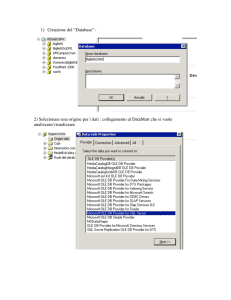
Che cos'è un database
Un Database è un insieme organizzato di dati: deve essere quindi visto come costituito da due entità
distinte, i dati e le regole di accesso.
Da un punto di vista puramente teorico i singoli record che compongono i dati potrebbero avere una struttura
libera, ma nella pratica (bisogna poi riuscire a costruire il Motore del Database, ovvero un'applicazione in
grado di implementare le Regole e fornire una interfaccia tra il Database e l'Utente) la struttura dei record è o
uguale per tutti o di alcuni tipi fissati. In quest'ultimo caso avremo un certo numero di sotto-insiemi di records
con struttura omogenea, che potremmo anche considerare come un certo numero di files distinti.
Le regole di accesso possono essere di qualsiasi tipo: il loro scopo è quello di permettere l'inserimento di
informazioni ed il loro successivo reperimento.
Un semplice file sequenziale non può quindi essere mai visto come un Database, poiché l'unica regola
possibile per ritrovare un record è leggerli tutti dal primo fino a quello cercato (magari l'ultimo).
Un passo avanti è il file ad accesso diretto (Random): in questo caso possiamo accedere direttamente al
record x° e quindi basterà avere un metodo per sapere che posizione occupa il record cercato per averlo
immediatamente disponibile.
Non converrà ovviamente complicarsi la vita con i Database se abbiamo a che fare con numeri di records
così piccoli da rendere ininfluente per l'Applicazione il tempo necessario per leggerli tutti.
Attenzione perché ininfluente è un concetto relativo: 10 secondi sono ininfluenti se per ogni dato devo
eseguire una elaborazione complessissima della durata di qualche minuto, ma 100ms sono una
esagerazione se il dato mi serve per una elaborazione in tempo reale.
Le prime applicazioni su Personal Computer (ambiente DOS)
Nel frattempo erano nati i primi Personal Computer; dopo pochi anni di vita cominciarono ad avere l'Hard
Disk e quindi la possibilità di archiviare i dati e sviluppare applicazioni gestionali.
Quasi a metà degli anni 80 nacque il primo prodotto di Database per PC ad opera della Ashon-Tate, il
dBase: agli inizi girava solo in interprete (esisteva anche un prodotto di run-time, ma ebbe scarsa rilevanza),
ma a partire dalla versione dBaseIII la Nantucket mise sul mercato un compilatore per i programmi dBIII in
grado di generare degli eseguibili indipendenti: il Clipper.
Nello stesso periodo nacque anche il Database della Fox.
I linguaggi di programmazione e le caratteristiche dei due prodotti erano abbastanza simili, tanto che il
linguaggio supportato dal compilatore Clipper (che era più esteso) permetteva di gestire i Db di entrambe le
case.
Il successo del prodotto fu notevole (versioni 1986 e 1987), al punto che praticamente tutte le applicazioni di
gestione dati erano in compilato Clipper con database in dBIII (o il successivo dBIV).
Inoltre essendo il Clipper scritto in C era anche possibile implementare nuove funzioni scrivendole in C e
creando con esse una nuova Libreria da passare al programma di Link all'atto della creazione del file .EXE.
Di particolare importanza furono le librerie prodotte da alcune case per la gestione della Grafica in quanto
Clipper usava esclusivamente lo schermo in modalità Testo (25 righe di 80 colonne), mentre con la nascita
della prima VGA IBM era possibile lavorare a 640x480 in 16 colori, rendendo così possibile realizzare
rappresentazioni grafiche (in genere diagrammi) di qualità soddisfacente.
I Database relazionali
Un Db si dice relazionale quando al suo interno è possibile stabilire relazioni tra sottoinsiemi di dati.
Facciamo un esempio: abbiamo 2 files, nel N.1 ci sono i dati di tutti gli impiegati di una Società, nel N.2 ci
sono i dati di tutti i reparti della Società; se nel record tipo 1 è presente il reparto di appartenenza allora
possiamo mettere in relazione gli impiegati con i rispettivi reparti.
Naturalmente l'esistenza di relazioni pone delle restrizioni: modifiche all'identificativo dei record tipo 2 o loro
cancellazione provoca la distruzione della relazione.
Un primo passo verso il Db relazionale nell'ambito Personal Computer fu l'introduzione sia per il dBaseIII che
per il Silver-Fox del comando SET RELATION TO .
