Materiale didattico per gli studenti del corso di laurea in Scienze e Tecnologie per l’Ambiente
frequentanti l’insegnamento (parte informatica INF-01):
-
Metodologie Statistiche per L’Ambiente (DM 270)
Metodologie Statistiche per l’Analisi di Dati Ambientali (DM 509)
Docente: Sergio Orefice ([email protected])
Programma del corso AA 2008-09:
- Architettura dei sistemi informatici:
Generalità sui sistemi informatici. Architettura dei sistemi informatici: hardware e software.
- Codifica binaria dell'informazione:
Sistemi di numerazione posizionali. Sistema binario. Sistemi ottale ed esadecimale.
Conversioni di base.
- Elementi di logica booleana:
Porte logiche AND, OR, NOT, NAND, NOR, XOR. Tavole di verità. Circuiti combinatori.
- Il modello di von Neumann:
Architettura della macchina di von Neumann. Organizzazione della RAM. Organizzazione
della CPU.
- Algoritmi e programmi:
Concetto di algoritmo. Diagrammi di flusso. Strategie di progettazione di algoritmi. Ricorsione.
Ricerca sequenziale e ricerca binaria. Programmi e linguaggi di programmazione.
Grammatiche. Ambienti di programmazione.
- Basi di dati:
Relazioni e basi di dati relazionali. Operazioni su basi di dati relazionali.
- Sistema Operativo:
Architettura del sistema operativo. Processi.
- Alberi Binari e algoritmi di visita (** solo per studenti DM 509 **)
1. Architettura dei sistemi informatici
1.1
Generalità sui sistemi informatici
Definire in modo “preciso” e allo stesso tempo “sintetico” che cos’è l’informatica non è semplice,
infatti l’informatica ormai abbraccia campi vastissimi tanto da rendere le varie definizioni che
spesso si danno vaghe, contraddittorie o riduttive. Il termine informatica traduce il termine inglese
computer science (scienza dell’elaboratore), ma in realtà il calcolatore è solo lo strumento finale col
quale vengono realizzate le applicazioni. Una definizione generale che possa abbracciare tutte le
discipline dell’informatica, ma non generale al punto tale da includere campi che effettivamente non
sono correlati ad essa, e che è stata anche accettata dal Ministero della Pubblica istruzione è la
seguente: l’informatica è la scienza della rappresentazione e dell’elaborazione dell’informazione.
Questa impostazione evidenzia che il prodotto principale della tecnologia informatica è
l’informazione e come essa viene strutturata ed elaborata, non è difficile quindi capire perché
l’informatica oggi stia diventando parte integrante di quasi tutte le attività umane. Ci sono diverse
tipologie di sistemi informatici che vanno dal più piccolo personal computer portatile al più grande
sistema informatico con molteplici utenti e grandi quantità di dati e programmi usato in
un’industria, ma nonostante le notevoli differenze, è possibile individuare degli elementi comuni a
tutti questi sistemi e studiarne le caratteristiche.
1.2
Architettura dei sistemi informatici: hardware e software
Per architettura di un sistema informatico si intende:
le componenti che formano il sistema;
i compiti che ogni componente svolge nel sistema;
come le varie componenti interagiscono tra loro.
La prima grande suddivisione che conviene adottare consiste nel distinguere l’hardware, cioè
l’insieme dei componenti fisici del sistema, dal software, cioè l’insieme dei programmi che
vengono eseguiti dal sistema.
SOFTWARE
firmware
HARDWARE
In realtà il confine è sottile: tra l’hardware ed il software c’è il firmware, ossia del software che è
implementato direttamente sull’hardware e non può essere cambiato. Come esempio, si considerino
due sistemi informatici quali un personal computer e un videogioco. Con il sistema videogioco è
possibile solo giocare perché è stato realizzato tramite firmware, ossia l’hardware della macchina è
stato realizzato in modo da implementare solo il gioco; invece con il personal computer è possibile
svolgere differenti attività come scrivere documenti di testo, disegnare immagini, ascoltare musica,
questo perché sul portatile c’è del software e quindi l’hardware è stato realizzato in modo da poter
accettare ed eseguire diversi programmi.
I principali componenti hardware sono:
Unità di elaborazione o processore (indicata anche come CPU dall’inglese Central Processing
Unit) è la componente che si occupa di elaborare i dati e coordinare il trasferimento degli stessi
all’interno del sistema. Ha il compito di eseguire i programmi, cioè interpretare ed eseguire le
istruzioni che compongono i programmi stessi.
Memoria centrale (indicata anche come RAM dall’inglese Random Access Memory) è la
componente che si occupa di memorizzare dati e programmi.
Le caratteristiche della memoria centrale sono:
o
capacità limitata ossia permette di memorizzare una quantità ridotta di dati o
programmi;
o
è volatile cioè il suo contenuto viene perduto quando viene spento
l’elaboratore, in presenza di guasti o di interruzioni di energia elettrica.
o
accesso alle informazioni veloce.
Si noti che affinché le informazioni possano essere elaborate il passaggio nella RAM è
obbligatorio.
Memoria secondaria (o memoria di massa) anch’essa memorizza dati e programmi ma le sue
caratteristiche sono opposte a quelle della memoria centrale:
o
capacità elevata ossia consente la memorizzazione di quantità elevate di
informazioni;
o
è persistente cioè l’informazione non viene persa in caso di mancanza di
energia elettrica;
o
accesso alle informazioni lento.
Tutte le informazioni devono poter essere disponibili nel tempo per poter essere
utilizzate, altrimenti la loro elaborazione sarebbe inutile. E’ necessario quindi disporre di
archivi che possano contenere quantità elevate di informazioni. A questo serve la
memoria di massa che dunque è indispensabile come unità di archiviazione.
Unità periferiche sono le componenti che permettono lo scambio di dati tra il calcolatore e
l’ambiente esterno. Le più comuni sono:
o Terminali dotati di una tastiera e di un video;
o Stampanti che producono uscite di tipo cartaceo.
Bus di sistema è l’unità che collega tutte le componenti hardware permettendo lo scambio di
dati tra le stesse.
Il software si divide in due livelli principali:
software di base, cioè programmi dedicati alla gestione dell’elaboratore e quindi di tutte le sue
componenti. Il principale programma del software di base è il sistema operativo, che gestisce e
coordina l’uso, da parte del software applicativo, di risorse hardware presenti nell’elaboratore
Il sistema operativo consente:
o
il funzionamento dell’elaboratore (se non è presente il sistema operativo il
calcolatore non può essere avviato);
o
l’interazione con l’elaboratore ( senza di esso non sarebbe possibile comunicare con
la macchina che diventerebbe inutilizzabile).
software applicativo, cioè programmi sviluppati per risolvere le specifiche esigenze
dell’utente. Esso opera al di sopra del software di base.
UTENTE
SOFTWARE APPLICATIVO
SOFTWARE DI BASE
HARDWARE
firmware
Esempi di sistemi informatici
Le tipologie più diffuse di sistemi informatici sono le seguenti:
o Personal Computer solitamente è composto da :
un corpo “box” che comprende il processore,la memoria centrale
e la memoria di massa, e ad esso sono collegati:
una tastiera e
un video.
Un personal computer generalmente ha il processore dedicato ad un unico utente.
La memoria di massa di un personal computer è costituita da due elementi:
disco fisso (hard disk) che ha un’elevata capacità ma è
inamovibile;
dischetti (floppy disk) che hanno capacità ridotta ma sono
estraibili e dunque portabili.
La memoria di massa, sia essa dischetti o disco fisso, è organizzata in archivi o file; un file ha un
proprio nome che ne permette l’individuazione all’interno della memoria di massa e può contenere
vari tipi di dati organizzati in vari modi. Per esempio può contenere testo, immagini, canzoni, ecc…
o Workstation solitamente è composta da :
un video di grandi dimensioni;
un processore capace di elevate prestazioni.
.
o Mini calcolatore è in grado di servire alcune decine di utenti, ciascuno collegato al mini
calcolatore tramite un terminale.
o Main frame capaci di gestire centinaia di utenti, con molti processori e grandi memorie di
massa. Ne sono un esempio i sistemi informatici per la gestione dei conti correnti di una banca,
o delle prenotazioni dei viaggi aerei.
o Reti di calcolatori sono sistemi informatici connessi tra loro. Le reti di calcolatori si
differenziano in due categorie principali:
reti locali che collegano terminali e calcolatori che sono fisicamente vicini
fra loro (stesso edificio o stesso ufficio) e sono molto veloci, cioè capaci di
trasmettere grandi quantità di dati in poco tempo;
reti geografiche che collegano fra loro elaboratori medio-grandi posti a
grande distanza fra loro (diverse regioni o diverse nazioni). La trasmissione
dell’informazione e più lenta e onerosa rispetto ad una rete locale.
