Politecnico di Milano
Scuola di Ingegneria Industriale e dell’Informazione
Dipartimento di Elettronica, Informazione e Bioingegneria
AIDA: Automatic Index with DAta mining
Tesi di Laurea Magistrale in Ingegneria Informatica
Relatore:
Prof. Letizia TANCA
Correlatore: Ing. Mirjana MAZURAN
Matteo SIMONI
Anno Accademico 2014-2015
Matr. n. 796384
Alla mia famiglia.
Sommario
Il lavoro di tesi propone una metodologia ed un tool a supporto della gestione automatica degli indici in una base di dati relazionale.
L’obiettivo fondamentale della metodologia è quello di liberare l’amministratore della base di dati dal gravoso e complesso compito di scelta degli
indici affindandosi ad un supporto automatico.
Il lavoro si basa su un idea già esistente in letteratura che viene modificata
introducendo l’utilizzo di tecniche di Data Mining in modo che il prodotto
finale possa, basandosi sulla storia passata, imparare ad anticipare gli eventi
che accadranno; la proposta è supportata da una tool che la integra e ne
dimostra il funzionamento.
III
Ringraziamenti
Desidero ringraziare la Professoressa Letizia Tanca e l’Ing. Mirjana Mazuran che mi hanno guidato nella realizzazione di questa tesi.
Grazie all’Ing. Francesco Merlo per aver proposto il problema iniziale da
affrontare.
Grazie a Riccardo, compagno in questi anni di università, con il quale ho
condiviso le fatiche, ma anche le gioie dello studio e del lavoro.
Grazie a Marta, la mia fidanzata, sempre pronta a sorreggermi quando tutto sembrava nero, a spronarmi a continuare senza mai mollare, a gioire e
festeggiare insieme a me.
Grazie ad Andrea, Amico fidato e compagno di mille avventure, di chiaccherate, racconti ed emozioni condivise.
Grazie a mio fratello Stefano, vero esempio e punto di riferimento.
Grazie a tutti i miei amici, a tutti coloro che hanno voluto e continuano
a condividere la loro strada con la mia: grazie perchè da tutti ho potuto
imparare qualcosa di nuovo e di bello.
Grazie a mamma e a papà perchè mi hanno dato la grande opportunità di
studiare e perchè sono sempre pronti a sacrificarsi per me, a spingermi a dare
il meglio e ad indicarmi la giusta via. Grazie perchè senza di voi non avrei
mai potuto raggiungere questo grande traguardo, questa tappa importante
della mia vita.
V
Indice
Sommario
III
Ringraziamenti
V
Indice
VII
Elenco delle figure
IX
Elenco delle tabelle
XI
Elenco degli algoritmi
XII
1 Introduzione
1
2 Stato dell’arte sui sistemi
6
2.1
Rassegna dei sistemi esistenti . . . . . . . . . . . . . . . . . .
7
2.2
Analisi dettagliata del sistema PIM . . . . . . . . . . . . . . .
17
3 Stato dell’arte sul SPM
21
3.1
Notazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
22
3.2
Categorie di algoritmi per SPM . . . . . . . . . . . . . . . . .
24
3.2.1
Algoritmi Apriori-like . . . . . . . . . . . . . . . . . .
24
3.2.2
Algoritmi BFS (Breadth First Search)-based . . . . .
25
3.2.3
Algoritmi DFS (Depth First Search)-based . . . . . .
25
3.2.4
Algoritmi closed sequential pattern based . . . . . . .
25
VII
VIII
INDICE
3.2.5
3.3
Algoritmi incremental based . . . . . . . . . . . . . . .
26
Analisi dettagliata di PrefixSpan . . . . . . . . . . . . . . . .
31
3.3.1
Notazioni preliminari . . . . . . . . . . . . . . . . . . .
31
3.3.2
L’algoritmo . . . . . . . . . . . . . . . . . . . . . . . .
33
3.3.3
Un esempio illustrativo . . . . . . . . . . . . . . . . .
34
4 L’approccio AIDA
38
4.1
Notazioni preliminari . . . . . . . . . . . . . . . . . . . . . . .
38
4.2
Alcuni esempi illustrativi . . . . . . . . . . . . . . . . . . . .
44
4.2.1
Timestamp semplificati . . . . . . . . . . . . . . . . .
44
4.2.2
Timestamp reali . . . . . . . . . . . . . . . . . . . . .
49
4.3
L’algoritmo . . . . . . . . . . . . . . . . . . . . . . . . . . . .
65
4.4
Scenari applicativi . . . . . . . . . . . . . . . . . . . . . . . .
68
5 Il software AIDA
70
5.1
L’architettura . . . . . . . . . . . . . . . . . . . . . . . . . . .
71
5.2
Il Manuale Utente . . . . . . . . . . . . . . . . . . . . . . . .
75
6 Sperimentazione
83
7 Conclusioni e sviluppi futuri
96
Bibliografia
99
Elenco delle figure
2.1
PIM - Architettura . . . . . . . . . . . . . . . . . . . . . . . .
17
4.1
Pattern Sequenziale nel nostro dominio applicativo . . . . . .
39
4.2
Pattern Sequenziale nel nostro dominio applicativo apliato
con il concetto di durata . . . . . . . . . . . . . . . . . . . . .
39
4.3
Pattern Sequenziale completo . . . . . . . . . . . . . . . . . .
40
4.4
Pattern Sequenziale di lunghezza 2 in forma grafica . . . . . .
50
4.5
Pattern Sequenziale di lunghezza 2 in forma grafica con tempi 52
4.6
Pattern Sequenziale di lunghezza 3 in forma grafica . . . . . .
4.7
Pattern Sequenziale di lunghezza 3 in forma grafica con tempi 54
4.8
Pattern Sequenziale di lunghezza 4 in forma grafica . . . . . .
4.9
Pattern Sequenziale di lunghezza 4 in forma grafica con tempi 57
5.1
Struttura di una riga del log delle operazioni di PostgreSql . .
71
5.2
Struttura di una riga del log delle operazioni di MySQL . . .
71
5.3
Paradigma Model-View-Controller . . . . . . . . . . . . . . .
72
5.4
Architettura del tool Aida . . . . . . . . . . . . . . . . . . . .
73
5.5
Fase di apprendimento − situazione iniziale . . . . . . . . . .
76
5.6
Fase di apprendimento − finestra di navigazione . . . . . . .
77
5.7
Fase di apprendimento − selezione delle teQuery . . . . . . .
77
5.8
Fase di apprendimento − teQuery selezionate . . . . . . . . .
78
5.9
Fase di apprendimento − output della fase di apprendimento
79
IX
52
55
X
ELENCO DELLE FIGURE
5.10 Fase di apprendimento − pattern sequenziale completo in
forma testuale . . . . . . . . . . . . . . . . . . . . . . . . . . .
80
5.11 Fase di previsione − schermata iniziale . . . . . . . . . . . . .
80
5.12 Fase di previsione − output . . . . . . . . . . . . . . . . . . .
82
6.1
Struttura della tabella “individuals syntonizations live” . . .
86
6.2
Prima ipotesi di calcolo di Precisione e Recupero . . . . . . .
87
6.3
Valori della Precisione con la prima ipotesi di calcolo . . . . .
88
6.4
Valori del Recupero con la prima ipotesi di calcolo . . . . . .
88
6.5
Pattern sequenziale su due finestre di query diverse . . . . . .
89
6.6
Seconda ipotesi di calcolo di Precisione e Recupero . . . . . .
90
6.7
Esempio di Ovefitting. Errore sui dati di training (blu) ed
errore sui dati di test (rosso) . . . . . . . . . . . . . . . . . .
91
6.8
Valori della Precisione con la seconda ipotesi di calcolo . . . .
91
6.9
Valori del Recupero con la seconda ipotesi di calcolo . . . . .
93
6.10 Sequential Pattern trovati con supporto minimo 0,3 . . . . . .
94
6.11 Sequential Pattern trovati con supporto minimo 0,35 . . . . .
94
6.12 Sequential Pattern trovati con supporto minimo 0,4 . . . . . .
94
6.13 Sequential Pattern trovati con supporto minimo 0,45 . . . . .
94
6.14 Valori della F-measure con la seconda ipotesi di calcolo al
variare del supporto minimo . . . . . . . . . . . . . . . . . . .
95
Elenco delle tabelle
2.1
Categorizzazione dei tool per la ricerca automatica di indici
(Parte 1)
2.2
14
Categorizzazione dei tool per la ricerca automatica di indici
(Parte 2)
2.3
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
15
Categorizzazione dei tool per la ricerca automatica di indici
(Parte 3)
. . . . . . . . . . . . . . . . . . . . . . . . . . . . .
16
3.1
Sequenze di ingresso . . . . . . . . . . . . . . . . . . . . . . .
22
3.2
Confronto tra gli algortimi per la ricerca di pattern sequenziali
(tratta da [24]) . . . . . . . . . . . . . . . . . . . . . . . . . .
29
3.3
Database di esempio . . . . . . . . . . . . . . . . . . . . . . .
32
3.4
I pattern di lunghezza 1 identificati . . . . . . . . . . . . . . .
34
3.5
I pDB rispetto ai pattern frequenti di lunghezza 1 . . . . . .
35
3.6
Estratto della Tabella 3.5 . . . . . . . . . . . . . . . . . . . .
36
3.7
Occorrenze dei pattern di lunghezza 1 . . . . . . . . . . . . .
36
3.8
S|<db> e S|<dc> . . . . . . . . . . . . . . . . . . . . . . . . . .
36
3.9
I pattern sequenziali di lunghezza uno (e le loro occorrenze)
derivati da S|<dc> . . . . . . . . . . . . . . . . . . . . . . . . .
37
3.10 I pattern sequenziali di lunghezza 3 . . . . . . . . . . . . . . .
37
6.1
Valori della Precisione con la seconda ipotesi di calcolo . . . .
92
6.2
Valori della Recupero con la seconda ipotesi di calcolo . . . .
92
XI
Elenco degli algoritmi
1
PrefixSpan Main . . . . . . . . . . . . . . . . . . . . . . . . . .
33
2
PrefixSpan . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
34
3
Aida . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
65
4
AidaTraining . . . . . . . . . . . . . . . . . . . . . . . . . . . .
66
5
AidaForecasting . . . . . . . . . . . . . . . . . . . . . . . . . .
68
XII
Capitolo 1
Introduzione
“Who controls the past controls the future. Who controls the present controls
the past.”
George Orwell
Il lavoro di tesi propone una metodologia ed un tool a supporto della
gestione automatica degli indici in una base di dati relazionale.
Un indice è una struttura dati realizzata per migliorare i tempi di ricerca di determinati valori all’interno di una base di dati. Una tabella senza
indici obbliga il sistema a leggere tutti i dati presenti in essa per ogni ricerca. L’indice, invece, consente di ridurre l’insieme dei dati da leggere per
completare la ricerca in esecuzione in modo da richiedere tempi più brevi.
Ad esempio, se si ha un insieme di dati disordinato, è possibile crearne
un “indice” in ordine alfabetico e sfruttare le proprietà dell’ordine alfabetico per arrivare prima al dato o ai dati cercati. Si potrebbe pensare, ad
esempio, di applicare una ricerca dicotomica sull’insieme ordinato per reperire in tempi più brevi le informazioni richieste. Nell’esempio si può pensare
di considerare per primo un dato a metà dell’insieme: se la lettera iniziale
1
2
CAPITOLO 1. INTRODUZIONE
del dato cercato viene alfabeticamente prima della lettera iniziale del dato
considerato, la seconda metà dei dati non viene considerata; in caso contrario è la prima metà dei dati a non essere considerata.
Gli indici possono anche avere, però, degli effetti negativi in quanto rendono
più lente le operazioni di inserimenti e modifica (update) ed aumentano lo
spazio occupato nella memoria di massa: poichè il numero di indici candidati per un determinato schema può essere enorme e a causa delle risorse
limitate a disposizione, prima di definire su quali campi creare gli indici occorre valutare quali siano le operazioni di selezione più frequenti. La giusta
scelta degli indici in uno schema, però, può migliorare notevolmente le prestazioni dell’operazione di lettura, ma una scelta errata può portare a un
crollo prestazionale.
Al giorno d’oggi, l’utilizzo di una base di dati può essere molto complesso, con un enorme volume di dati da gestire e la richiesta sempre crescente
di affidabilità e troughput alti e basso tempo di risposta. Per questo motivo
gli indici e la loro corretta scelta giocano un ruolo sempre più fondamentale. Anche nell’ambito del datawarehousing, sebbene non sia considerato
in questo lavoro, a causa dei tempi di esecuzione delle operazioni molto più
dilatati rispetto a quelli nell’ambito dei database, gli indici assumono una
fondamentale importanza per ottenere ragionevoli prestazioni.
Naturalmente un indice non è “giusto” in assoluto, ma la scelta viene fatta
in base all’interrogazione o alle interrogazioni di cui si vuole migliorare il
tempo di esecuzione. Questa scelta può essere fatta manualmente, ma risulterebbe molto costosa in termini di tempo e di risorse. In particolare, poi,
al crescere del numero di tabelle e del numero di attributi per ogni tabella, questo diventerebbe un compito ingestibile poichè l’amministratore della
base di dati dovrebbe avere una profonda conoscenza di numerosi aspetti
implementativi del DBMS, dell’hardware, delle strategie di progettazione
3
dei database fisici e delle caratteristiche dei dati salvati e di quelli che ancora devono essere gestiti [46]. Per questi motivi, fin dagli anni ’70, numerosi
studi sono stati svolti in questo campo e diverse tecniche e strumenti per
supportare automaticamente (o semi-automaticamente) il lavoro dei DBA
sono stati prodotti.
L’orientamento verso sistemi che potessero svolgere questo compito in modo
completamente automatico è stato più che naturale, ma diversi sono stati i
metodi per farlo.
L’obiettivo fondamentale del presente lavoro è quello di fornire una metodologia ed un tool a supporto degli amministratori di basi di dati (DBA)
per la manutenzione automatica degli indici in una base di dati relazionale
in modo da ridurre il tempo di esecuzione e quindi migliorare le performance
del sistema quando deve gestire delle operazioni particolarmente impegnative in termini di utilizzo di risorse e tempo di risposta. Molte tecniche sono,
come detto, già state proposte ed il campo notevolemente esplorato, ma il
lavoro si vuole inserire in questo contesto proponendo un nuovo approccio
con una metodologia mai prima d’ora utilizzata. La maggior parte di questi
metodi, infatti, sono reattivi, cioè agiscono dopo l’esecuzione di una query
e quindi dopo che il problema di performance è stato rilevato. Soltanto recentemente, è stato presentato [18], che cerca di agire prima dell’esecuzione
di una query con lunghi tempi di esecuzione prevedendo il momento in cui
essa sarà eseguita. Il modello proposto, infatti, riprende alcuni aspetti già
utilizzati da quest’ultimo in letteratura, ma utilizza un approccio innovativo attraverso tecniche di apprendimento dai dati, in particolare la ricerca
di sequenze frequenti nell’ambito del data mining. Esse, opportunamente
modificate per i nostri scopi, potranno essere utili per imparare dalla storia
passata delle interrogazioni eseguite e modificare il comportamento del sistema durante il suo funzionamento ottenendo migliori prestazioni grazie alla
4
CAPITOLO 1. INTRODUZIONE
capacità di prevedere e, quindi, di gestire al meglio attraverso una preventiva
manutenzione degli indici, l’esecuzione di una determinata query. In particolare esse non si focalizzano più, come succedeva fino ad ora, sulla storia
delle occorrenze di una determinata query di cui si vuole migliorare il costo
di esecuzione, ma anche sul “contesto” in cui quest’ultima è inserita. Con il
termine contesto intendiamo l’insieme di operazioni che precedono quella in
considerazione: in ambiti in cui queste sono ricorrenti e concatenate, infatti,
è probabile che una di esse ne segua altre ben precise e definite. Conoscendo,
quindi, le relazioni di ordinamento che intercorrono tra le diverse operazioni,
è possibile una migliore e più accurata previsione delle prossima esecuzione
della query considerata.
Per fare tutto ciò, AIDA, la metodologia presentata in questo lavoro, implementa le seguenti funzionalità:
• Identificazione delle “time-expensive queries” (da qui in poi teQuery,
definizione precisa come in [18]), cioè delle query che necessitano di un
miglioramento nei tempi di esecuzione;
• Estrazione dai dati delle esecuzioni già avvenute della conoscenza necessaria a predire la prossima esecuzione di una teQuery;
• Programmazione della manutenzione degli indici prima dell’esecuzione
della teQuery;
• Manutenzione degli indici dopo l’esecuzione di una teQuery o dopo la
fine di validità di una predizione.
Naturalmente, applicando questo metodo, supponiamo noti gli indici che
migliorano le prestazioni della teQuery in considerazione. Diverse possono
essere le modalità per identificarli: sarebbe possibile cercarli manualmente
oppure attraverso tecniche più strutturate presenti in letteratura. Il sistema
funziona in maniera continua e senza l’intervento del DBA. Per la parte di
5
estrazione della conoscenza dai dati viene utilizzata la tecnica del Sequential
Pattern Mining. Questa permette di conoscere la correlazione cronologica
di una determinata serie di queries ripetuta frequentemente e quindi utile a
sapere quando la teQuery sta per essere eseguita.
Il lavoro di tesi è strutturato come segue. Il capitolo 2 presenta una
rassegna dello stato dell’arte relativo agli strumenti fino ad oggi realizzati
e alle tecniche che essi implementano con un confronto con la metodologia
proposta in questo lavoro.
Il capitolo 3 introduce la tecnica del Sequential Pattern Mining per l’estrazione di sequenze ricorrenti da un insieme di elementi ordinati e fa una
categorizzazione degli algoritmi che realizzano questa tecnica spiegando quale verrà scelto per i nostri scopi e perchè.
Il capitolo 4, invece, presenta AIDA, spiegandone l’idea di base con alcuni esempi e presentando poi lo pseudocodice del suo funzionamento.
Il capitolo 5, presenta la demo del tool che implementa la nostra idea,
la sua architettura e il manuale d’uso. Esso spiega gli input necessari e gli
output ottenuti, oltre all’utilizzo, passo dopo passo, del software prodotto.
Il capitolo 6, presenta alcuni risultati della fase di sperimentazione della
metodologia e dello strumento software.
Il capitolo 7, infine, presenta le conclusioni del lavoro e accenna a suoi
possibili sviluppi futuri.
Capitolo 2
Stato dell’arte sui sistemi per
la costruzione automatica di
indici
“Historia magistra vitae.”
Cicerone
Con il passare del tempo i database sono diventati sempre più complessi e
hanno dovuto gestire un sempre crescente volume di dati. Nonostante questo, un alto troughput e un tempo di risposta sempre inferiore sono tra le
prime richieste avanzate dagli utenti. In questo scenario giocano un ruolo
fondamentale gli indici che possono notevolmente migliorare le prestazioni
di un Data Base Management System (DBMS). La scelta di questi indici e
la loro implementazione è un lavoro complesso, critico e altamente specializzato. Per questo si è iniziato a pensare a dei sistemi automatici fin dalla
seconda metà degli anni ’70 che sostituissero un lavoro altrimenti manuale.
