POLITECNICO DI BARI
Corso di Laurea Magistrale in
Ingegneria Elettronica
BIOINFORMATICA
DNA COMPUTING
Docente
Prof. Giuseppe Mastronardi
Sommario
Introduzione
Cenni di biologia
Modello di Adleman
Modello di Lipton
Implementazione
Conclusione
Introduzione
- Agli inizi del Novecento è iniziata la prima vera indagine sulla natura del mondo
microscopico che si è rivelato molto più elusivo di quanto si potesse immaginare e
profondamente diverso dal mondo macroscopico di cui ci si è fatto un preciso modello.
- Uno dei più grandi fisici di quegli anni, Richard Feynman, in uno straordinario
discorso tenuto nel 1959, aveva già delineato le incredibili prospettive del progressivo
processo di miniaturizzazione in atto nella tecnologia ed aveva ipotizzato che fosse
possibile arrivare a costruire dispositivi di varia natura utilizzando individualmente
persino gli stessi atomi.
- La miniaturizzazione dei componenti ha però un limite fisico, non si può andare sotto
le dimensioni atomiche. Una volta raggiunto tale limite, per ottenere un ulteriore
aumento delle prestazioni del calcolatore elettronico, si rende necessario cambiare
radicalmente tecnica. Molto lavoro di ricerca si sta sviluppando in tale direzione e si
stanno profilando almeno due ipotesi molto promettenti: i quantum-computer ed i
DNA-computer.
Cenni di biologia (1/6)
DNA = DeoxyriboNucleic Acid
- Il DNA è una macromolecola formata da due
lunghi filamenti uniti tra loro come lo sono i
montanti di una scala collegata dai pioli. Gli
elementi di costruzione del DNA sono
monomeri, detti nucleotidi, ognuno dei quali
contiene tre parti: uno zucchero a cinque atomi
di carbonio (il deossiribosio), un gruppo fosfato
e una base azotata (cioè contenente azoto).
- I nucleotidi del DNA contengono lo stesso tipo di zucchero e di gruppo fosfato,
ma differiscono per la base azotata. Ci sono quattro diversi tipi di basi: adenina
(A), citosina (C), guanina (G) e timina (T); si osserva che nei filamenti di RNA la
timina è sostituita dall’uracile (U).
Cenni di biologia (2/6)
CODONI = triplette di nucleotidi
- Le 4 basi azotate del DNA (A, T, C, G) costituiscono l’alfabeto genetico, mentre
ogni unità del codice genetico è una sequenza di 3 basi azotate che prende il nome
di codone. Ad esempio, il filamento di RNA UUUACACAG si compone di 3 codoni,
UUU, ACA e CAG, a cui corrispondono rispettivamente gli amminoacidi
fenilalanina, treonina e glutammina. Una catena di DNA costituita da diverse
centinaia di codoni può formare, usando solo i 4 nucleotidi, il codice per una
proteina complessa.
- Prendendo le 4 basi azotate a gruppi di 3 si possono ottenere 64 combinazioni
differenti (infatti 43=64); in natura, però, esistono solo 20 amminoacidi nelle
proteine ed è pertanto evidente che alcuni amminoacidi vengono indicati da più di
un codone. La ridondanza rende il codice genetico meno vulnerabile alle
mutazioni casuali.
Cenni di biologia (3/6)
codifica dei codoni
CODONI = triplette di nucleotidi
seconda base
U
U
C
prima
base
A
G
C
A
G
UUU fenilalanina
UUC fenilalanina
UUA leucina
UUG leucina, start
CUU leucina
CUC leucina
CUA leucina
CUG leucina, start
AAU isoleucina, start
AUC isoleucina
AUA isoleucina
AUG metionina, start
UCU serina
UCC serina
UCA serina
UCG serina
CCU prolina
CCC prolina
CCA prolina
CCG prolina
ACU treonina
ACC treonina
ACA treonina
ACG treonina
UAU tirosina
UAC tirosina
UAA ocra, stop
UAG ambra, stop
CAU istidina
CAC istidina
CAA glutammina
CAG glutammina
AAU asparagina
AAC asparagina
AAA lisina
AAG lisina
UGU cisteina
UGC cisteina
UGA opale, stop
UGG triptofano
CGU arginina
CGC arginina
CGA arginina
CGG arginina
AGU serina
AGC serina
AGA arginina
AGG arginina
GUU valina
GUC valina
GUA valina
GUG valina, start
GCU alanina
GCC alanina
GCA alanina
GCG alanina
GAU acido aspartico
GAC acido aspartico
GAA acido glutammico
GAG acido glutammico
GGU glicina
GGC glicina
GGA glicina
GGG glicina
Cenni di biologia (4/6)