2. Codifica binaria dell’informazione
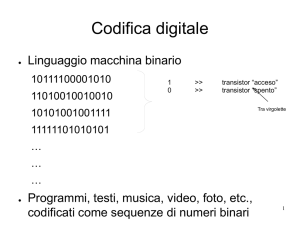
L’informazione (I) intesa come numeri, caratteri, testi, immagini e quant’altro si possa
memorizzare, in un sistema informatico è rappresentata (o codificata) in forma binaria, cioè
attraverso una sequenza di zero e uno.
I
sequenza di zero e uno
L’unità di informazione elementare in un sistema informatico è il bit.
I
sequenza di bit
Il bit corrisponde allo stato di un dispositivo fisico e può avere solo due valori: zero oppure:
0
stato di tensione elettrica alto
1
stato di tensione elettrica basso
BIT
La scelta di limitarsi a due stati, zero e uno, è dettata da motivazioni tecnologiche quali la minor
probabilità di guasti ed errori.
Come le unità di misura da noi comunemente usate come il metro, il grammo, ecc…, anche il bit ha
dei multipli che sono:
o
Byte
che corrisponde a 8 bit;
o
Kbyte
che corrisponde a 1024 byte;
o
Mbyte
che corrisponde a 10242 byte;
o
Gbyte
che corrisponde a 10243 byte.
2.1
Caso di studio: codifica binaria di numeri naturali
Si indichi con M un generico numero naturale e con ai l’i-esimo bit della sequenza binaria che
codifica il numero M:
M
an an-1 … ai
…a1 a0
indica il bit più significativo
CASO A:
M
an an-1 … ai
indica il bit meno significativo
…a1 a0
La codifica da sequenza binaria a numero naturale avviene secondo la seguente formula:
n
M = ai x 2i = an x 2n + an-1 x 2n-1 + …………+ a1 x 2 + a0 x 20
i=0
Esempio: trovare il numero naturale che corrisponde alla stringa binaria 101001011.
M = 1 x 28 + 0 x 27 + 1 x 26 + 0 x 25 + 0 x 24 + 1 x 23 + 0 x 22 + 1 x 21 + 1 x 20 =
= 256 +64 + 8 + 2 + 1 = 331
Esempio: trovare il numero naturale che corrisponde alla stringa binaria 1101001.
M = 1 x 26 + 1 x 25 + 0 x 24 + 1 x 23 + 0 x 22 + 0 x 21 + 1 x 20 =
= 64 + 32 + 8 + 1 = 105
Un modo più veloce per effettuare la codifica è considerare solo gli addendi che hanno uno
come fattore moltiplicativo (ossia i bit posti a uno): lo zero infatti dà un contributo nullo
nella moltiplicazione e quindi nell’addizione. L’esempio appena svolto può essere così
risolto nel seguente modo più rapido:
M = 1 x 26 + 1 x 25 + 1 x 23 + 1 x 20 =
= 64 + 32 + 8 + 1 = 105
L’uno nella moltiplicazione è un fattore neutro, e quindi può anch’esso essere omesso. In
questo modo otteniamo la seguente codifica:
M = 26 + 25 + 23 + 20 =
= 64 + 32 + 8 + 1 = 105
CASO B:
an an-1 … ai
M
…a1 a0
La codifica da un numero naturale alla corrispondente sequenza binaria avviene in accordo alle
seguenti regole:
Si effettuano successive divisioni per due del numero, fino a portarlo a zero;
Si considera la sequenza di bit (zero e uno) ottenuta, prendendo nell’ordine
generato (dal bit meno significativo a quello più significativo) i resti della
divisione. Informalmente possiamo dire che i resti vanno letti al contrario,
cioè dal basso verso l’alto.
Esempio : convertire in binario il numero 331.
331 : 2 = 165
165 : 2 = 82
82 : 2 = 41
41 : 2 = 20
20 : 2 = 10
10 : 2 = 5
5:2= 2
2:2= 1
1:2= 0
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
331
1
1
0
1
0
0
1
0
1
bit meno significativo
bit più significativo
101001011
Esempio : convertire in binario il numero 2010.
2010 : 2 = 1005
1005 : 2 = 502
502 : 2 = 251
con resto di
con resto di
con resto di
0
1
0
bit meno significativo
251 : 2 = 125
125 : 2 = 62
62 : 2 = 31
31 : 2 = 15
15 : 2 = 7
7:2= 3
3:2= 1
1:2= 0
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
2010
1
1
0
1
1
1
1
1
bit più significativo
11111011010
2.2 Sistema di numerazione posizionale
Il sistema binario è un caso particolare di sistema di numerazione posizionale.
Definizione:
Un sistema di numerazione posizionale è definito da una coppia (base p, alfabeto A di cifre),
in cui le cifre appartenenti all’alfabeto A assumono i valori compresi fra zero e p-1.
A = {ai : 0 < ai < p-1}
Esempio:
sistema binario:
p=2,
A = {0,1}
sistema decimale:
p = 10 ,
A = {0,1,2,3,4,5,6,7,8,9}
2.3 Conversioni di base
In generale il valore decimale del numero M in base p è dato dalla formula:
n
M = ai x pi
i=0
dove an an-1 ……a1 a0 è la sequenza che codifica Mp (con ai A)
Con questa formula si può codificare una stringa in una qualsiasi base p nell’equivalente nmero
decimale.
Esempio:
58710 = 5 x 102 + 8x 101 + 7 x 100
425 = 4 x 51 + 2 x 50 = 2210
1213 = 1 x 32 + 2 x 31 + 1 x 30 = 1610
Si noti che in generale cifre di un numero non vanno lette come in un sistema di
numerazione decimale, ma come stringa di cifre in una certa base.
Ad esempio, 4510
non va letto “quarantacinque”, ma come stringa “quattro cinque” in base dieci
2.4 Sistemi ottale ed esadecimale
Nei calcolatori, oltre al sistema binario, sono spesso usati ed hanno particolare importanza i sistemi
ottale ed esadecimale in quanto permettono una rappresentazione dell’informazione più sintetica
rispetto alla codifica binaria.
Sistema ottale:
Sistema esadecimale:
base
p=8
alfabeto
A = {0,1,2,3,4,5,6,7}
base
p = 16
alfabeto
A = {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F}
0 ≤ ai ≤ p-1
10
15
Altre conversioni di base
OTTALE
Esempio:
DECIMALE
convertire in decimale il numero ottale 534.
5348 = 5 x 82 + 3 x 81 + 4 x 80 = 320 + 24 + 4 = 34810
ESADECIMALE
Esempio:
DECIMALE
convertire in decimale il numero esadecimale B7F.
B7F16 = 11 x 162 + 7 x 161 + 15 x 160 = 2816 + 112 + 15 = 294310
Osservazione:
B7F16 = a2 a1 a0
con
a2 = 11
a1 = 7
a0 = 15
OTTALE
Per le conversioni : DECIMALE
ESADECIMALE
occorre passare prima per la codifica binaria.
Le conversioni binario-ottale e binario-esadecimale sono molto semplici, basta considerare il
seguente schema che associa a ogni cifra ottale (esadecimale) una corrispondente tripla (quadrupla)
binaria:
CIFRA OTTALE
TRIPLA BINARIA
0
1
2
3
4
5
6
7
CIFRA
ESADECIMALE
000
001
010
011
100
101
110
111
0
1
2
3
4
5
6
7
8
9
A
B
C
D
E
F
QUADRUPLA
BINARIA
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
Le tripla e le quadruple sono ottenute per mezzo della codifica binaria della rispettiva stringa ottale
e esadecimale. Si noti che in generale con n bit si possono codificare 2n numeri (tutti i numeri da 0 a
2n-1).
BINARIO
OTTALE
Si divide il numero binario in triple e si codifica ogni tripla nella corrispondente cifra ottale. Se il
numero binario non è multiplo di tre si aggiungono tanti zero a sinistra fino ad ottenere comunque
delle triple senza alterare il valore del numero.
Esempio: convertire in ottale il numero binario 1010110111
001 010 110 111
12678
1
2
6
7
Esempio: convertire in ottale il numero binario 111001100101
111 001 100 101
71458
7
1
4
5
BINARIO
ESADECIMALE
Si divide il numero binario in quadruple e si codifica ogni quadrupla nella corrispondente cifra
esadecimale. Se il numero binario non è multiplo di quattro si aggiungono zero a sinistra in modo
da ottenere comunque delle quadruple senza alterare il valore del numero.
