Facoltà di Ingegneria
Corso di Studi in Ingegneria Informatica
Elaborato di Algoritmi e Strutture Dati
Topological Sort
Anno Accademico 2011/2012
Professore
Carlo Sansone
Studente
Lampognana Francesca M63/000144
Topological Sort
Introduzione
Il seguente elaborato illustrerà il funzionamento del Topological Sort, algoritmo di
ordinamento topologico utilizzato nell’ambito della teoria dei grafi. Ne verranno mostrati i
dettagli di funzionamento e il relativo pseudocodice. Si procederà dunque ad effettuarne
l’analisi asintotica per quanto riguarda la sua complessità temporale ed, infine,
mostreremo un’implementazione software dell’algoritmo, effettuata tramite il linguaggio
di programmazione C. Tramite tale software, provvederemo a testare la complessità
temporale dell’algoritmo, verificando l’aderenza dei risultati a quanto calcolato
teoricamente mediante analisi asintotica.
2
Topological Sort
Descrizione dell’algoritmo
Nome capitolo
L’algoritmo Topological Sort si inserisce nel contesto della teoria dei grafi. In particolare
esso va a realizzare l’ordinamento topologico, che definiremo in modo formale nei
prossimi paragrafi. Inizieremo la trattazione andando a mostrare alcune definizioni
fondamentali della teoria dei grafi, senza le quali sarebbe impossibile procedere ad
un’accurata descrizione dell’algoritmo che effettua l’ordinamento topologico.
Un grafo G può essere definito formalmente dalla coppia: G = (V,E)
Ove V rappresenta l’insieme dei vertici del grafo ed E è l’insieme degli archi (o spigoli) ad
esso appartenenti.
Ogni grafo può essere orientato o meno, ovvero ogni arco può avere o meno un verso.
Formalmente, se il grafo è non orientato, dato un arco
, mentre se il
grafo è orientato non è detto che sia vera questa relazione.
Passiamo ora a descrivere in che modo avviene la rappresentazione di un grafo. Esistono
due modi diversi per rappresentare un grafo: la lista di adiacenza e la matrice di adiacenza.
Illustreremo, per rimanere fedeli allo scopo dell’elaborato, solo le liste di adiacenza.
Una lista di adiacenza consiste in un array Adj di |V| elementi, ove |V| rappresenta la
cardinalità dell’insieme dei vertici V. Ogni elemento di tale array punta a una lista
3
Topological Sort
concatenata. Per ogni u
, Adj[u] contiene tutti i vertici v per i quali esiste un arco
. Quindi Adj[u] contiene tutti i vertici adiacenti ad u nel grafo .
Mostriamo in figura un esempio di rappresentazione di un grafo orientato:
Figura 1: Rappresentazione mediante lista di adiacenza
Una proprietà delle liste di adiacenze è che, se il grafo è orientato, la somma delle
lunghezze delle liste è pari a |E|, cardinalità dell’insieme degli archi E. Se invece il grafo
non è orientato, tale somma sarà pari a 2|E| in quanto è necessario rappresentare sia l’arco
(u,v) che quello (v,u).
Topological sort: generalità
Mostriamo ora in che modo funziona l’algoritmo di ordinamento topologico.
L’ordinamento topologico è un ordinamento definito sui vertici di un DAG (directed
acyclic graph), un grafo orientato aciclico.
Possiamo definire il topological sorting del DAG G = (V,E) come un ordinamento lineare
dei suoi vertici, in modo tale che se
u appare prima di v.
Lo si può vedere come un ordinamento orizzontale dei vertici del grafo in modo che tutti
gli archi vadano da sinistra a destra. Questo spiega, intuitivamente, come mai non sia
possibile effettuare un ordinamento topologico su un grafo in cui sono presenti dei cicli.
Questo algoritmo è intimamente legato all’algoritmo di visita in profondità (DFS) dei grafi
e vedremo, anzi, che potrà essere realizzato andando a effettuare una modifica di tale
algoritmo. Quindi, prima di mostrare lo pseudocodice relativo al topological sort,
illustreremo il funzionamento della visita in profondità.
