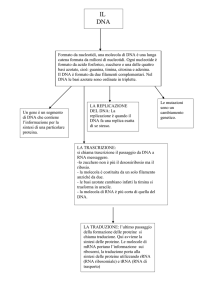
L'acido desossiribonucleico o deossiribonucleico (DNA) è un acido nucleico che contiene le
informazioni genetiche necessarie alla biosintesi di RNA (acido ribonucleico) e proteine,
molecole indispensabili per lo sviluppo ed il corretto funzionamento della maggior parte degli
organismi viventi.
Dal punto di vista chimico, il DNA è un polimero organico costituito da monomeri chiamati
nucleotidi (deossiribonucleotidi). Tutti i nucleotidi sono costituiti da tre componenti
fondamentali: un gruppo fosfato, il deossiribosio (zucchero pentoso) e una base azotata che si
lega al deossiribosio con legame N-glicosidico. Le basi azotate che possono essere utilizzate
nella formazione dei nucleotidi da incorporare nella molecola di DNA sono quattro: adenina,
guanina, citosina e timina mentre nell'RNA, al posto della timina, è presente l'uracile. Il DNA
può essere più correttamente definito come una doppia catena polinucleotidica (A,T,C,G),
antiparallela, orientata, complementare, spiralizzata, informazionale.
La struttura laterale del DNA è composta da unità
ripetute ed alternate di gruppi fosfato e di 2deossiribosio, uno zucchero pentoso (a cinque atomi di
carbonio) che si lega ai fosfati adiacenti attraverso
legami fosfodiesterici.
Ogni filamento di DNA ha un senso, determinato dalla
direzione dei legami fosfodiesterici. Le basi azotate,
invece, si uniscono in posizione 1' dello zucchero
desossiribosio con legami N-glicosidici.
La principale differenza tra il DNA e l'RNA è lo
zucchero pentoso utilizzato: l'RNA, infatti, utilizza
il ribosio e che al posto della Timina troviamo
l’URACILE. L’RNA è a singolo filamento il DNA a
doppio filamento.
Il DNA è un lungo polimero costituito da unità ripetute di nucleotidi.
L'ordine nella disposizione sequenziale dei nucleotidi costituisce l'informazione genetica, la quale è
tradotta con il codice genetico negli amminoacidi corrispondenti. La sequenza amminoacidica prodotta,
detta polipeptide, forma le proteine. Il processo di traduzione genetica (comunemente chiamata sintesi
proteica) è possibile solo in presenza di una molecola intermedia di RNA, che è generata per
complementarità con le quattro basi dei nucleotidi del DNA in un processo noto come trascrizione. Tale
processo non genera solo filamenti di RNA destinati alla traduzione, ma anche frammenti già in grado di
svolgere svariate funzioni biologiche (ad esempio all'interno dei ribosomi, dove l'RNA ha una funzione
strutturale). L'informazione genetica è duplicata prima della divisione cellulare, attraverso un processo
noto come replicazione del DNA, che evita la perdita di informazione nel passaggio tra diverse
generazioni cellulari.
Negli eucarioti, il DNA si complessa all'interno del nucleo in strutture chiamate
cromosomi. Negli altri organismi, privi di nucleo (procarioti), esso può essere organizzato
in cromosomi o meno (nei batteri è presente un'unica molecola di DNA circolare a doppia
catena, mentre i virus possono avere genomi a DNA oppure ad RNA). All'interno dei
cromosomi, le proteine della cromatina come gli istoni, le coesine e le condensine,
organizzano il DNA e lo avvolgono in strutture ordinate. Queste strutture guidano
l'interazione tra il codice genetico e le proteine responsabili della trascrizione,
contribuendo al controllo della trascrizione genica.
La doppia elica del DNA è stabilizzata dai legami idrogeno che si
instaurano tra le basi azotate presenti sui due filamenti. Le quattro
basi che sono presenti nel DNA sono l'adenina (abbreviata con la
lettera A), la citosina (C), la guanina (G) e la timina (T). Tutte e
quattro le basi hanno struttura eterociclica, ma adenina e guanina
sono, dal punto di vista strutturale, derivate della purina, e
pertanto dette basi puriniche, mentre citosina e timina sono
correlate alla pirimidina e dette basi pirimidiniche. Esiste una
quinta base, di tipo pirimidinico, chiamata uracile (U), ma essa
non è di norma presente nelle catene di DNA. L'uracile è altresì
presente nei filamenti di RNA al posto della timina, dalla quale si
differenzia per la mancanza di un gruppo metile. L'uracile è
presente nel DNA solo come prodotto della degradazione della
citosina.
