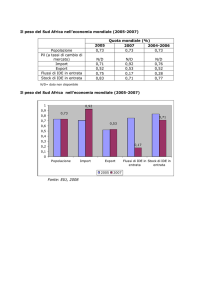
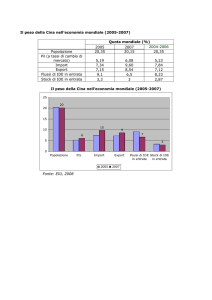
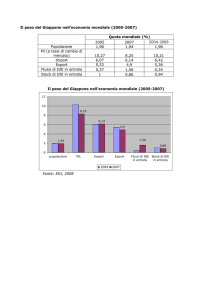
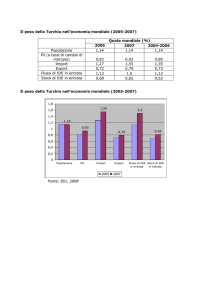
HIVE
Hive
Dove si posiziona nel panorama BigData ?
HIVE
PIG
Data WareHouse
in Hadoop: Hive
Hadoop consente normalmente di affrontare problemi di Data WareHouse, ma scrivere
job complessi per il map/reduce è un processo lungo e complesso
Nel mondo del Data WareHouse e dell'analisi dei dati, i linguaggi di query (SQL) sono
un modo molto comune di accedere ai dati e molti analisti di dati non sono a loro agio
con Java o un linguaggio di scripting come Pig
Hive si propone come strumento per la trasformazione e la gestione dei dati non
strutturati caratteristici di Hadoop fornendo un approccio simile al SQL
Data WareHouse
Cosa intendiamo
Per Data WareHouse intendiamo un archivio informatico contenente dei dati (di
un'azienda, di un ente di ricerca ecc...) progettati per consentire di produrre facilmente
analisi e relazioni utili a fini decisionali.
All'interno del Data WareHouse troviamo una serie di strumenti che vengono utilizzati
per localizzare, estrarre, trasformare e caricare i dati, gestire e recuperare i metadati e
tutti gli strumenti applicabili al business intelligence
Hive
Un po' di storia
Per la gestione dei dati in Facebook si usava abitualmente Hadoop
L'uso continuativo aveva però evidenziato alcune criticità del sistema:
- necessità di utilizzare unicamente map reduce
- codice scarsamente riutilizzabile
- propensione agli errori
- complesse sequenze di job map reduce
L'idea fu quindi quella di realizzare un tool per:
- poter gestire dati non strutturati come fossero delle tabelle
- basarlo su query SQL che possano agire direttamente su queste tabelle
- generare automaticamente catene di job se necessario
Hive
Un esempio pratico: WordCount
CREATE TABLE docs (line STRING);
LOAD DATA INPATH 'ebook' OVERWRITE INTO TABLE docs;
CREATE TABLE word_counts AS
SELECT word, count(1) AS count FROM
(SELECT explode(split(line, '\s')) AS word FROM docs)w
GROUP BY word
ORDER BY word;
Hive
Architettura
HIVE
CLI
HWI
Metastore
Thrift Server
JDBC
ODBC
Driver
(compilazione, ottimizzazione,
esecuzione)
Hive
Driver
Il Driver:
HIVE
Driver
(compilazione, ottimizzazione,
esecuzione)
Master
HDFS
HADOOP
JobTracker
NameNode
- riceve tutti i comandi e le query
- le compila
- ottimizza il di calcolo richiesto
- le esegue, tipicamente con
MapReduce
job
Quando sono richiesti lavori di MapReduce,
Hive non genera i programmi Java
MapReduce.
Utilizza un file XML per rappresentare il
workflow necessario con Mapper e Reducer
generici.
Comunica poi con il JobTracker per avviare
il processo MapReduce.
Non è necessario che Hive sia eseguito
nello stesso nodo master con il JobTracker.
