UNIVERSITÀ DEGLI STUDI ROMA TRE
FACOLTÀ DI INGEGNERIA
CORSO DI LAUREA IN INGEGNERIA INFORMATICA
Tesi di Laurea
Reingegnerizzazione di una Mediateca
per l’automazione dei processi
di creazione e gestione
Candidato
Paolo Papotti
Relatore
prof. P.Atzeni
Università degli studi Roma Tre
Correlatore
Prof. M.Crudele
Università Campus Bio-Medico Roma
Anno Accademico 2001/2002
A Chiara e Alberto, Lina e Dario
2
Indice
Indice.................................................................................................................................. 3
Indice delle figure ........................................................................................................... 6
Introduzione ...................................................................................................................... 7
1.
E-learning: lo stato dell’arte ........................................................................... 10
1.1
Introduzione ....................................................................................................... 10
1.2
La formazione a distanza di terza generazione.................................................. 11
1.2.1
Formazione in rete .................................................................................... 13
1.2.2
Formazione mista...................................................................................... 15
1.3
Alcune soluzioni esistenti .................................................................................. 15
1.3.1
IBM........................................................................................................... 16
1.3.2
Microsoft................................................................................................... 17
1.3.3
CISCO....................................................................................................... 18
1.3.4
TILS .......................................................................................................... 19
1.3.5
Altre offerte............................................................................................... 20
2.
La Mediateca-ELIS.......................................................................................... 21
2.1
Cosa è la Mediateca-ELIS?................................................................................ 21
2.2
Documentazione database esistente................................................................... 25
2.2.1
Dizionario dei dati .................................................................................... 25
•
Gestione degli eventi della Mediateca ............................................................... 26
•
Contenuti mediali di Mediateca......................................................................... 27
•
Organizzazione dei questionari rispetto a Moduli e Unità ................................ 39
•
Gestione degli utenti della Mediateca................................................................ 43
2.2.2
Regole aziendali........................................................................................ 47
2.2.3
Viste .......................................................................................................... 48
2.3
Use Case Model ................................................................................................. 53
2.4
Sequence diagram .............................................................................................. 56
3
2.5
Component diagram........................................................................................... 58
2.5.1
Security Management ............................................................................... 59
2.5.2
Server Components................................................................................... 62
3
I metadata per oggetti didattici ...................................................................... 63
3.1
Introduzione ....................................................................................................... 63
3.2
Standard proposti ............................................................................................... 66
3.2.1
IEEE LOM (http://ltsc.ieee.org/wg12/)........................................................ 66
3.2.2
IMS (http://www.imsproject.org/)................................................................ 68
3.2.3
Gestalt (http://www.fdgroup.co.uk/gestalt/).................................................. 69
3.2.4
Ariadne (http://www.ariadne-eu.org/) .......................................................... 70
3.2.5
Dublin Core (http://www.dublincore.org).................................................... 71
3.3
4
SCORM ............................................................................................................. 73
La soluzione adottata....................................................................................... 77
4.1
Analisi implementativa degli standard .............................................................. 77
4.2
Mediateca versione 4.0 e standard IMS- Dublin Core....................................... 79
4.2.1
General...................................................................................................... 84
4.2.2
Lifecycle ................................................................................................... 85
4.2.3
Technical................................................................................................... 85
4.2.4
Educational ............................................................................................... 86
4.2.5
Relation..................................................................................................... 88
4.3
5
Schema database Mediateca versione 4.0.......................................................... 89
I nuovi strumenti: ricerca e automazione...................................................... 90
5.1
Ricerca nel database........................................................................................... 90
5.1.1
5.2
Possibili aggiunte per la ricerca ................................................................ 92
Creazione nuove lezioni..................................................................................... 93
5.2.1
Creazione di lezione in presenza .............................................................. 93
5.2.2
Creazione lezioni dinamiche..................................................................... 96
5.3
6
Creazione moduli e corsi ................................................................................. 101
Implementazione............................................................................................ 102
6.1
Creazione di un corso ...................................................................................... 105
4
6.2
Creazione di un modulo................................................................................... 105
6.3
Creazione di una lezione statica da una lezione in presenza ........................... 106
6.4
Creazione di una lezione dinamica da risorse presenti nella Mediateca.......... 107
DEFAULT.ASP...................................................................................................... 108
CATALOGO.ASP .................................................................................................. 108
LEZIONE.ASP ....................................................................................................... 110
CONFERMA.ASP.................................................................................................. 113
START.ASP ........................................................................................................... 117
Conclusioni .................................................................................................................... 119
Appendice A .................................................................................................................. 122
A.1 XML: eXtensible Markup Language ................................................................... 122
A.2 SMIL: Synchronized Multimedia Integration Language..................................... 126
A.3 ASP: Active Server Page ..................................................................................... 137
Appendice B................................................................................................................... 142
ELIS: Educazione Lavoro Istruzione Sport ................................................................ 142
Centro ELIS ............................................................................................................ 142
Vivai d’impresa....................................................................................................... 143
Bibliografia .................................................................................................................... 146
Ringraziamenti.............................................................................................................. 151
5
Indice delle figure
Figura 2-1 Una lezione della Mediateca ...........................................................21
Figura 2-2 Fasi di elaborazione: dalla ripresa alla lezione ...............................22
Figura 2-3 Gestione eventi................................................................................26
Figura 2-4 Gestione contenuti Mediateca.........................................................27
Figura 2-5 Unità, moduli, corsi.........................................................................33
Figura 2-6 Entità coinvolte ...............................................................................37
Figura 2-7 Gestione dei questionari di valutazione ..........................................39
Figura 2-8 Gestione utenti ................................................................................43
Figura 2-9 Use case del tutor ............................................................................53
Figura 2-10 Use case dell’utente ......................................................................54
Figura 2-11 Use case “comunica” dell’utente ..................................................55
Figura 2-12 Use case “segue lezione” dell’utente ............................................55
Figura 2-13 Sequence diagram della creazione lezione....................................56
Figura 2-14 Sequence diagram della richiesta di una lezione ..........................57
Figura 2-15 Component diagram struttura Mediateca......................................58
Figura 2-16 Component view sicurezza ...........................................................59
Figura 2-17 Sequence diagram login utente esterno.........................................60
Figura 2-18 Sequence diagram login utente interno.........................................61
Figura 2-19 Component view server ................................................................62
Figura 3-1 Convergenza fra SCORM e standard per l’e-learning ....................74
Figura 3-2 Rapporti fra i testi che descrivono lo SCORM ...............................75
Figura 4-1 Gestione contenuti Mediateca ver. 4...............................................89
Figura 5-1 Schema interfaccia lezione..............................................................97
Figura 5-2 Esempio con due frammenti video................................................100
Figura 6-1 Sequence diagram processo creazione corso, modulo, lezione ....103
Figura 6-2 Sequence diagram processo creazione lezione dinamica..............104
6
Introduzione
In molti settori, negli ultimi anni, è diventata evidente l’importanza della
didattica a distanza, dell'aggiornamento professionale, dell'auto-formazione.
Esigenze particolarmente sentite in ambienti tecnici, dove il veloce susseguirsi di
nuove tecnologie e metodologie è continuo, tanto da far aumentare
costantemente la domanda di formazione in campi specialistici. Questo è ancora
più visibile e tangibile nel settore dell’ICT (Information Communication
Technology), per il quale sono nate improvvisamente molte società di
formazione, mentre quelle esistenti hanno allargato la loro offerta puntando in
maniera specifica su questi nuovi settori. Un fenomeno accompagnato
dall’introduzione massiccia di corsi “on-line”, erogati attraverso la rete Internet,
affiancati o addirittura alternativi a quelli di tipo tradizionale “in presenza”.
L'efficacia di queste nuove tecniche didattiche è ancora causa di accesi
dibattiti, ma risultati incoraggianti spingono verso una continua ricerca per
sviluppare soluzioni più avanzate e didatticamente sempre più valide. E’ evidente
come questo nuovo tipo di insegnamento permetta l’immagazzinamento di
un’enorme quantità di risorse didattiche. Basti pensare ai materiali video e audio,
oltre naturalmente ai testi, che vengono memorizzati in formato digitale,
riutilizzabili quindi all’infinito con estrema facilità in tutto il mondo. Se proviamo
ad allargare il discorso dalle risorse preparate appositamente per corsi all’immensa
mole di informazioni presente gratuitamente in rete, possiamo cogliere
l’importanza e la delicatezza del momento. E’ infatti un periodo di presa di
coscienza di tutta questa potenzialità tuttora inespressa, ma si fatica a trovare una
soluzione per poter sfruttare al massimo questa abbondanza di dati.
Uno dei problemi più importanti ed evidenti è la mancanza di catalogazione di
questo materiale. E, quando questa catalogazione esiste, si presenta il problema di
7
una certa anarchia nella decisione delle categorie o delle caratteristiche scelte per
definire una risorsa.
Naturalmente sono problemi che esistono da secoli, anche se in contesti
diversi. Il termine Metadata (letteralmente “dati sui dati”) è usato tradizionalmente
dai professionisti dell’informazione, come archivisti o addetti alla catalogazione in
biblioteche e musei, per riferirsi a informazioni di catalogazione o indicizzazione
creati da loro, necessari per descrivere un oggetto e migliorarne l’accesso. Se
limitiamo l’approfondimento ai sistemi per la didattica, questi oggetti vengono
allora definiti Learning Object, traducibile in “oggetti per l’insegnamento” o
“oggetti didattici”.
Mentre dagli anni sessanta esistono, in ambito bibliotecario, standard come il
MARC (Machine-Readable Cataloging format) per definire regole e strutture
uniche per i contenuti o come il LCSH (Library of Congress Subject Heading) per
la catalogazione per argomento, per i learning object non esiste ancora un
riferimento unico.
Obiettivo del mio lavoro è stato trovare una soluzione applicabile a due
problemi fondamentali dell’insegnamento a distanza: un’implementazione
semplice ed economica dei metadata per i learning object e il riutilizzo delle
risorse immagazzinandole con un livello di granularità ottimale.
Attraverso lo studio dei learning object, e delle soluzioni di standardizzazione
proposte per questi, è stato possibile modificare la struttura della Mediateca-ELIS
per rendere il sistema conforme a più di uno standard internazionale.
Il primo risultato di questo lavoro è la possibilità di interrogare il database
della Mediateca in maniera profonda e con risultati innovativi. Attraverso delle
soluzioni implementative, basate su strumenti disponibili sul mercato a costo zero,
è ora possibile ricercare nell’archivio del sistema per creare in maniera
automatizzata nuovi corsi attraverso la combinazione di lezioni già presenti
all’interno. Questo porta grossi vantaggi per i tutor in fase di creazione e
mantenimento di un corso, ma anche per gli studenti che vogliono approfondire
degli argomenti o ricercare esercitazioni particolari per preparare un esame.
Grazie alla granularità molto fine è stato inoltre possibile introdurre la
possibilità di creare dinamicamente nuove lezioni da quelle già presenti nel
8
database. Questo utilizzo delle risorse sfrutta al massimo le potenzialità dei
metadata e della catalogazione dei learning object in un database: il tutor - o lo
studente - con una semplice interfaccia assembla i contenuti di risorse già presenti,
realizzando una lezione pronta per l’utenza.
Un altro risultato dell’introduzione dei metadata è infine la possibilità di
scambiare dati con altri sistemi in maniera automatizzata, vedremo nel corso del
lavoro i modi e gli strumenti per implementarlo.
Dopo
il
primo
capitolo
sull’E-learning,
introduttivo
alla
tematica
dell’insegnamento a distanza, nel secondo è descritto lo scenario in cui si è
lavorato con un’ampia documentazione della Mediateca nella sua terza versione.
Da questa esperienza è stata avvertita l’esigenza di una maggiore attenzione al
momento della catalogazione delle risorse e nel terzo capitolo sono state analizzate
tutte le tematiche, con uno sguardo approfondito alle proposte di standard per i
metadata dei learning object attualmente in competizione.
Queste proposte vengono analizzate e applicate alla Mediateca come descritto
nel quarto capitolo e portate al loro utilizzo nel quinto, con la descrizione dei
processi di ricerca e di creazione delle lezioni in maniera dinamica.
Nel sesto capitolo vengono esposte e giustificate le scelte implementative
adottate, dalla progettazione alle realizzazione degli strumenti web per la creazione
dei corsi e delle lezioni.
Nelle appendici vengono analizzati alcuni strumenti utilizzati per lo sviluppo
della tesi, come XML, SMIL e ASP, e viene presentato il centro ELIS, la
struttura che mi ha accolto nei mesi di lavoro. Qui, all’interno del master per
laureandi “Vivai d’impresa”, ho potuto vivere esperienze di valore sia
professionale che umano, trovando una reale applicazione delle nuove tecnologie
ai valori richiamati dalla sigla ELIS: l’educazione, il lavoro, l’istruzione e lo
sport.
9
1. E-learning: lo stato dell’arte
1.1 Introduzione
Quando si pensa alle possibili applicazione delle nuove tecnologie alla
didattica, solitamente c’è un grandissimo entusiasmo pensando alle enormi
potenzialità dei mezzi, ma spesso questi nuovi strumenti si limitano ad essere
una scadente alternativa all’insegnamento “in presenza” con un docente.
Naturalmente questi problemi nascono da un’interpretazione errata e limitata
delle modalità d’uso delle tecnologie: l’innovazione e l’intervento produttivo
non consistono certo nella sostituzione del ruolo centrale dell’insegnante (come a
volte viene invece fatto).
Al contrario, si tratta di ripensare il modello didattico da utilizzare,
progettando e sperimentando nuove dinamiche tra docenza e studenti. Una
lezione a distanza che sappia sfruttare tecnologie multimediali su una rete di
utenti, come Internet, ha l'importante caratteristica di essere accessibile
istantaneamente ad una platea molto ampia. L'interattività degli studenti durante
la lezione è però naturalmente limitata dall’utilizzo di una tecnologia legata a
Internet: forum, mailing list, e-mail, bacheca e altri strumenti di interazione con
l'insegnante cercano di limitare questo problema.
In questi paragrafi non verrà affrontato il discorso da un punto di vista
prettamente pedagogico, ma si porrà l’accento sugli aspetti più significativi
riguardo ai nuovi strumenti tecnologici applicati alla formazione a distanza.
10
1.2 La formazione a distanza di terza generazione
La "formazione a distanza di terza generazione" è un nuovo tipo di FaD,
sviluppatasi negli ultimi anni e che va ad affiancarsi ai due precedenti modi di
erogare formazione attraverso la tecnologia, denominati di prima e seconda
generazione.
Nelle precedenti generazioni di formazione a distanza il materiale didattico è
prodotto e distribuito agli utenti e si assegna una priorità molto bassa al processo
comunicativo, che è reso per lo più a senso unico e molto raramente in maniera
biunivoca. Questa limitazione nella comunicazione ha creato dei forti pregiudizi
in questo tipo di formazione.
•
L'apprendimento della prima generazione è stato praticato
durante tutta la storia della civiltà occidentale, ma si è sviluppato
in modo efficace in termini quantitativi quando, alla fine del XIX
secolo, le nuove tecnologie di stampa ed il sistema ferroviario
hanno reso possibile la distribuzione di grosse quantità di
materiale a gruppi di alunni geograficamente lontani. Questo
modello di tecnologia prevede la distribuzione di corsi per via
postale attraverso materiali didattici su supporto cartaceo, anche
tecnologicamente avanzati (schede, questionari, unità operative,
moduli valutativi). Per la valutazione delle risposte degli utenti e
per la stessa produzione di materiali, sono utilizzate tecnologie
predisposte presso l'erogatore, mentre non è necessaria una
tecnologia presso l'utente. I processi di feedback studente-tutor e
tutor-studente sono limitati ai periodi in cui i programmi
prevedono che gli alunni sottopongano i compiti svolti.
•
La "seconda generazione" di insegnamento a distanza,
sviluppatasi nel ventesimo secolo e in particolare alla fine degli
anni sessanta, è chiamata anche insegnamento a distanza
multimediale ed integra l'uso degli stampati con sistemi
11
audiovisivi, CD e computer. I processi di feedback sono molto
simili a quelli visti per la "prima generazione", ma includono la
consulenza telefonica ed alcune lezioni individuali con eventuali
attività come, ad esempio, dei seminari.
Parallelamente all'evolvere della tecnologia si sono fatti strada i sistemi di
Formazione a distanza in rete di terza generazione, che non hanno alcuna
pretesa di sostituire né la formazione tradizionale in presenza, né le due
precedenti modalità di erogazione di corsi a distanza. Questo recente tipo di
formazione si presenta come una possibilità ulteriore all'interno del panorama
didattico, che può essere più funzionale in particolari contesti formativi e non in
altri, che richiede un'attenta analisi dei bisogni e una valutazione dei costibenefici che può portare. Ad esempio, dove il numero di fruitori è
particolarmente alto, un sistema di terza generazione, in cui gioca un ruolo
essenziale l'interazione e la collaborazione in piccoli gruppi, può risultare meno
funzionale rispetto ad uno di seconda o di prima generazione, che permette la
distribuzione e fruizioni di materiali didattici su larga scala e a basso costo.
Con la formazione a distanza di terza generazione si fa strada l'idea della
comunicazione e dell'apprendimento come processi sociali. Questo modo di
porsi rispetto al percorso di insegnamento da una parte, e quindi di
apprendimento dall’altra, è nuovo rispetto alle generazioni precedenti e porta a
rivedere il modo di progettare, condurre e valutare i corsi formativi, alla luce
anche di una diversa centralità che il discente assume.
A questo scopo devono essere progettati ambienti di apprendimento virtuale
idonei a garantire, oltre che la fruizione di materiali, anche l'interazione e la
collaborazione tra i corsisti, le due strategie educative attualmente maggiormente
utilizzate. Gli studenti diventano i veri protagonisti del percorso formativo e
alternano la loro attività tra momenti di riflessione individuale e momenti di
apprendimento collaborativo. Diventa essenziale in modo diverso e più
preponderante rispetto alla formazione tradizionale il supporto di uno staff di
tutor, che di volta in volta assume durante il corso il ruolo di assistente,
moderatore, organizzatore di attività e di lavori di gruppo ecc.
12
Oggi le tecnologie sono abbastanza mature da permettere il passaggio a
questi sistemi di ultima generazione, come testimonia la Mediateca-Elis e i suoi
corsi.
1.2.1
Formazione in rete
La Online Education, per usare la terminologia della Harasim (“Online
Education: A new Domain”, 1989) rappresenta un nuovo dominio che riprende
attributi propri dell'apprendimento in presenza e della Distance Education, ma
che presenta caratteristiche proprie. Gli elementi che caratterizzano questo
nuovo dominio sono l'indipendenza dal tempo (asincronicità) e dallo spazio, e
la possibilità di comunicare in maniera interattiva "molti a molti". Risulta
evidente che i modelli teorici e pratici propri della formazione in presenza non
sono adeguati per sostenere l'Online Education. Nella più abituale formazione
“faccia a faccia” è possibile comunicare molti a molti, ma l'interazione rimane
sottoposta ai vincoli spaziali e temporali. Nella Distance Education, sebbene si
perda la dipendenza spazio-temporale, diminuiscono i canali comunicativi e gli
unici modelli concessi sono quelli "uno a molti" o "uno a uno" (ancora Harasim,
1989).
Una delle peculiarità della formazione in rete, rispetto alla più tradizionale
formazione a distanza e a quella in presenza, consiste nella maggior attenzione
che si pone all'interazione tra i partecipanti al processo formativo (studenti, tutor,
docenti). L'elemento chiave dello sviluppo concettuale di questo modello è,
come già accennato, l'idea di comunicazione e apprendimento come processi
sociali. Dal punto di vista tecnologico esistono, ormai, molte piattaforme
interattive adatte a promuovere l'apprendimento come processo sociale e l'attività
didattica più in generale. Molte sono nate in ambito aziendale con precise
funzioni produttive e di mercato, con prezzi proibitivi e con finalità diverse
rispetto al mondo pedagogico e a quello didattico.
La formazione in rete è organizzata in una o più classi virtuali e prevede
l'alternarsi di momenti di studio individuale a momenti di interazione a distanza.
13
Di solito anche la formazione in rete più "pura" non è esente dall'organizzare
incontri in presenza: quasi obbligatori, per la buona riuscita del corso, si possono
considerare un incontro all'inizio e uno alla fine del percorso formativo.
L'incontro iniziale è finalizzato a favorire la socializzazione tra i corsisti e in
alcuni casi a determinare parte di un contratto formativo, cioè di un patto in cui
con i corsisti ci si accorda su alcune parti del corso. L'incontro finale ha
l'intenzione di essere un momento di sintesi di quanto è stato fatto, un momento
per raccogliere le impressioni e le riflessioni critiche utili per i corsi successivi,
o, come nel caso della Mediateca, è l’occasione per svolgere gli esami in
presenza. Inoltre, proprio in questa ottica, è stato progettato il sito della
Mediateca, dove, ad esempio, nella classe virtuale sono state inserite le foto
degli alunni per favorire la socializzazione, ed è stata implementata una chat,
molto semplice da utilizzare, che favorisce lo scambio di pareri sui corsi, ma
anche semplici battute fra “compagni di classe”.
In sintonia con i modi di formazione dell'adulto, dove la condivisione del
vissuto personale può giocare un ruolo molto forte, i partecipanti sono
organizzati in comunità di apprendimento, per permettere la riduzione
dell'isolamento del singolo e aiutare a valorizzare le conoscenze pregresse a
favore della crescita collettiva del gruppo.
La comunicazione all'interno dei gruppi virtuali può essere gestita attraverso
sistemi di computer conference (Berge, 1995), che tra le loro potenzialità
offrono la possibilità di inviare e ricevere messaggi elettronici, di condividere
file, che talvolta possono essere organizzati per aree tematiche. Anche questo
aspetto è presente nella Mediateca, dove è evidente come gli utenti gradiscano
sia la possibilità di condividere il materiale on-line, scambiando file su un’area
comune, che i forum tematici dove leggere o lasciare consigli e osservazioni sui
corsi.
Quando è possibile questa tecnologia è integrata con la videoconferenza
(Kaye, 1992) attraverso cui si possono avere anche degli incontri formativi con
esperti esterni o occasioni di confronto col tutor. Questo avviene anche nella
Mediateca anche se con canale a senso unico per quanto riguarda il flusso audio
14
e video: il tutor è trasmesso in diretta a tutti gli studenti, i quali possono
comunicare con lui, e fra loro, solo attraverso la chat testuale.
1.2.2 Formazione mista
Per formazione mista si intende un tipo di formazione a distanza dove si
alternano i processi di insegnamento e di apprendimento tra momenti di lezione
in presenza e momenti di fruizione a distanza. Nasce dal fatto che non sempre è
possibile attuare strategie pure di formazione in rete: alcuni contenuti potrebbero
mal adattarsi alla modalità di comunicazione tipica della Computer Mediated
Communications (CMC), basata prevalentemente su testo scritto, mentre
sarebbero più facilmente e meglio veicolabili se trasmessi alternando momenti
formativi in presenza e a distanza.
Questi due momenti sono complementari tra loro: l’attività in presenza, fatta
di lezioni, esercitazioni e seminari, dovrebbero gettare le basi per le successive
attività a distanza.
1.3 Alcune soluzioni esistenti
Numerose sono le proposte di servizi, sia gratuiti che a pagamento, per
materiale didattico on-line per tutti i settori ed a tutti i livelli. Spesso i prodotti
commerciali non danno alcuna indicazione sul procedimento di produzione e di
archiviazione del materiale didattico, e non offrono nessuna possibilità di
interfacciare l'archivio con altri software o motori di ricerca. Anche se questo
approccio può sembrare naturale e scontato per aziende che si mantengono
vendendo corsi on-line, c'è da sottolineare che la carenza di standard aperti in
questo settore ha danneggiato tutte le parti coinvolte, sia quelle a scopo di lucro
che quelle non profit. Soluzioni proprietarie limitano il riutilizzo del materiale
archiviato, e riducono moltissimo l'efficacia del retrieving. La proprietà
15
intellettuale, e quindi l'eventuale profitto, deve essere nei contenuti e non nello
schema di catalogazione delle risorse disponibili.
