Introduzione
alla
LOGICA MATEMATICA
Corso di Matematica Discreta.
Corso di laurea in Informatica.
Prof. Luigi Borzacchini
VIII. Insiemi e Strutture Dati
Insiemi come strutture dati
Insiemi, matrici e relazioni sono concetti fondamentali
non solo in matematica ma anche nello studio delle
strutture dati nella computer science.
Ogni linguaggio di programmazione ha il suo modo di
implementarle, ma la loro struttura logico-algebrica è
indipendente dal particolare linguaggio.
Le operazioni sono o interne alla struttura dati, come
le ordinarie operazioni algebriche (ad esempio in
ESSE3 estrarre un dato relativo ad uno studente dalla
base di dati), o sulla struttura per cambiarla, come le
operazioni insiemistiche (ad esempio aggiungere un
nuovo studente alla base di dati di ESSE3).
Il record
• Di norma le strutture dati sono ordinate dai numeri
interi, così che la struttura base è il record a, cioè
una sequenza di n elementi o n-upla (a1, a2,…., an).
Scriveremo anche ai come a[i], ove gli ai possono
appartenere ad insiemi diversi Mi, e quindi il record
è un elemento del prodotto cartesiano M1 M2
…Mn, in cui a1 M1, a2 M2 ….., an Mn,
• Possiamo considerare ad esempio il data-base di
ESSE3. In esso probabilmente ad ogni studente è
associato un record che contiene le informazioni a
lui relative.
• Un record a può essere ad esempio una sequenza di
informazioni personali di uno studente: (Michele,
Rossi, 18-09-1995, Bari), in cui i diversi ‘campi’
contengono informazioni di diverso tipo: (nome,
cognome, data di nascita, luogo di nascita).
• Nel nostro esempio ESSE3 M1 può essere l’insieme
dei Nomi, M2 l’insieme dei Cognomi, M3 l’insieme
delle date di nascita, M4 l’insieme dei luoghi di
nascita, etc.. Si usa anche la notazione
a:slotvalue, cioè a2 = a[cognome] =Rossi,
a1 = a[nome]=Michele, etc., ed il record appare allora
come una funzione aj = a[j-esimo tipo] = tMj
L’ array
Si può costruire una sequenza di records, ad esempio
in ESSE3 ognuno relativo ad uno studente: è l’array. Il
record è detto anche l’array monodimensionale. Il
concetto di array A infatti generalizza il concetto di
record ed equivale alla nostra definizione di matrice:
una matrice nm corrisponde allora ad un array
bidimensionale formato da n records, ciascuno con m
campi: in ESSE3 ci sono n studenti per ciascuno dei
quali sono memorizzati m campi di dati.
L’i-esima riga di A è il record dei dati dell’i-esimo
studente, A[i,j], ovvero Ai,j è il valore del j-esimo
campo per l’i-esimo studente, Ai,jMj
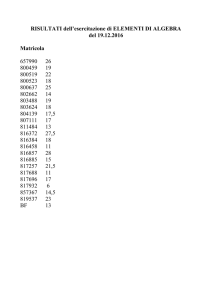
matricola, cognome, nome,
data di nasc., anno imm., città resid.,
indirizzo,
laurea
1645723
1645724
1645725
1645726
1645728
1645729
1645731
1645732
1645734
1645735
26/07/92
21/10/94
03/05/93
12/12/93
04/06/93
11/09/94
22/03/94
30/01/95
18/02/93
24/07/94
Via Matteotti 6
Via Amendola 3
Corso Italia 33
Via Cavour 21
Piazza Roma 6
Via Garibaldi 12
Via Napoli 71
Piazza Moro 18
Via Cairoli 60
Via Putignani 11
informatica
lettere
lingue
informatica
fisica
informatica
informatica
biologia
informatica
informatica
ROSSI
BIANCHI
LORUSSO
RENZI
CASSANO
LORUSSO
CONTE
BELLUCCI
GRILLO
BERLUSCONI
PAOLO
ANNA
NICOLA
MATTEO
ANTONIO
PIETRO
ANTONIO
MONICA
GIUSEPPE
SILVIO
2013-2014
2014-2015
2014-2015
2014-2015
2014-2015
2014-2015
2014-2015
2014-2015
2014-2015
2014-2015
Trani
Bari
Mola
Bari
Ruvo
Palo
Bari
Bari
Mola
Bari
Come operazione interna alla struttura posso ‘interrogare’ il
data-base per sapere quando si è immatricolato lo studente
NICOLA LORUSSO. Ed allora devo trovare i records con A[i,2]=
Lorusso A[i,3]=Nicola. Se non ci sono omonimi la relazione è
funzionale e troverò i* (3 nel nostro esempio, caratterizzato
dalla matricola 1645724). E quindi cercherò A[i*,5]
(trovandolo uguale a 2014-2015).
• Un array bidimensionale con la specificazione degli
n tipi di dati Mi che devono essere usati nei vari
campi è spesso detto una base di dati relazionale.
Infatti esso può essere visto come una relazione naria sul prodotto cartesiano M1 M2 M3 …. Mn
• Gli studenti possono comparire in altri data-base
(ad esempio relativi agli esami) e per identificarli nei
due data base occorre avere una ‘chiave’ univoca (il
numero di matricola elemento di M1).
• Questo vuol dire che la nostra relazione deve essere
funzionale in M1, cioè dato iM1, deve essere
univocamente determinato il record ad esso
relativo.
