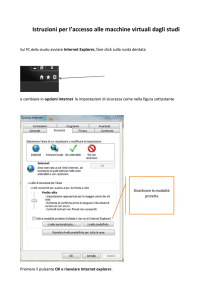
Università degli Studi di Perugia
Facoltà di Scienze Matematiche, Fisiche e Naturali
Corso di Laurea in Informatica
Tesi di Laurea
Sviluppo di un sistema di
management di ambienti di
esecuzione virtualizzati per
sistemi batch
Candidato
Riccardo Sbirrazzuoli
Relatore
Prof. Leonello Servoli
Correlatore
Riccardo M. Cefalà
Anno Accademico
2007-2008
2
Indice
Indice
5
Introduzione
Sinossi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Struttura della Tesi . . . . . . . . . . . . . . . . . . . . . . . . . . .
7
7
7
1 Cluster Computing
1.1 Introduzione . . . . . . . . . .
1.2 Tassonomia di Flynn . . . . .
1.2.1 SISD . . . . . . . . . .
1.2.2 SIMD . . . . . . . . .
1.2.3 MISD . . . . . . . . .
1.2.4 MIMD . . . . . . . . .
1.3 Cluster Computing . . . . . .
1.3.1 Nodi . . . . . . . . . .
1.3.2 Rete . . . . . . . . . .
1.3.3 Middleware . . . . . .
1.3.4 Batch System . . . . .
1.3.5 Il sistema operativo . .
1.3.6 Ambienti d’esecuzione
1.4 Grid Computing . . . . . . . .
1.4.1 LCG . . . . . . . . . .
1.5 Il cluster INFN di Perugia . .
1.5.1 Architettura . . . . . .
1.5.2 Problemi emergenti . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
2 Virtualizzazione
2.1 Introduzione . . . . . . . . . . . . . . .
2.2 Tipologie di virtualizzazione . . . . . .
2.2.1 Virtualizzazione di applicazioni
2.2.2 Virtualizzazione di rete . . . . .
3
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
9
9
10
10
10
11
11
13
14
14
15
17
19
19
20
22
22
23
25
.
.
.
.
29
29
29
30
30
4
INDICE
2.3
2.4
2.5
2.6
2.2.3 Virtualizzazione dei dispositivi di storage
2.2.4 Virtualizzazione di sistemi . . . . . . . .
Macchine virtuali . . . . . . . . . . . . . . . . .
2.3.1 Caratteristiche e architettura VMM . . .
2.3.2 Requisiti di Popek-Goldberg . . . . . . .
2.3.3 Problemi delle architetture x86 . . . . .
Tipologie di virtualizzazione dei sistemi . . . . .
2.4.1 Virtualizzazione a livello del kernel . . .
2.4.2 Virtualizzazione completa . . . . . . . .
2.4.3 Para-virtualizzazione . . . . . . . . . . .
2.4.4 Virtualizzazione hardware . . . . . . . .
2.4.5 Emulazione . . . . . . . . . . . . . . . .
Xen . . . . . . . . . . . . . . . . . . . . . . . .
2.5.1 Hypervisor . . . . . . . . . . . . . . . . .
2.5.2 Domain 0 . . . . . . . . . . . . . . . . .
2.5.3 Domain U . . . . . . . . . . . . . . . . .
2.5.4 Demoni e strumenti di gestione . . . . .
2.5.5 Performance . . . . . . . . . . . . . . . .
Applicazione della virtualizzazione . . . . . . . .
2.6.1 Vantaggi della virtualizzazione . . . . . .
2.6.2 Ambienti virtuali . . . . . . . . . . . . .
2.6.3 Applicazione locale . . . . . . . . . . . .
2.6.4 Ruolo del prototipo . . . . . . . . . . . .
3 Il prototipo: Virtdom
3.1 Introduzione . . . . . . . . . . . . . . .
3.2 Architettura del prototipo . . . . . . .
3.3 Scelte implementative . . . . . . . . . .
3.3.1 Linguaggio di programmazione
3.3.2 Sistema di comunicazione . . .
3.4 Protocollo di comunicazione . . . . . .
3.4.1 Messaggi del manager . . . . .
3.4.2 Messaggi del client . . . . . . .
3.5 Struttura del client . . . . . . . . . . .
3.5.1 Gestione file eseguibili . . . . .
3.5.2 Gestione proprietà . . . . . . .
3.5.3 Comunicazione con il manager .
3.5.4 Configurazione . . . . . . . . .
3.6 Struttura del manager . . . . . . . . .
3.6.1 Collezione delle informazioni . .
3.6.2 Comunicazione con i client . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
30
31
31
32
33
34
35
35
35
35
36
36
37
37
38
38
39
40
41
42
43
44
45
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
47
47
48
51
51
53
54
55
55
56
56
57
58
58
59
59
60
INDICE
3.7
3.8
5
3.6.3 Decisione: i trigger .
Configurazione del manager
Test e considerazioni . . . .
3.8.1 Test . . . . . . . . .
3.8.2 Considerazioni . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
4 Estensione del prototipo
4.1 Introduzione . . . . . . . . . . . .
4.2 Ambiente di test . . . . . . . . .
4.2.1 Code, tipi di VM e Dom0
4.3 Client: proprietà e azioni . . . . .
4.4 Manager: trigger . . . . . . . . .
4.5 Configurazione del batch system .
4.6 Test . . . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
61
63
64
64
66
.
.
.
.
.
.
.
69
69
69
69
69
69
69
69
5 Conclusioni
71
Ringraziamenti
74
Bibliografia
77
6
INDICE
Introduzione
Questo elaborato presenta il lavoro di tesi e stage svolto presso la sede INFN
di Perugia e il Dipartimento di Fisica dell’Università degli Studi di Perugia
nei mesi di marzo-aprile 2009.
Sinossi
TODO
Struttura della Tesi
La tesi è strutturata in cinque capitoli:
Capitolo Primo: Sono esposti i sistemi di calcolo distribuito, con particolare attenzione ai cluster di computer e a uno dei loro componenti principali, il batch system. Sono introdotte l’architettura e le problematiche
del Cluster INFN della sede di Perugia.
Capitolo Secondo: Si introducono i concetti chiave dei sistemi di virtualizzazione con riferimento alle basi teoriche, descrivendone le caratteristiche e i vantaggi. Vengono mostrate in particolare le caratteristiche
del sistema di para-virtualizzazione Xen. Si mostra come la virtualizzazione è attualmente impiegata nel cluster locale e come può essere
utilizzata più vantaggiosamente.
Capitolo Terzo:
Capitolo Quarto:
Capitolo Quinto:
Nell’Appendice A è contenuto il codice sorgente del prototipo.
7
8
INDICE
Capitolo 1
Cluster Computing
1.1
Introduzione
Il progresso della ricerca in quasi tutti i settori della scienza è strettamente legato alla capacità di elaborare grandi quantità di dati. Simulazioni climatiche,
esperimenti su particelle subatomiche, studi genetici, producono enormi moli
di dati che necessitano di rilevante potenza di calcolo per essere analizzati e
ricavarne informazioni utili.
Lo sviluppo di processori sempre più performanti ha parzialmente sopperito a questo bisogno nel corso degli anni, ma non è sufficiente: un singolo
processore impiegherebbe letteralmente secoli per analizzare i dati prodotti
degli odierni esperimenti. Inoltre si sta raggiungendo il limite fisico di integrazione nei processori di silicio comunemente utilizzati; questo significa che
la potenza di calcolo fornita da un solo processore è probabilmente destinata
ad aumentare sempre più lentamente fino a raggiungere un limite invalicabile.
La soluzione logica per aggirare questo problema è ripartire il carico computazionale su più processori o unità di elaborazione: il calcolo distribuito o
parallelo.
Questo capitolo prende in esame le diverse realizzazioni di calcolo distribuito che sono state proposte nel corso degli anni, fino ad arrivare a quelle che
possono essere considerate la soluzioni al momento più avanzate, il cluster
computing e il grid computing. Inoltre viene descritta nel dettaglio l’implementazione locale di questa soluzione, il cluster della sezione INFN di Perugia
ospitato presso il Dipartimento di Fisica.
9
10
CAPITOLO 1. CLUSTER COMPUTING
1.2
Tassonomia di Flynn
L’idea di distribuire il carico computazionale non è recente: già nel 1966
Michael J. Flynn propose una classificazione delle architetture dei sistemi di
calcolo secondo la loro capacità di elaborare parallelamente flussi di istruzioni
o dati. Tale ripartizione, nota come tassonomia di Flynn, è in linea di massima
valida ancora oggi. Le categorie proposte furono le seguenti:
• SISD (Single Instruction Single Data)
• SIMD (Single Instruction Multiple Data)
• MISD (Multiple Instruction Single Data)
• MIMD (Multiple Instruction Multiple Data)
1.2.1
SISD (Single Instruction Single Data)
Le istruzioni vengono eseguite sequenzialmente su un dato alla volta. Fanno
parte di questa categoria tutte le macchine con la classica architettura di
Von Neumann, che sono la maggior parte degli elaboratori per uso personale
disponibili sul mercato.
Su queste architetture è comunque possibile dare vita a una certa forma
di parallelismo, sia reale che percepito. Reale in quanto tramite tecniche di
pipelining si possono elaborare più istruzioni contemporaneamente in diversi
stadi di avanzamento; percepito perché ripartendo in modo appropriato l’utilizzo dell’unità di elaborazione tra vari processi (scheduling) si dà l’illusione
all’utente di eseguire più attività nello stesso momento.
1.2.2
SIMD (Single Instruction Multiple Data)
Le istruzioni vengono eseguite sequenzialmente su più dati alla volta. I processori delle macchine appartenenti a questa categoria sono anche detti “processori vettoriali” in quanto ogni singola istruzione di tali sistemi agisce su
array di dati. Il parallelismo di questi sistemi è detto “parallelismo sui dati”
proprio perché operano su più dati contemporanemente.
Mentre in precedenza il calcolo vettoriale era prerogativa esclusiva dei super computer (il primo di essi a sfruttare il calcolo vettoriale fu il Cray X-MP
del 1982), al giorno d’oggi la maggior parte dei microprocessori multipurpose
commerciali contiene sottoinsiemi di istruzioni che operano su più dati contemporaneamente (ad esempio le istruzioni SSEx dei processori x86 Intel),
1.2. TASSONOMIA DI FLYNN
11
cosı̀ come tutte le moderne schede grafiche sono equipaggiate con GPU (Graphical Processing Unit) capaci di calcoli vettoriali e matriciali per l’utilizzo
in applicazioni grafiche.
A dispetto della loro efficienza nell’esecuzione di algoritmi che operano
su vettori di dati, le architetture di tipo SIMD sono spesso molto complesse
e necessitano di software scritto ad-hoc. È per questo ed altri motivi come
l’alto costo di realizzazione, che nel panorama del calcolo ad alte prestazioni
i sistemi di questo tipo sono andati via via diminuendo, lasciando il posto a
sistemi con architettura di tipo MIMD.
1.2.3
MISD (Multiple Instruction Single Data)
Rientrano in questa tipologia tutti quei sistemi che sono in grado di eseguire
contemporaneamente più istruzioni sullo stesso dato.
Tipicamente nella maggior parte dei problemi si ha a che fare con grandi
quantità di dati. Perciò le architetture di tipo SIMD e MIMD sono state
impiegate in misura di gran lunga maggiore rispetto a quelle MISD. Non
esistono dunque sistemi commerciali di questa tipologia che hanno conosciuto
una rilevante diffusione.
1.2.4
MIMD (Multiple Instruction Multiple Data)
Appartengono a questa tipologia gli elaboratori che sono in grado di eseguire
contemporaneamente operazioni diverse su dati diversi, essendo dotati di
più unità di elaborazione. Il calcolo parallelo è l’impiego naturale di queste
macchine. I sistemi MIMD possono essere a loro volta suddivisi in base a
come le unità di elaborazione accedono alla memoria.
Memoria condivisa
Tutti i processori condividono la memoria per mezzo di hardware dedicato.
Le macchine di questa categoria, note anche come elaboratori SMP (Simmetric Multi Processing), possono essere ulteriormente suddivise in architetture
UMA e NUMA.
Le architetture UMA (Uniform Memory Access) condividono tra i processori tutta la memoria a disposizione. In caso di molti accessi concorrenti
questo può rivelarsi un “collo di bottiglia” di difficile soluzione.
Nelle architetture NUMA invece ogni processore, pur potendo accedere
alla memoria condivisa, ha a disposizione un’area di memoria locale, detta
cache, a cui accede esclusivamente e rapidamente. Questo migliora le prestazioni ma rende più complesso il meccanismo di condivisione della memoria,
12
CAPITOLO 1. CLUSTER COMPUTING
che deve mantenere la cache di ogni processore coerente con la memoria
globale. Per questo tali architetture sono anche note come ccNUMA (cache
coerent NUMA).
Memoria distribuita
In questa categoria vanno inseriti tutti i sistemi che possiedono un’area di
memoria separata per ogni unita di calcolo (detta anche nodo) ed ogni area
di memoria non è direttamente accessibile da parte di altri nodi; ci si può
riferire ad essi anche con l’acronimo MPP (Massively Parallel Processing).
Negli MPP ogni nodo contiene una o più unità di elaborazione e aree di
memoria ad essi associate. Ogni nodo è connesso agli altri con topologie spesso complesse, volte ad ottimizzare costi, ampiezza di banda e latenza. L’efficienza dell’interconnessione tra i nodi è cruciale per le performance dell’intero
sistema poichè non essendoci porzioni di memoria condivisa, il passaggio di
dati tra le unità di elaborazione può avvenire solo attraverso lo scambio di
messaggi. Tutti in nodi di elaborazione affiancati da altri nodi specializzati
per le operazioni di input/output contribuiscono a formare un unico grande
calcolatore.
La figura 1.1 mostra un tipico calcolatore MPP. É evidente la struttura
unitaria del sistema, che richiede un’architettura dedicata per collegare e
racchiudere i nodi di cui dispone.
Figura 1.1: Il supercomuter Cray T932, costruito nella seconda metà degli anni ’90
1.3. CLUSTER COMPUTING
13
Oltre ai sistemi MPP, la tipologia di sistemi MIMD a memoria distribuita
che negli ultimi anni ha ricevuto maggiori attenzioni da parte delle comunità
scientifiche e dai produttori di hardware è rappresentata dai cluster di computer (letteralmente“grappoli di computer”). Similmente agli MPP anche i
cluster di computer sono costituiti da più nodi, ma a differenza dei primi,
ogni nodo è costituito a sua volta da un sistema indipendente che comprende
unità di elaborazione, memoria e periferiche di input-output.
I cluster si sono ampiamente diffusi a partire dai primi anni del XXI secolo e rappresentano l’attuale frontiera del calcolo distribuito su scala locale.
Un gradino sopra ai cluster si pone il grid computing, il cui scopo è organizzare e mettere a disposizione in modo centralizzato risorse appartenenti a
più gruppi anche molto distanti geograficamente. Il paragrafo che segue mostra le caratteristiche rilevanti di un cluster e accenna al concetto di griglia
computazionale.
1.3
Cluster Computing
Un cluster di computer può essere definito nel modo seguente:
un sistema di calcolo distribuito, costituito da una collezione di
computer indipendenti interconnessi che lavorano insieme come
un’unica risorsa di calcolo integrata.
I computer che costituiscono il cluster vengono detti nodi e ognuno di essi
è capace di eseguire applicazioni individualmente; la connessione tra i nodi
è realizzata tramite LAN ad alta velocità. Un cluster tipicamente è soggetto
all’amministrazione di un unico ente ed è collocato fisicamente in un solo
ambiente appositamente preparato.
Dal punto di vista logico il cluster deve essere visto come un’unica entità,
a cui gli utenti possono sottomettere i calcoli da eseguire senza essere a conoscenza dell’architettura del sistema; ogni nodo però, poiché è in realtà un
sistema autonomo, con propri sistema operativo e componenti software, non
è a diretta conoscenza del contesto in cui è inserito. Per realizzare l’astrazione del cluster come un’unica risorsa si rende perciò necessario uno strato
aggiuntivo tra le applicazioni degli utenti e il software dei nodi: il middleware.
Questo strato deve essere in grado di monitorare lo stato dei nodi e del lavoro che stanno svolgendo, di distribuire il carico computazionale in modo
intelligente e trasparente e di offrire all’esterno un’interfaccia user-friendly
per sottomettere compiti al cluster.