In realtà solo di recente si è seriamente affrontato il problema di definire
standard di riferimento per la didattica a distanza. Il problema è molto
complesso data la grande varietà di materiale didattico e le diverse tecnologie
utilizzate, spesso non standard. Le tecnologie utilizzate, infatti, sono molto
diverse, da un semplice utilizzo di pagine HTML ad un avanzato uso di tecniche
multimediali e di realtà virtuale.
È
difficile
classificare
in
diverse
categorie
le
varie
soluzioni
commercialmente disponibili. Spesso si tratta di prodotti o servizi che utilizzano
approcci originali con tool che realizzano diverse funzionalità efficaci in alcuni
contesti. Si è scelto di mostrare molto brevemente alcune soluzioni per la
didattica a distanza proposte da quattro grandi aziende al fine di comprendere la
situazione attuale sul mercato e le prospettive future. Alla fine del capitolo
verranno elencate una selezione delle risorse di e-learning trovate in rete,
verificate al Marzo 2003.
1.3.1 IBM
IBM offre varie soluzioni per la didattica raggruppate con il nome: IBM
Learning Services (www-3.ibm.com/services/learning). In particolare per la
didattica a distanza c'è una serie di soluzioni nell’area Training Center.
Per l’e-learning ci sono tre proposte:
1. accesso generale: una soluzione basata su Internet, con punti di
ingresso e videate cui gli studenti possono accedere ogni volta che
ne hanno bisogno. La soluzione, basata su IBM LearninSpace 5,
include attività amministrative quali l'iscrizione degli studenti in
classi,
un
addestramento
didattico
basato
su
computer
(comprendente la multimedialità e l'addestramento via rete) e un
profilo delle conoscenze acquisite dallo studente;
16
2. collaborativo: l'accesso controllato prevede un sistema di
addestramento personalizzato su ciascuno studente che segue un
suo curriculum di formazione prestabilito. Le attività di gestione
ed amministrazione sono automatizzate, lasciando all'istruttore
l'incarico di fornire supporto ad alto valore aggiunto. Il prodotto
che realizza questa soluzione distributed learning con accesso
controllato è il Distributed Learning System;
3. portale della formazione: uno strumento che permette agli
utenti di attingere in maniera semplice alla formazione erogata
sotto forma di corsi on-line, ai documenti informativi necessari al
proprio lavoro, ai consigli/conoscenze degli esperti, agli strumenti
di comunicazione e che permette all'azienda di gestire le risorse e
le informazioni rese disponibili, verificando l'effettivo utilizzo ed
efficacia dei corsi predisposti.
Le soluzioni IBM valutate non prevedono un utilizzo di architetture di
metadata standard per gli oggetti didattici. Non sono fornite neanche
informazioni sui formati interni del materiale didattico.
1.3.2 Microsoft
Microsoft offre ampio spazio sulle proprie pagine web all'educazione ed
all'insegnamento a distanza ed offre numerosi prodotti per la didattica.
Il Microsoft Classroom Teacher Network (MCTN) e Microsoft TechNet for
Education sono rivolti, per lo più, all'insegnamento dell'informatica, in
particolare dei prodotti Microsoft. Appare grossa l'attenzione per la scuola
inferiore (K-12) e le superiori, ed in molti meeting e conferenze organizzate, si
discute dei problemi collegati. Molte pagine e diversi siti, ma in realtà non c'è
una grande quantità di materiale utile on line né per gli studenti né per gli
insegnanti.
17
Piuttosto
separato
dagli
altri
servizi,
c'è
Microsoft
e-Learn
(www.microsoft.com/elearn), decisamente più focalizzato sulle tecnologie
disponibili per la didattica a distanza. In questo settore Microsoft ha rilasciato
LRN 3.0 (Learning Resource iNterchange, pronunciato: learn), una specifica di
strutture dati per applicazioni per la didattica. LRN fa riferimento a IMS Content
Packaging Specification lo standard per i metadata, analizzato nel quarto
capitolo del volume, sviluppato da un consorzio di imprese per lo più americane.
1.3.3 CISCO
Cisco offre diverse soluzione molto interessanti per l’e-learning. Un
importante corso, il Networking Academy (www.netacad.it), è basato su 280 ore
di lezioni on-line costantemente aggiornate, erogate nell’arco di sei mesi.
Per quanto riguarda i metadata, Cisco ha sviluppato un proprio standard
proprietario chiamato RIO (Reusable Information Object). All’interno di questa
strategia sono coinvolti:
•
una metodologia di progettazione formativa
•
la struttura del contenuto
•
i metadata
•
il formato dei dati
Con questa soluzione attualmente vengono erogati vari tipi di corso con
diversi supporti, in questo caso è infatti possibile accedere ai formati interni
del materiale didattico.
18
1.3.4 TILS
Telecom Italia Learning Services è nata nel settembre del 2002 dall’unione
di alcune società del gruppo Telecom, tutte con esperienza nell’ambito della
formazione, in un'unica realtà operativa. Le competenze portate da queste
società posano ora su un’unica piattaforma, per fornire la copertura dei processi
di base dell'e-learning e per migliorare il collegamento fra il processo formativo
e le scelte che riguardano la gestione del personale.
Attraverso soluzioni integrate "end to end" vengono offerti oltre 800 corsi,
focalizzati in particolare nelle aree dell'Information & Communication
Technology e del Business Management.
La piattaforma su cui è basato il sistema -il Learning Management Systemintegra gli strumenti per gestire sia l’offerta formativa tradizionale che quella su
web. Il LMS gestisce quindi l’aula tradizionale come quella classe virtuale;
amministra i ruoli professionali ed i cammini formativi; consente di controllare
le strutture logistiche ed i passaggi organizzativi, abilita alla gestione del
catalogo e dei contenuti dei corsi, è in grado di monitorare le docenze e lo skill
management. L’insieme dei servizi LMS è offerto ad ogni tipo di utenza, dal
singolo alla grande impresa, garantendo facilità d’utilizzo senza perdere la
compatibilità con alcuni requisiti degli standard internazionali (Aicc, Scorm,
IMS) come gestibilità, integrabilità e usabilità.
Attraverso questa piattaforma vengono offerti servizi comuni a tutti i corsi:
•
Customer Relationship Management, per i legami fra aziende e
clienti;
•
Live collaboration, per la comunicazione fra gli utenti e con
esperti;
•
Business Intelligence, per una creazione automatica e dinamica di
report dell’utilizzo degli strumenti;
•
Servizi di Community, strumenti per migliorare la comunicazione
fra i corsisti: forum, news, newsgroup, faq;
19
•
Delivery sincrono, l’offerta di lezioni in real-time attraverso
Internet;
•
Tutorship, incontri uno-a-uno fra studenti ed esperti per risolvere
richieste di assistenza;
•
Knowledge Management, uno strumento di informazione e
aggiornamento
costante
sui
temi
di
interesse
selezionati
dall’utente: il KM identifica le informazioni più interessanti ed
affidabili e le invia attraverso posta elettronica o cartacea,
individualmente e in automatico.
Scopo del TILS è quindi garantire soluzioni complete e integrate, dalla
piattaforma di e-learning al billing, fino a una rete dedicata.
1.3.5 Altre offerte
Una selezione delle risorse in rete che offrono strumenti e servizi per l’elearning:
NewMindsets Inc. (www.newmindsets.com)
Click2learn (www.click2learn.com)
DigitalThink (www.digitalthink.com)
Docent (www.docent.com)
Edulife (edulife.centrorisorse.it/)
KnowledgeNet (www.knowledgenet.com)
Knowledge Planet (www.knowledgeplanet.com)
Learn2.com (www.tutorials.com)
NETg (www.netg.com)
Ninth House Network (www.ninthhouse.com)
Saba (www.saba.com)
SkillSoft (www.skillsoft.com)
20
2. La Mediateca-ELIS
2.1 Cosa è la Mediateca-ELIS?
Il sistema Mediateca-ELIS nasce dalla volontà di applicare le nuove
tecnologie alla lezioni filmate ogni giorno nella Scuola di Formazione Superiore
del Centro ELIS. Oltre alla ripresa vengono raccolte le slide delle presentazioni
elettroniche, i lucidi proiettati e gli appunti che il professore scrive sulla lavagna.
Il materiale viene poi codificato digitalmente con RealVideo e combinato in una
pagina SMIL composta da filmato, lucidi (o slide o fotografie della lavagna) e
voce dell’insegnante.
Figura 2-1 Una lezione della Mediateca
21
Con questo sistema di produzione di lezioni, con tempi e costi molto bassi, è
stato possibile organizzare il primo corso a distanza con rilascio di certificazione
IFTS in collaborazione con il Politecnico di Milano. Corso conclusosi con
un’alta percentuale di promossi soprattutto fra le persone più impegnate in altre
attività lavorative, ma fortemente motivate, disposte anche a studiare di notte per
superare i moduli per tutta la durata del corso.
Il sistema di produzione dietro la Mediateca è rappresentato molto bene nei
quattro passi rappresentati in questo diagramma:
Figura 2-2 Fasi di elaborazione: dalla ripresa alla lezione
E’importante sottolineare come le soluzioni tecnologiche della MediatecaELIS permettano di seguire le lezioni in streaming via web anche con un
22
semplice modem a 56 Kbyte: una connessione dial-up è quindi sufficiente per
seguire la lezione senza perdere audio o qualità delle immagini.
Come è stato appena descritto, la prima applicazione è quindi la didattica a
distanza, ma una soluzione interessante e innovativa promossa dall’ELIS è
quella utilizzare le lezioni della Mediateca anche all’interno di corsi “in
presenza”. Attraverso le risorse della Mediateca si può raggiungere facilmente lo
scopo di fornire materiale di introduzione a concetti di base, con una spesa molto
limitata e con un percorso individuale per ogni studente. Una volta che tutti gli
studenti hanno un livello soddisfacente di conoscenza, si arriva allora ad una
lezione reale con una forte interattività con il docente, con molte più possibilità
per chiarire e sviluppare, attraverso esercitazioni e approfondimenti, i concetti
appresi. Il vantaggio delle lezioni codificate in RealVideo con il formato SMIL
rispetto ai libri è l’utilizzo dell’audio e del video e, chiaramente, di essere in
formato elettronico e quindi indicizzabili e strutturabili come se fossero ipertesti.
Fornendo questo materiale, sempre reperibile per lo studente, si risolve il
problema di gruppi di studenti spesso molto disomogenei nella preparazione di
base: si evitano lezioni ripetitive per molti o troppo difficili per altri e si
valorizzano al massimo le lezioni con il docente che possono davvero essere
interattive e più produttive ai fini dell’apprendimento.
Naturalmente il materiale multimediale può tornare utile agli studenti anche
dopo la lezione in presenza con il docente: la modularità e l’indicizzazione delle
lezioni all’interno della Mediateca permettono infatti un facile reperimento delle
parti che si vogliono rivedere per chiarimenti e approfondimenti, con la
possibilità di rivedere il materiale quante volte si desidera secondo le proprie
esigenze e i propri tempi.
Dal punto di vista della distribuzione, nel sistema Mediateca-ELIS è
possibile trovare tutti e tre le possibili tipologie di comunicazione della didattica
a distanza:
23
1. Differita Archivio indicizzato di lezioni consultabili dagli utenti in
qualsiasi momento. Permette all’utente di scegliere di rivedere un
passaggio quante volte desidera ed è possibile consultare anche solo una
parte delle lezione.
2. Diretta monodirezionale Trasmissione audio/video in diretta dell'evento
didattico a tutti gli utenti connessi alla rete. Possibilità di interazione
diretta solo per gli studenti presenti.
3. Diretta bidirezionale Trasmissione dell’evento in diretta con possibilità
di interazione anche da parte degli studenti remoti attraverso una finestra
di chat con il docente.
Questa diverse erogazioni delle lezioni lasciano aperte tutte le possibilità:
sono state fatte lezioni in diretta mono e bidirezionali, così come incontri con il
tutor di un corso per chiarimenti e spiegazioni aggiuntive, ma naturalmente esiste
online un archivio di lezioni catalogate e sempre disponibili per la fruizione da
parte dell’utente.
Principalmente, per l’implementazione dei corsi, la soluzione adottata è stata
la differita basata sull’archivio della Mediateca. Questo sistema permette infatti
di:
riutilizzare all’infinito il lavoro di un professore ripreso durante
una lezione con un forte abbattimento dei costi
affrontare gli attuali limiti tecnologici, come la scarsa diffusione
delle connessioni veloci e quindi l’impossibilità di realizzare
comunicazioni bidirezionali multimediali con gruppi di studenti
connessi in rete
offrire corsi ad utenti su diversi fusi orari, con diverse disponibilità
di tempo, diverse curve di apprendimento
Senza entrare nei dettagli dell’implementazione dal punto di vista
tecnologico, è importante sottolineare anche i vantaggi tecnici portati dalla scelta
della differita. E’possibile infatti distribuire in maniera migliore i filmati, perché
24
diminuisce la probabilità di sovrapposizione di un numero elevato di utenti
collegati nello stesso momento. Inoltre è così possibile far scaricare parte delle
informazioni (in particolare le slide di supporto) per lasciare più banda possibile
allo streaming audio e video.
2.2 Documentazione database esistente
La base di dati della Mediateca, su cui ho basato il mio lavoro, è
implementata su una piattaforma SQL Server della Microsoft ed è stato disegnata
da Michele Crudele e Giuseppe Cinque nel 2000 in varie fasi. Il progetto
definitivo è arrivato alla versione 3.0, con cui è partito il primo corso in Italia a
distanza con certificazione IFTS (Regione Lombardia) nel settembre 2001.
Con l’utilizzo effettivo della base di dati per i primi corsi, sono usciti fuori
piccoli cambiamenti e aggiunte implementate da Crudele e Gianluca Sartori che
hanno portato in pratica alla versione 3.1 documentata in queste pagine.
2.2.1 Dizionario dei dati
In un sistema per la gestione delle basi di dati, il dizionario dei dati è una
tabella globale che contiene la definizione di tutti gli oggetti presenti nel
database. La tabella contiene informazioni sui dati contenuti nel database, tra cui
le informazioni riguardanti i record e i tipi dei campi, gli intervalli di valori
accettabili e le informazioni riguardanti le autorizzazioni per l´accesso ai record.
Il dizionario dei dati è un file di sistema e non un file utente. È anche noto come
file di catalogo o repository.
Il dizionario è’ stato rappresentato con una tabella per ogni entità (il nome è
preceduto da una t) o relazione (il nome è preceduto da una u) con:
25
Versione del database (con A per campi aggiunti, M per quelli
modificati e E per gli eliminati nella versione 3.1 rispetto alle
precedenti)
Nome del campo
Tipo dei dati
Descrizione informale
Regole (NOT NULL, DEFAULT, …)
Esempi
Il dizionario è stato realizzato mettendo in risalto le diverse funzioni del
database, alcune entità sono ripetute in quanto centrali in diversi contesti.
Versione: 3.1 - Nome del Database: Mediateca - Target DBMS: SQL Server
•
Gestione degli eventi della Mediateca
Figura 2-3 Gestione eventi
"tEvent" description: Eventi (chat con il tutor, esami, dirette)
tEvent
Version FieldName Type
3.1A
IDEvent
int()
Description
Rules
example
Identificativo PRIMARY KEY,
univoco
NOT NULL,
AUTO
INCREMENT
3.1A
IDUser
3.1A
Descripti nvarchar Descrizione
on
(128)
dell'evento
StartingD char(19)
ateTime
3.1A
int()
NOT NULL
26
NOT NULL
NOT NULL
Selezioni in
presenza
2002-01-15
20:00 Formato
Standard ISO
3.1A
3.1A
3.1A
EndingDat char(19)
eTime
Location nvarchar
(128)
URL
NOT NULL
Cefriel – via
Fucini 2 Milano
http://mediatec
a.elis.org/icta
d
nvarchar
(250)
"uCourseEvent" description: Eventi collegati al CORSO
uCourseEvent
Version FieldName Type Description
•
Rules
3.1A
IDCourse int() Corso in questione NOT NULL
3.1A
IDEvent
int()
Evento collegato
al Corso
NOT NULL
Contenuti mediali di Mediateca
Figura 2-4 Gestione contenuti Mediateca
27
example
"tResource" description: Una RISORSA coincide con una parte indirizzabile di un
MEDIUM. Esiste almeno una risorsa per ogni MEDIUM che descrive il medium stesso
nella sua integrità. Più risorse possono essere create per un MEDIUM dando la possibilità
di individuare una parte specifica dello stesso. (Es.: Una o più pagine di un documento
PDF oppure uno 'spezzone' di un video)
tResource
Version FieldName
Type
Description
Rules
3.0
IDResource
int()
Identificativo
univoco
PRIMARY
KEY, NOT
NULL,
AUTO
INCREMEN
T
3.0
IDLanguage
int()
Linguaggio
utilizzato dalla
risorsa
NOT NULL
A3.1
IDSource
int()
Eventuale
provenienza della
risorsa. Se presente
deve essere un URI
dell'originale
diverso da "teca"
3.0
IDMedium
int()
Medium al quale la
risorsa fa
riferimento
NOT NULL
3.0
DateCreated
char(10)
Data di creazione
NOT NULL
3.0
DateIssued
char(10)
Data pubblicazione
NOT NULL
char(10)
Data ultima
modifica. Coincide
con DateCreated se
non è stata fatta
nessuna modifica
NOT NULL
3.0
DateModified
3.0
DateTimeValid
char(19)
From
Valido DA
3.0
DateTimeValid
char(19)
To
Valido fino A
M3.1
Title
M3.1
DescriptionAb nvarchar(50
Breve descrizione
stract
0)
A3.1
DurationFrom
char(8)
Indica il secondo
iniziale
A3.1
DurationTo
char(8)
Indica il secondo
finale
A3.1
PageFrom
int()
Pagina iniziale
A3.1
PageTo
int()
Pagina finale
3.0
IsMPP
bit()
Specifica se si
tratta di una
risorsa MPP. Tutto
nvarchar(25
Titolo della risorsa NOT NULL
0)
28
Default
0
example
ciò che non è MPP
viene considerato
come 'Materiale
aggiunto'.
"uResourceRight" description: Relazione che contiene i diritti di proprietà di una
risorsa
uResourceRight
Version FieldName Type Description
3.0
IDResource int()
3.0
IDRight
Rules
Risorsa alla quale vengono
riconosciuti i diritti
int() Diritto riconosciuto
example
NOT NULL
NOT NULL
"tRight" description: Informazioni sui diritti (d'autore o simili)
tRight
Version FieldName
Type
Description
3.0
IDRight
int()
PRIMARY KEY,
Identificativo
NOT NULL, AUTO
univoco
INCREMENT
M3.1
Descrizione
Description nvarchar(250)
del diritto
Rules
NOT NULL
example
Copyright
ELIS,
Copyright
LINFA
"tLanguage" description: Linguaggio utilizzato dalla risorsa
tLanguage
Version FieldName
Type
Description
Rules
example
PRIMARY KEY, NOT
Identificativo
NULL, AUTO
univoco
INCREMENT
3.0
IDLanguage int()
M3.1
Lingua
Description nvarchar(250) utilizzata
NOT NULL
nella risorsa
Inglese
"tMedium" description: Un MEDIUM può essere considerato l'unità informativa della
Mediateca. Consiste in un file su disco che può essere un video, un file musicale, del
testo, un immagine o qualsiasi altro file dati.
29
tMedium
Version FieldName
3.0
E3.1
IDMedium
IDProtocol
Type
Description
Rules
int()
Identificativo
univoco
PRIMARY
KEY, NOT
NULL,
AUTO
INCREMENT
int()
Protocollo
utilizzato per
consultare il
medium. In base al
protocollo si
distingue anche la
locazione fisica
del medium, il cui NOT NULL
file può risiedere
nelle directory del
WEB Server
(protocollo HTTP)
oppure in quella
del Real/Media
Server
Programma
consigliato per la
NOT NULL
visualizzazione del
file
example
3.0
IDViewer
int()
M3.1
FolderName
Cartella nella
nvarchar(250) quale è memorizzato NOT NULL 103
il file
M3.1
FileName
Nome del file
nvarchar(250) contenente il
medium
3.0
FileSize
int()
3.0
FileDuration int()
Durata del file in
secondi
832
M3.1
FileFrameSize nvarchar(20)
Dimensione in
PIXELxPIXEL
1024x768
3.0
FilePages
int()
Numero di pagine
del file
Source
Provenienza del
file. Corrisponde
ad un codice se è
un VHS della
Mediateca ELIS. In
nvarchar(250)
genere può essere
un URL di
riferrimento oppure
una breve
descrizione libera
3.0
NOT NULL video.rm
Dimensione del file
NOT NULL 100
in MByte
30
"tViewer" description: Contiene i programmi utilizzati per visualizzare i MEDIUM. Ad
ogni MEDIUM è associato un programma.
tViewer
Version FieldName
Type
Description
Rules
int()
Identificativo
univoco
PRIMARY KEY,
NOT NULL,
AUTO
INCREMENT
3.0
IDViewer
M3.1
Nome e versione
del programma
utilizzato per
NOT NULL
Description nvarchar(250) vedere il
MEDIUM (in
formato
comprensibile)
example
RealPlayer
8
"tProtocol" description: Lista dei protocolli di comunicazione utilizzati per visionare
un medium. Il protocollo viene utilizzato anche per sapere in che directory ricercare i
medium. Se HTTP nella root del server web, se RTSP o MMS nella root del Real/Media
Server. La tabella è stata rimossa dal progetto originale.
tProtocol
Version FieldName
Type
Description
Rules
example
E3.1
IDProtocol int()
PRIMARY KEY, NOT
Identificativo
NULL, AUTO
univoco
INCREMENT
E3.1
Description nvarchar(256)
Nome del
protocollo
NOT NULL
HTTTP,
RTSP,
MMS
"tEncodingScheme" description: Definisce i tipi possibili di codifica
tEncodingScheme
Version FieldName
Type
3.0
IDEncodingScheme int()
M3.1
Description
Description
Rules
example
PRIMARY
Identificativo KEY, NOT
univoco
NULL, AUTO
INCREMENT
Nome della
nvarchar(250) codifica
utilizzata
31
NOT NULL
MESH2001,
CDD XI
"tSubject" description: Argomento della risorsa, è possibile catalogare rispetto a diversi
schemi
TSubject
Version FieldName
Type
Description
Rules
example
PRIMARY
KEY, NOT
Identificativo
NULL,
univoco
AUTO
INCREMENT
Codifica con
la quale viene NOT NULL
identificato
3.0
IDSubject
3.0
IDEncodingScheme int()
M3.1
Subject
nvarchar(250)
Code
Codice
attribuito
alla risorsa
193.120.1507.
