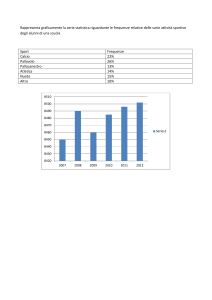
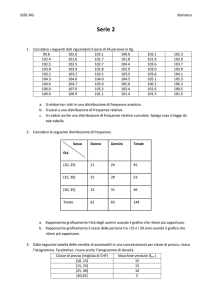
1
STATISTICA (a.a. 2013/14)
Mauro Reginato
AVVERTENZA IMPORTANTE
Gli appunti che seguono devono essere intesi come una traccia dei principali argomenti di
statistica univariata e bivariata trattati nel corso delle lezioni di Statistica serale; non
sostituiscono i libri di testo consigliati ma intendono solamente integrarli in alcune parti e
proporre alcuni esempi ed applicazioni numeriche.
Questi appunti sono messi a disposizione gratuitamente per gli studenti del corso serale e
non sono assolutamente in vendita.
INTRODUZIONE
"Metodo di osservazione scientifica e induzione applicato
allo studio dei fenomeni collettivi"
Parole chiave
osservazione scientifica
induzione
fenomeni collettivi
Campo di applicazione
economia
psicologia
medicina
sport
sociologia
…….
COME OPERA
1)
2)
3)
tradurre il fenomeno in misure
classificazione delle misure
tramite la classificazione, descrivere il fenomeno osservando:
- l’andamento
- la distribuzione
- i valori medi
- la variazione
- le relazioni
PARTIZIONE DELLA STATISTICA
METODOLOGICA - metodo di indagine
APPLICATA- applicazione del metodo ai fenomeni economici, sociali, demografici, biologici, .....
FASI DEL METODO STATISTICO
a - Rilevazione dei dati
b - Elaborazione dei dati
c - Interpretazione dei datI
2
a - RILEVAZIONE DEI DATI
1) Determinazione del piano di rilevazione
2) Rilevazione materiale
3) Spoglio dei dati e classificazione
4) Raccolta dei dati in tabelle
1) Piano di rilevazione
1.1 - Scopo
1.2 - Unità statistica e di rilevazione (es. nato morto, censimento)
1.3 - Notizie utili da conoscere
1.4 - Mezzi tecnici di osservazione (norme, chi esegue, i mezzi, quando)
1.5 - Estensione della rilevazione (tempo, durata, spazio, area)
1.6 - Limite di specializzazione (per le categorie)
Classificazione delle rilevazioni
Ampiezza
Possibilità di rilevazione
Metodo di rilevazione
Durata della rilevazione
di universo
di campione
dirette
indirette
automatiche
riflesse
continue
periodiche
occasionali
2) Rilevazione materiale
2.1 - raccogliere ed enumerare le unità statistiche
(necessità di una tecnica)
2.2 - poche unità da rilevare: enumerazione su elenchi o registri
2.3 - molte unità da rilevare: schede di rilevamento
3) Spoglio dei dati
- fissare un criterio di classificazione
- contare per ciascun carattere il numero di unità statistiche che ne sono in possesso. Come?
- suddividere le schede
- contare il numero di schede (metodo manuale o meccanografico)
4) Formazione delle tabelle
- primitive
- elaborate
- semplici
- multiple
- un carattere - più caratteri
3
b) - ELABORAZIONE DEI DATI
Trasformazione dei dati grezzi in dati utili o elaborati:
-
calcolo di rapporti
calcolo di valori medi
calcolo di simmetrie
calcolo di variabilità
calcolo di andamento
ERRORI STATISTICI
ACCIDENTALI
Boldrini:
- ignota origine, positivi e negativi
- si manifestano in modo imprevisto,
inevitabile
- dovuti al caso
SISTEMATICI
- prevalentemente a senso unico
- per scoprirli si adotta un ragionamento logico
tendenza all’arrotondamento
tare degli strumenti
inversione di cifre
A CARATTERE PSICOLOGICO
ERRORI PIU’ COMUNI
- equazione personale del ricercatore
- interpretazione soggettiva per influenza
dell’ambiente
- si possono prevedere, prevenire,
rintracciare, cercare di correggere
- non prevedibili, non prevenibili; se
rintracciabili cercare di correggere
- errori che rimangono celati
- DATO ANOMALO: controllare e poi
accettare o rifiutare
FONTI STATISTICHE
Rilevazioni
a) di stato:
censimenti della popolazione
altri censimenti (es: industria e servizi)
b) di movimento: registrazioni anagrafiche (per la popolazione)
registrazioni di altri fenomeni (es: commercio estero)
es. IL CENSIMENTO DEMOGRAFICO MODERNO
(caratteri)
a) Rilevazione
b) Data
Diretta – Nominativa – Universale – Simultanea - Periodica
Anno
finale 0-5, oppure 1-6
Mese
la scelta del mese è funzione delle caratteristiche geografiche ed
economiche dei singoli paesi (può variare nel tempo)
festivo
Giorno
4
es: Censimenti dell’Italia post-unitaria
31/12/1861
31/12/1871
31/12/1881
10/02/1901
10/06/1911
01/12/1921
21/04/1931
21/04/1936
04/11/1951
15/10/1961
24/10/1971
25/10/1981
24/10/1991
21/10/2001
09/10/2011
c) Oggetto del censimento Popolazione residente
Popolazione presente
d) Tecnica di rilevazione
Unità
statistica = individuo
di rilevazione = famiglia
PUBBLICAZIONI ISTAT
(una sintesi)
A carattere generale
Annuario statistico italiano
Compendio statistico italiano
Bollettino mensile di statistica
I conti degli italiani
Rapporto annuale
A carattere tematico (argomenti)
Ambiente e territorio
Popolazione
Sanità
Cultura
Pubblica amministrazione
Giustizia
Conti nazionali
Lavoro
Agricoltura
Industria
Servizi
Annuari
Annuario statistico italiano
Compendio statistico italiano
Commercio estero
Regioni in cifre
I conti degli italiani
Statistiche demografiche
Statistiche sanitarie
Statistiche della previdenza
Statistiche dell’istruzione
Statistiche culturali
Statistiche giudiziarie
Statistiche dell’agricoltura
Statistiche metereologiche
Statistiche degli incidenti stradali
Statistiche del lavoro
Statistiche delle cause di morte
Statistiche della navigazione
5
RAPPRESENTAZIONI GRAFICHE
Perché la rappresentazione grafica dei dati?
G. Leti: “Parafrasando l’antico proverbio cinese: “Una figura vale più di diecimila parole”, possiamo
affermare che la rappresentazione grafica dà informazioni sui fenomeni a tutti e con maggiore
facilità della tabella; infatti, rispetto alle cifre, le figure sono percepite con maggiore rapidità, facilità
e sintesi e meglio memorizzate dalla mente umana…”
C. Gini: “Il raffronto di lunghe colonne di dati numerici richiede pratica e fatica, le rappresentazioni
grafiche possono semplificare il compito e incidere meglio i dati nella memoria…
Molte ore di studio sopra tavole statistiche spesso non bastano a imprimerci l’andamento di
un fenomeno o a farci cogliere le relazioni tra fenomeni diversi così bene come un semplice
sguardo ad un ben costruito diagramma…”
M. Boldrini: “… Dopo la formazione dei dati statistici … si dovrebbe passare al momento
successivo e parlare del loro trattamento tecnico. Invero, lungi dall’esaurirsi con un vasto e
accurato accumulo di dati … la fase più conclusiva e forse più delicata della ricerca si inizia con la
loro elaborazione matematica … ma in anticipo ad essa si colloca un breve discorso sulle
rappresentazioni grafiche dei dati statistici, ossia sulla traduzione in schemi geometrici o figurativi
delle serie e delle seriazioni; ... i grafici sono fondati spesso – è vero – su criteri molto semplici e
alla portata di tutti; ma, alle volte, utilizzano concetti assai più progrediti … lo strumento geometrico
costituisce un mezzo interpretativo dei dati efficace ed immediato … conviene limitarsi a trattare
delle rappresentazioni grafiche più semplici, le quali, fortunatamente, sono le più utili e perciò
quelle che più urge conoscere.”
R. Satet, C. Voraz: “L’esame di tavole numeriche, anche di quelle più ingegnosamente disposte,
non permette di rendersi facilmente conto di certe caratteristiche; quali tendenza, irregolarità,
fluttuazioni, periodicità e rapporti in esse contenute. Le cifre che le compongono sono dei simboli
che è necessario interpretare … l’orientamento delle linee di un grafico, la densità di colore delle
superfici, le dimensioni relative delle linee, delle superfici e dei volumi formano un assieme molto
evidente, le cui principali caratteristiche vengono immediatamente notate dall’occhio … I grafici
vengono utilizzati per schematizzare i fatti e mettere in luce i loro rapporti essenziali. Essi sono di
notevole aiuto nella ricerca delle cause, soprattutto se illustrano l’applicazione delle regole dette
<<di concordanza, di differenza e delle variabili concomitanti>> di Stuart Mill. Essi non sono
destinati a sostituire le tabelle numeriche, ma a completarle rendendole più assimilabili.”
Utilità
- descrivere in forma visiva le caratteristiche del fenomeno rilevato
Scopo
- identificare variazioni nel tempo e/o nello spazio
- scoprire le relazioni con latri fenomeni o con altre manifestazioni dello stesso fenomeno
- illustrare un fenomeno senza ricorrere a lunghe esposizioni di cifre
Sono utili per indicare l’andamento nel tempo e suggerire una curva di perequazione
6
Doppio carattere
- Sintesi: avere una rapida visione d’insieme del fenomeno
- Analisi: scoprire le proprietà dei fenomeni
- si possono fare rappresentazioni diverse dello stesso fenomeno
- si possono rappresentare contemporaneamente più caratteri
- si possono rappresentare fenomeni diversi in relazione tra loro
Le rappresentazioni grafiche non sostituiscono le cifre ma servono come valido ausilio per facilitare
la comprensione, infatti:
- le cifre danno l’esatta misura dei singoli casi rilevati (analisi dei fenomeni)
- le rappresentazioni mettono in luce l’andamento dei dati (sintesi dei fenomeni)
Le rappresentazioni grafiche formano pertanto un linguaggio statistico ausiliario ma autonomo e
per poter essere comprese come linguaggio necessitano di:
- semplicità
- chiarezza grafica
ALCUNE REGOLE
a) Autonomia della rappresentazione grafica
Ogni rappresentazione grafica deve contenere in se stessa le indicazioni necessarie per la sua
identificazione:
- oggetto della rappresentazione
- epoca cui si riferiscono i dati usati per base
- ambito territoriale a cui i dati corrispondono
- fonte da cui i dati sono attinti
b) Scelta del sistema
Per ottenere efficaci rappresentazioni grafiche è necessaria una scelta giudiziosa del sistema di
rappresentazione più opportuno, cioè scegliere tra i vari sistemi di rappresentazione quello più
adatto al caso:
- se è possibile scegliere tra più rappresentazioni grafiche, optare per la più semplice, in quanto dà
meno errate interpretazioni
- dare precedenza alle rappresentazioni lineari, rispetto alle areali e volumetriche
- per fenomeni distribuiti territorialmente usare i cartogrammi
- mai omettere l’unità simbolica della scala di riferimento
7
PRINCIPALI RAPPRESENTAZIONI GRAFICHE
a) MODALITA’ QUALITATIVA
Ideogrammi :
figure che nella forma ricordano il fenomeno studiato
Cartogrammi:
carte geografiche nelle quali le intensità del fenomeno sono rappresentate da differente tratteggio
o colore
Diagrammi:
presentano le intensità del fenomeno con elementi geometrici (linee o aree)
- a segmenti rettilinei
- a superfici rettangolari
- a superfici non rettangolari (quadrati, triangoli, cerchi…). Le misure delle superfici sono
proporzionali al numero di casi osservati per ogni modalità del fenomeno
Area
Proporzionamento delle figure
(h = altezza; l = lato; r = raggio)
h = S/b
Rettangolo
Quadrato
S = b*h
S = l2
Cerchio
S=Πr
Triangolo
S = b*h/2
l=
2
S
r = S/Π
h = 2(S/b)
b) MODALITA’ QUANTITATIVA
Coordinate cartesiane
sull’asse delle ascisse (X) si pongono i valori della variabile indipendente;
sull’asse delle ordinate (Y) si pongono i valori della variabile dipendente (frequenze)
(es. serie di tempo)
variabile discontinua: diagramma a segmenti
variabile continua : diagramma a spezzata o curva di frequenza
Istogramma
viene utilizzato per rappresentare una seriazione continua i cui dati sono raggruppati in classi
Per determinare l’altezza dei singoli moduli rettangolari si deve tenere conto di come sono
formulate le classi:
- modulo costante (es.: hi = Yi)
- modulo variabile (es.: hi = Yi / di)
Importante: la forma dell’istogramma (e l’interpretazione del grafico) non cambia se per la sua
costruzione si utilizzano le frequenze relative anziché quelle assolute.
