UNIVERSITÀ POLITECNICA DELLE MARCHE
FACOLTÀ DI INGEGNERIA
Corso di Laurea in Ingegneria Informatica e dell’Automazione
Telerefertazione medica su
TCP/IP: Progetto e Realizzazione
degli opportuni Web-Service
Tesi di laurea di:
D’ALBERTO STEFANO
Relatore:
PROF. ING. ALDO FRANCO DRAGONI
Correlatori
PROF. PAOLO PULITI
PROF. GUIDO TASCINI
Anno Accademico 2006/2007
Capitolo 1. Struttura del progetto
1.1
1.2
1.3
1.4
Scopo e contenuto del documento…………………………........ pag.
3
Descrizione del progetto applicativo…………………………… pag.
3
Modello organizzativo………………………………………..... pag.
5
Glossario dei termini…………………………………………… pag.
7
Capitolo 2. Il Web service
2.1
2.2
2.2.1
2.2.2
2.2.3
2.2.4
2.3
2.4
Introduzione al Web service.................………………………... pag.
8
Cosa sono i Web services e come funzionano..............………... pag. 10
XML Schema…………………………………………………... pag. 11
UDDI…………………………………………………………… pag. 13
WSDL………………………………………………………….. pag. 13
SOAP…………………………………………………………… pag. 15
Perché creare un Web Service...............………………………... pag. 17
Apache Axis...............……………………………………...…... pag. 18
Capitolo 3. Preparazione dell’ambiente di sviluppo
3.1
3.3
Lato Server……………………………………………………... pag. 21
Fase di deploy………………………………………………….. pag. 36
Capitolo 4. La comunicazione Client-Server
4.1
4.2
Servizi offerti lato server……………………………………….. pag. 41
Axis Attachment……………...………………………………… pag. 57
Capitolo 5. Struttura del database
5.1
5.2
5.3
Specifica delle operazioni……………………………………… pag. 60
Specifiche di progetto………………………………………….. pag. 61
Progettazione concettuale della base di dati……………………. pag. 68
Un primo schema scheletro…………………………………….. pag. 68
1
5.3.1
5.3.2
5.4
5.5
Sviluppo delle componenti dello scheletro (inside-out)………... pag. 68
Traduzione verso il modello relazionale……………………….. pag. 75
Codifica SQL…………………………………………………... pag. 78
Capitolo 6. Configurazione Server di sviluppo
6.1
6.2
6.3
6.4
6.5
Ambiente di sviluppo.………………………………………...
pag. 82
Installazione Java sul Server ……….………………………….. pag. 83
Installazione TOMCAT su Server …………………….………. pag. 83
Installazione Oracle Database 10g XE…………...…….………. pag. 85
Installazione e configurazione di Apache …...………...………. pag. 92
Capitolo 7. Problematiche e miglioramenti
7.1
7.2
7.3
Il server Linux.………………………….……………………... pag. 94
Interoperabilità ed evoluzioni future…………………………… pag. 97
Possibili sviluppi futuri………...…………………….……….
pag. 98
Capitolo 8. Pubblicazione
8.1
8.2
Il firewall di Linux……………………………………………... pag. 101
Il comando iptables…………...…….………………………….. pag. 102
2
1. Struttura del progetto
1.1 Scopo e contenuto del documento
Scopo del presente documento è definire le specifiche per l’impostazione lato client e lato
server sia a livello concettuale che fisico dell’applicativo JTELEMED.
1.2 Descrizione del Progetto Applicativo
Per Telemedicina si intende l’erogazione di servizi sanitari, laddove la distanza
rappresenti un fattore critico da parte di professionisti nell’assistenza sanitaria che
utilizzino tecnologie dell’informazione e della comunicazione per lo scambio di
informazioni rilevanti, per la diagnosi, il trattamento e la prev.enzione delle patologie e per
l’educazione continuativa degli operatori sanitari, nell’interesse del miglioramento della
salute e delle comunità assistite.
Figura
1
–
Telemedicina
La Telemedicina utilizza le tecnologie della telecomunicazione per erogare assistenza
sanitaria specialistica, spesso a notevoli distanze, con la possibilità di contenere i costi
delle prestazioni. Questo avviene in special modo quando l’Assistenza Sanitaria è rivolta
ad aree isolate o comunque dove non sia disponibile direttamente la prestazione
specialistica del medico.
L’introduzione della telemedicina permette :
•
diagnosi e cure più rapide;
•
minor numero di spostamenti sia del personale medico che dei pazienti;
•
riduzione dei costi per personale, compreso quello di emergenza;
•
comunicazioni più veloci;
3
Capitolo 1
•
Struttura del progetto
aggiornamento più semplice e rapido delle informazioni riguardanti diagnosi e
metodi di cura;
•
miglior sostegno allo staff medico per la formazione sia teorica che pratica.
Nell’ottica di capillarizzare l’offerta sanitaria, può essere importante pensare ad una
struttura informatica che renda indipendenti le due fasi tipiche della diagnostica:
•
l’esecuzione dell’esame
•
la sua refertazione.
Mentre è possibile pensare di localizzare alcuni macchinari (di basso costo) anche nei
poliambulatorii più piccoli o distanti, può risultare sconveniente portare in questi
poliambulatorii personale di alta specializzazione.
Il termine Telemedicina si presta a svariate definizioni, non sempre univoche in
letteratura, che spesso focalizzano l’attenzione solo su alcuni aspetti della materia.
Si tratta sostanzialmente della trasmissione in tempo reale di informazioni a carattere
scientifico tra medico e cittadino o tra addetti ai lavori, attraverso sistemi di comunicazione
di tipo telematico/informatico.
La definizione più esaustiva del termine è senz’altro quella concordata a livello CEE da
una Commissione di esperti, che ha redatto un documento sulle prospettive di sviluppo
della telemedicina in Europa (Advanced Informatics in Medicine - AIM 1990) con
l’obiettivo di migliorare la qualità dei servizi sanitari, facilitare la formazione professionale
di medici e infermieri ed ottimizzare il trasferimento qualificato di dati ed esperienze tra i
vari Paesi europei.
Secondo la Commissione Europea, organizzatrice tra l’altro dell’EHTO (European Health
Telematics Observatory – Osservatorio delle applicazioni mediche della telematica), la
telemedicina è "l’integrazione, monitoraggio e gestione dei pazienti, nonché l’educazione
dei pazienti e del personale, usando sistemi che consentano un pronto accesso alla
consulenza di esperti ed alle informazioni del paziente, indipendentemente da dove il
paziente o le informazioni risiedano".
4
Capitolo 1
Struttura del progetto
1.3 Modello organizzativo
Figura
2
–
Modello
Organizzativo
L’applicativo JTELEMED consta di tre entità:
•
RICHIEDENTE
•
REFERTANTE (o EROGANTE)
•
REPOSITORY
Il RICHIEDENTE è caratterizzato dall’insieme delle strutture che producono i dati
digitali di un esame clinico e che si interfacciano nel nostro sistema come dei client di
laboratorio: sono quelli che attivano il processo di refertazione e attendono i risultati. Una
prerogativa importante di tutto il nostro applicativo è il mantenimento della privacy. Per
questo motivo i richiedenti non saranno mai individuati attraverso dati anagrafici personali
ma attraverso un identificativo univoco.
Il REFERTANTE è, invece, l’insieme di coloro che forniscono il servizio di refertazione,
una clinica specializzata, un semplice medico o una equipe di medici accreditati.
Il cuore del sistema è rappresentato dal REPOSITORY CENTRALE, che altro non è che
un server relazionale, cioè un server che gestisce un DataBase.
5
Capitolo 1
Struttura del progetto
L’effettuazione di un esame presso un laboratorio e la conseguente archiviazione del dato
in forma digitale genera ciò che viene chiamato evento.
L’evento non è il dato clinico vero e proprio ma rappresenta una sorta di meta-dato clinico
del dato digitale generato dai laboratori. E’ composto da una serie di informazioni che
riguardano il dato digitale prodotto dall’evento come ad esempio: l’unità che ha erogato la
prestazione, la data e l’ora dell’esame, la struttura che l’ha prodotto, il dottore richiedente
ed il codice dell’impegnativa, lo stato della fase di refertazione, e, cosa molto importante il
link che consente di scaricare il dato. Ogni evento quindi viene immagazzinato all’interno
di un apposito raccoglitore, definito appunto repository. Qualsiasi esame che può essere
memorizzato in forma digitale può essere associato ad un evento.
Chiarito il funzionamento dell’applicativo, non rimane altro che definire un meccanismo di
comunicazione tra il Repository e i suoi utilizzatori.
Come già detto in precedenza il repository centrale non è altro che un server relazionale
ovvero un server che gestisce un database; in realtà il suo funzionamento è ben più ampio
in quanto, oltre ad interfacciarsi con la base di dati, esso fornisce servizi accessibili con un
semplicissimo browser sia lato richiedente che lato refertante: esso realizza cioè
un’architettura web service.
Nel prossimo capitolo vedremo nel dettaglio la sua realizzazione.
6
Capitolo 1
Struttura del progetto
1.4 Glossario dei termini
Termine
JTelemed
Telemedicina
Esame clinico
Diagnosi
Cura
Richiedente
Refertante
Refertazione
Laboratori
Evento
Repository
Descrizione
E’ l’applicativo che si
vuole realizzare al fine di
fornire un servizio di
telemedicina a distanza
Uso di strumenti telematici
per effettuare esami clinici
a distanza
Indagine specialistica a
scopo diagnostico di un
organismo vivente o di un
organo.
Individuazione del quadro
morboso di un paziente in
base alla valutazione dei
sintomi, all’anamnesi e
alle analisi strumentali e di
laboratorio
Insieme dei rimedi usati
per guarire da una malattia
Strutture accreditate che
producono i dati digitali di
un esame clinico e che si
interfacciano nel nostro
sistema.
Colui che fornisce il
servizio di refertazione
Sinonimi
Applicativo
Collegamenti
Telemedicina
Sistema telematico JTelemed
di assistenza medica
Esame,
Analisi, Telemedicina
Ricerca, Indagine
Valutazione,
Opinione,
Accertamento
Refertante,
Refertazione
Terapia, Trattamento
Refertante,
Refertazione
Utente, Client di Esame clinico
laboratorio, Utente
richiedente
Clinica, Laboratorio, Laboratorio
Medico,
Utente
Erogante,
Utente
Refertante
Il risultato fornito dal Diagnosi
Diagnosi, Cura
refertante derivante da una
diagnosi
Locali dotati di apposite Clinica
Refertante
apparecchiature
per
ricerche cliniche
Effettuazione di un esame Esito, Risultato
Richiedente,
presso un laboratorio e
Refertante,
conseguente archiviazione
Repository
del dato in forma digitale
Server relazionale, ovvero Server
Richiedente,
un server che gestisce un
Refertante, Evento
DataBase.
7
2. Il Web service
2.1 Introduzione al Web service
Il paradigma del Service Oriented Computing è visto come una rivoluzione nella comunità
informatica e i Web Service una sua realizzazione. La possibilità di vedere il Web come un
grande sistema informativo in cui sono forniti innumerevoli servizi offre agli utenti finali
un potentissimo strumento che va al di là del mero scambio di informazioni che al
momento rappresenta il Web.
I servizi web, meglio noti come web services, sono diventanti uno degli argomenti più
attuali nel panorama dello sviluppo in ambiente Internet. Posti al centro delle più recenti
strategie di aziende del calibro di IBM, Microsoft e Sun, vengono spesso descritti come
una vera e propria rivoluzione nel mondo del web ed in particolare per tutto quanto attiene
allo sviluppo di applicazioni distribuite ed all'integrazione di applicazioni.
Secondo la definizione data dal World Wide Web Consortium (W3C) un Web Service
(servizio web) è un sistema software progettato per supportare l'interoperabilità tra diversi
elaboratori su di una medesima rete; caratteristica fondamentale di un Web Service è
quella di offrire un'interfaccia software (descritta in un formato automaticamente
elaborabile quale, ad esempio, il Web Services Description Language) utilizzando la quale
altri sistemi possono interagire con il Web Service stesso attivando le operazioni descritte
nell'interfaccia tramite appositi "messaggi" inclusi in una "busta" SOAP: tali messaggi
sono, solitamente, trasportati tramite il protocollo HTTP e formattati secondo lo standard
XML.
Focalizzando l’attenzione sul concetto di servizio è ovvio immaginare, anche alla luce di
quanto detto finora, come gli attori in causa siano necessariamente il fornitore e il
richiedente. Questo tipo di paradigma è il medesimo che si riscontra nella tipica interazione
di tipo client-server. Attraverso la SOA (Service Oriented Architecture) questa interazione
viene arricchita con un ulteriore attore detto Service Directory o Service Broker che, come
mostrato in figura 1, si inserisce all’interno della comunicazione tra fornitore e fruitore del
servizio.
8
Capitolo 2
Il Web Service
Figura 3 – Service Oriented Architecture
Service Provider
Chi realizza e mette a disposizione un servizio. Tramite l’operazione di publish il servizio
viene “pubblicizzato”, in quanto le caratteristiche del servizio realizzato vengono
memorizzate all’interno di un registry accessibile pubblicamente. Il Service Provider
rimane, quindi, in attesa che un utente richieda tale servizio.
Service Directory o Service Broker
Questo componente si occupa della gestione del registry, permettendo, a chi ha necessità,
di ricercare un servizio sulla base delle caratteristiche con le quali è stato definito e
memorizzato.
Naturalmente, il Service Directory può seguire politiche di controllo degli accessi sulle
interrogazioni in modo da limitare la visibilità sui servizi inseriti. Nel presente lavoro il
registry, viene considerato parzialmente accessibile.
Service Requestor
Rappresenta un potenziale utente che richiede un servizio. A tale scopo, tramite la
primitiva di find l’utente interagisce con il Service Directory per ottenere il servizio più
adatto ai propri obiettivi. Una volta individuato si collega al Service Provider
corrispondente (bind) e inizia a fruire del particolare servizio (use).
9
Capitolo 2
Il Web Service
Partendo da questa considerazione si può dire che una architettura per e-Service è
un’istanza di una SOA dove il mezzo di comunicazione è di tipo elettronico, mentre una
architettura per Web Service è un’istanza di una SOA dove il mezzo di comunicazione
considerato è il Web.
Figura 4 – Pila Protocollare dei Web Service
2.2 Cosa sono i Web services e come funzionano
Un Web service è un componente applicativo. Possiamo definirlo come un sistema
software in grado di mettersi al servizio di un applicazione comunicando su di una
medesima rete tramite il protocollo HTTP. Un Web service consente quindi alle
applicazioni che vi si collegano di usufruire delle funzioni che mette a disposizione. Esso
comunica tramite protocolli e standard definiti "aperti" e quindi sempre a disposizione
degli sviluppatori ed ha una caratteristica molto particolare ed utile al suo scopo: è autocontenuto ed auto-descrittivo, cioè è in grado di farci sapere che funzioni mette a
disposizione (senza bisogno di conoscerle a priori) e ci permette inoltre di capire come
vanno utilizzate.
Il protocollo HTTP si occupa di mettere in comunicazione il servizio web con
l'applicazione che intende usufruire delle sue funzioni. Oltre ad HTTP però, i servizi web
utilizzano molti altri standard web, tutti basati su XML, tra cui:
10
Capitolo 2
•
XML Schema
•
UDDI (Universal Description, Discovery and Integration)
•
WSDL (Web Services Description Language)
•
SOAP (Simple Object Access Protocol)
Il Web Service
È importante sottolineare che XML può essere utilizzato correttamente tra piattaforme
differenti (Linux, Windows, Mac) e differenti linguaggi di programmazione. XML è
inoltre in grado di esprimere messaggi e funzioni anche molto complesse e garantisce che
tutti i dati scambiati possano essere utilizzati ad entrambi i capi della connessione. Si può
quindi dire che i Web service sono basati su XML ed HTTP e che possono essere utilizzati
su ogni piattaforma e con ogni tipo di software.
2.2.1 XML Schema
Abbiamo detto che un Web service è auto-descrittivo. Con XML Schema cominceremo a
capire come fa un servizio web a disporre di questa caratteristica. XML Schema serve per
definire qual è la costruzione legale di un documento XML, come fanno per esempio i
DTD con le pagine web.
Vediamo una lista delle principali funzioni di XML Schema:
•
Definire gli elementi (tag) che possono apparire in un documento
•
Definire gli attributi che possono apparire in un elemento
•
Definire quali elementi devono essere inseriri in altri elementi (child)
•
Definire il numero degli elementi child
•
Definire quando un elemento deve essere vuoto o può contenere testo, elementi,
oppure entrambi
•
Definire il tipo per ogni elemento e per gli attributi (intero, stringa, ecc, ma anche
tipi personalizzati)
•
Definire i valori di default o fissi per elementi ed attributi
Ecco un esempio di XML Schema in grado di descriverlo:
11
Capitolo 2
Il Web Service
<?xml version="1.0"?>
<!-- iniziamo lo schema -->
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.XXXX.it/Guida_ai_Webservice"
xmlns="http://www.XXXX.it/Guida_ai_Webservice"
elementFormDefault="qualified">
<!-- definiamo l'elemento libro -->
<xs:element name="libro">
<xs:complexType>
<xs:all>
<!-- definiamo i vari elementi child di libro -->
<xs:element name="titolo" type="xs:string" />
<xs:element name="autore" type="xs:string" />
<xs:element name="numeroDiPagine" type="xs:integer" />
</xs:all>
</xs:complexType>
</xs:element>
</xs:schema>
Per ora concentriamoci sul primo elemento: schema. Questo è l'elemento che racchiude
tutti i tipi di dato che andiamo a descrivere. Il tag <schema> può avere diversi attributi.
•
xmlns:xs="..." stabilisce che gli elementi che iniziano con 'xs' provengono dal
namespace http://www.w3.org/2001/XMLSchema .
•
targetNamespace="..." definisce a quale namespace appartengono gli elementi
definiti con questo schema .
•
xmlns="..." definisce il namespace di default (quello applicato se non ne
escplicitiamo uno)
•
elementFromDefault="qualified" indica che ogni elemento usato nel documento
XML che utilizzerà questo schema dovrà essere qualificato.
Una volta aperto il tag <schema> bisogna inserire al suo interno tutti gli elementi che
vogliamo definire per il nostro documento. Esistono sostanzialmente due tipi di elementi:
•
gli elementi semplici non possono contenere altri elementi e avere attributi.
Possono contenere solo testo.
12
Capitolo 2
•
Il Web Service
gli elementi complessi possono contenere testo, altri elementi e attributi in qualsiasi
combinazione.