4
Topological Sort
Depth-First Search (DFS): funzionamento
Dato il grafo G, un algoritmo di visita ha come scopo la scoperta dei vertici che fanno
parte del grafo. In particolare, nel caso della ricerca in profondità, è possibile scoprire
sicuramente tutti i vertici del grafo, mentre nel caso dell’altro tipo di visita (BFS) ciò non è
assicurato.
Caratteristica fondamentale della DFS, dalla quale ne deriva il nome, è quella di procedere
in profondità: essa visita sempre il “successore” dell’ultimo nodo visitato; una volta
raggiunto il fondo della profondità, la procedura torna indietro e considera il primo nodo
che non era stato precedentemente considerato.
Per tenere conto delle varie caratteristiche dei nodi durante la procedura, ad ognuno di essi
è associato un colore. Ogni colore va a definire uno stato del nodo:
-
Bianco: Il nodo non è ancora stato scoperto;
-
Grigio: Nodo scoperto, ma non è ancora terminata la ricerca in profondità;
-
Nero: Nodo scoperto e la profondità è stata risolta almeno fino al suo livello;
Un ulteriore valore associato ad ogni nodo è . Per ogni nodo
rappresenta il
predecessore di v. Si dice che u è predecessore di v se il vertice v è stato scoperto
scorrendo la lista di adiacenze del vertice u.
Infine, altri due valori, caratteristici della DFS, associati ai nodi sono due timestamps:
-
Tempo di scoperta: v.d
-
Tempo finale: v.f
Per impostare tali tempi all’interno delle procedure sarà usata la variabile globale time.
La DFS si articola in 2 procedure:
-
DFS(G): effettua un ciclo di inizializzazione sui vertici del grafo, impostando il colore
come Bianco e il valore di
pari a NIL per ognuno di essi. Dopodichè inizia un altro
ciclo sui nodi e, se il nodo v è bianco, invoca la procedura DFS-VISIT(G,v), altrimenti
il nodo è già stato scoperto e la procedura non fa nulla;
5
Topological Sort
-
DFS-VISIT(G,u): a partire dalla sorgente v indicata effettua la ricerca Depth-First. La
procedura è ricorsiva. Incrementa la variabile time, imposta il tempo di scoperta u.d e
setta il colore u.color a Grigio. Controlla la lista di adiacenza del nodo u e per ogni
nodo v che ve ne fa parte controlla se tale nodo è bianco; in tal caso imposta il nodo u
come v. e richiama ricorsivamente la procedura questa volta indicando v come nodo
sorgente. La ricorsione procede finchè non si raggiunge un nodo per il quale tutti i
nodi della sua lista sono grigi. Per tale nodo quindi si imposta il colore Nero e si setta
il tempo finale. La procedura termina e si risale la ricorsione andando a impostare tutti
i tempi finali e i colori come Nero.
Depth-First Search (DFS): pseudocodice
Dopo aver illustrato il funzionamento della DFS, mostriamo qui di seguito gli
pseudocodici relativi alle due procedure di cui esso è composto.
6
Topological Sort
Depth-First Search (DFS): complessità
Mostriamo in che modo viene valutata la complessità temporale della visita in profondità
DFS. Calcolare questa complessità è fondamentale, in quanto rappresenta la quasi totalità
dei fattori che vanno considerati per valutare la complessità dell’algoritmo oggetto di
questo elaborato, il Topological Sort.
Per effettuare questa valutazione utilizzeremo l’analisi ammortizzata, in particolare il
metodo delle aggregazioni.
Nell’analisi ammortizzata, si effettua una media del tempo necessario a eseguire una
sequenza di operazioni secondo il caso peggiore. Il metodo delle aggregazioni afferma
che, per ogni n, una sequenza di n operazioni ha un tempo nel caso peggiore pari a T(n).
Questo tempo è definito come costo aggregato. Si dice che, nel caso peggiore, il costo
ammortizzato di ognuna della n operazioni è pari a T(n)/n.
