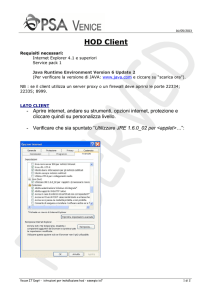
Università degli studi di Bologna
Facoltà di Ingegneria
Corso di laurea Specialistica in Ingegneria
Informatica
Relazione di reti di calcolatori L-S
Infrastruttura di supporto per
database distribuiti
Relazione di:
Federica Magnani
Anno scolastico 2004/2005
Indice
1. Introduzione.................................................. 3
2. Architettura del sistema .............................. 3
2.1 Il client .............................................................................................. 3
2.2 Il manager ........................................................................................ 4
2.3 Il server ............................................................................................. 4
2.4 Il gestore dei nomi........................................................................... 5
3 Descrizione del sistema ............................... 5
3.1 Tolleranza ai guasti......................................................................... 7
3.1.1
3.1.2
Guasto o fault del database .................................................................. 7
Guasto sul server ................................................................................... 7
4 Implementazione .......................................... 8
4.1 Server ................................................................................................ 8
4.1.1 L’interfaccia IServer ................................................................................... 8
4.1.2 L’interfaccia IServer_ Remote................................................................... 9
4.2 Il client ............................................................................................ 10
4.3 Il gestore dei nomi......................................................................... 10
5.1 Conclusioni................................................ 11
1. Introduzione
Il seguente lavoro sviluppa un’infrastruttura di supporto per interfacciare un
database distribuito.
Il progetto nasce dall’idea di possedere, all’interno di un istituto scolastico,
un’enciclopedia letteraria consultabile e modificabile in rete da varie postazioni.
L’architettura del sistema risulta essere aperta ed estendibile, in quanto è possibile
inglobare in un’unica struttura diversi istituti; i dati di ciascun istituto dovranno essere
sempre aggiornati e allineati con quelli degli altri istituti.
Il seguente articolo mostra tutti i dettagli sull’argomento ed in particolare
l’architettura del sistema e le soluzioni adottate per migliorarne l’affidabilità e conseguirne
l’atomicità.
Durante l’implementazione del progetto è stato sviluppato un primo prototipo che
fosse in grado di verificare e testare tutte le caratteristiche del sistema, sia in condizioni
normali, sia in caso di malfunzionamenti e guasti e sia in caso di sovraccarico nella rete.
2. Architettura del sistema
Il sistema si basa sul modello client/server in cui un utente effettua una richiesta ad
un servitore attendendo da esso una risposta. Nel sistema sono presenti più client legati
ciascuno ad uno ed un solo server: quando un utente accede al sistema gli viene associato,
in maniera dinamica da un manager, il nome di uno dei server attualmente attivi.
Nel seguito, verranno discussi oltre ai client, le funzionalità dei server remoti e tutti
i servizi, compreso il servizio dei nomi, associati all’utilizzo del sistema.
2.1 Il client
Il client del sistema è un qualsiasi utente che desidera consultare l’enciclopedia o
effettuare eventuali modifiche su di essa.
Come anticipato precedentemente, il client rimane legato allo stesso server finché
non decide di terminare la propria sessione e quindi l’esecuzione. Durante l’interazione,
l’utente effettua alcune operazioni sul server in modo a lui del tutto trasparente, che
possono comportare o meno modifiche nel database: nel caso in cui si vogliano
visualizzare i dettagli di un autore o di un’opera, il server effettua una connessione al
database, esegue la query creata ed invia al client i risultati; diversamente se l’utente deve
modificare o aggiornare i dati. In questo caso, infatti, è necessario prevedere una politica
di sincronizzazione per l’accesso ad una risorsa comune che serva a preservare sempre ed
in qualsiasi situazione la consistenza dei dati.
In entrambi i casi l’utente deve attendere la risposta del server: la comunicazione tra
client e server è di tipo sincrona bloccante.
2.2 Il manager
Il manager è un oggetto passivo che offre agli utenti, che ne fanno esplicita richiesta,
il servizio di connessione ai server.
Esso verifica quali sono i server attualmente attivi nel sistema quindi restituisce al
client un riferimento ad uno di essi (vedi figura 1). In realtà il manager è localizzato sulla
stessa macchina del client, per cui abbiamo un manager per ogni utente.
2.3 Il server
Il server rappresenta l’interfaccia di comunicazione con il database: esso offre ai
client, che ne fanno richiesta, la possibilità di consultare l’enciclopedia e di effettuare
modifiche o cancellazioni.