Poligono di frequenza
Per seriazioni continue con dati raggruppati in classi
8
Diagrammi a scala logaritmica
(semplice o doppia)
Coordinate polari
Raggio vettore
α
Asse polare
Istogramma scalare o “piramide della popolazione”
Diagramma a dispersione, o a “punti”, o a “nuvola”
TABELLE STATISTICHE
1- SERIE: per modalità qualitative
La modalità qualitativa, mutabile, viene espressa con aggettivi o attributi
2- SERIAZIONE: per modalità quantitative
La modalità quantitativa, variabile, viene espressa con un numero
3- MISTE: contengono più modalità; sono dette anche a “doppia entrata”
4- COMPLESSE o DERIVATE: unione di più tabelle semplici
SERIE
Tabella che si ricollega a modalità qualitative. Le modalità possono essere “ordinabili” e “non
ordinabili”. Il carattere qualitativo assume la denominazione di “mutabile” o “variabile qualitativa”,
per cui si possono fare le distinzioni che seguono:
Ordinabile
Rettilinea
Ciclica
Di tempo (storica)
Di spazio (territoriale)
Serie
Non ordinabile
Sconnessa
Di fatto (qualitativa)
9
SERIE STORICA
Le modalità si riferiscono ad istanti o periodi di tempo. Il tempo è la variabile indipendente o l’unità
di osservazione.
1- Serie storica di stato (istanti di tempo)
Es.: Popolazione residente a Torino a fine anno
Anni
2001
2002
2003
2004
2005
Popolazione
899.806
896.918
902.910
902.345
900.748
Anni
2006
2007
2008
2009
2010
Popolazione
900.736
908.129
909.345
910.504
908.501
2- Serie storica di flusso di flusso (intervalli di tempo)
Es.: Bilancio demografico della popolazione residente in Italia. Anni vari.
Anni
2001
2002
2003
2004
2005
Nati
539.389
538.198
544.063
562.599
554.022
Morti
559.956
557.393
586.468
546.658
567.304
Anni
2006
2007
2008
2009
2010
Nati
560.010
563.933
576.659
568.857
561.944
Morti
557.892
570.801
585.126
568.857
587.488
SERIAZIONI
Tabelle che si ricollegano a modalità quantitative. Si ottengono ordinando i dati secondo una
modalità quantitativa detta “variabile”.
Seriazioni continue
La modalità è continua, ossia tra una modalità e la successiva sono comprese altre infinite
modalità (es, altezza, tempo,…)
Seriazioni discontinue
La modalità quantitativa non può essere frazionata a piacere, ma è espressa in valori interi
Carattere
Un certo segno o qualifica che contraddistingue i soggetti di una categoria da quelli di un’altra (es.
sesso, età)
Modalità
Le diverse manifestazioni di quel carattere (es. maschio, femmina; anni 23…)
La variabile può essere espressa:
-) come grandezza (es. 0,1,2,….,k,…n)
-) come classe di intensità
(numero che esprime l’ammontare, la grandezza, la misura del carattere)
10
minore di 1
Ampiezza della classe
(è il numero di unità
espresse dalla classe)
uguale a 1
maggiore di 1
Come si definisce il numero delle classi?
a) non si possono dare delle regole fisse; il numero di classi dipende dalla scala di misure
adatta, da grado di precisione di successive elaborazioni; dal tipo di fenomeno studiatoM;
dall’esperienza del ricercatore;
b) si può utilizzare la regola di Sturges
K = 1 + (10/3) log10 N
dove
K = numero di classi;
N = numero di dati
Attenzione al calcolo del modulo di classe
a) seriazioni continue
b) seriazioni discontinue
Valore centrale di classe
c) seriazioni continue
d) seriazioni discontinue
L’età, un caso ambiguo
L’età può dare origine a seriazioni continue o discontinue
a) anni precisi
b) anni compiuti
c) anni iniziati
REGOLE PER LA SCELTA DELLE CLASSI
1- Gli estremi delle classi siano numeri arrotondati o con il minor numero di cifre decimali
2- L’ampiezza sia possibilmente costante
3- L’estremo inferiore della prima classe e l’estremo superiore dell’ultima siano il più vicino
possibile al più piccolo e al più grande valore osservato
4- Se la variabile statistica è continua, nessuna classe risulti con frequenza nulla
5- L’andamento dei gruppi di osservazione nelle classi che si succedono sia gradualmente
variabile, con (possibilmente) un solo, o al più, due massimi
6- In caso di un solo massimo, la distribuzione sia gradualmente crescente e poi decrescente; in
caso di due massimi può anche assumere la forma ad “U”
7- A parità di altre condizioni, l’ampiezza costante delle classi sia la più piccola possibile, perché
con grandi ampiezze l’andamento è meno disturbato ma anche meno fedele
8- Gli intervalli possono essere├ oppure ┤ o tali che il limite inferiore di una classe coincida con il
limite superiore della precedente (in questo caso si possono suddividere le frequenze a metà)
11
INCREMENTO
Assoluto
I = Xt – X0
Assoluto medio annuo
Im =
Relativo
Xt − X0
t
Xt − X0
Ir =
x 100
X0
TASSO DI INCREMENTO
Andamento
Xt = X0 (1 + rt)
Lineare
Geometrico
Xt = X0 (1 + r )t
Continuo
Xt = X0 ert
Tasso
Xt − X0
t *X0
Lineare
rl =
Geometrico
rg = t
Continuo
rc =
Xt
-1
X0
log(X t / X 0 )
t
es.: popolazione residente in Italia, in Piemonte e in Torino al 31.12 di ciascun anno
Anni
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
Italia
56.844.408
56.844.197
56.876.364
56.904.379
56.909.109
56.923.524
56.960.692
57.321.070
57.553.560
58.462.375
58.655.294
59.131.287
59.619.290
60.045.068
60.340.328
60.626.442
Piemonte
4.288.866
4.294.127
4.291.441
4.288.051
4.287.465
4.289.731
4.213.294
4.231.334
4.270.215
4.233.172
4.246.324
4.352.828
4.401.266
4.432.571
4.446.230
4.457.335
Torino
923.106
919.612
914.818
909.717
903.705
900.987
899.806
896.918
902.910
902.345
900.748
900.736
908.129
909.345
910.504
908.501
Esempio di calcolo del tasso di incremento (ipotesi: andamento geometrico)
Anni
1995-2000
2000-2005
2005-2010
1995-2010
Tasso di incremento
Italia
Piemonte
Torino
12
RAPPORTI STATISTICO-DEMOGRAFICI
Vengono detti rapporti statistici (e demografici) i rapporti fra due valori di cui almeno uno è un dato
statistico. Di solito sono espressi in percentuale e sono utilizzati per fare raffronti.
I rapporti statistici si suddividono in:
a) Rapporti di eliminazione semplice
b) Rapporti di eliminazione complessa
I primi sono quelli in cui il denominatore è a base 1, 10, 100, 1000, i secondi invece vengono
utilizzati per eliminare le cause che hanno portato a un determinato risultato.
Rapporti di eliminazione semplice
-
Rapporti di composizione
Rapporti di coesistenza
Rapporti di eliminazione
Rapporti di frequenza
Numeri indice
Rapporti di eliminazione complessa
-
Quozienti corretti
Quozienti normalizzati
Rapporti di eliminazione semplice
1) Rapporti di coesistenza:
mettono in relazione l’intensità di un fenomeno in luoghi diversi o due fenomeni nello stesso
luogo ( es. indice di vecchiaia, grado di invecchiamento, indice di mascolinità, carico di figli per
donna feconda…)
2) Rapporti di composizione:
evidenziano la relazione tra una quantità osservata (misura o conteggio) di una generica
modalità di un carattere e la quantità globale al cui interno è stata effettuata l’osservazione (es.
grado di invecchiamento, grado di celibato/nubilato, livello di coniugio, peso di un determinato
livello di titolo di studio…)
3) Rapporti di derivazione:
mettono in relazione l’intensità di un primo fenomeno con l’intensità di un secondo, che ne
costituisce il presupposto logico.
I rapporto di derivazione possono essere:
- generici (es. quoziente di natalità e di mortalità)
- specifici (es. quoziente di fertilità…)
4) Rapporti di frequenza:
mettono in relazione il n° dei casi di un fenomeno e le dimensioni del fenomeno stesso (es.
densità di popolazione, indice di affollamento…)
5) Numeri indice:
confrontano l’intensità dello stesso fenomeno in diversi momenti nel tempo (periodo di
riferimento e periodo base), descrivendone la variazione
13
ESEMPIO DI RAPPORTI STATISTICI PER LO STUDIO DELLE CARATTERISTICHE
STRUTTURALI DELLA POPOLAZIONE
LA STRUTTURA PER SESSO
La classificazione per sesso della popolazione permette di sottolineare immediatamente
l’esistenza o meno di uno squilibrio numerico tra i due sessi e il senso di tale squilibrio. Tuttavia,
per fare dei confronti sia temporali che territoriali sulla misura dello squilibrio tra i sessi, è
necessario ricorrere a misure relative.
MISURE IMPIEGATE
1) Il rapporto di composizione. E’ il rapporto fra l’ammontare della popolazione di un sesso
e l’ammontare globale della popolazione: fornisce la percentuale di popolazione di ciascun
sesso sulla popolazione complessiva.
M/(M+F)*100
F/(M+F)*100
Equilibrio=50
Se M>F: >50
Se M<F: <50
2) Il rapporto di coesistenza. E’ il rapporto tra l’ammontare della popolazione di un sesso e
quella dell’altro sesso.
M/F*100
F/M*100
Equilibrio=100
M>F: >100
M<F: <100
3) L’indice di eccedenza. E’ il rapporto della differenza tra l’ammontare di un sesso e quello
dell’altro sesso e la popolazione complessiva.
(M-F/M+F)*100
(F-M/M+F)*100
14
LA STRUTTURA PER ETA’
La composizione per età è l’elemento strutturale di gran lunga più importante dal punto di vista
demografico. Infatti essa rappresenta soprattutto la risultante del movimento naturale della
popolazione, ma costituisce a sua volta uno dei presupposti tanto della dinamica demografica,
quanto di altre caratteristiche strutturali della popolazione.
Così come per la classificazione per sesso, anche per quella per età è necessario ricorrere a degli
indici.
Ai fini dell’analisi dell’invecchiamento, la popolazione viene in genere suddivisa in tre classi di età:
0-14 (giovani), 15-64 (adulti), 65-ω
ω (anziani).
Il peso relativo di ogni classe è calcolato come il rapporto tra l’ammontare della singola classe e la
popolazione totale.
(P0-14/P)*100
(P15-64/P)*100
(P65-ωω/P)*100
INDICI PIU’ UTILIZZATI
1) Indice di vecchiaia, indica quanti anziani ci sono ogni 100 giovani.
Iv= (P65-ωω/ P0-14)*100
2) Indice di invecchiamento, indica quanti anziani ci sono ogni 100 abitanti.
Iiv= (P65-ωω/ P)*100
3) Indice di dipendenza, indica quante sono le persone che in via presuntiva non sono
autonome per ragioni demografiche (l’età) ogni 100 persone, che si presume debbano
sostenerle con la loro attività.
Id= (P0-14+P65-ωω/P15-64)*100
4) Indice di struttura della popolazione attiva, è il rapporto tra la popolazione in età 40-64
anni e la popolazione in età 15-39 anni.
Is= (P40-64/P15-39)*100
5) Indice di ricambio della popolazione attiva, rapporto tra la consistenza della popolazione
in età 60-64 anni e la popolazione in età 15-19 anni.
Ic= (P60-64/P15-19)*100
6) Indice di carico di figli per donna feconda, indica quanti sono i bambini rispetto alle
donne che sono in età fertile.
Ic= (P0-4/P15-49)*100
7) Età media. Non è un buon indice, ma è comunque indicativo.