Esempio: convertire in esadecimale il numero binario 1010110111
0010
1011
0111
2B716
2
B
7
Esempio: convertire in esadecimale il numero binario 101000111000
1010
0011 1000
A3816
A
DECIMALE
3
8
OTTALE
Questa codifica si può effettuare passando prima per la codifica binaria:
DECIMALE
BINARIO
OTTALE
Esempio:
convertire in ottale il numero decimale 4589610
45896 : 2 = 22948
22948 : 2 = 11474
11474 : 2 = 5737
5737 : 2 = 2868
2868 : 2 = 1434
1434 : 2 = 717
717 : 2 = 358
358 : 2 = 179
179 : 2 =
89
89 : 2 =
44
44 : 2 =
22
22 : 2 =
11
11 : 2 =
5
5:2=
2
2:2=
1
1:2=
0
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
4589610
0
0
0
1
0
0
1
0
1
1
0
0
1
1
0
1
bit meno significativo
bit più significativo
10110011010010002
A questo punto si spezza il numero binario in triple: 1 011 001 101 001 000
Il numero binario è composto di sedici cifre, per poter ottenere delle triple occorre dunque
aggiungere due zero a sinistra della stringa binaria:
001 011 001 101 001 000
1315108
1
3
1
5
1
0
In conclusione:
4589610
1315108
Esempio:
convertire in ottale il numero decimale 55510
555 : 2 =
277 : 2 =
138 : 2 =
69 : 2 =
34 : 2 =
17 : 2 =
8:2=
4:2=
2:2=
1:2=
277
138
69
34
17
8
4
2
1
0
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
55510
1
1
0
1
0
1
0
0
0
1
bit meno significativo
bit più significativo
10001010112
001 000 101 011
10538
1
0
5
3
In conclusione:
55510
DECIMALE
10538
ESADECIMALE
Anche questa conversione di base si può effettuare passando prima per la codifica binaria::
DECIMALE
BINARIO
ESADECIMALE
Esempio:
convertire in esadecimale il numero decimale 121310
1213 : 2 =
606 : 2 =
303 : 2 =
151 : 2 =
75 : 2 =
37 : 2 =
18 : 2 =
9:2=
4:2=
2:2=
1:2=
606
303
151
75
37
18
9
4
2
1
0
121310
0100
1011
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
1
0
1
1
1
1
0
1
0
0
1
bit meno significativo
bit più significativo
100101111012
1101
4BD16
4
B
D
In conclusione:
121310
4BD16
Esempio: convertire in esadecimale il numero decimale 50710
507 : 2 = 253
253 : 2 = 126
126 : 2 = 63
63 : 2 = 31
31 : 2 = 15
15 : 2 = 7
7:2=
3
3:2=
1
1:2=
0
50710
0001
1111
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
con resto di
1111110112
1011
1FB16
1
1
0
1
1
1
1
1
1
bit meno significativo
bit più significativo
In conclusione:
50710
OTTALE
1FB16
BINARIO
Per codificare un numero ottale in un numero binario basta prendere ogni singola cifra del numero
ottale e codificarla nella corrispondente tripla binaria. Gli zeri a sinistra non contribuiscono al
valore del numero e possono essere omessi (ad es. 010 corrisponde a 10).
Esempio:
convertire in binario il numero ottale 1578
1
5
7
001 101 111
Esempio:
11011112
convertire in binario il numero ottale 543718
5
4
3
7
9
101 100 011 111 001
ESADEC.
1011000111110012
BINARIO
Per codificare un numero esadecimale in un numero binario basta prendere ogni singola cifra del
numero esadecimale e codificarla nella corrispondente quadrupla binaria. Gli zeri a sinistra non
contribuiscono al valore del numero e possono essere omessi (ad es. 0010 corrisponde a 10).
Esempio:
convertire in binario il numero esadecimale F2D516
F
2
D
5
1111
0010
1101
0101
11110010110101012
Esempio:
convertire in binario il numero esadecimale A3716
A
3
7
1010
0011
0111
1010001101112
3. Elementi di logica booleana
I circuiti hardware possono essere costruiti a partire da elementi primitivi, detti porte, che vengono
combinati tra di loro. Una porta è caratterizzata da un simbolo grafico e da una tavola di verità. Il
simbolo è la rappresentazione grafica della porta e la tavola di verità è una tabella che dà il valore
dell’uscita in funzione degli ingressi delle porte.
3.1
Porte logiche NOT, AND e OR
PORTA
NOT
PORTA
AND
PORTA
OR
ingresso
uscita
ingressi
uscita
ingressi
uscita
0
1
00
0
00
0
1
0
01
0
01
1
10
0
10
1
11
1
11
1
Si noti che le porte AND e OR possono anche avere più di due ingressi, mantenendo la stessa
semantica nella tavola di verità (ossia la porta AND ha 1 in uscita se e solo se tutti gli ingressi
hanno valore pari a 1, mentre la porta OR ha 1 in uscita se almeno uno degli ingressi ha valore 1).
3.2
Circuiti combinatori
Un circuito combinatorio è definito ricorsivamente come segue:
Definizione:
- Le porte sono circuiti;
- Se N1 e N2 sono circuiti allora lo sono anche:
N1
N1
N2
N1
N2
La tavola di verità di un circuito si ottiene considerando tutte le possibili configurazioni dei valori
degli ingressi e, per ognuna di esse, si calcola il valore dell’uscita risolvendo man mano i valori
relativi alle porte interne che compongono il circuito applicando la corrispondente tavola di verità.
(Si noti che gli ingressi di un circuito sono le linee che non provengono da alcuna porta, invece le
uscite sono quelle che non entrano in nessuna porta).
Esempio:
Si consideri il seguente circuito combinatorio e si determini la sua tavola di verità
i1
i2
i3
u
i4
i5
i6
ingressi
uscita
ingressi
uscita
000000
000001
000010
000011
000100
000101
000110
000111
001000
001001
001010
001011
001100
001101
001110
001111
0
0
0
1
0
1
0
1
1
1
1
1
1
1
1
1
010000
010001
010010
010011
010100
010101
010110
010111
011000
011001
011010
011011
011100
011101
011110
011111
0
0
0
1
0
1
0
1
1
1
1
1
1
1
1
1
3.3
ingressi
100000
100001
100010
100011
100100
100101
100110
100111
101000
101001
101010
101011
101100
101101
101110
101111
uscita
0
0
0
1
0
1
0
1
1
1
1
1
1
1
1
1
ingressi
uscita
110000
110001
110010
110011
110100
110101
110110
110111
111000
111001
111010
111011
111100
111101
111110
111111
0
0
0
1
0
1
0
1
0
0
0
1
0
1
0
1
Caso di studio: Multiplexer e Demultiplexer
Si noti anzitutto che ogni circuito è caratterizzato da:
o
una specifica, cioè la definizione formale del circuito, che è unica;
o
una o più implementazioni, cioè possibili realizzazioni del circuito che
soddisfino la specifica.
Vediamo adesso la specifica e una possibile implementazione di due comuni circuiti combinatori, il
Multilplexer e il Demultiplexer.
MULTIPLEXER
Il multiplexer è un circuito usato per selezionare un bit in ingresso e instradarlo verso l’uscita.
Specifica:
Il multiplexer è un circuito con:
una linea di uscita w;
n linee di ingresso a0, … … , an-1 dette linee dati;
n linee di ingresso aggiuntive c0, … … , cn-1 dette linee gating con la condizione che
ad ogni istante solo una linea di gating ha valore 1 (linea attiva).
L’operazione svolta dal multiplexer è la seguente:
<< Se ci è la linea attiva, allora w = ai >>
Implementazione:
a0 c0
a1 c1
a2 c2
a3 c3
MULTIPLEXER 4 - 1
w
DEMULTIPLEXER
Il demultiplexer è usato per selezionare l’uscita del circuito sulla quale verrà instradato un bit in
ingresso. Esso è l’esatto contrario funzionale del multiplexer.