Manager
Client
Server
Manager
Client
Richiesta
Rete
Server
Risposta
Server
Manager
Client
Figura 1 Architettura del sistema
I server, per poter offrire le operazioni in remoto, si devono registrare presso un
servizio di registrazione e rimanere in attesa di eventuali richieste. I server sono legati ad
un database del quale conoscono la localizzazione e gli eventuali parametri di
autenticazione: username e password.
Quando un client riceve il riferimento al server è in grado di richiamare su di esso le
operazioni in modo trasparente: in figura 2 viene mostrata l’architettura di comunicazione
tra cliente e servitore. Il client ottiene un riferimento all’oggetto remoto tramite un
supporto intermediario che estende la visibilità di un oggetto nel distribuito: il proxy. Lo
stub e lo skeleton permetto a client e server di effettuare la serializzazione e la
deserializzazione dei dati, in modo che i dati scambiati durante la comunicazione siano
letti da entrambi i processi.
Client
Server
Stub
Skeleton
Figura 2 Comunicazine Client/Server
2.4 Il gestore dei nomi
Il gestore offre ai server il servizio dei nomi: quando un server intende registrarsi
interroga il gestore ottenendo da esso un nome univoco. Il gestore dei nomi è anch’esso un
server remoto che si è registrato presso il registry; esso è sempre in esecuzione ed offre
anche la possibilità di recuperare il nome di un server non più attivo mantenendo sempre
aggiornato un array.
3 Descrizione del sistema
Il sistema può essere visto come un modello ad oggetti attivi in cui il gestore dei
nomi ed il server rappresentano tali oggetti. Essi non permettono a processi esterni di
entrare nel proprio contesto di esecuzione ma solo di effettuare le richieste e,
eventualmente, depositarle in una coda: in questo modo gli oggetti sono protetti da
eventuali esecuzioni non desiderate. Il modello ad oggetti attivi permette al
programmatore di scegliere le politiche da adottare: come organizzare la coda delle
richieste e quella delle attività interne, la politica di scheduling, la gestione degli errori
ecc…
Nel progetto si è deciso di rispondere immediatamente alle richieste di
visualizzazione di un autore o di un’opera, mentre per le operazioni di modifica o
cancellazione è stato previsto un meccanismo di sincronizzazione attraverso l’uso di lock.
Solo il processo che possiede il lock può effettuare tali operazioni; al termine il lock viene
rilasciato e preso da un processo in coda scelto in modo non deterministico.
Si è deciso di utilizzare un modello ad esecuzione statica in cui l’allocazione delle
risorse viene decisa prima dell’esecuzione del sistema. In particolare è stato scelto di
replicare il database per ogni istituto scolastico in modo da poter offrire anche un
supporto ad eventuali indisponibilità di dati o guasti nel sistema.
Ad ogni database viene associato un server che permette agli utenti del servizio di
poter effettuare delle richieste di visualizzazione o di modifica dei dati. Nel caso di
modifiche o aggiornamenti, il server deve inoltrare la stessa richiesta a tutti gli altri server
attualmente attivi. Per questo motivo è stato predisposto un sistema ad anello in cui
ciascun server, dopo aver ricevuto il token ed effettuato le relative modifiche, inoltra la
stessa richiesta al nodo successivo. Dopo che tutti gli altri server hanno effettuato
l’allineamento dei dati esso restituisce all’utente una risposta di avvenuta modifica.
DB
Server 1
DB
Server N
DB
Server 2
Server 3
DB
Figura 3 Anello di coordinamento tra i server.
In figura 3 viene mostrata l’architettura ad anello tra i server: ciascun sistema
costituito da un insieme di server e da un database rappresenta un istituto scolastico in cui
è installata l’enciclopedia. Come è facile notare tutti gli istituti partecipano alla gestione
del sistema; in particolare ogni server comunica con il successivo, se è attivo, altrimenti
con il prossimo ancora.
Il modello di replicazione scelto è un modello attivo in cui tutte le copie eseguono in
modo sincrono e coordinato. Per quanto riguarda le politiche di aggiornamento abbiamo
predisposto l’aggiornamento eager (immediato e prima della risposta) di tutte le copie
attive: la copia che riceve una richiesta di aggiornamento la esegue e la inoltra al nodo
successivo. Solo quando tutti i nodi sono allineati allora viene ritornata una risposta al
richiedente.
3.1 Tolleranza ai guasti
Per quanto riguarda la tolleranza ai guasti si è deciso di replicare i dati su più
database localizzati su macchine separate, al fine di ottenere HIGH AVAILABILITY.
Nel seguito verranno mostrati i metodi utilizzati per garantire il servizio anche per
malfunzionamenti o guasti del server..
