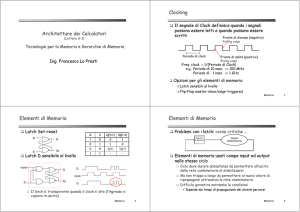
Clocking
Architetture dei Calcolatori
(Lettere A-I)
Il segnale di Clock definisce quando i segnali
possono essere letti e quando possono essere
scritti
Fronte di discesa (negativo)
Falling edge
Tecnologie per la Memoria e Gerarchie di Memoria
Periodo di clock
Prof. Francesco Lo Presti
Fronte di salita (positivo)
Rising edge
Freq. clock = 1/(Periodo di Clock)
e.g., Periodo di 10 nsec ⇒ 100 MHz
Periodo di 1 nsec ⇒ 1 GHz
Opzioni per gli elementi di memoria
Latch sensibili al livello
FlipFlip-Flop mastermaster-slave/edgeslave/edge-triggered
Elementi di Memoria
S
Q
!Q
Latch D sensibile al livello
clock
Q
!Q(t+1)
R
S
Q(t+1)
1
0
0
1
0
1
1
0
0
0
Q(t)
!Q(t)
1
1
-
-
T
D
Il periodo T deve essere scelto lungo abbastanza
da garantire che l’output della rete combinatoria
sia stabilizzato
clock
!Q
D
1
Periodo del Ciclo di Clock
Latch SetSet-reset
R
Memoria
Q
⇒Determina il limite superiore alla frequenza di
clock
Il latch e’
e’ transparente quando il clock e’
e’ alto (l
(l’ingresso e’
copiato in uscita)
uscita)
Memoria
Deve esserlo prima del periodo di apertura di del flipflip-flop
(set(set-up time)
Deve rimanere stabile per un certo tempo (hold(hold-time)
2
Memoria
3
Elementi di Memoria
Elementi di Memoria
Problemi con i latch: corse critiche …
Soluzione:
Soluzione: FlipFlip-Flops che cambiano lo stato (Q) solo sui fronti
del segnale di clock (master(master-slave)
Logica
Combinatoria
Elemento
di Memoria
D
D
D
Q
D-latch
Elementi di memoria usati come input ed output
nello stesso ciclo
Il clock deve rimanere ad 1 per un tempo
sufficiente da garantire che l’ingresso sia
memorizzato
…ma tale da non permettere il propagarsi del nuovo
valore attraverso la rete combinatoria
Difficile garantire entrambe le condizioni
Dipende dai tempi di propagazione e dalla presenza di
diversi percorsi attraverso la rete combinatoria
Memoria
clock
clock
!Q
!Q
clock
Master (primo DD-latch) copia in Q l’ingresso quando il clock e’
e’
alto (lo slave (secondo
(secondo D-latch) e’
e’ bloccato e non cambia stato )
Slave copia il valore del master quando il clock va a 0 (il master
e’ bloccato nel suo stato di memoria ed eventuali cambi
all’
all’ingresso non vengono letti)
letti)
Set-up time
4
Hold time
Setup e hold time per
un flip-flop D
Memoria
C
Registro
Leggere il contenuto di elementi di memoria
I valori sono input di una o piu’
piu’ reti combinatorie
Scrivere i risultati in uno o piu’
piu’ elementi di memoria
Combinational
logic
Simile ad un flip flop D eccetto
9 n bit di ingresso e uscita
9 Input Write
State
element
2
one clock cycle
D0
D1
Dn-1
Q1
!Q
D
Q
Flip-FlopD
clock
Q0
!Q
D
Q
Flip-FlopD
clock
Si assume che gli elementi di memoria siano scritti
ad ogni ciclo di clock
Qn-1
!Q
Altrimenti si aggiunge un esplicito segnale di write
9 In AND con il clock
D
Q
Flip-FlopD
clock
Write:
Write:
9 Se negato (0): i dati in uscita (Data
Out) non cambiano
9 Se affermato (1): i dati in uscita
(Data Out) divengono uguali ai dati in
ingresso (Data In)
clock
5
Registro
State
element
1
Q
D
Metodologia edgeedge-triggered
Comportamento tipico
!Q
Q
D-latch
Q
Assunzioni
clock
D
La scrittura avviene solo quando occorre la transizione
di
Memoria
livello attiva ed il segnale di controllo e’ affermato
clock
6
Write
Memoria
7
Banco di registri (2)
Banco di registri (register file)
Un banco di registri può essere implementato con un
Banco di registri ad accesso rapido per
multiplexer per ciascuna porta read,
read, un decoder per ciascuna
porta write ed un array di registri costruiti partendo da flipflipflop D
Esempio: implementazione di due porte read per un banco di
registri composto da n registri
memorizzare temporaneamente gli operandi
usati nelle istruzioni
Nel MIPS il banco dei registri è composto da
32 registri generali
Due porte in lettura da 32 bit
Una porta in scrittura da 32 bit
Tre porte per selezionare i registri da 5 bit
9 Read data 1/2
Read register
number 1
9 Write data
Register 0
Register 1
9 Read register #1 (#2) : primo (secondo
(secondo))
registro da leggere
9 Write register: registro da scrivere
Register n – 1
Register n
In AND con il clock (non mostrato)
Solo se Write=1 il valore in Write data e’
e’
scritto nel registro indicato da Write Reg.