2.2.2 UDDI
L'UDDI (acronimo di Universal Description Discovery and Integration) è un registry
(ovvero una base dati ordinata ed indicizzata), basato su XML ed indipendente dalla
piattaforma hardware, che permette alle aziende la pubblicazione dei propri dati e dei
servizi offerti su internet.
L ‘UDDI permette quindi la scoperta e l'interrogazione dei servizi offerti sul web, delle
aziende che li offrono e della maniera per usufruirne. Una "registrazione" UDDI consiste,
infatti, di tre diverse componenti:
•
Pagine bianche (White Pages): indirizzo, contatti (dell'azienda che offre uno o più
servizi) e identificativi;
•
Pagine gialle (Yellow Pages): categorizzazione dei servizi basata su tassonomie
standardizzate;
•
Pagine verdi (Green Pages): informazioni (tecniche) dei servizi fornite dall'azienda
L'UDDI è uno degli standard alla base del funzionamento dei Web Service: è stato
progettato per essere interrogato da messaggi in SOAP e per fornire il collegamento ai
documenti WSDL che descrivono i vincoli protocollari ed i formati dei messaggi necessari
per l'interazione con i Web Service elencati nella propria directory.
2.2.3 WSDL
Il WSDL serve a specificare dove si trovano i servizi e le operazioni esposte dal servizio
web.
Cominciamo subito a vedere come un documento WSDL definisce un Web service.
All'interno del documento esistono quattro elementi principali:
•
<types>
•
<message>
13
Capitolo 2
Il Web Service
•
<portType>
•
<binding>
<definitions>
<types>
<!-- definizione dei tipi di dato utilizzati... -->
</types>
<message>
<!-- definizione di uno dei messaggi impiegati dal web service per comunicare con l'applicazione client ->
</message>
<!-- naturalmente può esistere più di un elemento message all'interno del documento -->
<portType>
<!-- definisce una "porta" e le operazioni che possono essere eseguite dal web service.
Definisce inoltre i messaggi coinvolti nelle operazioni elencate -->
</portType>
<binding>
<!-- definisce il formato del messaggio ed i
dettagli di protocollo per ogni porta -->
</binding>
</definitions>
I types, message e portType sono elementi del messaggio WSDL all’interno di definitions
e sono usati per definire le operazioni:
• <types>
è usato per definire i tipi base necessari allo scambio dell’informazione.
• <message>
è usato per definire il messaggio spedito e ricevuto ed utilizza i tipi definiti
in types.
• <portTypes> è usato per definire il funzionamento delle porte allocate dal servizio come
i messaggi da utilizzare in input e output.
Gli elementi binding e service sono usati per definire il protocollo associato all’operazione:
• <binding> è usato per definire il protocollo da utilizzare per comunicare con la porta su
cui è allocata l’operazione (HTTP, SOAP,…).
• <service>
è usato per definire una porta come URL attraverso la quale si trova il
servizio.
14
Capitolo 2
Il Web Service
• Il WSDL inoltre definisce quattro tipi di operazioni attraverso il tag <operations>:
– One-way: è una chiamata asincrona al servizio.
– Request-responce: chiamata sincrona al servizio.
– Sollicit-responce: invia una risposta dopo un sollecito.
– Notification: ricevere una notifica.
2.2.4 SOAP
E’ utile sapere che tutte le informazioni che vengono definite da WSDL, è grazie a SOAP
(Simple Object Access Protocol) se vengono scambiate tra il Web service è l'applicazione
che vi accede. Questo protocollo fornisce una via per comunicare tra applicazioni eseguite
su sistemi operativi diversi, con diverse tecnologie e linguaggi di programmazione, tramite
HTTP ed XML.
Un messaggio SOAP è un documento XML che contiene i seguenti elementi:
•
Envelope, identifica il documento come un messaggio SOAP;
•
Un
elemento
Header
opzionale,
contenete
informazioni
specifiche
per
l'applicazione, che non sarà approfondito in questa sede ma che permette di definire
alcuni messaggi, anche con diversi destinatari nel caso il messaggio dovesse
attraversare più punti di arrivo;
•
Body è un elemento indispensabile che contiene le informazioni scambiate dalle
richieste/risposte;
•
Fault è un elemento opzionale che fornisce informazioni riguardo ad eventuali
errori manifestati durante la lettura del messaggio.
Le regole principali per realizzare un messaggio SOAP sono le seguenti:
•
Deve essere ovviamente codificato con XML
•
Deve utilizzare il SOAP Evenelope namespace (http://www.w3.org/2001/12/soapenvelope)
•
Deve utilizzare il SOAP Encoding namespace (http://www.w3.org/2001/12/soapencoding)
15
Capitolo 2
•
Il Web Service
Non deve contenere il collegamento ad un DTD e non deve contenere istruzioni per
processare XML
Lo "scheletro" di un messaggio SOAP:
<?xml version="1.0"?>
<soap:Envelope xmlns:soap="http://www.w3.org/2001/12/soap-envelope
(http://www.w3.org/2001/12/soap-envelope)"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Header>
...
</soap:Header>
<soap:Body>
...
<soap:Fault>
...
</soap:Fault>
</soap:Body>
</soap:Envelope>
All'interno dell'elemento Envelope abbiamo definito i namespace soap evelope ed
encoding che come abbiamo visto sono richiesti per questo tipo di documento. Se non
vengono definiti o si definiscono diversamente le applicazioni coinvolte nella
comunicazione potrebbero generare un errore o scartare il messaggio.
16
Capitolo 2
Il Web Service
2.3 Perché creare un Web Service
La ragione principale per la creazione e l'utilizzo di Web Service è il "disaccoppiamento"
che l'interfaccia standard esposta dal Web Service rende possibile fra il sistema utente ed il
Web Service stesso: modifiche ad una o all'altra delle applicazioni possono essere attuate
in maniera "trasparente" all'interfaccia tra i due sistemi; tale flessibilità consente la
creazione di sistemi software complessi costituiti da componenti svincolati l'uno dall'altro e
consente una forte riusabilità di codice ed applicazioni già sviluppate.
I Web service hanno inoltre guadagnato consensi visto che, come protocollo di trasporto,
possono utilizzare HTTP "over" TCP sulla porta 80; tale porta è, normalmente, una delle
poche (se non l'unica) lasciata "aperta" dai sistemi firewall al traffico di entrata ed uscita
dall'esterno verso i sistemi aziendali e ciò in quanto su tale porta transita il traffico HTTP
dei web browser: ciò consente l'utilizzo dei Web Service senza modifiche sulle
configurazioni di sicurezza dell'azienda (un aspetto che se da un lato è positivo solleva
preoccupazioni concernenti la sicurezza).
Un'ultima ragione che ha favorito l'adozione ed il proliferare dei Web Service è la
mancanza, prima dello sviluppo di SOAP, di interfacce realmente funzionali per l'utilizzo
di funzionalità distribuite in rete: EDI, RPC, ed altri tipi di API (Application Programming
Interface) erano e rimangono meno conosciute e di facile utilizzo che non l'architettura dei
Web Service.
17
Capitolo 2
Il Web Service
2.4 Apache Axis
Axis è il motore opensource più famoso per la creazione di Web Services in Java. Axis è
un progetto dell'Apache Software Fondation e deriva da SOAP4J, un progetto regalato
dall'IBM ad Apache.
Brevemente, si tratta di un’API di programmazione e deployment di Web services che
permette di lavorare ad un livello di astrazione elevato, evitando così di dover maneggiare
direttamente l’envelope SOAP. Con Axis è possibile, dunque, implementare Web services
e anche sviluppare client di servizi di terzi. Per semplicità, negli esempi che tratteremo
viene esposto solo l’aspetto di funzionalità RPC e non quello relativo ai vari approcci di
messaging supportati da Axis. Ciò è comunque in linea con la maggior parte della casistica
Web services che si basa su meccanismi request/response a dispetto del modello asincrono.
Axis 1.4 disponibile all’URL http://ws.apache.org/axis/ è composto da:
•
una web application che si occupa di gestire l'ambiente di esecuzione dei servizi
(routing, istance pooling, serializzazione e deserializzazione dei messaggi SOAP,
ecc...);
•
una API composta da classi di utilità per la scrittura di servizi web e da classi
necessarie al funzionamento della web application e dei tool;
•
una serie di tool, tra cui WSDL2Java per generare scheletri lato server e stub lato
client dei servizi web a partire dalla descrizione WSDL;
•
Java2WSDL per generare la descrizione come servizio web di una classe Java;
•
diversi tool per l'amministrazione e la gestione dei servizi installati;
•
un TCP monitor stand-alone ed un SOAP monitor integrato nella web application
per controllare la forma dei messaggi scambiati tra i servizi nelle fasi di debug e
test.
18
Capitolo 2
Il Web Service
Tra le caratteristiche più interessanti di Axis c'è la possibilità di creare web service in
maniera immediata a partire da classi Java molto semplici con estensione .jws (Java Web
Service).
Axis può essere quindi utilizzato in una serie di scenari anche molto diversi tra loro, ad
esempio può servire per:
•
la creazione di applicazioni client di servizi web già esistenti per i quali è
disponibile il WSDL: utilizzando WSDL2Java si possono creare in maniera
automatica gli stub per l'accesso a servizi esistenti implementati con qualsiasi
piattaforma. Le applicazioni client che utilizzano gli stub non necessitano di
ambienti di esecuzione particolari ma soltanto della presenza della libreria axis.jar
nel proprio classpath;
•
la comunicazione via JAX-RPC tra processi Java: le API di Axis implementano
una versione di JAX-RPC, rendendo possibile lo sviluppo di applicazioni
distribuite Java con protocollo di trasporto SOAP;
•
la creazione di servizi web a partire da classi Java: Axis offre diversi meccanismi
per l'implementazione dei servizi. Quello più semplice e completamente
trasparente per il programmatore è JWS, ma sono disponibili anche modelli di
servizi più complicati dove è possibile personalizzare, ad esempio, le modalità di
serializzazione dei messaggi, la struttura dei package ed il formato dei parametri,
senza mai occuparsi della descrizione WSDL o del formato SOAP dei messaggi,
grazie all'integrazione tra l'ambiente di esecuzione e Java2WSDL;
•
l'implementazione di servizi web a partire da descrizioni WSDL: il tool
WSDL2Java è particolarmente utile quando, come nel caso di Zlatan, si parte dalla
descrizione dei servizi per la realizzazione di un sistema piuttosto che dalla loro
implementazione.
I problemi principali di Axis riguardano lo stretto legame con il web application container
Tomcat (anche se è possibile con qualche sforzo installare l'ambiente in altri server, come
fatto con SJSAS8 in Zlatan) e la conformità soltanto parziale alle specifiche del WS-I.
Riassumendo possiamo dire che Axis non è che un SOAP engine: questo significa che è un
framework che si concentra unicamente sulle problematiche della creazione di client e
server e per la gestione di messaggi SOAP; in pratica consiste in un insieme di tool per la
19
Capitolo 2
Il Web Service
generazione automatica di classi e in una libreria che “incapsula” in classi Java l’accesso
alle tecnologie connesse ai Web Services.
L’architettura generale di Axis appare nella seguente figura nei suoi componenti principali:
Fig. 5 - Architettura generale di Axis.
Il requestor è un client che effettua una richiesta su alcuni dei protocolli supportati da Axis.
Generalmente è usato HTTP. Il requestor può essere una desktop application, una web
application, o un altro web service.
Il motore Axis agisce agevolando la comunicazione tra client e web service maneggiando
la traduzione ad e da web service standard.
Axis permette allo sviluppatore di definire una serie di handlers, allacciati alla richiesta o
alla risposta. Questi handlers sono simili a filtri servlet; ogni handler svolge uno specifico
compito adando avanti fino al prossimo handler in linea.
20
3. Preparazione dell’ambiente di sviluppo
3.1
Lato Server
Innanzitutto occorre istallare la JDK, la JRE e l’Application Server JAKARTA TOMCAT
con la stessa procedura vista a livello client.
Come IDE di sviluppo è stato scelto Eclipse: la versione a cui faremo riferimento è la WTP
1.5 AllInOne. Tale sigla sta per Web Tools Project, e contiene, fra l'altro, Eclipse 3.2.
In questa versione ci sono già molte funzionalità rivolte al web, come suggerisce il nome.
L'installazione è semplicissima, anzi, non necessita neanche di una installazione. Una volta
scaricato il file compresso è sufficiente scompattarlo ed Eclipse è già pronto.
Al termine dell'estrazione, nella directory "eclipse" (sotto la cartella di destinazione da noi
scelta) troviamo tutti i file e le directory coinvolte. È interessante notare come il processo
di installazione sia totalmente non invasivo a livello di sistema: in Windows, ad
esempio, non vengono inserite chiavi nel registry, non vengono installate dll o file di
sistema all'interno delle cartelle /Windows/System32. L'unica accortezza che bisogna
avere, prima di utilizzare Eclipse, è quella di avere installato una java virtual machine (ad
esempio scaricando il Java SE Development Kit sul sito Sun) che Eclipse stesso possa
utilizzare per compilare ed eseguire le applicazioni.
L'unica accortezza che bisogna avere, prima di utilizzare Eclipse, è quella di avere
installato una java virtual machine (ad esempio scaricando il Java SE Development Kit sul
sito Sun) che Eclipse stesso possa utilizzare per compilare ed eseguire le applicazioni.
La prima volta che avviamo Eclipse viene chiesta la directory dove salvare i nostri
progetti.
Fig. 6 Selezionare un
workspace
21
Capitolo 3
Preparazione dell’ambiente di sviluppo
Attraverso la check box in basso alla finestra di dialogo sarà, quindi, possibile scegliere se
utilizzare la medesima directory per tutti i progetti evitando di sceglierla di volta in volta.
Una volta ultimata la selezione del workspace, verrà visualizzata una schermata di
benvenuto.
Fig. 7 –
Schermata
di
benvenuto
di Eclipse
Il passo successivo prevede l’istallazione di APACHE AXIS che consiste nei due seguenti
passi:
Fig. 8 - Cartella
scompattata di Axis.
22
Capitolo 3
Preparazione dell’ambiente di sviluppo
1) Scompattare Axis, prendere la cartella lib e copiarla all'interno della installazione di
Eclipse.
2) Prendere la cartella axis dentro webapps e incollarla sull'omonima cartella di
Tomcat.
A questo punto abbiamo tutti gli strumenti necessari per creare il nostro Web Service, ma
prima di iniziare vediamo la disposizione delle varie librerie:
•
per un corretto funzionamento dell’applicativo lato server sono necessarie le
seguenti librerie nella directory della JDK (nel nostro caso versione 1.5)
C:\Programmi\Java\jdk1.5.0\jre\lib\ext.:
•
dnsns.jar
sunjce_provider.jar
localedata.jar
sunpkcs11.ja
le librerie necessarie sotto C:\TOMCAT554\common\lib sono:
activation.jar
mail.jar
commons-el.jar
naming-factory-dbcp.jar
jasper-compiler jdt.jar
naming-factory.jar
jasper-compiler.jar
naming-resources.jar
jasper-runtime.jar
ojdbc14.jar
jsp-api.jar
servlet-api.jar
23
Capitolo 3
•
Preparazione dell’ambiente di sviluppo
le librerie necessarie sotto C:\TOMCAT554\ webapps\axis\WEB-INF\lib sono:
activation.jar
jaxrpc.jar
axis-ant.jar
log4j-1.2.8.jar
axis.jar
mail.jar
commons-discovery-
saaj.jar
0.2.jar
wsdl4j-1.5.1.jar
commons-logging1.0.4.jar
Chiarite le posizioni delle varie librerie cominciamo a costruire il nostro web service a
partire dalla IDE di sviluppo Eclipse:
Innanzitutto selezionare dalla toolbar la voce File->New->Project (figura 1). Nella
successiva finestra indicare il tipo di progetto che si vuole realizzare,nel nostro caso
un Dinamic Web Project (figura 2).
24
Capitolo 3
Preparazione dell’ambiente di sviluppo
Figura 9 – Creazione del Web Service
Il primo step per la costruzione di un web service è rappresentato
dalla scelta del tipo di progetto tra quelli che eclipse mette a
disposizione.
25
Capitolo 3
Preparazione dell’ambiente di sviluppo
Figura 10 – Creazione di un Web service
Non è difficile riconoscere quale sia effettivamente il tipo di progetto da
selezionare per la creazione di un web service: aprire la directory Web e
selezionare la voce Dynamic Web Project
26
Capitolo 3
•
Preparazione dell’ambiente di sviluppo
Successivamente verrà chiesto di dare un nome al nuovo progetto e di lavorare con delle
impostazioni. Per il nostro scopo è possibile utilizzare le impostazioni di default e una
volta completata la procedura l’interfaccia di eclipse appare nel seguente modo:
Figura 11 - L’interfaccia di Eclipse
Come ultimo passo non rimane altro che testare il prototipo di applicazione
costruito; per fare ciò basta lanciare l’applicazione stessa all’interno di Eclipse
attraverso il comando Run. Poiché abbiamo però costruito una web application,
occorre definire il server su cui far girare il progetto: Eclipse a questo scopo ci
permette di impostare una sorta di server interno che si appoggia all’Application
Server istallato sulla macchina di sviluppo, nel nostro caso JAKARTA TOMCAT.
Vediamo brevemente come funziona il tutto. Con il tasto destro del mouse ciccare
sull’icona del progetto che appare nella Resource Navigator view e scegliere Run
As -> Run On Server (figura 12).
27
Capitolo 3
Preparazione dell’ambiente di sviluppo
Successivamente
selezionare
dall’elenco
messo
disposizione
desiderato,
il
nel
a
server
nostro
caso
Apache Tomcat v.5.5 (figura 5).
Anche in questo caso è possibile
modificare delle impostazioni,
ma
non
è
controindicativo
utilizzare quelle di default.
Concludendo tale procedimento
guidato l’istallazione del nostro
server interno è completata e
l’applicazione
Figura 12 – Impostare il server di Eclipse (1)
è
pronta
per
essere utilizzata (figura 13).
Figura 13 Impostare il server di
Eclipse (2).
E’
necessario
selezionare
dall’elenco
di
lo
figura
stesso
Application Server che
si
è
istallato
sulla
macchina di lavoro.
Come sempre facciamo
riferimento
al
nostro
caso che utilizza un
Tomcat versione 5.5
28
Capitolo 3
Preparazione dell’ambiente di sviluppo
Figura 14 – Impostare il server di Eclipse (3)
Come ulteriore verifica della funzionalità del server possiamo utilizzare la Console:
Figura 15 – La Console di Eclipse
Come vedremo più avanti Eclipse ci mette inoltre a disposizione un ulteriore
strumento di controllo in fase di utilizzo dei servizi, il TCP/IP Monitor.
