Database Systems
Chapter 9: Technology of a database server
Hash-based structures
• Ensure an efficient associative access to data, based on the
value of a key field, composed of an arbitrary number of
attributes of a given table
• A hash-based structure has B blocks (often adjacent)
• The access method makes use of a hash algorithm, which, once
applied to the key, returns a value between zero and B-1
• This value is interpreted as the position of the block in the file,
and used both for reading and writing tuples to the file
• The most efficient technique for queries with equality
predicates, but inefficient for queries with interval predicates
McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Features of hash-based structures
• Primitive interface: hash(fileid,Key):Blockid
•
The implementation consists of two parts
– folding, transforms the key values so that they become
positive integer values, uniformly distributed over a large
range
– hashing, transforms the positive binary number into a
number between 0 and B - 1
• This technique works better if the file is made larger than
necessary. Let:
– T the number of tuples expected for the file
– F the average number of tuples stored in each page,
then a good choice for B is T/(0.8 x F), using only 80% of the
available space
McGraw-Hill 1999
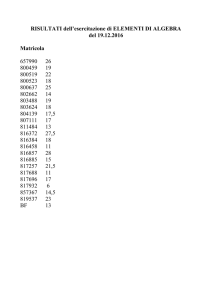
Esercizio Hashing
Si consideri una base di dati gestita tramite hashing,
il cui campo chiave contenga i seguenti nominativi:
Green, Lovano, Osby, Peterson, Pullen Scofield,
Allen, Haden, Sheep, Harris, MacCann, Mann,
Brown, Hutcherson, Newmann, Ponty, Cobbham,
Coleman, Mingus, Lloyd, Tyner, Fortune, Coltrane.
1) Proporre un algoritmo di hashing con B=8.
Una semplice funzione di hashing per i nomi dati è:
• Per ogni carattere del nome, considerare il
corrispondente numero in ordine alfabetico (a =
1, b = 2 …)
• Sommare tutti i numeri ottenuti e fare il
“modulo B” della divisione
In questo caso otterremo per ogni nome un
numero compreso tra 0 e B-1.
Soluzione:
Hash(Green) = (7+18+5+5+14) mod 8=1
Hash(Lovano) = (12+15+22+1+13+15) mod 8=6
Hash(Osby) = (15+19+2+25) mod 8=5
Hash(Peterson)=
(16+5++20+5+18+19+15+13) mod 8=7
...
• T = 100 e F = 4
1) Supponendo di utilizzare solo 80% dello spazio
disponibile, che valore assume la variabile B (#
blocchi)?
T = 100 # tuple nel file
F = 4 (numero medio di tuple nella stessa pagina)
1) Supponendo di utilizzare solo 80% dello spazio
disponibile, che valore assume la variabile B (#
blocchi)?
B = T/(u*F) -> B = 100 / (0,8 * 4) = 31,25 ≈ 31
Progetto di strutture hash
Si vuole memorizzare una tabella di 16000 record, della
dimensione fissa di 1KByte ciascuno e con chiave primaria
rappresentata da un intero ad autoincremento, tramite una
struttura ad accesso hash-based. In particolare, occorre
scegliere se impiegare pagine fisiche della dimensione di 4
oppure di 16 Kbyte. Si scelga un opportuno coefficiente di
riempimento nei due casi, si proponga una possibile
funzione di hash, e si indichi il numero di pagine necessarie
a contenere la tabella nei due casi, in base al progetto.
Scegliamo per semplicità un fattore di riempimento “lasco”, del 50%, e
una semplice funzione di modulo sulla chiave primaria come funzione di
hash, in entrambi i casi, assumendo distribuzione uniforme sui valori di
chiave (dopo molti insert e delete).
