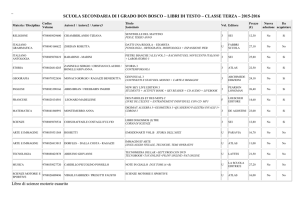
ATLAS
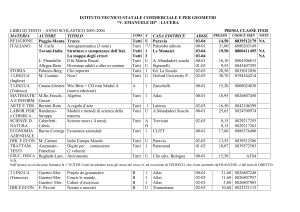
Le strategie per l’analisi
Gianpaolo Carlino
INFN Napoli
Workshop CCR e INFN-GRID 2009
Palau, 11-15 Maggio 2009
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
1
1
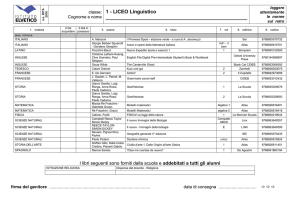
Cosa è necessario per l’analisi
1. Reperibilità dei dati
sistema di distribuzione dei dati efficiente e veloce
•
varie fasi di commissioning nel 2008-2009. DQ2 può essere finalmente
considerato un sistema di data management affidabile
•
efficienza dei siti italiani (T1 e T2s) sempre nella media di atlas
AOD e DPD (dati e MC) replicati completamente e automaticamente nei T2
Sottoscrizione dei dataset utenti on demand attraverso Webpage
2. Analysis Model
Chiarezza e stabilità nella definizione dei formati di dati e nei physics analysis tools
3. Analisi Distribuita
User Interface indipendente dalla Grid
Faciltà di utilizzo e trasparenza della struttura internza
•
Ricerca della location dei dati
•
Scelta del backend
•
Scelta delle risorse da utilizzare
Efficienza e velocità di processamento e recupero degli output
Training e supporto per gli utenti
4. Le risorse
Alta disponibilità e affidabilità (availability & reliability) dei siti
configurazione ottimale della rete (LAN 10 Gbps)
Facile accessibilità ai dati
Disponibilità di risorse, cpu e disco, adeguate:
•
Sistemi di prioritizzazione dei job
•
Risorse dedicate agli utenti italiani
•
Risorse locali (Tier3)
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
2
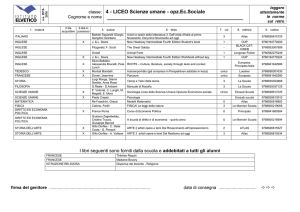
The ATLAS Computing Model
Hierarchical Computing Model optimising
the use of the resources
“Tier Cloud Model”
• need to distribute RAW data for storage and
NG
PIC
RAL
ASGC
SARA
NA
CERN
T3
grif
reprocessing
• distribute data for analysis in various formats in
order to make access for analysis as easy as
possible for all members of the collaboration
LNF
CNAF Cloud
CNAF
lpc
RM1
LYON
Tokyo
MI
Beijing
TRIUMF
FZK
lapp
Romania
BNL
BNL Cloud
NET2
• All Tier-1s have predefined
(software) channel with CERN
and with each other
• Tier-2s are associated with one
Tier-1 and form the cloud
• Tier-2s have predefined channel
with the parent Tier-1 only.
T1
Tier1. Data storage and
reprocessing of data with better
calibration or alignment constants
GLT2
MWT2
WT2
T0
Tier0 at CERN. Immediate data
processing and detector data quality
monitoring. Stores on tape all data
SWT2
Tier-2. Simulation and user Analysis
T3
Palau, 11-15 Maggio 2009
Tier-3. Non Grid user Analysis
G. Carlino – ATLAS: le strategie per l’analisi
3
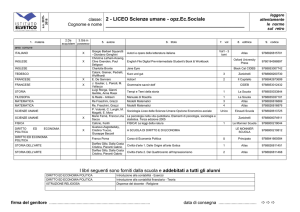
ATLAS DataWorkflows
L’analisi in Grid degli utenti viene svolta nei Tier-2.
Solo analisi di gruppo nei Tier1
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
4
Il Modello di Analisi distribuita
Gli utenti non devono necessariamente conoscere dove sono i dati e dove runnano i job
I job degli utenti vengono lanciati dove risiedono i dati
possono/devono selezionare la cloud in cui runnare
i risultati devono essere resi disponibili subito agli utenti (efficienza 100%)
I dati sono distribuiti ai Tier1 e Tier2 dal Data Distribution System DQ2
management, distribuzione e archivio automatico dei file nella griglia effettuato
usando un catalogo centrale, FTS, LFCs
•
•
I dati per l’analisi sono completamente replicati in tutte le cloud
Policy di replica dei dati secondo il Computing Model e shares determinate dalle
dimensioni dei siti in termini di risorse
I dati per l’analisi sono completamente replicati in tutte le cloud
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
5
Il Modello di Analisi distribuita
Standard Physics Analysis
codice basato su Athena o Athena Root Access, processa sequenzialmente
AOD/DPD files nella griglia
•
problemi accesso ai file in DPM con applicazioni ROOT
produce ROOT tuple (D3PD) poi analizzate nella griglia o localmente nei Tier3
Produzione piccoli sample privati di MC
uso delle Production System Tranformations (Geant o Atlasfast)
Detector
Performance Analysis
codice basato su Athena, processa RAW/ESD/DPD files nella griglia.