Specifica:
Il demultiplexer è un circuito combinatorio con:
una linea di ingresso x detta linea data;
n linee di ingresso addizionali c0, … … , cn-1 dette linee gating con la condizione che
ad ogni istante solo una linea di gating ha valore 1 (linea attiva).
n linee di uscita y0, … … , yn-1
L’operazione svolta dal multiplexer è la seguente:
<< Se ci è la linea attiva, allora yi = x >>
Implementazione:
c0
c1
c2
c3
x
DEMULTIPLEXER 1-4
y0
4.1
y1
y2
y3
Porte NAND, NOR e XOR
Le porte NOT, AND e OR formano un sottoinsieme completo, ossia con esse è possibile
implementare un qualsiasi circuito combinatorio. Altre importanti porte comunemente usate nella
realizzazione di circuiti combinatori sono le seguenti:
PORTA
NAND
(è il contrario dell’ AND)
PORTA
NOR
(è il contrario dell’ OR)
PORTA
XOR
(è l’ OR esclusivo)
ingressi
00
uscita
1
ingressi
00
uscita
1
ingressi
00
uscita
0
01
1
01
0
01
1
10
1
10
0
10
1
11
0
11
0
11
0
Sia la porta NAND che la porta NOR sono singolarmente complete, ossia possono essere usate da
sole per realizzare qualsiasi circuito combinatorio. (Un circuito fatto di sole porte NAND o di sole
porte NOR è però in generale più complesso, dunque meno efficiente e più costoso da realizzare).
Vediamo, ad esempio, come è possibile costruire un circuito fatto di sole porte NAND equivalente
alle porte AND, OR e NOT. Ciò dimostra che la porta NAND è completa.
a
b
a
w
w
b
a
a
b
a
w
w
w
b
a
w
4. Il modello di Von Neumann
La macchina di Von Neumann offre un modello descrittivo di base dell’architettura di un
calcolatore.
BUS
CPU
RAM
PERIFERICHE
Nel modello di Von Neumann le periferiche includono anche la memoria di massa in quanto essa
interagisce col sistema in modo funzionalmente equivalente a dispositivi di input/output come
terminali o stampanti.
4.1
Organizzazione della RAM
La memoria centrale è fatta da una sequenza di celle o parole di memoria. Ogni parola è fatta da
una sequenza di bit e contiene un dato o un’istruzione.
0
Parola di memoria
1
n-1
bit
Si definisce dimensione della memoria il numero di celle di cui è composta la memoria stessa. A
ogni cella è associato un numero (o indirizzo) che va da 0 a n-1.
Per poter essere utilizzate le informazioni debbono poter essere reperite dalla memoria. Di qui la
necessità di selezionare una determinata cella in modo univoco. Ogni cella può essere selezionata (o
indirizzata) attraverso un registro che si trova nella CPU e che si chiama registro indirizzi. In
generale, un registro è un dispositivo della CPU capace di memorizzare una sequenza di bit.
La codifica binaria della sequenza di bit contenuta nel registro indirizzi dà l’indirizzo della cella da
selezionare. Pertanto se il registro indirizzi ha k bit si possono indirizzare 2k celle di memoria i cui
indirizzi vanno da 0 a 2k-1. L’equazione che lega la dimensione n della RAM e la dimensione k del
registro indirizzi è quindi:
n = 2k
Come esempio si consideri un registro indirizzi a 10 bit e una RAM con 210 = 1024 celle.
0
1
i
1023
Registro indirizzi
K = 10 bit
Si supponga inoltreche la parola di memoria che si vuole indirizzare sia quella con indirizzo pari a
23, allora il registro indirizzi conterrà il valore 23 in codifica binaria, cioè:
Una volta che è stata selezionata una parola di memoria possono essere effettuate due operazioni:
o
LETTURA
o
SCRITTURA
Entrambe le operazioni utilizzano un secondo registro della CPU che si chiama registro dati e ha la
stessa dimensione (cioè numero di bit) delle parole di memoria.
LETTURA :
Il contenuto della cella di memoria selezionata è trasferito nel registro dati.
SCRITTURA :
Il contenuto del registro dati è trasferito nella cella di memoria selezionata.
Il seguente disegno illustra lo schema del funzionamento generale della RAM:
Dimensione n = 210 = 1024
H =16 bit
Registro dati
0
1
L
S
i
H =16 bit
S = scrittura
L = lettura
Registro indirizzi
1023
K = 10 bit
4.2
Organizzazione della CPU
La struttura della CPU è la seguente::
La CPU è formata dalle seguenti componenti:
ALU
L’unità aritmetico logica è un dispositivo capace di effettuare le operazioni
aritmetiche (somma, sottrazione,…) e logiche (and, or, not,…) di base fra i bit.
CLOCK
Il clock (orologio) è un dispositivo che sincronizza (cioè abilita e
disabilita) le varie componenti.
REGISTRI
Sono dispositivi che memorizzano bit. Essi sono caratterizzati dal
compito che svolgono e dalla dimensione. I principali registri sono:
o Registro dati (RD) contiene i dati o le istruzioni da leggere e
scrivere in memoria. Ha dimensione pari a h bit se h è la
lunghezza di una parola di memoria.
o Registro indirizzi (RI) contiene gli indirizzi delle celle di
memoria. Ha dimensione pari a k bit se 2k è la dimensione
della memoria.
o Registro istruzione corrente (RIC) contiene istante per istante
l’istruzione correntemente eseguita. Ha dimensione pari a h bit
se h è la lunghezza di una parola di memoria.
o Contatore di programma (PC) contiene l’indirizzo della cella
di memoria corrispondente alla prossima istruzione del
programma in esecuzione. Ha dimensione pari a k bit se k è la
dimensione del registro indirizzi.
o Accumulatore (A) contiene gli operandi e i risultati delle
operazioni fatte dall’ALU. Ha dimensione m h se h è la
dimensione di una parola di memoria.
La CPU esegue le istruzioni attraverso il classico schema fetch-execute:
1.
Legge la nuova istruzione dalla RAM ponendola nel RIC;
2.
Cambia il PC affinché punti alla prossima istruzione da eseguire;
3.
Determina il tipo di istruzione appena prelevata;
4.
Se l’istruzione usa dei dati in RAM, determina dove sono situati;
5.
Prende i dati dal registro dati (RD);
6.
Esegue l’istruzione;
7.
Memorizza il risultato al posto giusto;
8.
Ritorna al passo 1 e comincia ad eseguire l’istruzione seguente.
Questo ciclo si chiama “ciclo preleva, decodifica, esegui” e sta alla base del funzionamento di tutti
i calcolatori. Il limite principale del modello di Von Neumann sta nel fatto che le istruzioni sono
eseguite in stretta sequenza l’una dopo l’altra non permettendo alcuna forma di parallelismo,
presente invece nelle moderne architetture di elaboratori.
5. Algoritmi e programmi
I sistemi informatici sono esecutori di algoritmi.
Definizione:
L’algoritmo è una sequenza di passi (istruzioni) che determinano la risoluzione di un
problema.
Un algoritmo viene caratterizzato da alcuni parametri quali:
CORRETTEZZA
ALGORITMO
COMPLETEZZA
EFFICIENZA
Un algoritmo è corretto se risolve il problema per cui è stato creato, ossia se per ogni input calcola
correttamente l’output.
Un algoritmo è completo se considera tutti i possibili casi appartenenti al problema, ossia se
funziona per tutti i possibili input.
L’efficienza di un algoritmo viene espressa in termini di “spazio” e “tempo”. Lo spazio si riferisce
alla quantità di memoria occupata dall’esecuzione dell’algoritmo, il tempo si riferisce ai tempi di
risposta, ossia i tempi necessari all’esecuzione dell’algoritmo per ottenere la soluzione del
problema.
5.1
Un pseudo-linguaggio per la descrizione di algoritmi
Un algoritmo è fatto da una intestazione, contenente il nome dell’algoritmo e i suoi parametri input,
e da un corpo, contenente le istruzioni. Nel seguito gli algoritmi verranno descritti utilizzando un
piccolo sottinsieme di istruzioni con la seguente sintassi e semantica:
BEGIN END
Ogni blocco di istruzioni va racchiuso tra due parole chiave che formano il costrutto begin end e
che indicano rispettivamente l’inizio e la fine di un insieme di istruzioni.
BEGIN
Istruzione1
Istruzione2
…………
END
IF THEN
Il costrutto if then è caratterizzato dal fatto che le istruzioni del blocco che seguono la parola chiave
then siano eseguite se e solo se la condizione posta dopo la parola chiave if risulta essere vera.
IF
(condizione)
THEN
blocco istruzioni
IF THEN ELSE
Il costrutto if then else è caratterizzato dal fatto che se la condizione posta dopo la parola chiave if è
vera allora sono eseguite le istruzioni del blocco posto dopo la parola chiave then, altrimenti (ossia
nel caso in cui la condizione risulti falsa) vengono eseguite le istruzioni poste dopo la parola chiave
else.