diverso a
NOT NULL oppure
nvarchar(250)
seconda
011.137
dell'Encoding
Scheme
associato
M3.1
int()
Introduzione
Descrizione
NOT NULL
a UNIX
dell'argomento
"uResourceSubject" description: Relazione tra Risorsa e gli argomenti associati
uResourceSubject
Version FieldName Type Description
Rules
3.0
IDResource int()
Risorsa in
oggetto
NOT NULL
3.0
IDSubject int()
Oggetto della
risorsa
NOT NULL
32
example
Figura 2-5 Unità, moduli, corsi
"tUnit" description: Una UNIT è un insieme ordinato di risorse. Ogni UNIT raggruppa
una o più risorse coerenti allo scopo che vuole raggiungere (Può essere equiparata ad una
lezione in un corso)
tUnit
Version FieldName
Type
Description
Rules
3.0
IDUnit
int()
PRIMARY
KEY, NOT
Identificativo
NULL,
univoco
AUTO
INCREMENT
3.0
Title
nvarchar(128)
Titolo della
Unit
M3.1
Breve
descrizione
DescriptionAbstract nvarchar(500)
del contenuto
della Unit
33
NOT NULL
example
"uUnitResource" description: Relazione tra Unit e Resource. Contiene il numero che
identifica la posizione della risorsa all'interno dell'insieme ordinato della Unit alla quale
appartiene
uUnitResource
Version FieldName
Type Description
3.0
IDUnit
int() Unit in oggetto
3.0
IDResource
int() Risorsa presente nella Unit
Numero di sequenza della
3.0
SequenceNumber int() risorsa oppure 0 (Zero) nel
caso non abbia sequenza
Rules example
NOT
NULL
NOT
NULL
NOT
NULL
"tModule" description: Un modulo è un raccoglitore di Unit. Ogni modulo tratterà un
argomento sviluppato un più Unit(Lezioni) da seguire secondo un ordine preciso
tModule
Version FieldName
3.0
IDModule
Type
int()
3.0
Title
nvarchar(128)
3.0
Descriptio
nvarchar(512)
nAbstract
Description
Rules
example
Identificativo
univoco
PRIMARY
KEY, NOT
NULL,
AUTO
INCREMEN
T
Titolo del Modulo
Metodologia
di
NOT NULL
autoaggiorn
amento
Breve descrizione
degli obiettivi del
Modulo
NOT NULL
"uModuleUnit" description: Relazione tra Modulo e Unit. Contiene il numero di
sequenza indicante l'ordine con iul quale dovranno essere seguite le unit (lezioni)
uModuleUnit
Version FieldName
Type Description
Rules example
3.0
int() Modulo in questione
NOT
NULL
IDModule
34
NOT
NULL
3.0
IDUnit
int() Unit presente nel modulo
3.0
Numero di sequenza della Unit
SequenceNumber int() oppure 0 (Zero) nel caso non
abbia sequenza
NOT
NULL
"tCourse" description: Un corso è formato da un insieme di moduli da seguire in
successione
tCourse
Version FieldName
Type
Description
Rules
example
3.0
IDCourse
int()
PRIMARY
KEY, NOT
Identificativo
NULL,
univoco
AUTO
INCREMENT
3.0
Title
nvarchar(128)
Titolo del
Corso
M3.1
Breve
DescriptionAbstract nvarchar(500) descrizione
del corso
NOT NULL
3.0
DateTimeValidFrom
char(19)
Valido DA
NOT NULL
3.0
DateTimeValidTo
char(19)
Valido fino A NOT NULL
NOT NULL TLC@Home
"uCourseModule" description: Relazione tra Corso e Modulo.
uCourseModule
Version FieldName
Type
Description
Rules
3.0
IDCourse
int()
Corso in
questione
NOT NULL
A3.1
SequenceNumber
int()
Numero di
sequenza
DEFAULT 0
3.0
IDModule
int()
Modulo del
corso
NOT NULL
3.0
DateTimeValidFrom char(19)
Valido DA
NOT NULL
3.0
DateTimeValidTo
Valido fino A
NOT NULL
char(19)
example
"tCognitiveGoal" description: Lista delle competenze fornite da Unit, Moduli e Corsi
tCognitiveGoal
Version FieldName
3.0
Type
Description
IDCognitiveGoal int()
Rules
Identificativo PRIMARY KEY,
35
example
univoco
M3.1
Description
NOT NULL,
AUTO
INCREMENT
Descrizione
delle
NOT NULL
nvarchar(250)
competenze da
ottenere
"uUnitCognitiveGoal" description: Obiettivi che si propone la UNIT
uUnitCognitiveGoal
Version FieldName
Type Description
Rules
3.0
IDUnit
int() Unit in questione
NOT
NULL
3.0
IDCognitiveGoal int()
Obiettivi che si propone di
fornire la UNIT
example
NOT
NULL
"uModuleCognitiveGoal" description: Obiettivi che si propone il MODULO
uModuleCognitiveGoal
Version FieldName
Type Description
Rules
3.0
IDModule
int() Modulo in questione
NOT
NULL
3.0
IDCognitiveGoal int()
Obiettivi che si propone di
fornire il modulo
example
NOT
NULL
"uCourseCognitiveGoal" description: Obiettivi che si propone il CORSO
uCourseCognitiveGoal
Version FieldName
Type Description
Rules
int() Corso in questione
NOT
NULL
3.0
IDCourse
3.0
IDCognitiveGoal int()
Obiettivi che si propone di
fornire il CORSO
36
NOT
NULL
example
Figura 2-6 Entità coinvolte
"tEntity" description: Entità
TEntity
Version FieldName
Type
Description
int()
PRIMARY KEY,
Identificativo NOT NULL,
univoco
AUTO
INCREMENT
3.0
IDEntity
M3.1
Description nvarchar(250)
Descrizione
dell'Entity
Rules
NOT NULL
example
Luigi
Ciorciolini
- RAI
"tEntityResponsibility" description: Responsabilità dell'Entità sul Corso, Modulo o
Unità. Al momento sono solo tre
tEntityResponsibility
Version FieldName
Type
3.0
IDEntityRespon
int()
sibility
M3.1
Description
Description
Rules
example
Identificativo PRIMARY KEY,
univoco
NOT NULL
Responsabilità
nvarchar
attribuita
NOT NULL
(250)
all'Entity
37
Publisher,
Creator,
Contributor
"uUnitEntityResponsibility" description: Responsabilità sull’Unità
uUnitEntityResponsibility
Version FieldName
Type Description
3.0
IDUnit
int()
3.0
IDEntity
int() Entità responsabile
3.0
Tipo di responsabilità
IDEntityResponsibility int() dell'Entity sulla unit
in questione
Unit sulla quale grava
la responsabilità
Rules example
NOT
NULL
NOT
NULL
NOT
NULL
"uCourseEntityResponsibility" description: Responsabilità sul Corso
uCourseEntityResponsibility
Version FieldName
Type Description
3.0
IDCourse
int()
3.0
IDEntity
int() Entità responsabile
3.0
Tipo di responsabilità
IDEntityResponsibility int() dell'Entity sul corso
in questione
Corso sul quale grava
la responsabilità
Rules example
NOT
NULL
NOT
NULL
NOT
NULL
"uResourceEntityResponsibility" description: Responsabilità sulla risorsa
uResourceEntityResponsibility
Version FieldName
Type Description
Rules example
Risorsa sulla quale
NOT
grava la responsabilità NULL
3.0
IDResource
int()
3.0
IDEntity
int() Entità responsabile
3.0
Tipo di responsabilità
IDEntityResponsibility int() dell'Entity sulla
risorsa in oggetto
NOT
NULL
NOT
NULL
"uModuleEntityResponsibility" description: Responsabilità sul Modulo
uModuleEntityResponsibility
Version FieldName
Type Description
3.0
int()
IDModule
38
Modulo sul quale grava
la responsabilità
Rules example
NOT
NULL
3.0
IDEntity
3.0
Tipo di responsabilità
IDEntityResponsibility int() dell'Entity sul Modulo
in oggetto
•
int() Entità responsabile
NOT
NULL
NOT
NULL
Organizzazione dei questionari rispetto a Moduli e Unità
Figura 2-7 Gestione dei questionari di valutazione
"tQuestionnaire" description: Un questionario. Può essere legato ad un modulo oppure
ad una Unit. Se IDModule è 0 (Zero) viene considerato valido IDUnit e il questionario
sarà relativo ad essa.
tQuestionnaire
Version FieldName
3.0
Type
IDQuestionnaire int()
39
Description
Rules
Identificatore
univoco
PRIMARY
KEY, NOT
exam
ple
NULL,
AUTO
INCREMENT
3.0
IDModule
int()
Modulo al quale il
questionario si
riferisce
NOT NULL
NOT NULL
3.0
IDUnit
int()
Unit quale il
questionario si
riferisce. Viene
considerata solo se
IDModule = 0 (Zero)
3.0
Title
nvarchar(100)
Titolo del
questionario
NOT NULL
3.0
ProductionDate char(10)
Data di produzione
NOT NULL
Mode
DEFAULT
Modalità di
0, VALID:
visualizzazione dei
0, 1 ,2
questionari/risultati
,3
M3.1
int()
"tQuestion" description: Domanda di un questionario
tQuestion
Version FieldName
3.0
3.0
Type
IDQuestion int()
Description nvarchar(250)
Description
Rules
example
PRIMARY KEY,
Identificatore NOT NULL,
univoco
AUTO
INCREMENT
testo della
domanda
NOT NULL
Di che
colore è il
cavallo
bianco di
Napoleone?
"tAnswer" description: Risposta ad una domanda.
tAnswer
Version FieldName
Type
Description
Rules
int()
Identificatore
univoco
PRIMARY KEY,
NOT NULL,
AUTO
INCREMENT
3.0
IDAnswer
3.0
IDQuestion int()
Domanda alla quale
NOT NULL
la risposta si
riferisce
3.0
Description nvarchar(250)
Testo della
risposta
NOT NULL
M3.1
Score
Peso della
DEFAULT 0
real
40
example
risposta. 0 se è
una risposta
sbagliata. Il
totale dei pesi
delle risposte
giuste deve essere
1
"uUserQuestionnaire" description: L'utente ha spedito il questionario. Qui vengono
memorizzate le date ed il punteggio ottenuto
uUserQuestionnaire
Version FieldName
Type
Description
3.0
IDUser
int()
Utente che ha compilato il NOT
questionario
NULL
3.0
IDQuestionnaire int()
3.0
StartingDateTime char(19) Data e Ora d'inizio
NOT
NULL
3.0
EndingDateTime
char(19) Data e Ora di consegna
NOT
NULL
3.0
Score
int()
3.0
MaxPossibleScore int()
Rules example
Questionario compilato
dall'utente
NOT
NULL
Punteggio raggiunto dallo
studente
NOT
NULL
Punteggio massimo
raggiungibile nel
questionario
NOT
NULL
"uQuestionnaireQuestion" description: Relazione tra questionario e le domande che
contiene
uQuestionnaireQuestion
Version FieldName
Type Description
3.0
Questionario in
IDQuestionnaire int()
questione
3.0
IDQuestion
int()
Domanda del
questionario
Rules
example
NOT
NULL
NOT
NULL
"uQuestionnaireEntity" description: Autori del questionario
uQuestionnaireEntity
Version FieldName
3.0
Type Description
IDQuestionnaire int() Il questionario
41
Rules example
NOT
NULL
3.0
IDEntity
Autore del questionario.
Entity Responsibility non è
NOT
int() utilizzata perché non ci sono
NULL
responsabilità per un
questionario ma solo l'autore.
"uUserQuestionnaireQuestionAnswer" description: L'utente risponde ad una
domanda di un questionario.
uUserQuestionnaireQuestionAnswer
Version FieldName
Type
Description
Rules
Utente in
questione
NOT
NULL
IDQuestionnaire int()
Questionario
NOT
NULL
3.0
IDQuestion
int()
Domanda
NOT
NULL
3.0
IDAnswer
int()
Risposta
NOT
NULL
3.0
StartingDateTime char(19)
Data e ora di
inizio domanda
NOT
NULL
3.0
EndingDateTime
Data e ora di fine NOT
domanda
NULL
3.0
IDUser
3.0
int()
char(19)
42
example
•
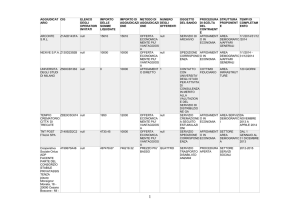
Gestione degli utenti della Mediateca
Figura 2-8 Gestione utenti
"tUser" description: Utente mediateca. Può ricoprire ruoli diversi all'interno di un corso
e possiede uno stato che ne indica, se studente, la valutazione per ogni modulo svolto e lo
stato di avanzamento nella Unit che sta seguendo.
tUser
Version FieldName Type Description
3.0
IDUser
Rules
example
Identificativo univoco
PRIMARY KEY,
int() corrispondente all'ID di un
NOT NULL
utente WAS
"tRole" description: Ruolo dell'utente all’interno di Mediateca
tRole
Version FieldName
Type
Description
3.0
int()
Identificatore PRIMARY KEY,
univoco
NOT NULL,
IDRole
43
Rules
example
AUTO
INCREMENT
3.0
Description nvarchar(50)
Ruolo in forma
NOT NULL
leggibile
Student,
Teacher,
Tutor,
Technician,
Coordinator
"tAssessment" description: Valutazione dell'utente per il relativo modulo.
tAssessment
Version FieldName
Type
Description
Rules
example
PRIMARY KEY,
Identificatore NOT NULL,
univoco
AUTO
INCREMENT
3.0
IDAssessment int()
3.0
Descrizione
della
Description nvarchar(250)
competenza
acquisita
NOT NULL
Competenza,
oppure
vuoto
"tCompletionState" description: Stato di avanzamento all'interno della Unit.
tCompletionState
Version FieldName
3.0
3.0
Type
Description
Rules
example
PRIMARY KEY,
Identificatore NOT NULL,
univoco
AUTO
INCREMENT
IDCompletionState int()
Stato di
completamento
NOT NULL
nvarchar(50)
in forma
leggibile
Description
"tLessonMode" description: modalità di fruizione della lezione.
tLessonMode
Version FieldName
Type
Description
Rules
example
PRIMARY KEY, NOT
Identificatore
NULL, AUTO
univoco
INCREMENT
3.0
IDLessonMode int()
3.0
Description nvarchar(50) Modalità di
44
NOT NULL
In aula,
A
distanza
fruizione in
formato
leggibile
"tQualityControl" description: Memorizza i dati sul controllo di qualità Controllo di
qualità associato alla Unit.
tQualityControl
Versi
FieldName
on
Type
Description
Rules
PRIMARY KEY,
NOT NULL,
AUTO
INCREMENT
3.0
IDQualityControl
int()
Identificatore
univoco
3.0
IDUser
int()
Utente in questione NOT NULL
3.0
IDUnit
int()
Unit in questione
NOT NULL
Modalità di
fruizione della
lezione
NOT NULL
3.0
IDLessonMode
int()
M3.1
Date
char(10
Data compilazione
)
NOT NULL
M3.1
Time
char(8) Ora compilazione
NOT NULL
PreviousKnowledge int()
Valore da 1(min) a
5(max) indicativo
NOT NULL
della precedente
conoscenza
dell'argomento
Comprehension
int()
Valore da 1(min) a
5(max) indicante il
NOT NULL
livello di
comprensione della
lezione seguita
TeacherEffectiven
int()
ess
Valore da 1(min) a
5(max) indicante il
NOT NULL
livello di
chiarezza del
docente
DocumentsEffectiv
int()
eness
Valore da 1(min) a
5(max) indicante il
NOT NULL
livello di
chiarezza dei
documenti proposti
3.0
Tiredness
int()
Valore da 1(min) a
5(max) indicante il
livello di
NOT NULL
stanchezza
raggiunto dopo aver
seguito la lezione
3.0
TechnicalProblems int()
Valore da 1(min) a
NOT NULL
5(max) indicante la
3.0
3.0
3.0
3.0
45
example
qualità della
realizzazione
tecnica
E3.0
TimeSpent
Tempo impiegato per
completare la
NOT NULL
char(8)
lezione (eliminato
nella 3.1)
3.0
PersonalComment
Spazio per commenti
nvarcha
NOT NULL
personali sulla
r(250)
lezione seguita
"uUserRoleCourse" description: Relazione che associa un ruolo ad un utente per un
corso
uUserRoleCourse
Version FieldName Type Description
Rules
3.0
IDUser
int() Utente in questione
NOT NULL
3.0
IDRole
int() Ruolo assunto dall'utente
NOT NULL
3.0
IDCourse int()
Corso per il quale l'utente
ricopre il ruolo
example
NOT NULL
"uUserAssessmentModule" description: Relazione che associa un utente alla sua
valutazione in un modulo che ha completato
uUserAssessmentModule
Version FieldName Type
Description
Rules
3.0
IDUser
Utente in questione
NOT NULL
3.0
Assessment int()
Valutazione dell'utente
NOT NULL
3.0
IDModule
int()
Modulo per il quale è
stato valutato
NOT NULL
M3.1
Date
char(10) Data registrazione stato NOT NULL
M3.1
Time
char(8) Ora registrazione stato
int()
example
NOT NULL
"uUserUnitCompletionState" description: relazione che associa un utente allo stato di
completamento di una Unit.
uUserUnitCompletionState
Version FieldName
Type
Description
Rules
3.0
Utente in questione
NOT
NULL
IDUser
int()
46
example
3.0
IDUnit
int()
Unit in questione
NOT
NULL
NOT
NULL
3.0
IDCompletionState int()
Livello di
completezza
raggiunto
dall'utente
M3.1
Date
char(10)
Data registrazione
stato
NOT
NULL
M3.1
Time
char(8)
Ora registrazione
stato
NOT
NULL
2.2.2 Regole aziendali
Esprimono delle vere e proprie regole per il dominio applicativo che stiamo
considerando. Attraverso delle asserzioni, affermazioni che devono essere
sempre verificate nella nostra base di dati, possiamo descrivere vincoli sui dati
dell’applicazione. Questo è fondamentale soprattutto nei casi di vincoli non
esprimibili direttamente con costrutti del modello Entità-Relazione.
Per motivi di chiarezza e per favorire l’implementazione, tali affermazioni
devono essere “atomiche”, non decomponibili quindi in altre frasi e altre
asserzioni. Inoltre, proprio perché usate per documentare uno schema E-R, le
asserzioni devono essere in forma dichiarativa e non in notazioni del tipo “ifthen-else” con delle condizioni.
Una struttura adatta per le regole di integrità (dalla cardinalità di relazioni
alle regole per gli stipendi dei dipendenti) sotto forma di asserzioni può essere:
< concetto > deve / non deve < espressione su concetti >
Mentre per le regole che esprimono derivazioni (inferenza o calcolo con
elementi dello schema) una struttura può essere:
< concetto > si ottiene < operazione su concetti >
Dove i concetti possono comparire nello schema E-R oppure essere
derivabili da essi. Una volta definiti possono essere “tradotti” a livello
implementativo sul database, attraverso trigger o stored procedure.
47
Per documentare queste regole si può far ricorso ad una tabella, nella quale
vengono elencate le varie regole, specificando di volta in volta la loro tipologia.
E’ importante rappresentare tutte le regole che descrivono vincoli non espressi
dallo schema, ma a volte risulta anche utile rappresentare regole che
documentano vincoli già espressi nello schema.
Nel database della Mediateca non sono presenti regole aziendali, ma
potrebbero essere introdotte con delle stored procedure per ottimizzare la fase di
creazione dei corsi da parte dei tutor o di inserimento delle risorse da parte
dell’operatore.
2.2.3 Viste
Una vista e' una rappresentazione logica di una tabella o d’una combinazione
di più di esse.
La vista non contiene fisicamente dei dati, ma li riceve dalle tabelle su cui e'
basata. Quindi non occupa spazio su disco come una tabella, ma solo le poche
righe necessarie per la definizione della query che la costituisce (ad esempio una
select).
Una volta creata la vista può essere utilizzata esattamente come una tabella
“reale”, interrogandola con query e, seguendo alcune restrizioni, e' possibile
anche modificare o inserire dei record. Questi ultimi, sono letti dalle tabelle sulle
quali e' stata definita, quindi si può affermare che una vista e' dinamica: se
cambiano i dati sulle tabelle questa e' aggiornata immediatamente.
Ci sono quindi molti vantaggi con l’utilizzo delle viste per lavorare con i
database:
• Forniscono un livello aggiuntivo di sicurezza, permettendo di
restringere l'accesso ad alcune colonne o record della tabella.
• Riducono la complessità di una query.
48
• Rendono
possibile eseguire interrogazioni che altrimenti
sarebbe impossibile effettuare con un'unica istruzione.
• Garantiscono l'indipendenza logica dei dati.
• Permettono di visualizzare i dati in modo differente da come
sono memorizzati.
Alcune viste sono presenti nella Mediateca:
vQualityControl
:mostra
informazioni
partendo dalle lezioni giudicate dagli utenti
SELECT
tQualityControl.IDUser,
tQualityControl.IDUnit,
tCourse.Title AS Course,
tUnit.Title,
tQualityControl.Date,
tQualityControl.PreviousKnowledge,
tQualityControl.Comprehension,
tQualityControl.TeacherEffectiveness,
tQualityControl.DocumentsEffectiveness,
tQualityControl.Tiredness,
tQualityControl.TechnicalProblems,
tQualityControl.PersonalComment
FROM
dbo.uModuleUnit
49
significative
INNER JOIN dbo.tQualityControl
INNER JOIN dbo.tUnit
ON dbo.tQualityControl.IDUnit = dbo.tUnit.IDUnit
ON dbo.uModuleUnit.IDUnit = dbo.tUnit.IDUnit
INNER JOIN dbo.tModule
ON dbo.uModuleUnit.IDModule =
dbo.tModule.IDModule
INNER JOIN dbo.uCourseModule
INNER JOIN dbo.tCourse
ON dbo.uCourseModule.IDCourse =
dbo.tCourse.IDCourse
ON dbo.tModule.IDModule =
dbo.uCourseModule.IDModule
vQuestionariICTADsvolti: mostra informazioni significative
per tutti i questionari sostenuti dagli utenti con risultato
ottenuto e massimo possibile
SELECT
uUserRoleCourse.IDUser,
uUserQuestionaire.StartingDateTime,
tQuestionaire.Title AS Questionario,
uUserQuestionaire.Score AS Risultato,
uUserQuestionaire.MaxPossibleScore AS [Massimo
possibile],
50
tModule.Title AS Modulo,
tCourse.Title AS Corso
FROM
dbo.uUserRoleCourse INNER JOIN
dbo.uUserQuestionaire ON
dbo.uUserRoleCourse.IDUser =
dbo.uUserQuestionaire.IDUser
INNER JOIN dbo.tQuestionaire ON
dbo.uUserQuestionaire.IDQuestionaire =
dbo.tQuestionaire.IDQuestionaire INNER JOIN
dbo.tUnit ON
dbo.tQuestionaire.IDUnit = dbo.tUnit.IDUnit INNER
JOIN
dbo.uModuleUnit ON
dbo.tUnit.IDUnit = dbo.uModuleUnit.IDUnit INNER JOIN
dbo.tModule ON
dbo.uModuleUnit.IDModule = dbo.tModule.IDModule
INNER JOIN
dbo.uCourseModule ON
dbo.tModule.IDModule = dbo.uCourseModule.IDModule
INNER JOIN
dbo.tCourse ON
dbo.uCourseModule.IDCourse = dbo.tCourse.IDCourse
WHERE
(dbo.uUserRoleCourse.IDRole = 1) AND
51
(dbo.tCourse.IDCourse = 5) OR
(dbo.tCourse.IDCourse = 6) OR
(dbo.tCourse.IDCourse = 7)
52
2.3 Use Case Model
Gli Use Case sono collezioni di scenari che riguardano l'utilizzo del sistema.
Ogni scenario descrive una sequenza di eventi possibili.
Use case per un tutor di un corso:
Interfaccia Mediateca
Accede al sistema
Crea corsi
Visualizza
questionari
Tutor corso
Aggiorna bacheca,
calendario, ....
Usa chat e forum
v ia w eb
Figura 2-9 Use case del tutor
53
Use case per un utente di un corso:
Interfaccia Mediateca
Segue lezione
+ Utente
+ Compila questionari
+ Giudica le lezioni
+ Naviga archivio lezioni
Accede al sistema
+ Seleziona lezione
Comunica
+ Utente
+ Consulta calendario, bacheca, ...
+ Usa chat e forum via web
+ Visualizza lezione streaming
Utente
Figura 2-10 Use case dell’utente
“Comunica” e “Segue lezione” sono raggruppati in package. Analizzandoli
possiamo mettere in evidenza i principali aspetti:
54
Consulta
calendario,
bacheca, ...
