DdR
SOCIOLOGIA E SCIENZE SOCIALI APPLICATE (SeSSA)
a.a. 2014-2015
Lezione del 15 APRILE 2015
ore 17:00-18:00, Aula B8
Prof.ssa Mary Fraire
L’Analisi Automatica dei Dati Testuali
(AADT): aspetti statistici introduttivi e
un’applicazione all’analisi del “corpus” dei post
del movimento “NO ALLA DISCARICA DEI
RIFIUTI NELLA ZONA DEL DIVINO
AMORE”
Prof.ssa Mary Fraire – Professore ordinario di Statistica
Dip.to di Scienze Sociali ed Economche (DiSSE)
e-mail: [email protected]
Sito web: http://www.sociologia.uniroma1.it/users/fraire
Facoltà di Scienze Politiche, Sociologia, Comunicazione
Università di Roma ‘La Sapienza’
Tab.2 - Bilancio lessicale del corpus
'File 46CIT2VAR.TXT': alcuni
parametri
Parametri
Valore
46CIT4VAR_
Nome
corpus_
Lingua
Italiano
N. testi
46
N.segmenti del testo 67
Occorrenze
1974
N.forme
907
N.Hapax
669
N.hapax in % forme 73,76%
N.hapax
in
%occorrenze
33,89
L’analisi ‘statistica’ dei dati testuali:
origini ed evoluzioni attuali nelle societa Web 2.0 e le nuove fonti di dati
digitali.
In passato, ed a tutt'oggi, molteplici sono le applicazioni della statistica all'analisi
linguistica (cfr. ad es. Yule,1939, 'On the sentence length as statistical characteristic of
style..'; Chomsky,1963, ' A new statistical approach to the study of language'; Rizzi, 1985,
'Alcune Analisi statistiche della lingua italiana'; De Mauro,1993 'Lessico di frequenza
dell'italiano parlato' ecc.ecc.). In particolare le applicazioni della statistica all’analisi del
contenuto ( Lasswell,, 1942;Shutz, 1950;Berelson,1952 ‘Content Analysis in communication
research’;ecc.ecc.).
E' da rilevare che l'analisi statistica dei dati testuali è diversa dalla lessicometria classica ossia
focalizza l'attenzione (anche se qui sarà trattato solo a livello solo introduttivoesemplificativo), ad un approccio relativo all’ambito metodologico-statistico di quella che
più propriamente oggi può essere denominata Analisi ‘Automatica’ dei Dati Testuali
(AADT), Text Mining, intendendo le procedure e tecniche statistiche uni e multidimensionali adatte all’analisi di file di dati testuali di grandi dimensioni e alla sua
importanza crescente come strumento adatto ad analizzare i cosiddetti SOCIAL BIG DATA
in concomitanza dello svilupparsi delle nuove fonti di dati digitali.
Per AADT si intendono le tecniche di analisi statistica multidimensionale, generalmente con
approccio descrittivo- esplorativo, dei testi , cosiddetti ‘corpora’, basate principalmente da
una parte sulla cluster analysis e l'analisi delle corrispondenze e dall'altra sui metodi di
ricampionamento (Monte Carlo, Jack Knife, Bootstrap).
Nuovi dati in forma digitale:
caratteristiche e strumenti di
analisi
Nell’ambito dell’analisi automatica dei dati testuali è crescente l’interesse
per l’utilizzo dei nuovi dati in forma digitale, derivanti dai Social media
(blog,socialnetwork,forum,chat ,sms ecc..) denominati Big data , non solo
per la dimensione ma per la differente natura dell’informazione:
fortemente eterogenea e destrutturata
da un utente passivo ad un utente “attivo” che interagisce con il web
realizzando suoi contenuti e collocandoli in rete.
Occorre avere strumenti innovativi di analisi per strutturare e analizzare
questi dati, testuali, di dimensione notevole: oggi sono disponibili attraverso
una serie di analisi statistiche la cosiddetta Analisi Automatica dei Dati
Testuali (AADT) che si effettua tramite appositi software (Taltac, Lexico,
Spad-T, Dtm-Vic di Lebart, Iramuteq)
Scopi e recenti applicazioni dell’AADT
In via del tutto generale si può dire che molteplici sono gli scopi e le applicazioni, attuali e
‘potenziali’, di queste analisi statistiche come, ad esempio, per citarne solo alcuni:
individuare a priori ‘unità di scomposizione’ ad es. le ‘unità di contesto’ ossia contesti
linguistici minimi aventi senso compiuto (ad es. segmenti = frasi di un certo numero di
parole e frequenza che sono più ripetuti in un testo) per la classificazione del/dei testi;
svelare (osservare) regolarità, organizzazioni linguistiche, 'mondi lessicali' nel confronto di
testi brevi, post di social network , oppure, risposte a domande ‘libere’ di un
questionario date da un campione di n individui a seconda delle loro caratteristiche sociodemografiche, economiche ecc.;
effettuare studi cronologici miranti a stabilire cambiamenti nell'impiego dei vocaboli non
osservabili tramite la semplice consultazione manuale dei testi ;
oggi in presenza della comunicazione digitale in una società Web 2.0 si moltiplicano le
applicazioni di analisi automatica di dati testuali (marketing, valutazioni della P.A., codifiche
statistiche, ecc.). Alcuni importanti esempi ISTAT recenti:
a) Recentemente la Dr.ssa Francesca Della Ratta-Rinaldi dell’ISTAT-DISA ha effettuato
un’analisi dei dati testuali su ‘Le opinioni dei cittadini sulle misure del benessere – Risultati
della
consultazione
‘on
line’
consultabile
in:
http://www.misuredelbenessere.it/fileadmin/relazione-questinarioBES.pdf
in cui si richiede ai cittadini di indicare quali sono secondo loro le dimensioni sociali rilevanti
che costituiscono i fondamenti del Benessere Equo e Sostenibile (BES) oggi definizione attuale di
Qualità della Vita proposta dal CNEL e ISTAT
b) Tramite procedure di Text Mining , sempre Dr.ssa Delle Ratta-Rinaldi ha è effettuato il
controllo e correzione della codifica delle attività economiche effettuate dai rilevatori Istat
nell’Indagine sulle Forze di lavoro. Consultabile in : http://www.istat.it/it/archvio/134852
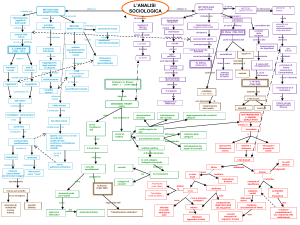
Richiamo metodologico:
l’Analisi Multidimensionale dei Dati (AMD)
come ‘sistema’: la mappa concettuale delle 7 fasi statistico-informatiche di
un’AMD
In passato l’applicazione di una tecnica statistica multivariata consisteva sinteticamente in:
tabella dei dati
tecnica statistica multivariata
output dei risultati
Oggi l’ampliarsi dei campi di applicazione dei metodi di analisi dei dati sia nelle scienze
sociali che naturali, la varietà e complessità delle situazioni specifiche di ricerca, hanno
portato a dare rilievo sia dal punto di vista metodologico che informatico ad una serie di
aspetti trascurati in passato: le 4 fasi ‘preliminari’ dell’AMD ossia la formalizzazione del
problema, le codifiche a priori e a posteriori.
In generale le fasi ‘preliminari’ di un’analisi dei dati sono relative al trattamento ‘a priori’ e
a posteriori’ dei dati rilevati per ‘giungere’ alla ‘tabella dei dati’ da sottoporre alla tecnica
statistica multivariata richiesta, esse costituiscono punti ‘cruciali’ dell’analisi statistica e
influenti su tutte le fasi successive e quindi i risultati stessi e per le quali spesso non vi sono
regole fisse o criteri unici di scelta, soprattuto nell’ambito della ricerca sociale.