3.1.1 Guasto o fault del database
Nel caso in cui non fosse disponibile un database è possibile contattare un altro
server ed utilizzare i dati dell’istituto vicino. L’utente già connesso ad un determinato
server deve quindi disconnettersi da esso, come esplicitamente descritto nell’interfaccia
grafica a lui disponibile, e richiedere al manager un nuovo nome al quale riferirsi. Il
manager, a questo punto, è in grado di riconoscere i nuovi server attivi ed assegnare al
cliente un server diverso.
Il database eventualmente disconnesso dalla rete dovrà poi essere allineato
manualmente.
3.1.2 Guasto sul server
Il guasto sul server può essere identificato a run-time dal client oppure da un altro
server al momento della richiesta di aggiornamento dell’anello.
Nel primo caso il client effettua una richiesta ed ottiene come risposta un invito a
collegarsi nuovamente poiché il server potrebbe non essere più disponibile. Il manager,
durante la richiesta di nuovo collegamento, sceglie in modo random un altro server e
restituisce il suo riferimento al client che potrà proseguire le sue ricerche senza accorgersi
di nulla.
Il server non più attivo viene rilevato dal suo predecessore al momento della ricerca
del token. Ogni volta che viene inoltrata una richiesta di aggiornamento dei dati, il server
corrente deve, come descritto precedentemente, possedere il token. Quindi rimane in
attesa dello stesso finchè nodo per nodo, in modo ordinato, gli arriva: in caso di guasti sui
server, il meccanismo di richiesta del token aggiorna i servitori attivi. In particolare viene
aggiornato l’array sul gestore dei nomi. Questo avviene perché il nodo corrente chiede al
nodo successivo se possiede il token: nel caso in cui il nodo chiamato non risponda allora
il server contatta il suo successivo e contemporaneamente aggiorna il gestore dei nomi.
Quest’ultimo possiede infatti, come verrà descritto in seguito, un metodo di
aggiornamento dei nomi dei server che non sono più disponibili.
4 Implementazione
Il prototipo è stato implementato utilizzando java RMI. Il Remote Method
Invocation permette di utilizzare oggetti remoti semplicemente invocando il registro RMI:
questo è un semplice servizio di nomi server-side che consente ai client di ottenere un
riferimento all’oggetto remoto.
Gli utenti possono connettersi all’infrastruttura sviluppata aprendo un opportuno
frame che è stato implementato per richiamare i metodi remoti e verificarne le
funzionalità. Nel seguito verranno descritte le principali classi e interfacce del progetto.
4.1 L’oggetto server
Il server possiede diverse interfacce che permettono la comunicazione in remoto sia
con il client che con i server dell’anello.
4.1.1 L’interfaccia IServer
L’interfaccia IServer mette a disposizione delle applicazioni remote i metodi di
interrogazione o aggiornamento del database. Ad esempio (vedi figura 4) i metodi
createAutore modifyAutore e deleteAutore permettono di creare, modificare o cancellare un
autore specificando i parametri opportuni per la tabella Autori, mentre i metodi
createOpera modifyOpera e deleteOpera permettono di manipolare la tabella Opera. I metodi
listAutori e listOpere restituiscono la lista degli autori o delle opere cercate.
public interface IServer
extends Remote {
int createAutore(String nome, String cognome, String data_nascita,
String data_morte) throws RemoteException;
int modifyAutore(String nome, String cognome, String data_nascita,
String data_morte) throws RemoteException;
int deleteAutore(String nome, String cognome) throws RemoteException;
List listAutori(String nome, String cognome) throws RemoteException;
int createOpera(String nome, String cognome, String titolo, String data,
String recensione) throws RemoteException;
int modifyOpera(String nome, String cognome, String titolo, String data,
String recensione) throws RemoteException;
int deleteOpera(String nome, String cognome, String titolo) throws
RemoteException;
List listOpere(String nome, String cognome, String titolo) throws
RemoteException;
String get_name() throws RemoteException;
}
Figura 4 Interfaccia IServer
4.1.2 L’interfaccia IServer_ Remote
L’interfaccia IServer_Remote mette a disposizione ai server remoti alcuni metodi di
aggiornamento dell’anello. In particolare, vedi figura 5, il metodo update_Server permette
di aggiornare tutti i database degli istituti. In questo metodo infatti ciascun server
dell’anello allinea i propri dati finché si ritorna al server che per primo ha effettuato la
richiesta. Una volta verificato l’aggiornamento di tutti i nodi il servizio termina
restituendo un messaggio di ritorno al client.
