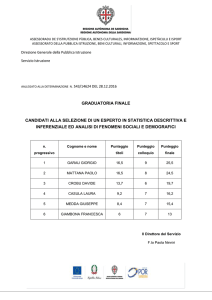
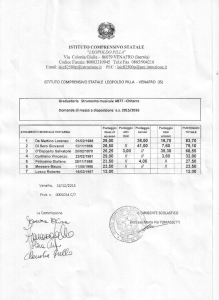
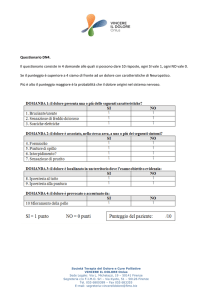
Strumenti informatici 7.5 - Realizzare l’analisi di regressione multipla
con SPSS
Nella sua forma base, Excel non consente di realizzare un’analisi di regressione multipla, mentre
SPSS offre un ventaglio di opzioni di analisi molto ampio. Supponiamo di avere a disposizione i
dati di 100 studenti di psicometria al primo anno riguardo al Genere, al punteggio in un test di
profitto in matematica, al numero di lezioni seguite durante il corso e al punteggio alla scala Spatial
di OSIVQ: il criterio da predire è l’ansia nei confronti della statistica, misurata anch’essa mediante
apposito test. I dati sono raccolti nel file regressione_esempio.sav.
Dopo aver organizzato i dati in colonne come abbiamo visto nel Scheda strumenti
informatici 7.4, il percorso da seguire è sempre Analyze → Regression → Linear. Nella finestra che
si apre, dovremo inserire la variabile dipendente Ansia nel campo Dependent e i predittori nel
campo Independent(s) (Figura 7.5.1)
Figura 7.5.1 Impostazione di un’analisi di regressione multipla in SPSS
Il riquadro che contiene il campo Independent(s) è indicato come Block 1 of 1. I blocchi sono i
gruppi di variabili che possono essere inserite o tutte insieme per realizzare una regressione
simultanea, o una o più alla volta per realizzare una regressione gerarchica. Clickando su Next il
nome del riquadro diventa Block 2 of 2 e il campo Independent(s) risulta vuoto, in quanto
costituisce il secondo blocco di variabili da inserire nell’equazione. Sempre clickando su Next si
possono inserire quanti blocchi si desidera. Per tornare ai blocchi precedenti basta clickare su
Previous. Sempre nel medesimo riquadro è presente anche il campo Method, con un menu a
tendina: mediante questa opzione è possibile scegliere se realizzare per quel blocco una regressione
simultanea (tutti i predittori inseriti nel modello simultaneamente, opzione Enter, che è anche quella
di default) o statistica. Oltre alle opzioni Stepwise, Forward e Backward descritte nel testo, è
presente anche un’ulteriore metodo, Remove. Remove può essere utilizzato solo dal secondo blocco
di variabili in avanti, poiché permette di decidere in anticipo la rimozione di alcune variabili dal
modello, indipendentemente dagli aspetti statistici. Ad esempio, potremmo inserire nel blocco 1
tutti i predittori, e decidere, al blocco 2, di rimuovere forzatamente il genere. Per far questo
inseriremo nel campo Independent(s), Block 1 of 1 tutti i predittori e sceglieremo il metodo Enter.
Clickeremo su Next e nel Block 2 of 2 inseriremo nel campo Independent(s) il Genere e sceglieremo
il metodo Remove. Ad ogni modo, è una procedura per certi versi insolita e che per essere applicata
richiede una notevole competenza nella specificazione del modello.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Il campo Selection Variable permette di specificare una variabile di selezione dei soggetti.
Supponiamo di voler realizzare l’analisi di regressione separatamente per maschi e femmine.
Inseriamo la variabile Genere nel campo Selection Variable, e clickiamo su Rule. Si aprirà una
finestra che ci consentirà di indiacre un valore, Value, e di scegliere la regola: equal to (uguale a),
not equal to (diverso da), less than (minore di), less than or equal to (minore o uguale a), greater
than (maggiore di), greater than or equal to (maggiore o uguale a). Nel caso del genere sceglieremo
dal menu a tendina equal to e nel campo Value inseriremo 0 per le femmine e 1 per i maschi. Si noti
che la variabile di selezione non può comparire fra i predittori nel campo Independent(s).
Nel campo Case Labels è possibile inserire una variabile che contiene le etichette delle unità
di analisi (numeri, nome, etc.). E’ utile perché l’etichetta viene riportata nei diagrammi a
dispersione, e consente di identificare direttamente dal grafico quale soggetto corrisponde ad un
determinato punto della nube: se è un potenziale outlier, è possibile sapere subito quale soggetto è.
Per poter sfruttare questa possibilità, però, occorre aver predisposto una variabile che contenga i
nomi o i codici dei soggetti.
Nel campo WLS Weight viene inserita una variabile che contiene dei pesi da assegnare ad
ogni caso per realizzare in base alla sua varianza. In pratica, i punti vengono pesati per il reciproco
della loro varianza, in modo che i soggetti con varianze maggiori abbiano minore impatto sui
risultati rispetto a quelli con varianze più contenute. Se il valore del peso è zero, negativo o
mancante, il caso viene escluso dall’analisi. Anche questa opzione viene utilizzata in analisi un po’
più complesse e che richiedono una preparazione più approfondita.
Clickando su Statistics si apre la finestra in Figura 7.5.2
Figura 7.5.2 Finestra Statistics per la scelta delle statistiche da produrre per un’analisi di regressione
multipla
Nel riquadro in alto a sinistra (Regression Coefficients) è possibile scegliere quali statistiche
ottenere per i coefficienti di regressione. E’ ovviamente spuntato di default Estimates, ossia le
stime, ma è possibile richiedere anche Confidence Intervals (intervalli di fiducia), che permette di
ottenere i limiti degli intervalli di fiducia delle stime dei parametri ad un livello del 95%, e
Covariance Matrix, ossia la matrice di covarianza e di correlazione dei coefficienti di regressione.
Questa matrice viene utilizzata per calcolare gli errori standard delle stime, e rappresenta una stima
delle correlazioni e delle covarianze che si osserverebbero fra i coefficienti di regressione se dalla
popolazione venissero estratti tutti i possibili campioni di n elementi e si stimassero i coefficienti di
regressione per ognuno di essi.
Nella parte di sinistra della finestra in Figura 7.5.2 troviamo le opzioni per ottenere gli indici
che ci permetteranno di valutare la bontà di adattamento del modello ai dati, la dimensione
dell’effetto ed eventuali problemi di collinearità.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Model fit produce le tabelle Model Summary e ANOVA che abbiamo visto in Figura 7.4.4
nella scheda Strumenti informatici 7.4 e che permettono di ottenere il valore di R (correlazione del
criterio col set di predittori), R2 (proporzione di variabilità del criterio spiegata dai predittori),
Adjusted R2 e l’errore standard della stima.
L’opzione R squared change è utile nel caso in cui si scelga una strategia di regressione
multipla di tipo gerarchico o statistico, in quanto mostrerà come varia il valore di R2 in base alla
successive inclusioni e/o esclusioni di predittori (o blocchi di predittori) a partire dal modello
iniziale e se questo cambiamento è statisticamente significativo. Questa informazione è
fondamentale soprattutto quando si studia la validità incrementale di un test: se l’aggiunta del
punteggio al test come predittore nell’equazione di regressione multipla non comporta un aumento
significativo della proporzione di variabilità spiegata dal predittore, il test non possiede validità
incrementale.
Descriptives permette di ottenere le statistiche descrittive (media, deviazions standard e
numero di casi validi) del criterio e dei predittori e, soprattutto, la matrice di correlazione bivariata
fra tutte le variabili interessate dall’analisi, che ci interessa particolarmente per due motivi: ci
consente infatti di:
1. valutare da subito l’entità della correlazione fra il criterio e i predittori, individuando
eventualmente i predittori da escludere dal modello poiché la loro correlazione bivariata col
criterio è inferiore, a |,20| (o altro valore di correlazione scelto)
2. realizzare un’esame iniziale delle possibili collinearità fra i predittori, indicate da
coefficienti di correlazione maggiori di ,50. Ad ogni modo, quale che sia il risultato di
questo “screening” iniziale, deve poi essere confermato dalle diagnostiche di collinearità
(vedi oltre)
L’opzione Part and partial correlations è anch’essa importante perché ci consente di ottenere nella
stessa tabella dove compaiono i coefficienti di regressione (Coefficients, vedi Figura 7.4.4 della
scheda Strumenti informatici 7.4) la correlazione di ordine zero (ossia le bivariate), la correlazione
parziale (Part) e la correlazione parziale indipendente (Partial) fra ogni predittore e il criterio1. La
correlazione Part è la correlazione residua fra predittore e criterio dopo che è stata rimossa
statisticamente la correlazione dovuta alla loro associazione con le altre variabili, ossia la
correlazione che rimane dopo che gli effetti lineari delle altre variabili indipendenti del modello
sono state rimosse da sia dal predittore in questione che dal criterio. La correlazione Partial,
invece, è la correlazione residua fra un predittore e il criterio dopo che gli effetti lineari degli altri
predittori sono stati rimossi solo dal criterio. Se elevato al quadrato, questo valore corrisponde al
cambiamento in R2 quando la variabile viene aggiunta all’equazione di regressione.
