Appendice 1
Mini-manuale di KStat
Questo breve manuale ha lo scopo di affiancare, non di sostituire, le altre risorse disponibili per l’apprendimento di Excel e di KStat. Non preoccupatevi se la
terminologia qui usata non vi è familiare: in questo momento non è importante
comprendere i concetti statistici bensì imparare quali sono i comandi da utilizzare in KStat. Per la comprensione delle nozioni statistiche c’è tutto il resto del libro! In questa appendice ci riferiremo alla versione di Excel 2007; le differenze
rispetto alle versioni precedenti del programma sono trascurabili, essendo essenzialmente di natura estetica.
KStat è un insieme di macro per Excel, grazie alle quali sarete in grado di svolgere tutti i calcoli statistici necessari per seguire agevolmente questo corso. Per avviare KStat dovete aprire, come fareste con un qualsiasi altro file di Excel, il file KStat.xls. È possibile che vi appaia un avviso di protezione, che vi chiede se
volete abilitare o meno le macro presenti nel file: perché KStat possa funzionare
dovete abilitare il contenuto. Dopo aver aperto il file potrete notare che tra le etichette delle schede, nella Barra multifunzione, è comparsa una nuova voce, Componenti aggiuntivi. Facendo clic su Componenti aggiuntivi si accede al menu principale di KStat, denominato Statistics.
Nel caso il menu non sia visibile, controllate che le impostazioni macro di
Excel, nel menu del pulsante Office, non siano settate su Disattiva tutte le macro
senza notifica; nelle versioni precedenti di Excel l’impostazione macro si trova in
Strumenti | Macro | Protezione. In questo manuale due o più comandi successivi (il primo da selezionare dal menu principale, i seguenti nei sottomenu) verranno separati con il simbolo | (pipe o barretta verticale). Per esempio, l’istruzione
Statistics | Charts | Residuals plots indica di aprire il menu Statistics, fare clic su
Charts, quindi fare clic su Residuals plots.
Appendice.indd 281
21-07-2010 10:16:28
282 statistica per manager
Operazioni iniziali
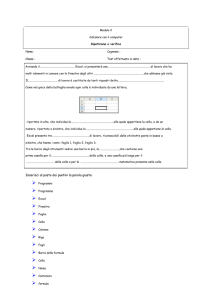
La prima cosa da fare è selezionare il comando Statistics | Options e spuntare
tutte le opzioni nella finestra di dialogo Global Options che apparirà.
Spuntando la prima casella di controllo si dirà a Excel di non sovrascrivere i risultati di una regressione quando se ne esegue un’altra nella stessa sessione di lavoro. Con la seconda opzione si fa in modo che KStat usi una notazione coerente con quella che abbiamo scelto di adottare in questo libro. La terza opzione fa
sì che le caselle di commento (in inglese) predisposte da KStat siano ben visibili. Una volta spuntate tutte le caselle di controllo, fate clic sul pulsante Done. Selezionando il comando Salva di Excel, KStat memorizzerà le impostazioni, che
non sarà più necessario ripetere a ogni apertura del file.
Appendice.indd 282
21-07-2010 10:16:31
appendice 1. mini-manuale di kstat
283
I fogli di lavoro di un file di Excel vengono utilizzati per elencare e analizzare
i dati e per riportare i risultati delle analisi. I loro nomi sono visibili in basso a sinistra, vicino alla cornice della finestra. Per passare da un foglio all’altro è sufficiente fare clic sulla relativa etichetta; il nome del foglio di lavoro attivo è sempre
in grassetto. È possibile rinominare, spostare o copiare i fogli entro uno stesso file di Excel (denominato “cartella di lavoro di Excel”) o tra file diversi.
Importare un file in KStat
All’avvio, KStat si presenta con un unico foglio di lavoro (Data), vuoto. È possibile inserire manualmente i dati in tale foglio, iniziando dalla cella A1, assicurandosi che i nomi delle variabili siano collocati nella riga 1, che ogni colonna sia relativa ai valori di una variabile e che i dati siano disposti in colonne adiacenti.
Di solito, però, i dati sono già disponibili: in questo caso vanno importati in
KStat. A tale scopo selezionate il comando Statistics | Import data | File, quindi
scegliete il percorso del file nella successiva finestra Import sample data e infine
premete Apri. Nella figura seguente, per esempio, è mostrata l’importazione del
file Capm.xls in KStat.