• In caso di distribuzione omogenea, ogni blocco contiene 4K x 50% / 1K
= 2 tuple, quindi occorrono 16000/2 = 8000 pagine, usando una
funzione h(t) = key(t) mod 8000, dove key() indica la chiave primaria
• Con pagine da 16K, invece, ogni blocco contiene 16K x 50% / 1K = 8
tuple, quindi occorrono 16000/8 = 2000 pagine, usando una funzione
h(t) = key(t) mod 2000,
Ovviamente diversi livelli di riempimento desiderati comportano un
diverso numero di pagine e una diversa funzione di hash.In particolare,
volendo differenziare i fattori di riempimento, ha più senso aumentarlo per
la variante B. Con un fattore di riempimento dell’80% avremmo 16000 /
(16K x 80%) x 1K = 1250 pagine, con quindi h(t) = key(t) mod 1250
Database Systems
Chapter 9: Technology of a database server
Tree structures
• The most frequently used in relational DBMSs
• Gives associative access (based on a value of a key, consisting
of one or more attributes) without constraints on the physical
location of the tuples
• Note: the primary key of the relational model and the
key of tree structures are different concepts
McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Tree structure organization
• Each tree has:
– a root node
– a number of intermediate nodes
– a number of leaf nodes
• The links between the nodes are established by pointers
• Each node coincides with a page or block at the file system and
buffer manager levels. In general, each node has a large
number of descendants (fan out), and therefore the majority of
pages are leaf nodes
• In a balanced tree, the lengths of the paths from the root node to
the leaf nodes are all equal. In this case, the access times to the
information contained in the tree are almost constant (and
optimal)
McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Information contained in a node (page) of a B+ tree
P0
K1
Sub-tree that contains
keys K < K1
P1
. . . . .
Kj
Pj
. . . . .
Sub-tree that contains
keys Kj ≤ K< Kj+1
KF
PF
Sub-tree that contains
keys K ≥ KF
© McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Split and merge operations on a B+ tree structure
initial situation
k1
k6
k1
k2
k4
k1
k3
k6
k5
a. insert k3: split
k1
k2
k3
k4
k5
b. delete k2: merge
k1
k6
k1
k3
k4
k5
© McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Difference between B and B+ trees
• B+ trees:
– The leaf nodes are linked by a chain, which connects them
in the order imposed by the key
– Support interval queries efficiently
– Mostly used by relational DBMSs
• B trees:
– There is no sequential connection of leaf nodes
– Intermediate nodes use two pointers for each key value Ki
• one points directly to the block that contains the tuple
corresponding to Ki
• the other points to a sub-tree with keys greater than Ki
and less than Ki+1
McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Example of B+ tree
Root node
Peter
First level
Mavis
Rick
Second level
Babs
David
Mavis
Peter
Rick
Tracy
Pointers to data (arbitrarily organized)
© McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Example of a B tree
k1
k2
k3
t(k2)
k4
k6
k 10
k5
t(k3) t(k4) t(k5) t(k1)
k7
t(k6) t(k10)
k8
t(k7)
k9
t(k8) t(k9)
© McGraw-Hill 1999
Esercizio 1
Costruire un B-Tree con i seguenti valori come chiave:
12, 18, 21, 28, 32, 47
12
http://slady.net/java/bt/view.php?w=800&h=600
12, 18, 21, 28, 32, 47
12
18
12, 18, 21, 28, 32, 47
18
12
-
21
12, 18, 21, 28, 32, 47
18
12
-
21
28
12, 18, 21, 28, 32, 47
18
12
-
21
28
-
32
-
12, 18, 21, 28, 32, 47
18
12
-
21
28
-
32
47
1) Inserimento 13
18
12
13
21
28
-
32
47
1) Inserimento 8
18
12
13
28
21
32
47
18
12
8
28
13
21
32
47
1) Cancella 47
18
12
28
13
8
32
21
47
18
12
8
28
13
21
32
1) Cancella 21
18
12
28
13
8
12
8
32
21
13
18
28
32
1) Inserimento 30
12
8
18
28
13
12
8
13
18
32
28
30
32
1) Inserimento 29
12
8
13
12
18
30
18
13
8
28
28
32
29
30
32
Esercizio 2
Esercizio
Si realizzi un albero B+ con F=3 (numero di valori di
chiave presenti in ogni nodo) per rappresentare i
valori: limone, cipresso, ciliegio, tasso, melo, agrifoglio,
acero, fico, pittosphoro, cotoneaster, noce, oleandro,
agave, euforbia, dracena.
Si mostri poi come potrebbe avvenire un inserimento
che richieda lo split di un nodo. Si costruisca anche un
albero B (ottimizzato) per gli stessi valori.