Memoria
M
u
x
Read data 2
8
Banco di registri (3)
Read data 1
Read register
number 2
Write:
Write: segnale di controllo
M
u
x
Memoria
9
Principali tecnologie per RAM
Esempio: implementazione di una porta write per
un banco di registri composto da n registri
Le memorie RAM sono di due tipi
Memorie statiche:
statiche: Static Random Access Memory (SRAM)
Memorie dinamiche:
dinamiche: Dynamic Random Access Memory (DRAM)
Memorie statiche
Il singolo elemento corrisponde ad un latch
Memorie dinamiche
Log2n to n
Il singolo elemento corrisponde ad un condensatore ed un
transistor
L’informazione è memorizzata sotto forma di carica del
condensatore
Richiedono un refresh periodico dell’
dell’informazione
Le memorie statiche sono (rispetto a quelle dinamiche)
Memoria
10
Più
Più veloci (5ns vs. 5050-100ns)
Più
Più costose (6 transistor per bit)
Persistenti (non è richiesto il refresh)
refresh)
Più
Più affidabili
Memoria
11
Memoria Principale, Cache e Tecnologie
SRAM
Realizzata con matrici di latch
Prestazioni della memoria principale
Latenza
Banda
La memoria principale è
Altezza H (# celle indirizzabili)
indirizzabili)
contemporaneamente
Esempio Chip 32k*8
DRAM
Chip Select
Output Enable
9 =1 per poter leggere e scrivere
9 RAS o Row Access Strobe
9 CAS o Column Access Strobe
Non e’
e’ possibile scrivere e leggere
Dinamica in quanto ha bisogno di essere rinfrescata periodicamente
periodicamente
(8 ms)
ms)
Indirizzi di memoria divisi in due parti (memoria come una matrice
matrice
2D):
La memoria cache usa
Larghezza W (# latch per cella)
cella)
9 Spesso piccolo W=1,4,8
9 Tempo di accesso: tempo tra quando arriva la richiesta e la parola
9 Tempo di ciclo: tempo tra richieste
9 =1 per abilitare l’uscita del chip su
un bus condiviso
SRAM
Write Enable
Chip Select
Output Enable
Write Enable
Din
Memoria
32K*8
8
Dout
8
Chip Select, Write
Enable, Address e Din
Per Leggere
12
Memoria: Ruolo Chip Select
SRAM
Per Scrivere
9 =1 per abilitare alla scrittura
No refresh (6 transistor/bit vs. 1 transistor)
Dimensione: SRAM/DRAM = 4-8
Costo/Tempo di Ciclo: SRAM/DRAM = 8-16
15
Address
Chip Select, Output
Enable, Address e
Dout
Memoria
13
Memoria
15
SRAM: Cicli Scrittura/Lettura
CE=CS
X*:
X*: segnale controllo X attivo a 0
Memoria
14
Realizzazione SRAM
Struttura di una SRAM 4x2
Tecniche realizzative diverse
rispetto a quelle del register file
Il buffer threethree-state è
incorporato nei flipflip-flop
che formano le celle di
base di una SRAM
(buffer controllato dal
segnale Enable)
Enable)
Tutti i latch di una
colonna sono collegati
alla stessa linea di
output
Il decoder serve ad
abilitare in
lettura/scrittura una
certa linea
Chip Select/Output
Select/Output
Enable omessi in figura
Grandi Mux,
Mux, Decoder non sono pratici
Per evitare il Mux in uscita
9 una linea condivisa i cui vari elementi di
memoria sono tutti collegati
9 Il collegamento alla linea avviene
tramite un buffer a tre stati
Un dispositivo a tre stati, in base
ad un segnale di controllo, si
comporta:
(b) controllo=1: come circuito chiuso
(c) controllo=0: come circuito aperto
Memoria
Din[1]
Write enable
Din[0]
D
D
C latch Q
Enable
D
D
C latch Q
Enable
D
D
C latch Q
Enable
D
D
C latch Q
Enable
D
D
C latch Q
Enable
D
D
C latch Q
Enable
D
D
C latch Q
Enable
D
D
C latch Q
Enable
0
2-to-4
decoder
1
Address
2
3
16
Dout[1]
Memoria
Struttura di una SRAM 4Mx8
Memoria DRAM
Per evitare grandi decoder si usa decodifica a due livelli
DRAM sono meno costose, piu’
piu’ capienti, ma piu’
piu’ lente rispetto
