
XXIX CONFERENZA ITALiANA DI SCIENZE REGIONALI
LIMITI E PROBLEMATICHE NELL’USO DI DATI INCERTI PER LA COSTRUZIONE DEL
SISTEMA DI CONOSCENZE
Ritrovato Giuliano1, Ceppi Claudia1
(1) Dipartimento di Architettura e Urbanistica - Politecnico di Bari, via Orabona 4, 70125, Bari
SOMMARIO
Il lavoro illustra brevemente l’evoluzione nell’ultimo ventennio delle tecniche, strumenti e
metodologie dei sistemi informativi territoriali (SIT). Tale filone che va delineandosi come settore
disciplinare a se stante, trova la sua collocazione nel complesso settore della teoria della
conoscenza. Non si vuole proporre una trattazione filologica sui SIT, ma piuttosto si tenta un
riordino nella “babele” che si è andata configurando negli ultimi anni in questo settore,
caratterizzato da una notevole espansione in ambiti disciplinari sempre più differenziati.
Si pone l’attenzione, sulla differenza tra di SIT e GIS, sulla definizione e differenza tra
informazione e dato. Si è soffermati, in particolare, sulla qualità dei dati ed i parametri e
caratteristiche che la caratterizzano. Infine si propone una riflessione e possibili percorsi operativi,
al fine di ridurre il grado di incertezza dell’informazione prodotta mediante analisi e trattamento di
basi di dati che soddisfino, o almeno dichiarino, un livello di qualità accettabile.
1
Introduzione
Mettere a confronto, su tematiche comuni, studiosi di discipline diverse, ma tutte riconducibili alla
matrice territoriale, costituisce, metodologicamente, la maniera più proficua per esaltare l’unitarietà
dei problemi e la miriade di sfaccettature sotto le quali possono essere colti, perciò, i loro grado di
complessità. La sfida posta dalla complessità della realtà territoriale postula la conoscenza dei
contenuti sui nuovi problemi che emergono, l’adeguamento conseguente delle tecniche e delle
metodologie di analisi, ma soprattutto nuove strategie di approccio fondate sulla cooperazione
disciplinare. L’approccio multidisciplinare che prevede il coinvolgimento di pareri afferenti a
diversi domini, ha come scopo principale la generazione del Sistema delle Conoscenze (SC),
caratterizzato dalle informazioni necessarie ed adeguate per lo studio di un certo fenomeno (Mura
1986).
Nell’ultimo ventennio la costruzione del SC si è orientato su due filoni ben distinti: il primo è
riferito a modelli e metodi operativi per la costruzione dei Sistemi Esperti (SE), il secondo riferito a
tecniche e soluzioni operative di supporto ai Sistemi Informativi Territoriali (SIT). Dalle classiche e
generiche definizioni, che si possono desumere dalla vasta bibliografia, si evince che i SIT, nel
senso più generale del termine, siano un sottogruppo o un’appendice del più vasto filone dei SE.
Ma l’evoluzione e le tendenze registrate dell’ultimo decennio, caratterizzato da una spiccata
territorializzazione delle informazioni , secondo metodologie e approcci tipici delle discipline della
Cartografia, il filone dei SIT può essere considerato parallelo e complementare ai Sistemi Esperti
nel vasto quadro della costruzione del Sistema delle Conoscenze, tale da delinearsi come un settore
disciplinare a se, in rapida e vasta diffusione.