14
CAPITOLO 1. CLUSTER COMPUTING
1.3.1
Nodi
I nodi di un cluster possono essere computer mono o multi processore di ogni
tipo: PC, Workstation, Server, stazioni SMP. Ecco una delle chiavi principali del successo dei cluster: i nodi solitamente sono elaboratori di grande
diffusione commerciale, di prezzo relativamente contenuto ma dalle buone
prestazioni. Questo permette di dare vita a un piccolo cluster anche con un
ridotto investimento iniziale, e di espanderlo man mano che se ne ha la possibilità. Per contro un elaboratore MPP avrebbe richiesto un budget elevato
e sarebbe stato assai meno espandibile e scalabile.
Ogni nodo contiene quindi l’hardware solitamente disponibile nei computer in commercio:
• una o più unità di elaborazione
• memoria centrale (RAM)
• una o più interfacce di rete
• memoria secondaria (hard disk o altri dispositivi di storage)
I nodi possono essere configurati secondo le necessità e dotati di hardware
aggiuntivo in base al compito a cui sono destinati. Attualmente sono in commercio elaboratori appositamente costruiti per far parte di un cluster, specie
dal punto di vista fisico: anziché essere nel tipico formato “a torre” dei PC
desktop sono nel formato standard 1U, basso e allungato, che permette di impilarli in appositi armadi detti rack. Soprattutto hanno caratteristiche hardware più performanti rispetto ai normali PC, ma il rapporto potenza/prezzo
li rende ancora preferibili rispetto alle soluzioni MPP dedicate.
La figura 1.2 mostra un esempio di cluster: si notano chiaramente i rack,
i nodi in essi contenuti e il cablaggio. É evidente la differenza architetturale
rispetto agli elaboratori MPP.
1.3.2
Rete
Spesso la tipologia di rete utilizzata per l’infrastruttura di connessione tra i
nodi è basata sullo standard Ethernet, che rappresenta un efficace compromesso tra compatibilità, efficienza e costi. La versione più recente, Ethernet
GigaBit, offre fino a 1Gbps di ampiezza di banda con costi relativamente
ridotti e tempi di latenza minimi.
Esistono tecnologie più costose che permettono di ottenere migliori prestazioni, come ad esempio Ethernet 10GigaBit. Nulla vieta di utilizzare tali
soluzioni per le porzioni della rete di maggior traffico e mantenere i prodotti
più economici nelle aree periferiche.
1.3. CLUSTER COMPUTING
15
Figura 1.2: Parte della sala calcolo del CERN di Ginevra
1.3.3
Middleware
Il middleware è un insieme di componenti software che si occupa di gestire
e mettere a disposizione la potenza di calcolo del cluster in modo trasparente, nascondendo i dettagli architetturali dovuti alla sua natura distribuita.
Ogni componente tipicamente è diviso in due sottocomponenti: una parte
(client) si trova presso ogni nodo e si occupa di raccogliere informazioni ed
eseguire comandi in locale; l’altra parte (server o manager) risiede presso un
nodo dedicato, comunica con i client tramite protocolli definiti e prende decisioni e ordina l’esecuzione di comandi in base allo stato delle varie risorse.
Uno dei componenti fondamentali del middleware, il batch-system, e anche
il prototipo oggetto di questa tesi lavorano in base a questo modello.
Un middleware efficiente e ben progettato deve garantire le seguenti condizioni:
• Efficiente gestione delle risorse di calcolo
• Proprietà di Single System Image.
• Alta disponibilità e tolleranza ai guasti
Gestione delle risorse di calcolo
La gestione ordinata delle risorse, o RMS (Resource Management e Scheduling) è un concetto chiave per un utilizzo efficiente di un cluster. Se ben rea-
16
CAPITOLO 1. CLUSTER COMPUTING
lizzata permette infatti di utilizzare senza sprechi l’hardware a disposizione
e di soddisfare le necessità di tutti gli utenti.
Per raggiungere questo obiettivo sono necessarie due componenti. La componente di “resource management” raccoglie informazioni relative alla presenza e allo stato delle risorse, si preoccupa di mantenere un’immagine dello
stato delle risorse disponibili nel cluster e provvede ad aggiornare la sua conoscenza del sistema in base ai cambiamenti dovuti ad allocazioni, deallocazioni o indisponibilità dipendenti da altre ragioni quali il malfunzionamento
dell’hardware. è suo compito inoltre raccogliere e autenticare le richieste di
allocazione delle risorse, insieme a creare le strutture dati necessarie all’identificazione dei processi delle applicazioni che ne richiedono l’utilizzo. La
componente di resource scheduling invece gestisce in modo equo le richieste
concorrenti per l’utilizzo delle risorse e le organizza in modo da minimizzare i
tempi di attesa. Per prendere le sue decisioni si basa su politiche configurabili
a seconda delle necessità locali e sullo stato delle risorse messo a disposizione
dal resource manager.
Single System Image
Il middleware deve nascondere la natura eterogenea del cluster dando l’illusione di avere a disposizione un’unica grande risorsa di calcolo. L’utente deve
poter accedere al cluster tramite un’interfaccia quanto più semplice possibile
e sottomettere i suoi lavori senza la necessità di sapere su quali nodi saranno
effettivamente ospitati.
Questo compito è svolto principalmente dalla componente di scheduling e
management sopra descritta. Contribuiscono a realizzare la proprietà di SSI
anche le componenti che gestiscono lo storage dei dati che, tramite filesystem
distribuiti, permettono di accedervi in modo indipendente dalla loro posizione. Alla proprietà di SSI è legato anche l’aspetto del virtual networking,
ovvero la capacità di utilizzare tutte le risorse del cluster indipendentemente
dalla topologia dell’infrastuttura di collegamento.
Alta disponibilità e alta affidabilità
Il middleware deve essere in grado di rendere il sistema tollerante ai malfunzionamenti hardware o software, permettendo agli utenti di continuare a
fruire dei servizi del cluster. Ad esempio nel caso che un nodo abbia un guasto mentre sta svolgendo un compito il middleware deve migrare il processo
presso un nodo funzionante senza perdere quanto fatto fino a quel momento.
Se invece il nodo offriva un certo servizio all’interno del cluster, tale servizio dovrebbe essere ripristinato quanto prima su un altra delle macchine a
1.3. CLUSTER COMPUTING
17
disposizione. Quando il guasto riguarda la perdita di informazioni contenute
nei dispositivi di storage, il middleware deve poter ricostruire e rimettere a
disposizione i dati mancanti.
1.3.4
Batch System
Il batch system è uno dei componenti più importanti e complessi del middleware ed ha un ruolo nel realizzare praticamente, per intero o in parte, tutte
e tre le proprietà descritte nel paragrafo precedente.
Il termine “batch” significa letteralmente “infornata” ed è stato utilizzato
in origine per quei processi industriali in cui le fasi operative della produzione sono svolte su gruppi di oggetti anziché pezzo per pezzo. L’applicazione
di questo concetto nel campo dell’informatica è detta “batch processing” e
la sua realizzazione ha subito diverse evoluzioni nel corso dei decenni. Attualmente un sistema che supporta il batch processing, detto “batch system”
deve essere in grado di ricevere in ingresso una serie di programmi utente,
detti “job”, e i relativi dati, eseguirli quanto più possibile senza l’interazione
dell’utente e restituire i risultati al termine dell’elaborazione. Un batch system funzionante nell’ambito di un cluster deve anche saper utilizzare tutte
le risorse a sua disposizione (i nodi del cluster) in modo trasparente: gli utenti
che sottomettono i job non si devono interessare di quale nodo li eseguirà,
ma devono percepire il cluster come un’unica entità; è il batch system che si
occupa di organizzare i job e dislocarli sui nodi appropriati.
Dal punto di vista fisico i nodi gestiti dal batch system possono essere
suddivisi in quattro categorie:
• central manager node
• execution node
• user interface node
• checkpoint server node
Il central manager node è il cardine del batch system. Su questo nodo
sono in esecuzione i programmi che ricevono i job, li ripartiscono sulle risorse
disponibili e monitorano l’andamento dell’intero sistema. Gli execution node
sono quelli che eseguono i job e sono, ovviamente, i più numerosi. Gli user
interface node sono i punti di accesso al batch system: gli utenti sottomettono
i propri job attraverso questi nodi, che si occupano di trasmetterli al central
manager node e di restituire i risultati al termine dell’operazione. Un’ altra
funzione importante dei nodi user interface è l’autenticazione degli utenti:
solo chi è accreditato può utilizzare le risorse del sistema. I checkpoint server
18
CAPITOLO 1. CLUSTER COMPUTING
node sono opzionali e ospitano i file di checkpoint prodotti dai job: in caso di
guasto di un nodo i job che vi erano in esecuzione possono essere ricostruiti
a partire da questi file e migrati presso un altro nodo.
Dal punto di vista logico il batch system è solitamente diviso in due
componenti:
• Scheduler
• Resource manager
Tipicamente sono in entrambi in esecuzione sul nodo centrale, anche se il
resource manager può essere replicato nei cluster di grandi dimensioni.
Lo scheduler ha lo scopo di decidere l’ordine di esecuzione dei job. I job
infatti sono di natura eterogenea per quanto riguarda durata e risorse richieste e spesso il loro ordine di arrivo non coincide con l’ordine di esecuzione
ottimale per il pieno utilizzo della potenza di calcolo a disposizione. Può anche essere necessario differenziare i job per classi di importanza, ognuna delle
quali avrà una diversa priorità. Lo scheduler, tenendo conto di tutte queste
variabili, programma l’attività futura del batch system cercando di mantenere l’equilibrio tra richieste degli utenti ed efficienza del sistema. Questo è un
compito molto complesso, oggetto di numerosi studi, e analizzarlo nel dettaglio esula dagli scopi di questa tesi. Il concetto importante è che il batch
system stabilisce autonomamente i job che di volta in volta devono essere
eseguiti e nessun altro componente del middleware dovrebbe interferire nelle
sue decisioni.
Se lo scheduler è la “mente” del batch system, il resource manager può
esserne considerato il “braccio”. Lo scheduler infatti solitamente non ha gli
strumenti per monitorare lo stato delle risorse ed impartire comandi ai nodi:
sono questi i compiti basilari del resource manager. Esso si occupa infatti di
prelevare i job sottomessi dagli utenti dai nodi user interface e di organizzarli
in strutture logiche dette “code” in base alle caratteristiche dei job stessi. Il
resource manager inoltre ha piena conoscenza dello stato di tutte le risorse
e dei job in esecuzione e mette ogni dato in suo possesso a disposizione
dello scheduler. Lo scheduler utilizza queste informazioni combinandole con
le sue politiche decisionali e comanda al resource manager di compiere certe
operazioni sui job, come ad esempio mandare in esecuzione quelli che ne
hanno maturato il diritto. Il resource manager può essere considerato un
componente distribuito, funzionante secondo il modello client-manager di cui
si è parlato all’inizio del paragrafo precedente: per raccogliere informazioni
ed eseguire fisicamente i comandi, infatti, è presente su ogni nodo un demone,
che comunica con il programma principale tramite protocolli propri del batch
system.
1.3. CLUSTER COMPUTING
19
Da questa breve descrizione è chiaro come il batch system realizzi la
maggior parte delle funzioni richieste al middleware descritte nel paragrafo
precedente. La gestione ordinata delle risorse, suddivisa in resource management e resource scheduling, è svolta appunto dal resource manager e dallo
scheduler; anche la proprietà di Single System Image è basata in gran parte
sul lavoro di gestione trasparente delle risorse fatto dal batch system; la proprietà di altà affidabilità, infine, è in parte garantita dai checkpoint server,
se esistenti, il cui contenuto può essere utilizzato dal batch system per non
perdere la computazione svolta da job ospitati in macchine che hanno subito
malfunzionamenti.
1.3.5
Il sistema operativo
Ogni nodo deve disporre del proprio sistema operativo, per accedere alle risorse hardware locali che mette a disposizione nel cluster. Nel dettaglio il
sistema operativo deve gestire l’utilizzo delle unità di elaborazione, della memoria, delle periferiche di rete, di I/O e qualunque altra periferica del nodo.
La componente di base del sistema operativo è il nucleo, o kernel, che fornisce
l’interfaccia alle applicazioni di livello superiore. Di queste applicazioni fanno
parte anche quelle proprie del sistema operativo, i processi di sistema, che
mettono a disposizione delle altre applicazioni diverse funzioni basilari.
Il middleware ha una grande rilevanza nella dotazione software di ogni
nodo: infatti non solo spesso la parte client delle varie componenti è in esecuzione su ogni nodo, ma anche il kernel deve essere opportunamente esteso
per consentire al middleware una piena operatività. Un normale kernel infatti organizza le risorse basandosi esclusivamente sulla visione locale di cui
dispone; le estensioni middleware permettono alle componenti di management e scheduling, che hanno una visione globale del sistema, di affiancare il
kernel nelle sue decisioni. Lo schema basilare dei sistemi operativi utilizzati
in ambienti cluster è mostrato in figura 1.3
In quest’ottica il sistema operativo scelto deve essere facilmente estendibile; per il funzionamento nell’ambiente del cluster è anche molto importante
che supporti i comuni standard di comunicazione e programmazione per garantire una piena interoperabilità. A motivo di ciò spesso la scelta ricade
sui sistemi operativi open source basati sullo standard POSIX, come Linux,
opportunamente modificati come appena descritto.
1.3.6
Ambienti d’esecuzione
Il livello che permette l’esecuzione delle applicazioni degli utenti è detto ambiente d’esecuzione ed è formato da tutte le librerie e i pacchetti software
20
CAPITOLO 1. CLUSTER COMPUTING
Figura 1.3: Schema del sistema operativo di un nodo nei cluster di computer
necessari per il corretto funzionamento dell’applicazione. In particolare le
applicazioni parallele che lavorano nell’ambiente del cluster suddividono il
carico computazionale tra i vari nodi tramite apposite librerie per parallelizzare il flusso d’esecuzione del programma secondo vari paradigmi, il più
usato dei quali è il message passing. Queste librerie permettono la creazione
di canali e lo scambio di messaggi tra i vari thread dell’applicazione parallela. Le librerie di message passing più diffuse e standardizzate sono le
librerie MPI (Message Passing Interface); altre librerie che sfruttano lo stesso modello sono le PVM (Parallel Virtual Machine). Un altro paradigma di
parallelizzazione invece prevede la creazione di un’area di memoria virtuale
condivisa tra i vari processi, ed è utilizzato dalle librerie DSM (Distributed
Shared Memory).
Qualunque siano le librerie utilizzate è necessario che siano disponibili in
tutti i nodi: questo può rappresentare un problema man mano che l’utenza del cluster si allarga, le librerie richieste dalle applicazioni aumentano e
cominciano a presentarsi problemi di incompatibilità tra librerie di diverso
tipo.
1.4
Grid Computing
Il cluster computing, benché ampiamente utilizzato e apprezzato, presenta a
sua volta dei limiti nei tentativi di raggiungere potenze di calcolo sempre più
elevate. Un cluster infatti comporta difficoltà di gestione sempre maggiori
all’aumentare della sua complessità. Aggiungere nodi a un cluster significa
aumentarne l’eterogeneità hardware, accrescere la probabilità di guasti, incrementare il consumo energetico sia a causa delle necessità dei nodi stessi
1.4. GRID COMPUTING
21
che per gli impianti di condizionamento, indispensabili per mitigare gli effetti
dell’alta dissipazione termica dei processori.
Il grid computing introduce un ulteriore entità nel tentativo di superare
questi limiti: la grid, o griglia computazionale. La grid in molti aspetti è simile
a un cluster, in quanto è formata da componenti eterogenei interconnessi
tra loro e necessità di uno strato middleware per gli aspetti gestionali. La
novità è che i nodi di una grid non sono soggetti al controllo di una stessa
organizzazione, possono essere dislocati su un ampia area geografica e possono
non essere singoli elaboratori: anche un intero cluster può essere un nodo della
grid. La grid può essere vista come un enorme cluster di cluster, espandibile
potenzialmente all’infinito.
La figura 1.4 mostra una rappresentazione di fantasia del concetto di
grid: si vuole mettere in evidenza l’estensione globale e l’eterogeneità di una
grid, che può includere dispositivi di ogni tipo, dai cluster ai comuni laptop,
dislocati su un’ampia area geografica.