Una volta che il file è stato importato, il foglio di lavoro Data dovrebbe apparire
come quello della figura seguente:
Appendice.indd 283
21-07-2010 10:16:33
284 statistica per manager
È comunque possibile anche aprire il file contenente i dati da importare, selezionarli tutti, copiarli e infine incollarli nel foglio di lavoro Data di una cartella vuota di KStat.
Statistiche di base e valori critici
Con KStat ed Excel potete facilmente ottenere alcune grandezze statistiche di base. Importate il file di dati adsales.xls (Capitolo 8). Il comando Statistics |
Univariate statistics genererà, riportandole nel foglio Univariate, alcune utili statistiche riassuntive per ciascuna variabile presente sul foglio Data. L’output sarà simile a quello mostrato in Fig. A1.1.
Il comando Statistics | Correlations consente di determinare i coefficienti di
correlazione fra tutte le coppie di variabili dell’insieme di dati. L’output di questo
comando, applicato ai dati del file adsales.xls, sarà simile a quello mostrato
in Fig. A1.2 e sarà inserito nel foglio Correlations. Nel nostro caso il coefficiente di
correlazione fra exp e sales vale 0,95549.
Potete usare le informazioni fornite nell’output di Univariate statistics in combinazione con la funzione Excel DISTRIB.T per eseguire un test t a un campione (si veda il Capitolo 2). Per confrontare le medie di due popolazioni usando un
test t a due campioni (si veda ancora il Capitolo 2) fate clic su una cella vuo-
Appendice.indd 284
21-07-2010 10:16:41
appendice 1. mini-manuale di kstat
285
Figura A1.1 Risultato del comando Univariate statistic applicato ai dati di adsales.xls
Univariate statistics
mean
standard deviation
standard error of the mean
exp
2,2900874
0,77765926
0,05929596
sales
16,8873778
0,86660475
0,06607799
minimum
median
maximum
range
0,35679829
2,30022073
4,84897232
4,49217403
13,6289663
16,9419794
19,0247002
5,39573383
skewness
kurtosis
0,314
0,568
–0,826
1,996
number of observations
172
t-statistic for computing
95%-confidence intervals
1,9739
Figura A1.2 Risultato del comando Correlations applicato ai dati di adsales.xls
Correlations
exp
sales
exp
1,00000
0,95549
sales
0,95549
1,00000
ta; quando avrete terminato l’inserimento della formula come spiegato di seguito, Excel presenterà il risultato del test in questa cella. Useremo la funzione Excel
denominata TEST.T, la quale restituisce il p-value associato a un test t per la differenza fra due medie. La sintassi di questa funzione è TEST.T(matrice1;matr
ice2;coda;tipo). Nel nostro caso matrice1 è la prima variabile, matrice2
la seconda, coda specifica il numero di code da usare (se coda=1, TEST.T usa
la distribuzione a una coda, se coda=2, TEST.T usa la distribuzione a due code),
e infine tipo è il tipo di test t da eseguire. In genere supporremo che in un test a
due campioni le variabili abbiano varianza diseguale, per cui assegneremo a tipo il valore 3.
Vi sono due modi per usare questa funzione Excel: selezionando la funzione
dall’elenco delle funzioni, oppure digitando direttamente la formula nella cella.
Nel primo caso basta fare clic sul pulsante Inserisci funzione della scheda Formule; nella successiva omonima finestra di dialogo scegliete la categoria Statisti-
Appendice.indd 285
21-07-2010 10:16:42
286 statistica per manager
che e cercate la voce TEST.T nell’elenco Selezionare una funzione. La finestra di
dialogo Inserisci funzione è mostrata nella figura seguente.
Una volta data conferma premendo OK, si aprirà una seconda finestra di dialogo.
Nella casella Matrice1 inserite l’intervallo di dati del primo campione, in Matrice2 quello del secondo campione, in coda digitate 1 se volete un test a una coda
o 2 se ne volete uno a due code; infine, nella casella tipo inserite il numero corrispondente al tipo di test che desiderate; scegliete 3, come detto, per il caso di varianze differenti. Una volta terminati gli inserimenti, la finestra di dialogo sarà simile alla seguente.
Appendice.indd 286
21-07-2010 10:16:43
appendice 1. mini-manuale di kstat
287
Potete leggere il p-value associato a questo test nella parte bassa della finestra,
dove c’è la scritta Risultato formula. Premendo OK Excel inserirà questo risultato
nella cella selezionata prima di avviare il test.