Dout[0]
17
alle SRAM
Decoder piu’
piu’ piccolo + batteria di mux
5-10 volte meno veloci
Cella di memoria con un transistor+capacita’
transistor+capacita’
Il condensatore memorizza il contenuto della cella ed il
transistor è usato per accedere alla cella (tramite Word Line)
9 Word line e’
e’ attivato sulla base dell’
dell’indirizzo richiesto
I condensatori mantengono i valori
memorizzati per alcuni ms
Necessario il refresh dinamico delle
DRAM, effettuato leggendo,
leggendo, e subito
dopo riscrivendo i valori appena letti
Es SRAM 4Mx8 (22 bit indirizzo)
indirizzo)
Suddiviso in 8 blocchi da 4Mbit (4Kx1024 bit)
Parte alta indirizzo [21[21-10] seleziona la medesima riga da ogni
blocco di 4Kx1024bit attraverso un decoder (12 a 4096)
Parte bassa indirizzo [9[9-0] seleziona un singolo bit dei 1024 in
output dai vari blocchi
Memoria
18
Il refresh avviene ad intervalli fissi,
fissi,
occupa il 2% del tempo, ed avviene
per righe
Memoria
19
DRAM: Esempio Organizzazione 2Mx8
DRAM: Esempio Organizzazione 2Mx8
DRAM usa un decoder a due livelli
Indirizzo di memoria suddiviso in row address e column
address
Accesso di riga seguito da accesso di colonna
Segnale di controllo RAS: Row Address Strobe
Segnale di controllo CAS: Column Address Strobe
Segnali inviati consecutivamente sugli stessi pin
Ciclo di Lettura
Memoria
20
SSRAM e SDRAM
Memoria
21
Tipi di Memoria a Semiconduttore
Synchronous SRAM e DRAM (SSRAM e SDRAM) permettono
SRAM (Static RAM): a flipflip-flop,
flop, molto veloce (~5
nsec)
nsec)
DRAM (Dynamic RAM): basata su capacità
capacità parassite;
richiede refresh, alta densità
densità, basso costo (~70 nsec)
nsec)
SSRAM/SDRAM (Synchronous DRAM)
di aumentare la banda di trasferimento
Ciclo di Scrittura
Possibilita’
Possibilita’ di specificare (tramite MMU) che si vuole trasferire
dalla memoria un burst di dati
9 Burst=sequenza
Burst=sequenza di celle consecutive, specificato da un indirizzo di
partenza ed dalla lunghezza
9 Le celle sono contenute all’
all’interno di una stessa riga
9 La memoria trasferisce una delle celle del burst sul bus dati ad ogni
ciclo di clock
9 Migliore Banda di Trasferimento
Sincrona (scambia dati con il processore in sincronia con un
segnale di clock esterno), prestazioni migliori
PROM (Programmable ROM)
EPROM (Erasable PROM): raggi UV
EEPROM: cancellabile elettricamente
Flash Memory:
Memory: tipo di EEPROM
Ciclo di Lettura
Memoria
22
Memoria
23
Problema: Divario delle prestazioni CPUmemoria
Obiettivo: Illusione di una Memoria Grande, Veloce
ed Economica
CPU
Velocità: 2x / 1.5 anni
Osservazioni:
Osservazioni:
“Legge di Moore”
100
Divario di prestazione
processore-memoria:
(aumenta 50% / anno)
10
Come creare una
una memoria
memoria che sia grande,
grande,
economica e veloce (per la maggior parte del
tempo)?
tempo)?
Gerarchia
Parallelismo
Parallelismo
DRAM
Velocità: 2x / 10 ann
1
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
Prestazioni
1000
Le memorie di grandi dimensioni sono lente
Le memorie veloci hanno dimensioni piccole
Tempo
Memoria
24
Gerarchia di memoria
di memoria
Aumenta la capacità
capacità
di memorizzazione
Fornire all’
all’utente una quantità
quantità di memoria pari a quella
disponibile nella tecnologia più
più economica
Fornire una velocità
velocità di accesso pari a quella garantita
dalla tecnologia più
più veloce
Processor
Livello 1
Control
Livello 2
Datapath
Livello n
Dimensione della memoria ad ogni livello
Memoria
26
Second
Level
Cache
(SRAM)
On-Chip
Cache
.
.
.