Questo discorso entra quando si valuta il numero di esecuzioni della procedura DFSVISIT. Possiamo infatti dire che essa è chiamata esattamente una volta
; a causa
del controlli fatti sia nel corpo della procedura DFS, sia nel corpo della stessa DFS-VISIT
sappiamo che il vertice v su cui è chiamato è bianco; dato che la prima cosa che si fa nella
DFS-VISIT è impostare il colore del nodo a grigio, siamo sicuri del numero di esecuzioni
della DFS-VISIT.
Nel corpo della procedura DFS-VISIT il ciclo for è eseguito Adj[v] volte. Dato che:
Il costo totale di tale ciclo è
. Allora, unendo a questo il risultato precedente,
possiamo dire che il tempo totale della Depth-First Search è:
7
Topological Sort
Depth-First Search (DFS): DF-Tree e aciclicità
Un ultimo concetto da introdurre prima di passare ad esporre il topological sort è l’output
della ricerca DFS. Infatti, alla fine di una Depth-First Search possono essere generati i
Depth-First Trees. La procedura va a settare i predecessori
generato il grafo
in maniera tale che venga
in cui i vertici sono i nodi del grafo G e gli archi sono di questo tipo:
(v. , v)
Questo grafo è in realtà visibile come uno o più alberi DF (possono essere più di uno nel
caso sia stato necessario usare più di una sorgente per la ricerca).
Mediante gli alberi DF possiamo effettuare una classificazione degli archi del grafo G.
Essi verranno divisi in 4 tipologie: archi d’albero, archi all’indietro, archi in avanti e archi
trasversali. Ai fini della trattazione, l’unico tipo di arco di cui parleremo sono gli archi
all’indietro.
Un arco all’indietro è un arco (u,v) che connette u con un suo antenato v nell’albero DF.
Vediamo un esempio in figura:
Figura 2: Foresta DF e archi all’indietro
Questi archi ci interessano poiché ci permettono di definire in quali casi un grafo è
aciclico.
Si dice che un grafo G è aciclico se e solo se il Depth-First Tree non presenta archi
all’indietro.
8
Topological Sort
Topological Sort: pseudocodice
Sulla base di quanto detto in precedenza possiamo passare a esporre lo pseudocodice della
procedura di ordinamento topologico.
Ripetiamo che questa procedura è eseguibile nell’ipotesi in cui il grafo G è aciclico.
Ai fini implementativi la procedura è stata realizzata modificando le funzioni DFS e DFSVISIT in modo che la prima restituisse la lista concatenata dei vertici e che la seconda
effettuasse gli inserimenti su tale lista.
Topological Sort: correttezza
Mostriamo ora che tale procedura è corretta e restituisce l’ordinamento topologico del
DAG G fornito in ingresso.
Ipotizziamo che venga svolta la DFS sul grafo diretto aciclico G = (V,E), determinando i
tempi di fine visita dei suoi vertici.
Dobbiamo dimostrare che per ogni coppia di vertici distinti, u,v
, se G contiene un
arco che va da u a v, allora v.f < u.f.
Consideriamo un arco (u,v) esplorato dalla DFS (G). Quando è esplorato, v non può essere
grigio poiché in tal caso v sarebbe un antenato di u e l’arco (u,v) sarebbe un arco
all’indietro (e implicherebbe la presenza di un ciclo nel grafo). Quindi v può essere nero
oppure bianco. Se v è bianco, diventa un discendente di u e quindi v.f < u.f. Se v è nero,
vuol dire che la sua visita è già terminata, v.f è già stato settato e quindi, dato che
dobbiamo ancora impostare u.f è ovvio che v.f < u.f anche in questo caso.
Quindi per ogni arco (u,v) nel DAG, v.f < u.f.
9
Topological Sort
Topological Sort: complessità
E’ molto semplice valutare la complessità temporale di questa procedura, avendo
precedentemente valutato la complessità della DFS(G).
Infatti, la DFS (G) ha un costo pari a
e per svolgere l’inserimento in testa alla
lista concatenata il tempo necessario è O(1). Quindi la complessità del topological sort è
pari a
Valuteremo se questo risultato ha un riscontro nella pratica nel prossimo capitolo, dedicato
all’analisi del software realizzato.