Il secondo modo per usare la funzione, come anticipato, è di scriverla direttamente nella cella; in questo caso occorre digitare (le formule iniziano sempre con
il simbolo =):
=TEST.T(A2:A173;B2:B173;1;3)
Regressione
In questo paragrafo faremo uso dei dati contenuti nel file Capm.xls (Capitolo 2).
Il comando che probabilmente userete più spesso è Statistics | Regression.
Eseguendolo si apre la seguente finestra di dialogo:
Selezionate la variabile dipendente dall’elenco Dependent variable e spuntate le
caselle di controllo accanto alle variabili indipendenti da utilizzare. per il nostro esempio selezioneremo smstk come variabile dipendente e sp500, crpbon
e tbill come variabili indipendenti.
Premiamo il pulsante Perform regression: KStat creerà tre fogli di lavoro: Regression, ANOVA e Residuals. Quello attivo sarà Regression, e l’output sarà simile a quello riprodotto in Fig. A1.3.
Come avrete notato, alcune celle dei fogli di lavoro hanno un triangolino rosso in alto a destra: ciò indica la presenza di un commento, che riporta una breve
spiegazione inerente il contenuto della cella. Per leggere un commento basta portare il puntatore del mouse sul triangolino rosso. Anche i commenti, come i comandi di KStat, sono in inglese.
Dall’output di Fig. A1.3 ricaviamo che l’equazione di regressione è
smstk = –0,0012814 + 1,36461728 · sp500 + 1,5466021 · crpbon –
– 2,5374467 · tbill
Appendice.indd 287
21-07-2010 10:16:44
288 statistica per manager
Figura A1.3 Regressione di smstk su sp500, crpbon e tbill
Regression: smstk
coefficient
std error of coef
t-ratio
p-value
beta-weight
constant
–0,0012814
0,00452835
–0,2830
77,7450%
sp500
1,36461728
0,05101924
26,7471
0,0000%
0,8455
standard error
of regression
R-squared
adjusted R-squared
0,06575673
77,31%
77,02%
240
236
1,97015
number of
observations
residual degrees
of freedom
t-statistic for
computing
95%-confidence
intervals
crpbon
1,5466021
0,40357477
3,8323
0,0163%
0,1399
tbill
–2,5374467
0,67671508
–3,7497
0,0223%
–0,1349
Dall’output ricaviamo informazioni sugli errori standard, sui t-ratio, sui p-value e
sugli indici beta per ciascun coefficiente, nonché l’errore standard della regressione, il valore di R quadro e quello di R quadro aggiustato. KStat fornisce inoltre il
numero di osservazioni, i gradi di libertà del termine di errore e la statistica test
per il calcolo degli intervalli di confidenza al 95%.
Passiamo ora a esaminare il foglio di lavoro ANOVA. L’output fornitoci da
KStat è riprodotto in Fig. A1.4.
Vi possiamo leggere la somma dei quadrati (di regressione) spiegata, la somma dei quadrati dei residui, la somma totale dei quadrati, l’F-ratio, i gradi di libertà e il p-value. Il p-value dell’esempio vale per la verifica di ipotesi in cui l’ipotesi nulla è che tutti i coefficienti siano uguali a zero. Essendo il p-value uguale a
zero, possiamo rifiutare l’ipotesi nulla con un alto livello di confidenza.
Passiamo quindi al foglio di lavoro Residuals. In esso sono riportati i valori
previsti e i residui per ciascuna osservazione del campione.
Per formulare una previsione usando l’ultima regressione eseguita fate clic
su Statistics | Prediction. Nel foglio di lavoro che otterrete potete effettuare delle previsioni e calcolare gli intervalli di confidenza e di previsione. Supponiamo
di voler prevedere il valore della variabile smstk in corrispondenza di sp500 =
0,05, crpbon = 0,01 e tbill = 0,02. Inserite questi numeri nelle celle gialle cor-
Appendice.indd 288
21-07-2010 10:16:44
appendice 1. mini-manuale di kstat
289
Figura A1.4 Output di regressione, foglio di lavoro ANOVA
Analysis of variance
regression
residual
total
sum of squares
3,476071636
1,020451604
4,496523241
F-ratio
degrees of freedom
p-value
267,9705
(3,236)
0,00000%
df
3
236
239
rispondenti a ciascuna variabile indipendente e premete il pulsante Predict che
vedete all’interno del foglio. Otterrete il seguente risultato:
In questo foglio di lavoro potete anche determinare gli intervalli di confidenza e
di previsione per i valori previsti. Per modificare il livello di confidenza digitate il
nuovo valore nella cella C12 e premete Invio. I risultati verranno ricalcolati automaticamente in base al nuovo livello impostato.
