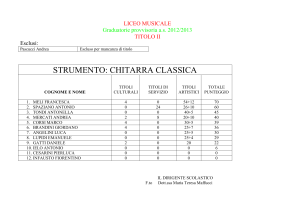
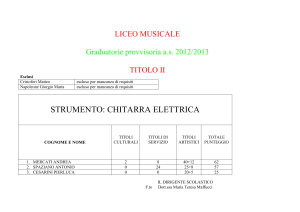
SISTEMI DISTRIBUITI
• Criteri di classificazione dei sistemi distribuiti
– Autonomia, distribuzione, eterogeneità
• Architetture per DBMS distribuiti
– Client/server
– Peer-to-peer
– Multi-database
• Regole di Date per sistema relazionale distribuito.
• Trasparenza.
• Sistemi paralleli.
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
1
Criteri classificazione DBMS distribuiti
•
•
•
•
I sistemi possono essere caratterizzati secondo tre dimensioni
Autonomia dei sistemi locali; indica il grado a cui i DBMS
individuali possono operare in modo indipendente
– Integrazione stretta
– Sistemi pienamente indipendenti, multi-database
– Gradi intermedi
Distribuzione dei sistemi; fa riferimento alla distribuzione fisica
dei dati (dall’utente sono comunque visti come un unico insieme
logico)
– Client / server
– Peer-to-peer
Eterogeneità dei sistemi (modello dei dati, linguaggi, protocolli di
gestione delle transazioni)
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
2
1
Criteri di classificazione: autonomia (1)
•
Elenco1 di requisiti che caratterizzano l’autonomia
– Le operazioni locali dei DBMS individuali non sono influenzate dalla
loro partecipazione ad un sistema multi-database
– Il modo in cui i DBMS individuali eseguono e ottimizzano le query
non dovrebbe essere influenzato dalla esecuzione di query globali che
accedono a database multipli
– L’operatività del sistema non dovrebbe essere compromessa da
DBMS individuali che si aggiungono o lasciano la confederazione
multi-database
•
Elenco2 di requisiti che caratterizzano l’autonomia
– Autonomia di progetto: i DBMS individuali sono liberi di usare i
modelli di dati e le tecniche di gestione delle transazioni che
preferiscono
– Autonomia di comunicazione: i DBMS individuali sono liberi di
decidere quale tipo di informazione comunicare all’esterno
– Autonomia di esecuzione: ogni DBMS può eseguire le transazioni che
gli vengono sottomesse nel modo che vuole
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
3
Criteri di classificazione: autonomia (2)
•
Integrazione stretta
– Anche se le informazioni sono allocate in più nodi, un utente vede una
immagine unica dell’intero database
– Dal punto di vista dell’utente, i dati sono logicamente centralizzati in
un unico database (sistema logicamente integrato)
•
Sistemi semiautonomi (detti anche federati omogenei o eterogenei)
– I DBMS possono operare in modo indipendente, ma hanno deciso di
partecipare ad una federazione per rendere spartibili i loro dati
– Ogni DBMS determina quali parti del proprio database sono
accessibili agli altri DBMS
– Non sono sistemi pienamente autonomi perché hanno bisogno di
essere modificati per poter scambiarsi informazioni
•
Isolamento totale
– I sistemi individuali sono DBMS stand-alone che non conoscono
l’esistenza di altri DBMS
– Al di sopra di essi c’è uno strato di software che permette di integrarli
in qualche modo, si parla di multi-database
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
4
2
Criteri di classificazione: distribuzione
• Client/server
– Gestione dei dati sul server e l’ambiente dell’applicazione
(compresa l’interfaccia utente) sul client
– L’onere della comunicazione è spartito tra client e server
– Alcuni siti sono client, altri server, e la loro funzionalità è
diversa
• Peer-to-peer
– Non c’è distinzione tra client e server
– Ciascun sito ha un DBMS pienamente funzionale e può
comunicare con altri siti per eseguire query e transazioni
– Questi sistemi sono anche detti “fully distributed”
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
5
Criteri di classificazione: eterogeneità
•
•
L’eterogeneità fa riferimento ai modelli di dati, ai query language,
ai protocolli di gestione delle transazioni
– Ogni modello di dati ha un certo potere espressivo e certe
limitazioni
– Il query language può essere diverso in relazione a modelli
diversi e anche in relazione allo stesso modello (es. SQL e
QUEL per il modello relazionale)
L’eterogeneità è ortogonale all’autonomia