L’opzione Collinearity diagnostics permette di ottenere le diagnostiche di collinearità, ossia
il valore di Tolerance e VIF nella tabella Coefficients e un’altra tabella, chiamata proprio
Collienarity Diagnostics, che permette un’analisi più approfondita delle eventuali cause di
collinearità.
Nel riquadro Residuals troviamo due opzioni importanti per la verifica delle assunzioni della
regressione e della presenza di outliers. Il Durbin-Watson è un test di autocorrelazione dei residui,
ossia degli errori di predizione, che in base alle assunzioni della regressione non devono essere
correlati fra loro. Il valore atteso di questo indice in caso di assenza di autocorrelazione fra i residui
è 2: se è inferiore a 2 l’autocorrelazione fra gli errori è negativa, se è superiore è positiva. Se
l’analisi è condotta su almeno 100 soggetti e con almeno 2 predittori, la gamma di valori accettabili
va da 1,5 a 2,2 (Dillon & Goldstein, 1984). L’opzione Casewise diagnostics permette invece di
1
In questo caso purtroppo i termini utilizzati da SPSS sono un po’ fuorvianti, in quanto la correlazione indicata come
Part corrisponde alla definizione di correlazione parziale (si veda la sezione 2.3.3 di questo capitolo), mentre la
correlazione indicata come Partial corrisponde a quella che usualmente viene chiamata correlazione semiparziale, in
quanto gli effetti della terza (o delle altre variabili) sono rimossi solo dalla variabilità di una delle due variabili
interessate dall’analisi.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
ottenere informazioni sui possibili outliers, perché produce una tabella con i valori dei residui (sia
grezzi che standardizzati), il valore atteso e il valore osservato del criterio per tutti quei casi che
presentano un residuo standardizzato superiore al numero di deviazioni standard indicate in Outliers
outside o per tutti i casi (All cases) e un’altra tabella, chiamata Residual Statistics che contienele
statistiche descrittive (minimo, massimo, media, deviazione standard e numero di casi validi) per i
valori predetti, per il residui, per i valori predetti standardizzati e per i residui standardizzati.
Se dalla finestra principale (Figura 7.5.1) clickiamo su Plots, otteniamo una finestra che ci
consente di richiedere la produzione di alcuni grafici che permettono l’esame visivo delle
assunzioni di normalità, linearità, e omogeneità delle varianze e di individuare casi non validi,
outliers e i cosiddetti “casi influenti” (influential data) (Figura 7.5.3)
Figura 7.5.3 Finestra di SPSS per l’impostazione dei grafici per la regressione multipla
Le etichette nel campo sulla sinistra della finestra significano:
DEPENDNT = punteggio grezzo nel criterio (variabile dipendente)
*ZPRED = punteggi predetti (stimati) standardizzati
*ZRESID = residui standardizzati
*DRESID = residui “cancellati” (D sta per deleted), ossia residui quando l’unità di analisi viene
eliminata dall’analisi
*ADJPRED = punteggio teorico “aggiustato” di un caso quando questo viene eliminato dalla
regressione
*SRESID = residuo “studentizzato” (da cui la S), che è un tipo particolare di residuo
standardizzato calcolato dividendolo per la sua deviazione standard e che dipende dalla distanza
dei valori di ogni caso sulle variabili indipendenti dalle medie delle variabili indipendenti.
*SDRESID = residuo cancellato studentizzato, che viene ottenuto dividendo il residuo per il suo
errore standard. La differenza fra un residuo cancellato studentizzato e il suo residuo
studentizzato indica quanta differenza fa eliminare quel caso sul suo valore predetto
Per costruire un diagramma a dispersione fra due di questi valori basta inserire nel campo Y: e nel
campo X: le variabili che si desidera compaiano sull’asse verticale e orizzontale, rispettivamente.
Per impostare più di un grafico occorre clickare sul pulsante Next.
Dal riquadro Standardized Residual Plots è possibile ottenere l’istogramma (Histogram) e il
grafico di probabilità normale (Normal probability plot), che rappresentano la distribuzione dei
residui standardizzati e il confronto fra la distribuzione dei residui standardizzati e una distribuzione
normale.
Se si spunta Produce alla partial plots si ottengono i grafici parziali, ossia i diagrammi a
dispersione dei residui di un singolo predittore e dei residui del criterio quando entrambe vengono
fatte regredire separatamente sul resto dei predittori (per cui è necessario che nel modello vi siano
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
almeno due variabili). Tali grafici possono essere utilizati per esaminare le assunzioni di linearità,
additività e omoschedasticità.
Se dalla finestra principale (Figura 7.5.1) clickiamo su Save si apre una finestra con lo stesso
nome che permette di scegliere quali risultati o indici salvare come nuove variabili nel file di dati.
L’esame di questi valori permette di evidenziare eventuali outliers (Figura 7.5.4).
Figura 7.5.4 Finestra di SPSS per la produzione degli indici per la valutazione degli outliers
I valori nei riquadri Predicted Value e Residuals sono gli stessi descritti a proposito della
finestra Plots. Si noti che Unstandardized in Predicted Values è semplicemente Ŷ e in Residuals è
Ŷ−Y.
Nel riquadro Distances è possibile chiedere la produzione di indici che permettono di
identificare gli outliers determinati da combinazioni rare di valori sui predittori.
Mahalanobis: è una misura della distanza di un caso dalla media di tutti i casi sui predittori e
consente di individuare quei casi che hanno valori estremi su uno o più dei predittori. E’
utile perché è distribuito come chi-quadrato con gradi di libertà uguali al numero di
predittori, da cui la possibilità di valutare statisticamente lo status di outlier di un caso. In
questo caso è raccomandato l’uso di un livello α di significatività di ,001.
Cook’s: è una misura di quanto i residui di tutti i casi varierebbero se un particolare caso
fosse escluso dalla stima dei parametri. Un valore elevato è indice di una variazione
sostanziale nei coefficientidi regressione se quel caso non fosse incluso nell’analisi, ma
differentemente dal caso delle distanze mahalanobiane quelle di Cook non possono essere
sottoposte a verifica delle ipotesi. Norusis (1998) suggerisce comunque di considerare con
sospetto valori superiori a 1.
Leverage values (o valori di influenza): sono un indice dell’influenza di un caso sulla bontà
di adattamento del modello di regressione ai dati. Tali indici variano fra 0 (nessuna
influenza) e n/(n − 1) (massima influenza), che è l’influenza massima. I valori dediserabili
per questo indice sono quelli inferiori a ,20, mentre valori fra ,20 e ,50 indicano casi sospetti
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
e valori superiori a ,50 identificano casi da prendere in seria considerazione per l’esclusione
dall’analisi (Barbaranelli, 2006).
Nel riquadro Influence Statistics viene offerta la possibilità di chiedere indici che consentono di
esaminare il cambiamento, sia come punteggio grezzo che standardizzato, che avverrebbe nel/nei
coefficiente/i di regressione (Dfbeta(s) e Standardized DfBeta(s)) e nei valori predetti dalla
regressione (DfFit e Standardized DfFit) se il caso venisse escluso dall’analisi. Cambiamenti in
valore assoluto nell’ordine di 2 / n (Norusis, 1998) o 3 / n (Pedhazur, 1997) sono da
considerarsi sostanziali. Il Covariance ratio indica quale sarebbe il risultato del rapporto fra il
determinante2 della matrice di covarianza se il caso venisse escluso dall’analisi e il determinante
della matrice di covarianza includendo nell’analisi tutti i casi. Il rapporto ottimale deve essere
vicino ad 1.
Nel riquadro Prediction Intervals è possibile chiedere la produzione dei limiti superiore e
inferiore degli intervalli dei punteggi previsti nel criterio, sia medi (Mean) che individuali
(Individual) per un certo livello di probabilità (Confidence interval). Il primo tipo di intervallo viene
ottenuto considerando l’errore standard medio dei punteggi predetti, il secondo tenendo conto di
una stima individuale. Per ragioni statistiche, l’intervallo medio sarà sempre più ristretto di quello
individuale.
L’ultimo riquadro (Export model information to XML file) consente di creare un file in cui le
informazioni sul modello siano esportate in un file di formato particolare (XML).
Se dalla finestra principale (Figura 7.5.1) clickiamo su Options, si apre la finestra in Figura
7.5.5.
Figura 7.5.5 Finestra di SPSS per le opzioni dell’analisi di regressione
Nel riquadro Stepping Method Criteria è possibile indicare i criteri statistici in base ai quali i
predittori vengono inseriti (Entry) o esclusi (Removal) dal modello di regressione se si usa una
strategia statistica (stepwise, remove, backward, forward). Se si seleziona Use probability of F, il
predittore è inserito nel modello se il livello di significatività di F è inferiore al valore indicato in
Entry ed escluso se il livello di significatività di F è superiore a Removal, oppure, se si seleziona
Use F value, il predittore viene inserito nel modello se il valore di F calcolato è maggiore di quello
indicato in Entry e viene escluso se il valore di F calcolato è minore di quello di quello indicato in
Removal.
2
Il determinante di una matrice è una funzione che associa ad ogni matrice quadrata un particolare valore che ne
sintetizza alcune proprietà algebriche.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
L’opzione Include constant in equation, se non spuntata, fa sì che l’intercetta del modello
venga fissata a zero. Di default, comunque, è selezionata.