Età media = ∑xipi/pi
dove ∑ pi= P
15
Esempio di indicatori
Indicatori di struttura della popolazione residente in Piemonte
Indicatore
Tasso di natalità (x1000)
Tasso di mortalità (x1000)
Tasso di crescita (x1000)
Indice di vecchiaia (x100)
Rapporto di mascolinità(x100)
1990
7,30
11,00
-3,70
124,87
93,99
1995
7,40
11,50
-4,10
154,99
93,92
2000
8,40
11,30
-2,90
172,60
94,30
2005
8,60
10,90
-2,30
178,00
94,10
2010
8,50
11,10
-2,60
178,40
94,14
NUMERI INDICE
Misura statistica usata per mostrare i cambiamenti di una variabile rispetto al tempo, alla
localizzazione geografica, o ad altri caratteri
Si possono costruire numeri indice:
a base fissa
a base mobile
di serie temporali
di serie spaziali
di serie di fatto
Serie
Intensità
Proporzioni
0
1
2
3
…
…
…
N
p0
p1
p2
p3
…
…
…
pn
…
p0 : p1 = 100 : x1
p0 : p2 = 100 : x2
p0 : p3 = 100 : x3
…
…
…
p0 : pn = 100 : xn
Numeri indice a base
fissa
(posto p0 = 100)
p0 = 100
x1 = (p1/ p0) 100
X2 = (p2/ p0) 100
X3 = (p3/ p0) 100
…
…
…
Xn = (pn/ p0) 100
Esempio di calcolo di numeri indice per una serie storica (matrimoni misti in Italia 2002-2008)
Anni
2002
2003
2004
2005
2006
2007
2008
Sposo italiano
Sposa straniera
Valori assoluti
15561
16098
17389
18481
19029
17663
18240
Sposo straniero
Sposa italiana
Valori assoluti
4491
4304
4446
4022
4991
5897
6308
Sposo italiano
Sposa straniera
NI (2002 = 100)
100
103,45
111,75
118,76
122,29
113,51
117,22
Sposo straniero
Sposa italiana
NI (2002 = 100)
100
95,84
99,00
89,56
111,13
131,31
140,46
16
Esempio di calcolo di numeri indice per una serie territoriale (Italia 2010) (completare la tabella)
Regioni
Piemonte
Valle Aosta
Lombardia
Trentino A.A.
Veneto
Friuli VG
Liguria
Emilia Romagna
Toscana
Umbria
Marche
Lazio
Abruzzo
Molise
Campania
Puglia
Basilicata
Calabria
Sicilia
Sardegna
ITALIA
Quozienti 2010 (x1000)
Nuzialità
Natalità
Mortalità
3,2
8,6
11,0
3,0
9,8
10,0
3,0
9,9
9,1
3,5
10,5
8,4
3,4
9,5
9,1
3,1
8,4
11,4
3,4
7,4
13,3
3,0
9,5
10,7
3,5
8,7
11,1
3,4
8,8
11,0
3,2
9,0
10,4
3,5
9,5
9,4
3,4
8,8
10,6
3,6
7,8
10,8
4,8
10,0
8,7
4,5
9,1
8,5
4,2
7,8
9,6
4,4
8,9
9,0
4,5
9,5
9,5
3,9
8,1
8,7
3,6
9,3
9,7
NI bf (Italia=100)
Nuzialità Natalità Mortalità
100
100
100
Esempi di calcolo di indicatori vari
Tav.1: Emigranti partiti dall’Italia soli o in gruppi familiari. Valori assoluti e relativi, 1876-1925
Anni
1876
1880
1885
1890
1895
1900
1905
1910
1915
1920
1925
Emigranti partiti
(val. assoluti)
soli
87714
87122
106374
152557
163675
246126
576192
512678
94726
538433
217880
in famiglia
21057
32779
50819
64687
129506
106656
150139
138797
51293
76178
62201
Emigranti partiti
(%)
Totale
108771
119901
157193
217244
293181
352782
726331
651475
146019
614611
280081
soli
80,64
72,66
67,67
70,22
55,83
69,77
79,33
78,69
64,87
87,61
77,79
in famiglia
19,36
27,34
32,33
29,78
44,17
30,23
20,67
21,31
35,13
12,39
22,21
totale
100
100
100
100
100
100
100
100
100
100
100
17
Tav.2: Emigranti partiti dall’Italia per destinazione. Valori assoluti, 1876-1925
anni
1876
1880
1885
1990
1995
2000
2005
2010
2015
2020
2025
Europa
86379
84224
78232
100259
105273
181047
266982
242381
74389
198171
171630
continenti di destinazione
America Africa
Oceania
19610
2544
0
33080
2555
15
72490
6217
158
113027
2228
291
183919
3432
154
165627
5417
535
444724
13072
765
400852
6670
1079
65877
5306
347
408184
7303
697
96435
6685
5182
Asia
0
27
96
49
403
156
788
493
100
256
149
Tav.3: Emigranti partiti dall’Italia per destinazione. Valori relativi, 1876-1925
anni
1876
1880
1885
1890
1895
1900
1905
1910
1915
1920
1925
Europa
79,41
70,24
49,77
46,15
35,91
51,32
36,76
37,20
50,94
32,24
61,28
Continenti di destinazione (%)
America
Africa
Oceania
18,03
2,34
0
27,59
2,13
0,01
46,12
3,96
0,10
52,03
1,03
0,13
62,73
1,17
0,05
46,95
1,54
0,15
61,23
1,80
0,11
61,53
1,02
0,17
45,12
3,63
0,24
66,41
1,19
0,11
34,43
2,39
1,85
Asia
0
0,02
0,06
0,02
0,14
0,04
0,11
0,08
0,07
0,04
0,05
Totale
100
100
100
100
100
100
100
100
100
100
100
Tav.4: Emigranti partiti dall’Italia soli o in gruppi familiari. Numeri indice, 1876-1925
Italia
1876
1880
1885
1890
1895
1900
1905
1910
1915
1920
1925
soli
87714
87122
106374
152557
163675
246126
576192
512678
94726
538433
217880
in famiglia
21057
32779
50819
64687
129506
106656
150139
138797
51293
76178
62201
NI
soli
100,00
99,33
121,27
173,93
186,60
280,60
656,90
584,49
107,99
613,85
248,40
NI in
famiglia
100,00
155,67
241,34
307,20
615,03
506,51
713,01
659,15
243,59
361,77
295,39
18
Tav.5: Emigranti partiti dall’Italia per destinazione. Numeri indice, 1876-1925
Italia
1876
1880
1885
1890
1895
1900
1905
1910
1915
1920
1925
Europa
86379
84224
78232
100259
105273
181047
266982
242381
74389
198171
171630
America
19610
33080
72490
113027
183919
165627
444724
400852
65877
408184
96435
Africa
2544
2555
6217
2228
3432
5417
13072
6670
5306
7303
6685
NI Europa NI America NI Africa
100,00
100,00
100,00
97,51
168,69
100,43
90,57
369,66
244,38
116,07
576,37
87,58
121,87
937,88
134,91
209,60
844,60
212,93
309,08
2267,84
513,84
280,60
2044,12
262,19
86,12
335,94
208,57
229,42
2081,51
287,07
198,69
491,76
262,78
DISTRIBUZIONI
FREQUENZE RELATIVE E PERCENTUALI
SCHEMA DI TABELLA A DOPPIA ENTRATA DI FREQUENZA
FENOMENO X
modalità di variazioni qualitative o quantitative
(j= 1…n)
Fenomeno X’
modalità di
variazioni
qualitative o
quantitative
(i= 1…m)
Totale
X1
X2
…
Xj
…
Xn
Totale
X’1
Y11
Y12
…
Y1j
…
Y1n
Y1.
X’2
Y21
Y22
…
Y2j
…
Y2n
Y2.
…
…
…
…
…
…
…
…
X’i
Yi1
Yi2
…
Yij
…
Yin
Yi.
…
…
…
…
…
…
…
…
X’m
Ym1
Ym2
…
Ymj
…
Ymn
Ym.
Y.1
Y.2
…
Y.j
…
Y.n
Σ Yij = Y
19
Distribuzione condizionata di riga
Distribuzione congiunta
Distribuzione marginale
delle righe
Distribuzione
condizionata
di colonna
Totale delle frequenze
Distribuzione marginale
delle colonne
Distribuzione semplice
Si usa indicare con Yi (Ni) la frequenza assoluta riferita ad un valore della distribuzione semplice
Es. Matrimoni in Italia (anno 2000)
Aree
Nord
Centro
Mezzogiorno
Totale
N. matrimoni
115.309
52.805
112.374
280.488
Simbolo
Y1
Y2
Y3
Σ Yi = Y
N. matrimoni
86113
39439
91633
217185
Simbolo
Y1
Y2
Y3
Σ Yi = Y
Es. Matrimoni in Italia (anno 2010)
Aree
Nord
Centro
Mezzogiorno
Totale
Distribuzione congiunta
Si usa indicare con Yij (Nij) la frequenza assoluta riferita ad un valore della distribuzione congiunta
Aree
Nord
Centro
Mezzogiorno
Totale
Rito religioso
Y11
Y21
Y31
Y.1
Rito civile
Y12
Y22
Y32
Y.2
Totale
Y1.
Y2.
Y3.
Σ Yij = Y
20
Es. Matrimoni in Italia per rito (anno 2000)
Aree
Nord
Centro
Mezzogiorno
Totale
Rito religioso
79.527
37.622
94.856
212.005
Rito civile
35.782
15.183
17.518
68.483
Totale
115.309
52.805
112.374
280.488
Rito civile
41837
17705
20568
80110
Totale
86113
39439
91633
217185
Es. Matrimoni in Italia per rito (anno 2010)
Aree
Nord
Centro
Mezzogiorno
Totale
Rito religioso
44276
21734
71065
137075
Le frequenze relative rappresentano una lettura differente di una distribuzione espressa in valori
assoluti, capace di offrire una informazione migliore.
Con le frequenze relative si possono fare comparazioni altrimenti non possibili
In genere si interpreta meglio la frequenza relativa se la si moltiplica per 10k.
es. per k = 2 si ottengono i valori PERCENTUALI
In taluni casi si può adottare una diversa potenza di 10 (es. 103, 104…)
es. Matrimoni in Italia per rito (anno 2000). Frequenze relative per riga.
Aree
Nord
Centro
Mezzogiorno
Totale
Frequenze relative
Rito
Rito civile
religioso
0,690
0,310
0,712
0,288
0,844
0,156
0,756
0,244
Totale
1,000
1,000
1,000
1,000
Frequenze percentuali
Rito
Rito civile
religioso
69,0
31,0
71,2
28,8
84,4
15,6
75,6
24,4
Totale
100,0
100,0
100,0
100,0
Proporzione (2000)
79.527 : 115.309 = x : 1
79.527 : 115.309 = x : 100
x = (79.527/115.309) * 1 = 0,690
x = (79.527/115.309) * 100 = 69,0
es. Matrimoni in Italia per rito (anno 2010). Frequenze relative per riga.
Aree
Nord
Centro
Mezzogiorno
Totale
Frequenze relative
Rito
Rito civile
religioso
0,5142
0,4958
0,5511
0,4489
0,7755
0,2245
0,6311
0,3689
Totale
1,000
1,000
1,000
1,000
Frequenze percentuali
Rito
Rito civile
religioso
51,42
49,58
55,11
44,89
77,55
22,45
63,11
36,89
Totale
100,0
100,0
100,0
100,0
21
Proporzione (2010)
44.276 : 86.113 = x : 1
44.276 : 86.113 = x : 100
x = 44276/86113)*1 = 0,5142
x = (44276/86113) * 100 = 51,42
es. Matrimoni in Italia per rito (anno 2000). Frequenze congiunte espresse in valore relativo e
percentuale.
Aree
Nord
Centro
Mezzogiorno
Totale
Frequenze relative
Rito
Rito civile
religioso
0,284
0,128
0,134
0,054
0,338
0,062
0,756
0,244
Totale
0,412
0,188
0,400
1,000
Frequenze percentuali
Rito
Rito civile
religioso
28,4
12,8
13,4
5,4
33,8
6,2
75,6
24,4
Totale
41,20
18,80
40,00
100,0
es. Matrimoni in Italia per rito (anno 2010). Frequenze congiunte espresse in valore relativo e
percentuale.