– Possiamo avere sistemi logicamente integrati formati da
componenti eterogenee e sistemi multi-database con
componenti omogenee
– Es. basi dati logicamente integrate con componenti omogenee:
sistema distribuito impiantato da zero
– Es. sistemi multi-database con componenti eterogenee:
integrazione di sistemi preesistenti che rimangono anche
autonomi
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
6
3
BDD logicamente integrate
• Descrizione dei dati
– Uno schema logico locale per ogni DBMS
– Uno schema logico globale
– Gli schemi esterni si appoggiano sullo schema logico globale
• Moduli funzionali (generalmente schema client server)
– Il server è composto da più client e più server
– Nella generazione dei piani di accesso ai dati, abbiamo una
ottimizzazione globale in cui il client decide i compiti da
affidare ai diversi server, e il server locale genera il piano di
accesso locale
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
7
Basi dati logicamente integrate
schema dei dati
Schema esterno
Schema esterno
Schema logico globale
Schema logico locale
Schema logico locale
Schema interno locale
Schema interno locale
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
8
4
Multi-Database Systems – descrizione dei
dati
• Unico schema logico globale
– Ogni database locale espone all’esterno parte dei suoi dati
– Lo schema globale unico fa riferimento a queste parti ,
rappresenta un sottoinsieme dell’unione dei vari database
• Assenza di un unico schema logico globale
– Ogni nodo ha degli schemi esterni locali a cui può essere fatto
accesso
– Si hanno più schemi esterni globali, ciascuno dei quali può far
riferimento ad un unico o a più schemi esterni locali
– L’eterogeneità dei sistemi appesantisce il mapping fra gli
schemi esterni locali e quelli globali
– I cosiddetti DBMS federati fa nno parte di questa categoria
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
9
Multi-Database Systems : schema dei dati
Schema est. globale
Schema est. globale
Schema est. globale
Schema est. globale
Schema est. locale
Schema log. globale
Schema est. locale
Schema est. locale
Schema log. locale
Schema log. locale
Schema log. locale
Schema log. locale
Schema int. locale
Schema int. locale
Schema int. locale
Schema int. locale
Con schema globale
F.Cesarini - Basi Dati
Distribuite
Senza schema globale
sistemi distribuiti
10
5
Multi-database Systems – moduli
funzionali
• I sistemi locali hanno una completa autonomia
• Al di sopra dei sistemi locali esiste un livello di software
di integrazione
– Decomposizione delle query in sotto-query da eseguire sui
sistemi locali
– Integrazione dei risultati parziali per ottenere il risultato
globale
– Mapping fra il linguaggio del sistema multi-database e i
linguaggi dei sistemi locali
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
11
Multi-database - integrazione
applicazione
applicazione
applicazione
software di integrazione
DBMS
F.Cesarini - Basi Dati
Distribuite
DBMS
sistemi distribuiti
12
6
Sistemi Client/Server (1)
ambiente centralizzato
•
•
Architettura a due livelli
Architettura molto usata per basi dati centralizzate
•
•
Il server effettua la maggior parte del lavoro che riguarda la
gestione dei dati: esecuzione e ottimizzazione delle query, gestione
delle transazioni, gestione della memorizzazione
Sul client viene eseguita l’applicazione, gestita l’interfaccia utente,
e gestiti i dati memorizzati nella cache del client
Le esigenze hw e sw di server e client sono diverse
•
Convenienza:
•
– Nel contesto delle basi dati le due funzioni sono bene identificate
– Client: PC con strumenti di produttività tipici dell’automazione dell’ ufficio
– Server: memorie di massa grosse e affidabili, efficienza delle operazioni di I/O,
buffer di grandi dimensioni
– Riduzione dei costi (più macchine specializzate al posto di una “complessiva”)
– Incremento della robustezza del sistema
– Aumento della scalabilità (possibilità di aggiungere nuove applicazioni e nuovi
utenti )
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
13
Operating
system
Architettura client/server
User interface
Application program
……..