La doppia elica è una spirale destrorsa. Con l'avvitarsi su sé stessi
dei due filamenti, restano esposti dei solchi tra i diversi gruppi
fosfato. Il solco maggiore e il solco minore La differente ampiezza
dei due solchi si traduce concretamente in una differente
accessibilità delle basi, a seconda che si trovino nel solco maggiore
o minore. Proteine che legano il DNA, come i fattori di trascrizione,
dunque, solitamente prendono contatto con le basi presenti nel
solco maggiore.
Il 1953 è l'anno in cui, attraverso ulteriori immagini da diffrazione a raggi X
realizzate da Rosalind Franklin, chimico-fisico inglese, James Watson e
Francis Crick presentarono, sulla rivista Nature, quello che è oggi accertato
come il primo modello accurato della struttura del DNA, ovvero il modello a
doppia elica.
Watson, Crick ricevettero congiuntamente il Premio Nobel per la medicina.
Ogni tipo di base presente su un filamento forma un legame con la base posta sul filamento
opposto. Tale evento è noto come appaiamento complementare. Le basi puriniche formano
legami idrogeno con le basi pirimidiniche: A può legare solo T e G può legare solo C.
L'associazione di due basi viene comunemente chiamata paio di basi ed è l'unità di misura
maggiormente utilizzata per definire la lunghezza di una molecola di DNA. Dal momento che i
legami idrogeno non sono covalenti, essi possono esser rotti e riuniti in modo relativamente
semplice, poiché questi sono legami ad alta energia. I due filamenti possono essere allontanati
tra loro, come avviene per una cerniera, sia dalle alte temperature che da un'azione
meccanica (come avviene durante la replicazione del DNA
I due tipi di paia di basi formano un numero differente di legami idrogeno: A e T ne formano
due, G e C tre. Per tale motivo, la stabilità del legame GC è decisamente maggiore di quello
AT. Di conseguenza, la stabilità complessiva di una molecola di DNA è direttamente correlata
alla frequenza di GC presenti nella molecola stessa, nonché alla lunghezza dell'elica: una
molecola di DNA è dunque tanto più stabile quanto più contiene GC ed è lunga
Il DNA può essere alterato dall'azione di numerosi agenti, genericamente definiti mutageni; è
fondamentale notare però come una mutazione -ovverosia un cambiamento raro, casuale, che alteri la
sequenza di basi azotate- non sia necessariamente un evento dannoso ma anzi sia alla base
dell'evoluzione: suddetta mutazione dovrà però farsi spazio nell'ambiente nel quale vive ed opera
l'organismo vivente in questione; qualora vengano superati questi punti di restrizione (altamente selettivi
vista la loro complessità intrinseca, la stragrande maggioranza delle mutazioni difatti si rivela non
vantaggiosa od anche neutra), si avrà un organismo arricchito dalla mutazione. Tra gli agenti alteranti
figurano ad esempio agenti ossidanti, agenti alchilanti ed anche radiazioni ad alta energia, come i raggi
X e gli UV. Il tipo di danno causato al DNA dipende dal tipo di agente: gli UV, ad esempio, danneggiano il
DNA generando la formazione di dimeri di timina, costituiti da ponti aberranti che si instaurano tra basi
pirimidiniche adiacenti. Agenti ossidanti come i radicali liberi o il perossido di idrogeno, invece,
producono danni di tipo più eterogeneo, come modificazioni di basi (in particolare di guanine) o rotture
del DNA a doppio filamento. Secondo diversi studi, in ogni cellula umana almeno 500 basi al giorno sono
sottoposte a danni ossidativi. Di tali lesioni, le più pericolose sono le rotture a doppio filamento, dal
momento che tali danni sono i più difficili da riparare e costituiscono l'origine primaria delle mutazioni
puntiformi e frameshift che si accumulano sulle sequenze genomiche, nonché delle traslocazioni
cromosomiche.
Molti agenti devono il loro potere mutageno alla capacità di intercalarsi tra due basi azotate consecutive.