Tale evoluzione, nella sua rapidità e per la varietà degli ambiti disciplinari coinvolti, ha evidenziato,
tuttavia, una serie di problematiche legate da un lato a questioni tecniche, relative alle tecnologie
informatiche in relazione alle esigenze di analisi in cui vengono evidenziate le architetture dei
sistemi nelle loro diverse componenti, come Hardware, Software, struttura dei dati, algoritmi di
processamento dati, dall’altro alla disponibilità delle metodologie di analisi dei dati per la
generazione di informazioni in grado di fornire vari livelli di interpretazione ed elaborare indicatori
sintetici per la descrizione di un certo fenomeno. Ovviamente si sta facendo riferimento
all’approccio dei SIT secondo la definizione di Burrough (Burrough, McDonnell et al. 1998) ove il
SIT è definito come un “sistema informatico che permette l'acquisizione, la registrazione, l'analisi,
la visualizzazione e la restituzione di informazioni derivanti da dati geografici”, pertanto un
approccio tecnico operativo che necessità, in questa fase della sua evoluzione, di alcune riflessioni.
2
I GIS nei SIT
In fase preliminare, non è affatto superfluo fornire una serie di precisazioni di ordine terminologico
e metodologico in merito alla costruzione di tali sistemi.
Nell’ampio panorama della “teoria della conoscenza”, la costruzione di un Sistema Esperto (SE),
secondo la definizione di Feigenbaum (Feigenbaum, McCorduck et al. 1988), prevede la
realizzazione di un sistema su supporto informatico finalizzato alla soluzione di problemi complessi
in forma non algoritmica e sufficientemente complessi entro un dominio cognitivo limitato. Ciò
richiede una forte interazione tra il progettista del sistema e l’esperto. Lo scopo del primo è
codificare nel sistema sia la conoscenza dell’esperto sia il meccanismo cognitivo dell’esperto.
L’esperto, a sua volta, deve individuare e definire, in termini precisi, la propria esperienza, fatta di
conoscenza del dominio, di regole euristiche, meccanismi di ragionamento abitualmente utilizzati
ed espedienti per semplificare l’operato . Le applicazioni, per rendere operative tali interazioni
tramite tecnologie informatiche, rientrano a tutti gli effetti nel campo operativo dell’ Intelligenza
Artificiale e i risultati significativi registrati nell’ultimo quindicennio, per il forte potenziamento
degli strumenti informatici, sono ancora racchiusi in ambiti teorici e sperimentali e non riferibili,
almeno nella pianificazione del territorio, ad applicazione di largo uso: ovvero i SE costruiti da
esperti per esperti, risultano pertanto essere, ancora oggi, la base teorica di partenza per la
costruzione di un SC.
Di contro lo sviluppo e la crescente diffusione, riferendosi alla varietà dei settori disciplinari
coinvolti nello studio del territorio, ovvero in quegli ambiti disciplinari che hanno trovato nella
regionalizzazione dei fenomeni (Fischer 1983), un valido approccio metodologico per il loro studio,
dei SIT ha ingenerato una notevole confusione in tutte le componenti teoriche ed applicative. Infatti
dall’avvento, nel 1962, del “Canada Geographic Information System” (Roger F. Tomlinson), che
viene definito da molti il primo SIT, la varietà delle definizioni, nate da contesti culturali differenti
hanno generato una problematica non ancora risolta che ha portato ad una proliferazione di gerghi
specifici e difficoltà di comprensione tra "addetti ai lavori". A tutti gli acronimi associati alle
applicazioni dell’informazione legata al territorio, come Geographic Information System (USA),
Geographical Information System (Europa), Géomatique (Francia, Canada), Sistemi Informativi
Territoriali, Sistemi Informativi Geografici (Italia), Geological Information System, Land
Information System, Spatial Information System, Georelational Information System, Geoscience
Numerical Cartography (legate a specifiche discipline), non sempre corrisponde un diverso
significato sostanziale, che invece si evince da subito, soprattutto in termini di approccio
metodologico, dalle definizioni date da Mogorovich (1988)[ “Il complesso di uomini, strumenti e
procedure (spesso informali) che permettono l'acquisizione e la distribuzione dei dati nell'ambito
dell'organizzazione e che li rendono disponibili nel momento in cui sono richiesti a chi ne ha la
necessità per svolgere una qualsivoglia attività”], Cowen (1988)[ “a decision support system
involving the integration of spatially referenced data in a problem solving environment”], e Carter
(1989)[“ an institutional entity, reflecting an organisational structure that integrates technology with
a database, expertise and continuing financial support over time”], rispetto a quelle fornite da
Burrough (1986)[ “a powerful set of tools for collecting, storing, retrieving at will, transforming and
displaying spatial data from the real world”] e Aronoff (1989)[ “any manual or computer based set
of procedures used to store and manipulate geographically referenced data”], in quanto si passa da
una trattazione informale dell’informazione a quella rigida, tipica degli strumenti e applicazioni
informatiche, in altri termini si enfatizza la differenza tra informazione e dato.