Da quegli anni fino ad oggi, molti tool sono stati proposti per soddisfare
quest’esigenza, ognuno con le sue peculiarità.
6
2.1. RASSEGNA DEI SISTEMI ESISTENTI
7
Generalmente questi sistemi ricevono in ingresso il log delle operazioni eseguite su una base di dati (detto “Workload”) e, a seconda della tipologia,
producono in uscita diversi risultati: alcuni restituiscono solamente gli indici
da costruire; altri, invece, eseguono anche l’operazione stessa di costruzione.
Questa operazione, in particolare, può essere fatta a seguito di una richiesta
al DBA oppure in modo completamenta automatico.
A seguire, sarà spiegato il significato di alcune caratteristiche utili a realizzare una precisa categorizzazione di tali tool:
• Offline (workload fisso in ingresso. Le operazioni eseguite vengono
salvate e periodicamente vengono passate tutte insieme al tool) o Online (monitora continuamente workload del DB. Quando un’operazione
viene eseguita sulla base di dati, viene anche passata come input al
tool)
• Manuale (suggerisce indici, ma non li implementa), Semi-automatico
(suggerisce indici e chiede al DBA se possono essere implementati. In
caso affermativo esegue l’operazione) o Automatico (implementa gli
indici senza richiedere il permesso al DBA)
• Reattivo (implementa indici in seguito all’esecuzione di una o più query) o Proattivo (implementa indici prima dell’esecuzione di una o più
query)
2.1
Rassegna dei sistemi esistenti
Tra i primi a lavorare in questo campo vi furono [1] e soprattutto [2] che
applicavano un algoritmo euristico (esso usa in particolare cinque euristiche per cinque problemi ben definiti) con un modello di costo semplice, ma
abbastanza flessibile (tenendo in considerazione il costo di creazione degli
indici e lo spazio che essi occupavano in memoria) che seleziona gli attributi
per i quali è più utile la costruzione di un indice in modo da ottenere un
8
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
minor costo di esecuzione delle operazioni sulla base di dati. L’algoritmo
raccoglie delle statistiche ad ogni esecuzione di un’interrogazione e, attraverso la tecnica dell’“exponential smoothing” ([3], [4]), - una tecnica che
utilizza i dati di serie temporali per fare stime dei valori futuri - le confronta
con le precedenti per identificare l’insieme di attributi più adatto alla costruzione degli indici. Questa tecnica, a differenza della media mobile in cui
le osservazioni hanno tutte lo stesso peso, attribuisce pesi esponenzialmente
decrescenti alle osservazioni passate in modo che esse incidano meno rispetto
ad osservazioni più recenti e, facendo ciò, la stima viene fatta sempre più
contestuale alle ultime osservazioni fatte. Successivamente hanno iniziato
a diffondersi strumenti a livello industriale e la ricerca in questo campo ha
preso sempre più piede.
Numerose realizzazioni di strumenti con diverse caratteristiche che svolgessero automaticamente la ricerca di indici appropriati per una base di dati
sono state sviluppate: nel 2007 [5] e [6] presentarono un tool intrusivo e online (costantemente in esecuzione) come componente di Microsft SQL Server
2005. Esso funziona come segue: nel processo di ottimizzazione di una query q, la chiamata all’ottimizzatore è deviata ad un modulo detto “Index
Analysis” (IA) che identifica - usando un albero AND/OR per le richieste un insieme di indici candidati che potrebbero ridurre il tempo di esecuzione
di q. Gli alberi di ricerca AND-OR sono una rappresentazione delle sequenze decisionali. Essi permettono di analizzare alcuni aspetti contingenti
dell’ambiente esterno al fine di rendere quasi istantanea la decisione finale
(decisione “meccanica“). Le condizioni OR sono le contingenze orizzontali
(due condizioni alternative), mentre le condizioni AND sono le contingenze verticali (due condizioni che devono essere valide contemporaneamente).
Successivamente la query q viene ottimizzata e processata come in un DBMS
tradizionale, ma durante l’esecuzione, IA stima i potenziali benefici appor-
2.1. RASSEGNA DEI SISTEMI ESISTENTI
9
tati dagli indici candidati e i benefici degli indici fisici. Dopo l’esecuzione
vengono analizzati questi benefici dal modulo “Cost/Benefit Adjustement”
e, basandosi su queste analisi, vengono inviate le richieste di creazione o
distruzione di indici allo scheduler, il componente atto a questo compito.
A seguire, poi, numerosi altri strumenti ed altrettante metodologie sono
stati pensati ed implementati. La maggioranza di essi, è stata realizzata
per uno specifico DBMS: in particolare, l’attenzione si è focalizzata su IBM
DB2 e PostgrSQL.
Riguardo al primo, [11] e [12] hanno proposto QUIET, un middleware (livello intermedio tra chi fa la richiesta e chi fornisce la risposta) che suggerisce
automaticamente la creazione di indici. La soluzione si basa su comandi
proprietari di DB2 e non è quindi compatibile con altri DBMS. Questo approccio comprende un modello di costo che tiene in considerazione i costi
per la creazione e per la manutenzione degli indici e una strategia di scelta
degli indici più adatti: essa, per ogni query, restituisce l’intero insieme di
indici utili che viene usato per aggiornare la configurazione globale degli indici (che comprende sia quelli virtuali che quelli materializzati). Una volta
fatto ciò, il tool, tenendo in cosiderazione lo spazio disponibile, decide se
mantenere gli indici già materializzati o se materializzare alcuni degli indici
virtuali basandosi sul modello di costo: se il profitto per la nuova configurazione (quella con implementato il nuovo indice) è maggiore del profitto di
quella vecchia (senza indice), allora esso viene implementato.
In [14] viene, invece, presentato un nuovo framework che può aiutare il DBA
a comprendere le interazioni nell’insieme di indici raccomandati. Viene formalizzata la definizione di interazione tra indici e presentato un algoritmo
10
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
per identificare queste ultime in un set di indici raccomandati. Inoltre vengono presentati due tool intrusiv semprei per IBM DB2 che utilizzano le
informazioni sulle interazioni tra indici.
Per quanto riguarda PostgreSQL, invece, un tool online che è stato implementato in modo intrusivo è COLT (Continuous On-Line Tuning) presentato
da [7] e [8]. Esso rimpiazza l’ottimizzatore di PostgreSQL con un “Extended Query Optimizer” (EQO) e aggiunge un “Self Tuning Module” (STM).
Anche questo, come il precedente, è un algoritmo reattivo: per ogni query
q, STM seleziona un insieme di indici candidati (CI) che comprendono sia
indici fisici che ipotetici. Per ogni indice i in CI, EQO genera un piano di
esecuzione per q e ne calcola il guadagno. Alla fine di un’epoca (fase di
osservazione che corrisponde al tempo di esecuzione di dieci query) l’insieme
CI viene analizzato e vengono fatte le opportune modifiche agli indici. Il
tempo fisso di un’epoca è uno svantaggio perchè il numero fisso di query
potrebbe non essere adatto ai bisogni del database.
Ancora un approccio intrusivo e online è [9]. Anch’esso è reattivo in quanto
è costituito da una fase di osservazione e di identificazione degli indici candidati per ogni query q (usando le euristiche descritte in [10]) alla quale segue
una doppia ottimizzazione (una volta considerando gli indici e una volta no)
e di valutazione con la conseguente fase di implementazione degli indici più
adatti. Anche qui viene usato il concetto di epoca di [7] e [8], ma in modo
più dinamico.
Negli ultimi anni, poi, sono state presentate soluzioni più interattive: PARINDA (PARtition and INDex Advisor), presentato da [15] e [16] è un tool
intrusivo che permette al DBA di suggerire manualmente un set di indi-
2.1. RASSEGNA DEI SISTEMI ESISTENTI
11
ci candidati per un dato workload e mostra i benefici portati da questo
insieme. Esso propone anche uno “scheduler” per implementare gli indici
suggeriti che monitora continuamente lo workload in ingresso per suggerire
nuovi indici (attraverso la tecnica ILP - Integer Linear Programming, programmazione lineare intera - che permette la scelta degli indici più adatti
mappando e risolvendo un problema di programmazione lineare proposta
da [19]) e nuove partizioni (usando la tecnica “AutoPart” proposta da [20])
quando questi portano a un sufficiente guadagno.
Questo aumento di interattività ha portato a una nuova tecnica di scelta
degli indici, chiamata “semi-automatic index tuning”, presentata da [17].
L’idea è quella di generare dei suggerimenti di indici non solo basati sulle
effettive prestazioni di una loro implementazione, ma anche sulle preferenze
del DBA che possono essere esplicite (il DBA vota positivamente l’indice
oppure no) o implicite (il DBA sceglie di implementare o di rimuovere l’indice). La responsabilità della materializzazione di indici è completamente
lasciata al DBA. Essi partono da un’idea di [21] che si concetrava, però, su
uno workload fisso (offline). Al contrario, essi, propongono una soluzione
online.
Tutti gli algoritmi e i tool presentati fino a questo punto sono reattivi: essi,
appunto, reagiscono dopo che sono stati rilevati problemi di prestazioni e
cambiano la configurazione di indici dopo che lo workload è stato eseguito.
Recentemente, invece, si è pensato ad un nuovo approccio proattivo che viene ripreso anche nella metodologia e nel tool presentati in questo lavoro.
Il problema dell’approccio reattivo è che esso deve aspettare che qualcosa
non funzioni bene per potersi adattare: ad esempio, si deve attendere l’e-
12
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
secuzione di una query con un lungo tempo di esecuzione perchè il sistema
decida di implmentare gli indici adatti ad una sua più rapida esecuzione.
L’approccio proattivo si discosta da quest’idea poichè fa delle previsioni sul
futuro e si adatta in base ad esse prima che il fatto predetto avvenga: cosı̀
facendo, nel caso in cui la previsione fosse giusta, il sistema sarebbe già
pronto per l’evento che sta per accadere. Nel nostro caso, si prevede quando una determinata query molto costosa in termini temporali sarà eseguita
e, prima che ciò avvenga, si implementano gli indici adatti ad una sua più
rapida esecuzione. Il punto sconveniente dell’approccio proattivo è che il
sistema, per poter fare previsioni, deve conoscere la storia passata e quindi, almeno inizialmente, si deve aspettare che essa avvenga senza poter fare
molto; d’altra parte, però, questo avviene solo nella fase iniziale, al contrario
dell’approccio reattivo in cui succede pressochè ogni volta.
In [18] viene presentato PIM (Proactive Index Maintenance), un tool indipendente dal DBMS che è continuamente in esecuzione e che non necessita
dell’intervento del DBA. Esso si interfaccia con i diversi DBMS attraverso
appositi driver specifici (a causa delle strutture diverse di questi ultimi) tra
cui: driver per l’accesso al workload, driver per l’accesso alle statistiche e
driver per gli aggiornamenti del DBMS. Il componente“Workload Obtainement” (WO), poi, ottiene i log di questi ultimi che inserisce nel suo metabase
nella forma <espressione SQL, piano di esecuzione, costo stimato>. Avendo
a disposizione il workload, identifica le teQuery (definizione completa nella
Sezione 2.2).
Questo, dopo aver ottenuto il piano di esecuzione reale da parte del DBMS
per la query in questione, lo analizza e cerca le operazioni che non fanno uso
di indici per rimpiazzarle con altre equivalenti che, però, usano gli stessi.
Una volta trovata le strutture di indici più appropriate per queste ultime,
anche la coppia <teQuery, struttura di indici> viene salvata nel “metabase”. Con un software esterno, poi, per ogni teQuery q, viene identificata la
2.1. RASSEGNA DEI SISTEMI ESISTENTI
13
distribuzione statistica (normale, binomiale, poisson, ecc) che meglio rappresenta la storia delle sue esecuzioni e da questa PIM identifica il miglior
modello di predizione (regressione lineare, MLP (Multi Layer Perceptron),
RBF (Radial Basis Function), ecc). A questo punto PIM è in grado di prevedere, basandosi sul modello di predizione, quando una query q sarà eseguita
la prossima volta: per fare ciò esso cattura dal Local Metabase le ultime n
esecuzioni di q (n dipende dalla finestra temporale usata per il modello di
predizione) e manda una richiesta nella forma <q, Iq , Nq -t> al DLL Generator (che poi la invierà a uno Scheduler che programma la creazione degli
indici per la notte prima di Nq -t), dove q è la query in questione, Iq è l’indice
adatto ad essa e Nq è la data prevista per la prossima esecuzione di q e t
è un intero che indica quanti giorni prima di Nq la creazione degli indici
deve avvenire. Aumentare t, quindi, aumenta la probabilità di avere una
predizione corretta, ma anche gli overhead dovuti all’update della tabella su
cui sono definiti gli indici. PIM, inoltre, analizza il workload del DBMS per
essere a conoscenza dell’esecuzione di un query q di cui era stata predetta
l’esecuzione e per cui erano stati creati proattivamente indici. In questo
approccio gli indici sono rimossi dopo uno dei seguenti eventi:
1. la query q è stata eseguita;
2. sono passati k giorni dopo Nq .
Nelle Tabelle 2.1-2.2-2.3 di seguito una classificazione dei tool sopra descritti.
14
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
Online
Online
Online
Offline
MANUALE/
AUTOMATICO/
SEMIAUTOMATICO
Automatico
Automatico
Automatico
Manuale
Offline
Online
Online
Online
Semi-automatico
Semi-automatico
Semi-automatico
Automatico
ONLINE/
OFFLINE
[5] [6]
[7] [8]
[11] [12]
[14]
[15] [16]
[19] [20]
[17]
[21]
[18]
REATTIVO/
PROATTIVO
Reattivo
Reattivo
Reattivo
Reattivo
Reattivo
Reattivo
Reattivo
Proattivo
Tabella 2.1: Categorizzazione dei tool per la ricerca automatica di indici
(Parte 1)
2.1. RASSEGNA DEI SISTEMI ESISTENTI
15
BENEFICIO/
COSTO
cost(W, S) =
n
∑
(ciSi + transition(si − 1, si))
i=1
dove transition(s0 , s1 ) =
[5] [6]
[7] [8]
[11] [12]
[14]
∑
I∈s1 −s0
(B ( S0 ))I
W:Workload
S: Configuration
(B ( S0 ))I : Costo creazione indice I per la configurazione S.
gain(I, q) = |cM − cI |
cM : costo esecuzione con gli indici materializzati
cI : costo esecuzione con gli indici in I in aggiunta
a quelli materializzati (se non sancora presenti)
o tolti da quelli materializzati (se già presenti).
profit(Q, I)=cost(Q)-cos(Q,I)
cost(Q): costo di escuzione di Q con gli indici già esistenti
cost(Q,I): costo di esecuzione di Q con, in aggiunta, gli indici di I
benefitq (X, Y) = costq (Y) costq (X ∪ Y)
tiene in considerazione il grado di interazione tra X e Y.
[15] [16]
[19] [20]
[17]
[21]
hline [18]
bik = max(0, c(i, ) c(i,Ck ))
c(i, ): costo di esecuzione di i senza indici
c(i,Ck ): costo di esecuzione di i con la configurazione di indici Ck
benefitq (X, Y) = costq (Y) costq (X ∪ Y)
tiene in considerazione il grado di interazione tra X e Y.
Utilizza il costo calcolato dal DBMS
Bi,q = max0, cost(q)-cost(q,i)
cost(q): costo di escuzione di Q senza lindice i
cost(q,i): costo di escuzione di Q con lindice i
Tabella 2.2: Categorizzazione dei tool per la ricerca automatica di indici
(Parte 2)
16
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
[5] [6]
[7] [8]
[11] [12]
[14]
OBIETTIVO
Diminuzione del tempo di
esecuzione di una query
Diminuzione del tempo di
esecuzione di una query
Diminuzione del tempo di
esecuzione di una query
Diminuzione del tempo di
esecuzione di una query
DBMS
Micorsoft SQL Server 2005
PostgreSQL
IBM DB2 Version 8.1
IBM DB2 Express-C
[15] [16]
[19] [20]
[17]
[21]
[18]
Diminuzione del tempo di
esecuzione di una query
Diminuzione del tempo di
esecuzione di una query
Diminuzione del tempo di
esecuzione di una query
Diminuzione del tempo di
esecuzione di una query
PostgreSQL [15], SQL Server 2000 [20]
IBM DB2 Express-C
Micorsoft SQL Server (versione non specificata)
Indipendente dal DBMS
Tabella 2.3: Categorizzazione dei tool per la ricerca automatica di indici
(Parte 3)
2.2. ANALISI DETTAGLIATA DEL SISTEMA PIM
2.2
17
Analisi dettagliata del sistema PIM
In questa sezione vogliamo fare un’analisi approfondita di PIM [18], la metodologia prima accennata che è stata usata come base su cui proporre la
nostra nuova tecnica. Essa, infatti, a nostro parere, propone idee buone e
innovative, ma con alcuni punti miglirabili.
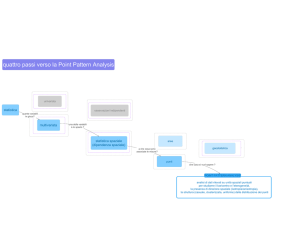
Di seguito, in figura 2.1, mostriamo l’architettura del sistema, utile a capirne
il funzionamento spiegato successivamente.
Figura 2.1: PIM - Architettura
Esso accede al workload del DBMS ed estrae, per ogni query, i relativi
dati nella forma <SQL expression, execution plan, costs, datetime> che
saranno usati per la ricerca automatica degli indici. Fattò ciò li inserisce nel
“Local Metabase” (LM), un database interno al sistema e strutturato per i
suoi scopi. Dopo aver decomposto il valore di datetime in giorno (1-31) e
18
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
mese (1-12) vengono selezionate le query time-expensive.
Una query si dice time-expensive se:
1. RTq > t, dove RTq è il tempo di risposta di q e t è un parametro
costante (9000s);
2. Fq < k, dove Fq è il numero di esecuzioni di q diviso per il periodo di
osservazione (in mesi) e k è un parametro costante (5. q è eseguita tra
una e quattro volte al mese in media);
3. c’è almeno una struttura di indici i tale per cui Bi,q > ECCi dove ECCi
è il costo stimato per la creazione della struttura i e Bi,q è il beneficio
dato dalla presenza della struttura di indici i durante l’esecuzione della
query q rispetto all’esecuzione della stessa senza quella struttura.