Requisito: tutti i nodi (tranne la radice) siano riempiti
per almeno la metà (almeno la metà dei puntatori di
ogni nodo siano diversi da NULL)
9
Il primo pensiero è di riempire l’albero in modo
sequenziale. Però un nodo intermedio risulta
sparso (ha 3 NULL)
OLE
CIL
DRA
ACE AGA AGR
CIL
LIM
DRA EUF
CIP
COT
FIC
LIM
OLE
PIT
TAS
MEL NOC
ATTENZIONE! I puntatori puntano ai NODI, non
agli specifici valori!!. Quelli tratteggiati puntano
alle tuple “fisiche”, e sono solo sulle foglie (B+).
I puntatori a NULL non sono rappresentati
10
I due nodi intermedi possono essere più
“bilanciati”, avendo rispettivamente due e tre
puntatori diversi da NULL
LIM
CIL
DRA
ACE AGA AGR
CIL
OLE
DRA EUF
CIP
COT
FIC
LIM
OLE
PIT
TAS
MEL NOC
Ora tutti i nodi tranne la radice sono “non sparsi”
11
Consideriamo ora l’inserimento del valore “betulla”:
dovrebbe posizionarsi nel primo nodo foglia, che però è
saturo e si “splitta” in due nodi (entrambi non sparsi).
ACE AGA AGR
CIL
DRA
CIL
CIP
COT
AGR
CIL
DRA EUF
FIC
DRA
ACE AGA
AGR BET
CIL
CIP
COT
DRA EUF
FIC
12
Costruiamo infine il B-tree, notando 15 = 3*(4+1)
Anche i nodi non-foglia hanno puntatori alle tuple
fisiche, poiché nessun valore è replicato.
CIL
EUF
NOC
ACE AGA AGR
OLE
FIC
CIP
LIM
PIT
TAS
MEL
COT DRA
I nodi foglia non hanno puntatori ad altri nodi
dell’indice, perché sarebbero tutti a NULL, ma solo alle
tuple (un dettaglio non menzionato nel libro).
13
Esercizio 3
Tema esame 16/04/1999
Si consideri la seguente sequenza di valori di chiave: Honda, Kawasaki, Piaggio,
Suzuki, Yamaha, Aprilia, Ducati, Cagiva, Laverda, Buell, Husqvarna, Ktm, Swm, Mv
Agusta, Moto Guzzi, Zundapp, Bmw, Harley Davidson
Costruire una struttura B+-tree e una B-tree, entrambe con F=3, contenenti tutti i
precedenti valori chiave.
HON, KAW, PIA, SUZ, YAM, APR, DUC, CAG, LAV, BUE, HUS, KTM, SWM,
MVA, MTG, ZUN, BMW, HAR
APR,BMW, BUE, CAG, DUC, HAR, HON, HUS, KAW, KTM, LAV, MTG, MVA,
PIA, SUZ, SWM, YAM, ZUN
B+-tree
KTM
CAG
APR
BMW
HON
-
-
-
MVA
SWM
MVA
PIA
-
BUE
HON
CAG
DUC
HUS
KAW
SUZ
SWM
HAR
KTM
LAV
MTG
YAM
ZUN
B-tree
MTG
CAG
APR
BMW
HUS
-
-
SWM
-
KAV
BUE
-
KTM
LAV
YAM
DUC
HAR
HOR
MVA
PIA
SUZ
ZUN
Green, Lovano, Osby, Peterson, Pullen Scofield, Allen, Haden,
Sheep, Harris, MacCann, Mann, Brown, Hutcherson, Newmann,
Ponty, Cobbham, Coleman, Mingus, Lloyd, Tyner, Fortune,
Coltrane.
1) Descrivere una struttura ad albero B+ bilanciato, con F=2, che contenga i dati
citati
2) Introdurre un dato che provochi lo split di un nodo al livello foglia, e mostrare
cosa accade al livello foglia e al livello superiore.
3) Introdurre un dato che provochi il merge di un nodo al livello foglia, e mostrare
cosa accade al livello foglia e al livello superiore.
4) Indicare una sequenza di inserimenti che provochi, ricorsivamente, lo split della
radice e l’allungamento dell’albero.
5) Descrivere una struttura ad albero B, con F=3, che contenga i dati citati.
1) Descrivere una struttura ad albero B+ bilanciato, con F=2, che contenga i dati citati
1) Introdurre un dato che provochi lo split di un nodo al livello foglia, e mostrare cosa
accade al livello foglia e al livello superiore.