Aree
Nord
Centro
Mezzogiorno
Totale
Frequenze relative
Rito
Rito civile
religioso
0,2039
0,1926
0,1001
0,0815
0,3272
0,0947
0,6312
0,3688
Totale
0,3965
0,1816
0,4219
1,000
Frequenze percentuali
Rito
Rito civile
religioso
20,39
19,26
10,01
8,15
32,72
9,47
63,12
36,88
Totale
39,65
18,16
42,19
100,0
22
I VALORI MEDI
Media di un insieme di numeri reali:
X1, X2, X3, …. Xn
é il risultato di una operazione eseguita con una data norma sopra le quantità considerate, il quale
rappresenta o una delle quantità considerate che non sia superiore o inferiore a tutte le altre
(MEDIA REALE O EFFETTIVA) oppure una quantità nuova intermedia tra la più piccola e la più
grande delle quantità considerate (MEDIA DI CONTO O FITTIZIA).
La precisazione della norma in questione porta alla definizione di un particolare tipo di media.
TIPI DI MEDIE
FERME
la media dipende dal valore di tutti i termini dell’insieme
es. m. aritmetica
LASCHE
la media tiene conto solamente di alcuni termini della distribuzione
es. (X1 + Xn) / 2
ANALITICHE
la media si può esprimere mediante formula matematica che esprime le operazioni da eseguirsi sui
termini dell’insieme dato
es. m. aritmetica
NON ANALITICHE
la media non può essere espressa mediante formula matematica del valore dei termini; sono dette
“di posizione” perché dipendono dal posto che i termini occupano nella successione che si ottiene
dall’insieme dato
es. mediana
UNIVOCHE
quali che siano i termini dell’insieme, esiste un solo valore medio del tipo considerato
es. m. aritmetica
PLURIVOCHE
possono esistere più valori medi del tipo considerato
es. la m. geometrica dei termini -9, -4, 4, 9 vale + 6
SINGOLE
la definizione individua un solo tipo di media
es. m. aritmetica
COMPRENSIVE
la definizione individua più tipi di medie
es. m. di potenze
X1 + X 2 + X 3 + … + X n
n
r
r
r
r
r
OGGETTIVE
La media viene calcolata per ottenere l’unica e reale intensità del fenomeno oggetto di studio,
ossia quando vi sia una sola grandezza alla quale si riferiscono le diverse misurazioni.
La media è definita oggettiva in quanto dà il valore oggettivo di una grandezza reale
23
SOGGETTIVE
La media è un valore di sintesi di più grandezze oggettive.
La media indica in quale misura si sarebbe verificato il fenomeno se la sua distribuzione fosse
stata uniforme.
PRECISAZIONE SULLE MEDIE DI CONTO O FITTIZIE
Media fittizia possibile
La modalità da essa assunta può essere assunta anche dal carattere in esame
es. consumo medio di pane per individuo
Media fittizia impossibile
La modalità da essa assunta non può essere assunta anche dal carattere in esame
es. numero medio di figli per famiglia
DEFINIZIONE DI CAUCHY
Media di un insieme di quantità è ogni quantità compresa tra le due quantità estreme dell’insieme,
un valore compreso tra il minimo e il massimo dei termini che si intende sintetizzare, non esterno
al campo di variazione.
Xmin < M < Xmax
DEFINIZIONE DI CHISINI
Media di una distribuzione
X1, X2, X3, … Xn
rispetto ad una certa funzione “F”, è quella quantità “M” che sostituita a ciascuno dei termini nella
funzione “F” lascia invariato il risultato
F (X1, X2, X3, … Xn) = F (M, M, M, …, M)
MEDIE DI POTENZA (di ordine r)
Dalla definizione di Chisini, prendendo
F = ∑ (...)
r
si ottiene
n
F ( X 1 , X 2 ,..., X n ) = ∑ X ir = X 1r + X 2r + ... + X nr
i =1
e
n
F ( M , M ,..., M ) = ∑ M r = nM r
i =1
24
n
∑X
Dall’uguaglianza
i =1
r
i
= nM r
n
Mr =
segue
∑X
i =1
r
i
n
Si definisce media di potenza di ordine r la radice:
n
Mr = r M r =
∑X
r
i =1
r
i
n
Nel caso di distribuzione con modalità X1, …, Xm con corrispondenti frequenze N1, …, Nm la
definizione è data da
m
∑X
Mr = M = r
r
i =1
m
r
r
i
Ni
∑N
i =1
i
ALCUNI TIPI DI MEDIE FERME
1) Media aritmetica (r=1)
m
∑X
n
x = M1 =
∑X
i =1
i
x = M1 =
i =1
m
i
Ni
∑N
n
i =1
i
osservazione
M1 lascia invariato il totale, cioè soddisfa la definizione di Chisini con F= Σ(…)
proprietà
a) la somma degli scarti tra ogni termine e la media aritmetica è uguale a zero (cioè x rappresenta
il baricentro della distribuzione)
∑ (X
n
i =1
i
)
n
− x = ∑ xi = 0
i =1
25
b) la somma del quadrato degli scarti è un minimo nei confronti della somma del quadrato degli
scarti da ogni altro valore che non sia la media aritmetica
∑ (X
n
i
−x
i =1
)
2
= min imo
cioè
∑ (X
n
i =1
i
−x
) < ∑ (X
n
2
i =1
i
− k)
k≠x
2
per
2) Media armonica (r= -1)
−1
m −1
∑ X i Ni
=
M −1 = i =1 m
N
∑ i
i =1
m
∑N
i =1
m
i
Ni
∑X
i =1
i
3) Media geometrica (r → 0)
M0 =
m
n
n
∏X
i =1
M0 =
i
∑ Ni
i =1
m
∏X
Ni
i
i =1
osservazione
M0 lascia invariato il prodotto, cioè soddisfa la definizione di Chisini con F=Π(…)
proprietà
a) la potenza di r.mo grado della media geometrica di “n” termini è uguale alla media geometrica
delle potenze r.me degli “n” termini
n
r
=n
X
∏
i
i =1
n
n
∏X
r
i
i =1
b) il reciproco della media geometrica di “n” termini è uguale alla media geometrica del reciproco
degli “n” termini
1
=
n
n
∏X
i =1
n
n
∏
i =1
i
1
Xi
26
c) la media geometrica di “n” rapporti è uguale al rapporto tra le medie geometriche dei numeratori
e dei denominatori
n
n
n
X
∏X
i =1
*
i
n
i =1
=
i
∏X
*
i
n
n
∏X
i =1
i
d) il logaritmo della media geometrica di “n” termini è uguale alla media aritmetica del logaritmo
degli “n” termini
1 n
log M 0 = ∑ log X i
n i =1
da cui M 0 = exp(logM 0 ) con il log in base “e”
e) la media geometrica di “m” termini che appaiono con differenti frequenze Ni (o Yi) è pari al
prodotto degli “m” termini elevati alla frequenza relativa Ni/N (oppure Yi/ΣYi)
m
M0 = N ∏ X
m
= ∏ Xi
Ni
i
i =1
i =1
Ni
N
dove
N =
m
∑N
i =1
i
GERARCHIA TRA LE MEDIE FERME
Al crescere di “r” cresce la media di potenza r-esima:
M r −1 ≤ M r ≤ M r + 1
e quindi
M −1 ≤ M 0 ≤ M 1 ≤M 2≤ M 3
con
M2 = media quadratica
M3 = media cubica
ALCUNI TIPI DI MEDIE LASCHE
1- VALORE MEDIANO (mediana)
2- VALORE MODALE (moda)
3- QUANTILI (in generale)
quartili, decili, centili
27
MEDIANA
a) serie di dati: la mediana è il valore che suddivide la serie di “n” valori in due parti uguali; tale valore
che corrisponde a quello che occupa la posizione:
per “n” dispari
per “n” pari
X n + X n +1
Me = X n +1
Me =
2
2
2
2
b) distribuzione di frequenze
- con modalità singole Xi di frequenza ni
Frequenza cumulata di Xi = Num(X ≤ Xi) = F(Xi)
F = funzione di ripartizione
(F è monotona non decrescente, assume valori compresi tra 0 e 1)
Me = primo valore tale che F(x) > 1/2
- con modalità raggruppate in classi
Classe
X0 -| X1
X1 -| X2
ni
n1
n2
fi
f1
f2
Xi-2 -| Xi-1
Xi-1 -| Xi
ni-1
ni
fi-1
fi
Si identifica la classe mediana con fi > ½ e all’interno di essa il valore mediano è dato da
Me = X i−1 + d i
dove
di = X i − X i −1
(1 2 − f )
i −1
f i − f i−1
è l’ampiezza della classe i-esima
VALORE MODALE (O MODA O NORMA)
b) serie di dati: il valore modale è quella modalità che compare il maggior numero di volte;
per “n” dispari
Me = X n +1
2
per “n” pari
X n + X n +1
Me =
2
2
2
28
b) seriazione: il valore modale è il valore della variabile alla quale corrisponde la massima frequenza;
- con modalità singole Xi di frequenza ni
Studente
Punteggio
A B C D E F G H L M N P Q R S
42 44 48 38 44 46 38 44 39 45 44 48 42 38 39
moda = 44 (compare quattro volte)
- con modalità raggruppate in classi:
Classe
X0 -| X1
X1 -| X2
ni
n1
n2
fi
f1
f2
Xi-2 -| Xi-1
Xi-1 -| Xi
ni-1
ni
fi-1
fi
Se le classi hanno modulo costante, classe modale è quella sulla quale cade il maggior numero di
frequenze.
Se le classi hanno modulo variabile bisogna dividere le frequenze contenute in ogni classe per i
rispettivi moduli di classe; la classe corrispondente al rapporto più grande sarà quella nella quale
cade la moda.
Per individuare l’esatto valore modale:
Yi-1
Yi
Yi+1
li
di
frequenze della classe che precede la classe modale
frequenze della classe modale
frequenze della classe che segue la classe modale
limite inferiore della classe modale
ampiezza della classe modale
Moda = l i + d i
Yi+1
Yi +1 + Yi −1
QUANTILI
Si definiscono “quantili” i “q-1” valori che ripartiscono la distribuzione in “q” parti uguali
a) Quartili:
per q = 4 → si ottengono 3 quartili
Q1 = X 1
n
4
(Q1 = primo quartile)
Q2 = Me = X 2
n
4
Q3 = X 3
n
4
(Q2 = secondo quartile, mediana)
(Q3 = terzo quartile)
29
Calcolo dei Quartili (con modalità raggruppate in classi)
Q1 = X i −1 + d i
(1 4 − F )
i −1
Q3 = X i −1 + d i
Fi − Fi −1
(3 4 − F )
i −1
Fi − Fi −1
b) Centili: per q = 100 → si ottengono 99 centili
1° centile =
X
2° centile =
X
1
n
100
2
n
100
…
25° centile =
= Q1
X 25
n
100
…
50° centile =
X 50
n
100
…
75° centile =
X 75
n
100
= Q2 = Me
= Q3
Calcolo dei Centili (con modalità raggruppate in classi)
Il calcolo dei centili avviene in modo analogo a quello dei quartili
FREQUENZE CUMULATE E FUNZIONE DI RIPARTIZIONE
In 1880 famiglie, viene rilevato il numero di componenti della famiglia:
Numero di
componenti (Xi)
1
2
3
4
5
6
7
8
Totale
Famiglie (ni)
153
225
335
564
346
133
75
49
1880
Xi*ni
153
450
1005
2256
1730
798
525
393
7309
Ni
ƒi
Fi
153
(153+225)=378
(378+335)=713
(713+564)=1277
… 1623
1756
1831
1880
0,081
0,120
0,178
0,300
0,184
0,071
0,040
0,026
0,081
0,201
0,379
0,679
0,863
0,934
0,974
1,000
Il carattere quantitativo discreto è ORDINATO (in modo crescente)
Considerando le frequenze assolute cumulate (Ni), possiamo leggere:
30
- vi sono al più 153 famiglie unipersonali
- vi sono 378 famiglie con al più 2 componenti
Considerando invece le frequenze relative cumulate (Fi):
- le famiglie composte da al più 4 persone sono 0.679, vale a dire il 68% circa
I dati della tabella possono essere rappresentati graficamente attraverso la funzione di
ripartizione, che si costruisce utilizzando le frequenze cumulate.
F(x) =
0
0,8
0,20
0,38
0,68
0,86
0,93
0,97
1
per x < 0
per 0 ≤ x ≤ 1
per 1 ≤ x ≤ 2
per 2 ≤ x ≤ 3
per 3 ≤ x ≤ 4
per 4 ≤ x ≤ 5
per 5 ≤ x ≤ 6
per 6 ≤ x ≤ 7
per x ≥ 8
La funzione di ripartizione consente di rilevare alcune caratteristiche della distribuzione di
frequenze.
