Il modello di calcolo distribuito
per gli esperimenti di Fisica delle
Alte Energie
Workshop su GRID computing e calcolo avanzato
Napoli, 6 maggio 2003
Leonardo Merola
Dipartimento di Scienze Fisiche - Università di Napoli “Federico II”
Istituto Nazionale di Fisica Nucleare - Sezione di Napoli
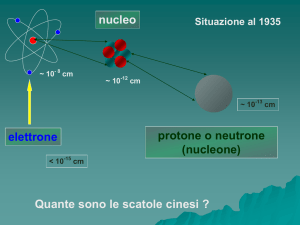
La Fisica delle Particelle delle Alte Energie studia i
costituenti fondamentali della materia (privi di
struttura interna ?), che costituiscono i “mattoni”
della Natura e le loro interazioni.
(1 m)
(10 -10 m)
(< 10 -18 m)
(10 -14 m)
(10 -15 m)
(10 -15 m)
(< 10 -18 m)
La tecnica più usata è la collisione di particelle ad altissima energia
prodotte in acceleratori. L’energia della collisione viene “spesa” per la
produzione di centinaia di particelle la cui natura e le cui caratteristiche
dinamiche dipendono dal tipo di interazione, dall’energia totale, dalla
natura delle particelle collidenti.
E = mc2
(c = velocità della luce nel vuoto
= 300.000 km/s)
Alte Energie significano anche alte temperature equivalenti e
conseguentemente riproduzione in laboratorio di condizioni
esistenti nel “lontano passato dell’Universo”
3 secondi
Energia e
particelle
esotiche
3 minuti
protoni e
neutroni
300.000 anni
nubi di atomi
di idrogeno e di
elio
1 miliardo di anni 15 miliardi di anni
stelle e
galassie in
formazione
l’universo
oggi
1
Mld
Adroni
Nuclei
Atomi -> Molecole
Galassie
O
G
G
I
10 32
10 15
10 13 10 9 6000
gradi Kelvin
18
3
Centro Europeo per la Fisica delle Particelle
LEP/ LHC
SPS
CERN
GINEVRA
LEP : Large Electron Positron collider (1989-2000)
LHC: Large Hadron Collider (2007-2020)
LEP : elettroni
LHC : protoni
positroni (ECM fino a 210 GeV)
protoni (ECM = 14000 GeV)
LEP / LHC
FRANCIA
CERN
PS
SPS
SVIZZERA
Aeroporto di Ginevra
Parametri della macchina LHC
F = 0.9, v = rev freq., N = Prot/bunch,
s= transv beam size
Gli Esperimenti a LHC
p-p
CMS
p-p
ATLAS
LHCb
p-p
Pb-Pb
Molteplici SFIDE
VASTE
COLLABORAZIONI
INTERNAZIONALI:
Decine di migliaia di
fisici, tecnologi, tecnici
Centinaia di Istituzioni
e Università in decine
di Paesi e vari
Continenti
APPARATI
SPERIMENTALI
GIGANTESCHI:
Peso: 12500 ton
Diametro: 15 m
Lunghezza: 21,6 m
Campo magnetico:
4 Tesla
CMS
FISICA DIFFICILE: Sezioni d’urto di produzione di eventi
interessanti (ad es. Ricerca del bosone di HIGGS) molto basse
e molto difficili da
riconoscere in modo
non ambiguo:
dN/dt = s L
N = N. eventi
s= Sezione d’urto del processo
L = Luminosità della macchina
stot = 70 mbarn
=>109 interazioni
al secondo
Higgs 10-2 - 10-1 Hz
Top
W
10 Hz
2 kHz
Simulazione al
calcolatore di un
evento di collisione
protone - protone
(14 TeV) a LHC
con produzione e
decadimento di un
bosone di Higgs:
H ZZ 4
m
Simulazione di un
evento: 3000
SpecInt95*sec
> 1 min su PIV 1GHz
SISTEMI DI RIVELAZIONE, ACQUISIZIONE DATI E
SELEZIONE ON-LINE E OFF-LINE SOFISTICATI:
Rivelatori,Trigger, DAQ, Computing
Frequenza di Bunch-crossing = 40 MHz Frequenza di Interazione ~109 Hz @ L = 1034 cm-2 s-1
1° livello di Trigger
75-100 kHz
• Combina informazioni dai
calorimetri e dallo spettrometro μ.
