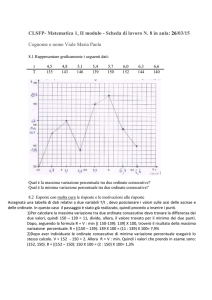
MAKING LIFE A SAFE ADVENTURE
Introduzione ai report di analisi statistica descrittiva
Il presente lavoro di analisi statistica descrittiva è riferito a tre distinte banche dati:
GIOVANI-ADULTI con disabilità,
GENITORI di ragazzi con disabilità,
OPERATORI/PROFESSIONISTI che lavorano con le famiglie di minori con disabilità.
I tre questionari usati per la raccolta dei dati presentano caratteristiche di struttura comuni, e quindi alcune
considerazioni possono essere fatte a prescindere dalla banca dati di provenienza.
•
La ricerca si basa quasi esclusivamente su variabili categoriali non ordinate (es. occupazione:
impiegato/ imprenditore/ libero professionista/…) e variabili categoriali ordinate, con modalità
espresse attraverso “score”, o meglio scale Likert da 1 a 4 punti (es. per niente/ poco/ abbastanza/
molto), da 1 a 3 punti (es. per niente/ sufficiente/ insufficiente), oppure con due sole modalità
(positivo/ negativo). Solo alcuni quesiti dei questionari riguardano informazioni esprimibili
attraverso caratteri quantitativi (es. età; anni di esperienza professionale; …). Questa prima
considerazione influenza non poco la scelta degli indicatori statistici adatti a riassumere le
informazioni delle banche dati:
-
in presenza di variabili quantitative si prenderanno in esame la media aritmetica, per
individuare la tendenza centrale della distribuzione, e la deviazione standard, come indice di
variabilità;
-
in presenza di variabili categoriali non ordinate si prenderanno in esame i valori modali, per
riconoscere le categorie prevalenti di risposta;
-
in presenza di variabili categoriali ordinate (tutte le risposte a punteggio) si prenderanno in
esame i valori mediani, per individuare la tendenza centrale della distribuzione.
•
Nella maggior parte delle domande a punteggio, l’intervistato ha sempre la possibilità di indicare un
tema non presente in elenco, inserendolo nella categoria “altro” e dando anche ad esso la propria
preferenza di punteggio. In alcuni casi è prevista anche la categoria “nessuno”, per gli intervistati che
non si riconoscono in nessuna delle caratteristiche elencate. Sarebbe richiesto un punteggio per ogni
tema dell’elenco, ma spesso le risposte sono parziali: ciò implica una serie di dati mancanti nei data
base. Inoltre pochi intervistati si sono avvalsi delle categorie “nessuno” ed “altro”, e non sempre la
specifica di questi ultimi risulta leggibile nell’archivio. Si sceglie di calcolare tutte le distribuzioni
di frequenza e le elaborazioni successive sulla base dei soli dati validi, trascurando i dati
© AIAS Bologna onlus, on behalf of the Daphne project 2005-1/136/YC consortium, 2008
1
MAKING LIFE A SAFE ADVENTURE
mancanti, il cui peso verrà riportato solo se particolarmente rilevante. Si sceglie di escludere le
categorie “altro” (insieme alle eventuali specificazioni aggiunte) e “nessuno” da ogni elaborazione,
in quanto generalmente poco usate dagli intervistati; si rimanda ad un successivo lavoro l’eventuale
analisi di queste variabili: potrebbe essere un interessante approccio al bagaglio esperienziale delle
persone oggetto della ricerca, che difficilmente può essere sintetizzato in pieno dallo strumento
statistico.
•
Affiancata all’analisi dei dati per le popolazioni totali, si propone l’analisi incrociata attraverso la
distinzione in sottogruppi significativi, secondo le variabili (due per ogni banca dati) indicate come
preferenziali dai responsabili della ricerca, ovvero:
BANCA DATI
VARIABILI PER DISCRIMINARE
I SOTTOGRUPPI
_________________________________________________________________________
Nazione
GIOVANI ADULTI
GENITORI
Tipo di disabilità
PROFESSIONISTI
Ambito di competenza
professionale
_________________________________________________________________________
•
Per individuare eventuali differenze significative nei dati incrociati con le variabili discriminanti,
sarebbe stato opportuno utilizzare l’analisi del χ2 , ma ad una verifica operata con SPSS è risultato
che quasi tutti gli incroci non soddisfano i criteri di applicabilità di tale test per il numero troppo alto
di caselle vuote o con frequenza attesa inferiore a 5. Si rimanda l’analisi del χ2 ad una eventuale
ricodifica delle variabili per ridurre il numero delle categorie al loro interno (es. trasformare le scale
Likert a 4 livelli in scale a 2 livelli). Nel presente lavoro si è scelto di calcolare l’intensità della
eventuale associazione tra le variabili attraverso:
-
il Coefficiente di contingenza “T” (detto anche Indice di Tschuprow), se si è in presenza di
variabili categoriali non ordinate;
-
l’Indice quadratico di dipendenza in media “η” (Eta), se si è in presenza di variabili
quantitative o variabili categoriali ordinate (tutte le risposte a punteggio).