Hive
Metastore
Il Metastore è un database relazionale a
parte dove Hive memorizza metadati di
sistema e gli schemi delle tabelle.
Per impostazione predefinita, Hive utilizza
Derby SQL Server, che fornisce funzionalità
limitate ma sufficienti per una macchina in
pseudo distributed mode.
Una delle maggiori limitazioni di Derby è
l'impossibilità di eseguire due istanze
simultanee CLI.
Quando però si passa a configurare un
cluster di dimensioni maggiori risulta
indispensabile utilizzare un database
relazionale esterno (ad es. MySql)
HIVE
Metastore
Hive
CLI e HWI
Con la CLI è possibile sottomettere delle
query su Hive da linea di comando. È
anche lo strumento che fornisce la
possibilità di scrivere script contenenti
sequenze di comandi e sottometterli al
sistema
La HWI (Hive Web Interface) ci fornisce
invece una semplice interfaccia web
chiamato Hive web per interagire con il
sistema
Possiamo inoltre interagire con Hive con
altri sistemi quali Hue, Karmasphere,
Qubole ecc
HIVE
CLI
HWI
Hive
CLI
La CLI di Hive è versatile, ci consente infatti di:
- interagire con Hive con una shell simile a quella di MySql
hive
- lanciare una singola query
hive -e '<comando>'
- effettuare il dump del risultato di una query
hive -S -e '<comando>' > out.txt
- eseguire uno script locale
hive -f myScript
- eseguire uno script presente nell'hdfs
hive -f hdfs://<namenode>:<port>/myScript
Hive
JDBC, ODBC e Thrift Server
Gli ultimi componenti di Hive forniscono
ulteriori vie d'accesso al sistema di
interrogazione, in particolare abbiamo:
HIVE
Thrift Server
JDBC
ODBC
- un server Thrift che fornisce l'accesso
(anche remoto) da parte di altri processi
che utilizzano linguaggi quali Java, C++,
Ruby ecc
- i moduli JDBC e ODBC che forniscono le
API d'accesso per le interrogazioni su Hive
Hive
Strumenti di sviluppo
Per
comodità
durante
la
d'utilizzo
parte
pratica
utilizzeremo un plugin che
consente
lanciare
di
i
scrivere
comandi
direttamente da browser.
e
Hive
Hive
HiveQL
Introduzione
al linguaggio
Hive
Primitive Data Types
Hive accetta i principali tipi di dato “ereditandoli” dal linguaggio Java:
TINYINT, dimensione 1 byte, signed integer
SMALLINT, dimensione 2 byte, signed integer
INT, dimensione 4 byte, signed integer
BIGINT, dimensione 8 byte, signed integer
BOOLEAN
FLOAT, single precision floating point
DOUBLE, double precision floating point
STRING, sequenza di caratteri (specificata con apici singoli o doppi)
TIMESTAMP, Integer, float, or string
BINARY, array di bytes
Hive
Collection Data Types: Struct
E' l'analogo di una struct C o a un “oggetto” semplice (privo di metodi) e ne rispecchia
sia le modalità di definizione che di accesso.
Ad esempio se si vuole definire una struttura chiamata date di tipo STRUCT
date STRUCT<year:INT, month:INT, day:INT>,
e successivamente per accedere ai singoli campi si utilizza la tipica notazione “punto”.
Ad esempio:
date.year
Hive
Collection Data Types: Array
Sono sequenze ordinate di dati aventi lo stesso tipo che sono indicizzabili utilizzando
degli interi.