L’introduzione del valore “Brooke”, causa uno split a livello foglia, come illustrato nella
seguente figura.
Introdurre un dato che provochi il merge di un nodo al livello foglia, e mostrare cosa accade
al livello foglia e al livello superiore.
La cancellazione del valore “Mann” causa un merge al livello foglia.
Indicare una sequenza di inserimenti che provochi, ricorsivamente, lo split della radice e
l’allungamento dell’albero.
Descrivere una struttura ad albero B, con F=3, che contenga i dati citati.
Database Systems
Chapter 9: Technology of a database server
Join methods
• Joins are the most costly operation for a DBMS
• There are various methods for join evaluation, among them:
– nested-loop, merge-scan and hashed
• The three techniques are based on the combined use of
scanning, hashing, and ordering
McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Join technique with nested-loop
Internal table
External table
JA
----------------
external
scan
a
JA
a
---------------
a
---------------
a
---------------
internal scan
or indexed
access
© McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Join technique with merge scan
Left table
Right table
A
-------------------------------
a
b
b
c
c
e
f
h
left
scan
right
scan
A
a
a
b
c
e
e
g
h
---------------
© McGraw-Hill 1999
Database Systems
Chapter 9: Technology of a database server
Join technique with hashing
a
hash(a)
Left table
Right table
A
hash(a)
A
d
e
a
c
J
j
j
J
J
e
m
a
a
j
z
© McGraw-Hill 1999
Esercizio 2
●
Elencare le condizioni (dimensioni delle tabelle,
presenza di indici o di organizzazioni sequenziali o
a hash) che rendono più o meno conveniente la
realizzazione di join con i metodi nested loop, merge
scan e hash-based; per alcune di queste condizioni,
proporre delle formule di costo che tengano conto
essenzialmente del numero di operazioni di
ingresso/uscita come funzione dei costi medi delle
operazioni di accesso coinvolte (scansioni,
ordinamenti, accessi via indici).
Dimensione della tabella
●
se siamo in una situazione in cui una delle tabelle è
molto grande rispetto all’altra, può essere una buona
soluzione l’utilizzo di un join con il metodo nested
loop, usando la tabella maggiore come esterna e
quella più piccola come interna. Se le tabelle hanno
la stessa dimensione il join con il metodo nested
loop è conveniente in presenza di indici o hashing su
una delle tabelle. Negli altri casi è meglio scegliere
un merge-scan.
Hashing
●
la presenza di una funzione di hash può suggerire
l’utilizzo di un join hash-based o nested loop. La
scelta dipende dalla dimensione di una tabella e dal
numero di partizioni prodotte dalla funzione di hash.
Organizzazione sequenziale
●
naturalmente, se le due tabelle hanno
un’organizzazione sequenziale sugli attributi del
join, il merge-scan è la scelta migliore. Se solo una
tabella ha un’organizzazione sequenziale il merge
scan può essere ancora una buona scelta se non ci
sono particolari condizioni (indici o hashing).
Indici
●
La presenza di indici in generale suggerisce un
nested loop. Comunque, se la tabella con gli indici è
molto piccola, o se l’indice è sparso, può essere
meglio non utilizzare l’indice e fare uno scan
completo.
●
Il costo di un join di tipo nested loop senza indici
può essere espresso come:
CNL=scan(T1) + T1 (scan (T2))
●
●
Dove T1 e T2 sono il numero di tuple delle due
tabelle, e scan(T) è il costo medio di un’operazione
di scansione.
Se c’è un indice sulla tabella 2:
CNL=scan(T1) + T1 (index (T2))
●
Un merge scan di un’organizzazione non
sequenziale ha un costo:
CMS= order(T1) + order(T2) + scan(T1) + scan(T2)
Esercizio 3
select C, L from R1, R2, R3 where R1.C = R2.D and R2.F = R3.G and R1.B = R3.L and R3.H > 10 Mostrare un possibile piano di esecuzione (in termini di operatori di algebra relazionale e loro realizzazioni; prestate attenzione anche alla DISTINCT, in quanto le relazioni degli operatori non producono necessariamente insiemi, ma liste di tuple), giustificando brevemente le scelte più significative, con riferimento alle seguenti informazioni sulla base di dati: –
la relazione R1(ABC) ha 100.000 tuple, una struttura heap e un indice secondario su C; –
la relazione R2(DEF) ha 30.000 tuple, una struttura heap e un indice secondario sulla chiave D; –
la relazione R3(GHL) ha 10.000 tuple, una struttura heap e un indice secondario sulla chiave G.