Utente
Usa chat e forum
v ia w eb
Figura 2-11 Use case “comunica” dell’utente
Na v iga a rc hiv io
le zioni
S e le ziona le zione
Ute nte
V is ua lizza le zione
s tre a m ing
Com pila
que s tiona ri
G iudic a le le zioni
Figura 2-12 Use case “segue lezione” dell’utente
55
2.4 Sequence diagram
Attraverso questi diagrammi possiamo modellare la comunicazione tra un
oggetto ed un altro in relazione al trascorrere del tempo.
•
Sequence diagram per un tutor che crea un corso:
"Carrello"
lezioni
motore.asp
Pannello
controllo
corsi
Utente
Database
Mediateca
Login (WAS Username)
Query (Username)
Corsi attivati dal tutor
Mostra corsi attivi per il tutor
Crea/modifica corso (ID, Course)
Query coi parametri
(keyword, ...)
risultato lezioni/moduli
Mostra elenco lezioni e moduli con checkbox
Seleziona lezioni per creare corso
Scrive il nuovo corso sul DB
Figura 2-13 Sequence diagram della creazione lezione
56
L'operazione di
ricerca per la
modifica di un
corso può essere
fatta quante volte
vuole il tutor .
Sequence diagram per un utente che richiede una lezione:
•
motore.asp
Pannello
controllo
corsi
Utente
RealPlayer
Server
Database
Mediateca
Login (WAS Username)
Richiede una lezione (ID, Course)
Mostra pagina download immagini e avvio lezione
Richiede immagini
Download file immagini.exe
Avvia file scaricato
Avvia lezione
Richiede file video
Riferimento web
Lezione in streaming
Figura 2-14 Sequence diagram della richiesta di una lezione
57
2.5 Component diagram
Rappresentiamo i componenti software usati per costruire il sistema.
Component v iew
+ Security Management
+ Server Components
Security Management
+ Browser Utente
Component
+ WAS
+ WAS Database
(from Component view)
Serv er Components
+ ASP Pages
I "component model" nelle pagine
successive mostrano i componenti
software usati per costruire il sistema.
Alcuni sono stati creati con il nuovo
progetto e altri sono eredità delle versioni
precedenti.
+ Firewall
+ SQL Server Database
+ Style.css
+ Web Server
(from Component view)
Figura 2-15 Component diagram struttura Mediateca
Anche qui sono stati utilizzati dei package per mettere in risalto la
separazione fra la gestione della sicurezza e le funzionalità del server.
Analizzando in profondità:
58
2.5.1 Security Management
Internet
Brow ser Utente
«https»
Serv er Components::Firew all
Il firewall blocca
il traffico HTTP
non valido e
lascia passare il
traffico sicuro.
Server Environment
WAS
GetUsername()
CheckAuthentication()
WAS
Database
Figura 2-16 Component view sicurezza
59
Sequence diagram per il login:
E’ necessario distinguere due casi. Nel primo l’utente non ha superato
un’autenticazione Microsoft (ad esempio: ha effettuato il login su un sistema con
windows2000 e il suo account ha i permessi per entrare) e dovrà inserire
username e password per accedere alla Mediateca.
Public WAS
Private WAS
Pagina
MediatecaELIS
Utente
Database
Mediateca
Request
Redirect(public_WAS)
from(Mediateca)
Login page
Auth (username, password)
CheckWAS(username, password)
True
Ticket
Enter
False
Access denied
Figura 2-17 Sequence diagram login utente esterno
60
Nel secondo caso, invece, il processo di autenticazione è completamente
trasparente all’utente di un sistema Windows abilitato all’accesso della
Mediateca.
Public WAS
Private WAS
Pagina
MediatecaELIS
Utente
Database
Mediateca
Request
Redirect(public_WAS)
from(Mediateca, username, password)
redirect(private_WAS)
from(Mediateca, username, password)
CheckWAS(username, password)
True
Ticket
Enter(Ticket)
False
Access denied
Figura 2-18 Sequence diagram login utente interno
61
2.5.2 Server Components
Il diagramma illustra il layout dei componenti del server principale:
«file»
Firewall
Style.css
Web Serv er
ASP Pages
DoRequest() : HTML Response
SQL Serv er Database
ProcessSQLRequest() : Recordset
Figura 2-19 Component view server
62
3 I metadata per oggetti didattici
3.1 Introduzione
L'archivio delle risorse didattiche della Mediateca è dunque un serbatoio di
contenuti ricchissimo per quantità e qualità del materiale a disposizione. Nella
fase di post produzione diventa quindi cruciale la catalogazione delle lezioni:
un’attenta soluzione in questo passaggio è fondamentale per poter identificare le
risorse e accedere direttamente ai contenuti di interesse.
Ma, come insegna l’esperienza di migliaia di archivisti, è quasi proibitivo
pensare un unico schema per catalogare tutta la conoscenza umana, un sistema
generale di catalogazione di oggetti completamente generici, solo in base alle
proprie proprietà semantiche. La difficoltà rimarrebbe invariata anche
restringendo il problema ai soli learning object, cioè limitandoci alle risorse
legate alla didattica.
Per risolvere questo problema un primo approccio è quello di cercare di
elencare i differenti tipi di metadata necessari in base alle funzioni. Si
individuano almeno cinque punti:
1. Amministrazione: diritti, versione, allocazione, informazioni
sull’acquisizione digitale.
2. Descrizione: indici, note, identificativo nel catalogo, collegamenti
fra risorse, informazioni per il ritrovamento: parole chiavi, etc.
3. Conservazione: documentazione sullo stato fisico delle risorse,
informazioni sulle soluzione scelte per conservare versioni fisiche
e digitali.
63
4. Tecnica: documentazione sull’hardware e il software necessari,
dati sulla sicurezza come chiavi di criptazione o password,
informazioni
sulla
digitalizzazione:
formati,
livello
di
compressione, etc.
5. Uso: attributi relativi al tipo e al livello di uso possibile delle
risorse, storia degli utilizzi e delle modifiche, informazioni su
materiale con più versioni o più lingue.
Un altro possibile approccio è quello di dividere i metadata in base alle
caratteristiche, sottolineando le differenze fra quelli creati in automatico da
sistemi informatici e quelli inseriti da un intervento umano:
1. Origine
metadata interni generati dall’agente autore del learning object al
momento della creazione della risorsa (header e nome del file, struttura
delle directory, formato e compressione del file)
metadata esterni aggiunti successivamente, solitamente da qualcuno
diverso dall’autore (record identificativo, informazioni legali)
2. Metodo creazione
metadata creati in automatico dal computer (log delle azioni degli
utenti, indici per parole chiave)
metadata inseriti da persone (descrizioni)
3. Natura
metadata creati da persone inesperte di catalogazione, spesso lo
stesso creatore della risorsa (metatag delle pagine web personali)
metadata creati da esperti (record MARC)
4. Stato
metadata statici che non cambiano mai una volta creati (titolo,
origine, data di creazione della risorsa)
64
metadata dinamici rispetto all’uso e alle modifiche (struttura delle
directory, log delle azioni degli utenti, risoluzioni delle immagini)
metadata a lungo termine (informazioni sui diritti)
metadata a breve termine, principalmente di transizione
5. Struttura
metadata strutturati secondo uno standard (MARC, EAD e TEI,
formati di database locali)
metadata non strutturati (campi per note e appunti)
6. Semantica
metadata controllati che corrispondano ad un vocabolario standard
(AAT, ULAN, AACR2)
metadata che non appartengono ad un vocabolario (HTML
metatag, note di testo)
7. Livello
collezione di metadata riferiti ad altri metadata (indice specialistico,
record di collezione come quelli di MARC)
metadata riferiti ad un singolo learning object (informazioni su un
formato particolare)
Sulla base di questi studi negli ultimi anni sono state proposte diverse
soluzioni per definire un’architettura unica per i metadata. Le più importanti
verranno analizzate nei prossimi paragrafi, soffermandosi in particolare su quelle
sviluppate appositamente per gli oggetti didattici.
65
3.2 Standard proposti
3.2.1 IEEE LOM (http://ltsc.ieee.org/wg12/)
LOM è l'acronimo di Learning Object Metadata, ed è un working group in
ambito IEEE che lavora per la definizione di uno standard per descrivere oggetti
didattici.
Questo gruppo (IEEE 1484.12) fa parte dell'IEEE Learning Technology
Standards Committee (LTSC), l'organo per gli standard sulla didattica.
Il gruppo si prefigge di definire una struttura di metadata per learning object.
Questa struttura è composta da un insieme degli attributi utilizzati per descrivere
le caratteristiche di generici oggetti per la didattica.
Questi oggetti sono definiti come qualunque entità, digitale e non, che può
essere usata, riusata o referenziata durante l'insegnamento con l'utilizzo di
moderne tecnologie.
Il lavoro del gruppo è iniziato nel dicembre 1997, ha sviluppato un Working
Draft che è stato approvato nel Giugno 2002 ed è tuttora in discussione per la
pubblicazione finale.
Gli obiettivi indicati dai creatori di LOM sono i seguenti:
• Abilitare studenti ed insegnanti alla ricerca, valutazione, acquisizione ed
utilizzo dei learning object.
• Abilitare la condivisione e scambio di learning object tra qualsiasi sistemi
didattici che utilizzano qualsiasi tecnologia.
• Abilitare lo sviluppo di learning object in unità che possono essere combinate
e decomposte in maniera significativa.
• Abilitare computer agent nel comporre automaticamente e dinamicamente
lezioni personalizzate per studenti individuali.
• Raggruppare il lavoro già fatto su standard focalizzati nell'abilitare learning
object multipli a lavorare insieme in un ambiente didattico aperto.
• Abilitare una forte e crescente economia per i learning object che supporti e ne
sostenga tutte le forme di distribuzione: non profit e for profit.
66
• Abilitare organizzazioni didattiche e di formazione, sia governative che
pubbliche e private, ad esprimere contenuti educativi e metodi di valutazione
in un formato standard, indipendente dal contenuto.
• Definire uno standard che sia semplice ed estensibile a vari domini e
giurisdizioni così da essere ampiamente adottato ed applicato.
• Supportare i necessari metodi di sicurezza ed autenticazione per la
distribuzione e l'utilizzo di learning object.
Lo scenario descritto è un ideale ambiente didattico globale e distribuito,
dove i contenuti vengono classificati in maniera organica, completa ed uniforme,
e vengono costruiti corsi personalizzati per studenti individuali, in maniera
automatica in base al loro curriculum.
Ogni risorsa didattica è descritta da dei metadata composti da 9 categorie
contenenti gruppi di attributi strutturati ad albero:
1. General Gruppi di caratteristiche generali, indipendenti dal contesto del
contenuto dell'oggetto didattico descritto.
2. Lifecycle Gruppi di caratteristiche relative al ciclo di vita della risorsa.
3. Meta-metadata Gruppi di caratteristiche della descrizione stessa e non
dell'oggetto descritto.
4. Technical Gruppi di caratteristiche tecniche della risorsa.
5. Educational Gruppi di caratteristiche educative e pedagogiche della
risorsa.
6. Rights Informazioni che hanno a che fare con le condizioni di utilizzo
della risorsa.
7. Relation Gruppi di caratteristiche della risorsa che la collegano ad altre.
8. Annotation Gruppi di caratteristiche che permettono la descrizione di
note sull'utilizzo educativo della risorsa.
9. Classification Gruppi di caratteristiche utili per classificare i contenuti
della risorsa.
L'insieme di queste categorie forma il Base Schema.
67
Molto ancora resta da fare, in particolare riguardo al binding di LOM con
tecnologie di rappresentazione dei metadata.
Nonostante la sua, forse eccessiva, complessità e l'architettura non
perfettamente modulare, LOM è una proposta di standard presa in
considerazione o come riferimento da tutte le altre proposte attuali.
3.2.2 IMS (http://www.imsproject.org/)
IMS (Global Learning Consortium Inc.) è un consorzio composto da varie
organizzazioni ed aziende, con lo scopo di definire uno standard per facilitare la
didattica on line.
IMS ha due obiettivi principali:
• Definire delle specifiche tecniche per l'interoperabilità di
applicazioni e servizi per la didattica distribuita.
• Supportare l'adozione delle specifiche IMS in prodotti e
servizi in tutto il mondo.
La struttura di metadata di IMS è basata su IEEE LOM, e da essa trae gran
parte del suo schema base.
Invece di utilizzare il nome Learning Object viene utilizzato Learning
Resource. Il Learning Resource Metadata è una versione leggermente modificata
del Learning Object Metadata. Addirittura le specifiche vengono rilasciate per
differenza rispetto a LOM.
L'approccio IMS è decisamente implementativo. A differenza di LOM, sono
stati da tempo rilasciati documenti relativi ad una possibile implementazione in
XML, nonché al corretto utilizzo dei metadata IMS.
La documentazione è ricca e ben curata sia per gli sviluppatori che per gli
utenti, ad esempio esiste una FAQ molto utile per un primo approccio al
problema dell’implementazione. Inoltre IMS ha definito l'Enterprise Information
Model, un modello per la gestione standard di persone e gruppi di persone
68
coinvolte (come autori, insegnanti e studenti) nell'utilizzo del materiale didattico
descritto nel Learning Resource Metadata Information Model.
Il modello proposto da IMS ha riscosso un notevole successo grazie alla
similarità con IEEE LOM, ma soprattutto all'approccio più pragmatico ed
orientato all'implementazione.
3.2.3 Gestalt (http://www.fdgroup.co.uk/gestalt/)
Gestalt (Getting Educational System Talking Across Leading-edge
Technologies) è un progetto per la definizione ed implementazione di un sistema
didattico distribuito utilizzando gli standard già esistenti e proponendone nuove
estensioni.
La visione di Gestalt prevede l'interazione delle varie parti coinvolte usando
il World Wide Web. Il nucleo dell'architettura è il Learning Enviroment (LE) che
utilizza un database interno e fornisce on line tutti i dati richiesti dagli altri
componenti. Così è possibile gestire i curricula e la creazione dei corsi, la
registrazione degli studenti, l'utilizzo dei corsi ed il monitoraggio da parte dei
docenti sui progressi di ogni studente.
Il componente Resource Discovery Service (RDS) permette agli utenti di
esplorare tramite interfaccia WEB quali corsi e moduli sono disponibili.
L'implementazione di RDF è basata su CORBA, ed i profili degli utenti sono
organizzati in una directory basata su LDAP.
La struttura dei dati in GESTALT include i seguenti componenti:
•
Courseware Content (GEMSTONES)
•
Student Profiling/Tracking (PAPI/EPAPI)
•
Curriculum Management
69
Il progetto di questi componenti è basato sul lavoro di altri gruppi nel campo
degli standard di metadata per la didattica. La struttura di metadata è infatti
basata su IEEE LOM, tenendo in considerazione il lavoro fatto in IMS Project,
ARIADNE e Dublin Core.
La struttura aggiunge tre categorie rispetto a IEEE LOM: Assessment, QoS,
Mappings.
Particolarmente interessante è l'idea di descrivere, nella categoria QoS, le
risorse di rete necessarie per utilizzare quella risorsa. La struttura di questo
metadata prevede una diversa versione per le reti ATM e per Diffserv, e
considera che i requisiti di rete possono cambiare nel tempo, aggiungendo per
ogni struttura dati la variabile t. Tutti i metadata sono scritti utilizzando XML.
Il contributo di Gestalt non si è limitato al progetto dell'architettura del
sistema e dei metadata, ma i componenti previsti nel sistema sono stati
implementati. Attualmente il progetto sembra essere stato abbandonato: il sito
non è aggiornato dall’aprile 2001.
3.2.4 Ariadne (http://www.ariadne-eu.org/)
Ariadne sta per: Alliance of Remote Instructional Authoring and
Distribution Networks for Europe, ed è un progetto nato attraverso il settore
"Telematics for Education and Training" del quarto programma quadro per la
ricerca e sviluppo dell'Unione Europea.
Il progetto focalizza i suoi sforzi sullo sviluppo di strumenti e metodologie
per la produzione, la gestione ed il riuso di elementi pedagogici.
Sono stati sviluppati diversi tool per la creazione e la ricerca di materiale
didattico.
Il gruppo ha sempre tenuto conto della sua "missione" di carattere europeo,
riservando particolare attenzione all'uso di più lingue.
Date le loro similarità dal punto di vista generale, esiste un accordo con IMS
su eventuali sinergie per raggiungere obiettivi comuni.
70
Il progetto Ariadne si è trasformato nella "Ariadne Foundation", per
continuare lo sviluppo di strutture di metadata per sistemi didattici avviato con
Ariadne e Ariadne II.
3.2.5 Dublin Core (http://www.dublincore.org)
Dublin Core (DC) è una proposta di un insieme minimale di elementi per
descrivere materiale digitale accessibile attraverso la rete Internet.
Fu inizialmente proposto in una conferenza nel marzo 1995 a Dublin, Ohio
(U.S.). I partecipanti al convegno erano prevalentemente bibliotecari, archivisti,
editori, ricercatori e sviluppatori di software, oltre ad alcuni membri dai gruppi
di lavoro dell'Internet Engineering Task Force (IETF).
L'intenzione fu di suggerire un insieme minimale di elementi che possano
essere forniti dall'autore o dall'editore dell'oggetto digitale, ed inclusi in esso, o
da esso referenziati.
Ora Dublin Core Metadata Initiative è attiva per la diffusione di DC su
Internet e per l'estensione della struttura proposta.
Data la sua semplicità DC è correntemente molto utilizzato, e praticamente
tutti gli standard fanno riferimento ad esso e ne specificano un mapping.
Gli elementi definiti sono:
1. Title Il titolo o il nome della risorsa attribuito ad essa dall'autore o
dall'editore.
2. Creator La persona o l'organizzazione primariamente responsabile
per la creazione del contenuto intellettuale della risorsa.
3. Subject L'oggetto trattato nella risorsa. Tipicamente questo campo è
utilizzato anche per contenere le parole chiave (keyword). L'uso di
vocabolari controllati e schemi di classificazione è incoraggiato.
71
4. Description Una descrizione testuale della risorsa, ad esempio
l'abstract nel caso di un articolo.
5. Publisher L'ente responsabile per rendere la risorsa disponibile nella
sua forma attuale.
6. Contributor La persona o l'organizzazione, non specificata
nell'elemento Creator, che ha realizzato una parte significativa nel
contenuto intellettivo della risorsa.
7. Date Data di creazione o della pubblicazione della risorsa. Per il
formato
da
utilizzare
si
veda
ISO
8601
(
http://www.w3.org/TR/NOTE-datetime)
8. Type La categoria della risorsa, ad esempio: "Home Page",
"Racconto", "Report Tecnico", etc... Per problemi di interoperabilità
dovrebbe essere espresso sempre in inglese e scelto da una lista
limitata di possibilità.
9. Format Il formato dei dati contenenti la risorsa ed opzionalmente le
sue dimensioni. Anche questo campo dovrebbe essere scelto da una
lista limitata standard.
10. Identifier Un identificatore univoco della risorsa. Ad esempio la sua
URI (Uniform Resource Identifier) oppure l'International Standard
Book Number (ISBN).
11. Source Eventuali informazioni su un'altra risorsa dalla quale la
presente è stata derivata.
12. Language La lingua utilizzata, espressa come definito nel RFC1766.
13. Relation Contiene l'identificatore di un'altra risorsa correlata.
72
14. Coverage Le caratteristiche spaziali e temporali del contenuto
descritto nella risorsa. Ad esempio per un libro di storia sull'Europa
nel medioevo.
15. Rights Un identificatore di una risorsa che definisce la licenza d'uso
della risorsa in questione.
Grazie alla sua semplicità DC, o spesso parte di esso, viene riconosciuto da
vari software e motori di ricerca su Internet.
È in corso anche uno sforzo per utilizzare questa struttura di metadata in
collegamento con le tecnologie sviluppate in ambito W3C, ad esempio RDF
(Resource Description Framework).
Vari esempi sono disponibili in rete per cui sembra che DC possa giocare un
ruolo importante anche nel prossimo futuro della rete Internet.
3.3
SCORM
Come è stato analizzato nei paragrafi precedenti, a partire dal 1997 diverse
organizzazioni studiano ed elaborano una varietà di standard e specifiche per
l'apprendimento a distanza. Questo movimento di standardizzazione venne
rilevato dal Dipartimento della Difesa (DoD) degli Stati Uniti che si impegnò,
assieme ad altre agenzie federali e aziende del settore privato, a sviluppare
specifiche e standard comuni per il campo del technology-based learning.
Da questo impegno arrivò nel 1999 la prima versione provvisoria del
Sharable Content Object Reference Model (SCORM), che cercò di incorporare
gli standard emergenti per i vari aspetti dell’e-learning (IMS, AICC: Aviation
Industry CBT Committee, Microsoft LRN, ARIADNE, IEEE) in un comune
modello di riferimento, integrando il lavoro di queste organizzazioni con
l’impegno dell'ADL (Advanced Distributed Learning) all’interno del DoD.
Nel gennaio 2000 fu presentata da ADL la prima versione dello SCORM
che venne sostituita dalla 1.1 nel gennaio 2001, quando cambiò il significato della
73
sigla: da “Sharable Coursware Object Reference Model” diventò “Sharable
Content Object Reference Model”, sottolineando la possibilità di applicare il
modello a differenti livelli di contenuto.
La versione odierna è la 1.2 e raggiunge alcuni degli obiettivi prefissati,
definendo un modello di aggregazione dei contenuti (Content Aggregation Model)
e un ambiente di elaborazione (Run-Time Environment) per learning object.
Per centrare questo risultato si è ricorsi all'uso di specifiche basate sul
linguaggio XML, proposte dall’IMS con il suo Content Packaging, che
permettono di collegare i "depositi" di contenuto informativo ai sistemi di
gestione dei contenuti, indicati spesso con LMS: Learning Management System.
Figura 3-1 Convergenza fra SCORM e standard per l’e-learning
I componenti fondamentali dello SCORM sono dunque il Content
Aggregation Model e il Run-Time Environment, descritti su due insiemi di testi
disponibili sul sito ufficiale. Nella documentazione c’è una terza sezione
introduttiva al modello, che va a completare la descrizione del sistema:
74
Figura 3-2 Rapporti fra i testi che descrivono lo SCORM
Nei testi dedicati al Content Aggregation Model sono contenute le indicazioni
per identificare e aggregare le risorse in un contenuto didattico strutturato. In
questa parte si descrivono un dizionario per i metadata dei contenuti, basato su
IEEE LOM, e un meccanismo di “impacchettamento” e di traduzione in XML,
basato su IMS.
Nei testi sul Run-Time Environment sono incluse la indicazioni per rendere
possibile il collegamento all'archivio dei contenuti, la comunicazione con esso e il
reperimento di un determinato contenuto. E’ infatti il modulo che rende possibile
il riutilizzo dei learning object e la interoperabilità tra molteplici Learning
Management System. Un risultato importante, ottenuto creando un meccanismo
comune di comunicazione fra i vari LMS e gli oggetti didattici partendo da un
vocabolario condiviso. Per assolvere questo scopo il Run-Time Environment è
composto da tre aspetti basati su AICC: Launch, Application Interface (API) e un
Data Model. Rispettivamente implementano: un modo comune di organizzare
l’avvio delle risorse d'apprendimento, un comune meccanismo fra queste per
75
comunicare con un qualsiasi LMS e un linguaggio predefinito che costituisce la
base della comunicazione.
76
4 La soluzione adottata
4.1 Analisi implementativa degli standard
Attraverso lo studio delle architetture esaminate nel capitolo precedente, si
nota come una singola struttura di metadata può descrivere una qualsiasi risorsa
didattica. Naturalmente, più si aumenta il livello di dettaglio – quindi il numero
degli attributi coinvolti per ogni oggetto- e più la descrizione è completa e
univoca. Questa caratteristica può essere un punto di forza in quanto si può
descrivere praticamente tutto utilizzando una sola struttura dati, uniforme per
tutti gli oggetti: un intero corso, una lezione, una trasparenza. Ma, allo stesso
tempo, questo approccio molto specifico può non essere efficiente in alcuni casi
e portare ad indecisioni su come utilizzare correttamente il modello dei metadata.