Vediamone l'uso e le limitazioni.
Si usavano delle aree di lavoro, in ognuna delle quali era possibile aprire un solo Db per volta; la sequenza
dei comandi sarebbe stata:
SELECT 1 sceglie l'area 1
USE REPARTI INDEX REPARTI apre REPARTI.DBF con indice REPARTI.NDX (IDX per SilverFox)
SELECT 2
USE IMPIEGAT INDEX IMPIEGAT
SET RELATION TO REPARTO ON REPARTI
col vincolo che il campo REPARTO esistesse in entrambi e con lo stesso formato ed inoltre fosse la Chiave
dell'indice in uso per REPARTI
Allora per ogni record di IMPIEGATI erano disponibili, oltre ai campi di quel Db, anche i campi del Db
REPARTI:
ad esempio A–>NOMEREP, dove A–> indicava l'Alias del Db: A=area 1, B=area 2, etc..
Non era molto ma si incominciava ad introdurre il concetto.
Anche perché nel frattempo erano nati i primi veri Db relazionali, ma la complessità dei loro motori li
confinava su macchine più grandi e potenti: poveri PC con i loro 640Kb di RAM!.
Uno di quei primi Db relazionali è ancora oggi vivo e vegeto ed è Oracle, ma il requisito minimo per utilizzarlo
è un server Windows NT ed alcune decine di milioni per la licenza.
Quindi d'ora in avanti ci limiteremo a Database relazionali che siano compatibili con i nostri PC, in particolare
Microsoft Access (ed il relativo motore: MS Jet) che, pur non essendo l'unico, ha praticamente
monopolizzato il mercato in ambiente Windows. Pur essendo nato sotto Windows 3.1 la sua diffusione su
larga scala è iniziata con Windows 95 e la sua integrazione nel pacchetto MS Office.
SQL - Structured Query Language
La sua nascita è dovuta all'esigenza di stabilire una interfaccia standard di accesso ai Database
indipendentemente dal tipo e dalla piattaforma.
Esamineremo in dettaglio l'SQL supportato dal motore MS Jet (quello dei Data Access Object di Visual
Basic) e dei comandi SQL ignoreremo in genere quelli non utilizzabili in Visual Basic.
» SELECT Statement
Ordina al motore Microsoft Jet di recuperare informazioni da un database sotto forma di un insieme di
records.
Sintassi:
SELECT [predicate] { * | table.* | [table.]field1 [AS alias1] [, [table.]field2 [AS alias2] [, ...]]}
FROM tableexpression [, ...] [IN externaldatabase]
[WHERE... ]
[GROUP BY... ] [HAVING... ]
[ORDER BY... ]
[WITH OWNERACCESS OPTION]
Parti del comando SELECT:
predicate: uno dei seguenti: ALL, DISTINCT, DISTINCTROW, o TOP (vedremo più avanti i dettagli).
Si usa il predicate per restringere il numero dei records restituiti; se omesso il default è ALL.
(*): Indica che sono scelti tutti i campi della Table (o delle Tables).
table Il nome della Table contenente i campi dalla quale vengono scelti i records.
field1, field2 Il nome dei campi contenenti i dati cercati. Se si includono più campi vengono restituiti
nell'ordine elencato.
alias1, alias2 I nomi da usare come testata delle colonne invece dei nomi di colonna originali della Table.
Da notare che qualora i campi provengano da più Tables in caso di sinonimi occorre utilizzare la sintassi
nometable.nomefield per determinare un campo in modo univoco.
» clausola FROM
tableexpression: una espressione che identifica una o più Tables contenenti i dati da cercare; l'espressione
può essere il nome di una Table, il nome di una Query salvata o il risultato di una INNER JOIN, LEFT JOIN,
o RIGHT JOIN (vedremo più avanti i dettagli).
externaldatabase: il nome del Database contenente le Tables in tableexpression se non è il Database
corrente.
» clausola WHERE
Indica il criterio di scelta: l'elemento base è nomefield operatore di confronto valore|nomefield; possono
essere concatenati più elementi base tramite gli operatori logici (And Or).
Esempio: WHERE NomeImpiegato="Paolo" And (ImportoOrdini>10000000 Or NumeroOrdini>100)
Note:
nell'eseguire questa operazione il motore database Microsoft Jet cerca la Table (o Tables) specificata,
estrae le colonne (=campi) scelte, individua le righe (=record) che soddisfano il criterio ed ordina o
raggruppa le righe risultanti nell'ordine specificato.