Nel riquadro Missing Values si può infine scegliere come trattare i dati mancanti, ossia se
considerare solo i casi validi per tutte le variabili (listwise, opzione consigliata), se calcolare i
coefficienti di regressione usando tutti i casi validi per le due variabili considerate in quella fase
dell’analisi (pairwise, si tenga però conto che i gradi di libertà sono basati sul valore di n minimo
per tutte le coppie di variabili analizzate) oppure se sostituire i dati mancanti con la media della
variabile interessata (Replance with mean). Questa opzione è in genere sconsigliabile, perché, oltre
a rendere disponibile per l’analisi un dato che di fatto non è stato osservato, tende a ridurre la
variabilità nei dati. Un caso in cui potrebbe essere utilizzata è quello in cui si hanno pochissimi
missing in pochi soggetti di un campione molto ampio e con molte variabili.
7.5.1 Analisi delle assunzioni
Prima di procedere con l’analisi di regressione, occorre che siano verificate le assunzioni per la sua
applicabilità. Utilizziamo in questo caso i dati nel file regressione_esempio.sav.
In primo luogo, dobbiamo assicurarci che tutte le variabili posseggano sufficiente variabilità,
perché costanti o in ogni caso variabili con dispersione dei punteggi molto bassa non devono essere
presenti nel modello. Inoltre, dobbiamo anche verificare che le variabili presentino valori di
skewness e curtosi inferiori a |1,00|, perché l’inclusione nel modello di regressone di variabili la cui
distribuzione è troppo diversa dalla normale può portare alla violazione delle assunzioni di linearità,
noamlità e omoschedasticità dei residui. Seguiamo il percorso Analyze → Descriptive Statistics →
Descriptives, inseriamo tutte le variabili nel campo Variable(s), spuntiamo Save standardized
values as variables e mediante Options spuntiamo anche i valori di skewness e curtosi. Il risultato è
quello in Figura 7.5.6
Descriptive Statistics
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Punteggio Ansia verso
la Statistica
Valid N (listwise)
N
Statistic
100
100
100
100
Minimum
Statistic
0
4
0
14
Maximum
Statistic
1
28
24
69
Mean
Statistic
,55
16,82
15,02
41,08
Std.
Deviation
Statistic
,500
5,364
5,059
12,188
100
23
79
52,20
12,331
Skewness
Statistic
Std. Error
-,204
,241
-,153
,241
-,293
,241
,137
,241
-,282
,241
Kurtosis
Statistic
Std. Error
-1,999
,478
-,447
,478
-,160
,478
-,293
,478
-,090
,478
100
Figura 7.5.6 Statistiche descrittive di predittori e criterio
La Figura 7.5.6 mostra che tutte le variabili hanno una deviazione standard sufficientemente
superiore a zero e che i valori di skewness e curtosi sono inferiori a |1,00|. L’unico valore al di fuori
di questa gamma è la curtosi del Genere, che però è una variabile dummy, ossia dicotomica. In
questo caso, poiché si tratta di una distribuzione binomiale, la skewness e la curtosi vanno calcolate
con le formule:
1 − 2P
1 − 2×,55
SK Binomiale =
=
= −0,02
nP(1 − P)
100×,55 × (1−,55)
1 − 6 P(1 − P) 1 − 6×,55 × (1−,55)
KU Binomiale =
=
= −0,02
nP (1 − P)
100×,55 × (1−,55)
dove P è la proporzione di casi con valore 1, che corrisponde alla media del Genere riportata in
Figura 7.5.6: la media è calcolata come somma dei valori diviso n, per cui se i valori sono tutti 1 o
0, la media risulta uguale alla somma degli 1 diviso il numero di soggetti, ossia la proporzione di
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
soggetti con valore 1, cioè i maschi. Anche nel caso del genere la distribuzione presenta valori di
Skewness e Curtosi adeguati.
Nel file dei dati sono state aggiunte le colonne relative ai punteggi standardizzati per ogni
variabile. Esaminando i valori standardizzati è possibile eseguire primo screening degli outliers
eliminando i casi che abbiano un punteggio standardizzato maggiore di 3 o minore di −3 su almeno
una delle variabili. Ignoriamo i punteggi standardizzati del genere, e consideriamo solo quelli nelle
altre variabili. Per eseguire rapidamente questa procedura, occorre ordinare i valori per ogni
variabile: per far questo, seguiamo il percorso Data → Sort Cases (Figura 7.5.7a) e inseriamo nel
campo Sort By: la variabile zmate, a cui corrisponde l’etichetta Z score: Profitto in matematica
(Figura 7.5.7b).
a
b
Figura 7.5.7 Procedura per ordinare i casi in base ai valori di un variabile in SPSS
Clickiamo su OK. A questo punti i casi saranno stati ordinati in base al punteggio nella variabile
zmate. Esaminiamo i punteggi più bassi e quelli più alti scorrendo verso l’alto e verso il basso il
dataset e troviamo che il punteggio standardizzato minore è −2,38989 del soggetto sogg014 e il il
punteggio standardizzato maggiore è 2,08416 del soggetto sogg094, per cui per questa variabile non
sono presenti outliers. Eseguiamo la stessa procedura per verificare la presenzadi outliers nelle altre
variabili. Non ci sono valori standardizzati superiori a |3,00| in nessuna variabile. Nella variabile
relativa al numero di lezioni seguite c’è un valore uguale a −2,96885 (caso sogg076, Figura 7.5.8).
Figura 7.5.8 Screening dei valori anomali in base ai punteggi standardizzati delle variabili
Non ci sono gli estremi per eliminarlo, ma se proprio lo vogliamo fare non dobbiamo far altro che
clickare col tasto destro del mouse sulla cella grigia a sinistra della finestra col numero 1 (e che
identifica la prima riga del foglio di dati) e scegliere Clear. Si tenga conto che tutte le volte che si
elimina un caso, le analisi per lo screening degli outliers vanno ricondotte da capo, in modo valutare
se la variazione nel set di dati prodotta dall’esclusione di quel caso non abbia reso outliers altri casi
inizialmente non identificati come tali. La procedura di screening degli outliers può quindi
comportare una serie di controlli, basati sull’ispezione degli indici, eliminazione di casi, nuova
ispezione degli indici, nuova eliminazione di casi, e così via. Si tenga conto del fatto che per
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
variabili distribuite in modo molto non normale le eliminazioni di casi possono essere numerose,
con conseguente di riduzione dell’ampiezza e/o della rappresentatività del campione. Nel caso di
individuino variabili con skewness al di fuori del range consigliato si può procedere con la
trasformazione dei punteggi vista nella sezione 2.3.1 di questo capitolo, ma non è detto che questo
risolva il problema e, in ogni caso, rende più complicata l’interpretazione del risultato.
Una volta controllati gli outliers a livello univariato (variabile per variabile), occorre
verificare quelli a livello multivariato (nelle variabili nel loro insieme). Per far questo utilizziamo le
opzioni offerte dalla procedura di regressione multipla di SPSS. Seguiamo quindi il percorso
Analyze → Regression → Linear, inseriamo i predittori nel campo Independent(s) e il criterio nel
campo Dependent. Clickiamo su Save e spuntiamo Mahalanobis. Clickiamo su OK e ignoriamo per
il momento l’output, concentrandoci sulla nuova variabile, MAH_1 che è stata creata nel dataset.
Perché un valore sia considerato un outlier, deve essere maggiore del chi-quadrato critico per α =
,001 e gradi di libertà uguali al numero di predittori. In questo caso abbiamo 4 predittori, per cui il
valore di chi-quadrato critico può essere individuato con la funzione di Excel =INV.CHI(,001;4),
che è 18.47. A questo punto ordiniamo i dati in base al valore di MAH_1 e vediamo che il valore
minimo è 1,01303 (caso sogg047) e il massimo è 11,26022 (caso sogg065). Nessun valore è
superiore al valore critico, per cui non sembrano essere presenti outliers univariati. Ci fossero stati,
avremmo potuto eliminarli, ma a quel punto avremmo dovuto riprendere tutta la procedura di
screening da capo.
Grazie ai valori delle distanze mahalanobiane è possibile calcolare anche un indice di
normalità multivariata, detto indice di curtosi multivariata di Mardia, che permette di verificare se
le relazoni fra le variabili possono essere considerate lineari. Per questo, seguiamo il percorso
Transform → Compute (Figura 7.5.9a) Nel campo Target Variable inseriamo il nome della nuova
variabile che stiamo per calcolare (ad esempio, MAH2). Selezioniamo la variabile MAH_1 e la
spostiamo campo Numeric Expression. Clickiamo sul tasto col doppio asterisco ( ) e aggiungiamo
“2”, e poi OK (Figura 7.5.9b)
a
b
Figura 7.5.9 Trasformare una variabile mediante un’operazione matematica in SPSS
Questo ci permette di ottenere una nuova variabile, MAH2, che corrisponde alle distanze
mahalanobiane elevate al quadrato. Mediante Analyze → Descriptive Statistics → Descriptives,
otteniamo la media di questa variabile, che è 21,03. Il valore critico con cui confrontare quello
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
ottenuto è uguale a numero di predittori k moltiplicato per il numero di predittori più due, k(k+2), e
perché sia soddisfatta la normalità multivariata il valore calcolato deve essere inferiore a questo.
Nel nostro caso abbiamo 4 predittori, quindi 4×(4+2) = 24. Poiché il valore calcolato (21,03) è
inferiore a quello critico (24), possiamo concludere che i dati presentano una normalità multivariata.