Per ogni teQuery viene trovato l’indice più appropriato e salvato (as esempio,
con la tecnica degli “Hypothetical Execution Plan”, dopo aver ottenuto il
piano di esecuzione reale da parte del DBMS per la query in questione, lo
analizza e cerca le operazioni che non fanno uso di indici per rimpiazzarle
con altre equivalenti che, però, usano gli stessi.) Fatto ciò, per ogni teQuery
si accede alla storia delle esecuzioni per trovare la distribuzione statistica che
meglio la rappresenta. A questo punto viene scelto il modello di predizione
più adatto tra regressione lineare, MLP (Multi Layer Perceptron) e RBF
(Radial Basis Function). Per ogni modello di predizione vengono valutate
diverse istanze caratterizzate da paramentri differenti. Per implementare,
istruire e validare le due reti neurali (MLP e RBF) viene usato Weka, mentre
per la regressione lineare viene usato un tool Java. Il risultato di questa
operazione è il miglior modello di predizione (con la configurazione associata)
per ogni teQuery. Per scegliere la migliore istanza del modello di predizione
per ogni query vengono usati il coefficiente di correlazione (compreso tra -1,
2.2. ANALISI DETTAGLIATA DEL SISTEMA PIM
19
negativamente correlati, e +1, positivamente correlati)
∑
∑
∑
n xy − ( x)( y)
r=√ ∑ 2
∑
∑
∑
[n x − ( x)2 ][n y 2 − ( y)2 ]
e la radice dell’errore quadratico medio (RMSE, Root Mean Square Error)
che è la misura della differenza tra i valori predetti da un modello e i valori
effettivamente osservati. Dopo aver trovato il moglior modello per ogni query q, PIM lo usa per prevedere la prossima esecuzione di una determinata
query ed inviare una richiesta di creazione degli indici in Iq al DDL Generator.
L’approccio che proponiamo in questo lavoro riprende gran parte dei concetti di PIM: anch’esso vuole essere un tool proattivo che possa implementare
gli indici prima che la teQuery venga eseguita, anch’esso calcola le strutture
indici più appropriate per le teQuery in questione e le salva per implementarle quando si predice che una delle suddette query stia per essere eseguita.
La parte in cui si differenzia sostanzialmente da PIM è la predizione della
prossima esecuzione della teQuery in questione: PIM, come già detto, analizza la distribuzione dei tempi di esecuzione di una determinata teQuery
e, attraverso tool esterni, trova la distribuzione statistica che meglio la rappresenta. A questo punto viene scelto il modello di predizione più adatto
tra regressione lineare, MLP (Multi Layer Perceptron) e RBF (Radial Basis
Function) che sarà poi usato per prevedere quando la query sarà eseguita
nuovamente. Facendo ciò, però, si prevede il momento dell’esecuzione di una
determinata query basandosi solo sulla storia delle esecuzioni passate della
stessa: il nostro approccio, invece, propone di considerare il “contesto” in
cui la query si trova, quindi anche l’esecuzione di altre operazioni prima di
essa. L’obiettivo è quello di poter sapere, osservando le operazioni eseguite sulla base di dati, se e tra quanto una determinata query sarà eseguita,
20
CAPITOLO 2. STATO DELL’ARTE SUI SISTEMI
in modo da potersi preparare implementando gli indici adatti per una sua
migliore esecuzione. Per fare ciò si è pensato di applicare tecniche di Data
Mining, in modo da poter istruire il tool osservando la storia passata dell’intero database e non solo delle occorrenze di una determinata query in modo
da renderlo in grado di fare predizioni.
In un primo tempo, l’idea è stata quella di applicare le regole di associazione per prevedere l’esecuzione di una teQuery basandosi sull’esecuzione di
altre query. Le regole di associazione [26] sono una tecnica di Data Mining
usata per scoprire relazioni di correlazione tra i dati in grandi insiemi di
transazioni. Il problema che è sorto è che esse guardano ai dati all’interno
di una transazione senza distinzione di ordine. Nel nostro dominio applicativo, però, poiché deve essere predetta l’esecuzione di una query basandosi
sull’esecuzione di altre, l’ordine in cui esse avvengono risulta essere fondamentale. Per questo motivo si è deciso di utilizzare la tecnica del Sequential
Pattern Mining (spiegata in modo preciso nel Capitolo 3) che consente di
trovare, in un insieme di dati, sequenze ricorrenti che, in quanti tali, tengono
in considerazione l’ordine degli elementi che le compongono.
Capitolo 3
Stato dell’arte sul Sequential
Pattern Mining
“Knowledge is what we get when an observer, preferably a scientifically
trained observer, provides us with a copy of reality that we can all recognize.”
Christopher Lasch
Il Sequential Pattern Mining (SPM) [22] è una tecnica di Data Mining
che permette di estrarre sequenze di elementi che si ripetono “spesso” nell’insieme di valori in ingresso. Esso tiene in considerazione l’ordine all’interno
della transazione al contrario delle regole di associazione che non lo fanno,
poiché cercano semplicemente nell’insieme degli elementi disponibili. Esso è
utilizzato nella organizzazione d’impresa, nell’area della biologia e nel web
mining per analizzare log distribuiti su più server. Nel nostro caso, poichè il
log di operazioni di un database relazionale è una sequenza temporale, per
noi è importante poter considerare l’ordine di queste ultime in modo da conoscere cosa è avvenuto prima dell’esecuzione della query in considerazione.
Per questo motivo il SPM risulta essere la tecnica più adatta.
21
22
CAPITOLO 3. STATO DELL’ARTE SUL SPM
Per chiarire il concetto di “spesso”, intoduciamo la definizione di supporto.
Questa può essere espressa in due modi:
• Supporto Relativo: indica il numero minimo di sequenze dei dati in
ingresso in cui deve essere presenta un pattern perchè possa essere
considerato frequente;
• Supporto Assoluto: indica la percentuale minima (compresa tra 0 e 1)
di sequenze dei dati in ingresso in cui deve essere presenta un pattern
perchè possa essere considerato frequente
Numerosi algoritmi sono stati presentati partendo dai più datati che si
basavano sulla proprietà dell’algoritmo Apriori [23].
3.1
Notazione
Una sequenza è una lista ordinata di eventi < e1 e2 . . . eI >. Date due sequenze α =< x1 x2 . . . xn > e β =< y1 y2 . . . ym >, allora α è detta sotto-sequenza
di β, ovvero α ⊆ β, se esistono degli interi 1 ≤ j1 < j2 < . . . < jn ≤ m tali
che x1 ⊆ yj1 , x2 ⊆ yj2 , . . . , e xn ⊆ yjn . Se α e β contegono le seguenti sequenze α = < (xy), t > e β = < (xyz), (zt) >, allora β è una super-sequenza
di α.
SID
10
20
30
40
Sequenza
<l(lmn)(ln)o(nq)>
<(lo)n(mn)(lp)>
<(pq)(lm)(oq)nm>
<pr(lq)nmo>
Tabella 3.1: Sequenze di ingresso
Si considerino i dati in Tabella 3.1. Essi sono una piccola parte di un database di sequenze in cui ogni riga è composta da un ID (SID è l’acronimo
3.1. NOTAZIONE
23
di Sequence ID, cioè ID della sequenza) che è chiave primaria e da una sequenza composta da un insieme di elementi. Ogni elemento può contenere
un item o un insieme di item (messi tra parentesi tonde). Gli item in un
elemento non sono ordinati e sono elencati in ordine alfabetico. Per esempio, riferendoci ai dati della Tabella 3.1, <l(mn)on> è una sottosequenza
di <l(lmn)(ln)o(nq)>. Se la soglia di supporto minimo è pari a 2, allora
<(lm)n> è un sequential pattern valido. (Esempio da [24]).
In questo contesto possono essere individuate tre categorie di pattern:
• Pattern Periodici: questo modello è usato per prevedere l’occorrenza
di alcuni eventi nel futuro. Esso, in una sequenza in ingresso come <x
y z x y z x y z>, trova il pattern <x y z>. Essendo molto restrittivo
viene introdotta la nozione di Pattern Periodico Parizale in cui i pattern trovati sono nella forma <x*y> dove * è un insieme di item di
dimensione qualunque.
• Pattern Statisticamente Significativi: vengono usati due indici, supporto e confidenza, per valutare i pattern. Quelli più rari rischiano
di andare persi ed esiste il problema di identificare la posizione dell’occorrenza di un pattern. Per informazioni più dettagliate, numerosi
lavori sono stati presentati in [25].
• Pattern Aprrossimati: i due approcci precedenti tengono in considerazione soltanto la corrispondenza perfetta dei pattern, mentre qui si
considera un pattern approssimato che è una sequenza di simboli le
cui occorrenze in una sequenza appaiono con un valore maggiore di
una determinata soglia.
Risulta utile, inoltre, definire una distinzione tra due tipologie di log su cui
gli algoritmi possono essere applicati:
24
CAPITOLO 3. STATO DELL’ARTE SUL SPM
• Log Statici: l’algortimo usa come ingresso un insieme di dati e, alla
successiva esecuzione, usa dati completamente nuovi, dimenticandosi
di quelli già usati.
• Log Dinamici: l’algortimo usa come ingresso un insieme di dati e, alla
successiva esecuzione, usa lo stesso insieme della precedente esecuzione
a cui aggiunge i nuovi dati.
Il problema di trovare pattern frequenti, quindi, corrisponde ad avere a disposizione uno stream di dati ed essere in grado di individuare delle sottosequenze di lunghezza finita che ricorrono nello stream in maniera frequente,
ovvero il cui supporto supera una soglia predefinita chiamata “supporto
minimo”.
3.2
Categorie di algoritmi per SPM
In [24] sono state individuate le seguenti categorie per gli algoritmi di SPM:
Apriori-like, BFS (Breadth First Search)-based, DFS (Depth First Search)based, closed sequential pattern based e incremental based.
3.2.1
Algoritmi Apriori-like
Si basano sulle tecniche dell’algoritmo Apriori [23] e sulla sua proprietà
fondamentale: “una sequenza è frequente solo se tutte le sue sotto-sequenze
sono a loro volta frequenti”. Questo significa che le sequenze frequenti di
lunghezza k possono essere ricavate nel seguente modo: dal database delle
sequenze vengono estratte quelle frequenti di lunghezza 1; queste sono poi
combinate per ricavare le sequenze frequenti candidate di lunghezza 2 e il
processo viene ripetuto fino a ricavare quelle di lunghezza k.
3.2. CATEGORIE DI ALGORITMI PER SPM
3.2.2
25
Algoritmi BFS (Breadth First Search)-based
Riprendono tecniche di Apriori poichè generano le sotto-sequenze “in ampiezza”: al primo passo generano tutte le sottosequenze di lunghezza uno,
al secondo tutte quelle di lunghezza due e cosı̀ via.
• GSP [27]
• MFS [28]
3.2.3
Algoritmi DFS (Depth First Search)-based
Generano le sottosequenze “in profondità”: per ogni sottosequenza frequente
di lunghezza uno trovata vengono subito generate tutte quelle di lunghezza
superiore fino a quella massima e vengono rimosse quelle che non rispettano
la soglia del supporto minimo.
• SPADE [29]
• FreeSpan [30]
• PrefixSpan [31]
• SPAM [32]
3.2.4
Algoritmi closed sequential pattern based
Un pattern sequenziale frequente, come detto, è un pattern che appare almeno in un numero di sequenze definito dal supporto minimo. Un closed
sequential pattern, invece, è un pattern che non è già incluso in un altro
pattern frequente che ha esattamente il suo stesso supporto. Questo contribuisce a diminuire il numero di sottosequenze generate con un gudagno in
termini di tempo e di spazio di memoria.
• CloSpan [33]
• BIDE [34]
26
CAPITOLO 3. STATO DELL’ARTE SUL SPM
3.2.5
Algoritmi incremental based
Usati per log incrementali in cui vengono aggiunte righe e quindi l’algoritmo
viene riapplicato su finestre sempre più grandi. I sequential pattern, inoltre,
vanno aggiornati e non ricalcolati da zero.
• SuffixTree [35]
• FASTUP [36]
• ISM [37]
• ISE [38]
• GSP+ e MFS+ [39]
• IncSP [40]
• IncSpan [41]
• IncSpan+ [42]
• MILE [43]
I campi di applicazione dei vari algoritmi, quindi, sono molto diversi e una
corretta scelta del miglior algoritmo dipende certamente dall’utilizzo che se
ne vuole fare, dai dati disponibili e dai risultati che si vogliono ottenere.
La Tabella 3.2 mette a confronto gli algoritmi citati analizzandoli sulla base
delle seguenti caratteristiche:
• Database Multi-Scan: viene analizzato il database originale per
sapere se le sequenze candidate prodotte sono frequenti oppure no.
• Candidate Sequence Pruning: gli algoritmi con questa caratteristica possono usare una struttura dati per anticipare nel processo
di estrazione, il pruning, cioè l’eliminazione, di alcune delle sequenze
candidate.
3.2. CATEGORIE DI ALGORITMI PER SPM
27
• Search Space Partitioning: è una caratteristica degli algoritmi
Pattern-Growth. Permette il partizionamento dello spazio di ricerca delle sequenze candidate generate per una gestione della memoria
più efficiente.
• DFS based approach: ogni percorso deve essere analizzato fino alla
fine prima di passare al percorso successivo. E’ un’analisi fatta in
profondità.
• BFS based approach: permette una ricerca livello per livello. (Tutti
i percorsi analizzati a un determinato livello, poi tutti analizzati al
livello successivo, ..)
• Regular expression constraint: gli algoritmi con questa caratteristica hanno la proprietà “growth-based anti-monotonic” per i vincoli
che dice: “una sequenza deve essere raggiungibile crescendo da ogni
componente che coincide con una parte dell’espressione regolare”.
• Top-down search: il mining dei sequential pattern può essere fatto
costruendo l’insieme dei “projected databases” (Concetto meglio spiegato nel capitolo successivo) e facendo il mining ricorsivamente su di
essi.
• Bottom-up search: approccio usato dagli algoritmi basati su Apriori
che trovano sequenze frequenti come composizione di sotto-sequenze a
loro volta frequenti.
• Tree-projection: questa caratteristica utilizza la ricerca condizionale
sullo spazio di ricerca rappresentato come un albero. E’ usato come
database “in-memoria” alternativo.
• Suffix growth vs Prefix growth: questa caratteristica permette
che le sottosequenze frequenti si compongano grazie a prefissi/suffissi
28
CAPITOLO 3. STATO DELL’ARTE SUL SPM
frequenti. Essa permette di ridurre la quantità di memoria richiesta
per mantenere tutte le diverse sequenze candidate che condividono lo
stesso suffisso/prefisso.
• Database vertical projection: gli algoritmi con questa caratteristica visitano il database solo una o due volte per ottenere uno schema
verticale (bitmap/position indication table) di quest’ultimo piuttosto
del classico schema orizzontale.
V
V
V
V
V
V
V
V
V
V
SPADE
V
V
V
V
FreeSpan
V
V
V
V
V
V
SPAM
V
V
V
V
ISM
V
V
V
V
IncSP
V
V
V
ISE
V
V
V
V
IncSPAN
Tabella 3.2: Confronto tra gli algortimi per la ricerca di pattern sequenziali (tratta da [24])
Static Database
Incremental Database
DataBase MultiScan
Candidate Sequence Pruning
Search Space Partitioning
DFS based Approach
BFS based Approach
Regular Expression Constraint
Top-down Search
Bottom-up Search
Tree-projection
Suffix Growth
Prefix Growth
Database Vertical Projection
GPS
V
AprioriAll
V
V
V
V
V
MILE
V
V
V
V
3.2. CATEGORIE DI ALGORITMI PER SPM
29
30
CAPITOLO 3. STATO DELL’ARTE SUL SPM
Tra i vari algoritmi presentati si è dovuto scegliere il migliore per l’approccio
presentato in questo lavoro.
Nella tecnica che sarà spiegata in dettaglio nei capitoli successivi (in particolare nel Capitolo 4), il log delle operazioni viene fornito periodicamente
in ingresso ed è un pezzo dello stream di dati che il sistema ha ricevuto.
Poichè, ad ogni esecuzione, il log in ingresso è sempre diverso da quello dell’esecuzione precedente, l’algoritmo per il SPM si trova a dover gestire ogni
volta un input totalmente nuovo che può quindi essere considerato come
un log statico. Per questo motivo sono stati esclusi tutti gli algoritmi che
funzionano bene per i log incrementali e ci si è concentrati su quelli pensati per i log statici. Non espandere i pattern sequenziali, ma ricrearli da
zero periodicamente, poi, nella nostra situazione ha perfettamente senso in
quanto è possibile e sensato che dopo un certo lasso temporale le operazioni
eseguite frequentemente su una base di dati non siano più le stesse. Tra
gli algoritmi rimanenti, infine, si è pensato di escludere quelli più vecchi
e con performance inferiori che richiedevano più passate sul database delle
sequenze da analizzare (AprioriAll e GPS). Anche SPADE richiede la generazione di candidate e l’utilizzo di molta memoria (avendo un approccio
basato su Apriori), caratteristiche che limitano fortemente le sue prestazioni, per questo è stato escluso. Tra i due rimanenti algoritmi (FreeSpan
e PrefixSpan) che hanno un approccio basato su Pattern-Growth è stato
scelto il secondo che è un miglioramento del primo. Entrambi si basano
sui projected-database che partecipano primariamente al costo totale dell’algoritmo: se un pattern appare in tutte le sequenze di un database, con
il primo algoritmo, il projected-database finisce per coincidere con l’intero
database richiedendo un enorme impiego di risorse. Il secondo algoritmo,
invece, proiettando soltanto sui prefissi frequenti, diminuisce l’impiego di
risorse garantendo prestazioni migliori. Per questo motivo l’algoritmo scelto
da implementare nel tool è PrefixSpan.
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN
3.3
31
Analisi dettagliata di PrefixSpan
PrefixSpan (Prefix-projected Sequential Pattern mining) [31] è un algoritmo
“pattern-growth” presentato nel 2001. Gli algoritmi “pattern-growth” sono
una delle metodologie per estrarre pattern frequenti. Il metodo “patterngrowth” analizza la collezione di dati con approccio “dividi e conquista”: per
prima cosa trova l’insieme dei pattern frequenti di dimensione 1 e poi, per
ogni pattern p, deriva il p-projected database ricorsivamente. Nei projecetddatabase, poi, vengono ricercati i sequential pattern frequenti. Poichè la collezione di dati è decomposta progressivamente in insiemi più piccoli, questo
approccio diminuisce le dimensioni del spazio di ricerca permettendo una
maggiore efficienza e scalabilità.
3.3.1
Notazioni preliminari
Poichè gli item all’interno di un elemento di una sequenza possono assumere
un ordine qualsiasi, senza perdita di generalità, si assume che siano in ordine
alfabetico in modo da rendere unica la rappresentazione di una sequenza.
Quindi <a(bac)d(ef)> sarà considerata come <a(abc)d(ef)>.
Data una sequenza α =< e1 e2 . . . en >, una sequenza β =< e′1 e′2 . . . e′m >
con (m<n) è detta prefisso di α se e solo se:
1. e′i =ei per (i<m-1);
2. e′m ⊆ em ;
3. tutti gli elementi in (em − e′m ) sono alfabeticamente dopo in e′m .
Data una sequenza α e una sequenza β tale che β è una sottosequenza di α,
una sottosequenza α′ di α è detta proiezione di α rispetto a β se e solo se:
1. α′ ha prefisso β
2. non esiste una supersequenza α′′ di α′ tale che α′′ è una sottosequenza
di α e ha prefisso β.
32
CAPITOLO 3. STATO DELL’ARTE SUL SPM
Sia α′ = <e1 e2 . . . en > la proiezione di α rispetto al prefisso β = <e1 e2 . . . em−1 e′m >
(m≤n). La sequenza γ = < e′′m em+1 . . . en > è detta suffisso di α rispetto al
prefisso β dove e′′m = (em − e′m ). Vediamo che α = β · γ.
