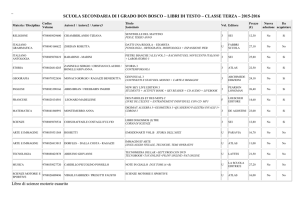
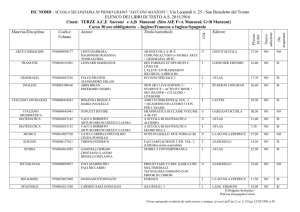
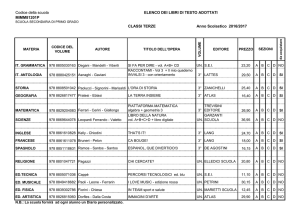
ATLAS: il Calcolo
Gianpaolo Carlino
INFN Napoli
Bari, 21 Settembre 2011
• Attività di Computing nel 2011
• Richieste Tier2 2012 –
discussione qualitativa
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
1
2011 LHC pp data taking
TB
Logical data
Lumonsità Integrata ~ 2.5 fb-1
Luminosità di picco = 2.37 x 1033 cm-2s-1
Bari, 21 Settembre 2011
Data in Italy
TB
TB
• Logical data: singola copia dei dati prodotti
• Physical data: insieme di tutte le copie prodotte
e replicate nelle cloud
G. Carlino – ATLAS: il calcolo
Physical data
2
Data export nella griglia
Export dal Tier0 ai Tier1
• RAW: 1 copia primaria (disco) + 1 copia
custodial (tape)
• ESD: 1 copia primaria e 1 copia secondaria
(su disco in siti diversi)
•AOD: 2 copie primarie + 1 copia secondaria
+copie secondarie ai Tier2 con il sistema
dinamico di replica
Significativa riduzione del numero di copie e
di formati di dati replicati nella griglia rispetto
agli anni passati
Suddivisione per attività:
• Data Brokering: replica dinamica dei dati
• Data Consolidation: pre-placement (T1-T1)
Efficienza trasferimento al primo tentativo: 93%
• 100% considerando i retries
Dati disponibili in tempo “quasi reale”:
• media trasferimento AOD dal Tier0 a un Tier1:
2.7 h per il completamento dei dataset
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
3
Data export nella griglia
ATLAS Cloud Model
Modello gerarchico basato sulla
topologia di rete di Monarc
Nel modello originale si tendeva a inviare
tutti i dati in ogni cloud
• Comunicazioni possibili:
• T0-T1
• T1-T1
• Intra-cloud T1-T2
• Comunicazioni vietate:
• Inter-cloud T1-T2
• Inter-cloud T2-T2
Limitazioni:
• Richiesta eccessiva di spazio disco:
impossibile fornire una replica di dati
per l’analisi ad ogni cloud
• Trasferimenti tra le cloud attraverso
salti multipli tra i Tier1
• User analysis outputs
• MC confinato nella cloud
• Tier2 non utilizzabili come repository
di dati primari
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
4
Data export nella griglia
ATLAS Cloud(less) Model
Breaking the Walls
Sviluppi del Computing Model
• La rete attuale permette il superamento del
modello a cloud: abilitazione delle
connessioni inter cloud tra Tier1 e Tier2
• Trasferimento dinamico dei dati nei Tier2
basato sulla popolarità dei dati (PD2P): solo i
dati effettivamente usati per l’analisi vengono
trasferiti
• storage nei Tier2 usato come cache:
cancellazione dei dati più vecchi o meno
popolari. Ottimizzazione spazio disco
• Introduzione dei Tier1 nel meccanismo
dinamico per compensare la diminuzione di
copie di dati nella griglia
• Superamento di una gerarchia stretta tra
Tier1 e Tier2
Classificazione dei Tier2 in base alle performance: efficienza e affidabilità per
l’analisi, velocità ed efficienza dei trasferimenti
• Non tutti i Tier2 sono uguali e ricevono la stessa quantità di dati (e quindi di job)
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
5
Tier2 Diretti
T2D – Tier2 “Directly Connected”
• Tier2 connessi direttamente tra di loro
a tutti i Tier1
• Storage per dati primari come i Tier1
• Preplacement di una quota di dati
• Group data
• Requirement molto stretti
• Metriche di trasferimento con tutti I Tier1
• Livello di commitment e relibility adeguato
Avg(Byterate)+StD(Byterate)
SMALL
<0.05MB/s
<0.1MB/s
≥0.1MB/s
MEDIUM
<1MB/s
<2MB/s
≥2MB/s
LARGE
<10MB/s
<15MB/s
≥15MB/s
T2D approvati nella prima fase:
INFN-NAPOLI- ATLAS, INFN-MILANO-ATLASC, INFN-ROMA1
IFIC-LCG2, IFAE, UAM-LCG2
GRIF-LPNHE, GRIF-LAL, TOKYO-LCG2
DESY-HH, DESY-ZN, LRZ-LMU, MPPMU
MWT2_UC,WT2, AGLT2,BU_ATLAS_Tier2, SWT2_CPB
UKI-LT2-QMUL, UKI-NORTHGRID-LANCS-HEP, UKI-NORTHGRID-MAN-HEP,
UKI-SCOTGRID-GLASGOW
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
Siti che faranno parte
da subito di LHCOne
6
Classificazione Tier2
4 Gruppi:
• Necessità di individuare i siti più affidabili per
• Alpha: (60% share): T2D con rel > 90%
l’analisi cui inviare la maggior parte dei dati.
