High Performance Computing Applications
High Performance Computing Applications
NEC simulation - TiltRotor
Unmanned
Transport
aircraft
aircraft
Space Vehicle
Center of Excellence for High Performance Computing
Hurricane forecast
Center of Excellence for High Performance Computing
HPCC
High Performance Computing Numerical Simulations
• Environmental Systems
• Quantum-mechanical modeling of molecules
• Turbulence in astrophysical and laboratory plasmas
• Optimization in transportation systems
Center of Excellence for High Performance Computing
Lava flow simulation using SCIARA model (Etna –
Nicolosi - July 2001)
First eight days reproduce the real event
Next days are simulated using SCIARA
model
Center of Excellence for High Performance Computing
Lava flow simulation using SCIARA model (Etna –
1669)
Detail of Catania
Etna area
Center of Excellence for High Performance Computing
Landslide simulation using SCIDDICA model (Sarno
May 1998)
Center of Excellence for High Performance Computing
Quantum-mechanical modeling of molecules
Center of Excellence for High Performance Computing
Physical case studies
• solar atmosphere
• solar wind
• planetary magnetospheres
• earth-sun interactions
Center of Excellence for High Performance Computing
Reconnection numeric simulation sample
Evolution
of
magnetic field
lines of force
and current in
a plasma.
Line of force
change
topology
during
simulation.
Center of Excellence for High Performance Computing
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
Simulation of travel request from stop n.7 to stop n. 14
HPCC
HPCC
High Performance Computing Center
Center of Excellence MIUR
for High Performance Computing
University of Calabria – Rende (CS) - Italy
HPCC
HPCC
Located at the University of Calabria
Established in 2001 thanks to Italian Ministry
funds for the creation of research centers of
excellence
Operating since October 2002
HPCC
HPCC – Research lines (WP1)
Workpackage 1 – A High Performance Computing Environment
for Scientific and Industrial Applications
Lagrangian relaxation for applications scheduling on computational grids
Applications
Agent
Agent
Agent
Auctioneer
Resources
Agent
Agent
HPCC
HPCC – Research lines (WP2)
Workpackage 2 – Turbulence in Astrophysical and
Laboratory Plasmas
Numerical simulations of kinetics equations in plasmas
Simulations of 3D MHD equations in plasmas
Montecarlo simulations for particles diffusion in
presence of collisions
Montecarlo simulations for particles diffusion in
presence of magneto-hydrodynamics turbulences
HPCC
HPCC – Research lines (WP2)
Workpackage 2 – Turbulence in Astrophysical and Laboratory
Plasmas
Solar atmosphere and wind
Planetary magnetosphere
Earth-Sun interaction
HPCC
HPCC – Research lines (WP3)
Workpackage 3 – Computational and Theoretical
Chemistry
Solvent effects in deMon code
Topological analysis of electron localization function.
Basis and applications
Parallelization of SCF equations (Self Consistent Field).
HPCC
HPCC – Research lines (WP3)
Workpackage 3 – Computational and Theoretical
Chemistry
Molecule’s quantum-mechanical models
HPCC
HPCC – Research lines (WP4)
Workpackage 4 – Parallel Models for Simulation of
Acentric Complex Phenomena
Genetic algorithms application in debris flows
HPCC
HPCC – Research lines (WP4)
Workpackage 4 – Parallel Models for Simulation of
Acentric Complex Phenomena
Cellular Automata SCIARA model:
application in 2001 and 2002
Etnean lava flows
HPCC
HPCC – Research lines (WP5)
Workpackage 5 – Parallel Computational Fluid Dynamics
POD (Proper Orthonormal Decomposition) code for solar
data analysis
HPCC
HPCC – Research lines (WP6)
Workpackage 6 – Computational Optimization for Large-Scale
Systems
HPC in financial scope
HPC in transportation scope
ECOBACH
DB
EBA
CH
BRINDISI
CLIENT
PRINTER CLIENT
HPCC
HPCC – High-level training
HPC technologies and grid computing Master (in
progress).
PhDs and research fellowships on HPC topics and
their multidisciplinary applications.