29
Capitolo 3
Preparazione dell’ambiente di sviluppo
• Ora tutto il nostro sistema è funzionante, ma prima di ultimare il lavoro occorre fare un
piccolo passo indietro. Conclusa la fase di editing con la creazione delle classi che
implementano i servizi occorre costruire il descrittore dei servizi, il WSDL. Ricordiamo
che il WSDL serve a specificare dove si trovano i servizi e le operazioni esposte dal
servizio web.
L’Eclipse
mette
a
disposizione un meccanismo
rapido ed efficiente per la
creazione automatica di tale
descrittore
che
fisicamente
non è altro che un file xml.
Cliccare con il tasto destro del
mouse sulla classe nella quale
sono definiti i servizi che il
nostro
progetto
realizzare.
vuole
Selezionando
la
voce Web Service -> Create
Web Service (figura 16)
si
apre
di
una
finestra
impostazioni
(figura
17):
“spuntare” le due voci Publish
the Web service e Monitor the
Web service; inoltre se è
necessario il TCP/IP Monitor
spostare
la
completamente
Successivamente
un’ulteriore
barra
(1)
in
alto.
apparirà
finestra
nella
quale è possibile selezionare
Figura 16 – Creazione del Web service (1)
tutti i servizi da inserire nel
wsdl e scegliere il cosiddetto
“Style and use” impostandolo
a RPC/Encoded.
30
Capitolo 3
Preparazione dell’ambiente di sviluppo
Questa caratteristica rappresenta la scelta del formato di un messaggio SOAP.
Le possibili scelte di SOAP: Body di un messaggio SOAP sono:
- document: il SOAP Body del documento contiene una o più "parts" che dal punto di
vista di XML sono childNodes di SOAP:Body. Non ci sono particolari regole sulla
struttura di questi nodi figli.
- RPC: il SOAP:Body contiene un elemento il cui nome corrisponde al nome della
procedura remota da invocare e un elemento per ogni parametro da fornire alla
procedura.
La serializzazione del SOAP: Body prevede:
- encoded: le regole di serializzazione sono dettate dalla sezione 5 della specifica SOAP
1.1 .
- literal: i dati sono serializzati nel rispetto di una specifica XML che ad oggi è XML
Schema Definition 1.0, domani potrebbe essere altro.
In .NET tutto questo si trasforma nell'utilizzare, come decorazione dei nostri
WebMethod, uno dei due seguenti attributi:
- SoapRpcMethod: il SOAP:Body sarà RPC/encoded.
- SoapDocumentMethod: SOAP:Body in formato document. Se la proprietà Use vale
SoapBindingUse.Literal il body sarà document/literal, se invece Use vale
SoapBindingUse.Encoded avremo un body document/encoded. Se la proprietà
ParameterStyle vale SoapParameterStyle.Bare avremo i parametri inviati tra i SOAP
Node posizionati direttamente all'interno del SOAP:Body. Se invece la proprietà
ParameterStyle vale SoapParameterStyle.Wrapped i parametri saranno inviati tra i due
SOAP node, racchiusi all'interno di un solo elemento, figlio di SOAP:Body. Il default di
ASP.NET è Literal, Wrapped.
31
Capitolo 3
Preparazione dell’ambiente di sviluppo
Barra (1).
Spostare la barra
completamente
in alto per avere
il TCP/IP
Monitor
Opzioni da
selezionare
Figura 17 – Impostare
il server di Eclipse (2)
Risultato di tutta questa procedura è un file .wsdl di cui riportiamo un piccolo frammento:
INTESTAZIONE
<?xml version="1.0" encoding="UTF-8"?>
<wsdl:definitions targetNamespace="http://services.jtelemed.it"
xmlns:apachesoap="http://xml.apache.org/xml-soap"
xmlns:impl="http://services.jtelemed.it" xmlns:intf="http://services.jtelemed.it"
xmlns:soapenc="http://schemas.xmlsoap.org/soap/encoding/"
xmlns:wsdl="http://schemas.xmlsoap.org/wsdl/"
xmlns:wsdlsoap="http://schemas.xmlsoap.org/wsdl/soap/"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<!--WSDL created by Apache Axis version: 1.3
Built on Oct 05, 2005 (05:23:37 EDT)-->
32
Capitolo 3
Preparazione dell’ambiente di sviluppo
DEFINIZIONE DEI METODI
<wsdl:message name="openeventResponse">
<wsdl:part name="openeventReturn" type="xsd:int"/>
</wsdl:message>
<wsdl:message name="userinfoResponse">
<wsdl:part name="userinfoReturn" type="xsd:string"/>
</wsdl:message>
<wsdl:message name="listeventsResponse">
<wsdl:part name="listeventsReturn" type="xsd:string"/>
</wsdl:message>
PORT TYPE
<wsdl:portType name="WSRepository">
<wsdl:operation name="echo" parameterOrder="value">
<wsdl:input message="impl:echoRequest" name="echoRequest"/>
<wsdl:output message="impl:echoResponse" name="echoResponse"/>
</wsdl:operation>
<wsdl:operation name="userinfo" parameterOrder="utn_cn username password">
<wsdl:input message="impl:userinfoRequest" name="userinfoRequest"/>
<wsdl:output message="impl:userinfoResponse" name="userinfoResponse"/>
</wsdl:operation>
33
Capitolo 3
Preparazione dell’ambiente di sviluppo
BINDING
wsdl:binding name="WSRepositorySoapBinding" type="impl:WSRepository">
wsdlsoap:binding style="rpc" transport="http://schemas.xmlsoap.org/soap/http"/>
wsdl:operation name="echo">
<wsdlsoap:operation soapAction=""/>
<wsdl:input name="echoRequest">
<wsdlsoap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="http://services.jtelemed.it" use="encoded"/>
</wsdl:input>
<wsdl:output name="echoResponse">
<wsdlsoap:body encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"
namespace="http://services.jtelemed.it" use="encoded"/>
</wsdl:output>
wsdl:operation>
SERVIZI
<wsdl:service name="WSRepositoryService">
<wsdl:port binding="impl:WSRepositorySoapBinding" name="WSRepository">
<wsdlsoap:address
location="http://localhost:8080/jtelemed/services/WSRepository"/>
</wsdl:port>
</wsdl:service>
Infine per testare l’effettivo funzionamento del nostro web service occorre creare un client
che si interfacci con i servizi messi a disposizione. Anche in questo caso l’Eclipse ha una
via veloce ed efficiente: riprendendo lo schema di figura 5, basta selezionare Generate
Sample JSPs.
34
Capitolo 3
Preparazione dell’ambiente di sviluppo
Nel Resource Navigator view di Eclipse apparirà una nuova directory:
Lanciando
server
l’applicazione
appare
una
sul
Directory
Listing For sampleWSRepository
dove WSRepository, per noi, è la
classe con la quale abbiamo
costruito il Web service.
La lista è composta da quatto link
ai file .jsp evidenziati in figura.
Selezionando “TestClient.jsp” si
accede alla fase di testing dei
servizi.
Figura 18 – Creazione del client di test
35
Capitolo 3
Preparazione dell’ambiente di sviluppo
3.2 Fase di deploy
Lo schema proposto dalla Sun Microsystem in quanto a Web Applications propone un
modello descrittivo dell'alberatura del progetto in modo da separare e descrivere meglio
tutta l'applicazione.
Questo approccio ha, come sappiamo, gli indubbi vantaggi della standardizzazione. Da una
parte consente a chi produce i tool di sviluppo e gli application server di rendersi
compatibili (e magari certificati da Sun) con le nuove specifiche, dall'altra permette a chi
sviluppa applicazioni Web di sapere che la struttura dell'applicazione deve essere fatta in
un certo modo e che un qualunque application server, se certificato, tratterà l'applicazione
allo stesso modo, garantendo quindi la portabilità assoluta.
Il nodo centrale della standardizzazione, come sappiamo, è dato da una definizione precisa
dell'alberatura dell'applicazione.
Come sappiamo la root della Web Application dovrà contenere le pagine HTML o JSP. In
alcuni casi le pagine JSP possono essere anche nella cartella JSP, in "css" ci sono i fogli di
stile, in "js" i file contenenti codice Javascript e dentro "WEB-INF" c'è una determinata
alberatura.
In particolare a partire dalla cartella "classes" vengono espansi i package Java
dell'applicazione, in "conf" ci sono i file deputati alla configurazione applicativa, in "lib"
tutte le librerie esterne sotto forma di JAR o ZIP, in "tld" eventuali tag libraries, in "log" i
log dell'applicazione.
Supponiamo di aver creato la nostra applicazione utilizzando questo schema, ad un certo
punto sarà necessario effettuare il deploy su una macchina differente da quella di sviluppo.
La macchine di sviluppo, soprattutto se si utilizzano ambienti di sviluppo molto sofisticati,
sono configurate diversamente da quelle di test, pertanto il passaggio da un ambiente
all'altro potrebbe non essere indolore.
Deploy - modo tradizionale
Per eseguire il deploy di questa Web Application in modo tradizionale, se si utilizza
Tomcat come application server, è necessario copiare l'alberatura così com'è sul file system
della macchina server ed editare il file
36
Capitolo 3
Preparazione dell’ambiente di sviluppo
TOMCAT_HOME\conf\server.xml
aggiungendovi la sezione relativa al nuovo context da creare per poter utilizzare la nuova
Web Application attraverso HTTP.
La sezione che ci serve è di questo genere:
<ContextManager>
<Context path="/nomeApplicazione"
docBase="c:\nomeApplicazione"
crossContext="true"
debug="0"
reloadable="true"
trusted="false" >
</Context>
</ContextManager>
Sarà nostra cura inoltre modificare il CLASSPATH di sistema in modo da includere tutte
le librerie esterne che debbano essere utilizzate dalle componenti della nostra applicazione.
Questo metodo funziona indipendentemente da come sia organizzata la Web Applicaton.
Al termine potremo raggiungere la nostra applicazione attraverso l'url:
http://localhost:8080/nomeApplicazione/
Cosa accade però in fase di manutenzione? In altre parole, cosa succede quando dobbiamo
riportare in ambiente di test delle modifiche che coinvolgono alcune parti della Web
Application?
Ci sono solitamente due alternative:
•
si sovrascrive l'intera alberatura con la versione aggiornata
•
si sovrascrivono selettivamente soltanto i file modificati
In ogni caso gli interventi da effettuare manualmente sono molti e la procedura non troppo
semplice, soprattutto se siamo di fronte ad applicazioni con un certo grado di complessità.
37
Capitolo 3
Preparazione dell’ambiente di sviluppo
Deploy - il file WAR
La specifica proposta da Sun non si limita a descrivere l'alberatura per la costruzione
dell'applicazione, ma ci consente anche di avere un buon sistema per effettuare il deploy
dell'applicazione utilizzando un singolo file, il file WAR. Un file WAR, come sappiamo,
viene generato attraverso il tool jar.exe contenuto nel JDK ed è pertanto un semplice file
JAR rinominato. Il fatto che sia un WAR e non un JAR, indipendentemente dal contenuto,
gli permette di essere automaticamente riconosciuto come una vera e propria Web
Application completa e dotata di vita propria, in questo modo l'application server sarà in
grado di autoconfigurarsi sapendo che il WAR contiene esattamente quel tipo di struttura.
Per effettuare il deploy su Tomcat di un file WAR è sufficiente crearlo, dopo essersi
posizionati all'interno della cartella contenente l’applicazione, attraverso il comando:
jar cvf nomeApplicazione.war .
Dopo aver ottenuto il file nomeApplicazione.war l'operazione di deploy si limita allo
spostamento del file WAR all'interno della cartella webapps di Tomcat.
Subito dopo il restart dell'Application Server potremo vedere la nostra applicazione
utilizzando il solito url:
http://localhost:8080/nomeApplicazione/
Quando l'Application Server parte, si scompatta automaticamente il file WAR e si crea il
context per poter raggiungere l'applicazione via http.
Utilizzando questo metodo di deploy la manutenzione si riduce ai tre passi seguenti:
•
creazione del nuovo file WAR
•
copia del nuovo WAR sulla macchina di test
•
eliminazione della vecchia alberatura estratta dal WAR precedente
Eclipse mette a disposizione un comando per la crazione del file WAR senza dover andare
a ricorrere al prompt dei comandi:
38
Capitolo 3
Preparazione dell’ambiente di sviluppo
Figura 19 Creazione del WAR file.
Cliccare con il tasto destro del
mouse sull’icona del progetto e
selezionare
la
voce
Export->WAR file.
Successivamente verrà richiesta
la path di destinazione del file e
il nostro WAR è pronto per il
deploy.
Ora occorre spostare il file WAR appena creato all'interno della cartella webapps di
Tomcat.
A tal proposito possiamo utilizzare due alternative:
•
Spostare fisicamente il file nella macchina di sviluppo
•
Utilizzare il manager del tomcat
Indirizzo del server
Path del WAR file
Fig. 20 - Tomcat
Application Manager
39
Capitolo 3
Preparazione dell’ambiente di sviluppo
Conclusioni
I vantaggi della seconda soluzione sono evidenti, è possibile effettuare un deploy su
qualsiasi Application server compatibile con le specifiche di Sun semplicemente copiando
il file nella posizione giusta ed effettuando il restart. Utilizzando il metodo tradizionale,
invece, dovremmo verificare caso per caso qual è la procedura di creazione del context e
specificando manualmente il CLASSPATH.
La scelta del WAR è indubbiamente la più interessante. Il vero problema è la migrazione
di applicazioni scritte utilizzando strutture differenti e molto spesso questa non è
un'operazione per niente banale.
40
4. La comunicazione client-server
4.1
Servizi offerti lato server
Funzioni utilizzate lato SERVER
Una qualsiasi applicazione JDBC deve:
1. Creare una connessione con il DataBase
2. Creare un oggetto Statement per interrogare il database.
3. Interagire con il database.
4. Gestire i risultati ottenuti.
Come detto ogni servizio richiede inizialmente di creare una connessione al DataBase,
che viene realizzata tramite il metodo setConnection().
setConnection():
L'API JDBC, racchiusa nel package java.sql.*, fornisce un'interfaccia unificata per
l'accesso ad un qualunque database, "mascherando" le peculiarità di ogni singolo DBMS
introducendo il concetto di driver.
Per capire meglio cosa questo significhi basta dare un'occhiata alla documentazione del
pacchetto java.sql: ci si accorge immediatamente che la maggior parte delle funzionalità
vengono fornite tramite interfacce (cioè tipi puramente astratti), mentre le classi vere e
proprie sono davvero poche. Cosa implica tutto ciò? Semplicemente, l'API JDBC si
limita in gran parte a dichiarare le funzionalità che un'interfaccia generalizzata per
l'accesso ad un database dovrebbe avere, delegando l'implementazione delle interfacce ai
driver che devono fornire l'accesso ai singoli DBMS. Quindi, compito di un driver
JDBC è fornire un insieme di classi che implementino tutte le interfacce dichiarate
nel pacchetto java.sql.
I parametri di connessione vengono recuperati da un file di Properties tramite l’istruzione
di load(…).
41
Capitolo 4
La comunicazione client-server
Il file DBConfig2 contenente tutti i parametri di connessione ed è situato nella cartella di
installazione del TOMCAT, mentre per recuperare informazioni scritte sul file viene
usato il comando getProperty(…).
Quindi
in
tal
modo
è
possibile
(props.getPropery(“JDBCConnectionURL.1”)
recuperare
e
il
l’URL
driver
di
connessione
necessario
per
la
connessione(props.getPropery(“JDBCConnectionURL.1”).
L’istruzione successiva carica in memoria il driver JDBC per l’accesso al DBMS, infatti
le specifiche JDBC redatte dalla Sun prevedono che, per poter essere utilizzato, un driver
JDBC deve essere caricato in memoria, e una volta che ciò è avvenuto, il driver stesso ha
il compito di registrarsi presso il Driver Manager, il quale ha quindi il compito di tenere
traccia dei driver JDBC disponibili, in modo da poter costruire correttamente le istanze
delle classi che implementano l'interfaccia java.sql.Connection quando queste vengono
richieste dalle applicazioni.
Successivamente vengono recuperate dal file di Property la Username per accedere al DB
(props.getProperty("UserName.1")) e la password (props.getProperty("UserName.1")).
Tramite l’istruzione setPropery() assegno alla stringa jdbc.driver il valore di driver_class,
ovvero il driver per la connessione al DB.
E’ molto importante settare il Driver in quanto converte chiamate JDBC in chiamate di
rete dirette utilizzando protocolli di rete specifici del database (socket), inoltre è
semplice da utilizzare in quanto non richiede di avere librerie o software speciali.
Ottenere una connessione al database tramite JDBC è abbastanza semplice ed
indipendente da quale tipo di DBMS si stia utilizzando. E’ necessario solamente indicare
all’applicazione, tramite il DriverManager, quale driver utilizzare e farsi rilasciare un
oggetto Connection che servirà per dialogare con la base dati. E’ da notare che per
identificare il database è necessario specificare l’URL, ossia l’indirizzo verso il quale
tentare la connessione. Questa stringa può variare in base al tipo di driver utilizzato, e,
alcune volte, può richiedere anche la specificazione di login e password dell’utente, come
nel nostro caso.
La classe DriverManager non è l'unica che permette la connessione con un DB, ma è
possibile utilizzare anche l'interfaccia Driver che permette di accedere a tutte le
informazioni che riguardano il db.
JDBC permette di sfruttare una delle caratteristiche piu' importanti dei Database ovvero
la gestione delle transazioni. Tale gestione si effettua attraverso due semplici metodi
42
Capitolo 4
La comunicazione client-server
della classe Connection: commit e rollback. Il significato dei due metodi e' quello che
ci si aspetta: il metodo commit rende definitive tutte le modifiche apportate usando la
connessione fino al precedente commit o rollback, viceversa il metodo rollback le
annulla fino al precedente commit. All'apertura di una connessione la connessione stessa
puo' rendere definitiva ogni singola modifica senza bisogno di chiamare esplicitamente il
metodo commit (Auto Commit).
Per fare in modo che la semantica dei metodi commit e rollback sia quella descritta
prima dobbiamo togliere l'Auto Commit nella connessione usando il metodo
setAutoCommit(false).