• Bravo: (30% share): non T2D con rel> 90%
• Classificazione in base alle performance (stabilità) • Charlie: (10% share): 80% < rel < 90%
• Delta: (0% share): rel <80%
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
7
Running jobs nella griglia: Produzione
Ricostruzione (T1), Simulazione e Analisi di gruppo (produzione centralizzata di D3PD in
alcuni gruppi di fisica)
• > 60k job simultanei durante presa dati 2011 (riduzione agosto per problemi con G4)
• ~ 500k job completati
Numero medio di jobs di produzione running per cloud
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
8
Running jobs nella griglia: Analisi
Numero medio di jobs di analisi running per cloud
Aumento attività analisi di
gruppo:
• aumento della coordinazione
Minore caoticità e duplicazione
dei dati
• centralizzazione della
produzione: in molti casi
“accountata” come produzione
• utilizzo preferenziale di
formati leggeri (ntuple)
Ridotto incremento job di
analisi nel 2011
> 15k/20k job simultanei negli ultimi mesi
Buona efficienza per i job di analisi
• continuo aumento dell’affidabilità della
griglia attraverso l’esclusione automatica
dei siti non performanti
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
9
Workflow di analisi
Produzione
• produzione centralizzata di AOD e ESD nella prompt
reconstruction al Tier0 e nei reprocessing ai Tier1
• produzione centralizzata di Derived AOD e ESD
(DAOD e DESD) attaverso skimming e slimming
• produzione di gruppo “centralizzate” di ntuple e di
gruppi di utenti (D3PD e NTUP)
Workflow (principale) di analisi
• fase 1: skimming da AOD/ESD/D3PD e produzione
di ntuple D3PD o NTUP
• eseguito centralmente dai working group
• eseguito in Griglia
• output in GROUPDISK o LOCALGROUPDISK
• fase 2: skimming/slimming dei D3PD e produzione
di NTUP di (sotto)gruppo leggere
• eseguito da utenti o gruppi locali
• eseguito in Griglia
• output in LOCALGROUPDISK
• fase 3: analisi finale
• NTUP nei LOCALGROUPDISK dei Tier2/3
• eseguita in Griglia con PRUN
• o eseguita in locale con ROOT/PROOF
Bari, 21 Settembre 2011
RAW
AOD
ESD
DESD
DAOD
D3PD
NTUP
Utilizzo formati di analisi
• RAW utilizzati solo per la ricostruzione e
presenti solo nei Tier1
• ESD utilizzati solo per analisi di
performance e presenti solo nei Tier1
• AOD/D3PD/NTUP molto utilizzati
• DAOD e DESD utilizzo molto marginale,
formato in via di estinzione
G. Carlino – ATLAS: il calcolo
10
Utilizzo dei formati di dati
# utenti individuali che accedono alle code di analisi in ITALIA
• AOD e Ntuple formati nettamente preferiti
• evidente incremento negli ultimi mesi
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
11
Ruolo dei Tier2 nell’analisi
Attivita’ ultimi 3 mesi
(T1 dovrebbe essere 25%)
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
12
Utilizzo risorse in Italia - CNAF
CPU consumptions. Aprile – Settembre 2011
% utilizzo risorse rispetto alle
risorse pledged 2011 (non ancora
totalmente in produzione)
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
13
Utilizzo risorse in Italia
CPU consumptions. Marzo – Agosto 2011
6
INFN-FRASCATI
10
9
INFN-MILANO
IT
Efficienza job produzione
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
14
Analisi nei Tier2
Eff. job analisi
CPU consumptions. Giugno – Agosto 2011
Nota:
non abbiamo
ancora installato le
risorse 2011
7
IT
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
15
Sharing risorse nei Tier2
Job running su un Tier2
nell’ultimo mese:
• Produzione
• Analisi WMS
• Analisi Panda
• Analisi Panda ruolo italiano
Attenzione:
• Gli italiani vengono mappati sia su
panda che su panda/it
• Analisi di gruppo (p.es calibrazione)
risulta come produzione
• gli italiani con certificato CERN (non
pochi) vengono mappati su panda
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
16
Uso del disco nei Tier2
• Il sistema di replica dinamico dei dati PD2P già dal 2010
ha ottimizzato l’uso del disco dei Tier2 permettendo la
copia di dati sempre nuovi e interessanti.