Ad esempio se vogliamo definire un campo chiamato volume di tipo ARRAY
volume ARRAY<INT>
Ipotizzando che essa contenga:
['31', '28']
per accedere al secondo elemento dovremo scrivere volume[1]
Hive
Collection Data Types: Map
È una collezione di coppie chiave-valore
Se vogliamo definire una MAP chiamata sellers
sellers MAP<STRING, FLOAT>
Ipotizziamo che contenga le coppie
<
<
<
'Connor'
'Malley'
'Burns'
, 65367
, 92384
, 52453
>
>
>
per ricavare il valore corrispondente alla chiave Burns scriveremo:
sellers['Burns']
Hive
Text Files Encoding
Tipicamente Hive legge dei dati da file di tipo testuale, ad esempio CSV o TSV
Hive utilizza dei caratteri di controllo di default che hanno meno probabilità di comparire
tra le stringhe da considerare come valore di campo.
In particolare
\n separatore di linea
^A rappresentato dalla stringa \001, separatore di colonna
^B rappresentato dalla stringa \002, separatore dei valori negli struct e negli array o
delle coppie chiave-valore nei map
^C rappresentato dalla stringa \003, separatore inserito tra la singola coppia chiavevalore all'interno del map
Hive
Text Files Encoding
Codice corrispondente alle impostazioni di default:
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE ;
Hive
HiveQL
Comandi
di base
Hive
Database
Per la creazione di un database in Hive usiamo il comando
CREATE DATABASE IF NOT EXISTS financials;
Possiamo anche aggiungere una serie di metadati (localizzazione dei dati, informazioni
sull'autore, sulla data di creazione, commenti ecc)
Ad esempio per specificare dove scrivere i dati sull'HDFS:
LOCATION '/user/hue/financials_db';
Hive
Database
Per visualizzare le proprietà di un certo database usiamo:
DESCRIBE DATABASE financials;
Per cancellarlo invece:
DROP DATABASE financials;
Hive
Tipologia di Tabelle
La creazione delle tabelle in Hive ricorda in maniera particolare la creazione delle
tabelle in SQL
Esistono due principali tipi di tabelle:
- Tabelle ordinarie (non partizionate)
- Tabelle partizionate
Che a loro volta possono essere suddivise in:
- Tabelle interne
- Tabelle esterne
Hive
Tabelle ordinarie: Tabelle Interne
In questo tipo di tabelle:
Hive assume di avere la “proprietà” dei dati
Abbiamo che il file contenente i dati viene spostato dalla posizione originale all'interno
della cartella che rappresenta la nostra tabella nell'HDFS
Questo perché:
- i dati importati non devono subire modifiche per il principio generale di “una sola
scrittura, molte letture”
- copiare i dati potrebbe voler dire copiare petabytes di file
Si ha che:
- il file importato viene spostato dalla sua posizione originale in una cartella, creata
all'interno dell'HDFS, che rappresenta la tabella
- la struttura della tabella viene memorizzata all'interno del metastore di Hive
Hive
Tabelle ordinarie: Tabelle Esterne
Utilizzano dei dati “al di fuori” dal controllo diretto di Hive in maniera da essere lasciati a
disposizione di eventuali altri tool (es. Pig) per effettuare ulteriori e/o differenti
elaborazioni.