Figura 1.4: Rappresentazione astratta dell’architettura e delle potenzialità di una grid
Una definizione più rigorosa è stata data da Ian Foster, uno dei pionieri
del grid computing. Una grid è un sistema che:
• coordina l’utilizzo di risorse non soggette ad un controllo
centralizzato;
• utilizza protocolli e interfacce standard, aperte e generalpurpose;
• fornisce diverse tipologie di servizi rilevanti
22
CAPITOLO 1. CLUSTER COMPUTING
Gli enti che partecipano alla costituzione della Grid vengono dette Virtual
Organizations (VO), e sottostanno a politiche di autorizzazione e autenticazione concordate insieme agli organi di coordinamento della Grid. L’organo
principale è la Globus Alliance, che sviluppa attivamente il pacchetto software Globus Toolkit sul quale sono basate molte delle implementazioni di
grid.
L’interconnessione tra i nodi della grid spesso avviene tramite Internet,
o reti WAN dedicate. La distanza tra i nodi è causa di alta latenza nella
comunicazione, che è l’unica limitazione reale nel grid computing; può comunque essere mitigata parallelizzando appropriatamente le applicazioni in
task semi-indipendenti che non necessitano di un elevato scambio di messaggi.
1.4.1
LHC Computing Grid (LCG)
L’implementazione più importante e di dimensioni maggiori a livello mondiale è la grid LCG del CERN. Essa sta permettendo a più di 500 istituti e
centri di ricerca in tutto il mondo di accedere e di analizzare i dati prodotti
dagli esperimenti afferenti all’LHC (Large Hadron Collider ), il più grande
acceleratore di particelle che sia mai stato costruito, entrato in funzione nell’ottobre del 2008. Si stima che la quantità di dati prodotta sarà dell’ordine
di decine di petabyte all’anno, a partire dalla fine del 2008 e per i successivi
15 di attività previsti.
LCG ha una struttura gerarchica a più tier e si affida a realtà regionali o nazionali già esistenti per creare un unica infrastruttura di gestione
e analisi dei dati su scala mondiale. La porzione italiana di LCG è affidata
all’INFN-Grid, ovvero la griglia computazionale compartecipata dagli istituti
che ospitano le sedi dell’istituto nazionale di fisica nucleare, connessi attraverso la rete GARR. La sezione INFN di Perugia partecipa all’INFN-Grid
mettendo a disposizione il cluster ospitato presso il Dipartimento di fisica,
per un totale di oltre 100 CPU. Al momento il cluster fornisce pieno supporto
a tutti gli esperimenti in corso nella LCG.
Il paragrafo seguente analizza la struttura del cluster locale e alcune delle
problematiche che si trova attualmente ad affrontare.
1.5
Il cluster INFN di Perugia
Prima dell’entrata in funzione del cluster i vari gruppi di ricerca all’interno
della struttura provvedevano autonomamente alla necessità di strumenti di
calcolo. Questo portava, oltre al moltiplicarsi dei costi gestionali, a un utilizzo inefficiente delle risorse: in momenti di intensa attività potevano rivelarsi
1.5. IL CLUSTER INFN DI PERUGIA
23
insufficienti per il fabbisogno del gruppo, negli altri periodi erano solitamente
sottoutilizzate. Si è deciso quindi di aggregare le risorse in un cluster dotato
di un batch system basato sul pacchetto software open source Torque (resource manager) + Maui (scheduler). In questo modo i costi e le difficoltà di
gestione sono stati sensibilmente abbattuti e la potenza di calcolo complessiva poteva essere usata in modo più razionale: ogni gruppo infatti beneficiava
nei momenti di necessità di tutte le risorse che gli altri gruppi non stavano
utilizzando.
Nel 2004 il cluster è entrato a far parte della grid INFN: benché ciò sia
stato un evento desiderabile e prestigioso, ha portato a tutta una serie di
conseguenze che saranno meglio descritte tra breve. Il concetto chiave è che
da quel punto le risorse dovevano essere condivise non solo tra i gruppi locali
ma anche con l’utenza della grid: è stata introdotta eterogeneità in un sistema
che era già piuttosto complesso.
1.5.1
Architettura
Dal punto di vista fisico il cluster è costituito dai nodi e da una rete di
interconnessione tra di essi. In questo paragrafo saranno esposte le caratteristiche hardware e software del cluster INFN di Perugia. Uno schema
dell’architettura è mostrato in figura 1.5.
Figura 1.5: Topologia della rete del cluster INFN di Perugia
24
CAPITOLO 1. CLUSTER COMPUTING
Nodi
I nodi del cluster possono essere suddivisi tra nodi interni e nodi di frontiera.
I nodi di frontiera sono quelli che realizzano le funzioni di interfacciamento
verso l’esterno e sono accessibili direttamente dagli utenti.
Possiamo distinguere le seguenti tipologie di nodi di frontiera:
• CE (Computing Element): c’è un solo nodo di questo tipo; è il più
importante in quanto è quello che ospita il batch system.
• UI (User Interface): tramite questi nodi l’utenza sottomette i job al
sistema; sono gli unici accessibili direttamente dall’esterno del cluster.
Nel caso in esame ogni gruppo dispone di una propria UI e tramite essa
può anche ottenere informazioni sullo stato dei job o accedere ai dati
ospitati nei nodi di storage.
• SE (Storage Element): la capacità di storage del cluster supera i 30 TB.
L’utente che voglia utilizzare parte di tale disponibilità può farlo tramite questi nodi, con la mediazione delle UI. Gli SE gestiscono la memoria
a disposizione come se fosse un unica risorsa e tramite meccanismi automatici per la gestione distribuita di file e directory permettono l’accesso
ai dati indipendentemente dalla loro locazione fisica.
• IS (Install Server ): questi nodi sono adibiti a repository di software, in
particolare delle immagini del sistema operativo in uso sui nodi, e semplificano notevolmente l’installazione el’aggiornamento di tali sistemi
I nodi interni, come suggerisce il nome, non sono raggiungibili dall’esterno.
Benchè siano raggruppati in due sole tipologie rappresentano la maggior parte
dei nodi del cluster. Abbiamo:
• WN (Worker Node): sono i nodi che eseguono fisicamente i job sulle
proprie risorse locali. Le caratteristiche dei WN sono variegate, sia in
termini di potenza di calcolo che di hardware a disposizione, e riflettono l’andamento evolutivo del cluster. Sono presenti computer biprocessori Intel Pentium III, nodi più recenti equipaggiati con processori
Intel Xeon Quad Core e sono in fase di inserimento 10 nuovi nodi
con ben 8 core e 16 GB di RAM: questi ultimi, una volta in funzione, rappresenteranno quasi un terzo della potenza di calcolo dell’intero
cluster.
• FS (File Server ): sono i nodi di storage, equipaggiati con sistemi RAID
per la gestione di array di dischi che permettono l’archiviazione di
grandi quantità di dati.
1.5. IL CLUSTER INFN DI PERUGIA
25
Rete
I nodi sono interconnessi da una LAN di tipo Ethernet con topologia a stella
a due livelli. Il primo livello è costituito da uno switch principale, da cui si
diramano le connessioni verso gli swtich del secondo livello. I criteri di organizzazione della rete dipendono dall’intensità del traffico, dalle capacità delle
interfacce dei nodi e dalla loro disposizione fisica. La connettività a Internet è
garantita dai nodi di frontiera, che solitamente dispongono di due interfacce
di rete, una verso l’interno del cluster e l’altra verso la rete dipartimentale,
che è collegata direttamente all’esterno. Le politiche di accesso sono gestite
tramite il firewall dipartimentale.
Una notevole caratteristica del cluster è l’utilizzo di reti nascoste e della tecnologia VLAN. Per sopperire alla carenza di IP pubblici, infatti, si è
deciso di porre i nodi interni in una rete nascosta; questo ha richiesto delle
modifiche al middleware che, dopo essere state testate con successo in ambito
locale, sono state incluse nel middleware ufficiale INFN ed utilizzate in molti altri siti INFN-grid. Lo standard 802.11Q, conosciuto come Virtual LAN
(VLAN), è stato impiegato nella ristrutturazione dell’intera rete dipartimentale. Esso permette di collegare macchine appartenenti a sottoreti diverse
come se fossero sulla stessa rete locale, o di dividere un singolo segmento
di rete in più sottoreti. Il cluster potrà beneficiare di questa caratteristica
in quanto potenzialmente ogni computer raggiunto dalla rete dipartimentale è associabile alla rete nascosta del cluster ed utilizzabile nei momenti di
inattività per incrementare la potenza di calcolo.
1.5.2
Problemi emergenti
Nel corso degli anni il cluster si è espanso sia in termini di risorse che di
utilizzatori. Come detto in precedenza, si sono aggiunti man mano diversi
nodi e all’utenza locale già variegata si è aggiunta l’utenza della grid. Oltre
a creare problemi dal punto di vista della disposizione fisica delle macchine,
questo ha portato inevitabilmente al sorgere di complicazioni organizzative
dovute all’eterogeneità dell’hardware e alle diverse necessità degli utenti. In
particolare si possono evidenziare difficoltà dovute a:
• Diritti d’utilizzo
• Caratteristiche ibride
Diritti d’utilizzo
È logico pensare che i gruppi locali che hanno dato vita al cluster condividendo i propri strumenti di calcolo si aspettino se non di trarne vantaggio
26
CAPITOLO 1. CLUSTER COMPUTING
almeno di non esserne penalizzati. È necessario garantire loro la possibilità
di disporre delle proprie risorse quando ne abbiano la necessità; questo non
è facilmente conciliabile con la natura condivisa del cluster, che al momento
di una richiesta potrebbe già essere occupato per intero da altri job. Riservare un certo numero di macchine per l’uso esclusivo di un gruppo non può
essere considerata una soluzione: nei periodi di scarsa attività questi nodi
sottoutilizzati rappresenterebbero uno spreco di risorse non tollerabile. Una
parte importante nell’affrontare il problema spetta al batch system, che è
stato oggetto di numerosi studi, anche locali, per ottimizzare l’utilizzo dei
nodi tenendo conto delle necessità degli utenti. Il prototipo oggetto di questa
tesi mira a raffinare ulteriormente questo equilibrio.
Caratteristiche ibride
Gli utenti della grid possono avere necessità diverse in termini di dotazione
software dei diversi nodi, per quanto riguarda sistema operativo, librerie, applicativi, ecc. Questo è vero particolarmente per le macchine che si desidera
mettere a disposizione della grid-INFN: è infatti richiesto che siano equipaggiate esclusivamente con il sistema operativo Scientific Linux CERN. I job
dei gruppi locali potrebbero però avere necessità diverse: per gestire questo
problema si è stabilito che i gruppi decidano autonomamente la percentuale
di nodi da destinare all’impiego in grid e quelli da riservare per l’uso locale. Questa separazione ha dato vita alla cosiddetta “ibridazione” del cluster,
i cui nodi non hanno caratteristiche omogenee ma variabili a seconda della destinazione d’uso. Ciò ha portato a dover dotare il cluster di più punti
d’ingresso, i nodi User Interface prima descritti, uno per ogni tipologia d’utenza, e a complicare la logica del batch system, che deve accettare job da
più sorgenti. Soprattutto è stato inevitabile suddividere le macchine in classi
di utenza e dotare ogni macchina di un diverso ambiente d’esecuzione in base
alla classe di appartenenza.
Anche questa suddivisione delle risorse può portare a un uso non ottimale
delle stesse. I nodi riservati per un certo utilizzo, con un ambiente operativo
specifico per i job di una determinata utenza, non sempre possono essere
impiegati per eseguire job di altri utenti nei periodi di inattività, in quanto
questi job potrebbero essere incompatibili con l’ambiente d’esecuzione installato sui nodi in oggetto. La figura 1.6 mostra un esempio semplificato delle
situazioni indesiderabili che potrebbero venirsi a creare.
Si potrebbe pensare di cambiare dinamicamente la classe di appartenza
dei nodi in base ai bisogni contingenti, ma questo compito non è banale e
comporta come minimo il riavvio della macchina, se su di essa sono installati
più sistemi operativi ognuno dei quali offre un diverso ambiente d’esecuzione.
1.5. IL CLUSTER INFN DI PERUGIA
27
Figura 1.6: Esempio di uso sub-ottimale a causa del partizionamento delle risorse del cluster. I nodi sono
suddivisi in due classi per accogliere altrettante tipologie di job tra loro incompatibili. La
componente di RMS raccoglie le richieste tramite due code separate e distribuisce il carico in
accordo alla distinzione in classi. In periodi di scarso tasso di sottomissione di job di classe 2
i nodi adibiti all’esecuzione di quest’ultimi non possono essere impiegati per l’altra classe di
job restando di fatto inattivi, mentre potrebbero essere sfruttati per i job di classe 1 in coda.
Il prototipo in discussione tenta di risolvere le difficoltà sopra esposte mediante il ricorso alla virtualizzazione. Il paragrafo seguente espone i concetti
basilari di questa tecnologia e spiega come può essere d’aiuto nella pratica.
28
CAPITOLO 1. CLUSTER COMPUTING
Capitolo 2
Virtualizzazione
2.1
Introduzione
In ambito informatico per virtualizzazione si intende genericamente l’astrazione di una risorsa fisica attraverso un’interfaccia logica che ne nasconde
i dettagli implementativi. Un esempio noto è la memoria virtuale: questa
tecnica permette di estendere la memoria centrale del computer (RAM), che
solitamente viene vista come un unico spazio di memoria contigua, utilizzando parte della memoria di massa (hard disk o altri dispositivi di storage,
come memorie flash), organizzata in blocchi non contigui e funzionante secondo principi del tutto diversi. In questo caso la risorsa fisica, la memoria
di massa, è virtualizzata in quanto il sistema la utilizza come se fosse memoria centrale benché le due cose abbiano ben poco in comune in termini di
organizzazione e di modalità di accesso.
Il capitolo elenca alcune delle più note tipologie di virtualizzazione esistenti, focalizzando poi l’attenzione sulla virtualizzazione nota come “machine virtualization” e sull’implementazione impiegata localmente, XEN. Soprattutto viene mostrato come può essere usata per risolvere con successo i
problemi elencati al termine del capitolo precedente.
2.2
Tipologie di virtualizzazione
Il termine “virtualizzazione” è attualmente molto in voga e a volte se ne
abusa, specie per dare maggiore attrattiva a un certo prodotto commerciale. Questa sezione descrive in breve cosa può realmente essere inteso come
“virtualizzazione”; il concetto basilare è che una risorsa si può definire virtualizzata se si fornisce ad essa un accesso logico indipendente dalla struttura
fisica.
29
30
2.2.1
CAPITOLO 2. VIRTUALIZZAZIONE
Virtualizzazione di applicazioni
Questo tipo di virtualizzazione consiste nel compilare un’applicazione in un
linguaggio indipendente, detto genericamente byte-code. Il computer in cui
verrà eseguita l’applicazione dovrà fornire un ambiente d’ in grado di tradurre il byte-code in istruzioni eseguibili direttamente dal processore locale,
il cosiddetto linguaggio macchina. Questo ambiente d’esecuzione è noto a
volte come “macchina virtuale”, da non confondere con le macchine virtuali
di cui si parlerà tra breve. La virtualizzazione di applicazioni astrae quindi
l’ambiente operativo di una macchina, permettendo a una stessa applicazione di essere eseguita da diversi sistemi operativi e perfino da processori
con un diverso set di istruzioni, se si ha a disposizione la macchina virtuale
appropriata. L’esempio più conosciuto di questo tipo di virtualizzazione è
il byte-code prodotto dai compilatori per il linguaggio di programmazione
Java. Anche Microsoft ha adottato questo approccio: la famiglia di linuaggi
.NET, infatti, viene compilata in un linguaggio intermedio detto CIL (Common Intermediate Language) che viene eseguito da un ambiente noto come
CLR (Common Language Runtime).
2.2.2
Virtualizzazione di rete
La virtualizzazione di rete consiste nella possibilità di riferirsi a risorse di rete
senza utilizzare la loro reale locazione fisica. Un esempio possono essere le reti
VPN (Virtual Private Network ), che permettono di collegare tramite Internet
computer molto distanti tra loro e farli comunicare come se facessero parte di
una rete locale; un altro esempio è la tecnologia VLAN, a cui si è accennato
prima, che permette di creare sottoreti virtuali su uno stesso segmento di
rete fisico.