IF
(condizione)
THEN
blocco1 di istruzioni
ELSE
blocco2 di istruzioni
Ciclo WHILE
Un ciclo è un blocco di codice che itera (ripete) un certo numero di istruzioni finché la condizione
di controllo del ciclo risulta vera.
WHILE (condizione)
DO
blocco istruzioni
RETURN
Il costrutto return restituisce un valore di output provocando l’interruzione dell’esecuzione
dell’algoritmo stesso.
RETURN
valore
5.2 Strategie di progettazione di algoritmi.
Esistono due principali strategie di progettazione degli algoritmi: l’iterazione e la ricorsione.
ITERAZIONE
Un algoritmo si dice iterativo quando esegue ripetutamente una o più istruzioni, in accordo al
verificarsi di determinate condizioni.
Esempio:
Calcolo del fattoriale
n! = n x n-1 x n-2 x ………x 2 x 1
esempio:
4! = 4 x 3 x 2 x 1 = 24
Algoritmo:
Fattoriale (N)
BEGIN
k=1
i=1
i ≤ N DO
WHILE
BEGIN
k=kxi
i=i+1
END
RETURN
k
END
Esecuzione dell’algoritmo per N = 3:.
N
k
i
3
1
1
1
2
2
3
6
4
RICORSIONE
Si parla di ricorsione quando la soluzione di un problema può essere ottenuta riconducendola allo
stesso problema ma su dati più piccoli. Ad esempio, si osservi che per calcolare il fattoriale di N si
può calcolare il fattoriale di N-1 e moltiplicarlo per N, cioè:
N! = 1
per
N=1
N! = N x (N-1)!
per
N>1
Questa è una definizione ricorsiva perché riconduce l’esecuzione di un calcolo su un certo dato (N),
all’esecuzione dello stesso calcolo su un dato più piccolo (N-1).
Un algoritmo si definisce ricorsivo se nel suo corpo contiene una chiamata a sé stesso. La versione
ricorsiva dell’algoritmo per il calcolo del fattoriale è la seguente:
Algoritmo:
Fattoriale (N)
BEGIN
IF
ELSE
N=1
THEN
RETURN
RETURN
1
N x Fattoriale (N-1)
END
I passi che l’algoritmo esegue se viene chiamato con un valore di N pari a 3 sono i seguenti:
N
3
return 3 x Fattoriale (2)
2
return 2 x Fattoriale (1)
1
return 1
Ricalcolando all’indietro i valori di ritorno delle varie chiamate ricorsive si otterrà il risultato finale
6.
Si noti che la soluzione ricorsiva ad un problema non è sempre possibile, gli algoritmi ricorsivi sono
più efficienti e naturali quando la natura stessa del problema si presta bene alla ricorsione, cioè
quando::
Un problema si ripropone al suo interno in sottoproblemi uguali all’originale, ma applicati
a sottoinsiemi dei dati, e la soluzione globale si ottiene come combinazione delle soluzioni
dei sottoproblemi.
5.3
Ricerca sequenziale e ricerca binaria
I problemi di ricerca di un elemento sono tra i più comuni nell’elaborazione dei dati e hanno
tantissime applicazioni pratiche. Tipici elenchi di dati che incontriamo nella realtà sono:
l’insieme dei volumi in una biblioteca;
l’elenco degli impiegati di un’azienda;
le persone appartenenti all’anagrafe di una certa città.
La struttura che si utilizza per memorizzare questi elenchi di dati è il dizionario. Un dizionario è
una collezione di su cui è possibile effettuare operazioni di inserimento, eliminazione e ricerca. La
ricerca è l’operazione fondamentale, perché comunque propedeutica alle altre due.
RICERCA SEQUENZIALE
Metodo:
Il dato da cercare viene confrontato sequenzialmente con i dati del dizionario finchè
esso viene trovato (successo) oppure termina la scansione del dizionario (fallimento).
L’algoritmo di ricerca sequenziale è iterativo e sempre applicabile. Il costo
dell’algoritmo (cioè il numero di volte in cui viene ripetuta l’operazione
fondamentale di confronto) è lineare nella taglia del dizionario.
Sia A un dizionario con n elementi e k il dato da cercare:
Algoritmo:
Ricerca_sq ( k , A )
BEGIN
i=1
i≤n
WHILE
DO
BEGIN
k = A(i)
IF
ELSE
THEN
RETURN
kA
“Successo”
i=i+1
END
RETURN
kA
“Fallimento”
END
RICERCA BINARIA
La ricerca binaria è applicabile quando sul dizionario è definito un ordinamento.
Metodo:
Il dato k da cercare viene confrontato con l’elemento centrale x del dizionario.
Se k = x la ricerca termina con successo.
Se k < x la ricerca procede con lo stesso metodo sulla prima metà della tabella.
Se k > x la ricerca procede con lo stesso metodo sulla seconda metà della tabella.
L’algoritmo di ricerca binaria è pertanto ricorsivo, ed ha un costo logaritmico in quanto ad ogni
passo lo spazio di ricerca (e quindi il numero di confronti) viene dimezzato.
Sia A un dizionario con n elementi e k il dato da cercare, siano i e j gli estremi del dizionario
(all’inizio i=1, j=n):
Algoritmo:
Ricerca_Bin ( k , A , i , j )
BEGIN
IF
m =
END
i>j
THEN
RETURN
“Fallimento”
kA
i+j
2
IF
k = A (m)
THEN
RETURN
“Successo”
IF
k < A (m)
THEN
Ricerca_Bin ( k , A, i , m-1)
ELSE
Ricerca_Bin (k , A , m+1 , j )
kA
Esempio:
Dizionario ordinato con 18 elementi.
1
2
3
4
5
6
7
8
9
10
2
4
5
11
13
20
47
49
52
67
11
12
13
14
15
16
17
104 120 125 200 207 310 350 450
Sia k = 47 il dato da cercare:
Al primo passo :
i=1
j = 18
M = ( 1 + 18 ) / 2 = 9
A [ 9 ] = 52 > k
M= (1+8)/2
A [ 4 ] = 11 < k
Al secondo passo : i = 1
J=8
Al terzo passo :
Al quarto passo :
= 4
i=5
J=8
M= (5+8)/2
= 6
A [ 6 ] = 20 < k
M= (7+8)/2
= 7
A [ 7 ] = 47 = k
i=7
J=8
18
quindi k A
5.4
Programmi e linguaggi di programmazione
I concetti di programma e algoritmo sono strettamente correlati:
Definizione: Un programma è la codifica di un algoritmo in un linguaggio di programmazione (in
modo che l’algoritmo possa essere eseguito su un calcolatore).
I linguaggi di programmazione si dividono in due grandi categorie:
general purpose, adatto a risolvere efficientemente ampie classi di problemi. Ne sono esempi
il C, Pascal, Java, etc.
specific purpose, adatti a risolvere efficientemente problemi in uno specifico dominio di
applicazione. Ne sono esempi il COBOL adatto per applicazioni gestionali e banche, Visual
Basic adatto per applicazioni grafiche, HTML adatto per applicazioni su Internet, etc.
Ogni linguaggio di programmazione è caratterizzato da una precisa sintassi e da una precisa
semantica. Da un punto di vista formale la definizione generale di linguaggio è la seguente:
Definizione: Un linguaggio formale è un insieme di stringhe su un alfabeto di simboli.
Esempio:
L = {ab , aab}
sull’alfabeto {a , b}
Linguaggio finito in quanto composto da un numero finito o contabile (due) di
stringhe.
L = {anb} con n 1
sull’alfabeto {a , b}
Linguaggio infnito in quanto composto da un numero infinito o non contabile di
stringhe (tutte le ripetizioni di ‘a’ con una ‘b’ alla fine).
Ogni linguaggio di programmazione è un linguaggio, infatti le stringhe del linguaggio sono tutti i
programmi sintatticamente corretti scritti in quel linguaggio di programmazione.
Grammatiche
Per specificare la sintassi (ossia la forma delle frasi) dei linguaggi si usa un formalismo chiamato
grammatica.
Definizione:
Una grammatica è una quadrupla G = (N, T, S, P) dove:
N è l’insieme finito di simboli non terminali;
T è l’insieme finito di simboli terminali;
S N, è il simbolo non terminale iniziale;
P è l’insieme finito di produzioni del tipo A con:
- A non terminale;
- stringa di terminali e/o non terminali.
Definizione: Una derivazione (⇒) è l’applicazione di una produzione, ossia il rimpiazzamento
della parte destra con la parte sinistra
Ad esempio, A ⇒
Il simbolo
se A è una produzione.
indica più passi di derivazione.