Ad esempio, <a>, <aa>, <a(ab)> e <a(abc)> sono prefissi della sequenza <a(abc)(ac)d(cf)>. <(abc)(ac)d(cf)> è il suffisso della stessa sequenza rispetto ad <a>, <( bc)(ac)d(cf)> rispetto ad <aa> e <( c)(ac)d(cf)>
rispetto a <ab>, dove il simbolo “ ” sta ad indicare che uno o più item del
primo elemento del suffisso fanno parte del prefisso rispetto a cui esso si
calcola. In <( bc)(ac)d(cf)>, infatti, l’item a del primo elemento fa parte
del prefisso rispetto a cui il suffisso è stato derivato.
Il projected-database (d’ora in poi “pDB”) è la proiezione del database
originale basandosi su un determinato criterio: in FreeSpan gli elementi
presenti nelle sequenze vengono ordinati per supporto decrescente in un
vettore f list e il p-projected database S|p è l’insieme di sequenze aventi
p come sottosequenza; in PrefixSpan il S|p è la collezione di suffissi delle
sequenze nel database originale che hanno come prefisso p. Ad esempio,
dato l’insieme di sequenze:
ID
10
20
30
40
Sequenza
<a(abc)(ac)d(cf)>
<(ad)c(bc)(ae))>
<(ef)(ab)(df)cb>
<eg(af)cbc>
Tabella 3.3: Database di esempio
il S|a è composto dai suffissi di ogni sequenza che hanno come prefisso
l’elemento a, quindi: <(abc)(ac)d(cf)> come suffiso di a nella sequenza con
id uguale a 10, <( d)c(bc)(ae)> come suffiso di a nella sequenza con id
uguale a 20, <( b)(df)cb> come suffiso di a nella sequenza con id uguale a
30 e <( f)cbc> come suffiso di a nella sequenza con id uguale a 40.
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN
3.3.2
33
L’algoritmo
L’algoritmo è composto dalla routine principale (Algoritmo 1) che viene
chiamata soltanto la prima volta e da una subroutine (Algoritmo 2) che si
richiama ricorsivamente.
L’ Algoritmo 1, come si vede nel campo Data, riceve in ingresso il database
delle sequenze e l’insieme vuoto di pattern sequenziali. Esso semplicemente
richiama la subroutine (riga 1) e finisce.
L’ Algoritmo 2 riceve in ingresso tre parametri, visibili nel campo Data: α:
un pattern sequenziale; l: la lunghezza di α; S|α : l’α-projected database, se
α ̸=<>; altrimenti la base di dati sequenziale S.
Per prima cosa scansisce S|α una volta, trova l’insieme degli item b frequenti (riga 1). Fatto ciò, tra quelli trovati, vengono mantenuti solo quelli tali
che: b può essere aggiunto all’ultimo elemento di α per formare un pattern
sequenziale o <b> può essere aggiunto ad α per formare un pattern sequenziale (righe 3-5).
Ogni item frequente b viene aggiunto ad α per formare un pattern sequenziale α′ (righe 7-13), e viene usato α′ come output (campo Result). Infine,
per ogni α′ , viene costruito l’α′ -projected database S|α′ (riga 14) e viene
richiamato PrefixSpan(α′ , l+1, S|α′ ) (riga 15).
Data: <>, S
1
Call PrefixSpan(<>, 0, S);
Algoritmo 1: PrefixSpan Main
34
CAPITOLO 3. STATO DELL’ARTE SUL SPM
Data: α, l, S|α
Result: α′
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
frequent set = findFrequentItem(S|α );
forall the items pi ∈ frequent set do
if add(pi , getLastElement(α)) == New Sequential Pattern ||
add(pi , α) == New Sequential Pattern then
pi ∪ completing set;
end
end
forall the items bi ∈ completing set do
if add(pi , getLastElement(α)) == New Sequential Pattern
then
α′ = add(pi , getLastElement(α));
end
else if add(pi , α) == New Sequential Pattern then
α′ = add(pi , α);
end
S|α′ = get pDB(S|α , α′ );
Call PrefixSpan(α′ , l+1, S|α′ );
end
Algoritmo 2: PrefixSpan
3.3.3
Un esempio illustrativo
Sia dato il database S della Tabella 3.3 nel quale si vogliono ricercare pattern
sequenziali con supporto minimo pari a 2.
Esso viene esaminato per trovare tutti gli elementi frequenti nelle sequenze.
Ogni item è un pattern sequenziale di lunghezza 1. Contando le occorrenze di questi pattern sequenziali, possiamo derivare la Tabella 3.4 che le
riassume.
<a>
4
<b>
4
<c>
4
<d>
3
<e>
3
<f>
3
<g>
1
Tabella 3.4: I pattern di lunghezza 1 identificati
Il pattern sequenziale <a>, ad esempio, compare in tutte le quattro
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN
35
sequenze che compongono S e lo stesso vale per <b> e <c>, mentre <d>
compare solo nelle sequenze con id uguale a 10, 20 e 30. Ragionamenti simili
sono fatti anche per gli altri pattern sequenziali trovati. Il pattern sequenziale <g> non viene considerato poichè ha supporto inferiore al supporto
minimo scelto per l’escuzione dell’algoritmo, infatti esso compare solo nella
sequenza con id uguale a 40. Una volta eliminati i pattern sequenziali che
non hanno supporto sufficiente, l’algoritmo divide lo spazio di ricerca in sei
sottoinsiemi: ognuno è il pDB del database iniziale S costruito rispetto ad
uno dei pattern sequenziali elencati nella Tabella 3.4.
S|<a>
<(abc)(ac)d(cf)>
<( d)c(bc)(ae)>
<( b)(df)cb>
<( f)cbc>
S|<d>
<(cf)>
<c(bc)(ae)>
<( f)cb>
S|<b>
<( c)(ac)d(cf)>
<( c)(ae)>
<(df)cb>
<c>
S|<e>
<( f)(ab)(df)cb>
<(af)cbc>
S|<c>
<(ac)d(cf)>
<(bc)(ae)>
<b>
<bc>
S|<f>
<(ab)(df)cb>
<cbc>
Tabella 3.5: I pDB rispetto ai pattern frequenti di lunghezza 1
S|<a> , ad esempio, è composto dai suffissi di <a> nelle sequenze di S in
cui esso compariva: essi, come già detto, si ottengono considerando la parte
di sequenza che segue l’elemento rispetto a cui si sta calcolando il pDB. Per
la sequenza <a(abc)(ac)d(cf)>, infatti, considerando l’elemento <a>, il suffisso è <(abc)(ac)d(cf)> ottenuto considerando ciò che segue la prima occorrenza di <a>; per la sequenza <(ad)c(bc)(ae)> il suffisso è <( d)c(bc)(ae)>;
per la sequenza <(ef)(ab)(df)cb> il suffisso è <( b)(df)cb> e per la sequenza
<eg(af)cbc> il suffisso è <( f)cbc>. L’insieme di questi suffissi costituisce
S|<a> . Lo stesso procedimento viene applicato agli altri pattern sequenziali
di lunghezza 1 trovati. Da notare che alcuni pDB hanno meno elemeni di
altri: questo avviene perchè si considerano solo le sequenze di S in cui l’elemento che si usa per calcolare i suffissi è effettivamente presente. S|<d> ,
36
CAPITOLO 3. STATO DELL’ARTE SUL SPM
ad esempio, è composto da tre elementi perchè <d> era presente solo nelle sequenze con id uguale a 10, 20 e 30. Per comodità di esempio e per
semplicità, scegliamo di concentrarci su uno dei pDB poichè il medesimo
procedimento viene ripetuto per gli altri. Scegliamo S|<d> come in Tabella
3.6.
S|<d>
<(cf)>
<c(bc)(ae)>
<( f)cb>
Tabella 3.6: Estratto della Tabella 3.5
Da questo vengono ricavati i pattern sequenziali di lunghezza 1 e viene
contata la loro occorrenza. Dal conteggio delle occorrenze si ricava la Tabella
3.7.
<a>
1
<b>
2
<c>
3
<d>
0
<e>
1
< e>
0
<f>
1
< f>
1
Tabella 3.7: Occorrenze dei pattern di lunghezza 1
Tenenedo in considerazione il supporto minimo, consideriamo soltanto
quelli che hanno un numero di occorrenze maggiore di 1. Ognuno di essi
viene usato insieme a <d> per trovare i pattern sequenziali di lunghezza 2
sul database iniziale S. I risultanti sono <db> e <dc>. Essi sono usati per
costruire S|<db> e S|<dc> che possiamo vedere nella Tabella 3.8.
<db>
<( c)>
<dc>
<(bc)>
<b>
Tabella 3.8: S|<db> e S|<dc>
In S|<db> non vengono contate le occorrenze dei pattern sequenziali di
lunghezza 1 poichè c’è solo una sequenza, quindi uno qualsiasi di essi non
avrà supporto minimo sufficiente per essere scelto. In S|<dc> , invece, possia-
3.3. ANALISI DETTAGLIATA DI PREFIXSPAN
37
mo trovare i pattern sequenziali elencati in Tabella 3.9 con il relativo numero
di occorrenze in S|<dc> .
<b>
2
<c>
1
Tabella 3.9: I pattern sequenziali di lunghezza uno (e le loro occorrenze)
derivati da S|<dc> .
Poichè il numero di occorrenze di <c> non è sufficiente a soddisfare il
supporto minimo, l’unico elemento che consideriamo è <b> che ci permette
di trovare un pattern sequenziale di lunghezza 3 valido: <dcb>. Calcolando
S|<dcb> otteniamo i risultati in Tabella 3.10. Come si può vedere esso è un
insieme vuoto , quindi l’algoritmo si ferma.
<dcb>
<>
Tabella 3.10: I pattern sequenziali di lunghezza 3
Come già specificato in precedenza, in questo esempio abbiamo seguito solo un ramo dell’albero delle soluzioni generato dall’algoritmo e quindi
quello mostrato è solo un sottoinsieme di queste ultime.
Capitolo 4
L’approccio AIDA
“Creating a new theory is not like destroying an old barn and erecting a
skyscraper in its place. It is rather like climbing a mountain, gaining new
and wider views, discovering unexpected connections between our starting
points and its rich environment. But the point from which we started out
still exists and can be seen, although it appears smaller and forms a tiny part
of our broad view gained by the mastery of the obstacles on our adventurous
way up.”
Albert Einstein
L’idea di base del nostro algoritmo chiamato “AIDA” (Automatic Index
with DAta mining) è simile a quella di “Proactive Index Maintenance” di Mederiros del 2012, ma, con due differenze: la prima è il metodo di predizione
dell’esecuzione di una teQuery, mentre la seconda è che, una volta prevista
l’esecuzione di una di esse, viene programmata la manutenzione e non la
creazione degli indici più adatti a migliorare le prestazioni dell’operazione.
4.1
Notazioni preliminari
Innanzitutto è necessario definire alcuni concetti: un pattern sequenziale è,
come già visto, una successione ordinata di elementi ricorrenti. Inizialmente,
38
4.1. NOTAZIONI PRELIMINARI
39
nel nostro dominio applicativo, si era pensato di associare ad ogni elemento
una query, ma si è poi ritenuto sensato ampliare il concetto, associando ad
ognuno di essi un’operazione eseguita sulla base di dati (query, inserimento,
update e cancellazione) e soltanto all’ultimo necessariamente una query (in
particolare una teQuery), come possiamo vedere in Figura 4.1. Gli elementi
in questione, d’ora in poi, saranno chiamati nodi nella nostra trattazione.
Come si può capire, nel nostro lavoro, usando le definizioni della Sezione
3.1, un nodo non è mai un elemento composto da più item, ma solo da un
singolo item.
Figura 4.1: Pattern Sequenziale nel nostro dominio applicativo
Ogni elemento che sta tra un nodo e il suo successivo all’interno del pattern sequenziale, invece, sarà definito arco.
Sono proprio gli archi che ci permettono di estendere il concetto di pattern
sequenziale: per applicare il nostro metodo, infatti, è necessario sapere quanto tempo trascorre tra l’occorrenza di un nodo e quella del suo successivo;
questo dato, che definiamo come durata di un arco, sarà associato all’arco
stesso, come da Figura 4.2.
Figura 4.2: Pattern Sequenziale nel nostro dominio applicativo apliato con
il concetto di durata
Questo significa che, nell’esempio, l’“operazione2” è avvenuta “durata1”
istanti di tempo dopo l’“operazione1” e che la “Time-expensive Query” è
avvenuta “durata2” istanti di tempo dopo l’“operazione2”.
Nella prima fase del nostro metodo, detta “fase di apprendimento”, oltre ad
essere estratti tutti i pattern sequenziali dal log statico in ingresso, vengono
40
CAPITOLO 4. L’APPROCCIO AIDA
anche arricchiti con le loro durate. Una volta fatto ciò, per ogni pattern,
avremo più di un’istanza con durate diverse associate agli archi: il nostro
obiettivo sarà quello di ottenere una sola istanza per ogni pattern che riassuma tutte queste informazioni. Per fare ciò, ad ogni arco, quindi, verrà
associato un valore del tipo (m±k), dove m è definita come la media e k
come la tolleranza. La prima non è altro che la media aritmetica di tutte le
istanze di durata associate a quell’arco, mentre la seconda è la metà della
differenza tra il valore massimo e il valore minimo tra le istanze di durata
associate a quello stesso arco, aumentata di 1.
Una volta fatto ciò, quello che si ottiene è un pattern sequenziale completo
come in Figura 4.3.
Figura 4.3: Pattern Sequenziale completo
Con m e k otteniamo un intervallo temporale che ben ricalca la situazione trascorsa e che sarà utile per conoscere quella futura. Quella descritta
fino ad ora, infatti, è la prima fase dell’algoritmo in cui il sistema analizza la
situazione passata per estrarne dati utili alla fase successiva; a questo punto
inizia la seconda detta “fase di previsione”. I valori trovati nella fase precedente saranno usati in due situazioni: la prima per vedere se le occorrenze
delle operazioni che compongono il pattern sequenziale avvengono nei tempi
minimi e massimi stabiliti, cioè per controllare che il pattern non si estenda
troppo nel tempo divenendo poco significativo, mentre la seconda per sapere quando programmare la manutenzione degli indici in modo da essere
pronti per l’esecuzione della teQuery. Inizialmente, come valore da utilizzare
per la tolleranza, si era pensato alla varianza dei valori delle durate delle
istanze associate agli archi, ma la scelta si è rivelata infruttuosa in quanto
il valore risultante era sempre molto alto. Ciò rendeva non significativi i
4.1. NOTAZIONI PRELIMINARI
41
tempi associati agli archi dei sequential pattern: (m-k) era sempre negativo,
mentre (m+k) era sempre molto grande e impediva alle sequenze frequenti
di scadere.
Nella fase di previsione, riprendendo il nostro esempio, una volta che il sistema vede che è stata eseguita l’“operazione1” si mette in allerta perchè ha
parzialmente riconosciuto il pattern: se l’“operazione2” avviene in un tempo
utile, quindi minore di (m1 +k1 ), allora viene riconsocito anche il secondo
nodo e il sistema può prevedere che entro un intervallo di tempo lungo al
massimo (m2 +k2 ) sarà eseguita la teQuery e quindi potrà regolarsi per la
manutenzione degli indici.
Il valore (m-k) è utile, invece, quando il tempo necessario alla manutenzione
degli indici per la teQuery in questione è più grande della durata associata
all’ultimo arco del pattern sequenziale: se cosı̀ fosse, una volta riconosciuto
l’ultimo nodo prima di quello associato alla teQuery, sarebbe inutile schedulare la manutenzione degli indici perchè si concluderebbe dopo l’esecuzione
della teQuery stessa. Per questo motivo, ogni volta che viene riconosciuto
un nodo di un pattern sequenziale, il sistema calcola la durata minima totale degli archi non ancora riconosciuti ad eccezione del primo, utilizzando
(m-k) come valore in modo da calcolare in modo conservativo quando, al più
presto, la teQuery potrebbe essere eseguita e schedulare la lunga manutenzione degli indici anche prima che il pattern sia completamente riconosciuto.
Nel nostro esempio, una volta riconosciuto il nodo associato all’“operazione1”,
il sistema calcola la durata minima di tutti gli archi successivi ad eccezione
del primo, quindi nel nostro caso semplicmente (m2 -k2 ) e, in caso il valore
ottenuto fosse inferiore al tempo necessario alla manutenzione degli indici
per la “Time-expensive Query”, schedulerebbe subito la manutenzione anche senza aver riconosciuto il nodo associato all’“operazione2”.
Il procedimento, ad un alto livello di astrazione, è il seguente:
42
CAPITOLO 4. L’APPROCCIO AIDA
1. Identificazione teQuery Usando la stessa definizione di [18]: “Una
query si dice time-expensive se:
• RTq > t, dove RTq è il tempo di risposta di q e t è un parametro
costante (9000s);
• Fq < k, dove Fq è il numero di esecuzioni di q diviso per il periodo
di osservazione (in mesi) e k è un parametro costante (5. q è
eseguita tra una e quattro volte al mese in media);
• c’è almeno una struttura di indici i tale per cui Bi,q > ECCi dove
ECCi è il costo stimato per la creazione della struttura i e Bi,q è
il beneficio dato dalla presenza della struttura di indici i durante
l’esecuzione della query q rispetto all’esecuzione della stessa senza
quella struttura.”
2. Ricerca dei pattern sequenziali e salvataggio degli stessi
• Per trovare i pattern sequenziali per la query B che è timeexpensive (<* qB>) il workload viene spezzato in vari pezzi:
ognuno di essi è delimitato da una nuova occorrenza di qB.
• Vengono trovati i squential pattern nella forma <* qB> che
possano essere utili ai nostri scopi (con un certo supporto minimo)
• Per ogni sequenza “valida” viene calcolata la durata di ogni arco
(differenza tra i timestamp delle operazioni che ne sono gli estremi
in ogni istanza del pattern sequenziale trovata nel log di input)
• m è la media delle “durate”
• k è un fattore di tolleranza pari a
(duratamax −duratamin )
2
+ 1.
3. Quando viene eseguita un’operazione che è la prima che compone un
pattern sequenziale:
• se il pattern sequenziale è una sequenza di lunghezza 2: viene
programmata la manutenzione degli indici per la teQuery.
4.1. NOTAZIONI PRELIMINARI
43
• se il pattern sequenziale è una sequenza di lunghezza n (con n>2):
il sistema rimane in allerta attendendo l’operazione successiva
presente nel pattern entro (m+k): se l’operazione non arriva
il pattern non viene tenuto in considerazione, altrimenti il tool
sarà sempre all’erta fino al momento di schedulare la manutenzione degli indici (tenendo in considerazione il tempo necessario
per questa operazione e, quindi, avendo la possibilità di schedularla anche prima che il pattern sequenziale sia completamente
riconosciuto, come già spiegato).
4. Prima di cancellare gli indici viene valutato se la teQuery considerata è molto frequente oppure no guardando i tempi trascorsi tra ogni
occorrenza della query (che chiude ogni chunk del log). Se i tempi
sono inferiori a una cera soglia può essere considerata frequente, e si
può pensare di mantenere la struttura indici per non doverla ricreare
ogni volta. Se la teQuery risultasse essere non abbastanza frequente,
vengono cancellati gli indici quando:
• la query per cui erano stati creati è stata eseguita;
• si arriva a (m+k) senza che la query per cui erano stati creati sia
stata eseguita.