CODONI = triplette di nucleotidi
Sigla
Ala
Arg
Asn
Asp
Cys
Gln
Glu
Gly
His
Ile
Leu
Lys
Met
Phe
Pro
Ser
Thr
Trp
Tyr
Val
start
stop
Nome
alanina
arginina
asparagina
acido aspartico
cisteina
glutammina
acido glutammico
glicina
istidina
isoleucina
leucina
lisina
metionina
fenilalanina
prolina
serina
treonina
triptofano
tirosina
valina
amminoacidi di start
amminoacidi di stop
codifica inversa
Codoni
GCU, GCC, GCA, GCG
CGU, CGC, CGA, CGG, AGA, AGG
AAU, AAC
GAU, GAC
UGU, UGC
CAA, CAG
GAA, GAG
GGU, GGC, GGA, GGG
CAU, CAC
AUU, AUC, AUA
UUA, UUG, CUU, CUC, CUA, CUG
AAA, AAG
AUG
UUU, UUC
CCU, CCC, CCA, CCG
UCU, UCC, UCA, UCG, AGU, AGC
ACU, ACC, ACA, ACG
UGG
UAU, UAC
GUU, GUC, GUA, GUG
AUG, GUG
UAG, UGA, UAA
Cenni di biologia (5/6)
Alcune tecniche di biologia molecolare
- Separazione (melting): divisione di una molecola o di un frammento di DNA nei due
filamenti complementari che lo costituiscono; tale operazione si effettua creando delle
adeguate condizioni di temperatura, acidità, ecc. per rompere il debole legame idrogeno
fra le basi azotate.
- Accoppiamento (annealing): unione di due filamenti di DNA complementari ottenuta
raffreddando la soluzione ed aggiungendo l’enzima ligasi per favorire il processo e
rendere più stabili gli accoppiamenti.
- Separazione o estrazione per affinità: è una tecnica che permette di estrarre dei
filamenti di DNA che hanno dei sottofilamenti con particolari configurazioni (pattern),
basandosi sul principio di complementarietà delle basi.
- Sintesi artificiale del DNA: permette di sintetizzare in laboratorio molecole di DNA con
una sequenza desiderata fino a 100 nucleotidi, in breve tempo e a costi contenuti; inoltre
con questa tecnica è possibile sintetizzare sequenze casuali di nucleotidi ancora più
lunghe.
Cenni di biologia (6/6)
Alcune tecniche di biologia molecolare
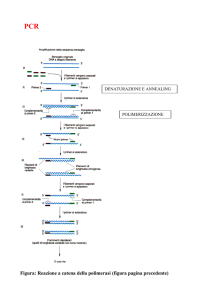
- Amplificazione: produzione di copie di un filamento di DNA mediante la reazione a
catena della polimerasi. È necessario l’utilizzo dell’enzima DNA-polimerasi per replicare
un filamento di DNA: l’enzima legge il filamento e sceglie da una miscela di basi azotate
presenti in soluzione quale inserire seguendo la regola della complementarietà. La
reazione consiste nella duplicazione a catena di un filamento iniziale di DNA, per cui
dopo n cicli si saranno prodotte 2n copie del filamento di partenza.
- Elettroforesi su gel: è una tecnica che permette di separare i filamenti di DNA sulla
base della loro lunghezza. Consiste nel mettere la soluzione contente il DNA in un
pozzetto all’estremità di un sottile strato di gel a cui viene applicata una corrente
elettrica; quindi le molecole di DNA verranno attirate verso l’anodo perché possiedono
una carica negativa. La caratteristica fondamentale di questa tecnica è che le velocità di
migrazione all’anodo per le molecole più corte è maggiore rispetto a quella delle
molecole più lunghe; questo determina la formazione di un “tracciato”. Il sistema così
ottenuto si può osservare utilizzando particolari reagenti ed illuminando il gel con luce
ultravioletta; inoltre è possibile calcolare esattamente il peso molecolare di ciascun
frammento separato con una semplice tecnica.
Modello di Adleman (1/4)
- Nel suo famoso articolo del 1994 Adleman mostrò la possibilità di eseguire delle
computazioni a livello molecolare; egli presentò una “soluzione biologica” per una
istanza del problema del percorso hamiltoniano.
- Un cammino hamiltoniano su un grafo orientato è un percorso che inizia da un
vertice ed arriva ad un altro dopo essere passato per tutti i vertici esattamente una
volta; tale cammino, se esiste, sarà formato da n-1 lati se il grafo ha n vertici
- Il problema del percorso hamiltoniano per un grafo orientato (PPHO) affrontato
da Adleman chiede di stabilire se in un dato grafo orientato, in cui siano stati scelti
due vertici, esiste almeno un cammino hamiltoniano che li unisce.