E' chiaro che i metodi per la gestione delle transazioni hanno effetto su tutte e sole le
operazioni effettuate sul DB tramite la connessione su cui vengono invocati i metodi
stessi.
public void setConnection()
throws
IllegalAccessException
, InstantiationException
, ClassNotFoundException
, SQLException
, FileNotFoundException
, IOException{
try {
Properties props= new Properties();
FileInputStream in = new
FileInputStream(System.getProperty("catalina.home")+
File.separator+"DBConfig2");
props.load(in);
in.close();
String
connectionURL=props.getProperty("JDBCConnectionURL.1");
String driver_class=
props.getProperty("JDBCDriver.1");
Class.forName (driver_class).newInstance();
String dbUser= props.getProperty("UserName.1");
String dbPassword= props.getProperty("Password.1");
System.setProperty("jdbc.drivers", driver_class);
conn = DriverManager.getConnection(connectionURL,
dbUser, dbPassword);
conn.setAutoCommit(false);
System.out.println("Connected.\n");
}
catch (IllegalAccessException e) {
System.out.println("Illegal Access Exception: (Open
Connection).");
e.printStackTrace();
throw e;
}
43
Capitolo 4
La comunicazione client-server
catch (InstantiationException e) {
System.out.println("Instantiation Exception: (Open
Connection).");
e.printStackTrace();
throw e;
}
catch (ClassNotFoundException e) {
System.out.println("Class Not Found Exception: (Open
Connection).");
e.printStackTrace();
throw e;
}
catch (SQLException e) {
System.out.println("Caught SQL Exception: (Open
Connection).");
e.printStackTrace();
throw e;
}
catch (FileNotFoundException e) {
System.out.println("Caught : FileNotFoundException
(Open connection).");
e.printStackTrace();
throw e;
}
catch (IOException e) {
System.out.println("Caught : IOException (Open
connection).");
e.printStackTrace();
throw e;
}
}
Come file di Properties abbiamo utilizzato un semplice file di testo all’interno del quale
sono settati i valori assegnati alle variabili per la connessione, ovvero il driver, l’URL di
connessione, la Username e la Password.
String driver_class = "oracle.jdbc.driver.OracleDriver";
String connectionURL = "jdbc:oracle:thin:@172.18.11.201:1521:ora920";
String dbUser="STAGE02";
String dbPassword="STAGE02";
authentication():
Ogni servizio per implementare un maggior livello di sicurezza richiede come parametro
username e password. Tramite la funzione authentication() il Web Service va a
44
Capitolo 4
La comunicazione client-server
controllare nel proprio data base l’esistenza effettiva dell’utente che ha richiesto di essere
loggato. Ciò equivale a realizzare la seguente query:
SELECT count(*) from tm_utenti,tm_unitaeroganti
WHERE utn_username='"+username+"' AND
utn_password='"+password+"' AND
utn_codente=uer_codente AND utn_codstruttura=uer_codstruttura
AND
utn_codspecialita=uer_codspecialita AND
utn_codunitaerogante=uer_codunitaerogante
Se il risultato è diverso da zero (dovrebbe essere al massimo uguale ad uno), significa
che il Web Service ha riconosciuto l’utente come utente autorizzato e gli permette
l’accesso all’interno dell’applicazione.
userInfo():
Tale metodo restituisce tutte le informazioni relative ad un dato utente.
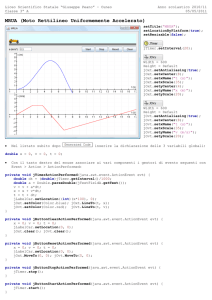
setConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT utn_id, utn_type,
utn_codente, utn_codstruttura, utn_codspecialita FROM tm_utenti
WHERE utn_cn = " + StringUtil.quoteString(utn_cn));
if (rs.next()) {
info = rs.getInt(1) + ";" + rs.getString(2) + ";" +
rs.getString(3)
+ ";" + rs.getString(4)+";"+rs.getString(5);
}
rs.close();
stmt.close();
conn.close();
Come visto precedentemente la connessione al data base viene effettuato tramite il
metodo setConnection(), successivamente viene creato la Statement e il ResultSet a cui
viene assegnato il risultato della query.
45
Capitolo 4
La comunicazione client-server
I comandi di scrittura come INSERT, UPDATE e DELETE restituiscono un valore che
indica quante righe sono state affette (inserite, modificate, cancellate) dall'istruzione. Essi
non restituiscono altre informazioni.
Le interrogazioni (query) restituiscono un result set (classe ResultSet).
È possibile spostarsi nel result set riga per riga (tramite il metodo next()). Si può accedere
alle colonne di ogni singola riga chiamandole per nome o per numero. Il result set può
essere costituito da un numero qualsiasi di righe. Esso comprende dei metadati che
indicano il nome, il tipo e le dimensioni delle colonne.
Per le stringhe viene utilizzato il metodo quoteString() della classe StringUtil contenente
funzioni di utilità per la loro gestione, soprattutto in fase di interfacciamento con i data
base(query e insert).
listEvents(double utn_id, double days):
Metodo usato dal refertante, che ritorna l’elenco degli eventi che il dottore è in grado di
refertare / visualizzare. Essendo un metodo utilizzato dal refertante inizialmente vi è una
select che controlla se l’utente è un erogante. In caso positivo viene fatto un controllo sul
tipo di esami che l’erogante è in grado di refertare, tramite la seguente query:
SELECT per_tes_codice FROM TM_PERMISSIONI WHERE per_utn_id = " + utn_id +
",
cioè restituisce il codice che identifica il tipo di esame di possibile refertazione.
I valori ottenuti dall’interrogazione devono essere inviati al client per alimentare la
griglia., quindi viene creato un file xml contenente il risultato della query.
fileName=FileUtil.createXML("SELECT evt_id, evt_dateopen, evt_utn_id,
utn_cn, evt_trf_codice, tes_descr, evt_sesso, evt_razza, evt_eta,
evt_altezza, evt_um_altezza, evt_peso, evt_um_peso,
evt_memo,COUNT(REF_IND) REFERTI
FROM TM_EVENTI, TM_TIPOESAMI, TM_UTENTI, TM_REFERTI
WHERE evt_utn_id=utn_id AND evt_trf_codice=tes_codice AND
evt_trf_codice IN (" +sql_viewexams+ ") AND evt_dateclose IS NULL AND
EVT_ID=REF_EVT_ID(+) AND evt_dateopen>=SYSDATE-"+days+" GROUP BY
evt_id, evt_dateopen, evt_utn_id, utn_cn, evt_trf_codice, tes_descr,
evt_sesso, evt_razza, evt_eta, evt_altezza, evt_um_altezza, evt_peso,
evt_um_peso, evt_memo ORDER BY REFERTI","ListEventE",(int)utn_id)
46
Capitolo 4
La comunicazione client-server
Ma come è possibile creare un file XML a partire da una query?
Il linguaggio di programmazione java, mette a disposizione tramite la libreria javax.xml
delle funzioni che permettono di fare ciò, ovvero di incapsulare i risultati della query
all’interno di tag XML. Il codice da noi utilizzato per realizzare tale scopo è il seguente:
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document doc=db.newDocument();
Element root=doc.createElement("root_element");
//connect to database
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(querySQL);
ResultSetMetaData rsmd = rs.getMetaData();
while(rs.next()){
Element row=doc.createElement("row");
for(int j=1;j<=rsmd.getColumnCount();j++){
String colName=rsmd.getColumnName(j);
String colValue=rs.getString(j);
Element e=doc.createElement(colName);
e.appendChild(doc.createTextNode(colValue));
row.appendChild(e);
}
root.appendChild(row);
}
doc.appendChild(root);
TransformerFactory tmf=TransformerFactory.newInstance();
Transformer tf=tmf.newTransformer();
DOMSource source=new DOMSource(doc);
//write to the stream
StreamResult result=new StreamResult(fileFullName);
tf.transform(source,result);
Creato il file Xml contenente il risultato della query, esso viene inviato come allegato
tramite il seguente frammento di codice:
message=(org.apache.axis.MessageContext.getCurrentContext()).getResponseMessage
();
message.addAttachmentPart(message.createAttachmentPart(newDataHandler(new
URL("file:"+File.separator+fileNamePath+fileName))));.
Essendo un argomento particolarmente delicato quello inerente agli allegati vi torneremo
in un secondo momento.
47
Capitolo 4
La comunicazione client-server
Inoltre, poichè molti degli altri servizi implementati, utilizzano la tecnica appena vista
(creazione del file XML e invio come allegato), non ci soffermeremo dettagliatamente
sulla loro descrizione.
openEvent(…):
Il metodo OpenEvent permette ad un richiedente di inserire un nuovo evento che poi sarà
soggetto a refertazione.
E’ uno dei pochi casi in cui non c’è la creazione del file xml e il suo funzionamento è
semplicissimo:
•
Ha come parametri le informazioni necessarie al nuovo evento
•
Prende tali parametri e fa un “INSERT” all’interno del database
Ora poiché la tabella oggetto dell’insert ha un campo BLOB (Binary Large OBject)
destinato a ricevere la codifica binaria dell’allegato (la documentazione relativa ad un
esame, eg. immagine di una radiografia o di una tac ecc…) abbiamo la necessità di una
particolare gestione:
•
Occorre dapprima inserire un “EMPTY_BLOB” nel campo BLOB della tabella
(FASE 1)
•
Selezionare tramite una query l’EMPTY_BLOB appena inserito (FASE 2)
•
Recuperare il vero BLOB come attachment (FASE 3)
•
Sovrascrivere l’EMPTY_BLOB con l’effettivo BLOB (FASE 4)
Vediamo come tutto questo viene realizzato:
FASE 1:
setConnection();
stmt = conn.createStatement();
stmt.execute("INSERT INTO tm_eventi (evt_utn_id, evt_trf_codice, evt_dateopen,
evt_codice_esterno, evt_sesso, evt_eta, evt_altezza,
evt_um_altezza, evt_peso, evt_um_peso, evt_memo,
evt_nomeallegato, evt_allegato)
VALUES (" +
utn_id + "," +
StringUtil.quoteString(evt_trf_codice) + ",TO_DATE('"
+
DateTime.getCurrentDateTime()+"','YYYY-MM-DD
HH24:MI:SS'),"
+
StringUtil.quoteString(evt_codice_esterno) + "," +
48
Capitolo 4
La comunicazione client-server
StringUtil.quoteString(evt_sesso) + "," +
evt_eta + "," +
evt_altezza + "," +
StringUtil.quoteString(evt_um_altezza) + "," +
evt_peso + ","+
StringUtil.quoteString(evt_um_peso) + "," +
StringUtil.quoteString(evt_memo)+","+
StringUtil.quoteString(evt_nomeallegato.trim())+
",EMPTY_BLOB())");
stmt.close();
FASE 2:
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT MAX(EVT_ID) FROM TM_EVENTI WHERE EVT_UTN_ID="+
utn_id);
if (rs.next()) evt_id=Integer.parseInt(rs.getString(1));
stmt.close();
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT EVT_ALLEGATO FROM TM_EVENTI WHERE
EVT_ID="+evt_id+" FOR UPDATE NOWAIT");
FASE 3:
if (rs.next()) {
oracle.sql.BLOB bcol = ((OracleResultSet)rs).getBLOB(1);
OutputStream blobOutputStream = bcol.getBinaryOutputStream();
//Recupera allegato dal messaggio di richiesta del client
message=(org.apache.axis.MessageContext.getCurrentContext()).getRequestMessage(
);
Iterator attachments = message.getAttachments();
//Se non ci sono attachment ritorna -5
if(!attachments.hasNext())return -5;
//Prendo solo il primo allegato
att = (AttachmentPart) attachments.next();
DataHandler dh = att.getActivationDataHandler();
//Ottengo la codifica in byte dell'allegato
BufferedInputStream bis = new BufferedInputStream(dh.getInputStream());
byte[] bs = new byte[bis.available()];
bis.read(bs, 0, bs.length);
bis.close();
FASE 4:
//Inserisco la codifica in byte dell'allegato nel campo BLOB del DB
blobOutputStream.write(bs, 0, bs.length);
blobOutputStream.flush();
blobOutputStream.close();
System.out.println("Generato nuovo evento con id "+(int)evt_id+".");
}
stmt.close();
conn.close();
49
Capitolo 4
La comunicazione client-server
closeEvent(int evt_id):
Tale metodo aggiorna lo stato dell’evento a chiuso, ovvero l’utente richiedente ha deciso
che non ha più bisogno di ulteriori refertazioni.
Per fare ciò va a valorizzare il campo evt_dateclose della tabella eventi con la
data corrente:
setConnection();
Statement stmt = conn.createStatement();
stmt.execute("UPDATE tm_eventi SET evt_dateclose = TO_DATE('" +
DateTime.getCurrentDateTime()+"','YYYY-MM-DD HH24:MI:SS') WHERE EVT_ID=
"+evt_id);
System.out.println("Evento "+(int)evt_id+" chiuso con successo.");
stmt.close();
conn.close();
downloadEvent(double evt_id):
Permette ad un client (refertante) di scaricare la documentazione relativa ad un dato
evento che egli intende refertare.
La procedura consta di 4 passi:
•
Recupero dal database del nome del file relativo all’evento richiesto dal client
•
Lettura dal database del BLOB corrispondente all’evento richiesto
•
Scrittura del BLOB in un file fisico
•
Invio del file appena creato come attachment
setConnection();
//Recupero nome del file
Statement stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT TRIM(EVT_NOMEALLEGATO) EVT_NOMEALLEGATO FROM
TM_EVENTI WHERE EVT_ID= "+evt_id);
if (rs.next())
fileName=rs.getString(1);
stmt.close();
String fileFullName=fileNamePath+fileName.trim();
//Recupero del BLOB
stmt = conn.createStatement();
50
Capitolo 4
La comunicazione client-server
rs = stmt.executeQuery("SELECT EVT_ALLEGATO FROM TM_EVENTI WHERE EVT_ID=
"+evt_id);
if (rs.next()) {
oracle.sql.BLOB bcol =((OracleResultSet)rs).getBLOB(1);
//Scrittura del blob su un file fisico
long inizio=1;
dati = bcol.getBytes(inizio,(int)bcol.length());
FileOutputStream inn=new FileOutputStream(fileFullName);
for(int i=0;i<dati.length;i++){
inn.write(dati[i]);
}
inn.close();
//Invio del file come attachment
message=(org.apache.axis.MessageContext.getCurrentContext()).getResponseM
essage();
/*LINUX*/
message.addAttachmentPart(message.createAttachmentPart(new
DataHandler(new
URL("file:"+File.separator+File.separator+fileNamePath+fileName))));
/*WINDOWS*/
//message.addAttachmentPart(message.createAttachmentPart(new
DataHandler(new ù
URL("file:"+File.separator+fileNamePath+fileName))));
//Cancellazione del file dalla cartella temp del Tomcat
FileUtil.deleteFiles();
System.out.print("Download documentazione evento "+(int)evt_id+"
scaricata con successo.");
}
stmt.close();
conn.close();
referta(…):
Analogo ad openEvent(), esso inserisce nella tabella dei referti l’evento appena refertato.
Anche in tal caso è presente un attachment, quindi un campo BLOB (documentazione del
referto) che deve essere gestito allo stesso modo a quanto fatto precedentemente.
Vediamo com’è stata strutturata la query d’inserimento:
setConnection();
stmt = conn.createStatement();
String query="INSERT INTO tm_referti (ref_evt_id, ref_utn_id, ref_datereferto,
ref_nomeallegato_referto, ref_allegato_referto, ref_memo,
ref_definitivo)
VALUES (" +
ref_evt_id + "," +
ref_utn_id + ",TO_DATE('" +
DateTime.getCurrentDateTime()+"','YYYY-MM-DD HH24:MI:SS'),"+
StringUtil.quoteString(ref_nomeallegato_referto.trim()) +
",EMPTY_BLOB()," +
StringUtil.quoteString(ref_memo)+","+
StringUtil.quoteString(ref_definitivo)+")";
51
Capitolo 4
La comunicazione client-server
stmt.execute(query);
stmt.close();
listEventReferted(double utn_id):
Visualizza gli eventi refertati relativi ad un specificato utente.
E’ costituito dalla solita struttura:
Creazione xml
Invio come attachment
Ci soffermiamo alla query con la quale viene creato l’xml:
fileName=FileUtil.createXML("SELECT evt_id, evt_trf_codice, tes_descr,
evt_dateopen,evt_codice_esterno, COUNT(REF_IND) REFERTI FROM TM_EVENTI,
TM_TIPOESAMI, TM_UTENTI, TM_REFERTI WHERE evt_utn_id=utn_id AND
evt_trf_codice=tes_codice AND evt_dateclose IS NULL AND
EVT_ID=REF_EVT_ID(+) AND utn_id="+utn_id+" GROUP BY evt_id,
evt_trf_codice, tes_descr, evt_dateopen,evt_codice_esterno ORDER BY
REFERTI DESC","ListEventR",(int)utn_id);
listEventRefertedByEvtId(double ref_evt_id):
Permette di visualizzare tutte le refertazioni relative ad un dato evento (ogni evento può
avere più di una refertazione).
Anch’esso si basa sul binomio creazione xml e invio come attachment:
fileName=FileUtil.createXML("SELECT REF_IND,REF_UTN_ID, UTN_CN,
REF_DATEREFERTO,TES_DESCR,REF_NOMEALLEGATO_REFERTO,REF_MEMO,REF_DEFINIT
IVO FROM TM_EVENTI,TM_REFERTI, TM_UTENTI, TM_TIPOESAMI WHERE
EVT_TRF_CODICE=TES_CODICE AND UTN_ID=REF_UTN_ID AND
REF_EVT_ID="+ref_evt_id+" AND
EVT_ID=REF_EVT_ID","ListRefertByEvtId",(int)ref_evt_id);
52
Capitolo 4
La comunicazione client-server
downloadRefert(double ref_ind):
Così come un refertante scarica la documentazione relativa all’evento che egli vuole
refertare, allora alla stessa maniera un utente richiedente a refertazione ultimata chiede di
scaricare il referto relativo alla sua richiesta.
setConnection();
//Recupero nome del file
Statement stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT TRIM(REF_NOMEALLEGATO_REFERTO)
REF_NOMEALLEGATO_REFERTO
FROM TM_REFERTI WHERE REF_IND= "+ref_ind);
if (rs.next())
fileName=rs.getString(1);
stmt.close();
String fileFullName=fileNamePath+fileName.trim();
stmt = conn.createStatement();
//Recupero del BLOB
rs = stmt.executeQuery("SELECT REF_ALLEGATO_REFERTO FROM TM_REFERTI WHERE
REF_IND=
"+ref_ind);
if (rs.next()) {
oracle.sql.BLOB bcol =((OracleResultSet)rs).getBLOB(1);
//Scrittura del blob su un file fisico
long inizio=1;
dati = bcol.getBytes(inizio,(int)bcol.length());
FileOutputStream inn=new FileOutputStream(fileFullName);
for(int i=0;i<dati.length;i++){
inn.write(dati[i]);
}
inn.close();
//Invio del file come attachment
message=(org.apache.axis.MessageContext.getCurrentContext()).getResponseM
essage();
/*LINUX*/
message.addAttachmentPart(message.createAttachmentPart(new
DataHandler(new
URL("file:"+File.separator+File.separator+fileNamePath+fileName))));
/*WINDOWS*/
//message.addAttachmentPart(message.createAttachmentPart(new
DataHandler(new
URL("file:"+File.separator+fileNamePath+fileName))));
System.out.print("Download referto "+(int)ref_ind+" effettuato con
successo.");
//Cancellazione del file dalla cartella temp del Tomcat
FileUtil.deleteFiles();
}
stmt.close();
conn.close();
53
Capitolo 4
La comunicazione client-server
showStoric(double utn_id):
Permette di visualizzare lo storico degli eventi di un determinato utente, ovvero gli eventi
che l’utente stesso ha deciso di chiudere.