Le assunzioni relative alla specificazione del modello (non omettere predittori rilevanti e
non includere predittori irrilevanti) possono essere verificate solo a livello teorico, in base alla
conoscenza che si ha del fenomeno, oppure valutando le correlazioni bivariate fra i predittori e il
criterio. Per far questo, dalla finestra in Figura 7.5.1, clickiamo su Statistics e spuntiamo l’opzione
Descriptives, che produrrà le statistiche descrittive di predittori e criterio e, soprattutto, le
correlazioni fra queste variabili. L’output è riportato in Figura 7.5.10
Correlations
Punteggio
Ansia verso
la Statistica
Pearson Correlation
Sig. (1-tailed)
N
Punteggio Ansia verso
la Statistica
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Punteggio Ansia verso
la Statistica
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Punteggio Ansia verso
la Statistica
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Genere
Profitto in
Matematica
Numero
lezioni
seguite
Punteggio
SPATIAL
1,000
,203
,384
,469
,468
,203
,384
,469
,468
1,000
,180
,207
,218
,180
1,000
,145
,271
,207
,145
1,000
,049
,218
,271
,049
1,000
.
,021
,000
,000
,000
,021
,000
,000
,000
.
,036
,019
,015
,036
.
,075
,003
,019
,075
.
,313
,015
,003
,313
.
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
Figura 7.5.10 Correlazioni fra i predittori e il criterio
Dalla matrice di correlazione in Figura 7.5.10 notiamo che tutti predittori sono correlati almeno a
|,20| con il criterio (prima colonna, Punteggio Ansia verso la statistica), per cui sembrerebbe che
tutte le variabili inserite nel modello abbiano una sufficiente relazione, almeno a livello bivariato,
con il criterio. I predittori sono solo debolmente correlati fra loro, e questo risultato è un primo
indice di assenza di collinearità, che comunque andrà verificata anche in seguito con altre
statistiche.
L’assunzione relativa all’assenza di errori di misurazione può essere verificata consultando
l’attendibilità dei punteggi se questi sono stati ottenuti mediante la somministrazione di test
psicologici (vedi Volume II). Per gli altri tipi di variabili, occorre assicurarsi prima di raccogliere i
dati che la procedura garantisca la raccolta di valori attendibili: ad esempio, per la variabile
“numero di lezioni frequentate”, si può tenere un registro delle presenze.
Il controllo più importante da eseguire dopo quello degli outliers è quello della collinearità
dei predittori. Per questo, seguiamo di nuovo il percorso Analyze → Regression → Linear,
clickiamo su Statistics e spuntiamo Collinearity diagnostics. Quindi clickiamo su Continue e poi su
OK. Cerchiamo nell’output la tabella Coefficients e consultiamo le colonne a destra (Figura 7.5.11)
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Coefficientsa
Model
1
(Constant)
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Unstandardized
Coefficients
B
Std. Error
12,290
4,562
-,205
1,953
,503
,183
1,024
,189
,394
,080
Standardized
Coefficients
Beta
-,008
,219
,420
,389
t
2,694
-,105
2,758
5,422
4,896
Sig.
,008
,917
,007
,000
,000
Collinearity Statistics
Tolerance
VIF
,904
,899
,944
,896
1,106
1,112
1,059
1,116
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.11 Tabella di output dei coefficienti con le statistiche di collinearità (destra)
Abbiamo visto nel testo che i valori di Tolerance devono essere maggiori di ,50 e quelli di VIF
inferiori a 2, ed è il caso dei valori riportati in Figura 7.5.10. Nell’output sotto a questa tabella ne è
presente un’altra chaimata Collinearity Diagnostics (Figura 7.5.12)
Collinearity Diagnosticsa
Model
1
Dimension
1
2
3
4
5
Eigenvalue
4,459
,357
,092
,063
,030
Condition
Index
1,000
3,535
6,979
8,415
12,237
(Constant)
,00
,01
,00
,01
,98
Variance Proportions
Numero
lezioni
Profitto in
seguite
Genere
Matematica
,01
,00
,00
,96
,01
,01
,00
,11
,70
,00
,77
,00
,03
,11
,28
Punteggio
SPATIAL
,00
,01
,16
,45
,38
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.12 Tabella di output con le diagnostiche di collinearità
Questa tabella ci permette di esaminare la correlazione fra i predittori. In particolare, ci interessa la
colonna Condition Index: se anche uno solo dei valori è compreso fra 15 e 30 siamo in una
condizione di sospetta collinearità, mentre la collinearità è grave se questo valore è superiore a 30
(Barbaranelli, 2006). Nelle colonne Variance Proportions vi è la proporzione di variabilità spiegata
per ogni predittore dalle dimensioni (colonna Dimensions sulla sinistra). Senza stare troppo ad
entrare nel dettaglio di questa analisi, diciamo solo che la condizione ideale è quella in cui per ogni
riga della sottomatrice Variance Proportions contiene un solo valore superiore a ,40 e tutti gli altri
prossimi a zero. Nella Figura 7.5.11, sulla riga della dimensione 4 abbiamo due valori superiori a
,40, relativi ai predittori “Profitto in matematica” e “Punteggio SPATIAL”. Questo significa che i
due predittori sono correlati, ma dato che il valore di Tolerance non ha suggerito problemi,
possiamo considerare questo risultato trascurabile. Se così non fosse stato, avremmo dovuto pensare
a come gestire la collinearità dei due predittori (si veda il testo per le possibili soluzioni).
Passiamo adesso a verificare le assunzioni sugli errori (residui). Nella finestra Statistics
selezioniamo Durbin-Watson e Casewise Diagnostics (lasciando a 3 la soglia per Outliers outside),
mentre nella finestra Plots inseriamo *ZRESID nel campo X e *ZPRED nel campo Y, e spuntiamo
Histogram, Normal probability plot e Produce alla partial plots. Eseguiamo quindi l’analisi.
Come primo passo, cerchiamo nell’output la tabella Residual Statistics (Figura 7.5.13).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Residuals Statisticsa
Predicted Value
Std. Predicted Value
Standard Error of
Predicted Value
Adjusted Predicted Value
Residual
Std. Residual
Stud. Residual
Deleted Residual
Stud. Deleted Residual
Mahal. Distance
Cook's Distance
Centered Leverage Value
Minimum
24,97
-3,250
Maximum
68,59
1,956
Mean
52,20
,000
Std. Deviation
8,378
1,000
N
1,314
3,249
2,017
,448
100
25,24
-22,770
-2,465
-2,497
-23,368
-2,570
1,013
,000
,010
68,46
31,564
3,417
3,476
32,663
3,701
11,260
,084
,114
52,22
,000
,000
-,001
-,018
,001
3,960
,009
,040
8,353
9,048
,980
1,002
9,466
1,019
2,324
,015
,023
100
100
100
100
100
100
100
100
100
100
100
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.13 Tabella di output delle statistiche dei residui
Nella tabella in Figura 7.5.13 ci interessa in particolare verificare se la media dei residui (Residual)
è uguale a zero, e così è. L’assunzione prevede poi che i residui siano distribuiti normalmente:
questo lo verifichiamo ispezionando i grafici *zresid Histogram e *zresid Normal P-P plot (Figura
7.5.14)
a
b
Figura 7.5.14 Grafici con la distribuzione dei residui della regressione
La Figura 7.5.14a mostra che la forma della distribuzione dei residui è molto prossima alla normale,
conclusione confermata dalla Figura 7.5.14b: in questo tipo di grafico se tutti i punti sono
perfettamente allineati sulla linea diagonale che taglia a metà il quadrante significa che la
distribuzione è perfettamente normale. Nel caso che stiamo considerando, gli scostamenti da questa
linea ideale sono rari e di entità limitata, per cui possiamo concludere che l’assunzione di normalità
della distribuzione dei residui (errori) è rispettata.
Cerchiamo adesso nell’output il grafico che ha sull’asse orizzontale i residui standardizati e
sull’asse verticale i valori predetti standardizzati (*zpred by *resid Scatterplot, Figura 7.5.15).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Figura 7.5.15 Diagramma a dispersione residui standardizzati per valori predetti standardizzati
Se nella nube di punti potesse essere distinta una qualche forma particolare (Figura 7.5.16) ci
sarebbero gli estremi per supporre una violazione dell’assunzione di linearità degli effetti, che non è
però il caso della Figura 7.5.15.
Residui Standardizzati
Residui Standardizzati
Valori Predetti Standardizzati
Residui Standardizzati
Autocorrelazione errori
Valori Predetti Standardizzati
Outliers
Valori Predetti Standardizzati
Non omogeneità delle varianze
Residui Standardizzati
Non linearità
Valori Predetti Standardizzati
Non normalità
Valori Predetti Standardizzati
Valori Predetti Standardizzati
Assunzioni rispettate
Residui Standardizzati
Residui Standardizzati
Figura 7.5.16 Esempi di diagrammi a dispersione residui standardizzati per valori predetti
standardizzati indicativi di una violazione delle assunzioni per l’applicazione della regressione
multipla (adattato da Barbaranelli, 2003)
Fin qui abbiamo valutato i predittori nel loro insieme. Vediamo invece nei grafici parziali i
predittori uno per uno (Figura 7.5.17).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Figura 7.5.17 Grafici di regressione parziale dei predittori
I grafici in Figura 7.5.17 non mostrano particolari relazioni fra i punteggi dei predittori (asse
orizzontale) e i residui del criterio (asse verticale), se si esclude forse una debole relazione nel caso
del numero di lezioni seguite e del punteggio SPATIAL (per aiutarci nella valutazione potremmo
modificare il grafico per inserire la retta di regressione, come abbiamo visto nella scheda Strumenti
informatici 7.4). Ad ogni modo, l’assunzione di assenza di relazione fra valori dei predittori e
residui sembra confermata.