La loro ‘esplicitazione’ formale e sostanziale è dunque indispensabile al mantenimento
della ‘scientificità’ dell’analisi empirica e all’interpretabilità-interpretazione dei risultati
della ricerca.
richiamo:
Le 7 fasi dell’AMD
• Per una descrizione dettagliata di tali fasi vedi:
• Fraire, Rizzi, Analisi dei dati per il Data Mining, Carocci ed. 2013
• Fraire - Metodi di Analisi Multidimensionale dei Dati - Ed. CISU, Roma 1994,
Cap.I.
Mappa concettuale delle 7 fasi di un’AADT
La scelta del ‘corpus’
TESTI-TESTI (saggi, biografie, discorsi parlamentari ecc.) o
TESTI-FRAMMENTI (testi corti, sms, tweet o chat, blog ecc.)
Creazione del
‘corpus’ file di testo ed eventuali
meta-variabili associate
La scelta delle
unità lessicometriche
di analisi :
-forme grafiche
-segmenti
Prime analisi
statistiche.)
Possibili feedback
Scelta della
Scelta
tabella dei
della
dati:
metrica:
-frammenti *forme es. ²
-forme *parti
- forma*forma
Metodo
e software*
di ADT:
Cluster Anal.
ACS e ACM
Output
risultati
- numerico
- grafici particolari
(nuvola lessicale,
grafo lessicale
* Taltac, Lexico, Spad-T, DtmVic di Lebart, Iramuteq
1^, 2^ e 3^ fase dell’AADT
•
•
•
•
•
•
•
•
1
La documentazione statistica di partenza : riguarda la scelta dei testi da analizzare es.
raccolta di messaggi brevi che possono essere: post di social network , blog , sms ecc. su
argomenti o trasmissioni radio-tv ma anche le risposte libere a domande ‘aperte’ di un
questionario unitamente alle caratteristiche degli intervistati da ritenere (es. sesso, età, titolo
di studio ecc.) in tal caso siamo in presenza di un corpus del tipo CORPUS TESTIFRAMMENTI). Analizzare invece interi testi, es. interi discorsi parlamentari per vari anni, o
saggi, libri ecc. riguarda il cosiddetto CORPUS TESTI-TESTI che qui non sarà considerato.
2 La codifica a priori (matrice dei dati testuali iniziali): riguarda la creazione del file di
testo , il cosiddetto “corpus”e l’eventuale file di dati-numerici meta-variabili ‘a priori’ (es.
genere, età, data ecc.) o a ‘a posteriori’ad esso associato (classificazioni fatte a posteriori:
argomenti, date ecc.). NOTA: per una stabilità statistica dell’AADT sono consigliate almeno
10.000 OCCORRENZE (n°tot.parole=forme grafiche).
In questa fase si deve effettuare una prima pulizia del testo NETTOYAGE digitato che
segue le regole del software impiegato . Occorre scegliere i separatori ‘forti’ per riconoscere
le frasi (es. : .;?! ) , fare attenzione all’uso delle maiuscole e nomi propri ecc.
3
Le codifiche a posteriori: riguardano sostanzialmente la scelta delle unità di analisi
sulle quali effettuare il conteggio lessicometrico:
A) Forme grafiche = parole oppure segmenti (n° parole componenti un segmento, es.: da 3 a
10 max e che si ripeta almeno tre volte);
B ) Disambiguazione tramite lemmatizzazione= per il riconoscimento delle categorie
grammaticali (nomi, agg. .articoli, verbi ecc.).
C) PRIME STATISTICHE TESTUALI SEMPLICI:
Il bilancio lessicale; le tabelle di frequenza delle forme attive, supplementari,, hapax ecc.
Particolari osservazioni sulla 2^ e 3^ fase
•
•
•
•
•
•
•
•
•
Le codifiche a posteriori nell’AMDT (2^ e 3^ fase) riguardano in sostanza la scelta delle unità
di analisi ossia il problema della definizione delle unità di analisi nell'AADT
Le parole di un testo sono sequenze di caratteri separate da uno spazio (Gross 1995). Esistono
tuttavia separatori più complessi dello spazio: trattini, apostrofo, punti di interiezione ecc. che
sono fondamentali per il trattamento statistico dei dati. Nelle procedure di conteggio il come
trattare tali separatori è una questione rilevante.
Focalizzare l'attenzione sull'aspetto formale delle parole ne esclude il significato; quest'ultimo è
invece il centro di interesse prevalente nell'Analisi Multidimensionale dei Dati Testuali nel senso
che le stesse parole possono avere più significati letterali.
Così come altre parole, tipo le preposizioni o avverbi di locazione, non hanno molto significato.
Si deve procedere quindi ad una loro disambiguazione.
Il trattamento statistico classico dei testi si basa sulle sequenze di parole semplici ed ignora le
difficoltà su accennate.
La disambiguazione del testo con la creazine di dizionari elettronici.
Alcune soluzioni sono state proposte come, ad esempio, le forme 'ridotte' consistenti
nell'impiegare parole composte da usare come un'unica unità (es. ‘che cosa’: una parola, ‘vi
sono’: una parola).
Dizionari elettronici di parole semplici e composte sono stati costruiti per diverse lingue, per
l'italiano, ad es. da A.Elia 1984, A.Elia, E.D'Agostino, M.Martinelli 1981.
Un esempio: il corpus 46CIT2VAR.TXT del caso di studio n.1 che vedremo
****01 *Sex_1 *Istr_3
È STATO TUTTO UN GIOCO FATTO PER FAR PRENDERE TEMPO ALL'ECOFER
CHE NEL FRATTEMPO HA SISTEMATO TUTTO. ADESSO A FINE 2013
INIZIERANNO DI NUOVO CON FALCOGNANA MA QUESTA VOLTA ARRIVERANNO
I CAMION SCORTATI DALL'ESERCITO.IL PROBLEMA NON È LA GENTE MA
IL FATTO CHE DOPO TUTTI I SOLDI SPESI DALL'ECOFER PER SCAVI,
INVASI, NE DUBITO SI ARRENDANO.
****02 *Sex_2 *Istr_3
SUI LAVORI C'È SCRITTO ITALGAS, MA NON CI FIDIAMO. BISOGNA FARE
QUALCOSA PER NON FAR PASSARE I TIR PERCHÉ E' DIVENTATO TROPPO
PERICOLOSO.
****03 *Sex_1 *Istr_3
AL CONVEGNO "ROMA VERSO RIFIUTI ZERO" IN CAMPIDOGLIO 13 DICEMBRE
CI SARÀ UN INTERVENTO DI MASSIMO PIRAS E PROMOTORI DEL CONVEGNO:
ZEROWASTE LAZIO,COMITATO DIAMOCIDAFARE.
IL VICEPRESIDENTE DEL PARLAMENTO EUROPEO É VENUTA A TROVARCI
DOPO AVER EFFETTUATO UN SOPRALLUOGO ALLA ECOFER.
…………………………………………………………………………………………………………………………………
****44 *Sex_2 *Istr_2
LA MISCELAZIONE DEL RIFIUTO ATTUALMENTE CONFERITO IN DISCARICA CON I
RESIDUI DELLE LAVORAZIONI DEL RIFIUTO INDIFFERENZIATO PROVENIENTE DA AMA.
ESISTONO STUDI IN MERITO AI POTENZIALI DANNI ALLA SALUTE?
LA SOCIETÀ GIUSTIFICA QUESTA DISPONIBILITÀ INIZIALE CONTENUTA PER
RASSICURARELA POPOLAZIONE LOCALE.NO COMMENT!!!