Naturalmente, applicando questo metodo, supponiamo noti gli indici che
migliorano le prestazioni della teQuery in considerazione e i loro tempi di
manutenzione. Diverse possono essere le modalità per identificarli: sarebbe
possibile cercarli manualmente oppure attraverso tecniche più strutturate
presenti in letteratura. Numerose tecniche sono state proposte per l’identificazione degli indici più adatti per una determinata query. Poichè lo scopo
del nostro lavoro non è quello di proporne una nuova, si può pensare di
basarsi su una già esistente: in paricolare, si pensi alla tecnica “Hypotetical Execution Plan” che, dopo aver ottenuto il piano di esecuzione reale da
44
CAPITOLO 4. L’APPROCCIO AIDA
parte del DBMS per la query in questione, lo analizza e cerca le operazioni
che non fanno uso di indici per rimpiazzarle con altre equivalenti che, però,
usano gli stessi.
Come già detto, quindi, l’algoritmo si divide sostanzialmente in due parti
abbastanza indipendenti: la prima è quella di apprendimento in cui, dal
log delle operazioni, l’algoritmo estrae le sequenze frequenti che saranno poi
utilizzate nella seconda parte; la seconda, appunto, è quella di previsione:
guardando al flusso di operazioni proveniente dal DBMS, il sistema può sapere con buona probabilità quando una teQuery sarà eseguita e in quanto
tempo, in modo da poter schedulare la manutenzione degli indici al momento
giusto.
4.2
Alcuni esempi illustrativi
Presentiamo ora alcuni esempi illustrativi. Come primo esempio introduttivo si è ritenuto più utile utilizzare un esempio “semplificato” che risulta
essere più intuitivo. Esso utilizza dei numeri interi come timestamp del log
e, in un secondo momento, verrà esteso con dei timestamp nel formato reale.
4.2.1
Timestamp semplificati
Sia dato il log di una base di dati nella forma “operazione - timestamp” dove
“o” sta per una generica operazione e “q” sta per una query:
oA 1
qB 2
oC 3
oD 4
oC 5
oA 6
4.2. ALCUNI ESEMPI ILLUSTRATIVI
45
qB 7
oC 8
oC 9
oC 10
oD 11
oA 12
qB 13
oC 14
oC 15
qB 16
Supponendo che qB sia una teQuery, il log viene spezzato dopo ogni occorrenza della stessa, come segue:
oA 1
qB 2
oC 3
oD 4
oC 5
oA 6
qB 7
oC 8
oC 9
oC 10
oD 11
oA 12
qB 13
46
CAPITOLO 4. L’APPROCCIO AIDA
oC 14
oC 15
qB 16
Fissata la soglia del supporto minimo relativo a 0.5 e applicando l’algoritmo PrefixSpan, otteniamo, tra i risultati, <oC qB> che è un pattern
sequenziale frequente (poichè compare in 3 pezzi di log su 4 ed ha quindi
supporto maggiore di 0.5) di nostro interesse poichè ha come ultimo nodo
la teQuery. Da notare che l’esempio si focalizza su sequenze frequenti di
lunghezza 2, ma potrebbe essere esteso a sequenze di lunghezza maggiore.
Ciò sarà fatto, in particolare, con gli esempi temporali che sono più realistici per il nostro studio. Una volta ottenuti, utilizzando l’algoritmo per il
SPM, i pattern frequenti, andiamo ad analizzare il log allo scopo di ricavare
le istanze dei tempi che intercorrono fra le operazioni associate ai nodi del
pattern in modo da poterle associare ad ogni arco.
Dato il primo frammento di log:
1. oC 3
oD 4
oC 5
oA 6
qB 7
Si ha che:
<oC qB> 7-3 = 4
<oC qB> 7-5 = 2
Nell’esempio qB è avvenuta all’istante 7, mentre abbiamo due diverse
occorrenze di oC alll’istante 3 e all’istante 5, quindi troviamo due
istanze diverse dell’arco tra oC e qB, una con durata 7-3 = 4 (tempo
4.2. ALCUNI ESEMPI ILLUSTRATIVI
47
trascorso tra la prima occorrenza di oC e l’occorrenza di qB) e l’altra
con durata 7-5 = 2 (tempo trascorso tra la seconda occorrenza di oC
e l’occorrenza di qB). Da qui in poi, nell’esempio, vengono fatti gli
stessi calcoli per estrarre dai dati le durate delle diverse occorrenze
degli archi della stessa sequenza frequente.
Dato il secondo frammento di log:
2. oC 8
oC 9
oC 10
oD 11
oA 12
qB 13
Si ha che:
<oC qB> 13-8 = 5
<oC qB> 13-9 = 4
<oC qB> 13-10 = 3
Dato il terzo frammento di log:
3. oC 14
oC 15
qB 16
Si ha che:
<oC qB> 16-14 = 2
<oC qB> 16-15 = 1
In questo modo abbiamo ricavato i singoli tempi relativi ad ogni istanza dell’arco del pattern frequente presente nel log. Per ottenere un unico tempo
48
CAPITOLO 4. L’APPROCCIO AIDA
che comprenda l’informazione apportata da ogni istanza, ci avvaliamo, come
già detto, della media e della tolleranza.
Facendo la media m dei tempi associati associati all’arco otteniamo:
m=
(4+2+5+4+3+2+1)
7
=3
Intuitivamente, questo tempo indica che, una volta eseguita oC, mediamente
dopo 3 istanti di tempo, viene eseguita anche la query qB. Di conseguenza, una volta che è avvenuta oC possiamo predire che probabilmente (con
probabilità pari al supporto del pattenr frequente) a distanza di 3 istanti
di tempo verrà eseguita anche qB. Per aumentare la flessibilità della predizione, introduciamo il fattore di tollerenza k che coincide con la metà della
differenza tra il valore massimo (che è pari a 5) e il valore minimo (che è
pari 1) trovati, aumentata di 1:
k=
5−1
2
+1=3
Cosı̀ facendo, si ottiene la sequenza che può predire la prossima esecuzione
di qB basandosi su oC:
<oC qB> (m±k)
che, nel nostro esempio, sarebbe:
<oC qB> (3±3).
Viene ora analizzato, più nello specifico, il medesimo funzionamento con
dei timestamp reali.
Per la parte di previsione, l’esempio è significativo con i timestamp reali e,
4.2. ALCUNI ESEMPI ILLUSTRATIVI
49
quindi, rimandiamo alla prossima sezione per il testo completo.
4.2.2
Timestamp reali
La granularità utilizzata è quella del secondo.
Log di una base di dati (sempre spezzato supponendo che qB sia una teQuery, quindi dopo ogni occorrenza della stessa) e relativi timestamp (nella
forma “yyMMdd hh:mm:ss”):
oA 140327 13:53:10
qB 140327 13:53:50
oC 140327 13:54:20
oD 140327 13:54:50
oC 140327 13:55:45
oA 140327 13:56:00
qB 140327 13:56:50
oC 140327 13:57:10
oC 140327 13:57:35
oC 140327 13:58:05
oD 140327 13:58:50
oA 140327 13:59:25
qB 140327 13:59:55
oC 140327 14:00:20
oC 140327 14:01:00
qB 140327 14:01:50
-
50
CAPITOLO 4. L’APPROCCIO AIDA
Fissata la soglia del supporto minimo a 0.5, applicando l’algoritmo PrefixSpan, otteniamo i seguenti pattern sequenziali frequenti:
• <oC qB> con supporto=0.75 poichè compare in 3 frammenti di log
su 4;
• <oC oC qB> con supporto=0.75 poichè compare in 3 frammenti di
log su 4;
• <oC oC oA qB> con supporto=0.5 poichè compare in 2 frammenti di
log su 4.
Per ognuno di questi pattern, ora, dobbiamo estrarre le durate delle istanze
di ogni arco per calcolare media e tolleranza.
Consideriamo il primo pattern sequenziale frequente, rappresentato graficamente in Figura 4.4.
Figura 4.4: Pattern Sequenziale di lunghezza 2 in forma grafica
Da ogni frammento di log sono estratte le durate delle occorrenze di ogni
arco:
1. oC oD oC oA qB
Durata arco oC-qB: 13:56:50-13:54:20 = 150 s
Durata arco oC-qB: 13:56:50-13:55:45 = 65 s
Nell’esempio qB è avvenuta all’istante 13:56:50, mentre abbiamo due
diverse occorrenze di oC all’istante 13:54:20 e all’istante 13:55:45, quindi troviamo due istanze diverse dell’arco tra oC e qB, una con durata
13:56:50-13:54:20 = 150 secondi (tempo trascorso tra la prima occorrenza di oC e l’occorrenza di qB) e l’altra con durata 13:56:50-13:55:45
4.2. ALCUNI ESEMPI ILLUSTRATIVI
51
= 65 secondi (tempo trascorso tra la seconda occorrenza di oC e l’occorrenza di qB).
Da qui in poi, nell’esempio, vengono fatti gli stessi calcoli per estrarre dai dati le durate delle diverse occorrenze della stessa sequenza
frequente.
2. oC oC oC oD oA qB
Durata arco oC-qB: 13:59:55-13:57:10 = 165 s
Durata arco oC-qB: 13:59:55-13:57:35 = 140 s
Durata arco oC-qB: 13:59:55-13:58:05 = 110 s
3. oC oC qB
Durata arco oC-qB: 14:01:50-14:00:20 = 90 s
Durata arco oC-qB: 14:01:50-14:01:00 = 50 s
Facendo la media m dei tempi associati alle regole per il numero di queste
ultime otteniamo:
m=
(150+65+165+140+110+90+50)
7
= 110s
alla quale viene applicata una tolleranza k che coincide con la metà della differenza tra il valore massimo (165 s) e il valore minimo (50 s) trovati,
aumentata di 1 (58.5 s), ottenendo la sequenza che può predire la prossima
esecuzione di qB basandosi su oC:
<oC qB> (m±k)
che, nel nostro esempio, sarebbe:
<oC qB> (110±58.5).
52
CAPITOLO 4. L’APPROCCIO AIDA
Esso, rappresentato graficamente, sarebbe come in Figura 4.5.
Figura 4.5: Pattern Sequenziale di lunghezza 2 in forma grafica con tempi
Questo pattern sequenziale fornisce un’informazione che il tool userà per
implementare gli indici più adatti per l’esecuzione della teQuery qB prima
che essa sia eseguita: quando verrà eseguita oC, infatti, probabilmente entro
110 secondi (con il fattore di correzione k) sarà eseguita qB, quindi il sistema
può schedulare la manutenzione degli indici più adatti.
Consideriamo il secondo pattern sequenziale frequente, rappresentato graficamente in Figura 4.6.
Figura 4.6: Pattern Sequenziale di lunghezza 3 in forma grafica
Da ogni frammento di log sono estratte le seguenti informazioni riguardanti la durata:
1. oC oD oC oA qB
Durata arco oC-oC: 13:55:45-13:54:20 = 85 s
Durata arco oC-qB: 13:56:50-13:55:45 = 65 s
Nel caso in cui i nodi che compongono il pattern sequenziale siano più
di due, anche il numero di archi aumenta. Nell’esempio sono due gli archi di cui dobbiamo calcolare le durate. Il primo ha due occorrenze di
4.2. ALCUNI ESEMPI ILLUSTRATIVI
53
oC come estremi, mentre l’altro una di oC e una di qB, ma con il vincolo che segua un’occorrenza di oC. Nell’esempio il primo oC è avvenuto
a 13:54:20, mentre il secondo a 13:55:45, quindi otteniamo la durata
dell’arco oC-oC come 13:55:45-13:54:20 = 85 secondi. Lo stesso vale
per qB che è avvenuta all’istante 13:56:50 e quindi la durata dell’arco
oC-qB è calcolata come 13:56:50-13:55:45 = 65 secondi. Notiamo che
l’arco oC-qB composto dalla prima occorrenza di oC (quella all’istante
13:54:20) e da qB non conta poichè non è preceduto da nessun’altra
occorrenza di oC.
2. oC oC oC oD oA qB
Durata arco oC-oC: 13:57:35-13:57:10 = 25 s
Durata arco oC-oC: 13:58:05-13:57:10 = 55 s
Durata arco oC-oC: 13:58:05-13:57:35 = 30 s
Durata arco oC-qB: 13:59:55-13:57:35 = 140 s
Durata arco oC-qB: 13:59:55-13:58:05 = 110 s
Anche in questo chunck di log possiamo notare come tre siano le occorrenze valide dell’arco oC-oC, mentre solo due siano quelle valide dell’arco oC-qB poichè la prima occorrenza di oC non può essere considerata
visto che non segue nessun’altra oC.
3. oC oC qB
Durata arco oC-oC: 14:01:00-14:00:20 = 40 s
Durata arco oC-qB: 14:01:50-14:01:00 = 50 s
Importante è far notare che se due occorrenze diverse di uno stesso pattern
sequenziale hanno un arco in comune, le istanze di durata di questo arco
non vengono duplicate, ma contate una volta soltanto. Facendo la media m
dei tempi associati alle regole per il numero di queste ultime otteniamo:
mcc =
85+25+55+30+40
5
= 47s
54
CAPITOLO 4. L’APPROCCIO AIDA
mcb =
65+140+110+50
4
= 91.25s
alla quale viene applicata una tolleranza k pari alla metà della differenza
tra il valore massimo e il valore minimo trovati, aumentata di 1:
kcc =
85−25
2
kcb =
140−50
2
+ 1 = 31s
+ 1 = 46s
ottenendo la sequenza che può predire la prossima esecuzione di qB:
<oC oC qB> (mcc ±kcc , mcb ±kcb )
che, nel nostro esempio, sarebbe:
<oC oC qB> (47±31, 91.25±46).
Esso, rappresentato graficamente, sarebbe come in Figura 4.7.
Figura 4.7: Pattern Sequenziale di lunghezza 3 in forma grafica con tempi
Intuitivamente questo pattern ha un significato ben chiaro: se venisse
eseguita l’operazione oC il sistema riconoscerebbe il primo nodo del pattern
e si metterebbe in allerta. Se il tempo di manutenzione degli indici fosse
minore di (91.25-46) secondi, tempo che coincide con la durata totale del
pattern ad esclusione del primo arco non ancora riconosciuto, allora resterebbe in attesa, mentre, se fosse maggiore, schedulerebbe subito la manuten-
4.2. ALCUNI ESEMPI ILLUSTRATIVI
55
zione. Nel caso in cui il sistema non dovesse programmare la manutenzione
degli indici, resterebbe in attesa di un’altra occorrenza dell’operazione oC
che è il secondo nodo del pattern frequente: se dopo (47+31) secondi questa non fosse avvenuta, il pattern non sarebbe più temporalmente valido
e sarebbe quindi cancellato. Se invece l’operazione oC fosse effettivamente
eseguita, allora il pattern sarebbe completamente riconosciuto (ad eccezione
della teQuery finale) e sarebbe schedulata la manutenzione degli indici per
migliorare i tempi di esecuzione della teQuery. Se, dopo il riconoscimento del
secondo nodo e la conseguente manutenzione, dovessero passare (91.25+46)
secondi senza che la teQuery fosse eseguita, il pattern non sarebbe più valido
temporalmente e sarebbe cancellato con una conseguente nuova manutenzione degli indici.
Consideriamo, infine, il terzo pattern sequenziale frequente, di lunghezza
4, rappresentato graficamente in Figura 4.8.
Figura 4.8: Pattern Sequenziale di lunghezza 4 in forma grafica
Da ogni frammento di log sono estratte le seguenti informazioni riguardanti la durata:
1. oC oD oC oA qB
Durata arco oC-oC: 13:55:45-13:54:20 = 85 s
Durata arco oC-oA: 13:56:00-13:55:45 = 15 s
Durata arco oA-qB: 13:56:50-13:56:00 = 50 s
2. oC oC oC oD oA qB
56
CAPITOLO 4. L’APPROCCIO AIDA
Durata arco oC-oC: 13:57:35-13:57:10 = 25 s
Durata arco oC-oC: 13:58:05-13:57:10 = 55 s
Durata arco oC-oC: 13:58:05-13:57:35 = 30 s
I calcoli appena eseguiti sono le durate di tutte le istanze dell’arco
oC-oC, calcolate come prima.
Durata arco oC-oA: 13:59:25-13:57:35 = 110 s
Durata arco oC-oA: 13:59:25-13:58:05 = 80 s
I calcoli appena eseguiti sono le durate di tutte le istanze dell’arco
oC-oA, calcolate come prima. Da notare che che la prima occorrenza
di oC non concorre in questi calcoli poichè non è preceduta da un’altra
occorrenze della stessa operazione e quindi da un arco oC-oC.
Durata arco oA-qB: 13:59:55-13:59:25 = 30 s
Il calcolo appena eseguito ha come risultato la durata dell’unica istanza
dell’arco oA-qB, calcolata come prima.
3. oC oC qB
Nessuna informazione utile può essere estratta da questo pezzo di log.
Il pattern sequenziale ha, infatti, supporto uguale a 2 poichè compare
soltanto in due delle sequenze in input all’algoritmo.
Facendo la media m dei tempi associati alle regole per il numero di queste
ultime otteniamo:
mcc =
85+25+55+30
4
mca =
15+110+80
3
mab =
50+30
2
= 48.75s
= 68.33s
= 40s
4.2. ALCUNI ESEMPI ILLUSTRATIVI
57
alla quale viene applicata una tolleranza k pari alla metà della differenza tra
il valore massimo e il valore minimo trovati, aumentata di 1:
kcc =
85−25
2
kca =
110−15
2
kab =
50−30
2
+ 1 = 31s
+ 1 = 48.5s
+ 1 = 11s
ottenendo la sequenza che può predire la prossima esecuzione di qB:
<oC oC oA qB> (mcc ±kcc , mca ±kca , mab ±kab )
che, nel nostro esempio, sarebbe:
<oC oC oA qB> (48.75±31, 68.33±48.5, 40±11).
Esso, rappresentato graficamente, sarebbe come in Figura 4.9.
Figura 4.9: Pattern Sequenziale di lunghezza 4 in forma grafica con tempi
Anche in questo caso l’utilizzo del pattern frequente è simile ai casi precedenti. All’occorrenza dell’operazione oC, il primo nodo verrebbe riconosciuto. Se il tempo di manutenzione degli indici per una migliore esecuzione
della teQuery dovesse essere maggiore di (68.33-48.5)+(40-11) secondi, che
coincide con la durata totale minima rimanente del pattern frequente ad
eccezione del primo arco non ancora riconosciuto, allora verrebbe subito
schedulata la manutenzione. In caso contrario il sistema attenderebbe l’ese-
58
CAPITOLO 4. L’APPROCCIO AIDA
cuzione dell’operazione associata al secondo nodo del pattern. In caso essa
non dovesse essere eseguita entro (48.75+31) secondi, il pattern sarebbe temporalmente invalido e sarebbe quindi cancellato; in caso contrario, invece,
sarebbe riconosciuto il secondo nodo e il procedimento sarebbe ripetuto. Se,
quindi, il tempo di manutenzione degli indici dovesse essere superiore a (4011) secondi, che coincide con la durata totale minima rimanente del pattern
frequente ad eccezione del primo arco non ancora riconosciuto, allora questa
verrebbe subito eseguita; in caso contrario il sistema attenderebbe l’esecuzione dell’operazione associata al terzo nodo. Se questa non dovesse accadere
entro (68.33+48.5) secondi, allora il pattern sarebbe temporalmente invalido e, quindi, cancellato; se, invece, fosse eseguita in tempo utile anche il
terzo nodo sarebbe riconosciuto e, quindi, il pattern sarebbe completo (ad
eccezione, come sempre, della teQuery) e per questo la manutenzione degli
indici sarebbe eseguita.