L’assunzione di autocorrelazione dei residui può essere verificata mediante il test DurbinWatson, che può essere richiesto nella finestra Statistics. La statistica comparirà nella tabella Model
Summary (Figura 7.5.18)
Model Summaryb
Model
1
R
R Square
,679a
,462
Adjusted
R Square
,439
Std. Error of
the Estimate
9,236
DurbinWatson
2,284
a. Predictors: (Constant), Punteggio SPATIAL, Numero lezioni seguite,
Genere, Profitto in Matematica
b. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.18 Tabella Model Summary con la statistica Durbin-Watson per la valutazione
dell’assunzione di autocorrelazione degli errori
Il valore riportato nella tabella in Figura 7.5.18 è 2,28, di poco al di fuori dell’intervallo 1,5-2,2
indicato in precedenza. Questo risultato sembrerebbe indicare che è presente una certa
autocorrelazione positiva fra gli errori, per cui eventuali risultati “anomali” dell’analisi dovranno
essere considerati con attenzione, perché potrebbero dipendere da questa lieve violazione di una
delle assunzioni.
La tabella Casewise Diagnostics (Figura 7.5.19) mostra che un soggetto, il 57, ha un residuo
standardizzato maggiore di 3, il che lo rende un caso potenzialmente influente sui risultati.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Casewise Diagnosticsa
Case Number
57
Std. Residual
3,417
Punteggio
Ansia verso
la Statistica
79
Predicted
Value
47,44
Residual
31,564
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.19 Tabella per l’analisi dei residui caso per caso
Per approfondire la questione, andiamo nella finestra Save e chiediamo che vengano salvate come
nuove variabili del dataset le distanze di Cook e i levarage values (riquadro Distances), i residui
standardizzati (Standardized in Residuals) e spuntiamo le opzioni Standardized DfBeta(s),
Standardized DfFit e Covariance ratio nel riquadro Influence Statistics. Una volta prodotto l’output
tutte queste nuove variabili compariranno nel dataset. Innazitutto verifichiamo la correlazione fra i
residui standardizzati della variabile dipendente e i predittori mediante il percorso Analyze →
Correlate → Bivariate (Figura 7.5.20)
Correlations
Standardized Residual
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Standardized
Residual
1
100
,000
1,000
100
,000
1,000
100
,000
1,000
100
,000
1,000
100
Genere
,000
1,000
100
1
100
,180
,072
100
,207*
,039
100
,218*
,029
100
Profitto in
Matematica
,000
1,000
100
,180
,072
100
1
100
,145
,149
100
,271**
,006
100
Numero
lezioni
seguite
,000
1,000
100
,207*
,039
100
,145
,149
100
1
100
,049
,625
100
Punteggio
SPATIAL
,000
1,000
100
,218*
,029
100
,271**
,006
100
,049
,625
100
1
100
*. Correlation is significant at the 0.05 level (2-tailed).
**. Correlation is significant at the 0.01 level (2-tailed).
Figura 7.5.20 Correlazioni fra residui standardizzati e valori de predittori
Le correlazioni fra residui standardizzati e predittori sono tutte uguali a zero (Figura 7.5.20, colonna
Standardized Residual). Si noti che questi coefficienti non corrispondono ai grafici parziali di
Figura 7.5.17, perché quei grafici sono prodotti dall’analisi di regressione parziale, ossia per un solo
predittore alla volta indipendentemente dagli altri, mentre in questo caso vengono cosiderati i
residui della regressione con tutti i predittori.
Mediante la procedura di ordinamento dei casi in base alle variabili vista in precedenza,
ordiniamo il dataset in base ai valori della distanza di Cook (COO_1). Il massimo valore è ,08416,
ben al di sotto dell’1 indicato da Norusis (1998) come critico. Allo stesso modo, i valori di leverage
(LEV_1) sono tutti al di sotto del valore ,20 considerato il limite superiore dei valori accettabili.
Quando andiamo a considerare i valori di rapporto di covarianza (COV_1), notiamo che c’è un caso
il cui valore è molto lontano da 1, che, non casualmente, è il soggetto 57, proprio quello che era
risultato con un residuo standardizzato troppo alto. Andiamo allora ad esaminare i sui valori di
influenza standardizzati (SDB0_1, SDB1_1, SDB2_1, SDB3_1, SDB4_1), che, come detto, non
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
devono essere superiori a a 2 / n o 3 / n in valore assoluto. In questo caso abbiamo 100
soggetti, per cui il primo valore critico è 0,20, il secondo 0,30. In effetti, il soggetto in questione ha
valori di influenzza standardizzati maggiori di 0,30 in valore assoluto per SDB01_1 (intercetta),
SDB1_1 (Genere) e SDB4_1 (Punteggio SPATIAL). Questo soggetto dovrebbe quindi essere
escluso dalle analisi. Naturalmente potremmo ordinare i casi per tutti i valori di influenza
standardizzati e valutare quali cadono al di fuori dell’intervallo che va da −0,30 a +0,30, e
considerarli per l’esclusione. Tuttavia, per eseguire correttamente questa operazione, i casi
dovrebbero essere eliminati uno alla volta, e le analisi ripetute dopo l’esclusione di questo caso.
Tale procedimento può essere molto lungo, e potrebbe portare all’esclusione di molti casi, per cui è
da eseguire con attenzione soprattutto quando si hanno pochi casi. Inoltre, è importante non
decidere l’esclusione solo in base ad un unico indice: il soggetto 83, ad esempio, mostra un indice
di influenza uguale ,42586 in SDB2_1, ma ha valori nella norma in tutti gli altri indici, per cui
potrebbe essere ragionevolmente mantenuto nel campione. Per semplicità, in questo esempio
eseguiremo le analisi escludendo il soggetto 57, che ha mostrato i maggiori problemi in una
molteplicità di indici.
7.5.2 Scelta della strategia di regressione da adottare
Dopo aver verificato le assunzioni, dobbiamo decidere quale strategia di regressione multipla
utilizzare. La Tabella 7.5.1 ci aiuta a capire come sceglierla in base alla domanda di ricerca.
Tabella 7.5.1 Scelta della strategia di regressione multipla in base alla domanda di ricerca
Strategia di regressione multipla
Domande di ricerca
da scegliere
Qual è la dimensione della relazione generale fra l’ansia nei
confronti della statistica e il genere, la competenza
matematica di base, il numero di lezioni seguite e il
Standard
punteggio alla scala Spatial di OSIVQ?
A quanta parte della relazione contribuisce singolarmente
ogni predittore indipendentemente dagli altri?
L’inserimento nel modello del numero di lezioni seguite
aumenta significativamente la precisione della predizione
dell’ansia nei confronti della statistica? E aggiungendo
Gerarchica
come ulteriore predittore il punteggio nella scala Spatial di
OSIVQ cosa succede?
Qual è la migliore combinazione lineare dei predittori per
predire con la maggiore precisione possibile l’ansia nei
Statistica
confronti della statistica?
Regressione standard
Nella regressione multipla standard i predittori vengono inseriti nel modello simultaneamente. Per
realizzare una regressione multipla standard in SPSS seguiamo il percorso Analyze → Regression
→ Linear e inseriamo tutti i predittori insieme nel campo Independent(s), e lasciamo selezionata
l’opzione di default per il metodo (Method: Enter). Clickiamo su Statistics e spuntiamo l’opzione
Part and Partial Correlations, che ci forniranno gli indici per calcolare la dimensione dell’effetto.
Realizziamo a questo punto l’analisi.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Nella prima tabella di output, Variables Entered/Removed, qui non riportata, vengono
indicate tutte le variabili inserite nel modello come blocco unico. Nella tabella successiva, Model
Summary, possiamo invece osservare la bontà di adattamento del modello ai dati mediante
l’ispezione del valore di R2 e Adjusted R2 (Figura 7.5.21)
Model Summary
Model
1
R
R Square
,712a
,506
Adjusted
R Square
,485
Std. Error of
the Estimate
8,675
a. Predictors: (Constant), Punteggio SPATIAL, Numero
lezioni seguite, Profitto in Matematica, Genere
Figura 7.5.21 Valori di bontà di adattamento del modello di regressione multipla standard ai dati
I dati in Figura 7.5.21 indicano che il modello ha un buon adattamento ai dati, poiché il valore di R2
è ,508 e quello di Adjusted R2 ,485: in pratica, il modello di regressione spiega quasi il 50% della
variabilità della variabile dipendente. La piccola differenza fra i due valori, peraltro, è un ulteriore
indice di assenza di ridondanza (collinearità) nei predittori. Non esistono linee guida precise per
valutare questi indici, perché R2 dipende dal numero di soggetti e dal numero di predittori: la
situazione migliore è quella in cui si riesce a spiegare gran parte della variabilità del criterio (più del
50%) con un numero ristretto di predittori, e il caso che stiamo considerando sembrerebbe ricadere
in questa situazione.
Nella tabella successiva, ANOVA, viene riportato il test di significatività che verifica
l’ipotesi nulla che R2 sia diverso da zero. La Figura 7.5.22 mostra che lo è ad un livello di
significatività p < ,001.