Se volete formulare previsioni per più di un insieme di valori, fate clic sul pulsante Make multiple predictions all’interno del foglio. Supponiamo di voler fare
previsioni per sp500 = 0,05, crpbon = 0,01 e tbill = 0,02, nonché per sp500
Appendice.indd 289
21-07-2010 10:16:46
290 statistica per manager
= 0,02, crpbon = –0,02 e tbill = 0,03. Dobbiamo inserire ogni insieme di valori per le variabili indipendenti in una colonna gialla distinta. Dopo aver premuto il pulsante Predict il foglio di lavoro sarà simile al seguente:
Dopo aver eseguito una regressione potete usare altre opzioni avanzate selezionando il comando Statistics | Model analysis. Questa opzione espanderà il foglio di lavoro Residuals, fornendo alcune utili statistiche. (Nella figura seguente è mostrato l’aspetto del foglio di lavoro esteso.) In particolare, oltre a quanto
era stato riportato sul foglio Residuals, è ora possibile ricavare anche le seguenti informazioni: la statistica test e il p-value per il test di eteroschedasticità
di Breusch-Pagan, i fattori di inflazionamento della varianza per i coefficienti
e gli outlier e i punti con elevato leverage. Tutti questi concetti sono presentati nel testo.
Appendice.indd 290
21-07-2010 10:16:49
appendice 1. mini-manuale di kstat
291
Grafici
In questo paragrafo useremo i dati contenuti nel file adsales.xls (Capitolo 8).
Importate questo file con Statistics | Import data | File.
Per ottenere il diagramma di dispersione di due variabili disponibili nei dati,
fate clic su Statistics | Charts | Scatterplots e selezionate tali variabili nella finestra di dialogo Scatterplot.
Se volete inserire anche la retta di regressione, spuntate la casella di controllo
Plot regression line. Selezionando le variabili mostrate nella figura precedente e
premendo OK otterrete un grafico simile a quello riprodotto in Fig. A1.5.
Appendice.indd 291
21-07-2010 10:16:51
292 statistica per manager
Figura A1.5 Diagramma di dispersione di sales in funzione di exp
Se volete salvare il grafico come foglio di lavoro fate clic sul pulsante Save all’interno del grafico stesso, altrimenti premete Done. Potete usare questa procedura
per ottenere il grafico di una qualsiasi coppia di variabili presenti nel foglio Data.
Per valutare un modello di regressione spesso torna utile il grafico dei residui
in funzione dei valori previsti. Ecco come generare tale grafico per una regressione di exp contro sales. Anzitutto eseguite una regressione in cui exp è la variabile dipendente e sales quella indipendente. Dopodiché fate clic su Statistics |
Charts | Residual plots. Si aprirà la seguente finestra di dialogo. Selezionate predicted values come mostrato, e premete OK.
KStat userà automaticamente i residui ottenuti nella regressione più recente che
avete eseguito nella attuale corrente. Otterrete così il grafico riprodotto in Fig. A1.6.
Appendice.indd 292
21-07-2010 10:16:52
appendice 1. mini-manuale di kstat
293
Figura A1.6 Grafico dei residui rispetto ai valori previsti basato sulla regressione di exp
su sales
Per inserire il grafico nel file di un altro programma, per esempio Microsoft
Word, salvate per prima cosa il grafico: verrà memorizzato in un foglio di lavoro della stessa cartella di Excel, denominato Kept01 (se salvate più di un grafico
nella stessa sessione, questi verranno memorizzati nei fogli Kept02, Kept03 ecc.).
Passate su Kept 01 e fate clic sul grafico (nella parte esterna), quindi premete
Ctrl+C o selezionate il comando Copia di Excel per disporre il grafico negli Appunti. A questo punto potete incollare la figura in un documento di Word.
Come ottenere i p-value
In questo paragrafo useremo i dati contenuti nel file newspaper.xls (Capitolo
4). Una regressione di Sunday contro Daily genera l’output riprodotto in Fig. A1.7.