PREGO IL PRESIDIO DI UNIRE LE LISTE DELLE FIRME!
****45 *Sex_1 *Istr_1
MANIFESTARE CONTRO QUESTI DUE FURBACCHIONI GIÀ PER SE È OBBLIGATORIO.
MA E' FATTO OBBLIGO A TUTTI PARTECIPARE IN QUANTO MANCANO 7 GIORNI
AL PUNTO DI NON RITORNO! CONDIVIDO FIRME AL PRESIDENTE NAPOLITANO
E AL PRESIDENTE DEL CONSIGLIO LETTA E CORTEO MERCOLEDÌ.
****46 *Sex_2 *Istr_1
BENE! IO SO CHE SIETE GRANDI!!!
=====
…………………………………………………………………………………………………………………………
4^-7^ fase dell’AADT: l’analisi multidimensionale dei dati testuali
4
La scelta della tabella dei dati testuali: riguarda la scelta del tipo di tabella dei dati
adatta alla tecnica statistica multivariata che si vuole applicare. Sono tre le tabelle testuali per
le analisi lessicali:
1) Per la cluster analysis una tabella frammenti (u.s.)* forme (parole diverse); scopo: trovare le
unità di contesto con la massima similarità in termini delle parole (nello stesso cluster= mondi
lessicali);
2) Per l’analisi delle corrispondenze semplice (ACS) una tabella di contingenza parole*testi
oppure tabella forme* parti (sub testi) a seconda della codifica a posteriori effettuata.
3) Per l’ACM una matrice di prossimità forme*forme (booleana, presenza-assenza)
5 Scelta di una misura di rassomiglianza dissomiglianza tra unità statistiche (distanze,
similarità) o di relazione tra caratteri (connessione, correlazione, dev e codev., var.covar.ecc.):
riguarda la scelta della metrica adatta e compatibile con il tipo di tabella dei dati e il tipo di
tecnica di AMD scelta, ad es., nel caso di un’ACS o ACM su una tabella di contingenza
parole*testi la metrica adatta è quella del ².
6 Metodo e software di AMD: riguarda la scelta della tecnica
statistica multivariata (es. Cluster Analysis, Analisi delle Corrispondenze ecc.) e del
programma per l’esecuzione dell’analisi. Nelle applicazioni di seguito esposte si è scelta, ad
es. la Cluster Analysis e l’analisi delle corrispondenze (ACS) con i software IRaMUTEQ e
SPAD.T.
7 Output dei risultati numerico e grafico. Ad es. nell’AADT e a seconda dei software
sono disponibili Dendrogrammi e Wordcloud, Piani fattoriali, Grafi lessicali ecc.
Osservazioni sulla 2^ e 3^ fase
•
•
•
•
•
•
•
La ‘segmentazione’ del testo
In generale nell'ADT una delle questioni preliminari più importanti è quella della scelta delle
unità statistiche sulle quali effettuare il conteggio lessicometrico ed essa non ha criteri unici,
regole fisse. Parole singole (=forme grafiche) o parole impiegate in associazione con altre, e
ripetute almeno due volte (=segmenti) sono i due diversi possibili approcci nella scelta delle unità
(di analisi) che presiede alla segmentazione del testo (Salem 1995).
Piuttosto che scegliere a priori, all'inizio, queste unità di analisi, è oggi possibile, tramite metodi
statistici ed appositi programmi (ad es. la procedura SEGME di SPADT) effettuare delle analisi
preliminari osservate simultaneamente su diversi tipi di unità di analisi ossia considerando, ad
es., il file di testo originale e una sua forma ridotta (‘segmentata’).
Le ‘altre’ codifiche a posteriori
Collegate alla scelta delle unità di analisi vi sono altre successive e ulteriori scelte di codifiche a
posteriori (cfr. 3^ fase dell'AMDT) della matrice dei dati iniziali costituita nel caso dell'AMDT da
file di testo o da file di risposte a domande libere di un questionario + eventuali file di dati
numerici associati (caratteristiche degli intervistati, dei testi ecc.) , digitati in versione originale,
ossia così come sono stati rilevati (2^ fase dell'AMDT) per la costruzione della tabella dei dati (4^
fase dell'AMDT) sulla quale effettuare le successive analisi:
- soppressione di alcune parole; - correzione degli errori di ortografia; - messa in equivalenza di
alcune parole: permette di rendere sinonimi delle parole giudicate equivalenti; - riduzione della
soglia di frequenza delle parole; - scelta della soglia di lunghezza delle parole;
- riduzione della soglia dei ‘segmenti’: sia fissando una soglia di frequenza dei segmenti ripetuti
sia fissando una soglia sulla lunghezza delle risposte (numero dei segmenti) da ritenere.
Le due analisi multidimensionali dei dati testuali più impiegate:
La Cluster Analysis di dati testuali
In una tabella Frammenti (u.s.) x parole si cerca di individuare le unità di contesto più
simili (cluster) in altri termini le parole che più caratterizzano ciascun cluster , ‘mondi
lessicali’, ‘profili lessicali’, in sostanza quindi dare una ‘struttura’ al corpus del file dei testi
L’Analisi delle Corrispondenze di dati testuali : interpretazione degli assi fattoriali in
chiave linguistica (S.Bolasco)
Una frase=struttura sintagmatica. Più due parole sono vicine sul piano fattoriale tanto più
esse CO-OCCORRONO NEL CORPUS. Gruppi di parole fra loro vicine sul piano
ricostruiscono interi contesti di significati. Se il corpus è composto di frasi brevi è facile
ritrovarsi in queste situazioni interpretabili.
CASO DI STUDIO N.1
MOVIMENTO DI FALCOGNANA
contro la discarica dei rifiuti di Roma nella
zona del Divino Amore
• Un esempio italiano di impiego dei social network per
organizzare, diffondere e sostenere le mobilitazioni di difesa
del territorio
Un esempio italiano di impiego dei social network per organizzare,
diffondere e sostenere le mobilitazioni di difesa del territorio:
Il caso di Falcognana e la mobilitazione contro la discarica del Divino Amore
A Falcognana la mobilitazione nasce il 30 luglio 2013 a seguito della dichiarazione
del Commissario Straordinario ai rifiuti che decreta l’area idonea come sito
alternativo a Malagrotta per raccogliere nei prossimi due anni i rifiuti trattati di Roma
capitale.
In entrambi i casi, Gamonal e Falcognana, la comunicazione tramite social network
è stata determinante sia per l’organizzazione che per il coinvolgimento
A titolo di esempio per analizzare nel caso di Falcognana N=96 post scritti e
scambiati tramite social network nel periodo 27 luglio 2013 –7 febbraio 2014 (data in
cui si è chiusa la mobilitazione ‘vincente’)si è impiegata come strategia di analisi
l’analisi automatica dei dati testuali (AADT)utilizzando i software statistici SPADT e
l’open source IRaMuTeQ
Numerose manifestazioni e blocchi della circolazione:
Roma-via dei Fori Imperiali
Città del Vaticano -SAN PIETRO
Le numerose manifestazioni e le mobilitazioni si
fermano a seguito di due eventi:
1)Il 28 novembre 2013 la soprintendenza dei beni
architettonici e paesaggistici chiede la sospensione
dei lavori che a dicembre vengono bloccati;
2)Il 7 febbraio 2014 viene postata la lettera del
Ministero dell’Ambiente in cui si afferma che non
sussistono i presupposti di urgenza per approvare
la discarica:
E’ LA VITTORIA!