Un possibile piano di esecuzione per l’interrogazione in oggetto
è basato essenzialmente sulla struttura fisica delle relazioni e
sulla loro cardinalità.
La parte dell’interrogazione da analizzare è quindi quella della
condizione, che viene riportata di seguito per comodità.
where R1.C = R2.D and R2.F = R3.G and R1.B = R3.L and
R3.H > 10
Si effettuano i seguenti passaggi:
●
●
●
MERGE SCAN sulle relazioni R1 ed R2, in quanto R1.C e
R2.D hanno un indice secondario.
NESTED LOOP sulle relazioni R2 e R3, ponendo R2.F =
R3.G, mantenendo R2 esterno e R3 interno.
Selezione, tramite una scansione, degli attributi R1.B = R3.L e
R3.H > 10
Esercizio 4
select distinct A, L from T1, T2, T3 where T1.C = T2.D and T2.E = T3.F and T1.B = 3 Mostrare un possibile piano di esecuzione (in termini di operatori dell’algebra relazionale e loro realizzazioni), giustificando brevemente le scelte più significative, con riferimento alle seguenti informazioni sulla base dati: ●
●
●
la relazione T1(ABC) ha 800.000 tuple e 100.000 valori diversi per l’attributo B, distribuiti uniformemente; ha una struttura heap e un indice secondario sulla chiave A •la relazione T2(DE) ha 500.000 tuple; è definito un vincolo di riferimento fra l’attributo E e la chiave F della relazione T3: ha una struttura heap e un indice secondario sulla chiave D la relazione T3(FL) ha 1.000 tuple e ha una struttura hash sulla chiave F.
Un possibile piano di esecuzione per l’interrogazione in oggetto è basato essenzialmente sulla struttura fisica delle relazioni e sulla loro cardinalità. La parte dell’interrogazione da analizzare è quindi quella della condizione, che viene riportata di seguito per comodità where T1.C = T2.D and T2.E = T3.F and T1.B = 3 Si effettuano i seguenti passaggi ●
●
●
Selezione, tramite una scansione, dell’attributo T1.B = 3. Questa soluzione ha un costo molto elevato, 800.000 accessi in memoria, ma permette di estrarre un numero molto basso di record, in quanto possiede 100.000 valori diversi e mediamente ci saranno 8 record per ogni occorrenza. JOIN di tipo nested loop sulle relazioni T1 e T2, ponendo T1.C = T2.D, tenendo il risultato del passo precedente come tabella interna e T2 come esterna. JOIN di tipo nested loop usando l’indice hash su T3.F
Esercizio 5
Calcolare il fattore di blocco e il numero di blocchi
occupati da una relazione con T = 1000000 di
tuple di lunghezza fissa pari a L = 200 byte in un
sistema con blocchi di dimensione pari a B = 2 kb.
Dimensioni tabella (DT):
DT = T L
DT = 1000000 200 byte = 200000000 byte = 190,73 MiB
Numero blocchi:
NB = DT/B
NB = 200000000/2048 = 97656.25 blocchi
Fattore di blocco:
FB = B/L
FB = (2Kb)2048/200(byte) = 10.24 record / blocco
Esercizio 6
Una tabella Pubblicazioni ha chiave primaria CodPubbl
e come chiave candidata l'ISBN. La tabella contiene
1.000.000 di tuple ed è memorizzata tramite
un'organizzazione fisica hash che utilizza l'attributo
CodPubbl come chiave e presenta un livello di
riempimento dell'80% (si hanno in media 10 tuple per
blocco, quindi il numero di accessi medi è pari a 1.11).
PRIMO QUESITO
a) Trascurando l'impatto dei meccanismi di caching e
quantificando solamente il numero di operazioni di lettura su
disco, valutare il costo di esecuzione della seguente query:
select * from Pubblicazioni
where ISBN = '001122345'
and ( CodPubbl = 'ABC123' or CodPubbl = 'DEF456' )
Soluzione primo quesito
Disponendo di una struttura basata su hash
per un attributo e nulla per l'altro, il planner
decide di accedere innanzitutto tramite la
parte "or".
