Strategie di gestione e analisi di database amministrativi: trasformare dati sincronici in vettori
diacronici
di Andrea Amico, Giampiero D’Alessandro
Lo sviluppo esponenziale delle capacità di trasmissione e immagazzinamento dei dati per via
informatica negli ultimi decenni ne ha ampliato enormemente la produzione. Questa crescente
disponibilità di informazioni e i costi elevati, monetari e temporali, della raccolta (e
all’informatizzazione) dei dati, rendono conveniente l’utilizzo di database già esistenti, sempre più
di frequente disponibili anche in versione open. La sfida delle attività di ricerca che sfruttano questo
genere di database, pur non incontrando gli ostacoli della progettazione degli strumenti, della
rilevazione e dell’informatizzazione del dato, incontra difficoltà nuove con riferimento
all’adattamento delle basi di dati esistenti agli scopi propri della ricerca sociale, spesso attraverso
complicate operazioni di organizzazione, controllo, pulizia e integrazione. Questa sfida passa,
frequentemente, per procedure di estrapolazione del dato dagli archivi informatici, processo che, se
non eseguito correttamente, può inficiare i risultati dell’indagine.
La maggior parte dei dati che quotidianamente vengono registrati e immagazzinati non sono,
infatti, progettati per scopi di ricerca, ma hanno finalità amministrative, gestionali o anche
comunicative. Resta dunque compito del ricercatore, in base al problema di indagine, l’individuazione
dei dati rilevanti (in base alle unità d’analisi, alla rilevazione delle proprietà di interesse, ecc.) e infine
la strutturazione di un database utile per i propri interrogativi di ricerca. Inoltre, quando si hanno a
disposizione numerose risorse informative, il bagaglio di conoscenze teoriche e tecniche in possesso
dell’utilizzatore finale del dato riveste un ruolo di primaria importanza. La costruzione o
ristrutturazione del dataset diventa, dunque, una questione centrale rispetto alla quale devono risultare
chiari gli obiettivi cognitivi da perseguire nonché le procedure di analisi che si intendono/si possono
utilizzare.
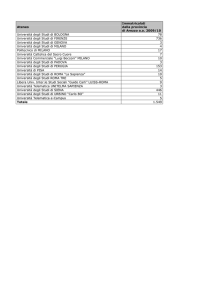
Il caso di studio fa riferimento alla strutturazione di un database longitudinale a partire da
informazioni di carattere puntuale riferite a studenti universitari e registrate nell’archivio
amministrativo della Sapienza Università di Roma. Le informazioni riguardano sostanzialmente
quattro macro aree: socio-anagrafica, formazione pre-universitaria, carriera universitaria alla
Sapienza e produttività. I dati contenuti in tale archivio hanno finalità amministrative, incentrate per
lo più sul monitoraggio del versamento delle quote di iscrizione e sulle informazioni circa il
superamento degli esami curriculari. Tali informazioni, però, sono registrate in archivi separati. Una
simile strutturazione del dato non favorisce lo studio delle dinamiche temporali, consentendo soltanto
operazioni di conteggio e controllo della regolarità.
Al fine di studiare al meglio una serie di fenomeni legati al contesto universitario,
dall’abbandono al fuoricorsismo, si è operata partendo da questi archivi una ristrutturazione, in forma
longitudinale, dei dati riuniti in un unico database grazie all’uso di “chiavi”, in comune quali ad
esempio la matricola degli studenti o il codice del corso e degli esami superati. Collocando i vari
eventi su di una stringa, temporalmente ordinata, è possibile controllare le dinamicità delle singole
carriere evidenziando in tal modo i fenomeni specifici, quali l’interruzione temporanea degli studi e
la mobilità interna all’Ateneo. Ovviamente tale strutturazione non è una questione di poco conto in
quanto il ricercatore deve effettuare scelte determinanti, nei momenti precedenti l’estrazione dei dati,
dalle quali dipenderà l’esito dell’intera ricerca. In questa fase può risultare decisiva l’adozione di un
approccio theory-driven, che tenga conto cioè dei principali approcci teorici riferiti al fenomeno, di
ipotesi specifiche e delle evidenze emerse da studi precedenti, nella selezione dei dati rilevanti e nella
strutturazione del nuovo database.