Gli intercalanti sono ad esempio l'etidio, talidomide. Perché un intercalante possa trovare posto tra le
due basi, occorre che la doppia elica si apra e perda la sua conformazione standard. Tali modifiche
strutturali inibiscono sia la trascrizione che la replicazione del DNA ed aumentano la possibilità di
insorgenza di mutazioni. Per tale motivo, gli intercalanti sono considerati molecole cancerogene, come
dimostrato da numerosi studi su molecole come il benzopirene, l'acridina, l'aflatossina ed il bromuro di
etidio.
Durante il processo di duplicazione semiconservativa, la doppia
despiralizza
elica di DNA si ……………..........................
e si apre a livello delle basi
azotate. Ciascuno dei due filamenti separati funge da
stampo
.......................................
per la sintesi del proprio filamento
complementare. Ciò avviene perché ciascuna base azotata
«richiama»
un
nucleotide
con
base
azotata
ad
complementare (ad esempio Adenina «richiama»
essa.......................................
timina.
.......................................)
I nucleotidi complementari sono legati in sequenza a opera di
particolari proteine, formando così due molecole figlie, ciascuna
costituita da un filamento appena sintetizzato e da uno proveniente
originaria
dalla molecola……………………..
Data la seguente sequenza di nucleotidi per un singolo filamento di DNA:
5'....AAATCGATTGCGCTATCG.....3'
scrivere la sequenza complementare, indicandone la polarità.
Risposta:
3’ ........TTTAGCTAACGCGATAGC......... 5’
Data la seguente sequenza di nucleotidi per un singolo filamento di
DNA:
1. scrivere la sequenza complementare
2. indicare la polarità del filamento complementare
3. Indicare il tipo e il numero dei legami tra le diverse basi azotate .
Legami idrogeno
Una molecola di DNA ha 180 paia di nucleotidi, dei quali il 20% è
costituito da adenina. Quanti nucleotidi di citosina sono presenti in
questa molecola di DNA?
Spiegazione:
Totale nucleotidi 180 x 2 = 360;
Per la regola di Chargaf: A=T; C=G; A+C=T+G
A+T =20+20=40%, perciò
G+C =60% e quindi C 30%.
30% di 360=108
Risposta:
108
Una molecola di DNA ha 280 paia di nucleotidi, dei quali il 30% è
costituito da timina. Quanti nucleotidi di citosina sono presenti in questa
molecola di DNA?
Spiegazione:
Totale nucleotidi 280 x 2 = 560;
Per la regola di Chargaf: A=T; C=G; A+C=T+G
A+T =30+30=60%, perciò
G+C =40% e quindi C 20%.
20% di 560=112
Risposta:
112
Data la seguente sequenza di nucleotidi per un singolo filamento di
DNA:
1. scrivere la sequenza del filamento di RNA che si ottiene dalla
trascrizione
2. indicare la polarità del filamento di rna
3’ – TCT AGT CGT CCT AAC – 5’ DNA
5’ – AGA UCA GCA GGA UUG – 3’ RNA
La traduzione è la seconda fase dell'espressione genica. La prima fase è la trascrizione, fase in cui una data sequenza
di DNA, chiamata gene strutturale, viene usata come stampo per la creazione di un filamento complementare di RNA.
La sequenza di RNA si compone di gruppi non sovrapposti di tre basi ciascuno, chiamati codoni. Ad ogni codone
corrisponde uno specifico amminoacido, si dice quindi che il codone codifica quell'amminoacido nel codice genetico.
Le basi dell'RNA sono quattro: adenina, guanina, citosina ed uracile (nel DNA l'uracile è sostituito dalla timina). Esistono
64 codoni possibili. 61 di essi codificano gli amminoacidi, mentre i restanti tre (UAA, UAG, UGA) codificano segnali di
stop (stabiliscono, cioè, a che punto deve interrompersi l'assemblamento della catena polipeptidica). Poiché gli
amminoacidi che concorrono alla formazione delle proteine sono 20, essi in generale sono codificati da più di un
codone (con l'eccezione di triptofano e metionina). Il codice genetico è pertanto detto degenere e codoni distinti che
codificano il medesimo amminoacido sono sinonimi.
Ad esempio, la sequenza di RNA UUUACACAG si compone di tre codoni, UUU, ACA, CAG, cui corrispondono
rispettivamente gli amminoacidi fenilalanina, treonina e glutammina. La sintesi proteica applicata a questa sequenza
produrrebbe quindi il tripeptide fenilalanina-treonina-glutammina.