Questo comporta due tentativi di trovare la
tupla (perché due sono i valori di
confronto), il che comporta 2,22 accessi in
media.
SECONDO QUESITO
b) È inoltre presente una struttura ad albero come indice
secondario sull'attributo ISBN, con fan out medio pari a 100.
Trascurando anche in questo caso il contributo dei meccanismi di
caching, valutare il numero medio di letture necessario per
eseguire la query precedente, motivando la risposta.
select * from Pubblicazioni
where ISBN = '001122345'
and ( CodPubbl = 'ABC123' or CodPubbl = 'DEF456' )
Soluzione
L'indice secondario ad albero sull'attributo ISBN
comporta non meno di 3 accessi al disco, in media
(se è ben bilanciato). Infatti log100106 = 3.
Quindi non conviene usarle tale indice, ma seguire
comunque la strategia precedente.
Esercizio 7
Si realizzi un albero B+ con F=3 (numero di valori di
chiave presenti in ogni nodo) per rappresentare i valori:
da 1 a 15.
Si mostri poi come potrebbe avvenire un inserimento che
richieda lo split di un nodo. Si costruisca anche un albero
B (ottimizzato) per gli stessi valori.
Requisito: tutti i nodi (tranne la radice) siano riempiti per
almeno la metà (almeno la metà dei puntatori di ogni
nodo siano diversi da NULL)
Esercizio 5
Si deve dimensionare un archivio gestito con tecnica
hashing relativo a 1.500.000 record ciascuno di
lunghezza 150byte. Sia 8MByte la dimensione di un
blocco fisico, e si supponga che lo spazio utile
all’interno del blocco per la memorizzazione dei dati sia
l’80%. Indicare la dimensione dell’archivio che consenta
una gestione efficiente degli accessi.
80% di occupazione delle pagine => dimensione del
File = 1.25 volte la dimensione dei dati
Soluzione
1.500.000*150*(1/0.8)=281 MByte
• 281M/8M=31MBlocchi
•
Esercizio 6
●
●
●
Un indice hash è una struttura di accesso secondaria che organizza un certo numero di
blocchi mediante una funzione hash calcolata sulla chiave dell'indice. Come negli indici
secondari costruiti in forma di alberi, nei blocchi si conservano solo i valori delle chiavi,
assieme ai puntatori fisici ai blocchi in cui (nella struttura primaria) sono conservate le
tuple (e l'organizzazione primaria può essere sequenziale, hash-based o ad albero). Si
supponga di avere una tabella
Studente(Matricola,Nome,Cognome,DataNascita,CorsoDiLaurea), di 200K studenti, con
un'organizzazione primaria ad albero B+ sull'attributo Matricola, che occupa 10K blocchi
e ha un fanout massimo pari a 100; è poi disponibile un indice secondario hash
sull'attributo Cognome, che occupa 2K blocchi. Stimare il costo, in termini di numero di
accessi a blocchi, per l'esecuzione delle seguenti query SQL:
(1) select * from Studente where Matricola = '623883'
(2) select * from Studente
where Cognome in ('Braga','Campi','Comai','Paraboschi') and Matricola > '575478'
(3) select * from Studente where Cognome < 'B'
Per semplicità, si trascurino le collisioni, l’effetto della cache e le differenze tra i vari tipi
di accesso a disco (random o sequenziali).
Facoltativo: cosa si può dire della query
(4) select * from Studente S1, Studente S2
where (S1.Nome,S1.Cognome)=(S2.Nome,S2.Cognome)
and S1.Matricola>S2.Matricola
Ogni nodo/blocco interno all’albero contiene fino a 99 matricole e 100
puntatori fisici, e in ogni nodo/blocco foglia dell'albero ci sono
invece 20 studenti (le intere tuple) e 1 solo puntatore fisico (al
blocco successivo nella “catena delle foglie”).
Immaginando molto densa la struttura ad albero (nodi
sostanzialmente tutti pieni e albero perfettamente bilanciato), oltre
alla radice abbiamo un livello intermedio di 100 blocchi interni e
10K blocchi “foglia”, il che corrisponde alla dimensione indicata
della struttura. L’albero avrà quindi una profondità pari a 3.