La creazione di questo tipo di tabelle è che:
- il file importato viene mantenuto all'interno della posizione originaria
- non viene creata, all'interno dell'HDFS, alcuna cartella che rappresenta la tabella da
creare
- la struttura della tabella viene memorizzata all'interno del metastore di Hive
Hive
Creazione delle Tabelle
Ipotizziamo di partire da un file così costituito
Hive
Creazione della Tabella Interna
CREATE TABLE financials.nyse (
exchange_col STRING,
stock_symbol STRING,
date STRUCT<year:INT, month:INT, day:INT>,
stock_price_open FLOAT,
stock_price_high FLOAT,
stock_price_low FLOAT,
stock_price_close FLOAT,
stock_volume INT,
stock_price_adj_close FLOAT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY '-'
STORED AS TEXTFILE ;
Hive
Importare i dati in una Tabella Interna
Il comando per importare i dati in una tabella è il seguente:
LOAD
DATA
INPATH
financials.nyse;
'/user/hue/nyse'
OVERWRITE
INTO
TABLE
Hive
Creazione della Tabella Esterna e Importazione dei Dati
CREATE EXTERNAL TABLE financials.stock (
exchange_col STRING,
stock_symbol STRING,
date STRUCT<year:INT, month:INT, day:INT>,
stock_price_open FLOAT,
stock_price_high FLOAT,
stock_price_low FLOAT,
stock_price_close FLOAT,
stock_volume INT,
stock_price_adj_close FLOAT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY '-'
LOCATION '/user/hue/data' ;
Hive
Cancellare una tabella
Per cancellare una tabella non dovremo fare altro che utilizzare il comando
DROP TABLE IF EXISTS financials.nyse;
Il comportamento è differente nel caso si tratti di una tabella interna o esterna:
- in caso di tabella interna, viene cancellato lo schema della tabella e anche tutti i dati
ad essa associati
- in caso di tabella esterna, viene cancellato lo schema della tabella ma non tutti i dati
associati
Hive
Tabelle Partizionate
La tabella partizionata è una tabella nella quale i dati d'origine vengono, in fase
d'importazione, suddivisi in sotto categorie (le partizioni) che corrispondono a una
differente gerarchizzazione dei dati all'interno dell'HDFS
L'utilizzo di queste tabelle comporta tre grossi vantaggi:
- maggior velocità delle query: non si va ad analizzare per intero un unico (o più) file di
grosse dimensioni ma si potrà usufruire di una prima scrematura dei dati
- gerarchia dei dati anche per altri tool (es. Pig)
- la dimensione complessiva dei dati diminuisce: vengono eliminati dai dati finali tutti i
riferimenti ai dati di partizionamento
Un'efficiente partizionamento dipende dalla conoscenza dei dati e dalle principali query
che l'utente potrebbe lanciare
Hive
Tabella Partizionata – Tabelle interne ed esterne
Anche le tabelle partizionate possono essere create come tabelle esterne.
Per le caratteristiche delle tabelle partizionate, e per i vantaggi che esse offrono, si ha
però una differenza comportamentale rispetto alle tabelle non partizionate:
●
l'importazione dei dati all'interno di una tabella partizionata comporta SEMPRE la
copia dei dati nella directory di riferimento per la tabella.
La cancellazione invece ha il medesimo comportamento:
●
●
la cancellazione della tabella partizionata, se interna, comporta la perdita dei dati;
la cancellazione della tabella partizionata, se esterna, consente di preservare i dati
per eventuali differenti usi.
Hive
Creazione delle Tabelle
Hive
Tabella Partizionata – Dati nell'HDFS
Nel momento della scrittura dei dati Hive suddivide i dati in ingresso in un albero di
cartelle su HDFS nella forma
…/ Anno / Stock Exchanges / Indice / Altri Valori
ad esempio:
…/ year=2012 / exchange_col=LSEG / stock_symbol=IBM / 000000_0
...
…/ year=2013 / exchange_col=NYSE / stock_symbol=AXE / 000000_0
…/ year=2013 / exchange_col=NYSE / stock_symbol=ANH / 000000_0
...