2.2.3
Virtualizzazione dei dispositivi di storage
Questa tipo di virtualizzazione è in grado di fornire uno spazio di storage
virtuale combinando le capacità di più dispositivi fisici; questo spazio è poi
suddividibile in sezioni logiche, dette volumi, su cui è possibile creare un file
system normalmente utilizzabile. Le più note implementazioni sono probabilmente la tecnologia RAID (Redundant Array of Independent Disks) o i file
system AFS (Andrew File System) e GFS (Global File System).
2.3. MACCHINE VIRTUALI
2.2.4
31
Virtualizzazione di sistemi
Meglio definibile con il termine inglese “machine virtualization” o “server virtualization”, questo tipo di virtualizzazione consiste nell’eseguire intere macchine virtuali, con differenti sistema operativo e applicazioni, su uno stesso
sistema hardware. Per permettere ciò deve esistere uno strato intermedio che
regoli l’accesso alle risorse fisiche da parte delle diverse macchine logiche, o
virtuali, detto Virtual Machine Monitor (VMM). È questa la categoria di
virtualizzazione su cui si focalizza questo capitolo ed è forse ciò a cui immediatamente si pensa quando si sente il termine “virtualizzazione”. Nei paragrafi seguenti verrano esaminati nel dettaglio i concetti di macchina virtuale
e VMM.
2.3
Macchine virtuali
L’idea di virtualizzare interi sistemi operativi tramite un’interfaccia software
al livello fisico risale agli anni 70’. Fu nel 1974, infatti, che Gerald J. Popek e
Robert P. Goldberg scrissero un articolo in cui diedero la prima definizione di
macchina virtuale e VMM e gettarono le basi teoriche della virtualizzazione.
I due ricercatori analizzarono i requisiti che l’architettura di un sistema di
calcolo deve avere per poter essere virtualizzato; benché si riferissero a sistemi di terza generazione, costruiti con i primi circuiti integrati, l’analisi che
fecero può essere considerata valida anche per i moderni sistemi di quarta
generazione, dotati di microprocessori ad alto grado di integrazione.
Il VMM viene definito come un software in esecuzione sulla macchina
reale che ne ha il completo controllo delle risorse hardware. Esso crea degli ambienti d’esecuzione, detti macchine virtuali (VM), che forniscono agli
utenti l’illusione di un accesso diretto alle risorse della macchina fisica.
La definizione che fu data di macchina virtuale è la seguente:
Un duplicato software di un computer reale nel quale un sottoinsieme statisticamente dominante di istruzioni del processore
virtuale viene eseguito nativamente sul processore fisico.
Questo significa in pratica che la maggior parte dell’interazione tra macchina
virtuale e processore dovrebbe essere permessa senza nessuna mediazione del
VMM; esso interviene, come si vedrà tra breve, solo per quelle istruzioni
che modificherebbero lo stato della macchina e l’assegnazione delle risorse
hardware.
32
CAPITOLO 2. VIRTUALIZZAZIONE
2.3.1
Caratteristiche e architettura VMM
Il VMM gestisce le risorse hardware e le esporta presso le macchine virtuali facendo sembrare loro di averne l’uso esclusivo. Esso deve possedere tre
caratteristiche principali:
• Equivalenza: Gli effetti dell’esecuzione di un programma attraverso il
VMM devono essere identici a quelli dello stesso programma eseguito
direttamente sulla macchina originale, ad eccezione al più del tempo
d’esecuzione dovuto all’overhead del VMM e alla ridotta disponibilità
di risorse.
• Efficienza: L’ambiente virtuale deve essere efficiente. La maggior parte
delle istruzioni eseguite all’interno di tali ambienti deve essere eseguita
direttamente dal processore reale senza che il VMM intervenga; questo
si traduce in un degrado minimo delle prestazioni.
• Controllo delle Risorse: Il controllo delle risorse hardware deve essere
di esclusiva competenza del VMM, senza interferenze da parte delle
VM.
Il VMM tipicamente è composto di diversi moduli:
• Il dispatcher, il cui compito è quello di intercettare le istruzioni sensibili
eseguite dalle VM e lasciare il controllo ai moduli preposti a gestire la
situazione.
• L’allocator, che si preoccupa di fornire alle macchine virtuali le risorse
necessarie evitando i conflitti, allo stesso modo di come farebbero le
componenti di un sistema operativo nell’amministrazione dei processi.
• L’interpreter, che si rende necessario in quanto le macchine virtuali
non possono avere accesso diretto alle risorse fisiche e non conoscono lo
stato dell’hardware reale, ma solo quello del loro ambiente virtuale. Le
istruzioni che fanno riferimento alle risorse sono simulate dall’interpreter in modo da riflettere la loro esecuzione nell’ambiente delle macchine
virtuali.
Si possono individuare due tipologie di VMM, in base alla collocazione
nell’ambiente della macchina fisica:
• Il VMM di tipo 1 è posto immediatamente sopra l’hardware ed dispone di tutti i meccanismi di un normale kernel o sistema operativo in
quanto a gestione delle memoria, delle periferiche e del processore; in
2.3. MACCHINE VIRTUALI
33
più implementa i meccanismi di gestione delle macchine virtuali. Le
macchine virtuali eseguite al di sopra del VMM dispongono di un proprio sistema operativo e sono dette macchine “guest”. Lo schema di un
VMM di tipo 1 è mostrato in figura 2.1 (a).
• Il VMM di tipo 2 è un normale processo in esecuzione nell’ambito di
un sistema operativo detto “host”. Gestisce direttamente le macchine
virtuali, che sono suoi sottoprocessi, mentre la gestione dell’hardware
è demandata al sistema ospitante. La figura 2.1 (b) mostra un sistema
con un VMM di tipo 2.
(a) VMM di Tipo 1, posto immediatamente sopra l’hardware.
(b) VMM di Tipo 2, ospitato nel
sistema operativo host.
Figura 2.1: Sistemi di virtualizzazione con VMM di tipo 1 e 2.
2.3.2
Requisiti di Popek-Goldberg
Per comprendere appieno la definizione di macchina virtuale occorre essere
a conoscenza di altri concetti, come gli stati di utilizzo di un processore e
i gruppi in cui possono essere suddivise le istruzioni, che verrano esposti in
questo paragrafo.
La gran parte dei processori moderni prevedono il funzionamento in almeno due modalità operative: user-mode e supervisor-mode. Il set di istruzioni
del processore (ISA) in user-mode è limitato a quelle che non presentano problemi di sicurezza, ad esempio che non modificano lo stato dei registri, mentre
in supervisor-mode può essere eseguita qualunque istruzione del set. Il processore si trova in uno stato piuttosto che nell’altro in base al processo che lo
sta utilizzando: tipicamente solo il kernel può utilizzarlo in supervisor-mode.
Se il processore è in stato di user-mode ma tenta di eseguire un’istruzione
che può essere eseguita solo in stato di supervisor-mode, viene generato un
interrupt che deve essere gestito dal sistema operativo.
Ai fini della virtualizzazione il set di istruzioni può essere suddiviso in tre
sottoinsiemi, non necessariamente disgiunti:
34
CAPITOLO 2. VIRTUALIZZAZIONE
• Privilegiate: sono le istruzioni eseguibili solo in supervisor-mode.
• Sensibili: sono le istruzioni che modificano lo stato delle risorse del
sistema, oppure dipendono da esse.
• User: tutte le altre istruzioni.
Popek e Goldberg, basandosi su questa classificazione, formularono una
condizione sufficiente per la virtualizzazione di un sistema:
la costruzione di un VMM è sempre possibile se il set di istruzioni sensibili del calcolatore è un sottoinsieme delle sue istruzioni
privilegiate.
In altre parole, un VMM può essere costruito per ogni computer sul quale
tutte le istruzioni che modificano o dipendono dallo stato della macchina reale
causano un interrupt se eseguite all’interno di una VM, che opera in usermode. L’interrupt cosı̀ generato può essere intercettato dal modulo dispatcher
e opportunamente gestito. Tutte le istruzioni eseguibili in user-mode, invece,
saranno eseguite dalla macchina virtuale direttamente sul processore fisico
senza mediazione del VMM, che nemmeno se ne renderà conto. Se i requisiti
di Popek-Goldberg sono rispettati, il VMM è in grado di soddisfare i tre
requisiti di equivalenza, efficienza e controllo delle risorse sopra esposti.
2.3.3
Problemi delle architetture x86
L’architettura x86 è l’architettura di microprocessori ideata e prodotta inizialmente da Intel, a partire dalla fine degli anni ’70. Prende il nome del
primo processore della famiglia, denominato 8086, a cui sono seguiti l’ 80286,
l’80386 e l’80486; nei processori più recenti è stata cambiata la nomenclatura
(si è passati dalle diverse versioni del Pentium all’attuale Core) ma non l’architettura. Nel corso degli anni anche i maggiori produttori concorrenti, come
AMD, hanno fabbricato soprattutto processori x86-compatibili. Attualmente
l’architettura x86 è la più diffusa nel campo dei PC, desktop e laptop, e in
quello dei server di dimensioni medio-piccole, in pratica nei sistemi che più
diffusamente si utilizzano per la virtualizzazione.
Il grande limite di quest’architettura è che non rispetta la condizione
di Popek-Goldberg: nel set d’istruzioni sono presenti istruzioni sensibili non
privilegiate. Se una VM esegue un’istruzione sensibile non privilegiata, essa
sfuggirà al controllo del VMM poiché l’istruzione non causerà un interrupt
che possa essere intercettato e gestito: c’è il rischio concreto che le VM interferiscano con il VMM nell’interazione con le risorse fisiche, portando al
mancato rispetto dell’essenziale requisito del controllo esclusivo delle risorse
2.4. TIPOLOGIE DI VIRTUALIZZAZIONE DEI SISTEMI
35
da parte del VMM. Per sopperire a questa mancanza sono state sviluppate
tecniche che consentono in qualche modo di intercettare anche queste istruzioni potenzialmente dannose e che permettono quindi di virtualizzare anche
architetture x86, con impatti più o meno negativi sulle performance. Il paragrafo seguente mostrerà le principali tipologie di virtualizzazione dei sistemi,
comprese alcune di queste teniche.
2.4
Tipologie di virtualizzazione dei sistemi
Lo scopo della virtualizzazione dei sistemi è quello di condividere in modo
trasparente le risorse hardware della macchina fisica tra i sistemi operativi
guest, di far comunque eseguire loro più istruzioni possibili direttamente sul
processore senza interazione del VMM e di risolvere potenziali cause di malfunzionamenti dovute alle eventuali mancanze dell’architettura nei confronti
dei requisiti di Popek-Goldberg.
Le principali metodologie di virtualizzazione sono di seguito elencate.
2.4.1
Virtualizzazione a livello del kernel
In questa tipologia le funzionalità per la virtualizzazione sono offerte direttamente dal normale kernel del sistema operativo. Le macchine virtuali cosı̀
create possono avere ognuna il proprio file-system, ma condividono il kernel
del sistema operativo host. Lo svantaggio di questo approccio è che possono
essere avviate macchine virtuali con un solo tipo di sistema operativo e che
un eventuale falla di sicurezza nel kernel si ripercuoterebbe su tutte le VM.
2.4.2
Virtualizzazione completa
Questo approccio prevede la completa simulazione software delle risorse hardware. Per far questo ogni istruzione eseguita dalle VM deve essere intercettata
e, se è sensibile, tradotta a runtime per mezzo di meccanismi software detti
“binary-translation”. Il VMM è tipicamente di tipo 2, ovvero un processo eseguito all’interno dell’ambiente del sistema operativo host. Il controllo di tutte
le istruzioni permette di aggirare i limiti delle architetture x86 ma provoca
inevitabilmente un degrado consistente delle prestazioni.
2.4.3
Para-virtualizzazione
Questa tecnologia tenta di migliorare la scarsa efficienza della virtualizzazione completa pur continuando a supportare le architetture x86. Per far ciò
36
CAPITOLO 2. VIRTUALIZZAZIONE
si avvale di un VMM di tipo 1, detto hypervisor, che gestisce direttamente le risorse hardware e ne offre alle VM un interfaccia software simile a
quella di un sistema operativo. L’interazione tra VM e hypervisor avviene
tramite speciali chiamate di sistema, dette “hypercalls”, che vanno a sostituire le “supercalls” utilizzate nei comuni sistemi operativi dalle applicazioni
che richiedono l’accesso all’hardware; le istruzioni non sensibili invece vengono eseguite dalle VM sul processore fisico, senza l’intervento del VMM.
Da quanto detto è evidente che i sistemi guest devono essere opportunamente modificati per utilizzare queste chiamate; per contro la virtualizzazione
completa permette di eseguire sistemi operativi non modificati. Questo svantaggio è compensato dalle ottime prestazioni, appena al di sotto degli stessi
sistemi non virtualizzati.
2.4.4
Virtualizzazione hardware
Dal 2005 Intel e AMD hanno cominciato a dotare alcuni dei processori da loro
prodotti di estensioni specifiche per gestire alcuni aspetti della virtualizzazione direttamente in hardware. Queste tecnologie, la VT di Intel e la Pacifica
di AMD, implementano parzialmente nel processore complessi meccanismi
per la gestione delle istruzioni sensibili non privilegiate o per la traduzione
degli indirizzi di memoria delle VM in indirizzi fisici, funzioni che solitamente
spettano al VMM. Piuttosto che essere considerato una tipologia a se stante,
si può dire che il supporto hardware alla virtualizzazione estende le tecnologie già esistenti; in particolare, su macchine dotate di questi processori,
si possono para-virtualizzare anche sistemi operativi non modificati. Questo
apre la porta della virtualizzazione con buone performance anche ai sistemi
a codice sorgente chiuso e quindi non modificabili, come quelli della famiglia
Windows.
2.4.5
Emulazione
L’emulazione non è una tipologia di virtualizzazione, ma poiché i due termini a volte vengono usati scambievolmente è bene conoscerne le affinità e le
differenze. Anche l’emulazione permette di eseguire diverse macchine virtuali
su un sistema operativo host, fornendo un’interfaccia software verso le risorse
fisiche. A differenza della virtualizzazione, l’emulazione non ha lo scopo di
eseguire più operazioni possibili nativamente sul processore fisico; al contrario
è certo che tutte le istruzioni saranno controllate ed eventualmente tradotte
prima di essere eseguite. Questo permette di eseguire anche ambienti compilati per architetture diverse da quelle della macchina host, ad esempio di
2.5. XEN
37
eseguire sistemi operativi e applicazioni compilati per architetture PowerPc 1
su processori x86 e viceversa; in pratica un’istruzione di un architettura può
essere convertita in una o più istruzioni equivalenti di un’altra architettura e
poi eseguita. La virtualizzazione invece non prevede questa eventualità, ma i
sistemi operativi guest devono essere compilati per la stessa architettura della
macchina fisica ospitante. Tra i prodotti per l’emulazione più noti si possono
ricordare QEMU, in ambiente Linux, e Microsoft Virtual PC, in ambiente
Windows.
2.5
Xen
Xen è un sistema di para-virtualizzazione opensource nato nel 2003 e giunto
attualmente alla sua terza versione. L’idea alla base di Xen è l’utilizzo di
un sistema operativo host, detto Domain 0 o Dom0, oltre al tradizionale
hypervisor, il quale resta comunque la componente più vicina all’hardware.
Il Dom0, esso stesso virtualizzato, fornisce le funzioni per gestire i sistemi
operativi guest, detti Unprivileged Domains o DomU, ed è l’unico che dialoga
con l’hypervisor e collabora con esso nella gestione delle risorse fisiche; i
DomU accedono all’hardware solo tramite particolari driver virtuali forniti
dal Dom0. A partire dalla fine del 2006 Xen è in grado di ospitare come guest
anche sistemi operativi non modificati, se il processore della macchina fisica
possiede le estensioni per il supporto alla virtualizzazione di cui si è parlato
precedentemente.
Il capitolo spiega più nel dettaglio le funzionalità di ogni componente e
mostra le potenzialità di Xen in termini di performance.