La traduzione inizia in corrispondenza di un codone di avvio (start) ma, a differenza del codone di termine, questi non
è sufficiente per avviare il processo di sintesi; in prossimità del codone di avvio devono infatti anche trovarsi alcune
sequenze tipiche che permettono all'mRNA di legarsi ai ribosomi. Il codone di avvio più noto è AUG, che codifica
anche la metionina. Altri codoni di avvio sono CUG, UUG e, nei procarioti, GUG e AUU.
Se A, T, C, G, U rappresentano le basi azotate, riempite gli spazi vuoti indicati dai trattini e indicate
le polarità delle catene polinucloetidiche e della catena polipeptidica.
A G A
_ _ _
_ _ _
DNA
_ _ _
A _ _
_ _ T
A _ _
_ C A
_ _ _
mRNA
_ _ _
_ _ _
A l a
polipeptide
Codice Genetico
Esercizio 10.3 Risposta:
5’
A G A
T C A
G C A
3’
T C T
A G T
C G T
5’
A G A
U C A
G C A
mRNA
N
A r g
S e r
A l a
polipeptide
DNA
Scrivere la sequenza del polipeptide che si ottiene dalla seguente sequenza stampo:
CTGTGGTACCACGTGGACTGAGGAGTGATTCGA
(DNA, filamento stampo)
Partiamo da una sequenza di DNA, che in questo esercizio, per ovvie ragioni, ha una dimensione molto minore rispetto a
quelle utilizzate realmente nei meccanismi cellulari.
Supponiamo che questa sequenza si trovi sul filamento stampo utilizzato per la trascrizione, ossia per ottenere il mRNA.
La sequenza dell’mRNA si ottiene scrivendo per ciascun nucleotide presente sul DNA, il nucleotide complementare
sull’mRNA, secondo gli abbinamenti: A→U, T→A, C→G, G→C. Applicando questa regola il risultato è:
GACACCAUGGUGCACCUGACUCCUCACUAAGCU (← RNA messaggero)
Abbiamo ottenuto l’mRNA necessario per ricavare il polipeptide.
La fase di trascrizione è seguita dalla traduzione, operata mediante i ribosomi. La traduzione inizia laddove la subunità
piccola del ribosoma incontra la tripletta obbligata AUG, che rappresenta il segnale di inizio. Percorriamo la sequenza e
mettiamo in evidenza la prima tripletta AUG che incontriamo:
AUG
GACACC
GUGCACCUGACUCCUCACUAAGCU
A questo punto sappiamo che, a partire dalla tripletta di inizio, ogni tripletta corrisponde ad un amminoacido. Per rendere
più visibile questo schema separiamo con un trattino le triplette codificanti:
GACACC-
AUG-GUG-CAC-CUG-ACU-CCU-CAC-UAA-GCU
[…]
[…] Ora si tratta di tradurre la sequenza di nucleotidi, ossia di far corrispondere ad ogni tripletta un
preciso amminoacido. Per sapere quale amminoacido corrisponde a ciascuna tripletta utilizziamo la
tabella del codice genetico.
GACACC-
AUG-GUG-CAC-CUG-ACU-CCU-CAC-UAA-GCU
Gli amminoacidi sono rappresentati con la sigla a 3 lettere. Ad esempio: Phe = fenil-alanina, Leu =
leucina. 61 triplette (o codoni) codificano per i venti diversi amminoacidi utilizzati nella
costruzione delle proteine, mentre 3 codoni corrispondono al segnale di stop.
Incominciamo con il primo codone: AUG. Questo codone “fisso” corrisponde all’amminoacido modificato
fMet (formil-metionina).
Il secondo codone è GUG. Cercando nella tabella al codone GUG corrisponde la sigla Val (valina). Ciò
significa che il secondo amminoacido del polipeptide è la valina: fMet-Val.
Procedendo con CAC si trova His, quindi l’istidina è il terzo amminoacido che si lega: fMet-Val-His.
Continuando con le triplette successive si arriva ad un peptide formato dai 7 amminoacidi: fMet-Val-HisLeu-Thr-Pro-His. Il codone successivo è UAA, che nella tabella corrisponde al segnale di stop.
Questo significa che il ribosoma si stacca e libera il polipeptide che ora ha esattamente la sequenza
prevista. Il processo di traduzione è terminato.
Generalmente il primo amminoacido (fMet) viene eliminato, perciò il risultato che abbiamo ottenuto è il
peptide formato dai sei amminoacidi
RISPOSTA:
Val-His-Leu-Thr-Pro-His
= il fattore ereditario mendeliano responsabile della espressione (manifestazione)
di un certo carattere ereditario. E' costituito da una o più sequenze specifiche di DNA.