• Identificazione del Bunch
Crossing ID
2° livello di Trigger
~1kHz
Utilizza le ROI formate dal
LVL1
Criteri di selezione piu’
stringenti
3° livello di trigger (EF)
~100 Hz
Utilizzo software offline
109 eventi/s con incroci dei fasci
a 40MHz (bunch-crossing 25 ns)
100 eventi/s su memoria di massa
1 MByte/evento 100MB/s
107 s tempo di raccolta dati/anno
GRANDE MOLE DI DATI:
~ 1 PetaByte/anno di dati “RAW”+
~ 1 PetaByte/anno di dati simulati
INGENTI RISORSE DI
CALCOLO: ~ 1 MSI95 (PIII 500
MHz ~ 20SI95) ~ 100.000 PC
CMS
Situazione analoga
per l’esperimento CMS
~ PetaByte/anno di dati “RAW”
COMPLESSITA’ DEI DATI DA TRATTARE:
Ricostruzione di vertici di interazione e di decadimento, ricostruzione di
tracce, identificazione di particelle, misura delle loro energie e degli impulsi:
– Ricca gerarchia di centinaia
di tipi di dati complessi (classi)
– Molte relazioni fra essi
– Differenti tipi di accesso
Uso della Tecnologia OO
(Object Oriented)
– per il software di simulazione
e ricostruzione di vertici e tracce,
– per il database degli eventi,
– per l’analisi dei dati
Uso degli strumenti più
avanzati SW e calcolo/analisi
Event
Tracker
Calorimeter
TrackList
Track
Track Track
Track
Track
HitList
Hit
Hit
Hit
Hit
Hit
C++, JAVA, PERL, ROOT, GEANT4, PAW, …
10,00
1,00
100
0,10
MHz
SI2000
€/SI2000
Capacity/Tape (GB)
100,00
1000
10000
1000,00
1000
100,00
100
10,00
10
1,00
1
0,10
€/GB
1000
2000
2001
2002
2003
2004
2005
2006
10000
€/SPECint2000
CPU
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
100000
GB/Drive
1ge
n1- 200
ge
0
n1- 200
ge
1
n2
0
1ge 02
n1- 200
ge
3
n1- 200
ge
4
n2
0
1ge 05
n20
06
MHz & SPECint2000
Nastri
10
10,00
1,00
100
0,10
0,01
Price/Capacity (€/GB)
Il problema non è l’hardware che è sempre più
potente e costa sempre meno:
GB/Drive
€/GB
Dischi
Cap
€/GB
Il problema è il software (e il middleware):
Scientist
M
I
D
L
E
W
A
R
E
Experiment
Analysis
Computing
Storage
Storage
Analysis
Experiment
Computing
Computing
Storage
Il fisico HEP (High Energy Physics) non
deve vedere le differenze degli ambienti di
calcolo a cui accede.
CLRC Daresbury
Il “Middleware”, una via di mezzo tra
hardware e software, deve assicurare la
compatibilità fra i vari ambienti.
Gli esperimenti di Fisica delle Alte Energie
stanno sperimentando una soluzione su scala mondiale per:
a) Calcolo intensivo distribuito
b) Accesso veloce e flessibile a grandi moli di dati
Le “griglie computazionali” << GRID >>
World Wide GRID
Costituiremo VIRTUAL ORGANIZATIONS (VO) per
la collaborazione e la condivisione delle risorse:
Esperimenti: ATLAS, CMS, ALICE, LHCb, BABAR, CDF, …
Utilizzeremo i SERVIZI DI GRID
Application
• High-Throughput Computing
– asynchronous processing
• On-Demand Computing
– dynamic resources
• Data-Intensive Computing
– databases
• Collaborative Computing
– scientists
User
Collective; es. RM
Application
Resource; es.CE,SE
Connectivity;es IP
Transport
Internet
Fabric; es. LSF..