HPCC
HPCC – The mission
Infrastructure
campus grid (4 equipped nodes and another 3 in
progress)
Geographic grid (SPACI)
Base and applied research
Technological transfer
High-level training
HPCC
HPCC – The infrastructure
The campus grid
HPCC
HPCC – The infrastructure
The center’s equipment
HP AlphaServer SC
CPU: 64 1.25 GHz Alpha
Performance: 160 GFLOPS
HPCC
HPCC – The infrastructure
The center’s equipment
HP Sierra XC 6000
CPU: 24 1.5 GHz Itanium-2
(Madison)
Performance: 144 GFLOPS
HPCC
HPCC – The infrastructure
The center’s equipment
NEC TX-7
CPU: 16 1 GHz Itanium-2
Performance: 64 GFLOPS
HPCC
Performance Development
11.7 PF/s
10
P flop/s
IBM Roadrunner
1.02 PF/s
1 Pflop/s
IBM BlueGene/L
NEC Earth Simulator
SUM
100 Tflop/s
9.0 TF/s
IBM ASCI W hite
1.17 TF/s
Intel ASCI Red
10 Tflop/s
6-8 years
#1
59.7 GF/s
Fujitsu 'NW T'
1 Tflop/s
#500
My Laptop
100 Gflop/s
2008
2007
2006
2005
2004
2003
2002
2001
2000
1999
1998
1997
1996
1995
1 Gflop/s
1994
10 Gflop/s
1993
0.4 GF/s
100 M flop/s
Jack Dongarra
INNOVATIVE COMPUTING LABORATORY
63
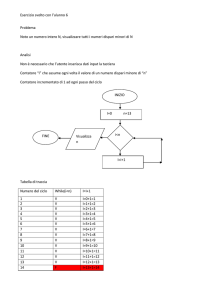
Caso esemplificativo
• Perché?
• This software will be developed to
investigate long numbers management
problems in the framework of the fast
prime numbers generators. Currently we
are working on the basical frame with the
aim to further refine the model and the
techniques. The main goal is to realize
algorithms at high efficiency and high
computation locality while low data
exchange between non-near processes
Fonte: wikipedia.org
Distanza primo-posizione
Distanza fra primo e primo
successore
Hai numeri primi hanno lavorato
•
•
•
•
•
•
•
•
Euclide
Eratostene
Marsenne
Fermat
Eulero
Goldbach
Legendre
Ramanujan
•
•
•
•
•
•
•
Riemann
Hadamard
Poussoin
Gauss
Landau
Bohr
Hardy
e molti altri…
La nostra posizione
• Ogni sciocco può porre questioni sui
numeri primi alle quali il più saggio degli
uomini non può rispondere
Hardy
La nostra posizione
• Ogni sciocco può porre questioni sui
numeri primi alle quali il più saggio degli
uomini non può rispondere
Hardy, docente a Cambridge
NESSUNA TEORIA SOLO
UN CASO DI STUDIO
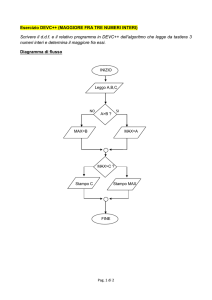
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
{
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
Dichiarazioni
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
{
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
Dichiarazioni
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
Controllo parametro
{
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
Dichiarazioni
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
Controllo parametro
{
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
return;
}
Allocazione memoria
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
Dichiarazioni
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
Controllo parametro
{
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
return;
}
Allocazione memoria
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
Uscita se memoria insufficiente
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
Cosa fa?
int *a;
if (argc < 2)
{
Individua tutti i numeri scaturiti
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
da un prodotto, gli altri sono
printf("%s <numero>\n", argv[0]);
primi
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
VANTAGGI
{
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
Molto efficiente:
printf("%s <numero>\n", argv[0]);
solo addizioni, for e moltiplicazioni
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
{
VANTAGGI
printf("errore: argomento mancante\n");
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
Facile da paralelizzare
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
Esempio di soluzione semplice
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
#include <stdio.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
int i, j, N;
int *a;
if (argc < 2)
{
Intervenendo su j è possibile
printf("errore: argomento mancante\n");
Parametrizzarla per n processori
printf("il formato corretto è\n");
printf("%s <numero>\n", argv[0]);
return;
}
N = atoi(argv[1]);
a = (int *) malloc(N*sizeof(int));
if (a==NULL)
{
printf("errore: memoria insuff. \n");
return;
}
for (i=2; i<N; i++) a[i]=1; // li pone tutti uguali ad 1
for (i=2; i<N; i++) // li scorre
if (a[i]) // se soddisfatta (valori diversi da zero) va avanti
for (j=i; i*j<N; j++) a[i*j]=0; // j è posta uguale ad i, se i*j è maggiore di N a[i*j] diventa 0 perché scaturito da un prodotto
for (i=2; i<N; i++) // li scorre
if (a[i]) printf("%d ", i); // se soddisfatta (valori diversi da zero) va avanti e
printf("\n", i); // stampa il numeratore iesimo
}
Fonte: Algoritmo presente in molte versioni d.p.d. su internet
In particolare
• In C/MPI
– Con l’uso delle if su numero processore
e della parametrizzazione degli indici,
attraverso MPI_SEND , MPI_GATER (su p0)
e MPI_RECV è possibile rendere questo
semplicissimo algoritmo imbarazzantemente
parallelo
Superiamo questo modello
• Desideriamo usare le griglie
• Desideriamo veicolare numeri di molte
cifre (simil-struct)
• Desideriamo operare su più algoritmi di
ricerca contemporaneamente
• Desideriamo una topologia dinamica di
processi
I test di primalità di buona
complessità computazionale
•
•
•
•
Miller-Rabin
Proth (Proth: k2n+1, k<n)
Fermat
Lucas-Lehmer (Mersenne: 2n-1)
Il calcolo distribuito
• La determinazione delle relazioni fra i nodi viene
effettuata nel seguente modo
• Ogni nodo invia un ping e attende un pong di risposta, mentre
lo attende effettua un loop incrimentale banale con conteggio
delle iterazioni
i nodi che rispondono in un tempo inferiore o uguale alla
media dei tempi (valore del conteggio) sono considerati near,
quelli che rispondono in un tempo superiore alla media dei
tempi sono considerati non-near
Distinzione fra algoritmi
• Quelli a bassa località e/o alta
comunicazione saranno locati sui
processori near , gli altri sui processi nonnear
Come agiranno i near
• Ogni volta che in un near viene identificato
un p-match è inviato al primo libero che
riparte da esso, se possibile con un test di
primalità differente. In pratica quando un
near finisce il proprio segmento riparte dal
p-match più alto.