Nei blocchi dell'indice hash (la cui chiave di accesso non è una chiave
primaria) ci sono puntatori fisici ai blocchi che contengono i dati di
circa (in media) 200K / 2K = 100 puntatori fisici, corrispondenti a
meno di 100 valori di chiave (sarebbero esattamente 100 se non
esistessero studenti con lo stesso cognome, in realtà se na
avranno in media significativamente meno). I blocchi avranno un
fattore di riempimento che dipende dal rapporto di dimensione tra
un cognome e un puntatore fisico, che i dati non permettono di
stimare.
Il costo è quindi
(query 1). 3 accessi tramite albero (2 blocchi interni e una foglia), e
ho subito l’intera tupla cercata.
(query 2). Se uso l’indice sul Cognome pago 4+4 = 8 acessi, avendo
4 condizini in OR e 4 puntatori ai blocchi fisici da seguire. È
ragionevole ritenere che la condizione sulla matricola sia
inservibile (non riteniamo probabile che esistano molto meno di
8x20 = 160 studenti con matricola superiore a 575478).
(query 3). Siccome in base alla traccia non possiamo garantire che la
funzione di hash dia valori correlati all’ordinamento alfabetico,
nessuna delle due strutture di accesso ci aiuta, e dobbiamo
scandire l’intera tabella (10K accessi)
Facoltativo:
(query 4). Si tratta di fare un self-join sul Cognome e verificare le altre
due condizioni. Possiamo pensare di applicare un hash join usando
la struttura secondaria, osservando che tutti gli studenti “puntati”
dia puntatori di ogni bucket devono essere confrontati solo con
qualli che, nello stesso bucket, sono associati alla stessa matricola.
Il numero di accessi dipende quindi direttamente dalla frequenza
delle omonimie, e non può essere efficacemente stimato senza
informazioni accurate sulla distribuzione dei valori. Una stima
molto grossolana si può avere immaginando di confrontare
comunque tutti gli studenti con tutti gli altri studenti all’interno
dello stesso bucket, e darebbe 2K x ( 1 (lettura indice) + 100x99 )
=~ 2K ( 10 K ) = 20M. Una strategia nested loop che usasse
l’albero, invece, avrebbe un costo pari a 10K + 260K x (2 + 10K / 2
) = 500M (dove per ogni matricola si cercano gli omonimi solo tra
quelli con matricola superiore, scandendo in media solo mezza
tabella), decisamente peggiore.
Esercizio
Su una tabella R(A,B,C,D,E) con 10.000.000 di tuple, sono
definiti 3 indici: Idx1(A,C,D), Idx2(B,C,E) e Idx3(B,D,A), in cui il
valore di chiave di ogni indice è composto in ordine dagli
attributi indicati da sinistra a destra. Gli attributi A, B, C, D, E
presentano una distribuzione uniforme di valori, con il
seguente numero di valori distinti: val(A)=1000, val(B)=100,
val(C)=1000, val(D)=2000, val(E)=10.
| R | = 10.000.000 Idx1(A,C,D), Idx2(B,C,E), Idx3(B,D,A)
val(A)=1000, val(B)=100, val(C)=1000, val(D)=2000, val(E)=10
Indicare quale indice converrà usare per eseguire la
seguente query SQL (argomentando molto brevemente la
risposta):
select * from R
where B=k1 and C=k2 and D=k3 and E=k4
Soluzione
Dovendo valutare le quattro condizioni in and
che offre, per gli attributi citati nei predicati, il maggior indice di
selettività, scartando subito Idx1 perché inizia con un attributo
che non è utilizzato dai predicati presenti nella condizione:
Idx2: 10.000.000/(100x1000x10) = 10 tuple in media da scandire
Idx3: 10.000.000/(100x2000) = 50 tuple in media da scandire
Quindi conviene usare
Idx2
Si supponga di avere una tabella
A tale of two Joins
Studente (Matricola,Nome,Cognome,DataNascita,CorsoDiLaurea)
che descrive 150K studenti su 10K blocchi, con un'organizzazione primaria hash, calcolata
sull'attributo Matricola. Si ha poi una tabella
Esame (Matricola,CodCorso,Data,Voto)
con 2M tuple su 8K blocchi con struttura sequenziale entry-sequenced e un indice secondario
sull'attributo Matricola, di fanout pari a 200. Si deve eseguire la query di join
select *
form Studente S join Esame E on S.Matricola = E.Matricola
Stimare il costo, in termini di accessi a disco, per eseguire uno hash join in cui la tabella
Esame viene ri-organizzata secondo la stessa funzione hash utilizza per la tabella Studente.