Essendo misure standardizzate, questi indici variano da 0 (= perfetta indipendenza) a 1 (= massima
associazione); si sceglie arbitrariamente di porre l’attenzione solo sui casi di incrocio da cui si ricava
© AIAS Bologna onlus, on behalf of the Daphne project 2005-1/136/YC consortium, 2008
2
MAKING LIFE A SAFE ADVENTURE
T ≥ 0.50 o η ≥ 0.50, evidenziati in grossetto nelle tabelle, essendo questo il valore che si pone
esattamente a metà tra l’ipotesi di indipendenza e di dipendenza massima tra le variabili esaminate.
Avremo così anche la possibilità di confrontare i valori ottenuti per l’indice T, come quelli ottenuti
per η, e operare così una comparazione del grado di connessione delle variabili.
PER UNA MAGGIORE COMPRENSIONE DEGLI INDICI T e η
L’indice “T” si basa sulla somiglianza delle distribuzioni parziali di frequenza (quelle cioè che si riscontrano
nei singoli gruppi in cui si è suddivisa la popolazione totale): esso vale 0 nel caso di connessione nulla, e 1 solo
nel caso di mutua dipendenza perfetta tra la variabile in esame e la variabile scelta per discriminare i gruppi:
questo si può avverare solo quando ad ogni modalità di una variabile si abbina una ed una sola modalità
dell’altra variabile (ciò si avvera naturalmente solo se è uguale il numero di modalità dell’una e dell’altra
variabile).
L’indice “η” si basa sull’uguaglianza delle distribuzioni parziali rispetto alla media aritmetica, e per esso vale
l’uguaglianza: η = (devianza tra i gruppi / devianza totale); η si annulla nel caso di indipendenza in media, cioè
nel caso in cui le medie della variabile nei singoli gruppi sono equivalenti, e quindi uguali alla media aritmetica
dell’intera popolazione: questo si avvera quando la variabilità tra i gruppi è nulla, e rimane solo la componente
di variabilità entro i singoli gruppi. Diversamente, η vale 1 quando non c’è variabilità entro i singoli gruppi, ma
tutte le unità statistiche entro ogni gruppo assumono un unico valore (uguale quindi al loro valore medio), e le
medie tra i gruppi sono tutte diverse: questo si avvera nel caso di dipendenza perfetta tra la variabile in esame
(variabile dipendente) e la variabile scelta per discriminare i gruppi (variabile indipendente).
Per la formula di calcolo dell’indice η, solo per η > 0.70 la variabilità tra i gruppi supera la variabilità entro i
gruppi: una scelta più restrittiva potrebbe essere quella di considerare i valori superiori a 0.70 come indicatori
di una più significativa dipendenza in media..
•
La scelta di trattare le variabili categoriali ordinate con gli stessi indicatori usati per le variabili
quantitative è conseguente all’ipotesi che i punteggi associati a “per niente”, “poco”, “abbastanza”,
“molto” e alle altre scale Likert siano le migliori traduzioni, in termini numerici, delle rispettive
categorie di risposta; si assume, cioè, l’ipotesi che tra una categoria di risposta e la successiva vi sia
esattamente lo scarto di 1 unità, tanto che la risposta “molto” abbia un peso pari a 4 volte la risposta
“per niente”. Questa ipotesi, largamente adottata anche in altre analisi statistiche, permette di tener
conto della natura ordinata delle risposte. Nonostante questa ipotesi, per le variabili categoriali
ordinate si sceglierà comunque la mediana (e non la media aritmetica) come indicatore della
tendenza centrale della distribuzione, perché reputata la statistica più adeguata, dal punto di vista
concettuale, a variabili che “nascondono” dietro a valori numerici delle categorie qualitative.
•
Vengono elaborate tabelle, grafici, statistiche descrittive, tavole di contingenza per gli incroci di
variabili, indici di connessione tra variabili…ecc. di cui ci si avvale per le affermazioni del presente
© AIAS Bologna onlus, on behalf of the Daphne project 2005-1/136/YC consortium, 2008
3
MAKING LIFE A SAFE ADVENTURE
report: solo alcune di queste elaborazioni vengono riportate in allegato e commentate sinteticamente,
ma tutte possono essere consultate per chiarimenti o successive analisi nel cd di accompagnamento
al presente lavoro.
•
Vengono fornite in allegato le seguenti tabelle e grafici:
-
per variabili quantitative: grafici a barre delle frequenze assolute distinte per sottogruppi
discriminanti, tabelle indicanti la media
aritmetica, la deviazione standard e l’indice “η”;
-
per var. categoriali non ordinate: tabelle delle frequenze relative, con individuazione del
valore modale e calcolo dell’indice “T”;
-
per variabili categoriali ordinate (tutte le risposte a punteggio): tabelle dei valori mediani
con calcolo dell’indice “η”;
N.B. Per le sole variabili anagrafiche delle popolazioni totali
(v. SEZIONE 1 di ogni
questionario) si offrono in allegato grafici a settore circolare per una lettura più agevole delle
frequenze relative.
•
La maggioranza delle domande dei questionari prevede una sola risposta; solo in rari casi è
specificata la possibilità di RISPOSTA MULTIPLA: questi insiemi di risposte, che hanno bisogno di
una particolare codifica dei dati e di un’analisi specifica in SPSS, verranno commentati per le sole
popolazioni totali, lasciando a successiva analisi il confronto di tali risultati con quelli ottenuti nei
sottogruppi presi a riferimento. Le tabelle delle domande a risposta multipla sono raggruppate in
fondo ai report.
© AIAS Bologna onlus, on behalf of the Daphne project 2005-1/136/YC consortium, 2008
4