• il nuovo meccanismo di brokering che include i Tier1 ha
inizialmente penalizzato pesantemente i Tier2 nel 2011:
uso ridotto dei del disco nel periodo maggio-luglio
• Inoltre, il formato più popolare e quindi trasferito è
NTUP, leggero!
Modifiche all’algoritmo da fine luglio con significativo
aumento, e utilizzo, dei dati trasferiti nei Tier2
• Circa 50 TB al mese di dati
principali per ogni Tier2
• Ulteriore aumento atteso
per pre-placement degli AOD
• Nessun rischio saturazione, i
dati sono secondari e quindi
cancellabili per copiarne di
nuovi. I Tier2 sono cache
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
17
Reliability & Availability – 2010/11
Valori medi 2011
Frascati
Milano
rel
ava
rel
ava
97%
96%
91%
91%
Napoli
Roma
rel
ava
rel
ava
94%
94%
98%
97%
Availability =
time_site_is_available/total_time
Reliability =
time_site_is_available/
(total_time-time_site_is_sched_down)
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
18
Accounting Tier2
Frascati
Milano
Problemi condizionamento in
agosto e allo storage non
dipendente dal sito
Napoli
Bari, 21 Settembre 2011
Roma1
G. Carlino – ATLAS: il calcolo
19
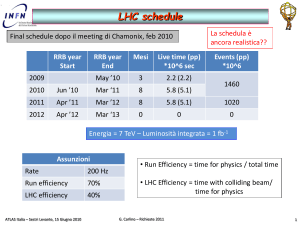
Richieste 2012 – discussione qualitativa
Modifica della stima delle risorse necessarie rispetto alle previsioni del 2010
a causa di:
o variazioni dell’attività di LHC: run 2012 e shut-down 2013 richiedono un
maggior numero di risorse per il computing
o pile-up molto più alto del previsto (μ=6 medio, atteso fino a μ=~25 in
autunno e nel 2012) provocato dall’aumento della densità dei fasci
raddoppio delle dimensioni degli eventi e del tempo di ricostruzione:
è in corso un’attività di ottimizzazione che sta portando ad una
riduzione di questi parametri
Risorse 2011 già determinate per cui si è reso necessario modificare il CM, in
particolare riducendo il numero di repliche dei dati primari nelle cloud:
1 copia di RAW nei Tier1
rolling buffer del 10% di ESD nei Tier1
10 copie di AOD (2 Tier1 e 8 Tier2) in tutte le cloud
2 copie di dESD nei Tier1 e 4 nei Tier2
• somma dESD = somma AOD
in base a questo modello le risorse 2012 aumentano molto poco o nulla
rispetto all’RRB 2010
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
20
Richieste 2012 – discussione qualitativa
Differenziazione delle risorse:
• Risorse “pledged” dedicate alle attività centrali di ATLAS e gestite
dall’esperimento
• richieste formulate per garantire ai siti italiani lo share corrispondente
alle dimensioni della cloud italiana
• richieste determinate non in base al semplice share della cloud italiana
in ATLAS ma analizzando criticamente le reali necessità delle attività
previste nei Tier1 e Tier2 (dettagli nelle slides di backup)
• ricostruzione nei Tier1
• simulazione nei Tier1 e Tier2 (55/45%)
• analisi di gruppo soprattutto nei Tier1
• analisi di utenti nei Tier1 e Tier2
• share del disco più basso grazie all’uso ottimizzato
• Risorse “italiane” nei Tier2 e Tier3 dedicate esclusivamente alle attività di
analisi italiane. Necessarie o indispensabili per garantire competitività ai
nostri gruppi
• determinate con un’indagine sull’utilizzo attuale delle risorse ed
estrapolando alla statistica raccolta a fine 2012
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
21
Organizzazione Spazio Disco in ATLAS
Organizzazione spazio
disco per gli utenti in
ATLAS
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
22
Risorse per attività italiane
Storage: Necessità assoluta
Spazio disco locale (LOCALGROUP) nei Tier2 e Tier3 per ogni attività italiana.