Parlamento europeo
Un esempio: il corpus 46CIT2VAR.TXT del caso di studio n.1 che vedremo
****01 *Sex_1 *Istr_3
È STATO TUTTO UN GIOCO FATTO PER FAR PRENDERE TEMPO ALL'ECOFER
CHE NEL FRATTEMPO HA SISTEMATO TUTTO. ADESSO A FINE 2013
INIZIERANNO DI NUOVO CON FALCOGNANA MA QUESTA VOLTA ARRIVERANNO
I CAMION SCORTATI DALL'ESERCITO.IL PROBLEMA NON È LA GENTE MA
IL FATTO CHE DOPO TUTTI I SOLDI SPESI DALL'ECOFER PER SCAVI,
INVASI, NE DUBITO SI ARRENDANO.
****02 *Sex_2 *Istr_3
SUI LAVORI C'È SCRITTO ITALGAS, MA NON CI FIDIAMO. BISOGNA FARE
QUALCOSA PER NON FAR PASSARE I TIR PERCHÉ E' DIVENTATO TROPPO
PERICOLOSO.
****03 *Sex_1 *Istr_3
AL CONVEGNO "ROMA VERSO RIFIUTI ZERO" IN CAMPIDOGLIO 13 DICEMBRE
CI SARÀ UN INTERVENTO DI MASSIMO PIRAS E PROMOTORI DEL CONVEGNO:
ZEROWASTE LAZIO,COMITATO DIAMOCIDAFARE.
IL VICEPRESIDENTE DEL PARLAMENTO EUROPEO É VENUTA A TROVARCI
DOPO AVER EFFETTUATO UN SOPRALLUOGO ALLA ECOFER.
…………………………………………………………………………………………………………………………………
****44 *Sex_2 *Istr_2
LA MISCELAZIONE DEL RIFIUTO ATTUALMENTE CONFERITO IN DISCARICA CON I
RESIDUI DELLE LAVORAZIONI DEL RIFIUTO INDIFFERENZIATO PROVENIENTE DA AMA.
ESISTONO STUDI IN MERITO AI POTENZIALI DANNI ALLA SALUTE?
LA SOCIETÀ GIUSTIFICA QUESTA DISPONIBILITÀ INIZIALE CONTENUTA PER
RASSICURARELA POPOLAZIONE LOCALE.NO COMMENT!!!
PREGO IL PRESIDIO DI UNIRE LE LISTE DELLE FIRME!
****45 *Sex_1 *Istr_1
MANIFESTARE CONTRO QUESTI DUE FURBACCHIONI GIÀ PER SE È OBBLIGATORIO.
MA E' FATTO OBBLIGO A TUTTI PARTECIPARE IN QUANTO MANCANO 7 GIORNI
AL PUNTO DI NON RITORNO! CONDIVIDO FIRME AL PRESIDENTE NAPOLITANO
E AL PRESIDENTE DEL CONSIGLIO LETTA E CORTEO MERCOLEDÌ.
****46 *Sex_2 *Istr_1
BENE! IO SO CHE SIETE GRANDI!!!
=====
…………………………………………………………………………………………………………………………
Il 'corpus ‘ dei dati testuali e il bilancio lessicale (software IRaMuteq)
•
•
•
I 46 post scambiati dai cittadini e
residenti è tecnicamente un ‘corpus’ del
tipo "testi frammenti“
la prima analisi quantitativa che si fa di
un corpus di dati testuali è il ‘bilancio
lessicale‘ in cui figurano:
il nome del file di testo; la lingua del
testo; il numero di testi (qui post)
esaminati; i segmenti del testo (frasi,
sequenze di parole adiacenti nel testo
che possono essere di varia lunghezza
(es. min 3-max 10 parole), le
occorrenze ossia il numero totale di
parole (=forme grafiche), il numero
delle forme (ossia parole diverse),
numero di hapax ossia parole che si
ripetono una sola volta nel testo, la
percentuale degli hapax rispetto alle
forme e alle occorrenze (indici della
ricchezza lessicale dei post analizzati)
Tab.2 - Bilancio lessicale del
46CIT2VAR.TXT': alcuni parametri
corpus
'File
Parametri
Valore
Nome
46CIT4VAR_corpus_
Lingua
Italiano
N. testi
46
N.segmenti del testo
67
Occorrenze
1974
N.forme
907
N.Hapax
669
N.hapax in % forme
73,76%
N.hapax in %occorrenze
33,89
NOTA: la numerosità del corpus
analizzato (1974 occorrenze: numero
parole) risulta puramente esemplificativa
perché per avere una discreta stabilità
dei risultati per le analisi statistiche
quantitative di dati testuali occorrono
almeno 10.000 occorrenze : quindi per i
big data testuali queste sono le analisi
dei dati più adatte!
Le prime analisi statistiche semplici del file A-Cittadini
• Il file A-Cittadini è risultato di N=46 post, sono stati scelti quelli per i quali
è stato possibile (tramite una nostra apposita ricerca sui blog) conoscere
le seguenti caratteristiche soci-demografiche dei ‘postanti’
• 1)Genere; 2)Titolo di studio; 3)Occupazione; 4)N° di post scritti dalla
stessa persona nel periodo considerato
• Attraverso il cosiddetto File Numerico associato ai post (Fichier
Numerique) fornito dal software Spadt si sono ottenuti i dati riportati nella
seguente Tabella.
considerato
GENERE
TITOLO DI
STUDIO
N
%
CONDIZ.
OCCUPAZIONALE
N
%
1.Maschi
21
45,6
1.Dipl. o Liceo
9
19,6 1.Occupato/a
26
56,5 1.Una sola volta
11 23,9
2.Femmine
25
54,4
2.Laurea
18
39,1 2.Nessun dato
20
43,5 2. Da 2 a 4 volte
17 36,9
Totale
46
100
3.Nessun dato
19
41,3
100 3.Da 5 e più
18 39,2
Totale
46
100
Totale
100 100
Totale
N
46
%
FREQUENZA
SCRITTURA
POST
N
%
L’Analisi lessicale statistica semplice
dei segmenti caratteristici:
Le Proc MOCAR e Proc RECAR
Per segmenti si intendono ‘frasi’ insiemi di parole (almeno due in SPADT) che si
ripetono almeno tre volte (in SPADT).
In particolare con SPADT e le procedure denominate PROC MOCAR e PROC RECAR si
ottengono delle “tipologie” dei contenuti dei post esaminati qui sono ora analizzati come
‘segmenti’.
Nel Graf.1 sono riportati sinteticamente i 7 tipi di segmenti caratteristici secondo il
genere.
Graf. 1 _Tipologia dei segmenti secondo il genere
M
F
•
A titolo esemplificativo delle potenzialità dell’AADT è stata impiegata con il software Iramuteq al
corpus 46CIT4VAR una cluster analysis al fine di individuare le unità di contesto più simili (cluster) in
altri termini al fine di individuare le parole che più caratterizzano ciascun cluster , ‘mondi lessicali’,
‘profili lessicali’, in sostanza quindi dare una ‘struttura’ al corpus del file dei testi
Cluster 1 individua i post inerenti la nuova discarica ,
caratteristiche negative del luogo, e netto rifiuto , mancanza di
una politica dei rifiuti basata sulla raccolta differenziata.
Cluster 2 individua invece le denunce,richieste, petizioni,
interrogazioni parlamentari rivolte alle istituzioni, molte in
particolare al sindaco di Roma Marino e al presidente della
Regione Lazio Zingaretti, sia di rifiuto della nuova discarica
nella zona del Divino Amore che della gestione da parte
dell'Ecofer (già compromessa con la precedente gestione
monopolitstica della discarica dei rifiuti di Roma nella
zona di Malagrotta).
Cluster 3 individua invece l’urgenza di unirsi, organizzarsi e
mantenere vivo il “Presidio No alla Discarica del Divino
Amore” con entusiasmo e coraggio, per la salute , contro i
tumori .