Si confronti questo costo con il costo richiesto dall'uso di un join nested loop con la
tabella Studente come tabella esterna. Si trascurino gli effetti delle collisioni e la presenza
del sistema di caching.
28
Studente ha 15 tuple per blocco e ogni accesso costa una operazione di i/o.
Esame ha 256 tuple per blocco ma non ha una struttura di acceso primaria a hash.
Per costruire la struttura hash-based (è l’unico modo per poterla usare!) occorre scandire
l’intera tabella e inserire ogni tupla nel “bucket” opportuno. Per applicare la stessa funzione
di hash (ad esempio Matricola mod 10.000) dobbiamo anche conservare lo stesso numero di
"bucket", che però - helas - saranno meno “pieni” (le tuple occupavano 8K, diventano 10K).
Pagheremo quindi 8K accessi in lettura per leggere e ben 4M in scrittura, perché dobbiamo
trovare per ogni esame il bucket giusto in cui inserirlo, e tale blocco dev’essere prima letto,
poi modificato aggiungendo l’esame nel punto giusto, e infine riscritto.
Lo hash-join poi costa 2 * 10K = 20K accessi per leggere i bucket via via associati allo
stesso valore della funzione di hash, per un totale di 4M + 28K accessi (è un costo notevole,
che però potrebbe essere ripagato col tempo per le successive esecuzioni dello stesso join se
si conserva la struttura a hash creata per l’occasione).
29
Calcoliamo ora il costo del nested loop con Esame come tabella interna (cioè nel caso in cui
leggiamo un blocco della tabella Studente (iterazione esterna) e per ogni studente cerchiamo in
Esame (iterazione interna) tutti gli esami sostenuti da quel particolare studente. Leggiamo un
nuovo blocco di Studente solo dopo aver esaurito tutti gli studenti nel blocco corrente).
L’albero ha profondità media pari a circa 3 ed è relativamente sparso (ha spazio per circa 8M
valori di chiave). La ricerca degli esami di un dato studente costa quindi 3 accessi ai nodi
dell’albero, più 1 accesso ai blocchi della struttura primaria entry-sequenced per recuperare
tutti i campi dell’esame (trascuriamo il caso in cui i puntatori agli esami di uno stesso studente
siano ripartiti su più di un nodo foglia dell’albero). In totale pagheremo 3 accessi per ogni
studente e uno per ogni esame, cioè 3*150K + 2M accessi.
Il caricamento di tutti i blocchi di Studente nell’iterazione esterna costa inoltre 10K accessi,
per cui in totale avremo = 2M + 460K accessi.
È un costo inferiore a quello di costruirsi la struttura ad-hoc (poco più di metà), il quale però
può ancora considerarsi un buon investimento se, conservando la struttura creata, velocizza poi
sostanzialmente le esecuzioni dello stesso join (20K contro 2,5M).
30
Calcoliamo infine, per completezza di analisi, benché non fosse richiesto dal testo, il costo del
nested loop con Esame come tabella esterna (che a prima vista sembra l’opzione più sensata,
dato che gli accessi random basati su matricola alla struttura primaria a hash dello Studente
costano molto meno di quelli a Esame basati sull’indice B+ (1 contro 4)).
Possiamo scandire tutta la tabella Esame pagando solo 8K accessi per la sua lettura,
sfruttando la struttura entry-sequenced (non avrebbe senso, infatti, scandire in sequenza le foglie
dell’indice B+ e accedere ai blocchi primari “uno studente alla volta”, dato che avere gli esami
in ordine di matricola non ci aiuta), e dobbiamo poi accedere 2M volte alla struttura hashed,
una volta per ogni esame, a recuperare i dati dello studente (più volte lo stesso studente, ogni
volta che ci imbattiamo in un suo esame – ma stiamo trascurando gli effetti della cache), per un
totale di 2M+8K accessi.
Il costo è minore, ma comunque dello stesso ordine di grandezza di quelli precedentemente
calcolati. Un ottimizzatore “miope” potrebbe continuare a scegliere questa ultima opzione
senza mai “imbarcarsi” nell’impresa di costruire la struttura hash-based, che invece si rivela
strategicamente la più conveniente se il join viene ripetuto frequentemente (come è probabile).