10
Topological Sort
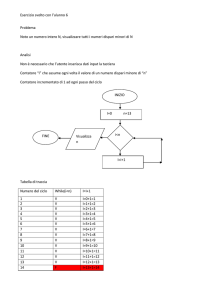
Analisi del Software
Nome capitolo
In questo capitolo verranno illustrate le prestazioni del software realizzato. Esse verranno
valutate mediante varie misure prese e si verificherà l’effettiva aderenza al risultato
formale relativo all’algoritmo Topological Sort mostrato nel precedente capitolo.
Per poter tracciare l’andamento delle prestazioni del software realizzato si sono effettuati
diversi test scegliendo volta per volta diversi input. Tramite i risultati ottenuti si è potuto
tracciare il grafico della funzione T(n) relativa alle prestazioni di topologicalsort.
Una volta ottenuto il grafico di questa funzione si è provveduto a verificare l’aderenza al
risultato teorico.
Tale risultato affermava che la complessità di Topological Sort è Θ(V+E). Per dimostrare
la validità di tale definizione, bisogna dimostrare che:
Detta f (V+E) la funzione che rappresenta il tasso di crescita del tempo di esecuzione di
Topological Sort, bisogna trovare c1,c2 e n0 tali che:
Il software realizzato acquisisce in input il numero di vertici del grafo e genera
casualmente gli archi rispettando sempre l’ipotesi di aciclicità del grafo. Dunque, dato che
11
Topological Sort
il numero di archi non è predicibile e può variare molto sono state effettuate molte misure.
Per effettuare la valutazione è stato poi sommato il numero di vertici richiesto V con il
numero di archi generato casualmente E. Queste somme rappresentano le ascisse dei punti
della funzione.
Mostriamo dunque di seguito il grafico relativo alle prestazioni ottenute con il software
sviluppato fornendo in input i valori precedentemente citati.
Figura 3: Prestazioni di Topological Sort
Il grafico mostra i tempi di esecuzioni espressi in microsecondi dell’algoritmo che lavora
su un vettore formato da numeri casuali di dimensione n. E’ confermata l’aderenza al
risultato teorico in quanto è stato possibile trovare due costanti c1 e c2 che hanno
permesso di generare le rette tratteggiate nel grafico. Le costanti c1 e c2 trovate valgono,
rispettivamente: 4,7 * 10-2 e 3,5* 10-2 . n0 è identificabile più o meno in 4,52 * 105
12
Topological Sort
Codice
Nome capitolo
Mostriamo qui di seguito il codice sorgente relativo all’algoritmo Topological Sort. Esso è
stato scritto utilizzando il linguaggio di programmazione C.
Evidenziamo prima alcuni aspetti del codice. In particolare, si vuole mettere in evidenza il
fatto che nel codice si è realizzata una funzione che genera in modo casuale un Directed
Acyclic Graph del numero di nodi desiderato. Questa funzione ovviamente non effettua la
generazione seguendo la definizione teorica e dunque identificando la presenza di un arco
all’indietro nell’albero DF a valle dell’esecuzione della ricerca DFS sul grafo. Per motivi
di praticità si è scelto di implementare tale funzione in maniera tale che, assegnato un
numero intero progressivo ai vertici del grafo, al suo interno può esistere un arco (u,v) solo
se u < v.
Ovviamente questa è solo una condizione sufficiente a non avere cicli in un grafo, ma non
è assolutamente una condizione necessaria.
Si è scelto di non far inserire il grafo in input all’utente neanche nel caso di ordinamento di
prova poiché sebbene di semplice realizzazione avrebbe solo appesantito il codice,
esulando dagli scopi effettivi di questo elaborato.
13
Topological Sort
/*Software che implementa il Topological Sort, algoritmo di ordinamento
topologico per DAG (grafi orientati aciclici). Il SW genera automaticamente
un grafo aciclico in maniera casuale.