…/ year=2014 / exchange_col=NYSE / stock_symbol=ANH / 000000_0
Hive
Tabella Partizionata – Struttura
La struttura logica delle tabelle partizionate prevede che vengano utilizzate le prime
colonne per rappresentare i campi non partizionati e che le partizioni, in ordine
gerarchico, vengano messe in coda alla tabella
{campo comune, … , campo comune, livello_partizione_1, … , livello_partizione_N}
A causa di questa struttura risulta complesso caricare i dati da file dove gli elementi non
siano correttamente disposti
Si preferisce effettuare l'import dei dati su una tabella non partizionata (anche esterna)
e poi effettuare una copia dei dati all'interno della tabella partizionata
Hive
Tabella Partizionata – Creazione
Possiamo creare la nostra nuova tabella partizionata con
CREATE TABLE financials.part (
month INT,
day INT,
stock_price_open FLOAT,
stock_price_high FLOAT,
stock_price_low FLOAT,
stock_price_close FLOAT,
stock_volume INT,
stock_price_adj_close FLOAT
)
PARTITIONED BY (year INT, exchange_col STRING, stock_symbol
STRING);
Hive
Tabella Partizionata – Importazione Implicita
E possiamo caricare i dati a partire dalla tabella esterna creata precedentemente e
chiamata financials.stock
INSERT OVERWRITE TABLE financials.part
PARTITION (year, exchange_col, stock_symbol)
SELECT date.month,
date.day,
stock_price_open,
stock_price_high,
stock_price_low,
stock_price_close,
stock_volume,
stock_price_adj_close,
date.year,
exchange_col,
stock_symbol
FROM financials.stock;
Hive
Tabella Partizionata – Importazione Esplicita
E possiamo caricare i dati a partire dalla tabella esterna creata precedentemente e
chiamata financials.stock
INSERT OVERWRITE TABLE financials.part
PARTITION (year='date.year',
exchange_col='exchange_col',
stock_symbol='stock_symbol')
SELECT date.month,
date.day,
stock_price_open,
stock_price_high,
stock_price_low,
stock_price_close,
stock_volume,
stock_price_adj_close
FROM financials.stock;
Hive
Tabella Partizionata – Importazione
A fronte di una visualizzazione logica dei dati completa
Il file fisico che li rappresenta risulta essere
… / year=2000 / exchange_col=NYSE / stock_symbol=AXE / 000000_0
Partizioni
Hive
HiveQL
Comandi
di base per le SELECT
Hive
Queries: SELECT … FROM
Come abbiamo visto in precedenza è possibile utilizzare il comando SELECT come
l'analogo operatore di proiezione presente nel SQL per andare a specificare la (o le)
colonne di nostro interesse.
Il FROM, in maniera analoga al SQL, specifica la tabella, la vista o la query annidata, dalla
quale bisogna partire al fine di effettuare il corretto SELECT.
Possiamo ad esempio scrivere:
SELECT date.year , stock_symbol FROM financials.stock;
SELECT fst.date.year , fst.stock_symbol FROM financials.stock fst;
dove nel secondo caso specifichiamo un alias per identificare la tabella di riferimento.
Hive
Select: Operatori aritmetici
Con il SELECT non si possono solo effettuare delle pure “selezioni” di dati ma è anche
possibile effettuare una serie di operazioni di manipolazione di diversa natura
Hive
Select: Altri Operatori e funzioni
In Hive sono presenti una serie di altri operatori:
●
●
●
●
●
●
●
operatori relazionali (> , <, ==, ecc);
operatori logici (AND, OR, ecc);
funzioni matematiche (rand, abs, sqrt, ecc);
funzioni legate alle collezioni di dati (size, contains, ecc);
funzioni legate alle date (timestamp, year, ecc);
funzioni legate alle stringhe (concat, length, locate, ecc);
funzioni di aggregazione (count, max, variance, ecc);
… ed altre ancora …
Tutti gli operatori e le funzioni sono comunque documentate nel wiki di Hive
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
Hive
Select: Esempi d'uso
SELECT lower(stock_symbol), date.year+13 FROM financials.stock;
SELECT count(*), avg(stock_volume) FROM financials.stock;
Hive
Select: Alias
Il risultato di un'operazione di SELECT può essere associato a una colonna “alias”: questa
colonna è un riferimento per eventuali SELECT concatenati
Ad esempio:
SELECT count(*) as rows,
avg(stock_volume) as avg_volume
FROM financials.stock;
Hive
Select: Where
Così come il SELECT seleziona le colonne da restituire, il WHERE filtra i singoli record in
base al loro contenuto.
La clausola WHERE può sfruttare differenti funzioni predicato.
