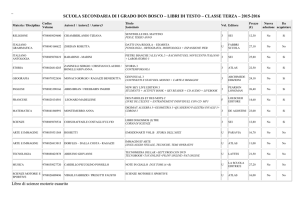
18/05/11
Attilio Picazio - Workshop ATLAS Italia
ATLAS Italia Physics Workshop
Napoli 18 e 19 maggio 2011
ANALISI DISTRIBUITA IN ATLAS
L’esperienza degli utenti
Attilio Picazio
Università di Napoli “Federico II” – INFN Napoli
18/05/11
Attilio Picazio - Workshop ATLAS Italia
2
Introduzione
• Grid Computing nel 2011
• Risultati dell’ “ATLAS Distributed Analysis User Survey”
• Un esempio di analisi
• Esperienza degli utenti italiani
18/05/11
Attilio Picazio - Workshop ATLAS Italia
Grid Computing
nel 2011
WLCG today
for LHC experiments
WLCG oggi per gli esperimenti di LHC
88!9.3-:8!5, 4=), <C!; 8<=!9.3-:>!5, 4=), <!"( 73<!9.3-:?<&
!
!
@8A=B!$GE !5*), <C!B6=!: U !H*. <V- ' /
; A=$CD!- 6<W
http://event.twgrid.org/isgc2011/slides/opening/1/K2_Bonacorsi_presentation.pdf
3
18/05/11
4
Attilio Picazio - Workshop ATLAS Italia
Site reliability in WLCG
AffidabilitàSite
dei reliability
siti in WLCG
in WLCG
>=8=$/ E6E$6EB.*+
>=8=$
/ E6E$
6EB.*+
76E-6$
E6$
F$93G
76E-6$E6$F$93G
2006
2006
2007
2007
2008
2008
2009
2009
Jul’ 06
2010
2010
2011
2011
Feb’ 11
Jul’06
Feb’11
>=8=$/ E6E$6EB.*+
76E-6$E6$F$93G
>=8=$/ E6E$6EB.*+
76E-6$E6$F$93G
2009
2009
ISGC’ 11 - Taipei - 22 Marzo 2011
2010
2010
@' <65!? *46=*)6
4P!*F!J
#$%!
Monitoraggio
di
base
dei
servizi WLCG
<65,
5!?< *46=*)64P!*F!J #$%!
<,@')+6
•<,! Ai
)+6
5, <, )Q9V: V8!7, +, 7<
' T0/T1/T2
=!X6
' =!X6
9V:
V8!7
7,</!64P), - 6, 4=!
A6=,! <!),
76', .)Q6
76=/!6
<!', +,!W
L’affidabilità
dei siti è un ( 3L 4P!
64!=B,
!<355,
A6=, <!),
76' . 6<<!*F!#N$!$*?
76=/!6<!' !W,/!64P), - 6, 4=!
ingrediente
chiave
per7' il. *)'
successo
!
1, <37
=!*F!' <<!*F!#N$!$*?
!B3P, !5*7
L (+,3L
!D *)W
64!=B,
!<355,
4P!
del! ! Computing
di
LHC
XB' 4W
#$%!'
4- !<6=, !' - ? 64<Y
1, <37<!=*!J
=!*F!' !B3P,
!5*7
7' . *)' L +, !D*)W
• Risultato di un enorme lavoro di
! XB' 4W
<!=*!J #$%!' 4- !<6=, !' - ? 64<Y
Daniele Bonacorsi [CMS]
4
collaborazione
ISGC’11 - Taipei - 22 Marzo 2011
Daniele Bonacorsi [CMS]
http://event.twgrid.org/isgc2011/slides/opening/1/K2_Bonacorsi_presentation.pdf
4
18/05/11
5
Attilio Picazio - Workshop ATLAS Italia
ATLAS Distributed Analysis User Survey
• Obiettivi:
Valutazione generale dell’esperienza degli utenti dell’Analisi Distribuita
Idee per possibili sviluppi futuri dell’Analisi Distribuita
21.2%
19.9%
15.4%
15.8%
13.3%
12.0%
None
Trigger
4.6%
Top
SUSY
Standard Model
Software
Jet/EtMiss
Inner Tracking
I risultati integrali del test si trovano al link:
https://twiki.cern.ch/twiki/bin/viewauth/Atlas/Dis tributedAnalysisSurvey2011
Tau
4.6%
1.7%
0.8%
Higgs
Heavy Ions
Flavour Tagging
Exotics
2.5%
Monte Carlo
5.8%
8.7%
8.3%
4.6%
Luminosity
9.5%
B Physics
–
241 Utenti
circa il 70%
Dottorandi e PostDoc
Diversi gruppi di
lavoro
e/gamma
–
–
27.0%
Data preparation
• Campione analizzato:
70
60
50
40
30
20
10
0
Q43: In which group(s) are you
working?