Il comando SELECT non modifica i dati del database.
La sintassi minima è:
SELECT fields FROM table
Usando un aterisco (*) si scelgono tutti i campi di una Table; l'esempio seguente: SELECT * FROM
Employees è equivalente ad usare come RecordSet Employees.
» Clausola GROUP BY
Combina i records con valori identici del campo specificato in un singolo record. Un valore riepilogativo è
creato se nel comando SELECT viene inclusa una funzione SQL di aggregazione, quale Sum o Count.
Sintassi:
[GROUP BY groupfieldlist]
groupfieldlist Il nome di fino a 10 campi usati per raggruppare i records; l'ordine dei campi in groupfieldlist
determina il livello di grouping da quello più alto a quello più basso.
Note:
I valori riepilogativi vengono omessi se non è indicata una funzione SQL di aggregazione nel comando
SELECT.
Valori Null nei campi di GROUP BY vengono raggruppati e non saltati; tuttavia i valori Null non vengono
considerati da alcuna funzione SQL di aggregazione.
Usare la clausola WHERE per escludere i records che non si vuole raggruppare, usare la calusola HAVING
per filtrare i records dopo che sono stati raggruppati.
Non possono essere usati come campi GROUP BY né campi Memo né campi OLE Object; possono invece
essere usati tutti gli altri campi di qualsiasi Table indicata nella clausola FROM, anche se detti campi non
sono inclusi nella lista della SELECT purché sia inclusa almeno una funzione SQL di aggregazione.
» Clausola HAVING
Specifica quali records raggruppati vengono restituiti da un comando SELECT con clausola GROUP BY.
Sintassi:
SELECT .........
FROM ...........
WHERE ..........
GROUP BY groupfieldlist
HAVING groupcriteria
groupfieldlist: già esaminato in precedenza.
groupcriteria: un'espressione che determina quali records raggruppati restituire; possono essere usate fino
a 40 espressioni collegate dagli operatori And e Or.
Esempio:
SELECT CategoryID, Sum(UnitsInStock)
FROM Products
GROUP BY CategoryID
HAVING Sum(UnitsInStock) > 100
Dalla Table Products per ogni CategoryID presente otteniamo un record con 2 campi (CategoryID e
UnitsInStock) contenente nel 2° la somma dei valori di tutti i records avente uguale CategoryID solo se detta
somma è maggiore di 100.
» Clausola ORDER BY
Ordina i records risultato di una query secondo uno o più campi specificati in sequenza ascendente o
discendente.
Sintassi:
SELECT .........
FROM ...........
[WHERE ..........]
[GROUP BY ...... [HAVING ....]]
[ORDER BY field1 [ASC|DESC][, field2 [ASC|DESC]][, ...]]]
field1, field2, I nomi dei campi di sort.
Note:
l'ordine di default è ascendente; i due esempi seguenti sono equivalenti:
SELECT LastName, FirstName
FROM Employees
ORDER BY LastName
SELECT LastName, FirstName
FROM Employees
ORDER BY LastName ASC
Per ordinare in senso discendente (Z ad A, 9 a 0) aggiungere DESC dopo il nome del campo; l'esempio
seguente ordina per stipendi decrescenti:
SELECT LastName, FirstName, Salary
FROM Employees
ORDER BY Salary DESC, LastName
Non è possibile specificare nella clausola ORDER BY né campi Memo né campi OLE Object; i records
vengono ordinati sul 1° campo e quelli con ugual valore vengono quindi ordinati sul 2° e così via.
Dichiarazione WITH OWNERACCESS OPTION
In un ambiente multiutente con sicurezze a livello di workgroup, utilizzare questa dichiarazione con una
query per dare all'utente della query le stesse abilitazioni del proprietario della query.
L'esempio seguente abilita l'utente a vedere dati salariali (anche se non è abilitato ad accedere alla Table
Stipendi) purché il proprietario della query abbia tale abilitazione:
SELECT Cognome, Nome, Salario
FROM Stipendi
ORDER BY Cognome
WITH OWNERACCESS OPTION
Questa opzione richiede che abbiate accesso al file System.mdw associato al Database; è utile solo in
implementazioni multiutente protette.
» Predicati ALL, DISTINCT, DISTINCTROW, TOP
Specificano i records restituiti dalla query SQL.
Sintassi.
SELECT [ALL | DISTINCT | DISTINCTROW | [TOP n [PERCENT]]]
FROM table [ altre clausole .......]