Primo
timeslice
p-match
p-match
p-match
p-match
p-match
p-match
Secondo
timeslice
Workflow dei job 1/3
• 1) Vengono lanciati n processi n-1 saranno
processi ”worker”
– Al momento tutti i processi sono collocati
nell'insieme non-near (a regime saranno
differenziati)
– P0 legge il file di partenza con l'elenco dei
”match” e crea un opportuno pool di segmenti
successivi di lavoro da distribuire ai ”worker”
Workflow dei job 2/3
• 2) I ”worker” attendono il proprio segmento
di lavoro, lo espletano ed escono
collocandosi in attesa se inattivi (in futuro
lavoreranno su nuovi segmenti quando
avranno terminato il proprio lavoro appena
P0 comunicherà loro un nuovo carico)
– I ”worker” comunicano ogni ”p-match” e lo
stato di inattività a p0
Workflow dei job 3/3
• 3) P0 riceve tutti i ”p-match” e li inserisce
ordinatamente in un file quindi esce (in
futuro ridistribuirà nuovi segmentidi lavoro
partendo dal ”p-match” più grande)
Schema di accesso ai dati
1,2,3,5,7,11
1,2,3,5,7,11,
13
iniziale
finale
Descrizione algoritmo attuale in
sviluppo
• - inizializzazioni
- dichiarazione variabili
- iniziallizazione ambiente parallelo
- se
_P0 allora leggi file e distribuisci
_Pn allora fai operzioni isolando i
candidati primi quindi notificali a
P0
_P0 e tutti Pn hanno terminato allora
salva ed esci
Problemi da risolvere
• Gestione efficiente dei numeri a molte cifre
– Con relativa gestione dei riporti
• Comunicazione ottimizzata a buffers
La zone near
• Test di primalità probabilistici
La zona non-near
• Test di primalità non probabilistici
(es.: elliptic curves)
• Algoritmi Genetici
(idea: distanze fra primi per individuazione
zone ad alta primalità)
Cosa intendiamo imparare
adesso sulle griglie
• Il funzionamento generale e le basi dello
sviluppo codici
• Accorpare i processi in insieme sulla base
dei tempi “attesi” di comunicazione
• Inviare ai processi “pacchetti di dati” da
utilizzare successivamente
HPCC
HPCC – Financed Projects
EGEE (Enable Grid for E-science in Europe – FP6)
Grid.it (FIRB)
Parallel optimization methods and resource management
through open source simulation software (FIRB).
Financial Optimization (CNR).
Stochastic Programming on computational grids (MIUR).
Financial planning under uncertain conditions (PRIN - MIUR).
General-purpose optimization software (FIRB).
WADI (WAter supply watersheD planning and management: an
Integrated approach): HPC for water resource management.
Avviso 901: updating of HPCC’s campus grid.
Alarico - International Center for Technology and Innovation:
international workshop on high performance and grid
computing.
HPCC
HPCC – SPACI
Southern Partnership for Advanced Computational
Infrastructure (PON – 2001)
Southern computational grid development
Partnership
University of Calabria - HPCC
prof. L. Grandinetti and prof. R. Musmanno
University of Lecce - Center For
Advanced Computational
Technologies (CACT)
prof. G. Aloisio
ICAR/CNR Naples - Research Center for
Parallel Computing and Supercomputers
prof. A. Murli
HPCC
HPCC – Projects under evaluation
WADI-2 (FP6)
Italian Ministries funds
MIMERICA
RISCHIO ZERO
GITA
DIGIdi
RACCORSU
Regional Ministries funds (POR)
HPCC
FINE