Computing
43 domande
Risposta multipla o aperta.
Combined Muon
• Modalità:
6
18/05/11
6
Attilio Picazio - Workshop ATLAS Italia
Formato dei dati utilizzati
per le analisi
Q3: Which data types/formats do you
analyse on the Grid?
180
Formato dei dati
prevalentemente
analizzati sulla Grid
70.1%
160
52.7%
140
120
100
35.3%
80
60
12.0%
40
13.3%
6.6%
20
0
Q2:
Which data types/formats do you analyse
AOD
D3PD
dAOD
dESD
ESD
Other
on your
local
workstation
or batch
system?
Formato dei dati
prevalentemente
analizzati su workstation
locali o sistemi batch
200
180
160
140
120
100
80
60
40
20
0
10
72.2%
27.0%
AOD
•
•
•
•
24.5%
12.0%
D3PD
8.3%
4.1%
dAOD
dESD
ESD
Other (User
ntuples,
etc…)
Strong local D3PD usage
ESD: Event Summary Data -> Contengono
tutte le informazioni dell’evento
9
AOD: Analysis Object Data -> Contengono le informazioni di maggiore interesse per l’analisi
D3PD: Derived Physics Data -> Formato in rappresentazione tipo ennupla derivato da gli AOD
dAOD e dESD: equivalenti a AOD e ESD rispettivamente ma con selezioni sugli eventi
18/05/11
Formato dei
Attilio Picazio - Workshop ATLAS Italia
Q10:
What is the output format7 of
your analysis?
dati di output
e Tools usati
200
File di Outputs dei jobs
eseguiti sulla Grid
73.0%
180
66.0%
160
140
120
100
80
23.2%
60
40
5.0%
20
5.4%
Q13:
Which of the following DA tools do
0
AOD use? D3PD
you
(selecthistograms
all that n-tuple
apply) Other
Large fraction with customized output formats
Tools di Analisi Distribuita
prevalentemente utilizzati
200
180
160
140
120
100
80
60
40
20
0
78.4%
66.4%
18
66.4%
29.9%
8.7%
3.7%
9.1% 5.4%
21
pAthena e Ganga: tools per girare Athena sulla Grid
pRun: tool per girare macro di root e programmi in C++ sulla grid
18/05/11
Attilio Picazio - Workshop ATLAS Italia
8
Sottomissione dei Job
=3.39
Quanto spesso i Jobs vengono
indirizzati verso particolari siti o clouds
=3.07
=3.34
Affidabilità complessiva della Grid Q30: Reliability of the grid: On average what fraction
of your
Grid are
jobsdirecting
fail when you
are processing a=3.10
large
Most users are not blindly submitting jobs
– they
them
somewhere known to be reliable. Not a good sign. dataset container?
Frazione di subjobs falliti per
sottomissione
Il fallimeto dei subjobs è spesso dovuto a
problemi di accesso alle risorse di Storage
30
38
18/05/11
9
Attilio Picazio - Workshop ATLAS Italia
Q32: What do you typically do with
your Grid output data?
Recupero dei dati in uscita
250
94.6%
200
150
Principali operazioni fatte
dagli utenti con i loro
outputs
35.7%
100
23.2%
50
0
0.4%
0.4%
Most want
outputs off
grid.
Dq2-get is
essential.
1.2%
0.4%
0.4%
43
Come si apprende l’uso della Grid?
Q35: How did you learn to use the Grid?
250
90.5%
200
150
49.4%
100
25.3%
18.3%
50
0
0.4%
4.1%
6.6%
2.5%
47
Percentuali molto alte di utenti
hanno imparato ad usare la Grid
grazie ai documenti delle Twiki e a
informazioni fornite dai colleghi.