Link
Internet Protocol Architecture
• Distributed Computing
– synchronous processing
Su RETI VELOCI
Modello di calcolo distribuito
per gli esperimenti a LHC
Gerarchia “funzionale” a più livelli (Tier-x)
CERN
Tier 0
desktop
CPU Server
CPU Server
CPU Server
CPU Server
desktop
Data Server Data Server
Tier 1 Data Server
(Centri Nazionali
e Regionali)
Tier 2
desktop
CPU Server
Tier 3-4
(Centri Nazionali
e Regionali)
(Dip. e Istituti)
desktop
Struttura a Tiers di ATLAS
US
Italy-INFN
CNAF-BO
MI
PV
GE
…
RM1
NA
Tipo di dati da produrre e conservare:
CERN
Tier 0/1
RAW DATA: 2 MB/evento, 100 Hz
(Data acquisition, Reprocessing, Event Reconstruction)
MC RAW DATA: 2 MB/evento, 3000 SI95*s
ESD, Event Summary Data, output
della ricostruzione: 500 KB/evento,
Tier 1
Regional
Centers
Y
X
Z
640 SI95*s
(Reprocessing, Event Reconstruction, MC simulation)
AOD, Analysis Object Data, formato
"pubblico" di analisi:
10 KB/evento, 25 SI95*s
(MC simulation, Physics Analysis)
Lab a
Tier2
Regional/National
Centers
Lab b Uni c
Tier3/4 Departments
DPD, Derived Physics Data, formato
“privato” di analisi, tipo n-pla: 1 KB/evento, 5 SI95*s
(Physics Analysis)
Desktop
PHYSICS ANALYSIS
Uni n
Risorse HW ATLAS a regime (2007)
CERN (T0+T1)
@ 1/3 del totale
Each RC T1+T2
(6 RC in totale)
S T1+T2 @ 1/3 del totale
Each T3
S T3+T4 @ 1/3 del totale
Total
1 T2: @ 10% RC
CPU
Tape
(MSI95) (PB)
Disk
(PB)
0,5
10
0,8
0,2
2
0,4
0,010
> 2
x
24
MCHF
8
MCHF
/RC
0,05
> 20 > 2
2003/4: @ 10% delle risorse a regime
@ 50 CPU + 4 TB
Data Challenges
Motivated by need to test scaling of solutions:
Hardware, Middleware and Experiment Software)
DC0 – 2001/2002
• Tests of the ATLAS software
DC1 - 2002/2003
• Pile-Up Production (High and Low Luminosity)
• Large scale Grid test for reconstruction
• Reconstruction start March 2003
• ~ 10**7 fully simulated events
DC2 - 2003/2004
•
•
•
•
•
•
Geant4 replacing Geant3
Pile-up in Athena
Use LCG common software
Use widely GRID middleware
Perform large scale physics analysis
As for DC1: ~ 10**7 fully simulated events
DC3 - 2004/2005 scale: 5 x DC2
DC4 - 2005/2006 scale: 2 x DC3
D
US
CERN
CPUs Italia:
46 RM1
40 CNAF
16 NA
10 LNF
J
I
F
grid tools used at 11 sites
La farm di ATLAS-Napoli
7 nodi diskless con 2 CPU PIII a 1 GHz,
RAM 512 MB, 2 schede di rete a 100 Mb/s.
Server con 2 CPU PIII a 1 GHz, 1 GB
RAM, 2 schede di rete a 100 Mb/s, 1 scheda
di rete a 1 GB/s
2 TB storage
ATLAS SW e primi tools di GRID
100 Mb/s
1 Gb/s
CPU
Server
Disk
Server
E’ in corso l’evoluzione dal ruolo di Tier-3 a quello di
Tier-2, con l’estensione delle risorse della farm:
25 biprocessori e 4 TB disco.