I metodi get_Token, set_Token e research_Token permettono di ricercare il token
all’interno dell’anello. Al reset il token è posseduto dal server di nome server1 per pura
scelta progettuale. Il token rimane attivo su questo server finché qualcuno ne fa esplicita
richiesta: ad esempio se sul server3 è necessario effettuare la cancellazione di un’opera, il
server3 chiama il metodo research_Token che andrà a prelevare il token da server1 e lo farà
passare ai nodi successivi, fino al nodo 3. Il token transita da nodo a nodo perché ciascun
server conosce solo il suo successore che viene invocato richiamando il metodo
getNextServer.
public interface IServer_Remote
extends Remote {
void update_Server(String query, String server) throws
RemoteException;
boolean get_Token() throws RemoteException;
void set_Token(boolean token) throws RemoteException;
void research_Token(String name) throws RemoteException;
IServer_Remote getNextServer() throws RemoteException;
}
Figura 5 Interfaccia IServer_Remote
4.2 Il client
Il client del progetto è costituito da un’interfaccia grafica con cui l’utente può
effettuare tutte le operazioni disponibili. Come specificato precedentemente il client
invoca, all’avvio del frame, il metodo connect sul Manager che permette di recuperare il
nome di uno dei server attualmente attivi. Esso sceglie in modo radom uno dei server
locali attualmente attivi: se il server non è più disponibile il manager aggiorna l’array sul
gestore dei nomi ed effettua la relativa unbind. Se non esistono server locali allora il
Manager ricerca quelli remoti, invocando sul gestore dei nomi il metodo getName. Se anche
il server remoto contattato non è più disponibile allora ne viene preso un altro, se presente,
e viene aggiornato l’array senza però poter effettuare l’unbind del servizio: il metodo è
invocabile solo in locale per problemi di sicurezza. Tutte le operazioni di aggiornamento
dei server attivi avviene in modo trasparente al client che attente solo di ricevere un
riferimento al server. Il client rimarrà legato per tutta la sua esecuzione allo stesso server;
questo perché il cliente deve interrogare il servitore più volte durante la stessa richiesta.
Ad esempio, è possibile ricercare gli autori selezionando la lettera di iniziale del cognome:
il server remoto interrogherà il database e restituirà al client tutti gli autori che cominciano
con la lettera selezionata. A questo punto l’utente seleziona il cognome ed attende una
nuova risposta dal servitore; come si può facilmente intuire le interazioni tra cliente e
servitore sono molto frequenti ed è per questo motivo che si è deciso di scegliere un
servitore e mantenerlo per tutto il ciclo di esecuzione del cliente.
4.3 Il gestore dei nomi
Il gestore dei nomi è un oggetto remoto che ha effettuato la registrazione presso il
registry. Come tale possiede l’interfaccia IGestoreNomi che permette ai server remoti di
effettuare due operazioni: il metodo getServer restituisce un nome univoco costituito da un
intero che viene incrementato ad ogni richiesta e il metodo di aggiornamento dei nomi o
updateServer. Quest’ultimo aggiorna un array contenente tutti i server che non sono più
attivi; in questo modo la prossima volta che viene invocato il metodo getServer questo
restituisce il nome del server disponibile.
public interface IGestoreNomi
extends Remote {
// Il metodo restituisce un nome univoco
public String getServer(String init) throws RemoteException;
// Il metodo aggiorna un array contenente i nomi dei server non più attivi
public void updateServer(int name) throws RemoteException;
// Il metodo restituisce l'indirizzo dei server al momento disponibili
public String [] getName() throws RemoteException;
// Il metodo restituisce l'ultimo valore assegnato al server
public long getValue() throws RemoteException;
}
Figura 7 IGestoreNomi
5 Conclusioni
Il progetto ha portato allo sviluppo di un primo prototipo in grado di mostrare le
potenzialità del servizio. In particolare, dopo una prima implementazione semplice ma
funzionante, è stato necessario introdurre nuovi accorgimenti per la continuità di un buon
servizio anche nei casi di mal funzionamenti e guasti di alcun tipo. Il prodotto sviluppato
lavora sia in caso di indisponibilità dei dati sia in caso di indisponibilità dei server,
potendo usufruire della replicazione dei dati e dei servitori su macchine separate.
Diversamente accade per il gestore dei nomi che risulta essere unico: in caso di guasti il
servizio non è più disponibile.
Possibili sviluppi futuri riguardano la sicurezza nell’accesso ai dati distribuiti: in
questo momento chiunque potrebbe accedere ai database e modificare i dati in essi
contenuti. Sarebbe necessario introdurre alcuni vincoli di accesso alle tabelle, in modo che
solo gli utenti autorizzati possano effettuare eventuali modifiche.
Altri aggiustamenti possibili riguardano la replicazione del gestore dei nomi: anche
in questo caso sarebbe necessario introdurre una politica di sincronizzazione e
coordinamento.