La mediana corrisponde a famiglie composte da non più di 4 componenti
Il primo quartile corrisponde a famiglie composte da non più di 3 componenti
Il terzo quartile corrisponde a famiglie composte da non più di 5 componenti
La percentuale di famiglie con meno di 3 componenti è meno del 50%
Il valore della funzione in F(4) è 0,68
La porzione di famiglie con più di 6 componenti è:
1-[F(7)+F(8)] = 1-(0,040+0,026) = 0,93
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0
1
2
3
4
5
6
7
8
31
Nel caso di dati raccolti in classi
es.: età di 20 individui
Classe di età
10├ 20
20├ 30
30├ 40
40├ 50
Totale
ni
6
7
4
3
20
fi
6/20 = 0,30
7/20 = 0,35
0,20
0,15
Ni
6
13
17
20
Fi
0,30
0,65
0,85
1
F(10) = 0/20 = 0
F(20) = 6/20 = 0,30
F(30) = 13/20 = 0,65
F(40) = 17/20 = 0,85
F(50) = 20/20 = 1
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0
10
20
30
40
50
32
VARIABILITA’
Attitudine che hanno i fenomeni quantitativi ad assumere diversi valori (diverse modalità).
Nella metodologia statistica si distinguono due aspetti della variabilità:
-
la dispersione, che caratterizza il maggiore o minore addensamento delle osservazioni
attorno ad una media prestabilita;
-
la disuguaglianza, che evidenzia le diversità delle varie osservazioni tra loro.
INDICI DI VARIABILITA’
Misurano la variabilità in senso assoluto
COEFFICIENTI DI VARIABILITA’
Esprimono una variabilità relativa, cioè rapportata ad una determinata intensità
CRITERI DI MISURA DELLA VARIABILITA’
a) indici e coefficienti che tengono conto solo di alcuni dati
b) indici e coefficienti che misurano la dispersione attorno ad un valore medio
c) indici e coefficienti che tengono conto delle differenze tra ogni dato e tutti gli altri
d) indici normalizzati, che tengono conto del livello di distribuzione dei dati
a)
Indici e coefficienti che tengono conto solo di alcuni dati
-
campo di variazione
Iv = X max – X min
-
coefficienti vari
cv =
-
Iv
X min
cv =
Iv
max
differenza interquartilica
diff. Interq. = Q3 – Q1
cv =
Iv
Xmedia
33
b)
Indici e coefficienti che misurano la dispersione attorno ad un valore medio
a) scarto semplice
e = Σ | Xi – M1| Yi / Σ Yi
e = Σ | Xi – M1| / n
b) scarto quadratico medio (sqm) (deviazione standard)
∑( X i − M 1 )
n
2
б=
∑ ( X i − M 1 ) Yi
∑ Yi
2
б=
c) varianza
∑( X i − M 1 ) Yi
б =
∑ Yi
∑( X i − M 1 )
б =
n
2
2
2
2
n
∑ Xi n
2
б =
2
i
i =1
N
− M1
2
in generale V(X) = M1 (X2) – [M1 (X)]2
d) coefficiente di variabilità basato su sqm e media aritmetica e coefficiente di variabilità basato sui
quartili e sulla mediana (eventualmente espressi in x 100)
cv =
σ
cv =
M1
Q3 − Q1
Mna
c)
Indici e coefficienti che misurano le differenze tra ogni dato e tutti gli altri dati
- differenza media semplice e differenza media con ripetizione
n ( n −1)
n2
∑ di
∆=
i =1
n(n − 1)
∆R =
∑ di
i =1
n2
esempio di calcolo della differenza media
Regioni
Trentino AA
Friuli VG
Liguria
Piemonte VA
Veneto
Lombardia
Num. Indice
(Italia =100)
10,40
181,00
206,20
92,10
110,70
82,60
Sp. pro capite
(euro)
0,49
8,60
9,79
4,37
5,26
3,92
Popolazione
(x1000)
943,00
1189,00
1621,00
4410,00
4541,00
9122,00
Sp. totale
(euro x1000)
465,84
10222,43
15876,88
19292,65
23877,71
35790,17
Trentino AA
465,84
Friuli VG
10222,43
Liguria
15876,88
Piemonte VA
19292,65
Veneto
23877,71
Lombardia
35790,17
totale per
dif media
diff media semp
34
Trentino
Friuli
Liguria
Piemonte Veneto
Lombardia
465,84
10222,43 15876,88 19292,65 23877,71 35790,17
0,00
9756,59 15411,04 18826,81 23411,87 35324,33 102730,63
0,00 5654,45 9070,22 13655,28 25567,74 53947,70
0,00 3415,77 8000,83 19913,29 31329,87
0,00 4585,06 16497,52 21082,59
0,00 11912,46 11912,45
0,00
0,00
442006,48
221003,24
14733,55
d)
Indici che tengono conto della “trasferibilità” dei fenomeni
- la concentrazione:
La concentrazione è un aspetto della distribuzione di una variabile statistica che viene studiato
solo per fenomeni trasferibili. Può essere spiegata come la tendenza dell'intensità totale della
variabile ad essere concentrata su poche delle n unità statistiche rilevate.
Il caso di studio della concentrazione più noto è quello riguardante la distribuzione della variabile
reddito nelle sue varie forme (individuale, familiare, ecc.). La concentrazione è forte quando ad un
limitato numero di individui corrispondono redditi più alti; è debole se numerosi individui
percepiscono redditi simili tra loro ossia se la distribuzione del reddito è egualitaria.
- rapporto di concentrazione
n −1
∑(p
∆
G=
2M 1
R=
I =1
i
− qi )
n −1
∑p
i =1
i
per entrambi:
0 = equidistribuzione
1 = massima concentrazione
a) esempio di calcolo della concentrazione (dati singoli)
Regioni
Trentino AA
Friuli VG
Liguria
Piemonte VA
Veneto
Lombardia
Sp. totale
(euro x1000)
465,84
10222,43
15876,88
19292,65
23877,71
35790,17
105525,68
Val. rel.
regioni
pi
0,167
0,167
0,167
0,334
0,167
0,500
0,167
0,667
0,167
0,834
0,167
2,502
1,000
Spesa
totale qi
pi-qi
0,002
0,002
0,165
0,041
0,043
0,290
0,103
0,146
0,354
0,177
0,323
0,344
0,269
0,593
0,241
0,408
1,000
1,395
1,000
35
1,00
0,90
0,80
0,70
0,60
0,50
0,40
0,30
0,20
0,10
0,00
0,00
0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90
Diff media semplice
rapp conc (con diff) (G)
R di Gini (Lorenz)
1,00
14733,55
0,42
0,56
c) esempio di calcolo della concentrazione (dati raggruppati in classi)
Popolazione delle alpi occidentali, 2001
Italia
Francia
Alpi Occ.
numero
comuni
numero
comuni
numero
comuni
fino a 1000
757
1601
2358
1000 - 5000
513
566
1079
5000 - 10000
73
95
168
10000-25000
49
46
95
25000-50000
18
19
37
50000-100000
7
6
13
100000-500000
1
3
4
oltre 500000
1
0
1
2336
3755
Popolazione
Totale
1419
(fonte: Ires: Atlante delle Alpi Occidentali)
Per il caso francese, sono riportati nella tabella successiva:
• le classi di ampiezza dei comuni
• il numero dei comuni per ogni classe
( nella regione francese esistono 1601 comuni con una popolazione inferiore ai 1000 abitanti, ecc.)
36
Classi
Fino a 1000
1000-5000
5000-10000
10000-25000
25000-50000
50000-100000
100000-500000
Totale
Numero
comuni
1601
566
95
46
19
6
3
2336
Valore
centrale
500
3000
7500
17500
37500
75000
300000
Ammontare
del carattere
800500
1698000
712500
805000
712500
450000
900000
6078500
% dei
comuni
68,54
24,23
4,07
1,97
0,81
0,26
0,13
100,00
% della
popolazione
13,17
27,93
11,72
13,24
11,72
7,40
14,81
100,00
pi
qi
pi - qi
68,54
92,77
96,84
98,81
99,62
99,98
100,00
13,17
41,10
52,83
66,07
77,79
85,19
100,00
55,37
51,66
44,01
32,74
21,83
14,68
0,00
Vengono calcolati
• i valori centrali di ogni classe, calcolati come media aritmetica degli estremi di classe: es.
(1000+5000)/2 = 3000;
• l'ammontare del carattere che esprime l'intensità della mutabile statistica calcolata
moltiplicando il numero dei comuni per il valore centrale di classe corrispondente;
• la percentuale dei comuni sul totale dei comuni;
• la percentuale della popolazione sul totale della popolazione ;
• pi = seriazione assommata delle frequenze relative alla distribuzione in percentuale dei comuni
(necessari per il diagramma di Lorenz);
• qi = seriazione assommata delle frequenze relative alla distribuzione in percentuale della
popolazione (necessari per il diagramma di Lorenz);
• pi- qi = differenze necessarie per il calcolo del rapporto di concentrazione;
(i valori relativi possono pare riferimento all’unità “1” oppure a ”100”)
Come realizzare il diagramma di Lorenz (in excel):
Riportare i valori relativi alle colonne pi e qi e aggiungere agli estremi i valori 0 e 100
Cliccare sul pulsante autocomposizione grafico. All'interno della scheda Tipi Standard nel
riquadro Tipo di Grafico selezionare il tipo Grafico a dispersione (xy). Dimensiona secondo un
quadrato e tracciare la retta di equidistribuzione.
diagramma di Lorenz - comuni francesi
pi
0
68,54
92,77
96,84
98,81
99,62
99,88
100,00
qi
0
13,17
41,10
52,83
66,07
77,79
85,19
100,00
100
90
80
70
60
Qi
•
•
50
40
30
20
10
0
0
50
Pi
100
37
LA DISTRIBUZIONE ANALITICA DEI FENOMENI
PEREQUAZIONE
La distribuzione analitica dei fenomeni può avere scopi descrittivi e scopi investigativi, che
possono essere evidenziati come segue:
a) Sintetizzare e descrivere con una funzione matematica i dati rilevati
b) Determinata la funzione matematica, inserire tra i dati rilevati eventuali dati
mancanti (interpolazione)
c) Determinata la funzione matematica, prevedere le frequenze o le intensità in
corrispondenza di valori della variabile indipendente al di fuori del campo di
rilevazione originale (estrapolazione)
d) Verificare se la distribuzione effettiva segue un modello teorico ipotizzato
e) Correggere gli eventuali errori, di causa accidentale o sistematica, che possono
“sporcare” una distribuzione effettiva. Il procedimento può essere visto come un
aggiustamento o lisciamento della spezzata che rappresenta i dati osservati
(“smoothing”)
PEREQUARE
Significa sostituire ai dati effettivi rilevati dei dati teorici ottenuti a calcolo secondo una
funzione matematica che esprime la legge di distribuzione del fenomeno.
METODI EMPIRICI
a) Perequazione grafica
b) Perequazione meccanica (medie mobili)
1- K (termine di perequazione) dispari
2- K (termine di perequazione) pari
PEREQUAZIONE ANALITICA
a) Perequazione per semimedie
b) Perequazione per punti noti
c) Perequazione con il metodo dei “minimi quadrati” (MMQQ)
38
PEREQUAZIONE MECCANICA (MEDIE MOBILI)
E’ un metodo empirico di perequazione; si usa per ridurre le oscillazioni accidentali di una
distribuzione, allo scopo di mettere in evidenza il movimento tendenziale.
Il concetto è semplice: si sostituisce a ciascun dato effettivo un dato teorico ottenuto come
media del dato stesso, del dato che lo segue e di quello che lo precede. Oppure dei 2 o 3
o “n” dati che stanno a cavallo del dato stesso.
Quando si perequa meccanicamente si usano in genere medie mobili calcolate con un
numero dispari di termini, che centrano immediatamente il termine teorico. Però, a volte, si
perequa anche con un numero pari di termini; in questo caso occorrerà fare una doppia
perequazione (o perequazione ponderata).
1- Perequazione con un numero dispari di termini (K dispari).
Siano Y1, Y2, Y3, …, Yk, …, Yn i termini di una distribuzione e si voglia perequare per
medie mobili aritmetiche di tre termini.
I termini perequati saranno:
Ŷ2 =
e così via.