Le due analisi multidimensionali dei dati testuali più impiegate:
L’Analisi delle Corrispondenze di dati testuali : interpretazione degli assi fattoriali in
chiave linguistica (S.Bolasco)
Una frase=struttura sintagmatica. Più due parole sono vicine sul piano fattoriale tanto più
esse CO-OCCORRONO NEL CORPUS. Gruppi di parole fra loro vicine sul piano
ricostruiscono interi contesti di significati. Se il corpus è composto di frasi brevi è facile
ritrovarsi in queste situazioni interpretabili.
Qualche osservazione conclusiva sui
contenuti dei post
Dai contenuti dei post analizzati si possono rilevare alcune caratteristiche
specifiche di questo movimento:
il carattere locale della protesta;
nasce e si sviluppa su uno scopo preciso e delimitato : “no alla discarica nella
zona del Divino Amore” ;
l'interesse a non connotare politicamente tramite partiti, l'organizzazione e i
contenuti del movimento;
l'assenza di gerarchie tra le varie associazioni, la totale orizzontalità.
Si possono denominare queste mobilitazioni dei cittadini per il territorio
“ Globalizzazione Territoriale”
CASO DI STUDIO N.2
•
•
• La qualità della Vita nelle Comunità Montane Italiane:
Il questionario “Scheda descrittiva per problemi socia rilevanti”: il corpus è
quindi del tipo TESTI-FRAMMENTI , risposte libere testuali a domande aperte
del questionario
Applicazioni dell’analisi multidimensionale dei dati testuali per la costruzione
della teoria ausiliaria alla individuazione di indicatori empirici della QdV
nelle CM
Oggi la QdV è oggi BES:
Recentemente la Dr.ssa Francesca Della Ratta-Rinaldi dell’ISTAT-DISA ha
effettuato un’analisi dei dati testuali su ‘Le opinioni dei cittadini sulle misure del
benessere – Risultati della consultazione ‘on line’ consultabile in
http://www.istat.it/it/archvio/134852
in cui si richiede ai cittadini di indicare quali sono secondo loro le dimensioni
sociali rilevanti che costituiscono i fondamenti del Benessere Equo e Sostenibile
(BES) oggi definizione attuale di Qualità della Vita proposta dal CNEL e ISTAT
:
La mappa concettuale della misurazione di un fenomeno
complesso tramite indicatori empirici
Schematicamente la misurazione statistica di un fenomeno complesso tramite indicatori e
eventuali indici sintetici possono essere rappresentate con la mappa concettuale seguente
(Fraire 1987, 1989):
La strategia di analisi multidimensionale dei dati testuali oggetto del presente caso di studio si
riferisce al contributo che queste analisi proprio perché riferite ad aspetti ancora in forma
‘lessicale’ ma già empirici (statisticamente osservabili) possono dare nel passaggio dalla
seconda alla terza fase ossia dagli aspetti costitutivi o dimensioni nei quali è stato definito ‘a
priori’ il fenomeno sociale o concetto agli indicatori empirici corrispondenti.
La mappa concettuale per l’AADT
La scelta del ‘corpus’
TESTI-TESTI (saggi, biografie, discorsi parlamentari ecc.) o
TESTI-FRAMMENTI (testi corti, sms, tweet o chat, blog ecc.)
Creazione del
‘corpus’ file di testo (txt)ed eventuali
meta-variabili associate
La scelta delle
unità lessicometriche
di analisi :
-forme grafiche
-segmenti
Prime analisi
statistiche.
Scelta della
Scelta
tabella dei
della
dati:
metrica:
-frammenti *forme es. ²
-forme *parti
- forma*forma
Metodo
e software*
di ADT:
Cluster Anal.
ACS e ACM
Output
risultati
- numerici
- grafici particolari
(nuvola lessicale,
grafo lessicale
* Taltac, Lexico, Spad-T, DtmVic di Lebart, Iramuteq
Aspetti metodologici:
La documentazione statistica di partenza: Indagine sulla Qualità della Vita (QdV) delle
Comunità Montane (C.M.) italiane (INEMO, 1983)
• Il questionario ‘Scheda descrittiva-per problemi’:
8 domande aperte miranti ad individuare le ‘preoccupazioni sociali rilevanti’(social worries) per le 8
aree di rilevanza sociale (social areas):
A: ‘Salute’ (Health) ;
B:’Istruzione e Formazione professionale’;
(Education and Training)
C: ‘Occupazione e Qualità del lavoro’;
(Employment and Quality of Labour)
D:’Impiego del tempo libero’; (Leisure)
E: ‘Situazione economica personale’;
(Personal Economic Situation)
F:’Ambiente fisico’; (Physical Environment)
G:’Ambiente sociale’;(Social Environment)
H: ‘Sicurezza personale’(Personal Security)
+ I: ALTRA(altra eventuale area)
Popolazione: 22 C.M. appartenenti a tutte le regioni italiane; Intervistati:22 operatori delle 22
C.M.
Matrice dei dati iniziali:
file di testo originario:tutte le risposte libere date dai 22 operatori delle CM per ciascuna delle 8 domande =
social areas .8 sub-files; *dimensioni: indice V/N da 17,9% a 34%.
file numerico associato (meta variabili a posteriori)al file di testo riguardante le caratteristiche delle N=22
CM. Nell’esempio considerato si è scelta come variabile attiva per le successive analisi la Ripartizione
geografica di appartenenza della C.M. con le 5 modalità: Nord Ovest; Nord Est; Centro, Sud; Isole.
il corpus dei dati testuali
(Il questionario:1^fase dell’AMD)
…………………………………
(2^fase dell’AADT) La matrice dei dati iniziali testuali :
il file di testo nell’Analisi dei Dati Testuali:
Il corpus ‘QdVCM.txt'
-
-
----01PIECN
A) ESISTENZA DI MALATTIE PROFESSIONALI:SILICOSI.
DIFFICOLTA DI ACCESSO ALLE PRESTAZIONI SANITARIE PER CARENZA
DI SERVIZI DI TRASPORTO.
++++
B)DIFFICOLTA DI ACCESSO ALLA SCUOLA MEDIA SUPERIORE E SCUOLE
PROFESSIONALI PER CARENZA TRASPORTI PUBBLICI.
PROBLEMA DELLA MENSA PER GLI ALUNNI PENDOLARI.
SCUOLE PROFESSIONALI SCARSAMENTE CORRELATE CON LE EFFETTIVE
ESIGENZE DEL MONDO DEL LAVORO.
++++
C)FINO AD UN ANNO FA NON VI ERANO GROSSE DIFFICOLTA DI
OCCUPAZIONE MA ATTUALMENTE IN VARI SETTORI INDUSTRIALI E
ARTIGIANALI VI E RIDUZIONE DELL'OCCUPAZIONE.
DIFFICOLTA SOPRATTUTTO PER I GIOVANI E LE DONNE IN CERCA DI
PRIMA OCCUPAZIONE.
AUMENTA IL LAVORO NERO E PART-TIME.
++++
D)LA ZONA PRESENTA SCARSE OPPORTUNITA DI CARATTERE CULTURALE.
PIU FAVOREVOLI INVECE SONO LE POSSIBILITA DI ATTIVITA SPORTIVE.
++++
E) IN GENERALE IL REDDITO PRO-CAPITE E DISCRETO.
PARTICOLARMENTE ONEROSO SPECIE PER LE CATEGORIE A BASSO REDDITO
E IL COSTO PER IL RISCALDAMENTO.
++++
F)PARTICOLARMENTE CARENTE E LA SS20 DEL COLLEDITENDA PER IL
TRAFFICO PROVINCIALE.
DEGRADO DOVUTO ALL'ATTIVITA DELLE CAVEE LA PRESENZA DI INDUSTRIE.
