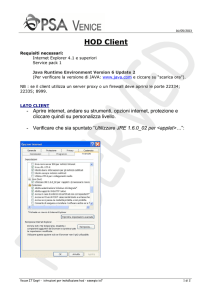
SISTEMI DISTRIBUITI
prof. S.Pizzutilo
Motore di riempimento DB
(generatore dati per simulazione)
Studente: Alessandro Balestrucci
617937
Corso di Laurea: Informatica Magistrale
Dipartimento di Informatica
Università degli Studi di Bari – A.Moro
Introduzione – problematica di interesse
L’esigenza di dover sempre più spesso interagire con
database di grandi dimensioni ci porta spesso a dover scrivere
funzioni (o trigger) che ci facilitano il raggiungimento dei
nostri obbiettivi di business.
Ma se queste funzioni che implementiamo, vanno a
modificare (update… set…), anche in modo irreversibile
(delete) sul DB su cui operiamo, potremmo intercorrere in
problemi gravi; si pensi a dati molto sensibili (db bancari,
azionari, medicali)
Obbiettivi di progetto
n
Limitare l’operatività diretta su DB di business per
operazioni di modifica e cancellazione
n
Realizzazione di un motore che astragga la struttura del
DB su cui vogliamo operare, e che permetta l’inserimento
di tuple simulate, anche da diversi client.
n
Invece di una copia (spesso si tratta di DB troppo grandi),
si generino dati nuovi e casuali, ma sempre coerenti con la
struttura del DB originale
n
Rendere la generazione un processo distribuito, dove
diversi client cooperano tra loro al fine di costruire files
contenenti le queries generative.
Aspetti di interesse
Per quanto concerne a questo corso di studi, si
vuole mostrare le proprietà di questo
software, e in particolare si illustrerà:
n Tipo
di architettura di sistema
n Strumento SW per la comunicazione
n Gestione della Concorrenza fra processi
n Server Multithreading
n Distributività e Cooperazione del sistema
Architettura del sistema
(client – server)
Il sistema che ho progettato e successivamente implementato,
possiede un architettura client-server.
Dove i diversi client effettuano richieste che possono o meno
modificare la risorse condivisa presente sul server oppure
ottenere un servizio/oggetto
Vantaggio: al server viene demandata tutta la responsabilità di
gestire la risorsa:
Svantaggio: crush del server.
Client side
La comunicazione con il server è prevista
esclusivamente per 2 scopi/servizi:
n Verifica
esistenza (in altri client) della Chiave
Primaria
n Richiesta
di un elemento da attribuire al vincolo
di Chiave esterna (take element)
Server side
Il server è il possessore e gestore della risorsa
condivisa tra i vari client; e dualmente a
quanto detto sul client viene interrogato per:
n eseguire
una ricerca su tale risorsa
n Aggiornamento incrementale della risorsa
n Restituzione degli esiti della ricerca
n Restituzione
di un elemento della risorsa
Strumento utilizzato per la
comunicazione (socket)
Lo strumento per la comunicazione più adeguato ai fini del mio
progetto, ho ritenuto essere la SOCKET con modalità STREAMING,
permettendomi così di poter usufruire di una comunicazione sincrona
tra client e server, stabile e full duplex.
Rappresentazione di un
indirizzo secondo
l’Internet Protocol (IP)
Inizializzazione socket
per connessione con
protocollo TCP (Ip
address del server e il
port di fruizione del
servizio)
Port è un astrazione
software con la
quale si associa un
servizio offerto
Utilizzata dal SERVER
per ascoltare eventuali
richieste che giungono
dai client, sulla PORT
specificata
Attraverso il metodo ACCEPT,
si restituisce una socket con la
quale avviene la comunicazione
lato server. (Socket to Socket)
Gestione della concorrenza (problema)
Il problema della gestione della concorrenza è stato un punto
cruciale nello sviluppo di questo sistema; le domande che mi posi
furono:
n E se invece che produrre i dati da solo, volessi farmi aiutare da
altri computer?
n Cosa succede se più client si connettono contemporaneamente?
n Cosa succede se più client producono lo stesso valore?
n Cosa succede se più client vogliono estrarre un valore?
Risorsa condivisa
Nel mio sistema i diversi client si contendono,
durante il procedimento di generazione, una
risorsa.