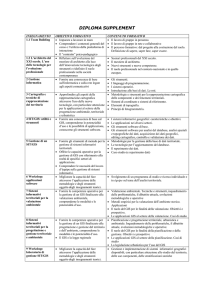
A tali definizioni, pertanto, sono associate applicazioni diversificate riassunte schematicamente
(Fig.1) da da DeMers M. N. (2000), Joanilli M. (2001) (Joanilli M. 2001) Schiavoni U. (2001), da
cui risulta enfatizzata una ulteriore caratteristica dei sistemi informativi legata alla spazialità e al
supporto geografico.
Figura.1 Tassonomia nella “Information System”
La regionalizzazione (Manfred M. Fischer 1983) dell’informazione unitamente al contesto
territoriale non può prescindere pertanto da tale classificazione negli approcci operativi tipici dei
sistemi informativi su base geografica. Quindi si è assistito negli anni ad uno sviluppo degli
strumenti informatici orientati secondo metodologie, tecniche e approcci classici della gestione
cartografica. E’ proprio dalla cartografia si desumono le caratteristiche per la valutazione della
qualità dei dati nella loro componente spaziale.
Quindi in riferimento allo schema proposto, le differenze tra SIT e GIS possono essere riassunte,
come già accennato al formalismo nel trattamento dei dati e la loro interconnessione con la matrice
territoriale.
Nei SIT i dati possono essere espressi anche in modo informale, e la relazione al territorio può
essere addirittura di tipo meramente descrittivo.
Nei GIS i dati devono avere una struttura, forma e contenuto rispondenti a requisiti rigorosi, in
particolare la componente spaziale deve rispondere ai requisiti di validità propri della cartografia.
3
Qualità dei dati
3.1 Dati e Informazioni
In tutte le operazioni di trattamento dei dati si prevedono diverse tipologie di analisi, statistiche o
spaziali, e le preliminari considerazioni, in merito alla qualità dei dati, acquistano sempre maggiore
importanza, in particolare qualora si vogliano utilizzare strumenti informatici, come già detto, basati
su tecnologie G.I.S. e M.I.S. (Managment Information System), che prevedono un controllo
rigoroso della qualità delle informazioni utilizzate ed una standardizzazione nel formato e nel
contenuto dei dati di input.
Due punti fondamentali possono essere evidenziati, per quanto riguarda la valutazione, da parte di
chi gestisca un Sistema Informativo Territoriale, dell’idoneità della base di dati relativamente alle
applicazioni di interesse. In primo luogo, la qualità di una base di dati georeferenziati può e deve
essere valutata in base a una serie di parametri, contenuti in standard internazionali quali quelli
definiti dai comitati tecnici ISO/TC 211: Geographic information - Geomatics e CEN/TC 287
(Carrion D. 2004).
Un altro punto da tenere in considerazione è la necessità che i dati cartografici siano corredati da
informazioni sufficienti perché l’utente possa giudicare se i dati gli siano davvero utili per i suoi
scopi e se abbiano la qualità che li rende tali.
In un GIS l’importanza dei dati è centrale. Tipicamente, i dati in un GIS sono molto numerosi e tutti
collegati gli uni agli altri. Lo scopo di un GIS, come già detto, è ottenere risposte a specifiche
domande, sulla scorta di procedure di analisi e gestione dei dati, fornendo informazioni.