*/
//Autore: Lampognana Francesca M63/144
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
//necessaria per l'utilizzo di QueryPerformanceCounter
//Dichiarazione delle variabili necessarie per il calcolo dei tempi d'esecuzione
static LARGE_INTEGER frequency;
// ticks per second
static LARGE_INTEGER t1, t2;
// ticks
static double elapsedTime;
//tempo trascorso
//Struttura che rappresenta un nodo del grafo
struct vertice {
int id;
struct vertice *next;
};
typedef struct vertice* vertpunt;
//puntatore a un nodo
int tempo;
//variabile globale necessaria per dfs
//Struttura contenente i dati associati alla dfs
struct visitdata {
int color;
int pi;
int d;
int f;
};
//Calcolo del tempo iniziaòe
void starttime(){
static int first=1;
if(first){
QueryPerformanceFrequency(&frequency);
first=0;
}
QueryPerformanceCounter(&t1);
}
//Calcolo del tempo finale
void endtime(){
QueryPerformanceCounter(&t2);
}
//Calcola la differenza tra i due tempi e la porta in microsecondi
double eltime(){
return ((double)t2.QuadPart - (double)t1.QuadPart) * 1000000.0 /
(double)frequency.QuadPart;
}
//Funzione che genera un nuovo puntatore a un nodo
vertpunt newpunt(){
vertpunt v;
v=(vertpunt)malloc(sizeof(struct vertice));
v->next=NULL;
return v;
14
Topological Sort
}
//Inizializza la lista di adiacenze
void init(vertpunt list[],int n){
int i;
for(i=0;i<n;i++)
list[i]=NULL;
}
//Inizializza i dati necessari per la dfs
void initdfs(struct visitdata dfs[],int n){
int i;
for(i=0;i<n;i++){
dfs[i].color=0;
dfs[i].pi=-1;
dfs[i].d=0;
dfs[i].f=0;
}
}
/*Genera una lista di adiacenze casuale, generata in maniera tale che il grafo
risulti sicuramente aciclico. Restituisce il numero di archi generati, info
necessaria per le valutazioni di complessità temporale*/
int AdjList(vertpunt list[],int n){
int k,i,j;
int e=0;
vertpunt nuovo,p;
for(i=1;i<n;i++){
//la lista è generata in modo che il grafo
for(j=0;j<i;j++){
//risultante sia sicuramente aciclico
k=rand()%2;
//Valore random che determina la creazione degli archi
if(k==1){
nuovo=newpunt();
nuovo->id=i;
p=list[j];
if(p==NULL){
list[j]=nuovo;
//crea arco j->i nel caso di 1° arco uscente da j
e=e+1;
} else {
while(p->next!=NULL)
p=p->next;
p->next=nuovo;
//genera l'arco j->i
e=e+1;
}
}
}
}
return e;
//e sarà necessario per le valutazioni di complessità temporale
}
/*Stampa la lista di adiacenze e la lista topologica generata a valle dell'uso
del Topological Sort. La procedura sarà usata solo nel caso in cui venga scelto
di effettuare un ordinamento di prova.