SELECT count(*) as rows,
avg(stock_volume) as avg_volume
FROM financials.stock
WHERE stock_volume > 57390*3;
Hive
Select concatenati
Un possibile esempio d'uso di SELECT concatenati è il seguente
FROM (
SELECT lower(stock_symbol) as lower_sym,
stock_volume as volume,
date.year+13 as update_age
FROM financials.stock
) sd
SELECT sd.update_age,
sd.lower_sym,
sd.volume
WHERE sd.volume > (57390 * 3);
Hive
Select: Like e Rlike
In Hive abbiamo due particolari operatori predicato a cui prestare attenzione: LIKE e RLIKE.
SELECT stock_symbol
FROM financials.stock
WHERE stock_symbol LIKE 'C%';
RLIKE viene utilizzato per specificare eventuali regular expression su cui non ci
soffermiamo qui
Hive
Select: Case … When … Then
Anche in Hive è possibile utilizzare un costrutto “if” in relazione al valore assunto da una
specifica colonna, ad esempio:
SELECT stock_symbol, stock_volume,
CASE
WHEN stock_volume < 57390 THEN 'low'
WHEN stock_volume < 57390*2 THEN 'middle'
WHEN stock_volume < 57390*3 THEN 'high'
ELSE 'very high'
END
FROM financials.stock LIMIT 5;
Hive
Select: Group By
Il GROUP BY viene utilizzato in funzioni di aggregazione per raggruppare i risultati di una o
più colonne.
SELECT stock_symbol as symbol, avg(stock_volume) as average
FROM financials.stock
GROUP BY stock_symbol;
Hive
Select: Having
Con la clausola HAVING possiamo poi specificare quali risultati andare a mostrare con il
nostro GROUP BY
SELECT stock_symbol, avg(stock_volume) as average
FROM financials.stock
GROUP BY stock_symbol HAVING average > 5000;
Hive
Select: Le viste
Quando una query diventa lunga o complicata le viste possono essere utilizzate per
nascondere la complessità e dividere la query stessa in più blocchi elementari
CREATE VIEW symbol AS
SELECT stock_symbol, avg(stock_volume) as average
FROM financials.stock
GROUP BY stock_symbol;
SELECT * FROM symbol;
Hive
Select: Order By e Sort By
A causa delle dimensioni dei database in HIVE sono presenti due diversi comandi per
effettuare l'ordinamento:
L'ORDER BY, simile nel funzionamento a quello degli altri linguaggi SQL, esso effettua un
ordinamento completo del risultato della query: tutti i dati vengono passati a un singolo
reducer con rischio di tempi d'attesa eccessivamente lunghi.
SORT BY: ordina i dati in ogni reducer realizzando un ordinamento “locale” e, al termine,
effettua una concatenazione dei risultati parziali.
L'ordinamento effettuato dai due sistemi potrebbe quindi risultare differente.
Hive
Order By
Map 1
Map 2
Map 3
Map 4
...
Map N -1
Map N
Reduce Globale
output
Hive
Sort By
Map 1
Reduce Locale 1
Map 2
Map 3
Reduce Locale 2
Map 4
...
...
Map N -1
Reduce Locale N
Map N
output
Hive
Order By e Sort By: confronto
Order By
Sort By
PRP
GVZ
PRP
GVZ
AFG
ANH
ZLS
RPP
Reduce
AFG
ANH
GVZ
PRP
RPP
ZLS
AFG
ANH
Reduce 1
Reduce 2
GVZ
PRP
AFG
ANH
...
ZLS
RPP
Reduce N
RPP
ZLS
GVZ
PRP
AFG
ANH
RPP
ZLS
Hive
Select: Order By e Sort By
SELECT stock_symbol, stock_volume, stock_price_close
FROM financials.stock
ORDER BY stock_symbol ASC, stock_price_close DESC;
SELECT stock_symbol, stock_volume, stock_price_close
FROM financials.stock
SORT BY stock_symbol ASC, stock_price_close DESC;
Hive
Join
Hive supporta, come nei linguaggi SQL i JOIN.
