Imputazione dati mancanti
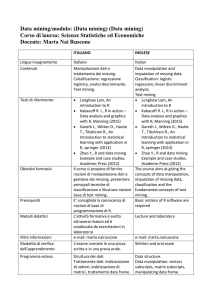
Una volta preparata la matrice dei dati, occorre
controllare alcuni aspetti delle variabili disponibili.
Missing Value
Range
Minimum & Maximum
Extreme Values
Per verificare la presenza di errori particolari, dati
mancanti e valori estremi
Dati mancanti
MISSING VALUE
Missing Completely At Random
Missing At Random
Missing non ingnorabili
MCAR
MAR
NMAR
Il processo che ha
determinato la non
rilevazione è completamente
indipendente dal valore
mancante e da qualsiasi
altra variabile disponibile
Il processo che ha
determinato la non
rilevazione è completamente
indipendente dal valore
mancante ma può dipendere
da altre variabili disponibili
Il processo che ha
determinato la non
rilevazione del valore
dipende dal valore
mancante
Missing completely at random (MCAR)
La probabilità che un certo valore per una data variabile sia
missing è indipendente da qualsiasi altro valore per qualsiasi
altra variabile, missing o osservata.
Ovvero i valori missing values sono distribuiti aleatoriamente.
Esempi
Esperimento
Sondaggi
Avviamo più prove sperimentali con un ordine casuale.
Concludiamole dopo 30 minuti.
Chiediamo un numero di domande sorteggiate casualmente
Limitiamo al 30% del campione (casuale) un certo item
Data entry
Inseriamo gli item in disordine sorteggiandoli dal mucchio
Fermiamo l’inserimento dati a intervalli aleatori.
Missing at random (MAR)
La probabilità che un valore sia missing è collegata ai
valori osservati disponibili
Esempi
Le donne meno spesso indicano l’età
I cinesi più spesso evadono le tasse
MAR se sesso e nazionalità sono osservati
Not missing at random (NMAR)
La probabilità che un valore sia mancante è collegata
ai valori mancanti
Esempi
I sovrappeso meno spesso indicano il peso
I ricchi il reddito
Gli appartenenti all’estrema destra il partito
NMAR: problema grave
Cosa fare?
Primo punto: individuare i missing utilizzando le funzioni
di calcolo per le frequenze, anche tavole doppie,
individuando così anche i dati anomali o errori di
inserimento particolari
Quindi, in fase di codifica ed inserimento dei dati, sia
assegnato un valore univoco ai dati mancanti, in modo
da distinguerli chiaramente dai valori effettivi.
Ne segue che, ai missing, spettano sempre valori al di
fuori dei campi di esistenza delle rispettive variabili,
magari identici per tutto il data set: ad esempio 0
se esistono variabili su scala a rapporti 0 è lecito? NO!
occorre un’alternativa? Sì un codice alfabetico NA
Strategia passiva
i dati missing vengono ignorati; l’analisi viene effettuata
esclusivamente sui dati presenti (complete case approach)
in due diversi modi: casewise o parwise deletion
casewise deletion (listwise deletion)
vengono analizzati solamente casi completi; in presenza di
molte variabili si ha una considerevole perdita di casi;
Non esiste una regola per decidere quando eliminare il
record o correggerlo con un’imputazione (strategia attiva).
Con grandi campioni e basse proporzioni di missing (5% o
meno) comunemente si procede ad una casewise/ listwise
deletion
Strategia passiva
Nella casewise deletion o listwise deletion il
problema principale dovuto è la perdita di informazioni e
quindi di potenza “statistica”.
Ad esempio, con l’1% di probabilità di avere un missing
per ognuna delle 100 variabili considerate risulterebbe
disponibile solo il 37% del campione.
Con 50 variabili avremmo solo il 60%
E con il 5% di probabilità di avere un missing, non si
avrebbe a disposizione nemmeno l’1% e l’8% del
campione, per 100 e 50 variabili complete
(come mai?)
Strategia passiva
pairwise deletion:
vengono analizzati casi che presentano dati missing per
ciascuna coppia di variabili considerate;
Ad esempio, il calcolo delle correlazioni può essere svolto
su un numero diverso di casi per ciascuna coppia di
variabili; l’insieme dei coefficienti di correlazione viene
allora stimato su un maggior numero di casi rispetto alla
situazione precedente.