miglioramenti per accesso ai dati in formato RAW
in crescita uso della griglia, finora limitato, per analisi dei cosmici e dei
rivelatori. Transizione dall’analisi al Tier0 per la limitazione delle risorse e
miglioramenti tool di analisi
•
Calibrazione
MuonCalibration Stream (NA e RM) per MDT, RPC e LVL1 Trigger calibration
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
6
The ATLAS Grids
3 Grid infrastructures: differenti mw, replica catalogues e tool per sottomettere i job
Questa complessità è un
problema per gli utenti
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
7
Il Modello di Analisi distribuita
2 Frontends: Ganga e Pathena
Ganga permette la sottomissione di job sia in locale che alle 3 griglie
al momento è l’unico modo per sottomettere job in molte cloud EGEE (IT, DE ..)
o Nordugrid
utilizza soprattutto la sottomissione via il gLite WMS
Pathena utilizza solo il backend Panda
sottomissione basata sul concetto di pilot jobs
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
8
Il Modello di Analisi distribuita
GANGA: tool unico per sottomettere/gestire/monitorare i job di utenti in Grid
Qualche numero:
Blocchi funzionali: un job è configurato da un set di
blocchi funzionali, ognuno con un ben definito scopo
Ganga usato da più di 1500 utenti
circa 150 utenti ATLAS alla
settimana, doppio dell’anno scorso
Ganga offre 3 modi di interazione per gli utenti
Shell command line
Interactive IPython shell
Graphical User Interface
Palau, 11-15 Maggio 2009
buon contributo italiano
10k job utenti al giorno, da
confrontare con 100k job di produzione
ci si aspetta un numero simile durante
la presa dati
G. Carlino – ATLAS: le strategie per l’analisi
9
Il Modello di Analisi distribuita
Ganga vs Pathena:
Dopo un difficile inizio dovuto alla diffidenza (motivata) della griglia, gli utenti di Atlas
hanno cominciato a fare analisi distribuita e hanno dovuto scegliere tra due sistemi
abbastanza diversi
Pathena non era un vero sistema di analisi distribuita, runnava tutto a BNL dove tutti i
dati sono replicati. Modo di sottomissione simile ai job locali di Athena
L’ideale per un utente, ma sicuramente non sarà possibile in futuro
attualmente un sistema di brokering interno permette di distribuire i job tra i siti
che hanno abilitato le code
da verificare come scala come sistema di analisi distribuito
Ganga ha sviluppato un approccio opposto per rispettare i dettami del calcolo distribuito
problemi all’inizio che hanno allontanato gli utenti
notevoli miglioramenti con il sistema di selezione della cloud, della black list dei siti e
del job splitting (per dataset non replicati completamente)
buon funzionamento per analisi standard
il WMS permette la gestione delle priorità dei job di utenti appartenenti a VOMS
groups/roles diversi. Fondamentale per definire le opportune priorità ai job di analisi
necessario migliorare l’integrazione con il WMS
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
10
Il Modello di Analisi distribuita
Ganga vs Pathena:
ATLAS vuole ridurre la proliferazione di sistemi simili (anche per la limitatezza
di manpower). Per l’analisi distribuita tende a utilizzare un unico frontend e un
unico backend.
Sforzo della comunità italiana di Atlas per
1.
garantire l’esistenza di Ganga come tool ufficiale di analisi visto che la
maggioranza di utenti italiani ha imparato a usarlo ed è il sistema più
flessibile e completo
2.
supportare il WMS l’unico a garantire una gestione locale e non
centralizzata delle priorità dei job.
Sinergie tra esperimento e INFN Grid per aumentare il contributo italiano nello
sviluppo e mantenimento del sistema in Atlas
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
11
L’analisi nei Tier2
Cosa succede quando un job atterra in un Tier2?