Anch’esso a partire da una query genera un file xml che poi verrà inviato come
attachment.
La query è la seguente:
SELECT evt_id, evt_trf_codice, tes_descr, evt_dateopen,evt_dateclose,
evt_nomeallegato, evt_codice_esterno, evt_memo,COUNT(REF_IND) REFERTI
FROM TM_EVENTI, TM_TIPOESAMI, TM_UTENTI, TM_REFERTI WHERE
evt_utn_id=utn_id AND evt_trf_codice=tes_codice AND evt_dateclose IS
NOT NULL AND EVT_ID=REF_EVT_ID(+) AND utn_id="+utn_id+" GROUP BY
evt_id, evt_trf_codice, tes_descr, evt_dateopen,evt_dateclose,
evt_nomeallegato, evt_codice_esterno, evt_memo ORDER BY REFERTI
Il filtro fondamentale è la presenza di una data di chiusura non nulla.
listRefertForErogants(double utn_id, double days):
E’ un servizio destinato ad un utente refertante e permette di visualizzare i referti da egli
effettuati che sono ancora aperti, ovvero che non sono stati dichiarati, sempre dallo stesso
refertante, definitivi. Inoltre tali referti sono filtrati secondo una specifica data, cioè il
refertante può consultare solamente quei referti che hanno una data di refertazione che
rientri in un range stabilito dalla data corrente e dai giorni selezionati da lui stesso
nell’interfaccia di visualizzazione.
Tramite una query viene creato un file xml che poi viene inviato al client come allegato.
Query:
SELECT ref_ind, ref_evt_id, evt_utn_id, utn_cn, evt_trf_codice,
tes_descr, ref_datereferto, ref_definitivo FROM TM_EVENTI,
TM_TIPOESAMI, TM_UTENTI, TM_REFERTI WHERE evt_utn_id=utn_id AND
evt_trf_codice=tes_codice AND evt_trf_codice IN (SELECT per_tes_codice
FROM TM_PERMISSIONI WHERE per_utn_id = ref_utn_id) AND evt_dateclose IS
NULL AND EVT_ID=REF_EVT_ID(+) AND ref_datereferto>=SYSDATE-"+days+" AND
ref_utn_id="+utn_id+" ORDER BY REF_DEFINITIVO
54
Capitolo 4
La comunicazione client-server
refertToEvent(double ref_ind):
Permette di visualizzare le informazioni di interesse relative alla richiesta di un evento
che è stato gia refertato, ad esempio tipo e codice esame, caratteristiche fisiche del
richiedente, informazioni sul referto.
Tale servizio viene invocato nel momento in cui un utente erogante (refertante) decide di
consultare la refertazione di un evento che ha già subito delle refertazioni da parte
dell’utente stesso o da altri utenti autorizzati. In tal caso vedrà visualizzate oltre alle
informazioni dell’evento anche la diagnosi con tanto di referto allegato.
Tutte le informazioni verranno visualizzate lato client in una griglia alimentata tramite un
file xml creato attraverso la seguente query:
SELECT ref_evt_id, evt_trf_codice, tes_descr, ref_definitivo, ref_memo,
evt_sesso, evt_eta,
evt_peso,evt_um_peso,evt_altezza,evt_um_altezza,evt_memo,
ref_nomeallegato_referto FROM TM_EVENTI, TM_TIPOESAMI, TM_UTENTI,
TM_REFERTI WHERE evt_utn_id=utn_id AND ref_evt_id=evt_id AND
evt_trf_codice=tes_codice AND evt_trf_codice IN (SELECT per_tes_codice
FROM TM_PERMISSIONI WHERE per_utn_id = ref_utn_id) AND evt_dateclose IS
NULL AND EVT_ID=REF_EVT_ID(+) AND ref_ind="+ref_ind
updateRefert(double ref_ind, ….):
Consente ad un utente refertante di poter modificare un qualsiasi suo referto dichiarato
non definitivo. E’ analogo al servizio “referta”, l’unica differenza sta nella query: si usa
un UPDATE anziché INSERT.
setConnection();
stmt = conn.createStatement();
String query="UPDATE tm_referti SET" +
"
REF_NOMEALLEGATO_REFERTO="+StringUtil.quoteString(ref_nomeallegato_referto.trim
()) + "," + " REF_MEMO="+StringUtil.quoteString(ref_memo)+ "," +
" REF_DEFINITIVO="+StringUtil.quoteString(ref_definitivo) + ","+
" REF_DATEREFERTO=TO_DATE('"+DateTime.getCurrentDateTime()+"','YYYY-MM-DD
HH24:MI:SS')"+
" WHERE REF_IND="+ref_ind;
stmt.execute(query);
stmt.close();
55
Capitolo 4
La comunicazione client-server
Per il campo BLOB viene utilizzata la stessa procedura ampliamente descritta in alcuni
dei servizi precedenti.
updateRefertWithoutBLOB(double ref_ind, ….):
E’ il servizio precedente senza però l’update del campo BLOB.
login(String user, String pswd):
Il servizio di login è molto simile al servizio “authentication”, ma leggermente più
comleto.
Infatti oltre ad andare a verificare l’esistenza dell’utente che ha richiesto l’accesso
all’applicazione sul database, esso, in caso affermativo, invia al client un file xml
contenete le informazioni principali dell’utente appena loggato, cosicché queste possano
essere visualizzate nell’interfaccia migliorando l’estetica e la leggibilità.
Tramite una query si reperiscono le informazioni dell’utente che vengono poi incapsulate
in un file xml e inviate come allegato al client.
Query:
String query="SELECT
utn_id,utn_cn,utn_type,utn_codente,utn_codstruttura,utn_codspecialita,u
tn_codunitaerogante,uer_descr from tm_utenti,tm_unitaeroganti WHERE
utn_username='"+user+"' AND utn_password='"+pswd+"' AND
utn_codente=uer_codente AND utn_codstruttura=uer_codstruttura AND
utn_codspecialita=uer_codspecialita AND
utn_codunitaerogante=uer_codunitaerogante";
56
Capitolo 4
4.2
La comunicazione client-server
Axis Attachment
LATO SERVER
a) Aggiungere un allegato al messaggio SOAP di risposta al client (upload)
import java.io.*;
import java.net.URL;
import javax.activation.DataHandler;
import javax.xml.soap.SOAPMessage;
import org.apache.axis.attachments.AttachmentPart;
// ……Servizio del Web Services……
SOAPMessage message=null;
message=(org.apache.axis.MessageContext.getCurrentContext()).getResponseMessage();
URL url= new URL("file:"+File.separator+fileNamePath+fileName)
message.addAttachmentPart(message.createAttachmentPart(new DataHandler(url));
Poiché si vuole allegare un file al messaggio di risposta del server verso il client, si deve
recuperare il Context (contesto) corrente e quindi il relativo messaggi di risposta
(getResponseMessage()).
Per
org.apache.axis.MessageContext
getResponseMessage().
La
realizzare
e,
classe
in
ciò
si
utilizza
ordine,
i
metodi
SOAPMessage
la
classe
di
Axis
getCurrentContext()
implementa
il
e
metodo
addAttachmentPart che permette, individuato l’URL del file e creata la classe
DataHandler, di creare una sezione del messaggio SOAP in cui posizionare effettivamente
l’allegato.
57
Capitolo 4
La comunicazione client-server
b) Recuperare un allegato dal messaggio SOAP di richiesta dal client (download)
Codice
import java.io.*;
import java.net.URL;
import javax.activation.DataHandler;
import javax.xml.soap.SOAPMessage;
import org.apache.axis.attachments.AttachmentPart;
//……Servizio del Web Services……
message=(org.apache.axis.MessageContext.getCurrentContext()).getRequestMessage();
Iterator attachments = message.getAttachments();
if(!attachments.hasNext())return -5; //Se non ci sono attachment ritorna -5
att = (AttachmentPart) attachments.next(); //Prendo solo il primo allegato
DataHandler dh = att.getDataHandler();
BufferedInputStream bis = new BufferedInputStream(dh.getInputStream());
byte[] bs = new byte[bis.available()];
bis.read(bs, 0, bs.length);
bis.close();
Poiché si vuole recuperare un allegato dal messaggio di richiesta del client verso il server,
si deve recuperare il Context (contesto) corrente e quindi il relativo messaggi di richiesta
(getRequestMessage()). La classe SOAPMessage mette a disposizione il metodo
getAttachments() che restituisce un iterator degli allegati. Si recupera, quindi, il primo
allegato (primo elemento dell’iterator) ed il relativo DataHandler attraverso il metodo
getDataHandler(). A questo punto si attivano i canali di stream per la successiva scrittura
del file sul file system.
58
Capitolo 4
La comunicazione client-server
TCP/IP Monitor
Abbiamo più volte parlato del TCP/IP Monitor come uno strumento per il controllo dello
scambio di messaggi tra client e server. Vediamo come appare la sua interfaccia:
Ora di invio della richiesta, tempo
di risposta, protocollo utilizzato
Richiesta del
client
Struttura del messaggio SOAP
contenente la richiesta da parte
del client di un determinato
servizio.
Risposta del
server
Struttura del messaggio SOAP
contenente la risposta da parte del
server al servizio richiesto dal
client.
La presenza di un attachement si nota dalla parola chiave _Part_ seguita da un numero di serie.
In questo caso il server ha risposto al client inviando un determinato file (nella maggioranza dei
casi xml) come allegato.
59
5. Struttura del database
5.1 Specifica delle operazioni
Il modello base impostato ha come concetti di riferimento l’Utente Richiedente, oggetto
del servizio di assistenza e l’Utente Erogante, soggetti che erogano il servizio di
refertazione. Il richiedente (accreditato) che si interfaccia con questo applicativo deve
avere la possibilità di fare una richiesta “generica” (senza un destinatario definito)
pubblicando il risultato di una indagine clinica. A questo punto un qualunque refertante
accreditato può interagire con il nostro applicativo e fornire una risposta al richiedente. Se
il richiedente è soddisfatto della refertazione ottenuta può chiudere il processo di
pubblicazione, altrimenti lasciare pubblicata la richiesta in attesa di refertazione da parte di
refertanti diversi.
60
Capitolo 5
Struttura del database
5.2 Specifiche di progetto
Gli utenti Database presenti sono:
•
ENTE RICHIEDENTE
•
ENTE EROGANTE
Innanzitutto nella pagina iniziale è presente un area di accesso riservato in cui vi è
l’identificazione dell’utente richiedente o dell’utente che emette il referto. In base
all’utente che si autentica viene fuori una maschera diversa.
Nella maschera
relativa all’ utente RICHIEDENTE
è presente una sorta di menù
contenente la gestione delle varie richieste, ossia le informazioni relative alla nuova
richiesta, lo stato delle richieste non chiuse ovvero il messaggio di consulta delle
61
Capitolo 5
Struttura del database
richieste non chiuse e uno storico delle richieste chiuse entro due mesi dalla data in cui la
richiesta viene chiusa.
Operazioni possibili di un utente richiedente
Informazioni utente: nome e tipo
Per inserire un nuovo evento il richiedente deve compilare un modulo in cui inizialmente
seleziona la lingua (Italiano/Inglese).
Successivamente inserisce tutte le informazioni personali quali sesso, età, altezza e peso.
Altre informazioni necessarie per identificare la richiesta sono: Riferimento della
richiesta, il tipo di riferimento, un campo note (per eventuali chiarimenti) e un campo
Allegati in cui è possibile inserire degli allegati, ovvero documenti digitali relativi agli
esami effettuati.
62
Capitolo 5
Struttura del database
Figura – Maschera di inserimento di un nuovo evento
Cliccando sulla voce “Eventi refertati” vengono visualizzati tutti gli eventi per cui l’utente
richiedente appena loggato ha richiesto una refertazione.
Numero di referti per un dato evento
Link ai dettagli di un dato evento
Possibilità di chiudere un evento
Selezionando invece “Eventi chiusi” appare una maschera simile alla precedente nella
quale sono elencati tutti gli eventi generati da un dato utente che per qualche motivo sono
63
Capitolo 5
Struttura del database
stati chiusi, ovvero l’utente ha deciso che non è più interessato ad alcuna refertazione o ad
alcuna ulteriore refertazione.
Un evento chiuso non è più visibile da un refertante.
Nella maschera relativa all’utente che effettua il referto è presente un menù contenente un
link ad una lista degli eventi aperti ed uno ai referti non definitivi.
Quando parliamo di lista di referti o lista di eventi aperti bisogna specificare che essi sono
tutti quelli del tipo per cui un utente erogante è specializzato, ovvero, per esempio, se
l’utente è un radiologo egli potrà refertare solo esami di radiologia (e non ad esempio
quelli di virologia).
Tali liste potranno essere consultate dai refertanti i quali in seguito potranno dare un loro
parere.
64
Capitolo 5
Struttura del database
Operazioni possibili di un utente erogante
Informazioni utente: nome e tipo
Filtro per data
Figura – Maschera di visualizzazione degli eventi aperti
Per inserire un referto è necessario cliccare sull’evento (nell’esempio il 469); si aprirà una
finestra con tutti i dettagli e con la possibilità di scaricare la documentazione relativa
all’evento.
65
Capitolo 5
Struttura del database
Successivamente occorre compilare un modulo che ha la seguente forma:
Compilato il modulo e inserito il referto come allegato per inoltrarlo al servar basta
premere il pulsante “Invia referto”.
66
Capitolo 5
Struttura del database
Infine, selezionando dal menù la voce “Referti aperti”, l’utente erogante può consultare le
refertazioni che lui stesso ha emesso o che sono in fase di emissione (refertazione non
definitiva).
Sempre dal menù sulla sinistra è possibile disconnettersi e tornare alla pagina iniziale:
67
Capitolo 5
Struttura del database
5.3. Progettazione concettuale della base di dati
Abbiamo seguito una strategia mista come andremo a descrivere.
5.3.1 Un primo schema scheletro (top-down)
Sono state identificate inizialmente le seguenti entità (che hanno vita propria e
indipendente l’una delle altre): Utente Richiedente e Utente Refertante. Ad un primo
livello di astrazione è concepito il seguente schema scheletro:
5.3.2 Sviluppo delle componenti dello scheletro (inside-out)
Utente
Sia l’Utente Richiedente che l’Utente Refertante appartengono a delle strutture cliniche
accreditate e si differenziano tra di loro solo per il ruolo che ricoprono nell’interfacciarsi
con l’applicativo. Si può pensare, quindi, di accorpare queste due entità in una sola entità e
sfruttare una relazione ricorsiva.
Ogni Utente è caratterizzato da:
-
un identificativo univoco dell’utente all’interno del sistema , ID
-
un CommonName che deve essere presente anche all’interno del certificato
digitale, CN
-
un tipo utente (R=utente richiedente, E=utente erogante), TYPE
-
un codice identificativo dell’ente, CODENTE
-
un codice identificativo della struttura, CODSTRUTTURA
-
un codice della specialità della struttura, CODSPECIALITA
-
un codice identificativo dell’unità erogante, CODUNITAEROGANTE
-
una username dell’ utente per l’accesso al repository, USERNAME
-
una password dell’ utente per l’accesso al repository, PASSWORD
68
Capitolo 5
Struttura del database
La chiave primaria per questa entità è l’ID univoco. Un utente richiedente può emettere
una o più richieste di refertazione [cardinalità (1,N)] mentre un utente erogante può
rispondere alle richieste di nessuno o più richiedenti [cardinalità (0,N)]
Unità eroganti
Ogni utente (richiedente o refertante) appartiene ad una unità erogante che è caratterizzata
da:
•
un identificativo dell’ente, CODENTE
•
un identificativo della struttura, CODSTRUTTURA
•
un identificativo della specialità, CODSPECIALITA
•
un codice dell’unità erogante, CODUNITAEROGANTE
•
una descrizione dell’unità erogante, DESCR
Sono chiave primaria il CODENTE, il CODSTRUTTURA, il CODSPECIALITA ed il
CODUNITAEROGANTE.
69
Capitolo 5
Struttura del database
Tipo_Esame
E’ possibile definire, a questo punto, un’entità Tipo_Esame che tiene traccia di tutte le
possibili patologie.
Ogni patologia è individuata da:
-
un codice identificativo della patologia dell’esame, CODICE
-
una descrizione della patologia dell’esame, DESCR
Evento
Ogni laboratorio accreditato che richiede una refertazione ad un altro laboratorio genera un
evento.
Le informazioni necessarie per tale evento sono:
-
identificativo univoco dell’evento all’interno del sistema, ID
-
identificativo univoco del richiedente, UTN_ID
-
tipologia dell’esame collegato all’evento, TRF_CODICE
-
data e ora di creazione dell’evento, DATEOPEN
-
data e ora di chiusura dell’evento, DATECLOSE
70
Capitolo 5
Struttura del database
-
il file allegato all’evento, ALLEGATO
-
nome del file allegato, NOMEALLEGATO
-
codice di ricerca esterna, CODICE_ESTERNO
-
dati aggiuntivi del paziente: RAZZA, SESSO, ETA, ALTEZZA, UM_ALTEZZA,
PESO, UM_PESO, MEMO
Un utente può generare uno o più eventi (richiesta di refertazione) mentre un evento è
legato ad uno ed un solo utente [cardinalità: (1,N) ; (1,1)]. Ad ogni evento, invece, è
associata un’unica patologia.
Il richiedente deve essere un utente accreditato e quindi già registrato nella tabella
UTENTI: per questo motivo UTN_ID è chiave esterna con l’ ID della tabella UTENTI. La
tipologia di esame deve essere una di quelle previste dalla tabella TIPO_ESAMI, perciò
TRF_CODICE è chiave esterna con il CODICE della tabella TIPO_ESAMI.
dateclose
71
Capitolo 5
Struttura del database
Referto
Quando un utente refertante fornisce una risposta ad un utente richiedente genera un
referto.