La scelta del sistema da utilizzare per la Mediateca è stata quindi fatta
tenendo conto del processo di produzione, attivo con successo da più di un anno,
e dell’operatore che dovrà catalogare le lezioni: una maggiore semplicità (Dublin
Core) è stata spesso preferita alla completezza di un altro sistema (LOM, IMS).
Questa scelta permette di realizzare i nuovo strumenti, analizzati nel capitolo
seguente, senza aumentare i tempi, e quindi di costi, in fase di post produzione
della lezione.
Con uno studio delle soluzioni adottate da altre piattaforme per
l’insegnamento a distanza si possono evidenziare principalmente tre soluzioni
per l’implementazione di uno standard per i metadata:
1.
modellare i dati su un modello entità-relazione: il learning object (o
entità), gli attributi che descrivono il learning object ed le relazioni che
collegano i learning object fra di loro.
Progettando il database con un mapping dai metadata previsti -ad es.
77
dall’IMS- agli attributi, si possono avere fino a 60 attributi per ogni
learning object. Questa implementazione è stata verificata da varie
soluzioni e ha dato buoni risultati solo con un numero di learning object
limitato.
Se è semplice fare il mapping dal documento XML al database, un
problema di questa soluzione è la difficoltà nel mantenere la struttura del
file XML nella ricostruzione dello stesso dal DB. Limitando i campi da
memorizzare è possibile inoltre che alcuni metadata vadano persi
nell’accettare learning object da enti esterni, a meno di modificare il
database per poter memorizzare anche questi. La situazione peggiora se
sono stati aggiunti metadata estendendo le specifiche dello standard.
Il problema più grave resta comunque l’efficienza di un database
relazionale con più di 60 elementi per ogni oggetto su decine di tabelle.
Per risolverlo l’approccio più utilizzato è quello di memorizzare nel
database solo pochi metadata (riducendo il numero anche fino a 10) per
poter permettere ricerche molto efficienti; anche se naturalmente aumenta
il rischio di perdere informazioni importando informazioni da altre fonti.
2. memorizzare un documento XML come Bfile (file binario esterno, la cui
dimensione è limitata dal sistema operativo), segnando la sua posizione
come record della base di dati. Lo svantaggio è nella diminuzione di
efficienza nell'elaborazione di query e scritture, oltre alla perdita di
benefici tipici delle base di dati: sicurezza, indici, backup e gestione delle
transazioni.
3. memorizzare l'intero documento XML in un singolo campo del database
come CLOB (Character Large OBject, grandi oggetti carattere che
arrivano fino a 4 GB). Un vantaggio di questa soluzione è quella di
ricreare il documento originale ogni volta che se ne ha bisogno
conservando alcuni vantaggi tipici delle base di dati: la gestione delle
transazioni e la sicurezza su tutto. La capacità di fare ricerche sui CLOB
varia molto con la base di dati utilizzata. Intermedia della Oracle, per
esempio, può indicizzarli; o se il CLOB è immagazzinato come oggetto,
78
lascia la possibilità di eseguire delle query su questo. Dai CLOB si può
inoltre fare un parsing direttamente in un documento XML e viceversa e
già molti strumenti XML possono essere utilizzati per ricercare nei
documenti, anche se naturalmente le ricerche saranno più lente di quelle di
una normale base di dati relazionale.
E’ possibile anche utilizzare soluzioni ibride, come memorizzare l’intero
documento XML in un CLOB con un mapping dei metadata più utilizzati in un
database relazionale. Ad esempio, la scelta dei dati può essere fatta su quelli
richiesti più frequentemente.
4.2 Mediateca versione 4.0 e standard IMS- Dublin Core
Nella scelta della soluzione per la nuova versione della Mediateca è doveroso
sottolineare i rischi, da una parte, di un approccio troppo generale: avrebbe
aumentato le possibilità di perdere aspetti specifici degli oggetti didattici della
Mediateca. Dall’altra, andava tenuto in considerazione che una soluzione con
troppi attributi avrebbe portato ad un appesantimento, non necessario, del
database e all’allungamento considerevole dei tempi di determinazione e di
inserimento di tutti i metadata.
Nella scelta di archiviare le lezioni secondo uno standard, non andavano
quindi persi di vista quali sono gli obiettivi che rimangono fondamentali per il
caso specifico della Mediateca: registrare informazioni sui contenuti delle
risorse, sulle conoscenze che saranno acquisite, sui pre-requisiti necessari
(didattici e tecnici) per sfruttare al massimo lezioni, slide e documenti presenti
nell’archivio.
Selezionando i metadata dello standard IMS più significativi è possibile
confrontarli con i corrispondenti attributi del database della Mediateca versione
3.1 e renderli compatibili anche con lo standard Dublin Core (indicato con la
sigla DC nella tabella). Una selezione accurata dei metadata e dei loro domini
79
permette di avere un sistema pronto per lo standard IEEE LOM appena questo
sarà completamente disponibile.
NOTE
1. l’asterisco * indica che è possibile un valore multiplo
2. i due trattini – indicano un metadata non implementato in Mediateca versione 3.1
Mediateca
IMS Metadata
1 General
1.1 identifier
IDResource
Corrisponde al DC.Identifier
1.2 title
Title
Corrisponde al DC.Title
1.4 language*
IDLanguage
Corrisponde al DC.Language
1.5 description*
tResource.DescriptionAbstract
Corrisponde al DC.Description
1.6 keywords*
--
1.7 coverage
--
Corrisponde al DC.Coverage
1.9 aggregationlevel
--
Descrizione livelli IMS:
Il livello 1 indica il più piccolo livello di
aggregazione,
ad
esempio
dati
multimediali grezzi o frammenti.
Il livello 2 si riferisce a collezioni di
atomi, ad esempio un documento HTML
con delle immagini immerse o una
lezione della Mediateca (testo, immagini,
video, audio)
Il livello 3 indica una collezione di oggeti
del primo livello, ad esempio una piccola
rete di documenti HTML con una pagina
indice che organizza le risorse o un’unità
80
Il livello 4 si riferisce al più grande livello
di granularità, ad esempio un corso.
2 Lifecycle
2.3 contribute*
Role
tRole.Description
Corrisponde al
DC.Creator/Publisher/Contributor
Entity* (vCard)
IDEntity
Date
DateCreated
Corrisponde al DC.Date
E’ importante notare che per il DC.Date
del Dublin Core e il datetime di IMS è
utilizzato il formato ISO8601 (aaaa-mmgg)
4 Technical
1.1
format*
--
Corrisponde al DC.Format
4.2 size
FileSize (Mbytes in Mediateca
fino alla 3.1, gli standard
vogliono Kbyte)
4.3 location*
Source
4.4 requirements*
4.4.1 type
--
Vocabolario IMS: Operating System,
Browser
4.4.2 name
-- (esiste descrizione del viewer)
4.4.3 minimumversion
-- (esiste descrizione del viewer)
4.6 other platform requirements
-- (esiste descrizione del viewer)
81
5 Educational
1.2 learning resource type*
--
Corrisponde al DC.Type
Vocabolario IMS: Exercise, Simulation,
Questionnaire, Diagram, Figure, Graph,
Index, Slide, Table, Narrative Text,
Exam, Experiment, ProblemStatement,
SelfAssesment
5.5 intended end user role*
Vocabolario
IMS:
Teacher,
--
Author,
Learner, Manager
5.8 difficulty
Vocabolario
IMS:
-very
easy,
easy,
medium, difficult, very difficult
6 Rights
6.1 cost
--
6.2 copyright
IDRight
6.3 description
tRights.Description
7 Relation*
7.1 kind
--
Corrisponde al DC.Relation
Il vocabolario IMS coincide con quello
del Dublin Core: IsPartOf, HasPart,
IsVersionOf, HasVersion, IsFormatOf,
HasFormat, References, IsReferencedBy,
IsBasedOn,
IsBasisFor,
Requires,
IsRequiredBy
7.2 resource
82
7.2.1 identifier
IDResource
9 Classification*
1.1
purpose
--
Se il purpose è Discipline corrisponde
al DC.Subject
in Mediateca corrisponde sempre a
Discipline e quindi coincide con il
Vocabolario
Prerequisite,
IMS:
Discipline,
Educational
Idea,
Dublin Core
Objective,
Accessibility Restrictions, Educational
Level, Skill Level, Security Level
9.2 taxonpath*
9.2.1 source
tEncodingScheme.Description
9.2.2 taxon*
tSubject.Code
In IMS la TaxonPath può avere una
profondità da 1 a 9. Valori normali sono
fra 2 e 4 (ad esempio: Physics/ Acoustics/
Instruments/ Stethoscope ; Medicine/
Diagnostics/ Instruments/ Stethoscope)
9.3 description
tSubject.Subject
E’ evidente che con dei cambiamenti alla base di dati è stato possibile
raggiungere la compatibilità con gli standard IMS e Dublin Core. Questo
mantenendo la libertà di descrivere le lezioni con più campi nei casi in cui la
struttura dell’IMS possa rivelarsi non sufficientemente dettagliata.
L'aspetto fondamentale, che spinge ad adottare lo standard IMS, è la
possibilità di far diventare la Mediateca compatibile con i tool di classificazione
e ricerca già sviluppati, rendendo veramente concreta l'interoperabilità tra sistemi
diversi ma aderenti a questo standard che è attualmente il più diffuso, senza
83
perdere la compatibilità con lo standard IEEE LOM, avendo già attributi
completamente coerenti con questa struttura.
Per i punti dove è già presente un attributo nella Mediateca basterà fare un
mapping nella creazione o nelle lettura dei file XML di scambio con gli altri
sistemi. E’interessante invece analizzare i punti dove sono necessarie modifiche
o l’aggiunta di nuovi attributi.
4.2.1 General
Per il punto 1.6 (keywords) è stato aggiunto un attributo Keywords nella
tabella tResource. E’un campo di tipo text dove vengono memorizzate le parole
chiave separate da virgola, il campo è poi utilizzato per ricerche su argomenti
specifici.
Per il punto 1.7 (coverage) non è stato aggiunto un campo, ma si sceglierà un
valore di default da passare sia all’IMS che al DC. In caso di importazione non
verrà considerato.
Per il punto 1.9 (aggregationlevel) sono stati definiti i quattro livelli come
nello standard, aggiungendo l’attributo AggregationLevel in tResource per ogni
elemento atomico della Mediateca. I livelli sono stati descritti in italiano e con
degli esempi:
•
Livello 1 il più piccolo livello di aggregazione: un testo, una
slide, un filmato per un argomento specifico o una definizione.
•
Livello 2 collezione di elementi atomici (livello 1): una pagina
web con testi e immagini, una porzione di lezione SMIL.
•
Livello 3 collezione strutturata di risorse di livello 2, come una
raccolta di documenti html, collegate fra loro e indicizzate da una
pagina index. Ad es. un manuale digitale con testi e immagini,
una lezione SMIL completa.
84
•
Livello 4 il più alto livello di aggregazione. Ad es. un corso
completo che unisce elementi dei livelli precedenti.
4.2.2 Lifecycle
Per il punto 2.3 (contribute) è necessario un mapping fra il dominio della
Mediateca e quello dell’IMS, evidenziando anche le corrispondenze con il
Dublin Core.
IMS metadata: Role
Mediateca metadata: tRole.Description
Vocabolario composto da:
Vocabolario composto da:
Author, Publisher,
Student
Unknown, Initiator,
Terminator, Validator,
Teacher: Author in IMS, DC.Contributor in Dublin Core
Editor, Graphical Designer,
Technical Implementer,
Tutor: Instructional Designer in IMS, DC.Contributor in
Content Provider, Technical
Dublin Core
Validator, Educational
Validator, Script Writer,
Technician: Technical Implementer in IMS, DC.Contributor in
Instructional Designer
Dublin Core
Coordinator: Publisher in IMS, DC.Publisher in Dublin Core
4.2.3 Technical
Per il punto 4.1 (format) è stato aggiunto un attributo Format nella tabella
tMedium. E’un campo di tipo varchar da 250 caratteri con il dominio definito
dal tipo MIME o dalla definizione “non digital”. Con questo attributo viene
identificato il tipo di dato da un punto di vista tecnico e il software necessario
per accedervi (a cui sarà poi associato attraverso la chiave esterna IDViewer), ad
85
esempio: video/mpeg, text/html, images/png. Corrisponde al DC.Format del
Dublin Core.
Per i punti che riguardano i requirements (4.4.1 type, 4.4.2 name, 4.4.3
minimumversion, 4.6 other platform requirementes) la descrizione del viewer li
include tutti. La perdita di informazioni particolareggiate e automatizzate è
giustificata dalla maggiore semplicità in fase di inserimento e di fruizione:
tenendo i viewer aggiornati viene risolto ogni problema ed è sempre possibile
fornire informazioni particolari attraverso la descrizione.
4.2.4 Educational
Per il punto 5.2 (learning resource type) mettendo a confronto i due
vocabolari utilizzati per descrivere i tipi di risorsa:
1
vocabolario IMS: Exercise, Simulation, Questionnaire, Diagram,
Figure, Graph, Index, Slide, Table, Narrative Text, Exam, Experiment,
ProblemStatement, SelfAssesment
2
vocabolario DC: Collection, Text, Image, Sound, Dataset, Software,
InteractiveResource, Event, PhysicalObject, Service
si può adottare il modello del DC per un dominio adatto alla Mediateca,
indicando fra parentesi il mapping con gli elementi dell’IMS. Aggiungiamo
l’elemento Lesson per indicare le lezioni composte da audio e video, elemento
principale della Mediateca.
Collection (Slide),
Text (Narrative Text, Table, ProblemStatement),
Image (Diagram, Figure, Graph),
Sound,
Dataset (Index),
86
Software,
InteractiveResource (Experiment, SelfAssesment, Exercise, Simulation,
Questionnaire, Exam),
Event,
PhysicalObject,
Service
Lesson
L’attributo aggiunto in tResource per memorizzare queste informazione è
Type, varchar(20).
E’ importante sottolineare cosa si intende con alcuni di questi attributi, si può
fare riferimento alle definizioni date dal consorzio Dublin Core:
“Dataset
structured information encoded in lists, tables, databases, etc., which will
normally be in a format available for direct machine processing. For example spreadsheets, databases, GIS data, midi data. Note that unstructured numbers and
words will normally be considered to be type text.
Event
non-persistent, time-based occurence. Metadata for an event provides descriptive
information that is the basis for discovery of the purpose, location, duration,
responsible agents, and links to related events and resources. The resource of
type event may not be retrievable if the described instantiation has expired or is
yet to occur. Examples - exhibition, web-cast, conference, workshop, open-day,
performance, battle, trial, wedding, tea-party, conflagration.
PhysicalObject
objects or substances. For example - a person, a computer, the great pyramid, a
sculpture, wheat. Note that digital representations of, or surrogates for, these
things should use image, text or one of the other types.
87
Service
A service is a system that provides one or more functions of value to the enduser. Examples include: a photocopying service, a banking service, an
authentication service, interlibrary loans, a Z39.50 or Web server.”
(http://dublincore.org/usage/terms/dcmitype, Febbraio 2003)
Con i punti 5.5 (intended end user role) e 5.8 (difficulty) l’implementazione
arricchirebbe sicuramente di informazioni il singolo oggetto, ma potrebbe essere
utile solo in pochissimi casi. Si può assumere che tutti gli oggetti siano destinati
agli studenti e che la difficoltà della lezione sia legata all’argomento che si sta
trattando, quindi con dei parametri che non sono giudicabili dall’operatore in
fase di ripresa o di post-produzione.
4.2.5 Relation
Per il punto 7.1 (kind) è introdotto un nuovo attributo in tResources:
RelationKind. I valori ammessi sono gli stessi del Dublin Core, adottati anche
dall’IMS, e sono definiti nel dominio RelationType:
a) Relazioni per individuare risorse fisiche o logiche di cui l’oggetto è
parte o risorse che sono parte dello stesso: IsPartOf, HasPart
b) Relazioni per gestire le versioni: IsVersionOf, HasVersion
c) Relazioni per documentare le trasformazioni di formato: IsFormatOf,
HasFormat
d) Relazioni per le referenze, quando un documento cita, confronta o è
integrato da un altra risorsa: References, IsReferencedBy
e) Relazioni per individuare risorse che sono risultato di una derivazione,
traduzione, adattamento o interpretazione di un altro documento:
IsBasedOn, IsBasisFor
f) Relazioni di dipendenza, per oggetti che richiedono un’altra risorsa per
funzionare o per essere compresi: Requires, IsRequiredBy
88
4.3 Schema database Mediateca versione 4.0
E’ utile, a questo punto, osservare i cambiamenti alla struttura del database
introdotti nei paragrafi precedenti.
Il centro del nuovo database è sicuramente la tabella tResource, arricchita e
resa più importante rispetto alle versioni precedenti. Per sottolineare queste
modifiche non viene riportato tutto lo schema del database, ma solo quello della
porzione più importante.
Figura 4-1 Gestione contenuti Mediateca ver. 4
89
5 I nuovi strumenti: ricerca e automazione
5.1 Ricerca nel database
Una volta implementati i metadata la più naturale applicazione per il loro
reale utilizzo è un sistema di ricerca. Attraverso degli pagine web è ora possibile
fare delle ricerche (libere e guidate) nel database della Mediateca, sia per gli
utenti che per i tutor.
La prima idea è stata quella di implementare un sistema di ricerca dove
l’utente avrebbe potuto decidere le priorità delle varie features legate alla qualità
della risorsa. Questo per quando riguarda gli aspetti disponibili per la ricerca,
oltre naturalmente alle ricerche per parole chiave. Un link diretto con la scelta
“qualità consigliata dal sistema” sarebbe stata la soluzione per gli utenti senza
preferenze particolari.
L’idea era quella di giudicare la qualità di una lezione sia utilizzando le
indicazioni degli utenti che quelle dell’operatore. Mentre l’operatore avrebbe
inserito i suoi giudizi attraverso i metadata in fase di produzione, gli utenti della
Mediateca possono giudicare già da diversi mesi ogni lezione attraverso il
controllo qualità via web:
Modalità di fruizione:
A distanza
Conoscevo l'argomento trattato dalla lezione?
[Rispondi]
Ho compreso l'argomento trattato in questa lezione?
[Rispondi]
Il docente è stato chiaro?
[Rispondi]
I supporti didattici (lucidi, lavagna, computer) sono stati
[Rispondi]
efficaci?
Mi sono stancato?
[Rispondi]
90
Ho avuto difficoltà a seguire per motivi tecnici?
[Rispondi]
Naturalmente i giudizi vengono memorizzati nel database e possono quindi
essere interrogati per stabilire la qualità della lezione vista da parte dell’utente
finale. Per questi giudizi il peso di default associato sarebbe potuto essere fra il 3
o 4, in un intervallo da 1 a 5.
A questi si sarebbero aggiunti gli indici assegnati dall’operatore che registra
la lezione (fra parentesi una prima ipotesi per i pesi di default, sempre fra 1 a 5):
1. Indicizzazione della lezione (3);
2. Qualità dei lucidi/lavagna/slide da pc (5);
3. Qualità audio (5);
4. Qualità ripresa (1 – giudicabile attraverso un voto per ogni operatore
da parte del responsabile);
5. Ritmo e chiarezza del professore (2);
6. Qualità della lezione per insegnamento a distanza (4);
7. Parole chiave (mostrando un indice di matching, sono possibili
ricerche anche con parole parziali): si chiedono all’insegnante prima
dell’inizio della lezione.
Si era stabilito anche un possibile algoritmo per le feature: moltiplicare per
uno i pesi associati alle caratteristiche nel caso l’utente scelga l’opzione “lezioni
consigliate dal sistema”, altrimenti l’utente avrebbe impostato le sue priorità e i
valori delle features sarebbero stati moltiplicati per un valore fra 1 e 2 (o si
sarebbe aggiunta una costante).
La soluzione che è stata adottata è più immediata e sintetizza tutta la
valutazione della risorsa didattica in due soli parametri: TeacherExposure e
MaterialQuality, due interi nell’intervallo fra 1 (pessimo) e 5 (ottimo).
Questa scelta, che può sembrare riduttiva, è dovuta alle difficoltà nella
91
valutazione di alcune caratteristiche per l’operatore e ai tempi di post-produzione
che sarebbero aumentati in maniera consistente. In realtà con due soli parametri
sulla qualità si raggiunge un compromesso ideale fra completezza, sintesi,
velocità e facilità di immissione da parte dell’operatore e di controllo da parte
del responsabile.
Con questa soluzione al momento della ricerca l’utente dovrà solo
selezionare una delle due opzioni, privilegiando la qualità del materiale o la
chiarezza e la ricchezza espositiva del docente. Il sistema non dovrà fare altro
che interrogare la base di dati e ordinare le lezioni disponibili, evidenziando le
risorse che hanno un valore più alto per il parametro scelto. Naturalmente c’è
una differenza nell’output a seconda di che tipo di utenza sta effettuando la
ricerca: nel caso dello studente verranno mostrate anche le dipendenze fra
lezioni, nel caso del tutor sarà facoltativo.
5.1.1 Possibili aggiunte per la ricerca
Un punto forte di miglioramento del sistema, strettamente integrato con la
ricerca, potrebbe essere l’integrazione di nuovi strumenti che permettano allo
studente di fare annotazioni su argomenti ed esercizi del corso o di porre
domande, visibili poi a tutti gli altri fruitori. Le annotazioni, le domande e le
risposte verrebbero immagazzinate nel database della Mediateca per essere poi
facilmente consultabili attraverso il motore di ricerca.
Una domanda, posta dallo studente, potrebbe partire da una lezione o da un
modulo, ed essere immediatamente riferita a questi; il sistema genererebbe
automaticamente il link all’argomento da cui è partita la domanda, affinché le
domande e le risposte vengano associate localmente a quell’argomento,
incrementandone i contenuti nel tempo in modo autoalimentato. Lo studente non
deve essere costretto a cercare in una lunga lista di FAQ o aspettare giorni per
avere risposte.
Il lavoro di risposta alle domande degli studenti può diventare sicuramente
92
un impegno gravoso per docenti e tutor soprattutto per corsi con un alto numero
di utenti. Occorre quindi disporre di meccanismi software che offrano la
possibilità di analizzare la domanda scritta in linguaggio naturale per estrarne un
modello di domanda paragonabile ad una già esistente, e quindi pronta per essere
smaltita con la risposta.
Algoritmi per questo ambito esistono già nelle ricerche di Intelligenza
Artificiale, in particolare ci sono ottimi risultati con l’utilizzo delle reti neurali.
Si tratta in pratica di intercettare le domande per gestirle con un sistema di
risposta automatica, attivando poi un feedback sullo studente del tipo "La
risposta è soddisfacente?": in caso negativo, c'è un intervento manuale e
specifico di rinforzo, che va comunque ad incrementare il database delle
risposte.
L'impegno del docente nel rispondere alle domande può essere diminuito
anche incoraggiando la costituzione di gruppi di studenti che discutono tra loro e
che pongono domande collettive (sfruttando ad esempio il forum, come già
avviene con la Mediateca-ELIS).
5.2 Creazione nuove lezioni
5.2.1 Creazione di lezione in presenza
Come già accennato per la ricerca, con l’implementazione dei metadata
aumentano gli strumenti per sfruttare il potenziale della Mediateca. Per ogni
lezione filmata, attraverso la regia in fase di ripresa e la post-produzione
successivamente, viene creato un indice con tutti i frammenti di lezione elencati
per argomento. In questo modo per un utente che visualizza una lezione è
possibile saltare da un argomento all’altro semplicemente cliccando sul titolo
nell’elenco presente a sinistra. Se ogni risorsa indicizzata viene memorizzata nel
database possiamo affermare che ci troviamo con una catalogazione con grana
molto fine, quindi un sistema con un’elevata modularità.
