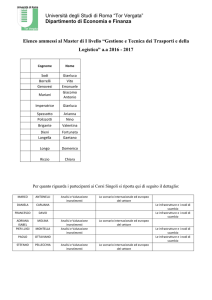
SISSA computing project 2012: HPC technical specification
giugno 2012
A.Lanza, P. Calucci: SISSA – Trieste
S. Cozzini: CNR-IOM DEMOCRITOS – Trieste
A.Ciampa, S. Arezzini, E. Mazzoni: INFN – Pisa
1
INTRODUZIONE
Questo documento costituisce una indicazione per la discussione riguardo alle caratteristiche generali
relative al nuovo sistema HPC in via di acquisizione da parte di SISSA. Non si tratta in alcun modo di un
capitolato tecnico, che seguirà nei tempi e modi previsti in modo legale.
Il sistema di calcolo deve rispondere alle esigenze di una variegata comunità computazionale. Le
caratteristiche dei codici e delle modalità d’uso delle risorse HPC hanno definito le specifiche tecniche.
In Appendice 1 è riportata una descrizione sintetica del sistema.
In Appendice 2 è riportata una serie di codici di riferimento che possono costituire elemento di valutazione
in questa fase preliminare.
2
ARCHITETTURA GENERALE DELLA MACCHINA
L’obiettivo è quello di un sistema HPC linux cluster formato da N nodi, con una percentuale di questi dotati
di GPGPU.
La macchina sarà una macchina “capacity”, ovvero punterà più sul throughput totale che sulla potenza di
picco assoluta. In ogni caso è attesa una capacità di calcolo raw fra i 100 e i 200 Tflops.
L’architettura del sistema che si intende realizzare e’ quella standard di un cluster:
nodi di management (master node) e di monitoring
nodi di calcolo
sistema storage
il tutto connesso da opportune reti, di seguito specificate.
1
3
NODI DI CALCOLO
Fattore di forma:
Vincolo essenziale è che i nodi di calcolo siano alloggiabili all’interno di rack standard; l’unità di base è un
server biprocessore (dual socket), sono accettate soluzioni basate su twin (1U) e twin square (2U). Sono
accettate anche soluzioni blade, in base alla convenienza economica delle stesse, e comunque per i blade
va individuata una soluzione che permetta un set di porte di rete dedicate per ciascuna singola lama.
Tipologia processori:
Processori multicore x86_64. Vengono indicati come base di partenza le seguenti architetture:
INTEL Sandy Bridge, con processori a 8 core
AMD Opteron, con processori a 16 core
Alimentazione dei nodi:
La ridondanza dell’alimentazione non è essenziale, quindi se è disponibile a causa del fattore di forma
proposto(ad esempio nel caso dei twin square) verrà apprezzata, ma senza costituire un elemento decisivo.
Disco a bordo:
Le macchine dovranno essere dotate di un disco di piccole dimensioni per il solo sistema operativo,
tecnologia SATA o SSD. Dato che il disco a stato solido potrebbe darci dei vantaggi in termini di rotture
valuteremo se inserire questa caratteristica nel capitolato tecnico.
Memoria RAM:
I nodi dovranno avere una memoria RAM di minimo 2GB per core. E’ prevista una percentuale (10%) di nodi
con memoria RAM maggiore (8 GB per core). Un certo numero di nodi (indicativamente 8) dovrà avere una
memoria di 16GB per core.
Sistema di management remoto dei nodi:
I nodi dovranno avere integrato un service processor per permettere il management completo del sistema
da remoto. Il service processor dovrà dialogare IPMI versione 2.0 e prevedere un sistema di “ remote
console” compatibile.
Nodi con GPU:
Un sottoinsieme di nodi (8 o 16 a seconda del numero totale dei nodi) dovrà essere equipaggiato con
almeno 2 schede GPU di ultima generazione (KEPLER).
2
Numero di core:
Dimensioniamo il numero di core per avere una prestazione di picco da 100TFlops (orientativamente
considereremo questi valori: per AMD ~10 Gflops a 2.5 GHz, per INTEL Sandy Bridge 20 Gflops a 2.5 GHz).
Pertanto:
INTEL Sandy Bridge (almeno 2.5 GHz ): 5.000 core pari a 625 processori di calcolo (non verrà
considerata la modalità hyper threading )
AMD Opteron (almeno 2.5 GHz ): 10.000 core pari a 625 processori di calcolo
4
NODI DI MANAGEMENT/LOGIN etc
5.
Si prevedono un certo numero di nodi per il management in modo tale da poter garantire tutti i
servizi del cluster in HA. Per questi masternode siamo interessati a macchine 2U completamente
ridondate in HW in particolare
doppio alimentatore,
dischi di sistema con raid HW
sistema di gestione remota su porta dedicata
possibilità di ridondanza della RAM
Memoria RAM di 32GB
Connettività ridondata completa verso ogni tipo di rete presente ( infiniband/FC/gigabit)
Si prevedono inoltre almeno 2 nodi di login (User Interface)che possono essere macchine standard
(nel senso che siamo interessati ad una configurazione non particolarmente dissimile da quella dei
nodi di calcolo).
Si prevede infine 1 nodo di monitoring esterno
RETE
Il sistema sarà dotato delle seguenti retI:
1. una rete di management interna (in-band):
si prevede una rete basata su ethernet (minimo 1GB), gestita dai masternode.
2. una rete di management esterna (out-of-band) su cui collegare tutti gli SP dei nodi
si prevede una rete basata su ethernet e gestita dal nodo di management.
3
3. una rete veloce per il calcolo parallelo: per questa rete prevediamo IB FDR (o almeno QDR), gestita
da un unico switch capace di connettere direttamente tutti i nodi di calcolo, i server di
management/login e, eventualmente se questa è la soluzione indicata, lo storage.