Vi è una sostanziale differenza tra informazione e dato. I dati sono rappresentazioni numeriche o
altri surrogati simbolici miranti a caratterizzare gli attributi di persone, organizzazioni, oggetti,
eventi o concetti (Nijkamp and Fischer 1993).
Informazione significa dati strutturati attraverso modellizzazione, organizzazione o trasformazione,
così da aumentare la penetrazione o il livello di conoscenza riguardo un certo fenomeno (Nijcamp
1990).
Si può affermare che un GIS è basato su una sistematica trasformazione dei dati che mira a fornire
un supporto analitico agli studiosi.
Ristrutturazione e trasformazione dei dati sono pertanto essenziali nei sistemi informativi.
Le operazioni che possono essere eseguite sui dati sono: raccolta, verifica, classificazione,
ordinamento, compendio, calcolo, previsione, simulazione, conservazione, rintracciamento e
comunicazione.
I costi di tali operazioni dipendono tra gli altri dalle necessità di personale, modularità, flessibilità e
versatilità del sistema di gestione, e dal controllo e velocità di tale processo.
I benefici sono determinati dall’accessibilità, onnicomprensività, accuratezza, appropriatezza,
tempestività, chiarezza, flessibilità, verificabilità e quantificabilità dell’informazione richiesta.
La fornitura di informazioni attendibili, maneggevoli e aggiornate, strutturate in modo logico sulla
base di una valida metodologia è essenziale per comprendere i processi e le relazioni che regolano e
descrivono un dato fenomeno.
3.2 La qualità dei dati
Tralasciando le considerazioni, innumerevoli, relative alle metodologie di analisi e trasformazione
dei dati, passiamo in rapida rassegna i punti fondamentali relativi alla qualità dei dati, all’uso degli
standard e agli organi internazionali che si occupano della loro definizione.
Il termine qualità è arrivato ad assumere un significato molto ampio nell'ambito di organizzazioni,
enti, aziende. La qualità può essere definita come il grado di eccellenza di un prodotto, di un
servizio o di una prestazione. La qualità è un risultato altamente desiderabile, e può essere raggiunta
attraverso una attenta gestione e controllo dei processi di produzione TQM (Total Quality
Management).
La definizione e la gestione della qualità di produzione dei dati sono discusse in diversi documenti
presentati all' International Conference on Survey Measurement and Process Quality 1995 (Liberg
(1997), deLeeuw and Collins (1997), Dippo (1997), Morganstein and Marker (1997), Colledge and
March (1997) e anche in Collins and Sykes (1999).
Questi criteri possono essere applicati al concetto di qualità di una base di dati, dal momento che
una base di dati è il risultato di un processo di produzione, e l’affidabilità con cui tale processo è
stato condotto ha un impatto sul valore e sull’utilità dei dati stessi.
3.3 Approcci ed indicatori per la valutazione della qualità dei dati
Per la valutazione della qualità dei dati sono maturati tre approcci corrispondenti ad altrettanti
modelli di valutazione (Carrion D. 2004).
Modello “minimo”. Il controllo e la valutazione di qualità vengono svolti a cura del produttore dei
dati, basandosi su strategie di test di conformità per identificare dati che soddisfano soglie di qualità
definite a priori. Si tratta di un approccio poco flessibile, il medesimo test in alcuni casi può
rivelarsi troppo restrittivo, e in altri troppo lasco.