93
Da un punto di vista tecnologico il cambio di argomento all’interno della
lezione è un semplice avanzamento, o viceversa un indietreggiamento, nel
filmato eseguito dal client RealPlayer. Questo client, un programma eseguito in
locale sulla macchina dell’utente, richiede al server lo streaming del video a
partire da un nuovo istante dello stesso filmato che stava visualizzando o da un
altro filmato che può essere anche fisicamente su un altro computer rispetto al
primo. Questa soluzione è resa possibile in maniera trasparente rispetto all’utente
attraverso
l’utilizzo
della
tecnologia
SMIL,
trattata
accuratamente
nell’appendice A.2. In particolare, l’indice della lezione è realizzato con un file
testuale con estensione “.rt” (RealText Clip) dove in fase di post-produzione
vengono memorizzate le corrispondenze fra tempi e argomenti esposti. Questo
file è un semplice documento di testo con un linguaggio di markup tramite tag,
molto simile all’html.
Un esempio da una lezione della Mediateca:
<window type="generic" width="192" height="231"
duration="01:34:22">
<font size="3" face="Arial"><b> INDICE</b><br>
<a href="command:seek(00:06:35.0)" target="_player">La
priorità</a><Br>
<a href="command:seek(00:20:29.0)"
target="_player">Swapping</a><Br>
<a href="command:seek(00:33:41.0)"
target="_player">Scheduler</a><Br>
[…]
</window>
Volendo sfruttare al massimo le possibilità offerte dai metadata e da questa
granularità molto fine nell’indicizzazione degli argomenti, è possibile
immaginare nuovi usi delle risorse disponibili nella Mediateca. Attraverso un
sistema di ricerca uno studente può trovare una definizione o un esempio molto
94
particolare in maniera estremamente semplice, combinare fra loro diverse
spiegazioni dello stesso argomento da parte di professori diversi, mettere insieme
tutte le esercitazioni svolte negli anni per preparare un esame e così via.
I cambiamenti necessari nel database sono stati una rivalutazione della
tabella uUnitResource, che permette di creare dinamicamente lezioni della
Mediateca (tUnit) in maniera indipendente dalle lezioni riprese dagli operatori,
riversate poi in digitale e catalogate in spezzoni di filmato (tResource).
Il processo di post-produzione subisce pochi cambiamenti, all’interno delle
Risorse (tResource) vengono inseriti gli spezzoni trascrivendo in maniera lineare
il foglio di regia in una pagina web parzialmente precompilata per ridurre i tempi
di immissione. Si tratta, in pratica, di seguire la divisione della lezione in
argomenti, individuati con dei tempi assoluti rispetto all’inizio del filmato, e di
riempire delle form. A questo punto il sistema crea un’unità (in tUnit) che
rispecchia fedelmente la lezione registrata in presenza. Questa operazione
corrisponde all’inserimento di un semplice record nella tabella tUnit e una serie
di record in quella uResourceUnit dove vengono associati tutti i frammenti di
lezione in maniera lineare (questa operazione è fatta in maniera automatica alla
fine dell’inserimento dei frammenti di filmato). In questo modo si mantiene la
lezione originale, riducendo i tempi di inserimento, e si aprono tutte le possibilità
di riutilizzo dei frammenti di lezione esposti nel paragrafo seguente.
Con questo sistema è possibile inserire nelle risorse anche solo le slide delle
lezioni, un manuale o delle dispense aggiuntive che il professore può aver citato
nella lezione senza distribuirle ai ragazzi. Trovare materiali diversi è possibile
grazie ad una query sui metadata delle risorse e l’integrazione e la fruizione di
questi è attuabile con dei semplici controlli sul tipo MIME delle risorse
selezionate.
95
5.2.2 Creazione lezioni dinamiche
Per arrivare ad un algoritmo per la creazione di lezioni nel formato della
Mediateca, unendo risorse già presenti nel database, è indispensabile esaminare
la struttura che c’è dietro la lezione visualizzata.
Nel processo produttivo della Mediateca, una volta codificata la lezione nel
formato Real e preparate le immagini delle slide, si crea la lezione assemblando
il video, le immagini e l’indice degli argomenti. Per ogni lezione visualizzata su
schermo, i file necessari sono:
1
lezione.rm: il file con il video codificato;
2
video.smi: il file per l’assemblaggio delle varie parti che costituiscono
la lezione;
3
videoI.smi: il file per l’assemblaggio della lezione con l’opzione di
scaricamento previo delle immagini;
4
immagini.rp: il file per la gestione delle immagini;
5
toolbar.rt: il file per la gestione dell’indice degli argomenti correlati al
video.
Il risultato finale dell’assemblaggio è organizzato graficamente con lo
schema seguente, progettato per una risoluzione minima di 800x600:
96
Figura 5-1 Schema interfaccia lezione
Se per la gestione dell’indice e del video il file più importante è il RealText
Clip contenuto nella cartella dell’unità, chiamato sempre “toolbar.rt”, per la
sincronizzazione delle immagini i tempi vengono memorizzati in un RealPix
Clip, chiamato “immagini.rp” o “slide.rp”.
Per la creazione di nuove lezioni con le risorse presenti è evidente che il
problema principale è quello della sincronizzazione dei tempi fra video e
immagini rispetto al nuovo sommario. Nella creazione automatica del file SMIL
bisogna infatti referenziare tutti gli argomenti rispetto all’istante zero della nuova
lezione.
La soluzione è naturalmente al momento della creazione del file. Questa
operazione, la creazione dello SMIL e quindi della lezione, avviene attraverso un
insieme di file nel linguaggio di scripting ASP, una tecnologia per pagine web
dinamiche sviluppata da Microsoft approfondita nell’appendice A.3. Il primo
obiettivo di questi file è interrogare il database per trovare gli spezzoni di lezione
utili per la nuova unità che si sta creando. Una volta che l’utente, studente o tutor
che sia, ha selezionato i frammenti che desidera mettere assieme, si può
realizzare la scrittura su disco dei nuovi file RealPix e RealText passando per
l’analisi di tutti i tempi delle lezioni in presenza.
97
Le informazioni sulla locazione delle risorse e sui tempi vengono estratti dal
database attraverso le tabelle tResource e tMedium. Isolando i dati significativi
per la creazione dei file RealPix e RealText si possono notare:
in tResource
1
DurationFrom
2
DurationTo
3
AggregationLevel
4
RelationKind
in tMedium
1
Source
2
Format
3
FileName
4
FolderName
Le procedure per la scrittura dei file si basano quindi su questi dati, in
particolare possiamo immaginare dei file di testo “modello” con delle variabili
da riempire con le informazioni estratte dal database. Prima di essere scritti è
necessario però che questi valori siano rielaborati accordando tutti i tempi fra
loro attraverso un algoritmo:
1. estrazione dei dati dal database con delle query;
2. elaborazione del primo frammento video selezionato: viene scritto nel
toolbar.rt (il file indice degli argomenti) il titolo dell’argomento con il
riferimento al file video remoto e il suo tempo per localizzarlo;
3. vengono ricercate le immagini che appartengono alla lezione in presenza e
si analizzano i tempi cercandone una che coincida o che appaia prima
dell’introduzione dell’argomento all’interno della lezione;
4. questa immagine viene copiata all’interno della cartella dell’unità che si sta
creando e viene segnata all’interno del file slide.rp con un tempo iniziale pari
a zero. L’operazione è ripetuta per tutte le immagini che vengono visualizzate
98
dal filmato “in presenza” fino al termine dell’intervallo temporale che si sta
considerando. Se l’istante di apparizione dell’immagine è precedente a quello
dell’inizio dell’argomento (video e audio) per la prima immagine non ci sono
problemi, ma per la seconda e le successive è necessario sottrarre al tempo
originale
la
differenza
fra
l’apparizione
dell’immagine
e
l’inizio
dell’argomento;
5. a questo punto il primo spezzone è diventato l’inizio della nuova lezione e
possiamo procedere in maniera iterativa per tutti i successivi:
6. si scrive nell’indice (toolbar.rt) il titolo dell’argomento con i
riferimenti assoluti per visualizzare video e audio;
7. si cercano l’immagine coincidente o la precedente all’istante di
partenza dello spezzone che ci interessa e si inserisce nel file
slide.rp con un istante di apparizione del primo coincidente con
l’ultimo dello spezzone precedente. Per tutte le immagini mostrare
nello spezzone esaminato c’è un inserimento con il tempo originale
a cui è sommato l’istante di ingresso della prima immagine e a cui
è sottratto l’eventuale anticipo di questa rispetto all’istante di
partenza del filmato;
8. al termine degli spezzoni si possono scrivere i file sul server e aggiungere il
record con la nuova lezione alla tabella tUnit.
L’andamento dei tempi è esemplificabile graficamente immaginando di voler
unire due argomenti che partono entrambi in ritardo rispetto alla slide
precedente.
Le operazioni fra parentesi rappresentano la parte in corsivo del punto 7
dell’algoritmo, i frammenti in grigio rappresentano gli argomenti selezionati
dall’utente, che vorrà visualizzare nella nuova lezione con le slide
corrispondenti.
99
Figura 5-2 Esempio con due frammenti video
Osservando l’esempio si nota come l’iterazione nei punti 6 e 7 dell’algoritmo
sia efficace anche nel caso base (per la prima slide), partendo da un istante
iniziale uguale a 0.
100
Se si vogliono coinvolgere nella creazione di un’unità anche altre risorse
diverse dai file video è opportuno individuare soluzioni pratiche per ogni
selezione lasciata al tutor e allo studente. Se in fase di creazione l’utente
seleziona:
1. solo file video: si crea un file SMIL con gli spezzoni;
2. file video e testi: si crea un file SMIL con gli spezzoni e la
possibilità di visualizzare all’interno del player i documenti
attraverso collegamenti sull’indice (se i documenti non sono
consultabili con il player vengono lanciati i programmi di default
riconosciuti attraverso il MIME);
3. solo file di testo o solo immagini: si crea un file SMIL
visualizzando le immagini e i testi all’interno del player stesso
(selezionabili dall’indice a lato), se sono formati che il player non
può gestire si lancia il programma di default nel sistema
operativo;
4. file video e immagini: si crea un file SMIL e si procede come al
punto 2 con i testi.
5.3 Creazione moduli e corsi
Per l’automazione dei processi di creazione e gestione dei corsi il problema è
decisamente più lineare rispetto alle lezioni. In questi casi, come vedremo nel
capitolo seguente, si tratta di interagire con il database della Mediateca attraverso
le tabelle che contengono le informazioni su corsi e moduli (tCourse e tModule)
e la tabella che realizza le relazioni molti a molti coinvolte (uCourseModule).
101
6 Implementazione
L’obiettivo, prefissato nei capitoli precedenti, è quello di dare la possibilità
ad un tutor, o ad uno studente, di creare in maniera sequenziale nuovi corsi,
stabilendo dei moduli didattici e infine aggiungendo a questi delle lezioni. Per le
caratteristiche delle Mediateca, e per integrare le funzionalità che ci interessano,
le lezioni da aggiungere ad un modulo possono essere statiche o dinamiche.
•
Le lezione statiche sono inserite dall’operatore provvisto del foglio di
regia di una lezione filmata in presenza. Il nuovo sistema di inserimento
dati guida l’operatore nell’immissione delle informazioni, aumentando
l’efficienza e permettendo di introdurre i metadata in maniera molto
semplice.
•
Le lezioni dinamiche sono realizzate attraverso una ricerca nel database
da parte di un tutor, possibile creatore di un nuovo corso o un nuovo
modulo. La ricerca è basata sulle parole chiave associate ai learning
object presenti nel database. Ogni argomento di una lezione e ogni
singola slide sono learning object con tutti i loro metadata.
Come è stato accennato nei capitoli precedenti, il sistema è basato su ASP
della Microsoft e sul database SQL Server che ospita la Mediateca. La scelta
dell’ASP è stata fatta per continuità con la struttura precedente e per le
caratteristiche proprie del linguaggio: permette l’utilizzo degli strumenti
realizzati da qualsiasi postazione internet, senza dipendenze di sistema operativo
e senza un software da installare sulla macchina dell’operatore o del tutor.
102
Sequence diagram dell’intero processo di creazione:
Tutor
default.
asp
conferma
corso.
asp
crea_modulo.conferma_modulo
asp
creazione
lezione
dinamica
statica/default.
asp
scrivi.
asp
submit (dati
Corso)
(IDCorso)
submit (dati Modulo)
(IDCorso, IDModulo)
(IDCorso, IDModulo)
(submit dati Unità)
Nuova lezione presenza
Nuova lezione dinamica
Nuovo modulo
Nuovo corso
Figura 6-1 Sequence diagram processo creazione corso, modulo, lezione
103
Sequence diagram della creazione dinamica della lezione:
lezione.asp
Tutor
conferma.
asp
catalogo.
asp
default.
asp
(form_chiave)
(titolo_lezione, autore_lezione, IDResource)
aggiungiRisorsa
cancellaRisorsa
Elimina lezione
submit(dati lezione)
isArray
Aggiungi altre risorse
nuova lezione
Figura 6-2 Sequence diagram processo creazione lezione dinamica
Oltre ai sequence diagram del processo può essere utile analizzare le varie
fasi con i file coinvolti, osservando in particolare il sottoinsieme per la creazione
delle pagine dinamiche.
104
6.1 Creazione di un corso
Cartella: root
File ASP: default, conferma_corso
La pagina iniziale è una semplice form per la raccolta delle informazioni
sul corso che si vuole creare. Di default sono presenti due date per accelerare
l’inserimento dei dati e per mostrare direttamente all’operatore il formato
corretto per l’immissione di queste. E’ inserito inoltre l’ID del corso radice del
database come corso “Parent” (il corso da cui è propedeutico quello che si sta
creando). In questo modo non possono esserci errori di inserimento, perché
comunque ogni corso avrà un padre, anche se fittizio. Sono presenti infine i link
per proseguire direttamente all’inserimento di un nuovo modulo o una nuova
lezione.
Nella pagina di conferma si ha un semplice messaggio di avvenuta scrittura
nel database e una tabella riassuntiva delle informazioni immesse.
Per realizzare questa scrittura c’è una connessione al database, vengono
recuperati i valori passati con la form e infine si crea un RecordSet per la
scrittura fisica. A questo punto viene selezionato l’ID più alto (che corrisponde
all’ultimo corso creato) e viene passato come variabile alla pagina successiva
attraverso un link.
6.2 Creazione di un modulo
Cartella: root
File ASP: conferma_modulo, crea_modulo
Di nuovo una semplice form per raccogliere i dati sul modulo che si vuole
aggiungere. Anche in questa fase è inserito di default il valore del modulo Parent
uguale al modulo radice. Se la pagina è invocata dallo step precedente (la
105
creazione del corso) verrà recuperato l’ID del corso a cui sarà aggiunto il modulo
e inserito di default.
Nella pagina di conferma avvengono di nuovo le operazioni di scrittura sul
database, ma questa volta viene aggiornata anche una tabella non direttamente
coinvolta nella creazione: uCourseModule per gestire la relazione molti a molti
fra tCourse e tModule. A questo punto si può procedere all’inserimento di
lezioni statiche o dinamiche, con il passaggio delle variabili con il numero di
corso e modulo ai quali ci si riferisce.
6.3 Creazione di una lezione statica da una lezione in
presenza
Cartella: lezione_presenza
File ASP: default, scrivi
Per inserire le informazioni sulla lezione è indispensabile indicare subito
quanti argomenti saranno inseriti e quante slide sono presenti al massimo per
ogni argomento.
A questo punto vengono inseriti di default il corso e il modulo ai quali sarà
aggiunta la lezione (se la creazione di questa è richiesta dalla conferma della
creazione di un modulo) e viene creata la griglia per l’inserimento dei dati,
parzialmente precompilata per abbassare i tempi di inserimento. Per questo
motivo di default sono presenti anche molti altri dati che solitamente non
variano: le dimensioni del filmato e delle slide, il nome del file video, la lingua,
la data del giorno di inserimento (che automaticamente è scritta nel database
anche come data dell’ultima modifica), l’ID dell’unità Parent dell’ultima lezione
creata durante la sessione o dell’unità radice negli altri casi. I campi che
rimangono da riempire manualmente sono quelli indispensabili: nome della
lezione, autore, cartella dove verrà immagazzinato il file video, giudizi sulla
qualità della lezione e del materiale, titolo e parole chiave per ogni argomento
106
della lezione con i tempi di inizio, nomi delle slide con tempi di inizio (le
immagini avranno automaticamente le stesse parole chiave dell’argomento a cui
si riferiscono).
Inviando la form tutte le informazioni vengono scritte nel database: ci sono
inserimento nella tabella tMedium (per i file fisici), tResource (per i learning
object composti dagli spezzoni di lezione come argomenti o dalle slides), in
uModuleUnit e uUnitResource per gestire le relazioni molti a molti fra le tabelle.
6.4 Creazione di una lezione dinamica da risorse presenti
nella Mediateca
Cartelle: lezione_dinamica, lezione_dinamica/player
File ASP: default, conferma, catalogo, lezione, start
Questo insieme di pagine ASP è lo strumento in grado di ricercare nel
database e tenere traccia delle risorse scelte dal tutor attraverso gli strumenti
web. E’ uno strumento semplice e con una business logic molto chiara: è in
grado di:
•
creare una nuova lezione / Recuperare le informazioni da una lezione
esistente;
•
gestire le operazioni di inserimento, cancellazione e modifica delle
risorse;
•
gestire la persistenza delle informazioni (compatibilmente con le scelte
operate dal tutor);
•
integrare le informazioni del carrello con la gestione dei moduli, dei
corsi, delle lezioni in presenza.
Un’altra importante premessa è che la soluzione proposta consente di
realizzare lezioni on the fly: il tempo di vita dei dati sulla lezione è pari alla
107
durata della sessione utente, evitando di rendere le informazioni persistenti
almeno fino alla conferma della creazione.
Da un punto di vista implementativo è stato utilizzato un semplice array, che
contiene le informazioni sulla lezione, affiancato all'oggetto Session, che
funziona come veicolo dell'array stesso. Il vantaggio di questa soluzione è che
con semplici e veloci operazioni sull'array possiamo gestire tutte le funzioni
previste. Naturalmente i due elementi si completano con l'interazione via ADO
con il database Mediateca.
DEFAULT.ASP
Il codice presente in questa pagina contiene semplicemente il messaggio
descrittivo, la form per la ricerca e due link testuali: uno per rivedere la lezione
che si sta modellando e uno per confermare la creazione se si è tornati indietro
alla pagina di ricerca.
E’ praticamente superfluo analizzare il codice di questa pagina, considerando
le sue limitate funzioni.
CATALOGO.ASP
La pagina di ricerca consente al tutor di selezionare (tramite caselle di
conferma) le risorse che preferisce dal risultato della ricerca appena effettuata,
ed inserirle virtualmente nella lezione. Confermando la selezione delle risorse,
l'utente consulterà automaticamente il contenuto della lezione. Lo script ASP ha
il compito di connettersi al database SQL Server attraverso ADO e recuperare i
dati relativi alle risorse.
Viene dunque costruita una tabella contenente le informazioni dei singoli
articoli, con la prima colonna di selezione attraverso una casella checkbox di
conferma per aggiungere le risorse alla lezione.
Vale la pena evidenziare alcuni passaggi critici della ricerca, in particolare il
collegamento col database e la creazione della tabella con alcuni metadata:
<%
[…]
' Apro la connessione verso il database usando ADO
108
Set rsRisorse = Server.CreateObject("ADODB.RecordSet")
StrConn = "Provider=SQLOLEDB.1;Persist Security Info=False;Initial
Catalog=mediateca4prototipo;Data Source=SQL;User
Id=MediatecaUser;PASSWORD=089786;"
rsRisorse.open "SELECT * FROM tResource where Keywords like
'%"&chiave&"%' ORDER BY IDResource ASC",StrConn
'Costruisco la tabella delle risorse con una casella di conferma
With rsRisorse
While not .eof
NewTd="<TD align=center><input type=checkbox name=risorse
value=" & .fields("IDResource") & ">"
NewTd=NewTd & "<TD width=200>" & .fields("Title") & "</TD>"
NewTd=NewTd & "<TD width=350>" &
.fields("DescriptionAbstract") & "</TD>"
NewTd=NewTd & "<TD width=50>" & .fields("TeacherExposure") &
"</TD>"
NewTd=NewTd & "<TD width=50>" & .fields("MaterialQuality") &
"</TD>"
NewTd=NewTd & "<TD width=50>" & .fields("Type") & "</TD>"
NewRow="<TR>" & NewTd & "</TR>"
Response.write NewRow
.MoveNext
Wend
End With
rsRisorse.Close
Set rsRisorse=nothing
%>
109
LEZIONE.ASP
Questa pagina consente al tutor di visualizzare la lista delle risorse
selezionate, di eliminarne dalla lezione, di cancellare direttamente tutta la
lezione oppure di confermarne la creazione.
Si può esaminare brevemente la sequenza delle azioni svolte dallo script:
•
verifica contenuto oggetto Session("lezione") (attraverso la funzione
isArray);
•
analisi delle richieste inoltrate alla pagina. Le richieste possono
provenire dal catalogo delle risorse (inserimento) oppure dalla lezione
stessa (cancellazione della lezione, eliminazione di risorse);
•
costruzione della lista degli ID delle risorse da visualizzare attraverso
una query SQL sulla tabella tResource, per recuperare le restanti
informazioni.
É possibile identificare nel codice alcune importanti funzioni, incluse come
script lato server, che non vengono trasmesse al client ma eseguite direttamente
sul server come per tutto il codice ASP. Queste funzioni realizzano le operazioni
fondamentali sulla lezione, come:
NOME FUNZIONE
DESCRIZIONE
AggiungiRisorse()
aggiunge una o più risorse provenienti dal
database
EliminaRisorse()
cancella le risorse selezionate dall'utente nella
lezione
AggiungiRisorse()
Questa funzione preleva la lista delle risorse da inserire nella lezione dalla
collezione request("risorse"), proveniente dal form contenuto nella pagina
“catalogo.asp”.
110
Prima di tutto verifica la presenza di risorse nell'array lezione; se vi sono
altre risorse effettua una ulteriore verifica per trovare eventuali duplicati; infine,
aggiunge le risorse mancanti. Naturalmente tutte le verifiche vengono evitate nel
caso di lezione vuota. L'inserimento di nuove risorse avviene con un
ridimensionamento dell'array.
<% sub aggiungiRisorsa()
'Questa routine aggiunge una nuova risorsa alla lezione
risorse=split(request("risorse"),",")
'Se la lezione non è vuota devo verificare
'se le nuove risorse sono già presenti
if presenti=1 then
for art=0 to ubound(risorse)
trovato=false
for righe=0 to ubound(lezione,2)
if clng(lezione(0,righe))=clng(risorse(art)) then
trovato=true
righe=ubound(lezione,2)+1
end if
next
if trovato=false then
'righe=ubound(lezione,2)
redim preserve lezione(1,righe)
lezione(0,righe)=risorse(art)
lezione(1,righe)=1
end if
111
next
else
redim lezione(1,nuoviArt-1)
for c=0 to nuoviArt-1
lezione(0,c)=risorse(c)
lezione(1,c)=1
next
end if
presenti=1
end sub
EliminaRisorse()
Questa funzione consente l'eliminazione delle risorse contrassegnate dal
tutor per la cancellazione, e fa uso della collezione request("elimina"),
presente nei checkbox della pagina stessa, per recuperare la lista delle risorse.