Il p-value uguale a 0,000% disponibile nella colonna Daily di Fig. A1.7 è relativo a una specifica verifica di ipotesi, in cui l’ipotesi nulla è che b1, il coefficiente
di Daily, sia uguale a zero. Questo p-value indica che possiamo rifiutare l’ipotesi
nulla con un alto livello di confidenza: siamo virtualmente sicuri al 100% che b1
sia diverso da zero. Se volessimo sottoporre a verifica qualche altra ipotesi nulla,
per esempio quella che b1 sia uguale a 1,1, dovremmo eseguire il test manualmente. La statistica test per tale verifica è la seguente:
1,35117342 – 1,1 = 2,7015
0,09297695
Appendice.indd 293
21-07-2010 10:16:54
294 statistica per manager
Figura A1.7 Regressione di Sunday contro Daily
Regression: Sunday
coefficient
std error of coef
t-ratio
p-value
beta-weight
constant
24,7631585
46,9866631
0,5270
60,1701%
Daily
1,35117342
0,09297695
14,5323
0,0000%
0,9300
standard error of regression
R-squared
adjusted R-squared
143,864401
86,49%
86,08%
number of observations
residual degrees of freedom
35
33
t-statistic for computing
95%-confidence intervals
2,0345
Possiamo ora utilizzare Excel per cercare il p-value corrispondente a questo valore di t. Per prima cosa fate clic su una cella vuota sul foglio di lavoro in cui vi trovate, quindi selezionate Inserisci funzione nella scheda Formule. Nell’omonima
finestra di dialogo scegliete la categoria Statistiche e la funzione DISTRIB.T, infine premete OK.
Appendice.indd 294
21-07-2010 10:16:55
appendice 1. mini-manuale di kstat
295
Si aprirà la finestra di dialogo per l’inserimento degli argomenti della funzione:
Come mostrato nella figura, inserite nella casella X il valore della statistica t calcolato manualmente, nella casella Grad_libertà i gradi di libertà e, dato che stiamo parlando della probabilità associata a un test a due code, inserite 2 nella casella Code. In basso, nella stessa finestra, potete leggere il p-value associato a
questo test come Risultato formula. Premendo OK, nella cella verrà inserita la formula
=DISTRIB.T(2,7015;33;2)
che potevate anche digitare direttamente. In ogni caso il valore ottenuto è uguale a 0,010812805: ciò significa che se il coefficiente di Daily fosse 1,1, ci sarebbe una probabilità pari solo all’1,081% di ottenere un coefficiente distante
1,35117342 da 1,1 per via della casualità dei dati. Dovremmo rifiutare l’ipotesi
nulla a ogni livello di confidenza sino a circa il 99% (o, nell’altro verso, a ogni livello di significatività sino all’1%).
Possiamo usare Excel, anziché una tavola della distribuzione t, anche per trovare i valori critici di t. Per ottenere la statistica t corrispondente ad a = 0,10 per
il nostro test a due code, fate clic su Inserisci funzione e selezionate la funzione
INV.T nella categoria Statistiche. Nella finestra di dialogo per gli argomenti:
Appendice.indd 295
21-07-2010 10:16:57
296 statistica per manager
inserite nella prima casella la somma delle probabilità che volete in entrambe le
code (0,1) e i gradi di libertà (33) nella seconda. Il risultato della formula ci dice che la statistica t è 1,692. Pertanto rifiuteremmo l’ipotesi nulla con a = 0,10 se
ottenessimo una statistica t maggiore di 1,692 o minore di –1,692 (cosa che abbiamo fatto). Questo ci dice, peraltro, che per un test a una coda con un’alternativa (“maggiore di” rifiuteremmo l’ipotesi nulla con a = 0,05 se ottenessimo una
statistica t maggiore di 1,692, e per un test a una coda con un’alternativa “minore di” rifiuteremmo l’ipotesi nulla con a = 0,05 se ottenessimo una statistica t minore di –1,692.