Le informazioni necessarie per tale referto sono:
-
indice progressivo del referto dell’evento, IND
-
identificativo univoco dell’evento all’interno del sistema, EVT_ID
-
identificativo dell’utente che ha scritto il referto, UTN_ID
-
file che contiene il referto in formato testo, ALLEGATO_REFERTO
-
nome del file del referto, NOMEALLEGATO_REFERTO
-
data e ora di inserimento del referto, DATEREFERTO
Un referto è la risposta ad un determinato evento: perciò EVT_ID è chiave esterna con l’ID
dell’evento. L’utente che ha effettuato il referto deve essere un ente accreditato e già
registrato nella tabella UTENTI: per questo motivo UTN_ID è chiave esterna con l’ID
della tabella UTENTI.
Si noti che ad un evento possono essere associati più referti (in generale potranno essere
forniti referti ad un evento finché l’evento non viene chiuso).
72
Capitolo 5
Struttura del database
Permissioni
Ogni utente refertante potrà eseguire refertazioni solo ed esclusivamente sulle patologie di
competenza, ovvero solo per le patologie a lui accreditate. Per questo motivo si inserisce
un’entità PERMISSIONI che, per ogni utente identifica i tipi referti a lui competenti.
Tale entità si compone di due campi:
-
identificatore dell’utente, IDUTE (che è chiave primaria e chiave esterna con l’ID
della tabella UTENTI)
-
identificatore della patologia di competenza, CODESAME
73
Capitolo 5
Struttura del database
Schema E-R completo
dateclose
74
Capitolo 5
Struttura del database
5.4 Traduzione verso il modello relazionale
Tabella TM_UTENTI
Nome del campo
Tipo
Dim. Identificatore
UTN_ID (Autonumber)
Number
10
UTN_CN
Varchar
128
UTN_TYPE
Varchar
1
UTN_CODENTE
Varchar
10
UTN_CODSTRUTTURA
Varchar
10
UTN_CODSPECIALITA
Varchar
10
UTN_CODUNITAEROGANTE Varchar
10
UTN_USERNAME
Varchar
208
UTN_PASSWORD
Varchar
20
Chiave esterna
Primary Key
TM_UNITAEROGANTI.
UER_CODENTE
TM_UNITAEROGANTI.
UER_CODSTRUTTURA
TM_UNITAEROGANTI.
UER_CODSPECIALITA
TM_UNITAEROGANTI.
UER_CODUNITAEROGANTE
Tabella TM_UNITAEROGANTI
Nome del campo
Tipo
Dimensione Identificatore
UER_CODENTE
Varchar
10
Primary Key
UER_CODSTRUTTURA
Varchar
10
Primary Key
UER_CODSPECIALITA
Varchar
10
Primary Key
UER_CODUNITAEROGANTE
Varchar
10
Primary Key
UER_DESC
Varchar
50
Chiave esterna
75
Capitolo 5
Struttura del database
Tabella TM_TIPOESAMI
Nome del campo
Tipo
Dimensione Identificatore
TES_CODICE
Varchar
10
TES_DESCR
Varchar
255
Chiave esterna
Primary Key
Tabella TM_EVENTI
Nome del campo
Tipo
Dimensione Identificatore
Chiave esterna
EVT_ID (Autonumber)
Number
10
Primary Key
EVT_UTN_ID
Number
10
TM_UTENTI.UTN_ID
EVT_TRF_CODICE
Varchar
10
TM_TIPOESAMI.TES_CODICE
EVT_DATEOPEN
Date
EVT_DATECLOSE
Date
EVT_ALLEGATO
Blob
EVT_NOMEALLEGATO
Varchar
25
EVT_CODICE_ESTERNO Varchar
10
EVT_RAZZA
Varchar
25
EVT_SESSO
Varchar
1
EVT_ETA
Number
3
EVT_ALTEZZA
Number
(8,4)
EVT_UM_ALTEZZA
Varchar
10
EVT_PESO
Number
(8,4)
EVT_UM_PESO
Varchar
10
EVT_MEMO
Varchar
255
Tabella TM_REFERTI
76
Capitolo 5
Struttura del database
Nome del campo
Tipo
Dimensione Identificatore
Chiave esterna
REF_IND (Autonumber)
Number
10
REF_EVT_ID
Number
10
TM_EVENTI.EVT_ID
REF_UTN_ID
Number
10
TM_UTENTI.UTN_ID
REF_ALLEGATO_REFERTO
Blob
REF_NOMEALLEGATO_REFERTO Varchar
REF_DATEREFERTO
Primari Key
25
Date
Tabella TM_PERMISSIONI
Nome del campo
Tipo
Dim.
Identificatore
Chiave esterna
PER_UTN_ID
Number
10
Primary Key
TM_UTENTI.UTN_ID
PER_TES_CODICE
Varchar
10
Primary Key
TM_TIPOESAMI.TES_CODICE
77
Capitolo 5
Struttura del database
5.5 Codifica SQL
CREATE TABLE TM_UNITAEROGANTI (
uer_codente VARCHAR(10) DEFAULT '' NOT NULL,
uer_codstruttura VARCHAR(10) DEFAULT '' NOT NULL,
uer_codspecialita VARCHAR(10) DEFAULT '' NOT NULL,
uer_codunitaerogante VARCHAR(10) DEFAULT '' NOT NULL,
uer_descr VARCHAR(50) DEFAULT NULL,
PRIMARY KEY
(uer_codente,uer_codstruttura,uer_codspecialita,uer_codunitaerogante)
);
-----------------------------------------------------------------------------------------CREATE TABLE TM_TIPOESAMI (
tes_codice VARCHAR(10) DEFAULT '',
tes_descr VARCHAR(255) DEFAULT '' NOT NULL,
PRIMARY KEY (tes_codice)
);
-----------------------------------------------------------------------------------------CREATE TABLE tm_utenti (
utn_id NUMBER(10) PRIMARY KEY,
utn_cn VARCHAR(128) DEFAULT NULL UNIQUE,
utn_type VARCHAR(1) DEFAULT 'M' NOT NULL,
utn_codente VARCHAR(10) DEFAULT NULL,
utn_codstruttura VARCHAR(10) DEFAULT NULL,
utn_codspecialita VARCHAR(10) DEFAULT NULL,
utn_codunitaerogante VARCHAR(10) DEFAULT NULL,
utn_username VARCHAR(20),
utn_password VARCHAR(20),
FOREIGN KEY (utn_codente, utn_codstruttura, utn_codspecialita,
utn_codunitaerogante)
REFERENCES TM_UNITAEROGANTI(UER_CODENTE, UER_CODSTRUTTURA,
UER_CODSPECIALITA, UER_CODUNITAEROGANTE)
);
CREATE SEQUENCE TM_UTENTI_SEQ
START WITH 1
INCREMENT BY 1
NOMAXVALUE;
CREATE TRIGGER TM_UTENTI_TRIGGER
BEFORE INSERT ON TM_UTENTI
FOR EACH ROW
BEGIN
SELECT TM_UTENTI_SEQ.NEXTVAL INTO :NEW.UTN_ID FROM DUAL;
END;
-----------------------------------------------------------------------------------------78
Capitolo 5
Struttura del database
CREATE TABLE tm_eventi (
evt_id NUMBER(10) NOT NULL,
evt_utn_id NUMBER(10) DEFAULT NULL,
evt_trf_codice VARCHAR(10) DEFAULT NULL,
evt_dateopen DATE DEFAULT NULL,
evt_dateclose DATE DEFAULT NULL,
evt_allegato BLOB,
evt_nomeallegato VARCHAR(25) DEFAULT NULL,
evt_codice_esterno VARCHAR(10) DEFAULT NULL,
evt_razza VARCHAR(25) DEFAULT NULL,
evt_sesso VARCHAR(1) DEFAULT NULL,
evt_eta NUMBER(3) DEFAULT NULL,
evt_altezza NUMBER(8,4),
evt_um_altezza VARCHAR(10),
evt_peso NUMBER(8,4),
evt_um_peso VARCHAR(10),
evt_memo VARCHAR(255),
PRIMARY KEY (evt_id),
FOREIGN KEY (evt_trf_codice) REFERENCES TM_TIPOESAMI(tes_codice),
FOREIGN KEY (evt_utn_id) REFERENCES TM_UTENTI(utn_id)
);
CREATE SEQUENCE TM_EVENTI_SEQ
START WITH 1
INCREMENT BY 1
NOMAXVALUE;
CREATE TRIGGER TM_EVENTI_TRIGGER
BEFORE INSERT ON TM_EVENTI
FOR EACH ROW
BEGIN
SELECT TM_EVENTI_SEQ.NEXTVAL INTO :NEW.EVT_ID FROM DUAL;
END;
-----------------------------------------------------------------------------------------CREATE TABLE tm_referti (
ref_ind NUMBER(10) NOT NULL,
ref_evt_id NUMBER(10) DEFAULT '0' NOT NULL,
ref_utn_id NUMBER(10) DEFAULT '0' NOT NULL,
ref_allegato_referto BLOB,
ref_nomeallegato_referto VARCHAR(25),
ref_datereferto DATE,
PRIMARY KEY (ref_ind),
FOREIGN KEY (ref_evt_id) REFERENCES TM_EVENTI (evt_id),
FOREIGN KEY (ref_utn_id) REFERENCES TM_UTENTI (utn_id)
);
CREATE SEQUENCE TM_REFERTI_SEQ
START WITH 1
INCREMENT BY 1
NOMAXVALUE;
79
Capitolo 5
Struttura del database
CREATE TRIGGER TM_REFERTI_TRIGGER
BEFORE INSERT ON TM_REFERTI
FOR EACH ROW
BEGIN
SELECT TM_REFERTI_SEQ.NEXTVAL INTO :NEW.REF_IND FROM DUAL;
END;
-----------------------------------------------------------------------------------------CREATE TABLE TM_PERMISSIONI (
per_utn_id NUMBER(10) DEFAULT '0' NOT NULL,
per_tes_codice VARCHAR(10) DEFAULT '' NOT NULL,
PRIMARY KEY (per_utn_id, per_tes_codice),
FOREIGN KEY (per_utn_id) REFERENCES TM_UTENTI(utn_id),
FOREIGN KEY (per_tes_codice) REFERENCES TM_TIPOESAMI (tes_codice)
);
------------------------------------------------------------------------------------------
Inserimenti per test
INSERT INTO TM_UNITAEROGANTI (uer_codente, uer_codstruttura,
uer_codspecialita, uer_codunitaerogante, uer_descr)
VALUES ('EN_001','ST_001','01','U_001','PoliAmbulatorio 2000');
INSERT INTO TM_UTENTI(UTN_CN, UTN_TYPE, UTN_CODENTE, UTN_CODSTRUTTURA,
UTN_CODSPECIALITA, UTN_CODUNITAEROGANTE, UTN_USERNAME, UTN_PASSWORD)
VALUES('Prova2', 'R', 'EN_001','ST_001','01','U_001','stage02',
'stage02');
INSERT INTO TM_UTENTI(UTN_CN, UTN_TYPE, UTN_CODENTE, UTN_CODSTRUTTURA,
UTN_CODSPECIALITA, UTN_CODUNITAEROGANTE, UTN_USERNAME, UTN_PASSWORD)
VALUES('Prova', 'R', 'EN_001','ST_001','01','U_001','stage01',
'stage01');
INSERT INTO TM_TIPOESAMI(tes_codice, tes_descr) VALUES
('ES_0001','Elettrocardiogramma');
INSERT INTO TM_TIPOESAMI (tes_codice, tes_descr) VALUES
('ES_0002','Radiografia');
INSERT INTO TM_PERMISSIONI(PER_UTN_ID, PER_TES_CODICE)
VALUES(2,'ES_0002');
INSERT INTO TM_PERMISSIONI(PER_UTN_ID, PER_TES_CODICE)
VALUES(1,'ES_0001');
INSERT INTO TM_PERMISSIONI(PER_UTN_ID, PER_TES_CODICE)
VALUES(1,'ES_0002');
Nota bene: su TM_EVENTI mettere dei default ai campi
80
Capitolo 5
Struttura del database
ALTER TABLE TM_EVENTI
MODIFY EVT_NOMEALLEGATO DEFAULT '--'
ALTER TABLE TM_EVENTI
MODIFY EVT_CODICE_ESTERNO DEFAULT '--'
ALTER TABLE TM_EVENTI
MODIFY EVT_RAZZA DEFAULT '--'
ALTER TABLE TM_EVENTI
MODIFY EVT_SESSO DEFAULT '-'
ALTER TABLE TM_EVENTI
MODIFY EVT_ETA DEFAULT 0
ALTER TABLE TM_EVENTI
MODIFY EVT_MEMO DEFAULT '-'
--- Aggiunto campo MEMO alla tabella dei referti --ALTER TABLE TM_REFERTI
ADD REF_MEMO VARCHAR(255)
ALTER TABLE TM_EVENTI
MODIFY EVT_MEMO VARCHAR(255)
--- Aggiunto campo REF_DEFINITIVO alla tabella dei referti che indica se
un referto è definitivo (Y) o ancora modificabile (N) --ALTER TABLE TM_REFERTI
ADD ref_definitivo CHAR(1);
81
6. Configurazione Server di sviluppo
6.1 Ambiente di sviluppo
Come detto nel capitolo 3 nella descrizione della fase di deploy, “le macchine di sviluppo,
soprattutto se si utilizzano ambienti di sviluppo molto sofisticati, sono configurate
diversamente da quelle di test, pertanto il passaggio da un ambiente all'altro potrebbe non
essere indolore”.
Nel nostro caso il server di sviluppo è una semplicissima macchina con piattaforma
Windows nella quale abbiamo istallato tutti gli strumenti per la realizzazione del Web
service (tomcat, axis, eclipse) mentre la macchina di test, quella che effettivamente è il
server e che permette la pubblicazione sul web, gira su un sistema operativo Linux.
Linux è un sistema operativo di tipo Unix. La principale differenza rispetto ai “veri”
sistemi Unix consiste nel fatto che Linux può essere copiato liberamente e gratuitamente
compreso l’intero codice sorgente.
Il termine Linux, per essere precisi, si riferisce solo al kernel. Il kernel è il nucleo
essenziale del sistema operativo che si occupa della gestione della memoria, ei processi e
del controllo hardware e che essenzialmente permette a tutti gli altri programmi di girare.
La maggior parte delle persone, comunque, quando parlano di Linux, intendono un sistema
operativo completo comprensivo delle applicazioni che ci girano sopra.
Nella fase di installazione del sistema operativo per un server Tomcat le partizioni da
creare sono le seguenti:
o /
o /boot
o /home
o /SWAP
o /tmp
o /usr
o /usr1
o /var
Nella ripartizione della memoria ad, usr1 deve essere assegnata la maggior parte della
memoria, circa 2/3. La restante parte va suddivisa sugli altri F.S.
82
Capitolo 6
Configurazione Server di sviluppo
6.2 Installazione Java sul Server
Scaricare Java nella versione j2sdk-1_4_2_07-rp.bin o copiare l’eseguibile da un altro
server. Portare il file sotto /usr/src/ e cambiare i permessi del file in 777 con chmod 777
j2sdk-1_4_2_07-rp.bin.
Lanciare l’eseguibile e seguire l’installazione guidata.
Con l’installazione viene generato nella stessa dir un file j2sdk-1_4_2_07.rpm.
Lanciare l’rpm con rpm-Uhv j2sdk-1_4_2_07.rpm.
Java verra installato sotto /usr/java/j2sdk, quindi per uniformarci alle altre installazioni
spostiamo l’installazione sotto /usr/local/java con l’istruzione mv /usr/java/j2sdk
/usr/local/java.
Andare sul server di test o produzione e copiare le librerie che si trovano sotto
/usr/local/java/jre/lib/ext.
Per copiarle utilizzare l’istruzione tar-czvf../libext.tar.gz*.
Spostare il file tar.gz nella dir ext di java appena installato ed eseguire tar xzvf
libext.tar.gz per compattare le librerie, senza sovrascrivere quelle esistenti.
Cambiare i permessi alle librerie per l’utente creato (es.Tomcat) con l’istruzione chown
tomcat:tomcat*.
6.3 Installazione TOMCAT su Server
Creare un utente Tomcat con le seguenti istruzioni:
groupadd –g 91 tomcat
useradd –d /home/tomcat –g tomcat –u 91 tomcat
Nella creazione del gruppo e dell’utente è importante specificare l’id del gruppo e
dell’utente solo se il web server in questione fa parte di un cluster. In questo caso gli id
devono essere identici su tutti i server.
Per
eseguire
l’installazione
bisogna
scaricare
tomcat
nella
versione
jakarta-
tomcat.4.1.31.gz sotto /usr/src.
Lanciare jakarta-tomcat.4.1.31.gz con l’istruzione tar xvzf jakarta-tomcat.4.1.31.tar.gz.
Viene generata una dir jakarta-tomcat.4.1.31 nella dir corrente.
Per allineare il server agli altri, muovere il contenuto della dir sotto /home/tomcat.
83
Capitolo 6
Configurazione Server di sviluppo
Entrare nella dir jakarta-tomcat.4.1.31 ed eseguire l’istruzione mv * /home/tomcat.
Oppure muovere l’intera dir sotto /home/tomcat con l’istruzione mv jakartatomcat.45.1.31 /home/tomcat.
Dal server di produzione o sviluppo copiare le librerie che si trovano sotto la home-dir di
tomcat sotto /common/lib.
Comprimerle con l’istruzione tar –czvf ../tomcatlib.tar.gz*. Il file compresso verrà
generato nella dir padre.
Muovere il file nella dir /common/lib di tomcat appena installato e decomprimerlo con
l’istruzione tar xvzf tomcatlib.tar.gz senza sovrascrivere le librerie esistenti.
Cambiare i permessi a tutti i file all’interno della della home-dir di tomcat per l’utente
tomcat con l’istruzione chown tomcat:tomcat –R*.