2.5.1
Hypervisor
L’hypervisor di Xen è responsabile per lo scheduling della CPU e il partizionamento della memoria tra le macchine virtuali in esecuzione su di esso. Cosı̀
come farebbe un sistema operativo con i processi, l’hypervisor sospende e
riavvia in modo trasparente le macchine virtuali; inoltre le VM non possono
accedere direttamente alla memoria centrale ma possono utilizzarla solo tramite i servizi forniti dall’hypervisor. Tutte le altre perifiche di I/O non sono
note all’hypervisor. Al momento dell’avvio della macchina il bootloader carica
1
PowerPC è la principale architettura per microprocessori concorrente all’x86. È stata
creata nel 1991 dall’alleanza Apple-IBM-Motorola, conosciuta come AIM. Attualmente la
diffusione dei processori PowerPC su macchine commerciali è in diminuzione, mentre è
la più utilizzata in settori come quello delle console (Sony Playstation 3 e Nintendo Wii
sono equipaggiate con processori basati su architettura PowerPC).
38
CAPITOLO 2. VIRTUALIZZAZIONE
l’hypervisor che, dopo aver riservato per se una minima porzione di memoria e aver inizializzato le strutture dati per la gestione della virtualizzazione,
lascia il controllo al Dom0.
2.5.2
Domain 0
Come Domain 0 possono essere utilizzati sistemi operativi Linux, NetBSD o
Solaris opportunamente modificati; i sistemi GNU/Linux sono i più diffusi,
anche localmente. Il Dom0 non è strutturalmente diverso dalle altre macchine
virtuali, ma riveste un ruolo molto importante, quello di fornire loro l’accesso alle risorse hardware non gestite direttamente dall’hypervisor; il Dom0
accede quindi a queste risorse, tipicamente le periferiche di rete e di storage, senza intermediazione dell’hypervisor e tramite i comuni device drivers.
Questo permette di sfruttare l’ampia selezione di device drivers sviluppati
per il kernel di Linux e nello stesso tempo di semplificare notevolmente il
lavoro dell’hypervisor. Per permettere l’utilizzo dell’hardware ai DomU, il
Dom0 include anche due particolari driver di backend, che virtualizzano le
periferiche di rete e i dispositivi a blocchi, detti Network Backend Driver e
Block Backend Driver : è attraverso questi strumenti che il Dom0 svolge le
sue funzioni di intermediario tra i DomU e le risorse fisiche.
2.5.3
Domain U
Tutte le macchine virtuali controllate dall’hypervisor, ad eccezione del Dom0,
sono dette Domain U. Come DomU possono essere utilizzati gli stessi sistemi
operativi validi per il Dom0 con l’aggiunta di sistemi operativi non modificati se la macchina è in grado di offrire la virtualizzazione hardware. I sistemi
operativi dei DomU svolgono autonomamente le funzioni di scheduling dei
processi e di gestione della memoria nelle risorse a loro assegnate dall’hypervisor. Per quanto riguarda l’accesso alle periferiche di I/O i DomU si servono
di speciali driver di frontend, che rappresentano le controparti nel dialogo con
i driver di backend del Dom0. La comune gestione delle periferiche attraverso
interrupt, operata dai sistemi operativi con accesso diretto all’hardware, viene sostituita da un meccanismo ad eventi che vengono segnalati al corretto
DomU. In questo modo l’hypervisor può catturare gli interrupt provenienti
dalle periferiche hardware e generare gli eventi di cui un determinato DomU
è in attesa, come ad esempio la presenza di dati da poter leggere su un socket.
Le immagini dei sistemi operativi guest possono essere ospitate su un’ampia
varietà di supporti visti dai domU come dispositivi a blocchi virtuali (VBD).
Essi possono essere ricavati da:
2.5. XEN
39
name = "DomU1"
#quantità di memoria da assegnare a DomU1
memory = 1024
#numero di CPU virtuali
vcpu = 2
#immagine del kernel modificato
kernel = "/boot/vmlinuz-2.6.16-1-xen"
#ip da assegnare all’interfaccia di rete virtuale
vif = [ ’ip=192.168.1.10’ ]
#dispositivi a blocchi virtuali
disk = [ ’phy:/dev/iscsi_02,hda2,w’,’phy:/dev/iscsi_01,hda1,w’ ]
#dispositivo virtuale contenente il root file system
root = "/dev/hda2 ro"
Tabella 2.1: File di configurazione per la definizione di un DomU.
• Dispositivi Fisici: partizioni fisiche ospitate da un dispositivo a blocchi.
• File: immagini di file system su file.
• LVM: volumi logici.
• NFS: file system forniti come export NFS.
I DomU sono definiti attraverso comuni file di testo che, attraverso un preciso
formato, permettono di specificare le caratteristiche della macchina da creare.
Un esempio è fornito in tabella 2.1.
2.5.4
Demoni e strumenti di gestione
La gestione dell’ambiente virtuale viene effettuata attraverso una serie di
demoni 2 e programmi che devono essere eseguiti sul Domain 0 e che permettono l’interazione con l’hypervisor. La figura 2.2 dà una visione d’insieme
dell’architettura di Xen, incluse le componenti di cui si parlerà in questo
paragrafo.
Tra di esse la principale è il demone xend. Xend ha il compito di fungere
da tramite tra l’amministratore del sistema e l’hypervisor che ne gestisce a
più basso livello l’allocazione delle risorse. Esso fa uso della libreria libxenctrl
per dialogare con lo speciale driver privcmd che rappresenta l’interfaccia di
2
In ambienti UNIX col termine demone (deamon) ci si riferisce ai processi di sistema
in esecuzione non interattiva che offrono servizi e funzioni di gestione.
40
CAPITOLO 2. VIRTUALIZZAZIONE
comunicazione attraverso il quale il Dom0 presenta all’hypervisor le richieste
sottomesse dall’amministratore. Queste richieste vengono effettuate attraverso l’applicazione a riga di comando xm, che consente di creare, spegnere,
riavviare, distruggere e monitorare le macchine virtuali.
Figura 2.2: Schema dell’archittetura di Xen
Ad esempio, nella creazione di un domU, l’amministratore prima specifica
i parametri della VM da creare visti nel precedente paragrafo; poi, attraverso
l’invocazione del comando “xm create”, ordina a xend di comunicare all’hypervisor le relative richieste di allocazione delle risorse e provvedere al caricamento del sistema operativo guest. Accanto xend vi è il demone xenstored
che gestisce parte dello scambio di informazioni tra il Dom0 e i DomU e mantiene delle strutture dati necessarie per effettuare lo scambio dati da e verso i
dispositivi di rete e a blocchi per conto dei DomU. La gestione dei dispositivi
infatti avviene con la mediazione di quest’ultimo demone, responsabile della
corretta gestione dei canali di comunicazione, detti event channel, che come
detto sostituiscono gli interrupt con un meccanismo ad eventi. Lo scambio
di dati vero e proprio da e verso i dispositivi avviene in modo asincrono e
per mezzo di aree di memoria condivisa sotto l’arbitrio dell’hypervisor, che
assicura l’isolamento degli spazi di memoria delle VM.
2.5.5
Performance
Sebbene non esistano benchmark 3 universalmente accettati per la valutazione delle prestazioni delle tecnologie di virtualizzazione, si può affermare che
3
Il termine benchmark è usato per indicare un insieme di applicazioni di test volte a
valutare le prestazioni dei sistemi di calcolo in determinati ambiti.
2.6. APPLICAZIONE DELLA VIRTUALIZZAZIONE
41
devono essere tenuti in considerazione due aspetti fondamentali:
• Impatto minimo: il tempo d’esecuzione di un programma di test in una
macchina virtuale deve avvicinarsi quanto più possibile al tempo che
lo stesso programma impiega in un sistema non virtualizzato
• Scalabilità: il degrado di performance deve aumentare in proporzione lineare rispetto all’incremento del numero di macchine virtuali. Ciò
è sinonimo di un’equa distribuzione delle risorse tra le macchine virtuali e un overhead dovuto alla gestione delle macchine praticamente
trascurabile.
Il gruppo di ricerca di Xen ha effettuato alcuni test per valutare le prestazioni di un ambiente GNU/Linux virtualizzato tramite Xen in paragone
con lo stesso ambiente non virtualizzato e con altre tecnologie di virtualizzazione; sono state prese in considerazione situazioni ad alto tasso di utilizzo
di CPU e RAM, altre con frequenti operazioni di I/O (tipicamente accessi
ripetuti ad un database) e altre che contemplano entrambi i casi (ad esempio
la compilazione del kernel, che utilizza intensamente la CPU ma esegue anche
molte operazioni di lettura e scrittura su file). I risultati, mostrati in figura
2.3, evidenziano che in situazioni di utilizzo intensivo della CPU la differenza
tra applicazione nativa e virtualizzata è quasi impercettibile, mentre per le
operazioni di I/O il programma virtualizzato è penalizzato in misura inferiore al 5%. Inoltre le prestazioni di Xen sono notevolmente superiori a quelle
di altri software di virtualizzazione.
Il secondo aspetto, la scalabilità, è stato tenuto in gran considerazione
dai progettisti di XEN: l’obiettivo dichiarato è quello di eseguire contemporaneamente fino a 100 macchine virtuali sulla stessa macchina fisica. I test
effettuati a questo riguardo hanno rilevato che il tempo di calcolo dei programmi di test in molti casi cresce linearmente all’aumentare del numero di
macchine virtuali: è il comportamento ottimale. È chiaro quindi che le tecnologie di para-virtualizzazione, e Xen in particolare, sono sufficientemente
efficienti per essere utilizzate in ambienti dove le alte prestazioni sono una
condizione irrinunciabile, quello dei cluster e delle griglie computazionali.
2.6
Applicazione della virtualizzazione
La virtualizzazione offre molti vantaggi. Questo paragrafo ne mostra i principali e spiega come possono essere utilizzati nell’ambiente del cluster locale.
42
CAPITOLO 2. VIRTUALIZZAZIONE
Figura 2.3: Risultati di alcuni test di benchmark effettuati dall’Università di Cambrige. Vengono comparati un sistema Linux non virtualizzato (L), un sistema virtualizzato con Xen (X) e sistemi
virtualizzati con altri due software molto popolari, VMware Workstation (V) e User Mode
Linux (U). Il test SPEC INT2000 utilizza intensivamente la CPU, con rare operazioni di
I/O: il valore riportato è il punteggio assegnato dal benchmark. Un altro test ha riguardato il tempo di compilazione del kernel di Linux. Il terzo test, OSDB-OLTP, è realtivo alla
valutazione delle performance di database, ovvero operazioni orientate all’I/O: il risultato è
espresso in tuple accedute o modificate al secondo. L’ultimo test, SPEC WEB99, riguarda la
prontezza del sistema nel fornire servizi di web server: il valore indicato è il massimo numero
di connessioni simultanee supportate.
2.6.1
Vantaggi della virtualizzazione
Unitamente alle buone prestazioni, la virtualizzazione dei sistemi è di grande
aiuto per un’amministrazione flessibile e un pieno uso delle risorse. Sono
formalizzati di seguito i settori in cui la virtualizzazione è un gradino sopra
al tradizionale utilizzo diretto della macchina fisica.
Consolidamento
Spesso i moderni calcolatori sono più performanti di quanto necessiti un singolo ambiente operativo. La virtualizzazione, eseguendo più sistemi operativi
sulla stessa macchina, permette di utilizzarne completamente le risorse. Questo si traduce in una riduzione dei costi: per espandere le potenzialità del
proprio parco macchine si può sfruttare meglio quanto si ha a disposizione
anziché acquistarne di nuove.
Isolamento
Per fornire servizi poco affidabili o pubblici possono essere predisposte apposite VM che, grazie ai meccanismi della virtualizzazione, saranno eseguite in
un ambiente del tutto separato, garantendo la sicurezza del resto del sistema.
2.6. APPLICAZIONE DELLA VIRTUALIZZAZIONE
43
Controllo delle risorse
Ad ogni macchina virtuale si possono assegnare risorse in base a precisi criteri. Ciò evita che alcune applicazioni possa sfruttare eccessivamente CPU,
memoria od altro a discapito di altre applicazioni che vedrebbero la propria
funzionalità ridotta.
Test
Tramite la virtualizzazione possono essere predisposti ambienti di test, anche distribuiti, senza dotarsi di hardware aggiuntivo. Inoltre le applicazioni
possono essere testate per più sistemi operativi, tra quelli che possono essere
ospitati dalle VM.
Facilità d’amministrazione
L’implementazione di una macchina virtuale richiede molto meno sforzi da
parte degli amministratori. Inoltre le macchine virtuali possono essere fermate, messe in pausa, riavviate o addirittura clonate su altre macchine fisiche
senza dover interrompere il funzionamento della macchina reale. Ciò consente
di utilizzare la virtualizzazione per implementare meccanismi di fail-over o di
bilanciamento del traffico molto più efficaci rispetto alla semplice replicazione
hardware.
2.6.2
Ambienti virtuali
Un ambiente d’esecuzione è tipicamente costituito da un sistema operativo e
da una collezione di librerie, programmi e servizi di sistema volti all’espletamento di particolari funzioni richieste dall’utenza. Generalmente tutte queste
componenti devono essere installate e configurate manualmente dagli amministratori. Come detto in precedenza, i job sottomessi al cluster necessitano
di diversi ambienti d’esecuzione, che devono essere tutti forniti in qualche
modo dal cluster. La soluzione adottata inizialmente è stata quella di suddividere le macchine in classi, ognuna delle quali mette a disposizione un certo
ambiente. La difficoltà nel modificare l’ambiente installato in una macchina
rende questa suddivisione piuttosto statica e rende difficile al batch system
bilanciare i carichi di lavoro in base alle necessità contingenti.
La virtualizzazione viene d’aiuto tramite la definizione di ambienti d’esecuzione virtuali, che è un altro dei concetti chiave di questa tesi. Un ambiente virtuale deve essere inizialmente configurato come un normale d’ambiente
d’esecuzione, ma può poi essere eseguito su tutte le macchine fisiche che supportano la virtualizzazione, con l’ulteriore vantaggio della quasi completa
44
CAPITOLO 2. VIRTUALIZZAZIONE
indipendenza dallo strato hardware; possono anzi essere definiti alcuni parametri fisici della macchina virtuale che ospiterà questo ambiente, come il
numero di CPU virtuali, la quantità di RAM o lo spazio disco. Gli ambienti
virtuali beneficiano inoltre di tutti i vantaggi della virtualizzazione descritti
nel paragrafo precedente.
La realizzazione di un ambiente virtuale in Xen avviene tramite l’installazione di un sistema operativo e dei pacchetti software necessari in un file
immagine 4 ; questo file può essere eventualmente replicato in una partizione,
in uno share NFS o in uno degli altri dispositivi a blocchi virtuali supportati
da Xen. Nel file di configurazione di Xen vanno invece definiti i parametri
dell’hardware virtuale. La coppia file immagine - file di configurazione identifica l’ambiente virtuale ed è sufficiente a Xen per avviare una o più macchine
virtuali in grado di offrire tale ambiente.
2.6.3
Applicazione locale
Un ambiente virtuale semplifica notevolmente l’amministrazione degli ambienti operativi, in quanto basta creare il file immagine e il file di configurazione una volta per tutte e replicarli su tutte le macchine che si desidera
mettano a disposizione tale ambiente. Nel caso locale si può pensare di definire un ambiente virtuale per ogni classe di utenza e rendere ogni ambiente
avviabile da più macchine fisiche del cluster. Ovviamente tutte le macchine
impiegate dovranno disporre di una tecnologia di virtualizzazione; localmente, com’è intuibile, è stato scelto Xen. In base alle necessità ogni macchina
fisica può rendere disponibili uno o più ambienti virtuali, della stessa classe o
di classi diverse, ed è quindi in grado di accogliere contemporaneamente job
di classi incompatibili o comunque di accettare un carico di lavoro superiore.
Per modificare la destinazione d’uso di una macchina basta avviare o interrompere l’ambiente o gli ambienti virtuali che si desidera che la macchina
offra o meno in quel momento.
Per permettere alle macchine virtuali cosı̀ avviate di interagire con il
batch system, l’ambiente virtuale deve includerne il componente client nella
sua dotazione software. In questo modo quando una macchina viene avviata
in risposta a una certa necessità questo componente notifica al batch system
la disponibilità di un nuovo nodo, pronto ad accogliere job di una determinata
classe. Dal punto di vista del batch system, quindi, i nodi non sono più le
macchine fisiche ma le macchine virtuali; una macchina fisica potrà dunque
4
A titolo esemplificativo, nei sistemi basati su distribuzioni Debian questa operazione
si realizza semplicemente grazie al tool debootstrap.