= variante di un gene; può essere, ad esempio, dominante o recessivo, a seconda
che si esprima o meno in un dato fenotipo.
= la cellula riproduttiva aploide (che contiene cioè solo una delle due varianti
alleliche di ciascun carattere ereditario) che, unendosi ad un altro gamete (processo detto
"fecondazione"), dà origine allo zigote, la prima cellula di un nuovo Individuo.
= la manifestazione di un carattere ereditario (esempio: il colore giallo o la
forma liscia dei semi del pisello).
= una qualunque coppia di fattori ereditari (alleli) presenti nel patrimonio
ereditario di un individuo (Esempio: G/g o L/L).
= una coppia di fattori ereditari (genotipo) diversi. Esempio: G/g.
= una coppia di fattori ereditari (genotipo) uguali. Esempio: G/G o g/g; il
primo è detto omozigote dominante, il secondo omozigote recessivo.
1
Legge della dominanza (o legge della omogeneità di fenotipo): gli individui
nati dall'incrocio tra due individui omozigoti (PP x pp) che differiscono per una
coppia allelica, avranno il fenotipo dato dall'allele dominante mentre scompare il
carattere definito recessivo (F1). Può essere definita come legge dell'uniformità
degli ibridi di prima generazione.
2
Legge della segregazione (o legge della disgiunzione): legge della separazione
dei caratteri dice che: Incrociando 2 individui eterozigoti per un carattere, nella
seconda generazione (F2) i 2 caratteri di partenza ricompaiono in quantità
numeriche esprimibili con numeri semplici, in rapporto di 3:1.
3
Legge dell'assortimento indipendente (o legge di indipendenza dei caratteri):
Incrociando individui con più caratteri distinti si ottengono nella 2° generazione
individui nei quali i caratteri si trasmettono indipendemente l'uno dall'altro. Se i
caratteri sono 2, il rapporto sarà 9 : 3 : 3 : 1 Possiamo perciò comprendere che
quando si formano i gameti, gli alleli di 2 o più geni si separano e non vengono
ereditati assieme, ma indipendentemente.
Mendel incrociò tra loro le piante ibride di prima
generazione che presentavano il solo carattere dominante.
Da esse ottenne tanto individui col carattere dominante
quanto individui col carattere recessivo. Applicando in modo
felice l'esame statistico, l'autore accertò che il numero dei
primi stava al numero dei secondo come 3:1.
Questo risultato portò all'enunciazione della 'legge della
segregazione': incrociando individui ibridi di prima
generazione si vede ricomparire in un quarto degli individui
di seconda generazione il carattere scomparso negli ibridi di
prima generazione (cioè il carattere recessivo).
Un ulteriore sforzo di Mendel fu quello di incrociare due
ceppi di piselli di 'linea pura' che differivano non per una,
ma per due coppie di caratteri. Ad esempio: piante che
producevano semi gialli e lisci con piante che producevano
semi verdi e grinzosi. Nella prima generazione ottenne
tutte piante che producevano semi gialli e lisci (cioè con i
due caratteri dominanti).
Attraverso l'incrocio di questi 'diibridi' Mendel ottenne:
• piante con i due caratteri dominanti;
• piante con un carattere dominante e uno recessivo
(semi verdi e lisci);
• piante con l'altro carattere dominante e l'altro recessivo
(semi gialli e grinzosi);
• piante con entrambi i caratteri recessivi: la proporzione
tra queste quattro categorie era eguale a 9.3.3.1.
Ottenendo da questa e altre prove simili sempre risultati
costanti sotto il profilo statistico l'autore ricavò la 'legge
dell'indipendenza' che si può così enunciare: Quando si
incrociano individui che differiscono per due coppie di
caratteri, ciascuna coppia si comporta in modo
indipendente dall'altra. Questa legge può essere formulata
anche con: il comportamento ereditario di un carattere
che si presenta in due forme alternative può venire
studiato prescindendo dal comportamento degli altri
caratteri. Tale legge consente grande semplicità di
impostazione delle analisi genetiche.