Dizionario (HashTable) di corrispondenze
nomeCampoChiave (primaria) e array degli
oggetti (elementi veri e propri prodotti dai vari
client), saranno i valori di FK per altre tabelle
[key]
dbCoord = DBAccess.getNome()+“-”+tabella.getNome()+"."+ pk.getNome();
Multithreading (server)
Multithreading (server) – sicurezza 1/2
Multithreading (server) – sicurezza 2/2 [β]
Sezione critica
n Esistenza
del Valore generato per la chiave primaria
n Esistenza
del Campo Chiave Primaria in Dizionario
Synchronized (funzionamento)
n
La parola riservata synchronized consente una accurata gestione dei metodi.
n
Garantisce un accesso sincronizzato ad eventuali risorse gestite da tali metodi, per
mezzo di un lock.
n
Quando un THREAD sta utilizzando un oggetto per mezzo di un metodo
synchronized, tale oggetto viene bloccato (locked) per evitare altri accessi
concorrenti.
n
In pratica tale parola chiave, racchiude il concetto di Monitor, strumento che ci
consente di garantire la mutua esclusione sulla risorsa condivisa; in grado di
bloccare e risvegliare threads.
Distributività e Cooperazione
Connessione DB
n Server
IP: ubicazione fisica del DB di Prova
da riempire (IP o Logic name)
n Name of DB: nome del Database
n PORT: porta servizio DBMS
n User_role & Password: credenziali di accesso
n Ram DB Server (IP): indirizzo del Server
Estrazione struttura DB – ADT Database
n
n
Inizializzazione Struttura Astratta DB
Estrazione caratteristiche struttura DB
– Caricamento dizionario DataType del DBMS
– Estrazione delle tabelle dal DB attraverso i metaData
– Costruzione dei tipi astratti delle tabelle, con il settaggio di tutte le
colonne e delle loro proprietà (nome, tipo, not null, precisione, lung
stringa, ecc)
n
Aggiunta vincoli intra ed inter relazionali per tutte le tabelle, e
settaggio dei rispettivi campi e delle classi vincolo (FK)
– Estrazione del campo chiave primaria (metaData)
– Estrazione del campo chiave esterna (metaData),
– Attribuzione ai rispettivi campi della struttura tabella di questi
vincoli
– Per ogni chiave esterna si specifica sia la tabella referenziata che il
campo
– Settaggio dei campi che esportano le chiavi esterne
Procedura prioritaria di ordinamento tabelle
n Estraggo
l’array contenente le tabelle già settate
n Priorità principale a tutte le tabelle senza FK
n Priorità secondaria alle tabelle le cui FK
referenziano unicamente alle tabelle e ai campi,
di cui prima,
n E così via
Vincoli sui campi (opzionali)
Algoritmo di generazione - CORE
n
n
n
n
Passaggio di parametri al metodo di generazione della query (tabella, keyServer, Sokstream)
Si distingue il caso in cui la chiave primaria sia composta da uno o più campi
Per ciascun campo/colonna si distingue se sia una Chiave primaria, una chiave esterna o
semplicemente un campo senza vincoli
CASO CHIAVE PRIMARIA: si genera elemento RANDOM a seconda del tipo e
– si interroga il server, attendendo una sua risposta.
– eventualmente produce un altro valore e si ripete.
n
n
n
CASO CHIAVE ESTERNA: non avviene alcuna generazione ma un interrogazione al server,
al quale si chiede di restituire un elemento della risorsa condivisa usando come chiave il
campo chiave primaria della tabella a cui fa riferimento
CASO CAMPO NON VINCOLATO: si genera un elemento RANDOM a seconda del tipo
(Data Type) che possiede
I valori degli elementi generati sono prodotti in due possibili modi:
– RANDOM, coerentemente a datatype e alle proprietà del campo nel DB
– VINCOLATA, ma sempre in modo RANDOM, utilizzando dei parametri di limitazione in merito
alla generazione
» MEMORIA LOCALE, in caso di estrazione da File, questo viene conservato nello stack.
n
n
Si costruisce la tupla in modo incrementale, concatenando i valori.TOSTRING alla query
parziale.
Terminati i campi e costruita la stringa di query il processo di generazione termina e si
procede al TEST della tupla
Test tupla, output files e FTP Upload
n
n
Test tupla
FTP Upload
n
Output Files
Work in progress (β)
n Elaborazione
misure di sicurezza in relazione
alle prestazioni del Server (accennato nel
mutithreading)
n Trasferimento al server della procedura di
ordinamento delle tabelle, per ogni DB su cui
vogliono operari i client
n Miglioramenti nella procedura di Test tuple
n Costruzione dell’applicazione MASTER per la
generazione del file “simulazioneDati.sql”
n Interfacciamento con più DBMS
n Espansione formati (xml, json, ecc..)
GRAZIE PER L’ATTENZIONE