Un pattern sequenziale composto da più di due operazioni viene utilizzato in un modo simile al precedente composto da due sole operazioni, ma
garantisce una maggiore certezza riguardo all’esecuzione della teQuery.
Di seguito si continua l’esempio precedente analizzando nel dettaglio la parte
di predizione per meglio comprendere i concetti prima intuitivamente spiegati.
Il sistema, nella parte di apprendimento, ha estratto e arricchito i pattern
sequenziali riportati nelle Figure 4.5, 4.7 e 4.9. A questo punto osserva il
flusso delle operazioni eseguite sul DBMS per riconoscere i pattern frequenti.
Supponiamo noto il flusso delle operazioni, esse saranno poi analizzate una
alla volta:
4.2. ALCUNI ESEMPI ILLUSTRATIVI
59
oA 140327 15:02:30
qB 140327 15:02:45
oA 140327 15:02:55
oC 140327 15:03:05
oA 140327 15:03:30
oD 140327 15:03:55
oC 140327 15:04:24
qB 140327 15:04:30
oC 140327 15:04:54
oD 140327 15:05:30
oD 140327 15:05:55
oA 140327 15:06:20
oD 140327 15:06:45
qB 140327 15:07:12
Supponiamo, inoltre, che il tempo per la manutenzione degli indici utili
a migliorare i tempi dell’esecuzione di qB sia tqB =35 secondi.
• oA 140327 15:02:30
L’operazione oA non è associata al primo nodo di nessun pattern e
nessun pattern è già stato parzialmente riconosciuto, quindi non viene
fatta nessuna operazione.
• qB 140327 15:02:45
La teQuery qB è stata eseguita senza che l’indice utile a migliorare i
tempi della sua esecuzione fosse implementato.
• oA 140327 15:02:55
L’operazione oA non è associata al primo nodo di nessun pattern e
nessun pattern è già stato parzialmente riconosciuto, quindi non viene
fatta nessuna operazione.
60
CAPITOLO 4. L’APPROCCIO AIDA
• oC 140327 15:03:05
L’operazione oC coincide con il primo nodo di tutti i pattern:
– Il primo è di lunghezza due ed è, quindi, già completamente riconosciuto ad eccezione della teQuery: per questo motivo viene
schedulata la manutenzione degli indici per qB con associato il
timestamp di questa operazione.
– Per il secondo viene calcolata la durata totale rimanente: 91.2546=45.25 secondi; questa è superiore a tqB , quindi nessuna operazione viene fatta.
– Per il terzo viene calcolata la durata totale rimanente: (68.3348.5)+(40-11)=48.83; questa è superiore a tqB , quindi nessuna
operazione viene fatta.
Tutti e tre vengono inseriti nella lista dei pattern parzialmente riconosciuti con il primo nodo marcato.
Lista pattern sequenziali freqenti parzialmente riconsociuti (sottolineati i nodi già riconosciuti):
1. <oC qB>
2. <oC oC qB>
3. <oC oC oA qB>
Timestamp indice per qB: 140327 15:03:05.
• oA 140327 15:03:30
L’operazione oA non è associata al primo nodo di nessun pattern e
non completa nessun pattern già parzialmente riconosciuto, quindi non
viene fatta nessuna operazione.
• oD 140327 15:03:55
L’operazione oD non è associata al primo nodo di nessun pattern e
4.2. ALCUNI ESEMPI ILLUSTRATIVI
61
non completa nessun pattern già parzialmente riconosciuto, quindi non
viene fatta nessuna operazione.
• oC 140327 15:04:24
L’operazione oC completa alcuni pattern sequenziali frequenti parzialmente riconosciuti, in particolare il numero 2 e il numero 3 della
lista.
– Il numero 2 è completamente riconosciuto ad eccezione della teQuery: per questo motivo viene schedulata la manutenzione degli
indici per qB con associato il timestamp di questa operazione che
aggiorna quello già presente.
– Per il numero 3 viene calcolata la durata totale rimanente: 4011=29 secondi; essa è inferiore a tqB , quindi un’altra schedulazione di manutenzione degli indici viene eseguita (anche se resa
inutile da quella appena fatta).
Oltre a questo, l’operazione oC, come all’esecuzione della quarta operazione del flusso in questione, inizia altri tre pattern che sono uguali
ai precedenti, ma più recenti. Essi vengono quindi aggiunti alla lista
di quelli parzialmente riconosciuti.
Lista pattern sequenziali freqenti parzialmente riconsociuti (sottolineati i nodi già riconosciuti):
1. <oC qB>
2. <oC oC qB>
3. <oC oC oA qB>
4. <oC qB>
5. <oC oC qB>
6. <oC oC oA qB>
62
CAPITOLO 4. L’APPROCCIO AIDA
Timestamp indice per qB: 140327 15:04:24.
• qB 140327 15:04:30
La teQuery qB è stata eseguita mentre l’indice utile a migliorare i
tempi della sua esecuzione era implementato.
L’indice e i pattern sequenziali completi vengono rimossi: anche il
pattern di lunghezza 4 viene considerato completo, poichè è già stato
utilizzato per schedulare una manutenzione di indici.
Lista pattern sequenziali freqenti parzialmente riconsociuti (sottolineati i nodi già riconosciuti):
1. <oC oC qB>
2. <oC oC oA qB>
Timestamp indice per qB: -.
• oC 140327 15:04:54
L’operazione oC completa alcuni pattern sequenziali frequenti parzialmente riconosciuti, in particolare il numero 1 e il numero 2 della
lista.
– Il numero 1 è completamente riconosciuto ad eccezione della teQuery: per questo motivo viene schedulata la manutenzione degli
indici per qB con associato il timestamp di questa operazione che
aggiorna quello già presente.
– Per il numero 2 viene calcolata la durata totale rimanente: 4011=29 secondi; essa è inferiore a tqB , quindi un’altra schedulazione di manutenzione degli indici viene eseguita (anche se resa
inutile da quella appena fatta).
Oltre a questo, l’operazione oC, come all’esecuzione della quarta operazione del flusso in questione, inizia altri tre pattern che sono uguali
4.2. ALCUNI ESEMPI ILLUSTRATIVI
63
ai precedenti, ma più recenti.
Lista pattern sequenziali freqenti parzialmente riconsociuti (sottolineati i nodi già riconosciuti):
1. <oC oC qB>
2. <oC oC oA qB>
3. <oC qB>
4. <oC oC qB>
5. <oC oC oA qB>
Timestamp indice per qB: 140327 15:04:54.
• oD 140327 15:05:30
L’operazione oD non è associata al primo nodo di nessun pattern e
non completa nessun pattern già parzialmente riconosciuto, quindi non
viene fatta nessuna operazione.
• oD 140327 15:05:55
L’operazione oD non è associata al primo nodo di nessun pattern e
non completa nessun pattern già parzialmente riconosciuto, quindi non
viene fatta nessuna operazione.
• oA 140327 15:06:20
L’operazione oA completa un pattern parzialmente riconosciuto, in
particolare il numero 2 della lista. Questo, però, a causa di tqB era già
stato utilizzato per schedulare la manutenzione degli indici e quindi
non può più essere utilizzato. Se tqB fosse stato inferiore, il pattern
sarebbe stato usato a questo punto per schedulare la manutenzione
poichè sarebbe stato totalmente riconosciuto ad eccezione della teQuery.
Lista pattern sequenziali freqenti parzialmente riconsociuti (sottolineati i nodi già riconosciuti):
64
CAPITOLO 4. L’APPROCCIO AIDA
1. <oC oC qB>
2. <oC oC oA qB>
3. <oC qB>
4. <oC oC qB>
5. <oC oC oA qB>
Timestamp indice per qB: 140327 15:04:54.
• oD 140327 15:06:45
L’operazione oD non è associata al primo nodo di nessun pattern e
non completa nessun pattern già parzialmente riconosciuto, quindi non
viene fatta nessuna operazione.
• qB 140327 15:07:52
Prima dell’esecuzione di qB, in particolare agli istanti 15:07:13 e 15:07:42
sono scaduti rispettivamente i pattern numero 1-2 e numero 3 della lista che erano quelli che avevano generato la manutenzione degli indici.
Per questi motivi, l’indice per qB è stato rimosso a 15:07:42 per vincoli
temporali e, quindi, questa esecuzione della teQuery è avvenuta senza
che l’indice adatto fosse implementato.
Lista pattern sequenziali freqenti parzialmente riconsociuti (sottolineati i nodi già riconosciuti):
1. <oC oC qB>
2. <oC oC oA qB>
Timestamp indice per qB: -.
Questo esempio ha riassunto tutte le casistiche che possono accadere durante il funzionamento del sistema per una comprensione intuitiva e pratica. Per una definizione più formale dei meccanismi che lo costituiscono,
nel capitolo seguente, verranno presentati gli algoritmi che ne regolano il
comportamento.
4.3. L’ALGORITMO
4.3
65
L’algoritmo
Come spiegato nei paragrafi precedenti, l’algoritmo si divide in due parti:
apprendimento e previsione. Lo pseudocodice che segue ricalca questa divisione: l’algoritmo principale, infatti, chiama due sotto-algoritmi che coprono
una parte ciascuno.
Data: S, teQuery
1
spList = call Aida-Training(S, teQuery);
2
forall the flowing queries qi do
3
4
call Aida-Forecasting(spList, qi , tindex maintenance );
end
Algoritmo 3: Aida
L’Algoritmo 4, chiamato alla riga 1 dell’Algoritmo 3, si occupa della
parte di apprendimento. Esso riceve il log di operazioni come parametro
(S nella sezione Data) e lo spezza in chunck seguendo le occorrenze della
teQuery come si vede nelle righe 2-7, ricerca le sequenze frequenti in questi chunck applicando l’algoritmo PrefixSpan (riga 8) e, una volta ottenute
queste ultime, scarta quelle che non hanno come ultima operazione la teQuery (righe 9-13). Una volta ottenute tutte e sole le sequenze utili, esso
le arricchisce con la durata e il fattore di correzione per ogni arco (righe
14-26). In particolare, per ogni sequenza frequente trovata, scorre tutti i
chunck e controlla in ognuno di essi se è presente o meno (righe 15-16). In
caso lo fosse, salva la durata di ogni arco della sequenza nell’istanza trovata
(righe 17-19). Fatto ciò, i dati raccolti per ogni arco vengono utilizzati per
calcolare i due indici prima accennati: la media è semplicemente la media
aritmetica delle durate registrate per quell’arco (riga 23), mentre il fattore
di correzione (riga 24) è calcolato come la differenza tra il valore più alto e
il valore più basso delle durate registrate. Il risultato ottenuto viene, poi,
diviso per 2 e ad esso viene sommato 1.
66
CAPITOLO 4. L’APPROCCIO AIDA
Data: S, teQuery
Result: The sequential pattern list
1
let c=0;
2
forall the queries qi ∈ S do
3
chunckc ∪ qi ;
4
if qi == teQuery then
c++;
5
6
end
7
end
8
spList = call PrefixSpan(<>, 0, chunck);
9
forall the spi ∈ spList do
10
if last operation of spi ̸= teQuery then
remove spi from spList;
11
12
end
13
end
14
forall the spi ∈ spList do
15
forall the chunckj ∈ chunck do
if spi ∈ chunckj then
16
forall the edge ek ∈ spi do
17
time duration d ∪ dListek
18
end
19
end
20
21
end
22
forall the edge ek ∈ spi do
23
durationk = mean(dListek );
24
tolerancek =
25
26
max(dListek )−min(dListek )
2
+ 1;
end
end
Algoritmo 4: AidaTraining
4.3. L’ALGORITMO
67
La seconda parte, quella di previsione, viene poi gestita dall’Algoritmo
5. Esso ha tre parametri in ingresso (sezione “Data”) che sono la lista dei
pattern sequenziali, l’operazione da controllare e il tempo necessario per la
mautenzione degli indici adatta alla teQuery. Esso mantiene, oltre alla lista
dei pattern sequenziali passata come input, una lista dei pattern seqenziali
parziali (riga 1), cioè dei quali le prime operazioni sono effettivamente già
state eseguite. Esso, per ogni operazione che viene eseguita, controlla prima
se essa completa una delle sequenze frequenti parzialmente riconosciute solo
nel caso in cui esse siano ancora temporalmente valide (righe 5-6) e controlla che il tempo necessario alla manutenzione degli indici sia maggiore della
somma delle durate degli archi non ancora riconosciuti a meno del primo del
pattern sequenziale (riga 8). Il primo arco non riconosciuto non viene considerato poichè questo calcolo serve a sapere se, in base al tempo necessario
alla manutenzione degli indici, posso attendere anche il riconoscimento della
prossima operazione che compone il pattern o se devo schedulare subito la
loro manutenzione. In caso il tempo rimanente - sempre non considerando il
primo arco non ancora riconosciuto - fosse minore del tempo necessario per
la manutenzione, essa viene schedulata (riga 9). Nel caso in cui un pattern
sequenziale non fosse più valido temporalmente perchè è trascorso troppo
tempo dall’ultima operazione riconosciuta (riga 12), allora esso viene rimosso dalla lista delle sequenze frequenti parziali (riga 10). Dopo aver fatto
ciò, l’algoritmo controlla se la stessa operazione è l’inizio di un nuovo pattern sequenziale tra quelli presenti nella lista passata come parametro (righe
16-17): in caso lo fosse, la prima operazione che lo compone viene segnata
come riconosciuta (riga 18) e il pattern frequente viene aggiunto alla lista
dei pattern parzialmente riconosciuti (riga 19).
68
CAPITOLO 4. L’APPROCCIO AIDA
Data: spList, qi , tindex maintenance
1
let partialSpList;
2
if qi ==teQuery then
3
schedule index maintenance;
4
end
5
forall the spt ∈ partialSpList do
6
if next node n to check in spt == qi ∧ spt is time-valid then
7
increment n in spt ;
8
if (residual duration of spt - next edge duration) <
tindex maintenance then
schedule index maintenance;
9
end
10
11
end
12
else if spt is NOT time-valid then
remove spt from partialSpList;
13
14
end
15
end
16
forall the spr ∈ spList do
17
if next node n to check in spr == qi then
18
increment n in spr ;
19
spr ∪ partialSpList;
20
21
end
end
Algoritmo 5: AidaForecasting
4.4
Scenari applicativi
Come la spiegazione precedente lascia intuire, il nostro approccio richiede
una certa ricorrenza e periodicità nelle operazioni eseguite sulla base di dati.
4.4. SCENARI APPLICATIVI
69
Per questi motivi gli scenari applicativi che per primi vengono considerati
sono quelli in cui le operazioni da fare sono estremamente meccaniche e
strutturate: tra questi vi sono, ad esempio, le banche e gli uffici in cui le
serie di operazioni da eseguire, spesso, sono sempre le stesse.
Come spiegato da [45], però, anche nelle ricerche sul web si può trovare
una certa periodicità e quindi, con i dovuti accorgimenti riguardanti le performace del tool vista la mole di dati da processare, anche questo potrebbe
essere un interessante applicazione. In particolare si nota un certo fattore di
ripetizione settimanale nelle query, con una particolare distinzione tra quelle
eseguite nei giorni feriali e quelle eseguite nei giorni festivi.
Gli stessi acquisti online, infine, possono essere un altro scenario interessante: una delle più famose applicazioni delle tecniche di Data Mining, infatti,
è proprio legata agli acquisti. Se, quindi, un utente acquista un determinato
articolo, potrebbe essere molto probabile, in un meccanismo molto simile a
quello dei suggerimenti d’acquisto, che la successiva ricerca sia per un determinato oggetto correlato a quello appena acquistato. Ad esempio, dopo
l’acquisto di un notebook è molto probabile che l’utente cerchi una borsa per
trasportarlo o un mouse per utilizzarlo più comodamente. Per questo, anche
quello degli acquisti potrebbe essere un interessante scenario applicativo per
la metodologia e il tool presentati in questo lavoro di tesi.
Capitolo 5
Il software AIDA
“Experience without theory is blind, but theory without experience is mere
intellectual play.”
Immanuel Kant
AIDA, oltre ad essere il nome dell’algoritmo proposto e spiegato nei capitoli precedenti, è anche il nome dello strumento Java che implementa lo
stesso. Esso integra l’algoritmo PrefixSpan dal tool SPMF (Sequential Pattern Mining Framework) [44] rilasciato in modalità open source da Philippe
Fournier-Viger, professore alla University of Moncton (Canada). A causa
della sua struttura estrememente modulare, è risultato molto facile estrarre
le classi necessarie per eseguire il nostro algoritmo ed integrarle con il nostro
tool.
L’input necessario è un file in formato “csv” (Comma-separated value, a
volori separati da virgola) contenente un log delle operazioni eseguite sulla
base di dati. Esso verrà poi analizzato e filtrato in modo da estrarre solo
i dati significativi ai nostri scopi: essi sono, in modo particolare, l’elenco
delle operazioni eseguite con i relativi timestamp. Di seguito riportiamo la
struttura dei log di due fra i DBMS più diffusi per mostrare che i campi di
70
5.1. L’ARCHITETTURA
71
nostro interesse sono presenti e gestibili.
In Figura 5.1 è riportata la struttura di PostgreSql, mentre in Figura 5.2 è
riportata quella di MySql.
Figura 5.1: Struttura di una riga del log delle operazioni di PostgreSql
Figura 5.2: Struttura di una riga del log delle operazioni di MySQL
5.1
L’architettura
Nella presente sezione si analizza l’architettura del tool sviluppato. Esso
segue il classico paradigma Model-View-Controller (MVC, vedi Figura 5.3)
che disaccoppia la logica di presentazione da quella applicativa. Utilizzando
72
CAPITOLO 5. IL SOFTWARE AIDA
questa architettura a livelli, il software prodotto risulta essere molto modulare con un grande guadagno in pulizia, semplicità e riutilizzo del codice.
Nello specifico la parte di Model definisce le strutture dati tipiche del sistema
a cui appartiene e si occupa della gestione della persistenza/memorizzazione
di queste ultime fornendo i metodi necessari; la parte di View visualizza i
dati contenuti nel Model e si occupa dell’interazione con utenti; la parte di
Controller, infine, riceve i comandi dell’utente (in genere attraverso la View)
e li attua modificando lo stato degli altri due componenti.