Definizione: Il linguaggio generato da una grammatica , L (G), è l’insieme delle stringhe di soli
terminali derivati dal simbolo non terminale iniziale:
L (G) = {w / S
w}
Esempio:
Scrivere una grammatica per il linguaggio L = {ab, ccb}
G = (N, T, S, P)
con
N = {S}
T = {a, b, c}
S=S
P = { S → ab
S → ccb}
oppure:
G = (N, T, S, P)
con
N = {S, A}
T = {a, b, c}
S=S
P = { S → Ab
A→a
A → cc}
Esempio:
Scrivere una grammatica per il linguaggio L = {an b} con n 1.
G = (N, T, S, P)
con
N = {S, A}
T = {a, b}
S=S
P = { S → Ab
A→a
A → aA}
La coppia di produzioni A → a A → aA usata per specificare ripetizioni infinite si chiama cappio.
Grammatica per espressioni aritmetiche
Definizione: Un’espressione è ricorsivamente definita come segue:
un numero è un’espressione;
se E è un’espressione lo sono anche:
- (E)
- E+E
- E–E
- E*E
- E/E
La grammatica che genera espressioni aritmetiche è la seguente:
G = (N, T, S, P)
N = {E, Num, C}
T = { (, ), +, *, /, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
S=E
P = { E → Num
E → (E)
E→E+E
E→E–E
E→E*E
E→E/E
Num → C
Num → Num C
C→0
C→1
C→2
C→3
C→4
C→5
C→6
C→7
C→8
C → 9}
Dove E sta per espressione, Num sta per numero e C sta per cifra.
Automi
Un altro formalismo per la specifica dei linguaggi sono gli automi. Le grammatiche generano i
linguaggi, ovvero esse generano le stringhe dei linguaggi; gli automi invece, riconoscono i
linguaggi, ossia data una stringa l’automa riconosce se la stringa appartiene o meno al linguaggio.
Definizione: Un automa è una quintupla
M = (Q, A, q0, F, t)
dove:
-
Q è l’insieme finito degli stati;
-
A è l’alfabeto;
-
q0 Q è lo stato iniziale;
-
F Q è l’insieme degli stati finali;
-
t è la funzione di transazione del tipo t: Q x A → Q
Gli automi vengono descritti attraverso i diagrammi stati-transizioni. Una stringa è accettata, o
riconosciuta, se e solo se esiste un cammino che va dallo stato iniziale a quello finale del digramma.
Esempio:
Dare l’automa per il linguaggio L = {ab, aab}.
M = (Q, A, q0 , F, t)
con:
Q = {1, 2, 3, 4}
A = {a, b}
q0 = 1
F = {3}
t={
(1, a) = 2
(2, a) = 4
(2, b) = 3
(4, b) = 3 }
Diagramma stati-transizioni:
Esempio:
Descrivere l’automa del linguaggio L = {an b}.
M = (Q, A, q0 , F, t)
con:
Q = {1, 2, 3}
A = {a, b}
q0 = 1
F = {3}
t={
(1, a) = 2
(2, a) = 2
(2, b) = 3}
Diagramma stati-transizioni:
5.5 Ambiente di programmazione
Per poter scrivere ed eseguire programmi in un certo linguaggio di programmazione occorrono due
software applicativi, l’editor e il compilatore:
-
EDITOR serve per creare file di testo, in particolare per scrivere i programmi.
Il programma creato con l’editor si chiama programma sorgente.
-
COMPILATORE serve per tradurre il programma sorgente in linguaggio
binario direttamente eseguibile dall’hardware del calcolatore. Il programma
ottenuto dal compilatore si chiama programma target.
Questi due software applicativi formano un ambiente di programmazione di cui ogni linguaggio di
programmazione è fornito.
Ci sono vari tipi di editor, ad esempio:
- Word processor che permette di scrivere testi;
- Editor di ambienti di programmazione che permettono di scrivere programmi sorgente
per uno specifico linguaggio di programmazione.
- Editor grafici che permettono di creare oggetti grafici.
L’architettura di un compilatore è la seguente:
Programma
sorgente
Programma
target
COMPILATORE
errori
Tipicamente il compilatore opera secondo il modello ANALISI – SINTESI, dove i moduli software
di analisi si occupano di analizzare la correttezza del programma sorgente, mentre quelli di sintesi
derivano il formato target finale.
COMPILATORE
Programma
sorgente
ANALISI
Rappresentazione
intermedia
SINTESI
Programma
target
I compilatori si basano su specifiche grammaticali del linguaggio sorgente. Uno dei moduli
software più importanti nella parte di analisi è il Parser che, sostanzialmente, è un automa che
verifica se un programma sorgente è sintatticamente corretto oppure no, riconoscendolo o meno
come stringa appartenente al linguaggio generato dalla grammatica sorgente.
CICLO DI VITA DEI PROGRAMMI
Lo schema che modella la risoluzione automatica dei problemi tramite algoritmi/programmi è il
seguente:
PROBLEMA
Il programmatore progetta un ALGORITMO per la soluzione del problema
Il programmatore scrive, utilizzando un editor, un PROGRAMMA sorgente in un certo linguaggio
di programmazione che codifica l’algoritmo
Il programma viene COMPILATO per mezzo del compilatore dello specifico linguaggio
Il programma target viene ESEGUITO
L’esecuzione finale del programma target fornisce la soluzione del problema di partenza.
6. Basi di dati
Nella vita quotidiana può capitare spesso di consultare una base di dati, quando ad esempio si
consulta l’elenco telefonico o le pagine gialle, oppure il tabellone degli orari di partenza e arrivo dei
treni. Quando grandi quantità di dati sono mantenute nei calcolatori, occorrono software particolari
per la loro organizzazione e per la loro gestione. Questi software applicativi si chiamano DBMS
(Data Base Management Systems) e sono tra i più importanti software applicativi dei calcolatori.
Esistono tre tipologie di basi di dati che variano a seconda del tipo di strutturazione dei dati:
- Basi di dati gerarchiche caratterizzate da un’organizzazione gerarchica dei dati (le
strutture dati sono alberi);
- Basi di dati reticolari caratterizzate da un’organizzazione reticolare dei dati (le strutture
dati sono grafi);
- Basi di dati relazionali caratterizzati da un’organizzazione tabellare dei dati (le
strutture dati sono tabelle).
ALBERO
GRAFO
TABELLA
6.1 Relazioni e basi di dati relazionali
Nel seguito introduciamo alcune definizioni e nozioni di base sulle basi di dati relazionali:
Definizione: Una base di dati relazionale è un insieme di relazioni.
Definizione: Una relazione è una tabella con un numero fisso di colonne (che rappresentano gli
attributi) e un numero variabile di righe (che sono dette tuple).
Esempio:
La relazione conto-corrente può essere rappresentata nel seguente modo:
NUMERO C.C.
NOME
INDIRIZZO
SALDO
1
Rossi
Via anemoni 5
2
Bianchi
Via bolla 64
664,00
3
Brunelli
Via Dante 41
2564,60
4
Grandi
Via Romolo 3
1.700,20
3.678,00
Definizione: Lo schema di una relazione è definito dal nome della relazione e dall’elenco dei suoi
attributi.
Esempio:
Lo schema della precedente relazione conto-corrente è:
(CONTO-CORRENTE, (numero c.c., nome, indirizzo, saldo) )
Definizione: L’istanza di una relazione è l’insieme delle tuple della relazione presenti in un
particolare istante di tempo.
Esempio:
L’istanza della relazione conto-corrente in un determinato momento è:
1
Rossi
Via anemoni 5
3.678,00
2
Bianchi
Via bolla 64
664,00
3
Brunelli
Via Dante 41
2564,60
4
Grandi
Via Romolo 3
1.700,20
Si noti che lo schema di una relazione è fisso, mentre l’istanza è variabile.
Definizione: Lo schema di una base di dati relazionale è dato dall’insieme degli schemi delle
relazioni presenti nella base di dati.
Esempio:
Lo schema di una base di dati che raccoglie informazioni sugli studenti di una
università potrebbe essere del tipo:
( (STUDENTE, (matricola, nome, data-nascita, anno-corso, corso-laurea) ),
(CORSO, (codice-corso, titolo, docente) ),
(ESAME, (codice-corso, matricola-studente, data, voto) ) )
Definizione: L’istanza di una base di dati relazionale è data dall’insieme di tutte le istanze delle
relazioni presenti nella base di dati in un particolare istante di tempo.
Definizione: La chiave di una relazione è il sottoinsieme minimale di attributi, tale che non
possono esistere più tuple con valori uguali in quegli attributi.