Organizzazione di Atlas e della cloud italiana per ottimizzare l’analisi:
Ottimizzazione e gestione delle risorse
Storage: aree di storage per attività e utenti “locali”
CPU: fair share e job priorities
Rete: connessione rapida tra WN e storage. Hammer cloud
Stabilità dei siti
Eliminazione dei Single Point of Failure nella cloud: replica dell’LFC
Shift per il monitoraggio dei siti e delle attività di computing in Italia
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
12
Storage nei Tier2
DATA
Managed with space tokens
Example for a 200 TB T2
MC
CPUs
CPUs
CPUs
CPUs
GROUP
Analysis
tools
Detector data
110 TB
RAW, ESD, AOD, DPD
Centrally managed
Simulated data
40 TB
RAW, ESD, AOD, DPD
Centrally managed
Physics Group data
20 TB
DnPD, ntup, hist, ..
Group managed
SCRATCH
User Scratch data
20 TB
User data
Transient
LOCAL
Local Storage
Non pledged
IT User data
Locally managed13
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
13
Le CPU nei Tier2
ATLAS Computing Model: nei Tier2 50% attività di sumulazione e 50% analisi utenti
CPU non pledges e parte del 50% riservate agli utenti sono dedicate al gruppo atlas/it
Necessario un sistema di fairshare per “difendere” l’analisi dall’attività centrale di
simulazione e garantire risorse dedicate per gli utenti italiani
LSF – Multi VO test:
Fairshare Targets:
ATLAS 50%:
User 30%
Prod 70%
LHCB 50%
User 50%
Prod 50%
Palau, 11-15 Maggio 2009
46
42
atlasIT
38
prod
34
26
22
18
14
9
5
atlas
30
100
90
80
70
60
50
40
30
20
10
0
1
Group Share (%)
Mean WallClockTime
Time Windows (1h)
PBS – Multigroup test:
Fairshare Targets:
ATLAS 40%
ATLAS PROD 30%
ATLAS IT 30%
10 Time Windows 1h long
Job lenght: 2 hours
G. Carlino – ATLAS: le strategie per l’analisi
14
Rete nei Tier2
Connessione a 1 Gbps
I Test di stress dell’analisi distribuita (hammer
cloud, circa 200 jobs simultanei) hanno lo scopo di
individuare limitazioni o malconfigurazioni dei siti,
in particolare carichi sbilanciati sullo storage o
rete non adeguata.
Si è verificata la necessità di connessione a >1
Connessione a 10 Gbps
Gbps tra WN e Storage per i tipici job di analisi
che richiedono alto throughput (~4 MBps a core).
Si passa da un event rate di 3 Hz a > 10 Hz
Sistema di rete usato nei Tier2 in
attesa dei risultati del gruppo di
rete della CCR
1 Gbps
10 Gbps
Fibra
10 Gbps
RACK
m
RACK
m+1
Cluster di Rack 1
Palau, 11-15 Maggio 2009
10 Gbps
RACK
n
RACK
n+1
Cluster di Rack 2
G. Carlino – ATLAS: le strategie per l’analisi
15
Stabilità dei siti
Gli utenti hanno bisogno di siti che
100%
90%
80%
70%
60%
50%
40%
30%
20%
10%
0%
atlas rel
LNF rel
MI rel
NA rel
RM1 rel
ja
n0
fe 8
bm 08
ar
-0
ap 8
rm 08
ay
-0
ju 8
n08
ju
l-0
au 8
g0
se 8
p0
oc 8
t-0
no 8
v0
de 8
c0
ja 8
n0
fe 9
bm 09
ar
-0
9
siano stabilmente up and running
Shift 7/7 dei membri dei Tier2 (a breve estesi anche a utenti “volontari”) per
controllare il funzionamento dei siti, dei servizi di grid e delle attività di
computing di Atlas in Italia
Eliminazione dei Single Point of Failure della cloud:
•
Sistema di replica a Roma dell’LFC del CNAF (db Oracle) con il sistema
Dataguard messo a punto in collaborazione con il CNAF
•
Testato con successo durante il down del CNAF a fine marzo per il
trasferimento delle risorse nella sala definitiva
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
16
Conclusioni
La strategia di analisi di Atlas ha raggiunto una maturità soddisfancente
in molte sue parti
I dati arrivano ai Tier con velocità ed efficienza
I tool di analisi distribuita sono diventati familiari ad una grande
comunità di utenti: l’analisi viene effettuata in grid
Stress test hanno permesso di individuare gli aspetti critici
esistenti nel sistema di analisi distribuita e vengono eseguiti
periodicamente per evidenziare problemi di configurazione nei siti
I servizi di grid e i siti hanno raggiunto una stabilità sufficiente
Cosa c’è ancora da fare
Estendere l’uso dei tool di analisi distribuita ad analisi non standard
Aumentarne la diffusione tra gli utenti
Analisi locale: definire il ruolo e le dimensioni dei Tier3
Palau, 11-15 Maggio 2009
G. Carlino – ATLAS: le strategie per l’analisi
17