Registers
Diminuisce il costo
per bit
Obiettivi della gerarchia di memoria:
Differenti tempi di accesso e di costo corrispondenti ai diversi
livelli di memoria
CPU
Aumenta il tempo di
accesso
25
Gerarchia di memoria (2)
La memoria di un calcolatore è implementata come una gerarchia
Memoria
Main
Memory
(DRAM)
Speed (ns): 1
10
100
Size (bytes): 100
K
M
Secondary
Storage
(Disk)
10,000,000
(10 ms)
G
Tertiary
Storage
(Tape)
10,000,000,000
(10 sec)
T
Memoria
27
Gerarchia di memoria: Esempio del Pentium
Memoria Cache
La memoria principale (DRAM) è sempre più
più lenta del processore e
tende a rallentarlo
Sono disponibili memorie più
più veloci (SRAM) ma solo per dimensioni
limitate
cache opera alla velocità
velocità del processore, e quindi nasconde la
“lentezza”
lentezza” della memoria
Scopo della cache: disaccoppiare le velocità
velocità di processore e RAM
Contiene le ultime porzioni di memoria acceduta: se il processore
processore
richiede l’l’accesso ad una di esse evita un accesso alla memoria
Funziona bene sfruttando il principio di località
località dei riferimenti
La
Memoria
28
Memoria
Hit rate e tempo medio di accesso in
memoria
Strategia di Utilizzo della Cache
La prima volta che il processore richiede dei dati si ha un
cache miss
Hit rate: frazione degli accessi in memoria risolti nel livello
Miss rate: 1 – (Hit rate)
superiore della gerarchia di memoria
Hit rate = numero di hit / numero di accessi in memoria
Le volte successive, quando il processore richiede l’
l’accesso
ad una cella di memoria
Tempo medio di accesso in memoria (AMAT):
Se il dato è presente in un blocco contenuto nella cache, la
richiesta ha successo ed il dato viene passato direttamente al
processore
AMAT = c h+ (1(1-h)m
9 Si verifica un cache hit
I dati vengono caricati dalla memoria principale e vengono
copiati anche nella cache
9 Si legge un blocco di parole contigue
29
Altrimenti la richiesta fallisce ed il blocco contenente il dato
viene anche caricato nella cache e passato al processore
9 Si verifica un cache miss
Obiettivo: aumentare quanto più
più possibile il tasso di cache
hit
Memoria
30
c: hit time (tempo di accesso alla cache)
h: hit rate
1-h: miss rate
m: miss penalty=access time + transfer time (tempo per accedere al
livello inferiore della gerarchia di memoria più
più tempo per trasferire
il blocco dal livello inferiore della gerarchia)
Hit time << miss penalty
Memoria
31
Principio di località
Migrazione dei dati
Osservazione: i programmi accedono ad una porzione
relativamente piccola del loro spazio di indirizzamento
Esistono due tipi differenti di località
località
1. Località
Località temporale (nel tempo): se un elemento (dato o
istruzione) è stato acceduto, tenderà
tenderà ad essere acceduto
nuovamente in un tempo ravvicinato
2. Località
Località spaziale (nello spazio): se un elemento (dato o
istruzione) è stato acceduto, gli elementi i cui indirizzi sono
vicini tenderanno ad essere acceduti in un tempo ravvicinato
Esempio
Blocco: la minima unità
unità di informazione che può essere
trasferita tra due livelli adiacenti
Hit (successo): il dato richiesto dal processore è presente in
un blocco del livello superiore
In caso contrario si ha un miss (fallimento):il livello inferiore
della gerarchia deve essere acceduto per recuperare il blocco
contenente il dato richiesto
Processore
I programmi contengono cicli: le istruzioni ed i dati saranno
acceduti ripetutamente (località
località temporale)
Gli accessi agli elementi di un array presentano un’
un’elevata località
località
spaziale; nell’
nell’esecuzione di un programma è altamente probabile
che la prossima istruzione sia contigua a quella in esecuzione
Probabilità
di
riferimento
Memoria
32
0
n
Spazio di indirizzamento 2 -1
Principio di località (2)
Come è gestita la gerarchia di memoria?
Come sfruttare la:
1. Località
Località temporale
2.
Spostando blocchi contigui di parole al livello superiore
Dal Processore
Dall’
Dall’hardware
Memoria ↔ Dischi
Al Processore Memoria di
Superiore
Dal compilatore (programmatore?)
Cache ↔ Memoria
Località
Località spaziale
33
Registri ↔ Memoria
Tenendo gli elementi acceduti più
più frequentemente vicino
al processore
Memoria
Dall’
Dall’hardware e dal sistema operativo (memoria virtuale)
Dal programmatore (file)
Memoria di
Livello Inf.
Blk X
Blk Y
Memoria
34
Memoria
35