Modificar i file :
-
catalina.sh
-
tomcat-user.xml
-
.bash_profile
-
server.xml # solo se deve essere effettuato un reindirizzamento
Nel file catalina.sh dopo la prima parte inserire quanto segue modificando
opportunamente le variabili d’ambiente:
JAVA_OPTS=”-server –Xms256M –Xmx750M –XX:MaxPermSize=size”
JAVA_HOME=/usr/local/java; export JAVA_HOME
CATALINA_HOME=/usr1/Jakarta-tomcat-5.5.4; export CATALINA_HOME
CATALINA_OPTS=”-Djava.awt.headless=true –Djava.net.preferIPv4Stack=true”;
export CATALINA_OPTS
CATALINA_OPTS=”-Djava.awt.headless=true”; export CATALINA_OPTS
PATH=$PATH:$JAVA_HOME/bin; export PATH
Nel file tomcat-user.xml eliminare tutto e copiare quanto segue modificando gli utenti e le
password se necessario:
<?xml version=’1.0’ encoding=’utf-8’?>
<tomcat-users>
<role rolename=”tomcat”/>
<role rolename=”manager”/>
<role rolename=”admin”/>
<role rolename=”role1”/>
<user username=”admin” password=”admin” roles=”admin, manager”/>
<user username=”tomcat” password=”tomcat” roles=”tomcat”/>
<user username=”both” password=”tomcat” roles=”tomcat, role1”/>
<user username=”role1” password=”tomcat” roles=”role1”/>
84
Capitolo 6
Configurazione Server di sviluppo
</tomcat-users>
Nel file .bash_profile eliminare tutto ed inserire quanto segue:
if [ -f ~/.bashrc ]; then
.~/.bashrc
fi
export JAVA_HOME=/usr/local/java
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin; export PATH
export CATALINA_HOME=/home/tomcat4
unset USERNAME
Dal server di produzione o di test copiare il file tomcat che si trova sotto /etc/rc.d/init.d e
riportarlo nel server interessato nella stessa posizione.
Dopo averlo importato modificare i permessi del del file rendendoli equivalenti agli altri.
Lanciare Tomcat lanciando il file tomcat con ./tomcat start e fermarlo con ./tomcat stop
6.4 Installazione Oracle Database 10g XE
Oracle Database 10g XE si basa sul codice di Oracle Database 10g Release 2, consente a
chiunque di provare a costo zero tutte le funzionalità presenti in Oracle Database 10g. . La
versione light di Oracle offre infatti gli stessi strumenti del fratello maggiore, dando la
possibilità agli utenti di sviluppare applicazioni in ambiente Java, .NET e PHP.
Oracle XE utilizza al massimo 1 GB di memoria, gestisce una base di dati con una
dimensione massima di 4 GB e permette l'esecuzione di una sola istanza per sistema, gira
sui sistemi operativi Windows e su una gran varietà di distribuzioni Linux.
Con il suo nuovo database gratuito, rilasciato negli scorsi giorni in versione beta, Oracle
intende rivolgersi in modo particolare agli sviluppatori, alle piccole e medie aziende e agli
studenti. Della prima categoria il colosso corteggia i developer open source e, più in
generale, coloro che utilizzano tecnologie come PHP, Java e MS.NET.
85
Capitolo 6
Configurazione Server di sviluppo
La licenza che accompagna Oracle Database XE blinda il codice sorgente del software,
tuttavia consente agli sviluppatori di ridistribuire il programma e di inglobarlo all'interno
delle proprie applicazioni senza pagare alcuna royalty.
I programmatori possono inoltre sfruttare la piena compatibilità di XE con i suoi fratelli
maggiori: ogni applicazione sviluppata per l'edizione Express gira infatti, senza alcuna
modifica, anche sulle edizioni Standard ed Enterprise di Oracle database 10g.
Alcuni sostengono che con questa mossa Oracle intenda contrastare l'avanzata, nel mercato
delle piccole e medie aziende, di software open source come MySQL e PostgreSQL. C'è
tuttavia da sottolineare come Oracle Database contenga diverse limitazioni tecniche, tra cui
il supporto ad un solo processore e ad un massimo di 1 GB di memoria RAM e di 4 GB di
dati utente. Guarda caso queste sono le stesse restrizioni che caratterizzeranno l'imminente
SQL Server Express di Microsoft, a cui Oracle Database 10g XE va chiaramente a pestare i
piedi.
Installazione
Installazione di un web Server e di un db Server utilizzando:
1. GNU/Linux;
2. il web server Apache;
3. Oracle in versione 10g Express Edition, rilasciata per il pinguino.
Requisiti di sistema e limitazioni di Oracle Database XE:
Oracle Database XE presenta una serie di limitazioni relativamente all’hardware su cui il
sistema viene installato e, in particolare:
1. se Oracle Database XE è installato su un computer con più di una CPU (incluse
anche le CPU dual core), esso utilizzerà esclusivamente le risorse di una sola CPU;
2. su un singolo computer può essere effettuata l’installazione di una sola copia di
Oracle Database XE; in aggiunta, gli utenti possono far girare una sola istanza del
database Oracle su ciascun computer. Quest’ultima limitazione può comunque
essere aggirata in quanto, anche sulla stessa installazione di Oracle Database XE
possono convivere più schemi, ciascuno dei quali contenente le proprie tabelle. Di
86
Capitolo 6
Configurazione Server di sviluppo
fatto, è come se sulla stessa macchina fossero presenti più database
simultaneamente;
3. la quantità massima di dati contenuta in un database Oracle 10g XE non può
superare i 4 gigabytes di spazio disco, tuttavia se i dati degli utenti dovessero
superare tale quota, il sistema invia l’errore ORA-12592;
4. la quantità massima di memoria RAM che il server Oracle Database XE utilizza
non può eccedere un gigabytes, anche se ne è disponibile una quantità maggiore sul
sistema usato come server. La quantità di memoria totale utilizzata dal server
Oracle viene ricavata come somma della System Global Area (SGA) e della
Program Global Area (PGA) aggregata;
5. il protocollo HTTPS (Secure HTTP) non è supportato nativamente dal listener
HTTP presente in Oracle XE, quindi è necessario far uso di un web server, come
Apache, che supporti tale protocollo.
Spazio di swap richiesto per Oracle Database XE Server:
Memoria RAM presente sul server
Tra 0 e 256 MB
Tra 256 e 512 MB
512 MB e oltre
Spazio di swap richiesto
3 volte la dimensione della RAM
2 volte la dimensione della RAM
1024 MB di RAM
Installazione e configurazione di Oracle Database XE Server:
La procedura di installazione e configurazione della componente server di Oracle Database
XE si suddivide in tre passaggi fondamentali.
1. Impostazione dei parametri del kernel:
E’ necessario settare alcuni parametri del kernel per un funzionamento ottimale di Oracle.
Nella tabella seguente riporto i parametri necessari ed il corrispondente valore che essi
dovrebbero assumere:
87
Capitolo 6
Parametro del kernel
sem
semmns
semopn
semmni
shmmax
shmmni
shmall
file-max
ip_local_port_range
rmem_default
wmem_default
rmem_max
wmem_max
Configurazione Server di sviluppo
Valore
250
32000
100
128
536870912
4096
2097152
65536
1024-65000
262144
262144
262144
262144
Per prima cosa diamo un’occhiata per verificare che il valore impostato di default sulla
nostro distribuzione per questi parametri del kernel sia coerente con quanto indicato nella
tabella precedente, tramite il comando sysctl.
# /sbin/sysctl -a | grep shm
kernel.shmmni = 4096
kernel.shmall = 2097152
kernel.shmmax = 536870912
kernel.shm-use-bigpages = 0
# /sbin/sysctl -a | grep sem
kernel.sem = 250 32000 100 128
# /sbin/sysctl -a | grep file-max
fs.file-max = 65536
# /sbin/sysctl -a | grep ip_local_port_range
net.ipv4.ip_local_port_range = 1024 65000
# /sbin/sysctl -a | grep rmem_default
net.core.rmem_default = 262144
# /sbin/sysctl -a | grep rmem_max
net.core.rmem_max = 262144
# /sbin/sysctl -a | grep wmem_default
net.core.wmem_default = 262144
# /sbin/sysctl -a | grep wmem_max
net.core.wmem_max = 262144
Se tali parametri non sono corretti è necessario editare il sysctl.conf, oppure usare il
seguente comando:
88
Capitolo 6
Configurazione Server di sviluppo
# cat >> /etc/sysctl.conf <<EOF
kernel.sem = 250 32000 100 128
kernel.shmmax = 536870912
kernel.shmmni = 4096
kernel.shmall = 2097152
fs.file-max = 65536
net.ipv4.ip_local_port_range = 1024 65000
net.core.rmem_default=262144
net.core.wmem_default=262144
net.core.rmem_max=262144
net.core.wmem_max=262144
EOF
2. Installazione e configurazione di Oracle Database XE:
Accettato il contratto di licenza, è necessario installare prima di tutto la libreria libaio,
come indicato precedentemente (la libreria glibc, infatti, è presente di default in questa
distribuzione), quindi potete procedere all’installazione dell’rpm di Oracle Database Server
XE come utente root:
# rpm –ivh oracle-xe-[versione].rpm
Per chi usa Debian, o Ubuntu, invece, una volta scaricato il deb corrispondente sempre
dalla pagina web indicata, il comando da lanciare è il classico dpkg:
# dpkg –i oracle-xe-[versione].deb
in questo caso non è necessario l’installazione di nessuna libreria aggiuntiva.
Bene, ora è giunto il momento di passare alla configurazione del nostro Oracle Database
Server. Nella directory /etc/init.d/ si trova uno script di configurazione di Oracle chiamato
oracle-xe, da lanciare con l’opzione configure:
# ./oracle-xe configure
•
Lo script vi richiede una serie di informazioni per la configurazione del database
Oracle tra cui:
il numero di porta (per default la 8080) tramite cui è possibile raggiungere
l’interfaccia web per la configurazione di Oracle all’url:
http://[hostname o indirizzo IP]:8080/htmldb
•
il numero di porta (per default la 1521) su cui si mette in attesa il “listener” di
Oracle Server, ossia un demone preposto a ricevere e servire le richieste di
connessione al server Oracle, appunto. Se il vostro firewall è configurato in modo
89
Capitolo 6
Configurazione Server di sviluppo
tale da filtrare la porta di default per il listener di Oracle, specificate un valore a voi
più congeniale!
•
quando far partire l’istanza di Oracle Database Server; si può decidere se
schedulare la partenza di Oracle al boot del sistema (e questo implica anche la
partenza immediata del DBMS), oppure se eseguirla manualmente di volta in volta.
Per verificare se il DB è attivo bisogna controllare tramite il comando:
# ./oracle-xe status
LSNRCTL for Linux: Version 10.2.0.1.0 - Beta on 14-FEB-2007 10:14:01
Copyright (c) 1991, 2005, Oracle. All rights reserved.
Connecting to
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521)))
<— EVVAI IL LISTENER E’ ATTIVO!!!
STATUS of the LISTENER
————————
Alias LISTENER
Version TNSLSNR for Linux: Version 10.2.0.1.0 - Beta
Start Date 14-FEB-2007 10:13:44
Uptime 0 days 0 hr. 0 min. 17 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Default Service XE
Listener Parameter File
/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/network/admin/listener.ora
Listener Log File
/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/network/log/listener.log
Listening Endpoints Summary…
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=localhost)(PORT=1521)))
Services Summary…
Service “PLSExtProc” has 1 instance(s).
Instance “PLSExtProc”, status UNKNOWN, has 1 handler(s) for this service…
The command completed successfully
3. Impostazione delle variabili d’ambiente:
Un ultimo passo infine riguarda la configurazione delle variabili d’ambiente, senza cui non
è possibile accedere nemmeno al prompt di SQL*Plus per le classiche operazioni di
90
Capitolo 6
Configurazione Server di sviluppo
gestione del database come inserimenti, modifiche, cancellazioni e consultazioni di dati e
così via.
Per procedere in questo senso, è sufficiente lanciare uno script di configurazione delle
variabili d’ambiente di Oracle Database XE, disponibile in due distinte versioni a seconda
della shell che si utilizza. Lo script in questione, che si trova nella directory:
/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/bin/
è oracle_env.sh (valido anche per le shell Bourne e Korn, mentre per C e tcsh shell, lo
script da usare è oracle_env.csh, presente sempre nella medesima directory).
Lo script oracle_env.sh, si occupa di:
1. impostare la variabile ORACLE_HOME con il path dell’installazione di Oracle
Database XE;
2. impostare la variabile ORACLE_SID che conterrà il nome del database;
3. impostare la variabile NLS_LANG con il valore ritornato dallo script nls_lang.sh;
quest’ultimo si occupa di determinare il character set predefinito con cui i dati
verranno inseriti nel database e visualizzati tramite un’applicazione client come, ad
esempio SQL*Plus. Il parametro NLS_LANG utilizza il seguente formato:
NLS_LANG = LANGUAGE_TERRITORY.CHARACTER_SET
LANGUAGE specifica il linguaggio con cui vengono visualizzati i messaggi di Oracle ed
i nomi dei giorni e dei mesi; TERRITORY specifica le convenzioni culturali per date,
numeri, tempo e formati monetari, mentre il valore CHARACTER_SET indica la lingua
da utilizzare per l’inserimento e la visualizzazione dei dati nel database di Oracle.
4. impostare la variabile PATH con il percorso che porta alla directory contenente gli
eseguibili di Oracle database XE;
5. impostare la variabile LD_LIBRARY_PATH con il percorso della directory
contenente le librerie principali per Oracle XE.
Va ricordato che riavviando il computer, i settaggi impostati con lo script oracle_env.sh
vengono persi, perciò è buona norma inserire la stringa:
91
Capitolo 6
Configurazione Server di sviluppo
/usr/lib/oracle/xe/app/oracle/product/10.2.0/server/bin/oracle_env.sh
all’interno del file .bash_profile; inoltre, per poter mantenere le stesse impostazioni
all’apertura di ogni nuova shell durante la sessione corrente, è conveniente aggiungerlo
anche all’interno del file .bashrc.
6.5 Installazione e configurazione di Apache
Una volta che il db server Oracle è installato e configurato, si può procedere con
l’installazione del web server Apache tramite i pacchetti forniti dalla vostra distro oppure
da sorgenti.
Questi sono i comandi che bisogna lanciare per il download, lo scompattamento e
l’installazione di Apache sul mio server:
# wget -c http://apache.fis.uniroma2.it/httpd/httpd-2.2.3.tar.gz
# tar xzf httpd-2.2.3.tar.gz /usr/local/src/
# ./configure --prefix=/usr/local/apache2/
# make && make install
il parametro –prefix passato al comando configure richiede il path in cui verrà installato il
web server Apache. Dalla documentazione del web server si legge che il percorso di
default è /usr/local/apache2/ e io ho usato proprio questo. Terminata la compilazione di
Apache, è necessario modificare opportunamente il file di configurazione httpd.conf (per
chi ha compilato da sorgenti senza specificare un path di installazione diverso da quello di
default proposto nella documentazione di Apache, questo file è posizionato in
/usr/local/apache2/conf/).
92
Capitolo 6
Configurazione Server di sviluppo
Figura – Istallazione di Apache
93
7. Problematiche e miglioramenti
7.1 Il Server Linux
Nonostante siano state prese tutte le dovute precauzioni in fase di programmazione,
soprattutto nella gestione delle path di file e di directory, qualche piccolo, ma
fondamentale aspetto rendeva le due fasi (di sviluppo e di test) non completamente
dipendenti e perciò nel passaggio alla fase di test ogni volta bisogna avere l’accortezza e la
pazienza di tornare sul codice.
Vediamo brevemente di cosa si tratta.
PRECAUZIONI:
La disponibilità di implementazioni della JVM (Java Virtual Machine) per diversi ambienti
operativi è la chiave della portabilità di Java, proclamata nello slogan write once, run
everywhere ("scrivi una volta, esegui dappertutto"). La macchina virtuale realizza infatti un
ambiente di esecuzione omogeneo, che nasconde al software Java (e quindi al
programmatore) qualsiasi specificità del sistema operativo sottostante. Ciò ha permesso di
non dover andare a modificare metodi e funzioni specifiche e soprattutto di poter definire
univocamente una delle questioni più delicate nella gestione di files: le path.
La grande maggioranza dei servizi implementati si basa sui due seguenti passi:
•
Creazione di un file .xml tramite una query SQL;
•
Invio del file appena creato;
Il file xml viene salvato fisicamente sul file system nella cartella temp dell’Application
Server (il tomcat). Onde evitare incompatibilità tra i vari sistemi operativi definiamo tale
percorso come:
Path=System.getProperty("catalina.home")+File.separator+"temp"+File.separ
ator;
94
Capitolo 7
Problematiche e miglioramenti
Che corrisponde:
WINDOWS
C:/TOMCAT554/temp/
LINUX
/var/jakarta-tomcat-5.5.4/temp/
System.getProperty("catalina.home") restituisce il valore della variabile di
ambiente CATALINA HOME impostata in fase di istallazione dell’Apllication Server
mentre il File.separator inserisce il carattere di separazione della path assoluta di
un file (slash per Linux, back-slash per windows).
Questo è stato un semplice esempio di portabilità di java in quanto siamo riusciti a passare
da windows a linux senza dover effettuare nessun cambiamento.
Purtroppo però le cose non vanno sempre così, infatti in fase di attachment:
//Invio del file xml ottenuto dalla query come allegato
message=(org.apache.axis.MessageContext.getCurrentContext()).getResponseM
essage();
/*VERSIONE PER LINUX*/
message.addAttachmentPart(message.createAttachmentPart(new
DataHandler(new
URL("file:"+File.separator+File.separator+fileNamePath+fileName))));
/*VERSIONE PER WINDOWS*/
message.addAttachmentPart(message.createAttachmentPart(new
DataHandler(new URL("file:"+File.separator+fileNamePath+fileName))));
Come si può notare dal frammento di codice i due sistemi operativi si comportano in modo
differente nella gestione dell’oggetto URL. La sintassi in questione è:
file: //
Protocollo
FilePath+FileName
Doppio File.separator
Nome del file
L’incongruenza tra i due sistemi sta nel fatto che windows accetta una sintassi con un solo
file separator, mentre linux una sintassi con due file separator.
Risultato di ciò è che se non si accetta questa predisposizione si ha un errore in
compilazione.
95
Capitolo 7
Problematiche e miglioramenti
Un altro aspetto di fondamentale importanza sempre riguardo all’utilizzo di due sistemi
operativi differenti è la gestione degli attachments.
Dopo un lungo studio e una lunga fase di test abbiamo imparato che quando la dimensione
dell’allegato al messaggio SOAP supera una certa soglia il sistema operativo si fa carico di
prendere tale allegato e salvarlo temporaneamente sotto una sua ben specificata directory
per poi poterlo inviare al destinatario.
Il percorso di questa directory è specificato in un file di configurazione, serverconfig.wsdd che viene creato, lato server, automaticamente dall’eclipse in fase di
generazione del Web service.