ATLAS non considera nessuna area di storage permanente per gli utenti
Queste aree possono essere ospitate sia nei Tier2 che nei Tier3 con diverse
funzionalità e dimensioni:
• Tier2: dimensione O(100 TB) – per salvare campioni completi dei dati prodotti da
tutti gli utenti e i gruppi italiani
• Tier3: dimensione O(10 TB) – per salvare campioni ridotti dei dati per definire e
tunare le analisi con tool interattivi e batch locale. Sviluppo del codice
• Le aree locali nei Tier2 e Tier3 vanno considerati complementari. L’aumento
dell’attività nei Tier3 porta a rimodulare le richieste diminuendo lo spazio disco
richiesto nei Tier2 a favore di quello dei Tier3 per i quali confermiamo la richiesta di un
piccolo finanziamento
• Inoltre il nuovo modello di utilizzo del disco dei Tier2 come cache permette di
limitare le richieste pledged a favore dell’area locale di storage permanente
CPU: aumento della competitività
La disponibilità di CPU oltre le risorse pledged da dedicare agli italiani permette di
aumentare notevolmente la competitività dei siti.
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
23
Conclusioni
• in ATLAS è in corso una significativa attività di revisione critica del
Computing Model che ha già portato a ottimizzazioni nell’uso delle risorse
e nelle performance dei siti e della griglia
• allo studio la possibilità di usare modelli diversi (per esempio cloud
computing). Lo shutdown del 2013 permetterà una completa
riscrittura del modello
• Il giudizio delle griglia dal punto di vista della Fisica delle Alte Energie è
positivo:
• alte efficienze e velocità. I fisici hanno familiarizzato con i tool di
analisi e gestione dei dati. Tuttavia l’analisi locale è ancora
significativa.
• è però fallita completamente l’ambizione di portare la griglia oltre
HEP soprattutto per la sua difficoltà di utilizzo (riscontrata e criticata
anche dai fisici LHC)
• I siti italiani dimostrano di essere competitivi e all’altezza del compito
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
24
Backup slides
25
Computing Model – Input parameters
Campagne di ottimizzazione in
corso in ATLAS che hanno
portato alla riduzione della
dimensione degli eventi e dei
tempi di ricostruzione:
• RAW = 1.2 MB
(compressione dati)
• ESD e AOD = 1.1 e 0.161 MB
(riduzione aggressiva delle
informazioni senza penalizzare
il contenuto fisico)
• Full Sim: 4950 HS sec
• Real Recon: 108 HS sec
Il risparmio di risorse
permette un di aumentare il
trigger rate come richiesto dai
gruppi di fisica
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
26
Computing Model – Input parameters
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
27
Risorse “pledged” per attività - CPU
Attività principali:
Simulazione e analisi di gruppo
e di utente.
Simulazione e analisi di gruppo
condivise con i Tier1.
leggero aumento rispetto al 2011 per l’attività degli utenti. In assoluto aumenti molto contenuti
grazie alla modifica del Computing Model. Richieste identiche a quelle effettuate nell’RRB 2010!!!!