Client DBMS
Communication software
SQL query
Result relation
Communication software
Operating
System
Semantic Data Controller
Query Optimizer
Transaction Manager
Recovery Manager
Runtime Support Processor
Data Base
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
14
7
Sistemi Client/Server (2)
ambiente distribuito
•
•
•
•
In un contesto distribuito una transazione può coinvolgere più
server
Multiple client / single server: il database è memorizzato su una
unica macchina (abbiamo quindi un ambiente centralizzato)
Multiple client / multiple server
– Ciascun client gestisce la propria connessione con il server
appropriato
• Si semplifica il codice del server ma si appesantisce il client (heavy
client)
– Ciascun client conosce il proprio “home server”, ed è questo che
comunica con gli altri server se necessario
• Le funzionalità di gestione dei dati sono concentrate sui server
(light client)
• La trasparenza dell’accesso ai dati è fornita dall’interfaccia d el
server
L’utente ha sempre la visione di un unico database mentre a livello
fisico i dati possono essere distribuiti
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
15
Sistemi distribuiti Peer–to-Peer
•
•
•
•
Con questi termini ci si riferisce in genere alle caratteristiche
seguenti che riguardano un ambiente pienamente distribuito
Non c’è distinzione tra client e server, tutti i siti hanno le stesse
funzionalità
Si ha uno schema logico globale che è visto da tutti i siti; le
applicazioni vedono schemi esterni costruiti su questo schema
Su ogni sito abbiamo il componente user processor
–
–
–
–
•
User interface handler
Semantic data controller
Global query optimizer and decomposer
Distributed execution monitor / distributed transaction manager
Su ogni sito abbiamo il componente data processor
– Local query optimizer
– Local recovery manager
– Run-time support manager (interfaccia col sop, buffer manager …)
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
16
8
Componente user processor
•
User interface handler
– Interpreta i comandi utente e formatta i risultati da restituire
all’utente
•
Semantic data controller
– Usa i vincoli di integrità e le autorizzazioni definite a livello di schema
logico globale per controllare se la query utente può essere eseguita
•
Global query optimizer and decomposer
– Determina una strategia di esecuzione cercando di minimizzare una
funzione costo
– Trasforma la query globale in query locali utilizzando il catalogo
globale, lo schema logico globale, gli schemi logici locali
•
Distributed execution monitor, distributed execution manager
– Coordina l’esecuzione distribuita della richiesta utente
– Viene in genere fatto riferimento a più di un sito, quindi i vari
execution monitor comunicano fra di loro
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
17
Componente data processor
•
Local query optimizer
– Sceglie il cammino di accesso migliore per accedere ai dati (es. un
indice)
•
Local recovery manager
– Ha la responsabilità di mantenere il database locale consistente anche
se ci sono dei fallimenti o guasti
•
Run-time support manager
– Accede fisicamente ai dati
– Include il database buffere manager
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
18
9
Regole di Date per sist. relazionale distr.
Cfr. Albano Ghelli Orsini “Basi di dati relazionali e a oggetti” , Zanichelli.
•
Autonomia locale
– I dati locali sono gestiti in modo indipendente dagli altri siti
•
Uguaglianza dei siti
•
Continuità delle operazioni
– Non esiste un sito “centrale” con servizi particolari
– Nessuna attività pianificata dovrebbe comportare interruzioni del
servizio
•
Indipendenza dalla localizzazione
– Gli utenti e i programmi non necessitano di conoscere la
localizzazione fisica dei dati
•
Indipendenza dalla frammentazione
– Gli utenti e i programmi non necessitano di conoscere la
frammentazione dei dati
•
Indipendenza dalla replicazione
– Gli utenti e i programmi non necessitano di conoscere la replicazione
dei dati e di mantenerne l’allineamento
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
19
Regole di Date per sist. relazionale distr.