ANOVAb
Model
1
Regression
Residual
Total
Sum of
Squares
7254,741
7073,765
14328,505
df
4
94
98
Mean Square
1813,685
75,253
F
24,101
Sig.
,000a
a. Predictors: (Constant), Punteggio SPATIAL, Numero lezioni seguite, Profitto in
Matematica, Genere
b. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.22 Tavola di ANOVA per una regressione multipla standard
Poiché questo test statistico è fortemente influenzato dall’ampiezza campionaria, è preferibile
eseguire una valutazione della bontà di adattamento del modello ai dati basata sulla dimensione di
R2.
Nell’ultima tabella, Coefficients, troviamo le stime de parametri e la loro significatività
(Figura 7.5.23)
Coefficientsa
Model
1
(Constant)
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Unstandardized
Coefficients
B
Std. Error
10,867
4,302
-,993
1,847
,518
,171
1,021
,177
,426
,076
Standardized
Coefficients
Beta
-,041
,231
,429
,430
t
2,526
-,538
3,021
5,758
5,602
Sig.
,013
,592
,003
,000
,000
Zero-order
,189
,402
,477
,504
Correlations
Partial
-,055
,297
,511
,500
Part
-,039
,219
,417
,406
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.23 Tavola dei coefficienti di regressione per una regressione multipla standard
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
La colonna della significatività dei predittori (Sig.) mostra che il Genere non è un predittore con un
coefficiente di regressione statisticamente diverso da zero (p = ,592), mentre tutti gli altri predittori
e l’intercetta lo sono. Questo ci porta concludere che il genere non è un predittore dell’ansia nei
confronti della statistica, mentre lo sono il profitto in matematica, il numero di lezioni seguite e il
punteggio nella scala Spatial di OSIVQ. Interpretare i coefficienti di regressione non standardizzati
non ci aiuta particolarmente, in quanto dovremmo affermare che per ogni punto in più alla prova di
profitto in matematica l’ansia nei confronti della statistica aumenta, in media, di ,518 punti, così
come per ogni lezione in più seguita il punteggio di ansia umenta di 1,021 punti, e per ogni punto in
più alla scala Spatial il punteggio di Ansia aumenta di ,426 punti. Per quanto corretta da un punto di
vista statistico, tale interpretazione ha poco significato da un punto di vista pratico. Passiamo allora
ad analizzare la dimensione dell’effetto f2 dei vari predittori:
R 2 − Rk2−1 ,506 − (,231×,402+,429×,477+,430×,504)
2
=
=
= −0,02
f Genere
1−,506
1− R2
R 2 − Rk2−1 ,506 − (−0,041×,189+,429×,477+,430×,504)
2
f Profitto matematica =
=
= 0,19
1−,506
1− R2
R 2 − Rk2−1 ,506 − (−0,041×,189+,231×,402+,430×,504)
2
f Numero
=
=
= 0,41
lezioni
1−,506
1− R2
R 2 − Rk2−1 ,506 − (−0,041×,189+,231×,402+,429×,477)
2
=
=
= 0,44
f Spatial
1−,506
1− R2
In base alla dimensione dell’effetto, possiamo osservare che il numero di lezioni seguite e il
punteggio alla scala Spatial, ossia uno stile cognitivo di tipo analitico, sembrano contribuire in
modo consistente (dimensione dell’effetto Grande, vedi Tabella 7.33) alla predizione del punteggio
di ansia nei confronti della statistica, mentre il profitto in matematica contribuisce in modo
Moderato. Si noti che la dimensione dell’effetto così calcolata riguarda la variabilità spiegata
complessivamente dai predittori, comprensiva del loro contributo unico e del contributo simultaneo,
dovuto alla loro parziale associazione. Se volessimo separare le due componenti, dovremmo
moltiplicare i coefficienti standardizzati beta per le Part Correlations e sommare questi prodotti, in
modo da ottenere la quota di variabilità del criterio spiegata in modo unico dai predittori,
indipendentemente da effetti di sovrapposizione. In base ai dati in Figura 7.5.23, il contributo unico
dei predittori ∑ β rPart è ,406, che sottratto a ,506 dà ,100. Questo significa che un 10% della
variabilità del criterio è spiegato da effetti congiunti dei predittori, mentre quasi il 41% è spiegato
unicamente dai predittori.
In una tesi di laurea o in un articolo scientifico riporteremo la tabella con i coefficienti in Figura
7.5.23 e scriveremo:
E’ stata eseguita sui dati provenienti di 100 soggetti un’analisi di regressione multipla standard per
la predizione dell’ansia nei confronti della statistica in base al genere, ai punteggi di un test per il
profitto in matematica, al numero di lezioni del corso di psicometria seguite e al punteggio nella
scala Spatial di OSIVQ. Le analisi preliminari hanno rivelato l’assenza di problemi di collinearità e
che un soggetto era probabilmente un outlier, per cui stato escluso dall’analisi. Tutti i predittori
tranne il genere sono risultati statisticamente significativi (vedi Tabella coi coefficienti). Il modello
spiega il 51% di variabilità dell’ansia nei confronti della statistica (R2 aggiustato = ,485) e in base
alla dimensione dell’effetto f2 sono risultati predittori più importanti il punteggio alla scala Spatial
(f2 = ,44) e il numero di lezioni seguite (f2 = ,41), mentre il profitto in matematica aveva una
dimensione dell’effetto meno forte (f2 = ,19).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Regressione gerarchica
Nel caso della regressione gerarchica, la domanda di ricerca di Tabella 7.5.1 indica che vogliamo
sapere quanto può contribuire in più alla spiegazione della variabilità del criterio il predittore
“numero di lezioni seguite” rispetto al genere e al profitto in matematica, e, in seguito, quanto può
contribuire a sua volta il punteggio nella scala Spatial. Questo significa che i predittori devono
essere inseriti nel modello in fasi successive. Per farlo, dopo aver seguito il percorso Analyze →
Regression → Linear, inseriamo nel campo Independent(s) solo Genere e Profitto in Matematica,
poi clickiamo su Next, e inseriamo nel campo Independent(s) il numero di lezioni seguite, clickiamo
di nuovo su Next e inseriamo nel campo Independent(s) il punteggio nella scala Spatial. A questo
punto il nome del riquadro dovrebbe essere Block 3 of 3. Come Method lasciamo sempre Enter in
ogni blocco.
Clickiamo su Statistics e spuntiamo R squared change: nella regressione gerarchica questa
opzione è fondamentale perché ci permette di verificare che la quota di variabilità spiegata del
criterio che aggiungono i predittori o i blocchi di predittori successivi al primo sia statisticamente
diversa da zero. Eseguiamo quindi l’analisi.
Nella prima tabella di output, Variables Entered/Removed, osserviamo che sono stati
verificati tre modelli (colonna Model), e per ogni modello vengono indicate le variabili inserite
(Figura 7.5.24).
Variables Entered/Removedb
Model
1
2
3
Variables
Entered
Profitto in
Matematica
a, Genere
Numero
lezioni a
seguite
Punteggio
a
SPATIAL
Variables
Removed
Method
.
Enter
.
Enter
.
Enter
a. All requested variables entered.
b. Dependent Variable: Punteggio Ansia
verso la Statistica
Figura 7.5.24 Tabella dei modelli verificati per una regressione multipla gerarchica
In gergo ogni modello successivo è detto “step”. Questo significa che allo Step 1 sono state inserite
nel modello Profitto in Matematica e Genere, allo Step 2 il numero di lezioni seguite e allo Step 3 il
punteggio di Spatial, esattamente come specificato.
Nella tabella successiva, Model Summary, vengono riportati i valori di R2 e Adjusted R2 per
ognuno dei tre step, con il test di significatività di R2 nel passaggio da un modello all’altro (parte
destra della tabella in Figura 7.5.25).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Model Summary
Change Statistics
Model
1
2
3
R
,418a
,584b
,712c
R Square
,175
,341
,506
Adjusted
R Square
,158
,321
,485
Std. Error of
the Estimate
11,097
9,966
8,675
R Square
Change
,175
,167
,165
F Change
10,176
24,027
31,387
df1
df2
2
1
1
96
95
94
Sig. F Change
,000
,000
,000
a. Predictors: (Constant), Profitto in Matematica, Genere
b. Predictors: (Constant), Profitto in Matematica, Genere, Numero lezioni seguite
c. Predictors: (Constant), Profitto in Matematica, Genere, Numero lezioni seguite, Punteggio SPATIAL
Figura 7.5.25 Tabella con gli indici di bontà di adattamento dei dati e i test di significatività per gli
incrementi di R2 ad ogni step per una regressione multipla gerarchica
Il test del cambiamento in R2 (R Square Change) per lo Step 1 riguarda il miglioramento della
predizione rispetto ad un modello privo di predittori, ed è statisticamente significativo al pari di tutti
gli altri cambiamenti. Questo significa che non solo genere e profitto in matematica premettono una
predizione migliore dell’ansia nei confronti della statistica rispetto a quella che potremmo ottenee
“tirando a indovinare”, ma anche che l’aggiunta del numero di lezioni seguite, prima, e del
punteggio alla scala Spatial, poi, consentono un ulteriore miglioramento della predizione.
La tavola di analisi della varianza (ANOVA) che segue mostra i test di significatività di R2
modello per modello (Figura 7.5.26).