4. una rete per lo storage
Queste ultime due possono essere una stessa rete purché con adeguate capacità in termini di banda
passante e latenza.
La topologia della rete va discussa in dettaglio tenendo conto di alcuni aspetti:
1. essendo la macchina una macchina “capacity” il taglio medio in termini di core dei job paralleli non
supererà un decimo del totale dei cores complessivi (max 512 cores quindi)
2. Le performance del sistema di storage dovranno minimo essere di 3 GB/secondo.
6
STORAGE
Il sistema deve essere dotato di un sistema di storage con caratteristiche minime di questo tipo:
capacità iniziale di circa 400TB raw, espandibile fino ad un massimo di 3 PB.
performance in scrittura/lettura del sistema di almeno 3 GB/secondo (da misurarsi con benchmark
standard (iozone/IOR etc) calibrati opportunamente sul nostro caso.
compatibilità con soluzioni di filesystem paralleli (Lustre 2.x e/o GPFS) che parleranno via rete
veloce con i clients (nodi di calcolo)
adeguati meccanismi di failover su dischi/controller e sistemi.
l’HW dello storage deve garantire nel caso di FS paralleli ridondanza piena sui metadati del FS
parallelo (ad esempio nel caso Lustre MGS e MDT devono essere garantiti in HA su due distinti
server)
Il sistema di storage sarà partizionato in un’area scratch (maggioritaria) gestita dal FS parallelo e in
una area utenti (/home max 15 TB) che sarà soggetta a backup sul sistema centrale Sissa, che
richiederà un livello di ridondanza più elevato, e che potrà essere gestita da un FS tradizionale non
essendo richiesto un livello particolare di prestazioni.
Saranno prese in considerazione sia soluzioni di storage con porte IB native, sia con porte FC, nel qual caso
dovrà essere previsto un numero congruo di file server e i necessari switch FC.
4
7
SOFTWARE
Sistema di gestione cluster:
L’installazione sarà fatta dal team locale. Si valuteranno eventuali prodotti di cluster management
presentati dai venditori.
LRMS Scheduler:
Al momento ci si sta orientando su una delle seguenti soluzioni:
-
Torque/Maui;
-
LSF
-
PBSPro
Le caratteristiche minime:
fair sharing
job pre-emption
gestione job hybrid openMP/MPI
accounting
Monitoring/Management system:
Tutte le componenti HW (switch/PDU, etc) devono essere monitorabili e facilmente gestibili. Ogni
sottosistema idealmente dovrebbe essere in grado di essere “scriptabile” e/o in grado di avere/definire
plugins per sistemi di monitoring come nagios. In particolare devono poter essere gestite in maniera noninterattiva la raccolta la misurazione dei principali parametri (temperature, correnti, …) e l'accensione e lo
spegnimento.
5
Appendice 1: riassunto del sistema
- Core
o 10.000 con architettura AMD Opteron
o 5.000 con architettura INTEL Sandy Bridge
- Processori e server di calcolo
o 625 processori (16 core/processore
core/processore nel caso Sandy Bridge)
nel
caso
AMD,
8
o 313 server di calcolo biprocessori, in entrambi i casi
- RAM per server di calcolo
o 279 server con 2 GB di RAM/core
o 30 server con 8 GB di RAM/core
o 4 server con 16 GB di RAM/core
- Coprocessori
o 4 o 8 server dovranno essere equipaggiati almeno con due schede
Nvidia KEPLER ciascuno
- Server di management
o 2 server biprocessori in High Availability, come descritto nel testo,
dotati di 2 GB di RAM/core
o 3 server biprocessori con 2 GB di RAM/core
6
- Rete
o Rete IP: una porta da 1 Gb/sec per server o lama biprocessore
o Rete IP di management: una porta da 1 Gb/sec per server o lama
biprocessore
o Rete Infiniband: una porta QDR (preferibile FDR) per server di
calcolo o lama biprocessore
o Switch per le reti IP: architettura “switch top of the rack” (o uno
switch per coppia di rack) piu’ un livello di aggregazione
o Switch per rete IB: uno switch unico con almeno 650 porte
- Storage
o File system: Lustre o GPFS
o Dimensioni raw: almeno 400 TB espandibili fino a 3 PB
o Prestazioni: almeno 3 GB/sec sia in read che in write
7
Appendice 2
Listiamo qui una serie di codici/tecnologie comunemente impiegate dai ricercatori SISSA.
Siamo anche in grado di fornire una serie di casi di studio per permettere ai venditori di validare/testare
internamente le performance ottenute sulle componenti HW e SW che si intendono proporre.
Le applicazioni selezionate sono:
quantum-simulation package:
Quantum_Espresso, CP2K,
MD packages:
-NAMD, GROMACS, LAMMPS,Amber,
Quantum MonteCarlo
TurboRVB and other locally developed packages.
Astronomy and cosmology:
GADGET, N-body code locally developed, CosmoMC
Computational Fluido dynamics
openFoam, locally developed packages, based on libraries like SAMRAI, Deal.II, Trilinos, PETSc
Particle Physics
QCD codici sviluppati localmente.
Per ciascuna di queste applicazioni sono in corso di raccolta presso i ricercatori Sissa una serie di casi di
studio completi di inputs e outputs (benchmark suite). La dimensione in termini di memoria e richieste
computazionali di questi benchmark saranno variabili. In alcuni casi saranno volti a capire le prestazioni
all’interno di un tipico nodo di calcolo della macchina che si intende realizzare. In altri casi misureranno le
prestazioni della rete e la scalabilità del sistema anche se limitatamente al range di interesse.
Forniremo a breve una tabella iniziale di performance di detti casi di studio ottenuta su piattaforme
attualmente usate dalla comunità scientifica.
8