;
Ŷ3 =
;
Ŷ4 =
;…
Volendo perequare per medie mobili aritmetiche di cinque termini, i termini perequati
saranno:
Ŷ3 =
Ŷ5 =
;
;…
Ŷ4 =
;
e così via.
2- Perequazione con un numero pari di termini (K pari).
Siano Y1, Y2, Y3, …, Yk, …, Yn i termini di una distribuzione e si voglia perequare per
medie mobili aritmetiche di quattro termini.
I primi termini medi calcolati saranno:
39
;
;
;
;…
facendo una seconda perequazione per due termini si ottiene una perequazione
ponderata e si centra il termine teorico:
Ŷ3 =
;
Ŷ4 =
;…
Si usa perequare con un numero pari di termini quando in una distribuzione ciclica o
periodica si vuole eliminare l’influenza del ciclo o periodo (es. dati rilevati per mese ed
anno).
Difetti del metodo per medie mobili:
-
se si perequa per “K” termini, risulteranno mancanti “K-1” termini;
-
la somma dei dati perequati non è pari alla somma dei dati effettivi;
-
la spezzata che rappresenta l’andamento dei dati perequati dimostra ancora delle
oscillazioni;
-
il criterio di scelta del valore “K” è, in molti casi, arbitrario.
40
IL METODO DEI MINIMI QUADRATI (MMQQ)
CONDIZIONE
La somma del quadrato degli scarti tra i valori della distribuzione effettiva e quelli della
distribuzione teorica è un minimo.
∑ Ŷ = minimo
Ciò si ricava in quanto tale metodo consente di ricavare la migliore curva possibile che si
può sovrapporre alla spezzata che rappresenta graficamente la distribuzione effettiva.
Non è detto che essa sia la migliore in senso assoluto, in quanto se l’andamento è
rettilineo e si inserisce una curva parabolica, quest’ultima non è la migliore. Però, tra tutte
le rette che si possono inserire, la migliore è quella inserita con il metodo dei MMQQŶ, tra
tutte le parabole la migliore è quella inserita con tale metodo, e così via.
Si dà un esempio di perequazione per una retta, una parabola, una esponenziale.
PEREQUAZIONE DI UNA DISTRIBUZIONE EFFETTIVA CON UNA RETTA
Y = a + bX
Siano Y1, Y2, Y3, …. Yn i valori di una distribuzione effettiva.
Sia Y = a + bX l’equazione della retta
La condizione sia:
∑ Ŷ ∑ 2 = minimo
Si indichi la ∑ 2 con F (a, b), ossia la funzione di “a” e di “b”.
Si devono ricercare i valori di “a” e di “b” che rendono minima la funzione F (a, b).
La condizione è rispettata quando le derivate parziali della funzione si annullano
contemporaneamente rispetto ad “a” ed a “b”.
= - 2 ∑ = - 2 ∑ X
41
- 2 ∑ = 0
Uguagliare a zero le derivate parziali:
- 2 ∑ X = 0
Dividere per 2, svolgere le parentesi e mettere in sistema:
ΣY na bΣX 0
ΣXY aΣX b∑ 0
na bΣX ΣY
aΣX b∑ ΣXY
da cui:
Calcolo di “a” e “b”:
1- Metodo dei determinati
2- Slittamento dell’asse delle ordinate dall’origine “0” fino al valore medio x
3- Slittamento di entrambi gli assi fino alla nuova origine x e
1 - Metodo dei determinanti
Si tiene conto dei valori originali delle variabili X e Y
()
∑*
∑*) ∑* +
a= ,
∑*
∑* ∑* +
a=
b=
()∗∑* + .∑*∗∑*)
,∑* + .∑*+
,∗∑*).∑*∗∑)
,∑* + .∑*+
, ∑)
∑*)
b= ,
∑*
∑* ∑* +
da cui:
y
42
2 - Slittamento dell’asse delle ordinate dall’origine “0” fino al valore medio x
Si sostituiscono ai valori originali della variabile indipendente X, gli scarti dalla media, per
cui i valori di X si trasformano in “X - x = x”
Il sistema di equazioni diventa allora:
na b 0 x 0 Y
/
a 0 x b 0 x 0 XY
∑x = 0
Ma, per la prima proprietà della media aritmetica,
perciò:
na = ΣY
b ∑ x ∑ xY
a=
,
Σ
e
da cui:
∑ 2
b = +
∑2
3 - Slittamento di entrambi gli assi fino alla nuova origine x e
y
Si prendono come misura della variabile indipendente e della variabile dipendente gli
scarti dalle due medie x e
y (x
=X- x e y=Y-
y)
Il sistema di equazioni diventa allora:
na b 0 x 0 y
/
a 0 x b 0 x 0 45
na 0
b ∑ x ∑ 45
Per la prima proprietà della media aritmetica si avrà: Σx = 0 e Σy = 0
a=0
b=
627
∑8 +
per cui:
43
Calcolati i valori di “a” e “b”, seguendo uno dei metodi esposti, questi si sostituiscono
nell’equazione generale e, in corrispondenza di ciascun valore della variabile
indipendente, espressa in termini reali o di scarto “x”, si ottengono i valori della
distribuzione teorica Ŷ.
PEREQUAZIONE DI UNA DISTRIBUZIONE EFFETTIVA CON UNA PARABOLA
Y = a + b X + c X2
Si pone come condizione
∑ Ŷ ∑ : 2 = minimo
La condizione è rispettata quando le derivate parziali della funzione si annullano
contemporaneamente rispetto ad “a”, rispetto a “b” e rispetto a “c”.
;
= - 2 ∑ : = - 2 ∑ : X
= - 2 ∑ : X2
Eguagliando a zero, dividendo per due, togliendo le parentesi e mettendo in sistema si
ottiene:
?
=
na b 0 X c 0 X 0 Y
a 0 X b 0 X c 0 X 0 X Y
>
= 0 X b 0 X c 0 X 0 X Y
<
Calcolo di “a”, “b” e “c”:
1- Metodo dei determinati
44
2- Slittamento dell’asse delle ordinate dall’origine “0” fino al valore medio x
3- Slittamento di entrambi gli assi fino alla nuova origine x e
y
1 - Metodo dei determinanti
Si tiene conto dei valori originali delle variabili X e Y.
Il calcolo di “a”, “b” e “c” è piuttosto laborioso.
()
(* (* +
(*) (* + (* A
(* + ) (* A (* B
a=
,
(* (* +
(* (* + (* A
(* + (* A (* B
a=
b=
c=
+
,
()
(* +
(*
(*) (* A
(* + (* + ) (* B
b=
,
(* (* +
(* (* + (* A
(* + (* A (* B
,
(*
()
(* (* + (*)
(* + (* A (* + )
c=
,
(* (* +
(* (* + (* A
(* + (* A (* B
()∗C(* + ∗(* B .(* A D–(*∗F(*)∗(* B .(* A ∗(* + )G(* + ∗F(*)∗(* A .(* + ∗(* + )G
+
,∗(* + ∗(* B .(* A + .(*∗(*∗(* B .(* A ∗(* + (* + ∗C(*∗(* A .(* + (* + + D
,∗F(*)∗(* B .(* A ∗(* + G–()∗F(*)∗(* B .(* A ∗(* + G(* + ∗F(*∗(* + ).(*)∗(* + G
+
,∗(* + ∗(* B .(* A + .(*∗(*∗(* B .(* A ∗(* + (* + ∗C(*∗(* A .(* + (* + + D
+
,∗F(* + ∗(* + ).(*)∗(* A G–(*∗F(*∗(* + ).(*)∗(* + G()∗C(*∗(* A .(* + D
+
,∗(* + ∗(* B .(* A + .(*∗(*∗(* B .(* A ∗(* + (* + ∗C(*∗(* A .(* + (* + + D
2 - Slittamento dell’asse delle ordinate dall’origine “0” fino al valore medio x
Si sostituiscono ai valori originali della variabile indipendente X, gli scarti dalla media, per
cui i valori di X si trasformano in “X - x = x”
Il sistema di equazioni diventa allora:
na bx c∑4 ΣY
H aΣx b∑4 c∑4 ΣxY
a∑4 b∑4 c∑4 Σx2Y
Ma, per la prima proprietà della media aritmetica,
distribuzione simmetrica degli scarti anche
Σx = 0 e per la proprietà della
Σx3 = 0, perciò:
na c∑4 ΣY
H
b∑4 ΣxY
a∑4 c∑4 ∑4 Y
da cui
b=
45
62
∑8 +
e rimane un sistema di due equazioni con due incognite di più facile risoluzione
na c∑4 ΣY
a∑4 c∑4 ∑4 Y
Calcolati i valori di “a” e “b”, seguendo uno dei metodi esposti, questi si sostituiscono
nell’equazione generale e, in corrispondenza di ciascun valore della variabile
indipendente, espressa in termini reali o di scarto “x”, si ottengono i valori della
distribuzione teorica Ŷ.
PEREQUAZIONE DI UNA DISTRIBUZIONE EFFETTIVA CON UNA CURVA
ESPONENZIALE
Y = c dX
L’equazione esponenziale può essere trasformata applicando i logaritmi:
Log Y = Log :J * Log Y = Log c + X Log d
Poniamo:
Log c = a
e
Log d = b
L’equazione (1) diventa:
Log Y = a + b X
Si pone come condizione
∑KLM KLMŶ minimo
∑KLM 2 = minimo
(1)
46
La condizione è rispettata quando le derivate parziali della funzione si annullano
contemporaneamente rispetto ad “a” ed a “b”.
= - 2 ∑ KLM = - 2 ∑ KLM X
Eguagliando a zero le derivate, dividendo per 2 ed eliminando le parentesi si ottiene:
na bΣX ΣKLM
aΣX b∑ ΣXKLM
-
Slittamento dell’asse delle ordinate dall’origine “0” fino al valore medio x
Si sostituiscono ai valori originali della variabile indipendente X, gli scarti dalla media, per
cui i valori di X si trasformano in “X - x = x”
Le equazioni normali si possono scrivere:
na bΣx ΣKLM
aΣx b∑4 ΣxKLM
Ma, per la prima proprietà della media aritmetica,
Σx = 0 perciò:
na = ΣLogY
b ∑4 = Σ xLog Y
da cui:
a=
e
6NOP)
,
Sostituendo nella
b=
62NOP)
∑8 +
Log Ŷ = a + b x i valori di “a” e “b” per ogni valore della variabile
indipendente, espresso come scarto “x”, si otterranno i logaritmi dei dati perequati.
Calcolando gli antilogaritmi si otterranno i dati perequati “Ŷ”.
Si può giungere direttamente all’equazione originale Ŷ = c dX calcolando subito gli
antilogaritmi di “a” e “b”.
47
LE SERIE DI TEMPO
MOVIMENTO TENDENZIALE
Pur presentando oscillazioni nelle successive unità di tempo rilevate, il fenomeno dimostra
una certa regolarità che si manifesta con un tendenziale accrescimento, o una
diminuzione, o un andamento costante.
MOVIMENTO PERIODICO
Il fenomeno subisce delle oscillazioni ritmiche dovute a varie cause che imprimono una
ciclicità che si manifesta con valori a tratti crescenti ed a tratti decrescenti.
-
Ciclico (massimi e minimi che si ripetono in periodi pluriennali)
-
Stagionale (massimi e minimi che si ripetono nell’ambito di un anno)
-
Settimanale – Giornaliero (il ciclo è dato dai giorni della settimana o dalle ore del
giorno
MOVIMENTO OSCILLATORIO
E’ detto anche casuale o accidentale. Riguarda le piccole oscillazioni dovute al “caso”.
MOVIMENTO OCCASIONALE
Il fenomeno registra abbassamenti o rialzi improvvisi che modificano la “regolarità”
dell’andamento dimostrata in precedenza.
48
IL MOVIMENTO STAGIONALE
Per il calcolo della stagionalità in una serie di tempo si può fare riferimento al metodo della
“serie ideale dei 12 mesi” oppure al metodo degli “indici a catena”, i quali mettono in
evidenza il movimento stagionale tramite il calcolo di un indice di stagionalità.
Viene di seguito descritto il primo dei due.
Metodo della serie ideale dei 12 mesi
In una serie di tempo pluriennale i dati sono stati rilevati per ciascun mese e si suppone
che non vi sia né movimento ciclico, né movimento tendenziale oppure che tali movimenti
siano stati già eliminati con una precedente perequazione, ad esempio procedendo con
una perequazione meccanica per medie mobili.
Il metodo è di elementare applicazione e viene usato, qualche volta, anche quando i dati
presentano un movimento tendenziale o ciclico.