Y Giallo Dominante
y Verde Recessivo
R Liscio Dominante
r Rugoso Recessivo
Possono però esserci delle eccezioni alla legge della dominanza, ad esempio in caso di codominanza, in cui
entrambi gli alleli, essendo entrambi dominanti, si manifestano insieme. Ad esempio, nel sangue gli alleli sono
A, B e 0. Se un bambino nasce da due genitori entrambi con il sangue di tipo 0 avrà sangue di tipo 0 (due alleli
di tipo 0, quindi 00); se i genitori sono di tipo 00 e BB o BB e BB il suo sangue sarà di tipo B (in realtà, B0 nel
primo caso, BB nel secondo); se invece sono di tipo 00 e AA o AA e AA, il sangue del bambino sarà di tipo A (in
realtà, A0 nel primo caso, AA nel secondo). Questo dimostra che A e B sono due fattori dominanti, perciò, se
un genitore ha sangue di tipo AA, e l' altro di tipo BB, il sangue del bambino sarà di tipo AB, visto che questi
fattori sono entrambi dominanti e perciò codominanti. Nel calcolo del gruppo sanguigno si deve in realtà
sempre considerare la possibile presenza dell'allele 0, nascosto poiché recessivo; quindi se un genitore ha il
sangue A, ma i suoi geni sono di tipo A0, ed il secondo ha il sangue di tipo B, ma con geni B0, i figli possono
nascere con qualsiasi gruppo sanguigno, tranne che con AA e BB (ma possono avere i gruppi AB, A0, B0 e 00).
Altra eccezione alle leggi di Mendel si ha in caso di dominanza incompleta: ciò si verifica quando un allele è
dominante sull'altro, ma in modo incompleto. Ne consegue che l'altro allele ha possibilità di esprimersi,
anche se in misura minore rispetto all'allele dominante. Il fenotipo manifestato dall'eterozigote è un
fenotipo intermedio tra quelli dei due omozigoti (dominante e recessivo).
Le leggi di Mendel si applicano solo a caratteri in cui il fenotipo deriva dall'espressione di un
singolo gene (come appunto i caratteri esaminati dall'abate), non si possono applicare per
caratteri dovuti all'interazione tra molti geni e l'ambiente esterno (es. altezza, vigore, forza,
produzione, capacità cognitive ecc), di questi si parla nella genetica quantitativa o metrica.
Il pelo corto nei conigli è determinato dal fattore genetico “L” (dominante),
mentre il pelo lungo dal recessivo “l”. Il colore nero del pelo è il risultato
dell’espressione del fattore “B” (dominante), mentre quello marrone del
recessivo “b”. Calcola la percentuale di conigli con pelo lungo e nero attesa
dall’incrocio tra un coniglio L/l B/b e un altro dal pelo lungo e marrone.
Il coniglio con pelo lungo e marrone sarà evidentemente di linea pura e cioè l/l
b/b. Quindi l’incrocio è il seguente:
L/l B/b x l/l b/b
I gameti prodotti dal coniglio L/l B/b (pelo corto e nero) saranno dunque i
seguenti: LB, lb, Lb, lB, mentre quelli prodotti dal coniglio l/l b/b (pelo lungo e
marrone) tutti lb. Costruiamo il solito schema per visualizzare tutte le possibili
combinazioni dei caratteri ereditari nella progenie:
gameti
lb
LB
L/l B/b
lb
l/l b/b
Lb
L/l b/b
lB
Gli unici esemplari che manifesteranno i caratteri in questione (pelo lungo e
colore nero) sono quelli l/l B/b, nella percentuale del 25%.
Il colore nero del corpo del moscerino della frutta (Drosophila melanogaster) è
determinato da un fattore genetico recessivo “b”, mentre il colore grigio dal
dominante “B”.
Una femmina con il corpo grigio viene fatta accoppiare con un maschio dal corpo
nero e ne nascono moscerini con il corpo grigio e moscerini con il corpo nero.
Spiega tale risultato.
Il risultato è possibile solo ammettendo che la femmina non sia di linea pura.
Infatti, se fosse B/B, il suo contributo genetico alla generazione successiva sarebbe
sempre e comunque B e tutti i moscerini figli, possedendo la coppia di fattori B/b (il
recessivo ereditato dal padre b/b), avrebbero il corpo di colore grigio. La femmina
quindi deve essere B/b, infatti:
B/b x b/b
dà come risultato proprio un 50% di individui con carattere dominante e un 50% con
carattere recessivo.





![mutazioni genetiche [al DNA] effetti evolutivi [fetali] effetti tardivi](http://s1.studylibit.com/store/data/004205334_1-d8ada56ee9f5184276979f04a9a248a9-300x300.png)