18/05/11
Attilio Picazio - Workshop ATLAS Italia
10
Selezione di Siti e Clouds Utilizzate
• Molti users hanno personali “Black-list” dei siti (da
esperienza maturata) e preferiscono l’utilizzo delle
Clouds: US, DE
• Buona percentuale di users preferiscono la Cloud
IT e TRIUMF
• Considerevole quantità di jobs mandati ai T2, data
la disponibilità di dati sui LOCALGROUPDISK
• La risposta più frequente degli utenti nella
selezione di siti e cloud è stata: “quello più
disponibile al momento”
18/05/11
Attilio Picazio - Workshop ATLAS Italia
11
Un esempio di workflow: l’esperienza del gruppo di Napoli per gli
studi sulle performance del trigger muonico
data10_7TeV.00167776.physics_Muons.recon.ESD.f299
JpsiIT: il nostro tool di analisi
•
•
•
Girato con pAthena sulla
grid
Produce N-tuple di grandi
dimensioni
non selezioniamo una cloud
preferita
JpsiIt
Formato dati ESD:
6 pb-1
Spazio disco ~3.6
TB
N Eventi 7318938
N Files 4015
JpsiItDumper
Principali utilizzi del nostro
codice:
T&P per lo studio delle
effiienze di trigger muonico
analisi della J/ψ in protoneprotone e in Heavy Ions
JpsiItDumper: Macro di
taginvmass1
taginvmass2
485457
Entries 257279
2.98
3.008
Mean
0.4431
0.5879
RMS
Massa invariante(GeV) per q=0
6000
massa invariante
5000
Massa invariante(GeV) per q=0
Massa invariante(GeV) per q=/0
4000
3000
2000
1000
2
2.2
2.4
2.6
2.8
3
3.2
3.4
3.6
4
3.8
m (GeV)
Root che esegue un ulteriore
skimming degli eventi
• Girato con pRun sulla grid
• Gira sui Datasets di output
di JpsiIt
18/05/11
Attilio Picazio - Workshop ATLAS Italia
12
Esperienza di altri utenti italiani
Tra gli utenti italiani “intervistati” si possono distinguere due categorie di analisi:
Performance e trigger
Formato dati utilizzato: ESD e AOD
La dislocazione dei datasets
(soprattutto degli ESD), non
permette di scegliere una
particolare cloud.
Gli utenti scrivono delle liste
personali con l’elenco dei siti
più problematici al momento
dell’analisi.
Analisi di fisica
(Bphys, SM, Higgs, SUSY…)
Formato dati utilizzato: D3PD e AOD
Per queste analisi spesso si
ricorre alla sottoscrizione dei
datasets nei local group disk
per usufruire delle risorse dei T2
Affidabilità riscontrata dagli utenti italiani contattati dell’ordine del 90%
18/05/11
Attilio Picazio - Workshop ATLAS Italia
13
La Grid è uno strumento essenziale per l’analisi dei dati ad LHC ma…
c’è qualche perplessità sull’attuale modello di calcolo
La tendenza degli utenti negli ultimi mesi è quella di creare delle ntuple o D3PD comuni per gruppi di analisi. Questo comporta una
diminuzione dell’utilizzo complessivo della grid.
code meno affollate?
No, perché i dati ultimamente sono
replicati solo ai T1
La replica ai T2 è solo a valle di una procedura di ranking
Si gira poco o niente ai T2 e l’analisi globale ne risulta rallentata
18/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
14
ANALISI DISTRIBUITA IN ATLAS
Computing Point of View
G. Carlino
INFN Napoli
18/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
15
IL CM – analisi critica e sviluppi
Presa dati 2010. Sufficiente esperienza per una valutazione critica del CM
• La griglia sembra funzionare
• scala oltre i livelli testati nelle varie fasi di commissioning
• gli utenti stanno familiarizzando con i tool di analisi e gestione dei
dati, selezionando quelli migliori (panda vs. WMS), sono mediamente
soddisfatti
• Critiche negli anni al nostro CM
• richiesta eccessiva di spazio disco
• proliferazione del formato dei dati
• eccesso di repliche dei dati
• Superamento dei punti deboli
• accounting dell’accesso ai dati: determinazione della loro popolarità
• cancellazione automatica dei dati meno popolari
• replica dinamica ai Tier2 solo dei dati utilizzati dagli utenti
Gianpaolo Carlino- Workshop ATLAS Italia
18/05/11
16
Data popularity & deletion
•
•
•
•
Accounting dell’accesso ai dati
Alla base del sistema di cancellazione delle repliche
Fornisce una statistica dei formati più utilizzati (popolari) per l’analisi
Fornisce una statistica dell’uso dei siti
Fornisce una statistica dei tool di analisi più usati
I dataset meno popolari possono essere cancellati dopo essere stati replicati nei siti
• bisogna assicurare la custodialità prevista dal Computing Model
• replica sempre tutti i dati nuovi per l’analisi senza penalizzare le cloud più piccole
• risparmio significativo di spazio disco
ATLAS usa un sistema automatico di cancellazione basato sulla classificazione dei dataset e
la misura del numero di accessi
• custodial data: cancellabili solo se obsoleti (RAW, ESD o AOD prodotti nella cloud)
• primary data: cancellabili solo se diventano secondary (dati previsti dal CM)
• secondary data: solo questi possono essere cancellati se non popolari in base alla loro
anzianità
Cancellazione dei dati secondari meno
popolari quando lo spazio disco occupato
supera una soglia di sicurezza
Permette una continua rotazione dei dati
Gianpaolo Carlino- Workshop ATLAS Italia
18/05/11
17
Evoluzione del Computing Model – PD2P
Perché replicare i dati se poi vengono cancellati?