Uso di metadati. In questo modello l’errore è visto come un accadimento inevitabile, e non
vengono imposti standard minimi a priori; è l’utente finale ad essere il responsabile della
valutazione della “idoneità dei dati all’uso”, mentre il produttore dei dati è responsabile della loro
documentazione tramite i metadati. Questo approccio è flessibile, ma non è solitamente previsto che
l’utente finale fornisca un riscontro (“feedback”) al produttore di dati, quindi l’informazione viaggia
“a senso unico” e il produttore non è in grado di correggere gli errori
Uso di standard e riscontro da parte dell’utente. Il flusso delle informazioni è “bidirezionale”, con
un riscontro da parte dell’utente relativamente alle questioni della qualità dei dati; questo feedback è
processato e analizzato per identificare i problemi significativi e gli interventi prioritari da avviare
sui dati. Questo modello è utile non solo in un contesto di mercato, per assicurare che la base di dati
corrisponda alle necessità e alle aspettative degli utenti e che il produttore possa intervenire per
migliorarne la qualità.
La qualità dei dati solitamente viene misurata in base a un insieme di indicatori (o parametri), di cui
si riportano quelli principalmente usati, accuratezza, risoluzione, scala, consistenza logica e
completezza, con le loro definizioni e caratteristiche (Migliaccio, 2002).
Accuratezza. E’ l’inverso dell’errore, cioè della discrepanza fra il valore registrato nella base di dati
e il valore ”vero” (per quanto lo si può conoscere) o accettato come tale.
La valutazione dell’accuratezza di una osservazione (misura) può essere fatta solo per confronto
con la misura più accurata che sarebbe possibile ottenere.
Il risultato è appunto la misura dell’errore e per i dati di tipo numerico (essenzialmente, dati di
posizione) vengono usati indici di tipo statistico, quali media e s.q.m., mentre per i dati di tipo non
numerico (di solito, classificazioni) si possono valutare gli errori tramite la matrice dell’errore di
classificazione.
Si possono inoltre definire:
Accuratezza spaziale: accuratezza della componente spaziale di una base di dati; la metrica usata
dipende dalle dimensioni delle entità in esame.
Accuratezza temporale: concordanza fra il valore codificato e il valore reale delle coordinate
temporali di un’entità. Spesso per i dati di tipo geografico le coordinate temporali sono
rappresentate dall’epoca alla quale l’entità era “valida”, e in molti casi ciò vale
contemporaneamente per tutta la base di dati.
Accuratezza tematica: accuratezza dei valori degli attributi codificati in una base di dati; la metrica
usata dipende dalla scala di misura dei dati.
Risoluzione. Si riferisce alla quantità di dettaglio che è possibile distinguere nella componente
spaziale, temporale o tematica. La risoluzione è sempre finita, perché non esiste un sistema di
misura infinitamente preciso e perché comunque le basi di dati sono intenzionalmente generalizzate
per ridurre il grado di dettaglio. In funzione dell’applicazione, non sempre un’elevata risoluzione è
la scelta migliore; a volte una bassa risoluzione è più opportuna, se si vogliono ottenere modelli
generali. Anche in per la risoluzione si possono definire:
Risoluzione spaziale: indica la più piccola differenza distinguibile fra due valori misurabili. Poiché
la risoluzione spaziale è una informazione collegata al grado di dettaglio con cui i dati
rappresentano la realtà, ci dice qual è il più piccolo oggetto distinguibile grazie ai dati a
disposizione. Per i dati raster, la risoluzione è semplicemente definita dalla dimensione del pixel.
Per i dati vettoriali, può essere definita come la minima dimensione dell’entità cartografica
rappresentabile.
Risoluzione temporale: è la lunghezza (durata temporale) dell’intervallo di campionamento.
Risoluzione tematica: indica la precisione delle misure per un particolare tematismo.
Per i dati quantitativi è analoga alla risoluzione spaziale; per dati qualitativi (categorie) rappresenta
il dettaglio di definizione di una classe tematica.
Scala. In assenza di altri dati sulla risoluzione spaziale e sull’accuratezza, la scala della cartografia
di origine dei dati digitali può essere un parametro interessante. Infatti la scala di una carta contiene
implicitamente informazioni sulla risoluzione spaziale (grado di dettaglio) dei dati. La linea più
sottile che è possibile disegnare su una carta rappresenta un limite alla risoluzione raggiungibile a
una determinata scala: nessun oggetto di dimensioni inferiori può essere registrato.