Obiettivi GRID a breve termine
della Farm di ATLAS Napoli
1.
Prendere parte ai test di ricostruzione con il Middleware EDG che già
coinvolgono RAL, Lione, CNAF (e in seguito Milano, Cambridge e Roma).
2.
Registrare le risorse nella Virtual Organization di ATLAS e configurare
diverse macchine della Farm come elementi della griglia mediante
l'installazione del middleware di EDG.
3.
Istallare un Computing Element (che gestisce localmente l’allocazione del
lavoro), uno Storage Element (che gestisce lo storage) e diversi Worker
Nodes (che girano i job).
4.
Pubblicare le informazioni relative alle risorse dela Farm sulla GRID in
modo che mediante un Resource Broker i job vengano assegnati alla Farm.
Il Modello di CMS
Il Modello di calcolo di CMS Italia è un modello integrato
di Funzionalità dei Tier1, Tier2 e Tier3.
Tier2 di riferimento a Legnaro
Schema di “calcolo” distribuito sulle Sedi.
Alcune funzioni e specificita’ (chiamate in gergo “services”) sono
tipiche di una gerarchia
Modello di Tier0, Tier1, Tier2, Tier3 …
Altre sono tipiche di una distribuzione paritaria
Modello distribuito alla “GRID”
Ruolo del Tier1 (comune per l’INFN)
~40% del commitment italiano
Assorbimento dei picchi di CPU (shared con gli altri Esperimenti)
Mass Storage e accentramento dei dati di simulazione e analisi
Riferimento core software (supporto)
Ruolo dei Tier2 (incluso il Tier2 di riferimento)
~40% del commitment italiano
CPU e storage (solo dischi e/o archive) per l’analisi (distribuita)
Dimensionamento delle attivita’ in funzione delle competenze ed interessi
locali (dal farming alla analisi)
Ruolo dei Tier3
~20% del commitment italiano
Punto di forza in item specifici sia di analisi che di software e/o supporto
e/o middleware
Software in comune con gli altri esperimenti LHC
Prodotti software che non hanno a che fare con “Dati e Calcolo
distribuiti” (Grid independent): es. Generatori di Fisica, (Detector
Description DataBase), …
Prodotti software (middleware) che gestiscono la distribuzione
dei dati e del calcolo (Grid dependent): es. Brokering dei job, Data
replication, Information System, Monitoring, …
Prodotti software che sono influenzati dalla caratteristica
distribuita del Calcolo (Grid-aware): es. Persistenza, meta-data
structure, Bookkeeping…
Prodotti che NON “possono” essere comuni:
programmi di ricostruzione dei vari detector, tools di gestione
specifici dell’architettura del Computing Model, …
Logical components diagram
Software release
Experiment
Software
Software
Repository
Data Management
System
New dataset
request
Data
Materializer
Job
Definition
Job
Monitoring
Definition
Data management operations
Dataset
Catalogue
Input data
location
Dataset
Definition
Software
Release Manager
Data
Resource Monitoring
System
Retrieve
Resource
status
Workload
Management System
Job submission
Storage
Service
Resource
Directory
Job assignment to resources
Job
Catalogue
Job Monitoring
System
Job type definition
By Claudio Grandi
Job
Book-keeping
Publish
Resource
status
Computing
Service
Push data
or info
Pull info
Layout farm LNL 2002:
production + analysis + grid
= grid enabled element
Production N1
computing
nodes
N24
N24
N1
N24
N1
FastEth
FastEth
FastEth
SWITCH
SWITCH
SWITCH
To WAN
34 Mbps 2001
~ 1Gbps 2002
Analysis
computing
nodes
32 – GigaEth 1000 BT
GW
S1
S9
Production
servers
Production
control
SE
S10 S11 S12
CE
G1
Analysis
servers
Remote login