Dopo aver verificato la presenza di risorse da eliminare, la funzione inizia la
scansione fino a trovare quella da cancellare. A questo punto viene impiegata
una tecnica di shifting che scambia l'elemento da eliminare con l'ultimo presente
nell'array, per poi ridurre opportunamente quest'ultimo di un elemento. Verifica
inoltre che siano rimasti altri elementi nell'array, ed imposta di conseguenza la
variabile “presenti” rispettivamente pari a 1 o 0.
sub cancellaRisorse()
'Questa routine elimina una risorsa dalla lezione
'con una tecnica di shifting degli elementi
risorse=split(request("elimina"),",")
presenti=true
112
for k=0 to ubound(risorse)
x=0
do
if cint(lezione(0,x))=cint(risorse(k)) then
'Verifico se si tratta dell'ultimo elemento
if x<ubound(lezione,2) then
ultimo=ubound(lezione,2)
lezione(0,x)=lezione(0,ultimo)
lezione(1,x)=lezione(1,ultimo)
end if
if ubound(lezione,2)=0 then
erase lezione
presenti=false
else
redim preserve lezione(1,ubound(lezione,2)-1)
end if
exit do
else
x=x+1
end if
loop
next
end sub %>
CONFERMA.ASP
Il tutor esprime la propria volontà di creare la lezione con il link "Conferma
creazione" presente in default.asp, oppure con il tasto "Crea lezione" presente in
lezione.asp. Quando richiesto dalla home page, l'utente è invitato a confermare
113
se visualizzare la lezione prima di confermare, oppure procedere direttamente.
Lo script contenuto nella pagina, conferma.asp appunto, esegue semplicemente
l'annullamento della variabile Session("lezione"), in modo che la lezione risulti
nulla, e scrive i file SMIL necessari. Rimangono quindi due possibilità: avviare
la lezione appena creata per visualizzarla attraverso il RealPlayer o tornare alla
home page per una nuova ricerca.
Prima di tutto viene creata la nuova cartella che ospiterà i file SMIL sul
server. Di questi il primo a essere scritto è video.smi:
Dim fsob, file
Set fsob = CreateObject("Scripting.FileSystemObject")
IF fsob.FileExists(completov)=true THEN
Response.write("Impossibile creare il file video.smi.
<br>Il file esiste già.")
ELSE
Set file = fsob.CreateTextFile(completov)
file.Writeline("<smil>")
file.Writeline("<head>")
file.Writeline("<!-- Presentation attributes. -->")
file.Writeline("<meta name=""title"" content="" " & titolo
& " ""/>")
file.Writeline("<meta name=""author"" content="" " & autore
& " ""/>")
file.Writeline("<meta name=""copyright""
content=""ELIS""/>")
[…]
for k=0 to ubound(lezione,2)
tempo_inizio= campi("DurationFrom")
tempo_fine= campi("DurationTo")
temp = (DateDiff ("s", campi("DurationFrom"),
campi("DurationTo")))
114
file.WriteLine ("<video src=""rtsp://teca.elis.org/"
& campi("FolderName") & "/lezione.rm"" clipbegin="""&tempo_inizio&""" clip-end="""&tempo_fine&"""
region=""video_region"" fill=""remove"" />")
rsRisorse.MoveNext
next
file.WriteLine("</seq>")
file.WriteLine(" ")
file.WriteLine("<textstream
src=""file:///c|/paolo/test/prova" & numerocaso
"/toolbar.rt""
&
region=""toolbar_region"" />")
file.WriteLine("<img
src=""file:///c|/paolo/test/prova" & numerocaso
&
"/immagini.rp"" region=""slide_region""/> -->")
file.WriteLine("</par>")
file.WriteLine("</body>")
file.WriteLine("</smil>")
file.Close
Response.Write("Ho creato il file smile.<br>")
END IF
rsRisorse.MoveFirst
Set file=Nothing
A questo punto vengono creati i due file con l’elenco degli argomenti della
lezione (toolbar.rt) e il file che gestirà la visualizzazione delle immagini
(immagini.rp) con un procedimento simile, ma con l’algoritmo mostrato nel
quinto capitolo per la gestione dei tempi.
115
Un frammento del codice per l’inserimento nel file delle immagini:
tempo_start="00:00:00"
for k=0 to ubound(lezione,2)
Set RsAppoggio= Server.CreateObject("ADODB.RecordSet")
StrConn3="Provider=SQLOLEDB.1;Persist Security
Info=False;Initial Catalog=mediateca4prototipo;Data Source=SQL;User
Id=MediatecaUser;PASSWORD=089786;"
stringasql="select count(*) from tMedium inner join
tResource on tMedium.IDMedium=tResource.IDMedium where Type='Slide'
and IDParent = ("& lezione(0,k) &") "
RsAppoggio.open stringasql,StrConn3
contatore = RsAppoggio(0)
for j=0 to contatore-1
file.Writeline("<image handle="""&iSlide&"""
name=""http://teca.elis.org/" & campi2("FolderName") & "/immagini/"
& campi2("FileName") &"""/>")
file.Writeline("<fadein start=""" & tempo_start & """
duration=""0"" target="""&iSlide&"""/>")
iSlide = iSlide +1
tempo_start=campi2("DurationTo")
rsSlides.MoveNext
next
' i tempi d'inizio dell'argomento!
temp2 = (DateDiff
("s",campi("DurationFrom"),campi("DurationTo")))
tempo_temp = DateAdd("s",temp2,"00:00:00")
tempo_start= Replace(tempo_temp, ".", ":")
116
rsRisorse.MoveNext
next
START.ASP
Per visualizzare la lezione è sufficiente un solo file ASP per invocare il player
per qualsiasi lezione creata.
Il file start.asp mostra infatti la lezione andando a leggere proprio i file SMIL
appena creati nella nuova cartella, se la lezione è una combinazione di risorse già
presenti, o il file SMIL originale di una lezione completa già presente nel database.
Questo avviene grazie al passaggio della variabile con l’ID della lezione richiesta.
Questa variabile viene letta proprio all’inizio del file (da notare che se viene
invocata la pagina senza variabile viene restituita una pagina di errore):
<% mpID = Request("ID")
if mpID = "" then
response.Redirect("/error.asp?ErrorID=0")
%>
<html>
<head>
A questo punto viene avviato il Real Player, immerso nella finestra del browser
ed invocato con una stringa di inizializzazione:
<embed name="MediatecaPlayer"
id="MediatecaPlayer"
type="audio/x-pn-realaudio-plugin"
src="rtsp://teca.elis.org/<%=mpID%>/video.smi"
width="692"
117
height="375"
autostart="true"
controls="ImageWindow"
console="MediatecaPlayer">
</embed>
Il passaggio della variabile, evidenziato in neretto, permette di poter richiamare
qualsiasi lezione in maniera dinamica semplicemente invocando il file.
118
Conclusioni
All’inizio di questo lavoro di tesi mi ero prefissato l’obiettivo di progettare e
realizzare un database compatibile con i metadata, che attraverso questa
innovazione riuscisse ad utilizzare completamente le possibilità dei learning
object.
Per arrivare a destinazione mi sono confrontato con tutti gli elementi
coinvolti nel processo, dall’operatore video al docente ripreso, dagli addetti alla
post produzione agli studenti finali a cui è rivolta la lezione a distanza. Sono
stato il primo fruitore di questa tecnologia per preparare delle docenze e delle
esercitazioni che ho avuto l’occasione di offrire a dei ragazzi di un corso sulle
nuove tecnologie.
Mi sono dovuto confrontare con le difficoltà di una lotta per uno standard
definitivo, le implicazioni e le ristrettezze degli interessi commerciali e i passi
faticosi delle soluzioni più aperte, con tempi di gestazione lenti e macchinosi. Ho
affrontato un’esperienza di reverse engineering su un database progettato e
implementato anni prima e mi sono immerso nella progettazione di una nuova
struttura con diversi strumenti, sfruttando pienamente le possibilità della
modellazione software con l’UML (Unified Modeling Language). Una volta
preparato il sistema sulla carta ho avuto la possibilità di implementarlo e di
testarlo direttamente, imparando molto della programmazione orientata ai
database sul web, sperimentando i vantaggi e le difficoltà di scelte concrete,
come la ricerca di un equilibrio efficace fra la completezza e la semplicità di
utilizzo per l’utente.
Infine, ho avuto la possibilità di svolgere il mio lavoro in un ambiente
produttivo sereno e stimolante, dove non ho smesso di approfondire argomenti
collegati al mio lavoro o scoprirne di nuovi, anche grazie a dei “colleghi” che
non hanno esitato ad accogliermi.
Al termine di questo lavoro posso dire che gli obiettivi sono stati raggiunti.
119
E’ evidente che una delle potenzialità più importanti della Mediateca,
divenuta chiara e facilmente accessibile con l’implementazione dei metadata, è la
modularità. Per ogni lezione filmata, attraverso la regia in fase di ripresa e la
post-produzione successivamente, vengono create una serie di risorse che
possono essere riutilizzate con i nuovi strumenti sviluppati. Sfruttando al
massimo le possibilità offerte dai metadata e da questa granularità molto fine
nell’indicizzazione degli argomenti, è ora possibile utilizzare al meglio le risorse
disponibili nella Mediateca. Attraverso il sistema di ricerca un utente può trovare
una definizione o un esempio molto particolare in maniera estremamente
semplice. Qualsiasi studente ha la possibilità di combinare fra loro diverse
spiegazioni dello stesso argomento, anche di professori diversi, scegliendo
l’aspetto della lezione che vuole privilegiare, o può mettere insieme tutte le
esercitazioni svolte negli anni passati per preparare un esame.
Anche dal punto della creazione dei corsi sono arrivato a delle soluzioni
ottimali. Con il gran numero di lezioni raccolto dalla Mediateca negli anni è già
possibile creare dei corsi anche significativamente diversi da quelli originali.
Attraverso la combinazione dei singoli argomenti, estratti da corsi e lezioni
differenti, si possono creare veri e propri nuovi corsi o semplicemente integrare,
aggiornare, migliorare quelli già esistenti. I casi pratici che si possono
immaginare sono molti e facilmente intuibili: integrare un ottimo corso di base
con approfondimenti successivi, aggiornare una lezione con un argomento
recente, estrarre solo gli argomenti significativi da un corso molto completo per
chi deve avere solo una conoscenza di base di una tematica, e così via.
Tutto questo è stato automatizzato e reso accessibile attraverso strumenti
indipendenti da piattaforma e locazione dell’utente, con delle soluzioni che mi
hanno portato ad un’ottima conoscenza della progettazione UML prima, e
dell’implementazione attraverso ASP e SMIL poi.
L’ultimo risultato fondamentale è la possibilità di importare ed esportare dati
con qualsiasi altra base di dati conforme ad uno standard fra Dublin Core, IMS o,
per la struttura essenziale, IEEE LOM. Questa possibilità apre la strada
all’interazione con altri progetti già avviati all’interno dell’ELIS e apre le
conoscenze e le competenze raccolte in questi anni a qualsiasi tipo di
120
collaborazione dove sia prevista uno scambio di dati tramite XML, lo standard di
fatto per lo scambio delle informazioni sul web.
121
Appendice A
A.1 XML: eXtensible Markup Language
Extensible Markup Language (XML) è un semplice e flessibile formato per i
testi derivato da SGML (ISO 8879), un metalinguaggio ideato negli anni ’60 per
definire linguaggi di tipo markup, ossia linguaggi basati su marcatori.
XML è uno dei risultati di questo lavoro, in particolare è il linguaggio
specifico per scrivere dati in maniera strutturata.
Un esempio molto semplice di XML:
<nota>
<a>Paolo</a>
<da>Claudio</da>
<soggetto>Reminder</soggetto>
<corpo>Ricordati la riunione sabato</corpo>
</nota>
Questa, come è facilmente intuibile, è una scrittura in XML di dati relativi ad
un appunto fra due colleghi.
Dall’esempio si possono intuire le principali caratteristiche di questo
linguaggio:
1
è un linguaggio di markup molto simile all’HTML
2
è concepito per descrivere dati
3
i tag non sono predefiniti e cercano di essere auto-descrittivi
E’ possibile notare la somiglianza con l’HTML per quanto riguarda la
122
sintassi, ma è importante sottolineare le differenze concettuali:
1
l’HTML è per la visualizzazione dei dati (come mostrare i dati)
2
XML è per la descrizione e lo scambio di questi fra sistemi (cosa
sono i dati)
Tutto ciò che hanno in comune questi linguaggi è, quindi, la sintassi base
utilizzata e l'idea di scrivere i dati di un documento o di un record in maniera
strutturata.
E possibile inoltre aggiungere degli attributi (per l’esempio precedente basta
pensare all’attributo “data” con un valore di otto cifre) con una sintassi del tipo:
<nometag attributo="valore"> contenuto del tag </nometag>
ma la stessa espressione può anche essere scritta:
<nometag >
<attributo> valore </attributo>
contenuto di nometag
</nometag>
In questo modo il valore dell’attributo è più facilmente estraibile con un
programma, se ne possono elencare più di uno e possono essere estesi in un
futuro con molta elasticità.
Ogni tag ha un nome e può avere più attributi, ognuno con un valore, e deve
essere aperto e chiuso.
Un documento XML si dice Well Formed se è sintatticamente corretto
secondo le specifiche del linguaggio.
Un documento non well formed è ad esempio:
<prova> <uno> <due> testo del test </uno> </due>
perché il tag <prova> non è chiuso, e i tag <uno> e <due> non sono annidati
correttamente.
Come è stato accennato, per tutti gli standard il linguaggio XML è
considerato lo strumento ideale per scambiare informazioni strutturate.
123
Ad esempio, diversi software bancari potrebbero scambiare dati con una
struttura XML di questo tipo:
<conto id=”BB1357246”>
<cod_banca>ABI9988</cod_banca >
<saldo>
<data_saldo>20001127</data_saldo>
<valuta>euro</valuta>
<valore>+4000</valore>
</saldo>
</conto>
Per definire la struttura con cui poi si scambieranno i dati si possono
utilizzare due strumenti: i DTD (Document Type Definition) oppure i più recenti
XML-Schema. Un documento XML che rispetta la struttura definita da un DTD
o da uno Schema, si dice Valid rispetto ad esso.
Permettono entrambi di definire in maniera formale e univoca la struttura di
un documento XML: quali tag possono essere annidati e all'interno di altri, quali
attributi sono ammessi per un certo tag, quali elementi sono obbligatori, la
cardinalità ammessa per ogni elemento e così via.
DTD proviene dal mondo SGML ed è una tecnologia affermata, ma non
sempre semplice da comprendere e limitata da un set di funzionalità ristretto.
XML-Schema è uno standard molto giovane, ma con diversi vantaggi, primo fra
i quali il fatto di essere stato scritto proprio in XML. E’ naturale quindi che i
software capaci di leggere ed editare XML possono automaticamente lavorare
con gli schema. E’ importante anche notare che gli schema sono più
autoesplicativi rispetto ai criptici DTD, ed hanno anche la possibilità di definire
tipi per i valori dichiarati (i DTD possono definire solo vincoli sulla struttura del
documento e non sui valori). Per questi motivi è facile ipotizzare un futuro con
124
gli XML-Schema sempre più utilizzati e i DTD destinati a sparire lentamente.
125
A.2 SMIL: Synchronized Multimedia Integration Language
Dietro l’acronimo SMIL (che si pronuncia come la parola inglese ‘smile’)
c’è un “Linguaggio di integrazione e sincronizzazione di file multimediali”.
Un linguaggio a marcatori (TAG) come l'HTML, sviluppato come
un’estensione XML, che consente l'integrazione di filmati e suoni e testo,
soprattutto in un’ottica di maggiore fruizione di questi via web. Come per tutte le
estensioni
dei linguaggi a marcatori XML, non è scontato trovare
un'applicazione che la apra; sono esemplari, in questo campo, le differenze di
visualizzazione tra i vari browser per i file HTML, uno standard in uso da più di
dieci anni e che ancora non trova stabilità e una riproduzione univoca. Per i file
SMIL, riconoscibili dal suffisso “.smi”, attualmente le uniche applicazioni che li
riproducono sono i prodotti della Real, a partire dal G2 Player Plus.
Queste
applicazioni
naturalmente
supportano
principalmente
i
file
RealAudio, RealMedia, RealPix, RealText, ed è possibile trovarle sia come
programmi stand-alone che come plug-in nelle versioni più recenti dei più
diffusi browser Netscape e Internet Explorer. All’interno dei file SMIL è
possibile anche inserire file multimediali più comuni, ma perdiamo molte delle
proprietà dei file .rt (RealTxt), .rp (RealPix) e così via.
La soluzione migliore è quindi quella di acquisire i file multimediali con una
semplice scheda di acquisizione in un formato supportato dalla periferica (ad
esempio .avi, . mpg, .mov) e successivamente convertirli in .rm, il formato Real
per i file video, con un semplice encoder gratuito (come l’Helix Basic offerto
gratuitamente proprio dalla Real).
Diverso discorso meritano, come vedremo, i file .rp Real Pix per i file
grafici .rt Real text per i file di testo.
Come per tutti i linguaggi per il web, le specifiche sono decise dal W3C (il
consorzio per il World Wide Web) come estensione XML. Per presentare gli
elementi principali della sintassi si può esaminare un file della Mediateca:
126
<smil>
<head>
<!-- Presentation attributes. -->
<meta name="title" content="10 - Introduzione alle reti locali"/>
<meta name="author" content="Silvano Gai - Reti di calcolatori"/>
<meta name="copyright" content="Elis - Linfa"/>
<layout>
<!-- Width, height, and background color of entire presentation. ->
<
root-layout
width="692"
height="375"
background-
color="white" />
<!-- Video region. -->
<region
id="video_region"
left="0"
top="0"
width="192"
width="500"
height="375"
height="144" />
<!-- Images region. -->
<region
id="slide_region"
left="193"
top="0"
background-color="white" />
<!-- Toolbar region. -->
<region id="toolbar_region" left="0" top="145" width="192"
height="231" />
</layout>
</head>
<body>
127
<par>
<!-- Play these streams concurrently (in parallel). -->
<video src="lezione.rm" region="video_region" />
<img src="slide.rp" region="slide_region" />
<textstream src="toolbar.rt" region="toolbar_region" />
</par>
</body>
</smil>
Naturalmente questo codice è estratto da un file con estensione .smi e per
aprirlo è bastato un semplice editor di testi come Notepad o TextPad. Si nota
subito l’utilizzo dei tag (marcatori) come nell’HTML, SMIL è infatti un diretto
discendente dello SGML.
Il primo tag che incontriamo, e che non può mancare, è proprio lo stesso che si
chiude alla fine del documento:
<smil>
</smil>
Il tag è fra parentesi acute, questo permette di identificare le “parole chiave” al
parser che elaborerà il semplice file di testo per creare il documento
multimediale.
Come per l’HTML, dopo i marcatori principali che identificano il tipo di file
(in HTML al posto di <smil> abbiamo proprio <html>) incontriamo un altro tag
128
che racchiude del codice:
<head>
</head>
All’interno troviamo inizialmente dei marcatori che servono ad identificarlo
in maniera univoca, fissando vari attributi (titolo, autore e copyright nel nostro
caso):
<!-- Presentation attributes. -->
<meta name="title" content="10 - Introduzione alle reti locali"/>
<meta name="author" content="Silvano Gai - Reti di calcolatori"/>
<meta name="copyright" content="Elis - Linfa"/>
Andando avanti incontriamo una sintassi per il layout fortemente ispirata ai
CSS2 (Cascade Style Shett 2, la seconda versione dei fogli di stile in sequenza),
istruzioni quindi per disporre e coordinare sulla schermata i vari file
multimediali.
<layout>
<!-- Width, height, and background color of entire
presentation. -->
< root-layout width="692" height="375" backgroundcolor="white" />
<!-- Video region. -->
<region id="video_region" left="0" top="0"
width="192" height="144" />
129
<!-- Images region. -->
<region id="slide_region" left="193" top="0" width="500" height="375"
background-color="white" />
<!-- Toolbar region. -->
<region id="toolbar_region" left="0" top="145"
width="192" height="231" />
</layout>
Possiamo notare gli attributi fondamentali del marcatore root-layout:
1
heigth: l'altezza della finestra nell' applicazione in cui appariranno i
file multimediali misurata in pixel;
2
width: l'altezza della finestra nell' applicazione misurata in pixel;
3
background-color: il colore dello sfondo nell’applicazione.
All’interno del marcatore <root-layout></layout> c’è un altro tag ripetuto tre
volte:
<region id />
che associa a determinate zone dell'applicazione un id delle proprietà precise.
Ogni zona conterrà un elemento multimediale diverso, video_region mostrerà un
video, slide_region immagini statiche e così via.
Naturalmente ogni regione dovrà essere definita anche in maniera molto
precisa, andrà settato infatti: il titolo di questa zona o parte o area, la distanza in
pixel da sinistra, la distanza in pixel dall'alto, l'altezza in pixel, la lunghezza in
pixel e –facoltativamente- il colore di sfondo.
130
Terminata la parte dell’ <head> entriamo nell’applicazione vera e propria, il
corpo, quella che vedremo materialmente sullo schermo, con il marcatore
<body>.
<body>
<par>
<!-- Play these streams concurrently (in parallel). -->
<video src="lezione.rm" region="video_region" />
<img src="slide.rp" region="slide_region" />
<textstream src="toolbar.rt" region="toolbar_region" />
</par>
</body>
Il marcatore che si può notare è <par>, contiene tutti gli altri elementi del
<body> ed è chiuso subito prima del </body> finale. Il tag <par> indica degli
oggetti
multimediali
che
andranno
mostrati
in
parallelo
all’interno
dell’applicazione. In alternativa si utilizza il marcatore <seq> per avere oggetti
in sequenza.
All’interno sono elencati gli oggetti multimediali, con dei marcatori molto
simili all' <img src></img> usato in HTML. Con questi tag possiamo includere
i file dei video (lezione.rm, RealMedia), dell’indice (testuale, tollbar.rt,
RealText) e delle immagini (slide.rp, RealPix), associandoli alle regioni definite
precedentemente nell’header.
131
Analizzando nel dettaglio un file RealPix si possono notare altre
caratteristiche interessanti:
<imfl>
<head
timeformat="dd:hh:mm:ss.xyz"
duration="42:53"
preroll="10.0"
bitrate="12000"
width="500"
height="375"
aspect="true"/>
<image handle="1" name="slide/1.jpg"/>
<image handle="2" name="slide/2.jpg"/>
[…]
<image handle="23" name="slide/23.jpg"/>
<!-- Prima Foto di presentazione -->
<fadein start="0" duration="5" target="1"/>
<fadein start="00:00:14" duration="0" target="2" />
<fadein start="00:01:27" duration="0" target="3" />
<fadein start="00:02:05" duration="0" target="4" />
[…]
132
<fadein start="00:42:46" duration="0" target="23" />
</imfl>
Un file RealPix è un semplice file di testo, scritto in XML, che organizza i
comuni file jpg o png o gif con una codifica speciale.
Questi file possono effettuare, attraverso marcatori in linguaggio XML, una
sequenza (slideshow) di file grafici con effetti grafici (es: fadein) e indicazioni
temporali e altro ancora. Il principale marcatore di questo tipo è <imfl>.
Come nell’esempio precedente il tag head segue il principale, ma in realtà ha
delle caratteristiche particolari:
<head
timeformat="dd:hh:mm:ss.xyz"
duration="42:53"
preroll="10.0"
bitrate="12000"
width="500"
height="375"
aspect="true"/>
Come si nota subito la prima differenza è che si conclude nella medesima
parentesi angolare <head/>. La seconda è che ha attributi diversi:
1
Height Altezza file jpg
2
Width Larghezza file jpg
3
Il secondo in cui inizia la sequenza
4
Duration La durata della sequenza
133
5
Timeformat La misura in cui viene contato il tempo (ore, minuti,
secondi, ecc.)