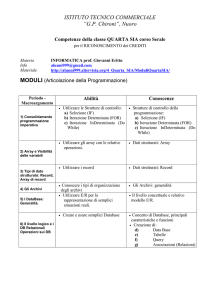
n.ro, data,
matricola, cognome,
nome,
anno immatr., CFU,
voto,
7
15/09/14
1645723
ROSSI
PAOLO
2013-2014
9
28
no
9
15/09/14
1645726
RENZI
MATTEO
2014-2015
9
23
si
12
15/09/14
1645729
RUSSO
PIETRO
2014-2015
9
21
no
18
20/09/14
1645731
CONTE
ANTONIO
2014-2015
9
30
no
19
20/09/14
1645734
GRILLO
GIUSEPPE
2014-2015
9
18
si
23
20/09/14
1645735
BERLUSCONI
SILVIO
2014-2015
9
18
si
Supponiamo di avere i data-base relativi agli esami, ad
esempio Matematica Discreta. Il numero di matricola ci
consente di vedere che lo studente Paolo Rossi, matricola
1645723, ha preso 28: possiamo così incrociare diversi
data-base e ricavare da essi il curriculum di uno studente.
I dati possono essere anche utilizzati come input per
algoritmi: ad esempio si può calcolare il voto medio degli
studenti con una certa residenza o immatricolati un certo
anno.
flag
Code e Stacks
• La struttura del record è la base per tipi di dati più
specifici per il tipo di operazioni insiemistiche su di
essi. Ad esempio le code e gli stacks si
caratterizzano per avere operazioni particolari per
l’aggiunta e l’estrazione di dati.
• La coda (queue) è detta anche first-in-first-out,
FIFO, poiché gli elementi si aggiungono alla fine del
record e si estraggono al suo inizio. Sia C la coda:
a
b
c
d
e
f
g
h
i
l
• Il primo elemento ad essere estratto sarà a, l’ultimo
ad essere stato inserito sarà l. Più precisamente
•
•
•
•
•
‘mettere in coda’, enquieu: MCode Code
enquieu(m,C)= a b c d e f g h i l m
‘estrarre dalla coda’, dequieu: Code MCode
dequieu(C)= (a, b c d e f g h i l )
Analogo è lo stack, detto anche last-in-first-out,
LIFO, poiché sia l’estrazione che l’aggiunta degli
elementi avviene sulla fine del record. Sia C lo stack:
a
b
c
d
e
f
g
h
i
l
• Le operazioni base sugli stacks sono usualmente
denominate con push (aggiungi allo stack) e pop
(elimina dallo stack), così definite
push(m,C)= a b c d e f g h i l m
pop(C)= (l, a b c d e f g h i )
Grafi e alberi
• Sia V un insieme di elementi (vertici), e E un insieme
di coppie di vertici (archi), con |V|=n e |E|=m. La
coppia (V,E) si dice grafo, diretto se le coppie sono
ordinate, indiretto se non lo sono.
•
•
•
•
•
a
a
b
c
b
c
d
d
e
e
f
f
• Una sequenza di archi (a1, a2),(a2, a3), …,(ai-1, ai),…,(an-1, an),
si dice una catena, un cammino se il grafo è diretto; un ciclo
se a1= an, un circuito se il grafo è diretto.
• Un cammino (circuito) si dice hamiltoniano se passa una e
una sola volta per tutti i vertici, euleriano se passa una e
una sola volta per tutti gli archi.
• Abbiamo usato i grafi diretti per rappresentare le
relazioni binarie, gli alberi per le tassonomie.
• Un grafo senza cicli si dice un albero. Se in un albero
scegliamo un vertice come radice e ordiniamo da
esso tutti i vertici, l’albero viene univocamente
ordinato (verso il basso) a partire dalla radice. Gli
•
a
b
•
•
c
d
f
si dicono foglie. Nell’albero in figura sia
d o b la radice e ordiniamo l’albero,
ottenendo l’albero diretto:
d
e
g
b
c
In un albero
m=n-1
f
c
d
f
a
g
e
a
b
e
g
• I grafi si rappresentano in genere tramite matrici.
• La matrice di incidenza M è nm, definita come Mi,j
= 1 sse il vertice i l’arco j, 0 altrimenti (per grafi
indiretti), oppure Mi,j = +1 se i è vertice terminale di
j, Mi,j = -1 se è vertice iniziale, 0 altrimenti (per grafi
diretti).
• La matrice di adiacenza A è nn, definita come Ai,j =
1 sse l’arco (i,j)E, 0 altrimenti (per grafi indiretti A
è simmetrica). a 1 1 0 0 1 0 0 0
1 1
1
a
•
•
•
•
a
b
c
e
b
d
c
f
d
e
M f
1 0 1 0 0 0 0 0
0 1 1 1 0 0 0 0
0 0 0 0 0 1 1 0
0 0 0 1 1 1 0 0
0 0 0 0 0 0 1 1
b
c
d
e
A
f
1
1
1
1
1
1
1
1
1
1
1
1
•
•
•
a
b
c
d
e
f
M
•
•
•
•
a
b
c
d
e
f
+
+
+
-
+
-
-
-
+
+
+
a
b
c
d
A e
f
1
1
1
1
1
1
1
e
d
f
c
b
a
g
Importante l’ordine di esplorazione di un
albero: si può usare la depth first, in cui
si scende lungo i rami, memorizzando le
diramazioni, da esplorare quando un
ramo sia terminato (backtracking).
Un’altra tecnica è la breadth first, in cui si
esplorano i livelli in successione, ma occorre
memorizzare tutta l’esplorazione precedente.