dei Tier2
permettendo la copia di
dati interessanti.
AOD
1000
500
0
ESD
DAOD
Circa +90 TB al mese
Nessun rischio
saturazione, si possono
cancellare i dati secondari
23
Availability / Reliability 2011-2012
Valori medi 2011/2013
Frascati
Milano
rel
ava
rel
ava
97%
90%
89%
90%
Napoli
Availability =
time_site_is_available/total_time
Reliability =
time_site_is_available/
(total_time-time_site_is_sched_down)
24
Roma
rel
ava
rel
ava
94%
95%
97%
97%
Multiprocessing e concurrent framework
Le risorse Grid in WLCG sono limitate come agreement a 2GB/core
Il software di ricostruzione di ATLAS fatica a mantenere questo limite
Non è ancora possibile girare la ricostruzione a 64 bit tranne che in nodi speciali dove è
disponibile più memoria
Tale situazione certamente peggiora con l’aumento dell’energia e del pileup
Le nuove tecnologie vanno in direzione di CPU many-core, perciò
l’approccio corrente non è più sostenibile, nonché l’ultilizzo di eventuali
risorse HPC praticamente impossibile
ATLAS prevede di rendere operativo AthenaMP durante LS1 e iniziare lo
sviluppo di un nuovo framework concorrente con Full threading e
parallelismo a livello di eventi e algoritmi
Collaborazione con IT/OpenLab, PH-SFT, LHCb e CMS
Questo nuovo approccio richiederà anche la migrazione del sistema di
Computing distribuito, a partire dalle configurazioni delle code fino alle
convenzioni di nomenclatura dei file
Necessaria una chiara strategia per i siti, in fase di sviluppo
Nonostante l’approccio di AthenaMP, per job di ricostruzione ad alto pile up si avrà comunque,
secondo le proiezioni correnti, una RSS/core di circa 3GB, mentre per altri tipi di job sarà minore
Ogni sito che girerà la ricostruzione dovrà fornire delle code multicore
2
Utilizzo della farm HLT durante LS1
La farm HLT di ATLAS verrà usata come un “sito” Grid
opportunistico durante LS1
~14k core, corrispondenti ad un grande T2 (se non un T1)
Infrastruttura overlay di tipo Cloud basata su OpenStack
CERN IT (Agile), CMS (HLT Farm) e BNL già utilizzano OpenStack
26
ATLAS: as study case for GPU sw trigger
• The ATLAS trigger system has to cope with the very demanding conditions of
the LHC experiments in terms of rate, latency, and event size.
• The increase in LHC luminosity and in the number of overlapping events poses
new challenges to the trigger system, and new solutions have to be developed
for the fore coming upgrades (2018-2022)
• GPUs are an appealing solution to be explored for such experiments,
especially for the high level trigger where the time budget is not marginal and
one can profit from the highly parallel GPU architecture
• We intend to study the performance of some of the ATLAS high level trigger
algorithms as implements on GPUs, in particular those concerning muon
identification and reconstruction.
Slide from G. Lamanna / A. Messina
27
Altre evoluzioni
Completa migrazione ed utilizzo dell’ATLAS Grid Information System in
produzione
Definitivo abbandono dei servizi di IS di Grid in favore di AGIS
Abbandono anche del WMS, finora utilizzato ancora solo per le installazioni del
software
Test dei servizi con IPv6 necessario
SHA-2
Inizio ufficiale delle migrazioni ad SL6 a giugno 2013
Alcune delle release necessitano di una patch per funzionare con l’analisi a causa
delle opzioni diverse di compilazione
Possibile soluzione generica trovata di recente, in fase di test
In ogni caso le release più utilizzate sono state già sistemate o comunque funzionanti
nativamente
Migrazione ad IPv6
Sorgente primaria di informazioni per Panda e DDM
Migrazione ad SL6
Installation System migrato completamente ad AGIS + Panda
Migrazione imminente, necessario un controllo dei servizi
Finalizzazione dell’integrazione di gLexec in Panda
28
PRIN: Cloud Computing
Utilizzo del Cloud Computing per servizi o elaborazione dati
Servizi di grid
Workload Management
Servizi interattivi on-demand
Virtualized WN con Panda
Cluster di analisi su Cloud
Data Preservation
Altri tipi di servizi in alta affidabilità
Roma
OpenStack + glusterfs + cloud-init
In collaborazione con il gruppo cloud INFN
Stessa infrastruttura di base di CERN Agile Infrastructure
Possibilità di unire più siti grid in una unica infrastruttura
Sperimentazione su Tier2 distribuito, tramite LHCONE
Stato
Facility iniziale, esportabile anche ad altri siti entro fine anno
29
PRIN: EventIndex
Studiare la possibilità di semplificare il TagDB di ATLAS
trasformandolo in un indice degli eventi (EventIndex)
con puntatori allo storage che contiene gli eventi in vari
formati (da RAW a NTUP)
EventIndex è l'equivalente del catalogo di una biblioteca
Sostituzione del database in Oracle con storage strutturato (Hadoop)
Divisione delle tre categorie di dati nei Tag odierni:
Identificazione dell'evento e quantità immutabili (lumi block, trigger pattern)
Quantità dipendenti dalla ricostruzione (topologia, particelle, ecc.)