Esempio:
Nella relazione conto-corrente di sopra la chiave è {numero c.c.} perché non possono
esistere due correntisti con lo stesso numero di conto.
Esempio:
Nella seguente relazione con informazioni ferroviarie avente schema:
( TRENI, (binario, ora-partenza, ora-arrivo, destinazione) )
la chiave è {binario, ora-partenza} perché da un binario in una certa ora può partire
uno ed un solo treno.
6.2 Operazioni su basi di dati relazionali
Una base di dati relazionale si definisce fornendone lo schema, si popola inserendone le tuple e si
consulta applicando opportune operazioni. Le principali operazioni su relazioni sono:
Selezione
Unarie
Proiezione
Operazioni
Join
Binarie
Unione
Differenza
Le operazioni unarie si applicano ad una sola relazione e producono come risultato una nuova
relazione. Le operazioni binarie si applicano a due relazioni e producono come risultato una nuova
relazione.
SELEZIONE
L’operazione di selezione si denota con
pR
dove:
- è il simbolo della selezione;
-
R è la relazione argomento;
-
p è un insieme di vincoli detto predicato.
e costruisce una relazione costituita dalle tuple di R che soddisfano p.
Esempio:
Si consideri la relazione R:
A
B
C
D
1
a
2
a
2
b
2
f
3
a
4
g
4
b
3
b
Se il predicato è p = {A < C} ne segue che pR dà come risultato la relazione:
A
B
C
D
1
a
2
a
3
a
4
g
Se invece il predicato è p = {B = b AND C = 2} allora pR dà come risultato:
A
B
C
D
2
b
2
f
PROIEZIONE
L’operazione di proiezione si denota con LR dove:
- è il simbolo della proiezione;
- R è la relazione argomento;
- L è un sottoinsieme degli attributi di R.
e costruisce una relazione che comprende i soli attributi di L con le relative tuple.
Esempio:
Si consideri la relazione R:
A
B
C
D
1
a
2
a
2
b
2
f
3
a
4
g
4
b
3
b
Se è L = {A B} ne segue che ABR dà come risultato la relazione:
A
B
1
a
2
b
3
a
4
b
Se è L = {D A C} ne segue che LR da come risultato:
A
C
D
1
2
a
2
2
f
3
4
g
4
3
b
JOIN
L’operazione di join si denota con R ⋈p S dove:
- ⋈ è il simbolo di join;
- R e S sono le due relazioni argomento;
- p è un insieme di vincoli.
e costruisce una relazione ottenuta concatenando le tuple di R e S che soddisfano p.
Esempio:
Si considerino le relazioni:
R
S
A
B
C
D
E
1
a
2
a
1
2
b
2
f
2
3
a
4
b
3
4
b
5
Se è p = {C = E} ne segue che R ⋈C=E S dà come risultato la relazione:
A
B
C
D
E
1
a
2
f
2
2
b
2
f
2
Se è p = {C = E AND A = 1} ne segue che R ⋈P S dà come risultato:
A
B
C
D
E
1
a
2
f
2
UNIONE
L’operazione di unione si denota con R ∪ S dove:
- ∪ è il simbolo dell’unione;
- R e S sono le relazioni argomento.
e costruisce una relazione costituita dall’unione insiemistica delle tuple di R e S.
Osservazione: Per poter applicare la relazione di unione alle relazioni R e S, queste ultime devono
essere compatibili, ossia avere lo stesso numero di attributi definiti sugli stessi
domini di valori.
Esempio:
Si considerino le due relazioni compatibili:
R
S
A
B
C
D
E
F
1
a
2
1
a
2
2
b
2
2
b
3
3
a
4
3
a
1
4
b
3
4
b
3
L’operazione R ∪ S dà come risultato:
Osservazione:
A
B
C
1
a
2
2
b
2
3
a
4
4
b
3
2
b
3
3
a
1
Per convenzione nell’unione si prende lo schema di attributi di una delle relazioni
argomento (nell’esempio si è scelto quello di R cioè’ ABC’).
DIFFERENZA
L’operazione di differenza si denota con R – S dove:
- – è il simbolo della differenza;
- R e S sono le relazioni argomento.
e costruisce una relazione data dalla differenza insiemistica delle tuple di R e S.
Come per l’unione, anche per applicare l’operazione di differenza le relazioni
Osservazione:
argomento devono essere compatibili.
Esempio:
Si considerino le due relazioni:
R
S
A
B
C
D
E
F
1
a
2
1
a
2
2
b
2
2
b
3
3
a
4
3
a
1
4
b
3
4
b
3
L’operazione R – S dà come risultato:
A
B
C
2
b
2
3
a
4
Osservazione: Si noti che la differenza non è commutativa (R – S ≠ S – R), infatti l’operazione
S – R nell’ esempio precedente dà come risultato:
A
B
C
2
b
3
3
a
1
7. Il sistema operativo
Il sistema operativo ha una architettura software cosiddetta “a buccia di cipolla” in quanto costituita
da una serie di strati software ognuno dei quali realizza un determinato insieme di funzionalità.
Questi strati (dal basso verso l’alto) sono: nucleo, gestore della memoria, gestore delle periferiche,
file system e interprete dei comandi.
NUCLEO
Il nucleo è lo strato software del sistema operativo che gestisce i processi.
- Il programma è un oggetto statico perché resta invariato nel tempo;
- Il processo è un oggetto dinamico perché cambia nel tempo.
Definizione: Un processo è una coppia (E, S) dove E è il codice eseguibile del processo
(tipicamente il programma target prodotto dalla compilazione del corrispondente
programma) e S è l’insieme dei valori contenuti in RAM e nei registri della CPU.
Se ci troviamo in un sistema informatico a più processi si ha che, in ogni istante, un processo può
trovarsi in uno dei seguenti stati:
- In esecuzione, ossia il processo sta venendo eseguito dalla CPU;
- In attesa, ossia il processo attende che termini un’operazione di input/output;
- In pronto, ossia il processo si trova in memoria centrale pronto per essere eseguito.
L’interruzione è un meccanismo che sospende l’esecuzione di un processo quando questo richiede
ad esempio un’operazione di input/output che coinvolge una periferica (che tipicamente richiede
tempo). Nel frattempo quel processo passa in stato d’attesa e la CPU è assegnata a un altro
processo. Quando la periferica ha completato l’operazione di input/output, quel processo va in stato
di pronto, e a questo punto il nucleo gestisce il ripristino dei processi (cioè seleziona dalla coda dei
processi pronti quello che passa in esecuzione). Le politiche con cui si ripristinano i processi sono
molte, tra queste:
- FIFO (first in first out) i processi vengono eseguiti in ordine di arrivo, cioè il primo
arrivato nella coda dei processi pronti è il primo ad essere eseguito;
- PRIORITA’, i processi vengono eseguiti in base alla loro priorità, ossia ad ogni
processo viene associato un valore che ne determina l’ordine di esecuzione. Le priorità
possono essere “interne”, come il limite di tempo entro il quale il programma eseguito
deve restituire la soluzione al problema iniziale, il numero di file aperti, la lunghezza
media di operazioni di input/output e la lunghezza media delle operazioni riguardanti la
CPU, oppure “esterne”, come l’importanza del programma, il tipo e la quantità dei fondi
pagati per l’uso del calcolatore da parte dei proprietari del programma, etc.
E’ compito del nucleo del sistema operativo gestire questa alternanza fra i processi in termini di
una quanto più possibile equa rotazione.
GESTORE DELLA MEMORIA
Il gestore della memoria è lo strato software del sistema operativo che si occupa della gestione e
della suddivisione della memoria centrale (ossia come ripartire la memoria centrale tra i vari
programmi da eseguire).
Le principali problematiche del gestore della memoria riguardano:
- l’allocazione ossia:
o tecniche per suddividere la memoria;
o assegnamento di porzioni della memoria a programmi.
- la rilocazione ossia la trasformazione degli indirizzi logici presenti nel programma in
indirizzi fisici corrispondenti alla locazione di memoria dove le istruzioni sono
effettivamente caricate.
I due principali meccanismi di allocazione della memoria sono:
- la segmentazione in cui la memoria viene suddivisa in blocchi di lunghezza variabile
detti segmenti;
- la paginazione in cui la memoria viene suddivisa in blocchi di lunghezza fissa detti
pagine.
Nel suddividere e assegnare la memoria, il gestore della memoria deve attuare la miglior politica
possibile di gestione evitando la frammentazione, e garantendo sempre che le istruzioni eseguite
siano in memoria centrale.