Tutti i dati relativi alle caratteristiche socio-anagrafiche e alla formazione pre universitarie
sono statici e registrati una sola volta per ciascun studente. La carriera universitaria, invece è registrata
attraverso una serie di variabili (ad es. facoltà di iscrizione, corso di iscrizione, votazione media
conseguita nell’anno accademico, crediti, posizione amministrativa, ISEE dichiarato, ecc..) con valori
differenti per ogni anno di iscrizione. La ripetizione di queste informazioni rende possibile ricostruire
nei minimi dettagli tutta la carriera di ogni singolo studente e la creazione di indici che tengano conto
dei cambiamenti, ovvero delle regolarità, occorsi durante l’intera carriera. I dati, provenienti da due
differenti database e con diverse date di aggiornamento, permettono di seguire gli immatricolati preriforma sino al 2006-2007, mentre quelli post-riforma sino al 2013-2014.
Il lavoro, inoltre, presenta brevemente tre studi resi possibili dalla strutturazione del database
longitudinale (diacronico) a partire da dati di carattere trasversale (sincronici) riferiti a caratteristiche
di ingresso, percorso ed esito delle carriere degli studenti universitari immatricolati alla Sapienza
Università di Roma.
Il primo disegno di ricerca è volto alla valutazione dell’impatto della riforma universitaria del
“3+2” sulla Sapienza Università di Roma, adottando un’ottica quasi-sperimentale. L’analisi è riferita
a 10 coorti di immatricolati pre-riforma e 9 coorti post riforma, considerando per ciascuna coorte
l’insieme di studenti immatricolati per la prima volta ad uno dei corsi di Sapienza in uno specifico
anno accademico. Un primo problema di ricerca è stato quello di identificare un momento specifico
per confrontare studenti immatricolati in anni e a corsi differenti. Considerando le principali criticità
del sistema universitario italiano fino al processo di Bologna (scarso numero di laureati, elevato tasso
di abbandono e prolungamento delle carriere) si è individuato come momento di osservazione il
doppio della durata legale del corso di studi di immatricolazione. Questa scelta ha consentito di:
confrontare carriere di studenti immatricolati a corsi dalla durata differenti (intra e tra le coorti);
confrontare carriere appartenenti a diversi ordinamenti didattici (tra le coorti).
La seconda ricerca è orientata all’individuazione di modelli per la descrizione e l’analisi
longitudinale con un focus specifico sulle carriere non lineari e alla mobilità studentesca. Facendo
riferimento alla prima coorte di immatricolati “puri” al nuovo ordinamento (a.a. 2001-2002), tramite
gli strumenti della Sequence Analysis, sono state analizzate le carriere degli studenti tenendo in
considerazione anche eventuali interruzioni o secondi percorsi attivati dopo il conseguimento del
primo titolo di studio. Le analisi mirano a individuare modelli di traiettorie e indagarne le possibili
determinanti secondo regressori di input, throughtput e output. Lo studio della mobilità studentesca
intra-Ateneo completa l’analisi delle carriere non lineari. Attraverso gli strumenti della Network
Analysis la mobilità è studiata in una prospettiva longitudinale individuando modelli di mobilità intrafacoltà/inter-corso o inter-facoltà stabili nel tempo e fattori che possono concorrere a determinati esiti
di carriera (laurea, abbandono, fuoricorsismo).
La terza ricerca è mirata all’individuazione dei fattori di successo o insuccesso delle carriere
universitarie, attraverso l’integrazione dei dati individuali con altri riferiti a contesti meso (Sapienza)
e macro (economici). Al tal scopo sono stati implementati modelli di analisi di Event History in grado
di tener conto contemporaneamente dei cambiamenti avvenuti nel tempo, in contesti diversi, fra attori
differenti. L’ipotesi principale è, infatti, che questi “contesti” incidano sullo svolgimento delle
carriere universitarie, ad esempio incentivando ovvero ostacolando il conseguimento della laurea in
tempi brevi.