*/
void VisualizzaLista(vertpunt list[],int n,vertpunt tops){
int i;
vertpunt p,punt;
printf("\nLista di adiacenza:\n");
for(i=0;i<n;i++){
15
Topological Sort
printf("\nLista[%d]-->",i);
p=list[i];
while(p!=NULL){
printf("[%d| ]-> ",p->id);
p=p->next;
}
printf("/ \n");
}
punt=tops;
printf("\nLista topologica:\n");
while(punt!=NULL){
printf("[%d| ]-> ",punt->id);
punt=punt->next;
}
}
/*Aggiunge un elemento in testa alla lista topologica. La prodcedura viene usata
all'interno della dfs_visit a valle del settaggio del colore di un nodo a NERO*/
vertpunt settops(vertpunt tops,int i){
vertpunt nuovo;
nuovo=newpunt();
nuovo->id=i;
nuovo->next=tops;
tops=nuovo;
return tops;
}
/*Procedura dfs_visit leggermente modificata per integrare le operazioni
necessarie al topological sort. In particolare restituirà una lista di nodi,
ovvero la lista topologica, che sarà aggiornata alla fine di ogni chiamata*/
vertpunt dfs_visit(vertpunt list[],struct visitdata dfsdata[],int i,vertpunt
tops){
vertpunt p,punt,nuovo;
int k;
tempo=tempo +1;
dfsdata[i].color=1; //Colore grigio
dfsdata[i].d=tempo;
p=list[i];
while(p!=NULL){
k=p->id;
if(dfsdata[k].color==0){
dfsdata[k].pi=i;
tops=dfs_visit(list,dfsdata,k,tops);
}
p=p->next;
}
dfsdata[i].color=2;
//Colore nero
tempo=tempo+1;
dfsdata[i].f=tempo;
tops=settops(tops,i); //Inserimento in testa nella lista topologica
return tops;
}
/*Procedura principale della dfs, leggermente modificata in accordo al
topological sort. In particolare restituite la lista topologica, una volta che
è stata completata*/
vertpunt dfs(vertpunt list[],int n,vertpunt tops){
16
Topological Sort
int i;
vertpunt p;
struct visitdata dfsdata[n]; //Struttura dati che contiene i dati dfs
initdfs(dfsdata,n);
//Inizializza tale lista
tempo=0;
for(i=0;i<n;i++){
//Per ogni v appartenente a G.V
if(dfsdata[i].color==0)
//Colore bianco
tops=dfs_visit(list,dfsdata,i,tops);
}
return tops;
}
/*Funzione del topological sort. Di fatto è superflua, in quanto non fa niente
oltre a richiamare una funzione e restituirne il risultato. E' stata tenuta
solo per fini espositivi.*/
vertpunt TopologicalSort(vertpunt list[],int n){
vertpunt tops=NULL;
tops=dfs(list,n,tops);
//Esegue dfs modificata: ogni volta che è
settato
//un tempo finale di un nodo aggiunge tale
nodo in testa
return tops;
//alla lista tops
}
/*MAIN*/
int main(){
int n,i,option=0, fine=0, r=1,e;
srand(time(0));
//Setta il seme della rand(). srand va eseguito una sola
volta
printf("***\tTOPOLOGICAL SORT\t***\n\n");
do {
do{
printf("Effettua una scelta tra le seguenti:\n");
printf("1 - Ordinamento di prova con DAG di piccola dimensione e stampa a
video\n");
printf("2 - Misura dei tempi con DAG generato casualmente e output su
file\n");
printf("3 - Termina il programma\n");
printf("Scelta: \t");
scanf("%d",&option);
} while((option<1) || (option>3));
switch(option){
case 1:
{
printf("\nInserisci il numero di nodi: \t");
scanf("%d",&n);
vertpunt lista[n];
vertpunt tops=NULL;
init(lista,n);
//Inizializzo la lista
17
Topological Sort
e=AdjList(lista,n);
//Genera lista di adiacenze di un
DAG
tops=TopologicalSort(lista,n);
VisualizzaLista(lista,n,tops);
printf("\nNumero di archi: %d",e);
printf("\n");
}
break;
case 2:
{
printf("\nInserisci il numero di nodi: \t");
scanf("%d",&n);
printf("\nRipetizioni della misura:\t");
scanf("%d",&r);
vertpunt dag[n];
for(i=0;i<r;i++){
vertpunt toplist=NULL;
init(dag,n);
//Inizializzo la lista
e=AdjList(dag,n); //Genera lista di adiacenze di un
DAG
starttime();
toplist=TopologicalSort(dag,n);
endtime();
elapsedTime=eltime();
printf("\nTempo %d: %f us\n",i,elapsedTime);
//Stampa dei tempi su file di testo
FILE *pf1;
char *nomefile1 = "topologicalsort.txt";
pf1 = fopen(nomefile1, "a");
if(pf1){
fprintf(pf1, "%f\t%d\n", elapsedTime,n+e);
fclose(pf1);
}
}
printf("\nMisurazione terminata. Output stampati sul
file 'topologicalsort.txt'");
printf("\n");
}
break;
case 3:
{
fine=1;
}
break;
}
} while(fine==0);
return 0;
}
18