ANOVAd
Model
1
2
3
Regression
Residual
Total
Regression
Residual
Total
Regression
Residual
Total
Sum of
Squares
2506,398
11822,107
14328,505
4892,813
9435,692
14328,505
7254,741
7073,765
14328,505
df
2
96
98
3
95
98
4
94
98
Mean Square
1253,199
123,147
F
10,176
Sig.
,000a
1630,938
99,323
16,421
,000b
1813,685
75,253
24,101
,000c
a. Predictors: (Constant), Profitto in Matematica, Genere
b. Predictors: (Constant), Profitto in Matematica, Genere, Numero lezioni seguite
c. Predictors: (Constant), Profitto in Matematica, Genere, Numero lezioni seguite,
Punteggio SPATIAL
d. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.26 Tavola di ANOVA per tutti i modelli verificati in un’analisi di regressione multipla
gerarchica
Come era prevedibile, in tutti i modelli R2 è statisticamente diverso da zero (Sig. < ,001).
Nella tavola successiva, Coefficients, troviamo i coefficienti di regressione e il loro test di
significatività ad ogni step dell’analisi (Figura 7.5.27).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Coefficientsa
Model
1
2
3
(Constant)
Genere
Profitto in Matematica
(Constant)
Genere
Profitto in Matematica
Numero lezioni seguite
(Constant)
Genere
Profitto in Matematica
Numero lezioni seguite
Punteggio SPATIAL
Unstandardized
Coefficients
B
Std. Error
36,015
3,723
2,863
2,279
,852
,212
23,831
4,166
,980
2,082
,747
,191
,998
,204
10,867
4,302
-,993
1,847
,518
,171
1,021
,177
,426
,076
Standardized
Coefficients
Beta
,119
,380
,041
,333
,420
-,041
,231
,429
,430
t
9,675
1,256
4,027
5,720
,471
3,905
4,902
2,526
-,538
3,021
5,758
5,602
Sig.
,000
,212
,000
,000
,639
,000
,000
,013
,592
,003
,000
,000
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.27 Tavola coi coefficienti di regressione e la loro significatività per ogni step di
un’analisi di regressione multipla gerarchica
La tabella in Figura 7.5.27 permette di osservare se e come sono variate le significatività dei
predittori inseriti nei primi step con le aggiunte successive degli altri. Tali analisi vengono condotte
come se ad ogni step i predittori presenti nel modello venissero tutti inclusi simultaneamente. Nel
caso che stiamo considerando, il genere risulta fin da subito un predittore non significativo, mentre
gli altri lo sono appena inseriti nel modello e lo rimangono fino alla fine. Non è però raro trovare
che alcuni predittori sono significativi nei primi step e poi cessano di esserlo con l’inclusione di altri
predittori (in questi casi va escluso mediante le diagnostiche che questo non avvenga a causa della
collinearità).
L’ultima tabella, Excluded Variables, presenta i coefficienti standardizzati beta che
otterrebbero le variabili che in quel momento non sono inserite nell’analisi se venissero incluse nel
modello di regressione multipla allo step successivo rispetto a quello nel quale è esclusa (Figura
7.5.28). Si noti anche che viene riportato il valore di Tolerance, che consente quindi di valutare,
passo per passo, eventuali problemi di collinearità
Excluded Variablesc
Model
1
2
Numero lezioni seguite
Punteggio SPATIAL
Punteggio SPATIAL
Beta In
,420a
,419a
,430b
t
4,902
4,730
5,602
Sig.
,000
,000
,000
Partial
Correlation
,449
,437
,500
Collinearity
Statistics
Tolerance
,945
,894
,894
a. Predictors in the Model: (Constant), Profitto in Matematica, Genere
b. Predictors in the Model: (Constant), Profitto in Matematica, Genere, Numero lezioni seguite
c. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.28 Tavola delle variabili escluse nei vari modelli di regressione multipla gerarchica
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Ad esempio, nello step 1 il numero di lezioni seguite era esclusa: se fosse stata inserita allo step
successivo avrebbe ottenuto un beta di ,420, che infatti è quello che troviamo nella tabella in Figura
7.5.27 allo Step 2.
In una tesi di laurea o in un articolo scientifico riporteremo la tabella in Figura 7.5.25 con i
cambiamenti in R2, quella con i coefficienti in Figura 7.5.27 e scriveremo:
E’ stata eseguita sui dati provenienti di 100 soggetti un’analisi di regressione multipla gerarchica
per la predizione dell’ansia nei confronti della statistica in base al genere, ai punteggi di un test per
il profitto in matematica, al numero di lezioni del corso di psicometria seguite e al punteggio nella
scala Spatial di OSIVQ. Le analisi preliminari hanno rivelato l’assenza di problemi di collinearità e
che un soggetto era probabilmente un outlier, per cui stato escluso dall’analisi. Genere e profitto in
matematica sono stati inseriti nel modello allo Step 1, il numero di lezioni seguite allo Step 2 e il
punteggio nella scala Spatial allo Step 3. Il modello finale spiega il 51% di variabilità dell’ansia nei
confronti della statistica (R2 aggiustato = ,485) e ad ogni step l’incremento in R2 è risultato
statisticamente significativo (vedi tabella con R2). Complessivamente, tutti i predittori tranne il
genere sono risultati statisticamente significativi (vedi Tabella coi coefficienti). In base alla
dimensione dell’effetto f2 sono risultati predittori più importanti il punteggio alla scala Spatial (f2 =
,44) e il numero di lezioni seguite (f2 = ,41), mentre il profitto in matematica aveva una dimensione
dell’effetto meno forte (f2 = ,19).
Regressione statistica
Se utilizziamo una strategia di regressione multipla di tipo statistico il nostro scopo è
fondamentalmente quello di trovare la combinazione di predittori che massimizzi l’accuratezza
della previsione dei valori del criterio.
Per realizzare una regressione multipla di tipo statistico Stepwise procediamo come nel caso
della regressione standard, ma scegliamo Stepwise dal menu a tendina di Method3. In questo tipo di
regressione è decisiva la scelta dei criteri statistici di inclusione ed esclusione dei predittori dal
modello. I valori di SPSS di default (,05 per l’inclusione e ,10 per l’esclusione) di solito assicurano
un buon compromesso fra errori di I e II tipo, ma a seconda delle necessità potrebbero essere reso
più restrittivo il criterio di entrata (ad esempio, ,01) se si hanno molti predittori e si vuole mantenere
nel modello solo i più importanti, o rilassato il criterio di esclusione (ad esempio, ,15), se si hanno
pochi predittori e lo scopo è mantenere più predittori possibile nel modello. Queste modifiche
possono essere operate dalla finestra Options. In pratica, la procedura di analisi comincia con un
modello senza predittori: ad ogni passo verrà inserito il predittore con la p (o Sig.) più bassa fra
quelle che hanno una p inferiore al criterio di entrata, ed escluso il predittore con p più alta fra
quelle che hanno una p superiore al criterio di esclusione. Questo significa che una variabile inserita
allo Step 2 può essere esclusa in uno di quelli successivi se soddisfa il criterio statistico di
esclusione − cosa che non capita nella regressione gerarchica, in cui le variabili vengono incluse in
base a criteri teorici e rimangono nel modello fino alla fine. L’analisi termina quando non ci sono
più predittori da inserire, le variabili escluse hanno una probabilità associata maggiore del criterio di
entrata e quelle incluse hanno una probabilità associata minore del criterio di esclusione.
3
Naturalmente si può scegliere anche un altro metodo di selezione fra quelli disponibili (Remove, Backward e
Forward), ma se lo scopo dell’analisi è quello indicato, la procedura Stepwise è quella che garantisce il miglior
compromesso fra quelle disponibili. Il lettore è comunque invitato, come esercizio, a valutare i risultati dell’analisi
utilizzando queste altre opzioni.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Anche nel caso di una regressione statistica è importante poter esaminare la significatività
dei cambiamenti in R2, dato che l’analisi procede per steps come quella gerarchica, per cui è utile
scegliere questa opzione nella finestra Statistics.
La prima tabella di output è nuovamente Variables Entered/Removed (Figura 7.5.29).
Variables Entered/Removeda
Model
1
2
Variables
Entered
Variables
Removed
Punteggio
SPATIAL
Numero
lezioni
seguite
Profitto in
Matematic
a
3
.
.
.
Method
Stepwise (Criteria:
Probability-of-F-to-enter <= ,050,
Probability-of-F-to-remove >= ,100).
Stepwise (Criteria:
Probability-of-F-to-enter <= ,050,
Probability-of-F-to-remove >= ,100).
Stepwise (Criteria:
Probability-of-F-to-enter <= ,050,
Probability-of-F-to-remove >= ,100).
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.29 Tabella dei modelli verificati per una regressione multipla statistica
La tabella in Figura 7.5.29 mostra che allo Step 1 è stato inserito il punteggio di Spatial e non è stata
rimossa alcuna variabile (la colonna Variables Removed è vuota), che al secondo Step è stato
inserito il numero di lezioni seguite e al terzo step è stato inserito il punteggio di profitto in
matematica. Il fatto che la colonna Variables Removed sia completamente vuota indica che le
varabili inserite non sono mai state rimosse, quindi hanno dapprima soddisfatto il criterio di entrata,
e poi non hanno mai soddisfatto quello di uscita. Il fatto che non compaia il Genere non significa
che non è mai stato preso in considerazione, ma che non ha mai raggiunto il criterio di entrata. Per
ogni step sono riportati i criteri statistici di inclusione/esclusione.