Puntatori ai files con gli eventi (GUID e offset interni)
Utilizzo della tecnologia più appropriata per ogni categoria di dati
Sviluppo (o adattamento) dei servizi esterni
Event counting, picking, skimming, consistency checks
Connessione a ProdSys e DDM per l'upload dei dati e la loro utilizzazione
Stato
Genov
a
Testbed attivo al CERN
30
PRIN: PoD per PBS, gLite-WMS, Panda
Dedicare alcune risorse di calcolo ad una farm da
utilizzare per l'analisi con PROOF.
Sviluppare e perfezionare PoD, Proof on Demand, un
insieme di tool pensati per interagire con un RMS locale o
globale ed avviare i demoni di PROOF.
Test per provare i plugin di PoD per PBS e PanDA (gLiteWMS non più supportato da ATLAS), con i dati acceduti
con protocollo XrootD e in futuro anche HTTP:
Test di performance di accesso al disco
Job che legge circa 40% dell’evento
Test di latenza di startup
Stato
Infrastruttura funzionante tramite PanDA
Test di performance e scalabilità in corso
Talk a CHEP 2013
LNF
Milano
Napoli
31
PRIN: LHCONE
Sviluppo di una nuova generazione di reti geografiche di
comunicazione dati (overlay L2 network) denominata LHCONE
(LHC Open Network Environment)
Configurazione dinamica degli apparati attivi (router o switch
multilayer) che costituiscono la rete stessa
Realizzazione di servizi di Bandwidth on Demand (BOD)
Integrazione con il software di esperimento
Stato
Napoli
Infrastruttura stabile già in produzione al T1
e nei T2
Ottimizzazione e studi su configurazioni dinamiche in corso
Sperimentazione su T2 distribuito in fase di allestimento
Inter-site VLAN (NA-RM)
Failover di servizi core in WAN, con collegamento a 10 Gbps (GARR-X) a bassa latenza
32
GPU: GAP Realtime (FIRB)
“Realization of an innovative system for complex calculations and
pattern recognition in real time by using commercial graphics
processors (GPU). Application in High Energy Physics experiments to
select rare events and in medical imaging for CT, PET and NMR.”
FIRB partito ad inizio del 2013
Per ciò che riguarda la comunità HEP, verrà studiato
l’utilizzo di trigger hardware di basso livello con
latenza ridotta e trigger software di alto livello
Si studieranno I casi di NA62 L0 e l’High Level Muon
Trigger di ATLAS come “casi fisici”
Roma coinvolta nello studio del trigger di ATLAS
33
Trigger rate 2015
• Luminosity expected to increase from 7×1033 to 2×1034 corresponding to
about a factor 3 in rates
• Pile up will increase affecting the effective trigger rates
• Moving to √s=14 TeV cross sections will increase on average by a factor 2.5
Rates would increase by about one order of magnitude. To keep the increase
within a factor ~2 (50kHz→100kHz L1 and 450Hz→1kHz EF) selections have
to be improved/tightened minimizing the impact on physics.
PS: The physics (Higgs, top ...) remains the same.
Slide from C. Gatti / D. Orestano
34
Trigger menu 2012 vs 2015
Current menu scaled to 1034
Slide from C. Gatti / D. Orestano
35
Trigger menu 2012 vs 2015
Menu at 2×1034 and 14 TeV
Increase single
e/gamma threshold
Increase single and
di muon thresholds
Increase single and
di tau thresholds
Increase Jet and
MET thresholds
Slide from C. Gatti / D. Orestano
36
Risorse CPU Attività ATLAS 2015-2017
Richieste di ATLAS per il 2015-2017, aggiornate al 28/08/2013, non ancora referate
I valori in [] sono relativi alle richieste presentate in precedenza
37
Risorse Disco Attività ATLAS 2015-2017
Richieste di disco ATLAS per il 2015-2017, aggiornate al 28/08/2013, non ancora referate
38
ATLAS: Richiesta Risorse 2015 [preliminare]
Le risorse per le attività italiane 2014/2015 sono già disponibili e non inclusi nel disponibile
“pledged” e non sono necessarie ulteriori richieste
ATLAS
Share
IT
ATLAS IT
2015
ATLAS IT
disponibile
Attività
2015
462
10%
46.2
35.5*
10.7
39
10%
3.9
3.3*
0.6
530
9%
47.7
35.1
12.6
55
7%
3.9
3.5
0.4
CPU T1
(kHS06)
Disco T1
(PB)
CPU T2
(kHS06)
Disco T2
Totale 2015 - PRELIMINARE
(PB)
CPU T2
[kHS06]
Disco T2
[TB]
Attività
Italiane
2015
Obs
2015
Richieste
2015
k€
2015
0
12.6
12.6
302.4
0
656
400
369.6
Valori preliminari non referati,
aggiornati al 28/08/2013.
I valori finali saranno
disponibili a ottobre
(+ networking e server)
Prezzi stimati:
•CPU = 12 k€/kHS
•Disco = 350 k€/PB
39
Missioni
Responsabilita'
Calcolo
TOT
MU
nome
dettaglio responsabiilita'
Livello mu
CNAF
Tupputi
SAM monitoring deputy coord
L3
1
GE
Barberis
ATLAS database coordinator
L2
4
NA
Carlino
Scrutiny Group
L2
2
RM1
De Salvo
GRID softw release coord
L2
1
De Salvo
V0 manager
L2
2
De Salvo
Coord nazionale
L1
1
11
40