Leggendo le righe di codice di questo file, ad un certo punto si incontra il seguente
frammento:
<globalConfiguration>
<parameter name="sendMultiRefs" value="true"/>
<parameter name="disablePrettyXML" value="true"/>
<parameter name="adminPassword" value="admin"/>
<parameter name="attachments.Directory"
value="C:\workspace\.metadata\.plugins\org.eclipse.wst.s
erver.core\tmp0\webapps\jtelemed\WEBINF\attachments"/>
<parameter name="dotNetSoapEncFix" value="true"/>
Facendo un deploy dell’intero progetto come war sul server linux anche il file serverconfig.wsdd viene importato con tutte le sue caratteristiche e soprattutto con la sua
attachments.Directory impostata con una path valida sotto windows ma non sotto
linux: occorre definire una nuova path:
<globalConfiguration>
<parameter name="sendMultiRefs" value="true"/>
<parameter name="disablePrettyXML" value="true"/>
<parameter name="adminPassword" value="admin"/>
<parameter name="attachments.Directory"
value="/var/jakarta-tomcat5.5.4/webapps/jtelemed_server/WEBINF/attachment"/>
<parameter name="dotNetSoapEncFix" value="true"/>
96
Capitolo 7
7.2
Problematiche e miglioramenti
Interoperabilità ed evoluzioni future
I Web Services sono nati soprattutto per superare i problemi di interoperabilità tra le
normali architetture a componenti. Questo scopo non è ancora stato completamente
raggiunto a causa della giovinezza degli standard, dalla mancanza di standardizzazione e
dell'assenza di implementazioni di riferimento. Attualmente l'XML Protocol Working
Group è ancora al lavoro, e ha prodotto il Working Draft delle specifiche SOAP 1.2.
Esistono vari tipi di problemi che possono pregiudicare la comunicazione tra le varie
implementazioni, ma sono raggruppabili in problemi che riguardano il file WSDL, il
protocollo SOAP, e il protocollo di trasporto.
Il modello dei Web Services è ancora molto giovane, quindi molti punti importanti presenti
nelle architetture più diffuse sono ancora in attesa di una definizione e/o standardizzazione.
Ad esempio la gestione della sicurezza, dell'autenticazione, delle transazioni,
dell'interazione fra più componenti, sono ancora tutte da definire e standardizzare.
Esistono alcuni protocolli che sono stati proposti per risolvere questi problemi:
•
•
•
•
•
XML Signature e SOAP-DS (SOAP Digital Signature) - Sono protocolli per la
gestione di messaggi XML e SOAP con firma elettronica, per garantire l'integrità
dei messaggi e la loro provenienza
SOAP with Attachments - È un protocollo per la gestione degli allegati per
messaggi SOAP
XAML - È un protocollo basato su XML per la gestione di transazioni utilizzanti lo
schema Two-Phase Commit
WSFL e XLANG - Sono protocolli per la gestione del workflow di componenti e la
gestioni di transazioni utilizzanti il metodo della compensazione
XML Encryption - È un protocollo per la cifratura di documenti XML.
Nessuno di questi protocolli è ancora uno standard affermato, sono solo proposte più o
meno supportate.
XML Signature e XML Encryption sono in corso di approvazione da parte del W3C.
97
Capitolo 7
7.3
Problematiche e miglioramenti
Possibili sviluppi futuri
Un ultima considerazione va fatta in considerazione dei possibili sviluppi futuri riguardano
l’uso di ambienti di sviluppo alternativi a Site Painter e Portal Studio che si sono rilevati
molto efficienti ma che comunque non sono freeware. Quindi l’attenzione in questo
paragrafo si sposterà sul trovare degli IDE (Integrated development environment) di
sviluppo alternativi al Site Painter e al Portal Studio della Zucchetti, ma ugualmente
efficienti.
Jdeveloper 5.0
Jdeveloper 5.0 si rivela uno strumento originale, e un'ottima piattaforma di sviluppo in
Java per creare Web service, ed inoltre è completamente gratuito. Jdeveloper non serve
solo per scrivere in codice Java. È un vero e proprio trampolino per il mondo dei servizi
Web. Infatti Oracle sostiene che questo componente della sua piattaforma Oracle9i
rappresenta una importante unificazione delle tecnologie chiave per lo sviluppo di
applicativi per Internet: Java, XML e SQL.
Oracle9i offre il supporto all'UML (Unified Modeling Language), allo sviluppo di tipo
Rapid Application Development attraverso wizard e alla costruzione di report, query e
analisi per la business intelligence integrata.
Oracle sostiene che la nuova versione di Oracle 9i Jdeveloper aiuterà gli sviluppatori a
scrivere codice Java corretto e ottimizzato e che, grazie al supporto di standard come
SOAP, UDDI e WSDL, garantirà interoperabilità fra servizi e massima integrazione con le
applicazioni preesistenti.
In sintesi
Jdeveloper 5, l’ambiente Java gratuito di Oracle, si rivela un tool set elegante e completo,
in grado di competere con concorrenti che, invece, costano parecchio, anche nel nuovo
campo dello sviluppo di servizi Web. Molto configurabile, lavora su Linux e Solaris, oltre
che Windows Nt, e supporta tutte le più recenti tecnologie Xml, come Wsdl.
Pro - Possibilità di personalizzare la vista delle finestre; tutorial; ambiente completo ed
elegante
98
Capitolo 7
Problematiche e miglioramenti
Contro - Il tool di diagnostica richiede l’intervento manuale dello sviluppatore; piccoli
malfunzionamenti su Windows 2000.
IDE di Kylix
Un’applicazione con Kylix viene creata raggruppando form, codice sorgente e risorse in un
progetto: una collezione di file generata dal programmatore e dall’ambiente al fine di
ottenere le specifiche dei moduli da compilare e per poter eseguire una compilazione
incrementale dei soli moduli effettivamente modificati.
Tutte le distribuzioni di Kylix 2 supportano la programmazione di un’ampia gamma di
applicazioni grafiche, oggetti condivisi, package ed altri programmi. La novità maggiore
consiste nella possibilità di utilizzare componenti per lo sviluppo di Web Service:
BizSnap, WebSnap, DataSnap.
BizSnap, estende le funzionalità di Linux e Apache con il supporto per XML e tecnologie
WSDL e SOAP. La piattaforma di sviluppo BizSnap semplifica l’integrazione business-tobusiness mediante l’utilizzo di XML/SOAP per connettere in modo trasparente
applicazioni WEB. Kylix, inoltre, permette di scambiare, trasformare e manipolare
documenti XML e creare applicazioni che possano comunicare direttamente con quelle dei
partner, con piattaforme abilitate ai Web Service come .Net e BizTalk di Microsoft e Sun
ONE di Sun Microsystems.
WebSnap rende Apache un potente server di classe enterprise per applicazioni Web
database-driven.
DataSnap supporta i più diffusi database server grazie ai driver nativi per Oracle, DB2,
Informix, PostreSQL, MySQL e Borland InterBase e si basa sull’elevata produttività di
Kylix 2 per creare applicazioni scalabili all’aumentare del volume di transazioni e del
numero di utenti. DataSnap, basato su tecnologie standard quali SOAP, serve ad integrare
applicazioni esistenti in primo luogo quelle per e-commerce.
All’avvio di Kylix appare l’insieme degli strumenti dell’IDE: toolbar, menu, palette delle
componenti, editor per il codice, code explorer ed il project manager. La finestra
99
Capitolo 7
Problematiche e miglioramenti
principale, che occupa la parte alta dello schermo, contiene il menu, le toolbar (per un
accesso immediato alle funzioni del menu più utilizzate) e la palette dei componenti.
Un altro utile tool messo a disposizione dall’IDE di Kylix è il repository degli oggetti
(Object Repository) che contiene componenti, con caratteristiche generali, pronti per essere
utilizzati o ereditati, nei progetti.
La caratteristica fondamentale di Kylix (ed in generale degli strumenti RAD) è la
metodologia con cui, nei progetti, si costruiscono le interfacce utente. Uno strumento RAD
permette di comporre, nel vero senso della parola, una applicazione a partire da
"mattoncini" software predefiniti; quindi è possibile trovare componenti visuali come
bottoni, edit box oppure label; e componenti non visuali quali: data module, timer oppure
socket.
100
8. Pubblicazione
8.1 Il Firewall di Linux
Un Firewall linux non è altro che un semplice personal computer normalmente collegato
fisicamente (con dei cavi) a più di una rete.
Un firewall avrà quindi installata una scheda di rete (interfaccia) per ogni rete cui sarà
collegato. Inoltre, dovrà costituire l'unico punto di contatto tra le reti cui è connesso, ovvero
dovrà costituire l'unico punto di collegamento tra due o più reti. Un po' come un ponte che
collega due o più isole. Senza entrare nei dettagli del protocollo ip, tutte le comunicazioni tra
queste reti saranno quindi costrette a passare da questo computer.
Questo computer, una volta configurato come firewall, sarà in grado di decidere cosa far
passare, cosa scartare o come reagire a determinati eventi. Tornando all'esempio del nostro
ponte, configurare il computer come firewall può essere considerato equivalente a mettere una
stanga e 2 finanzieri che controllano tutti i veicoli e le persone in transito.
Questi 2 finanzieri saranno quindi in grado di agire secondo le istruzioni che gli verranno date
dal ministero, bloccando veicoli, arrestando i contrabbandieri o sparando a vista ai ricercati.
In linux, la stanga e i finanzieri sono messi a disposizione direttamente dal kernel. Per
controllare il kernel, per dare cioè le direttive ai finanzieri, vengono messi a disposizione
diversi comandi: con il kernel 2.4, i principali e più avanzati sono comunque il comando ip, tc
e iptables, i primi due inclusi nel pacchetto iproute mentre il terzo distribuito
indipendentemente.
Procedendo con ordine, in linea di principio il comando ip consente di creare nuove isole e
nuovi ponti, di gestire quindi le tabelle di routing e le interfacce di rete, il comando iptables di
istruire i finanzieri dicendo cosa far passare e cosa non far passare o come reagire a
determinate condizioni, consente cioè di creare dei filtri. Infine, il comando tc, consente di
stabilire delle priorità e dei limiti sul traffico in ingresso ed in uscita. Ad esempio, un compito
che esula dal filtraggio e che quindi riguarda tc potrebbe essere quello di riservare alcune
corsie al passaggio di veicoli di emergenza o di servizio, limitando magari il traffico
automobilistico, di riservare cioè determinate quantità di banda a determinate tipologie di
traffico.
101
Capitolo 8
Pubblicazione
Riassumendo, quindi, si parlerà del comando:
•
ip per configurare, attivare, disattivare o creare interfacce di rete, nonché per gestire le
tabelle di routing (da solo rimpiazza i comandi ifconfig, route e arp).
•
iptables per bloccare, consentire o registrare il traffico, per effettuare cioè firewalling,
ovvero per modificare alcune caratteristiche dei pacchetti in transito, per effettuare cioè
NAT (Network Address Translation).
•
tc per assegnare delle priorità, imporre delle precedenze o dei limiti di banda (tc sta
per traffic classifier.), in poche parole, per effettuare dello shaping.
Quello che più ci interessa è il comando iptables.
8.2 Il comando iptables
Dovendo parlare di iptables, è indispensabile una piccola introduzione. Il parente più stretto di
iptables è sicuramente ipchains il quale aveva introdotto il concetto di catena.
iptables ha ripreso il concetto di catena per estenderlo tramite l'introduzione di tabelle.
Prima di parlare di tabelle però, ci conviene chiarire il concetto di catena. L'idea di base è
abbastanza semplice: un computer collegato in rete con una o più interfacce ha a che vedere
con tre tipi di pacchetti:
•
Pacchetti destinati al firewall stesso
•
Pacchetti che devono transitare dal firewall ma destinati a qualcun altro
•
Pacchetti originati dal firewall stesso
Di default ipchains ed iptables mettono quindi a disposizioni rispettivamente 3 catene:
•
La catena di input
•
La catena di forward
•
La catena di output
In un computer normale (o in un server) verrebbero principalmente utilizzate le catene di input
e di output per filtrare il traffico ricevuto e generato dalla macchina presa in considerazione.
102
Capitolo 8
Pubblicazione
In un firewall invece, i pacchetti transiterebbero da una scheda di rete all'altra, passando quindi
attraverso la catena di forward.
Ogni catena è poi costituita da un insieme di regole. Ad ogni regola, è associata un'azione
(target). Ogni volta che un pacchetto transita per una catena, tutte le regole vengono
controllate in ordine, dalla prima inserita fino all'ultima.
Quando una regola risulta applicabile al pacchetto (viene trovato un match) viene applicata al
pacchetto l'azione specificata e viene interrotto il processo di ricerca.
Se non viene trovata una regola applicabile al pacchetto, la sua sorte (l'azione d'applicare)
viene scelta in base alla politica (policy) della catena stessa. In pratica, la policy indica cosa
fare di tutti i pacchetti che non rientrano in nessuna regola.
Sia ipchains che iptables poi, consentono di creare o rimuovere catene e di specificare come
azione quella di percorrere un'altra catena.
Definizione delle policy
Iniziamo quindi a parlare di iptables, ed iniziamo proprio definendo la politica di default delle
catene di base, cioè l'azione che deve essere presa nel caso in cui nessuna regola si possa
applicare al particolare pacchetto. Per fare questo, basta dare:
iptables -P INPUT DROP
iptables -P OUTPUT DROP
iptables -P FORWARD DROP
Qui vediamo proprio che se un match non viene trovato, i pacchetti devono essere buttati via
(DROP), proprio come se non fossero mai stati ricevuti (o richiesto l'invio, a secondo della
catena).
Oltre a DROP, esistono molte altre azioni che è possibile specificare, dove le principali sono:
•
ACCEPT , lascia passare il pacchetto
•
QUEUE, passa il pacchetto ad un programma in userspace
Spesso però capita di usare delle target extensions, ossia dei particolari target che sono forniti
tramite dei moduli esterni. E' buona abitudine mettere come politica di default quella di buttare
103
Capitolo 8
Pubblicazione
via i pacchetti, dopodiché consentire esplicitamente tutto ciò che vogliamo fare passare.
Questo principalmente per due motivi:
•
è facile rendersi conto di cosa si è dimenticato chiuso (molti degli utenti telefoneranno
fino alla saturazione delle linee telefoniche pur di vedere il loro client preferito
funzionare), mentre è molto più difficile vedere cosa si è dimenticato aperto.
•
non è facile riconoscere tutto ciò che c'è da bloccare. Per esempio, usando una politica
di ACCEPT, è estremamente difficile prevedere ciò che potrà essere utilizzato per
aggirare le restrizioni, contando che spesso non è obbligatorio seguire gli standard e
una persona un po’ sveglia potrebbe modificare il kernel di due macchine linux per
utilizzare un protocollo che nulla ha a che vedere col tcp e che mai noi ci saremmo
immaginati di dover bloccare (trattandosi, magari, di un protocollo inventato di sana
pianta).
Un comando che può essere utile nello scrivere le regole si chiama nstreams: questo stamperà
a video l'elenco di tutte le connessioni in corso su una rete.
Modifiche on the fly - iptables da riga di comando
Sebbene sia veramente poco piacevole, è possibile utilizzare iptables direttamente da riga di
comando.
Nonostante questo, alcune di queste funzioni possono risultare molto utili in fase di testing. Ad
esempio, dovendo fare delle misure di banda può essere utile consentire temporaneamente
solo il traffico tra determinate macchine, e non è il caso di perdere tempo a modificare file di
configurazione o script dalla provata affidabilità. Iniziamo quindi col vedere le regole attive
sul kernel, col comando
iptables -nL
dove n dice di non risolvere i nomi (passando da indirizzi ip a nomi di domini) e L di listare o
elencare (in italiano) tutte le regole.
Vediamo alcuni esempi:
[root@jtelemed ~]# iptables –nL
Chain INPUT (policy DROP)
target prot opt source destination
104
Capitolo 8
ACCEPT
ACCEPT
ACCEPT
REJECT
Pubblicazione
all
tcp
all
tcp
-----
0.0.0.0/0
0.0.0.0/0
0.0.0.0/0
0.0.0.0/0
0.0.0.0/0
0.0.0.0/0 tcp dpt:22
0.0.0.0/0 state RELATED,ESTABLISHED
0.0.0.0/0 reject-with tcp-reset
Chain FORWARD (policy DROP)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
-n viene usato principalmente perché altrimenti ci vorrebbe molto tempo a generare l'output
(tentando di connettersi al database). Un problema di iptables -nL (rispetto ad usare un
file di configurazione) è che molti dettagli non vengono mostrati e comunque la leggibilità è
molto minore.
Per avere più dettagli, comunque, è possibile utilizzare l'opzione -v o -vv, con un comando
simile a
iptables –v -nL
[root@jtelemed ~]# iptables –L -v
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target
prot opt in out source
1062 124K RH-Firewall-1-INPUT all -- any any anywhere
destination
anywhere
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target
prot opt in out source
0
0
RH-Firewall-1-INPUT all -- any any anywhere
destination
anywhere
Chain OUTPUT (policy ACCEPT 1337 packets, 1311K bytes)
pkts bytes target
prot opt in out source
destination
Chain RH-Firewall-1-INPUT (2 references)
pkts bytes target prot
opt in
37
6707 ACCEPT all
-- lo
43
2630 ACCEPT icmp
-- any
0
0
ACCEPT ipv6-crypt -- any
0
0
ACCEPT ipv6-auth
-- any
0
0
ACCEPT udp
-- any
0
0
ACCEPT udp
-- any
880
100
ACCEPT all
-- any
ESTABLISHED
0
0
dpt:http
0
0
out
any
any
any
any
any
any
any
source
anywhere
anywhere
anywhere
anywhere
anywhere
anywhere
anywhere
destination
anywhere
anywhere icmp any
anywhere
anywhere
224.0.0.251 udp dpt:5353
anywhere
udp dpt :ipp
anywhere state RELATED,
ACCEPT
tcp
--
any any
anywhere
anywhere state NEW tcp
ACCEPT
tcp
--
any any
anywhere
anywhere state NEW tcp
--
any any
anywhere
anywhere state NEW tcp
--
any any
anywhere
anywhere rejec with icmp-
dpt :https
3
144
ACCEPT tcp
dpt:8085
99
13912 REJECT all
hosts-proibited
105
Capitolo 8
Pubblicazione
Se si è interessati ad un'unica catena, si può specificarne il nome dopo il -nL. Con qualcosa di
simile a iptables –vv -nL INPUT si vedrà solo la catena di INPUT ed un dump delle
informazioni del kernel. Come altre opzioni generiche, si possono utilizzare -x, che mostrerà i
valori esatti dei contatori, mentre -Z li azzererà, oppure -t nometabella per visualizzare altre
tabelle.
106