• Nel 2010 si sono replicati milioni di file (spesso molto piccoli)
• replica in tutti i siti (70+) e solo in pochi sono stati realmente acceduti
Non esiste un metodo più intelligente?
• Evoluzione del Computing Model verso un modello meno rigido che ottimizzi le risorse
disponibili: riduzione del disco necessario e utilizzo di tutte le CPU
• il paradigma è invariato: i job vanno dove sono i dati ma, sfruttando l’efficienza del sistema di
data management e le performance della rete, la replica dei dati è triggerata dai job stessi
Panda Dynamic Data Placement Model (PD2P)
Modello di distribuzione dei dati basato sull’idea di considerare gli storage dei T2 come cache
• nessun dato pre-placed nei Tier2, stop alle repliche automatiche
• immutata la distribuzione automatica dei dati nei Tier1
• Panda esegue la replica dei dati verso un Tier2 della stessa cloud quando c’è un job al Tier1
che li richiede
• i successivi job girano o al Tier1 o al Tier2 dove è stata eseguita e completata la replica
• clean up dei Tier2 quando lo storage
è pieno basato sul sistema di popolarità
Evitata la catastrofe
ultravioletta nei Tier2
1818/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
18
PD2P nel 2011
Nel 2010 il PD2P ha dato risultati positivi. Estensione del modello anche a causa delle
nuove condizioni di run di LHC che hanno reso necessaria una sensibile riduzione del
numero di repliche di dati nella griglia
•
•
•
Cancellazione dei cloud boundaries: trasferimenti infra-cloud tra Tier1 e Tier2
Trasferimenti anche tra Tier1
Extra repliche in base al riutilizzo dei dati già trasferiti e al numero di richieste di accesso
contemporanee al singolo dataset
Primi risultati del nuovo modello
•
•
L’algoritmo di brokering dei dati e dei job di analisi, basato sul numero di job running nei
siti, sembra stia favorendo troppo i Tier1 penalizzando i Tier2.
• Pochi dati ai Tier2 (in tutte le cloud)
• Pochi job di analisi nei Tier2 (in tutte le cloud)
Utilizzo non efficiente delle risorse di ATLAS e insoddisfazione da parte degli utenti
L’ ADC team in collaborazione con le cloud sta analizzando il modello per verificarne la
bontà e determinare le modifiche necessarie
• modifiche dell’algoritmo di brokering
• preplacement di una frazione di dati nei T2D
TIM Workshop a Dubna a inizi giugno nel quale descriverò l’esperienza degli utenti italiani
(feedback very welcome)
1918/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
ATLAS Cloud Model
19
Modello gerarchico basato sulla
topologia di rete di Monarc
• Comunicazioni possibili:
• T0-T1
• T1-T1
• Intra-cloud T1-T2
• Comunicazioni vietate:
• Inter-cloud T1-T2
• Inter-cloud T2-T2
Limitazioni:
•
•
•
Impossibile fornire una replica completa
di dati per l’analisi ad ogni cloud
Trasferimenti tra le cloud attraverso salti
multipli tra i Tier1
• User analysis outputs
Tier2 non utilizzabili come repository di
dati primari per il PD2P o di gruppo
2018/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
20
ATLAS Cloud(less) Model
Breaking the Wall
•
•
•
La rete attuale permette il
superamento del modello Monarc:
• molti Tier2 sono già ben
connessi con molti Tier1
• Abilitazione delle connessioni
inter cloud
Superamento di una gerarchia
stretta tra Tier1 e Tier2
Scelta dei Tier2 adatti
•
•
alcuni Tier2 sono mal collegati
anche con il proprio Tier1
Non tutti i Tier2 hanno le
dimensioni e le performance
necessarie
2118/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
21
Tier2 Diretti
T2D – Tier2 “Directly Connected”
• Tier2 connessi direttamente tra di loro