Consistenza logica. Si riferisce al fatto che non ci siano dati in contraddizione fra di loro. Per
valutare tale fatto si possono istituire test di consistenza logica, per il controllo degli eventuali
vincoli matematici o logici (relazioni matematiche o logiche fra i dati), o test di controllo dei vincoli
topologici, per individuare ad esempio bordi mancanti o poligoni non etichettati.
Anche la consistenza può essere definita in riferimento alle tre dimensioni (spaziale, temporale,
tematica) dei dati geografici.
Completezza. E’ un parametro relativo alla mancanza di errori di omissione all’interno della base di
dati, e si riferisce ai criteri usati per selezionare le informazioni da inserire fra i dati. La sua
valutazione è basata su verifiche relative all’inclusione fra i dati di oggetti appartenenti a liste note
oppure su verifiche relative all’inclusione fra i dati di oggetti di dimensioni (area o spessore)
minime. Ci sono due tipi di completezza. La completezza dei dati è riferita agli errori di omissione;
una base di dati è completa se contiene le informazioni relative a tutti gli oggetti definiti nelle
specifiche. La completezza del modello è riferita alla concordanza fra le specifiche della base di dati
e il modello che è necessario definire per una particolare applicazione; una base di dati contiene un
modello completo se le sue specifiche sono appropriate per una particolare applicazione.
Ovviamente, anche la completezza può fare riferimento alle tre dimensioni (spaziale, temporale,
tematica) dei dati geografici.
Quindi, riepilogando, la qualità dei dati definisce il grado di eccellenza di una base di dati e viene
valutata relativamente alle specifiche della base di dati, che definiscono il livello voluto di
generalizzazione e astrazione. Volendo, si possono valutare anche la qualità di queste specifiche e la
loro adeguatezza per determinate applicazioni. La valutazione della qualità dei dati è svolta in
funzione di diversi parametri, inclusi l’accuratezza, la risoluzione, la consistenza e la completezza.
Ogni componente di una base di dati geografica può essere valutata secondo le dimensioni di
spazio, tempo e tematismo (essendo queste le tre dimensioni fondamentali dei dati geografici)
(Pegoraro C. 2004).
4
Orientamenti:
4.1 Definizione e funzione del GIS
La rassegna appena proposta, sulla definizione della qualità dei dati e dei parametri necessari per la
sua determinazione, rappresenta il punto di partenza per fornire nuovi percorsi operativi per la
costruzione di un sistema informativo su base territoriale. Non si vuole, comunque, fornire nuovi
schemi di architetture di Sistemi Informativi Territoriali, che possono assumere configurazioni
differenti a seconda del caso. Piuttosto, appare necessario discriminare, quanto più possibile, i
diversi sottosistemi che comunemente lo compongo, e specificare ulteriormente le effettive
potenzialità dei GIS in tali sistemi.
Tale discriminazione non può essere pienamente esplicitata se non si elimina, in un primo stadio di
discussione, l’ambiguità in termini di definizione dei SIT, già precedentemente evidenziata. Infatti
l’anomalia, europea ma soprattutto italiana, di associare allo stesso acronimo significati differenti,
come Sistemi Informativi Territoriali, Sistemi Informatici Territoriali, Sistemi Informativi su base
Territoriale, ect., non potrà essere superata con una definizione condivisa dei SIT, in quanto tale
acronimo risulta essere inflazionato in applicazioni e approcci ben lontani da quelli per cui tali
sistemi sono stati concepiti e sviluppati. Tanto meno l’introduzione di nuovi acronimi, non farebbe
che aumentare il livello di confusione, dovuto in primo luogo alla inadeguatezza delle competenze
coinvolte che non riescono distinguere gli stessi acronimi quando sono riferiti a sistemi, prodotti,
tecniche o software.