Questa opzione è solitamente poco preferibile, appunto
perché il calcoli sono fatti su sottocampioni diversi e la
matrice di varianza \ covarianza può generare problemi
Strategia esplorativa
Abbiamo detto che i dati missing di una variabile sono
raccolti in un solo codice, gestito sullo stesso modo delle
altre modalità della variabile attiva.
Tale strategia consente di verificare se i valori mancanti
si riferiscono ad osservazioni sistematicamente diverse
da quelle complete e di studiare le differenze tra unità
complete e unità incomplete.
Strategia esplorativa
Strategia esplorativa
Strategia esplorativa
Strategia esplorativa
Strategia attiva (imputazione)
L’obiettivo in questo caso è quello di sostituire ciascun
valore mancante con uno plausibile, stimato sulla base
dei valori validi delle altre variabili completo.
Supponiamo, ad esempio, di voler stimare il valore
mancante per la variabile “peso” conoscendo “sesso” e/o
l“età” per ogni intervistato.
Si dovrebbe considerare in modo molto cauto l’uso
dell’imputazione, per via del suo potenziale impatto,
talora molto forte, sull’analisi dei dati.
Strategia 1 listwise
n=20
donne (grigio) più riservate
per le variabili
peso (Y)
età (X2)
caso sesso (X1 ) età-20 (X2 ) peso (Y)
1
0
28
2
1
19
218
3
1
37
235
4
0
24
150
5
1
18
6
1
176
7
1
8
0
9
0
28
10
1
46
195
11
0
23
12
0
29
13
1
44
221
14
0
15
0
21
16
1
41
204
17
0
40
18
1
37
208
19
0
20
1
43
Simulazione listwise
cancello tutti i casi con valori
missing
lavoro solo sui record completi
è il default nei software
In questo caso il campione risultante
non è selezione in funzione del
peso Y, ma del sesso X.
La cancellazione listwise è stata
selettiva per sesso, non per
peso.
Se il peso non dipende dal sesso, il
campione residuo non è distorto
per peso
caso sesso (X1) età-20 (X2) peso (Y)
1
0
28
2
1
19
218
3
1
37
235
4
0
24
150
5
1
18
6
1
176
7
1
8
0
9
0
28
10
1
46
195
11
0
23
12
0
29
13
1
44
221
14
0
15
0
21
16
1
41
204
17
0
40
18
1
37
208
19
0
20
1
43
LD conviene, in generale, su dati MCAR
LD non porta a distorsioni salvo la cancellazione
dipenda da Y
Strategia 2: media
Si calcola la media dei casi
completi Y per sostituirla
nei casi mancanti
Lo stesso per X1,
Il modello implicito
X2…
Y=Y
X1=1
X2=2
…
Problemi
Si oscura la relazione
tra X e Y
si sottostima la
varianza di Y e la
covarianza tra Xi e Y
Strategia 2: media condizionata
Si calcola la media sui casi completi, ma condizionatamente
ai valori noti X1, X2 …
il modello implicito
Y è missing
Y = X1 1
se
Problemi
Si ignora la componente random (manca )
si sottostima la varianza della variabile
Y imputata
Strategia 3: media condizionata +
Come la media condizionata più un residuo aleatorio
Il modello implicito
se
Y è missing
Y = 0 X1 1 Y
Problemi
con Y modifico artificialmente la correlazione tra
Y e X1
introduco un'altra sorgente di variabilità nei miei dati
Problemi con l’imputazione singola
Si sottostima la variabilità delle variabili missing e quindi
anche la variabilità delle stime campionarie svolte anche
con i dati imputati
Infatti si trattano i valori imputati come osservati,
mentre sono più “incerti” sono ulteriori stime!
In altri termini, quando si considera l’aggiunta di un
residuo aleatorio () ipoteticamente dovuto al modello
aleatorio considerato, si introduce una sorta di ulteriore
campionamento quindi una aleatorietà aggiuntiva oltre a
quella primaria dovuta all'estrazione iniziale del
campione