Analysis
UI
G2
Grid enabled
Analysis
Il progetto LCG
(LHC Computing Grid)
The Goal of the LHC Grid
To help the experiments’ computing projects prepare,
build and operate the computing environment needed to manage and
analyze the data coming from the detectors
LCG
2003 –
LCG-1
•
Establish the LHC grid as a reliable, manageable, permanently available
service including the Tier 1 and many Tier 2 centres
•
Serve as one of the computing facilities used for simulation campaigns
during 2H03
2004 –
•
Stable service for batch analysis
•
Scaling and performance tests, commissioning of operations infrastructure
•
Computing model tests – 4 collaborations
Tier 0 – Tier 1 – Tier 2 – Tier 3 Computing TDRs at end 2004
LCG-3
2005 –
•
Full prototype of initial LHC service – second generation middleware
- validation of computing models (4 collaborations)
- validation of physical implementation – technology, performance, scaling
•
LCG TDR – sizing/cost/schedule for the initial LHC service – July 2005
2006–2008
•
acquire, build and operate the LHC computing service
La GRID dei TIER per LHC
Le Capacità Richieste per LHC
• CERN (Somma di tutti gli esperimenti):
– Mass Storage: 10 Peta Bytes (1015 B)/anno
– disk: 2 PB (100.000 Dischi da 20GB)
– CPU: 20 MSPECint2000 (40.000 Pentium@1GHz)
• Per ogni Tier 1 Multi-esperimento :
– Mass Storage: 1 - 3 PB/anno
– disk: 1.5 PB
– CPU: 10 MSPECint2000
• Networking Tier 0 (CERN) --> Tier 1:
– 2 Gbps (>4.000 connessioni ADSL)
Esperimento BaBar a SLAC (California, USA)
Struttura a Tiers di BABAR
Tier 0: SLAC Stanford CA, USA
TierA/B : Lione IN2P3, RAL, INFN-PD, INFN-CNAF
Tier C: NA, ….
•
Role of Tier A sites: reduce significantly computing burden at
SLAC
–
–
–
•
Primarily analysis: IN2P3, RAL
Production: INFN-Padova
Issues:
•
•
•
•
data replication at Tier A’s
data partitioning at Tier A’s (micro, mini, beam data, MC)
transparent access to data across Tier A’s (BabarGrid)
specialization of Tier A’s: skimming, (re-)processing, etc.
Role of Tier C sites: smaller sites at remote institutes
–
–
main contribution so far in MC production (majority of MC events
produced away from SLAC)
analysis at Tier C’s has been difficult due to problems with data
distribution need to resolve with new Computing Model
Il processo di analisi
1.
2.
3.
4.
5.
Identificazione dei campioni di dati da analizzare con strumenti di
bookkeeping
• Omogenei per dati e Monte Carlo
Sottomissione (e monitaggio) job di l’analisi
• Analisi combinatoria (D, D*, B-reco, …)
• Calcolo delle quantità fisiche
• Scrittura nuovo micro-DST ridotto contenente le informazioni per l’analisi
Working Group
• Produzione centralizzata per tutta la collaborazione (ogni 3 mesi)
Riduzione dei micro-DST per le analisi specifiche
Produzione dei risultati con accesso interattivo ai micro-DST (ROOT, …)
• Oppure produzione di ntuple ridotte e istogrammi nel formato finale per
l’analisi
Preparazione dei documenti di analisi
CONCLUSIONI
Stiamo costruendo un prototipo di sistema di calcolo
distribuito basato su GRID.
Dobbiamo essere pronti per lo startup di LHC: 2007
Numerosi sono i progetti su GRID nazionali (es. INFNGRID, FIRB GRID.IT) ed europei (es. DataTAG, LCG,
EGEE) in cui noi fisici delle Alte Energie siamo coinvolti.
Auspichiamo una collaborazione stretta anche con
altri settori scientifici per la realizzazione di una
infrastruttura comune di GRID anche a livello locale.