Per risolvere tale ambiguità si potrebbe ereditare in toto la definizione e concezione di GIS secondo
le tendenze maturate negli USA. Tale concezione è basata sulle definizioni di Burrough (1986) e
Aronoff (1989). Sulla scorta di tale concezione si assume, nel tentativo di dare un riordino di
carattere terminologico, che:
i GIS sono una parte dei SIT
i GIS gestiscono dati caratterizzati da struttura, formalismo e contenuti per un loro utilizzo
mediante strumenti informatici improntati su una logica booleana e sulla teoria degli insiemi
classica
i GIS mediante opportune procedura di analisi, svolgono la funzione di trasformazione dei
dati, in modo da fornire un nuovo dato che viene assunto come informazione da gestire nei
SIT.
ai GIS deve essere attribuita la funzione di gestione di una categoria di dati, che possono
essere sottoposti a criteri di valutazione di qualità. La valutazione della qualità dei dati è
svolta in funzione di diversi parametri, come l’accuratezza, la risoluzione, la consistenza e la
completezza. Dalla valutazione della qualità dei dati si può desumere la qualità
dell’informazione che si può generare.
La costruzione del GIS non è il fine, ma un tramite per costruire l’informazione.
4.2 Incertezza: dati e informazione
Il processo articolato e complesso che porta alla realizzazione di un’applicazione GIS ha il solo
scopo di generare informazione attraverso un opportuno ed adeguato trattamento dei dati.
L’informazione che ne deriva sarà tanto più pertinente ed idonea quanto più i dati iniziali siano
accurati e specifici per le analisi di interesse che si vogliono effettuare.
Il GIS rappresenta pertanto uno strumento per realizzare la base informativa, inoltre considerare una
sua applicabilità per la descrizione e le analisi di fenomeni complessi propone non pochi problemi
di linguaggio e di innovazione delle metodologie.
Secondo (Molenaar M. 1998), l’utilizzazione dei dati nei sw GIS si basa su un’interazione tra
modelli e processi. La prima fase è quella analitica che, oltre a fondarsi su molteplici modelli
cognitivi, utilizza tecniche molto differenti (rilievo, remote sensing, interpolazioni geostatistiche).
Per esaminare queste analisi è necessario memorizzarle secondo varie tipologie di modelli
(vettoriali, raster, TIN). Dal semplice dato si passa poi alle analisi settoriali ed intersettoriali,
(geologia, idrologia, morfologia, infrastrutture, ecologia, etc.) che, oltre a seguire altri canoni
scientifici, sono vincolate da rigidi dettami informatici di selezione dal database geografico.
Queste fasi moltiplicano una serie di forme di incertezza che dipendono sia dai caratteri intrinseci
dei dati, sia dai caratteri contestuali del problema per il quale il dato è raccolto, analizzato ed
elaborato (Longley P.A. 2002).
Infatti i problemi di rappresentazione riguardano l’incertezza nel rilievo, l’accuratezza e l’eventuale
misura degli errori. Ma l’incertezza può anche non dipendere dalle proprietà relative ai dati, ma può
essere vista come una misura della differenza tra il dato ed il significato ad esso assegnato
dall’utente (Zhang J. 2002). In altre parole l’incertezza può essere vista come un indicatore della
diversità tra l’attuale contenuto del database e l’informazione che l’utente vorrebbe costruire in
futuro mediante una perfetta e diretta osservazione della realtà (Murgrante B 2006).
Pertanto possono distinguersi due forme di incertezza: una relativa alla qualità dei dati e l’altra alla
informazione e/o interpretazione prodotta.
Alla luce di quanto precedentemente esposto appare evidente, che solo il livello di incertezza
relativo alla qualità dei dati iniziali può essere controllato. Ciò è possibile se la basi di dati utilizzata
risponde ai requisiti di idoneità richiesti per una data applicazione e se questa è corredata di tutte le
informazioni di corredo che ne identifichino la loro affidabilità per lo scopo voluto.