Figura 5.3: Paradigma Model-View-Controller
L’architettura vera e propria del sistema presentato in questo lavoro è
definita nel diagramma UML (Unified Modeling Language, linguaggio di
modellazione unificato utile per descrivere le architetture software, in particolare nell’ambito orientato agli oggetti) in Figura 5.4. Esso ricalca in
buona parte il paradigma Model-View-Controller presentato sopra (Figura
5.3) incorporando anche altri componenti esterni.
Figura 5.4: Architettura del tool Aida
5.1. L’ARCHITETTURA
73
74
CAPITOLO 5. IL SOFTWARE AIDA
Il Model definisce la struttura di ciò che sta alla base del nostro approc-
cio: i sequential pattern. Essi sono composti (come già detto nel Capitolo
4) da nodi e archi (gli archi, come possiamo notare dal diagramma UML,
poichè sono stati arricchiti per il nostro approccio, sono entità più complesse
e necessitano di una classe a sè poichè devono mantenere un’intera struttura
dati, al contrario dei nodi, entità più semplici e implementate attraverso tipi
primitivi nella classe SequentialPattern, poichè devono mantenere solamente
un dato). Per un vero disaccoppiamento tra la parte di logica e le strutture
dati, poi, vi è un componente chiamato “Manager” che è l’unica entità che
interagisce con queste ultime. Tutte le richieste e le risposte tra le strutture
dati e il resto del sistema, quindi, devono passare attraverso il Manager che
le può cosı̀ regolarizzare. Vi è, poi, un ultimo componente detto “teQueryState” che è respondabile della gestione degli indici: esso sa quali indici
sono implementati e per quali teQuery, sa per quanto tempo questi ultimi
dovranno restare attivi per poi essere distrutti.
La parte di View si occupa della semplice visualizzazione delle maschere
di input e degli output. Essa è totalmente slegata dalla logica applicativa in
modo da poter essere facilmente modificabile e sostituibile. Essa ha anche
un componente chiamato “GraphDesigner” il cui compito è quello di disegnare su alcuni grafici i valori di Precisione e Recupero misurati per la fase
di sperimentazione (vedi Capitolo 6).
La parte di Controller, infine, è quella che implementa la logica del tool.
Essa incorpora “AidaController” che è il componente dedito a gestire la
successione di tutte le fasi previste dal nostro metodo.
Nella fase di previsione esso riceve gli input dati dall’utente attraverso la
View (log delle operazioni, teQuery e tempi di implementazione degli indici
per le teQuery, supporto minimo) e, richiamando il modulo “PrefixSpan”,
5.2. IL MANUALE UTENTE
75
esegue la ricerca di pattern sequenziali frequenti sul log opportunamente
preparato. Quando il modulo che implementa l’algoritmo di Data Mining
fornisce come risultato i sequential pattern frequenti, il Controller si occupa
di arricchirli con le durate e i fattori di tolleranza facendo ulteriori analisi
sui dati forniti in ingresso.
Una volta fatto ciò, può iniziare la fase di previsione (sempre ricevendo un
input da parte dell’utente attraverso la View). In questa fase, il Controller
si occupa di attivare dei componenti detti “Listener”: ad ogni sequential
pattern trovato ed arrichito viene assegnato un Listener. Quando un’operazione viene eseguita dal DBMS, poi, la sua esecuzione viene inoltrata anche
al tool: qui i Listener controllano che l’operazione appena eseguita faccia
parte del sequential pattern a cui sono associati e, in particolare, che sia la
prima non ancora riconosciuta seguendo l’ordine della sequenza frequente.
Quando un Listener riconosce l’ultima query utile (considerando i tempi di
implementazione degli indici) del sequential pattern associato, schedula la
manutenzione degli indici necessari per la teQuery che è l’ultimo elemento
di quest’ultimo.
5.2
Il Manuale Utente
In questa sezione si analizza, passo passo, l’utilizzo del tool sviluppato che
copre solo alcuni tra i punti del metodo proposto: innanzitutto esso non
si lega ad un DBMS, ma chiede un log delle operazioni come un input; in
secondo luogo, poi, esso non calcola il tempo necessario alla manutenzione
degli indici per una determinata teQuery, ma chiede anch’esso come input.
All’avvio del software, la schermata che si presenta è quella in Figura 5.5.
Come si può notare, sono presenti due diverse pagine: una per la fase
di apprendimento e una per la fase di previsione (inizialmente disabilitata).
76
CAPITOLO 5. IL SOFTWARE AIDA
Figura 5.5: Fase di apprendimento − situazione iniziale
E’ necessario, a questo punto, fornire gli input al sistema: per prima cosa
dobbiamo caricare il log delle operazioni in formato csv. Per fare ciò basta
cliccare sull’icona della cartella e si aprirà una finestra di navigazione che
permette di selezionare il file corretto, come da Figura 5.6.
Una volta selezionato il file corretto, poiché è un file csv, si devono indicare il numero della colonna che contiene le operazioni e di quella che
contiene i timestamp. Una volta confermati questi input, il sistema analizza
il log ed estrae le operazioni che utilizza in un menu a tendina per poter
selezionare la/le teQuery. Come da Figura 5.7, è possibile inserire più di
una teQuery alla volta e, per ognuna di esse, è necessario indicare il tempo
necessario per la manutenzione degli indici più adatti e il supporto minimo che i pattern sequenziali con quest’ultima come ultimo elemento devono
avere nei vari chunck - creati come già spiegato - del log delle operazioni.
Una volta scelto il numero di teQuery da considerare e inseriti tutti i
5.2. IL MANUALE UTENTE
77
Figura 5.6: Fase di apprendimento − finestra di navigazione
Figura 5.7: Fase di apprendimento − selezione delle teQuery
dati per ognuna di esse (da notare che il tempo per la manutenzione degli
indici deve essere inserito in millisecondi e che il supporto minimo deve essere compreso tra 0 e 1), come in Figura 5.8, si conclude la fase di inserimento
degli input e inizia la fase di esecuzione vera e propria riguardo alla parte
78
CAPITOLO 5. IL SOFTWARE AIDA
di apprendimento del nostro tool. Naturalmente, nel menu a tendina che
si crea dinamicamente con le operazioni estratte dal log, vengono via via
tolte le teQuery già selezionate in righe precedenti. Per avviare la fase di
esecuzione è necessario premere il pulsante “START”.
Figura 5.8: Fase di apprendimento − teQuery selezionate
Il risultato della fase di esecuzione della parte di apprendimento, viene
visualizzato nella parte destra della schermata, come da Figura 5.9.
Come possiamo notare sono numerosi i contenuti prodotti: innanzitutto, per comodità di visualizzazione, ad ogni operazione viene associato un
codice univoco che sarà usato da lı̀ in poi. Nell’esempio, per citarne una,
alla query “SELECT light FROM sensors” è associato il codice 4, quindi, da
ora in poi, l’interrogazione sarà chiamata q4. A seguire, per ogni teQuery
selezionata come input, viene visualizzato il log delle operazioni diviso nei
chunck utili alla computazione (ognuno di essi, come già detto, si chiude
con una occorrenza della teQuery in considerazione). Infine sono visualiz-
5.2. IL MANUALE UTENTE
79
Figura 5.9: Fase di apprendimento − output della fase di apprendimento
zati tutti i pattern sequenziali trovati per ogni teQuery e che rispettano il
supporto minimo desiderato. Per comodità di visualizzazione da parte dell’utente, essi sono rappresentati in forma grafica. Questa rappresentazione,
però, nasconde alcune informazioni riguardanti gli archi, in particolare durata e fattore di tolleranza. Queste ultime, però, sono visualizzabili in forma
testuale usando l’apposita funzione “See Complete SP” che visualizza una
finestra che le contiene, come da Figura 5.10. Da notare, infine, che una
volta conclusa la parte di apprendimento, viene attivata la pagina per la
fase di previsione, fino ad ora disabilitata.
Nell’esempio in Figura 5.10, vediamo la visualizzazione completa in forma testuale di un pattern sequenziale. Esso visualizza nella prima riga la
struttura con i vari elementi (node0 | mean1 # tolerance1 | node1 | mean2 #
tolerance2 | node2), mentre nella seconda riga sono visualizzati i rispettivi
valori e il supporto (come numero di chunck in cui la sequenza compare). A
questo punto sono stati cercati e salvati tutti i pattern sequenziali arricchiti
80
CAPITOLO 5. IL SOFTWARE AIDA
Figura 5.10: Fase di apprendimento − pattern sequenziale completo in forma
testuale
necessari per la fase di previsione ed è necessario andare sulla pagina corrispondente. La schermata che si presenta è quella in Figura 5.11.
Figura 5.11: Fase di previsione − schermata iniziale
5.2. IL MANUALE UTENTE
81
Questa schermata, come si può vedere dalla Figura 5.11, si divide in
tre grandi aree: la prima è quella che visualizza il flusso di esecuzione delle operazioni eseguite (nel caso reale in cui il tool fosse collegato ad un
DBMS, sarebbe il flusso di operazioni che passa per quest’ultimo); la seconda, sottostante alla prima, visualizza gli output del tool che possono
essere la rimozione di un pattern sequenziale dalla lista di quelli parzialmente riconosciuti a causa di invalidità temporale, di esecuzione effettiva
della teQuery o di scadenza del timer associato agli indici oppure l’avviso
per la manutenzione degli indici per una determinata teQuery a causa del
riconoscimento completo di un pattern sequenziale. Nell’ultima area vengono visualizzati, in forma grafica, i pattern sequenziali completamente o
parzialmente riconsociuti. Come possiamo vedere dalla Figura 10, i nodi già
riconosciuti hanno sfondo rosso, mentre quelli ancora da riconoscere hanno
sfondo grigio. Quando un pattern sequenziale è stato completamente riconosciuto ed è stata schedulata la manutenzione per gli indici della teQuery
associata, allora tutti i suoi nodi vengono colorati di verde. I tre pulsanti
“START FLOW”, “PAUSE FLOW” e “STOP FLOW” servono a gestire il
flusso delle operazioni in ingresso al tool nella fase di previsione.
82
CAPITOLO 5. IL SOFTWARE AIDA
Figura 5.12: Fase di previsione − output
Capitolo 6
Sperimentazione
“Misurate ciò che è misurabile e rendete misurabile ciò che non lo è”
Galileo Galilei
In questo capitolo sono spiegate dettagliatamente le prove eseguite con
il tool per valutarne i risultati.
In particolare è stato utilizzato un dataset contenente informazioni circa lo
share dei programmi televisivi e le visualizzazioni dei singoli utenti. Queste
ultime, in particolare, si avvicinano abbastanza bene all’idea di dato per cui
la metodologia presentata in questo lavoro è stata pensata. Su questi dati
sono state misurati due comuni indici statistici: precisione e recupero. La
precisione può essere vista come una misura di esattezza o fedeltà, mentre
il recupero è una misura di completezza. Nell’Information Retrieval, la precisione è definita come il numero di documenti attinenti recuperati da una
ricerca diviso il numero totale di documenti recuperati dalla stessa ricerca,
e il recupero è definito come il numero di documenti attinenti recuperati da
una ricerca diviso il numero totale di documenti attinenti esistenti. Dalla
definizione, è possibile intuire che precisione e recupero sono grandezze inversamente proporzionali: maggiore è la precisione in una ricerca, minore
sarà il recupero, e viceversa.
83
84
CAPITOLO 6. SPERIMENTAZIONE
Nella nostra situazione in particolare, sono stati utilizzati le seguenti misure
per il calcolo di questi indici:
• Misura 1 : numero di volte in cui sono stati implementati gli indici
per una teQuery ed essa è stata effettivamente eseguita mentre questi
erano ancora presenti.
• Misura 2 : numero di volte in cui sono stati implementati gli indici per
una teQuery ed essa non è stata eseguita entro il periodo di validità
degli stessi.
• Misura 3 : numero di volte in cui sono non stati implementati gli indici
per una teQuery ed essa è stata eseguita mentre questi non erano
ancora presenti.
Da queste, la definizione di precisione e recupero:
• precisione =
• recupero =
M isura1
M isura1+M isura2
M isura1
M isura1+M isura3
La precisione, quindi, è un indice di quanto le previsioni fatte sono corrette, mentre il recupero di quante teQuery riusciamo a prevedere correttamente rispetto al totale.
Per valutare al meglio la metodologia proposta in questo lavoro attraverso gli
indici sopra citati, si è adottato un metodo statistico classicamente usato per
valutare i modelli predittivi: la “cross-validazione”. Preso un campione di
dati, esso viene suddiviso in sottoinsiemi, alcuni dei quali vengono usati per
la costruzione del modello (insiemi di allenamento) e altri per confrontare
le predizioni del modello (insiemi di validazione). In particolare, nel nostro
caso, si è optato per un unico insieme di allenamento e un unico insieme di
validazione. Le percentuali per la suddivisione del dataset sono state: 60%
per la parte di allenamento e 40% per quella di validazione. Normalmente
85
i valori scelti in letteratura si avvicinano più a un rapporto 80%-20%, ma
nel nostro lavoro si è deciso di aumentare la porzione di dati dedicata alla
validazione poichè, come già detto, essi si avvicinano abbastanza all’idea di
dato per cui la metodologia è stata pensata, ma, non avendo una grande
periodicità, è necessario un insieme più corposo per validare le previsioni
fatte.
Come già accennato, il dataset appartiene ad una società con lo scopo di
raccogliere e pubblicare dati sull’ascolto televisivo. Esso contiene informazioni molto diverse tra loro: per prima cosa sono presenti diverse tabelle
di anagrafica degli utenti singoli e delle famiglie, dei canali, delle emittenti
e delle fasce orarie; in secondo luogo, poi, ci sono tabelle che contengono
informazioni sul palinsesto, sulla visualizzazione dei canali e sullo share. Un
utente, per esempio, è caratterizzato da diversi fattori: tra gli altri sesso,
età, città in cui si trova e classe socio-economica; un programma, invece, è
caratterizzato dal suo titolo, dal genere, dal sottogenere e dalla fascia oraria
in cui viene mandato in onda. Tra gli altri dati, infine, ci sono quelli sulla
visualizzazione da parte di utenti singoli o da parte di famiglie che sono
caratterizzati, appunto, da chi guarda il programma, dal programma stesso,
dall’emittente e dai tempi di inizio e di fine visualizzazione.
In particolare, delle 38 tabelle che costituiscono il dataset, è stata utilizzata quella che tiene traccia dei canali guardati dai vari utenti (Tabella
“individuals syntonizations live”) in Figura 6.1.
86
CAPITOLO 6. SPERIMENTAZIONE
Figura 6.1: Struttura della tabella “individuals syntonizations live”
Essa, come già accennato, ha un significato abbastanza intuitivo: tiene
traccia delle sintonizzazioni dei singoli utenti; per ognuna di esse specifica
da che utente è stata fatta, l’orario di inizio e quello di fine, l’emittente, il
canale e il programma tv visualizzato. Questa tabella è composta da oltre
21 milioni di record, ma, non può essere direttamente utilizzata come dato
in ingresso poichè comprende le visualizzazioni di tutti i singoli utenti: per
i nostri scopi, invece, è necessaria la selezione di questa tabella rispetto ad
un determinato utente, in modo da trovare dei sequential pattern del tipo
“quando un utente ha guardato per due volte la pubblicità di un film, poi
guarderà anche il film stesso”. In questo esempio semplice e forse banale,
il film (di lunga durata rispetto alle pubblicità) può essere equiparato alla
teQuery che ha un response time lungo rispetto alle normali operazioni (le
pubblicità, appunto). Usando la tabella senza selezione per trovare pattern
sequenziali frequenti nella visualizzazione dei canali, invece, ne avremmo
trovati molti privi di significato perchè con nodi che si sarebbero riferiti a
visualizzazioni di utenti diversi.
Per i dati usati di seguito è stato scelto l’utente 11293 poichè era quello
che offriva il maggior numero di dati in questa tabella (14451 record). Il
campo “emittente” è stato utilizzato come l’equivalente delle operazioni sul-
87
la base di dati considerate dal nostro metodo, per cui quelle tra cui c’è la
teQuery di cui si deve prevedere l’esecuzione. Il campo “startTime” è stato
considerato come il timestamp di esecuzione di queste operazioni.
Inizialmente, per la valutazione di precisione e recupero, si è pensato di
calcolarli su un intervallo fisso di 100 query. Per il successivo intervallo si
sarebbero ricalcolati gli stessi, senza tenere in considerazione quello precedente e considerando cosı̀ gli intervalli indipendenti l’uno dall’altro, come in
Figura 6.2.
Figura 6.2: Prima ipotesi di calcolo di Precisione e Recupero
Si è scelta l’emittente 2 come teQuery poichè è la terza più frequente
nella tabella risultante dalla selezione per utente di quella originale. Non
si sono scelte le emittenti 16 e 1, le due più frequenti, per due motivi:
il primo è che che le teQuery, per loro definizione, non sono mai troppo
frequenti, altrimenti non necessiterebbero di previsione; il secondo, invece,
è dovuto al fatto che i chunck di log risultanti sarebbero stati troppo corti e
non avrebbero permesso di applicare il Sequential Pattern Mining in modo
che ritornasse risultati interessanti. Con queste premesse, e con un tempo
di implementazione degli indici pari a 1000 ms, si è fatto uno studio dei
due indici già citati al variare del supporto minimo scelto. In particolare,
i supporti minimi scelti sono stati “0,3”, “0,4”, “0,5”. I risultati ottenuti
sono riportati in Figura 6.3 e in Figura 6.4.
88
CAPITOLO 6. SPERIMENTAZIONE
Figura 6.3: Valori della Precisione con la prima ipotesi di calcolo
Figura 6.4: Valori del Recupero con la prima ipotesi di calcolo
89
Come si può notare i risultati non hanno un andamento definito, ma
sono molto rumorosi. Questo fa sı̀ che non portino nessuna informazione
interessante al nostro studio.
Come conseguenza di questi risultati, si è allora pensato di cambiare l’approccio in due punti:
• Aumentare la dimensione dell’intervallo di query che definisce ogni
quanto i valori di precisione e recupero vengono calcolati in modo
da diminuire il numero di sequential pattern che sono parzialmente
riconosciuti in un intervallo, ma completati solo nel successivo. Può
accadere, infatti, come in Figura 6.5 che i primi nodi di un pattern
siano riconosciuti in una finestra di query, ma che il riconoscimento
completo si concluda nella finestra successiva. Questo porta ad un
calcolo che tende ad allontanarsi dalla realtà per i valori di precisione
e recupero associati alle varie finestre;
Figura 6.5: Pattern sequenziale su due finestre di query diverse
• Cambiare l’insieme su cui calcolare i due indici: non considerare più
i singoli intervalli in modo indipendente, ma considerare un unico intervallo che cresce sempre più in modo incrementale, come in Figura
6.6.
90
CAPITOLO 6. SPERIMENTAZIONE
Figura 6.6: Seconda ipotesi di calcolo di Precisione e Recupero
Per studiare i diversi comportamenti al variare del supporto minimo, in
questo caso, si è deciso di ridurre la differenza tra un valore e l’altro usando
“0,3”, “0,35”, “0,4”, “0,45”. Supporti troppo bassi non sono stati utilizzati
a causa della difficoltà nella loro gestione, ma ancor più per lo scarso significato che avrebbero avuto: abbassando troppo il supporto, infatti, la fase di
apprendimento avrebbe generato un numero enorme di sequential pattern
che sarebbero stati, però, estremamente specifici richiando cosı̀ l’overfitting.