++++
G) L'AMBIENTE SOCIALE E DIVERSO NEL FONDO-VALLE RISPETTO A QUELLO
DELL'ALTA-VALLE. NEI PAESI DI FONDO-VALLE.NEI PAESI DI
FONDO-VALLE IL SERVIZIO SOCIALE SI OCCUPA DEI PROBLEMI DEI
GIOVANI E DELLE FAMIGLIE MENTRE NELL'ALTA VALLE I PROBLEMI
RIGUARDANO L'ASSISTENZA AGLI ANZIANI.
FENOMENO DIFFUSO E INOLTRE L'ALCOOLISMO MENTRE EMERGENTE E QUELLO
DELLA DROGA.
++++
H) SONO IN AUMENTO NEL SETTORE DEI REATI I FURTI. IN GENERALE LA
SICUREZZA PERSONALE NON PRESENTA PARTICOLARI PROBLEMI.
----02VADAO
A)ASSENZA DI PRESTAZIONI SANITARIE SPECIALISTICHE
DIFFICOLTA DI ACCESSO ALLE PRESTAZIONI SANITARIE PER CARENZA
DI TRASPORTI.
++++
B)LA FREQUENZA ALLE SCUOLE ELEMENTARI NON PRESENTA PROBLEMI
MENTRE LA FREQUENZA ALLE SCUOLE SUPERIORI E UN PROBLEMA PER I
BAMBINI CHE ABITANO NELLE FRAZIONO ALTE DELLE VALLATE.
MANCA UNA SEDE UNIVERSITARIA.
++++
………………………...
----22SARNU
3^fase
AMD
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
Analisi dei dati testuali
Un esempio di codifiche a posteriori di 3^ fase:
la selezione delle risposte caratteristiche
Selezione delle risposte caratteristiche secondo le ripartizioni geografiche. (Criterio del Chi-quadrato)
INDICE CHI-QUADRATO
RISPOSTE CARATTERISTICHE
Nord-Ovest
.447 -1 ESISTENZA DI MALATTIE PROFESSIONALI:SILICOSI.
.592 -2 ASSENZA DI OSPEDALI E PRONTO SOCCORSO
2 MALATTIE TIPICHE DEGLI ANZIANI.NEOPLASIE.
.738 -3 ASSENZA DI PRESTAZIONI SANITARIE SPECIALISTICHE
3 DIFFIC.DI ACCESSO ALLE PRESTAZ.SANITARIE PER CARENZA DI TRASPORTI.
Nord-Est
.480 -1 ELEVATA PRESENZA DI GOZZO PER CARENZA DI IODIO NELL'ACQUA POTABILE.
1 ALTO TASSO DI INVALIDI IN AGRICOLTURA PER INCIDENTI.
.725 -2 ALTO TASSO DI HANDICAP E INVALIDI.
.754 -3 NON FUNZIONALITA DEI DISTRETTI DI BASE
3 ASSENZA DI STRUTTURE PER HANDICAPPATI.
.766 -4 CLIMA UMIDO MALATTIE REUMATICHE E BRONCHIALI .
.864 -5 DIFFICOLTA DI ACCESSO ALLE PRESTAZIONI SANITARIE IN CASO DI EMERGENZA.
Centro
.534 -1 STRUTTURE SANITARIE ACCENTRATE PRESSO L'OSPEDALE CIVILE.
1 DIFFIC.DI ACCESSO ALLE PRESTAZ.SANITARIE IN CASO DI EMERGENZA PER ASS.DISTR DI BASE.
.640 -3 CARENZA DI UN CONSULTORIO FAMILIARE
3 ASSENZA DI CENTRI DI IGIENE MENTALE
.735 -4 ASSENZA DI PRESTAZIONI SANITARIE PERIFERICHE.
.804 -5 ALTO TASSO MALATTIE REUMATICHE PER CLIMA UMIDO.
5 ALTO TASSO DI ANZIANI PER SPOPOLAMENTO.
Sud
.501 -1 ASSENZA DI ASILI NIDO E STRUTTURE PER HANDICAPPATI
504
2 ALTO TASSO DI HANDICAPS E INVALIDI CIVILI.
2 DIFFIC.DI ACCESSO ALLE PRESTAZ.SANITARIE IN CASO DI EMERGENZA PER ASS.DI DISTR.DI BASE
.561 -3 ALTO TASSO DI HANDICAPS PER POLIOMIELITE.
.772 -4 ASSENZA DI SERVIZI PER ANZIANI.CARENZA DI STRUTTURE PER HANDICAPPATI.
.778 -5 ALTO TASSO DI INVALIDI
5 ASSENZA DI PRESTAZIONI SANITARIE PUBBLICHE.
Isole
.376 -1 ASSENZA DI UN CENTRO DI RIANIMAZIONE.
1 CARENZA DI CENTRI DI SERVIZIO SOCIALE IN AMBITO USL
.695 -2 ALTO TASSO DI INVALIDI CIVILI.CARENZA DI SERVIZI SANITARI.
.937 -3 ALTO TASSO DI HANDICAP E INVALIDI.
Le forme lessicali caratteristiche:
un esempio
Area A: Salute. Selezione di alcune delle risposte (segmenti) caratteristiche
secondo le ripartizioni geografiche. (Criterio del Chi-quadrato)
INDICE CHI-QUADRATO
ALCUNE RISPOSTE CARATTERISTICHE
Nord-Ovest
.738 -- DIFFICOLTA’DI ACCESSO ALLE PRESTAZ.SANITARIE PER CARENZA DI TRASPORTI.*
Nord-Est
.864 -- DIFFICOLTA DI ACCESSO ALLE PRESTAZIONI SANITARIE IN CASO DI EMERGENZA.
Centro
.804 -- ALTO TASSO MALATTIE REUMATICHE PER CLIMA UMIDO.
ALTO TASSO DI ANZIANI PER SPOPOLAMENTO.
Sud
.778 -- ALTO TASSO DI INVALIDI
ASSENZA DI PRESTAZIONI SANITARIE PUBBLICHE.
Isole
.937 -- CARENZA DI SERVIZI SANITARI. *
ALTO TASSO DI HANDICAP E INVALIDI.*
(*) segmenti con scarsa frequenza
Osservazione 1: In alcuni casi i segmenti caratteristici sono
assimilabili a veri e propri indicatori lessicali empirici delle ‘situazioni’ o
‘preoccupazioni
sociali
rilevanti’
basati
sulla
valutazione/percezione/conoscenza personale dell’operatore ossia
indicatori soggettivi lessicali empirici.
Osservazione 2: Si nota la diversità tra Nord, Centro e Sud dei bisogni
legati all’area considerata (es. A:Salute)
L’Analisi dei dati a 3-vie
La scelta della tabella dei dati a 3-vie
• Scopo: mediante l’analisi dei dati a tre-vie esaminare tutte insieme,
contemporaneamente e globalmente, le 8 aree di rilevanza sociale
(occasioni), le u.s. (5 ripartizioni geografiche) e le tre variabili (primi 3
fattori di ogni area) ossia le 8 tabelle di contingenza nella forma di
tabelle di dati quantitativi ottenute dall’ACS.
• Codifiche a posteriori:
si sono impiegate le 8 tabelle di dati quantitativi
i X n , k (i=1,..,8
aree di rilevanza sociale; n=1,..,5 ripartizioni
geografiche; k=1,..,3 coordinate dei primi 3 fattori (punteggi fattoriali)
di ciascuna area), per l’analisi a 3-vie. In tali tabelle sono state
considerate diverse le 3 variabili rilevate nelle 8 occasioni (8 aree di
rilevanza sociale) e uguali le u.s. (5 ripartizioni geografiche).