5
Conclusioni
La rapida rilettura sulla evoluzione della teoria della conoscenze relativa al complesso sistema dei
fenomeni territoriali, nelle sue componenti antropiche e naturali, pone in evidenza alcune
problematiche non del tutto risolte. L’inquadramento dei SIT nel più ampio panorama teorico ed
applicativo inerenti la costruzione del Sistema delle Conoscenze. La classificazione e l’ordinamento
gerarchico delle diverse componenti di un SIT. I confini specifici e limitati delle applicazioni basate
su tecnologia GIS. La differenza tra informazione e dato. La definizione della qualità dei dati e del
loro utilizzo al fine di costruire l’informazione desiderata.
Tutte le tematiche su citate rappresentano da se vasti ambiti di ricerca, ma che purtroppo non
trovano, tra la maggior parte dei fruitori e gestori dei SIT, la dovuta considerazione.
Va precisato che non si vuole enfatizzare l’apporto attuale ed in prospettiva dell’informatica alla
conoscenza completa dell’informazione dei fenomeni territoriali, derivanti fondamentalmente dagli
indiscutibili progressi registrati negli ultimi anni dal settore dell’informatica, ma piuttosto si vuole
porre l’accento su come un corretto e pertinente utilizzo dei dati, disponibili o da realizzare, in
determinati ambienti informatici di gestione, possono contribuire in modo sostanziale alla qualità
dell’informazione, derivanti da analisi e trattamento dei dati stessi. In altri termini si vuole porre
l’accento sui limiti dell’utilizzo di dati, che il più delle volte risultano essere incerti, nella loro
consistenza, accuratezza e completezza nell’ambito dei diversi processi di valutazione, cercando di
definire i caratteri di affidabilità che la base di dati utilizzata dovrebbe garantire.
Bibliografia
Burrough, P. A., R. McDonnell, et al. (1998). Principles of geographical information systems.
Oxford ; New York, Oxford University Press.
Carrion D., M. F. (2004). Importanza degli Standard nella valutazione della qualità dei dati in un
Sistema Informativo Territoriale. ASITA. CATANIA.
Feigenbaum, E. A., P. McCorduck, et al. (1988). The rise of the expert company : how visionary
companies are using artificial intelligence to achieve higher productivity and profits. New York,
Times Books.
Fischer, M. M. (1983). "Progress and problems in the methodology of regional science."
Regional Science Association: 214-218.
Joanilli M. (2001). Fondamenti di Sistemi Informativi Geografici. Roma.
Longley P.A., G. M. F., Maguire D.J. Rhind D.W. , (2002). Geographic information system and
science.
Molenaar M. (1998). An Introduction to the Theory of Spatial Object Modelling for GIS.
London.
Mura, P. M. (1986). Una geografia di valori ambientali. Roma.
Murgrante B (2006). Questioni inerenti l'incertezza della rappresentazione nell’analisi finalizzata
al GIS Supported Planning ASITA.
Nijcamp, P. (1990). Multidimensional Spatial Data and Decision Analysis. North-Holland
Nijkamp, P. and M. M. Fischer (1993). Geographic information systems, spatial modelling and
policy evaluation. Berlin ; London, Springer-Verlag.
Pegoraro C., G. L. (2004). Regole di implementazione in tema di specifiche per i dati spaziali e
loro armonizzazione secondo le aspettative della Commissione Europea. Conferenza Nazionale
ASITA 2004. ASITA. Catania. 1.
Zhang J., G. M. F. (2002). Uncertanty in geographic information. London.










![(Microsoft PowerPoint - webgis.ppt [modalit\340 compatibilit\340])](http://s1.studylibit.com/store/data/000832499_1-6588715594e5dda94042a0a8ff3b531b-300x300.png)