6
Bitrate L'indicazione della velocità alla quale il file jpg deve
essere trasmesso (in bit al secondo)
7
Url Eventualmente un Url, dal quale si deve scaricare l'immagine
Non viene dichiarato un marcatore body, ma un marcatore <image handle />
che numera i file jpg da maneggiare (handle appunto) e gli assegna un
identificatore:
<image handle="1" name="slide/1.jpg"/>
<image handle="2" name="slide/2.jpg"/>
[…]
<image handle="23" name="slide/23.jpg"/>
Esistono,
infine,
dei
marcatori
(<wipe/>,
<image/>,
<animate/>,
<crossfade/>, …) che indicano, attraverso vari attributi, in che maniera deve
avvenire la sequenza per ogni singolo file grafico. Nel caso della Mediateca è
stato utilizzato il tag <fadein/>:
<fadein start="0" duration="5" target="1"/>
<fadein start="00:00:14" duration="0" target="2" />
<fadein start="00:01:27" duration="0" target="3" />
<fadein start="00:02:05" duration="0" target="4" />
134
[…]
<fadein start="00:42:46" duration="0" target="23" />
RealPix è dunque un file XML che definisce una sequenza di file grafici (jpg,
png, gif). L' <head/> definisce le caratteristiche come la durata e la dimensione,
l’<image handle/> numera e nomina i file, <wipe/> indica i vari modi di
mostrarli.
Analizzando infine il file RealText apriamo il file toolbar.rt con un editor di
testo:
<window type="generic" width="192" height="231" duration="42:53.0">
<font face="Arial"><b>INDICE</b><br>
<a href="command:seek(00:00:00)" target="_player">Introduzione</a><Br>
<a href="command:seek(00:01:19)" target="_player">Indice</a><Br>
[…]
<a href="command:seek(00:39:09)" target="_player">Domande</a>
</font>
</window>
Il marcatore che racchiude il codice è <window> caratterizzato da una serie
di attributi:
1 window type Il tipo di visualizzazione;
135
2 height L'altezza in pixel del testo;
3 width La larghezza in pixel del testo;
4 underline_hyperlinks Se il testo, eventualmente linkato, è sottolineato
o meno (se sottolineato: true);
5 duration La durata, misurata in secondi, in cui il testo dovrà apparire;
6 link Il colore dell' eventuale collegamento;
7 bgcolor Il colore dello sfondo.
Dentro un marcatore <window> possiamo inserire marcatori HTML: <font>
e <br>, ad esempio.
<font face="Arial"><b>INDICE</b><br>
All'interno del tag <a></a> inseriremo un comando per il player, indicando
l’istante in cui deve iniziare a visualizzare il video se il link viene cliccato dall’utente.
<a href="command:seek(00:00:00)" target="_player">Introduzione</a><Br>
<a href="command:seek(00:01:19)" target="_player">Indice</a><Br>
In questo modo si può passare a vari istanti del video che si sta mostrando, in
questo caso ai vari argomenti indicizzati raggiungibili attraverso i link.
136
A.3 ASP: Active Server Page
Superare i limiti dell'HTML, per creare dei siti sempre più rispondenti alle
esigenze dei visitatori, è stato una delle mete a cui i programmatori di linguaggi
di scripting hanno puntato nel corso della storia del web. Dalle prime pagine
statiche, siti vetrina o di presentazione, si è progressivamente arrivati non solo
all'esplosione del multimediale, ma, soprattutto, al diffondersi di pagine
interattive, in grado non solo di affascinare, ma di fornire un utile strumento a
chi le volesse usare.
Superare la staticità delle pagine web, mantenendo al contempo una
semplicità di programmazione, è possibile grazie ai linguaggi di scripting. Fra
questi si distingue ASP (Active Server Pages) per la rapidità e flessibilità di
utilizzo che lo caratterizzano, controbilanciate però da uno svantaggio non
indifferente: l'utilizzo di questo linguaggio è confinato ai server Microsoft, come
ad esempio IIS, e non funziona quindi con tutti gli altri server che popolano il
web a meno di soluzioni particolari, instabili e molto poco efficienti. La sempre
maggiore diffusione dei server Windows contribuisce però a rendere meno
limitante questo ostacolo con il passaggio dal mondo Unix ai server Windows.
Va ricordato che esiste una valida alternativa all’ASP per i server Unix: il PHP,
dove l’acronimo ricorsivo sta per: “PHP: Hypertext Preprocessor”.
Grazie all'utilizzo delle pagine ASP, l'utente può quindi creare dei documenti
che possono fornire informazioni, rispondendo dinamicamente in modo diverso
alle differenti richieste dei navigatori.
Ma quali sono, in breve, i vantaggi nell'utilizzo di questo linguaggio di
scripting?
1) Le pagine ASP sono completamente integrate con i file HTML.
2) Sono facili da creare e non necessitano di compilazione.
3) Sono orientate agli oggetti e usano componenti server ActiveX.
137
Visti i vantaggi, e viste anche le limitazioni accennate in precedenza, si
possono riassumere le tecnologie coinvolte nello sviluppo e funzionamento delle
active server pages in quattro punti:
1) Windows NT o 2000 o XP
2) Protocollo tcp/ip
3) Un web server che supporti Active Server, come IIS
4) ODBC (Open DataBase Connectivity) e un server database.
Esaminando più da vicino la struttura di questo genere di pagine possiamo
constatare che esse sono costituite da tre differenti parti:
1) Testo
2) Marcatori HTML
3) Comandi script
In un documento con estensione “.asp” è consentito infatti utilizzare
variabili, cicli, istruzioni di controllo, etc. grazie alla possibilità di richiamare la
sintassi un linguaggio di scripting, come ad esempio il VBScript e il JScript, ma
anche il Perl.
Prima di esamine qualche rudimento di programmazione ASP tramite esempi
commentati è utile uno sguardo alla sintassi per capire come esso funzioni,
naturalmente senza fare un elenco completo di tutti i comandi, ma solo per capire
come lavora.
Una prima distinzione a livello di codice sorgente è sui comandi nativi,
propri di ASP, e comandi di scripting che appartengono al particolare linguaggio
utilizzato. Tra i marcatori fondamentali di ASP ci sono sicuramente i
delimitatori, che come nell'HTML delimitano l'inizio e la fine di una sequenza di
codice, e sono rappresentati dai simboli <% e %>.
Ad esempio il comando: <% x="ELIS" %> assegna alla variabile x il valore
"ELIS".
138
Come già detto, è possibile includere anche script nel codice ASP e utilizzare
così funzioni create, ad esempio, in JScript o VBScript, richiamandole tramite il
comando nativo <% Call _ %>, ad esempio:
<% Call PrintDate %>
<SCRIPT LANGUAGE=JScript RUNAT=Server>
function PrintDate()
{
var x
// x è un'istanza dell'oggetto Date
x = new Date()
// il comando Response.Write scrive la data sul navigatore
Response.Write(x.getDate())
}
// Questa è la definizione della procedura PrintDate.
// Questa procedura manderà la data corrente al navigatore.
</SCRIPT>
E’ stato introdotto il concetto di oggetto, è utile quindi ricordare brevemente
la sua natura: un oggetto è un'astrazione di una struttura dati, di cui non interessa
sapere come è implementata (information hiding), ma quali sono le operazioni
possibili su di essa.
ASP possiede degli oggetti precostituiti, sui quali si può operare con i
metodi, che sono delle funzioni intrinseche all'oggetto: per fare un esempio,
sull'oggetto automobile un metodo può essere rappresentato dall'operazione di
“svuota_array”, rappresentabile facilmente con una notazione del tipo
lezioni.svuota_array.
Sebbene si rassomiglino, bisogna fare attenzione a non confondere i metodi
dalle funzioni; queste ultime infatti sono definite dal programmatore e risultano
esterne all'oggetto.
139
Ritornando all'esempio precedente, la funzione PrintDate definita in JScript è
scritta tra i marcatori <SCRIPT> e </SCRIPT> come sempre, però questa volta
sono stati inclusi gli elementi LANGUAGE=JScript e RUNAT=server.
Un indubbio vantaggio che deriva dall'uso del delimitatore RUNAT di script
è costituito dal fatto che il codice sorgente non è mai presente nella pagina
HTML che viene spedita al navigatore dal server. Infatti, il sorgente viene
rielaborato dal server che invia come risultato una pagina costruita "al volo"
nella quale sono visibili solo i codici HTML e quelle funzioni per le quali non
sia stato specificato il valore "server".
E’ utile esaminare infine alcuni oggetti fondamentali per programmare in ASP:
1
Response, il quale consente di gestire l'interazione fra il server e il
client. Molto importante il metodo Response.Write per la scrittura a
video: richiede una stringa di testo tra virgolette, o una funzione che
restituisca una stringa
2
Request, che può essere definito come oggetto intrinseco al server:
rappresenta l'elemento di connessione tra il programma client ed il web
server. Si occupa infatti di trasmettere le informazioni provenienti da
alcune variabili del server (le collections), mentre l'oggetto Response si
occupa dell'interazione tra server e client tramite l'utilizzo di metodi
quali Write. La sintassi di questo oggetto è: Request[.Collection]
("variabile")
3
RecordSet, che rappresenta il set di record estratti da una tabella del
database interrogato. La sintassi per creare l'oggetto RecordSet è la
seguente:
<%
Dim objRS
Set objRS = Server.CreateObject("ADODB.RecordSet")
%>
140
Per poter popolare il RecordSet con i record di una tabella bisogna utilizzare
il metodo OPEN
<%
objRS.Open Fonte, ConnessioneAttiva, TipoCursore,
TipoBlocco, Opzioni
%>
dove Fonte rappresenta un elemento che restituisce un nome di variabile oggetto
valido: un'istruzione SQL, un nome di tabella, una chiamata di una stored
procedure oppure il nome del file di un RecordSet protetto (opzionale);
ConnessioneAttiva rappresenta l'elemento che restituisce un nome di variabile
Connection valido o un elemento String contenente i parametri ConnectionString
(opzionale); TipoCursore rappresenta il valore CursorTypeEnum che determina
il tipo di cursore che il provider deve utilizzare quando apre il RecordSet (è
opzionale); Opzioni rappresenta il valore Long che indica come il provider deve
valutare l'argomento Fonte se questo non rappresenta un oggetto o che il
RecordSet deve essere ripristinato da un file in cui era stato precedentemente
salvato (opzionale).
141
Appendice B
ELIS: Educazione Lavoro Istruzione Sport
Attività per la formazione della gioventù lavoratrice e per la solidarietà sociale
Centro ELIS
Il Centro ELIS fu eretto nel 1965 con i donativi offerti dai cattolici di tutto il
mondo in omaggio al papa Pio XII in occasione del suo ottantesimo genetliaco.
Da allora l’ELIS opera come struttura di solidarietà in Italia e in altri Paesi in
tutti i continenti realizzando attività e iniziative educative allo scopo di prevenire
il disagio umano e sociale, trasmettendo professionalità, comunicando uno stile
di vita e una cultura del lavoro.
Gli Enti giuridici che dirigono le attività e le iniziative sono tutti organismi
civili e sia gli organismi che le attività appartengono alla categoria del non profit.
Nell’ ELIS operano diversi enti:
1
Associazione Centro ELIS: riconosciuta dallo Stato con Dpr n.738 del
26 maggio 1965 e, in quanto organismo non governativo, organizzazione non
lucrativa di utilità sociale (ONLUS).
Nel Centro ELIS, chiamato anche "Centro Internazionale della Gioventù
Lavoratrice" sono promosse e gestite iniziative che spaziano dal volontariato ai
campi di lavoro per i giovani, alla formazione professionale, dai club di studio
alla formazione avanzata tecnologica e informatica. Tutte le iniziative sono
finalizzate alla formazione di giovani di varia origine ed estrazione sociale, di
nazionalità e religione diverse, facendo maturare in tutti la consapevolezza delle
proprie potenzialità umane, per diventare individui capaci di assumersi
personalmente il compito della loro formazione, agendo collettivamente in
relazione fra loro e adoperandosi per il conseguimento di un bene comune al
142
quale tutti cooperano;
2
Cedel: cooperativa sociale educativa e di solidarietà.
Cedel eredita le esperienze umane e professionali dell’Associazione Centro
ELIS e ne condivide le finalità educative e solidaristiche, agendo in favore dei
giovani e dei lavoratori sia in campo nazionale che internazionale. La missione
sociale della Cooperativa consiste quindi nel promuovere e supportare in vario
modo le iniziative finalizzate alla valorizzazione del lavoro ed alla educazione
professionale dei giovani, in modo tale da poterne favorire l’inserimento nel
tessuto lavorativo, puntando alla ricerca di soluzioni innovative per dare risposta
ai problemi sociali, combinando l’attività di formazione a quella pedagogica,
psicologica ed educativa. A tale scopo, collabora con agenzie governative ed
aziende pubbliche e private;
3
Consel: consorzio fra imprese impegnate nella formazione di qualità
professionale ed umana.
Consel nasce per formalizzare il rapporto tra il Centro ELIS e un gruppo di
imprese altamente qualificate che sono i fruitori privilegiati delle iniziative
formative. Consel, attingendo al patrimonio di conoscenze e valori dei
consorziati, si occupa di favorirne il trasferimento all'interno dei corsi Elis
affinché questi siano allineati alle esigenze delle imprese;
4
Avel: associazione per il volontariato organizzato.
L'AVEL , oltre a contribuire alla realizzazione e al sostegno delle attività del
Centro Elis, si propone di svolgere attività sociali e di volontariato in tutti i
campi delle organizzazioni non profit, sulla base delle proprie disponibilità
finanziarie e umane.
Vivai d’impresa
"Vivai d'impresa" è un’iniziativa del centro ELIS, finanziata dalle imprese
aderenti al Consel, per realizzare un Master per laureati e laureandi in cerca di
143
una tesi di Laurea su progetti avanzati in contesti aziendali di telecomunicazioni
e produzione multimediale. Il Master è orientato alla creazione d'impresa,
facilitata dall'inserimento nell'incubatore ELIS.
Si tratta di un vero e proprio "vivaio", un ambiente in grado sia di favorire la
generazione di nuove idee d'impresa (in base alle proposte provenienti dalle
aziende), sia di dare ospitalità alle start up companies in un ambiente basato
sulla fiducia e sulla collaborazione. L'iniziativa si viene a configurare quale
esempio di "educational institution" di tipo completamente innovativo, basata
sulla metodologia dell'imparare facendo.
Il progetto Vivai è composto da due fasi:
1
Master per la creazione di internet companies
2
Ospitalità alle start up companies
La prima fase, della durata di sei mesi, è un periodo di formazione e ricerca
finalizzato alla genesi di nuove idee imprenditoriali. Accoglie giovani laureandi
o laureati che possiedono già conoscenze specialistiche del settore ICT
(Information and Communication Technology), ma che ancora non le hanno
applicate a progetti reali.
La formazione si basa sulla didattica per progetti. Sul modello delle società
di consulenza, i vivaisti, dopo un colloquio di orientamento, vengono assegnati
ai progetti commissionati dalle aziende promotrici (Telecom Italia; Siemens;
EDS; RAI; WIND; ESA; HP;…) sotto la supervisione di un senior manager che
ha anche il compito di seguirne l'apprendimento e effettuare, al termine del
progetto, la valutazione e certificazione delle effettive competenze maturate.
Questa fase prevede interventi formativi con cadenza periodica. L'attività di
formazione copre un 30% del tempo, suddivisa fra seminari su tematiche
tecnologiche avanzate e di cultura d'impresa, e interventi specialistici d'interesse
per i singoli progetti. Un certo tempo viene dedicato anche ad attività di
comunicazione sia interna che esterna, perché tutti i partecipanti siano aggiornati
periodicamente sull'evoluzione di tutti i progetti in corso.
Durante questo periodo, è possibile ottenere la certificazione CISCO Systems
(leader mondiale nelle tecnologie per il Networking), essendo il Centro ELIS la
144
prima Regional Academy italiana e l’unico Training Centre.
Al termine della prima fase, ciascun gruppo di lavoro è invitato a presentare i
risultati del progetto e le relative idee d'impresa.
Nel secondo stadio del vivaio (di durata compresa tra sei e diciotto mesi), i
vivaisti hanno la possibilità di dar vita al proprio progetto imprenditoriale e viene
loro offerta ospitalità negli spazi attrezzati del progetto: “Incubatore d'Impresa –
ELIS”.
L'Incubatore è una team room con sistema di videoconferenza ISDN ad alta
velocità e stazioni di lavoro dotate di PC in rete locale con connessione
permanente a Internet ad alta velocità.
Gli Incubatori non svolgono solo la funzione di “hosting” fisico delle
imprese consentendo a queste ultime di abbattere i costi di uso locali e impianti
(costi di start up). Questa funzione, pur importante, è secondaria rispetto al reale
punto di forza dell’Incubatore e cioè la creazione di un’economia distrettuale,
una rete di imprese che, lavorando in uno stesso luogo (l’Incubatore appunto)
spesso su uno stesso settore, sviluppano quei fenomeni di cooperazione e
concorrenza il cui equilibrio è il fattore trainante dell’economia distrettuale. Con
un neologismo, si potrebbe parlare di “co-opetition” come conciliazione tra “cooperation” e “competition”.
Proprio all’interno dei Vivai si è svolta la mia esperienza, con un progetto
per lo sviluppo della Mediateca-ELIS, il sistema di fruizione via Internet di
lezioni filmate in diretta o registrate, lo strumento utilizzato per i corsi a distanza
della Scuola di Formazione Superiore del Centro ELIS.
145
Bibliografia
•
American Federation of Teachers
“Guidelines for good practice”
2000, http://www.aft.org/higher_ed/downloadable/distance.pdf
•
Atzeni P., Ceri S., Paraboschi S., Torlone R.
“Basi di dati”
1999, McGraw-Hill Italia
•
Baca M.
“METADATA Pathways to Digital Information”
2000, Getty Information Institute
•
Berge Z. L.
“The Role of the Online Instructor/Facilitator”
1995, http://www.emoderators.com/moderators/teach_online.html
•
Cox B.
“Evolving a Distributed Learning Community”
1997, http://www.virtualschool.edu/cox/OnlineClassroom.html
•
Cross J., Hamilton I.
“The DNA of eLearning”
2002, http://www.internettime.com/Learning/articles/DNA.pdf
•
Crudele M., Dragoni G., Marcovati L.
“ICTAD – il primo corso a distanza con certificazione pubblica IFTS, basato su
videolezioni via Internet”
2002, http://www.crudele.it/papers/00232.pdf
146
•
Ghislandi P.
“E-learning: opportunità e rischi per la didattica accademica”
2001, http://cepad.unicatt.it/home/Convegni/Ottobre2001/Materiali/Ghislandi.pdf
•
Harasim L.
“Online Education: A new Domain”
in Mason, R, Kaye, A., Mindweave: “Communication, Computer and Distance
Education”, 1989, Pergamon Press, Oxford
•
Horton W.
“Leading e-Learning”
2001, The American Society for Training and Development
•
Institute for Higher Education Policy (The)
“What’s the difference?”
1999, http://www.ihep.com/Pubs/PDF/Difference.pdf
•
Kapp K.
“Learning Requirements Planning: An Enterprise-Wide Learning Management
Approach”
2001, Bloomsburg Institute for Interactive Technology
http://www.e-learningguru.com/wpapers/kapp_lrp.pdf
•
Kaye A.
“Collaborative Learning Through Computer Conferencing”
1992, Springer-Verlag, Berlin
•
Kearsley G.
“Learning and Teaching in Cyberspace”
2001, http://home.sprynet.com/~gkearsley/chapts.htm
•
Martignago E.
147
“Argomenti di Apprendimento in Rete”
2002, http://www.martignago.com/libri/elearning_toolbook/
•
Olimpo G., Trentin G.
“La telematica nella didattica: come e quando”
1993, Istituto Tecnologie Didattiche
http://www.spbo.unibo.it/pais/giovgraz/td3.htm
•
Russell T. L.
"The No Significant Difference Phenomenon”
Articoli dal libro omonimo
1999, http://teleeducation.nb.ca/nosignificantdifference/
•
Tanenbaum A.S.
“Reti di computer”
1997, Prentice Hall/UTET
•
Tannenbaum A.
“METADATA SOLUTIONS“
2001, Addison Wesley
•
Trentin G.
“Dalla formazione a distanza alle comunità di pratica attraverso l’apprendimento
in rete”
2000, Scuolanews
http://www.forminform.it/files/tab2/dista/nds06110.htm
•
Wiley D.A.(Edited by)
“The Instructional Use of Learning Objects”
Association for Instructional Technology
http://www.reusability.org/read/
148
RISORSE WEB:
•
ARIADNE
ARIADNE Foundation for the European Knowledge Pool,
http://www.ariadne-eu.org
•
CISCO
Cisco Networking Academy Program,
http://www.netacad.it/default.asp
•
DC
Dublin Core Metadata Initiative,
http://www.dublincore.org/
•
IBM
IBM Learning Services,
www-3.ibm.com/services/learning/
•
ICDL
International Centre for Distance Learning,
http://icdl.open.ac.uk/
•
IMS
IMS Learning Resource Meta-data Information Model,
http://www.imsglobal.org/
•
LOMWG
IEEE LOM Working Group,
http://ltsc.ieee.org/wg12/
•
MICROSOFT eLearn
Le proposte MS per l’e-learning,
http://www.microsoft.com/elearn/
149
•
REAL
RealNetworks produzione e sviluppo,
http://service.real.com/
•
SCORM
Sharable Content Object Reference Model,
www.adlnet.org
•
SMIL
Synchronized Multimedia Integration Language,
http://www.w3.org/AudioVideo/
SMIL nella “RealNetworks Production Guide”
http://service.real.com/help/library/guides/realone/ProductionGuide/HTML/realp
gd.htm
•
TILS
Telecom Italia Learning Services,
http://www.tils.com
•
XML
Extensible Markup Language,
http://www.w3.org/XML/
150
Ringraziamenti
I miei genitori, Franca e Virgilio, e mia sorella Lidia, per le possibilità che
mi hanno dato e la pazienza nei momenti di nervosismo da studio “matto e
disperatissimo”.
I professori che ho incontrato in cinque anni, per la disponibilità e la voglia
che mi hanno trasmesso di uscire dall’università con molto più di “un pezzo di
carta”. Il Prof. Atzeni in particolare, per la fiducia che ha avuto in me.
L’ELIS per l’accoglienza e il supporto, in particolare il Prof. Crudele per le
conoscenze e i metodi che mi ha aiutato ad avvicinare, condividendo un corso e
diversi momenti di verifica con me. I ragazzi con cui fianco a fianco ho
affrontato il lavoro e condiviso musica, pranzi e risate: Gianluca P, Flavio,
Gheorghe, Gianluca F, Giuseppe, Gianluca S, Manuel e in particolare Federico,
Roberto, Antonello e Nicola.
Gli amici dentro e fuori l’università, per avermi regalato anni dove nello
studio non è mai mancato il divertimento e l’aiuto reciproco. In particolare
abbraccio chi ha passato con me tante ore in “aula piscina”, Daniele per i primi
anni di musica sulla sua Punto e non solo, Anna, Paoletto e Marco per i loro
ritmi folli, Andrea e la sua chitarra, Davide e i sabato pomeriggio a S.Paolo,
Ciccio e i suoi stornelli, Mattia, Damiano, Francesca, Benedetta, Stefagna,
Adriana, Paola; Antonio per BombaCarta e la sua attenzione, Valentina,
Michela, Domenico ddt; Franz e Davide dal quel settembre a Taizè, Pasquale, il
“cuginetto” Alberto e infine Silvia, per i mesi durante la scrittura di questa tesi.
Ringrazio davvero queste persone e tutte quelle che in questi cinque anni e
mezzo mi sono state accanto con amore: nei viaggi, nella scrittura, nell’amicizia
151
quotidiana, nella preghiera. Sono loro che mi hanno aiutato a vivere lo studio
come una parte molto bella delle mie giornate, e mai come la mia vita. Grazie.
152