ALL = tutti; assunto di default: il motore Microsoft Jet sceglie tutti i records che soddisfano le condizioni nel
comando SQL.
DISTINCT Omette i records contenenti dati duplicati nei campi indicati; per esempio più impiegati nella Table
Employees possono avere lo stesso LastName.
Se 2 records contengono Smith nel campo LastName il seguente comando SQL ritorna un solo record
contenente Smith:
SELECT DISTINCT LastName FROM Employees
L'output di una query che usa DISTINCT non è Updatable.
DISTINCTROW: omette i dati basati su records interamente duplicati. Per esempio voi create una query che
unisce le Tables Customers e Orders sulla base del campo CustomerID; Customers non contiene
CustomerID duplicati, ma Orders può in quanto ogni customer può avere vari orders. Il seguente comando
SQL produce una lista delle compagnie che hanno almeno un ordine (anche se senza alcun dettaglio
riguardo agli ordini):
SELECT DISTINCTROW CompanyName
FROM Customers INNER JOIN Orders
ON Customers.CustomerID = Orders.CustomerID
ORDER BY CompanyName
DISTINCTROW ha effetto solo si scelgono campi da alcune ma non tutte le Tables usate nella query ed è
ignorata se la query include una sola Table o se si scelgono campi da tutte le Tables.
TOP n [PERCENT]: ritorna solo un cero numero dei records che cadono all'inizio o alla fine di una
graduatoria specificata da una clausola ORDER BY ; vogliamo i nomi dei migliori 25 studenti diplomati nel
1994:
SELECT TOP 25 FirstName, LastName
FROM Students
WHERE GraduationYear = 1994
ORDER BY GradePointAverage DESC
Se si omette la clausola ORDER BY la query ritorna un insieme arbitrario di 25 records della Table Students
che soddisfano la clausola WHERE.
TOP non sceglie tra valori uguali: se il 25° ed il 26° studente hanno la stessa media la query restituisce 26
records.
Se si usa PERCENT viene restituita quella percentuale dei records che soddisfano la query: se invece dei
migliori 25 vogliamo il 10% peggiore dei diplomati 1994:
SELECT TOP 10 PERCENT FirstName, LastName
FROM Students
WHERE GraduationYear = 1994
ORDER BY GradePointAverage ASC
ASC e DESC specificano il senso dell'ordinamento (ascending o descending); il valore che segue TOP deve
essere un intero senza segno.
Operazioni di JOIN, LEFT JOIN, RIGHT JOIN in SQL
» INNER JOIN
Combina records da due tables quando hanno valori corrispondenti in un campo comune.
Sintassi:
FROM table1 INNER JOIN table2 ON table1.field1 compareop table2.field2
table1, table2: inomi delle Tables dalle quali combinare i records.
field1, field2: inomi dei campi oggetto della join. Devono essere dello stesso data type e contenere la stessa
specie di dati, ma non è necessario che abbiano lo stesso nome.
compareop: un' operatore relazionale: "=," "<," ">," "<=," ">=," o "<>."
Note:
se si usano come campi di join campi Memo o OLE Object si causa un errore.
Tra due campi numerici è possibile la join solo se sono dello stesso tipo: per esempio AutoNumber
(Contatore) e Long sono dello stesso tipo; Single e Double non sono dello stesso tipo e si causa un errore.
La INNER JOIN combina i records da due Tables quando hanno valori corrispondenti in un campo comune
ad entrambe le Tables.
Potete usare INNER JOIN con le Tables Departments e Employees per ottenere tutti gli impiegati di ogni
dipartimento. Se invece volete tutti i dipartimenti (anche se non hanno alcun impiegato assegnato) o tutti gli
impiegati (anche se qualcuno non è assegnato ad alcun dipartimento), dovete usare una operazione LEFT
JOIN o RIGHT JOIN per creare una "outer join".
L'esempio mostra la join delle Tables Categories and Products tramite il campo CategoryID:
SELECT CategoryName, ProductName
FROM Categories INNER JOIN Products
ON Categories.CategoryID = Products.CategoryID
CategoryID è il campo di join, ma non è incluso nell'output della query non essendo incluso nella fields list
della SELECT; per includerlo aggiungere il nome del campo, ovvero Categories.CategoryID.
Si possono collegare più clausole ON in una JOIN usando la seguente sintassi:
SELECT fields
FROM table1 INNER JOIN table2
ON table1.field1 compopr table2.field1 AND
ON table1.field2 compopr table2.field2) OR
ON table1.field3 compopr table2.field3)]
Si possono nidificare le operazioni di JOIN usando la seguente sintassi:
SELECT fields
FROM table1 INNER JOIN
(table2 INNER JOIN [( ]table3
[INNER JOIN [( ]tablex [INNER JOIN ...)]