Cfr. Albano Ghelli Orsini “Basi di dati relazionali e a oggetti” , Zanichelli.
•
Elaborazione distribuita delle interrogazioni
•
Gestione distribuita delle transazioni
– L’ottimizzazione delle query tiene conto della distribuzione dei dati
– Transazioni concorrenti che modificano dati in più siti devono essere
serializzabili (controllo della concorrenza) e devono lasciare la base di
dati distribuita in uno stato consistente in caso di malfunzionamenti
(controllo dei malfunzionamenti)
•
Indipendenza dall’hardware
– Il DBMS deve offrire le stesse funzionalità nei vari siti a prescindere
dall’hardware disponibile, con tutti i sistemi che partecipano in modo
paritetico
•
Indipendenza dal software
– Il DBMS deve offrire le stesse funzionalità nei vari siti a prescindere
dal software di sistema disponibile, con tutti i sistemi operativi che
partecipano in modo paritetico
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
20
10
Regole di Date per sist. relazionale distr.
Cfr. Albano Ghelli Orsini “Basi di dati relazionali e a oggetti” , Zanichelli.
•
Indipendenza dalla rete
– Il DBMS deve offrire le stesse funzionalità nei vari siti a prescindere
dal software di rete disponibile, con tutte le reti che partecipano in
modo paritetico
•
Indipendenza dal DBMS
– Il DBMS deve offrire le stesse funzionalità nei vari siti a prescindere
dal DBMS disponibile, con tutti i DBMS che partecipano in modo
paritetico
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
21
TRASPARENZA
•
•
•
Un sistema “trasparente” nasconde all’utente i dettagli della
implementazione
Separazione tra la semantica ad alto livello di un sistema e le
questioni di implementazione a basso livello
DBMS centralizzato: indipendenza dai dati
– Logical data independence: se una applicazione è costruita sopra un
opportuno insieme di viste, rimane inalterata anche se lo schema
logico cambia, purché le viste non cambino (cambieranno le modalità
di costruzione delle viste)
– Physical data independence: una applicazione vede le relazioni, e
quindi è indipendente dai dettagli della loro implementazione
•
DBMS distribuito
– Trasparenza di frammentazione
– Trasparenza di replicazione
– Trasparenza di linguaggio
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
22
11
Trasparenza di frammentazione: esempio
cfr. Atzeni, Ceri, …”Basi di dati – architetture e linee di evoluzione”,
McGraw-Hill, 2003
•
Esempio:
–
–
–
–
•
Azienda con impiegati a Firenze e Torino: Imp (cod, nome, sede)
Imp1 = σsede=‘FI’ Imp
Imp2 = σsede=‘TO’ Imp
[email protected] [email protected] [email protected]
Query: dato un codice si vuole il nome dell’impiegato
Trasparenza di frammentazione (la query è uguale a quella che si
avrebbe per una relazione non frammentata)
PROCEDURE Q1 (:cod, :nome);
SELECT nome INTO :nome
FROM Imp
WHERE cod = :cod;
END PROCEDURE;
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
23
Trasparenza di allocazione: esempio
cfr. Atzeni, Ceri, …”Basi di dati – architetture e linee di evoluzione”, McGraw -Hill,
2003
Imp1 = σsede=‘FI’ Imp
Imp2 = σsede=‘TO’ Imp
[email protected] [email protected] [email protected]
Query: dato un codice si vuole il nome dell’impiegato
•
Trasparenza di allocazione: si conosce la struttura dei frammenti
ma non la loro allocazione; in particolare non si conosce neanche
se un frammento è replicato o no (trasp. di replicazione)
PROCEDURE Q2 (:cod, :nome);
SELECT nome INTO :nome
FROM Imp1
WHERE cod = :cod;
IF :empty THEN
SELECT nome INTO :nome
FROM Imp2
WHERE cod = :cod;
END PROCEDURE;
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
24
12
Trasparenza di linguaggio: esempio
cfr. Atzeni, Ceri, …”Basi di dati – architetture e linee di evoluzione”, McGraw -Hill,