GESTORE DELLE PERIFIRICHE
Il gestore delle periferiche è lo strato software del sistema operativo che gestisce le unità periferiche
e mette a disposizione dell’utente una serie di funzioni per eseguire operazioni di input/output
nascondendone le caratteristiche hardware. In questo modo, nei sistemi multi utente, grazie al
gestore delle periferiche, l’utente ha l’impressione di avere le periferiche totalmente dedicate a lui.
Un esempio di funzionalità del gestore delle periferiche è lo spooling system che gestisce le
molteplici richieste di stampa provenienti da vari utenti. Lo spooling system accoda le varie
richieste una dopo l’altra facendo in modo che le stampe degli utenti vengano prodotte
compiutamente, senza sovrapposizioni.
FILE SYSTEM
Il file system è lo strato software del sistema operativo responsabile della gestione dei file in
memoria di massa e consente a un utente di :
- creare un file;
- dargli un nome;
- collocarlo in memoria di massa;
- accedervi in lettura o scrittura;
Queste operazioni sono possibili grazie a comandi che nascondono all’utente la struttura interna.
I file sono inclusi in strutture chiamate directory, che sono organizzate ad albero (ogni directory può
contenere a sua voltadirectory o file). L’intero file system è organizzato ad albero:
ROOT
BIN
DEV …… USR
MARIO
F1
F2
UGO
PIERO
D1
F3
F4
INTERPRETE DEI COMANDI
L’interprete dei comandi è lo strato più alto del sistema operativo responsabile di ricevere e
interpretare i comandi dell’utente.
Questi comandi richiamano funzioni di strati più bassi del sistema operativo oppure mandano in
esecuzione programmi utente o programmi di sistema. Tra le funzioni dell’interprete dei comandi vi
è anche l’inizializzazione del calcolatore.
Esempio:
Un utente manda in esecuzione un certo programma P. L’interprete, per attivare P,
svolge trasparentemente all’utente le seguenti operazioni:
- accede al programma (che si trova nella memoria di massa) tramite il file
system;
- alloca memoria e carica il programma nella RAM tramite il gestore della
memoria;
- attiva un processo tramite il nucleo ed esegue P.
ARCHITETTURA DI UN SISTEMA INFORMATICO
8. Alberi, Alberi Binari e Algoritmi di visita
** (solo per studenti DM 509) **
Molte informazioni sono strutturate in modo gerarchico, cioè l’informazione principale comprende
informazioni di livelli successivamente inferiori fino al raggiungimento di informazioni elementari
da cui non dipende nessun’altra informazione. Come esempi, si pensi all’organigramma di
un’azienda, all’albero genealogico di una stirpe, alla descrizione di una fattura commerciale, etc.
La struttura dati Albero per memorizzare informazioni nei programmi è così definita:
Definizione:
Dato un insieme prefissato E di elementi:
- un albero può essere vuoto, ossia non contenere elementi
- un albero non vuoto può consistere di un solo elemento e in E detto nodo oppure può consistere di
un nodo e in E collegato mediante archi a un numero finito di altri alberi
La precedente definizione è ricorsiva, e sostanzialmente definisce un albero come un insieme di
nodi (dove ci sono le informazioni) collegati mediante archi. Gli alberi si rappresentano
graficamente attraverso un insieme di cerchietti (nodi) collegati gerarchicamente da linee (archi).
Esempio di albero:
Terminologia:
- Radice. E’ il nodo che non ha archi entranti (tipicamente viene disegnato in alto)
- Foglie. Sono i nodi terminali, ossia che non hanno archi uscenti
- Nodi interni. Sono i nodi che non sono radice o foglie
- Padre/Figlio. Se c’è un arco che va dal nodo a al nodo b, allora a è padre di b, e b è figlio di a
- Cammino. Un cammino dal nodo a al nodo b è una sequenza di archi contigui da a a b. La
lunghezza del cammino è il numero di archi che lo compongono (cioè il numero di nodi toccati
meno 1)
- Livello (di un nodo). E’ la lunghezza del cammino che va dalla radice a quel nodo
- Profondità o Altezza (di un albero). E’ la lunghezza del cammino più lungo che va dalla radice a
una foglia
- Sottoalbero. E’ un sottinsieme dei nodi dell’albero collegati da archi tale che è a sua volta un
albero
Nel seguito ci restringiamo a un caso particolare di alberi chiamati alberi binari e cosi definiti:
Definizione:
Un albero binario è un albero in cui ogni nodo ha al più due figli.
Per gli alberi binari esistono i concetti (intuitivamente riscontrabili nella rappresentazione grafica)
di figlio sinistro, figlio destro, sottoalbero sinistro, sottoalbero destro.
Per esempio, il seguente albero (dove per semplicità nei nodi sono state inserite informazioni
numeriche) è un albero binario, in cui, ad esempio, 8 è figlio sinistro di 9, e 5 è figlio destro della
radice 7:
7
9
5
8
8.1
Algoritmi di visita su alberi binari
“Visitare” un albero binario significa esaminare tutti i suoi elementi, toccandoli una e una sola
volta. Esistono vari modi per visitare un albero binario che variano a seconda dell’ordine in cui si
toccano i suoi nodi; per esempio un metodo è quello della visita simmetrica (anche detta in
preordine sinistro) che effettua la visita secondo lo schema ricorsivo:
radice - sottoalbero sinistro - sottoalbero destro
nel senso che questa visita tocca prima la radice, poi tutti i nodi nel sottoalbero sinistro (sempre
ricorsivamente usando lo stesso schema), e poi tutti i nodi nel sottoalbero destro (sempre
ricorsivamente usando lo stesso schema). Ad esempio, per l’albero binario disegnato nell’esempio
della sezione precedente, l’ordine di visita simmetrica dei suoi nodi è: 7 9 8 5
Di seguito elenchiamo tutti i possibili metodi di visita con il corrispondente ordine di visita:
Visita Simmetrica/in Preordine Sinistro:
radice - sottoalbero sinistro - sottoalbero destro
Visita Anticipata:
sottoalbero sinistro - radice - sottoalbero destro
Visita Posticipata:
sottoalbero destro - radice - sottoalbero sinistro
Visita in Preordine Destro:
radice - sottoalbero destro - sottoalbero sinistro
Visita in Postordine Destro:
sottoalbero destro - sottoalbero sinistro – radice
Visita in Postordine Sinistro:
sottoalbero sinistro - sottoalbero destro – radice
Vediamo alcuni esempi. Per l’albero binario disegnato nella sezione precedente, la visita simmetrica
tocca i nodi nell’ordine 7 9 8 5; la visita anticipata tocca i nodi nell’ordine 8 9 7 5; la visita
posticipata tocca i nodi nell’ordine 5 7 9 8; e così via per gli altri metodi.
Per ogni metodo di visita può essere scritto un algoritmo che ne implementa la corrispondente
strategia di visita. Di seguito riportiamo i vari algoritmi di visita. Sia A un albero binario:
Algoritmo Visita Simmetrica (A)
BEGIN
IF A non è vuoto THEN
BEGIN
RETURN radice(A)
RETURN Visita Simmetrica (sottoalbero sinistro di A)
RETURN Visita Simmetrica (sottoalbero destro di A)
END
END
Algoritmo Visita Anticipata (A)
BEGIN
IF A non è vuoto THEN
BEGIN
RETURN Visita Anticipata (sottoalbero sinistro di A)
RETURN radice(A)
RETURN Visita Anticipata (sottoalbero destro di A)
END
END
Algoritmo Visita Posticipata (A)
BEGIN
IF A non è vuoto THEN
BEGIN
RETURN Visita Posticipata (sottoalbero destro di A)
RETURN radice(A)
RETURN Visita Posticipata (sottoalbero sinistro di A)
END
END
Algoritmo Visita PreordineDestro (A)
BEGIN
IF A non è vuoto THEN
BEGIN
RETURN radice(A)
RETURN Visita PreordineDestro (sottoalbero destro di A)
RETURN Visita PreordineDestro (sottoalbero sinistro di A)
END
END
Algoritmo Visita PostordineDestro (A)
BEGIN
IF A non è vuoto THEN
BEGIN
RETURN Visita PostordineDestro (sottoalbero destro di A)
RETURN Visita PostordineDestro (sottoalbero sinistro di A)
RETURN radice(A)
END
END
Algoritmo Visita PostordineSinistro (A)
BEGIN
IF A non è vuoto THEN
BEGIN
RETURN Visita PostordineSinistro (sottoalbero sinistro di A)
RETURN Visita PostordineSinistro (sottoalbero destro di A)
RETURN radice(A)
END
END