• Software impiegato per le elaborazioni dei dati: ACT- Méthode
STATIS.
La tabella dei dati testuali a tre vie
T
X N , K(t 1,2,..., T ; n 1,2,..., N ; k 1,2,..., K )
N
Unità statistiche
5 RipGeo
X
Occasioni
es. 8 Domande libere
(8 aree di ril.soc.)
T N,K
8 Aree
rilev.soc.
T
Parole (prime 3 assi
fattoriali (punteggi)
5 Ripartiz.geograf.
K
Variabili
primi 3 fattori
A. Analisi dell’interstruttura
L’analisi dell’interstruttura consente attraverso la
rappresentazione globale di tutte le tabelle di conoscere:
•le tabelle che hanno una struttura simile o diversa (tramite
la matrice dei coefficienti RV di Escoufier indicanti la
relazione tra tutte le coppie di tabelle);
•le tabelle che contribuiscono maggiormente alla parte di
variabilità eccedente quella comune rappresentata dalla
matrice compromesso WD ossia la matrice media
(mediante la rappresentazione sul piano delle prime due
componenti centrate rispetto alla matrice WD delle 8 aree
di rilevanza sociale) .
Matrice dei coefficienti RV di Escoufier
1
1
2
3
4
5
6
7
8
1.000
.668
.610
.633
.802
.596
.643
.767
2
3
4
5
1.000
.637
.704
.658
.935
.973
.620
1.000
.926
.779
.723
.706
.750
1.000
.660
.695
.704
.838
1.000
.687
.702
.670
6
1.000
.973
.624
7
1.000
.577
8
1.000
Osservazione1: le matrici aventi struttura più simile sono risultate
nell’esempio considerato quelle relative alle coppie di occasioni:
2-6:’Istruz. e Formaz.Prof.’/’Ambiente fisico’ (RV=0,935);
2-7:’Istruz. e Formaz.Prof.’/’Amb.Sociale’ (RV=0.973);
3-4: ‘Occupaz. e QdL/’Impieghi del T.L.’ (RV=0.926);
6-7: ‘Ambiente Fisico’/ ‘Ambiente Sociale’ (RV=0.973).
Osservazione2 :la similitudine tra matrici riguarda la similitudine della
nuvola dei punti-unità nelle diverse coppie di occasioni nel senso che gli
individui che hanno la stessa struttura hanno le posizioni dei punti
omologhi che non sono cambiate (sono stabili) a prescindere dal
cambiamento delle variabili nelle diverse occasioni considerate (cfr. ad
es. Bolasco 1999).
B)Analisi dell’intrastruttura:
la collocazione delle aree di rilevanza sociale
attravero l’analisi dell’interstruttura(matrice compromesso)
Fig.2
-
Rappresentazione sul primo piano fattoriale centrato (72,04%)
rispetto alla matrice compromesso delle 8 aree di rilevanza
sociale
-----------------------------------------------------------------------------------------------------------------------1!
!
1
!
2 28,14%
2!
!
!
3!
!
!
4!
!
!
5!
!
!
6!
!
!
7!
!
!
8!
!
!
9!
!
!
10!
!
!
11!
!
!
12!
!
!
13!
!
!
14!
!
!
15!
!
!
16!
!
!
17!
!
5
!
18!
!
!
19!
!
!
20!
!
!
21!
!
!
22!
!
!
29!
!
!
30!
!
!
31!
!
!
32!
!
!
33!
!
!
34!
!
!
35!
!
!
36!
!
!
37!
!
!
38!
2
!
39!
!
!
1 43,90%,
40!
!
!
41!7
-------------------------------------------------------- WD
-------------------------------------------------------!
42!
!
!
!
45!
!
8
!
46!
!
!
47!
6
!
48!
!
!
49!
!
!
50!
!
!
51!
!
!
52!
!
!
53!
!
!
54!
!
!
60!
!
!
61!
!
!
62!
!
!
63!
!
!
64!
!
!
65!
!
!
66!
!
!
67!
!
!
68!
!
3
69!
!
!
70!
!
!
71!
!
!
72!
!
4
------------------------------------------------------------------------------------------------------------------------
(salute)
(Situaz.econ.person.)
(Istruz.e Form.Prof.)
(Ambiente sociale)
(Ambiente fisico)
(Sicurezza sociale)
(Occupazione)
(Impieghi del t.l.)
Questa classificazione ‘a posteriori’ in due clusters delle 8 aree definite ‘a priori’ emerge
comunque dall’analisi della parte di variabilità delle 8 tabelle eccedente la variabilità ‘media’.
Esaminiamo allora più dettagliatamente sia rispetto alle u.s. che alle variabili le caratteristiche
della variabilità ‘media’.
B)Analisi dell’intrastruttura:
la collocazione delle ripartizoni geografiche (u.s.)rispetto alle
preoccupazioni sociali rilevanti
Rappresentazione delle 5 ripartizioni geografiche (5 punti
unità-medi)
rispetto
ai
primi
due
assi
compromesso
(60,48%)
-----------------------------------------------------------------------------------------------------------------------1!
SUD !
!
2
2!
!
!
3!
!
!
4!
!
!
5!
!
!
6!
!
!
7!
!
!
8!
!
!
9!
!
!
10!
!
!
32!
!
!
33!
!
!
34!
!
!
35!
!
!
36!
!
!
37!
!
!
38!
!
!
39!
!
!
40!
!
!
41!
!
!
42!
!
!
43!
!
!
1
44!
!
!
45!------------------------------------ !
--------------------------------------------------------------------------------!
46!
NEst
!
47!
!
!
48!
!
!
49!
!
!
50!
!
!
51!
!
!
52!
!
!
53!
!
NOvest
54!
!
!
55!
!
!
56!
!
!
57!
ISOL
!
58!
!
!
59!
!
!
60!
!
!
61!
!
!
62!
!
!
63!
!
!
64!
!
!
65!CENTRO
!
!
------------------------------------------------------------------------------------------------------------------------
28,00%
32,48%
Sul primo asse si evidenzia la contrapposizione tra NEst (-) e Novest (+), mentre sul secondo
asse la contrapposizione tra Sud (+) e Isole (-). Il Centro come già rilevato nell’Analisi delle
corrispondenze è scarsamente correlato (contributi assoluti molto bassi) su entrambi gli assi.
C)Analisi delle traiettorie
Fig.4
–
Traiettorie
delle
5
Ripartizioni
geografiche
primo
(4a)e
al
secondo
(4b)asse
fattoriale
in
funzione
di
rilevanza
sociale.
rispetto
al
delle
8
aree
0!-----------------------------------------------------------------------------------------------------------------------1!
Fig.4a
:
32, 48%
1
2!
A
!
3!
A
!
4!
!
5!
!
6!
A
A
!
7!
!
8!
!
9!
A
A
!
10!
!
11!
!
12!
!
13!
!
14!
!
15!
A
!
16!
NOvest A
!
17!
!
24!
!
25!
NEst
B
!
26!
!
27!
!
28!
!
29!
D
!
30!
!
31!
!
32!
D
!
33!
B
!
34!------------1
----------2
---------3E
--------4
----------5B
--------6
----------7
----------8E
-------------------35!
36!
D
!
37!
D
D
!
38!
E
D
B
!
39!
D
E
!
40!
E
!
41!
Isole
E
B
!
42!
Centro
C
B
!
43!
Sud
D
C
!
44!
E
!
45!
!
46!
E
C
C
C
B
C
!
47!
!
48!
B
!
49!
C
!
50!
C
!
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------1!
2!
3!
4!
5!
6!
7!
8!
9!
10!
11!
12!
13!
Fig.4b:
2
28,00%
D
D
D
D
Sud
D
D
D
I°asse
D
!
!