Attenzione: sono supportati unicamente i Join di tipo equi-joins, quelli cioè dove l'unico
operatore matematico accettato è l'uguaglianza matematica. Ad esempio:
●
●
●
●
●
●
Inner JOIN
LEFT OUTER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN
LEFT SEMI JOIN
Cartesian Product JOIN
La documentazione completa è disponibile a questo indirizzo:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
Hive
Join: Inner Join
In un INNER JOIN vengono eliminati tutti i record che non corrispondono al criterio di
matching desiderato
SELECT a.date, a.stock_price_close, b.stock_price_close
FROM financials.stock a JOIN financials.stock b
ON a.date = b.date
WHERE a.stock_symbol = 'CLI' AND
b.stock_symbol = 'CHP';
Hive
outer join
Pig supporta anche l' outer join. che consente di non scartare i record per cui non è
stata trovata una corrispondenza in una delle due tabelle, sostituendo la parte mancante con
dei null.
Gli outer join possono essere di tre tipi
●
left → vengono inclusi i record della tabella a sinistra
●
right → vengono inclusi i record della tabella a destra
●
full →
vengono inclusi i record di entrambe le tabelle
Hive
Join: LEFT OUTER JOIN
In questo JOIN vengono mostrati tutti i record della tabella a “sinistra” che corrispondono al
vincolo imposto dalla clausola WHERE.
Se i campi della tabella di “destra” non hanno valori che coincidono con il criterio specificato
da ON allora viene inserito un NULL.
SELECT a.date, a.stock_symbol, a.stock_price_close, b.dividends
FROM financials.stock a LEFT OUTER JOIN financials.dividends b
ON a.date = b.date AND a.stock_symbol = b.stock_symbol
WHERE a.stock_symbol = 'CLI';
Hive
Join: RIGHT OUTER JOIN
In questo JOIN vengono mostrati tutti i record della tabella a “destra” che corrispondono al
vincolo imposto dalla clausola WHERE.
Se i campi della tabella di “sinistra” non ha valori che coincidono con il criterio specificato da
ON allora viene inserito un NULL.
SELECT a.date, a.stock_symbol, a.stock_price_close, b.dividends
FROM financials.dividends b RIGHT OUTER JOIN financials.stock a
ON a.date = b.date AND a.stock_symbol = b.stock_symbol
WHERE a.stock_symbol = 'CLI';
Hive
Join: FULL OUTER JOIN
In questo JOIN vengono mostrati tutti i record di tutte le tabelle che corrispondono al vincolo
imposto dalla clausola WHERE.
Il valore NULL viene usato per i campi che non contengono un valore valido.
SELECT a.date, a.stock_symbol, a.stock_price_close, b.dividends
FROM financials.dividends b FULL OUTER JOIN financials.stock a
ON a.date = b.date AND a.stock_symbol = b.stock_symbol
WHERE a.stock_symbol = 'CLI';
Hive
Join: LEFT SEMI JOIN
In questo JOIN vengono mostrati tutti i record della tabella a “sinistra” se il record trovati
nella tabella di destra soddisfano il predicato ON
SELECT a.date, a.stock_symbol, a.stock_price_close
FROM financials.stock a LEFT SEMI JOIN financials.dividends b
ON a.date = b.date AND a.stock_symbol = b.stock_symbol;
Hive
Join: CARTESIAN PRODUCT JOIN
In questo JOIN tutte le tuple della tabella di sinistra vengono associate a tutte le tuple della
tabella di destra.
In questo modo se la tabella di sinistra ha 5 righe e quella di destra ha 6 righe. Il risultato è
di 30 righe.
Corrisponde a realizzare un INNER JOIN senza però l'utilizzo del predicato ON
SELECT *
FROM financials.stock a JOIN financials.stock b
WHERE a.stock_symbol = b.stock_symbol AND a.stock_symbol = 'AXE';