2.6. APPLICAZIONE DELLA VIRTUALIZZAZIONE
45
ospitare più di un nodo. Questo non fa nessuna differenza per il batch system,
che anzi vede “nascere” dinamicamente le risorse di cui ha bisogno.
Questo meccanismo dà una risposta valida ai problemi esposti nel capitolo
precedente:
• Diritti d’utilizzo: grazie agli ambienti virtuali è possibile soddisfare almeno parzialmente tutti gli utenti anche nei momenti di maggior carico.
Se ad esempio si desidera mandare in esecuzione un job anche se tutte le
risorse sono già impegnate, è sufficiente avviare una macchina virtuale
della classe di quel job su una macchina fisica a scelta, preferibilmente
quella con minor numero di altre macchine virtuali già attive. Naturalmente tutti i job ospitati dalle VM della macchina selezionata e il
job in oggetto aumenteranno il loro tempo di esecuzione, a causa della
condivisione delle risorse fisiche tra un maggior numero di ambienti virtuali. In ogni caso, se non utilizzato a sproposito, questo modo di agire
può portare a un utilizzo più efficiente delle potenzialità del cluster;
non è inoltre da sottovalutare l’aspetto psicologico: un utente che vede
attivare il proprio job poco dopo averlo sottomesso è certamente più
soddisfatto di uno che lo vede attendere per ore.
• Ibridazione: come ampiamente discusso, grazie agli ambienti virtuali
è possibile variare dinamicamente gli ambienti d’esecuzione supportati
da una stessa macchina fisica. Aumentando o diminuendo le macchine
virtuali di una certa classe disponibili complessivamente nel cluster
è possibile rispondere in tempo quasi reale al variare del tipo di job
correntemente in coda presso il batch system.
2.6.4
Ruolo del prototipo
La virtualizzazione è già in parte utilizzata nel cluster, in particolare per
implementare meccanismi di alta affidabilità. Sono virtualizzati ad esempio
i nodi più importanti, come il Computing Element e le User Interface, in
modo che in caso di guasti della macchina fisica tali servizi possano essere
ripristinati in breve tempo avviando il relativo ambiente virtuale presso un
altro nodo.
La gestione dinamica degli ambienti virtuali come sopra descritta, invece, non è ancora attiva. Il motivo fondamentale è che necessiterebbe di un
massiccio intervento umano, per monitorare costantemente lo stato del batch
system e delle risorse del cluster e avviare e distruggere appropriatamente le
macchine virtuali necessarie al momento; è infatti auspicabile che il tempo di
reazione ai cambiamenti di stato sia il più breve possibile. Sarebbe necessario
46
CAPITOLO 2. VIRTUALIZZAZIONE
un sistema che gestisca automaticamente un pool di Domain 0 attivi sulle
macchine fisiche, e su di essi attivi una serie di ambienti virtuali (Domain
U), in risposta alle richieste e le disponibilità contingenti: questo permetterebbe di migliorare notevolmente i tempi di soddisfacimento delle richieste
di servizi, eliminando la necessità di interventi umani.
È proprio questo l’obiettivo che si pone il prototipo oggetto della tesi:
realizzare uno strumento che sia in ogni momento a conoscenza dello stato
del batch system e dei Dom0 sotto il suo controllo e che reagisca in tempi
brevi alle richieste in arrivo creando o distruggendo ambienti virtuali, con lo
scopo di ottimizzare l’utilizzo delle risorse e il grado di soddisfacimento delle
richieste. Questo strumento sarà a tutti gli effetti un componente middleware
aggiuntivo, che affianca e facilita il lavoro del batch system.
Il capitolo che segue mostra l’architettura generale del prototipo che, come si vedrà, è altamente flessibile ed estendibile e può essere utilizzato per
una grande varietà di scopi, anche in ambienti diversi dal cluster e non relazionati a tecnologie di virtualizzazione; questa parte era stata già realizzata
precedentemente alla stesura di questa tesi. Il capitolo ancora seguente mostra invece i moduli aggiunti per permettergli di svolgere in pratica il compito
per cui è stato ideato, il gestore dinamico di ambienti virtuali.
Capitolo 3
Virtdom
3.1
Introduzione
La virtualizzazione può essere di grande aiuto all’interno di un cluster, permettendo di slegare la macchina fisica e il suo hardware dagli ambienti di
esecuzione che essa fornisce e di sfruttarne appieno la potenza di calcolo; da
sé, però, non è sufficiente, in quanto servirebbe comunque un costante intervento umano per regolare l’avvio e la distruzione degli ambienti virtuali in
base allo stato del batch system, che cambia piuttosto frequentemente. Si è
pensato quindi di dare vita ad un componente middleware che, tenendo in
considerazione le necessità contingenti del batch system e lo stato di occupazione dei nodi, avvii finchè possibile macchine virtuali adatte ad accogliere
i job in coda o distrugga quelle non più necessarie. Questo componente è
perciò un gestore di ambienti o domini virtuali, da cui deriva il nome che gli
è stato assegnato, Virtdom (Virtual Domains). Lo sviluppo di Virtdom ha
avuto inizio alla fine del 2007; quando è stato dato inizio a questo lavoro di
tesi era già pronta una prima versione della struttura portante del prototipo
e ne erano state testate con successo le funzionalità basilari. Questo capitolo
mostra l’architettura generale del prototipo, le iniziali scelte implementative,
il protocollo di comunicazione, le modalità di collezione delle informazioni e
di definizione delle politiche decisionali 1
1
Nel corso di questo lavoro di tesi sono state effettuate piccole modifiche rispetto alla
versione iniziale. Quello che è presentato è il prototipo nel suo stato attuale, incluse quindi
tali modifiche.
47
48
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
3.2
Architettura del prototipo
L’applicazione ha la tipica struttura client-server dei programmi middleware:
abbiamo una componente centrale, detta manager, e una componente distribuita, composta dai client in esecuzione su ogni macchina da monitorare. La
relazione tra manager e client è del tipo master-slave, ovvero il manager è su
un livello logico gerarchicamente superiore, è l’unico autorizzato a prendere
decisioni e i client sono subordinati alle sue richieste. La figura 3.1 mostra
l’architettura generale del prototipo.
Figura 3.1: Schema generale di Virtdom
Nel dettaglio i compiti del manager sono:
• Interrogare i client.
• Concentrare le informazioni.
• Prendere decisioni in base allo stato dei client.
• Ordinare ai client l’esecuzione di comandi.
Il manager è a conoscenza delle informazioni esportate da ogni client e le
organizza in apposite strutture dati. La logica decisionale è implementata
configurando appositi trigger che scattano ciclicamente o all’accadere di determinati eventi. I trigger analizzano le informazioni in possesso del manager
e determinano quali azioni devono essere eseguite dai client; a questo scopo
3.2. ARCHITETTURA DEL PROTOTIPO
49
al manager sono note le azioni che ogni client è in grado di compiere. La
figura 3.2 mostra la struttura e le funzionalità del manager.
Figura 3.2: Schema del manager
I compiti dei client invece sono:
• Raccogliere informazioni sensibili dalla macchina locale
• Eseguire comandi per conto del manager
Ogni informazione che il client è in grado di prelevare è detta proprietà.
Una proprietà è definita dal valore d’interesse e da un’etichetta descrittiva:
ad esempio si può specificare la proprietà “cpucount” che indica il numero
di cpu della macchina. Le proprietà non hanno limitazioni di tipo: possono
essere valori numerici, stringhe, valori di verità. Le modalità di raccoltà delle
proprietà sono di competenza del client: tipicamente ci si serve di programmi
o script che ritornano i valori richiesti; in riferimento all’esempio precedente,
per ottenere il numero di cpu della macchina in un sistema Linux basta creare
uno script in un qualsiasi linguaggio di scripting che esegua il comando
cat /proc/cpuinfo | grep processor | wc -l
2
2
Il comando stampa il contenuto del file speciale /proc/cpuinfo, contenente informazioni sui processori a disposizione della macchina, e ne conta il numero di righe contenenti la parola ‘‘processor’’.
50
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
e ne restituisca l’output. Le proprietà sono aggiornate periodicamente da ogni
client e mantenute in attesa delle richieste del manager. I client sono anche
in grado di eseguire azioni dietro richiesta del manager. A questo scopo sono
definiti e messi a disposizione del client una serie di comandi, che pure in
questo caso sono solitamente script o programmi, già esistenti o creati ad
hoc.
La figura 3.3 mostra nel dettaglio il funzionamento di un client.
Figura 3.3: Schema del client
Un concetto chiave è che sia le proprietà e i comandi per i client che la
logica decisionale per il manager sono totalmente configurabili, flessibili ed
estendibili in base all’ambiente. Proprietà, comandi e trigger sono considerabili a tutti gli effetti dei plugin, ovvero dei moduli separati che aggiungono
al programma principale ogni tipo di funzionalità. Virtdom mette a disposizione i meccanismi di comunicazione, di concentramento delle informazioni
e di gestione dei plugin, che vanno definiti tramite appositi file di configurazione, ma nel suo stato iniziale non è in grado di compiere nessuna azione. Il
prototipo deve perciò essere esteso ed adattato in base alle necessità dell’ambiente; inoltre, mentre il manager è unico, ogni client può essere configurato
per fornire diverse proprietà ed eseguire diverse azioni in base al suo ruolo
specifico.
Il lavoro oggetto di questa tesi riguarda proprio l’estensione del prototipo,
attraverso la scrittura di appositi script e trigger, per permettergli di assolvere
3.3. SCELTE IMPLEMENTATIVE
51
a un compito specifico, ovvero il monitoraggio di un cluster e la gestione
appropriata di ambienti virtuali all’interno dello stesso.
3.3
Scelte implementative
Diverse peculiarità del prototipo sono rese possibili dal linguaggio di programmazione utilizzato e dal metodo scelto per lo scambio di messaggi a
basso livello tra manager e client. Il linguaggio in cui è stato scritto Virtdom è Python. Il pacchetto software utilizzato per il sistema di comunicazione è il Toolkit Spread. Il paragrafo analizza le motivazioni di queste scelte
evidenziando le caratteristiche di Python e di Spread che si sono rivelate
particolarmente utili nello sviluppo del prototipo.
3.3.1
Linguaggio di programmazione
Python è un linguaggio di programmazione orientato agli oggetti pseudocompilato. I programmi scritti in Python per essere eseguiti devono prima
essere convertiti in bytecode, che è appunto il risultato della pseudocompilazione del codice sorgente. Un particolare programma detto interprete si
occuperà di tradurre il bytecode in liguaggio maccnhina e quindi eseguirlo.
Le caratteristiche basilari che hanno portato alla scelta di Python sono:
• Facilità di apprendimento
• Codice leggibile e ben manutenibile
• Buona efficienza, nonostante sia interpretato
• Gran numero di librerie in Python e wrapper
altri linguaggi
3
per librerie scritte in
• Ampia diffusione; è incluso di default in tutte le distribuzioni Linux
• Supporto, anche se non particolarmente avanzato, al multi-threading
Alcune caratteristiche particolari e risultate utili, se non indispensabili,
nel corso dello sviluppo, sono i tipi di dato strutturati disponibili nativamente
(come liste e dizionari) e alcune funzioni proprie del linguaggio, come le
funzioni eval, exec o compile. Una breve descrizione di queste caratteristiche
aiuterà a comprendere con maggior precisione il funzionamento del prototipo.
3
Nel linguaggio informatico un wrapper è un oggetto che incorpora e rende disponibili
in un certo linguaggio funzionalità messe a disposizione da librerie già esistenti
52
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
Liste e dizionari
In Python una lista non è nient’altro che quello che nei linguaggi tradizionali
viene chiamato array: una collezione ordinata di oggetti accessibili tramite un indice. Python rende semplice inserire in una lista oggetti complessi
o eterogenei e mette a disposizione funzioni native per l’ordinamento o la
ricerca.
Un dizionario è invece una collezione non ordinata di oggetti. Ogni elemento è identificato univocamente da una chiave, generalmente una stringa,
anziché da un indice. è perciò possibile accedere a un elemento tramite la sua
chiave, senza conoscerne la posizione; l’implementazione efficiente dei dizionari, basata su funzioni hash, fa sı̀ che l’accesso avvenga in tempo costante.
Anche i dizionari possono contenere elementi eterogenei.
Nel codice del prototipo si fa un uso estensivo di liste e dizionari, specie
nelle strutture dati del manager: ad esempio è presente una lista di tutti
i client, oppure ogni client ha un dizionario con la lista delle proprietà. In
quest’ultimo caso è evidente la potenzialità di questi tipi di dato: in un’unica
struttura sono contenute proprietà di tipi diversi (interi, stringhe, ma anche
a loro volta liste o dizionari) accessibili tramite l’etichetta assegnata ad ogni
proprietà.
Funzioni eval, exec e compile
La funzione compile riceve in input una stringa e restituisce pseudocodice
direttamente eseguibile dall’interprete sotto forma di un oggetto detto code
object. La funzione eval riceve in input una stringa o un code object e la
valuta come se fosse un espressione python: se ad esempio riceve una stringa
che rappresenta una lista restituisce la lista stessa. La funzione exec riceve
in input una stringa o un code object e la considera come se fosse codice
python, eseguendolo tramite l’interprete e restituendone l’output.
Sia la funzione eval che la exec hanno due parametri opzionali, locals e
globals, due dizionari che rappresentano il namespace locale e quello globale,
in pratica l’elenco delle variabili visibili a livello di funzione e quello delle
variabili e delle funzioni dell’intero modulo. Questo permette di richiamare
porzioni di codice separate facendole lavorare nello stesso namespace della
funzione chiamante, o parte di esso. Queste tre funzioni, come si vedrà, sono
fondamentali per il meccanismo dei triggers.
3.3. SCELTE IMPLEMENTATIVE
3.3.2
53
Sistema di comunicazione
Lo Spread Toolkit consiste di un demone server che implementa le funzioni di
gestione dei messaggi e di una libreria da utilizzarsi per la realizzazione delle
applicazioni client. Il demone spread gestisce lo scambio di messaggi a basso
livello, l’ordinamento del flusso e l’affidabilità della consegna, la divisione dei
client in gruppi e l’invio in multicast. La libreria offre un set di funzioni che
permette alle applicazioni di collegarsi a una rete spread, entrare o uscire
dai gruppi e ovviamente scambiarsi messaggi con diverse priorità e affidabilità. L’API della libreria è scritta in C ma esistono wrapper per diversi altri
linguaggi, tra cui il Python.
In una rete spread possono esistere più demoni server e ogni client deve
essere registrato presso uno di essi; nel nostro caso si è utilizzato un solo
demone, presso la macchina su cui è in esecuzione il manager. Ogni client ha
associato un nome spread lungo al massimo 32 caratteri: il nome completo
del client, utilizzato per l’invio dei messaggi, sarà dato dall’unione del nome
del client e dell’hostname del server, nel formato
#nome_client#hostname_server
Dal punto di vista del prototipo la comunicazione tra manager e client è
gestita tramite una connessione spread: entrambi sono quindi client rispetto
al demone spread. Una caratteristica che si rivela molto utile per il prototipo è quella già accennata della divisione dei client spread in gruppi: questo
permette di differenziare i client in Virtdom in base alle caratteristiche della
macchina su cui sono in esecuzione o a una qualunque altra classificazione. I messaggi possono quindi essere inviati in modalità multicast, a tutti i
componenti di un determinato gruppo, oltre che, ovviamente, in modalità,
point-to-point, ad un singolo client. Ogni client può appartenere a più di un
gruppo; il manager apparterrà invece a tutti i gruppi definiti.
Messaggi spread
Come già accennato per ogni messaggio si può specificare l’affidabilità di
consegna e l’ordinamento. Nel nostro ambiente i messaggi sono inviati con
l’attributo di alta affidabilità: questo significa che in caso di perdite di messaggi sarà il demone spread ad occuparsi della ritrasmissione. Inoltre si richiede
che i messaggi siano inviati con un ordinamento totale. Questi due parametri
garantiscono la consegna di tutti i messaggi nel corretto ordine.