ON table3.field3 compopr tablex.fieldx)]
ON table2.field2 compopr table3.field3)
ON table1.field1 compopr table2.field2
Una LEFT JOIN o una RIGHT JOIN possono essere nidificate dentro una INNER JOIN, ma una INNER
JOIN non può essere nidificata entro una LEFT JOIN o una RIGHT JOIN.
» LEFT JOIN, RIGHT JOIN
Sintassi:
FROM table1 [ LEFT | RIGHT ] JOIN table2
ON table1.field1 compopr table2.field2
La sintassi è identica a quella della INNER JOIN.
Note:
se si usano come campi di join campi Memo o OLE Object si causa un errore.
L'operatore LEFT JOIN crea una join esterna sinistra, ovvero include tutti i records della prima (left) Table
anche se non c'è corrispondenza con i records nella seconda (right) Table.
L'operatore RIGHT JOIN crea una join esterna destra, ovvero include tutti i records della seconda (right)
Table anche se non c'è corrispondenza con i records nella prima (left) Table.
Per esempio useremo LEFT JOIN con le Tables Departments (left) e Employees (right) per ottenere tutti i
dipartimenti, inclusi quelli che non hanno impiegati assegnati; per ottenere invece tutti gli impiegati, inclusi
quelli non assegnati ad un dipartimento, useremo RIGHT JOIN.
LEFT JOIN o RIGHT JOIN possono essere nidificate all'interno di INNER JOIN, ma INNER JOIN non può
essere nidificata entro LEFT JOIN o RIGHT JOIN; per la sintassi di nidificazione vale quanto detto per
INNER JOIN, così come per le clausole ON multiple ed i campi Memo o OLE Object.
Altri comandi SQL
» SELECT .... INTO Statement
Query di creazione di una Table.
Sintassi:
SELECT field1[, field2[, ...]] INTO newtable [IN externaldatabase]
FROM source
Crea una nuova Table, eventualmente in un Db esterno, avente i campi specificati nella fields list; non può
essere utilizzata per aggiungere records ad una Table esistente.
» DELETE Statement
Query di cancellazione dei records di una Table che soddisfano un determinato criterio.
Sintassi:
DELETE [table.*]
FROM table
WHERE criteria
DELETE serve per cancellazioni multiple; inoltre se la Table da cui si cancella è posta in una relazione unoa-molti con altre Tables vengono cancellati anche i records relativi dalle altre Tables.
Per esempio se la Table "Customers" è in relazione uno-a-molti con la Table "Orders" cancellando alcuni
clienti da Customers si otterrà anche la cancellazione degli ordini relativi da Orders.
» INSERT INTO Statement
Query di inserimento di uno o più records in una Table (append query).
Sintassi:
(Multiple-record append query):
INSERT INTO target [(field1[, field2[, ...]])] [IN externaldatabase]
SELECT [source.]field1[, field2[, ...]
FROM tableexpression
(Single-record append query):
INSERT INTO target [(field1[, field2[, ...]])]
VALUES (value1[, value2[, ...])
Qualora la Table di destinazione abbia un campo Contatore (Autonumber) non inserire tale campo nella
fields list; la clausola FORM può anche contenere JOIN di più Tables.
» UPDATE, DELETE e INSERT Statements
Le applicazioni SQL-based effettuano gli aggiornamenti delle Tables con l'esecuzione dei comandi UPDATE,
DELETE ed INSERT. Questi comandi fanno parte del "Minimum SQL grammar conformance level" e devono
essere supportati da tutti i drivers e da tutti i Database.
Sintassi:
UPDATE table-name
SET column-identifier = {expression | NULL}
[, column-identifier = {expression | NULL}]...
[WHERE search-condition]
DELETE FROM table-name [WHERE search-condition]
INSERT INTO table-name [(column-identifier [, column-identifier]...)]
{query-specification | VALUES (insert-value [, insert-value]...)}
Questi comandi sono riportati a puro titolo esemplificativo non essendo utilizzabili nella programmazione
Visual Basic dove invece si ricorre in genere a Metodi applicati agli Oggetti.
Approfondimenti
» "Interactive/On-line SQL Tutorial" di F. Torres
» "SQL Index"
» "Interactive SQL" di Jean Anderson
» "Database glossary"
» "Starting a Career in Databases"
» "A pratical SQL Tutorial"