!
!
!
!
!
!
!
!
!
!
23!
B
!
24!
!
25!
NEst
B
!
26!
!
27!
!
28!
B
B
!
29!
A
!
30!------------1
----------2
----------3
----------4
----------5
----------6
----------7
----------8
----------------------!
31!
E
B
!
32!
E
A
C
!
33!
A
!
34!
C
B
!
35!
A
!
36!
!
37!
E
A
E
!
38!
Centro
C
A
A
!
39!
B
E
!
40!
NOvest
A
E
E
!
41!
B
!
42!
C
E
!
Is ole
43!
!
44!
C
C
45!
!
46!
!
47!
C
!
48!
!
49!
!
50!
C
!
------------------------------------------------------------------------------------------------------------------------
II°asse
Legenda:Ripart.
Geograf.:
A:Novest;
B:NEst;
C:
Centro;
D:Sud;
E:Isole.
AreediRil.Soc.:1:Salute;2:Istruz.eForm.Prof.;3:Occup.eQdL;4:ImpieghiT.L.;5:S
it.Econ.Pers.;6:
Ambiente
Fisico;7:
Ambiente
Sociale;
8:
Sicurezza
Personale.
Le linee tratteggiate ma qui sono solo strumentalmente impiegate per facilitare il confronto delle
diverse traiettorie delle 4 Ripartizioni Geografiche x 8 aree di rilevanza sociale sovrapposte.
Si noti (rispetto alle traiettorie del primo asse (Fig.a) è la ripartizione NOvest che si differenzia
nettamente dalle altre nell’articolazione delle 8 aree di rilevanza sociale che costituiscono la definizione
di QdV ipotizzata mentre rispetto al secondo asse (Fig.4b) è il Sud a differenziarsi nettamente dalle
traiettorie delle altre ripartizioni.
Inoltre, pur nella diversità dei ‘percorsi’ delle ripartizioni dovuti ad una diversa struttura delle
preoccupazioni sociali rilevanti di ciascuna area, vi sono delle aree vicine ad esempio nella Fig.I°asse:
l’area 1:‘Salute’ nelle Isole, Centro e Sud; l’area 7: ‘Ambiente sociale’ nel NEst e Sud; Centro e Isole;
l’area 4: ‘Impieghi del T.L.’ per il Centro e NEst.
Alcune considerazioni sull’utilità per la ricerca
sociale dell’AADT nel caso considerato
Attravero la strategia di analisi proposta è stato possibile:
esplicitare empiricamente il contenuto degli aspetti costitutivi (social areas) impiegati
per la definizione del fenomeno complesso (QdV) tramite gli indicatori lessicali
empirici;
individuare le dimensioni (social areas) più diverse nella loro struttura globale
(interstruttura) e nel contempo quelle che contribuiscono di più alla differenziazione tra
le u.s. (le ripartizioni geografiche) (intrastruttura);
intravedere i possibili motivi delle differenziazioni tra le u.s.(ad es. l’emergere di due
clusters di aree di rilevanza sociale assimilabili a bisogni ‘strutturali’ e
‘sovrastrutturali’ come fattori della differenziazione tra le ripartizioni geografiche);
confrontare le diverse traiettorie delle u.s. (ripartizioni geografiche) disponendo così
di un’analisi ‘compatta’ della dinamica tra le occasioni (es. aree di rilevanza sociale
‘diacroniche’ o ‘sincroniche’ rispetto ai bisogni espressi).
Siti web per il downloading dei software
di Analisi Statistica dei Dati Testuali
IRaMuTeQ: http://www.iramuteq.org
Interface de R pour les Analyses Multidimensionnelles de Textes et de
Questionnaires
DtM-Vic Lebart ("Data and Text Mining: Visualization, Inference,
Classification“) http://www.dtmvic.com/05_SoftwareI.html
TaltacC2 (versione 2.10): www.taltac.it
,
Riferimenti bibliografici
ACT (1989), Installation e Description de la Méthode STATIS, CISIA, France
Bolasco S., 1999, Analisi Multidimensionale dei Dati. Carocci Ed., Roma
Bolasco S., 2013, L’Analisi automatica dei testi. Fare ricerca con il text mining., Carocci Ed.2013.
Cannavò L.,1999, Teoria e Pratica degli Indicatori nella Ricerca Sociale, ed.LED, Milano, 1999 vol.I: Teorie e Problemi della Misurazione Sociale
Chomsky N.,1969, L’analisi formale del linguaggio, Boringhieri, 1969
Della Ratta-Rinaldi,2000, L’analisi testuale: uno strumento per la ricerca sociale, in Sociologia e Ricerca Sociale anno XXIn.61 pagg.102-127.
Della Ratta-Rinaldi (2005), L’interpretazione sistematica del materiale derivante da focus group attraverso l’analisi testuale, in Sociologia e Ricerca
Sociale, pagg.91-104
De Mauro T., 1993, Lessico di frequenza dell’italiano parlato
De Saussure F., 1972, Cours de linguistique générale, ed. con le note di T. De Mauro, Payot, 1972.
Elia A., 1995, Dizionari elettronici e applicazioni informatiche, in JADT 1995, Roma Ed. CISU
Fraire M.(1989), Problemi e metodologie statistiche di misurazione di fenomeni complessi tramite indicatori e indici sintetici, in Statistica, n.2,1989.
Fraire M., 1994 - Metodi di Analisi Multidimensionale dei Dati, Ed.CISU, Roma, 1994
Fraire M., 2000, Analisi a tre vie nelle risposte a domande aperte e indicatori empirici, in Sociologia e Ricerca Sociale anno XXIn.61 pagg87101
Fraire M.Rizzi A., 2011, Analisi dei Dati per il data mining, Carocci Ed. 2011
Gross M., 1995 - On counting meaningful units in texts - in JADT 1995, Roma Ed.CISU
Iezzi D.F. (2012) A new method for adapting the k-means algotithm to text mining, in Statistica Applicata-Italian Journal of Applied Statistics (special
issue: Advances in Textual Data Analysis and Text Mining) 22,1, 2010 pp.65-76
INEMO (1983), Scheda descrittiva per problemi di 22 Comunità montane, in Inemo-informazioni, n.3/4 luglio/Dicembre 1983.
Lebart L., 1995 - Analyse statistique des données textuelles: quelques problèmes actuels et futurs - in JADT 1995, Roma Ed. CISU
Morrone A., 1995 - Una strategia di trattamento del testo per l’individuazione di variabili testuali rilevanti, in JADT 1995, Roma Ed. CISU
Reinert M., 1995 - Quelques aspects du choix des unité d’analyse et leur controle dans la methode ‘ALCESTE’ - in JADT, 1995, Roma Ed. CISU
Rizzi A., 1985, Alcune analisi statistiche della lingua italiana, Statistica n.1,1985
Rizzi A. (1985), Analisi dei dati, Ed. NIS, Roma, 1985.
Rizzi A.(1987), Sulla matrice media, Quaderni del Dip.to SPSA,Università di Roma ‘La Sapienza’, Serie A-Ricerche n.2/1987
Rizzi A.,1992 - Orientamenti attuali della statistica linguistica - Quaderni del Dip.to di Statistica Probabilità e Statistiche Applicate, Serie A-Ricerche
n.21,1992.
Salem A. 1995, Les unités lexicometriques - in JADT 1995, Roma Ed.CISU
SPAD.T (1993), Introduction à SPAD.T intégré.Version 1.5P.C., CISIA, Saint-Mandé, France
Statera G. (1997), La ricerca sociale. Logica, strategie, tecniche, Ed.SEAM, Roma
Zipf G.K. (1935), The psychobiology of language. An introduction to Dynamic Philology, Houghton-Mifflin, Boston