I messaggi spread sono divisi in due tipologie: messaggi Membership e
messaggi Regular. I messaggi Membership hanno il formato descritto in tabella 3.1 e vengono generati in occasione di eventi come con l’entrata o l’uscita da un gruppo da parte di un client o di una disconnessione dalla rete
54
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
spread. Il tipo dell’evento è specificato da una costante numerica indicata
nel campo reason. Una caratteristica interessante è che si può decidere se un
client spread riceverà o meno questi messaggi. Nel nostro caso solo il manager è interessato alla ricezione dei messaggi membership, per conoscere lo
stato dei gruppi e dei singoli client, mentre i client possono ignorarli senza
conseguenze, benché è importante che li generino.
Campi
Tipo
Significato
MEMBERSHIP MESSAGE
intero
Id messaggio
group
stringa
Nome gruppo
reason
intero
Id evento
extra
stringa
Nome client
Tabella 3.1: Rappresentazione dei campi rilevanti per il prototipo di un messaggio di tipo Membership
I messaggi Regular hanno il formato indicato in tabella 3.2. Nel campo
groups va indicato il destinatario del messaggio, che può essere uno o più
nomi di client spread, uno o più nomi di gruppi o una combinazione dei
due. Il campo message contiene il contenuto informativo del messaggio, il
cosiddetto “payload”. Il campo msg type è un intero a 16 bit e contiene la
categoria del messaggio in relazione alla particolare applicazione. È utilizzato
per realizzare in pratica il protocollo di comunicazione: il mittente tramite
esso indica il significato del contenuto del campo message, mentre il ricevente
lo utilizza per estrarne in modo appropriato le informazioni.
Campi
Tipo
Significato
REGULAR MESSAGE
intero
Id messaggio
groups
lista
Destinatari
message
stringa
Dati
msg type
intero
Codice
sender
stringa
Mittente
Tabella 3.2: Rappresentazione dei campi rilevanti per il prototipo di un messaggio di tipo Regular
3.4
Protocollo di comunicazione
Il protocollo di comunicazione tra manager e client è stato costruito attraverso la definizione di tipologie di messaggi, differenziabili attraverso l’apposito
campo (msg type) nei messaggi regular di spread. La semantica del campo
dati (message) dipenderà appunto dalla tipologia del messaggio. Le costanti
numeriche che identificano il tipo di ogni messaggio sono definite in un apposito file. Sia per il manager che per i client l’operazione preliminare è la
connessione alla rete spread e la dichiarazione dell’appartenenza a uno o più
gruppi; i messaggi saranno poi inviati o ricevuti attraverso un oggetto spread
detto MailBox.
3.4. PROTOCOLLO DI COMUNICAZIONE
3.4.1
55
Messaggi del manager
Il set di messaggi del manager comprende le seguenti categorie:
• Messaggi per la richiesta di proprietà. Rientrano in questa categoria i
messaggi identificati dalle costanti GETPROP e FETCHPROP. Se il
campo dati è vuoto il messaggio indica la richiesta della lista delle proprietà, altrimenti il campo dati conterrà l’etichetta della proprietà di cui
si richiede il valore. La differenza tra i due messaggi è che FETCHPROP
forza l’aggiornamento della proprietà prima dell’invio.
• Messaggi per ordinare l’esecuzione di comandi. Questa categoria comprende il solo messaggio EXECUTE, nel cui campo dati sarà indicato il
nome del comando da eseguire e gli eventuali parametri; se il campo dati è vuoto indica invece la richiesta della lista dei comandi a disposizione
del client.
• Messaggi per il controllo della connessione dei client. I messaggi di questa categoria permettono al manager di ordinare al client di eseguire
determinate azioni sulla sua connessione. Abbiamo il messaggio STOP,
per forzare la disconnessione del client, il messaggio RCON, per ordinare la reinizializzazione della connessione, il messaggio RJOIN, per
ordinare al client di riassociarsi al gruppo indicato nel campo dati
3.4.2
Messaggi del client
Solitamente ad ogni messaggio del manager corrisponde un messaggio di risposta del client, detto messaggio di callback. I messaggi di callback rientrano
nelle seguenti categorie, speculari a quelle del manager:
• Valori delle proprietà richieste. I messaggi di questa categoria sono
identificati dalle costanti PROPLIST, per inviare la lista delle proprietà
esportate dal client, PROPVAL, per restituire il valore della proprietà
richiesta, e PROPERR, in caso di richiesta del valore di una proprietà
mancante.
• Risultato dell’esecuzione di un comando. Appartengono a questa categoria i messaggi EXECLIST, con la lista dei comandi che il client è in
grado di eseguire, e EXECRET, che ritorna i risultati dell’esecuzione
di un comando o il suo codice d’errore.
• Messaggi informativi. In questa categoria si trovano i messaggi inviati
in risposta a messaggi di controllo da parte del manager e servono
soprattutto per la diagnostica di eventuali problemi.
56
3.5
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
Struttura del client
I due compiti principali del client sono tenere aggiornata una lista di proprietà
ed eseguire comandi per conto del manager. Questo paragrafo spiega nel
dettaglio come ogni client assolve a queste reponsabilità e le modalità di
configurazione. La figura 3.4 mostra la struttura di un client, comprendente
i moduli che verranno man mano descritti.
Figura 3.4: Schema dettagliato di un client e dei suoi moduli.
3.5.1
Gestione file eseguibili
Per raccogliere informazioni dal sistema ed eseguire comandi il client si appoggia a una collezione di file eseguibili, propri del sistema o creati ad hoc.
Poiché il demone client è in esecuzione con pieni privilegi all’interno del sistema operativo è necessario limitare il suo raggio d’azione. Per gestire questo
meccanismo il client è dotato di un apposito modulo, chiamato Runner, che
indicizza tutti i file eseguibili presenti in una lista di cartelle indicata nel file
di configurazione; l’esecuzione di un comando avviene tramite questo modulo,
che è in grado di utilizzare solo gli eseguibili a lui noti.
Il comando viene eseguito dal modulo tramite i metodi forniti dal namespace command del python; in particolare il metodo getoutput riceve in input
il nome del comando e gli eventuali parametri, lo esegue nella shell del sistema e ne restituisce l’output sotto forma di stringa, che verrà utilizzato per
3.5. STRUTTURA DEL CLIENT
57
aggiornare il valore di una proprietà o restituire il risultato dell’esecuzione,
in base allo scopo per cui è stato eseguito il comando.
3.5.2
Gestione proprietà
Si è detto che una proprietà è un valore collegato a una etichetta, una stringa
che ne indica il significato. Può essere utilizzato come proprietà un qualunque
attributo del sistema prelevabile tramite gli eseguibili noti al modulo Runner;
ad esempio, si è fatto prima riferimento al numero di cpu della macchina
e allo script necessario per ottenere tale informazioni. Poichè tali attributi
possono variare nel tempo (ad esempio la quantità di memoria RAM libera),
deve essere previsto un meccanismo per prelevare periodicamente i valori
aggiornati delle proprietà.
Dal punto di vista del client una proprietà è quindi definita dalle seguenti
componenti:
• Etichetta descrittiva
• Comando per ottenerne il valore, con eventuali parametri
• Tipo di dato che la proprietà rappresenta
• Intervallo di aggiornamento
Il tipo di dato non è utile tanto al client, che memorizza tutti i valori sotto
forma di stringa, cosı̀ come sono restituiti dal modulo runner, ma al manager,
che quando riceve le proprietà è cosı̀ in grado di memorizzarle e utilizzarle
nel corretto formato. Accanto ai tipi di dato tradizionali (intero, stringa,
booleano, ecc.) è stato definito anche un tipo di dato fittizio, eval, che include
tutti i tipi di dato complessi (liste, dizionari), espressi sotto forma di stringa,
che l’istruzione eval è in grado di riportare al tipo di dato originario. Il tipo
eval permette perciò lo scambio di tipi di dato complessi evitando al manager
più o meno complesse operazioni di decodifica.
I valori delle proprietà sono mantenuti dal client in un’apposito dizionario,
pronti ad essere letti e inviati dietro richiesta del manager.Per permettere
l’aggiornamento periodico dei lavori il client si serve di un altro modulo,
ReaderDaemon, che viene eseguito in un thread separato e attiva un ciclo
generico di esecuzione in base a quanti di tempo definibili arbitrariamente
nel file di configurazione.
58
3.5.3
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
Comunicazione con il manager
Il client ha un ruolo totalmente passivo nella comunicazione: esso resta infatti in attesa di ordini da parte del manager e l’invio di messaggi avviene
esclusivamente in risposta a tali ordini. Fanno eccezione i messaggi di membership, che vengono inviati implicitamente quando il client compie azioni
relative alla rete spread. La ricezione e l’invio di messaggi di risposta sono
permessi al client da un terzo modulo, IFaceDaemon. Anche questo modulo è
eseguito in un thread separato e periodicamente controlla l’oggetto MailBox
alla ricerca di nuovi messaggi: se ne trova ne determina la categoria ed esegue
l’operazione richiesta, al suo interno o attraverso gli altri moduli. Per l’invio
di messaggi il modulo mette a disposizione un apposito metodo che riceve un
messaggio come parametro e lo invia al manager.
3.5.4
Configurazione
La configurazione del client avviene attraverso un file principale e uno o più
file aggiuntivi e opzionali in cui vengono definite le proprietà. La struttura
dei file segue lo standard dei file di inizializzazione, costituiti da sezioni e
parametri.
Nel file di configurazione principale deve essere presente la sezione “config” contenente le impostazioni di inizializzazione. Tutte le altre sezioni, nel
file principale e negli altri file, sono interpretate come proprietà. Le informazioni sono estratte dai file attraverso appositi metodi forniti dai namespace
del python che offrono funzionalità di parsing dei file di configurazione.
La struttura del file principale di configurazione è la seguente:
[config]
exe_path = ...
fetch_interval = ...
user_properties = ...
spread_daemon = ...
spread_port = ...
local_name = ...
manager_name = ...
groups = ...
[proprietà]
command = ...
parameters = ...
return_type = ...
3.6. STRUTTURA DEL MANAGER
59
ticks = ...
Il parametro exe path definisce le directory contenenti i file eseguibili cche
devono essere a disposizione del modulo runner. La definizione non è ricorsiva:
le sottodirectory delle directory indicate devono essere incluse esplicitamente. Il parametro fetch interval specifica in secondi il quanto di tempo di base
per l’aggiornamento delle proprietà. Il parametro user properties contiene il
percorso di uno o più file di configurazione contenenti definizioni di proprietà.
Benché si possano definire proprietà all’interno del file principale, questo permette di dividere in classi le proprietà accomunate logicamente. I parametri
spread daemon e spread port indicano l’hostname della macchina su cui è in
esecuzione il demone spread e la porta su cui esso è in ascolto. Il parametro local name indica il nome spread del client: solitamente è consigliabile
farlo corrispondere all’hostname della macchina; manager name indica il nome spread del manager in esecuzione sulla rete al quale il client deve essere
associato. Il parametro groups definisce i gruppi spread a cui il client deve
richiedere l’appartenenza appena dopo essersi connesso alla rete spread.
In ogni altra sezione del file principale, e per tutte le sezioni degli altri
file, il nome della sezione è interpretato come etichetta di una proprietà. I parametri che seguono corrispondono alle altre tre componenti di una proprietà
dal punto di vista del client prima descritte. Il parametro command indica
l’eseguibile che permette di ottenere il valore della proprietà, mentre il parametro parameters specifica gli eventuali parametri da passare al comando.
Il parametro return type indica il tipo di dato della proprieà. Il parametro
ticks definisce il numero di quanti di tempo base che devono passare prima
di aggiornare la proprietà: la frequenza di aggiornamento in secondi di una
proprietà si ottiene quindi attraverso l’operazione ticks * fetch interval.
3.6
Struttura del manager
I compiti del manager sono principalmente quelli di collezionare le proprietà
dei client, prendere decisioni in base ed esse ed ordinare ai client l’esecuzione
di azioni corrispondenti. Il paragrafo descrive nel dettaglio il funzionamento
del manager e la sua configurazione.La figura 3.5 mostra le strutture dati e
i moduli del manager che saranno ora descritti.
3.6.1
Collezione delle informazioni
Il manager possiede apposite strutture dati per mantenere informazioni sui
client e sul loro stato. La classe base utilizzata è chiamata ClientDomain,
che rappresenta un singolo client. Questa classe contiene un dizionario con
60
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
Figura 3.5: Schema dettagliato del manager.
tutte le proprietà del client e una lista con i nomi dei gruppi spread a cui
il client appartiene. Nel manager è quindi definito un dizionario, chiamato
clients, in cui le etichette sono i nomi dei client noti e i valori sono gli oggetti
ClientDomain corrispondenti. Un secondo dizionario e chiamato groups, che
fa corrispondere a ogni nome di gruppo spread la lista dei nomi di client
appartenenti a quel gruppo; lo scopo di questo dizionario è ricavare rapidamente i client associati a un gruppo senza esaminare tutto il dizionario
clients. Queste strutture dati vengono appropriatamente modificate in base
agli eventi che si presentano sulla rete, come si vedrà nel paragrafo seguente,
che esamina le modalità di comunicazione tra manager e client.
3.6.2
Comunicazione con i client
A differenza dei client il ruolo del manager è attivo, in quanto genera ed
invia messaggi regular per l’interrogazione e il controllo dei client. Il manager
è l’unico che indica al demone spread la necessità di ricevere i messaggi di
membership, che utilizza per controllare lo stato della rete e aggiornare le
proprie strutture dati. Inoltre utilizza due moduli separati, Listener per la
ricezione e Sender per l’invio. Il modulo Listener controlla periodicamente
l’oggetto MailBox creato al momento della connessione alla rete spread in
attesa di nuovi messaggi e se ne trova esegue le azioni corrispondenti. Se il
messaggio è di membership il comportamento del manager è quello mostrato
nel diagramma in figura.
3.6. STRUTTURA DEL MANAGER
61
I messaggi regular in entrata che allo stato attuale il manager è in grado
di gestire sono solo quelli riguardanti le proprietà. Come si nota nel diagramma in figura, quando il manager viene a conoscenza di un nuovo client invia
un messaggio di richiesta della lista delle proprietà. Quando il messaggio di
callback viene ricevuto, le proprietà contenute nel messaggio vengono inserite
nell’apposito dizionario delle proprietà contenuto nell’oggetto ClientDomain
relativo al nuovo client. Quando il manager riceve invece un messaggio contenente il valore di una certa proprietà di un client, viene aggiornato il dato
corrispondente nel dizionario delle proprietà.
Il modulo Sender si occupa invece dell’invio di messaggi, fornendo appositi metodi per le diverse tipologie di messaggi. La gran parte dell’invio di
messaggi avviene, come si vedrà, all’interno dei trigger. È possibile scegliere
in fase di configurazione se l’invio di messaggi deve avvenire in modo immediato o periodicamente. Nel secondo caso il messaggio passato al modulo
viene inserito in una coda FIFO, da cui i messaggi vengono estratti ed inviati
a intervalli regolari; questo metodo è preferibile in quanto viene garantito un
tempo minimo tra l’invio di un messaggio e l’altro, evitando di saturare la
rete nei momenti di maggior traffico.
Caduta del manager
Una situazione particolare si viene a verificare nel caso in cui il manager venga temporaneamente a mancare. Quando questo accade i client proseguono
nella loro attività di prelievo delle proprietà, senza la possibilità di accorgersi
dell’evento. Quando il manager viene riattivato e si ricollega alla rete spread
ha perso tutte le informazioni relative ai client. Per riprendere il controllo
della situazione è previsto che al suo avvio il manager mandi un messaggio di
tipo RJOIN in multicast a tutti i gruppi di cui è a conoscenza; in risposta gli
eventuali client attivi usciranno e rientreranno nei relativi gruppi, causando
messaggi di membership che il manager utilizzerà per ricostruire le proprie
strutture dati.
3.6.3
Decisione: i trigger
Il manager deve essere in grado di tenere costantemente sotto controllo lo stato dei client ed eseguire azioni in risposta a determinate situazioni o eventi.
È stato perciò creato un potente meccanismo per definire ed attivare trigger che prendano decisioni in base allo stato delle risorse note al manager. I
trigger non fanno parte del prototipo nel suo stato iniziale, ma vanno appositamente scritti in moduli separati ed aggiunti tramite i file di configurazione;
62
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
essi infatti dipendono fortemente dalle proprietà e dai comandi esportati dai
client, che variano a seconda dell’ambiente d’utilizzo del prototipo.
Un trigger consiste di due componenti fondamentali:
• Una condizione, che ne determina o meno l’avvio.