- L’algoritmo è il seguente:
passo 1) si generano tutti i cammini attraverso il grafo;
passo 2) si considerano solo i percorsi che iniziano dal nodo di partenza e terminano
nel nodo di arrivo;
passo 3) si considerano solo i percorsi che attraversano esattamente n vertici;
passo 4) si considerano solo i percorsi che passano per un vertice una sola volta;
passo 5) si verifica se almeno un percorso è rimasto dopo le selezioni dei passi
precedenti; in caso positivo quello è il cammino che si stava cercando.
Modello di Adleman (2/4)
- Adleman utilizzava dei frammenti di DNA come oggetti di calcolo e particolari
enzimi e tecniche di biologia molecolare come operatori. L’implementazione di
questo algoritmo si basava sull’intuizione di Adleman di codificare in maniera
opportuna l’istanza del problema da risolvere.
- Adleman codificò il grafo con le seguenti regole:
• ad ogni vertice i del grafo G si associa un filamento di una sequenza casuale
di DNA della lunghezza di 20 nucleotidi;
• ogni arco i → j in G viene codificato con un filamento di DNA di 20 nucleotidi
ottenuto concatenando gli ultimi 10 nucleotidi del vertice i ed i primi 10
nucleotidi del vertice j.
- In questo modo i filamenti potevano accoppiarsi per formare una macromolecola
che codificasse un percorso attraverso il grafo: uno dei filamenti è la concatenazione
delle sequenze di codifica di archi
consecutivi, l’altro filamento è la
concatenazione delle sequenze
complementari associate ai vertici
del percorso considerato.
Modello di Adleman (3/4)
-L’“algoritmo biologico” proposto da Adleman è il seguente:
passo 1) per ogni vertice e per ogni lato si codificano un numero sufficientemente
grande di filamenti di DNA che si mettono in una provetta con acqua, con l’enzima
ligasi, sali ed altre sostanze che favoriscono l’accoppiamento. In questo modo si
codificano pressoché istantaneamente (quasi) tutti i possibili cammini tra i vertici.
passo 2) si procede con la reazione a catena della polimerasi per amplificare solo
quei filamenti di DNA che possiedono il corretto vertice di partenza e di arrivo;
passo 3) con l’elettroforesi su gel si separano tutte le molecole di DNA che hanno la
lunghezza giusta (120 nucleotidi nell’esperimento di Adleman in cui il cammino
hamiltoniano era lungo 6 lati da 20 nucleotidi ciascuno).
passo 4) si selezionano i percorsi che passano per tutti i vertici con la tecnica di
separazione per affinità. Questa tecnica permette di estrarre tutte le sequenze che
contengono la codifica di un dato vertice, sfruttando il principio di complementarietà
delle basi; ripetendo questa estrazione per ogni vertice si riescono ad estrarre tutti i
percorsi che passano per ogni vertice.
passo 5) si verifica se almeno un filamento di DNA è rimasto dopo le selezioni dei
passi precedenti procedendo prima ad amplificazione con polimerasi e poi con
elettroforesi su gel che permette di individuare l’eventuale filamento; se esiste, quel
filamento codifica il cammino hamiltoniano che si stava cercando.
Modello di Adleman (4/4)
- Questo esperimento non dimostrò soltanto la possibilità di ottenere una “soluzione
biologica” al problema di ricerca del cammino hamiltoniano, ma anche e
soprattutto la possibilità più generale di calcolare con il DNA.
- Il numero di operazioni richieste in laboratorio cresce linearmente con il numero
n di vertici del grafo, benché è noto che questo problema è NP-completo. Il numero
di molecole diverse richieste per la computazione è lineare nel numero m degli archi
del grafo; infatti il passo 1 richiede la sintesi artificiale di n+m sequenze di DNA, il
passo 4 richiede la ripetizione della procedura per n volte e gli altri passi si svolgono
in un tempo costante.
- Questo significa che un computer a DNA offre una enorme capacità di calcolo
parallelo che può renderlo molto più rapido di un supercomputer elettronico per la
risoluzione di alcuni problemi, soprattutto all’aumento del numero di variabili
coinvolte. Nell’esempio del PPHO il parallelismo si manifesta nella velocità con cui
all’inizio si codificano (quasi) tutti i possibili cammini attraverso il grafo.
- Inoltre la capacità di memorizzazione del DNA è enormemente superiore rispetto
a un computer tradizionale poiché un grammo di DNA, equivalente all’incirca ad
un centimetro cubo, può immagazzinare l’informazione contenuta in circa mille
miliardi di CD.