In Data Mining, l’overfitting si ha nel caso in cui l’apprendimento è stato
effettuato troppo a lungo o il numero di esempi di allenamento era scarso:
questo fa sı̀ che il modello si adatti troppo all’insieme di dati di apprendimento ed estragga informazioni estremamente specifiche da questi che non
sono poi effettivamente reali sui dati non visionati. Per questo motivo l’errore sui dati di allenamento diminuisce, ma quello sui dati di validazione
aumenta, come in Figura 6.7.
91
Figura 6.7: Esempio di Ovefitting. Errore sui dati di training (blu) ed errore
sui dati di test (rosso)
I risultati ottenuti con i valori di supporto minimo sopra citati, quindi, sono quelli riportati nelle Tabelle 6.1 e 6.2 e poi disegnati sui grafici
appropriati in Figura 6.8 e in Figura 6.9.
Figura 6.8: Valori della Precisione con la seconda ipotesi di calcolo
92
CAPITOLO 6. SPERIMENTAZIONE
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
0,3
0,25523013
0,18283582
0,15426695
0,15046297
0,13677265
0,13544668
0,12611517
0,12032356
0,11623832
0,11574074
0,11100875
0,110749185
0,110749185
0,110749185
0,110749185
0,35
0,33566433
0,2755102
0,24948025
0,24501425
0,22516556
0,22222222
0,20827068
0,2
0,19423287
0,1919192
0,18537635
0,184765
0,184765
0,184765
0,184765
0,4
0,29447854
0,23011364
0,21352313
0,2160804
0,20218037
0,20358306
0,19303136
0,1873165
0,18326488
0,18202555
0,1772933
0,17722502
0,17722502
0,17722502
0,17722502
0,45
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Tabella 6.1: Valori della Precisione con la seconda ipotesi di calcolo
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
5500
6000
6500
7000
7500
0,3
0,81333333
0,7903226
0,7790055
0,8158996
0,8172043
0,82697946
0,8315508
0,8439716
0,8468085
0,83798885
0,8441331
0,84577113
0,84577113
0,84577113
0,84577113
0,35
0,64
0,6532258
0,6629834
0,7196653
0,7311828
0,73313785
0,7406417
0,7541371
0,7595745
0,7430168
0,7548161
0,7562189
0,7562189
0,7562189
0,7562189
0,4
0,64
0,6532258
0,6629834
0,7196653
0,7311828
0,73313785
0,7406417
0,7541371
0,7595745
0,7430168
0,7548161
0,7562189
0,7562189
0,7562189
0,7562189
0,45
0,64
0,6532258
0,6629834
0,7196653
0,7311828
0,73313785
0,7406417
0,7541371
0,7595745
0,7430168
0,7548161
0,7562189
0,7562189
0,7562189
0,7562189
Tabella 6.2: Valori della Recupero con la seconda ipotesi di calcolo
93
Figura 6.9: Valori del Recupero con la seconda ipotesi di calcolo
Questi dati sono nettamente più significativi dei precedenti e diverse sono le considerazioni che possiamo fare.
Innanzitutto possiamo notare che, in generale, la precisione ha un andamento decrescente (vedi Figura 6.8), mentre il recupero ha un andamento
crescente (vedi Figura 6.9). Ciò è facilmente spiegabile rifacendosi alle già
citate definizioni di questi due indici statistici. Più query vengono eseguite, più sequential pattern saranno completati e, quindi, maggiore sarà il
numero di previsioni sbagliate fatte rispetto al numero di quelle corrette:
questo porta ad un aumento del denominatore della formula per calcolare
la precisione e ad una conseguente diminuzione dei suoi valori. Dualmente,
però, completando più sequential pattern e facendo, quindi, più previsioni,
aumenta anche il numero di teQuery eseguite effettivamente predette sul
totale e quindi il recupero, come si può vedere dal grafico, tende ad aumentare. Al variare del supporto minimo, poi, varia il numero e la lunghezza dei
sequential pattern estratti nella fase di apprendimento: nelle Figure 6.10,
6.11, 6.12 e 6.13 di seguito, riportiamo i risultati trovati.
94
CAPITOLO 6. SPERIMENTAZIONE
Figura 6.10: Sequential Pattern trovati con supporto minimo 0,3
Figura 6.11: Sequential Pattern trovati con supporto minimo 0,35
Figura 6.12: Sequential Pattern trovati con supporto minimo 0,4
Figura 6.13: Sequential Pattern trovati con supporto minimo 0,45
Più il supporto minimo è basso, più alto sarà il numero e la lunghezza dei
sequential pattern estratti: essi, però, saranno sempre più specifici del set di
dati usato per l’allenamento, quindi meno frequenti nel resto dei dati, meno
generalizzabili e, in definitiva, meno utili a fare previsioni. Al contrario con
un supporto minimo più alto, i sequential pattern saranno in numero minore
e più brevi, ma molto più frequenti e quindi estremamente generalizzabili
e utili a fare previsioni. Se quindi aumentiamo il supporto minimo, il nu-
95
mero di sequential pattern che il sistema riesce a completare guardando il
flusso delle operazioni sarà inferiore e, quindi, sarà inferiore anche il numero delle previsioni fatte e delle teQuery effettivamente ben gestite. Questo
porta ad un abbassamento del recupero all’aumentare del supporto minimo.
Al contrario la precisione aumenta poichè, con un supporto minimo basso,
le previsioni fatte sono in numero inferiore, ma quando avvengono è molto
probabile che effetivamente, poi, venga eseguita la teQuery.
Si riporta, infine, il grafico relativo alla F-measure: essa è la media armonica pesata tra precisione e recupero. Per definizione, la media armonica
di n termini è definita come il reciproco della media aritmetica dei reciproci:
Mh = ∑Nn
1
i=1 xi
. Possiamo quindi definire la F-measure, utilizzando la versio-
ne tradizionale o bilanciata, come F =
2∗P recisione∗Recupero
P recisione+Recupero .
Il grafico che ne deriva, è riportato in Figura 6.14.
Figura 6.14: Valori della F-measure con la seconda ipotesi di calcolo al
variare del supporto minimo
Questa misura è utile per fare un’unica valutazione per i valori di precisione e recupero.
Capitolo 7
Conclusioni e sviluppi futuri
“Facts are more mundane than fantasies, but a better basis for conclusions.”
Amory Lovins
Come discusso nel Capitolo 2, numerose sono le metodologie proposte
per espletare l’annoso compito della manutenzione automatica degli indici
in una base di dati, ma solo una minima parte di esse utilizza il nuovo approccio proattivo per prepararsi in anticipo alla situazione da migliorare. Il
presente lavoro di tesi si è mosso proprio in tale direzione, riprendendo un
modello esistente ed integrandolo con innovative tecniche di Data Mining,
fino ad ora mai utilizzate per questi scopi.
L’applicazione di tali tecniche permette di ottenere una profonda conoscenza
dei dati in possesso, utile per una previsione ed un conseguente adattamento
del sistema a ciò che sta per accadere.
La metodologia sviluppata, quindi, permette in primo luogo l’identificazione
delle teQuery, supponendo noti gli indici più adatti per un miglioramento
delle performance al momento dell’esecuzione delle stesse (operazione che
sarebbe possibile eseguire manualmente o con tecnice più strutturate, come
gli Hypotetical Execution Plan, presenti in letteratura). La metodologia
proposta, inoltre, fornisce la capacità di previsione del momento in cui le te96
97
Query verranno eseguite attraverso la tecnica del Sequential Pattern Mining
“arricchita” in cui ogni nodo di un sequential pattern è una determinata
operazione eseguita dal DBMS e, in particolare, l’ultimo è una teQuery: per
fare ciò, sugli archi tra ogni nodo vi sono le durate, cioè i tempi utili alla
previsione. Da ultimo, la metodologia proposta, in seguito alla previsione,
permette l’adattamento degli indici materializzati alla teQuery che sta per
essere eseguita attraverso la richiesta preventiva di una manutenzione degli
indici stessi. Da notare, in modo particolare, che essa non gestisce solo la
creazione, ma anche la cancellazione e l’aggiornamento di questi ultimi.
I risultati ottenuti mostrano come, in un contesto in cui le operazioni da
eseguire sono sempre le stesse e tra loro correlate, questa tecnica permetta
di prevedere in modo abbastanza accurato l’esecuzione di una determinata
interrogazione basandosi sul “contesto”, cioè sulle altre operazioni che la
precedono.
Nell’ottica di sviluppi futuri è significativo sottolineare alcuni aspetti che
in questo lavoro, per motivi di tempo e di impegno, non sono stati considerati.
La scelta del parametro corrispondente al supporto minimo per una teQuery al momento dell’esecuzione dell’algoritmo per l’estrazione delle sequenze
frequenti è, ad ora, totalmente arbitraria. Studi più approfonditi, magari
accompagnati da risultati empirici, potrebbero portare ad una scelta più
accurata del valore di questo importante parametro.
Nella fase di sperimentazione, poi, si è scelto uno degli utenti più significativi per i valutare la precisione e il recupero. Sarebbe utile misurare
questi indici su più utenti, in modo da poter ricavare comportamenti co-
98
CAPITOLO 7. CONCLUSIONI E SVILUPPI FUTURI
stanti.
Inoltre, ci siamo concentrati sugli indici di precisione e recupero per misurare la fedeltà e la completezza dei risultati prodotti dal sistema: sarebbe utile
e significativo poter collegare il tool a una base di dati reale e funzionante
in modo da misurare le sue prestazioni in un caso pratico e valutare, se
venissero evidenziati dei punti deboli, possibili miglioramenti. Per fare ciò,
sarebbe necessario sviluppare dei driver che permettano la connessione del
tool ai diversi DBMS, indipendentemente dalla loro tipologia. Applicandolo
ad un caso reale, poi, sarebbe possibile implementare anche i primi due passi del metodo proposto: identificazione automatica delle teQuery (trattato
nella metodologia proposta, ma non nella demo del tool) e degli indici più
adatti per la loro esecuzione e il conseguente tempo di manutenzione degli
indici (non trattato nella metodologia proposta), necessario a preventivare
l’esecuzione di una determinata operazione.
Bibliografia
[1] Farley, Gilles, and Stewart A Schuster. “Query execution and index
selection for relational data bases.” Proceedings of the 1st International
Conference on Very Large Data Bases 22 Sep. 1975: 519-519.
[2] Hammer, Michael, and Arvola Chan. “Index selection in a self-adaptive
data base management system.” Proceedings of the 1976 ACM SIGMOD international conference on Management of data 2 Jun. 1976:
1-8.
[3] Brown, Robert G. “Statistical forecasting for inventory control.” (1959).
[4] Brown, Robert Goodell. Smoothing, forecasting and prediction of
discrete time series. Courier Dover Publications, 2004.
[5] Bruno, Nicolas, and Surajit Chaudhuri. “An online approach to physical design tuning.” Data Engineering, 2007. ICDE 2007. IEEE 23rd
International Conference on 15 Apr. 2007: 826-835.
[6] Bruno, Nicolas, and Surajit Chaudhuri. “Online autoadmin:(physical
design tuning).” Proceedings of the 2007 ACM SIGMOD international
conference on Management of data 11 Jun. 2007: 1067-1069.
[7] Schnaitter, Karl et al. “Colt: continuous on-line tuning.” Proceedings
of the 2006 ACM SIGMOD international conference on Management
of data 27 Jun. 2006: 793-795.
99
100
BIBLIOGRAFIA
[8] Schnaitter, Karl et al. “On-line index selection for shifting workloads.”
Data Engineering Workshop, 2007 IEEE 23rd International Conference
on 17 Apr. 2007: 459-468.
[9] Liihring, M et al. “Autonomous management of soft indexes.” Data
Engineering Workshop, 2007 IEEE 23rd International Conference on
17 Apr. 2007: 450-458.
[10] Valentin, Gary et al. “DB2 advisor: An optimizer smart enough to
recommend its own indexes.” icde 28 Feb. 2000: 101-11.
[11] Sattler, Kai-Uwe, Ingolf Geist, and Eike Schallehn. “Quiet: continuous query-driven index tuning.” Proceedings of the 29th international
conference on Very large data bases-Volume 29 9 Sep. 2003: 1129-1132.
[12] Sattler, K-U, Eike Schallehn, and Ingolf Geist. “Autonomous querydriven index mining.” Database Engineering and Applications Symposium, 2004. IDEAS’04. Proceedings. International 7 Jul. 2004:
439-448.
[13] Morelli, EMT et al. “Automatic reindexation in relational dbmss.” Proceedings of the Brazilian Symposium on Databases. Fortaleza, Brazil
2009.
[14] Schnaitter, Karl, Neoklis Polyzotis, and Lise Getoor. “Index interactions in physical design tuning: modeling, analysis, and applications.”
Proceedings of the VLDB Endowment 2.1 (2009): 1234-1245.
[15] Heinis, Thomas et al. “PARINDA: An Interactive Physical Designer
for PostgreSQL.” Proceedings of 13th International Conference on
Extending Database Technology 2010.
BIBLIOGRAFIA
101
[16] Polyzotis, Neoklis et al. “An Automated, yet Interactive and Portable DB designer.” Proceedings of the ACM SIGMOD International
Conference on Management of Data 2010.
[17] Schnaitter, Karl, and Neoklis Polyzotis. “Semi-automatic index tuning:
Keeping dbas in the loop.” Proceedings of the VLDB Endowment 5.5
(2012): 478-489.
[18] Medeiros, André et al. “Proactive Index Maintenance: Using Prediction
Models for Improving Index Maintenance in Databases.” Journal of
Information and Data Management 3.3 (2012): 255.
[19] Papadomanolakis, Stratos, and Anastassia Ailamaki. “An integer linear programming approach to database design.” Data Engineering
Workshop, 2007 IEEE 23rd International Conference on 17 Apr. 2007:
442-449.
[20] Papadomanolakis, Stratos, and Anastassia Ailamaki. “Autopart: Automating schema design for large scientific databases using data
partitioning.” Scientific and Statistical Database Management, 2004.
Proceedings. 16th International Conference on 21 Jun. 2004: 383-392.
[21] Bruno, Chaudhuri. “Interactive physical design tuning.” (2010).
[22] Agrawal, Rakesh, and Ramakrishnan Srikant. “Mining sequential
patterns.” Data Engineering, 1995. Proceedings of the Eleventh
International Conference on 6 Mar. 1995: 3-14.
[23] Agrawal, Rakesh, and Ramakrishnan Srikant. “Fast algorithms for mining association rules.” Proc. 20th int. conf. very large data bases,
VLDB 12 Sep. 1994: 487-499.
[24] Slimani, Thabet, and Amor Lazzez. “Sequential Mining: Patterns and
Algorithms Analysis.” arXiv preprint arXiv:1311.0350 (2013).
102
BIBLIOGRAFIA
[25] Wang, Wei, and Jiong Yang. Mining sequential patterns from large data
sets. Springer, 2006.
[26] Agrawal, Rakesh, Tomasz Imieliski, and Arun Swami. “Mining association rules between sets of items in large databases.” ACM SIGMOD
Record 1 Jun. 1993: 207-216.
[27] Srikant, Ramakrishnan, and Rakesh Agrawal. “Mining quantitative association rules in large relational tables.” ACM SIGMOD Record 1 Jun.
1996: 1-12.
[28] Pei, Jian et al. “Mining access patterns efficiently from web logs.”
Knowledge Discovery and Data Mining. Current Issues and New
Applications (2000): 396-407.
[29] Zaki, Mohammed J. “SPADE: An efficient algorithm for mining
frequent sequences.”Machine learning 42.1-2 (2001): 31-60.
[30] Han, Jiawei et al. “FreeSpan: frequent pattern-projected sequential
pattern mining.” Proceedings of the sixth ACM SIGKDD international
conference on Knowledge discovery and data mining 1 Aug. 2000: 355359.
[31] Pei, Jian et al. “Prefixspan: Mining sequential patterns efficiently
by prefix-projected pattern growth.” 2013 IEEE 29th International
Conference on Data Engineering (ICDE) 2 Apr. 2001: 0215-0215.
[32] Ayres, Jay et al. “Sequential pattern mining using a bitmap representation.” Proceedings of the eighth ACM SIGKDD international conference
on Knowledge discovery and data mining 23 Jul. 2002: 429-435.
[33] Yan, Xifeng, Jiawei Han, and Ramin Afshar. “CloSpan:
Mining
closed sequential patterns in large datasets.” Proceedings of SIAM
International Conference on Data Mining 1 May. 2003: 166-177.
BIBLIOGRAFIA
103
[34] Wang, Jianyong, and Jiawei Han. “BIDE: Efficient mining of frequent closed sequences.”Data Engineering, 2004. Proceedings. 20th
International Conference on 30 Mar. 2004: 79-90.
[35] Wang, Ke, and Jye Tan. “Incremental discovery of sequential patterns.”
1996 ACM SIGMOD Data Mining Workshop: Research Issues on Data
Mining and Knowledge Discovery (SIGMOD’96) 4 Jun. 1996: 95-102.
[36] Lin, Ming-Yen, and Suh-Yin Lee. “Incremental update on sequential
patterns in large databases.” Tools with Artificial Intelligence, 1998.
Proceedings. Tenth IEEE International Conference on 10 Nov. 1998:
24-31.
[37] Parthasarathy, Srinivasan et al. “Incremental and interactive sequence mining.” Proceedings of the eighth international conference on
Information and knowledge management 1 Nov. 1999: 251-258.
[38] Masseglia, Florent, Pascal Poncelet, and Maguelonne Teisseire. “Incremental mining of sequential patterns in large databases.” Data &
Knowledge Engineering 46.1 (2003): 97-121.
[39] Zhang, Minghua et al. “Efficient algorithms for incremental update
of frequent sequences.” Advances in Knowledge Discovery and Data
Mining (2002): 186-197.
[40] Lin, Ming-Yen, and Suh-Yin Lee. “Incremental update on sequential
patterns in large databases by implicit merging and efficient counting.”
Information Systems 29.5 (2004): 385-404.
[41] Cheng, Hong, Xifeng Yan, and Jiawei Han. “IncSpan: incremental mining of sequential patterns in large database.” Proceedings of the tenth
ACM SIGKDD international conference on Knowledge discovery and
data mining 22 Aug. 2004: 527-532.
104
BIBLIOGRAFIA
[42] Nguyen, Son N, Xingzhi Sun, and Maria E Orlowska. “Improvements of
IncSpan: Incremental mining of sequential patterns in large database.”
Advances in Knowledge Discovery and Data Mining (2005): 442-451.
[43] Chen, Gong, Xindong Wu, and Xingquan Zhu. “Mining sequential patterns across time sequences.” New Generation Computing 26.1 (2007):
75-96.
[44] SPMF - http://www.philippe-fournier-viger.com/spmf/
[45] Sanderson, Mark, and Susan Dumais. “Examining repetition in user
search behavior”. Springer Berlin Heidelberg, 2007.
[46] Chaudhuri, S. and Narasayya, V. “Self-tuning database systems: A
decade of progress.” Proceedings of the International Conference on
Very Large Data Bases. Vienna, Austria (2007): 3-14.