Simulazione: 10% di ATLAS
• 5600 HS
Attività gruppi: 8 gruppi (2 gruppi a Milano, Napoli e Roma e 2 nuovi gruppi a Frascati)
su ~ 100 gruppi ATLAS
• 46400 HS
Analisi ATLAS: 10% di ATLAS (quota “pledged” escludendo l’attività italiana)
• 18000 HS
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
28
Risorse “pledged” per attività - disco
Simulazione MC: 50% di una replica completa
• 1000 TB + 60 TB (buffer produzione)
Dati pp: 50% di una replica completa
• 1313 TB
Attività gruppi: 8 gruppi (2 gruppi a Milano, Napoli e Roma e 2 nuovi a Frascati)
• 600 TB (75 TB per gruppo)
Analisi: area scratch per utenti generici
• 100 TB (area scratch per utenti generici)
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
29
Risorse “pledged” - riepilogo
Attività
CPU (HS06)
LHC data taking
1320
Simulazione
5600
1060
Gruppi ATLAS
4640
600
Analisi
18000
100
Totale
28240
3080
T2 Italia
T2 ATLAS
T2 It/ATLAS
CPU
(kHS06)
28,2
295
9.6%
Disco
(PBn)
3,08
49
6,3%
Bari, 21 Settembre 2011
Disco (TBn)
G. Carlino – ATLAS: il calcolo
Nel nuovo modello di calcolo di ATLAS
per i Tier2 acquista maggiore
importanza la disponibilità di CPU
rispetto allo storage. Utile per la
competitività dei siti
• conservare le stesse pledge 2010 per il
disco (~6%)
• aumentare quelle delle CPU a ~10%
come al CNAF
30
Risorse per attività italiane
• # gruppi attivi: ~ 50 nelle 13 sezioni
• alcune attività clusterizzate tra varie sedi
• dimensioni dei gruppi e utilizzo risorse molto vario
Dimensionamento medio risorse necessarie:
• misura risorse necessarie attualmente con 1 fb-1
• stima con 10 fb-1, considerando sia l’aumento dei dati che del MC (non lineare)
• statistica attuale o ultimo fb conservabile su LOCALGROUP al Tier3, statistica
intera necessariamente da ospitare in LOCALGROUP al Tier2
Analisi Italiana – Disco
• 11 TB medi per attività considerando in prospettiva la statistica totale del 2012
• 25 TB in ogni Tier3 (2 in attività finanziati nel 2011 (RM3, GE) + 2 in attività con
altri finanziamenti (BO, UD) + 2 da finanziare nel 2012 (LE, RM2)) = 150 TB
• 400 TB nei Tier2 (~200 TB gia’ occupati)
Analisi Italiana – CPU
• 200 HS medio per attività
• 600 HS in ogni Tier3 (6 Tier3) = 3600 HS
• 6400 HS nei Tier2
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
31
Risorse totali - riepilogo
Bari, 21 Settembre 2011
Attività
CPU (HS06)
Disco (TBn)
Pledged
28240
3080
Analisi Italiana
6400
400
Totale
34640
3480
G. Carlino – ATLAS: il calcolo
32
Risorse disponibili
Richieste Tier2 2012
CPU (HS06)
Disco (TBn)
Frascati
2321
258
Milano
7820
856
Napoli
8079
864
Roma
7880
864
Tot
26100
2842
Richieste
CPU
HS06
Disco
K€
TBn
Necessità attività 2012
34640
3480
Risorse disponibili 2011
26100
2840
Richieste 2012
8540
153
640
K€
282
Server
Rete
K€
K€
40
32
40
32
Per la stima dei costi di CPU e Disco si è considerata l’esperienza
delle ultime gare e le analisi di mercato che continuiamo a svolgere
CPU: 18 €/HS06
Disco: 440€/TBn
Per la stima dei costi necessari per server e rete ci si è attenuti all’algoritmo Bozzi:
• Server: ~10% Disco e CPU
• Rete: ~8% Disco e CPU
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
33
Richieste Tier2 2012
Dettaglio per Tier2
è in corso la validazione di Frascati come Tier2 ufficiale
pieno supporto del Direttore dei Laboratori e del gruppo
lavori infrastrutturali in corso
referaggio concluso
divisione delle risorse in parti uguali tra i 4 Tier2 a parte piccoli aggiustamenti
CPU
HS06
Disco
K€
TBn
Rete
Server
Totale
Cons.
K€
K€
K€
K€
K€
Frascati
2690
505
57
160
0
70
8
10
145
5
Milano
1950
414
43
160
38
87
8
10
148
5
Napoli
1950
1154
56
160
0
70
8
10
144
5
Roma
1950
1493
62
160
0
70
8
10
150
5
Tot
8540
obs
218
640
obs
297
32
40
587
Le risorse acquistate nel 2008 per le CPU e precedenti per il disco vanno considerate obsolete nel
2012 e sostituite da nuove: (obs) nelle colonne HS06 e TBn. Il dettaglio per ogni Tier2 è presente
nelle tabelle consegnate ai referee
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
34
Richieste Tier3
Tier3 in attività in ATLAS:
Bologna, Genova, Roma3, Udine/Trieste
Richieste 2012 per 2 nuovi Tier3:
Lecce
• farm già esistente in sezione con risorse ridotte e vecchie
• richiesta di diventare Tier3 “Grid enabled”
• CPU: 2 twin (4 WN) = 9 K€
• Disco: sostituzione dischi da 750 GB a 2 TB, totale 26 TB = 6 K€
Roma2
• nuova farm
• richiesta di diventare Tier3 “Grid enabled”
• CPU: 2 twin (4 WN) = 9 K€
• Disco: NAS con 20 TB = 6 K€
Bari, 21 Settembre 2011
G. Carlino – ATLAS: il calcolo
35