Modello di Lipton (1/3)
- Uno scienziato di Princeton, Richard Lipton, ha inventato uno schema per tradurre
le coppie di basi del DNA in sequenze di 0 e di 1. Egli è anche stato in grado di
sviluppare una tecnica che consente alle molecole di DNA nella provetta di reazione di
simulare il comportamento delle porte logiche di un computer elettronico.
- Lipton ha così mostrato come un computer molecolare può utilizzare anch’esso la
logica booleana degli operatori NOT, OR, AND ed essere quindi sostanzialmente
programmabile come qualsiasi altro computer general-purpose.
- Lipton ha affrontato in particolare il problema della soddisfacibilità di una formula
booleana (SAT-problem) che ha da subito suscitato notevole interesse nella comunità
scientifica.
- Nel 1995 Richard Lipton propose uno schema teorico di algoritmo per la risoluzione
con il DNA del problema della soddisfacibilità per una formula booleana. Egli considerò una formula booleana nella forma normale disgiuntiva, cioè tipo FB
,
1
B
2.
.. B
m
in cui ogni Bi è una particolare formula booleana detta clausola; una clausola si presenta nella forma BX
, in cui ogni Xi è una delle n variabili o una delle n
1
X
2.
.. X
k
possibili negazioni.
Modello di Lipton (2/3)
- L’algoritmo utilizzato da Lipton per trovare la soluzione al SAT-problem è il
seguente: si generano tutte le possibili combinazioni di valori per le n variabili della
formula booleana; poi si eliminano tutte le assegnazioni che non soddisfano la prima
clausola B1 e si ripete progressivamente la stessa operazione per tutte le assegnazioni
che non soddisfano la clausola Bi, con i = 2, …, m; infine si verifica se sono rimaste
delle assegnazioni di valori per le variabili e, in caso positivo, quelle assegnazioni
soddisfano la formula booleana.
- L’implementazione proposta da Lipton si basava sulla codifica di un grafo
orientato con la stessa tecnica adottata da Adleman, in cui ogni nodo xi rappresenta
una variabile della formula booleana ed ogni xi’ la sua negazione. I cammini che
vanno dal nodo a1 al nodo an+1 si possono considerare come la codifica di un numero
binario ad n cifre, in cui si può stabilire per convenzione che se dal vertice ai il cammino va verso un vertice xi allora quel tratto codifica uno 0,
altrimenti se va verso un vertice
xi’ codifica un 1.
Modello di Lipton (3/3)
- All’inizio dell’esperimento si mettono in soluzione nella provetta t0 un numero sufficientemente grande di copie di filamenti di DNA della lunghezza di 20 nucleotidi che
codificano i vertici e gli archi di questo grafo così costruito. A questo si aggiungono
copie di sequenze q1’ e pn’, dove indichiamo con q1’ il filamento complementare degli
ultimi 10 nucleotidi che codificano a1 e con pn’ il filamento complementare dei primi
10 nucleotidi che codificano an+1.
Con il procedimento di accoppiamento si formeranno tutti i possibili percorsi attraverso il grafo ed inoltre la presenza dei frammenti q1’ e pn’, assicureranno la formazione prevalente di cammini dal nodo a1 al nodo an+1; inoltre la simmetria del grafo
implicherà che questi cammini si formeranno nella medesima quantità.
Partendo dalla provetta t0 si eliminano i frammenti di DNA che corrispondono alle
assegnazioni che non soddisfano la prima clausola B1 della formula booleana. L’operazione che si effettua è l’estrazione per affinità che può essere vista come una funzione E(t,i,a) che denota l’insieme di tutte le sequenze contenute nella provetta t che
hanno la componente i-esima uguale ad a, con a {0,1}.
Quindi per passi successivi si costruiscono le provette t1, t2, …, tm, in cui la provetta ti
contiene tutte le sequenze di ti-1 che soddisfano la clausola Bi. In questo modo nella
provetta tm resteranno, se esistono, solo i frammenti di DNA che soddisfano tutte le
clausole, ovvero l’intera formula booleana F. Pertanto a questo punto basta solo
verificare la presenza di DNA nella provetta per dare una risposta al problema di
soddisfacibilità della formula booleana considerata.
Implementazione – Progetto 1
Implementazione – Progetto 2


![mutazioni genetiche [al DNA] effetti evolutivi [fetali] effetti tardivi](http://s1.studylibit.com/store/data/004205334_1-d8ada56ee9f5184276979f04a9a248a9-300x300.png)



![(Microsoft PowerPoint - PCR.ppt [modalit\340 compatibilit\340])](http://s1.studylibit.com/store/data/001402582_1-53c8daabdc15032b8943ee23f0a14a13-300x300.png)