• Il trigger vero e proprio, che generalmente consiste di una serie di
ulteriori valutazioni sullo stato delle risorse e l’invio di messaggi che
ordinano ai client l’esecuzione di appropriati comandi.
Per permettere al trigger di operare sulle strutture dati del manager pur
facendo parte di un modulo separato sono di fondamentale importanza le
funzionalità del python mostrate nel paragrafo. Tramite il metodo compile il
manager, al suo avvio, precompila tutte le condizioni e i relativi trigger di cui
viene messo a conoscenza dai file di configurazione, salvando i code object
risultanti in apposite strutture dati. Per valutare la condizione di un trigger
viene utilizzata la funzione eval, che ne restituisce il valore booleano. Se il
valore risultante è vero il trigger viene eseguito tramite la funzione exec. Sia
eval che exec ricevono in input i code object che il manager ha precedentemente prodotto e memorizzato e i dizionari locals e globals, appositamente
costruiti in modo da contenere le informazioni in possesso del manager utili
per l’esecuzione dei trigger. In particolare, il corpo del trigger, eseguito dalla
funzione exec, è messo a conoscenza di tutte le strutture dati del manager, e
gli viene messo a disposizione il modulo Sender, in modo che siano in grado
di inviare messaggi ai client tramite i consueti meccanismi del prototipo.
Un altra caratteristica fondamentale dei trigger è la loro modalità di attivazione, da specificare in fase di configurazione, che può essere periodica
o conseguente a una modifica dello stato dei client. Il manager mantiene in
due strutture dati separate i trigger di diversa tipologia. Per il primo caso
è stato predisposto un modulo, TriggerDaemon, che periodicamente valuta
le condizioni dei trigger interessati e, per ogni condizione verificata, esegue
l’azione corrispondente. Nel secondo caso il meccanismo di valutazione ed
eventuale esecuzione è svolto da un apposita funzione, che va richiamata del
manager in tutte le occasioni che si verifica un cambiamento di stato, ovvero, allo stato attuale, in caso di entrata o uscita di un client da un gruppo,
di disconnessione di un client dalla rete spread o di invio del valore di una
proprietà da parte di un client. Il tipo di evento tipicamente va discriminato
nella condizione del trigger: per permettere ciò nel dizionario locals passato
alla funzione eval sono indicati il nome del client che ha causato l’evento, il
gruppo di appartenenza, l’eventuale nome della proprietà e il tipo di evento,
identificato da una costante numerica; nel dizionario globals sono presenti
invece tutti i dati contenuti nelle strutture del manager. I trigger di questo
3.7. CONFIGURAZIONE DEL MANAGER
63
secondo tipo permettono perciò di eseguire azioni in immediata risposta a
cambiamenti di stato, in modo da agire su valori di proprietà appena giunti
e quindi certamente aggiornati; al contrario, i trigger del primo tipo agiscono
su valori di cui non si conosce l’effettiva corrispondenza al reale stato delle
risorse.
3.7
Configurazione del manager
La configurazione del manager è molto simile a quella del client. Segue la
stessa struttura, con una sezione “config” iniziale e un numero variabile di
sezioni seguenti, interpretate tutte come trigger, che possono essere contenute
nel file principale o in file aggiuntivi.
Il modello del file principale di configurazione è il seguente:
[config]
spread_daemon = ...
spread_port = ...
local_name = ...
groups = ...
queued_sending = yes/no
queued_sending_interval = ...
triggers_eval_interval = ...
user_triggers = ...
[trigger]
expr = {...}
cmd = {...}
on_update_check = yes/no
ticks = ...
I parametri spread daemon, spread port e local name hanno lo stesso significato descritto per i client. Il valore del campo local name dovrà corrispondere al valore del campo manager name nel file di configurazione di tutti
i client sotto il controllo del manager. Il campo groups indica tutti i gruppi
di cui si desidera che il manager abbia il controllo; come si è visto nel paragrafo questo elenco è particolarmente utile in caso di caduta del manager, in
quanto è l’unica informazione sulla configurazione della rete spread che esso
possiede al suo avvio. Gli attributi queued sending e queued sending interval
indicano rispettivamente se si desidera che il manager utilizzi una coda FIFO
per l’invio di messaggi e, in caso affermativo, l’intervallo di tempo in secondi tra un invio e il successivo. Il parametro triggers eval interval definisce il
64
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
quanto di tempo base, in secondi, per la valutazione dei trigger attivati su
base temporale. L’ultimo campo, user triggers, specifica il percorso di uno o
più file di configurazione contenenti definizioni di trigger.
Ogni altra sezione è interpretata come un trigger. Il parametro expr indica
la condizione che viene valutata per decidere se avviare o meno l’esecuzione del trigger. Tale parametro deve essere scritto in codice python ed essere
un’espressione logica unitaria e correttamente interpretabile. Il campo cmd
contiene il corpo del trigger, che può essere scritto direttamente nel file di configurazione o in un file separato. In quest’ultimo caso il campo deve contenere
il percorso di tale modulo esterno preceduto dalla stringa “file:”. L’attributo
ticks indica il numero di quanti di tempo basilari devono trascorrere per la
valutazione del trigger; come per l’intervallo di aggiornamento delle proprietà
di client, il valore dell’intervallo di valutazione dei trigger in secondi si ricava
attraverso l’operazione ticks * triggers eval interval. Se il valore del campo
ticks contiene un numero negativo, il trigger corrispondente non verrà mai
valutato su base temporale. Il parametro on update check definisce invece se
il trigger deve essere valutato o meno in seguito a cambiamenti di stato.
3.8
Test e considerazioni
Durante e al termine della prima fase di sviluppo di Virtdom sono stati
effettuati diversi test per verificare il corretto funzionamento del prototipo,
sia in termini di affidabilità che di efficienza. Quest’ultimo paragrafo mostra
alcuni risultati dei test ed espone ulteriori considerazioni.
3.8.1
Test
Come ambiente di test è stato utilizzato quello che sarà meglio descritto
nel prossimo capitolo. Si può dire brevemente che è costituito da un pool
di Xen Domain-0, su uno dei quali è stato attivato il manager e sugli altri
un numero variabile di client per ciascuno. I client non prelevavano nessuna
proprietà dalla macchina locale, ma ne possedevano una fittizia costituita
da 10Kb di caratteri random; sul manager era impostato un solo trigger,
per prelevare costantemente tale proprietà da tutti i client ogni 10 secondi.
La dimensione della proprietà è significativa in quanto spesso le proprietà
comunemente utilizzate sono di gran lunga più piccole. Come strumento di
monitor è stato usato un apposito script, in esecuzione sulla macchina dove
era ospitato il manager, che prelevava costantemente, tramite gli strumenti
forniti dal sistema operativo, i valori locali di utilizzo della rete, della cpu e
della memoria. Durante i test si è cercato di ridurre al minimo qualunque altra
3.8. TEST E CONSIDERAZIONI
65
attività sulla macchina in esame, in modo che i valori ottenuti rispecchiassero
quasi fedelmente il reale consumo di risorse da parte del prototipo.
Nel primo test sono stati utilizzati complessivamente 300 client e il manager è stato configurato per inviare messaggi senza intervalli forzati tra
l’uno e l’altro. La situazione è stata monitorata per 300 secondi. Il risultato
è mostrato in figura 3.6.
Figura 3.6: Test di comunicazione con 300 client senza l’uso di una coda FIFO.
Vanno evidenziati i picchi in download di circa 3000 Kb/s: il client inviava i messaggi di richiesta delle proprietà a tutti i client quasi contemporaneamente e allo stesso modo giungevano le risposte. Il valore ottenuto è
consistente con l’ambiente di test: 300 client che inviano insieme al manager
un messaggio da 10Kb, per un totale di 3000 Kb/s.
Il secondo test utilizzava invece 100 client, e il manager era impostato per
inviare i messaggi tramite la coda FIFO, al ritmo di 10 al secondo. Anche
in questo caso la situazione è stata monitorata per 30 secondi. Per questo
test,invece, il valore in download non presenta picchi consistenti, ma si attesta
intorno ai 100 Kb/s. Anche questo valore è consistente con l’ambiente creato:
ipotizzando una risposta immediata dei client, al manager sarebbero giunte
10 messaggi da al secondo da 10Kb ciascuno, per un totale di 100 Kb/s, che
è praticamente il valore medio ottenuto. Il grafico di questo test è mostrato
in figura 3.7.
Per effettuare test di scalabilità sono state mantenute le impostazioni del
manager come nel secondo dei test precedenti, aumentando gradualmente il
numero dei client e monitorando l’andamento per circa 5 minuti dopo ogni
66
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
Figura 3.7: Test di comunicazione con 100 client con l’utilizzo di una coda FIFO.
incremento, effettuando poi la media dei valori ottenuti per ognuno degli
intervalli. Si sono ottenuti cosı̀ i grafici dell’utilizzo medio delle risorse di
rete, della CPU e della memoria RAM all’aumentare del numero dei client,
mostrati nelle figure 3.8 (a), (b) e (c).
I grafici mostrano come l’utilizzo delle risorse aumenti in modo praticamente lineare in relazione al numero dei client. Questo indica che la scalabilità
del prototipo all’aumentare del numero delle risorse amministrate è buona,
e che non ci sono evidenti debolezze o “colli di bottiglia” anche in una situazione piuttosto al limite. È interessante notare come il valore di utilizzo
in upload si attesti ad un valore costante oltre i 100 client. Questo è perfettamente in sintonia con le impostazioni del manager, che genera e mette in
coda le richieste di proprietà per tutti i client ogni 10 secondi, ma è in grado
di inviarne al massimo 100 in questo intervallo (10 al secondo).
3.8.2
Considerazioni
Nel corso dei test per il prelievo delle proprietà dai client è stato utilizzato
un semplice trigger, cosı̀ definito:
[trigger]
expr = { len(manager.clients) != 0 }
cmd = { sender.send_get_property() }
on_update_check = no
ticks = 10
3.8. TEST E CONSIDERAZIONI
(a) Utilizzo CPU.
67
(b) Utilizzo RAM.
(c) Utilizzo rete.
Figura 3.8: Test di scalabilità: è mostrato l’aumento dell’utilizzo delle risorse da parte del manager
all’aumentare del numero dei client.
Questo trigger utilizza semplicemente il metodo send get property fornito dal
modulo Sender, che, se richiamato senza parametri, richiede i valori di tutte
le proprietà a tutti i client noti. La condizione indica che il trigger deve essere
eseguito se c’è almeno un client attivo.
Benché si sia detto che i trigger devono essere definiti in base all’ambiente
d’esecuzione e allo scopo del prototipo, un trigger uguale o simile a questo è
praticamente necessario in ogni situazione. Il manager infatti richiede automaticamamente solo la lista delle proprietà di un client, quando tale client
si unisce alla rete spread per la prima volta, ma non è prevista una funzionalità di richiesta e aggiornamento delle proprietà nativamente, all’interno
del manager. Se non si hanno a disposizione i valori delle proprietà, e non
si aggiornano con una certa frequenza, il manager, e soprattutto i trigger,
perdono il loro valore e la loro funzionalità.
Il prossimo capitolo mostrerà come Virtdom è stato esteso per gestire
macchine virtuali all’interno di un cluster, al servizio del batch system. Per
far questo sono stati scritti e testati appositi script di prelievo delle proprietà,
script di esecuzione di azioni per conto del manager e trigger. Il trigger sopra
68
CAPITOLO 3. IL PROTOTIPO: VIRTDOM
definito è stato il primo ad essere aggiunto alla configurazione del manager.
Capitolo 4
Stage
4.1
Introduzione
4.2
Ambiente di test
4.2.1
Code, tipi di VM e Dom0
4.3
Client: proprietà e azioni
4.4
Manager: trigger
4.5
Configurazione del batch system
4.6
Test
69
70
CAPITOLO 4. ESTENSIONE DEL PROTOTIPO
Capitolo 5
Conclusioni
TODO
71
72
CAPITOLO 5. CONCLUSIONI
Ringraziamenti
Thanks to...
RIKKA
73
74
CAPITOLO 5. CONCLUSIONI
Bibliografia
[1] R. Buyya. High Performance Cluster Computing: Architectures and
Systems, Volume I. Prentice Hall, 1999.
[2] M. Baker et al. Cluster Computing White Paper.
cs.DC/0004014, 2000.
Arxiv preprint
[3] G.F. Pfister. In search of clusters. Prentice-Hall, Inc. Upper Saddle
River, NJ, USA, 1998.
[4] BC Brock, GD Carpenter, E. Chiprout, ME Dean, PL De Backer, EN Elnozahy, H. Franke, ME Giampapa, D. Glasco, JL Peterson, et al. Experience with building a commodity intel-based ccNUMA system. IBM
J. RES. DEV, 45(2):207–227, 2001.
[5] H.W. Meuer. The TOP500 Project: Looking Back over 15 Years of
Supercomputing Ex-perience. 2008.
[6] J.J. Dongarra, H.W. Meuer, E. Strohmaier, and altri. TOP500 Supercomputer Sites. URL http://www. top500. org/.(updated every 6
months), 2008.
[7] F. Cantini. Studio delle prestazioni di un batch system basato su
torque/maui, 2007.
[8] I. Foster. What is the Grid? A Three Point Checklist. Grid Today,
1(6):22–25, 2002.
[9] I. Foster. The Grid: A new infrastructure for 21st century science.
Physics Today, 55(2):42–47, 2002.
[10] I. Foster, C. Kesselman, and S. Tuecke. The Anatomy of the Grid.
[11] M. Baker, R. Buyya, and D. Laforenza. Grids and Grid technologies for
wide-area distributed computing.
75
76
BIBLIOGRAFIA
[12] I. Neri. Installazione, configurazione e monitoraggio di un sito INFNGrid., 2005.
[13] Lcg project overview.
[14] G.J. Popek and R.P. Goldberg. Formal requirements for virtualizable
third generation architectures. Communications of the ACM, 17(7):412–
421, 1974.
[15] M. Tim Jones. Virtual linux an overview of virtualization methods,
architectures, and implementations. 2006.
[16] S.N.T. Chiueh. A Survey on Virtualization Technologies.
[17] R. Rose. Survey of System Virtualization Techniques. 2004.
[18] B. Quetier, V. Neri, and F. Cappello. Selecting A Virtualization System For Grid/P2P Large Scale Emulation. Proc of the Workshop on
Experimental Grid testbeds for the assessment of largescale distributed
applications and tools (EXPGRID06), Paris, France, 19-23 June, 2006.
[19] K. Adams and O. Agesen. A comparison of software and hardware
techniques for x86 virtualization. Proceedings of the 12th international conference on Architectural support for programming languages and
operating systems, pages 2–13, 2006.
[20] J.S. Robin and C.E. Irvine. Analysis of the Intel Pentium’s ability to
support a secure virtual machine monitor. Proceedings of the 9th conference on USENIX Security Symposium-Volume 9 table of contents, pages
10–10, 2000.
[21] M.F. Mergen, V. Uhlig, O. Krieger, and J. Xenidis. Virtualization for
high-performance computing. ACM SIGOPS Operating Systems Review,
40(2):8–11, 2006.
[22] W. Huang, J. Liu, B. Abali, and D.K. Panda.
Performance Computing with Virtual Machines.
A Case for High
[23] P. Barham, B. Dragovic, K. Fraser, S. Hand, T. Harris, A. Ho, R. Neugebauer, I. Pratt, and A. Warfield. Xen and the art of virtualization.
Proceedings of the nineteenth ACM symposium on Operating systems
principles, pages 164–177, 2003.
BIBLIOGRAFIA
77
[24] B. Clark, T. Deshane, E. Dow, S. Evanchik, M. Finlayson, J. Herne, and
J.N. Matthews. Xen and the art of repeated research. Proceedings of the
Usenix annual technical conference, Freenix track, pages 135–144, 2004.
[25] P.R. Barham, B. Dragovic, and K.A. Fraser. Xen 2002. 2003.
[26] H.K.F. Bjerke. HPC Virtualization with Xen on Itanium. PhD thesis, Master thesis, Norwegian University of Science and Technology
(NTNU), July 2005.
[27] A. L. Lopez. Uso di macchine virtuali (XEN) per garantire servizi di
Grid, 2006.
[28] Xen 3.0 Users Manual, 2008.
[29] Xen 3.0 Interface Manual for x86, 2008.