Fasi del metodo
1) Si rilevano le intensità mensili di un fenomeno per un certo numero di anni e si
raccolgono in una tavola i dati dei mesi di ugual nome;
Anni
Gennaio Febbraio Marzo
Aprile
anno 1
g1
f1
m1
a1
n1
d1
anno 2
g2
F2
m2
a2
n2
d2
anno 3
g3
f3
m3
a3
n3
d3
gn
fn
mn
an
nn
dn
…
Novembre Dicembre
…
…
…
anno n
2) Si fanno le medie delle intensità dei mesi di ugual nome, ragguagliando tutti i mesi
alla durata standard di 30 giorni;
media dei mesi di gennaio
∑ PQ
,
∑ RQ
49
,
media dei mesi di febbraio
∑ SQ
,
media dei mesi di marzo
…
…
∑ TQ
,
media dei mesi di dicembre
3) Dalle dodici medie mensili si ricava una media generale (media delle dodici medie);
media generale =
∑ UV
∑ XV
∑ ZV
W … W W
Si ottengono le seguenti misure:
1) Stagionalità assoluta: differenza tra ciascuna media mensile e la media generale:
stagionalità assoluta del mese di gennaio:
stagionalità assoluta del mese di febbraio:
∑ PQ
,
∑ RQ
….
stagionalità assoluta del mese di dicembre:
,
- media generale
- media generale
∑ TQ
,
- media generale
2) Numero indice di stagionalità: rapporto tra ciascuna media mensile e la media
generale, fatta questa uguale a 100; si ricava dalla seguente proporzione:
media mensile : media generale = indice di stagionalità : 100
indice di stagionalità di gennaio =
indice di stagionalità di febbraio =
∑ UV
W
S[TQP[,[\][
∑ XV
W
S[TQP[,[\][
4100
4100
50
….
indice di stagionalità di dicembre =
∑ ZV
W
S[TQP[,[\][
4100
3) Stagionalità relativa: differenza (positiva o negativa) tra l’indice di stagionalità
mensile e 100:
` stagionalità relativa del mese di gennaio = _
4100e – 100
abJMb`bcdb
∑ M
∑ f
` stagionalità relativa del mese di febbraio = _abJMb`bcdb
4100e – 100
…
stagionalità relativa del mese di dicembre = _
` 4100e – 100
abJMb`bcdb
∑ J
Conoscendo la stagionalità di un fenomeno si può capire in quali mesi sarà al di sopra
della media annuale e in quali sarà al di sotto; ciò può essere utile per ricercare le cause.
51
IL BIVARIATO
-Analisi della distribuzione di due variabili
-Ricerca delle relazioni statistiche tra fenomeni = Ricerca della connessione
-Due fenomeni sono in connessione quando le distribuzioni dell’uno e dell’altro sono legate da
qualche relazione
1° carattere
Collettivo
statistico
Riga madre X
1
n.1
X
2
n.2
X
3……
2° carattere
X
j….
X
r
n.3 …. n. j ... n.r
Colonna madre Y 1 Y 2 Y 3…. Y i…. Y s
n1. n2. n3. ... ni. ...ns.
∑ X j n. j
x=
∑ n. j
y=
∑ Yi ni .
∑ n.i.
CONNESSIONE
a) tra modalità QUANTITATIVE
b) tra modalità QUALITATIVE
c) tra modalità QUANTITATIVE e QUALITATIVE
MISURE DI CONNESSIONE
a) INDICI DI DIPENDENZA: misurano l’intensità 0-1
b) INDICI DI CONCORDANZA: intensità e direzione
-1
+1
X↓
X↑
Y↑
Y↑
Lineare
RELAZIONE TRA DUE VARIABILI
Non Lineare
52
REGRESSIONE LINEARE
Sia X = variabile indipendente
Y = variabile dipendente
Conoscendo la relazione che lega x e y si potranno esprimere i valori stimati di y ( Yˆ i) per ogni
valore di X i
FUNZIONE DI REGRESSIONE: è la funzione matematica che esprime tale relazione.
PERFETTA RELAZIONE LINEARE: ad ogni valore della variabile x esiste uguale (o proporzionale)
valore di y.
x
Tra tutte le rette la migliore è quella che soddisfa la condizione di minimo
Yˆ = a + bX
Yˆ = a + bx
Yˆ = bx
Retta di regressione
b =
∑ xy
∑ x
2
Un chiarimento:
Regressione e Correlazione: due concetti collegati
-Regressione: quando esiste una certa direzione nel collegamento tra i due fenomeni
-Correlazione: quando non esiste una direzione logica
53
CORRELAZIONE LINEARE
DIRETTA
INVERSA
ASSENTE
PRIMO CASO
RELAZIONE TRA MODALITA’ QUALITATIVE
χ2 e 2 Ι c
La relazione è messa in evidenza dalle differenze tra frequenze effettive e frequenze teoriche,
dette “CONTINGENZE”.
Y = frequenza effettiva
Yˆ = frequenza teorica
Yi – Yˆ i = contingenza
Le frequenze teoriche possono essere calcolate:
a) con uno schema probabilistico
b) con delle proporzioni
TEOREMI FONDAMENTALI DELLA PROBABILITA’
-
TEOREMA DELLA PROBABILITA’ TOTALE
La probabilità del verificarsi di uno o l’altro di più eventi fra di loro incompatibili è data dalla
somma delle probabilità semplici del verificarsi degli eventi stessi
Esempio:
Dado: faccia 2: probabilità 1/6
faccia 5: probabilità 1/6
Probabilità totale: 1/6 + 1/6
54
EVENTI COMPATIBILI E INCOMPATIBILI
INSIEMI DISGIUNTI
EVENTI INCOMPATIBILI
INSIEMI CONGIUNTI
EVENTI COMPATIBILI
DEFINIZIONI DI PROBABILITA’
CLASSICA
IMPOSTAZIONE
FREQUENTISTA
IMPOSTAZIONE CLASSICA
-
Probabilità matematica (a priori)
Probabilità (evento) = p =
Es. dado, moneta
g°;hQRiO\[iO]Q
g°;hQjOhhQQ]Q
IMPOSTAZIONE FREQUENTISTA
-
Probabilità statistica (a posteriori)
Probabilità (evento) = p’ =
,′
=
g′
g°[i[,kQ\[]QllkQ
Es. numero di incidenti ad un incrocio
-
g°j\Oi[Rkk[
TEOREMA DELLA PROBABILITA’ COMPOSTA
1) EVENTI INDIPENDENTI
La probabilità del verificarsi di due o più eventi tra loro indipendenti è data dal prodotto delle
probabilità semplici del verificarsi degli eventi stessi.
Es. dado: contemporaneamente facce 2 e 5
Probabilità evento = 1/6 * 1/6
55
2) EVENTI DIPENDENTI
La probabilità del verificarsi di due o più eventi dipendenti è data dal prodotto delle probabilità di
ciascun evento, calcolate tenendo conto che gli altri eventi prefissati si siano verificati nell’ordine
prestabilito.
Es. estrarre 4 fanti da un mazzo di 52 carte
Probabilità evento = 4/52 * 3/51 * 2/50 * 1/49
a) Consideriamo una tabella a doppia entrata con due modalità qualitative
Xj
X
X i′
X′1
X′2
X′3
M
X′i
M
X′s
TOT
X
1
2
X
3
…
X
j
…
X
TOT
r
Y
11
Y
12
Y
13
Y 1j
Y
1r
Y
21
Y
22
Y
23
Y 2j
Y
2r
Y 1.
Y 2.
Y
i1
Y
i2
Y
i3
Y ij
Y
ir
Y i.
Y s3
Y .3
Y sj
Y .j
Y sr
Y .r
Y s1
Y .1
Y s2
Y .2
-La probabilità semplice di avere frequenze nella riga “i” è data da
Y s.
Σ Y ij
Yi .
∑ Yij
- La probabilità semplice di avere frequenze nella colonna “j” è data da
Y. j
∑Y
ij
- La probabilità composta di avere frequenze che cadano contemporaneamente nella riga “i” e
nella colonna “j” è data da
Y. j
Yi . .Y. j
Yi .
⋅
=
∑ Yij ∑ Yij (∑ Yij )2
Per ottenere le frequenze teoriche (o attese) nella cella di incontro della riga “i” e colonna “j” si
procede come segue:
Ŷij =
Y. j
Yi. .Y. j
Yi.
⋅
⋅ ∑ Yij =
∑ Yij ∑ Yij
∑ Yij
b) Sfruttiamo le relazioni di proporzionalità.
In caso di indipendenza, le proporzioni della distribuzione nella riga marginale devono
ritrovarsi in ciascuna riga dalla tabella.
Es.
Y22
deve essere pari a
Y2.
Y.2
∑ Yij
56
Più in generale, la frequenza teorica Ŷij deve rispettare la proporzione
∑Y
Ŷij : Yi. = Y.j :
Ŷij =
da cui
ij
Yi.Y. j
∑Y
ij
PROPRIETA’:
∑ Ŷ = ∑ Y
i vari ∑ Yˆ e ∑ Yˆ
•
ij
•
ij
i.
.j
sono uguali ai vari
∑Y
i.
e
∑Y
.j
DOMANDA: Vi è o meno indipendenza tra i due caratteri? Ossia, esiste o non esiste
connessione tra i due caratteri?
Una prima misura: il χ2
(chi quadrato)
a) determinare le Ŷij
Yij - Ŷij
b) calcolare le contingenze
∑ Ŷ = ∑ Y
poiché
∑
ij
ij
contingenze =
∑ (Y
(
ij
c) elevare al quadrato Yij − Yˆij
d) rapportare a Ŷij
)
− Yˆij = 0
)
2
per ricondursi ad una particolare distribuzione teorica
e) sommare tutti i rapporti
(Y
ij
− Yˆij
Yˆ
)
2
ij
χ =∑
2
(Y
ij
− Yˆij
Yˆ
)
2
ij
per χ2 = 0
per
tutte le Yij = Ŷij indipendenza - non esiste connessione
χ2 ⟩ 0 esiste connessione
Una misura descrittiva della contingenza :
L’INDICE QUADRATICO MEDIO DI CONTINGENZA
2
Ic
Rapporta il valore di χ2 al valore massimo che il χ2 può raggiungere nella tabella considerata,
nella quale “n = numero totale di casi”
(n=
∑Y
ij
)
Valore massimo = χ2+ n
57
2
Ic =
χ
2
0 = non esiste connessione
χ +n
2
1 = connessione massima
2
I c = 1 è puramente teorico
esiste un altro massimo di
max =
1−
2
Ic
1
1−
n
1
K
K = eguale numero di righe e colonne (tabella quadrata)
K = minore numero tra righe e colonne (tabella rettangolare)
ESEMPIO DELLA RICERCA DEL VALORE DI CONNESSIONE MASSIMA
2
χ=
∑
(Y
ij
− Yˆij
Yˆ
)
E
F
G
H
Tot
A
3
---3
B
---2
2
C
-4
--4
D
--2
-2
Tot
3
4
2
2
11
E
F
G
H
Tot
A
0,82
1,09
0,54
0,54
3
B
0,55
0,73
0,36
0,36
2
C
1,09
1,45
0,73
0,73
4
D
0,55
0,73
0,36
0,36
2
Tot
3
4
2
2
11
2
= 33,12
ij
2
I c = 0,86 infatti
1−
1
= 0,86
K
58
POSSIBILITA’ ALTERNATIVA PER DETERMINARE IL χ2
2
χ=
∑
(Y
ij
− Yˆij
Yˆ
)
2
∑
=
(Y
2
ij
∑
∑
Ŷij =
Y =n
ij
Y 2 ij
∑ Yˆ − n
ij
Y
2
∑ Yˆ
ij
=
Yij 2
∑ Ŷ
∑ Y + ∑ Ŷ
−2
ij
ij
ij
χ 2=
Yij 2
∑ Ŷ
−n
ij
2
Ic =
=
allora
di conseguenza da I c =
2
)
ij
ij
ma
− 2Yij Yˆij + Yˆ 2 ij
Yˆ
=
χ2
si ha:
χ2 + n
Y 2 ij
∑ Yˆ − n
ij
Y 2 ij
∑ Yˆ
−n+n
ij
ij
SECONDO CASO
Relazione tra modalità qualitative e quantitative
Dipendenza in media
Indice
di Pearson
η
Consideriamo due caratteri, uno dei quali quantitativo (es. età), l’altro qualitativo (es. stato civile).