2003
Imp1 = σsede=‘FI’ Imp
Imp2 = σsede=‘TO’ Imp
[email protected] [email protected] [email protected]
Query: dato un codice si vuole il nome dell’impiegato
•
Trasparenza di linguaggio: si è a conoscenza della struttura dei
frammenti e della loro locazione; in caso di replicazione si deve indicare
un nodo; si ha però un unico linguaggio per riferirsi ai diversi frammenti
PROCEDURE Q3 (:cod, :nome);
SELECT nome INTO :nome
FROM [email protected]
WHERE cod = :cod;
IF :empty THEN
SELECT nome INTO :nome
FROM [email protected]
WHERE cod = :cod;
END PROCEDURE;
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
25
Sistemi paralleli per data base
•
•
•
•
•
Vengono usate architetture multiprocessore per migliorare le prestazioni
Nota: negli anni 80 furono studiate architetture speciali per basi di dati
(data base machine), orientate ad eliminare il cosiddetto I/O bottleneck;
non ne derivarono soluzioni di ampio utilizzo a causa di un alto rapporto
costo/prestazioni
Negli anni 90 si sono diffuse le architetture multiprocessore generiche
(non dedicate alle basi di dati)
Idea di base: sfruttare il parallelismo per aumentare le prestazioni
– Se memorizziamo un database di dimensione D su un disco di
throughput T, il throughput del sistema è limitato da T
– Se partizionamo il database su n dischi, di capacità D/N e throughput
T, idealmente con n processori possiamo ottenere un throughput di
nT
Un sistema per database parallelo dovrebbe aumentare
– Le prestazioni
– La disponibilità dei dati (eventuale replicazione)
– Estensibilità (aggiungendo processor e memoria)
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
26
13
Architettura shared-memory
P1
Pn
cache
cache
Memory1
Memoryn
bus
disk1
F.Cesarini - Basi Dati
Distribuite
diskn
sistemi distribuiti
27
Architettura shared-memory
•
•
•
•
•
Ogni processore può avere accesso ad ognuno dei moduli di
memoria o dei dischi attraverso una connessione veloce (bus o
cross-bar switch)
Le meta-informazioni (dizionario) e le informazioni di controllo
(es. lock) possono essere spartite da tutti i processori
Il parallelismo inter-query è insito nell’architettura
Il parallelismo intra-query richiede una opportuna
parallelizzazione
Limitazioni dell’approccio
– Alto costo dell’interconnessione (ogni processore deve essere connesso
con ogni memoria e con ogni disco)
– L’estensibilità è limitata (10-20 processori)
– Il fallimento di una memoria può mettere in crisi più processori
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
28
14
Architettura shared-disk
P1
P2
local
memory
local
memory
………….
Pn
local
memory
interconnection network
disk
F.Cesarini - Basi Dati
Distribuite
disk
………
disk
sistemi distribuiti
29
Architettura shared-disk
•
•
•
•
•
•
Ogni processore ha accesso a qualsiasi disco attraverso l’accesso
esclusivo alla propria memoria
Ogni processore può accedere alle pagine del database sul disco
spartito e copiarle nella propria cache
I processori comunicano attraverso messaggi o dati su disco
Il costo della interconnessione è minore che nell’architettura
shared memory poiché può essere usato un bus standard
Poiché ciascun processore ha abbastanza cache, le interferenze sul
disco spartito possono essere minime
Limitazioni
– Mantenere la coerenza delle copie può causare un notevole overhead
– Sono necessari protocolli di database distribuito, come locking
distribuito e commit a due fasi
•
Esempio di architettura
– implementazione di ORACLE su DEC’s VAXcluster
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
30
15
Architettura shared-nothing
interconnection network
P1
P1
local memory
local memory
disk
disk
F.Cesarini - Basi Dati
Distribuite
P1
…..