Nella tabella che segue, Model Summary, vengono riportati gli indici di fit e i cambiamenti
2
in R (Figura 7.5.30)
Model Summary
Change Statistics
Model
1
2
3
R
,504a
,677b
,710c
R Square
,254
,458
,505
Adjusted
R Square
,247
,447
,489
Std. Error of
the Estimate
10,494
8,993
8,642
R Square
Change
,254
,204
,047
F Change
33,112
36,079
8,952
df1
df2
1
1
1
97
96
95
Sig. F Change
,000
,000
,004
a. Predictors: (Constant), Punteggio SPATIAL
b. Predictors: (Constant), Punteggio SPATIAL, Numero lezioni seguite
c. Predictors: (Constant), Punteggio SPATIAL, Numero lezioni seguite, Profitto in Matematica
Figura 7.5.30 Tabella con gli indici di bontà di adattamento dei dati e i test di significatività per gli
incrementi di R2 ad ogni step per una regressione multipla statistica
In questo caso la tabella in Figura 7.5.30 non è molto utile sul piano teorico, in quanto l’ordine di
inserimento dei predittori del modello non è stato basato su un’ipotesi di ricerca, ma su criteri
statistici “ciechi” alla teoria. Ad ogni modo si può apprezzare come ad ogni step il valore di R2
aumenti significativamente.
La tabella di ANOVA che segue riporta la significatività dell’R2 ad ogni passo dell’analisi
(Figura 7.5.31).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
ANOVAd
Model
1
2
3
Regression
Residual
Total
Regression
Residual
Total
Regression
Residual
Total
Sum of
Squares
3646,427
10682,078
14328,505
6564,377
7764,128
14328,505
7232,979
7095,526
14328,505
df
1
97
98
2
96
98
3
95
98
Mean Square
3646,427
110,125
F
33,112
Sig.
,000a
3282,189
80,876
40,583
,000b
2410,993
74,690
32,280
,000c
a. Predictors: (Constant), Punteggio SPATIAL
b. Predictors: (Constant), Punteggio SPATIAL, Numero lezioni seguite
c. Predictors: (Constant), Punteggio SPATIAL, Numero lezioni seguite, Profitto in
Matematica
d. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.31 Tavola di ANOVA per tutti i modelli verificati in un’analisi di regressione multipla
statistica
Nella tavola dei coefficienti (Coefficients, Figura 7.5.32) possiamo valutare la significatività dei
predittori passo per passo. Si noti che, in base ai criteri di inclusione/esclusione dei predittori, ad
ogni passo sono inseriti solo quei predittori che a quel passo hanno una p < ,05 e successivamente la
loro p non supera mai ,10.
Coefficientsa
Model
1
2
3
(Constant)
Punteggio SPATIAL
(Constant)
Punteggio SPATIAL
Numero lezioni seguite
(Constant)
Punteggio SPATIAL
Numero lezioni seguite
Profitto in Matematica
Unstandardized
Coefficients
B
Std. Error
31,310
3,735
,500
,087
16,133
4,078
,477
,075
1,075
,179
11,077
4,268
,418
,074
1,003
,174
,508
,170
Standardized
Coefficients
Beta
,504
,481
,452
,422
,422
,226
t
8,382
5,754
3,956
6,395
6,007
2,596
5,624
5,780
2,992
Sig.
,000
,000
,000
,000
,000
,011
,000
,000
,004
a. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.33 Tavola coi coefficienti di regressione e la loro significatività per ogni step di
un’analisi di regressione multipla gerarchica
Anche in questo caso i predittori statisticamente significativi sono punteggio alla scala Spatial,
numero lezioni seguite e profitto in matematica. Ad ogni modo, però, l’ordine di inserimento dei
predittori rivela che inizialmente il predittore con la p più bassa era il punteggio Spatial, che infatti è
stato inserito per primo, e che nel secondo Step il numero di lezioni seguite aveva una p inferiore a
quella del profitto in matematica, che comunque è stato inserito nello Step 3 in quanto la sua p era
comunque inferiore a ,05. Parte di queste informazioni sono deducibili anche dall’ultima tabella,
Excluded Variables (Figura 7.5.34).
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
Excluded Variablesd
Model
1
2
3
Genere
Profitto in Matematica
Numero lezioni seguite
Genere
Profitto in Matematica
Genere
Beta In
,077a
,287a
,452a
-,017b
,226b
-,041c
t
,853
3,305
6,007
-,209
2,992
-,538
Sig.
,396
,001
,000
,835
,004
,592
Partial
Correlation
,087
,320
,523
-,021
,293
-,055
Collinearity
Statistics
Tolerance
,947
,927
,997
,909
,910
,899
a. Predictors in the Model: (Constant), Punteggio SPATIAL
b. Predictors in the Model: (Constant), Punteggio SPATIAL, Numero lezioni seguite
c. Predictors in the Model: (Constant), Punteggio SPATIAL, Numero lezioni seguite, Profitto in
Matematica
d. Dependent Variable: Punteggio Ansia verso la Statistica
Figura 7.5.34 Tavola delle variabili escluse nei vari modelli di regressione multipla statistica
Anche nel caso della Figura 7.5.34 viene fornito il valore di Tolerance per il controllo di eventuali
collinearità.
In una tesi di laurea o in un articolo scientifico riporteremo la tabella in Figura 7.5.30 con i
cambiamenti in R2, quella con i coefficienti in Figura 7.5.33 e scriveremo:
E’ stata eseguita sui dati provenienti di 100 soggetti un’analisi di regressione multipla stepwise per
la predizione dell’ansia nei confronti della statistica in base al genere, ai punteggi di un test per il
profitto in matematica, al numero di lezioni del corso di psicometria seguite e al punteggio nella
scala Spatial di OSIVQ. Le analisi preliminari hanno rivelato l’assenza di problemi di collinearità e
che un soggetto era probabilmente un outlier, per cui stato escluso dall’analisi. Per essere
completata l’analisi ha richiesto tre step: nel primo è stata inserito nel modello il punteggio alla scal
Spatial, nel secondo il numero di lezioni seguite, nel terzo il profitto in matematica. Nessuna delle
variabili inserite è stata esclusa negli step successivi a quello di entrate e il genere non ha mai
raggiunto il criterio per l’inclusione. Il modello finale spiega il 51% di variabilità dell’ansia nei
confronti della statistica (R2 aggiustato = ,485) e ad ogni step l’incremento in R2 è risultato
statisticamente significativo (vedi tabella con R2). In base alla dimensione dell’effetto f2 sono
risultati predittori più importanti il punteggio alla scala Spatial (f2 = ,44) e il numero di lezioni
seguite (f2 = ,41), mentre il profitto in matematica aveva una dimensione dell’effetto meno forte (f2
= ,19).
Considerazioni conclusive
I lettori più attenti potranno aver avuto delle perplessità, considerando i segni dei coefficienti di
regressione, sui risultati ottenuti. Se sembra plausibile, infatti, che i predittori proposti siano
effettivamente in relazione con il criterio, appare molto meno logico che siano predittori positivi,
ossia che a livelli maggiori di profitto in matematica, di numero di lezioni seguite e di punteggio di
stile cognitivo analitico corrispondano livelli maggiori, e non minori (nel qual caso i coefficienti
avrebbero avuto segno negativo), di ansia nei confronti della statistica. Il fatto è che seguendo passo
per passo le indicazioni di questo e delle altre schede di questo volume il lettore riuscirà con ogni
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia
probabilità ad eseguire le analisi statistiche proposte, ma nessuna procedura “meccanica” si potrà
mai sostituire alla conoscenza del fenomeno, che può essere ottenuta solo con lo studio
approfondito e critico della letteratura scientifica relativa. I risultati in apparenza contradditori delle
analisi di questa scheda possono essere spiegati in vari modi: ad esempio, il punteggio di ansia
potrebbe essere stato calcolato al contrario, per cui a punteggi alti nella scala corrispondono
punteggi bassi di ansia (pensate che questo errore non sia possibile, vero? E invece…), oppure certe
relazioni causali possono essere anche al contrario: nei modelli proposti abbiamo supposto che chi
segue molte lezioni (predittore,o variabile indipendente) abbia livelli di ansia minori (criterio, o
variabile dipendente), ma potrebbe essere il contrario, ossia che le due variabili si scambino i ruoli
di predittore e criterio e quindi il fatto di essere molto in ansia porti a seguire il maggior numero di
lezioni possibile. Per verificarlo, dovremmo specificare altri modelli di regressione multipla, o
procedere con analisi più sofisticate. Oppure le nostre ipotesi di partenza non sono state confermate
dai risultati ottenuti. In questo caso il problema non è il non aver avuto ragione: il vero ricercatore
non usa la ricerca per soddisfare il proprio narcisismo, sbandierando i risultati “positivi” e tacendo
accuratamente quelli “negativi”, ma per placare la propria curiosità e contribuire al progresso della
conoscenza: di fronte ad un risultato non compreso fra quelli attesi, il suo primo problema non sarà
come torturare ulteriomente i dati pur di aver ragione (posto che abbia eseguito le analisi corrette,
ovviamente), ma trovare una spiegazione a quanto ottenuto che possa fungere da base per ulteriori
indagini.
Carlo Chiorri, Fondamenti di psicometria – Copyright © 2010 The McGraw-Hill Companies S.r.l., Publishing Group Italia