Sappiamo che possiamo rappresentare in una tabella a doppia entrata il carattere età ( X j ) ed il
carattere stato civile ( X i′ ).
X
X′1
X′2
X i′
X
1
2
X
3
…
Xj
Xj …
X
r
TOT
Media
parziale
x1
x2
Y
11
Y
12
Y
13
Y
1j
Y
1r
Y
21
Y
22
Y
23
Y
2j
Y
2r
Y 1.
Y 2.
X′3
M
X′i
Y
i1
Y
i2
Y
i3
Y
ij
Y
ir
Y i.
xi
M
X′s
Y s1
Y s2
Y s3
Y
sj
Y sr
Y s.
TOT
Y .1
Y .2
Y .3
Y .j
Y .r
Σ Y ij =Y
xs
x
i = 1 → s righe
j = 1 → r colonne
= Σ Y i.
= Σ Y .j
Riga: rappresenta la distribuzione del carattere X j condizionata dal carattere X i′
59
Domanda: esiste o meno una dipendenza tra i caratteri confrontati e se sì in quale misura esiste?
Trasformiamo le Y ij in valori relativi (es. f ij )
X
X′1
X′2
f
f
M
X′i
M
X′s
TOT
1
X
21
f
f
f
i1
f
s1
11
f .1
2
…
X
22
f
f
f
i2
f
s2
12
f .2
j
…
X
r
TOT
1r
1
2j
f
f
f
ij
f
ir
f
sj
f
sr
1
1
1
1
1
f .r
1
1j
f .j
2r
Se non esistesse una connessione le distribuzioni condizionate sarebbero simili tra loro e simili alla
distribuzione marginale.
Le medie di ogni riga (sottogruppo) (parziali) sarebbero uguali tra loro e uguali alla media generale.
All’opposto: se le medie parziali differiscono tra loro e differiscono dalla media generale, allora vi è
connessione.
Possiamo vedere tutto ciò in un grafico
Età
- Diagramma a tre dimensioni
- Stereogrmma
45
44
43
42
41
40
celibe/
coniugato/a divorziato/a vedovo/a
nubile
Stato civile
- Possiamo pensare ad una misura di connessione
- Prende in esame i valori medi parziali
- Sostituisce la misura delle differenze tra i valori medi della distribuzione alla misura delle
differenze tra le varie distribuzioni.
- Allora: si parla di dipendenza in media
- E’ nulla se:
- Aumenta:
60
Misura assoluta della connessione:
Media quadratica delle differenze tra le medie parziali e la media generale
x i = medie parziali
x = media generale
∑( x − x) Y
∑Y
2
connessione assoluta =
i
i.
i.
Indice di connessione:
Si rapporta il valore della connessione assoluta al valore che assumerebbe in caso di massima
connessione
∑ (x i − x)
η=
2
Y i.
∑ Y i.
∑ ( X j − x)
=
2
Y. j
Σ(
x
Σ(x
i
−
j
−
x
x
)2
)2
Y
Y
i.
. j
0
η
∑ Y. j
1
Esempio: ricerca della connessione tra l’età e lo stato civile
Stato civile
Celibe/nubile
Coniugato/a
Divorziato/a
Vedovo/a
Totale
η=
∑(x
∑(X
i
− x ) 2 Yi⋅
i⋅
− x ) Y⋅ j
2
=
20-25
(22,5)
8
6
2
1
17
25-30
(27,5)
4
9
4
2
19
196,45
3134,80
x1 =
22,5 ⋅ 8 + 27,5 ⋅ 4 + 32,5 ⋅13 + 37,5 ⋅ 5
= 30
30
x2 =
22,5 ⋅ 6 + 27,5 ⋅ 9 + 32,5 ⋅ 7 + 37,5 ⋅18
= 32,1
40
x3 =
30-35
(32,5)
13
7
6
3
29
x4 =
22,5 ⋅17 + 27,5 ⋅19 + 32,5 ⋅ 29 + 37,5 ⋅ 40
=31,9
x=
105
Età
35-40
(37,5)
5
18
8
9
40
Totale
medie ( x i )
30
40
20
15
105
30,0
32,1
32,5
34,2
31,9
61
num : (30 − 31,9) ⋅ 30 + (32,1 − 31,9) ⋅ 40 + (32,5 − 31,9) ⋅ 20 + (34,2 − 31,9) ⋅15 = 196,45
2
2
2
2
den : (22,5 − 31,9) ⋅17 + (27,5 − 31,9) ⋅19 + (32,5 − 31,9) ⋅ 29 + (37,5 − 31,9) ⋅ 40 = 3194,80
2
2
2
2
Esempio di connessione tra modalità qualitativa e modalità quantitativa
Nati per stato civile e classe di età della madre al parto (età centrali). Provincia di Torino. Anno di
iscrizione 2008. (Istat)
Stato civile
della madre
Nubile
Coniugata
Altro
Totale
Età al parto
20-25
261
497
15
25-30
461
1259
23
Stato civile
della madre
Totale
30-35
620
2422
35
Valori centrali di classe
22,5
27,5
32,5
Nubile
Coniugata
Altro
Totale
TERZO CASO
Relazioni tra modalità quantitative
RAPPORTO DI CORRELAZIONE DI PEARSON
Parte dal concetto di una retta perequante un insieme di punti X i , Yi
r=
35-40
435
1744
78
∑ (Y − Yˆ )
1−
∑ (Y − y )
2
0
2
1
NUMERATORE = somma quadrato scarti tra Yi e Yˆi
DENOMINATORE = somma quadrato scarti tra Yi e y
a) correlazione perfetta: tutti i dati si trovano sulla retta di regressione
Yˆi = Yi ; numeratore = 0 ; r = 1
37,5
Totale
62
b) non esiste correlazione: i punti di coordinate X i , Yi danno luogo ad una retta parellela all’asse
delle X
Yˆ = y ; numeratore = denominatore ; r = 0
Da Pearson a Bravais-Pearson
r = 1−
∑ (Y − Yˆ )
∑ (Y − y )
r2 = 1− ∑
2
2
(Y − Yˆ ) 2
∑ (Y − y )
num:
den:
2
∑ (Y − Yˆ ) = ∑Y
2
− a∑Y − b∑ XY
2
∑ (Y − y ) = ∑ (Y − 2 yY + y ) = ∑ Y
∑ Y − 2 y ∑ Y + ny = ∑ Y − 2 y
=
2
2
2
2
r
2
r
2
∑Y
= 1−
∑Y
=
r2 =
2
n
2
n
n
− a ∑ Y − b∑ XY
∑Y
2
− ny 2
− ny 2 − ∑ Y 2 + a ∑ Y + b∑ XY
∑Y
2
− ny 2
− ny 2 + a ∑ y + b∑ xy
∑y
2
− ny
2
=
b∑ xy
∑ xy ⋅ ∑ xy = (∑ xy)
=
∑x ∑ y ∑x ∑ y
∑y
2
r
2
2
2
2
− 2 y ∑ Y + ny 2 =
2
+ y2 =
2
2
n
2
2
2
∑Y
n
2
− y 2 = ∑ Y 2 − ny 2
63
∑ xy
∑x ∑y
r=
2
2
rapporto di correlazione di Bravais-Pearson
-1
r
campo di variazione di r Bravais-Pearson
+1
a) y = bx relazione diretta
r=
∑ x(bx)
∑ x ∑ (bx)
2
=
2
b∑ x 2
b (∑ x 2 ) 2
=1
b) y = −b′x relazione inversa
r=
∑ x(−b′x)
∑ x ∑ (−bx)
2
=
2
yˆ = ay + byxX → byx =
− b′∑ x 2
b′ (∑ x 2 ) 2
∑ xy
x
xˆ = ax + bxyY → bxy =
;
2
= −1
∑ xy ⋅ ∑ xy = (∑ xy)
byx ⋅ bxy =
∑x ∑ y ∑x ∑ y
∑ xy
∑y
2
2
2
2
2
2
byx ⋅ bxy = r 2
r = byx ⋅ bxy
Altre relazioni
1) r =
∑ xy
∑ x2 ∑ y 2
=
∑ xy
∑ xy
n
n
∑ x2
∑ y2
n
n
=
∑ xy ∑ y
∑ xy =
2) byx =
∑x
∑x ⋅ ∑x ⋅ ∑ y
σ x 2σ y 2
Covarianza
=
Media geom. varianza
2
2
2
2
2
moltiplicare numeratore e denominatore per
∑y
2
64
∑y
∑ y2
=r
n = rσy
∑ x2 σ x
=r
∑ x2
2
dividere numeratore e denominatore per
n
byx = r
σy
σx
bxy =
per
bxy = r
σ
σ
∑ xy
∑y
la dimostrazione è analoga alla precedente
2
x
y
CALCOLO DELLA CORRELAZIONE IN UNA DISTRIBUZIONE BIVARIATA
(tabella a doppia entrata)
X j ... r
1
2
Yi...s
3
1
2
3
K
j
K
r
n11
n21
n31
n12
n21
n32
n13
K
n1 j
K
n23
K
n2 j
K
n33
K
n3 j
K
n1r
n2 r
n3 r
n1⋅
n2⋅
n3⋅
ni1
ni 2
ni 3
K
nij
K
nir
ni⋅
n⋅1
n⋅2
n⋅3
n⋅ j
K
n⋅r
N
M
i
M
s
K
i = righe
j = colonne
∑n = ∑n
i⋅
r=
=N
⋅j
∑ xy
∑x ∑y
2
2
media generale delle X
x=
media generale delle Y
y=
r=
∑x
∑x
j
yi nij
2
j ⋅j
∑y
n
2
i
ni ⋅
∑X
j
n⋅ j
N
∑ Yi ni⋅
N
n
65
Dalle coppie di dati di una distribuzione di frequenza alle coppie di dati di una tabella a doppia
entrata
a) Coppie di dati di una distribuzione di frequenza
Xi
Yi
Soggetti
Voto mat.
Voto stat.
xi
yi
xi yi
xi2
yi2
A
B
C
D
E
F
G
H
21
25
24
28
27
27
27
24
22
21
25
24
22
30
22
22
-4,37
-0,37
-1,37
+2.63
+1,63
+1,63
+1,63
-1,37
-1,5
-2,5
+1,5
+0,5
-1,5
+6,5
-1,5
-1,5
6,55
0,93
-2,06
1,32
-2,45
10,60
-2,45
2,06
14,50
19,10
0,14
1,90
6,92
2,66
2,66
2,66
1,90
37,94
2,25
6,25
2,25
0,25
2,25
42,25
2,25
2,25
60,00
x = 25,37
y = 23,50
r=
∑x y
∑x ∑ y
i
2
i
i
2
i
=
14,50
= 0,30
37,94 ⋅ 60
byx = 0,38
a y = 23,50
yi = 23,50 + 0,38xi
Per un voto matematica pari a 20 quanto vale il voto in statistica?
b) Coppie di dati in una tabella a doppia entrata
Xi
Yi
Soggetti
Voto mat.
Voto stat.
xi
yi
1
2
3
4
5
6
7
8
9
24
21
27
24
27
27
24
24
21
22
22
22
25
22
28
25
22
22
-2,4
-5,4
0,6
-2,4
0,6
0,6
-2,4
-2,4
-5,4
-2,3
-2,3
-2,3
0,7
-2,3
3,6
0,7
-2,3
-2,3
M
M
M
M
M
30
24
30
-2,4
5,7
x = 26,4
y = 24,3
yˆ = 21,46
66
Voto
Matematica ( Yi )
21
24
27
Totale
r=
∑x
j
yi nij
∑x n ∑ y
2
j ⋅j
Voto Statistica ( X j )
22
2
1
3
6
25
3
3
4
10
28
1
2
1
4
30
2
5
3
10
Totale
8
11
11
30
=
2
i
ni ⋅
22,6 ⋅ 6 + 25 ⋅10 + 28 ⋅ 4 + 30 ⋅10
= 26,4
30
21⋅ 6 + 24 ⋅11 + 27 ⋅11
= 24,3
y=
30
x=
(22 − 26,4)(21− 24,3) ⋅ 2 + (25 − 26,4)(21− 24,3) ⋅ 3 + ..... + ..... + (30 − 26,4)(27 − 24,3) ⋅ 3+ =
[(22 − 26,4) ⋅ 6 + (25 − 26,4) ⋅10 + ....] [(21 − 24,3) ⋅ 8 + .....(24 − 24,3) ⋅11.....] = .....
2
2
2
2