Possiamo inoltre usare Excel al posto di una tavola della distribuzione z. Supponiamo di voler cercare il p-value corrispondente a z = 2,7. Per prima cosa fate
clic su una cella vuota sul foglio di lavoro in cui vi trovate, quindi selezionate Inserisci funzione nella scheda Formule. Nell’omonima finestra di dialogo scegliete
la categoria Statistiche e la funzione DISTRIB.NORM.ST, infine premete OK. In
questo modo si aprirà la finestra di dialogo per l’inserimento degli argomenti della funzione:
Appendice.indd 296
21-07-2010 10:16:59
appendice 1. mini-manuale di kstat
297
Come mostrato nella videata, inserite nella casella X il valore della statistica
z. Come risultato otterrete P(z ≤ 2,7 = 0,996533). Premendo OK, nella cella verrà
inserito questo risultato.
Supponiamo di voler trovare la statistica z corrispondente ad a = 0,10 per un
test a due code. Facciamo clic al solito su Inserisci funzione e selezioniamo la
funzione INV.NORM.ST.
Questa volta inseriamo la probabilità (ovvero l’area) ed Excel ci fornirà la statistica z. Nella finestra di dialogo, quando inseriamo la probabilità r, Excel ci restituisce il numero x tale che vi è una probabilità pari a r di essere al di sotto di x.
Vogliamo che il numero x sia tale per cui vi sia una probabilità pari al 5% (ossia
a / 2%) di trovarsi al di sopra di x o, equivalentemente, una probabilità del 95%
di trovarsi al di sotto di x. Inseriamo 0,95 nella casella Probabilità, ottenendo come statistica z il valore 1,6448.
Creare nuove variabili
A volte è necessario creare una nuova variabile, oltre a quelle presenti in un file.
Per esempio si può voler usare come predittore o come risposta il logaritmo naturale di una variabile anziché la variabile stessa. A titolo di esercizio, create una
nuova colonna, che includa il logaritmo della variabile exp. A tale scopo importate nuovamente il file adsales.xls e attivate la cella C1 del foglio Data. Inserite il nome prescelto per la variabile (per esempio lnexp) in C1. Fate clic su C2 e
inseritevi la funzione LN, appartenente alla categoria delle funzioni Matematiche
e trigonometriche.
Appendice.indd 297
21-07-2010 10:17:03
298 statistica per manager
Premendo OK si aprirà la solita finestra per l’inserimento degli argomenti della
funzione:
Fate clic su A2 senza uscire dalla finestra (è la cella contenente il valore di cui
volete calcolare il logaritmo naturale da porre in C2). Premete OK. Nella cella
C2 dovreste avere il risultato della formula =LN(A2), che potevate anche inserire direttamente. Adesso copiate questa formula (cioè selezionate la cella e fate
clic su Copia) e incollatela nel resto della colonna C, fino all’ultima riga per cui
c’è un valore nella colonna A. Una volta terminato, il foglio di lavoro avrà questo aspetto:
Appendice.indd 298
21-07-2010 10:17:06
appendice 1. mini-manuale di kstat
299
Abbiamo terminato. È stata creata una nuova variabile lnexp, i cui valori sono
dati dai logaritmi naturali delle corrispondenti osservazioni di exp.
In Excel sono disponibili molte altre funzioni matematiche di cui potete servirvi per fare calcoli; vi suggeriamo di cercarle e provare ad applicarle per vedere come funzionano.
Un altro tipo di variabile che potremmo voler creare usando Excel è una variabile dummy per i cicli stagionali. Nell’insieme di dati contenuti nel file soda.
xls (Capitolo 9) abbiamo le variabili winter, spring e summer. La variabile
winter, per esempio, è una colonna con la seguente sequenza di numeri:
1 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0
Vi è un 1 per ogni riga di dati che corrisponde al trimestre invernale, e uno 0 per
ogni riga che corrisponde a uno degli altri trimestri. Un modo per costruire una
variabile come questa consiste per prima cosa nel digitare winter nella prima
cella della colonna, scrivere un 1 nella seconda cella e tre 0 nella terza, quarta e
quinta cella. Dopodiché si copiano queste celle contenenti 1 e 0 e le si incolla in
corrispondenza delle appropriate celle di destinazione (è una serie ripetuta). Nell’esempio del file importato, occorre incollare questa sequenza per tre volte.
Appendice.indd 299
21-07-2010 10:17:14
300 managerial statistics: a case-based approach
Ulteriori funzioni e comandi
Excel e KStat sono in grado di eseguire molti altri calcoli che qui non abbiamo
descritto. Studiando ed esercitandovi con i problemi proposti in questo testo acquisirete maggiore familiarità con il programma e con le sue funzioni.
Appendice.indd 300
21-07-2010 10:17:14