local memory
disk
sistemi distribuiti
31
Architettura shared-nothing
•
•
•
•
•
Ciascun processore ha accesso esclusivo alla propria memoria e al
proprio disco, i processori comunicano attraverso messaggi
Ciascun nodo può essere visto come un sito locale in database
system distribuito
Esempi: Teradata DBC (che può avere fino a 1024 processori) e
Tandem NonStopSQL
È necessaria una implementazione delle funzioni di database
distribuito che assuma la presenza di un gran numero di nodi
Il bilanciamento del carico di lavoro dipende strettamente dal
partizionamento del database
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
32
16
Architettura shared-nothing
•
•
•
Questa architettura è la migliore sia per scale-up che per speed-up
Linear scale-up: all’aumentare del numero di nodi aumenta la
complessità del problema che si può risolvere
Linear speed-up: all’aumentare del numero di nodi aumenta la
velocità con cui un problema può essere risolto
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
33
Parallelismo
•
•
Le elaborazioni svolte da un DBMS si prestano ad essere eseguite
in parallelo
Parallelismo inter-query
– Esecuzione di query diverse in parallelo
– È particolarmente utile in ambiente OLTP (On Line Transaction
Processing), transazioni semplici molto frequenti, centinaia o migliaia
al secondo
– Più processi server allocati sui vari processori; le interrogazioni
vengono raccolte da un dispatcher che ridirige l’interrogazione su un
server
•
Parallelismo intra-query
– Esecuzione in parallelo di parti della stessa query
– È particolarmente utile in ambiente OLAP (On Line Analytical
Processing), poche interrogazioni molto complesse su grosse quantità
di dati
– L’ottimizzatore deve individuare una decomposizione della query in
sotto-query, e coordinarle e sincronizzarle
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
34
17
Esempio da [4] - OLTP
ContoCorrente (Ccnum, Nome, Saldo)
Movimento (Ccnum, Data, Progr, Causale, Ammontare)
– Tabelle frammentate per intervalli di Ccnum
– Ogni coppia di frammenti relativa allo stesso intervallo associata ad
un processore
•
Query OLTP (richiesta del saldo di un conto)
Procedure Queryx (:cc-num, :saldo);
select Saldo into :saldo
from ContoCorrente
where Ccnum = :cc-num;
End procedure
•
La interrogazione OLTP viene indirizzata ad uno specifico
frammento in base al predicato di selezione
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
35
Esempio da [4] - OLAP
ContoCorrente (Ccnum, Nome, Saldo)
Movimento (Ccnum, Data, Progr, Causale, Ammontare)
• Query OLAP (richiesta dei correntisti che nel 2004 hanno avuto
movimenti per un ammontare totale maggiore di 50000 euro)
Procedure Queryy ();
select Ccnum, sum (Ammontare)
from ContoCorrente join Movimento
on (ContoCorrente.Ccnum = Movimento.Ccnum)
where Data between (1/01/04, 31/12/04)
group by Ccnum
having sum (abs(Ammontare)) > 50000;
End procedure
•
La query è indirizzata su tutti i frammenti in parallelo
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
36
18
Partizionamento dei dati
(shared-nothing)
network
P1
network
P2
P3
P1
P2
P3
hash
network
P1
P2
P3
a–h
k–s
t-z
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
37
Partizionamento dei dati
•
Round Robin partitioning
– Con n partizioni, la i-esima tupla è assegnata alla partizione (i mod n)
– L’accesso sequenziale a una relazione può essere fatto in parallelo
– L’accesso a tuple individuali, in base a un predicato, richiede l’accesso
a tutta la relazione
•
Hash partitioning
– Viene applicata ad un attributo una funzione hash che da il numero di
partizione
– Una query di ricerca esatta sull’attributo di partizionamento viene
eseguita solo su un nodo
– Le altre query possono essere elaborate in parallelo
•
Range partitioning
– Le tuple sono distribuite in base ad intervalli di valore di un attributo
– Una query di ricerca esatta sull’attributo di partizionamento viene
eseguita solo su un nodo
– È adatto alle range query
– Se non si ha una distribuzione uniforme dei valori dell’attributo, si
può avere uno sbilanciamento del carico
F.Cesarini - Basi Dati
Distribuite
sistemi distribuiti
38
19