e a tutti i Tier1
• Storage per dati primari come i Tier1
• Preplacement di una quota di dati
• Data source per il PD2P
• Group data
• Disponibilità di una quota di disco nei Tier1 come
cache
• Requirement molto stretti
• Metriche di trasferimento con tutti I Tier1
• Livello di commitment e reliability adeguato
Avg(Byterate)+StD(Byterate)
SMALL
<0.05MB/s
<0.1MB/s
≥0.1MB/
s
MEDIUM
<1MB/s
<2MB/s
≥2MB/s
LARGE
<10MB/s
<15MB/s
≥15MB/s
T2D approvati:
INFN-NAPOLI- ATLAS, INFN-MILANO-ATLASC, INFNROMA1
IFIC-LCG2, IFAE, UAM-LCG2
GRIF-LPNHE, GRIF-LAL, TOKYO-LCG2
DESY-HH, DESY-ZN, LRZ-LMU, MPPMU
MWT2_UC,WT2, AGLT2,BU_ATLAS_Tier2, SWT2_CPB
UKI-LT2-QMUL, UKI-NORTHGRID-LANCS-HEP, UKINORTHGRID-MAN-HEP, UKI-SCOTGRID-GLASGOW
Siti che faranno parte
da subito di LHCOne
18/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
Attività in ATLAS
22
Numero medio di jobs di produzione running per cloud
• > 50k job simultanei.
• Produzione: Ricostruzione (T1),
Simulazione e Analisi di gruppo
(produzione centralizzata di D3PD
in alcuni gruppi)
Numero medio di jobs di analisi running per cloud
• ~ 10k job simultanei. riduzione analisi
nel 2011.
• aumento attività analisi di gruppo:
• aumento della coordinazione.
Minore caoticità e duplicazione dei
dati
• centralizzazione della produzione:
in molti casi accountata come
produzione
• analisi finale off grid su ntuple
18/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
WCT consumptions dei job di produzione.
Giugno 2010 – Maggio 2011
Utilizzo risorse in Italia
23
18/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
24
Sharing delle risorse
Tra le attività
nei Tier2
Attività nei Tier2
Job running su un Tier2
• Produzione
• Analisi WMS
• Analisi Panda
• Analisi Panda ruolo italiano
(Gli italiani vengono mappati sia su
panda che su panda/it, risorse dedicate)
Buona efficienza in tutti i siti, superiore alla media, anche per i job di analisi
18/05/11
25
25
Gianpaolo Carlino- Workshop ATLAS Italia
Reliability & Availability – 2010/11
Valori medi 2011
Frascati
Milano
rel
ava
rel
ava
95%
94%
93%
93%
Napoli
Buona affidabilità in tutti i siti, superiore
alla media WLCG. Molto spesso i problemi
ai siti sono dovuti a cause esterne
Availability =
time_site_is_available/total_time
Reliability =
time_site_is_available/
(total_time-time_site_is_sched_down)
Roma
rel
ava
rel
ava
93%
92%
98%
97%
18/05/11
Gianpaolo Carlino- Workshop ATLAS Italia
26
Osservazioni conclusive
L’attività di computing in ATLAS è soddisfacente ma il frequente cambiamento delle condizioni al
contorno comporta la necessità di continue modifiche al CM per adattarsi ad esse e alle necessità
degli utenti. Reazioni sufficientemente veloci nei limiti del possibile
Analisi
• appartente variazione del workflow di molte analisi comportano una riduzione dell’attvità nella
griglia, temporanea?
• utilizzo delle risorse tra Tier1 e Tier2 al momento sbilanciato, tuning in corso
Tier1 e Tier2 italiani
• Il CNAF è tra i migliori Tier1 di ATLAS
• le CPU al CNAF e ai Tier2 sono quasi sempre sature
• Le efficienze e le affidibilità dei siti sono superiori alla media
Utilizzo delle risorse italiane
• la riduzione del numero di repliche di dati nella griglia e l’uso dei container di dataset non
permettono di selezionare i siti o la cloud su cui runnare i propri job
• può però essere intensificato l’uso dei Tier2 italiani per le attività dei nostri gruppi in modo da
sfruttare le risorse di CPU e disco dedicate agli utenti sottoscrivendo gli output del primo step delle
analisi nei LOCALGROUP